
Abstract
We consider the problem of bias arising from conditioning on a post-outcome collider. We illustrate this with reference to Elwert and Winship (2014) but we go beyond their study to investigate the extent to which inverse probability weighting might offer solutions. We use linear models to derive expressions for the bias arising in different kinds of post-outcome confounding, and we show the specific situations in which inverse probability weighting will allow us to obtain estimates that are consistent or, if not consistent, less biased than those obtained via ordinary least squares regression.
Keywords
Sociologists are becoming increasingly aware of the dangers of bias arising from conditioning on colliders. While specific examples have been discussed in both the substantive (Sharkey and Elwert 2011) and methodological (Breen 2018) literature, it is probably Elwert and Winship’s (2014) paper that has done most to bring this issue to wider attention. They present the problem through a discussion of the bias that can arise from conditioning on colliders at different points on the causal path. In this paper, we consider one of these: post-outcome colliders. Conditioning on these is a common source of bias, not least because it often arises as part of the processes of sample selection, either deliberately or as a result of missing data. We discuss the problem with reference to the examples considered by Elwert and Winship (2014) (henceforth E&W), but we ask a question they did not address: to what extent can we recover, via reweighting, unbiased or consistent estimates of parameters of interest in the face of post-outcome collider bias? Inverse probability weighting (IPW) has a long history (Horvitz and Thompson 1952) and has frequently been employed to deal with missing data (Seaman and White 2011). It has recently become popular through its use in marginal structural models (Lawrence and Breen 2016; Sharkey and Elwert 2011). Although it is not the only method that might be used to address the problems we discuss here, it is a well-known and powerful tool with an appealing simplicity.
Our paper proceeds as follows. We begin with a brief discussion of collider bias, then we focus on specific instances of post-outcome collider bias, tying these to the examples presented by E&W but developing them where this is useful. Using both directed acyclic graphs (DAGs) and linear models we show why causal estimates of interest in these cases are biased and we provide formulae for the biases. For most of the cases we consider, IPW will not yield consistent estimates, but there is one important exception: when selection is a function of the outcome variable only. We illustrate this case using data from Britain. In those instances in which IPW does not yield consistent estimates, we show that it is often less biased than ordinary least squares (OLS) and the magnitude of its bias can be quite small. Throughout we use linear models. This is certainly restrictive compared with the non-parametric DAGs used by E&W, but linear models are widely employed to estimate models that are represented by DAGs. Furthermore, they are transparent, and proofs of the kind we provide are much easier to demonstrate. In the words of Pearl (2013) they are a “useful microscope for causal analysis.”
Colliders and Conditioning on a Post-Outcome Collider
Colliders play a very important role in DAGs. A collider is a node in a graph that has more than one arrow going into it: in Figure 1, R is a collider on the path linking P and Q. A collider blocks a path on which it sits: so, according to this DAG, P and Q are independent. But conditioning on a collider opens the path: conditional on R, P and Q are no longer independent. Conditioning on a post-outcome collider arises when the data used are selected depending on their values of the outcome variable, Y. This may happen directly, as part of the design of the study or through decisions made about the analysis, or it may happen indirectly, through selecting data according to its values on a non-outcome variable which induces selection on the outcome. A common reason for conditioning on a post-outcome collider is missing data: people with low values of Y might have been less likely to report their value of Y in an interview or there may be missing values of a predictor of Y, say X, and so the pairs (X,Y) will be absent from the analysis when X is missing.
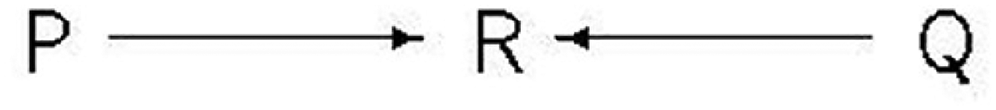
A collider.
The layout of our paper is shown in Table 1. We consider five cases 1 corresponding to examples presented by E&W, with different mechanisms for determining whether data are observed or not and which variables, X and/or Y, are partially, rather than fully, observed as a result. We give an example of each case for expositional purposes. We treat our first case as canonical since it is the most general, and discussions of the later cases refer back to it. We consider a single outcome, Y, and a single predictor, X, but it is straightforward to generalize to more predictors. At the end of the paper, prompted by a reviewer's comment, we have included a short section in which we show how, under certain circumstances, IPW can be combined with instrumental variables estimation to overcome combined post-outcome collider bias and omitted variable bias in the relationship between X and Y.
The Cases we Consider.

Case 1: Missing Data on X and Y: Complete Cases Analysis
In Figure 2, X is a predictor of Y but whether or not we have data on both depends on X and Y. This duplicates Figure 6 of E&W (page 39). Unlike E&W we show the disturbance terms in the DAG: this will prove useful for explaining how collider bias arises. In E&W's example, we suppose we have data on a sample of divorced fathers and we want to know how their income, X, affects how much they pay in child support, Y. But some fathers do not respond to the study: M is a dummy variable indexing whether or not a father responds, and this depends both on a father's income and how much child support he pays.
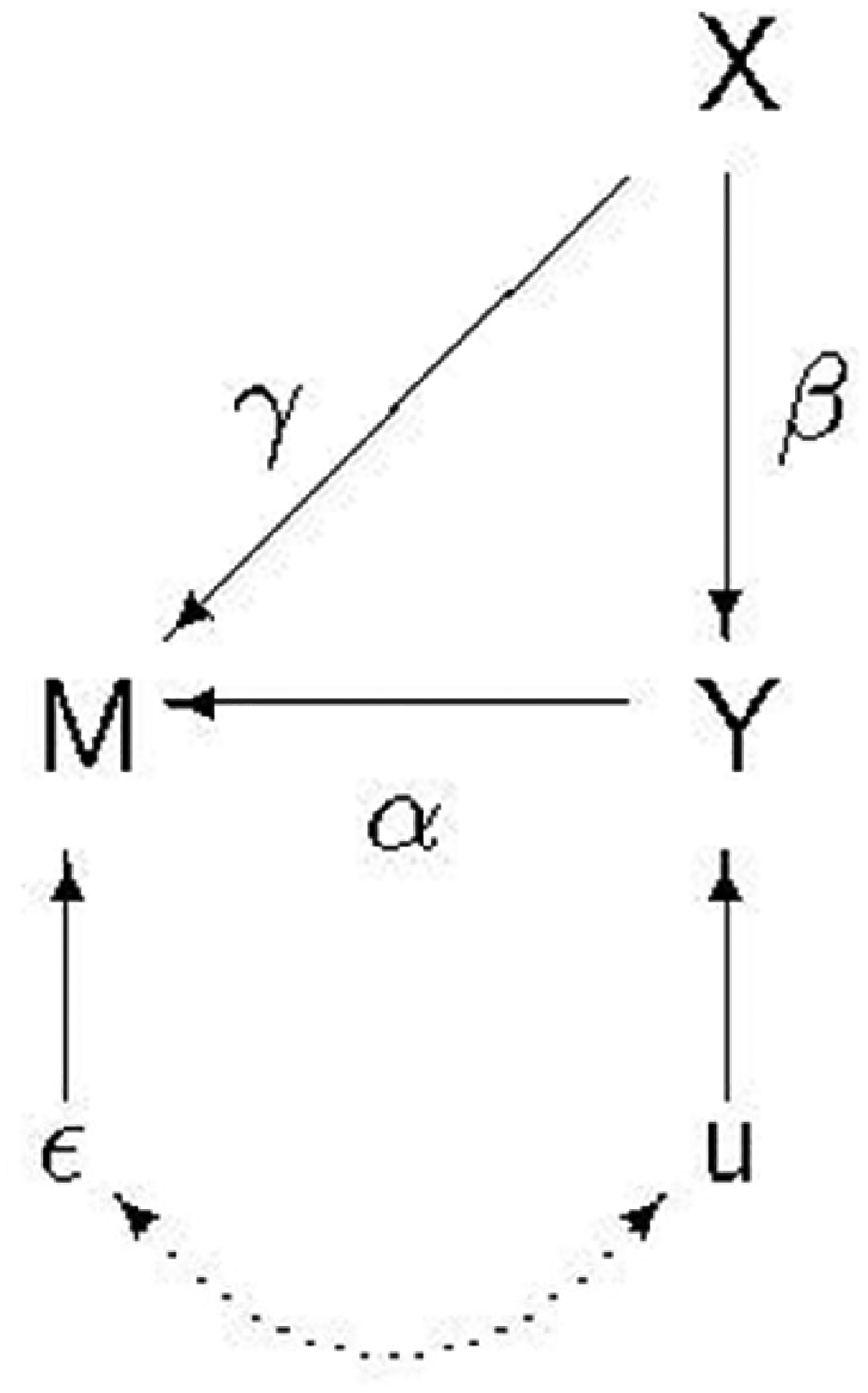
Post-outcome collider.
Linear models consistent with this DAG are

We assume
In our data we only observe cases for which 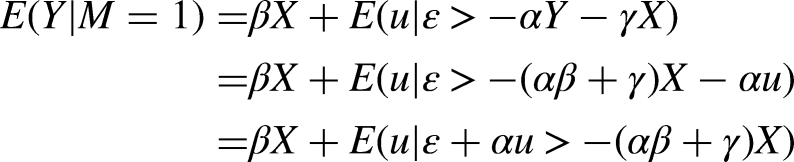
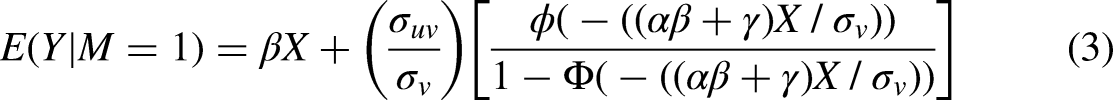
The ratio in brackets is Heckman's “lambda” (Heckman 1979), or the inverse Mills ratio, which we denote as
We can derive the sign of the bias in the OLS estimate of
We can use the DAG in Figure 2 to show, in a more general and intuitive way, how the bias arises when trying to estimate the effect of X on Y when conditioning on M. There are three biasing paths. Because M is a collider on the path from X to
Inverse Probability Weighting
The IPW estimator weights the data by 1/
In order for IPW to produce a consistent estimate of a treatment effect, we need a conditional independence assumption (CIA), analogous to the propensity score theorem (Rosenbaum and Rubin 1983; see also Angrist and Pischke 2009:80). Suppose the treatment X is dichotomous and
The CIA theorem states that:
If
Now suppose that X is observed for everyone, but Y is not. Then, analogously, let
If
There are three issues: (1) Can we assume that the CIA holds in these two special cases? (2) If so, can we obtain consistent estimates of
Case 2: Missing Data on Y Only
Suppose that we have a situation in which there are missing values on Y but not on X; continuing the previous example, we suppose that all divorced men were interviewed and provided information about their income but some of them refused to answer the question about how much child support they pay. However, the naïve OLS model will still have to be fitted to data for which
IPW could be used here, however, because we have fully observed X and M. Our model to predict M would be
But if the true missing data mechanism is as shown in equation (2), then
Case 3: Truncation of Y
A superficially similar situation to case 2 is when Y is observed only if it exceeds or falls below a particular value. An example of this is E&W's Figure 5. E&W's example concerns education, X, affecting income, Y, but the sample contains only people with low incomes 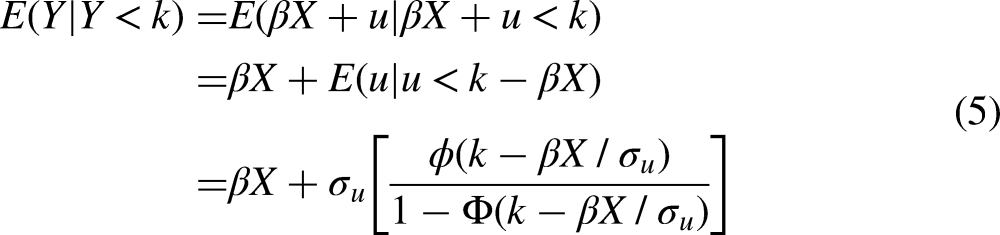
Case 4: Ascertainment Bias
E&W Figure 7 (page 40) shows an example of ascertainment bias (Rothman, Greenland, and Lash 2008), and Figure 2 of this paper applies here too. In E&W's exposition, X is the commercial success of an album measured by whether it topped the Billboard charts, and Y is whether the album was included in the Rolling Stone 500. The sample of 1,700 albums on which the analysis (Schmutz 2005) was carried out was formed by selecting all albums in the Rolling Stone 500 and 1,200 other albums “all of which had earned some other elite distinction, such as topping the Billboard charts or winning a critics’ poll. Among the tens of thousands of albums released in the United States over the decades, the 1,700 sampled albums clearly represent a subset that is heavily selected for success.” (Elwert and Winship 2014:40).
Here the model of equations (1) and (2) applies with the minor change that Y is now binary (inclusion in the Rolling Stone 500 or not). So, in place of equation (1) we could write the latent variable model: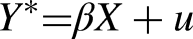
In our case 1, if
Case 5: Missing Data on X Only and M Independent of X
A situation in which there is collider bias but IPW can correct for it to yield unbiased estimates is shown in Figure 3. The difference between this and Figure 2 is that M is no longer affected by X and so we have
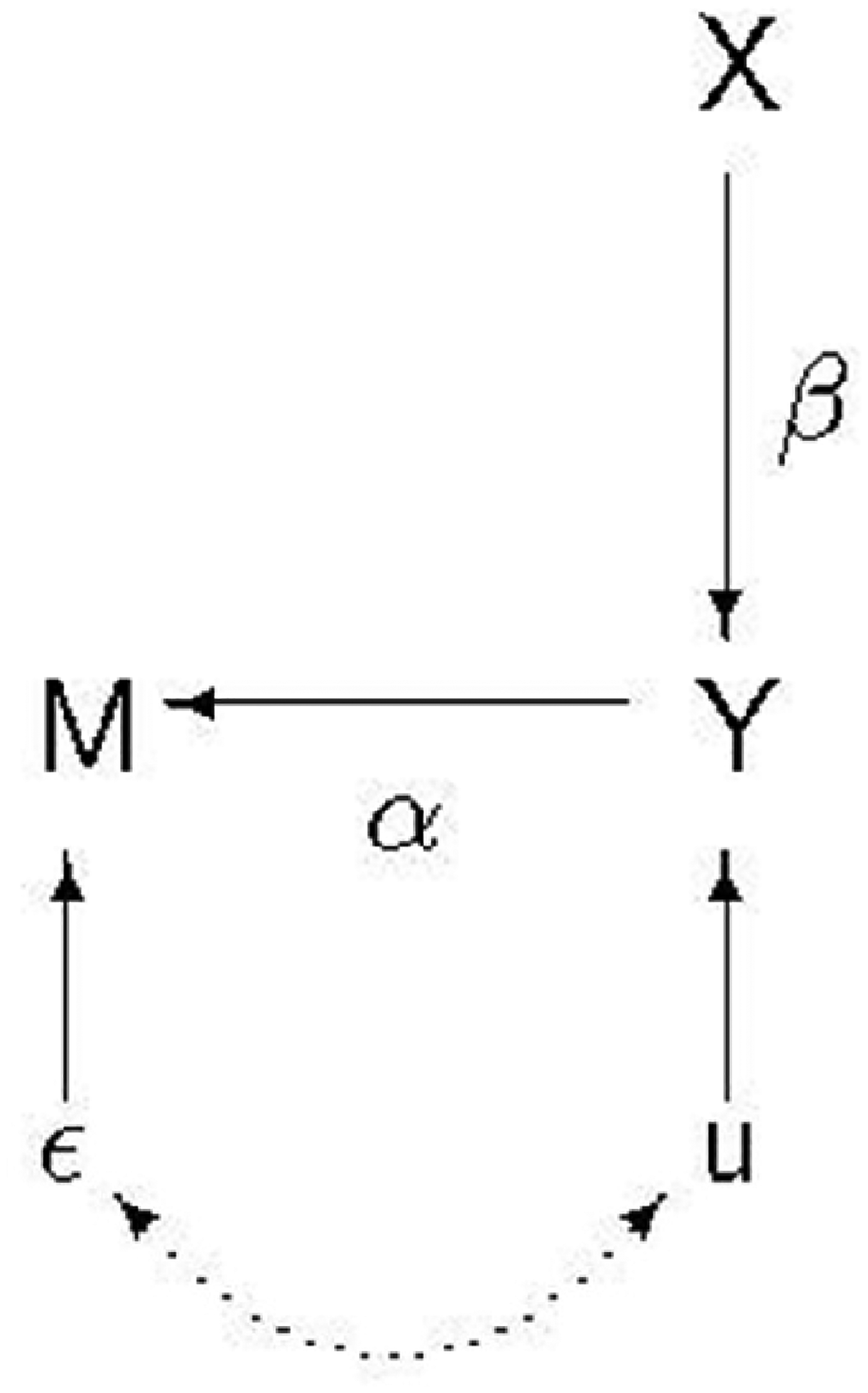
Selection on the outcome.
One situation in which this set-up will arise is in the use of survey data, where, although respondents provide information on an outcome (such as their own years of education), whether or not they respond to a question concerning a determinant of the outcome may depend on their outcome: for example, respondents with more years of education might be more likely to provide information about their own parents’ education. This is a particular example of a more widespread problem: studies of status attainment and inter-generational mobility almost always rely on respondents’ reports of their social origins (measured by parental occupation, and/or education) and whether or not this information is collected may depend on respondents’ own status (or class destination). Ignoring this is likely to lead to bias in estimates of intergenerational associations.
In this case, OLS will once again yield biased estimates, but 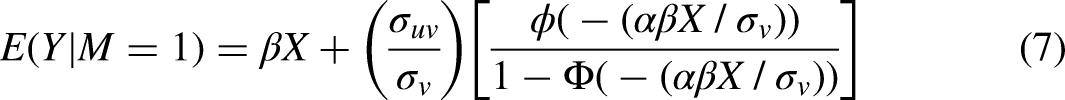
In this case, however, IPW can be used under certain conditions. In the model to predict missingness, based on equation (6) above, we require that the estimate of 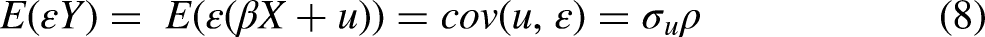
Bareinboim, Tian and Pearl (2014) address problems of selection bias using a graphical, non-parametric approach with the goal of recovering the probability of an outcome, Y, conditional on one or more predictors, X in the face of sample selection.
4
Their approach is more general than ours and so our results for cases 1 and 2, for example, are special cases of results they demonstrate. For our case 5, we are able to recover the conditional mean
Monte Carlo Simulations
Table 2 shows the OLS estimates using simulated data generated according to equations (1) and (2). Each simulation assumes that X is a standard normal variable uncorrelated with
Comparison of Simulated OLS and IPW Estimates of
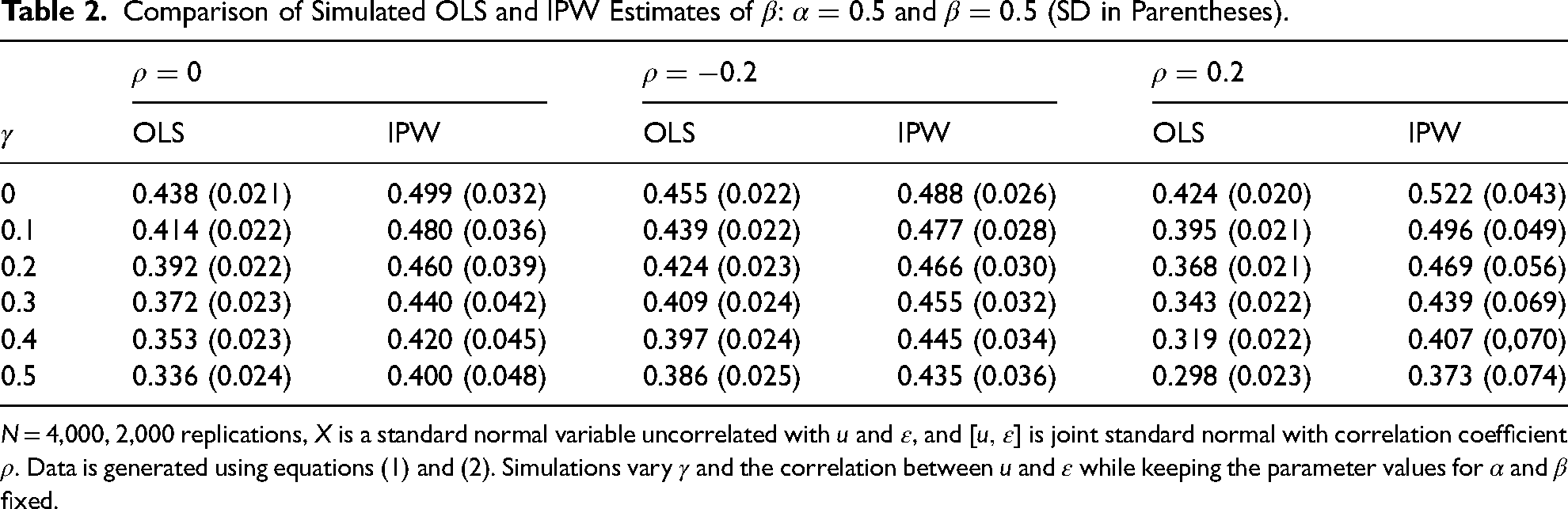
Table 2 indicates that, at least in the parameter configurations illustrated, when the condition
Table 3 illustrates how the IPW estimates of
Variation in IPW Estimates of
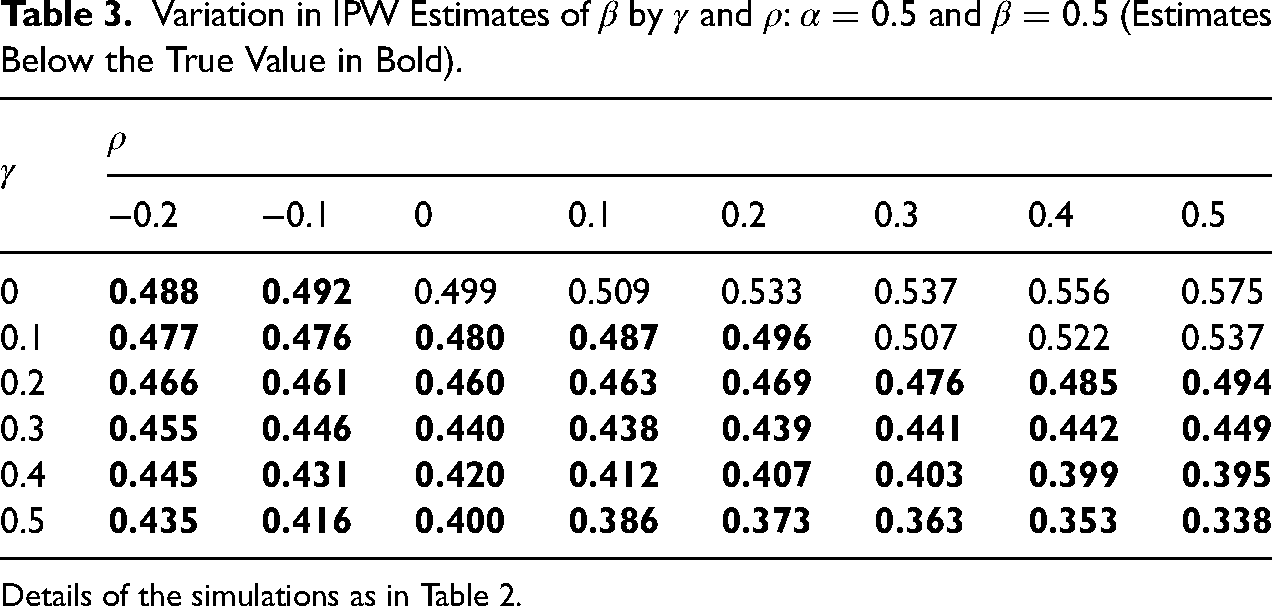
Details of the simulations as in Table 2.
However, there are constellations of parameters in our model setup in which OLS produces unbiased estimates. This would happen for non-zero
With
We conclude that the types of collider bias considered imply inconsistent OLS estimation of linear models. But the simple IPW estimator appears to do better than OLS in the case when selection depends on Y only, and under some plausible parameter restrictions the estimates of
An Illustration: Intergenerational Transmission of Education
We use data from the British Household Panel Study (BHPS) to estimate the effects of parents’ education on the educational attainment of their adult (respondent) children. In the BHPS information on parents’ highest education level was not collected until wave 13 (2003). Evidence indicates that people with higher education are less likely to leave the panel (lower attrition), suggesting that respondents with higher education are more likely to be observed and to provide data on parents’ education, which is indeed confirmed by the BHPS data.
6
Because it is the respondent who is making the decision about continuing participation in the panel, IPW estimation of a selection model based solely on the respondent's own education may perform quite well because, in terms of the parameters of equations (1) and (2),
For easier comparability between generations, we focus on a simple binary indicator of highest education: whether a person has a university degree or not. Among 4,369 persons born during 1955–85, 19.7% obtained a degree, and among those for which we observed father's education (2,672), 10% of fathers had a degree. The analogous statistics for mother's education are 2,745 observed with 6.7% of mothers having obtained a degree. Thus, father's (mother's) education is observed for 61% (70%) of the sample.
In the models we estimate we also allow the probability of sample selection and child's education to depend on year of birth and sex, which are observed for everyone. In Table 4, only the coefficients associated with education are reported. The first two models estimate the parameters for one or other of the parent's education on its own; a third estimates separate parameters for each parent's education using the selected sample in which both parents’ education is observed. The coefficients in the selection model are from a probit model and those in the intergenerational education equation are from a linear model.
Estimates of the Intergenerational Education Equation a .
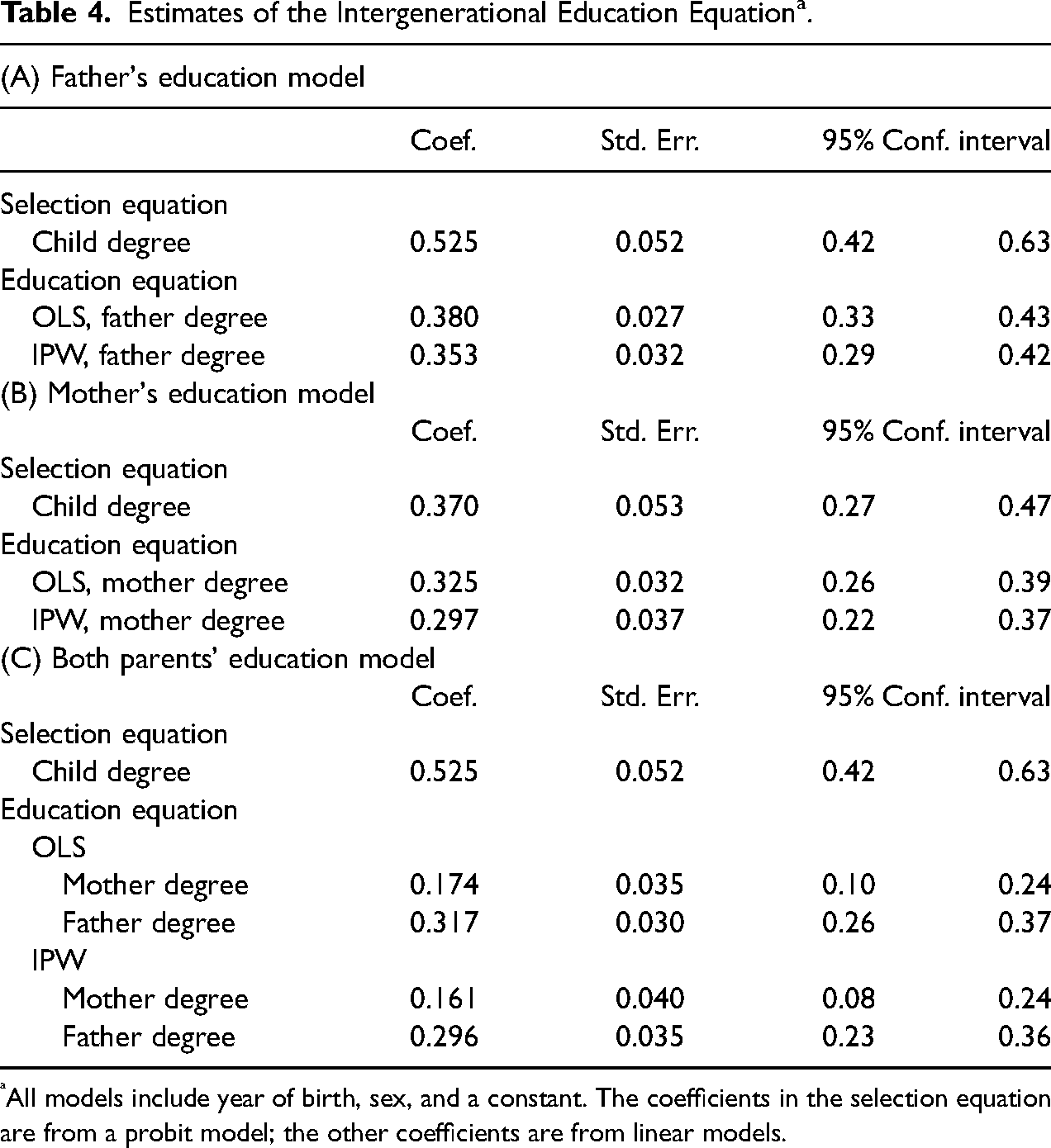
All models include year of birth, sex, and a constant. The coefficients in the selection equation are from a probit model; the other coefficients are from linear models.
Table 4 indicates that, in all models, the IPW estimates of the parents’ education coefficient are below the OLS ones, but generally close to them, as judged by the confidence intervals of each. This could happen because
Combining IV and IPW
In Case 5 and the DAG shown in Figure 3, the crucial assumption that allows us to overcome post-outcome collider bias is
We write the first stage of the IV estimator as

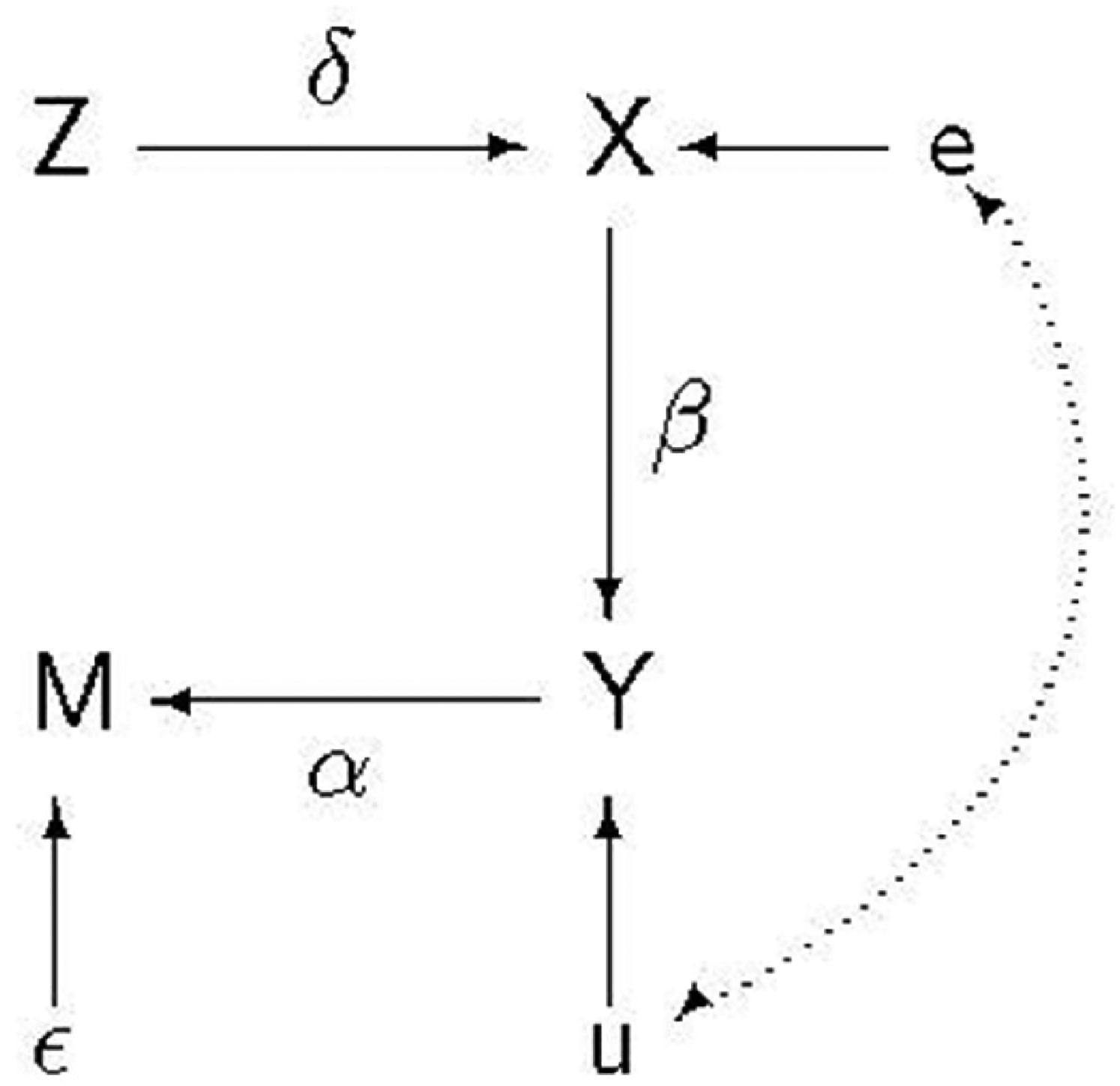
Omitted variable bias and conditioning on a post-outcome collider.
But we cannot estimate (9) because X is only observed when 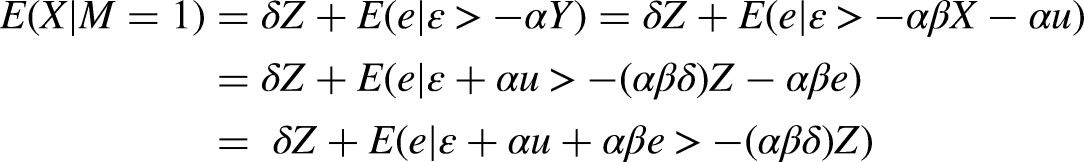
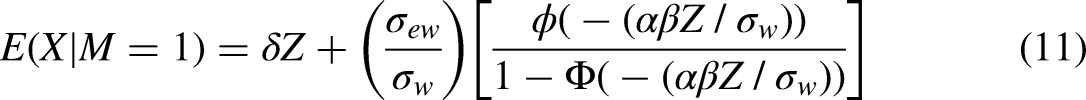
The second term on the RHS of (11) is the bias from using OLS, which then transfers to the IV estimator making it inconsistent. However, just as, in our fifth case, we could use IPW to estimate
Indeed, because in this example M depends only on Y, we do not require that Z is fully observed. Assuming we only observe Z when
Conclusions
Conditioning on a post-outcome collider is not an uncommon occurrence in the social sciences. Elwert and Winship (2014) presented a number of examples to illustrate the problems that can arise. We have built on their work but we have also investigated possible solutions. Using linear models, we have derived expressions for the bias arising in different kinds of conditioning on a post-outcome collider, we have shown how the biases arise, and we have explained the specific situations in which IPW will allow us to obtain estimates that are either consistent or, if not consistent, then less biased than those from OLS regressions.
Footnotes
Acknowledgements
We are grateful for helpful comments from two reviewers and the editor.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: John Ermisch's contribution to the work was funded by a Leverhulme Trust Grant for the Leverhulme Centre for Demographic Science, University of Oxford.
Notes
Author Biographies
Appendix 1: Bias and the Probability of Selection
Figure A1 illustrates how
Using the same parameter values, Figure A2 illustrates how
Appendix 2: IPW Weights: Bias and Covariation With True Weights
The true weights are given by
Table A1 indicates that
Table A2 examines the same issue in a different way by looking at the correlation between the computed and true weights. It shows that when
These simulations suggest that IPW based on