
Abstract
This paper argues that an important type of experiment-target inference, extrapolating causal effects, requires models to be successful. Focusing on extrapolation in Evidence-Based Policy, it is argued that extrapolation should be understood not as an inference from an experiment to a target directly, but as a hybrid inference that involves experiments and models. A general framework, METI, is proposed to capture this role of models, and several benefits are outlined: (1) METI highlights epistemically significant interactions between experiments and models, (2) reconciles some differences among existing accounts of experiment-target relationships, and (3) facilitates critical appraisal of inferential practices from experiments.
Keywords
1. Introduction
Experiments and models are routinely used as surrogate systems in the social sciences (Mäki 2009): they are studied independently of target systems of interest, allow us to isolate phenomena and exercise discriminate control over them, and they facilitate inferences about these phenomena as they occur in distinct targets.
The existing literature has detailed how experiments and models, respectively, relate to targets, permit learning about them, and how their epistemic capabilities can differ. Models (and simulations drawing on them) are thought to relate to targets by means of abstract relationships such as formal similarity, resemblance, (partial) isomorphism, etc., and to permit reliable inferences when such relationships are adequately realized (e.g., Da Costa and French 2003; Frigg and Nguyen 2020; Giere 2010; Khosrowi 2020; Mäki 2005; Weisberg 2013). Experiments, by contrast, are often thought to promote learning about targets in virtue of exhibiting concrete relationships, such as material analogy, ontological equivalence, representativeness, or specimenhood (e.g., Currie and Levy 2020; Guala 2002, 2005; Morgan 2003, 2005), and there has been extensive debate concerning whether experiments are epistemically privileged in virtue of such concrete relationships (see Parker 2009; Winsberg 2009; and Parke 2014, who resist such conclusions).
An issue that has received somewhat less attention is how experiments and models can be integrated to facilitate learning about the world. 1 In this paper, I focus on the practice of extrapolating causal effects from experiments, which is increasingly common in various social sciences, including particularly in Evidence-Based Policy and economics. I argue that extrapolation requires (good) models to be successful. To extrapolate a causal effect from a study population to a novel target, one needs to support that populations are sufficiently similar, or account for how they differ. This is where models play important but underappreciated roles (see Cartwright and Stegenga 2011). Good causal models of both populations are needed for (1) guiding the search for similarities and differences, (2) making these accessible to investigators, and (3) deriving predictions about the effects of interest. These crucial roles for models suggest that it is unhelpful to understand extrapolation as an inference proceeding directly from an experiment to a target. Rather, I argue it is better understood as a hybrid inference, called Model-Mediated Experiment-Target Inference (METI), which involves both experiments and models.
METI is detailed as a general framework to elucidate several important aspects of experiment-target inference. First, it highlights epistemically significant interactions between experiments and models: together, they enable conclusions not accessible with either tool alone. Second, METI emphasizes that experiment-target inference proceeds through thick layers of abstract experiment-target relationships. This departs from existing accounts like Morgan’s (2003, 2005) and Guala’s (2002; 2005), which characterize experiment-target inference as anchored in concrete relationships obtaining directly between experimental and target systems. Accommodating related arguments by Parker (2009), METI maintains that both concrete and abstract relationships play important roles, and neither takes priority over the other. Third, METI helps critically appraise inferential practices: extrapolation always requires models, but the models relied on in practice are likely to remain implicit, difficult to scrutinize, and inadequate for underwriting good inferences.
I proceed as follows. Section 2 characterizes extrapolation in the context of Evidence-Based Policy, elaborates the challenges encountered there, and details how extrapolation requires models. Section 3 focuses on two strategies for extrapolation, explaining how both involve models but differ in how explicit these are made. Section 4 elaborates METI as a framework for understanding (some kinds of) experiment-target inference, highlights several desirable features of this framework, and considers questions about its relation to existing accounts as well as its scope. Section 5 responds to an objection. Section 6 concludes.
2. Extrapolation in Evidence-Based Policy
Evidence-Based Policy (EBP) is the movement according to which public policy should be based on high-quality evidence of ‘what works’. Specifically, using experimental evidence from randomized controlled trials (RCTs) and other credible study designs, EBP seeks to clarify whether policies (e.g., universal basic income) are effective in doing what they are supposed to do (e.g., improving individual’s welfare). Such evidence, in turn, is systematically reviewed, summarized, and collated in evidence libraries that offer decision-makers up-to-date evidence on interventions addressing a wide range of policy issues (Duflo 2004; Parkhurst 2017 ch.2).
In pursuing these goals, EBP faces a substantial obstacle: extrapolating causal effects measured in a study population to an eventual policy target. Extrapolation is challenging because populations often differ in causally important respects (Vivalt 2020): an intervention distributing free bed-nets to decrease malaria infection rates might be highly effective in one place, but fail in another because individuals experience incentives to use the nets for fishing instead (McLean et al. 2014). More generally, the causal mechanisms underwriting the effectiveness of an intervention in one place might be disrupted in another, institutions and individuals’ dispositions to respond to interventions can differ, crucial background conditions needed for an effect might be absent, and so forth. So, in making an inference to a new population, extrapolation requires conscientiously seeking out information pertaining to causally relevant similarities and differences, as failure to do so runs the risk of mistaken conclusions.
Extrapolation can take various forms. Some problems are easier to handle than others, such as when study populations are representatively sampled from a target. In many cases, however, evidence is brought to bear on questions about populations that can importantly differ from a study population. 2 In the following, I assume that we face these more severe extrapolation problems.
In these cases, we proceed from a causal effect of
Successful extrapolation requires that we can either assume that populations are similar at each of these three layers of causal analysis, or, if they differ, that we can express how these differences bear on the effect of interest in a target. 4 Either way, extrapolation is challenging since we need to make extensive causal assumptions about both populations and support these assumptions empirically. Let me outline how models can help make these assumptions explicit, which is an important precondition for attempts at supporting them.
2.1. Extrapolation Requires Models
Extrapolation requires models in two senses. The first is that in making an inference to a new environment one needs to make some assumptions about how populations are related causally (Banerjee and Duflo 2009:160). Even the most unsophisticated form of extrapolation, that is, naïve extrapolation (cf. Steel 2009 on simple induction), which predicts that an effect will be the same in a target as in a study, will need to make some implicit causal assumptions—in particular, that the causal makeup of both populations is such that an effect is the same in
Implicit causal models are typically unhelpful (cf. Cartwright 2013a): the details of their assumptions remain vague and cannot be scrutinized; it remains unclear what empirical support might be needed to justify their assumptions, whether such support is available, and how it should be sought; and they cannot be easily investigated and manipulated to exploit their derivational resources. What is more, the implicit models relied upon by naïve extrapolation are also particularly unhelpful, since populations can routinely differ in important ways (Cartwright 2013b; Fuller 2019; Reiss 2019; Steel 2009; Vivalt 2020). So not only is naïve extrapolation relying on models likely to lack adequate support, resist scrutiny, and elude further analysis, but is also likely to rely on models that are inadequate, thereby precluding successful extrapolation.
Conversely, as others have stressed (see Cartwright and Stegenga 2011), successful extrapolation is importantly facilitated by models that are explicit and well-supported. These virtues go hand in hand: the more explicit and detailed causal models are, including their ability to resolve different layers of causal analysis (e.g., those outlined earlier), the easier it is to tell which particular assumptions they encode, which assumptions are in need of support, and whether there is enough support in their favor. Recognizing these important benefits provides us with a second sense in which extrapolation requires models: one that arises not out of necessity but one that is normative in character and up to us to cater to. 6 Successful extrapolation requires not just some model, but good models: models that are explicit and well-supported. 7
Unfortunately, there are reasons to think that extrapolation in EBP often proceeds against the background of bad, implicit models. While some authors have recently more fully acknowledged the intricacies involved in extrapolation (e.g., Peters, Jain, and Gaarder 2019), methodological guidelines issued by central EBP institutions remain unhelpfully thin on issues of extrapolation (e.g., Guyatt et al. 2011; Schünemann et al. 2019). They suggest that it is essential to consider whether populations are sufficiently similar, but provide little guidance beyond the level of such slogans. So, unless extrapolators move considerably beyond what the guidelines ask, extrapolation risks proceeding in a methodological vacuum and the models underlying these inferences may remain implicit, poorly justified, and often inadequate causal accounts of the populations of interest.
To help elaborate more fully the important role that good, explicit models can play, let me turn to consider two approaches to extrapolation: statistical and causal graph-based approaches. While both involve models, they differ in how explicit these models are made, which bears on their ability to resolve important causal detail and promote the process of justifying extrapolation.
3. Two Approaches to Extrapolation
Among the various approaches to extrapolation that have been proposed and discussed (e.g., Cartwright 2012, 2013a, 2013b; Cartwright and Hardie 2012; Guala 2010; Muller 2013, 2014, 2015; Steel 2009, 2010; van Eersel, Koppenol-Gonzalez, and Reiss 2019), statistical and causal graph-based approaches stand out because they offer resources to overcome a wide variety of problems of extrapolation. Specifically, unlike other approaches, they offer formal recipes for how to adjust an effect estimated in one population to accommodate differences between populations. Let me introduce a working example to illustrate how both approaches work, before highlighting their differences.
Assume we are interested in the effect of a microfinance intervention intended to improve household welfare of the rural poor. The intervention seeks to help people lacking access to credit obtain the necessary capital for starting small businesses, which, in turn, is hoped to increase household income and ultimately welfare. Assume further that we have measured the effect of our intervention in a study population
Statistical approaches have been proposed in the microeconometrics literature (Crump et al. 2008; Hotz, Imbens, and Mortimer 2005; see Khosrowi 2019; Muller 2013, 2014, 2015 for discussions) and other proposals have since followed their general rationale (van Eersel, Koppenol-Gonzalez, and Reiss 2019). In enabling extrapolation even when populations differ relevantly, statistical approaches focus on differences in the distribution of modifying variables. Let us focus on the role of age in our microfinance example: assume we know that the microfinance effect depends negatively on age in
In enabling such extrapolations, statistical approaches require a wide range of assumptions (see e.g., Khosrowi 2019; Muller 2013, 2014, 2015), including causal assumptions about
By contrast, graph-based approaches (Bareinboim and Pearl 2012, 2016) proposed in the computer science literature offer a richer set of resources to make such assumptions explicit. They involve three main ingredients. The first are structural causal models (SCMs), that is, a set of structural equations that encode the causal relationships assumed to hold between variables. Second, the relationships stipulated by SCMs are captured by corresponding graphical causal models, called directed acyclic graphs (DAGs). In extrapolation, the graph-based approach involves building a special kind of DAG, a so-called selection diagram, which represents experimental and target populations in a single graph and uses selection nodes to encode differences between populations, such as when the distribution of a variable or the functional relationship between two variables differs. Figure 1 illustrates a selection diagram for our microfinance example.
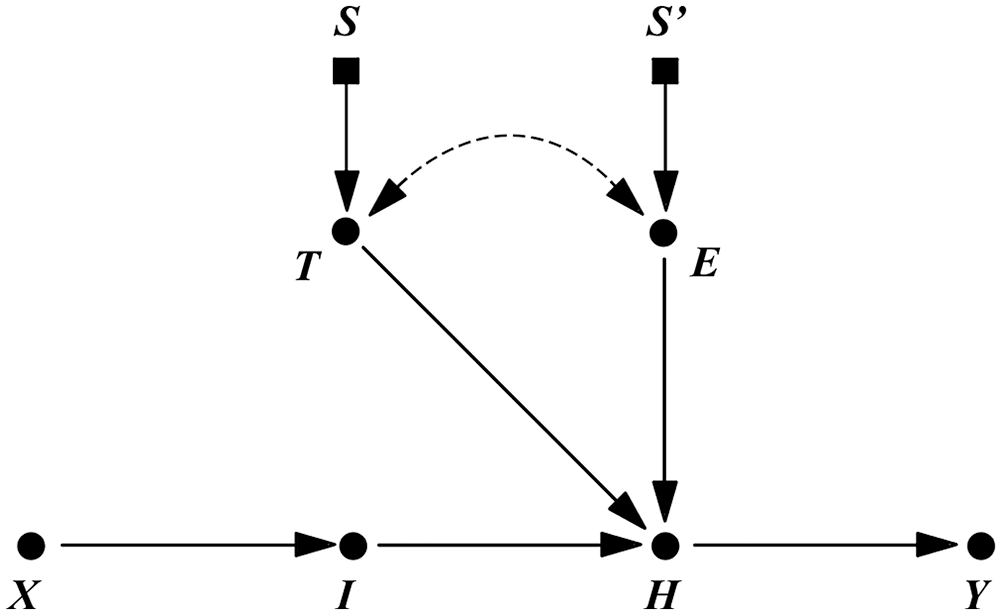
Selection diagram encoding causal assumptions and relevant differences.
The main causal pathway proceeds from microfinance (
In facilitating causal inference, the graph-based approach relies on a third important element: an inference engine. Specifically, it offers a powerful formal calculus that helps us derive so-called transport formulae, that is, formal expressions that answer a causal query (such as: what is the effect of intervening on
The outline provided above helps us recognize a key difference between statistical and graph-based approaches: the extent to which they make the causal models needed for extrapolation explicit. While statistical approaches model explicitly how an effect depends, statistically, on certain modifying variables, they keep crucial causal assumptions, and hence a substantial part of the models needed for an inference, implicit. The graph-based approach, by contrast, is firmly committed to the idea of making models explicit (as far as existing causal knowledge permits) in the form of an SCM, DAGs, and, in particular, through selection diagrams, that is, joint causal models encoding similarities and differences between populations.
Of course, an explicit model is not automatically a good model, as it may involve assumptions that are not adequately supported, or might indeed be wrong. Yet, making models explicit is an important step in facilitating successful extrapolation as it offers three important benefits.
First, having explicit models makes it easier to assess which assumptions, exactly, an extrapolation involves; whether they appear plausible; whether they enjoy sufficient support; and what one should do to substantiate them. Consider our microfinance example: in helping us detail the causal structure governing the welfare outcome in both populations, a joint causal model helps us recognize which kinds of similarities are essential for an extrapolation. It makes clear that the ways in which
A second important advantage of making models explicit is that it helps make fine-grained details of the causal and correlational structures of both populations salient to investigators, details that the statistical approach likely fails to recognize. Recall that our microfinance example assumes that, in
Finally, a third important advantage of having a well-supported joint causal model of both populations is that such a model can also offer derivational resources for answering a range of further causal queries, such as what co-interventions are needed to help achieve a specific effect. For instance, if a target differs in age distribution (higher mean) and entrepreneurial ability (lower mean) but is otherwise causally similar, we might consider complementing our microfinance program with a co-intervention that improves individuals’ entrepreneurial ability (e.g., a skills training program).
In sum, through making models explicit, the graph-based approach offers crucial resources for turning the models that are invariably involved in extrapolation into explicit and good models, that is, models that (1) adequately capture the causal makeup of both populations, including important differences between them, (2) facilitate the process of providing support for licensing our inferences, and (3) can be used for a variety of further epistemic and practical purposes.
With these ideas in place, let me detail in a more systematic way how we can understand extrapolation as a hybrid inference involving experiments and models.
4. Experiment-Model-Target Inference
In elucidating what successful learning from experiments requires, the existing literature has tended to focus on the kinds of relationships that obtain between experimental and target systems directly. For instance, in the context of making epistemologically pertinent distinctions between experiments and simulations, Morgan (2005) argues that experiments exhibit distinctive epistemic powers in virtue of exploiting ontological equivalences between study and target entities of interest. Similarly, Guala (2002, 2005) argues that experiments permit successful inferences about targets to the extent that experimental and target systems are materially analogous, for example, because the entities figuring in them are of the same kind, the same material causes operate in both systems, or they exhibit analogies at some other material level of description.
What these proposals have in common is that they focus on a relationship
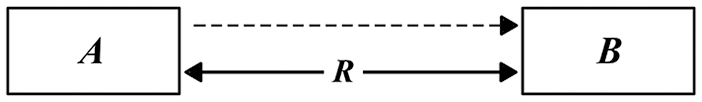
Direct experiment-target inference justified by appeal to
Here
However, in focusing on
As the preceding discussion made clear, such inferences are unlikely to be successful without explicit models that encode similarities and differences between populations. Because of this, experiment-target inference is not usefully characterized as an inference from an experimental system to a target system directly, and underwritten by reference to
Since
In light of the above, it seems that extrapolation is not well understood as an inference from an experiment to a target directly, but rather as a hybrid inference, which is mediated by causal models of both populations and a joint causal model encoding similarities and differences between them, and facilitated by an inference engine operating on the inputs from these models. Call this Model-Mediated Experiment-Target Inference (METI).
METI departs significantly from more straightforward experiment-target inference underwritten by reference to
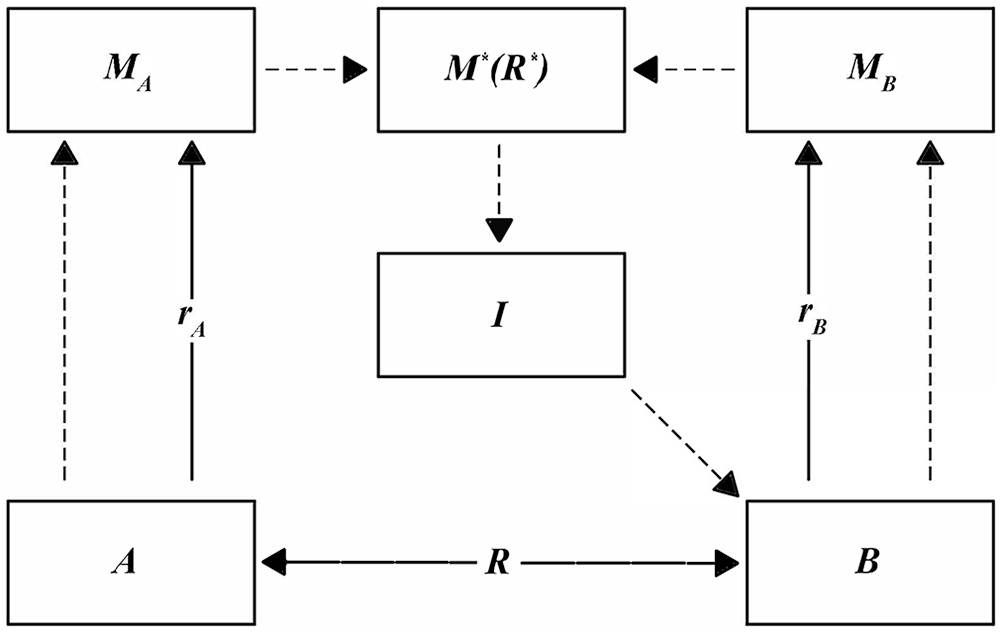
METI as a hybrid, mediated inference from A to B.
Here, we find the populations
Importantly, METI characterizes the resources involved in extrapolation as an epistemic whole whose ingredients interact in ways that have not been recognized by existing accounts. An experimental result, by itself, might inspire hypotheses about what an effect in a target could be, but unless it is joined by a causal model that helps clarify relevant similarities and differences, and how these bear on the effect to be expected in a target, it remains largely uninformative about that effect. Likewise, even a sophisticated joint causal model, by itself, is unlikely to permit conclusions about an effect in the target with the same confidence as when it is complemented by a well-identified causal effect obtained from an experiment. It can tell us, for instance, that whatever an effect is in
Beyond elucidating the role of models in experiment-target inference, METI can also be useful for critically appraising such practices. As emphasized earlier, a key methodological shortcoming of EBP’s methodological guidelines is that they say little on extrapolation and thereby tolerate that models often remain implicit. METI gives us some normative leverage for refining these guidelines, for example, to demand that models be explicit, amenable to scrutiny, and well-supported.
It is also important, however, to emphasize that METI is limited in its ameliorative scope: it tells us that good models are needed for successful inference, but not how to build such models. There are indeed important challenges to be overcome in building the kinds of explicit and well-supported models that can facilitate extrapolation. One is simply that constructing such models is rarely straightforward and requires substantial epistemic resources, which is perhaps why even proponents of model-heavy approaches, such as Bareinboim and Pearl, say little on how causal models are constructed, and simply assume that an investigator is in possession of sufficient empirical knowledge to build them (see Hyttinen et al. 2015). But we are not completely empty-handed when it comes to positive proposals: advocates of realist evaluation (Astbury and Leeuw 2010; Pawson 2013) as well as philosophers and methodologists (Cartwright 2020; Cartwright and Hardie 2012), have made important progress in furnishing details for how to construct so-called program theories or logic models that systematically and iteratively refine our understanding of the causal mechanisms by which policy interventions are effective and the conditions under which these interventions are likely to work best. These proposals constitute promising avenues for catering to METI’s demand for good models.
There is also a second, more principled challenge to be acknowledged when emphasizing the role of models in experiment-target inference: the extrapolator’s circle (Steel 2009; see also Khosrowi 2019). In a nutshell, the extrapolator’s circle cautions that the causal knowledge about a target required for an extrapolation must not be so comprehensive that we could answer our causal query on the basis of that knowledge alone. So maintaining that extrapolation requires explicit and well-supported causal models, as METI does, must stop well short of demanding models strong enough to obviate the need to extrapolate at all, as that would be self-effacing.
Yet, while the extrapolator’s circle is indeed an important challenge, METI is not especially vulnerable to it, nor does it remain mute on the issues to be addressed in overcoming it. For one, it is important to recognize that the extrapolator’s circle is a challenge for any sincere attempt at extrapolation, with or without the help of models. Moreover, it seems that aiming to extrapolate by means of explicit causal models can indeed be helpful for evading the extrapolator’s circle. A statistical approach to extrapolation, for instance, will often need to support similarity assumptions en-bloc. For lack of encoding finer-grained details about the causal makeup of two populations, it requires that they exhibit similarities wholesale at certain levels of causal analysis. This is problematic because such wide-ranging assumptions generally require more extensive support, for example, about mechanistic similarities from start to finish, rather than at particular stages.
By contrast, following METI’s call to make models explicit can help us spell out in a more fine-grained way which assumptions are needed, which of these we can safely bet on and which ones are in need of further support, and whether providing such support would demand too much causal knowledge about a target. This is perhaps why existing proposals for overcoming the extrapolator’s circle (Steel 2009, 2010) already take a model-based approach toward delineating what assumptions need to be made and elaborating which of these we should focus on to avoid trivializing our inferences.
So while METI emphasizes that good models are needed to facilitate extrapolation, it does not claim that models are a silver bullet or come for free. It acknowledges that there remain substantial challenges in the way of constructing models that are powerful enough to facilitate extrapolation while not requiring extensive causal knowledge about a target. And it also emphasizes that explicit models can play important roles in overcoming these challenges, for example, by helping us recognize which inferences are prone to raise concerns about the extrapolator’s circle in the first place.
With these clarifications made, let me briefly touch upon two further issues to complete my detailing of METI: how it relates to existing accounts of experiment-target relationships, and whether its scope extends beyond extrapolation.
First, METI can help us improve on existing views of experiment-target relationships such as those offered by Morgan (2003, 2005) and Guala (2002, 2005). These views have so far not fully distinguished between ontic and epistemic layers of experiment-target inference. Focusing on the ontic layer of concrete experiment-target relationships
What about the scope of METI? I have proposed METI as a characterization of extrapolative inference from experiments in EBP and social science more generally. But we might ask whether METI can also be helpful in elucidating other kinds of experiment-target inference. Here, it seems that much depends on the kind of inference at issue. We might think, for instance, that even the most straightforward cases of experiment-target inference, for example, those facilitated by justificatory strategies involving sampling-type or material analogy-type arguments, could be understood to involve models, too (at least implicitly). But it is questionable whether making these models explicit could provide epistemic benefits, so not much seems to be gained by thinking about experiment-target inference in terms of METI. Between these easier cases and more involved ones, like those encountered in extrapolation, there is however a whole spectrum of inferences that differ in various important respects, including in (1) the aims they pursue (e.g., inferring whether phenomena/effects are the same in a target vs. predicting precise quantities), (2) the severity of the challenges faced (in what ways populations/systems might differ and to what extent, and what resources are available to clarify this), (3) the availability of justificatory strategies that appeal directly to
With this overview of METI in place, let us briefly consider an important objection against METI’s core claim, that is, that some kinds of experiment-target inference need models.
5. Models proper?
While it is clear that good inferences from experiments need plenty of additional resources, including causal assumptions enjoying adequate support, one might nevertheless have reservations about whether this is enough to conclude that what is needed are models proper. The assumptions involved in extrapolation might be understood as causal models, but perhaps these causal models should not be counted as scientific models in the general sense, and no broader conclusions about interactions between models and experiments should be drawn beyond those specifically pertaining to causal models in the context of extrapolation.
Let me defend here in more detail why the models involved in extrapolation, at least if built conscientiously, should be considered capital-M scientific models in the most general sense. This is because they exhibit a range of essential characteristics that figure prominently in existing accounts of scientific models:
(1) They are artifacts that are constructed and used for pursuing particular epistemic purposes, that is, extrapolating causal effects, and they figure as surrogates for real-world systems (cf. Mäki 2009), that is, they allow us to answer causal queries about a target without studying that target directly.
(2) They are formal/mathematical and/or diagrammatical representations of the causal makeup of real-world systems. In virtue of this, they raise standard issues of scientific representation (Frigg and Nguyen 2020; Giere 2010; Khosrowi 2020; Suárez 2003; Teller 2001; van Fraassen 2008; Weisberg 2013), that is, to promote certain epistemic purposes, they need to be suitably related (e.g., sufficiently similar, structurally isomorphic, etc.) to their targets in epistemically relevant respects.
(3) They involve abstractions. In order to remain analytically tractable, causal models omit inessential details, such as when an extraneous causal relationship understood to be inessential for an effect is omitted from a model, or when a relationship between two variables is represented as analytically primitive even though we believe it is underwritten by a finer-grained causal structure in the real world.
(4) They involve idealizations. For instance, a parametric structural equation model might assume linear functional forms throughout if it is understood that this is a reasonable approximation for the epistemic purpose at hand.
(5) Context matters. Fidelity desiderata and contextual factors co-determine whether a particular model is adequate for a purpose (Parker 2020). For instance, we would expect a model to resolve greater causal detail if we are interested in precise quantitative predictions rather than qualitative predictions. Similarly, the stakes involved in acting on a prediction, and other contextual factors related to epistemic risk (Biddle and Kukla 2017), may bear on the fidelity desiderata imposed on both model construction and justification.
(6) To be useful, the models at work in extrapolation need to be empirically informed with measurements of certain variables and structural parameters relevant to an effect, much like structural models in economics and econometrics need to be populated with measurements and calibrated before being put to use successfully (see e.g., Boumans 2002).
(7) They are autonomous epistemic instruments (Morrison and Morgan 1999) that can be used for epistemic and practical purposes beyond extrapolation, for example, by facilitating understanding of causal phenomena (see e.g., de Donato Rodríguez and Zamora Bonilla 2009), such as how effects vary between populations and individuals; by guiding efforts to unpack finer-grained details of a given causal structure; and, as argued earlier, by inspiring novel interventions, such as when helping us realize that a co-intervention might be useful to achieve a certain desired effect.
In sum, the above characteristics suggest that we should take the causal models involved in extrapolation seriously as capital-M scientific models proper.
6. Conclusions
I have argued that an important class of experiment-target inference is not well understood as proceeding from an experimental system to a target directly, but rather as a hybrid inference, METI, which involves experiments and models. I have focused on the practice of extrapolation in EBP and argued that extrapolation requires models for two reasons: first, because we need to make at least some implicit causal assumptions, and second, because good, explicit models play essential roles in facilitating successful extrapolation: they guide the search for relevant similarities and differences, encode such information at an epistemic level, and help with deriving predictions about the effects of ultimate interest. Recognizing the importance of models has three important benefits: (1) it brings to the fore epistemically significant but heretofore unrecognized interactions between experiments and models as part of epistemic wholes enabling conclusions that would remain inaccessible otherwise, (2) it helps critically appraise inferential practices involving experiments and offers normative leverage to ask that the models involved be made explicit, and (3) it reconciles some differences among existing views on experiment-target relationships by clarifying that both concrete and abstract relationships are important for successful inference.
In light of these benefits, it seems interesting to explore whether METI can also be informative for understanding and critically appraising other kinds of experiment-target inference beyond extrapolation, an issue that has not been explored here. It is hoped, however, that the first sketch of METI developed here can figure as an interesting starting point to further advance the larger philosophical project of elucidating how experiments and models, on their own, or when joined together, facilitate learning about the world.
Footnotes
Acknowledgements
I wish to thank Wendy Parker, Finola Finn, Lukas Beck, the audience at the ENPOSS 2020 virtual conference, as well as two anonymous reviewers for their very valuable comments and suggestions, which helped significantly improve the ideas developed in this manuscript.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Work on this paper was financially supported by an AHRC Northern Bridge Doctoral Studentship (grant number: AH/L503927/1), a Durham Doctoral Studentship, and a Royal Institute of Philosophy Jacobsen Studentship.