
Abstract
For the textile industry, fabric defect detection is an important part of production. In order to make the automatic fabric defect detection system used in production sites, this article proposes a lightweight algorithm Lightweight Single Shot Multi-Box Detector (LW-SSD) to address the issues of low detection accuracy, high computational complexity, and difficulty in deploying on hardware devices with limited computing power in fabric defect detection. Firstly, MobileNetv3 is introduced as the backbone network to reduce the number of model parameters. Secondly, in the feature fusion module, down-sampling stacking is used to fuse the feature maps processed by maximum pooling and regular 3 × 3 convolution, respectively, to enhance the generalization and small target feature extraction capability of the network. Then, the dilated convolution is incorporated into the Inceptionv3 to form a multi-branch parallel dilated convolution module, which can expand the receptive field of the feature layer and enhance the extraction of the target information. Finally, a dual-channel attention module is added, which adds the maximum pooling operation based on the efficient channel attention for deep convolutional neural networks (ECA) channel attention mechanism to highlight defect features and suppress background noise features. The experiments show that the accuracy of the system is improved while maintaining the faster detection speed. Among them, the LW-SSD algorithm has an accuracy improvement of 10.03% on the self-made dataset, a reduction of 58% in the number of model parameters compared to the Single Shot Multi-Box Detector (SSD) algorithm, and the detection speed reaches 48 frames per second.
Keywords
Textile quality detection is a critical step in the textile industry’s production process. 1 However, factors such as the materials used, yarn types, and sample sizes can affect the quality and price of textiles, and one of the most important factors is the presence of defects in the fabric. 2 Defective textiles can affect sales volume and price positioning, leading to economic losses of up to 45–60%. Machine failures and production operations mainly cause defects in the fabric, so it is necessary to perform defect detection on fabrics. 3 In fabric production, most of the detection is performed manually, having low efficiency with only 70% accuracy, and the high labor cost is overwhelming for many companies. 4 Thus, automated fabric defect detection has become an urgent need for developing the textile industry.
With continuous improvement of the computer power of the hardware device, automatic defect detection systems using machine vision algorithms with high detection accuracy and low-cost computation are gradually becoming the mainstream of fabric defect detection. 5 Traditional machine vision algorithms are mainly classified as model-based, statistical, structural, and filtering methods.6 –8 Although these methods solve the shortcomings of manual detection, their operation process in image feature processing is more cumbersome, it is easy to lose feature information, and these methods are not universal. 9 In recent years, deep learning methods for defect target detection have gradually become a hot topic of interest in automation, textile, and other fields. 10 The difference with traditional detection methods is that deep learning methods use a convolutional neural network (CNN) to extract features from images, which can have robust classification and feature extraction ability even under image transformation invariance.
The gradual maturity of convolutional neural networks promotes the development of object detection. More classical network models such as YOLO, 11 SSD, 12 and Faster R-CNN 13 are widely used in various scenarios in target detection, such as UAV aerial photography, vehicle detection, and mask-wearing detection. Regarding fabric defect detection, attention mechanism, feature pyramid, and Focal Loss function etc. are applied into a series of CNNs with excellent performance such as YOLOv3 and EfficientDet to improve the detection accuracy of the algorithm.14 –16 The improved algorithms have better feature extraction capability on target information, weakening the impact of fabric texture on object detection, and data distribution imbalance. With the pursuit of algorithm performance, the complexity of the network is higher, and the number of model parameters is gradually increasing, resulting in higher requirements for device computing power.17,18 However, the industrial field may be unable to provide high computational hardware devices, so the practical application value of complex networks could be lower. Industrial production will pursue higher productivity, and fabric defect detection in industrial scenarios belongs to real-time detection. 19
Fabric defect detection has always been a challenging area for the textile industry. The first difficulty is that there are several categories of defect, and the number in each category varies greatly. The second difficulty is the number of small object defects. The third difficulty is that the defects have extreme aspect ratios. 20 Furthermore, due to complex networks, large numbers of parameters, large physical memory, and long training times, fabric defect detection algorithms are difficult to apply in some mobile terminals, such as smartphones, drones, or other cheap devices. In particular, the ultrahigh delay caused by limited hardware equipment has a great impact on detection speed. Many scholars have conducted extensive research on the above issues. Zhang et al. 21 used the SSD algorithm with MobileNetv2 as the backbone network on the Camouflage dataset. They added the focal loss function to the algorithm to balance the number of negative samples, and the detection accuracy was improved by 10.03%. The number of model parameters was 2.878 MB, and the detection speed was 14.49 FPS. Chen et al. 22 embedded Gabor filters into Faster R-CNN on a homemade fabric defect dataset and used a genetic algorithm and backpropagation to train the model. Their dataset was acquired from multiple resources, including apparel factories, literatures, and the “Xuelang Manufacturing AI Challenge”. The algorithm improved detection accuracy by 5.59% over the original algorithm. Song et al. 16 used EfficientDet to detect fabric faults and used TensorRT to accelerate the model to obtain shorter inference times. In EfficientDetD0-7, the model FLOPs gradually increased as the detection accuracy increased, and the network could not be performed on lower computationally intensive embedded devices. Wu et al. 23 proposed an algorithmic model based on Faster R-CNN, using a dilated convolution module to expand the receptive field of the feature layer and enhance feature extraction, using jump connections for feature fusion, and designing candidate frames of different sizes for the types of fabric defects. Although the improved Faster R-CNN model has been reduced in size, there is still a lot of room for improvement in detection speed. Suryarasmi A et al. 20 proposed a lightweight fabric defect detection architecture based on CNN, FN-Net, which used categories based on adaptive thresholds to determine the probability values generated by the network. The experimental results showed that the FN-Net architecture could complete 3–33 times the training with fewer graphics processing units and memory consumption on the fabric image dataset of a Taiwanese fabric company. Zheng et al. 24 proposed a fabric defect detection method based on improved YOLOv5. Adding the SE module to the YOLOv5 backbone, and replaces the conventional Leaky Rectified Linear Unit (ReLU) activation function of YOLOv5 cross stage partial (CSP) with the ActivateOrNot (ACON) activation function. Trained on the Tianchi fabric defect dataset, the YOLOv5 algorithm achieved a detection accuracy of 95%. Several operations, such as replacing the backbone network, adding an attention mechanism, adding inflated convolution, and performing feature fusion in the above study, were effective in improving the detection accuracy of the algorithm. In the real production environment of textile manufacturing, the real-time and accuracy of fabric defect detection needs to be considered. The faster detection speed and smaller model size make CNNs possible to detect defects in industrial production fields.
The SSD algorithm implements a relatively elegant and simple object detection framework, using a one-stage network for the object detection task. The SSD algorithm combined the regression idea of YOLO and the anchor mechanism of Faster R-CNN, which have shown effective results in both accuracy and real-time. In addition, with the development of lightweight backbone networks, there is still room for improvement in the backbone network of the SSD algorithm.25 –27 However, because the limited number of shallow characteristic layers single, the SSD algorithm is prone to the problem of missed and false detection when detecting small targets. Regarding the issues with SSD algorithm and current fabric defect detection algorithms, this article proposes a lightweight algorithm LW-SSD to address the problems of fabric defect detection and the complex structure of SSD algorithm models, target omissions, and detection errors.
The main contributions of the article are described as follows.
Due to the high computational cost, an object detection algorithm is difficult to deploy on hardware devices with limited performance. In order to solve the problem, the article replaces the backbone network of the SSD algorithm with MobileNetv3, which can make the improved algorithm model more lightweight. The computational cost of the algorithm is effectively reduced. In order to detect the small and many features in detection tasks, the article proposes a new feature fusion module (FFM) and multi-branch parallel dilation (MPD) convolution module. The shallow feature maps are down-sampled and stacked in feature fusion. The maximum pooling operation is fused with the feature maps processed by ordinary 3 × 3 convolution, which can fully use the shallow features and improve feature extraction of small target information. In order to solve the interference problem of background noise in the target detection process, the article proposes a dual-channel attention module, which is added to enhance the distinction between small targets and backgrounds and to suppress excessive noise information.
Methodology
In this section, we propose a detection network used in resource constrained scenarios. Based on MobileNetv3-SSD, to improve the poor performance of small defect detection, the FFM and MPD convolution module are introduced into the network to fuse feature information of different scales and expand the receptive field of shallow feature layer. Introducing a dual-channel attention mechanism into the network can suppress background noise, highlight the defect features of the target, and enable the detection network to predict small defects more accurately.
SSD architecture
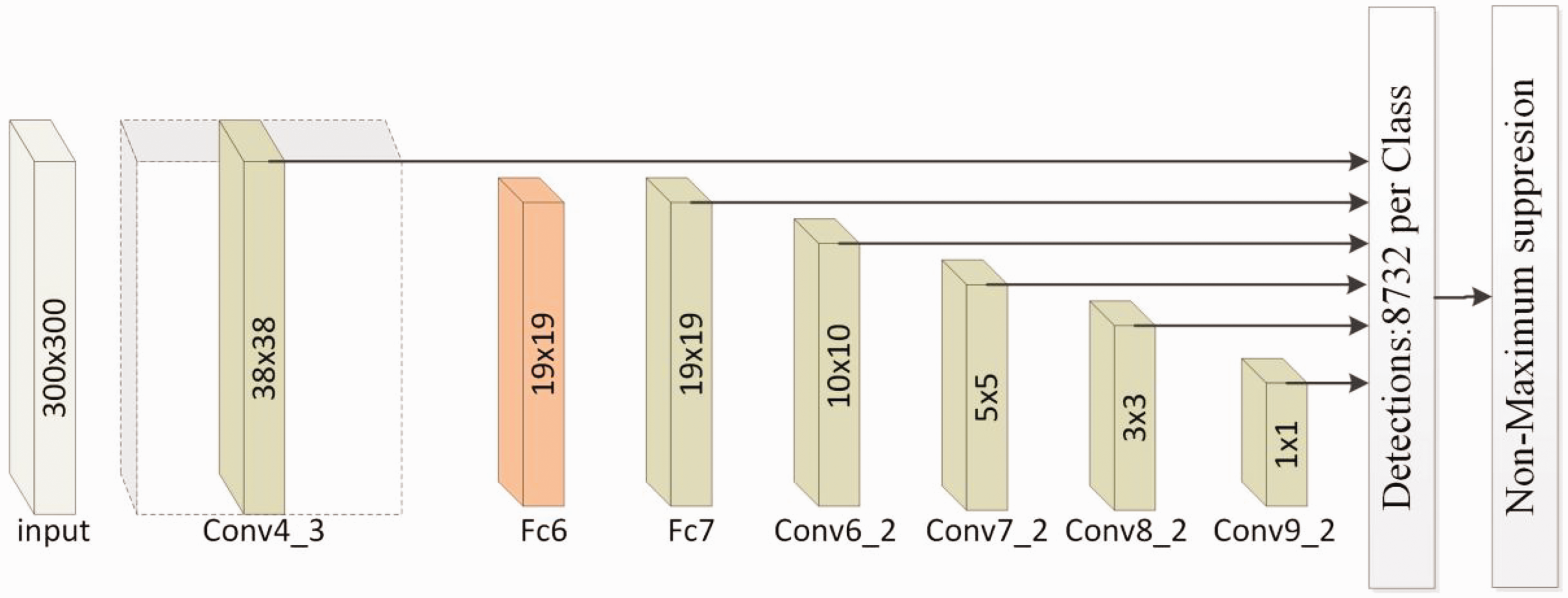
The network structure diagram of the SSD algorithm is shown in Figure 1. It consists of a backbone network VGG16 28 and four other convolutional layers. The images are processed to produce feature maps at six scales, after which classification and regression prediction are performed. The SSD algorithm achieves multi-scale target detection but still suffers from the following limitations:
Architecture of SSD.
Using VGG16 as the backbone network makes the whole model with many parameters, affecting the model’s detection speed.
Although shallow feature maps are utilized to find little objects, they lack adequate semantic detail. Additionally, due to the limited resolution of small objects, SSD struggles to accurately detect them.
Each feature layer is detected separately, lacking information exchange between feature layers. The feature map has a large amount of channel information, which is not conducive to filtering useful target information.
LW-SSD architecture
Aiming at the shortcomings of SSD algorithm, three optimization strategies are adopted, which are optimizing the backbone feature extraction network, introducing the FFM, MPD convolution, and constructing a dual channel attention module based on ECANet. The network structure diagram of the LW-SSD algorithm is shown in Figure 2. Firstly, MobileNetv3 is used as the new backbone network with six feature layers of sizes 19 × 19, 10 × 10, 5 × 5, 3 × 3, 2 × 2, and 1 × 1, respectively. The structure details of the backbone network are detailed in the section on the MobileNetv3 network. Secondly, the MPD module is added to the network to expand the receptive field of the shallow feature layer and enhance the extraction of small targets. The structure details of the MPD module are detailed in the section on the MPD module. Third, a feature fusion module is added to the network to fuse the shallow and deep feature layers. The structure details of the FFM are detailed in the section on the FFM. Finally, a dual-channel attention module is added to the network to the network to extract more refined defect features under the complex background disturbance, which improves small defect detection accuracy. The structural details of the dual attention mechanism module are detailed in the section on the attention mechanism below.
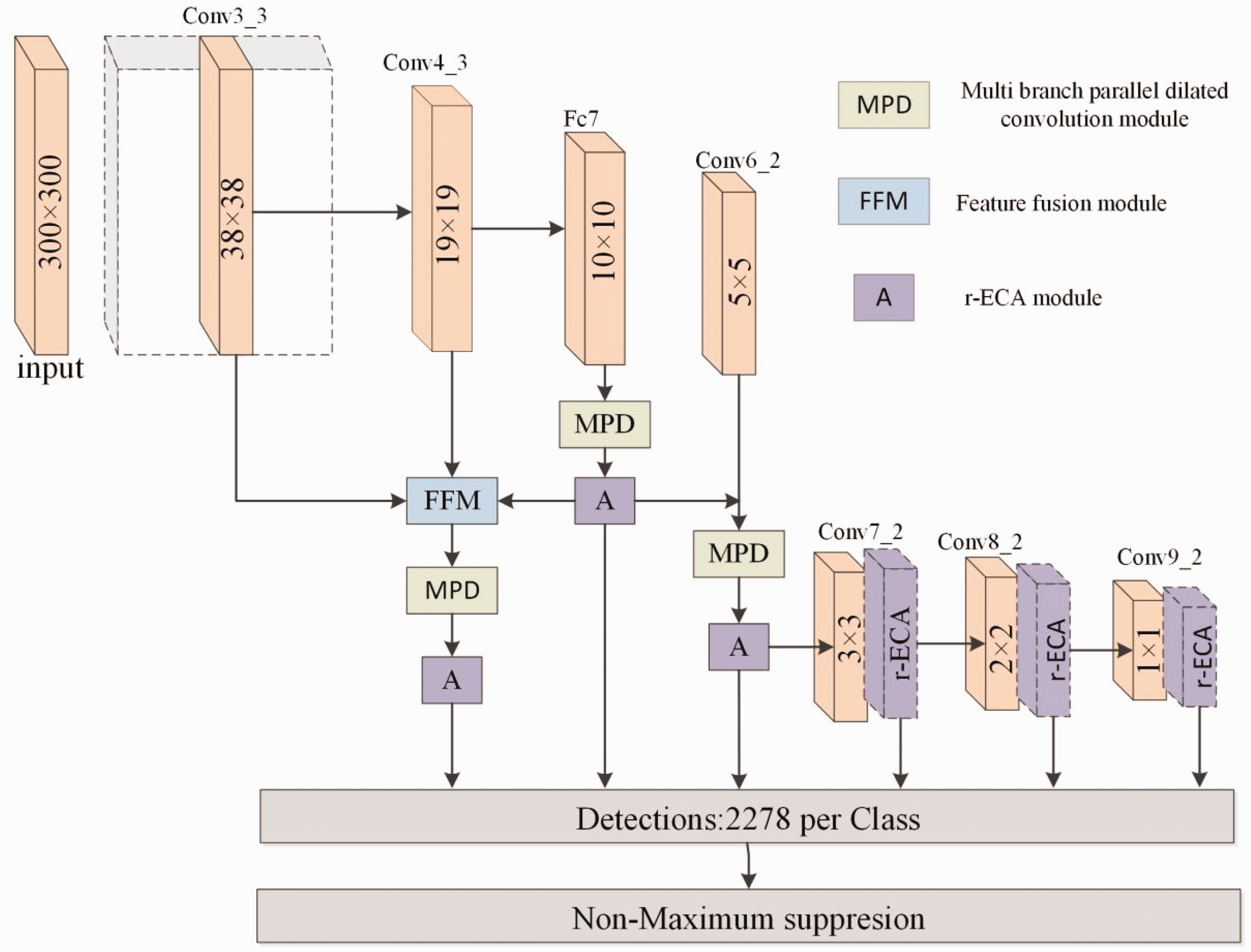
Architecture of Lightweight Single Shot Multi-Box Detector (LW-SSD).
MobileNetv3 network
To improve the target detection speed of the SSD algorithm in hardware devices with limited computing power, this article uses MobileNetv3
27
to become the new backbone feature extraction network. MobileNetv3 draws the advantages of MobileNetv2
26
and MobileNetv1
29
by using deep separable convolution
30
and an inverse residual structure with a linear bottleneck to reduce the number of parameters in the model. In addition, the SE attention mechanism
31
and h-swish function are added to the network architecture to improve the detection accuracy of the network, which is calculated as in equation (1).
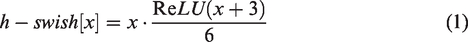
Specifically, MobileNetv1 uses depth wise separable convolution in the network architecture for feature extraction, effectively reducing the number of parameters in the model, and uses the ReLU activation function 32 to improve the fitting ability of the network. However, with the loss of dimensional information caused by down-sampling the network feature layer to lower dimensions, the ReLU function is replaced by a linear activation function in MobileNetv2. The inverse residual structure is used to perform dimensionality enhancement using 1 × 1 convolution, followed by feature extraction using 3 × 3 depth wise separable convolution, and finally, dimensionality reduction using 1 × 1 convolution to keep it consistent with the number of input feature map channels.
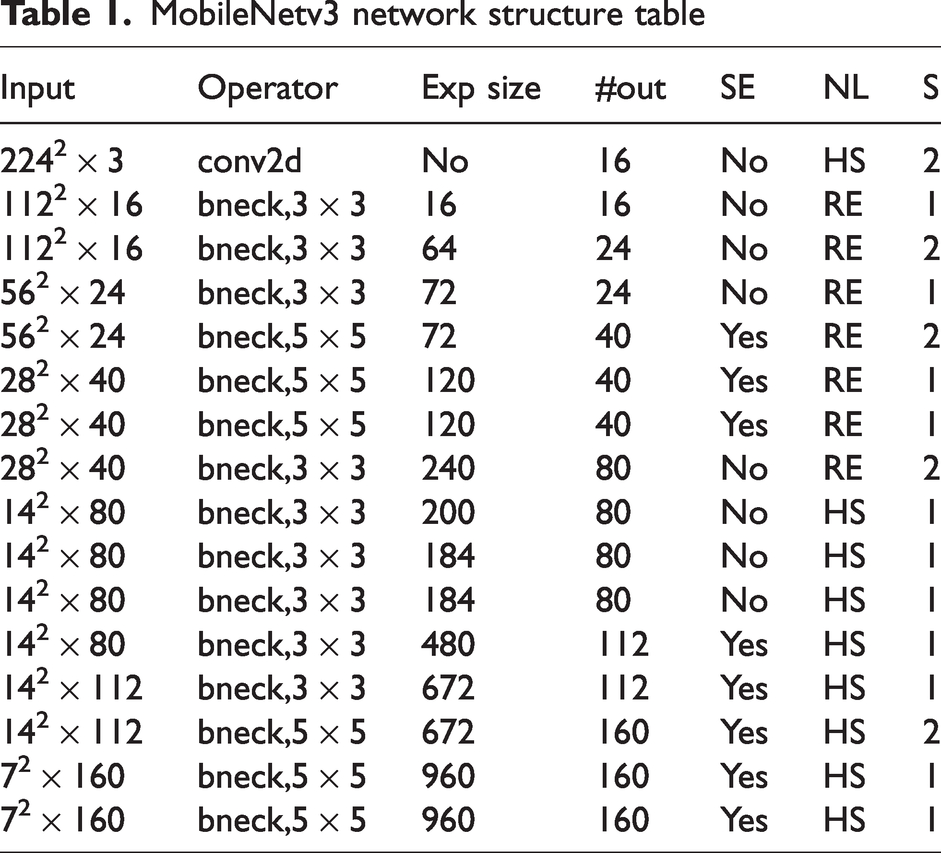
The overall network structure of MobileNetv3 is shown in Table 1. Input indicates the change in the size of each feature layer, Operator indicates the convolution structure each feature layer is about to experience, Exp size indicates the number of channels up after the feature layer undergoes convolution, #out indicates the number of channels from input to the next feature layer, Squeeze and Excitation (SE) indicates whether the attention mechanism is introduced at the current layer, NL indicates whether the activation function is HS (h-swish) or RE (ReLU), S indicates the step size experienced by each convolution.
MobileNetv3 network structure table
MPD module
We wanted to address the problem that the shallow feature layer receptive field in the SSD algorithm is too small to obtain more semantic and detailed information, which affects the detection of small and medium-sized targets. In this article, we propose the MPD module, which adopts the residual structure and combines the ideas of Inceptionv3 33 and dilated convolution. Dilated convolution can increase the receptive field of the feature map without losing image information. Figure 3 shows the schematic diagrams of ordinary convolution and void convolution with an expansion rate of two, respectively. The MPD module expands the receptive field of the feature layer by adding different expansion rates (rate=1, 3, 5, 7) of dilated convolution to expand the receptive field of the feature layer, and can obtain four different sizes of semantic information for feature fusion. The fused feature maps facilitate feature extraction of small targets and improve the detection accuracy of targets.
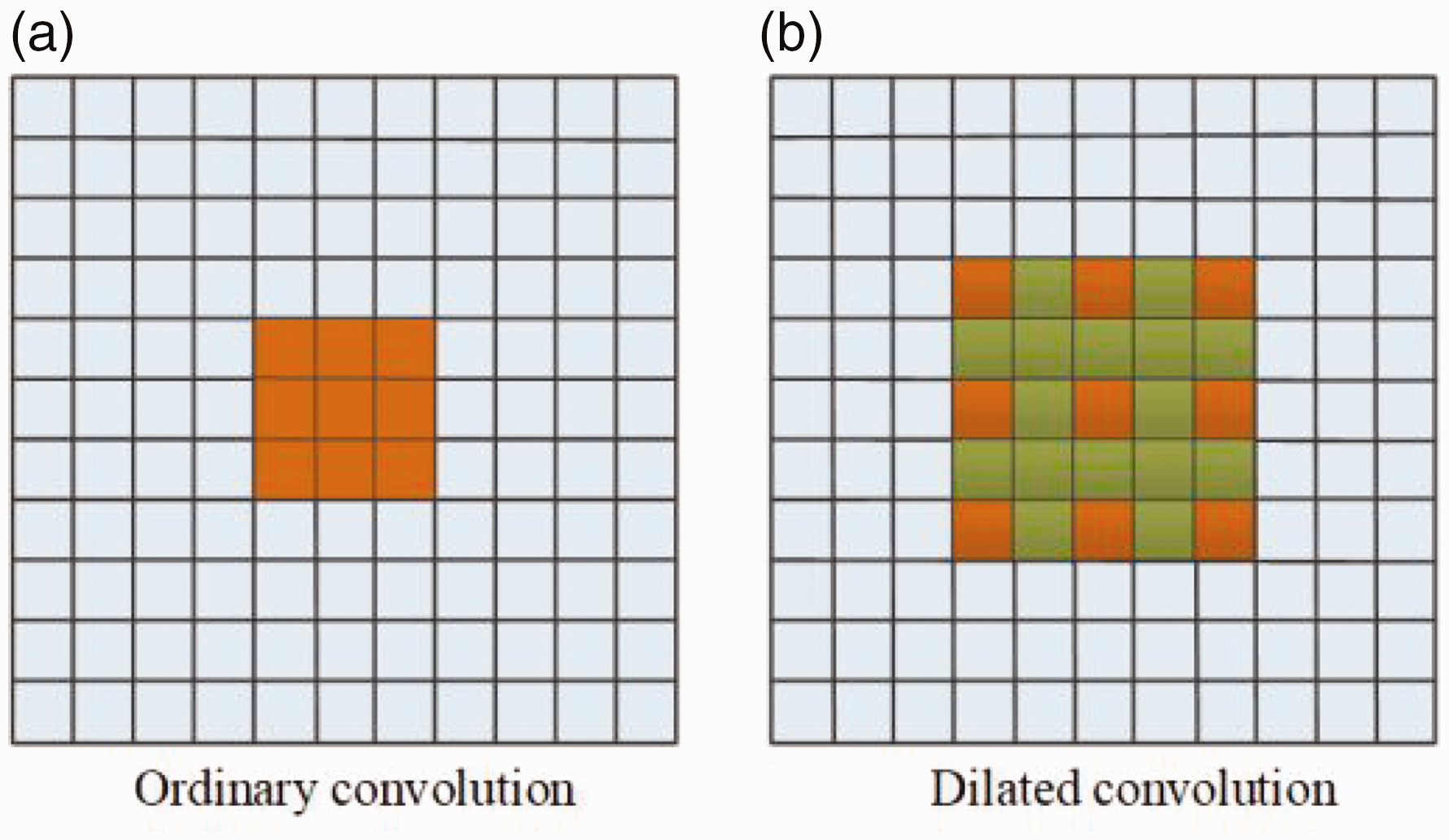
Schematic diagram of ordinary convolution and dilated convolution.
In order to reduce the number of parameters in the MPD module and improve the detection speed of the model, the MPD module uses 1 × 3 and 3 × 1 convolution instead of the ordinary 3 × 3 convolution before the dilated convolution. In addition, the ordinary 3 × 3 convolution in the dilated convolution is replaced by the 3 × 3 depth separable convolution. Assuming the ordinary 3 × 3 convolution whose input channel is N and output channel is M, the formula is shown in equation (2).

The formula for the depth-separable convolution is shown in equation (3).
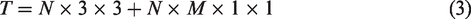
As a result, the covariance ratio between the depth-separable convolution and the ordinary 3 × 3 convolution is calculated as shown in equation (4).

From the above equation, it is helpful to reduce the number of parameters by applying depth-separable convolution instead of ordinary convolution in the MPD module, and the structure of the MPD module is shown in Figure 4.
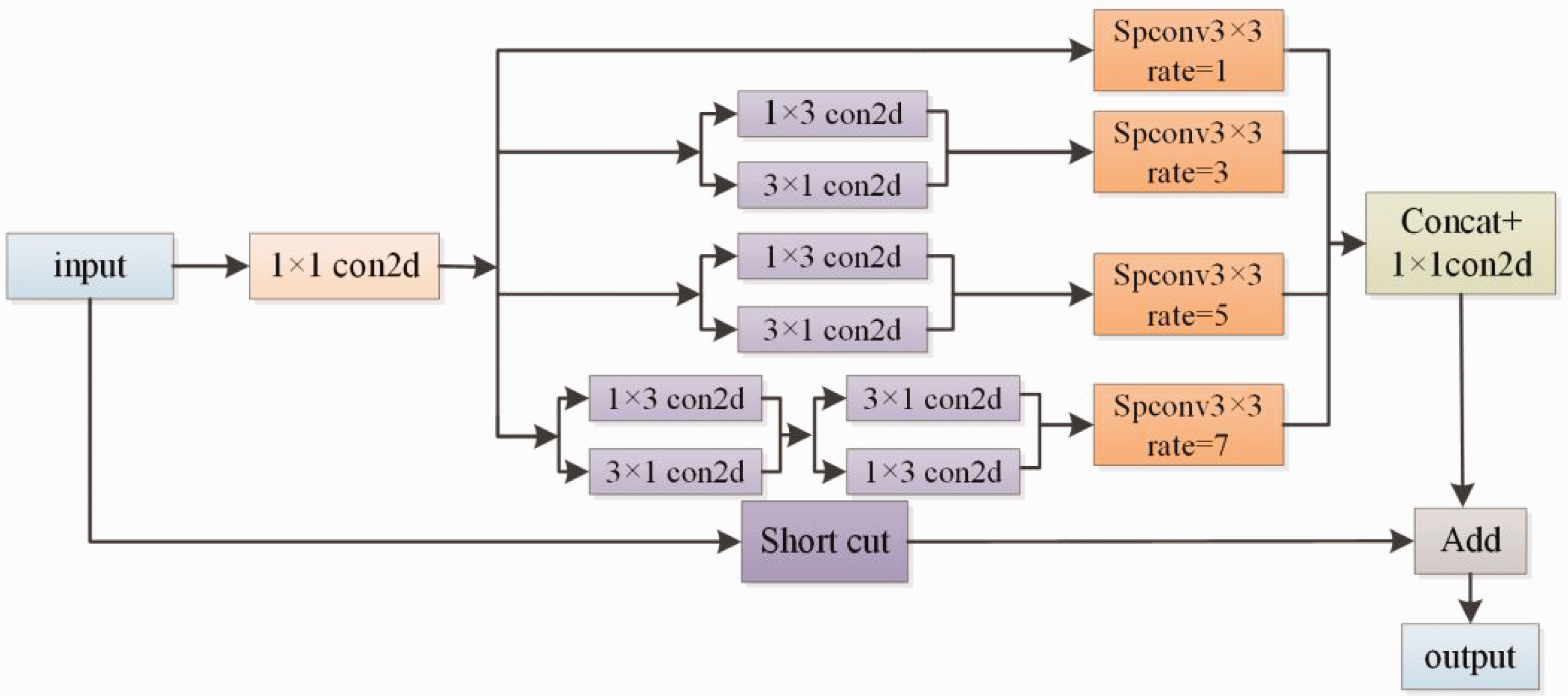
Multi-branch parallel dilated convolution module.
FFM
The small targets and large deformation scale targets in fabric defect detection often bring great difficulties to the detection task. With the deepening of the network, semantic information becomes increasingly rich, but the loss of location information will also become more severe. Therefore, in order to better fuse the position information of shallow networks and improve the detection performance of algorithms, this article proposes a FFM. Drawing on the fusion structure in the Deconvolutional Single Shot detector (DSSD) 34 algorithm, a top-down approach is used to fuse different scale feature layers. Multiple upsampling of feature maps may introduce a lot of noise information and increase the complexity of the network, reducing the speed of object detection. Therefore, only three feature layers, Conv3_3, Conv4_3, and Fc7, are fused in the algorithm of this article.
The structure of the FFM is shown in Figure 5. Firstly, Conv3_3 is down-sampled, differing from the traditional use of only a 3 × 3 convolution kernel, a convolution with a step size of 2, or a maximum pooling layer with a step size of two for down-sampling. The improved downsampling method fuses the two approaches, with the upper branch connecting a 1 × 1 convolution to adjust the number of channels after height and width compression in Conv3_3 with a maximum pooling layer of stride 2, and the lower branch connecting a 1 × 1 convolution to adjust the number of channels after using a 3 × 3 convolution kernel with a convolution of stride 2. “Concat” is used to fuse the output feature layers of the upper and lower branches.
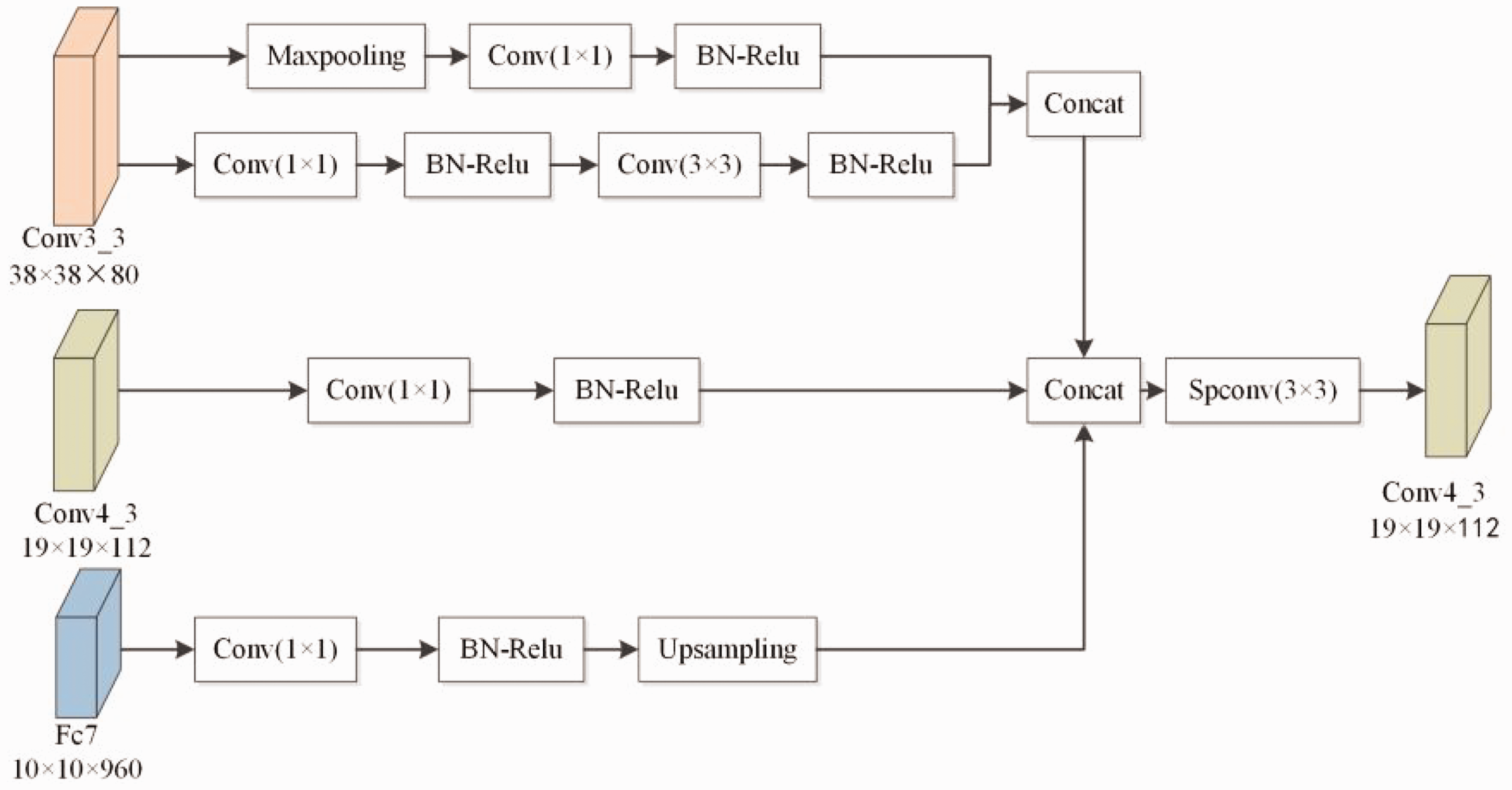
Feature fusion module.
Attention mechanism
Considering that small defects and complex texture backgrounds in the dataset can have an impact on the performance of object detection, most researchers incorporate attention mechanisms into the detection model. Attention mechanisms are divided into three main categories: channel attention, spatial attention, and channel-space attention. 35 Considering the issues such as the length of model training time and the ability of the model to focus on the target, we chose to improve on the basis of channel attention mechanism ECANet (efficient channel attention for deep CNNs) 36 and designs an r-ECA (dual channel attention mechanism) module.
The original ECA module uses global average pooling (GAP) when compressing features, which is not conducive to extracting more feature information, and its structure is shown in Figure 6. An r-ECA module uses both maximum pooling (Maxpool) and GAP to compress the feature layer, and its structure is shown in Figure 7.
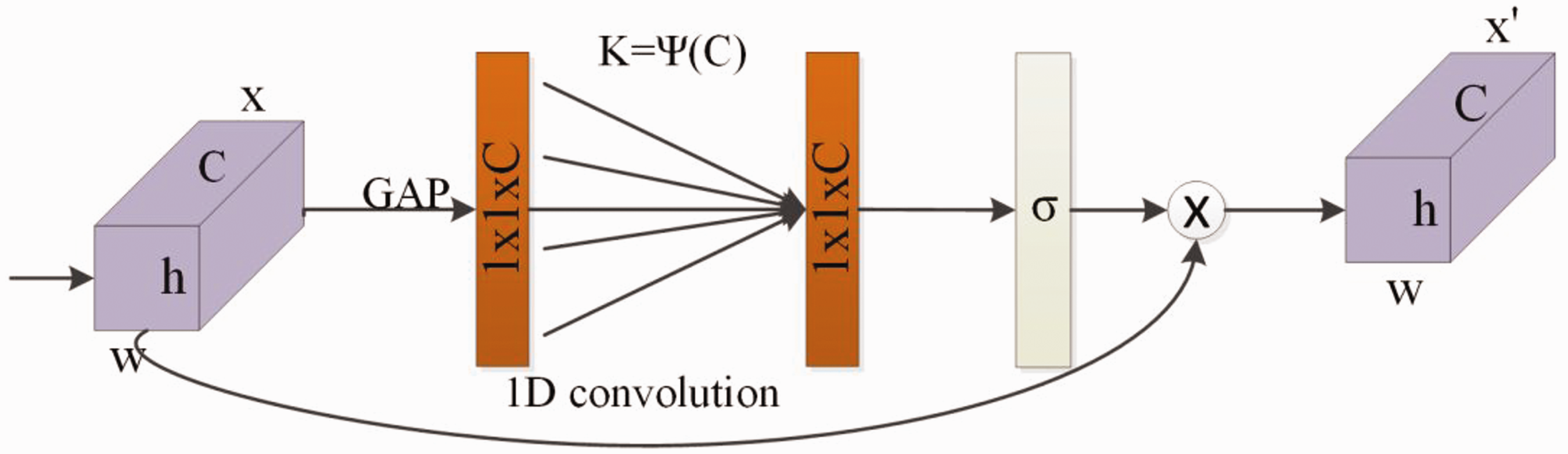
ECA module. GAP: global average pooling.
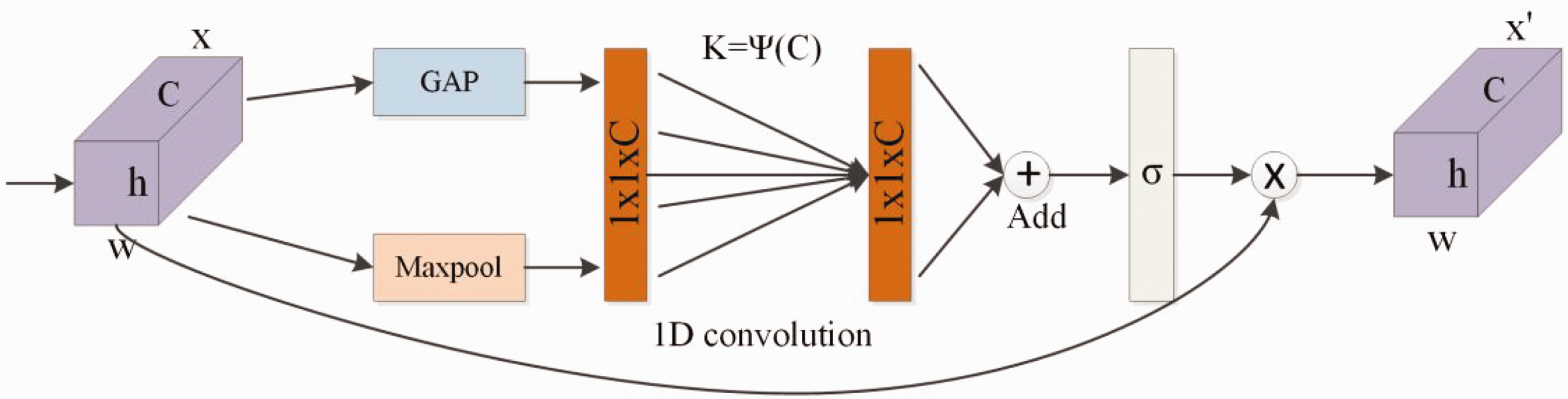
r-ECA module. GAP: global average pooling.
It first compresses the input feature map using Maxpool and GAP, respectively, and then learns the weights of each channel using a 1D convolution to obtain the consequences. Finally, the “add” operation is used to concatenate the extracted feature information. The sigmoid activation function accepts the new channel weights, multiplied by the input feature map, to obtain the output feature map. The mapping relationships are shown in equations (5) and (6).
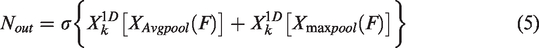

Equation
Heatmap observes the effectiveness of introducing the r-ECA module. The darker the Heatmap color area is, the more accurately the target is identified in that area. Figure 8(a) shows the original image with the target area marked, Figure 8(b) shows the effect of the heat map with the original ECA module added, and Figure 8(c) shows the impact of the heat map with the r-ECA module added. Comparing the images in Figure 8(b) and (c) shows that adding the r-ECA module makes the model pay more attention to the valuable target information and suppresses the noise interference and useless background information.

Heat map visualization: (a) original picture; (b) add the ECA module and (c) add the r-ECA module.
Experiment
Dataset production
The textile industry currently produces different fabrics, such as cloth, towels, fancy cloth, and many other fabric products. Considering the current popular publicly available fabric defect datasets, most of them are made for defect images of patterned, plain, or cotton fabrics, and there is no separate dataset made for finished fabrics such as white towels. In response to the above issues, we went to the textile factory to collect image samples of defects in the finished fabric and created the fabric defect dataset for this article. In addition, the complex texture of white towel fabric, high similarity of image noise and tiny defects, and susceptibility to light intensity, false detections are prone to occur during the detection process. To address the problems of white towel fabric, this article creates a dataset using defective images of towel fabric collected from industrial sites, with a total of 2221 original images of defects, including seven common defects such as edge defects, unfilled corner, hair, misprint, smudge, wire drawing, and thread residue. The statistical results of the number of defects in various types of fabrics are shown in Table 2.
Defect category and quantity

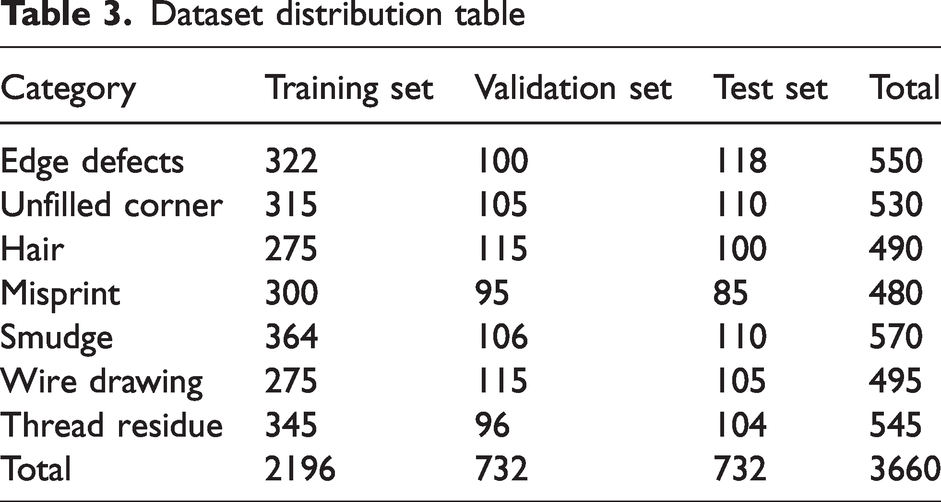
In order to make the model learn more invariant image features and prevent over-fitting, data augmentation techniques such as cropping, padding, and horizontal flipping are used. The training set is expanded to 3660 images by performing random flipping, cropping, scaling, and flipping operations on the dataset where the photos were located to make the algorithm detection more robust. The dataset is randomly divided according to the ratio of training set: validation set: test set = 6:2:2. The specific distribution of each category is shown in Table 3. The format of the dataset is converted into the format of the Visual Object Classes (VOC) dataset. During this process, this article uses the VOC diagram tool “labelImg” to mark the target object area and generate an Extensible Markup Language (XML) format location file. The specific process is shown in Figure 9.
Dataset distribution table
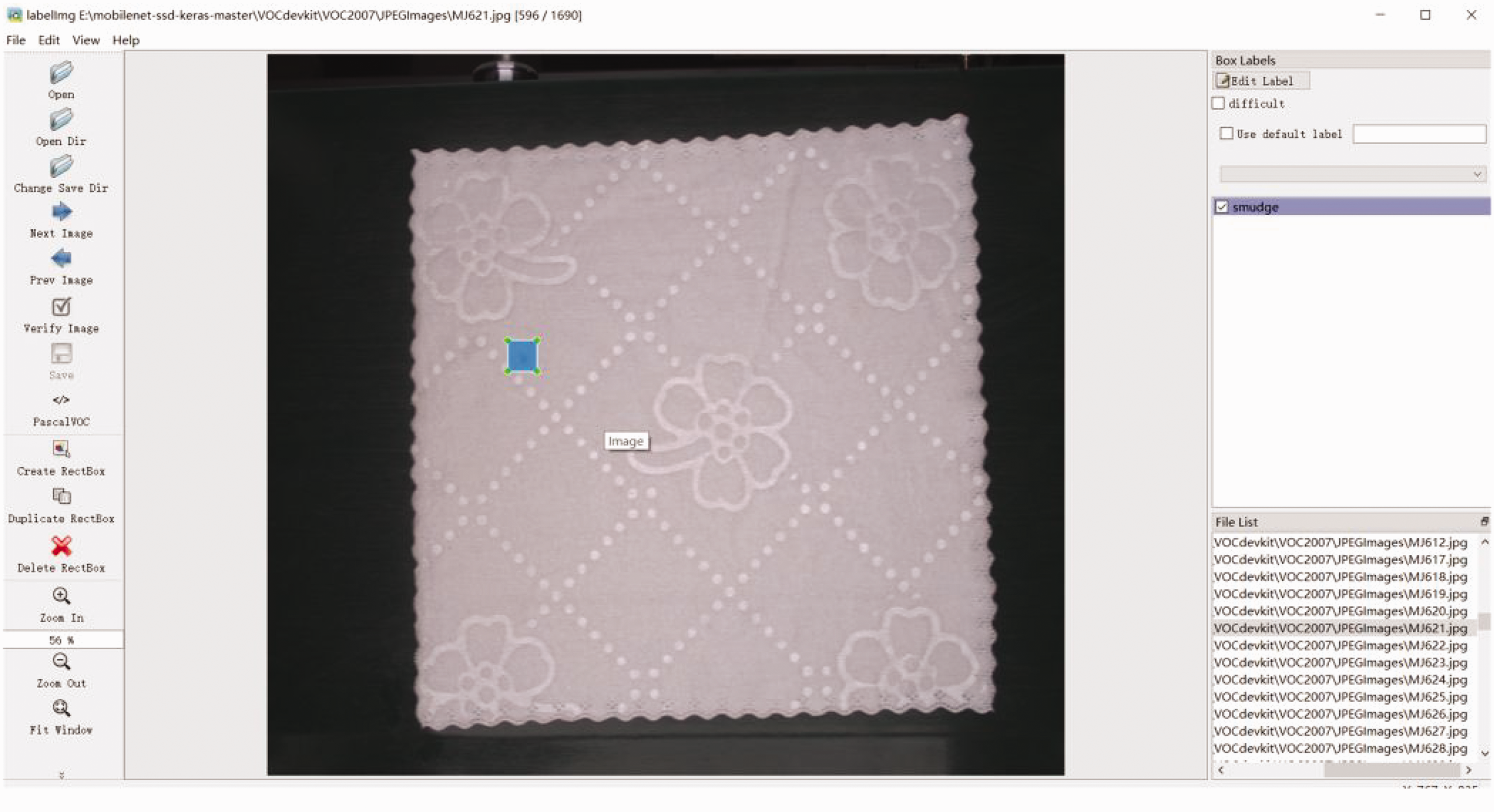
Labellmg labeling diagram.
Environmental configuration and training details
The environmental configuration is as follows: The operating system of this host is 64-bit Microsoft Windows 11, the CUDA version is 11.0, the programming language is Python 3.7, and the deep learning framework is Tensorflow 2.4.0. The host configuration used in the experiment is as follows: the computing host consisted of an Intel Core i9-9900k CPU @3.60 GHZ and an NVIDIA RTX 3050 GPU. The parameters in the training are set as follows: the model optimizer is SGD, the momentum parameter is set to 0.9, the weight decay coefficient is 0.0005, and the initial learning rate is 0.001. To speed up the convergence of the models, each model uses the preconditioned weights on ImageNet to initialize the backbone network weights.
The experimental collection platform takes into account the requirements of actual distance and collection speed. The camera used for collecting fabric image data is a CMOS array industrial camera produced by Zhejiang Dahua Technology, model A7500CG20, with a pixel size of 5 MP. The lens adopts the Kangbiaoda industrial lens model M0824-MPW, with a resolution of 5 million pixels and a fixed focal length of 8 mm. During the image collection process, factors such as capital cost, service life, and brightness are considered, and Light Emitting Diode (LED) lights are selected as the light source for the image collection system. The workflow of the fabric defect detection system is shown in Figure 10. Firstly, the industrial camera captures the fabric image on the conveyor belt, and then the image is conveyed to the monitor through the computer for display.
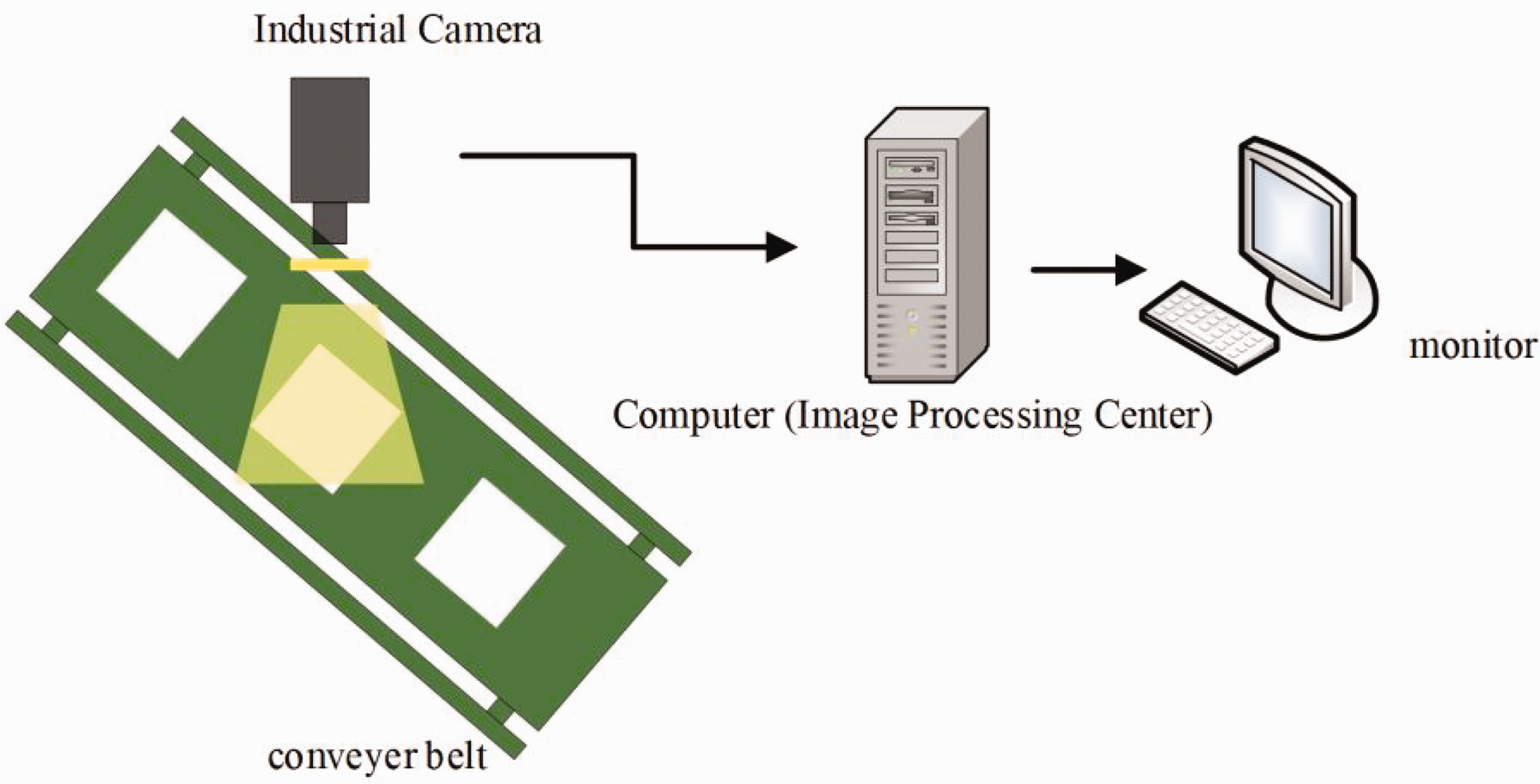
Fabric defect detection system.
Evaluation metrics
During the detection process, it is significant to focus on not only accuracy but also speed, so we used mean average precision (mAP), model parameters (Params), model memory size (Size) and frame rate per second (FPS) as our assessment criteria to evaluate the accuracy. The mAP is calculated with recall and precision. The Intersection over Union (IoU) threshold is set as 0.5. That means we consider the model predicts correctly when the number calculated between the ground-truth boxes and predicted boxes is larger than 0.5. The smaller the parameter quantity and memory of the model, the lower the performance requirements of the hardware and the easier it is to build in low-end devices and embedded devices. The metric equations are shown in equations (7)–(11):





Model loss curve
Figure 11 shows the training loss diagrams of SSD algorithm and LW-SSD algorithm. The vertical axis “Train loss” in Figure 11 represents the number of iterations, the horizontal axis “epoch” in Figure 11 represents the training loss value, the black line represents SSD, and the red line represents LW-SSD. As can be seen from the loss line graph, the loss of LW-SSD is generally lower than the loss of SSD, the loss of two models drops rapidly in the first 50 times of iteration, LW-SSD’s loss decreases from 23 to 2.5, SSD algorithm’s loss falls from 14 to 3.5. Loss decreased slowly and gradually stabilized in the subsequent iteration, the loss of SSD is stable at about 4-3.5, the loss of LW-SSD is stable at about 3-2.5. In general, the performance of the model is better when the loss function is lower.
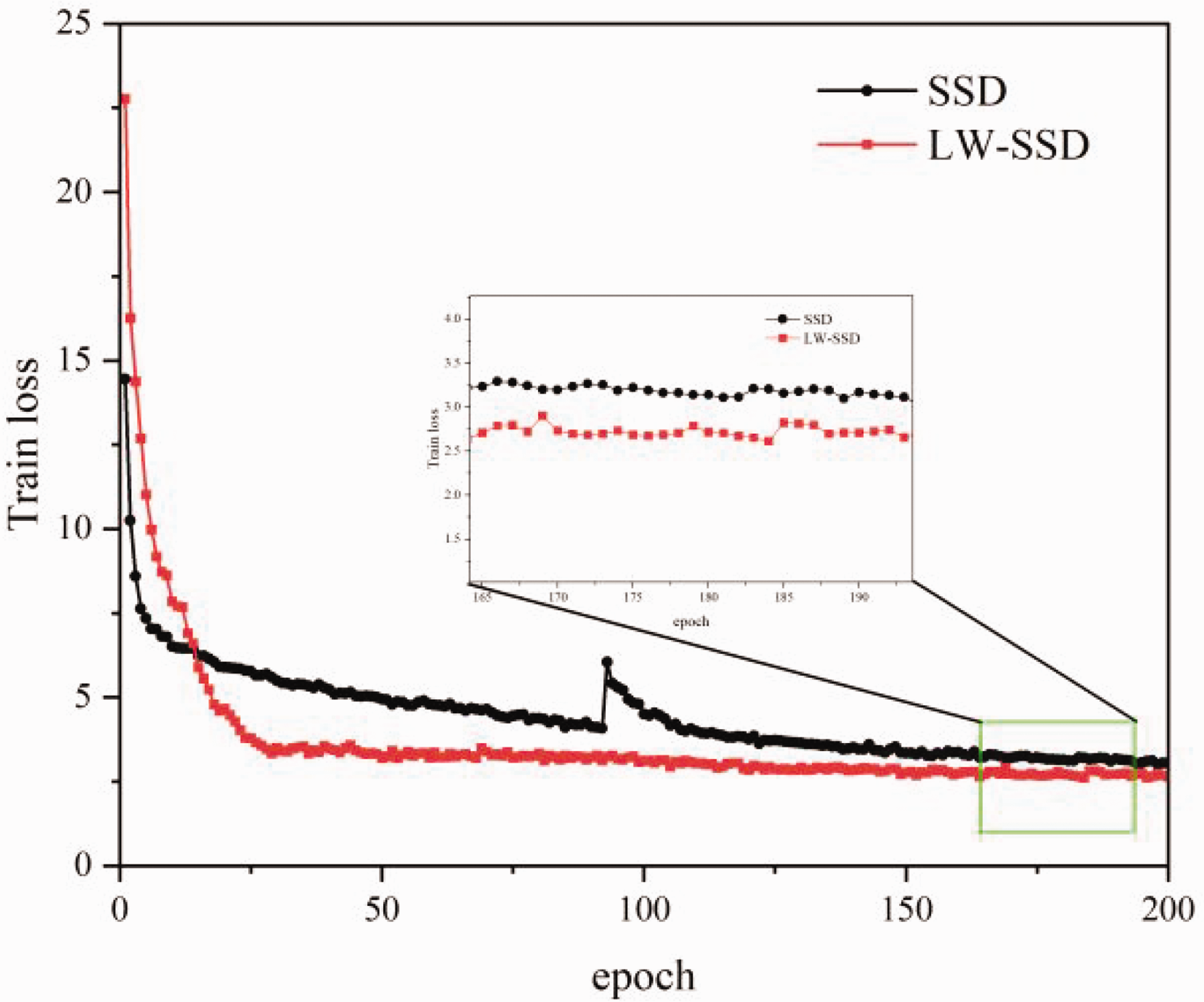
Model loss curve.
Experiment setup
Firstly, for selecting the backbone network in the SSD algorithm, this article sets up the comparison experiment of the backbone network. Secondly, a comparison experiment is set up on the fabric defect dataset to verify the differences between the algorithms in this study and other target detection algorithms. Thirdly, an ablation experiment is performed to demonstrate the effectiveness of the improved SSD algorithm. Finally, the feasibility of this study’s algorithm is demonstrated by comparing and verifying it with the original SSD algorithm on the fabric defect data set.
Results and discussion
Choice of backbone network
In the experiment, the popular large backbone networks VGG16, ResNet50, 37 lightweight backbone MobileNetv2, and MobileNetv3 are selected for comparison. The above backbone networks are used to replace the feature extraction network in SSD algorithm, and trained on the fabric defect dataset of this article.
The accuracy result curve of training is shown in Figure 12. The horizontal axis “epoch” represents the number of iterations, and the vertical axis mAP(%) represents the detection accuracy of the model. As shown from Figure 12, after convergence of each model, the ResNet50 network has the highest mAP value, which is 0.96%, 2.04%, and 4.17% higher compared to VGG16, MobileNetv2, and MobileNetv3 networks, respectively. However, the performances of different backbone networks in the SSD algorithm are tested to combine the accuracy and real-time performance of the model. The test results are shown in Table 4, where Params denotes the size of the model’s number of parameters, Size represents the memory size of the model, and FPS represents the frame rate of the model’s scanned images per second. Table 4 shows that the SSD algorithm with VGG16 as the backbone network does not have an advantage in detection accuracy and speed. The number of model parameters is 24.41 M, the memory is 93.1 MB, and the detection speed is 44 FPS. MobileNetv3 has the fastest detection speed among the four types of backbone networks, but its detection accuracy still has a particular gap compared with the ResNet50 network. The comparison of the backbone networks shows that MobileNetv3 has a balance of real-time and accuracy and is more suitable for application in fabric defect detection. Therefore, MobileNetv3 is selected as the backbone network for SSD.
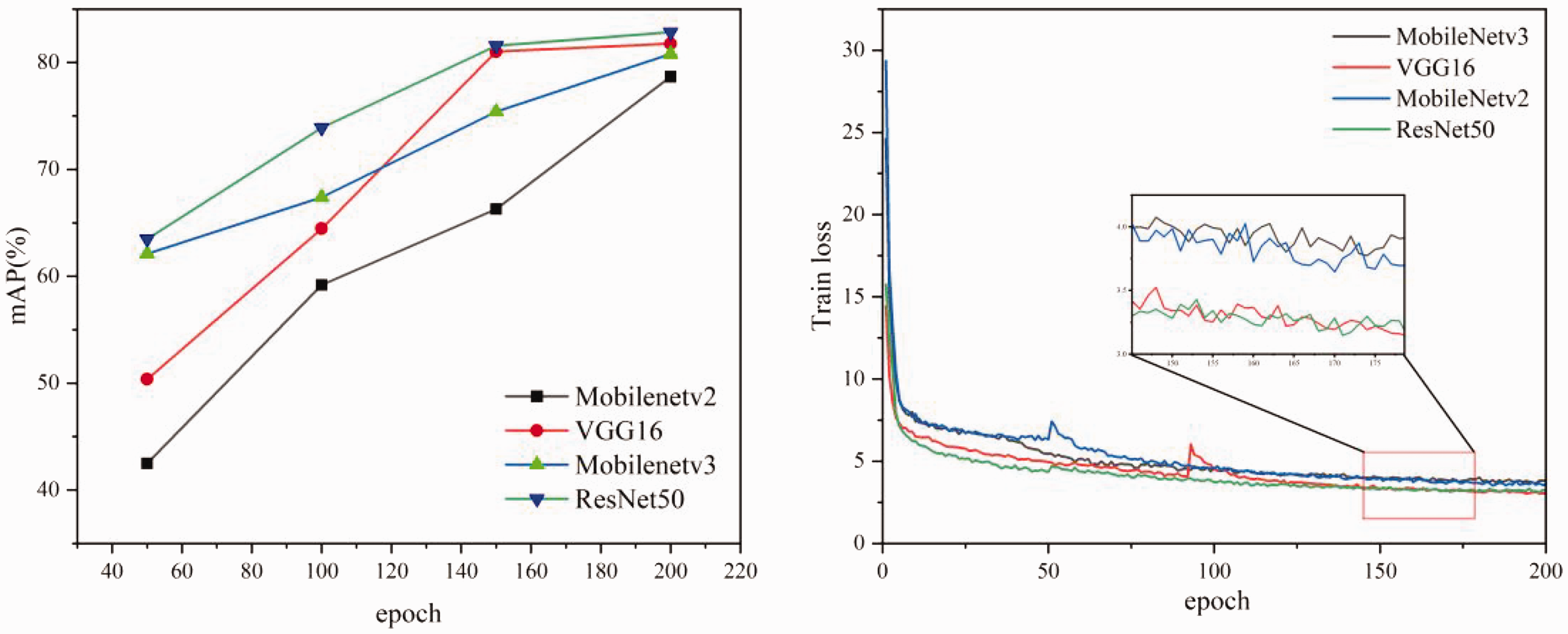
Training curves of different backbone networks on the dataset.
Performance comparison of SSD algorithm under different backbone
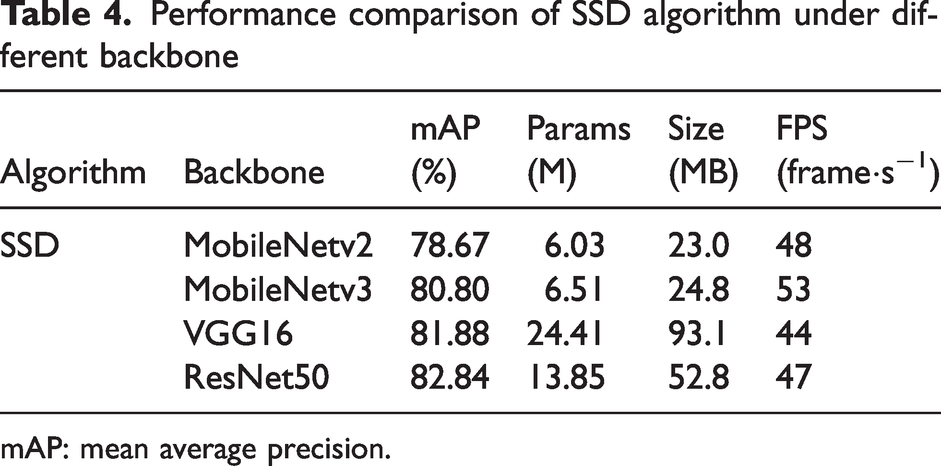
mAP: mean average precision.
Analysis of algorithm comparison results
During the experiments, the original SSD, RFB-Net, Faster R-CNN, Yolov3, EfficientDet-D0, and the LW-SSD SSD algorithm are compared, and the data of the detection results are compared and analyzed. The comparison of the detection results of different targets is shown in Table 5, and the comparison of the detection results of different algorithms is shown in Table 6.
Comparison of different target detection results
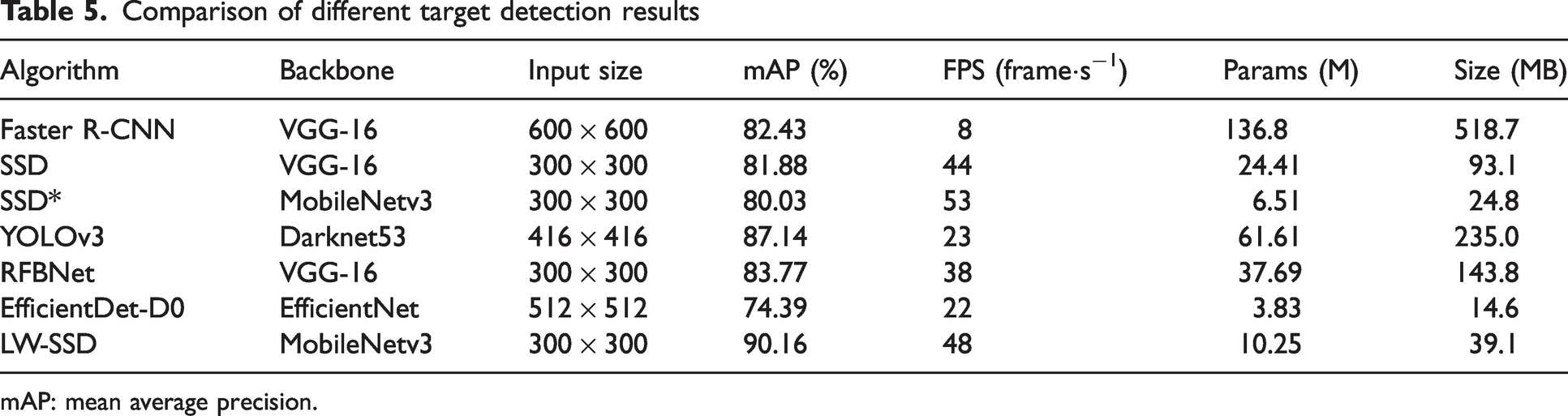
mAP: mean average precision.
Comparison of detection results of different algorithms
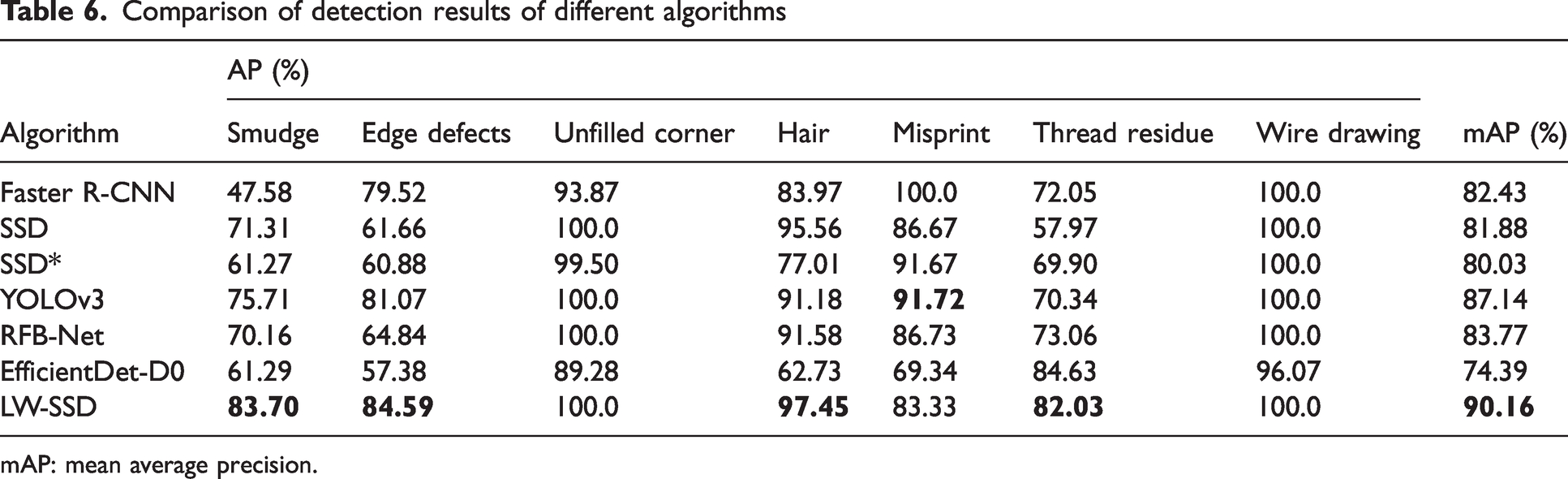
mAP: mean average precision.
As can be seen from Table 5, the accuracy of the LW-SSD algorithm is 90.16%, which is 10.13%, 8.28%, 6.39%, 8.73%, 3.02%, and 15.77% higher than MobileNetv3, SSD, RFB-Net, Faster R-CNN, Yolov3, and EfficientDet-D0 algorithms, respectively. The number of parameters of the LW-SSD algorithm is reduced by 58% compared with the SSD algorithm. Compared to the SSD algorithm, the LW-SSD algorithm reduces memory by 58%. The FPS is slightly higher than the SSD algorithm, which meets the real-time industrial requirements and is easier to apply to hardware devices with limited computing power.
As seen from Table 6, compared with the SSD algorithm, the detection accuracy of this study improved by 12.4% and 23.7% on the two types of small targets, “smudge” and “thread residue,” respectively. The detection accuracy of “edge defects” is improved by 22.93%, the detection accuracy of “hair” is enhanced by 1.89%, and the detection accuracy of “misprint” is decreased by 3.34%. The detection accuracy of the seven types of defects and the average accuracy of each variety of algorithms, the detection effect of this article, is better than the other five algorithms, demonstrating its effectiveness.
Figure 13 shows the scatter plot plotted by this algorithm and other algorithms. The horizontal coordinate mAP (%) represents the detection accuracy, and the vertical coordinate FPS represents the frame rate of scanned images per second. It can be seen from the figure that the detection accuracy of the LW-SSD algorithm is better than other algorithms.
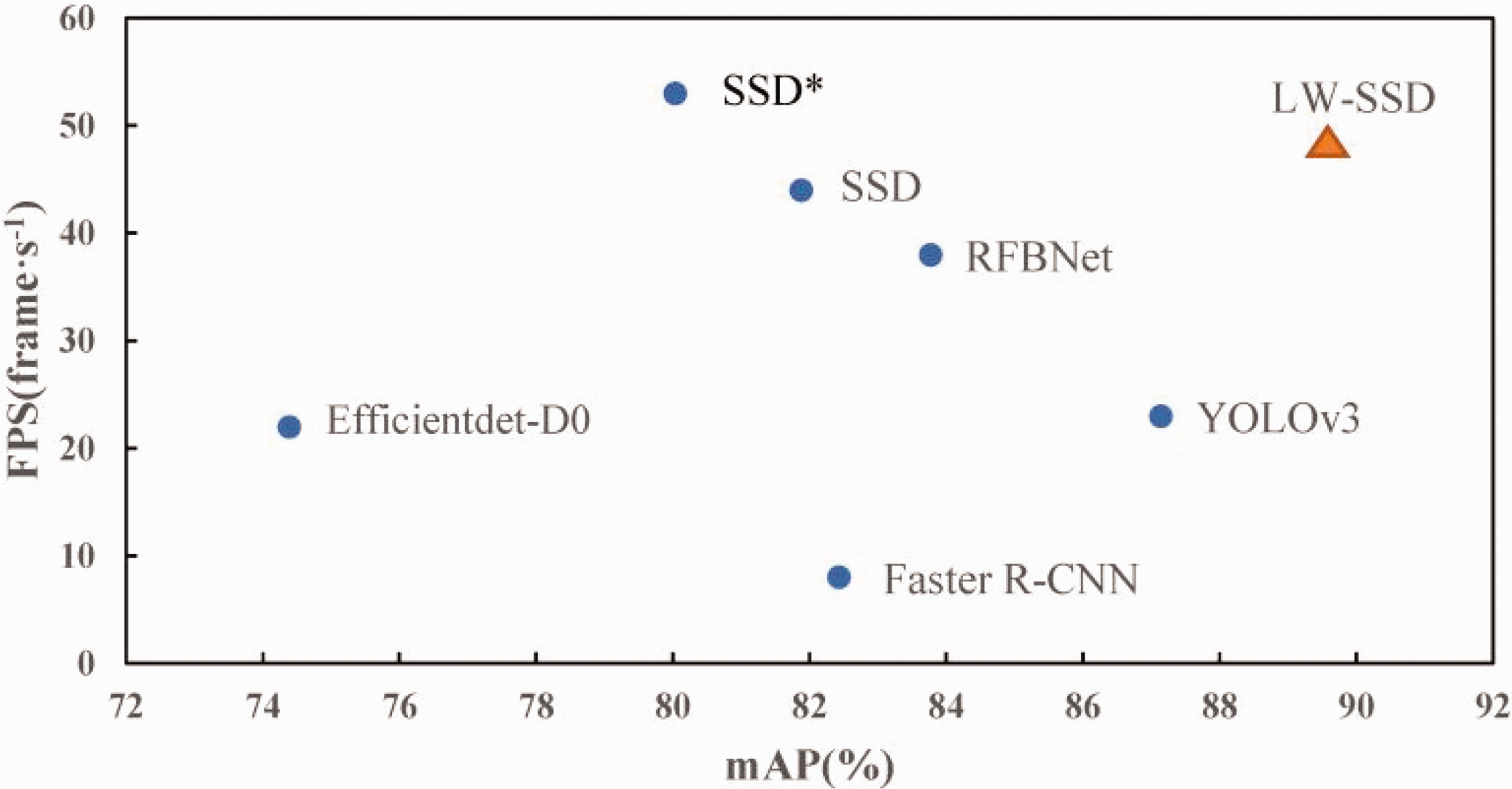
Scatter plot of speed and accuracy of different detection algorithms.
Results of ablation experiment
The selected baseline model is the SSD with backbone of MobileNetv3. Firstly, the strategies mentioned are combined with the baseline model individually to show the contribution of the strategies to the LW-SSD algorithm. Then, all the strategies are introduced into the SSD algorithm and trained to evaluate the final algorithm performance. The above algorithms are used to train on self-made fabric defect dataset.
The training curve is shown in Figure 14, where Train loss is the training loss value and epoch is the number of iterations of the training. To further compare the detection performance of each module added to the SSD algorithm, the performance indicators of each module in the ablation experiment are recorded, as shown in Table 7. On the self-made fabric defect dataset, for the MobileNetv3-SSD model, by adding the FFM to the MobileNetv3-SSD algorithm the mAP is improved by 0.85%, proving that fusing the shallow and deep feature layers effectively improves the algorithm’s accuracy. Adding the MPD module, the mAP has only a small improvement, which proves that adding the MPD module alone can expand the receptive field of the feature layer, but the detection accuracy will not be greatly improved. Adding the FFM or the r-ECA module on top of this, the mAP is improved by 0.55% and 5.63%, respectively, emphasizing the importance of fusing the information of different layers or emphasizing the weight of the channel information of each feature layer after expanding the receptive field. By adding the r-ECA module separately, the mAP of the improved algorithm will increase by 3.7%, emphasizing the importance of filtering important channel information to improve algorithm accuracy. The simultaneous addition of the above three modules improves mAP by 10.13%, which proves the effectiveness and reliability of the above-improved operations.
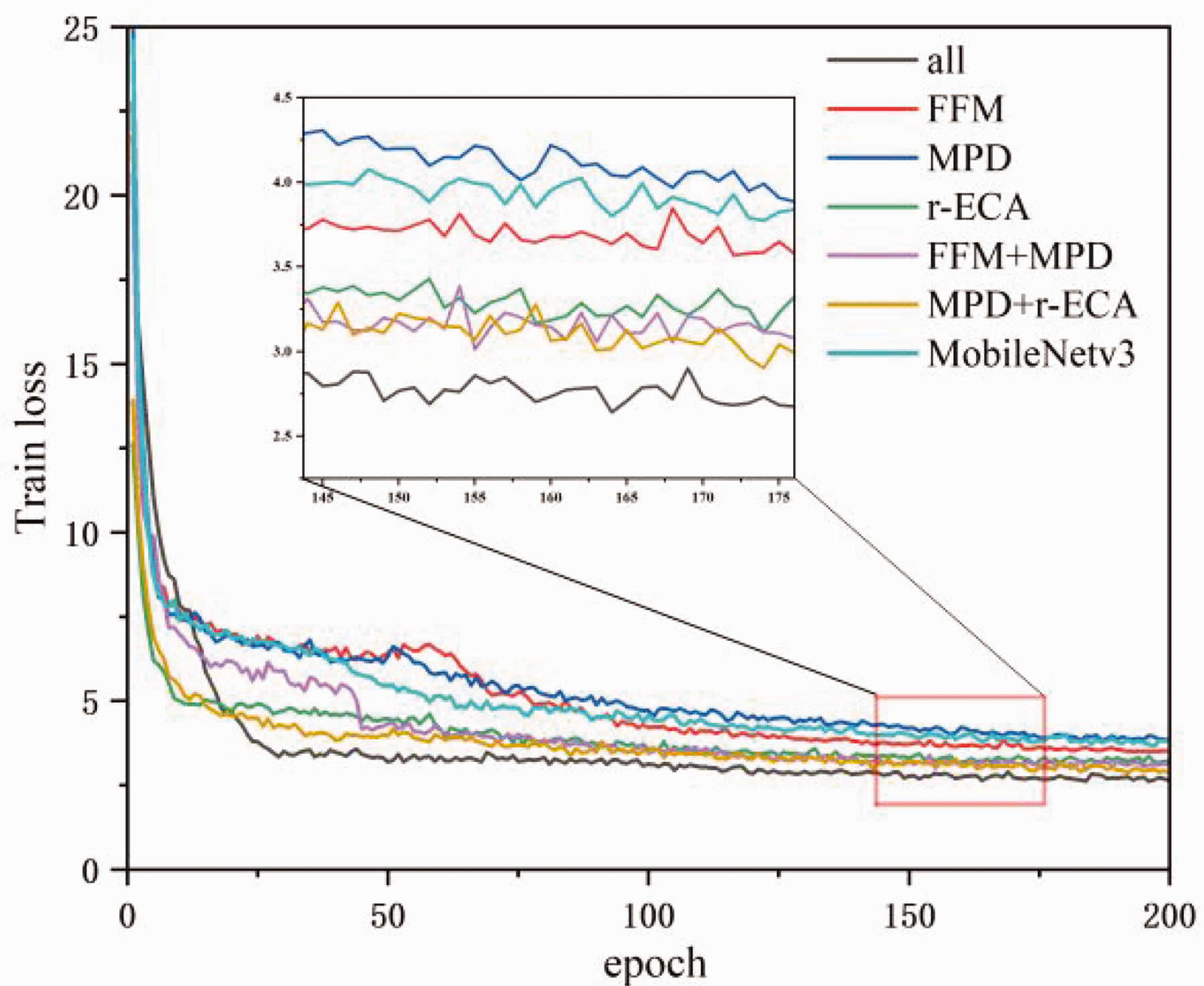
Module training loss curve.
Ablation experiments
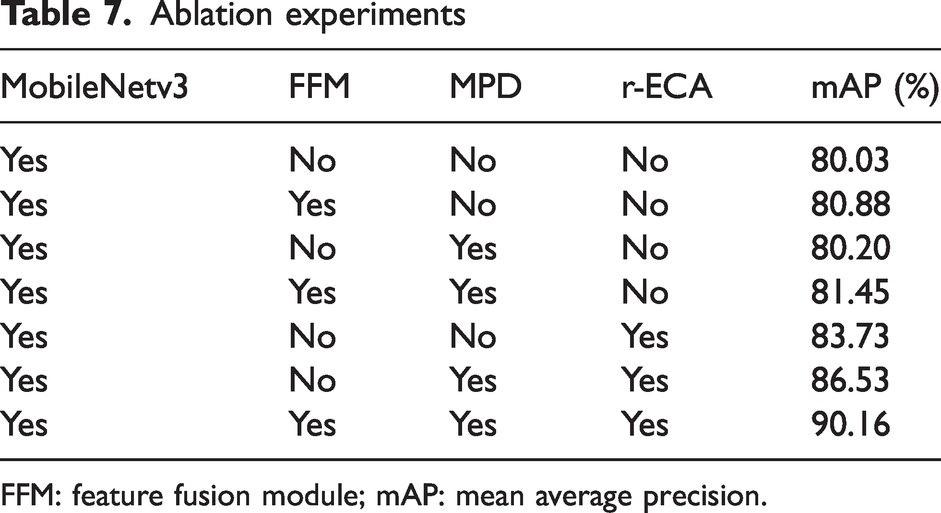
FFM: feature fusion module; mAP: mean average precision.
Visualization of test result
To verify the target detection performance of the algorithm in this article under different lighting conditions. The attribute labels are extracted from the fabric defect test set and the images are classified into three categories of scenes. Table 8 shows the experimental results of the proposed article under different lighting environments, where N represents the number of samples. It can be seen that the proposed method is satisfactorily adapted in terms of the light environment. In most cases, mAP can be guaranteed to be within an acceptable range, except in low light conditions where the mAP value will decrease significantly.
Test results for different lighting environments.

mAP: mean average precision.
The detection results of some samples are visualized below. Figure 15 shows the detection examples of the LW-SSD algorithm and the original SSD algorithm on the fabric defect dataset. The two sets of images in Figure 15(a) and (b) show the detection results of the two algorithms. Among them, Figure 15(a) group images show partial detection results of the SSD algorithm, and Figure 15(b) group images show partial detection results of the LW-SSD algorithm. From the detection results of groups (a) and (b), it can be seen that the detection effect of the LW-SSD algorithm is significantly improved for small targets of “smudge” and targets with large deformation scale of “edge defects.”

Different algorithm detection results: (a) SSD algorithm detection results and (b) Lightweight Single Shot Multi-Box Detector (LW-SSD) algorithm detection results.
Figure 16 shows the detection performance of the LW-SSD and SSD algorithms under three different lighting conditions. The lighting scenes in Figure 16(a) and (b) are normal light, shimmer, and low light respectively. From the detection results, it can be seen that the proposed algorithm can effectively detect fabric defects in the above scenarios, and the detection results are consistent with the actual judgment. Despite the above-mentioned interference, the LW-SSD algorithm can still achieve relatively satisfactory detection results. The test results show that for the untrained test data, the proposed algorithm can still complete the rapid detection of fabric defects ahead in different lighting scenes, which proves that the proposed algorithm is effective.

Comparison of experimental results of fabric defect datasets under different lighting conditions: (a) detection results of SSD algorithm under different lighting conditions and (b) detection results of Lightweight Single Shot Multi-Box Detector (LW-SSD) algorithm under different lighting conditions.
Conclusion
This article proposes a fabric defect detection method based on a LW-SSD algorithm to detect fabric defects accurately. Firstly, this addresses the problem that the number of model parameters of the SSD algorithm is large and not easy to deploy on hardware devices with limited computing power, so this article uses lightweight MobileNetv3 to replace the original backbone network, reducing the calculation of the model. Secondly, to address the problem of low accuracy of small target detection, the FFM and MPD module are added to the algorithm to improve the average accuracy of small target detection by expanding the receptive field of the shallow feature layer and fusing semantic feature information of different levels. Finally, the r-ECA module is added to the LW-SSD algorithm to make the detection network pay more attention to the defect location and weaken the inference of the background. Experiments show that the robustness of this method is improved for small defects and complex background datasets while preserving the original inference speed, and can deal with more different classes of fabric defect detection. The detection accuracy of the LW-SSD algorithm is 90.16%, the model parameter quantity is 10.25 M, the model memory is 39.1 MB, and the detection speed is 48 FPS. It meets the requirements of industrial production for improving accuracy and real-time object detection. Compared with other algorithms, the proposed algorithm has relatively comprehensive precision and inference speed, which provides theoretical and technical support for real-time detection based on embedded platforms.
Future prospects
Thus far, the work performed in this study has been introduced. In this article, a lightweight target detection algorithm, LW-SSD, is designed. LW-SSD takes into account the detection effect and calculation cost and offers some advantages over the current efficient fabric defect detection algorithm. In addition, we provide a model optimization idea for relevant study. We believe that in some scenarios, reducing the calculation cost of the model is more practical than improving the accuracy. Especially with the popularity of mobile devices, the lightweight model is more suitable for running on such devices. However, there are still some deficiencies raised by this article. The fabric defect dataset we captured is for textile finished products, but its types and quantities are relatively low, which means we cannot comprehensively summarize the impact on the detection of all textile products. We will continue to collect images of fabric defects and add them to the dataset to improve the practical applicability of the proposed algorithm. In addition, we will continue to consider making the dataset public to facilitate other researchers’ research and comparison. At the same time, we hope that relevant scholars will pay more attention to the lightweight nature of the model and the detection of small targets. We will also focus on these two directions.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China (nos. 62003129, 61903122).