
Abstract
Decision makers in the behavioral health disciplines could benefit from tools to assist them in identifying and implementing evidence-based interventions. One tool is an evidence-based program resources website (EBPR). Prior studies documented that when multiple EBPRs rate an intervention, they may disagree. Prior research concerning the reason for such conflicts is sparse. The present study examines how EBPRs rate interventions and the sources of disagreement between EBPRs when rating the same intervention. This study hypothesizes that EBPRs may disagree about intervention ratings because they either use different rating paradigms or they use different studies as evidence of intervention effectiveness (or both). This study identified 15 EBPRs for inclusion. One author (M.J.L.E.) coded the EBPRs for which “tiers of evidence” each EBPR used to classify behavioral health interventions and which criteria they used when rating interventions. The author then computed one Jaccard index of similarity for the criteria shared between each pair of EBPRs that co-rated interventions, and one for the studies used by EBPR rating pairs when rating the same program. The authors used a combination of chi-square, correlation, and binary logistic regression analyses to analyze the data. There was a statistically significant negative correlation between the number of Cochrane Risk of Bias criteria shared between 2 EBPRs and the likelihood of those 2 EBPRs agreeing on an intervention rating (r = −.12, P ≤ .01). There was no relationship between the number of studies evaluated by 2 EBPRs and the likelihood of those EBPRs agreeing on an intervention rating. The major reason for disagreements between EBPRs when rating the same intervention in this study was due to differences in the rating criteria used by the EBPRs. The studies used by the EBPRs to rate programs does not appear to have an impact.
What do we already know about this topic?
The conclusions reached by EBPRs when assessing interventions may vary based on the criteria they use or the supporting studies evaluated in support of intervention effectiveness.
How does your research contribute to the field?
This research identifies that variations in the criteria used by EBPRs are a significant factor in agreement on intervention ratings between EBPRs.
What are your research’s implications toward theory, practice, or policy?
The findings of this research can inform clinicians, decision-makers, and funders about issues that may impact the reliability of EBPR rating summaries and may help them to better understand the implications of these discrepancies.
Introduction
Service providers in the behavioral health disciplines are increasingly expected to use evidence-based interventions in their treatment of various behavioral health problems.1-4 Evidence-based interventions are interventions that have “demonstrated positive outcomes through high quality clinical or organizational research” (p.1). 5 One type of publicly available resource for locating information about evidence-based interventions is the evidence-based program resources website (EBPR).1,2,4 These EBPRs are databases of “reports that summarize the available evidence of programs’ effectiveness, including programs in social services, education, public health, and criminal justice” (p. 409). 2
EBPRs use sets of criteria to evaluate the merit and worth of social interventions, typically using existing research and evaluation studies.1,2,6 EBPRs tend to follow well-accepted hierarchies of evidence that define randomized controlled trials (RCTs) as producing the highest quality of evidence for intervention effectiveness.1,6 The ultimate result of EBPR evaluations of social interventions is a summary rating of evidence, or placement in an evidence category, depending on the EBPR.
Statement of the Problem
Even though these EBPRs use similar hierarchies of evidence to rate interventions, the ratings they produce may appear to disagree, or even be contradictory.1,4,6,7 These discrepancies may lead to confusion for users who have neither the time nor the expertise to conduct further investigation. This could ultimately threaten the credibility of the conclusions presented by the EBPRs, thereby making their utilization less likely.1,4 Two major sources of such discrepancies found in the literature are variations in the criteria that constitute the intervention rating categories, and variations in the bodies of literature used as evidence of intervention effectiveness.4,8,9
Background
Differences in Evidence Criteria Among Intervention Rating Paradigms
Definitions of what constitute an evidence-based intervention vary depending on who or what agency defines them.3,10,11 Likewise, variations in the criteria used by EBPRs to construct those rating categories are examined in several studies. For example, the Pew-MacArthur Charitable Trusts (PEW) found that specific details about the way different EBPRs construct their rating categories make it difficult to compare the ratings given to the same interventions. 12 Some EBPRs require positive outcomes from an RCT as a minimum for acceptance as an evidence-based intervention (eg, Social Programs That Work), while others allow quasi-experimental designs (eg, Crimesolutions.gov). Still others require that an intervention’s impact only needs to be statistically significant as compared with an alternative (eg, Blueprints for Healthy Youth Development), sometimes also requiring a minimum effect size (eg, Promising Practices Network).
EBPR rating paradigms tend to use 2 approaches in assessing interventions—the quality of evidence in support of the intervention and the strength of evidence in support of the intervention. Quality of evidence refers to the way primary evaluation studies of the intervention are conducted, and strength of evidence refers to the degree of positive outcomes (ie, statistical significance or effect size). The scales used by the EBPRs in the present study tend to primarily consider the quality of evidence, although many also include a requirement that a statistically significant outcome is demonstrated in the evaluation studies. The application of these scales leads to a rating of effectiveness of an intervention.
On the whole, these scales are constructed in one of 2 ways—they either include or exclude interventions or they place the intervention in a tier, or category, of evidence (eg, Effective, Promising, etc.). No matter which of these is used, the categories of evidence that are assigned to interventions by the EBPRs are delineated by arbitrary “cut points” into discreet categories, with the exception of a few EBPRs that use a rubric that produces a continuous rating of the strength of evidence (such as the What Works Clearinghouse).
The use of these types of scales is criticized in the literature. Some criticisms include: quality is contextual,13-19 the inclusion, and weighting of scale items often do not have sufficient justification,15-17,20-22 the validity of the scales vary widely,4,16,21,23 their use is subjective and prone to bias,15,17,19,21,24,25 and that they are dependent on the assumption that all aspects of a study are reported.16-18,21,24-28 A better solution offered in the literature is a component analysis approach, where EBPRs assess risk of bias based on critical study domains rather than an assessment of overall evaluation designs and arbitrary cut points.
In 2008, the Cochrane Collaboration (now simply Cochrane) released a Risk of Bias (ROB) tool, which has been updated several times and is considered by researchers to be gold standard in component analysis. 29 Risk of bias here means the degree to which study operations in each component domain are likely to result in over- or underestimation of a treatment effect. 17 Studies with low risk of bias are thought to be more likely to provide a valid assessment of a treatment effect than those with higher risk of bias. 17
The ROB Tool is the preferred method for assessing study quality in Cochrane Reviews. 19 There are 15 criteria areas that are sorted into the following general domains: selection bias, attrition and missing data, reliability, and validity of measures, implementation fidelity, blinding, and other reactivity, analytic methods, and power analysis, and reporting of effects. The present study uses these ROB criteria as the foundation for the analysis of the impact of rating scale rigor on disagreements in rating of interventions. Research “rigor” has been defined as the “strict application of the scientific method to ensure unbiased and well-controlled experimental design, methodology, analysis, interpretation, and reporting of results” (p. n.p.). 30
Differences Based on Different Evaluation Literature Used for the Ratings
The way that EBPRs screen studies varies across the EBPRs, and EBPRs do not treat all supporting studies equally. Many of the EBPRs have minimum requirements for studies to be assessed. For example, the What Works Clearinghouse (WWC) 31 evaluates studies in support of interventions using 2 categories—“meets WWC standards without reservations” and “meets WWC standards with reservations.” If a study does not fall into one of those categories, then it WWC does not consider that study as part of the supporting evidence for an intervention. However, other EBPRs do not have the same standards as WWC, and therefore may assess studies that do not fall into one of the WWC categories. As a result, when both the WWC and another EBPR assess the same interventions, they may not use the same supporting studies. Therefore, important information may be missing from one of the evidentiary assessments, which would impact whether 2 EBPRs reach the same conclusion. Two prior studies attribute differences in intervention ratings to differences in the primary studies reviewed by different EBPRs when assessing interventions.8,9
Purpose of the Study
As discussed, the literature points to 2 major reasons for discrepancies in intervention ratings across EBPRs: differences in the content and relative strictness of criteria used to rate interventions and differences in the bodies of literature assessed in support of interventions.4,8,9,32 The present study seeks to answer the question, “What accounts for the variations in the ratings of effectiveness given to the same interventions by different EBPRs?”
Methods
Coding
The present study examined the ratings given to behavioral health interventions by 15 EBPRs included in Burkhardt et al. 1 and Means et al. 6 The present study includes all behavioral health interventions included in the EBPRs, with no exclusions. The list of EBPRs included in the present study appears in Table 1.
Included Websites, Acronyms, and URLs.

Number of interventions included in each EBPR.
EBPR rating systems use variable numbers of rating categories across EBPRs, and these categories do not directly align with each other as the EBPRs originally define them. One author (M.J.L.E.) placed the ratings assigned to all interventions included in the 15 EBPRs into 4 analytic categories based on qualitative review of the criteria used by each EBPR to define their ratings. Author M.J.L.E. assigned these categories, while author S.M. reviewed these classifications. These categories are:
Category 1 (Top category/evidence-based—Ratings that show that interventions are superior. In the case of single category EBPRs, any interventions listed on the EBPR are considered to be in Category 1.
Category 2 (Mid category/promising)—Ratings that show uncertainty in intervention effects. These categories may also reflect methodological deficiencies that may bias intervention effects. Also known as promising interventions.
Category 3 (No effect/harmful) —Ratings that show that an intervention has either no effect or a negative effect.
Category 4 (Not reviewed/not rated)—Ratings where an EBPR considered an intervention, but that intervention did not meet minimum criteria for full assessment.
Author M.J.L.E. coded Each EBPR according to which Cochrane Risk of Bias criteria the EBPR incorporated into its rating system by observing which ROB criteria were present or absent. The author’s coding was confirmed in interviews with the primary managers (ie, administrators) responsible for the operation of each EBPR to ensure accuracy.
Additionally, author M.J.L.E. computed a Jaccard index of agreement (JI) for the interventions rated by each possible pairing of EBPRs. The Jaccard index is a measure of overlap between 2 sets of data, which is defined as the degree of intersection of the 2 sets expressed as a proportion of the degree of union of the 2 sets. 33 The Jaccard index is calculated as:
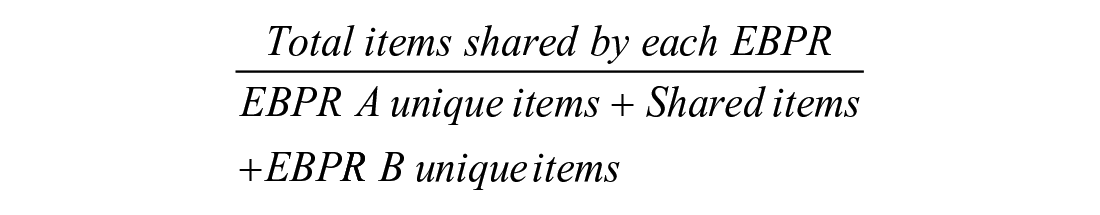
Thus, for the case where EBPR A has 7 unique items, EBPR B has 7 unique items, and they share 23 items:
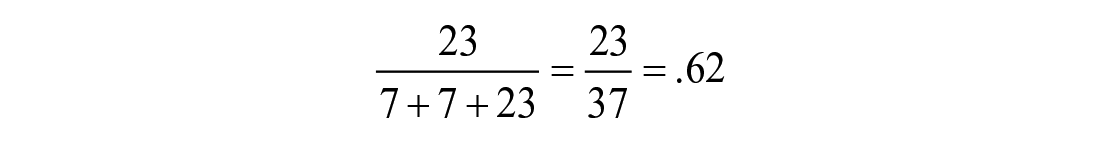
It should be noted that in the context of this study, “items” can mean interventions rated by 2 EBPRs, ROB criteria shared between 2 EBPRs, or studies assessed by 2 EBPRs.
Author M.J.L.E. coded each EBPR pair for level of agreement in ratings for each intervention they co-rated. The possible outcomes of these paired ratings are:
Substantial agreement—this occurs when both EBPRs in a pair rate the same intervention as category 1 or category 2
Partial disagreement—this occurs when one EBPR rates an intervention in category 1 and another EBPR rates an intervention in category 2
Substantial disagreement—this occurs when one EBPR rates an intervention in category 1 or 2 and another EBPR rates an intervention in category 3.
Author M.J.L.E. calculated a Jaccard index of agreement for ROB criteria shared for each possible pair of EBPRs. Some pairs of EBPRs used more criteria overall than others, leading to an issue where a pair that uses 2 criteria with one overlapping had the same Jaccard index as a pair that used 8 criteria with 4 overlapping. To account for this, the author calculated a weighted Jaccard index by dividing the total number of criteria used by either EBPR by 15, which was the total possible ROB criteria that could be used by a pair and multiplying the Jaccard index by this weighting factor. For example, if 2 EBPRs together used a total of 10 criteria, the weighting factor would be 0.67 (10 criteria used divided by 15 total criteria).
To understand the agreement or disagreement between EBPR ratings in context of supporting study overlap, the authors create a matched sample of interventions that had at least one discrepant rating (one EBPR rates the intervention as category 1 and another rates the intervention in category 3) and interventions that had at least one major agreement rating. This sampling method was used to highlight differences that would otherwise be ambiguous if the partial disagreement category were included in the analysis. Figures 1 and 2 below present the number of interventions identified in each phase of the sampling process.

Sampling procedure for the substantial disagreement sample.

Sampling procedure for the substantial agreement sample.
Once the final agreement sample was derived, the disagreement sample was noted to only have 30 cases with data. The samples were balanced by removing 3 cases at random from the agreement sample. The final total number of paired ratings per agreement/disagreement group was, 30 with a total of 60 paired ratings overall. A Jaccard index was calculated for the studies assessed in support of interventions rated by each possible EBPR pair in this matched subsample.
Data Analysis
Descriptive statistics were obtained for the distribution of intervention ratings by analytic category and the frequencies of each type of disagreement in rating outcome between each possible EBPR pair when rating interventions. A correlation analysis was conducted between 3 indices of agreement in criteria used by each pair of EBPRs and the outcome of agreement or disagreement in ratings. These were the raw number of criteria shared between 2 EBPRs, the Jaccard index of agreement for shared ROB criteria, and the weighted Jaccard index of agreement for shared ROB criteria. A Jaccard index was calculated for the number of references used by both EBPRs in a rating pair when rating each intervention in the disagreement analysis sample. This Jaccard index was used in a chi-squared analysis of high and low Jaccard index and substantial agreement or substantial disagreement in intervention ratings given by each EBPR pair.
To assess the impact of both shared rigor and shared studies on the likelihood of agreement or disagreement in intervention ratings between pairs of EBPRs, the weighted Jaccard index for shared rigor and the Jaccard index for shared references were regressed on a binary outcome (0 = substantial disagreement, 1 = substantial agreement).
Results
Distribution of Intervention Ratings
In total, 1 151 ratings were given to the included interventions by the EBPRs. Of those, 23% were category 1 (top category/evidence-based) ratings, 38% were category 2 (mid category/promising) ratings, 13% were category 3 (harmful/no effect) ratings, and 27% were category 4 (reviewed/not rated) ratings.
Overall Rigor of the Rating Scales
The largest proportion of criteria used by the EBPRs was 7 to 9 (40%). Roughly 47% of the EBPRs used 6 or less criteria, while roughly 53% used 7 or more criteria (Table 2).
Overall Rigor of the Rating Scales Used by EBPRs.

The most used criteria were selection bias controls and implementation fidelity (Figure 3). The EBPRs varied in their degree of use of the other ROB controls.

Risk of bias (ROB) criteria used by EBPRs.
Disagreements in Intervention Ratings (Table 3)
Disagreements in Intervention Ratings (N = 1199 Paired Ratings).

One EBPR in a rating pair gave an intervention rating of Category 4.
Impact of Shared Rigor on Shared Intervention Ratings
Correlations were obtained for the percentages of intervention ratings for each EBPR pair for each category and the 3 agreement indices for each EBPR pair (Table 4). An example of the data for this analysis is presented in Table 5 and the results of the analysis are presented in Table 6.
Impact of Shared Rigor on Shared Intervention Ratings (N = 943 Valid Paired Ratings).

Sample Data for Correlation Analysis.
Including partial disagreement and substantial disagreement.
Correlations Between Criteria Agreement Indices and Rating Outcomes (n = 1198).

Correlation is statistically significant at α = .01.
A statistically significant negative correlation was observed between the Weighted Jaccard index for a rating pair and the percentage of ratings where the rating pair substantially agreed on an intervention’s rating. Additionally, a statistically significant positive correlation was found between the Weighted Jaccard index for a rating pair and the percentage of any type of disagreement in paired rating. The correlations in Table 6 indicate that EBPR pairs that are more similar in their rating criteria are less likely to agree on intervention ratings.
The most commonly shared criteria (Figure 4) included controls for selection bias in general, controls for attrition, and implementation integrity. It should be noted that a substantial proportion of EBPRs required that studies report statistically significant impacts only.
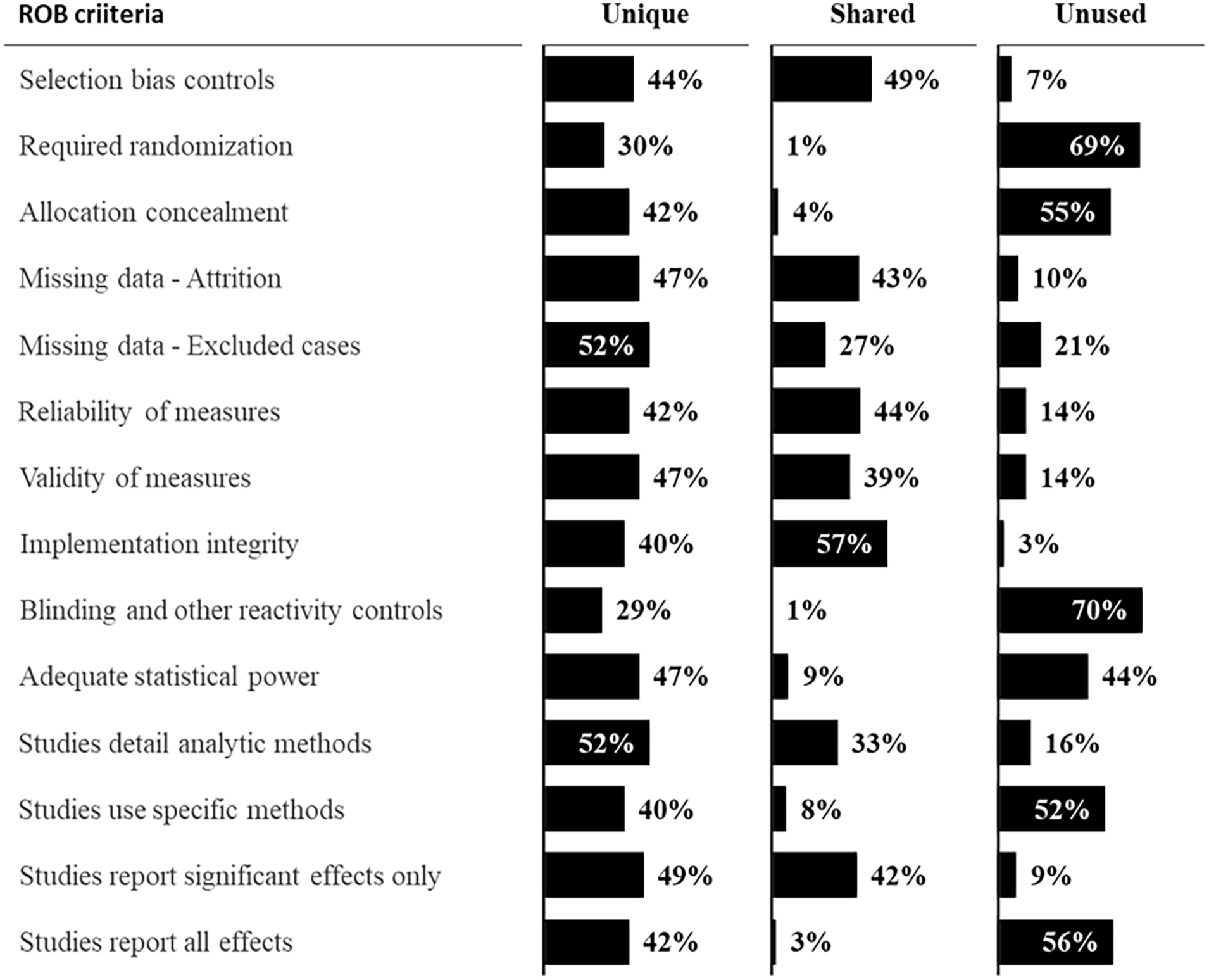
Shared, unique, and unused ROB criteria.
Impact of Shared Evaluation Literature on Shared Intervention Ratings
A chi-square test for independence did not indicate any significant relationship between the number of studies that are shared in a rating pair and the outcome of the rating (substantial disagreement or substantial agreement; χ 2 = .267, df = 1, P ≥ .05). The contingency table for this analysis appears in Table 7.
Impact of Shared Studies on Rating Outcomes.

Predictive Model
A binary logistic regression analysis was also conducted by regressing the Weighted Jaccard index for criteria and the Jaccard index for shared studies on a binary rating outcome variable (0 = substantial disagreement, 1 = substantial agreement). Partial disagreement was not used as an outcome category in the regression as no data was collected on studies shared in partial disagreement cases per study protocol. The results of the binary logistic regression indicated that these variables, when taken as a whole, were not significant predictors of agreement on intervention ratings as defined in the present analysis (Cox & Snell R Square = .01, Nagelkerke R Square = .014, df 8, P > .05).
Discussion
Approximately 46% of paired ratings resulted in a substantial agreement on the intervention ratings, while the number of substantial disagreements was low (6%). If partial disagreements are considered, then 33% of paired ratings resulted in some type of disagreement. However, the situation where one EBPR gives a Category 1 rating and another gives a Category 2 rating (partial disagreement) is a special case that requires interpretation on the part of the decision maker. One could view this situation as a disagreement in intervention ratings, since the second EBPR is clearly saying that the intervention is not a Category 1 intervention. However, this situation could also be interpreted as meaning that the intervention is recognized by each EBPR as having some degree of evidentiary support. This speaks to the issue of granularity. The more rating categories each EBPR has, the more potential there is for some discrepancies in ratings that require additional interpretation by decision makers.
There was a statistically significant negative correlation between the number of shared Cochrane ROB criteria and the probability of substantial agreement. This means that as the percent of shared Cochrane ROB criteria between EBPRs increases the similarity of their ratings of the same intervention decreases. One would expect the opposite. It would be reasonable to assume that as agreement in the rating criteria increases, so should the likelihood that 2 raters would agree, because they would be essentially using the same rating scale. It is possible that this negative correlation could be associated with which criteria the 2 EBPRs in a pair shared. For example, sharing the requirement for using an RCT may lead both EBPRs to rate the intervention into a specific category (such as Category 1) more frequently than if both EBPRs shared a requirement for adequate blinding of participants. This would increase the likelihood that the 2 EBPRs would agree.
It is also possible that as the complexity of the rating paradigms used by each EBPR increases, the likelihood of either EBPR placing an intervention in Category 1 would decrease because it would be harder for an intervention to be classified into Category 1 by either EBPR. Thus, the cumulative impact of the use of a larger number of rating criteria by either EBPR would decrease the likelihood of agreement between the 2 EBPRs by chance alone. Finally, evaluation is a human process, so even seemingly objective criteria can be applied subjectively. Under this idea of human subjectivity, it would seem that the more criteria used by 2 raters, the more chance there is for disagreement based on a fine point of contention.
One of the most important criteria typically used in determining rigor of research is the use of randomized controlled trials. In the present study, the specific requirement of randomization (vs simply requiring use of general selection bias controls) was not found at all in over 66% of the pairings and was unique to one EBPR in approximately 30% of the pairings. It is possible that if both EBPRs in a rating pair required randomization specifically as a Category 1 criterion, the chance that they would agree on an intervention rating would increase.
The same is true for 2 other important aspects of methodological rigor. These are the use of studies with adequate statistical power and the use of supporting studies that report all effects (not just significant ones). The requirement for adequate statistical power as an assessment criterion was missing or unique to one EBPR in almost 90% of the ratings pairs included in this study. The requirement that studies report all effects was missing or unique in approximately 96% of the pairs. This again means that important methodological criteria were not agreed upon in many of the EBPR pairings.
As with overlap in Cochrane ROB criteria used, one could infer that the more shared studies used by an EBPR pair, the greater the likelihood that those 2 EBPRs would agree on an intervention rating, as they are using the same pool of evidence to rate the interventions. However, this study demonstrates no relationship between the number of shared studies and the outcome of the paired rating. This appears to indicate that between the 2 explanatory factors (ie, rigor of the rating paradigm and the number of shared studies), the rigor of the rating paradigm has a more salient relationship.
The analysis of shared studies and shared criteria together as predictors of rating agreement was statistically non-significant. This finding, when paired with the findings of the individual analyses of the relationship between shared Cochrane ROB criteria and shared ratings, appears to indicate that the idiosyncrasies of the current rating paradigms may contribute more to the differences in paired ratings than shared evaluative rigor or shared evidence. This appears to align with prior research that indicated that using methodology-based scales with arbitrary cut points (such as those used by the EBPRs currently) is not as effective as a bias reduction model in rating interventions as evidence-based.
Conclusions and Recommendations
The major finding of this study is that when a perceived substantial disagreement in intervention ratings occurs, it is likely due to differences in the intervention rating paradigms used, particularly in relation to the number of shared Cochrane ROB criteria used. Thus, when a decision maker encounters conflicting ratings, they may need to make themselves aware of how the structure of the EBPR rating paradigms affects those ratings. Future work in this area could involve the creation of a comprehensive user guide that includes multiple EBPRs and gives advice on how to manage conflicting ratings between the EBPRs.
One other aspect of understanding and resolving seeming conflicts in ratings is understanding the degree of the conflict. Substantial disagreements (ie, when one EBPR rates an intervention as evidence-based and another EBPR rates an intervention as having no effect) are the most serious type of conflict in that the 2 EBPRs directly conflict with each other. Resolution such conflict is imperative, in that the user must decide which EBPR is correct if they are going to justifiably implement a given intervention. In this case, the user would be well-advised to consult another EBPR, carefully read the primary research, or seek the advice of a trusted expert to resolve the conflict.
The second type of disagreement is a partial disagreement (or partial agreement). This type of disagreement occurs when one EBPR rates an intervention as top-tier and another rates the intervention as mid-tier. This is the less serious of the 2 types of disagreements. In this case, a decision maker could correctly infer that the intervention does possess some amount of evidence base. If decision-makers are permitted to implement mid-tier/promising interventions, then the seeming conflict is not consequential. If decision makers are only permitted to implement top-tier interventions, then they still could make the case that there are indications that the intervention is, in fact, evidence-based.
One final thought on the issue of conflicting ratings based on the rating paradigms themselves is that EBPRs vary in the number of rating scales used. Some EBPRs, such as NREPP, had both a quality of research and a readiness for dissemination scale. Other EBPRs, such as the CEBC consider relevance to the population of interest and still other EBPRs have specific impact ratings that go beyond the quality of the research (eg, WWC). These additional scales may also provide information that can help decision makers manage conflictual ratings. They may decide to use an intervention even if it has conflictual ratings, so long as that intervention shows readiness for implementation and is appropriate for the desired clinical context.
Implications for Future Research
The present study examined 2 major reasons why intervention ratings may vary among different EBPRs. However, more research is needed to further understand these variations. Future research may ask the following questions:
Which criteria are more or less important in arriving at intervention ratings?
What other factors beyond methodological issues may influence differences in intervention ratings?
How can EBPRs improve their rating paradigms by explicitly integrating Cochrane ROB criteria?
Future research could help us further understand how decision makers resolve conflicts in ratings between EBPRs. Answering the above questions could ultimately help the EBPRs to improve their assessment processes, and also to help decision makers in understanding how to resolve conflictual ratings between EBPRs. This could improve the value of EBPRs for decision makers and other EBPR users.
Limitations of the Present Study
The data for the present study was collected in 2014 and 2015 for a parent study. However, the use of these older data for the present study is justified for the following reasons:
The identity of the EBPRs has remained relatively stable over the last decade; only three of the original 15 that were studied have ceased operations. Moreover, inspection of the websites indicates that the substantial majority of the original interventions remain listed. Finally, the original data were collected in part through contact with EBPR managers, who confirmed data coding concerning the use of ROB criteria in EBPR rating paradigms. Because the funded study has concluded, the authors do not have access to the EBPR managers required to confirm any updated coding. This means that any new coding could be less valid than coding from the original dataset.
A second limitation is that single-category EBPRs were conceptualized as rating an intervention as Category 1 if they included an intervention as an evidence-based intervention with no gradations of evidence. This was done because the assumption was that including the intervention indicated it was evidence-based, in the same way that the concept of Category 1 for multiple-category EBPRs also indicates that an intervention is evidence-based. However, it is unclear if that assumption holds. These 2 types of categories may be semantically different. For example, include/exclude-type ratings simply tell whether an intervention met minimum criteria for inclusion, but do not indicate if some interventions are truly superior to others. However, Category 1 ratings from multiple-category EBPRs do imply superiority because some interventions clearly did not make the cut.
A third limitation is that this study used the number of Cochrane ROB criteria as an indicator of methodological rigor only. Some EBPRs also include requirements that an intervention shows a significant effect, and that requirement may contribute to some of the disagreement between EBPRs that is outside the influence of the Cochrane ROB criteria alone. In other words, the fact that the EBPRs do not explicitly use the Cochrane ROB criteria as their rating paradigms may make the comparisons in the present study less reliable. However, this may have been offset by the fact that the EBPR managers confirmed which Cochrane ROB criteria were approximated within their rating paradigms.
The final limitation is that we only hypothesized 2 explanations for disagreements in intervention ratings. Those were variations in the content and relative strictness of EBPR rating paradigms and variations in the bodies of literature used by EBPRs as evidence of intervention effectiveness. There may be other explanatory factors such as considerations of readiness for dissemination and consideration of intervention effects that may also explain differences in intervention ratings. Additionally, the present study did not control for which Cochrane ROB criteria were shared by the EBPRs when rating interventions, and that may have also had impacts on the ratings outcomes.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Data collection was partially supported by National Institutes on Drug Abuse grant # 1R21DA032151-01.
Declaration of Ethics
Our study did not require an ethical board approval because it did not involve human subjects research.
Declaration of Informed Consent
Our study did not require informed consent as it did not involve human subjects research.