
Abstract
Conversational agents have been widely used in education to support student learning. There have been recent attempts to design and use conversational agents to conduct assessments (i.e., conversation-based assessments: CBA). In this study, we developed CBA with constructed and selected-response tests using Rasa—an artificial intelligence-based tool. CBA was deployed via Google Chat to support formative assessment. We evaluated (1) its performance in answering students’ responses and (2) its usability with cognitive walkthroughs conducted by external evaluators. CBA with constructed-response tests consistently matched student responses to the appropriate conversation paths in most cases. In comparison, CBA with selected-response tests demonstrated perfect accuracy between system design and implementation. A cognitive walkthrough of CBA showed its usability as well as several potential issues that could be improved. Participating students did not experience these issues, however, we reported them to help researchers, designers, and practitioners improve the assessment experience for students using CBA.
Keywords
Over the last few decades, advances in the fields of computational linguistics, cognitive science, discourse processes, and artificial intelligence (AI) have facilitated the constructions of conversational agents or systems (e.g., Graesser et al., 2014). These agents or systems allow a person to interact with the computer using their own language instead of a programming language or clicking on buttons. Thanks to rapid advancements in AI, modern conversational agents bring better interaction and dialogue to conversational agents than earlier generations of agents (Maedche et al., 2019). The world's global technology leaders harness conversational agents such as Google Assistant, Apple's Siri, and Amazon's Alexa to better meet customer needs while trying to increase engagement with their products.
The use of AI-based conversational agents has not been limited to commercial applications. For example, educational researchers have developed AI-based conversational agents to personalize and improve student learning (Goel & Joyner, 2017; Graesser et al., 2014). AI-based conversational agents embedded within interactive learning environments (e.g., intelligent tutoring systems) aim to provide learners with one-on-one tutoring (or instruction) and thereby facilitate their learning. Recently, researchers have begun to apply conversational agents to educational assessments (e.g., Jackson et al., 2018), creating a novel form of assessment called conversation-based assessments (CBA). Similar to intelligent tutoring systems, CBA relies on the interaction between a student, or more broadly, a learner, and a digital device (e.g., a computer) to administer interactive assessments. The main idea behind CBA is to build a digital assessment environment that measures and supports student learning through interactive conversations generated by a conversational agent (e.g., Lopez et al., 2021). That is, CBA aims to mimic how students would experience a typical conversation on a particular topic and leverage content through interaction to target specific information (Jackson & Zapata-Rivera, 2015). Thus, it combines digital assessment and feedback by simulating human teachers to monitor and enhance student learning through interactivity, which is often missing in digital assessments (e.g., computer-based tests) and feedback.
Designing a Conversational Agent
Four elements must be considered to design, develop, and deploy a conversational agent that aims to promote student learning: (1) the type of conversational agent; (2) the subject being assessed; (3) the learner's knowledge level; and (4) dialogue strategy sophistication (Yildirim-Erbasli, 2022; Yildirim-Erbasli & Bulut, 2021). The first element, the type of conversational agent, refers to the technologies used to create the conversational agent, such as chatbots or animated agents. Graesser and his colleagues investigated the features of AutoTutor that might account for improvements in learning with conversational agents (Graesser et al., 2003, 2004, 2008; VanLehn et al., 2007). Their experiments showed that most of the improvement was because of the dialogue content, not the agent's speech or animated facial display. Thus, their findings suggest what has been expressed in a conversation matters to promote student learning. This highlights that the medium does not convey the message; the message itself is the message. In addition, suppose the mediums of communication used by the agent and student are different (e.g., in the AutoTutor, students type their responses and the chatbot speaks). In that case, this can confuse, demotivate, or frustrate students (D’Mello & Graesser, 2013).
The second element (i.e., subject) refers to the topic or area of study that is being supported (e.g., mathematics, history, or English language). For example, AutoTutor worked better when the content was for qualitative domains (Graesser et al., 2005), whereas ELLA-Math was better at reading responses to questions that needed students to write a number than questions that required students to write words (Lopez et al., 2021). However, many of the existing conversational agents have been designed to support the learning of verbal or qualitative content (e.g., Azevedo et al., 2009; Howard et al., 2017; Katz et al., 2021; Rus et al., 2015; Yang & Zapata-Rivera, 2010), rather than numerical or quantitative content (e.g., Lopez et al., 2021).
The third element, the knowledge level of the learner, refers to the level of understanding and knowledge that the learner has in relation to the subject. Conversational agents should be designed to meet the needs of the learner, whether they are a beginner or an advanced learner. Regarding this element, a conversational agent could work better when it is designed for students with low to medium levels of knowledge rather than students with a high level of knowledge (Graesser et al., 2005). When students with a high level of knowledge interact with an agent, it has been found that both dialogue participants (i.e., the agent and the student) expect a higher level of precision and this can lead to a higher risk of failing to meet the expectations of both participants (Graesser et al., 2005).
The last element, the sophistication of the dialogue strategies, represents the level of complexity of the conversational agent's ability to engage in dialogue with the learner. In earlier studies on conversational agents, researchers investigated tutoring strategies by analyzing novel human tutors and found that they rarely used sophisticated tutoring strategies (e.g., Graesser et al., 1995; Graesser & Person, 1994). They instead tended to guide students using expectation and misconception-tailored (EMT) dialogue. In EMT dialogue, human tutors typically have a list of anticipated correct answers (called expectations) and a list of anticipated incorrect answers (called misconceptions) associated with each question or problem (Graesser et al., 2005; Lopez et al., 2021). They ask questions that are within the student's ability to answer correctly, compare student input with their anticipated expectations and misconceptions, and then provide support when students give an incorrect answer. This EMT dialogue approach is common in human tutoring (Graesser et al., 2005) and can be effective.
Design-Related Limitations of Conversational Agents
Although there are technological challenges to overcome when creating a conversational agent, research continues to pursue the creation of these innovative technologies. Simple activities, such as scheduling an appointment based on an e-mail request, might be completed by an agent with minimal human participation. More difficult activities or decisions may require more human participation. CBA is not yet well developed to comprehend content at the level we consider necessary and grade the content quality of student answers (e.g., Lopez et al., 2021). Thus, we must be cognizant of this technology's current limitations.
Irrelevant Responses
According to previous research, conversational agents function well with selected responses (e.g., multiple choice) or short responses (e.g., typing yes or no). Problems, such as irrelevant responses, tend to arise when open-ended responses are enabled (Huang et al., 2019; Valério et al., 2018). One of the main challenges is the result of student questions being mostly unpredictable, making it impossible to consider every possible question-answer pattern (Graesser, 2016). As conversational agents can only answer a modest proportion of student questions correctly, some students may get frustrated when breakdowns occur (e.g., failure to comprehend the student's inquiry and inability to provide an adequate response) (Bailey et al., 2021; D’Mello & Graesser, 2013). Learners have reported dissatisfaction with the responses provided by a foreign language practice agent because of poorly performing pattern-matching mechanisms (e.g., repeated or irrelevant responses; Jia, 2003). Lopez et al. (2021) reported that CBA was more accurate in interpreting student responses to questions that require writing numbers rather than writing words as well as shorter responses (e.g., numbers and one or two words) rather than longer responses. They also found CBA was more accurate when it could accept more flexible answers (e.g., multiple synonyms for summative assessment) than when specific terms were required (e.g., criterion-referenced or absolute grading). See Lopez et al. (2021) for other examples. Given these limitations simple short responses or button response options, are suggested by researchers to minimize irrelevant responses (e.g., Valério et al., 2018).
Misleading Support
Conversational agents are generally designed to give positive feedback for a more complete answer (e.g., AutoTutor). That is, if the student's answer is partially correct, then the agent still provides negative or neutral feedback for their partial answer. This is likely to frustrate some students since they may expect to receive positive feedback or encouragement from the system (Graesser, 2016). Furthermore, conversational agents can provide negative feedback if a correct answer is matched with negative feedback or the opposite scenario. For example, even if the initial response is correct, the system may occasionally direct student responses that contain misspelled words to other discussion pathways. If this happens, students may receive inaccurate hints or feedback (e.g., Lopez et al., 2021). In their research, Lopez et al. (2021) found that almost half of the students reported that the CBA system failed to comprehend their answers and thus provided inaccurate support. This misleading support can also confuse, demotivate, and frustrate students (Graesser, 2016; Lopez et al., 2021). To deal with this, researchers suggest using neutral short feedback rather than negative or positive long feedback to prevent student demotivation or frustration when mismatches occur (Graesser, 2016).
Excessive Interaction
One study compared two versions of AutoTutor (Kopp et al., 2012). In the control version, the system engaged students in dialogues using six questions. While, in the experimental version, the system engaged students in dialogues using three questions and then presented three additional questions but did not engage students in dialogues and instead provided a predetermined short response and explanation. The results showed that students in the experimental condition learned as much as students in the control condition in less time, implying that extended interaction is not always required. Another study compared two versions of Rimac: (1) the control version that always decomposes a step to its simplest sub-steps regardless of student knowledge level, and (2) the experimental version that adaptively decides to decompose a step based on student knowledge (Jordan et al., 2016, 2018). The results showed that students who used the experimental version learned similarly to those who used the control version yet spent less time. Those who used the control version were frustrated when they believed the agent was forcing them to engage in a lengthy discussion about known content rather than tackling content that they required assistance with.
Research on the comparison of adaptive and non-adaptive or short and lengthy dialogues suggests that students may regard dialogues in conversational agents to be too protracted and judge the conversational agents to be unsatisfactory and unhelpful in providing support (e.g., Katz et al., 2021; Kopp et al., 2012). Also, there are conversational agents where emotional support is embedded (e.g., AutoTutor). However, emotional support may not motivate students because most students aim to learn the content rather than obtain emotional support (D’Mello & Graesser, 2013). To overcome these problems, more knowledgeable students who provide correct answers can be permitted to proceed to a more difficult problem, while less knowledgeable students can receive additional assistance. The benefits of this approach can extend beyond simply improving the understanding of less knowledgeable students to maintaining the engagement and motivation of more knowledgeable students.
Current Study
Conversational agents can help student learning and motivation or they can confuse, demotivate, and frustrate students by providing misleading support, unnecessarily extending the interaction, or only correctly answering a modest proportion of student questions. These limitations still exist in conversational agents despite recent advances. To address these limitations, this study designed and implemented a new CBA and investigated its functionality in answering student responses accurately and its usability. In addition, this study contributed to the research on CBA as most conversational agents integrate instruction, and thus, our knowledge of CBA is limited and incomplete.
Methodology
CBA was designed to measure higher education students’ knowledge and provide support and feedback to scaffold their learning. It was shared with two sections of an undergraduate course and offered to students as an additional and optional formative assessment tool by the course instructors in the winter semester of the 2021–2022 academic year.
Research Aims
Performance of CBA in Answering Student Responses
Following prior research on the use of CBA for administering different test formats (e.g., Lopez et al., 2021; Ruan et al., 2019), we used two constructed and three selected-response tests. Selected-response tests combined assessment and feedback to measure student knowledge and provide timely feedback. Constructed-response tests combined assessment, scaffolding, and feedback to measure student knowledge, give a second attempt for their initial incorrect or out-of-scope responses, and provide students with feedback. The back-and-forth dialogue was intended to be a turn-taking conversation. CBA with the selected-response tests was available for both sections of the course (n1 = 290 and n2 = 119), while CBA with the constructed-response tests was only available for the second section (n2 = 119), following course instructors’ assessment preferences for their sections. Table 1 shows further details about each test, including the availability period and the number of items, and participating students. Conversation data from each test was used to calculate the intent classification (i.e., the purpose of the user input) and confidence score to investigate whether CBA answered student responses accurately.
A Summary of the CBA Designs.
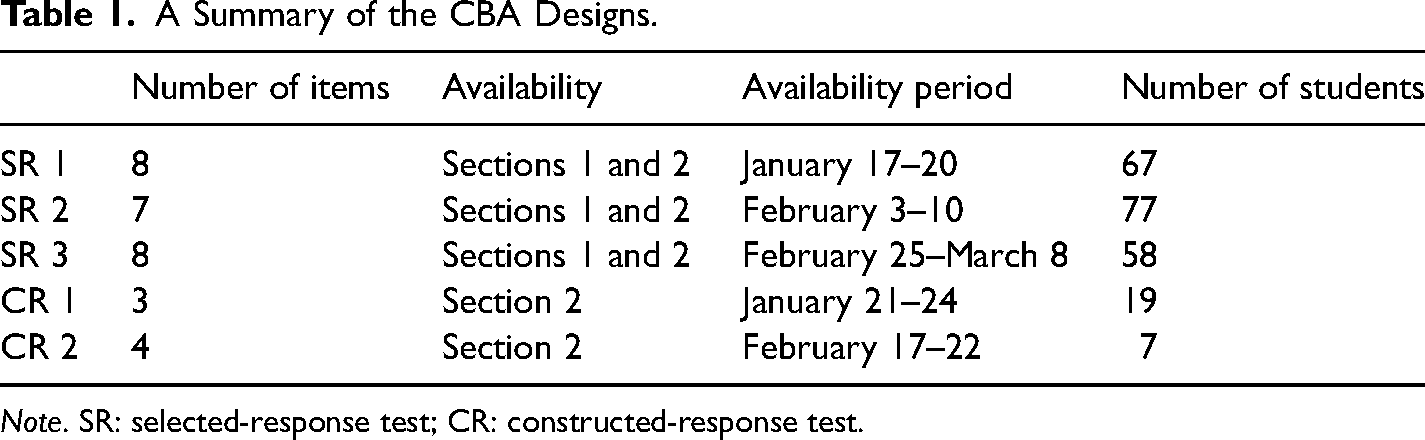
Note. SR: selected-response test; CR: constructed-response test.
Usability of CBA by a User-Centered Approach
CBA was shared with students (n3 = 106) enrolled in a human–computer interaction course in which students learn various usability evaluation methods. These students acted as external evaluators by applying the cognitive walkthrough technique for course credit. The course instructor determined when the CBA was available for students’ service-learning task.
Students were not trained on how to use CBA. They were grouped into 21 teams and performed a cognitive walkthrough to evaluate the usability of CBA for potential usage scenarios. Each team prepared a report answering the following questions for each action that is part of a predefined user goal (Lewis & Rieman, 2011):
Will the user try to achieve the right effect (i.e., outcome)? Will the user notice that the correct action is available? Will the user associate the correct action with the effect trying to be achieved? If the correct action is performed, will the user see that progress is being made? How can it be improved?
Design of CBA
Following the aforementioned parts in the design of a conversational agent (i.e., type of the conversational agent, subject, knowledge of the learner, and sophistication of the dialogue strategies), (1) CBA was designed to be a text-based chatbot rather than a speech-based one. Thus, both students and the agent communicated using the same medium (i.e., text). The aim was to avoid the problem of being confused, demotivated, or frustrated due to the different communication mediums. (2) Considering the varying results in the literature regarding the effectiveness of conversational agents for different content areas (e.g., Graesser et al., 2005; Lopez et al., 2021), the focus of CBA was to adapt qualitative content into a conversational agent that uses an open-ended response format, given the high number of successful implementations on qualitative subjects where student responses were also qualitative. (3) The course instructors were involved in the design process to obtain the knowledge level of the students. The instructors created questions, hints, and feedback that were tailored to the specific needs of their students. The approach of involving course instructors in the design of CBA helped ensure that the conversational agent was better equipped with the relevant information to meet student knowledge and skill levels. Thus, the aim was also to deal with the limitation of unexpected student input that can lead to conversational-agent unresponsiveness. (4) Finally, this study employed EMT dialogue, and thus, the dialogue mechanism in CBA was similar to what human tutors do: CBA asks a question and assesses the student's knowledge based on a list of expectations, provides hints, corrects misconceptions, and gives feedback. The expectations and misconceptions associated with each question were stored in the CBA script (i.e., the major content repository of questions and dialogue moves).
CBA Script
The CBA script included daily conversation, questions, correct answers (expectations), incorrect answers (misconceptions), hints, prompts, and feedback. For each question, there were correct and incorrect answers that students were expected to provide. These expectations and misconceptions were coded into the CBA script along with questions. CBA (1) started with a daily conversation, (2) asked questions, (3) gave hints to revise initial incorrect answers for constructed-response items, (4) provided feedback, (5) summarized answers and (6) supported student self-assessment.
Daily Conversation
In Ruan et al. (2019)'s study, researchers found that about 12% of the total time on conversational systems was not spent on learning. For example, 4% of the total time was a manual delay because of the deliberately introduced delays that aimed to make it feel like a real person, and 2% of the total time was chatting with the chatbot for fun. They suggested that the removal of these casual aspects can negatively affect student interest or motivation. Following their suggestion, when designing CBA, we took the trade-off between engagement and efficiency into account. Thus, the daily conversation at the beginning of CBA was short to prevent potential inefficiencies in assessment caused by the social conversation feature of CBA. In CBA, students greet the agent, and the agent identifies the greeting intent and responds accordingly.
Questions
Regarding the constructed-response tests, short-answer questions were written to allow for better input recognition to deal with the limitations of natural language processing and the potential for inaccurate feedback (Katz et al., 2021). Also, questions in both CBA formats (i.e., constructed and selected) were written through consultation with the course instructors who possess the most accurate and relevant information regarding the topics that students tend to struggle with, the areas where they might require additional assistance, and their expected correct and incorrect responses. The goal was to have a comprehensive list of students’ expected responses and thus address the problem of unexpected student inputs in constructed-response questions, which can lead to irrelevant responses or misleading support. Through consulting the course instructors, we also aimed to avoid underexposing students who did not understand the material and overexposing students who firmly understood the material. Finally, like most conversational agents (e.g., AutoTutor), the order of the questions in both CBA formats was fixed.
Support and Feedback
CBA followed a specified order to select a dialogue turn to provide support or feedback. Support and feedback were built into the conversations and triggered by what CBA matched the student's response to. CBA provided feedback in selected-response tests and support and feedback in constructed-response tests (e.g., a hint and a follow-up question to shift the conversation from the agent to the student) to allow the student to correct their initial incorrect answers. If a student's response was matched with the set of expectations, CBA presented some sort of positive message using informal expressions (e.g., yup, you’re correct, good work) and short content feedback at the beginning of its next turn. In contrast, if there was a match between the student response and the set of misconceptions, CBA presented some sort of negative message (e.g., oops, nope) and provided a hint at the beginning of its next turn (for constructed-response tests). It prompted the student in this scenario by providing them with a second chance to respond. If the hint failed (i.e., the student could not correct their inaccurate answer), CBA delivered feedback and sent the next question. Therefore, as the student expressed information over the turns, CBA compared the information with anticipated correct and incorrect answers and formulated the dialogue moves based on the student's input.
Summary and Self-assessment
CBA also gave a summary along with feedback to recap the answer to a question before presenting the next question. There were two reasons to provide a summary: (1) to help students focus on the next question, and (2) to counteract when students answered correctly using flawed thinking or guessing. In these situations, it could be beneficial to explicitly cover and summarize the question before presenting the next one. This summary was short to avoid forcing students to engage in lengthy interactions. Once students finished the assessment, they were asked to self-assess their performance. The purpose of the self-assessment was to provide general support to students based on their own evaluation of their performance.
Conversation Paths
Once students selected or typed their answers to the questions, their inputs were compared with anticipated correct or incorrect answers to match a path in CBA and provide a response. This is similar to what human instructors do: they give the answers with respect to matching correct or incorrect answers to guide students. CBA controlled the direction of the interaction to support pattern completion because it was impractical to write every possible pattern to provide relevant and accurate answers to student questions (e.g., Graesser, 2016). To handle this, CBA guided students in their responses. For example, the agent offered an assessment to practice, but the student influenced the direction of the conversation based on their input; that is, the student input influenced the outputs of CBA.
When a question was presented, the question was answered through an interaction between the agent and the student following a frame-based architecture: (1) the agent presented a question, (2) the student gave an answer, (3) the agent gave feedback or hints based on the type of question (i.e., constructed or selected-response item) and the student answer (i.e., correct or incorrect answer), and (4) the agent summarized the answer and showed the following question. Within this architecture, CBA followed a tree structure and selected an action based on student input to achieve pattern completion.
CBA included several conversation paths. For constructed-response items, there were four possible paths (see Figure 1). In the correct conversation path, the student provides the correct response, receives positive feedback, and is given the next question. In the partially correct conversation path, the student initially provides an incorrect response, receives a hint, provides the correct response, receives positive feedback, and is given the next question. In the incorrect conversation path, the student provides an incorrect response even after receiving a hint and receives negative feedback, with no further advancement. The student then receives the next question. The out-of-scope conversation path involves the student providing an out-of-scope response and receiving a default response. For the selected-response items, there are only two possible conversation paths (see Figure 1). The student either provides the correct response and receives positive feedback or provides an incorrect response and receives negative feedback. In both cases, students are given the next question.
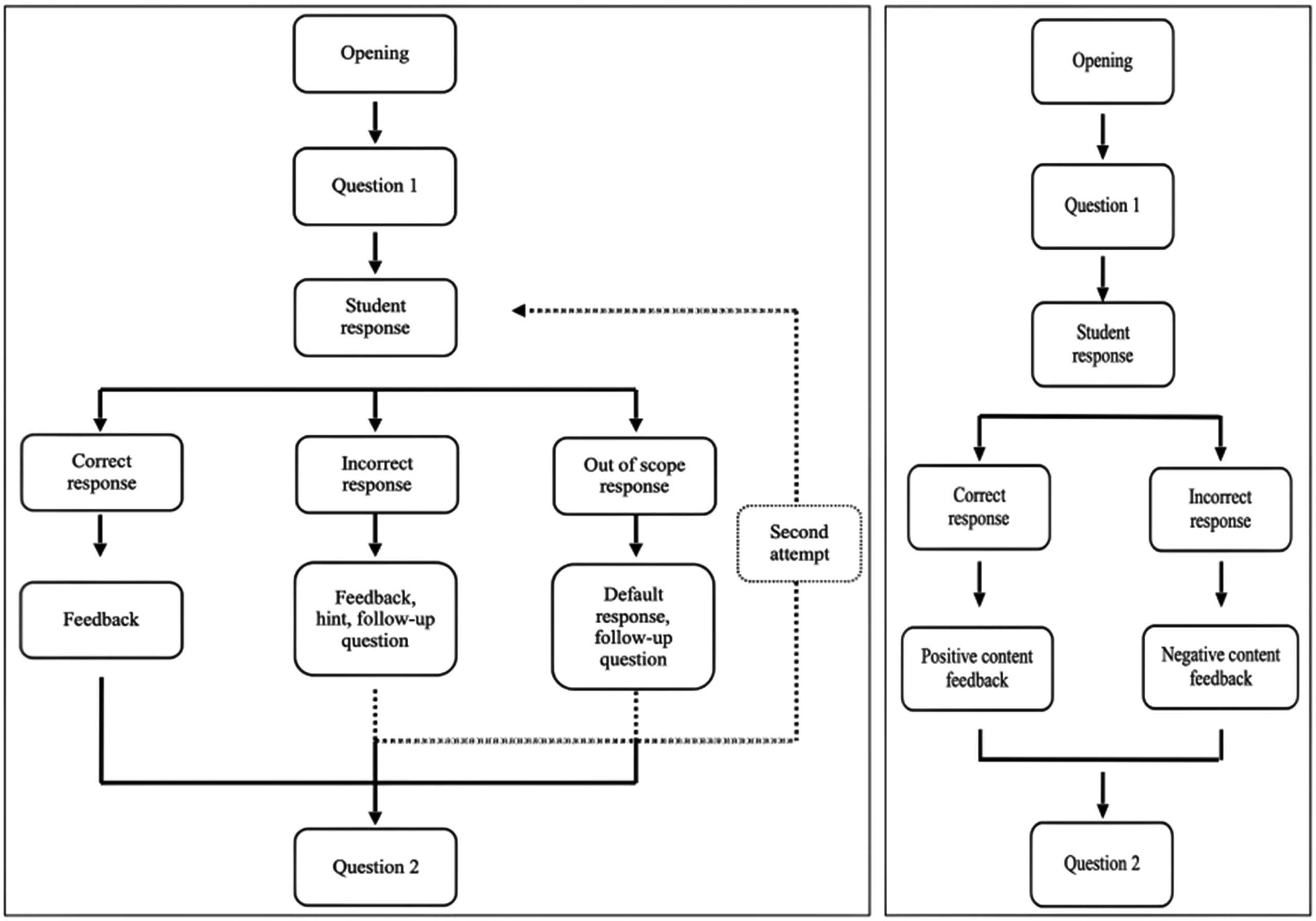
Conversation Diagram in CBA with Constructed (left) and Selected-Response Items (right).
Rasa Framework
A natural language understanding (NLU) tool was used to interpret learner input (Kerly et al., 2008). Previous studies evaluated the most popular NLU tools, including IBM Watson, Google Dialogflow, Rasa, and Microsoft LUIS (Abdellatif et al., 2021). Rasa showed the highest confidence scores for accurately classified intents. That is, classification is highly likely to be correct when Rasa produces a high confidence score for it. Considering the high confidence score Rasa produces, CBA was designed using Rasa to match student inputs to the list of expectations or misconceptions. Once the student provided an answer, CBA received and compared the student's input with the possible expectations or misconceptions. It calculated probabilities for each intent defined and matched it with the highest probability. Rasa includes two modules: Rasa NLU and Rasa Core for dialogue management.
Rasa NLU
The NLU extracted structured information (i.e., the intent) from unstructured student responses using machine learning and natural language processing approaches (Abdellatif et al., 2021). When CBA received a student response, it used the NLU to analyze the response. Similar to other NLUs, Rasa NLU classified the intents from a given student response if they existed in the CBA script. Rasa NLU was modularized using a pipeline that defines how student responses were processed. The default spell-check and correction configuration were used. To configure the Rasa NLU, the following pipeline was used (Rafla & Kennington, 2019):
Whitespace Tokenizer breaks text into terms. REGEX Featurizer creates a vector representation. Count Vectors Featurizer creates a bag-of-words representation. Dual Intent Entity Transformer classifies intents. Response Selector builds a response retrieval model. Fallback Classifier classifies an input as a fallback (i.e., backup) when the confidence score falls below a specified threshold.
Rasa Core
Rasa Core handled dialogue management, which entailed choosing what actions CBA took following student responses (Shahriar Khan et al., 2021). In CBA, Rasa Core used rule- and machine learning-based policies in the following order:
Rule Policy handled conversation parts that followed a fixed behavior and made predictions using rules that had been set. It enabled responses for out-of-scope communication, allowing CBA to fall back to a default response when confidence values fell below a set threshold. A suitable threshold is important to determine as the threshold affects chatbot performance, but identifying a suitable threshold remains a barrier for developers because systematic approaches have yet to be developed (Abdellatif et al., 2021). Following the literature, we set the threshold to 0.3 using trial-and-error. The default response in CBA was: “I’m not quite sure what you mean by that response. It's okay to take your best guess to answer the question. Try again!” In cases where students responded with “I don't know,” they were also directed to the predetermined default response. Memorization Policy determined whether the present dialogue corresponded to the stories defined. Transformer Embedding Dialogue leveraged transformers to decide which action to take.
Data Organization for Rasa
Rasa necessitated the division of the CBA script into three files (Shahriar Khan et al., 2021).
NLU file was required for NLU training and contained expected student responses to each question organized into intents, with each intent including different instances. A set of intents was defined in CBA. For each intent, the NLU was trained on a collection of student responses that were written through consultation with the course instructors and that included different ways a student could communicate the same response. For example, the input “formative assessment” can also be shared with “assessment for learning.” These inputs were used to train the NLU to identify the formative assessment intent. Domain file contained CBA outputs (e.g., questions, feedback, and hints) to each corresponding student response in the NLU file. Stories file contained dialogue sections, with each section containing (1) a series of sequential intents that were extracted from the NLU file, and (2) actions that were given when a student response was categorized under a certain intent. A story represented the conversation between a student and CBA in each chat flow.
Rasa Flow
Rasa NLU and Core are fully decoupled, allowing learned dialogue models to be reused across languages and Rasa NLU and Core to be used independently of one another (Bocklisch et al., 2017). Rasa processed student responses in a series of phases, as shown in Figure 2. Rasa NLU performed only the first step, while Rasa Core performed the rest. The NLU module took a student response (Student input) and converted it into a structured output that included the original text and intents (Rasa NLU). Rasa Core updated the current state of the output from the previous state and maintained the state of the conversation (Tracker). Policies defined in the Core (Policy) used the output from the tracker to select an appropriate response from the domain file and execute an action (Action and Agent output). When an action was completed, it was given a tracker instance (Action and Tracker), which allowed it to use any relevant information gathered throughout the dialogue history.
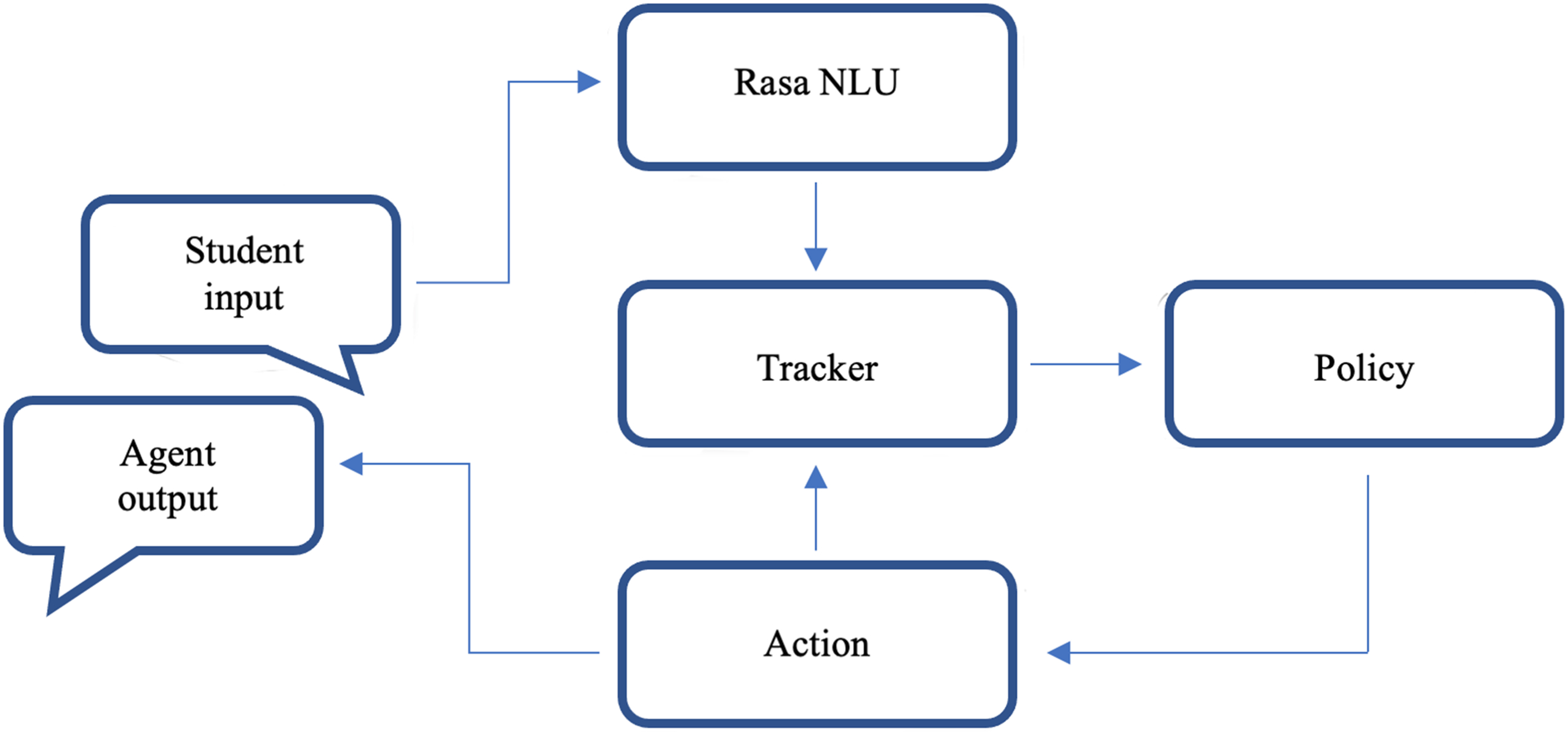
Phases From Input to Output in Rasa. Note. Adapted from “Rasa: Open source language understanding and dialogue management,” by Bocklisch et al. (2017), arXiv preprint, p. 3.
Deployment and Pilot Study
Rasa has built-in connectors that allow agents to be integrated with communication platforms. After CBA was written in Rasa, it was connected to Google Chat to be delivered to students over the Internet. The trained NLU and Core modules were deployed to a hosted web server. The Google Cloud Platform was used to build a connection between the hosted web server and Google Chat to take an assessment with the trained CBA. That is, students had access to CBA through their institutional Google Chat. CBA was tested by the course instructors and teaching assistants and refined before it was considered mature enough for student use. Ethical approval was obtained from the Research Ethics Office and participants’ interaction with CBA indicated their consent. The conversation data of participating students were stored in a password-protected computer using an SQL database.
Analysis of Conversation Data
Intent Classification
Intent classification represents whether the NLU correctly identifies the intent of student responses. NLU tends to misclassify intents that more frequently share words with other intents. The literature suggests that there is an increase in the accuracy of the intent classification when intents contain exclusive words (Abdellatif et al., 2021). In addition, according to studies, NLUs perform better when categorizing inputs with more examples involving various ways of communicating that intent (Abdellatif et al., 2021). To increase intent classification, intents were created with exclusive words in the CBA script, and with different ways a student could communicate the same response (e.g., synonyms).
Considering the binary classification of a student response can be either positive (i.e., classification of student response as correct) or negative (i.e., classification of student response as incorrect), true positives (TP; the number of correctly classified correct responses), false positives (FP; the number of incorrectly classified correct responses), true negatives (TN; the number of correctly classified incorrect responses), and false negatives (FN; the number of incorrectly classified incorrect responses) were calculated. Using these indices, standard classification performance measures––precision (
Confidence Score
Another approach for evaluating CBA performance is the confidence score (Abdellatif et al., 2021). Confidence scores were provided by the NLU during classification and range from 0 to 1 (not confident to completely confident). The NLU should provide high confidence scores for intents that are correctly classified while providing low confidence scores for intents that are incorrectly classified. We report the median and range of confidence scores for the correctly classified intents of each task as was done by Abdellatif et al. (2021).
Standard classification performance measures and the median and range of confidence scores were provided to characterize CBA performance, with slightly different purposes for each CBA format. In terms of the constructed-response format, these measures were calculated to evaluate how well CBA processed student written responses. For the selected-response format, this evaluation informs how accurately the CBA design was implemented.
Analysis of Cognitive Walkthrough: From Codes to Themes
Usability flaws in user interfaces were investigated and evaluated using an analytical inspection procedure known as a cognitive walkthrough (Atiyah et al., 2019; Shekhar & Marsden, 2018). This method determines whether a novice user could use the tool without any prior training or understanding (Ren et al., 2019). CBA with one selected-response test was shared with external evaluators (n3 = 106) because the other tests were not completed when teams conducted their cognitive walkthroughs. The evaluators were grouped into 21 teams and performed the cognitive walkthrough method to identify possible usability flaws. Each team prepared a report including what they were able to do and not do for the actions they attempted.
The from codes to theme approach was used to inductively analyze the reports following particular to a more general perspective (Creswell, 2013). Analysis was conducted without searching for any specific confirmation of the results from the conversation data of the participating students. Reports were examined to determine which topics (i.e., usability indicators and issues) were discussed. The first step was to write memos (e.g., short statements) while reading the reports. Memos were helpful for comparing reports with each other and making connections, and they were used to create initial codes from the reports (Creswell, 2013; Holton, 2010). Codes were simple, clear, and short and were created with the goal of representing each element of the data (Holton, 2010). Two types of coding were used: topic coding (Richards, 2009) and the constant comparative method (Charmaz, 2006). First, topic coding was conducted because it requires little understanding and interpretation (Richards, 2009). Second, following the constant comparative method, statements within the same report and then in different reports were compared to identify similarities and differences. With these two approaches, codes were created. After the coding process, similarities between codes and their relationship with each other were investigated. Then, to reduce the number of codes, related codes were classified and combined, and themes that showed different aspects of initial codes were created (Creswell, 2013). The themes were: planned actions, unplanned actions, and assessment actions.
Results and Discussion
Performance of CBA
Figure 3 shows examples of constructed and selected-response items from CBA. In terms of the selected-response tests, the precision, recall, and F1-score were all 100%. This was expected as each item was coded with the button options. Furthermore, this result shows that the CBA script was correctly coded into Rasa following its structure. Students typed to CBA to initiate and end a conversation, and the accuracy measures for these intents, namely greeting and bye, were also 100%.
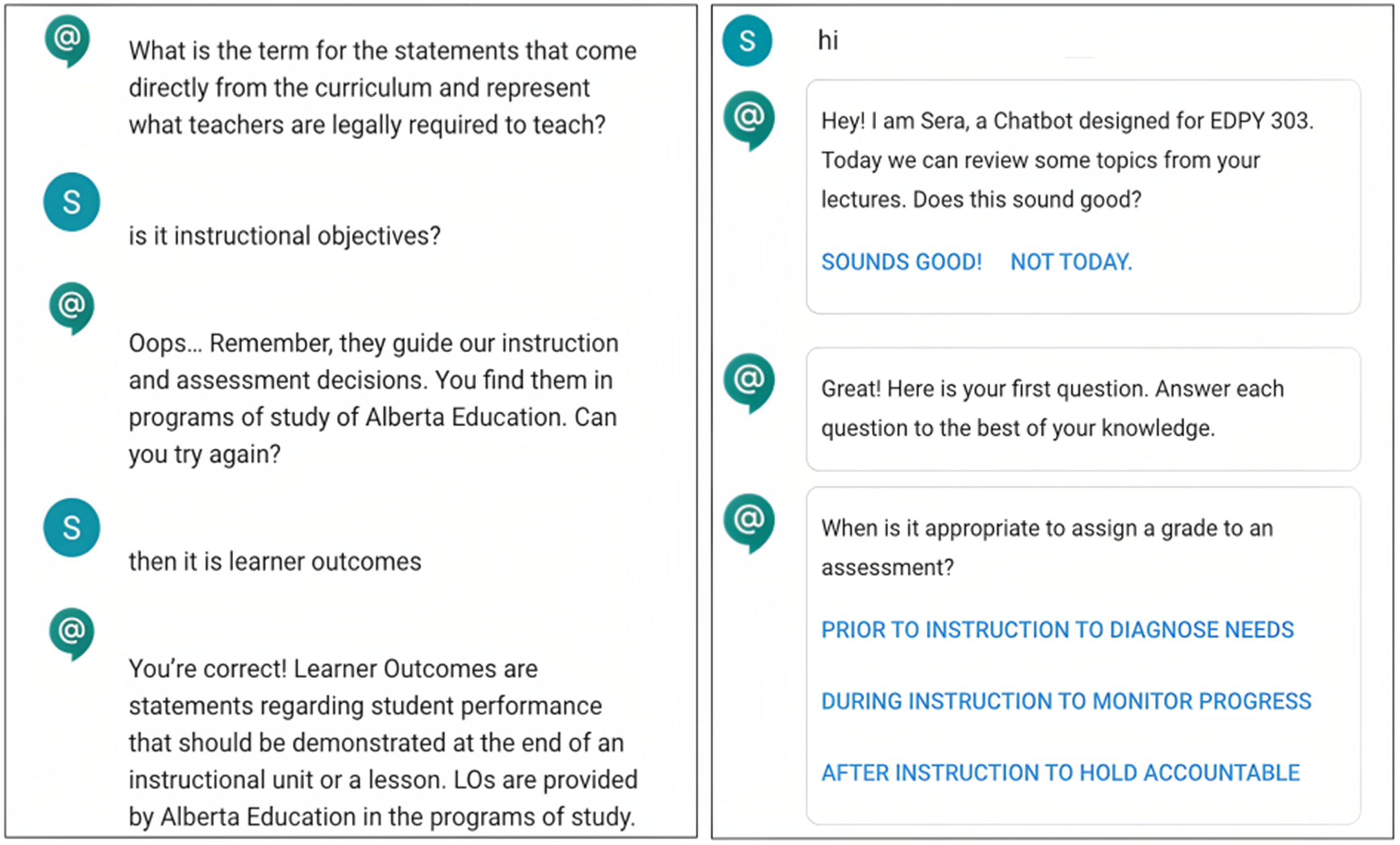
Examples of Constructed (left) and Selected-Response Items (right).
Regarding the constructed-response tests, the recall for each item was 100%. However, the precision measures ranged from 80% to 100%, and F1-scores ranged from 89% to 100% (see Table 2). Regarding these misclassifications, CBA matched these responses with inaccurate conversation paths, possibly because of an overlap between the student response to that item and the expected responses for another item. Even though multiple choice, true or false, and short response items were written in CBA to prevent irrelevant and inaccurate responses (e.g., D’Mello & Graesser, 2013; Graesser, 2016; Lopez et al., 2021), students still experienced problems. These results confirm previously identified design and implementation challenges (e.g., Jackson & Zapata-Rivera, 2015; Yu et al., 2017).
Confidence Score and Classification Performance in CBA With Constructed-Response Items.
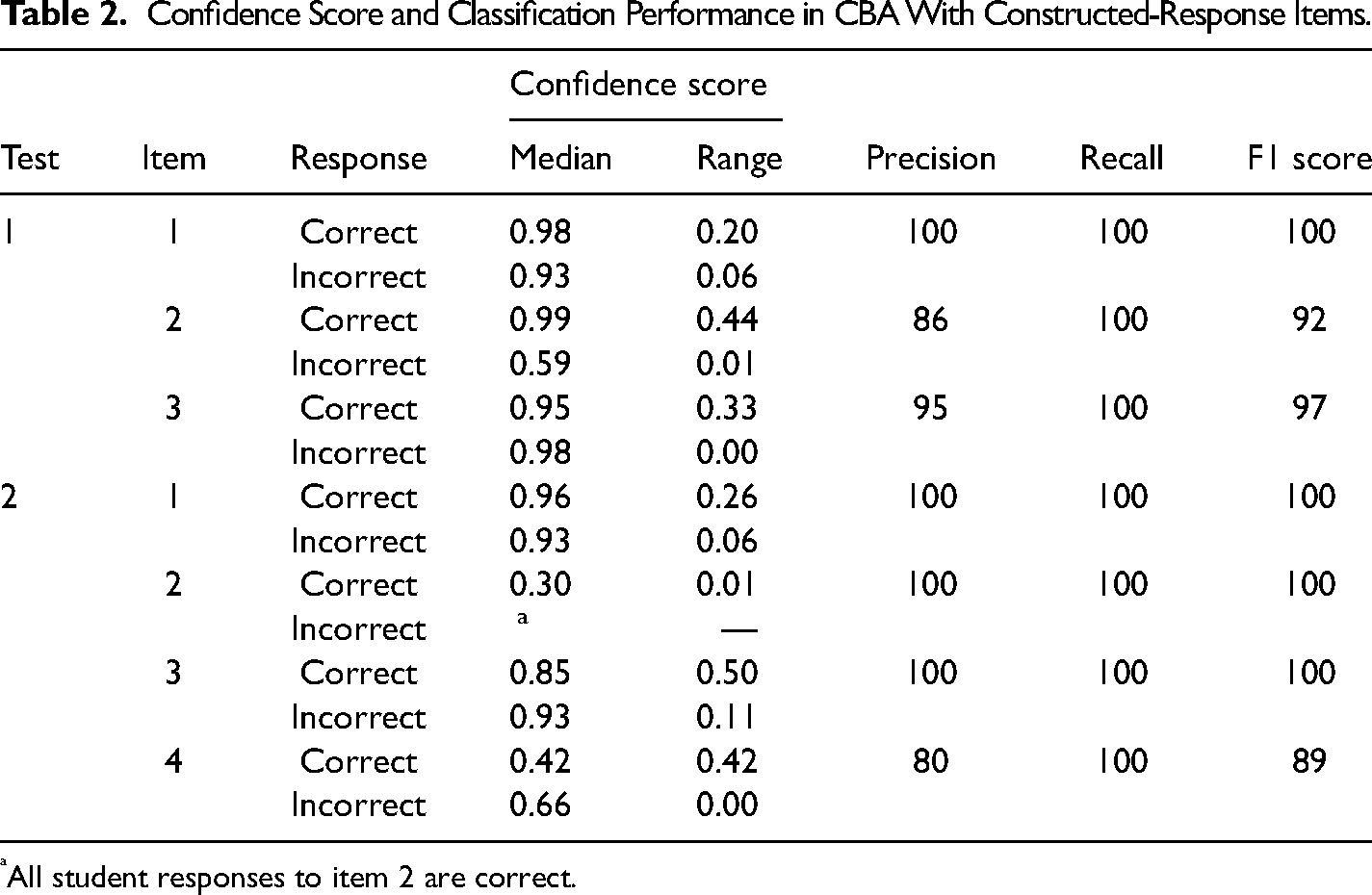
All student responses to item 2 are correct.
In addition to intent classification, median and range of confidence scores for correctly identified intents were reported. For the selected-response items, all classifications of intents were correct. The median confidence scores for each intent were approximately 1, meaning the NLU was confident in classifying each input. These findings partially support the literature, indicating that CBA showed improved results for selected responses (Huang et al., 2019; Valério et al., 2018).
Regarding the constructed-response items, the median confidence scores for each correctly classified response went from 0.30 to 0.99 for correct responses, which suggests that for half of the correct responses, CBA had a relatively low to high level of confidence that the given response was correct (see Table 2). For the incorrect responses, the median confidence score went from 0.59 to 0.98, indicating that for half of the incorrect responses, the model had a moderate to high level of confidence that the response was incorrect (see Table 2). Regarding the variability of confidence scores, the smaller ranges (i.e., 0 or closer to 0) suggest that CBA showed more consistency in identifying students’ incorrect responses. However, larger variability in correct responses could indicate that CBA was inconsistent in its predictions, which may impact its ability to accurately respond to students’ correct responses. Based on the confidence scores, it appears that CBA performed reasonably well for both formats, but with some room for improvement, in particular, for interpreting students’ written correct responses. The low confidence score for correct responses might indicate that the system was uncertain about its classification for some of the correct responses.
CBA showed similar performance in interpreting the students’ very short (e.g., a confidence score of 0.95 for the response “formative”) or relatively long responses in most cases (e.g., a confidence score of 0.92 for the response “provide a grade, assessment of learning, see if the student has learned the content”). That is, it cannot be concluded that CBA was more successful in understanding shorter or longer responses in contrast to previous studies (e.g., Huang et al., 2019; Lopez et al., 2021; Valério et al., 2018). CBA was able to understand expressions that convey similar meanings in the responses and to direct the conversation to the accurate path (e.g., “students demonstrate achievement of learning,” “to assign a grade to students”). These results can be attributed to the data generation process, in which the course instructors provided the relevant information, which was then coded into Rasa following its structure (i.e., NLU, domain, and stories files). In addition, participating students provided answers with incorrectly spelled words or insufficient grammar, but as long as the words they used were associated with the listed words in the Rasa space, it made the correct pattern match because spell-check and correction enabled CBA to accurately interpret responses containing some misspelled words (e.g., “formatibe assessment”).
Regarding unexpected inputs by students which were not defined in CBA with both constructed and selected-response tests (e.g., a student types “more questions please” after answering all selected-response items), CBA sent the default message. The default response aimed to address the problem of inaccurate responses to students. In addition, students received the default response when they typed “I don’t know” or other expressions with a similar meaning (e.g., “Idk”). Once students finished the assessment, they were asked to self-assess their performance with the question “Thank you for reviewing some topics with me. How would you rate your own performance on these questions?” using buttons to select one of “inadequate, moderate, or excellent”. There were no issues found during the execution of the self-assessment.
Cognitive Walkthrough of CBA
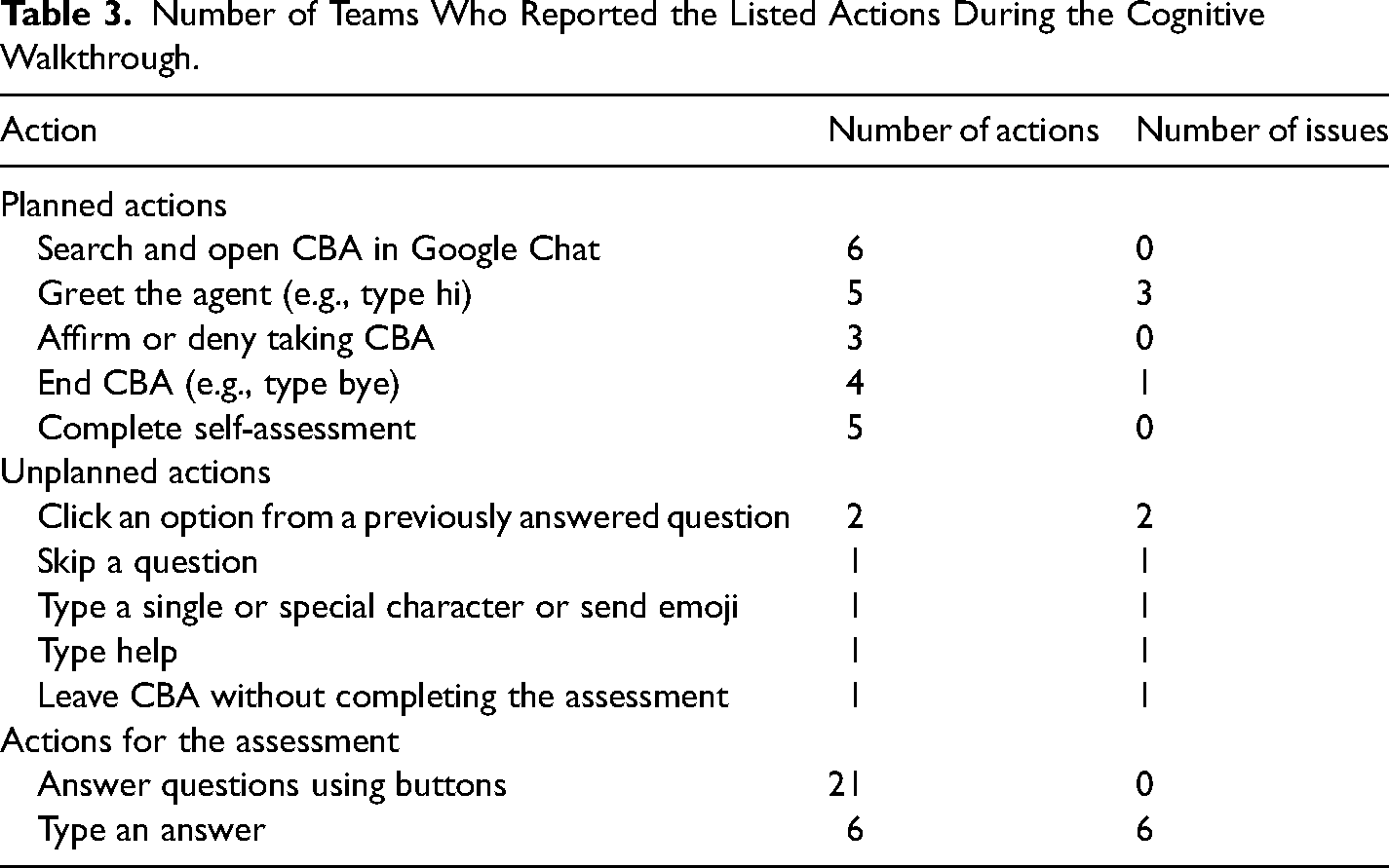
The actions attempted by the 21 teams who evaluated CBA using cognitive walkthroughs are summarized in Table 3. The findings from the cognitive walkthroughs that assessed the usability of CBA were split into three sections: planned actions for CBA (i.e., actions that CBA was trained for and not related to answering questions), unplanned actions for CBA (i.e., actions that CBA was not trained for), and assessment actions (i.e., actions related to answering questions).
Number of Teams Who Reported the Listed Actions During the Cognitive Walkthrough.
Planned Actions for CBA
Some teams reported a bug when they opened CBA: CBA sent them a question before they greeted the agent. Fortunately, the participating students did not encounter this bug when CBA was shared with them. Teams suggested an extended introduction about CBA by the agent in terms of the acceptable actions users could take, including explanations about purpose and use (e.g., how to answer questions: type or click). In addition, one team also suggested a more distinct goodbye message (e.g., a goodbye image) by the agent as it was unclear to them if they had completed the assessment. Teams also suggested more social interaction at the beginning before the agent asked if students wanted to take an assessment or not. Even though their concern was understandable, the decision regarding short social interaction was made based on the literature (e.g., the trade-off between engagement and efficiency; Ruan et al., 2019) and the discussions with the course instructors.
Unplanned Actions for CBA
Some teams attempted to perform actions that CBA was not designed for and thus the agent failed to execute these actions and responded with either a default response or an inaccurate conversation path (see Table 3).
The usability issues associated with the action of clicking an option from a previously answered question is an important concern because it is possible that a student can attempt this action intentionally or accidentally, even though this did not occur when the participating students interacted with CBA. To handle this issue, teams suggested making the options of the previous questions unclickable once a student chooses their answer.
One team attempted to type a single or special character or send emoji, and they received the default response. Even though the team identified this issue as a usability problem, this was not necessarily considered a problem for CBA because CBA was designed for assessment, and it controlled the direction of the conversation by asking questions and sending feedback to student responses. Thus, it was expected students would receive a default response if they typed a single or special character that was not related to the content and sent an emoji.
One team attempted to type “skip,” “help,” and “leave” in the chat and received the default response as these actions were not included in the CBA script. For these unplanned actions, teams suggested adding new buttons. These suggestions should be considered for further improvement of CBA because even though participating students did not attempt these actions, it is possible that students would. While a possible solution to these concerns could be a new button, the solution also depends on the purpose of the assessment or the instructor. For example, the instructors did not suggest skipping a question during consultation. In addition, CBA was designed to guide students through an assessment in a specific order. Skipping a question and returning to it later can disrupt the flow. By following the intended flow, CBA can effectively support the students’ assessment experiences and provide a more engaging and productive environment. However, this issue could be further investigated in future studies to determine if there are any potential solutions or modifications that can be made to allow for a more flexible assessment experience while still maintaining the effectiveness of CBA.
Assessment Actions
The action of answering questions was clear because this interaction uses (1) a common known format (i.e., selected-response items), (2) clickable button options with blue color, larger font size, and full capitalized letters, (3) a red dot indicating an unread message, and (4) a throbber to indicate that something is happening once a student types or selects an answer. Despite familiarity supporting usability, the evaluators reported several usability problems: it is not clear (1) how to respond to the questions: type or click, (2) the total number of items that will be asked through CBA, and (3) a score bar showing performance.
For the first concern, when they typed their selected response for a multiple-choice item, the agent directed them to the correct path. However, when they typed their selected response for a true or false item, the agent either sent the default response or directed them to the wrong path. This unforeseen problem was due to the expectation that users would select their answers, not type them. As a result of this expectation, the questions with the same response options (i.e., true or false items) were not distinguished from each other in the CBA script. It should be noted that this problem did not occur in data collection from the participating students because they selected their responses from the given options instead of typing. However, the concern is important for the future use of CBA. The teams suggested (1) providing an explanation at the beginning about how to respond to questions; (2) making the text box unavailable for the selected-response items, or (3) updating the CBA script to make sure students will be directed to the correct conversation path if they type. It is important to carefully consider these suggestions made by external evaluators to enhance the effectiveness of CBA. While the suggestion to make the text box unavailable for selected-response items may seem like a simple solution, it is important to consider the potential drawbacks of this approach. By making the text box unavailable, students would not be able to end the conversation if they wanted to, which could lead to a negative user experience. In light of this, it may be prudent to consider other suggested solutions: providing a detailed explanation at the beginning or updating the CBA script. These may provide a more balanced solution that meets the needs of both the students and the system.
The second usability problem for the action of answering questions was the lack of information about the total number of items on the test and the question number they were answering. CBA should be updated to provide information about how many items students will answer. Even though the agent says “first, next, or final question” to direct students, CBA should be updated by numbering the questions. Teams also suggested a progress bar indicating how many questions students answered. While their suggestion may seem reasonable, it may not be appropriate in the context of a chatbot. This is because chatbots typically involve a conversational interaction method, rather than clicking buttons, and a progress bar may not accurately reflect the student's engagement with the material.
The final concern was the lack of information about their performance; the teams recommended a score bar showing how many questions they answered correctly and incorrectly. Even though this concern was reasonable from the user's perspective, the goal of CBA was to provide an interactive environment for students to assess their knowledge and scaffold their learning, so a score bar is misaligned with the tool's intent. Providing an opportunity for students to review their progress could be valuable and could be achieved through other mechanisms, such as dashboards (Bull et al., 2014; Demmans Epp & Bull, 2015). This could allow for a more in-depth understanding of their performance and could facilitate the learning process further.
Other Suggestions
In addition to the cognitive walkthrough of the actions in CBA, teams reported valuable suggestions to improve user interaction with CBA. One team suggested giving students more time to read the feedback or adding a follow-up question to confirm if users read and understood the feedback before sending the next question. Despite the potential value of this suggestion, previous research highlights the negative impact of excessive interaction (e.g., Katz et al., 2021). As a result, this suggestion should be thoroughly evaluated before implementation. The other suggestion was to send a reminder message to users if they do not respond for some time without ending the assessment. This action of CBA would help make it more interactive. CBA can be updated by scheduling a reminder to be executed after a certain time if the user stops interaction without completing the assessment.
Conclusion
This study designed and implemented a CBA with constructed and selected-response items for higher education students to investigate its performance and usability. Previous research on conversational agents has mainly discussed the benefits and limitations of conversational agents in education using conversation or survey data. This study contributes to the literature by providing an applied example of the design, implementation, and evaluation of a chatbot for formative assessment and highlights the importance of cognitive walkthroughs in its evaluation. The cognitive walkthrough of CBA contributed to this research and the literature by providing valuable insights into the usability problems of a chatbot designed and developed for assessment purposes. The external evaluators were able to identify areas for improvement and highlight the strengths and weaknesses of the design, which can inform future CBA designs. For example, one crucial usability problem was the lack of a detailed introduction by the agent. Considering the results from conversation data and cognitive walkthroughs, a detailed introduction at the beginning could prevent potential problems later. It is challenging to design a perfect conversational agent that answers all expected and unexpected inputs from students. However, this study suggests that with a proper introduction explaining the agent's purpose and what the agent can and cannot do, some potential problems can be prevented proactively.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.