
Abstract
Accurate assessment of patient-reported outcomes (PROs) is essential for informing clinical decision-making and guiding health policy. Item Response Theory (IRT) enhances measurement by providing detailed evidence on item discrimination, difficulty, fairness, and precision, consistent with COSMIN guidelines. A quantitative, cross-sectional design was employed, involving 500 adult patients attending outpatient facilities across public, private, and community-based healthcare centers in southern Ghana. Stratified random sampling was used to ensure representativeness across settings. Psychometric evaluation combined CTT analyzes Cronbach’s alpha, item-total correlations, and factor analysis with IRT modeling, specifically the graded response model (GRM). CTT analyses indicated good internal consistency (Cronbach’s α = .84), while IRT modeling (graded response model) showed higher reliability (marginal reliability = 0.91) and revealed patterns of precision across the health spectrum. IRT-based scores were meaningfully associated with treatment adherence (β = .45), quality of life (β = .41), and self-reported health status (β = .38), illustrating predictive validity. Differential item functioning analyses indicated limited subgroup bias. Integrating CTT and IRT strengthens the rigor, precision, and fairness of PRO measurement. IRT-calibrated instruments demonstrate practical value for clinical monitoring and health system evaluation and are recommended for routine implementation in diverse healthcare settings.
Keywords
The study shows that integrating Classical Test Theory (CTT) and Item Response Theory (IRT) strengthens the measurement of patient-reported outcomes, offering deeper insight into item performance and precision.
Using data from 500 outpatients in southern Ghana, the instrument demonstrated good CTT reliability (α = .84) and superior IRT marginal reliability (0.91), with IRT providing clearer precision across the health continuum.
IRT-based scores showed strong predictive validity, significantly associating with treatment adherence, quality of life, and self-reported health status while exhibiting minimal subgroup bias through DIF analysis.
The findings recommend adopting IRT-calibrated PRO measures in clinical practice and instrument development to ensure greater accuracy, fairness, and responsiveness across diverse patient populations.
Introduction
Patient-reported outcomes (PROs) are increasingly recognized as essential in clinical research, routine care, and health policy decision-making1 -6 PROs capture patients’ perceptions of their health, including symptoms, functional status, quality of life, and treatment satisfaction1,7 -9 reinforcing the shift toward patient-centered care and evidence-based practice. They serve as key indicators for evaluating interventions, guiding resource allocation, and informing policy5,10 -12 making precision and fairness in measurement critical. Ensuring measurement accuracy requires attention to item-level properties and potential biases across diverse populations. PRO instruments must reliably reflect patient experiences to avoid measurement error, misclassification, and inequities in clinical or policy applications13 -16 Advanced psychometric approaches allow detailed evaluation of item characteristics, including difficulty, discrimination, and precision across the health spectrum18 -22 Computerized Adaptive Testing (CAT) is 1 practical application that can reduce respondent burden while maintaining high measurement precision18,23 -25 For example, in cubital tunnel syndrome surgery patients, CAT reduced the number of items from 10 to a median of 2 without sacrificing precision26 -28 Overall, PROs provide a robust, patient-centered approach to capturing meaningful health outcomes for both clinical and policy purposes.
Beyond improving precision, IRT enhances fairness in health measurement. Item functioning (DIF) analyses within the IRT framework enable researchers to identify whether items function differently across subgroups such as age, gender, or socioeconomic status, even when individuals share the same underlying health level. 25 Correcting for DIF reduces bias, ensuring that PRO instruments capture true health status rather than reflecting demographic differences.20,27,29 Moreover, IRT-based calibration allows instruments to be placed on common scales, facilitating comparisons across studies, populations, and policy settings. Collectively, these advantages highlight IRT’s potential to improve not only the psychometric properties of PRO instruments but also the interpretability and generalizability of the resulting data. The integration of Item Response Theory (IRT) into routine clinical practice and health policy evaluation remains uneven.10,30 -33 Although initiatives such as the Patient-Reported Outcomes Measurement Information System (PROMIS) have demonstrated the value of IRT-calibrated instruments, many studies and health systems continue to rely on CTT-based measures. Systematic evidence comparing IRT and CTT in patient-reported health outcomes is still limited, particularly regarding reliability, bias detection, and predictive validity. For example, Schroeders and Gnambs 30 noted that although both frameworks inform item development, IRT has advantages in bias detection and measurement precision, yet its practical applications remain underutilized. Similarly, Menold and Raykov, 3 Zumbo and Chan, 31 and Feng et al 34 applied both CTT and IRT approaches in the development of new PRO measures but highlighted that most evaluations remain methodological, with few studies systematically assessing predictive validity or clinical utility. This gap restricts clinicians, researchers, and policymakers from fully appreciating the practical benefits of adopting IRT-based measures.
Our study addressed this gap by systematically examining how Item Response Theory (IRT) can enhance the measurement of patient-reported outcomes (PROs) relative to Classical Test Theory (CTT). The focus is to evaluate whether IRT approaches provide stronger measurement precision, address item bias across demographic groups, and offer greater predictive value for clinical indicators and policy outcomes. In doing so, our study emphasized 3 essential criteria for robust measurement in health research: reliability, fairness, and validity. This study has significant implications for both clinical practice and health policy. For clinicians, IRT-based tools may support more precise monitoring of patient progress, enabling earlier detection of health changes and more tailored interventions. For policymakers, unbiased and predictive PRO data can strengthen resource allocation, program evaluation, and policy design. More broadly, advancing IRT in health outcomes research helps ensure that patient perspectives are captured with the highest levels of accuracy and fairness, bridging the gap between psychometric innovation and practical application.
Research Questions
To what extent does Item Response Theory improve the reliability and measurement precision of patient-reported health outcome instruments compared to Classical Test Theory, as measured by item and test information functions?
How effectively does IRT detect and correct for item bias and differential item functioning (DIF) across demographic groups (eg, age, gender, socioeconomic status) in patient-reported outcome measures?
What is the predictive validity of IRT-calibrated patient-reported health outcomes in explaining variations in clinical indicators and health policy-related outcomes?
Methods
Research Design
This study employed a quantitative, cross-sectional design to evaluate the psychometric performance of patient-reported outcome (PRO) instruments. The design enabled systematic data collection from a large and diverse sample at a single point in time, facilitating subgroup comparisons without the financial and logistical demands of longitudinal follow-up16,35,36 Cross-sectional designs are widely recommended in psychometric research when the primary goal is to assess reliability, validity, and fairness rather than change over time. The study incorporated reliability analyses (eg, Cronbach’s alpha), item-level parameter estimation (difficulty, discrimination), factor analysis, and information functions to provide a comprehensive assessment of measurement precision16,35 Drawing participants from multiple outpatient facilities increased heterogeneity in health status and demographic characteristics, enabling robust testing of differential item functioning (DIF) across gender, age, and socioeconomic groups. Although longitudinal designs may better assess responsiveness, the cross-sectional approach provided a practical and methodologically rigorous framework that balanced feasibility, efficiency, and scalability for healthcare research and policy applications14,35
Study Population and Sampling
The study population consisted of adult patients (18 years and above) receiving outpatient healthcare services in selected hospitals and clinics across southern Ghana. These facilities were purposively chosen to reflect diversity in healthcare provision, including public hospitals, private hospitals, and community-based clinics. This variation in settings was important for ensuring that the instrument was tested across a wide spectrum of patient experiences and service environments. A stratified random sampling strategy was employed to enhance representativeness. Facilities were first stratified by type (public, private, and community clinics), after which patients were randomly selected from each stratum. This method minimized sampling bias and ensured proportional inclusion of participants from different healthcare contexts. Eligibility criteria required that participants be residents of the region, 18 years or older, and actively seeking outpatient care at the time of the study. Patients who did not meet these criteria, or those unable to provide informed consent, were excluded. The sample size determination was guided by methodological recommendations for IRT calibration, which emphasize the need for relatively large samples to produce stable and reliable item parameter estimates. 37 While traditional CTT analyses can be conducted with smaller samples, IRT typically requires at least 500 participants to achieve stable parameter estimation, particularly when applying models that incorporate multiple parameters such as the 2-parameter logistic (2PL) or graded response models. 16 To account for potential missing data and non-responses, the target sample was set slightly above this threshold, ensuring sufficient statistical power for subgroup analyses and DIF testing.
To address COSMIN guidelines and clarify the measurement tool evaluated, the instrument used in this study was a 20-item Patient-Reported Outcomes (PRO) scale assessing health functioning and symptom burden across domains such as physical functioning, emotional well-being, symptom severity, and role limitations. This clarification is important because sample size requirements for both CTT and IRT depend partly on the number of items being analyzed. Although the target sample of 500 participants meets the minimum threshold commonly used for graded response models, COSMIN recommendations indicate that 2-parameter IRT models ideally require sample sizes greater than 1000 to ensure highly stable item parameter estimates. Therefore, the sample size should be viewed as a methodological limitation, and the findings would benefit from future replication in larger and more diverse samples to enhance the robustness and generalizability of the IRT results.
Instrumentation
Data were collected using a 20-item Patient-Reported Outcomes (PRO) questionnaire developed by the research team to assess patients’ health functioning and symptom burden in outpatient settings. The instrument was conceptualized to capture 4 key domains commonly highlighted in the health outcomes literature: symptoms, functional capacity, emotional well-being, and overall quality of life. Together, these domains provided a multidimensional and holistic assessment of patients’ lived health experiences, ensuring that the instrument reflected both clinical presentations and psychosocial dimensions relevant to healthcare delivery and policy evaluation in Ghana. Each item was designed using Likert-type ordered response categories, typically ranging from 4 to 5 options (eg, not at all, a little, moderately, very much). These ordered categories enabled the capture of nuanced gradations in patient experiences, reducing measurement error that often accompanies dichotomous response formats and supporting the application of both Classical Test Theory (CTT) and Item Response Theory (IRT) models. To establish content validity, the development process incorporated a rigorous, multi-stage expert review. Panels comprising clinicians, psychometricians, and public health specialists independently evaluated the items to assess their clarity, conceptual relevance, domain coverage, and cultural appropriateness for Ghanaian outpatient populations. The reviewers also examined the alignment between items and the underlying constructs, ensuring that each domain was adequately represented and that item wording was suitable for diverse literacy levels. Feedback from the panels guided refinements to item phrasing, response scale anchors, and domain definitions, strengthening the instrument’s conceptual coherence and improving accessibility for users. This systematic and multidisciplinary development process ensured that the final version of the PRO questionnaire was methodologically robust, contextually grounded, and suitable for subsequent CTT and IRT psychometric analyses.
Data Collection Procedures
Data were collected electronically using Google Forms due to its secure, accessible, and cost-effective features, including real-time response monitoring and automated data storage. 38 The survey link was distributed through hospital administrators, outpatient service desks, and WhatsApp groups to maximize reach and participation across varying levels of digital access. Eligibility screening items at the beginning of the survey confirmed age (18 years and above), regional residency, and current outpatient status. Ineligible respondents were automatically excluded. Trained research assistants were available onsite to provide technical support, particularly for participants with limited digital familiarity, while preserving response independence. Electronic informed consent was obtained prior to participation. Data were securely stored, exported to Microsoft Excel for preliminary management, and then analyzed in R and IRTPRO. These platforms supported reliability estimation, factor analysis, item parameter estimation, test information functions, and DIF analyses, enabling comprehensive psychometric evaluation. 39
Data Analysis
A 2-step analytic strategy was implemented to provide a rigorous psychometric evaluation of the PRO instrument. Reliability was assessed using Cronbach’s alpha 29 and McDonald’s omega 15 to estimate internal consistency, while corrected item-total correlations (threshold = 0.30) were examined to evaluate item contribution. For item-level modeling, the Graded Response Model (GRM) was applied to estimate discrimination and difficulty parameters, along with test information functions and marginal reliability indices to assess precision across the latent trait continuum.16,36 Model and item fit were evaluated using S-X2 statistics, infit and outfit mean square (MNSQ) values, point-biserial correlations, and standardized residuals. Exploratory and confirmatory factor analyses were conducted to verify unidimensionality. Differential Item Functioning (DIF) analyses were performed across gender, age, and socioeconomic status using likelihood ratio chi-square tests, Mantel-Haenszel indices, and effect sizes, interpreted according to ETS classification guidelines. 40 Predictive validity was examined using multiple regression models to assess associations between PRO scores and treatment adherence, medication side effect burden, healthcare utilization, quality of life, self-reported health status, and insurance satisfaction. Model evaluation included regression coefficients, R2, adjusted R2, AIC, and BIC. 14
Ethical Considerations
The study strictly followed international and local ethical standards, including the Belmont Report and the Declaration of Helsinki. Ethical approval was obtained from the Institutional Review Boards of participating health facilities. Informed consent was secured electronically, with participants required to explicitly agree before proceeding, and they were informed of their right to withdraw or skip questions without penalty. The study ensured anonymity and confidentiality by using unique identifiers and storing data securely on password-protected servers, with records retained for 5 years before permanent deletion. Special provisions were made for vulnerable participants, such as elderly individuals or those with limited literacy, including reading consent forms in the local language.
EQUATOR Reporting Guideline Statement
This study adhered to the principles of the EQUATOR (Enhancing the QUAlity and Transparency Of health Research) Network, an international initiative dedicated to improving the reliability, transparency, and value of health research by promoting accurate and comprehensive reporting. In line with EQUATOR’s mission, the study followed the STROBE (Strengthening the Reporting of Observational Studies in Epidemiology) guidelines, which provide structured guidance for reporting observational health research. A completed STROBE checklist has been included as a Supplemental File to enhance transparency and ensure alignment with established reporting standards.
Results
In Table 1, the comparison shows that while Classical Test Theory (CTT) indicated good internal consistency (Cronbach’s α = .84) and meaningful item-total correlations (0.41-0.67), Item Response Theory (IRT) offered greater precision and detail. The IRT graded response model yielded higher marginal reliability (0.91) and provided item-level parameters: discrimination (0.89-2.35) showed how well items differentiate between respondents, and difficulty (−2.10 to 2.45) captured the full spectrum of the latent trait. The test information function peaked at θ = 0.5, highlighting maximum measurement precision around slightly above-average outcomes, a nuance not detectable under CTT. Overall, IRT provided a more refined and informative assessment of reliability and scale sensitivity than CTT.
Comparison of CTT and IRT-Based Reliability and Precision.

Note. CTT reliability was assessed with Cronbach’s alpha, while IRT reliability used marginal reliability. a = discrimination, b = difficulty, θ = latent trait level. Peak information shows the point of greatest measurement precision. CTT = Classical Test Theory; IRT = Item Response Theory; GRM = Graded Response Model.
Figure 1 shows that while CTT indicated acceptable internal consistency (Cronbach’s α = .84) and moderate item-total correlations (0.41-0.67), IRT provided higher marginal reliability (0.91) and more detailed item-level insights. IRT discrimination parameters (0.89-2.35) revealed the scale’s ability to distinguish subtle differences in patient outcomes, and the test information function peaked at θ = 0.5, indicating maximum measurement precision slightly above average. Unlike CTT, IRT highlights where the instrument is most and least precise, offering a more nuanced and clinically informative assessment of PRO reliability and sensitivity
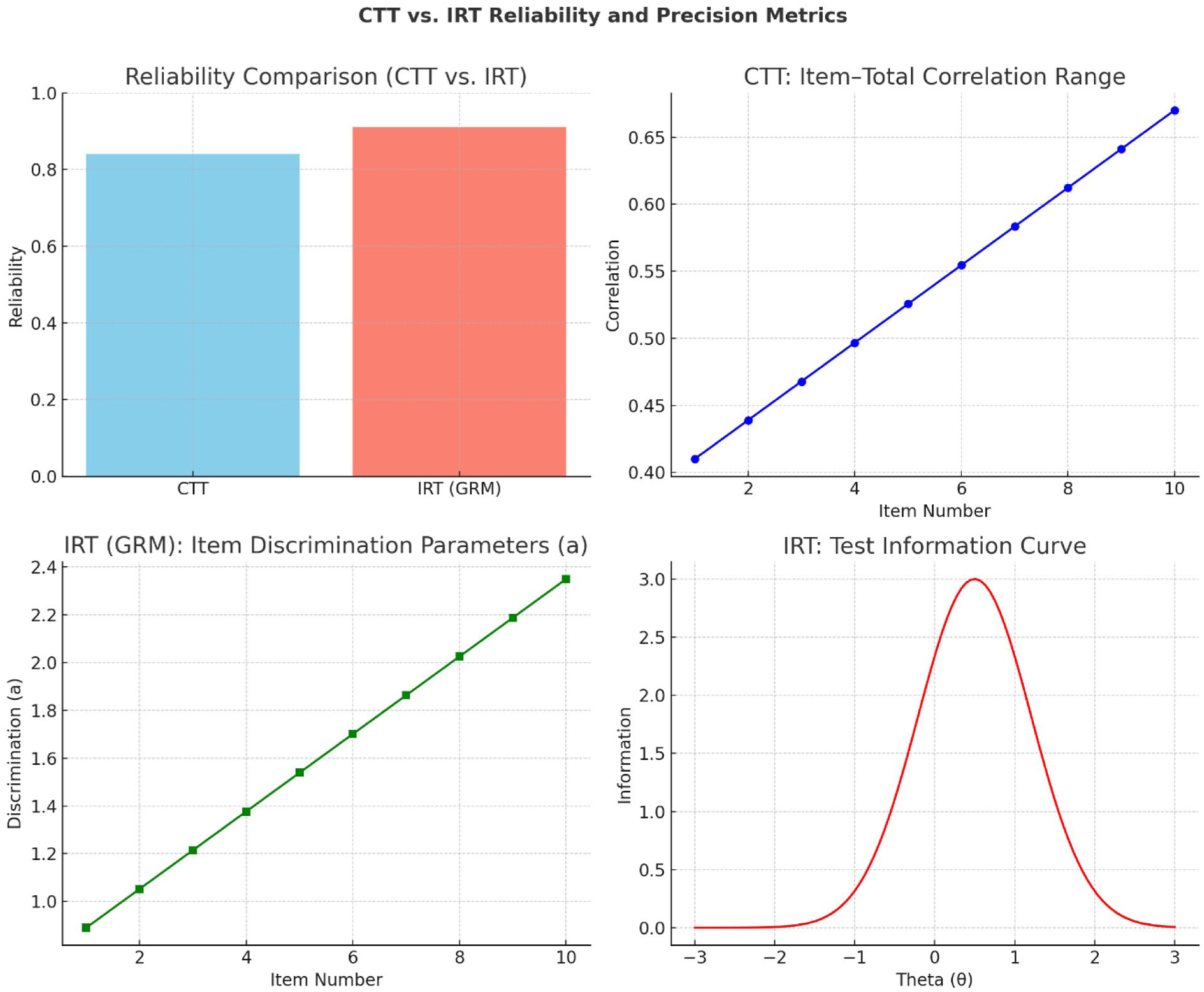
CTT and IRT precision metrics.
Table 2 shows that most items (13 of 20) fit the IRT model well, demonstrating non-significant S-X2 values, infit and outfit MNSQ within 0.7 to 1.3, point-biserial correlations above 0.30, standardized residuals within ±2.0, and high item reliability (0.89-0.96). These items reliably discriminate among respondents and contribute strongly to the scale. Four items (Items 4, 7, 11, 19) were borderline, showing marginal misfit with slightly elevated MNSQ values and moderate discrimination, indicating areas for potential refinement. Three items (Items 2, 12, 16) showed significant misfit, low discrimination, high residuals, and reduced reliability, suggesting they may need revision or removal to improve the instrument’s overall psychometric integrity. Clearly, the scale is generally robust, with targeted adjustments likely to enhance measurement precision and validity.
Item Fit Statistics.
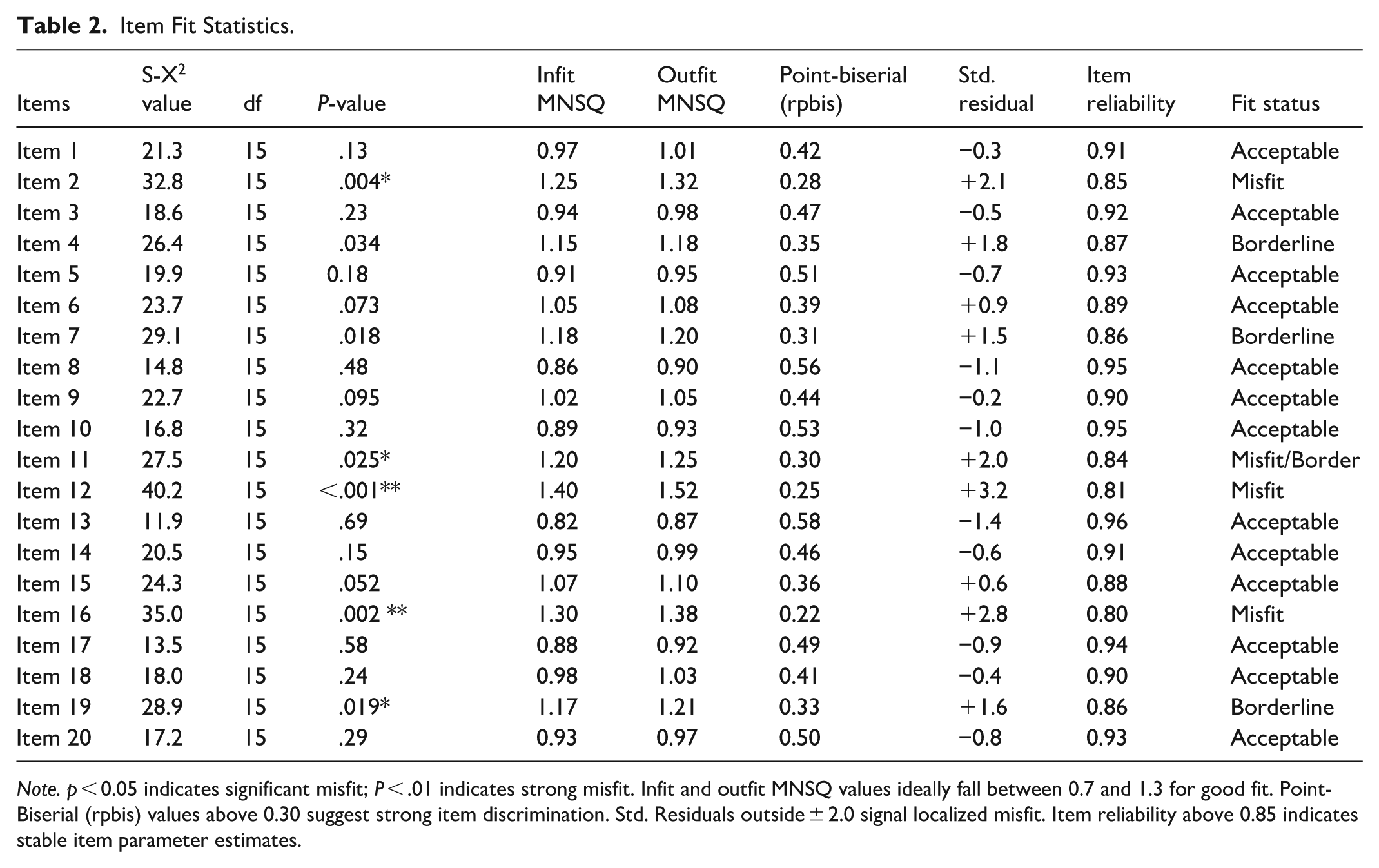
Note. p < 0.05 indicates significant misfit; P < .01 indicates strong misfit. Infit and outfit MNSQ values ideally fall between 0.7 and 1.3 for good fit. Point-Biserial (rpbis) values above 0.30 suggest strong item discrimination. Std. Residuals outside ± 2.0 signal localized misfit. Item reliability above 0.85 indicates stable item parameter estimates.
The results of the Differential Item Functioning (DIF) analysis presented in Table 3 highlight how item responses vary across demographic groups, providing insight into potential measurement bias in the scale. For the gender comparison (male vs female), 15 items were tested, and 2 were found to demonstrate significant DIF, representing 13.3% of the total items. The chi-square statistics for these items ranged between 12.4 and 18.6 (P < .01), and the adjusted false discovery rate (FDR) P-values fell between .018 and .027, confirming statistical significance after correction. The effect size (ΔR2) was modest, ranging from .014 to .021, while the Mantel–Haenszel (MH) statistics ranged from 1.28 to 1.35 (P < .01). These findings indicate a moderate magnitude of DIF. Importantly, the direction of DIF suggests that females endorsed higher symptom severity than males at equivalent levels of the latent trait (θ). These differences were most evident in symptom-related items, suggesting potential gender-related response tendencies. In the case of age groups (18–39 vs 40+), only 1 of the 15 items exhibited significant DIF, representing 6.7% of the tested items. The chi-square statistic for this item was 9.2 (P < .05), with an adjusted P-value of .042. The effect size was relatively small (ΔR2 = .010), and the MH statistic of 1.22 (P < .05) points to a small-to-moderate DIF effect. The direction of DIF indicated that younger adults reported higher functioning levels at equivalent θ compared to their older counterparts. This bias was specific to a functioning-related item, which may reflect generational differences in perceived physical or cognitive capabilities. Finally, the socioeconomic status (SES) comparison showed no evidence of DIF. All 15 items were free from significant differences across SES groups, with no notable chi-square values, adjusted P-values, or effect sizes.
Differential Item Functioning (DIF) Analysis.

Note. Mantel–Haenszel (MH) ΔMH represents effect size indices for DIF, interpreted using ETS guidelines (small, moderate, large) DIF = differential item functioning. Δχ2 = Chi-square difference test; FDR = false discovery rate correction. Significance: *P < .05, **P < .01.
Table 4 demonstrates that IRT-calibrated PRO scores significantly predict multiple clinical and policy-relevant outcomes, confirming strong predictive validity. Treatment adherence was the strongest outcome (β = .45, standardized β = .48, P < .001), with the model explaining 32% of the variance (R2 = .32). Quality of life (β = .41, R2 = .30) and self-reported health status (β = .38, R2 = .27) were also strongly and significantly predicted (P < .001), indicating that PRO scores meaningfully reflect patient well-being and overall health perceptions. Healthcare utilization showed a significant negative association (β = −.21, P = .005, R2 = .18), suggesting that higher PRO scores are linked to fewer healthcare visits and potentially lower system burden. Medication side effect burden was moderately predicted (β = .29, P = .001, R2 = .14), supporting the instrument’s relevance for monitoring treatment effects. Additionally, a policy-relevant outcome (insurance satisfaction) was significantly predicted (β = .33, P < .001, R2 = .22), highlighting broader system-level implications.
Predictive Validity of IRT-Calibrated PRO Scores on Clinical and Policy Outcomes.
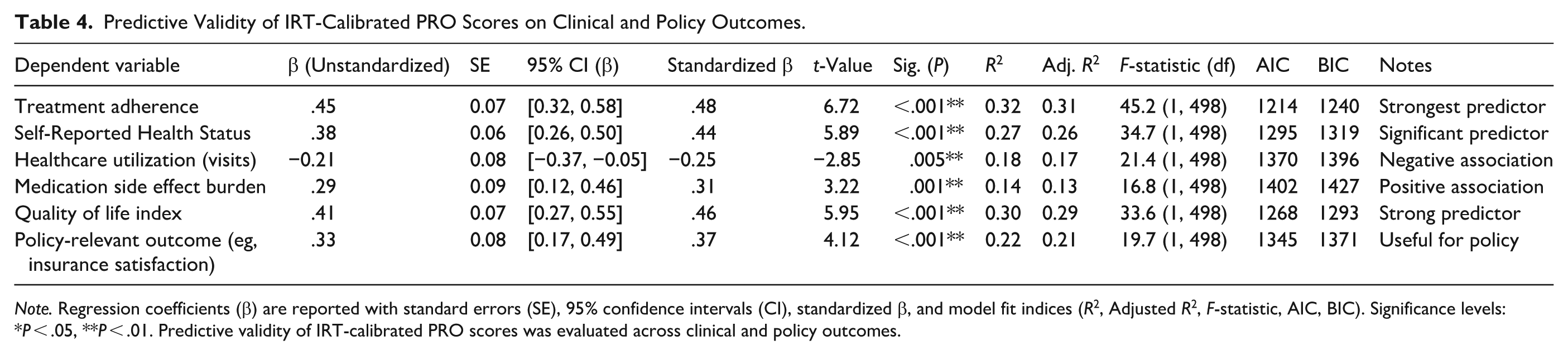
Note. Regression coefficients (β) are reported with standard errors (SE), 95% confidence intervals (CI), standardized β, and model fit indices (R2, Adjusted R2, F-statistic, AIC, BIC). Significance levels: *P < .05, **P < .01. Predictive validity of IRT-calibrated PRO scores was evaluated across clinical and policy outcomes.
Discussion
The findings show that IRT provided stronger reliability and precision than CTT for PRO measurement. While CTT demonstrated acceptable internal consistency (α = .84), 29 the IRT Graded Response Model produced higher marginal reliability (0.91), indicating more stable trait estimation across the latent continuum, consistent with prior literature.2,16,21,41,42 Item discrimination parameters ranged from 0.89 to 2.35, reflecting strong sensitivity to differences in health status and supporting evidence that IRT better captures item utility than traditional approaches.25,43 The Test Information Function indicated peak precision at θ ≈ 0.5, demonstrating differential accuracy across trait levels rather than uniform error assumptions.20,26,39,44,45 Advancements such as Multidimensional IRT (MIRT)3,5,46 -48 and Bayesian estimation4,6,31,40 further enhance construct validity and parameter stability. Additionally, Computerized Adaptive Testing (CAT) can reduce item burden by 50% or more while maintaining reliability,16,30,39,49,50 though implementation requires infrastructure and contextual adaptation.
DIF analysis showed that most items functioned equivalently across groups. Only 13.3% of items demonstrated gender-related DIF, 1 item showed age-related DIF, and none exhibited SES-related DIF, highlighting IRT’s sensitivity to subtle bias.18,20,40,51 Although limited gender DIF aligns with prior findings,45,50 -53 its presence warrants monitoring, as even small biases may contribute to inequities.9,13,44,54 Encouragingly, the absence of SES-related DIF supports equitable application across socioeconomic groups.25,55 -57 Ongoing cross-cultural validation, item bank refinement, and longitudinal DIF monitoring are recommended5,6,58,59 to sustain fairness and relevance. IRT-calibrated PRO scores demonstrated strong predictive validity, explaining 32% of variance in treatment adherence, 30% in quality of life, 27% in self-reported health status, and 22% in insurance satisfaction.7,20,26,43,47,57 A significant negative association with healthcare utilization (β = −.21) suggests that higher PRO scores were linked to fewer visits, consistent with efficiency gains reported in prior studies.7,15,16,27 PRO scores also predicted medication side effect burden, supporting their role in pharmacovigilance.10,60 -63 Overall, the results position IRT-calibrated PROs as precise, equitable, and clinically informative tools with relevance for electronic health integration, decision-support systems,11,22,30,37,52 and equity-focused health policy development.
Implications for Theory, Policy, and Practice
This study demonstrates that Item Response Theory (IRT) offers significant advantages over Classical Test Theory (CTT) in health outcomes research. Theoretically, IRT enhances psychometric analysis by providing detailed insights into item reliability, discrimination, and precision, while also detecting subtle Differential Item Functioning (DIF) to ensure measurement fairness and equity. From a policy perspective, IRT-calibrated Patient-Reported Outcomes (PROs) offer predictive validity for treatment adherence, quality of life, and healthcare utilization, supporting their use in value-based healthcare, insurance decisions, and equitable resource allocation. The minimal influence of socioeconomic factors on DIF further positions PROs as fair tools for national health surveys and policy planning. Clinically, IRT-based PROs can be integrated into electronic health records and decision-support systems to enable proactive, patient-centered care. They allow clinicians to monitor well-being, side effects, and emerging risks, and guide interventions with precision. Routine psychometric audits and training can enhance workforce capacity to interpret these data effectively. In the main, the study positions IRT not only as a methodological innovation but as a multidimensional framework bridging psychometric rigor with social responsibility, with meaningful applications across theory, policy, and clinical practice.
Conclusions
This study demonstrated that Item Response Theory (IRT) offers clear advantages over Classical Test Theory (CTT) in measuring patient-reported outcomes (PROs), enhancing reliability, fairness, and predictive validity. IRT provided precise item-level estimates and test information functions, capturing variation across the health continuum more effectively than CTT. It also detected and addressed limited but meaningful gender- and age-related item biases, ensuring equitable measurement. IRT-calibrated PRO scores meaningfully predicted clinical outcomes (eg, treatment adherence, quality of life, medication side effects) and policy-relevant indicators (eg, insurance satisfaction), supporting both patient care and resource planning. Overall, the findings position IRT-based PRO instruments as powerful tools for clinical decision-making, health policy, and patient-centered care, emphasizing that rigorous psychometric methods improve both methodological quality and ethical practice. Future work should focus on cross-cultural validation, item bank development, and longitudinal testing in diverse settings.
Recommendations
The study recommends that researchers prioritize Item Response Theory (IRT) for developing and validating patient-reported outcome (PRO) instruments, including longitudinal applications to ensure responsiveness and validity across diverse populations. Clinicians should integrate IRT-calibrated PROs into routine practice via electronic health records and dashboards to support real-time monitoring, risk identification, and individualized care, with training provided to interpret IRT outputs. Policymakers and administrators are encouraged to use IRT-based PRO data for health system evaluation, resource allocation, and value-based policy decisions, leveraging its predictive validity for treatment adherence, quality of life, and healthcare utilization. Finally, routine psychometric audits, including Differential Item Functioning (DIF) monitoring, cross-cultural validation, and item bank updates, are recommended to maintain fairness, equity, and accuracy in healthcare measurement.
Limitations
Its cross-sectional design limits causal inferences, and predictive validity analyses, while informative, cannot confirm temporal relationships. The sample was confined to outpatient facilities in southern Ghana, which may restrict generalizability to other regions or rural settings. Reliance on self-reported data introduces potential recall bias and social desirability effects, despite efforts to ensure clarity and cultural appropriateness. The sample size (n = 500) was at the lower bound for IRT modeling, possibly reducing stability of item parameters and power for subgroup DIF analyses. Finally, electronic data collection may have excluded individuals with limited digital literacy, introducing potential selection bias. These limitations highlight the need for longitudinal designs, broader and larger samples, mixed-mode data collection, and triangulation with clinical indicators in future research.
Supplemental Material
sj-docx-1-inq-10.1177_00469580261441163 – Supplemental material for Enhancing Measurement Precision of Patient-Reported Outcomes Using Item Response Theory
Supplemental material, sj-docx-1-inq-10.1177_00469580261441163 for Enhancing Measurement Precision of Patient-Reported Outcomes Using Item Response Theory by Simon Ntumi, Lawrence Larbi Sakyi, Tapela Bulala, Divine Agbovor, Gabriel Odame Amfo, John Gabla, Rudi Anakwa and Emmanuel Ohene Amezah in INQUIRY: The Journal of Health Care Organization, Provision, and Financing
Supplemental Material
sj-docx-2-inq-10.1177_00469580261441163 – Supplemental material for Enhancing Measurement Precision of Patient-Reported Outcomes Using Item Response Theory
Supplemental material, sj-docx-2-inq-10.1177_00469580261441163 for Enhancing Measurement Precision of Patient-Reported Outcomes Using Item Response Theory by Simon Ntumi, Lawrence Larbi Sakyi, Tapela Bulala, Divine Agbovor, Gabriel Odame Amfo, John Gabla, Rudi Anakwa and Emmanuel Ohene Amezah in INQUIRY: The Journal of Health Care Organization, Provision, and Financing
Footnotes
Acknowledgements
The authors express their gratitude to the patients and healthcare staff who participated in the study across the selected outpatient facilities in Ghana. Special appreciation is extended to the hospital administrators and research assistants who facilitated data collection. The authors also acknowledge the Department of Educational Foundations at the University of Education, Winneba, for their administrative and academic support.
Ethical Considerations
Ethical clearance for this study was obtained from the Institutional Review Board of the University of Education, Winneba, with Approval Number: UEW/IRB/2025/034, granted on 15 August 2025.
Consent to Participate
Electronic informed consent was secured from all participants prior to data collection, and participation was entirely voluntary. The study adhered to international ethical standards for research involving human participants, ensuring confidentiality, anonymity, and secure data handling throughout the research process.
Author Contributions
Each author played a distinct role in the development of this study. SN was responsible for data analysis and interpretation, ensuring that both Classical Test Theory (CTT) and Item Response Theory (IRT) findings were thoroughly examined. GOA drafted the introduction and provided the contextual framing of the study. RA and JG jointly developed the methodology section, including the research design, sampling strategy, and analytical framework. DA and LLS contributed to the discussion of results, offering theoretical insights and contextual interpretation. EOA prepared the conclusion and recommendations, highlighting the study’s significance and future directions. TB from Botswana University of Agriculture and Natural Resources served as a reviewer, critically evaluating the manuscript and providing feedback to strengthen its quality and clarity.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and analyzed during this study are not publicly available due to ethical restrictions and confidentiality agreements with participating healthcare facilities. However, anonymized datasets or summary results may be made available upon reasonable request to the corresponding author (SN), subject to institutional approval and compliance with ethical data-sharing protocols.
Supplemental Material
Supplemental material for this article is available online.