
Abstract
Scientific models can be performative: they can causally affect the phenomena they are intended to represent. The existing literature offers two responses. The appraisal view emphasizes that performativity can sometimes be a good-making model attribute, e.g., when predictions steer the public’s behavior in desirable ways. The mitigation view seeks to endogenize agents’ behavioral response to model-issued forecasts to get rid of performativity instead. This paper argues that neither approach is fully compelling: the appraisal view encounters severe concerns about moral values illegitimately encroaching on how modelers construct and use models, while the mitigation view fails to acknowledge that endogenization is itself a choice that involves substantive value-judgments relating to the desirability of certain social outcomes.
1. Introduction
Scientific models can be performative: in addition to serving various epistemic purposes, they can also causally affect phenomena, such as when agents’ behaviors change in response to model predictions. In recent years, philosophers have made substantial progress in delineating different forms of performativity and characterizing the problems they can pose, such as when the forecasts researchers derive from models are self-defeating and compromise models’ epistemic functioning (Avery et al. 2020b; Godman and Marchionni 2022; Jiménez-Buedo 2021; Northcott 2022; Tee 2019; van Basshuysen 2022; van Basshuysen et al. 2021; Vergara-Fernández, Heilmann, and Szymanowska 2023; Winsberg and Harvard 2022).
The existing literature offers two broad types of response to model performativity. First, to maintain models’ predictive performance one can endogenize, i.e., explicitly model how agents will respond to a prediction and accommodate this response in the predictions made. This mitigation approach has been pursued by social scientists as early as the 1950s (Grunberg and Modigliani 1954; Simon 1954) and currently enjoys renewed interest (Avery et al. 2020b; Perdomo et al. 2021). A second approach was recently outlined by Philippe van Basshuysen, Lucie White, Mathias Frisch, and myself in the context of epidemiological models informing policy responses to the SARS-CoV-2 pandemic (van Basshuysen et al. 2021). There, we argued that performativity can sometimes be understood as a good-making model attribute, e.g., when predictions derived from models, such as that critical care demand will exceed capacity, steer the public’s behavior in desirable directions. Our appraisal approach hence understands models as tools that have both epistemic and performative capabilities, both of which should be considered in model evaluation, and permits (some forms of) performativity to count as a good-making feature of models (see Vergara-Fernández, Heilmann, and Szymanowska 2023 for related proposals).
In this paper, I argue that neither approach is fully compelling. 1 The appraisal approach recognizes that performative models may have good-making performative features, but, as we stress in van Basshuysen et al. (2021), struggles with providing guidance for adjudicating models’ epistemic and performative roles when they are in tension. Specifically, while it might sometimes seem appropriate to appraise models post-hoc for having made performative contributions (e.g., helping agents manage their response to a new wave of SARS-CoV-2 infections), performativity should not figure as a criterion in model construction since doing so can incentivize unacceptable value influences to encroach on the construction and use of models and may threaten the epistemic integrity of model-based science (cf. Winsberg and Harvard 2022).
The mitigation approach, by contrast, does not seem to get into such murky waters. It maintains that performativity is a phenomenon that can be kept in check by endogenizing individuals’ behavioral response to model outputs. However, I argue that in aiming to keep performativity in check, the approach disregards that (1) by “endogenizing away” agents’ behavioral response to align forecasts with actual behaviors, it neglects the potential real-world pragmatic benefits that performative models can harbor, and (2) because endogenizing behavioral response can prevent such benefits from obtaining, endogenization is itself a choice that involves substantive value-judgments. There is hence no value-neutral stance when deciding whether to let model outputs influence behaviors or to prevent such effects from obtaining.
With neither option able to keep important value-related concerns at bay, I offer some constructive proposals for managing performativity, i.e., acknowledging models’ performative contributions, while ensuring that their epistemic integrity remains uncompromised. I especially focus on carving out clearer principles to help keep value-influences from illegitimately meddling with the production and use of models to inform policy. Several decision points concerning model construction and use must be kept independent of researchers’ views regarding the desirability of potential performative effects. What is more, while decision-makers may legitimately make value-laden choices about how to interpret model outputs, how to use them in decision-making, and how to communicate their decisions to the public, they must refrain from suggesting that their decisions follow straightforwardly from model outputs (e.g., claiming that they merely “follow the science”). This is to ensure that models do not carry excessive justificatory burden in grounding value-laden decisions.
The discussion is organized as follows. Section 2 clarifies the concept of model performativity and briefly outlines the case of performative Covid models discussed in the literature. Section 3 outlines the two major approaches for dealing with performativity, appraisal and mitigation, reconstructs and sharpens the main concerns about the appraisal strategy, and argues that mitigation is susceptible to related concerns about illegitimate value influences. Section 4 further elaborates the central tensions arising when models have performative capacities, emphasizes important contextual features that bear on how performativity may be addressed, and proposes a general principle to mitigate the most severe value-related concerns raised by performativity. Section 5 concludes.
2. What is Model Performativity?
Model performativity is now situated in a rich and growing conceptual forest with cognate notions tracking several related phenomena, including reactivity, reflexivity, interactivity, and others (see Buck 1963; Godman and Marchionni 2022; Henshel 1993; Jiménez-Buedo 2021; Vergara-Fernández, Heilmann, and Szymanowska 2023). I will not explore these related concepts and the interesting arguments they ground, nor offer a general account of performativity or trace its rich intellectual history (see Callon and Roth 2021; Guala 2007; Mäki 2013; MacKenzie 2006; Perdomo et al. 2021; van Basshuysen 2022). For the purposes of this paper, I understand model performativity simply according to the following broad, causal construal (cf. Buck 1963; Henshel 1993):
2
Let me add some clarifications right away. First, by capacity I mean an actualized disposition to causally affect a target. All kinds of models could have any number of unactualized dispositions to affect a target, but these will be bracketed here. So, a model is performative when it actively changes aspects of a target, by itself or through particular ways of using it. Second, a performative effect is the difference to a target system that is, causally, due to the model and its outputs. Third, in understanding model performativity, it is important to note that models are rarely performative as such but typically become performative only when embedded in a concrete context of use, which establishes causal connections between the model and its target (see Vergara-Fernández, Heilmann, and Szymanowska 2023). It often takes a user who does something with a model (e.g., derive and publicize a prediction) to establish such a connection. Finally, performativity can come in many different forms, but the discussion here will mostly focus on cases where a model’s predictions affect some of the quantities to be predicted, e.g., by triggering behaviors of agents in a target that affect these quantities.
3
Several subtypes of performative model predictions are routinely distinguished (Buck 1963; Henshel 1993). For instance, self-fulfilling performativity obtains when a model correctly predicts a quantity
Despite some detailing, the working construal of model performativity offered here is still extremely broad (cf. Callon and Roth 2021; Perdomo et al. 2021). Virtually all models whose outputs are involved in decision-making can count as performative to some degree, e.g., when ecologists use models to inform ecosystem preservation policies and these policies are efficacious in making a difference to features of the system modeled. Or, moving away from scientific models, when a physical scale model of a building is used to make design or engineering decisions that affect how the building is eventually constructed at scale. We might hence worry that this construal of performativity is too inclusive. While I do not see serious problems with the extension of performativity being large, a first pass to focus on a narrower class of phenomena is to make a distinction of significance: model performativity of potential interest to philosophers of science is simply the subset of cases where performativity raises significant epistemic-ethical issues. So architectural models would not regularly make the cut, or really any mundane use of models to achieve unproblematic practical aims relating to changing a target.
A second, less haphazard way of detailing performativity is to explore what makes some cases seem more significant. One feature that plays an important role here is the extent to which model users and agents whose behaviors are influenced by the model are aware of a model’s performativity. Conscientiously and successfully using a model to inform efforts to change a target, as such, is often unproblematic and perhaps not especially philosophically significant. 5 However, using a model for predictive purposes and remaining unaware that a target’s behavior is influenced by the very predictions that are supposed to provide epistemic access to it, can indicate that something is going wrong, epistemically, ethically, or both. Awareness of whether a model is performative comes in degrees and model builders, users, and those exposed to any performative effects may each have different degrees of such awareness. Speaking generally, it seems that the less aware relevant stakeholders are of a model’s performativity, the more likely it is that some epistemically and/or ethically problematic is going on, e.g., when users of an economic model are unaware that they are not merely predicting a financial crisis, but rather facilitating it and agents remain unaware that the prediction was not inescapable but merely self-fulfilling. This is not to suggest, however, that awareness of a model’s performativity makes a case unproblematic or uninteresting. For instance, it is now widely understood that models used to predict user engagement and guide what information we are exposed to on social media can be performative: they not only serve to predict what contents are most interesting but can also cement or induce interests, preferences, and behaviors (Cinelli et al. 2021). It seems that especially in cases where modelers make value-laden choices in model construction to promote or hinder certain performative effects and this ends up negatively affects agents’ outcomes without them being aware of this, agents are wronged in a special kind of way: a lack of awareness or understanding often implies a lack of agency, e.g., to resist, respond to, or challenge a prediction or the dynamics triggered by it. Finally, even if relevant stakeholders are aware of a model’s performativity but this performativity is unintended and/or contravenes at least some values held or goals pursued, this equally has the capacity to make a case of performativity epistemically and ethically significant, either because it points to the inadequacy of the model for the purpose at hand, or because its use has undesirable consequences for at least some stakeholders.
I expand in more detail later on additional contextual factors that can moderate whether performativity is epistemically or ethically problematic and which avenues are best for managing it. For now, let me introduce a working example, performative epidemiological models of the SARS-Cov-2 pandemic, which will help elaborate the two main strategies to manage performativity. Although the case of Covid models is, arguably, not a paradigmatic instance of performativity in social science contexts, there are several reasons for discussing it as the central case study here. First, the recent literature engaging with the epistemic-ethical aspects of model performativity has focused on this case (van Basshuysen et al. 2021; Winsberg and Harvard 2022) and the contributions offered there are best discussed and critically challenged in their original context. Second, the case of Covid models is tractable: the models used were often simple and the dynamics of how individuals may respond to model forecasts are intuitively graspable. Third, arguably, people responding to model forecasts about the trajectory of a pandemic involves causes and concepts that figure centrally in social scientific analysis, e.g., individual constrained optimization in light of tradeoffs, norms, institutions, and so on, which are familiar modes of analysis to social scientists. In virtue of this, the lessons learned from this case can also be easily transferred to other cases of interest (I point to some later on).
2.1 Performative Covid Models
In the early stages of the SARS-Cov-2 pandemic, modeling groups around the world built epidemiological models to forecast the trajectory of key pandemic variables, e.g., number of infections, deaths, and so on. In van Basshuysen et al. (2021), we argued that these forecasts recognizably shaped policy advice offered to policy makers in the US and UK: shortly after release of the infamous ICL Report 9 study (Ferguson et al. 2020), policy makers changed policies dramatically from mitigation toward aggressive suppression measures, including strict lockdowns. In addition, especially in the early stages of the pandemic, it seems likely that dramatic forecasts such as those made in Report 9, i.e., around 510k deaths in the UK and 2.2 M in the US if viral spread were left unmitigated, had direct effects on individuals’ behaviors, too, e.g., people reducing contacts and self-isolating ahead of lockdown policies, or interpreting rules more strictly (Friedson et al. 2020; Sears et al. 2023). The epidemiological models in this case were performative in the sense that they causally affected some or all of the features of the target systems they represented. If people became more cautious in response to model forecasts and increased cautiousness decreased contacts and thereby infection numbers and deaths, this directly affected the quantities targeted and would hence be an archetypal case of model performativity. Importantly, performative effects such as the ones sketched in van Basshuysen et al. (2021) often imply that a model’s predictive abilities are diminished: when a model is used to (publicly) predict
Let me reconstruct and elaborate two competing views that deal with this problem in different ways. First, the appraisal view, which acknowledges that performativity can be epistemically undesirable, but maintains that performative effects can nevertheless be a good-making feature of models. Second, the mitigation view, which prioritizes models’ epistemic functioning by getting rid of performative effects. Aiming to make progress on understanding which of these views is more plausible, I argue that while the appraisal view faces severe concerns about illegitimate value influences in model construction and use, the mitigation strategy, despite promising to do better, is vulnerable to similar concerns.
3. Responding to Model Performativity
3.1 The Appraisal View
Covid models have been widely criticized for their poor predictive performance (Avery et al. 2020a; Ioannidis, Cripps, and Tanner 2020; Winsberg, Brennan, and Surprenant 2020). Against the background of such criticisms, we argued that when assessing Covid models, we should not only look at their forecast accuracy but also at their performative contributions (van Basshuysen et al. 2021). More specifically, while there are good reasons to think that many Covid models have been predictively far from impressive, it is unclear whether this alone is enough to conclude that they were bad models, full stop. For one, we emphasize that in assessing the epistemic contributions of Covid models, we must understand a majority of their outputs as conditional forecasts 6 for counterfactual scenarios rather than as straightforward predictions of actual courses of events (see also Fuller 2021; Schroeder 2021). So, if a conditional forecast predicts millions of deaths for a scenario where no measures are taken and, in response to that, aggressive suppression measures are implemented, it should be no surprise that actual death tolls are much lower than the forecast. Due to the policy measures implemented, the relevant quantity to assess forecast accuracy is now a counterfactual quantity that cannot be observed and at best estimated (Friedman et al. 2021; Winsberg and Harvard 2022). To be sure, many Covid models have also been used to issue a range of different scenario forecasts, including some capturing scenarios that more closely resembled actual policy trajectories taken. But even when looking at these scenario forecasts, some critics maintain that forecast accuracy has been poor, with many models overestimating infection numbers and deaths (Winsberg, Brennan, and Surprenant 2020; Winsberg and Harvard 2022).
So, should we conclude that Covid models have been bad models? In van Basshuysen et al. (2021) we argued that such a conclusion would be too hasty, sketching what I call the appraisal view. Specifically, we maintain that we should not only focus on forecast accuracy when evaluating Covid models, but should instead take an all-things-considered view, which takes into account their performative contributions to the achievement of (some) social goals (though possibly at the expense of others; see Winsberg and Harvard 2022). In a nutshell, the appraisal view maintains that it can be a good-making feature of Covid models that they helped individuals understand the likely trajectories of the pandemic, choosing response profiles that were (more) consistent with their preferences, and thereby contributing to lower infection numbers and death tolls. Performative effects such as these are part of what we should consider when assessing the overall goodness of models. Figure 1 captures this line of thinking in an idealized fashion. Beneficial performative effects.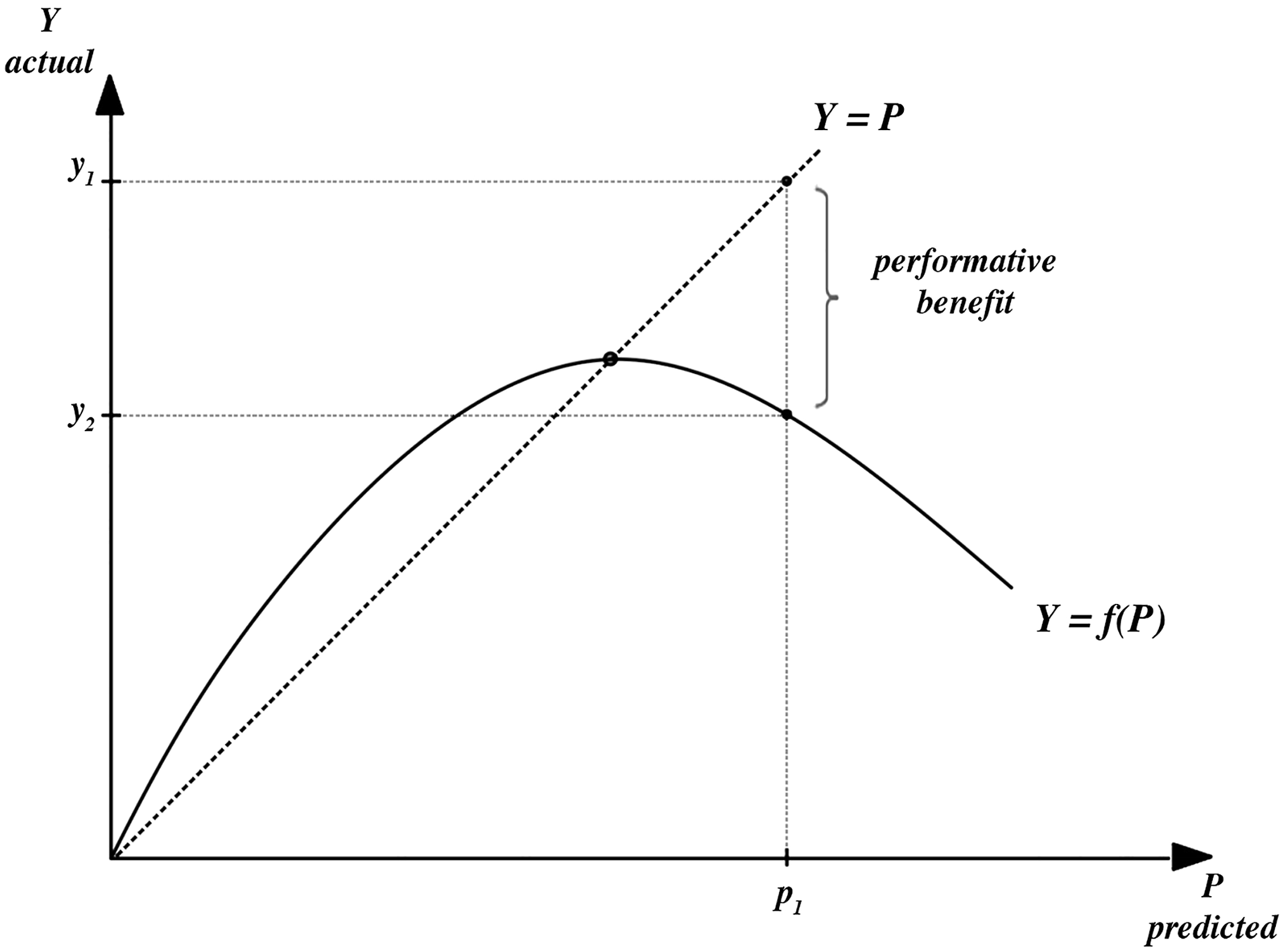
Focusing on infection numbers as the quantity to be predicted, the P-axis plots model predictions and the Y-axis plots actual infection numbers. In a non-performative world with perfectly accurate models, the predictions from a model would be on the dotted 45° line, perfectly coinciding with observed values, i.e.,
Is the appraisal view plausible? Endorsing performativity as a good-making feature may seem inappropriate for a wide range of scientific models. When a model is designed for purely epistemic purposes, it will often seem unhelpful at best and problematic at worst to think that a causal coupling between a model and target that systematically prevents a model from producing accurate forecasts can be a good-making feature. However, Covid models were constructed and used specifically for the purpose of (helping decision-makers with) inhibiting and controlling the spread of the virus, and the performative effects outlined in van Basshuysen et al. (2021) promote those same practical goals. So, broadly following an adequacy-for-purpose type view on model appraisal (Parker 2020), why should we not consider the achievement of these goals to be a good-making feature if models causally contributed to it?
Winsberg and Harvard (2022) argue that performative effects should never be considered good-making features of models. One of two main worries they flag is that any inaccurate forecast could always be explained as the result of performative effects and allowing performative effects to count toward a positive appraisal of a models’ overall goodness would only make it easier to conjure up such ad hoc defenses. An important constraint on the appraisal view, therefore, should be that models’ counterfactual forecasts (sans performativity) must be approximately accurate:
9
if a model forecasts high infection numbers (
Even if such efforts were successful, however, there is a second important problem with the appraisal view that we anticipated in van Basshuysen et al. (2021) and that Winsberg and Harvard further discuss. To appreciate this problem, let me cast the appraisal view in somewhat clearer outlines:
As we emphasize in van Basshuysen et al. (2021, 123), the second condition can be met in two significantly different ways, giving rise to two quite different renditions of the appraisal view. To see this, let us assume that there is a set of moral and political values
In van Basshuysen et al. (2021, 123), we caution that this normative rendition of the appraisal view is highly problematic, since it invites tuning model forecasts to steer people’s behaviors in certain directions. Even if the purposes that modelers sought to promote this way were successfully tracking an uncontroversial set of values Imagine holding an annual race in which we tell runners that the goal is to complete 10 km in the fastest possible time, but where, year after year, we award the medals to runners who most quickly reach the 5 km mark. Hopefully it is clear that we cannot neatly separate how runners will be evaluated from what they will eventually adopt as their goal. The same will be true of modelling. If those who judge the suitability, adequacy, or usefulness of a model give it high marks when it succeeds performatively (according to the values of the judges in question), they will be sending the signal that modellers should adopt this goal. (Winsberg and Harvard 2022, 4)
So, even if we managed to ensure that models got their counterfactuals right, and pressed modelers to demonstrate that this is so, counting (some) performative effects as good-making features of models could induce incentives that divert modelers’ attention away from epistemic goals such as forecast accuracy toward performative goals, such as issuing forecasts that are likely to steer behaviors in putatively beneficial ways. Modelers’ goals, we might insist, should primarily focus on doing as good of an epistemic job as possible, which includes getting counterfactual and actual scenario forecasts right, and the best way to ensure this is to exclude performative effects from consideration in model appraisal. According to Winsberg and Harvard, then, the best way of shutting the door on the normative rendition of the appraisal view is to reject the appraisal view altogether.
So if appraisal is no good, how should we deal with model performativity instead? Let me consider a second strategy for dealing with performativity, the mitigation view, which, at face value, promises to evade these concerns, but ultimately falls prey to similar worries.
3.2 The Mitigation View
The mitigation view aims to deal with model performativity by getting rid of it. Starting in the 1950s, economists and political scientists began investigating how publicizing election polling results could alter election outcomes (Grunberg and Modigliani 1954; Simon 1954). Two widely-discussed ways in which this could happen are the bandwagon and underdog effects. 12 The former captures a case where a candidate A is predicted to win an election against B and, because of this public prediction, more voters than otherwise turn out in support of A. The underdog effect describes the converse: if A is predicted to be ahead in the race, some voters who would have otherwise voted for A end up voting for B, because they want to vote for whoever is behind in the race. In either case, the first-stage prediction of the election result will turn out to be inaccurate because agents respond to the public prediction—it is performative.
Against the background of such cases, Grunberg and Modigliani as well as Simon undertook analytical investigations to determine conditions under which public predictions could be modified so as to endogenize peoples’ behavioral response, i.e., to explicitly model how individuals respond to a prediction and to formulate an adjusted prediction that takes that response into account and brings predictions in line with actual results in equilibrium. Similar efforts to endogenize peoples’ behavioral response have recently been undertaken by epidemiological modelers and computer scientists (see Avery et al. 2020b for an overview; see Perdomo et al. 2021 for efforts in machine learning). Figure 2 captures how following the mitigation strategy could look like in the Covid modeling case. The harm from endogenizing.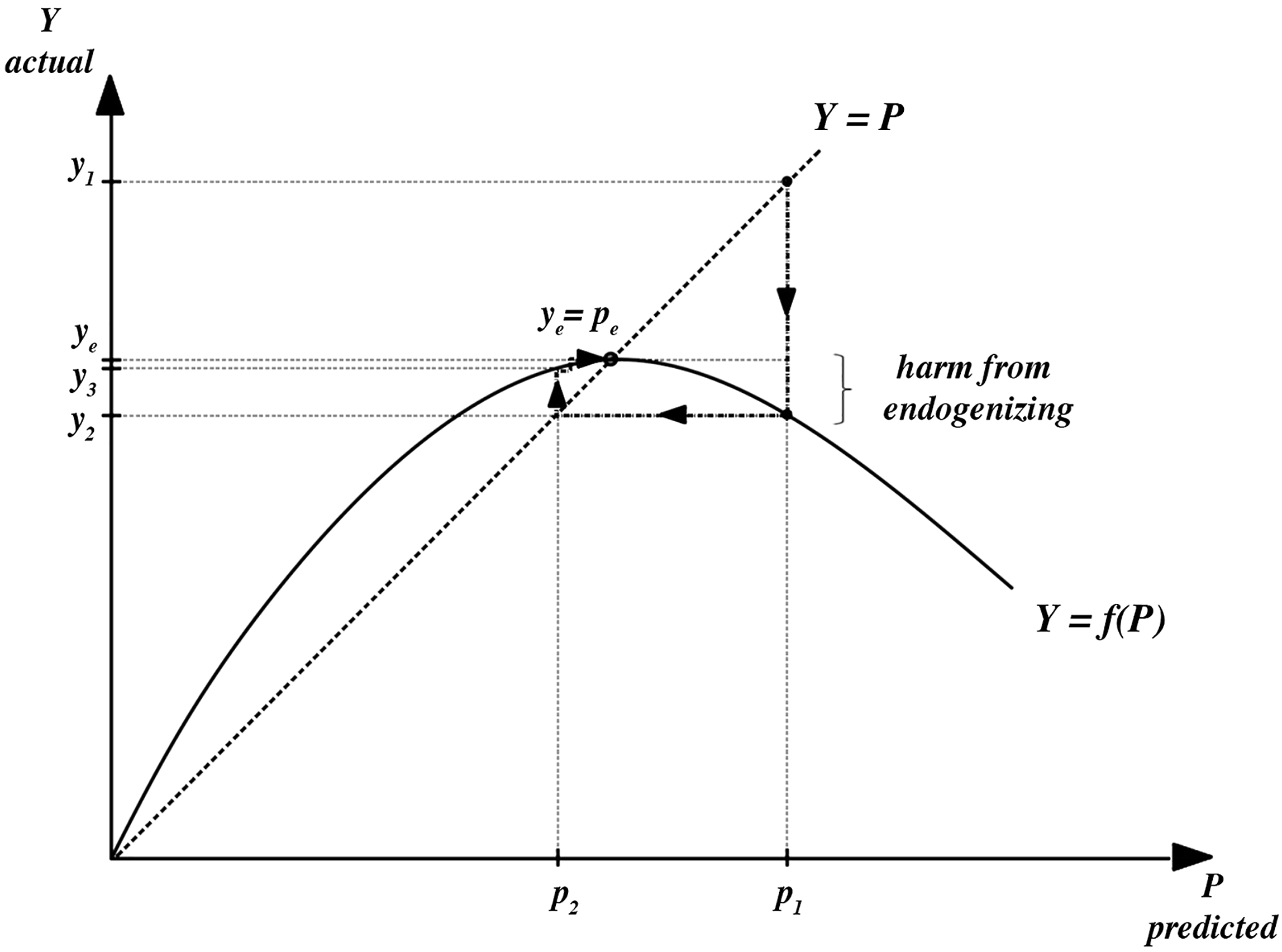
The response curve is the same as before. In addition, the dash-dotted lines and arrows capture schematically how behavioral response is endogenized.
13
The first-stage prediction,
Is this a good way of dealing with performativity because it avoids moral and political value judgments encroaching on the appraisal and thereby the construction of scientific models? Not necessarily. Importantly, when taking the mitigation route,
What is important to note, then, is that there can be trade-offs between epistemic and practical purposes and the mitigation view settles this trade-off in favor of epistemic purposes at the potential cost of inferior social outcomes. The appraisal view, by contrast, is open to accepting compromises in predictive performance in exchange for practical benefits. Crucially, this means that both routes reflect a value-laden stance on the trade-off, and despite initial appearances to the contrary, the mitigation strategy is subject to concerns about illegitimate value influences, too (see also Brown 2017). Why, after all, should we think that it is overall better to have a model accurately predict infection numbers when this means that those numbers would be higher than if we had not endogenized behavioral response? Why should not we think it can be preferable to have a model overestimating infection numbers (i.e., making first-stage predictions that do not consider performative effects), thereby contributing to behaviors that realize lower numbers? Answering these questions, necessarily, involves moral values because the choice of whether to endogenize or not is not only a choice between better and worse predictive performance but also a choice between two different social outcomes (
The mitigation view hence leaves us an uncomfortable epistemic-ethical bind. Model performativity can sometimes yield beneficial outcomes, and there are reasons to think that these may be counted toward the overall goodness of a model in epistemic-practical terms. Such a view, however, must also manage concerns about illegitimate value influences that threaten to undermine the epistemic integrity of specific models, and model-based science more generally. An alternative can be to “endogenize away” performative effects by modeling how agents respond to predictions. However, this route similarly faces difficult questions about what legitimizes modelers to make modeling choices that ultimately select different social outcomes than would have been realized without mitigation attempts. Recognizing this helps us appreciate that Winsberg and Harvard’s call to reject the appraisal view for the threats posed by its normative rendition does not take us very far when the relevant alternative, mitigation, is subject to similar concerns about illegitimate value influences. Worries that the appraisal view opens the door to such influences are hence misplaced—the door has been open all along, but proponents of mitigation-type approaches have so far not adequately recognized it. Faced with a choice between a rock and a hard place, let me now turn to explore whether we can find some smoother pebbles in between, by considering (1) what principles could help keep the most severe value-related concerns affecting both views at bay and (2) how contextual factors bear on the adequacy of both strategies for managing performativity.
4. Managing Performativity
It is clear now that both routes to deal with model performativity need a safeguarding principle to mitigate concerns about illegitimate value influences at central stages of model construction and use. The main target of such a principle is to prevent moral and political values from illegitimately encroaching on the construction and use of models, be that through modelers tuning models to effect specific behavioral responses or by modelers endogenizing behavioral response and thereby, at least tacitly, making value-related commitments that favor some social outcomes over others. A general principle that could help break these tensions is: (
Addressing the appraisal view, orthogonality requires that the choices modelers make in constructing and using models be robust over changes in their views on the desirability of certain social outcomes. Taking the Covid case, regardless of whether modelers think that saving lives is of utmost importance or that aggressive suppression policies are inappropriate because they unacceptably infringe on civil liberties, their choices of what to model, how to model it, and so on should not be steered by these considerations. Importantly, orthogonality goes both ways and does not only focus on putatively positive performative effects: if a model foreseeably has negative performative effects, this should not influence modeling choices either. For instance, consider a case where policy makers’ and the public’s priors on the severity of the pandemic early on are wildly exaggerated, anticipating Millions of deaths within weeks (
Addressing the mitigation view, orthogonality insists that, in the first instance, the choice of whether to endogenize or not should not depend on modelers’ assessment of the desirability of the performative effects to be endogenized. However, orthogonality does not go further than that. It cannot help with the fact that the choice of whether to endogenize or not may invariably promote some social outcomes over others and is therefore, necessarily, a value-laden choice. I expand shortly on how orthogonality may help at least in ensuring decisions such as these are made by agents who are (more) suitably legitimized than modelers, e.g., democratically elected decision-makers.
Whether orthogonality is important, and whether mitigation or appraisal seem more appropriate also depends importantly on contextual factors. Let us consider some cases, including some more fully located in the social science realm, to see this. First, suppose an extreme case where climate modelers across different modeling groups begin to systematically meddle with climate model parameters to exaggerate the extent and projected impacts of anthropogenic climate change. Their aim, let us suppose, is to motivate policy makers and the public to take more drastic action in reducing greenhouse gas emissions and investing in climate change adaptation and mitigation policies. This practice would be highly problematic, for it may undermine the credibility of specific simulation results and of modeling/simulation studies in climate science more generally. Even if the first-order effects on policy and the public’s behaviors were desirable as such, promoting performativity in this way should be resisted. Contrast this with a second case involving central banks. Suppose central banks begin to parameterize their macroeconomic forecasting models to induce specific inflation expectations on the part of institutional and private actors so that these behave in ways that help the banks achieve their inflation targets. While certainly questionable, this case does not seem as problematic as the climate science case. First, central banks have a mandate (at least derivatively) to steer inflation expectations, and are widely understood to pursue actions within the envelope of this mandate. Their role is hence significantly different from that of climate scientists, who do not have a mandate to intervene in socioeconomic systems with the aim of effecting, say, specific policy trajectories or certain levels of global warming. A second important difference is that there is a much more level epistemic playing field. Institutional actors (e.g., banks and insurance companies) have their own epistemic resources that can help them resist unduly manipulative attempts on the part of central banks to steer expectations. So, while promoting performative effects seems less problematic in the central bank case for the shared understanding of what central banks’ roles are, it will also be substantially less effective, since other actors can more easily tell whether central banks are making epistemically faithful forecasts or are rather trying to steer expectations. What these contextual differences suggest is that performativity is especially problematic when epistemic resources are unevenly distributed, when communicating modeling results to policy makers and the public must rely on a substantial but ultimately fragile architecture of trust, and when agents’ shared understanding of scientists’ role maintains that they do not, and should not, attempt to steer policy and behavioral response in specific ways. Finally, third, an altogether different case obtains when models themselves, as epistemic tools made available to a population, can have performative effects in shaping outcomes of a target. An interesting case study in this regard are financial market models such as the capital asset pricing models (CAPM) recently discussed by Vergara-Fernández, Heilmann, and Szymanowska (2023). Such models may afford (certain) financial market actors with novel abilities to intervene in the market, including in socially undesirable way, e.g., by creating novel products, institutions, or ways of engaging the market that involve problematic forms of risk imposition on the general public (e.g., increasing the risk of financial and economic crises). Models are epistemic technologies, and when they enable (perhaps foreseeably) negative outcomes by virtue of their performative capacity to re-shape market interactions, we may consider whether modelers who furnish these technologies have special epistemic-ethical responsibilities regarding such effects (Vergara-Fernández, Heilmann, and Szymanowska 2023, 20). Here, orthogonality would seem misplaced, as we may think that value judgments relating to the potential harms induced by releasing models into the wild should play an important role in regulating decision-making at various points. Perhaps these should not be modelers’ own values, but values, as such, are clearly needed and orthogonality should steer clear of ruling out their appropriate involvement.
Despite some progress made on understanding when orthogonality seems important to pursue, it nevertheless remains an extremely general principle, more akin to a goal rather than a recipe for how to achieve that goal. This is a feature shared with many existing attempts in the values-in-science literature to formulate general principles to regulate the ways in which values may bear on the conduct and outputs of scientific research, e.g., versions of the value-free ideal (Betz 2013; Biddle 2013; Brown 2017; Douglas 2009; Elliott 2017). Like such contributions, orthogonality marks an attempt to formulate a general principle which can subsequently be assessed for its plausibility over a range of contexts and refined accordingly. In fine-graining orthogonality, it seems important to consider with regard to what aspects of model use it seems an appropriate goal to pursue, including: 1) How should models be built? What is modeled and how? 2) How should model outputs be interpreted and communicated? 3) What recommendations should be made based on model outputs? 4) How should modeling study results be used in decision-making? 5) How should decisions be communicated to the public?
Across these aspects, orthogonality is only plausible for some and not others. Specifically, it seems that concerns about illegitimate value influences in regards to appraising, facilitating, mitigating, or managing performativity predominantly affect the first two aspects. This is where concerns about wishful modeling are most likely to occur, and where orthogonality is needed.
Turning to stage 3), the issue of whether and how researchers should make recommendations based on model outputs is contentious (Carrier 2022; John 2018; Gundersen 2020). I will not engage here with the various positions that have been offered in the literature and only note that much depends on specifics of the context and what type of view one takes on appropriate roles for scientists advising policy. For instance, when research is specifically commissioned to address concrete evidentiary needs arising in a decision-making context and decision-makers issue a mandate to researchers that allows or instructs them to let specific, independently determined value judgments inform the recommendations they make, this can make orthogonality seem less pertinent. To the extent that decision-makers are suitably legitimized in letting specific values bear on decision-making and researchers are understood to operate as advisors who take pre-determined value-judgments on board when issuing recommendations, orthogonality seems misplaced. Of course, we may still insist that researchers’ own values should remain orthogonal to what recommendations are made and that they should properly enable the value-influences sanctioned by decision-makers even if these contravene their own values. So, depending on such contextual factors, orthogonality may seem important to pursue, or rather misplaced, and no general judgment concerning its appropriateness regarding (3) seems plausible.
Focusing on (4) and (5), it is clear that the decisions at issue here are rarely made by modelers, but usually (or so I assume) by suitably legitimized decision-makers afforded with a mandate to make value-laden decisions on behalf of others. Orthogonality, as articulated earlier, trivially does not apply here, since it was framed in terms of modelers’ choices. But we could envision a wider reading of orthogonality, according to which model construction and use should be independent also of users’ and decision-makers’ views on the desirability of certain performative effects. For instance, there might be concerns about decision-makers specifically commissioning studies that are likely to yield outcomes, which they can use to provoke certain desired responses on the part of the public, e.g., by asking researchers to explicitly focus on modeling worst-case scenarios, or by cherry-picking evidence to help promote certain goals. Yet, aside from playing a role in regulating wishful thinking in regard to what research is commissioned or what studies are considered, it seems that orthogonality is not an especially plausible general principle for governing decision-making at (4) and (5). Determining how to use modeling study results in decision-making, making such decisions, and communicating them to the public is fully in the realm of policy-making, so it should neither be surprising that moral and political values play important roles here, nor especially worrying that they do (though the specific values involved will often be contestable). Yet, while the role of orthogonality will be relatively less important in regard to (4) and (5), it should be emphasized that there can nevertheless be more general concerns about performativity that arise here, too.
For one, while we might cynically say that much of public policy making is about steering the public’s behaviors in certain, putatively desirable ways, it is important to insist that policy-makers do not misuse models for these purposes. Specifically, decision makers should not claim that the policies they adopt follow straightforwardly from modeling studies, emphasizing that they merely “follow the science.” Models may play a justificatory epistemic role in helping decision-makers justify beliefs that enter into a decision-making procedure, but they should not play an unmediated justificatory role in recommending specific actions be taken, especially if the values involved in selecting those actions remain poorly articulated. Winsberg and Harvard share this concern when emphasizing that “[…] we should guard against models being used to justify existing political views by representing their favoured policies as the ones that ‘follow the science’. Otherwise, our standards of scientific and democratic scrutiny will suffer” (Winsberg and Harvard 2022, 6). Reinforcing these concerns, we might indeed insist on a dependency principle, which requires decision-makers to articulate how their decisions depend not only on model forecasts but also on values that are necessarily involved in arriving at decisions that are informed by such forecasts.
A second, related concern is that policymakers acting on a forecast can itself have performative effects by lending further credibility to that forecast (or diminishing it), thus additionally influencing individual’s response to forecasts, and it seems unclear what epistemic-ethical obligations policy makers have in regard to referring to specific modeling results as underwriting their decision-making (see Carrier 2022). This relates intimately to broader concerns about deciding whether to communicate model study results at all to the public, which results to communicate, and how to do so. Policy-makers could conceivably choose to withhold forecasts from the public if they believe that publicizing them would have undesirable performative effects. This, of course, can be highly controversial, just like cherry-picking evidence or wishful modeling. Importantly, however, these are controversies about the justification and communication of political decision-making rather than about the construction and use of models by modelers and so insisting on orthogonality here does not seem to be the right kind of way to deal with these controversial aspects of public policymaking.
How can orthogonality be achieved in those cases where it is appropriate to pursue? I will not provide detailed recipes here, as this issue hinges significantly on contextual factors, including the stakes involved, the purposes for which models are used, how level the epistemic playing field is, what epistemic and practical resources are available, and so on. So, this is best left for future work. That said, it seems likely that existing proposals to manage the influence of moral and political values on the conduct and outcomes of scientific research provide a fruitful menu of options to explore (see also Godman and Marchionni 2022; Nixon et al. 2022 for related proposals), including measures such as (1) considering what kinds of institutional designs can help facilitate a clearer division of labor in regard to what decisions are made by which types of agents, (2) making progress in further articulating the epistemic-ethical duties of modelers and policy-makers (see Winsberg and Harvard 2022, 6) and exploring what roles modelers may legitimately refrain from playing (e.g., making decisions about how to handle performativity), (3) facilitating transparency and public understanding of the invariably value-laden nature of using models for policy, and (4) promoting open science measures, such as open data, open code, open peer review, pre-registration and pre-analysis plans, and related instruments that prompt researchers to articulate the epistemic and practical purposes of their modeling studies to help promote public scrutiny.
5. Conclusions
Model performativity is a thorny phenomenon that raises important value-related concerns about using models for informing policy and the public. When models have performative capacities, such concerns are unavoidable. In the words of Grunberg and Modigliani, “[…] whenever the agent reacts to the public prediction, the forecaster becomes—however unintentionally—a manipulator, since his pronouncement affects the operations performed by the agent upon some variables” (1954, 471; italics in the original). Neither the appraisal view, by insisting on an evaluative interpretation and eschewing a normative one, nor the mitigation view, by promising to endogenize the problem away, can keep such concerns at bay. Both approaches can be appropriate ways to respond to model performativity in some contexts, but both must also be accompanied by strong safeguarding principles and good institutional designs to minimize illegitimate value-influences on central aspects of model construction and use. I have proposed orthogonality as a general constraint on mitigation and appraisal, which aims to ensure that central stages of model construction and use proceed in a way that is independent of modelers’ valuations of certain performative effects. Since orthogonality is a goal, rather than a practical recipe, additional work is needed to articulate concrete principles for governing the construction and use of models to inform policy and the public. As my arguments suggest, it can be fruitful to explore, through further case studies, the conditions under which model performativity raises important epistemic-ethical problems, to consider how contextual features bear on whether mitigation or appraisal seem more appropriate, and to explore what institutional designs may help ensure that orthogonality is attained (Nixon et al. 2022). Further pursuing this project, I hope, may support modelers and policy makers in constructing and using models in an ethically and epistemically more responsible fashion.
Footnotes
Acknowledgements
I wish to thank Julian Reiss and Philippe van Basshuysen for their very helpful comments and criticisms, the attendants at the LUH-LMU-Wuppertal Workshop 2022, the audiences at ENPOSS 2022, SPSP 2022, the 12th Braga Meetings on Ethics and Political Philosophy, the ISEC Colloquium at the University of Witten/Herdecke, and at INEM 2021, as well as two anonymous reviewers for their valuable comments and suggestions, which helped significantly improve the ideas developed in this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.