
Abstract
It is common for social scientists to use formal quantitative methods to compare ecological units such as towns, schools, or nations. In many cases, the size of these units in terms of the number of individuals subsumed in each differs substantially. When the variables in question are counts, there is generally some attempt to neutralize differences in size by turning variables into ratios or by controlling for size. But methods that are appropriate in many demographic and epidemiological contexts have been used in settings where they may not be justified and may well introduce spurious relations between variables. We suggest local regressions as a simple diagnostic and generalized additive models as a superior modeling strategy, with double-residualized regressions as a backup for certain cases.
A considerable amount of work in sociology uses quantitative methods to model counts at an ecological level, such as the number of crimes, protest events, or organizations in a country, state, county, city, community area, or census tract. The lion’s share of the discussion of ecological data deals with the issues of cross-level inference (see Achen and Shively [1995] for a balanced treatment)—the attempt to use data at the ecological level to make statements about lower level (paradigmatically individual) relations. However, there is a simpler, nearly inescapable problem with the use of ecological data that has not, so far as we can tell, been appreciated in its starkness, for it suggests a wholesale reevaluation of certain research techniques. The problem arises when the units of analysis vary significantly in population size and when both the outcome (y) and the predictors (x) are strongly related to the number of individuals per unit of analysis (n) in ways that we do not understand and that cannot easily be modeled. In these cases, we cannot account for differences in population size by turning the variables into ratios or by adding a control for population size, methods that would be appropriate in many epidemiological or demographic contexts.
Yet this is accepted as current best practice: Online Appendix A lists relevant publications in the American Journal of Sociology, the American Sociological Review, and Social Forces since 2000. All the examples use one of these methods—either transformation into ratios (e.g., numbers 15, 31, and 35 in Online Appendix A) or the use of linear (e.g., 8 and 19) or loglinear (e.g., 7, 9, 11, 12, and 14) controls, or both (e.g., 3). 1 Such methods are used in studies of crimes (e.g., 1–3, 5, 16, 21–25, 27, 30, 32, 33, and 38–40), social movement events (e.g., 6, 18, 26, and 34), or membership rates (e.g., 20).
In some cases, commonly used approaches are appropriate. Obviously, if either the dependent variable or the independent variables are not highly correlated with population size, there is little reason to fear that the statistical relationship between x and y will be spurious due to confounding with n. For example, the degree of political openness of some country, judged on a scale from −3 to 3 by political scientists, may have no relation to n. Compositional diversity measures (such as a segregation index) may also be relatively independent of n. Even where such independence is unlikely, we may reasonably expect a linear relationship between n and y in cases where we have a well-defined risk set. That is, two random subsets of sizes n′ and n″ from the risk set will be expected to have counts of y that stand in the same ratio as n′ to n″. For example, let y be the number of new pregnancies observed in a month, and n the number of women in the unit, then 0 ≤ y ≤ n. For this reason, we often feel confident comparing units not in terms of y but in terms of the ratio r = y/n. This might be especially true when we are interested in the effect of some independent variable x which also has a theoretically well-defined relation to this risk set. For example, we might be interested in the number of women in any unit who are employed. We might therefore regress y/n on x/n without any complications (assuming independence of units, no threshold effects, etc.). 2
However, this is only a subset of all the types of situations in which we have good reason to expect that both x and y are strongly related to n. In many other cases, we cannot be confident that we have a clearly defined risk set, although we still expect the predictors and dependent variable to be related to n. For example, in a time of widespread protest, although we might expect larger areas to have more protest events, we do not think that each individual is “at risk” of initiating such an event. This situation, if uncorrected, would lead to Type I errors—the analyst rejecting the null hypothesis of no relation between x and y when, in fact, x and y are independent conditional on n. If we have no clear way of specifying the nature of either of these relations (x-n and y-n), we cannot predict, in advance, the pattern of data that should be implied by a null hypothesis. In these cases, even minor model misspecifications can lead to misleading results.
Sociologists dealing with longitudinal data are familiar with a similar problem. They are used to analyzing series of data (e.g., data on national economic trade patterns and median population wealth) in which all the analyzed variables tend to be bound up with the time of the observation. No one doing such analyses would rely on a simple linear control for time as a way of addressing this issue. Instead, scholars often go to elaborate lengths to purge their data of nonstationarity before conducting multivariate analyses. Yet, we have relied on such simple linear controls for count data and population size, as our survey of the literature indicates.
This article proceeds as follows. We first diagnose the problem and discuss it in more detail using a combination of real-world data and simulations. We then propose a simple diagnostic technique to check whether an independent variable is a valid predictor of the dependent variable, even net of population size. Finally, we suggest superior estimation strategies, test their applicability, and discuss limiting cases.
The Problem
Data Example
Let us take the case in which y is a count of organizations or events, which we hope to relate to some x which is a similar count. Say, for example, that we are interested in the relationship between the strength of a social movement and the strength of religious organizations. It has often been noted that political movements draw their capacity to mobilize from preexisting organizations, in many cases churches (see Morris [1984] for the Civil Rights Movement). As a running example, we take the case of the Tea Party movement and ask whether the movement produced more events in areas where there were more evangelical churches than in areas that had fewer of these preexisting organizations.
Figure 1 shows data on the relationship between the number of evangelical churches and the number of Tea Party events in the U.S. counties from June to Election Day 2010. 3 The top panel gives the relation in raw form; the bottom panel presents the relation between the logarithms of both counts. As can be seen, there is a strong positive relation between the two variables. Model 1, Table 1, is a bivariate linear regression which confirms this positive relation. 4 The problem is that such a relation should be expected even if there is no true effect of churches on events. Simply put, we should expect that places with more residents will have both more churches and more events. The raw correlation, in other words, cannot be used to test the null hypothesis of no relation between the two variables. Somehow, we need to purge the relation between our variables of the common covariance due to population if we are to see whether there is something about the presence of evangelical churches, and not the mere population size, that predicts Tea Party events.
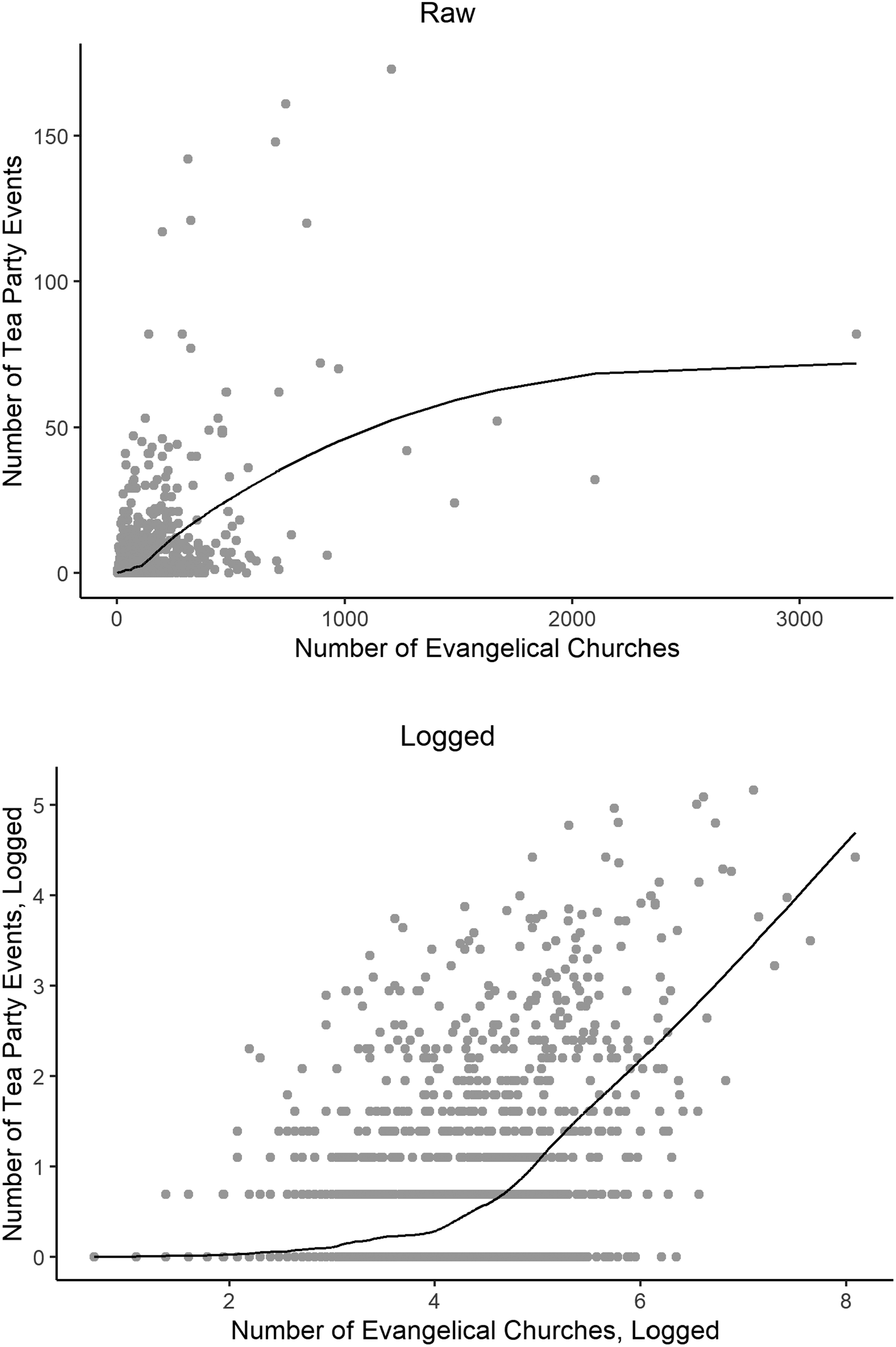
Tea Party events by evangelical churches, county level. Note: The curves show loess fits with span = .3 and degree = 2.
Models for Number of Tea Party Events, County Level.
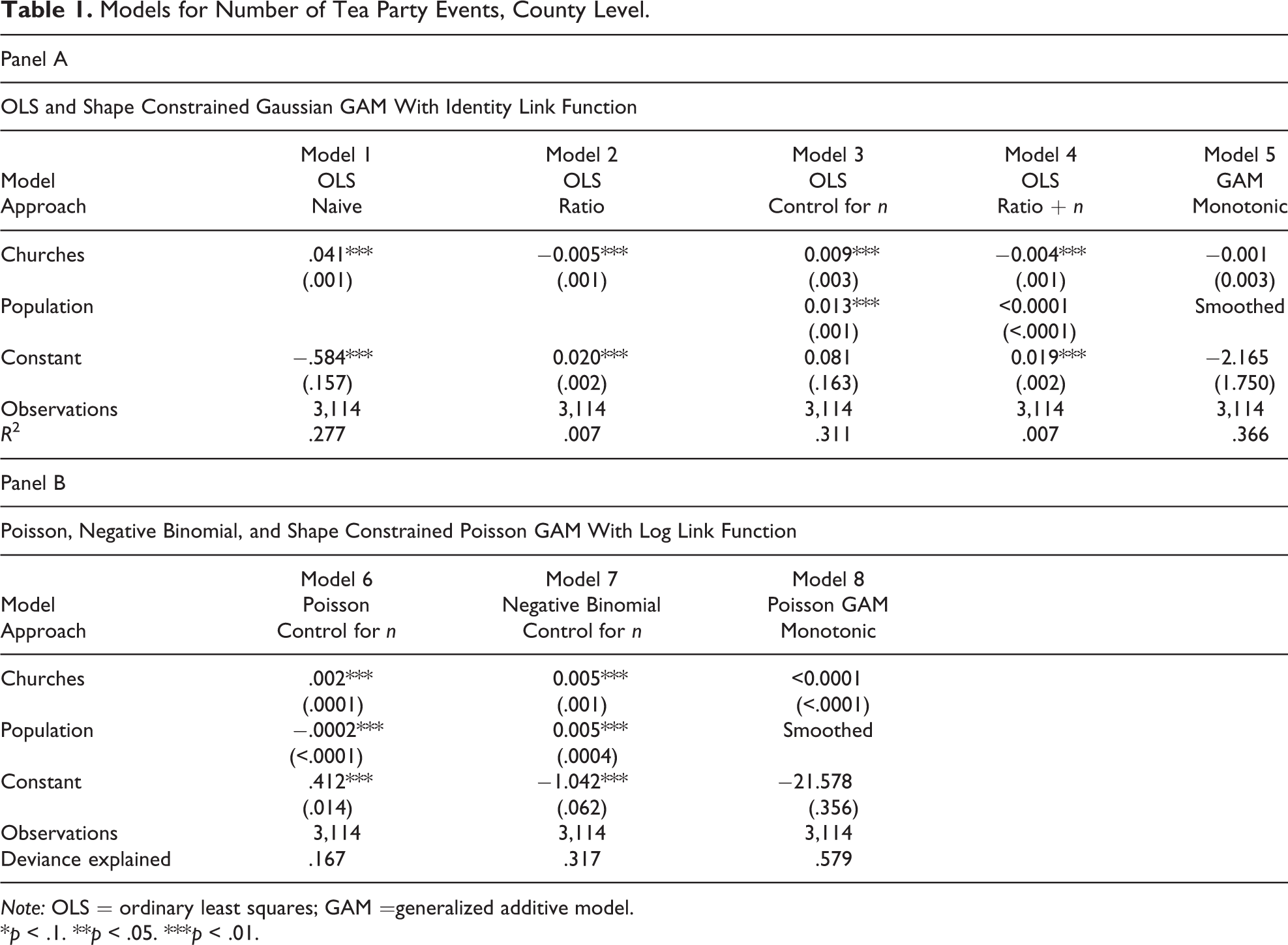
Note: OLS = ordinary least squares; GAM =generalized additive model.
*p < .1. **p < .05. ***p < .01.
Perhaps our problem is that we should not be looking at the sum of total events and total number of churches but the events-per-person and churches-per-person ratios. Model 2, Table 1, shows the results of regressing Tea Party events per person on evangelical churches per person. Again, the relationship is highly significant. But now it is a negative relation. This might seem surprising. Perhaps even more surprising are the results when we replicate, only now, instead of using ratios, regressing Tea Party events on the number of churches in each county, but controlling for n (model 3, Table 1). Here, we see that the relation is positive, and again, statistically significant.
We might not initially expect such a radical difference between the results of these two models, given that model 2 fits

while model 3 fits
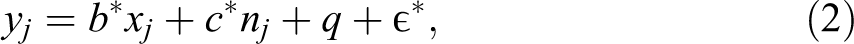
where J is the number of units, the * indicates that the parameters in equation (2) are different from the corresponding ones in equation (1), and q denotes the new intercept in equation (2). It seems that in equation (2), we have merely multiplied equation (1) by nj, which would change nothing. But the two equations are not the same; equation (2) has three free parameters and equation (1) only two. For this reason, it has been recommended that analysts include a term of (1/nj) when fitting the ratio model or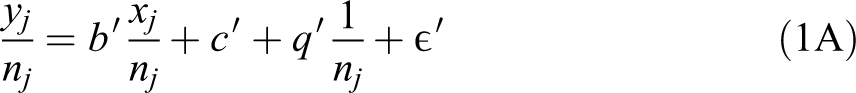
Because equation (2) has one more free parameter than does equation (1), we might think that the results of model 3 are more robust than those of model 2 and that this model produces the correct estimate of the relation between evangelical churches and Tea Party events. But, given the fact that the ratio and the control model have opposite signs, we might suspect that the two methods may have compensating biases. For this reason, we might think that the most conservative approach would be to do both at once. Model 4, Table 1, shows that doing this, by adding population as a control to the ratio model, really makes no difference, as it gives the same results as the ratio model (and not, as we might have guessed, the more flexible model 3). For this reason, we might now suspect that the ratio model is correct, as it seems to have successfully purged our data of confounding by n. Certainly, we cannot decide which model to prefer by looking at explained variance, for in many cases (although not for the example discussed here) the explained variance will be greatest for equation (1), which has the effect of n on both sides of the equation.
We have, in sum, two very different interpretations of the data: In one, there is a strong positive, and in the other, a strong negative relation. Neither interpretation is justified, as we will go on to show. (To anticipate, a null effect is found in model 5, Table 1.) There is no reason to think that the number of evangelical churches has any relation to the number of Tea Party events that is not a result of population size. In other words, neither technique works to test the null hypothesis of no relation, and we believe that, for this reason, it is likely that similar work has also falsely rejected the null hypothesis when it should not be rejected.
How can this be? The answer is that in both techniques, too much rests on the linearity assumption. While there is good reason to believe that both our dependent and our independent variables covary strongly with population, there is no reason to think that this covariation is linear. Such a combination of strong but nonlinear effects means that both techniques do not remove the confounding due to n, but in fact, can actually increase it. We go on to demonstrate this with a set of simulations.
Simulation Example
We begin by showing how nonlinear relations between variables and population size produce false relations between predictors and dependent variables. We conduct simulations as opposed to using real data because we can be sure that there is no true relation between our dependent variable and our predictors. We sample J = 1,000 observations for n from a uniform distribution
5
and generate four variables as follows:
Simulated Data.
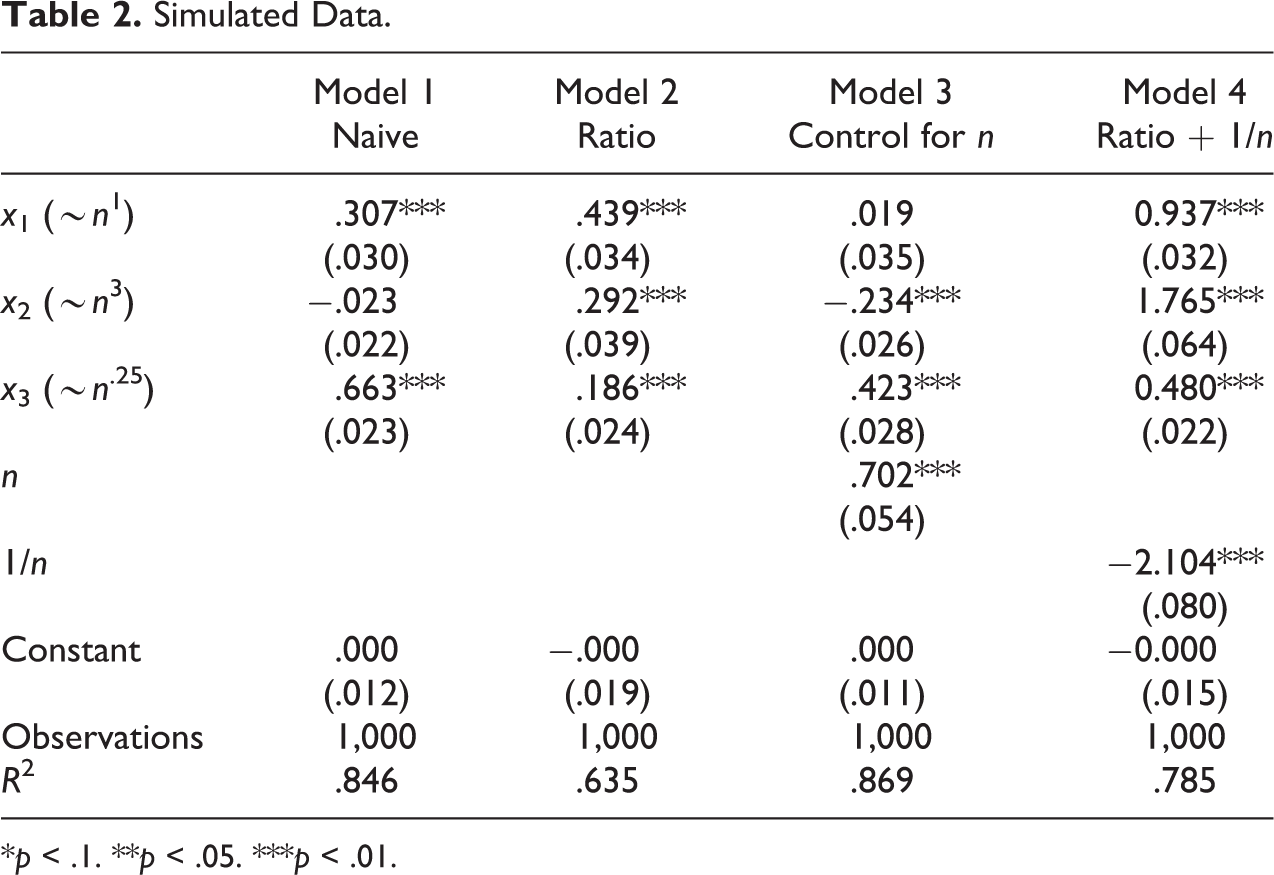
*p < .1. **p < .05. ***p < .01.
Model 2, Table 2, presents the results when we turn all our variables into ratios, corresponding to model 2, Table 1. The ratio model likewise does not correctly identify null relations. 6 Model 3, Table 2, employs a control for population corresponding to model 3, Table 1. Adding the control for population works to eliminate the spurious significance of the variable that scales linearly with population (x1). But it does not identify the spurious relations of y with the other predictors. Indeed, we now see a significant negative relation between y and x2 where this was not present in the naive model. Model 4, Table 2, follows Firebaugh and Gibbs (1985) and adds (1/n) as an additional control to the ratio model. Far from this technique correctly leading us to accept the null hypothesis for our coefficients, the estimates are all larger than in the simple ratio model.
In sum, even the flexibility of the control model, which allows for any linear relation, is not sufficient to remove false positive findings if the true relations are not linear. Of course, it is always true that an improperly specified functional form means that our model results are misleading. What is important about the set of cases discussed here is that we have extremely good reasons to believe that many of the variables of interest are strongly dependent on n, but that there is no reason that these relations should be assumed to be linear, or even of any form that can be specified in advance (for work on the different functional forms relating various aggregate variables to size, see Bettencourt et al. 2007; also Bettencourt 2013).
One response to this, taken in some kindred fields, has been to treat the scaling of any variable as an empirical matter. Here, one usually proposes that the true relation between some variable x and n takes the form

and constructs
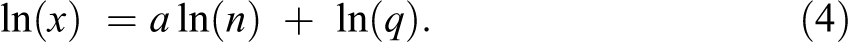
We can estimate a either by fitting equation (3) directly or by fitting equation (4) as a linear model (the results, however, will generally be different; see Petersen 2017; also Stolzenberg 1980:460-63). We thus generalize from a linear relation to a power law.
For an example, Table 3 gives estimates of the exponent linking the number of the amenities in any U.S. county to the number of residents of this county. 7 On one extreme, the number of lawyers or landscapers scales nearly linearly with population. On the other hand, the number of distilleries grows quite slowly with population. It is worth emphasizing that these relations are nonlinear enough to lead to spurious conclusions with rather moderate sample sizes. To illustrate this point, we create two variables, one that scales with n at the level of marinas and another that scales with n at the level of fine arts schools (see Table 3). We find that if we regress one on the other using a control for n, we would wrongly reject the null hypothesis around half the time when the number of cases is around 250; if we use a ratio approach (whether or not we add a term for 1/n), we would reach this point at around 50 cases (and there are in fact 3,073 counties in these data). 8 Of course, if these estimates of the exponents could be relied upon, we could adjust any regression involving them accordingly. However, what we need is not the marginal distribution of some x against n, but the structural relation that would allow us to correctly estimate various regression coefficients. We cannot estimate such exponents unless we already know the coefficients linking the independent to the dependent variable.
Estimated Scaling Constants.

Still, if the relation between these x’s and n were quite strong (with high predictive power), we might feel confident in using the observed relation between the two (as in Table 3) as an estimate of the structural coefficient. However, these relations in many cases will be noisy. Even when the fit in a logarithmic metric is rather good (Figure 2, top left, for lawyers; the value of the estimated coefficient a is given in the bottom right corner of each plot), we see that the explained variance is low on the right side of the untransformed data curve (Figure 2, top right), as most observations tend to be on the left. With cases that scale sublinearly (Figure 2, bottom left and right), the relations are even more inexact. The empirically fit line therefore has a tendency to produce large residuals at the right tail, which then become outliers that can lead to misleading results. The fact that the observations are clustered at the left tail, where the power-law relation tends to break down, also leads to a discrepancy in estimates depending on whether we are using the log or the linear metric.
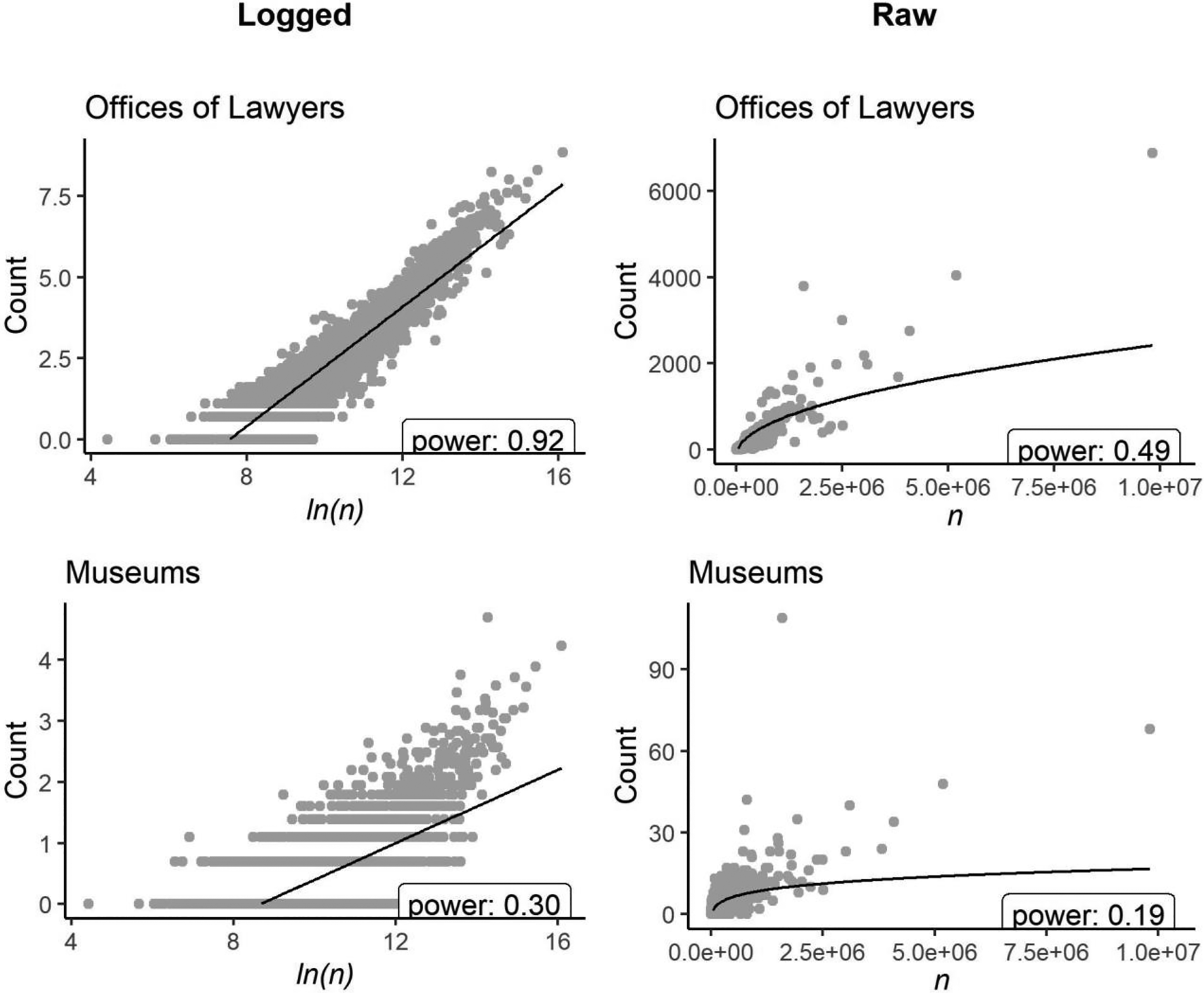
Empirical relations, amenities by county.
For this reason, we go on to propose a more flexible approach that has two prongs. The first is one of diagnosis, in which we attempt to determine whether or not we are safe in rejecting the null hypothesis of no effect of x (or of multiple x’s) on y. Second, we go on to suggest two ways of attempting to quantify the effect of x on y given an unspecified relation of both with n. The first approach, which uses a double-residualized locally smoothed regression, is extremely conservative, which makes sense: Given the demonstrated tendencies for false positives in such data, we believe it is important to err in the other direction. However, we also suggest the use of generalized additive models (GAMs) which, we demonstrate, perform well in a wide variety of situations (though not all).
Techniques for Analysis
Diagnosis: Local Effects
If one of our independent variables x really is a valid predictor of the dependent variable y (let us assume a positive slope), even net of n, we should expect to find positive relations between x and y in subsets of the data that are similar in their n. Thus, the simplest diagnostic procedure is to stratify the data by n, take subsets of the data (“windows”) that are similar in n, and examine the proportion of such windows that have a positive relation between x and y. Where this proportion is not large, we should refrain from attempting to model the relation of y and x.
The graphical representation of these local relations, however, can be more enlightening than the sheer percentage count. Figure 3 shows the effects for x1, x2, and x3 from local regressions applied to the simulated data used in Table 2, where we order the cases by n and then run our regression of y on x1, x2, and x3 with a moving window of nine cases. If there was a positive (negative) effect for some variable, we would expect the line corresponding to its local slope to spend more time above (below) the zero point than below (above). Instead, all lines show very little order. This is quite different from a case in which the relation between y and x tends to be positive at one end of the scale and negative on the other, despite this leading to a similar overall statistic. In such a case, we might believe that there was a true connection between y and x, though one that differs by unit size. In the case at hand, however, we seem to have a strong signal of no relation (and this is of course quite correct).
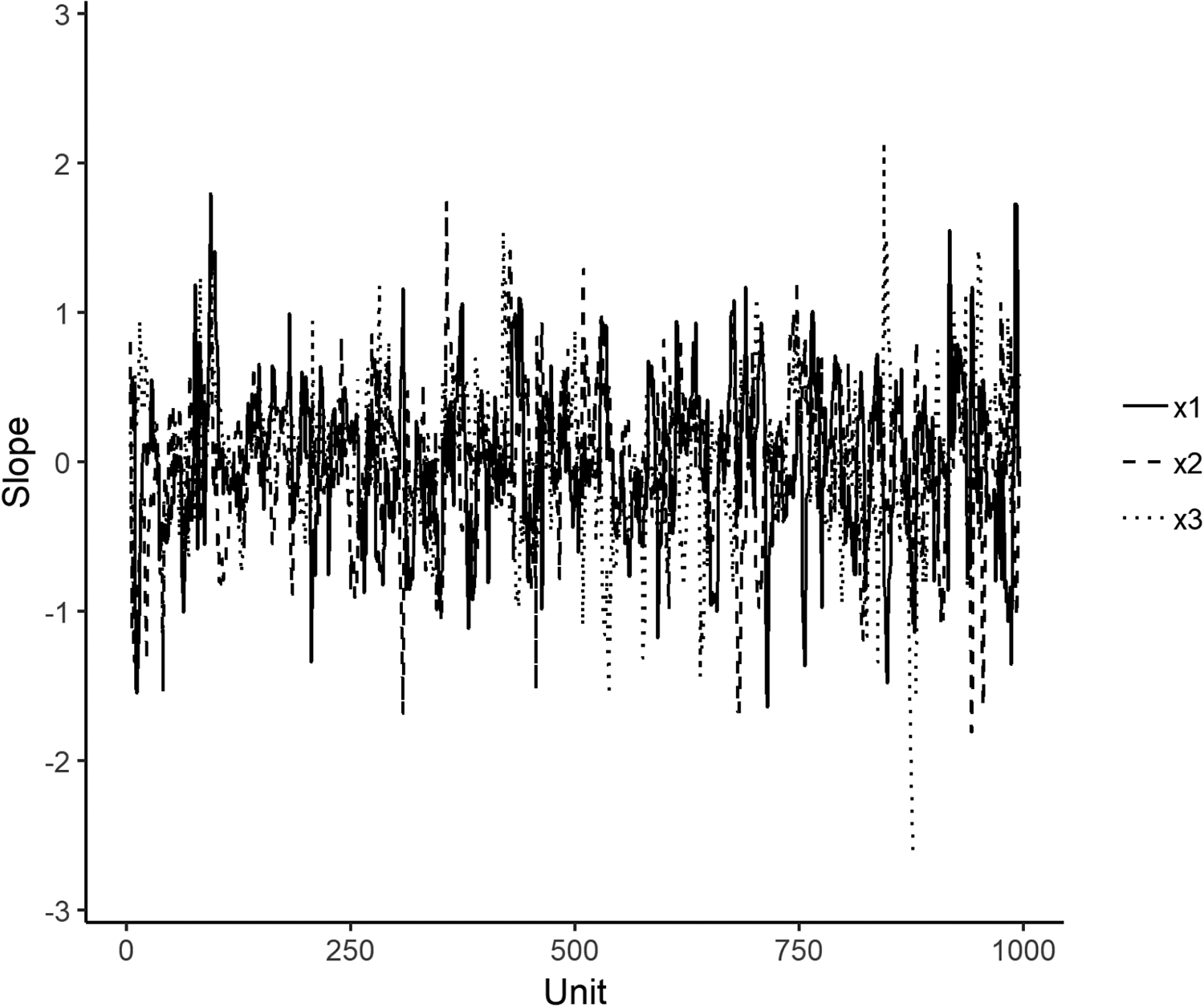
Local regression effects, simulated data with true effect = 0.
One might worry that a small window leads to estimates that are too unstable to be of use; on the other hand, a large window will have too much variation in n to provide a good test. One way to avoid erring on either the side of too large or too small a window, then, is to determine whether any local slope goes steadily toward zero as the width of the moving window decreases. Figure 4 gives the results of the average slope for the same x1, x2, and x3 analyzed above when we successively decrease the size of the window from the full original data (which is equivalent to the global model) to a minimum of seven. As we can see, there is a clear trend toward effects of zero as the window gets smaller. This again suggests that we should not reject the null hypothesis of no relation. Where the results of the diagnostics are as clear as these, we would believe there would be no reason to pursue an investigation of the effect of x on y.
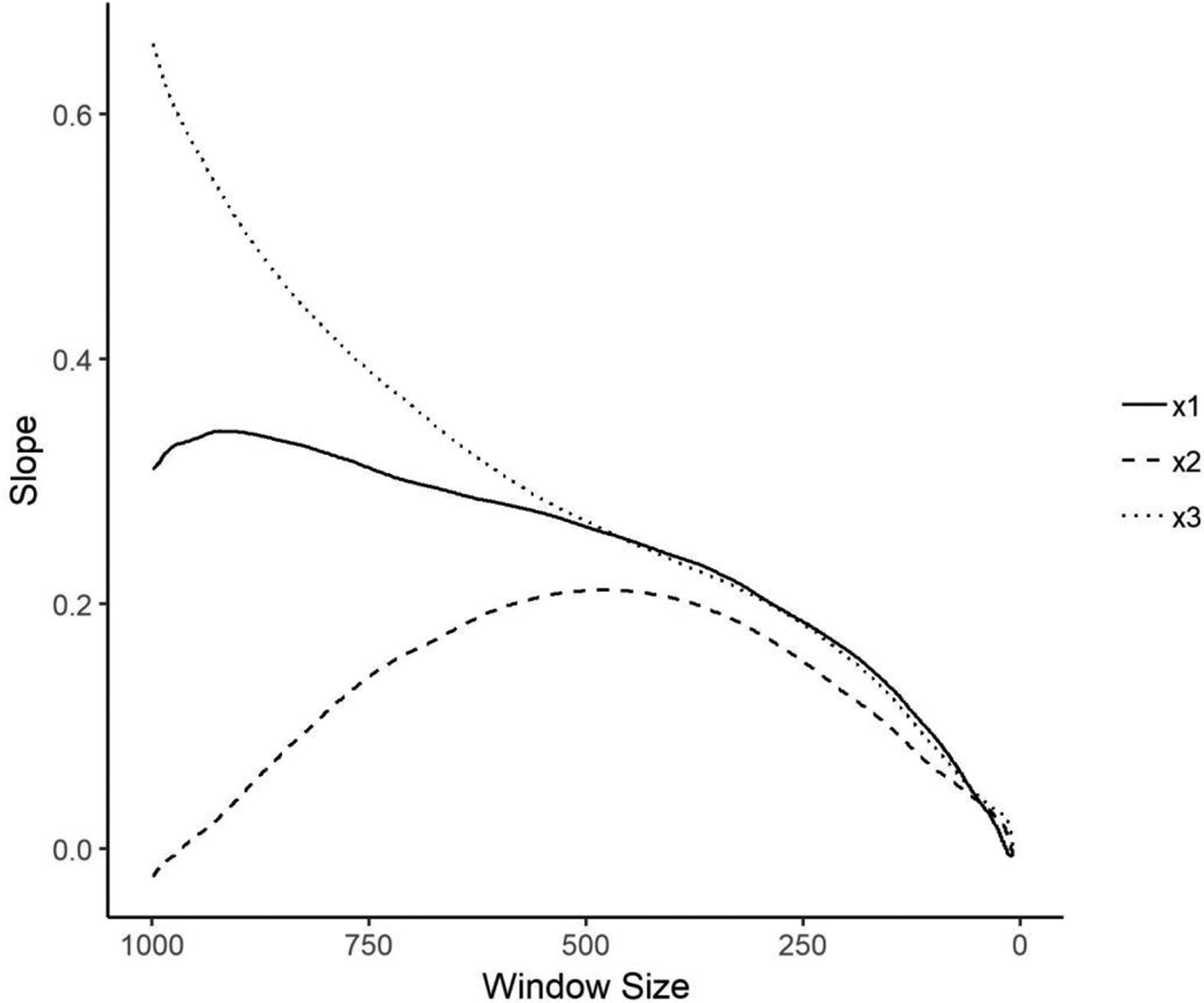
Effects of moving window size, simulated data with true effect = 0.
Replicating Figure 3 with a moving window of size 15 for our case of the relationship between Tea Party events and the number of evangelical churches (results not shown), we find that in 37 percent of the windows, the slope of events on churches is positive, and in 63 percent, it is negative. Although the proportion of negative cases is substantially larger than 50 percent, we do not see an interpretable pattern such as a change from a zero relation to a negative one at larger or smaller windows, such that we could accept the fact that the relation is usually, though not always, negative as theoretically significant. More important, Figure 5 replicates Figure 4 for the Tea Party events data and sees a steady decline in the value of the estimated effect. As we can see, we have little reason to believe that in fact there is any relation between the number of churches and the number of events that is not easily explainable by n.
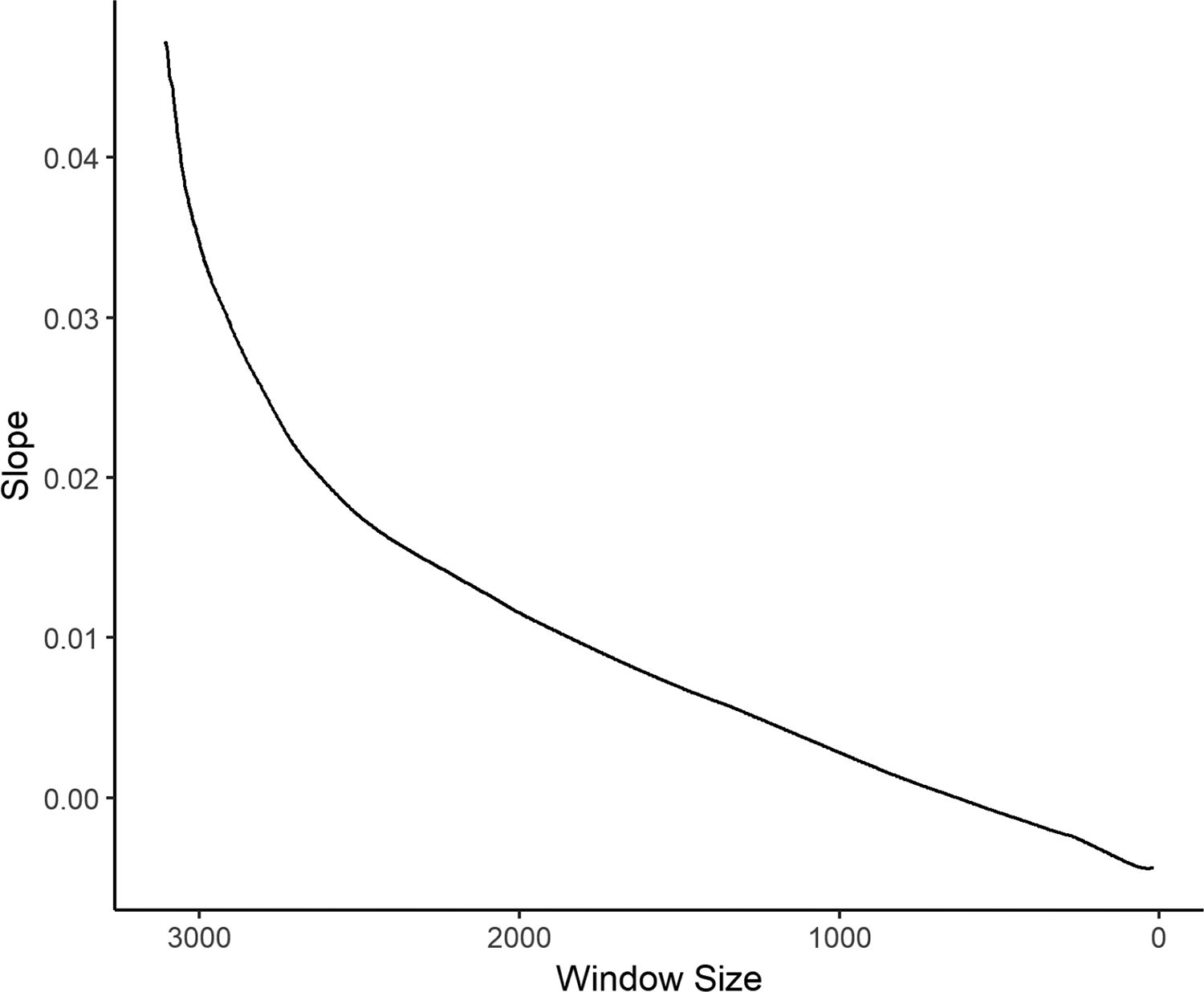
Effects of moving window size, Tea Party events.
To demonstrate the capacity of this technique to correctly identify nonzero associations, however, we need data in which we know the real relation between x and y. Let us develop a general framework for simulating data from two variables, each of which is related to n in a nonlinear way. Let
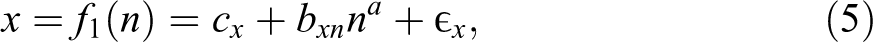
and
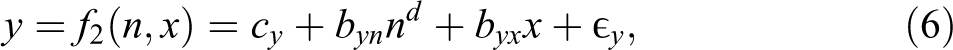
where

and

Here, we produce two simulated data sets, in both of which there is a true relation between x and y independent of n (byx = 1.0). In the first, both x and y scale sublinearly with n (
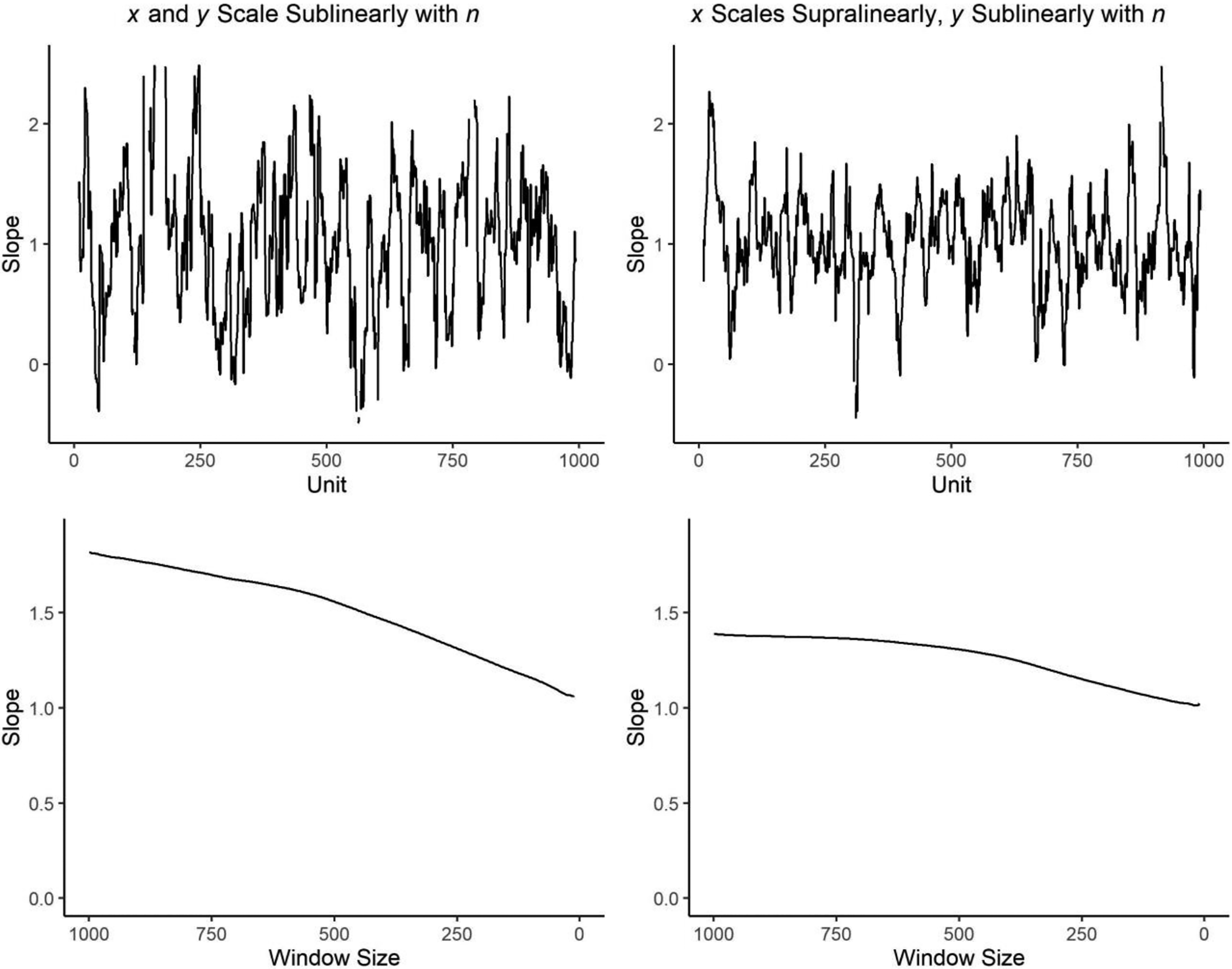
Local regression effects and effects of moving window size, simulated data with true effect = 1.
While these simple techniques seem surprisingly effective at indicating the magnitude of an effect, in addition to indicating whether it is likely to be zero, these are still rule-of-thumb procedures and give us no way of properly estimating the size of the coefficients and the standard errors. We go on to propose two different approaches to this task.
A Two-stage Approach
As we noted above, the problem with the commonly used techniques to determine the effect of some x on y independent of n, including that which fits a power-law distribution, is that deviations from the assumption of the functional form relating n to y may be consequential, given that many independent variables will also increase with n in a hard-to-predict way. We therefore propose that rather than divide the observed counts by n or include a function of n as a control, we residualize them on a smoothed curve of y on n. Thus, we replace y with y* = y − f(n). 9
Of course, the results are likely to be somewhat sensitive to the degree of smoothing used. Further, such a curve might at some points head downward (i.e., the predicted y decreases locally with increases in n), which goes against the core assumptions motivating our concern. We take for granted that there are a number of unmeasured processes all of which mean that counts of our variables will tend to be higher in units with larger n, even though the relation is likely to be nonlinear, perhaps even discontinuous. Certainly, we have no reason to imagine a negative relation between these processes and n. For this reason, we propose adjusting any algorithm used for such smoothing so that it is monotonically nondecreasing. Several algorithms for monotonically increasing smooths have been put forward.
10
We use shape-constrained B-Splines as proposed by Ng and Maechler (2007) and implemented in the R package
We would then be interested in the regression coefficient in a model regressing y* on x or on additional predictors (such an approach has been taken to dealing with spurious correlation induced in temporal series data by Fischer and Hout [2006:252-56]). However, such residuals y* may lead to biased estimates, by taking out of y all the covariance with x that overlaps with the shared covariance with n (Freckleton 2002). Accordingly, there are two techniques that have commonly been suggested to correct estimates of byx derived from models linking y* to x. The first is to include n on the right side, thereby soaking up the effect of the removed common covariance, and the second is to residualize x on n as well, and model y* = x* + c (we shall call this model “double residualization” [DR] henceforward). While these two techniques lead to similar results where the true relations are linear, in cases where x or y is a nonlinear function of n, we show that the latter is superior.
To demonstrate the utility of this technique, we need data for which we are sure that the true relation between x and y is zero. To create such data, we take the Tea Party data on U.S. counties used above and construct a variable x following equation (5). We vary a, the exponent linking n to x, and set bxn = 1 and σ x = sd(na)/3. Because we want to examine the performance of ratio models, we also want our x to be strictly nonnegative. We therefore adjust cx such that min(x) = 0. By construction, we set x to be unrelated to y conditional on n (byx = 0 in equation [6]). We then use this constructed x to predict y, which in this case is the observed number of Tea Party events held in some county. Table 4 contains results in which the columns represent seven models linking y to x. The first column is the result from the naive regression, y = f(x), the second is from the ratio model (equation [1]), the third is from the model that controls for n (equation [2]), the fourth is from the ratio model that includes (1/n) as a control (equation [1A]), the fifth is from the regression of y* on x (“single residualization” [SR]), the sixth is from the regression of y* on x that also includes n as a predictor, and the seventh is from a regression of y* on x* (DR). The values in any cell are the percentage of trials (out of 500 done for each value of a) in which the null hypothesis was rejected at p < .05.
Percentage (False) Rejection of H0, Simulated Tea Party Data.
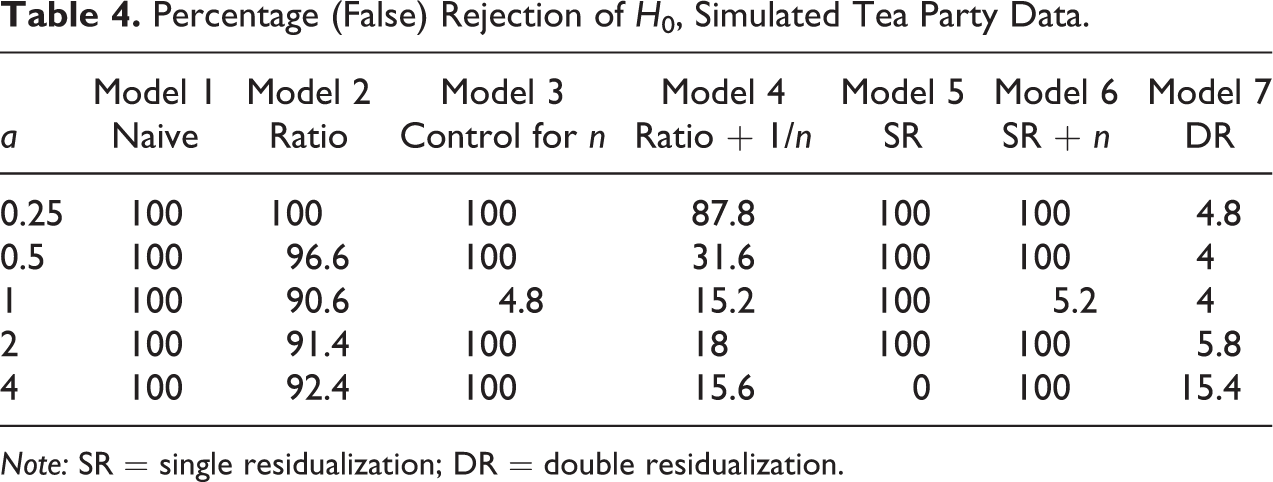
Note: SR = single residualization; DR = double residualization.
As expected, in the case where x is a linear function of n (
This suggests that DR is good at failing to reject the null hypothesis when in fact it is correct. This does not, of course, mean that it is useful in correctly estimating the effect of x on y when this effect is nonzero. Figure 7 displays the results of simulations in which we use equations (5–8) to generate data in which both x and y are strongly influenced by n, but there is a true relation of x on y conditional on n. We set bxn = 1, σ
x
= sd(na)/3, and σ
y
= sd(bynnd + bxnx)/3. We choose byn such that var(bynnd) = var(bxnx), making sure that x and n contribute equally to y across simulations. Finally, we adjust cx and cy such that min(x) = min(y) = 0. Each layer represents one particular value of byx, with the two dimensions of any layer being the exponent a linking n to x (on the vertical) and the exponent d linking n to y (on the horizontal). The value displayed via the coloration is the average of the absolute value of the percentage error of the estimated coefficient, that is, the average of
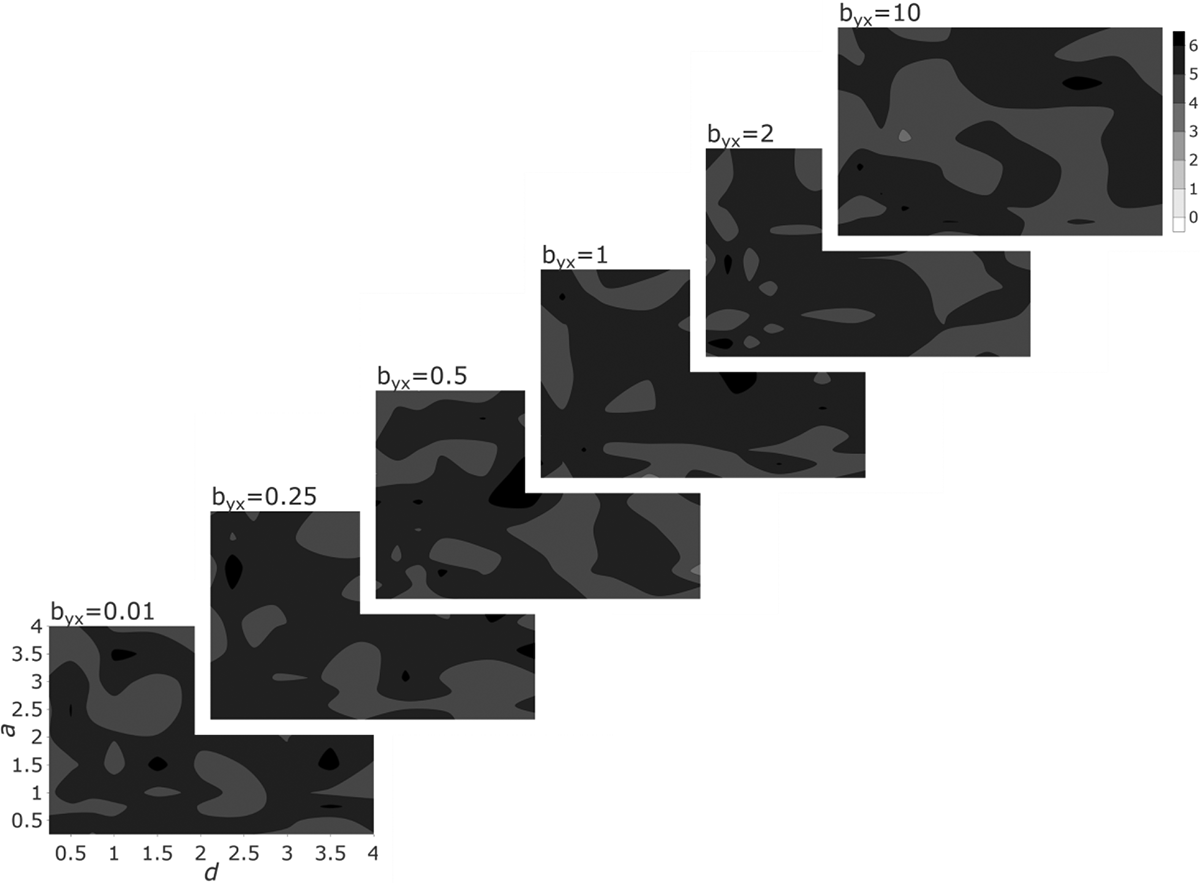
Estimation error of double residualization. Note: The contour plots show the absolute value of the percentage error,
As we can see, the method produces estimates that are close to the correct value of byx across a wide range of parameter values. Further, the error is much lower than that produced by SR or SR and the inclusion of n as a covariate. Figure 8 demonstrates this by overlaying three distributions: (a) the distribution of percentage error by SR, (b) that of SR and a control for n, and (c) that of DR. The difference between the mean of any distribution and zero indicates the bias of that technique and the width of the distribution the degree of error. DR is the only technique that is unbiased, and its error is reasonably low.
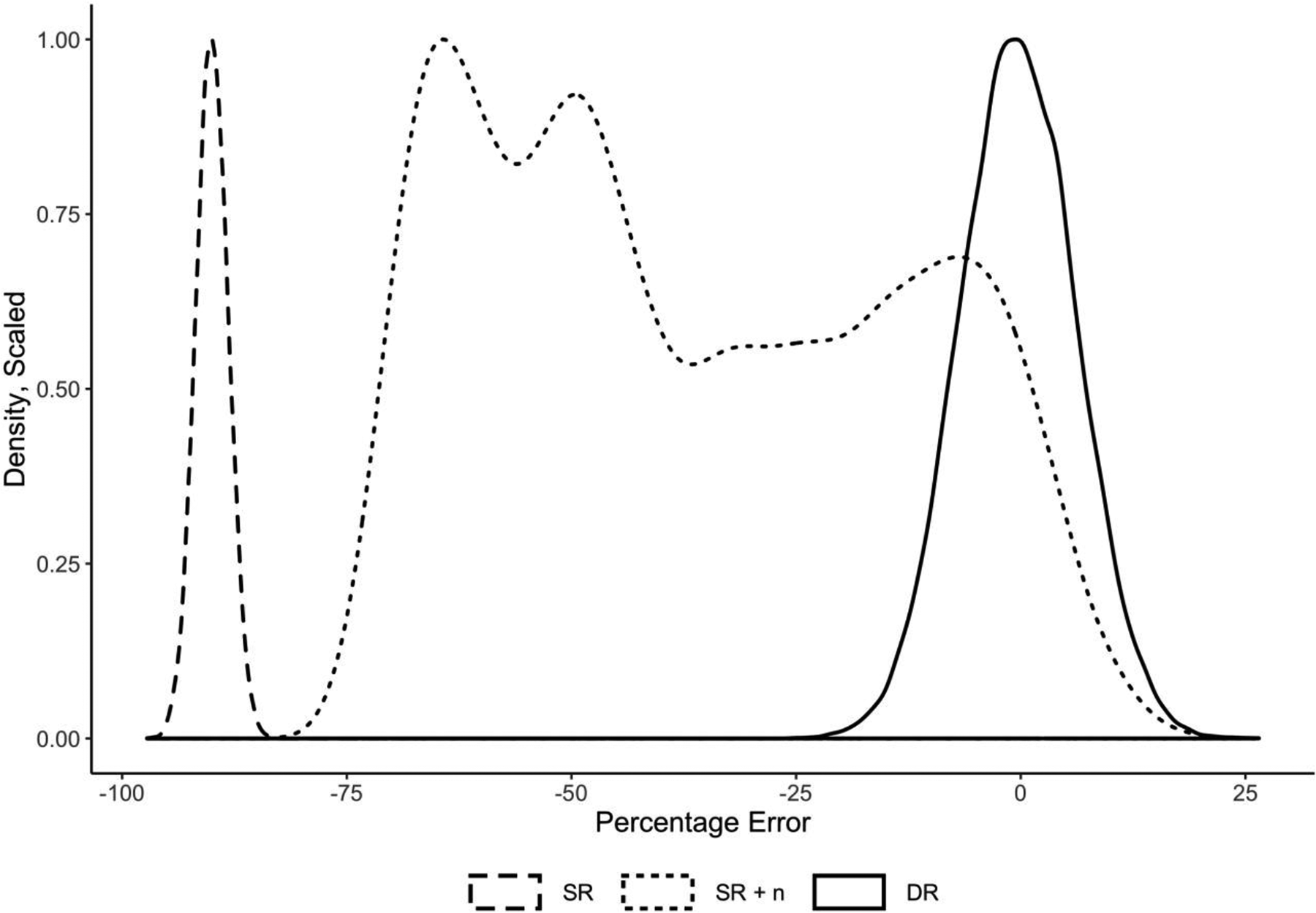
Comparison of error densities, three modeling approaches. Note: The densities were scaled to a maximum of 1. The error is defined as
Limitations
DR, then, seems to work reasonably well at estimating coefficients from simple models. There is, however, an important limitation. This method, based on residualization, only works where our variables are reasonably normally distributed—most importantly, where y >> 0. But in many cases of aggregate data, our dependent variables are counts that are on the order of 0–10. In particular, we often have many cases of relatively small n and fewer of large n, which means that we have many cases in which the dependent variable is quite small. In such cases, no method that relies on residualization can be expected to work correctly (see, e.g., Angrist and Pischke 2009), as we will tend to have many impossibly negative predictions for the cases with small n’s. For these reasons, we go on to propose and investigate the application of semiparametric models that may be used with Poisson distributed data.
GAMs
Here, we adopt a semiparametric modeling approach known as GAMs (Hastie and Tibshirani 1986, 1990; Hastie, Tibshirani, and Friedman 2009:295-304). Such models combine conventional parametric prediction with nonparametric prediction. The nonparametric aspects may be conducted via a number of different methods including loess smoothing and various forms of spline functions. In other words, given some nonparametric function f of n, we estimate the model
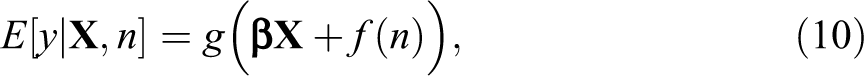
where g() is some link function,
It was this method that was used in Table 1, model 5—the model that did not reject the null hypothesis. While models 1 and 3 produced a significant positive effect of the number of churches on the number of Tea Party events and models 2 and 4 produced a significant negative effect, only the GAM suggested that we should not actually reject the null hypothesis of no relation between the two variables. As indicated by our diagnostics, the GAM was correct in not rejecting the null hypothesis.
It will be noted that when g() is the identity (linear) function, this model becomes

which is quite similar in expression to the model for the residuals, namely

The difference lies in the simultaneous estimation of f() and

where

and choose λ such that the average

where
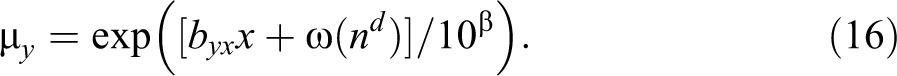
Because of the logarithmic link in the Poisson model between the outcome and the predictors, we make the formula for μ y take an exponentiated form of the n term. To compensate for the increased scale, we then divide by 10β where β is a tunable parameter chosen so as to give us the desired mean of y. We choose ω such that
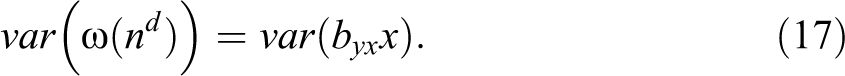
In other words, we try to make sure that x and n are contributing the same degree of variance in y across simulations. We here use a = d = .3 and byx = 2.
Figure 9 displays the results of simulations in which we vary the mean of y. For each method (GAM and DR), we display a line showing the average error (the bias) over 50 simulations, as well as surrounding lines indicating where the 25th and 75th percentiles of estimates lie. The distribution for the GAM is shaded and uses solid lines; that for the DR is unshaded and uses dashed lines. We can see that as the mean of y goes down, the error rises both for the double-residualized estimates and for those of the GAM. The GAM, however, performs well until the mean gets quite small and continues to have somewhat smaller errors at the lowest values of y.
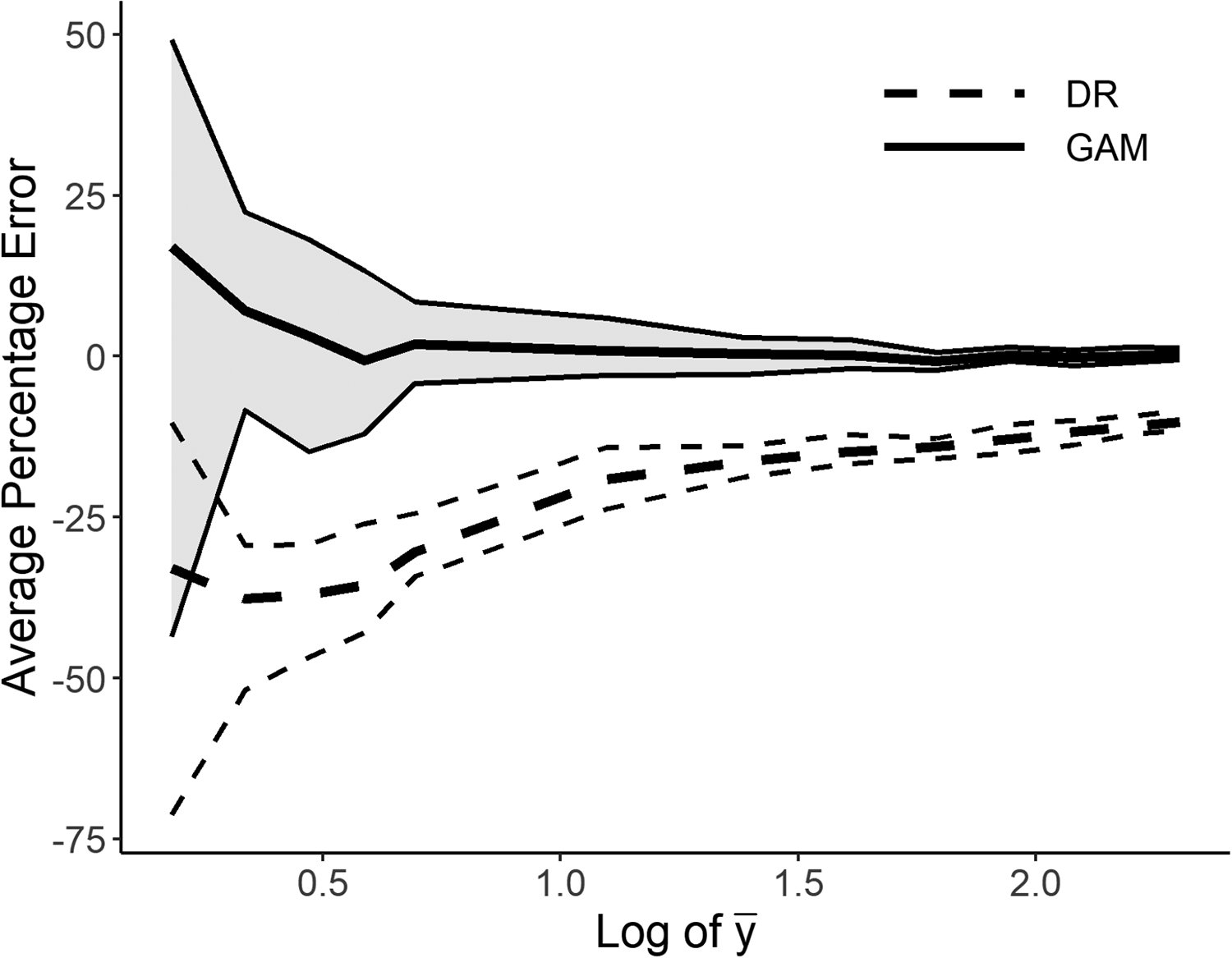
Comparison of average degree of error, double residualization, and generalized additive model. Note: Average percentage error (thick line) as well as the 25th and 75th percentile of the errors (thin lines). We drop values of mean(y) smaller than 1.2 because the variance of the errors gets very large, making the graph illegible.
Given that such a modeling approach seems to solve all our problems in one fell swoop, it may be asked why we should proceed with the DR model at all, as opposed to recommending the GAMs in all instances. First, there are extreme cases (illustrated in our provided code) in which the GAM is more likely to incorrectly reject a true null hypothesis than is the DR technique. 14 Second, the method of DR can be used to fit more complex models that cannot now be combined with the GAM, models that are likely to be of interest to scholars using aggregate data that come from areal units. Double-residualized methods could be combined with autoregressive (Anselin 1988) or nonstationary (Congdon 2006) models for spatially located data. We leave this for further exploration.
Conclusion
Some may respond to the critique offered in this article that since all of our models are wrong, and we must always simply hope that we have a reasonable specification, it is unfair to pick on certain types of analyses to be held to a higher standard than others. We have two responses to this objection. First, when it comes to aggregate data in which n varies across cases and puts some constraints on the distribution of both independent and dependent variables, we have good reason to think that our models have extremely high degrees of nonlinear interrelations, such that forms of misspecification that would, in other cases, be a minor problem, here lead to the generation of false positive results. Second, we do not object to subjecting all types of analyses to this standard. While we introduce and discuss this problem for the case of ecological data in which the goal is to control for population size, the argument is more general and can be applied to other cases in which both the independent variables and the dependent variable are complex functions of a third variable. As we have noted, similar approaches have been taken for data structures in which time forms a spine on which all covariance hangs.
We have demonstrated that it is possible to diagnose such problems and, when our data survive such diagnostics, to come up with better estimates of key parameters than is currently attempted in some subfields of sociology. These methods are no longer difficult to implement (our code is public allowing readers both to replicate our results and to use these approaches to determine the robustness of their own conclusions) 15 and may greatly improve our capacity to avoid falsely rejecting null hypotheses in ecological data when they are in fact correct.
Supplemental Material
Supplemental Material, sj-pdf-1-smr-10.1177_0049124120986188 - How (Not) to Control for Population Size in Ecological Analyses
Supplemental Material, sj-pdf-1-smr-10.1177_0049124120986188 for How (Not) to Control for Population Size in Ecological Analyses by Benjamin Rohr and John Levi Martin in Sociological Methods & Research
Supplemental Material
Supplemental Material, sj-zip-1-smr-10.1177_0049124120986188 - How (Not) to Control for Population Size in Ecological Analyses
Supplemental Material, sj-zip-1-smr-10.1177_0049124120986188 for How (Not) to Control for Population Size in Ecological Analyses by Benjamin Rohr and John Levi Martin in Sociological Methods & Research
Footnotes
Authors’ Note
An earlier version of this article was presented at the 2018 Annual Meetings of the American Sociological Association.
Acknowledgments
The authors are grateful to Peter Bearman, Tom Dietz, Ken Frank, James Murphy, Adam Slez, Rafe Stolzenberg, Steve Vaisey, Joshua Mausolf, Xi Song and the anonymous reviewers for their comments and discussion.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.