
Abstract
Deep learning has shown promise in textile defect detection, but its reliance on large high-quality labeled datasets poses challenges in real-world industrial applications. This study presents a novel unsupervised defect detection framework that effectively detects various types of texture defects with limited defect-free texture samples. The framework integrates texture and semantic information using a bilateral-branch network architecture (TSUBB-Net). Specifically, TSUBB-Net employs a weighted centering loss to cluster complex texture units, emphasizing semantic information within defect regions through a channel attention mechanism. It further fuses contextual semantic information to achieve precise defect localization. Thus, the efficient fusion method combines texture and semantic information, enabling the representation of complex texture structures and mitigating the impact of image acquisition quality on defect recognition. To evaluate the effectiveness of our proposed method, we build a unique dedicated database of textile defect image segmentation, which serves as the benchmark for textile defect detection. Experimental results demonstrate that TSUBB-Net surpasses state-of-the-art methods, exhibiting excellent performance in textile defect detection. The proposed framework holds significant potential for practical applications in the textile industry, improving defect detection capabilities.
In industrial textile production, various types of surface defects often occur due to complex manufacturing processes. These defects manifest as localized regions with texture structure destruction or light intensity variation, which can seriously affect product quality. Over the past few decades, numerous methods for detecting surface texture defects have been developed to address these challenges. These methods can be broadly categorized into two classes based on their feature extraction strategies: traditional methods and deep learning methods.
Traditional detection methods encompass several processing methods for texture defects, roughly classified into five groups: spectral-based, 1 structured-based, 2 statistical-based, 3 learning-based,4,5 and model-based. 6 These methods have demonstrated relatively good detection accuracy for complex textile defects. However, the efficacy of these methods relies on acquiring a high-quality set of defective samples with manual labeling of each type of defect. Meanwhile, substantial computing resources are required to ensure detection accuracy. In addition, these traditional detection methods fail to provide a suitable manual feature annotation approach to deal with defect images with various texture surfaces.
Recently, texture defect detection has greatly benefited from the rapid development of deep learning, a method recognized for its efficient texture feature extraction. Within the context of deep learning, these techniques are often differentiated into supervised and unsupervised learning methods, depending on the labeling of the training data. For instance, Zhang et al. 7 devised a semi-supervised convolutional network that adeptly merges spectral (graph convolutional network (GCN)) and spatial (convolutional neural network (CNN)) features and adaptive weight adjustments, thus providing an alleviation of the issues of label scarcity and sample deficiency. Xiao et al. 8 used a coordinate attention mechanism and spatial pyramid pooling to improve feature extraction, and combined a compound loss function to address challenges such as complex backgrounds and relatively small defect sizes. However, collecting sufficient defective samples in textile industrial applications remains challenging. Moreover, accurately distinguishing defects from complex background textures poses a significant difficulty.
In contrast, the unsupervised method offers the advantage of processing a huge quantity of unlabeled data and defines appropriate clusters, highlighting its potential to bring significant benefits to textile industrial production. For example, Schlegl et al. 9 proposed the AnoGAN network, which effectively utilizes generative adversarial networks (GANs) in an unsupervised manner to distinguish defects by identifying significant deviations from the learned normal data distribution. Yi and Yoon 10 proposed an advanced unsupervised approach that leverages the support vector data description to detect anomalies by capturing the global structure and local texture variations in the data distribution. However, practical industrial textile datasets are often composed of complex textures intertwined, as shown in Figure 1. These textures are variable, encompassing both regular and irregular, dense and sparse patterns. Furthermore, defects in these textures can result in significant variations in appearance, including irregular changes in brightness, variable shapes and sizes, and low contrast. Previous unsupervised deep learning methods have faced limitations in terms of their performance. While they could efficiently represent basic texture features, these methods' training relied on high-quality datasets. However, more adaptability and robustness are needed to account for real-world environmental influence.
Examples of industrial textile defects datasets: (a) irregular texture; (b) dense texture; (c) irregular shape; (d) fuzzy border; (e) low contrast and (f) uneven lighting.
In this study, we introduce a novel framework, TSUBB-Net, which innovatively integrates texture and semantic information via a bilateral-branch network architecture. The central objective of this work is to navigate the complex challenge of effectively representing intricate texture structures while evading limitations imposed by sample quality. Unlike conventional methods that primarily focus on texture or semantic information in isolation—resulting in potential omissions or inaccuracies—TSUBB-Net simultaneously handles these two dimensions, providing a more comprehensive solution. The network's unique operational approach entails accurate texture background image reconstruction to capture inherent texture patterns in the input. At the same time, it identifies substantial reconstruction errors in defective regions and accurately segments and locates these defects, thus ensuring thorough defect detection. Then, the residual images are obtained by subtracting the texture backgrounds from the input images. Finally, the defect detection result is obtained by fusing the residual images from the two branches via the feature fusion module (FFM). Our proposed network simultaneously tackles multi-scale texture feature clustering and semantic feature fusion. Therefore, it can efficiently and simultaneously detect various texture defects by utilizing only a small number of defect-free industrial textile surface samples. The main contributions of this study are threefold.
We propose an innovative bilateral-branch network framework that adeptly integrates texture and semantic information, adapts to complex textile textures, and minimizes the impact of image acquisition quality on defect recognition. We present a novel texture-reconstruction-based deep clustering method that trains an autoencoder (AE) by minimizing the weighted centering loss of the texture unit and cluster center, utilizing soft group assignments as sample weights, consequently boosting the effectiveness and accuracy of texture classification. We construct a self-attention fusion module (SAFM) that integrates contextual semantic information and enhances semantic prediction by incorporating additional low-level information near boundaries, thereby enabling precise localization of defect positions.
Related works
Autoencoders and their extensions
AEs are a type of artificial neural network model that have been widely applied in various fields, including shape retrieval,
11
target recognition,
12
and object detection,
13
for learning effective encoding of unlabeled data. Autoencoders utilize the input data itself as a supervisory signal, enabling the neural network to learn a mapping relationship Fθ: x → x to achieve image reconstruction. The AE
The first subnetwork, commonly referred to as the encoder, maps the input data


Recently, to overcome these limitations, convolutional autoencoder (CAE) networks 14 have been widely applied in machine vision applications, combining the powerful feature representation capability of CNNs with the foundation of a MLP. Mei et al. 15 proposed a multi-scale convolutional denoising autoencoder (MSCDAE) network that incorporates a certain amount of random noise before the sample input and can obtain powerful representations from the original noisy data. However, optimizing the noise level selection is required, and adding noise affects the model's training speed, requiring a balance between noise size and training efficiency. Zhou et al. 16 proposed a semi-supervised fabric defect detection method based on variational autoencoders (VAEs) and Gaussian mixture models (GMMs). This method can more accurately construct defect region boundaries by synthesizing detection results from image content and latent space. However, a moderate number of labeled samples is needed to improve performance, which is greatly influenced by the quality and quantity of the labeled samples. In this study, aiming to accommodate actual industrial production and boost efficiency, a novel bilateral-branch network framework is proposed to integrate texture and semantic information to adapt to the complex and diverse irregular texture structures of textile images, while eliminating the impact of image acquisition quality on defect recognition.
Clustering methods
Over the past few decades, clustering methods have been proposed that can be broadly classified into four categories: connectivity-based,
17
centroid-based,
18
distribution-based,
19
and density-based.
20
However, these methods have several limitations that need to be considered. For instance, clustering is sensitive to parameter choice, impacting the quality of grouping results. In addition, clustering can be computationally intensive, especially when dealing with large datasets or high-dimensional feature spaces. Another limitation is the dependence on specific assumptions or probability distributions, which may not hold for all data types. Lastly, clustering algorithms can be susceptible to outliers in the data, which may affect the accuracy and reliability of the clustering results. Recently, Qian et al.
21
proposed a deep embedding-based unsupervised clustering method. This method first applies a self-organizing map algorithm for an initial round of clustering, mapping data samples from high-dimensional space to low-dimensional space. Subsequently, an efficient dense subspace clustering algorithm performs a second round of clustering, reducing human interference with the parameters. However, it still requires a complex preprocessing step for the images. Yang et al.
22
proposed a novel center-constrained clustering method that detects anomalous features by learning the distribution of latent features in the intermediate layer of an AE. However, the accuracy of locating clustering centers depends largely on the initial
Proposed method
The training parameters and learning procedure of TSUBB-Net were described in the last section. The overall architecture of TSUBB-Net is shown in Figure 2, and consists of five components: (I) the feature extraction network (FEN); (II) the feature decoding network (FDN); (III) the texture reconstruction branch (TRB); (IV) the semantic localization branch (SLB); and (V) the FFM.
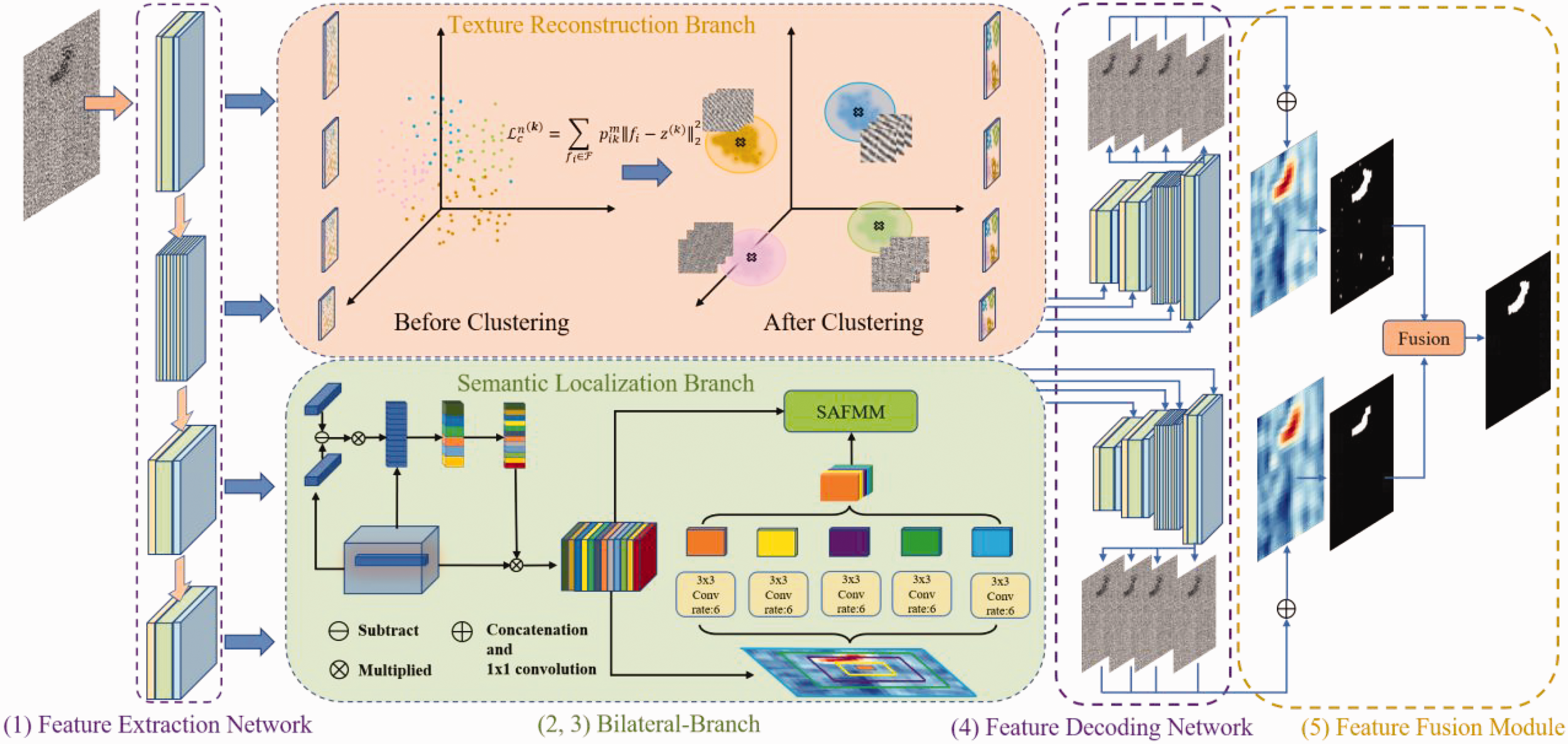
Overall architecture of the proposed TSUBB-Net method. TSUBB-Net consists of a feature extraction network (FEN), a feature decoding network (FDN), a texture reconstruction branch (TRB), a semantic localization branch (SLB), and a feature fusion module (FFM). The original input image undergoes the FEN and FDN to extract and reconstruct multi-scale information. The TRB and SLB combine the bilateral branch at each scale to process texture and semantic information. In the testing stage, the reconstructed background image is fused by the FFM to obtain the final defect image.
Feature extraction network and feature decoding network
The FEN and FDN serve the respective purposes of directly extracting feature maps with varying receptive fields from the entire input image and reconstructing original images from feature maps at different scales, thereby maximizing the representation of information within the textile images.
Feature extraction network
Here, we propose an enhanced textile image feature extraction model that adopts ConvNeXt
23
as the primary FEN. This technique is renowned for its high-quality representation in image feature extraction. The proposed module comprises four layers, which can capture a diverse range of perceptual scales. Each layer consists of various stacked blocks arranged in a 1:3:1:1 configuration, which deviates from the original ConvNeXt model's 1:1:3:1 configuration. Texture features in high-layer spaces are unordered and can extract irrelevant information with conventional convolutional layers operating with sliding windows. In contrast, low-layer spaces contain a rich texture and fine-grained information that aids in uncovering local texture structures. However, low feature dimensions can introduce significant noise impairing performance. Our module effectively captures texture features at various levels to enhance feature representation. To optimize model performance while mitigating over-encoding-induced reconstruction distortion, we adjust the quantities to 2:6, instead of the original ConvNeXt model's 3:9 configuration. Ultimately, the input image
Feature encoding network
Within the FEN, outputs from each layer are processed through a bilateral branch, generating comprehensive feature representations.
As depicted in Figure 3, the original image

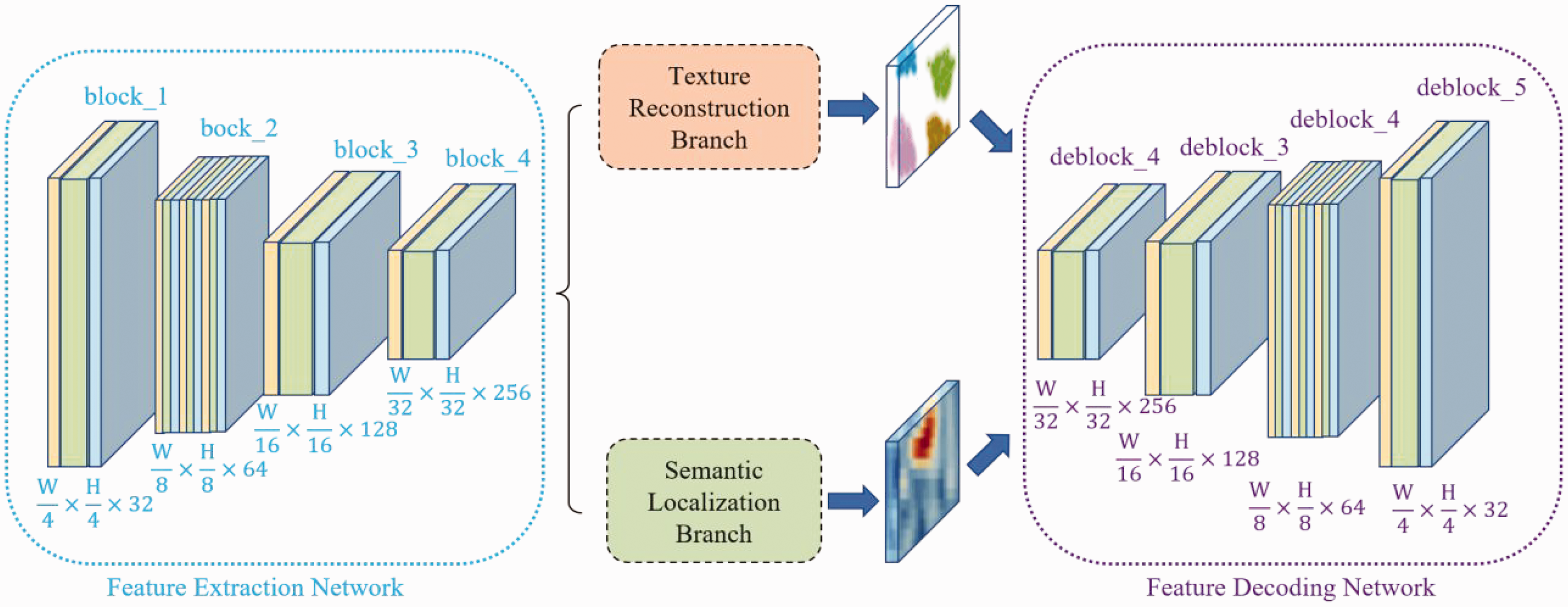
Architecture on the fourth scale in TSUBB-Net.
Texture reconstruction branch
Current unsupervised texture defect detection methods, based on deep CNNs, are significantly influenced by the initial centroid choice in the k-means clustering process. Moreover, these strategies estimate texture information by analyzing data distribution, resulting in redundant and entangled positive samples. To address this issue, we propose a novel clustering method for texture reconstruction to attain stable texture unit representations in high-dimensional feature spaces, thereby enhancing the discriminative power for complex textures.
As illustrated in Figure 4, the TRB structure consisting of encoding, texture clustering, and decoding modules. The entire process can be represented with the following mathematical expressions:


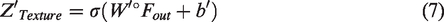
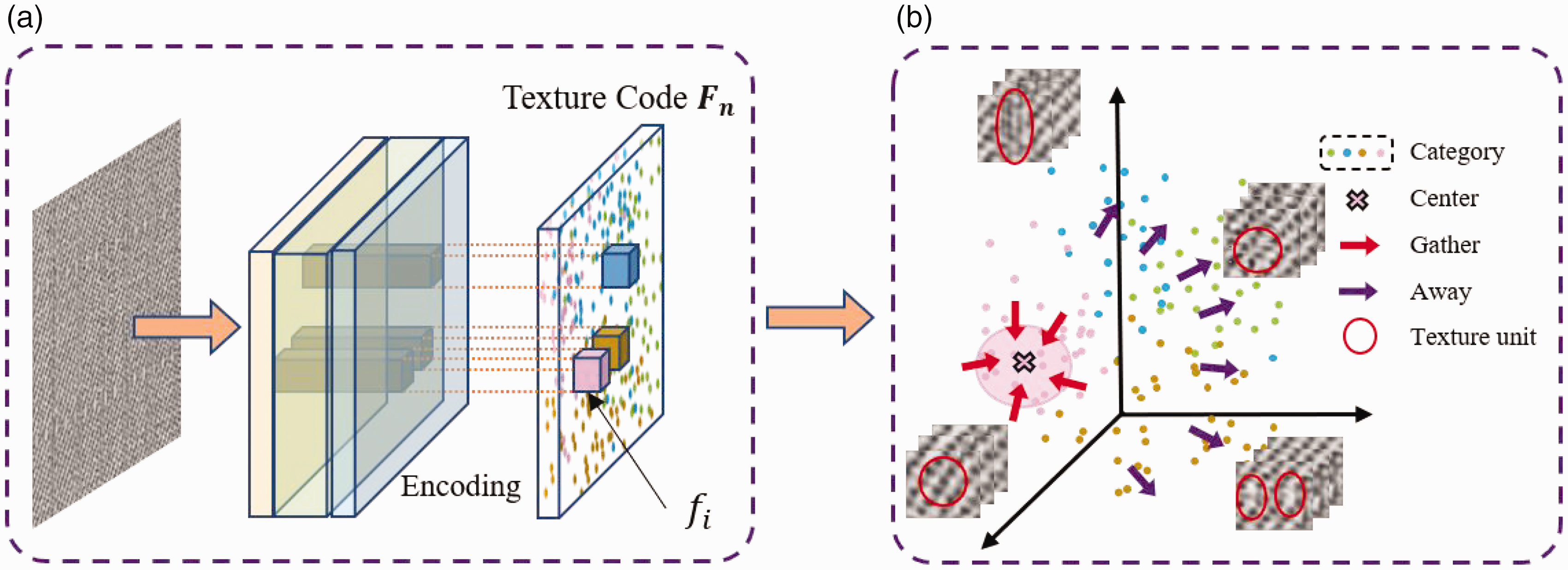
Schematic diagram of the texture reconstruction branch. Textures of the same class are close to each other, and textures of different classes are far away from each other.
Standard texture images are characterized by basic microstructures, herein referred to as ‘textures.' As illustrated in the Figure 4, the texture code feature vector
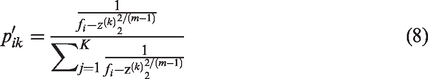


Semantic localization branch
In textile defect detection, most existing methods primarily focus on the reconstruction of defects based on texture features. However, some samples may need clearer texture information due to limited industrial sampling conditions. In addition, interference from noise points can easily lead to false detections in the reconstructed images, directly impacting the defect detection’s precision. In this study, we propose a SLB that includes a channel attention module (CAM) and a SAFM. This branch aims to localize textile defects based on semantic information accurately.
Channel attention module
High-level features possess rich semantic information, with each channel mapping considered a class-specific response. These responses affect the final semantic prediction to varying degrees. We improve the CAM based on the Convolutional Block Attention Module (CBAM).24 CBAM is an attention mechanism module that combines both spatial and channel attention mechanisms. Our enhanced approach selectively emphasizes the importance of defect information in optimally locating defect locations. Firstly, it obtains the global average information and global maximum information, which characterize the base texture information and defect information, respectively. On this basis, the absolute value of their difference is weighted to
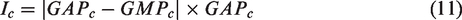

Self-attention fusion module
High-dimensional feature maps contain semantically rich information but may lose some fine-grained details, while low-dimensional feature maps have a higher resolution. Combining features from different layers is crucial for predicting semantic information. However, effective alignment of different feature maps can be challenging due to the complex texture structure. To address this limitation, we propose the SAFM, which computes the correlation between pixels in different feature maps using matrix multiplication, and uses the correlation as a weight vector for low-dimensional features. This approach fuses rich semantic information from a higher-dimensional perspective into the low-dimensional features, enhancing their ability to discriminate defects.
As illustrated in Figure 5, the SAFM receives information from two dimensions. One is the feature map

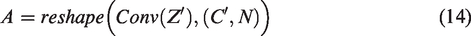
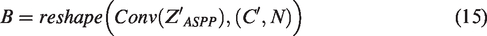
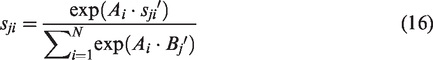


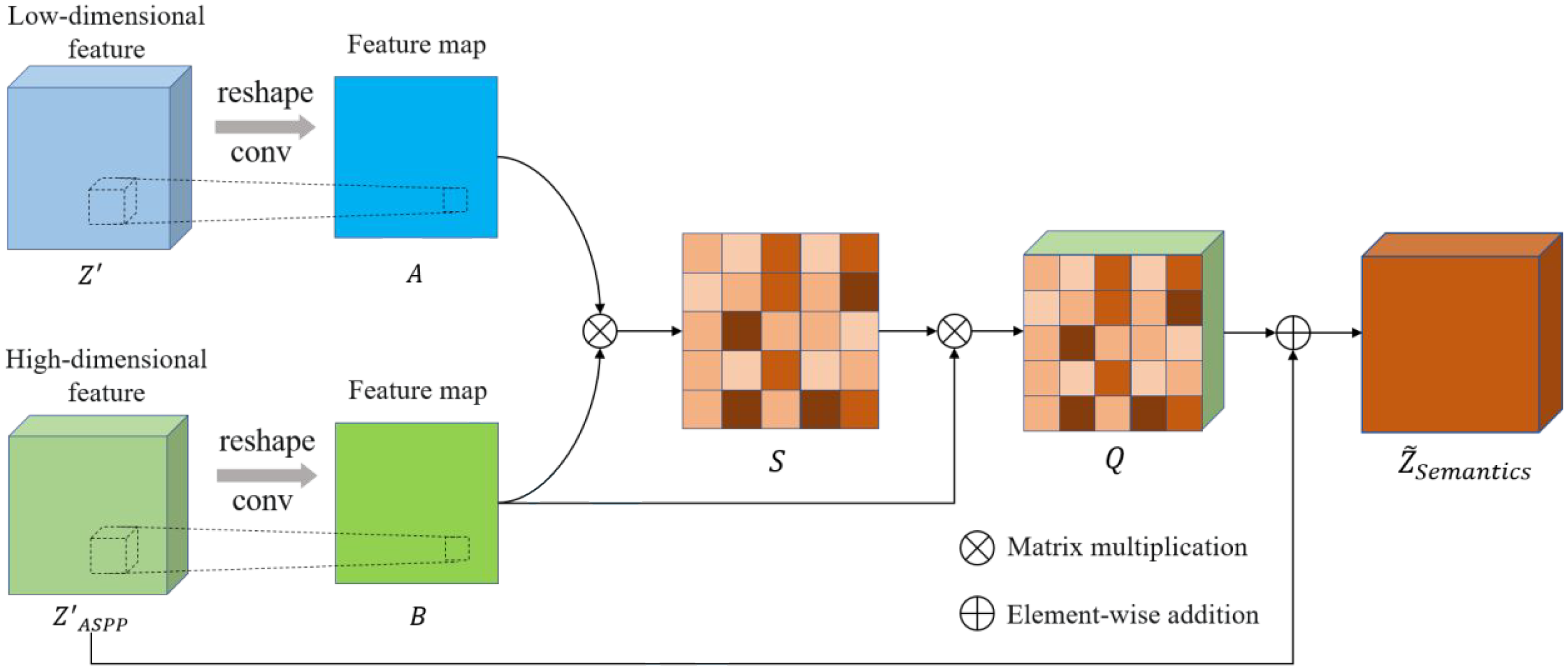
Schematic diagram of the self-attention fusion module structure.
Feature fusion module
To maximize the utilization of texture and semantic information, we propose an innovative FFM. This module integrates the dimensionality-reduced multi-scale images from separate branches, thus capturing information across diverse abstraction levels while mitigating the risk of overfitting. It employs a unique AND operation to integrate the defect detection results from these branches, culminating in a comprehensive final detection outcome.
The FDN reconstructs the feature maps
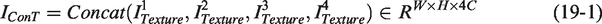

A 1 × 1 convolution is applied to reduce the dimensionality to 1:
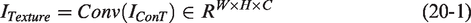
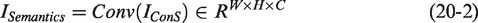
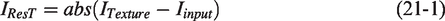
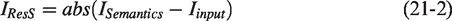
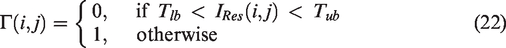




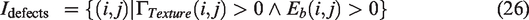
Model training strategy
To accurately reconstruct texture background images, stably represent complex texture units, and maximize the utilization of defect information, we propose a novel and effective loss function composed of a background reconstruction loss and a weighted centering loss at multiple scales to train TSUBB-Net. The background reconstruction loss aims to minimize the gap between the background reconstruction image and the original input image, enabling TSUBB-Net to fully learn the global and local information of the positive fabric samples. We employ the mean squared error as the metric for training:
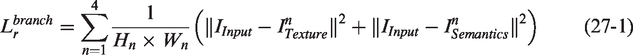
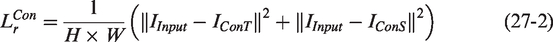



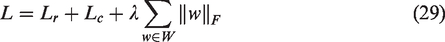
As the background reconstruction loss and the weighted centering loss of TSUBB-Net represent opposite optimization directions, TSUBB-Net adopts a two-stage optimization strategy. Firstly, the part model of the feature clustering module in TSUBB-Net is executed, which enables the model to have the ability to express image features. Then, standard k-means clustering is performed in the feature space to obtain
Experimental evaluation and discussion
Datasets and evaluation metrics
Dataset overview
In this study, as depicted in Figure 6(a), the process of raw textile image acquisition is implemented utilizing a charge-coupled device (CCD) camera. Some of the images are captured under varied illumination conditions, providing alterations in scale, orientation, and lighting, with the intricate interplay of complex pattern textures proving quite distinct from each other. It yields a challenging defect detection dataset that aligns with real-time samples in industrial production. The textile defect segmentation image dataset (DHU-DS1100) encompasses a range of defect-free (normal) and five types of defective samples (broken picks, holes, stains, cracks, and felters). Some representative samples, both normal and defective, are illustrated in Figure 6(b).

(a) The charge-coupled device camera utilized for fabric defect detection and (b) Normal and defective samples collected by the test bench.
The DHU-DS1100 dataset is composed of 1100 samples, inclusive of 1000 defective images (with 200 images per defect type) and 100 defect-free textile images. For the sake of convenient processing, all images have been standardized to a resolution of 224 × 224. Subsequent experimentation involved validation of our model against this database, serving the dual purpose of evaluating both its robustness and accuracy.
Evaluation metrics
To evaluate the effectiveness of the TSUBB-Net model, several multi-label metrics are selected. We use the criteria of


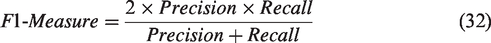
Comparing TSUBB-Net with the state-of-the-art models
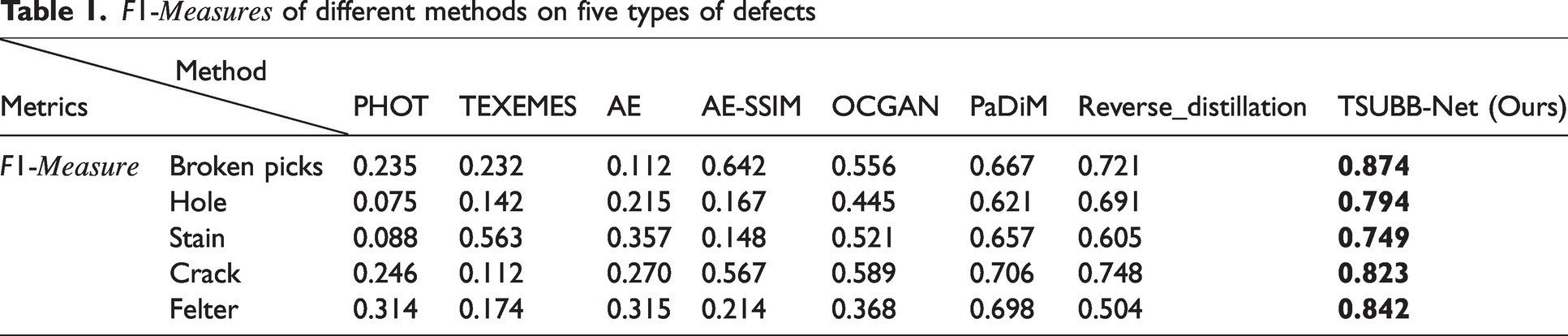
To verify the performance of the proposed TSUBB-Net method, a comparative analysis was conducted against an array of existing detection techniques, which included conventional methods such as PHOT 26 and TEXEMS, 27 and unsupervised methods including the AE, 28 AE-SSIM, 29 OCGAN, 30 PaDiM, 30 and Reverse_distillation. 32 The evaluation benchmark chosen was the DHU-DS1100 dataset, with the TSUBB-Net model being trained on merely 100 non-defective samples derived from industrial real-world scenarios, subsequently tested on the dataset.
Our experiments highlight the varying performance of different methods when processing five texture samples. Conventional approaches, such as PHOT and TEXEMS, struggle to handle intricate textile textures, relying on pre-determined feature sets, which limits their adaptability to unknown or complex texture surfaces, as shown in Figure 7(e). The AE, a deep learning-based approach, excels at learning texture representations through convolution operations but struggles under high-noise environments with intricate defect boundaries, as evidenced in Figures 7(a)–(d). AE-SSIM augments the AE with the structural similarity index (SSIM) to assess image quality, rather than detect defects accurately, especially in situations where defects exhibit similar textures to normal samples, as evidenced in Figures 7(a) and (d). OCGAN, an unsupervised method for learning the distribution of normal samples to detect defects, may require extensive computational resources and struggles with processing interconnected defects that deviate from the original distribution, as seen in Figures 7(a) and (c). PaDiM identifies regions that encapsulate normal data samples and eliminates anomalous samples rather than directly detecting defects, leading to misclassifications of normal samples as defective in situations where defect textures subtly intertwine with normal textures, as illustrated in Figures 7(b) and (e). Reverse_distillation generates training samples through inverse distillation, which could compromise the integrity of the original texture and structural information, ultimately introducing erroneous data during model learning, as exemplified in Figure 7(e).

Examples of the defect inspection performances of the compared methods: (a) Broken pick. (b) Hole. (c) Stains. (d) Cracks. (e) Felters.
In contrast to the above methods, our proposed TSUBB-Net outperforms existing methods in detecting surface defects across diverse textures. On average, TSUBB-Net enhances 0.098%
TSUBB-Net ablation experiment
In this section, we argue that the TRB and the SLB incorporated into the proposed TSUBB-Net model enhance both the completeness and precision of textile defect detection.
Texture reconstruction branch
The TRB is developed to acquire a stable representation of texture units in a high-dimensional feature space. This is achieved through a texture reconstruction-based clustering approach, where each class of textures in z space is treated as a texture unit cluster and assigned to the nearest center cluster. As depicted in the second row of Figure 8, in the absence of the TRB, latent features become entangled. However, the presence of the TRB results in the scattering of texture units from different classes and the condensing of similar texture units, as shown in the third row of Figure 8. In experiments comparing models with and without the TRB, TSUBB-Net demonstrates improved

Influence of clustering in the texture reconstruction branch. (a)–(f) represent different types of defects. The first line represents the original image, the second line represents the distribution of texture units before clustering, and the third line represents the distribution of texture units after the clustering module.
Component analysis for the TSUBB-Net on the DHU-DS1100
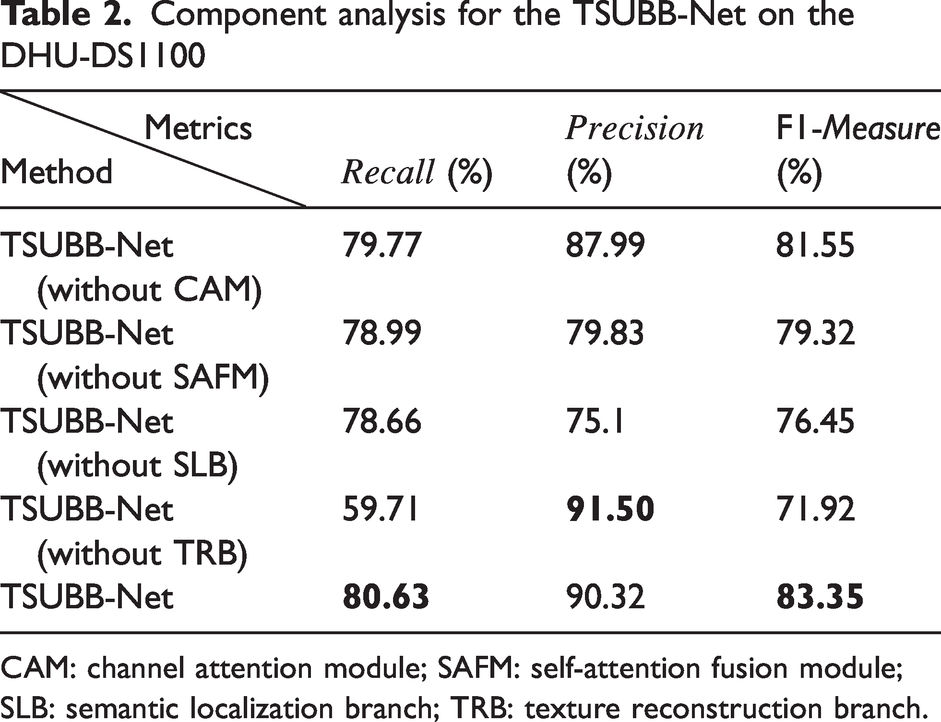
CAM: channel attention module; SAFM: self-attention fusion module; SLB: semantic localization branch; TRB: texture reconstruction branch.
Semantic localization branch
Existing methods for textile defect detection rely on texture feature-based defect reconstruction, which can be prone to misidentification due to interference from noise points. The SLB is developed to locate textile defects with greater precision based on semantic information. Two essential modules underpin the SLB's success: the SAFM and the CAM.
The SAFM module serves to efficiently fuse and align high- and low-dimensional features, thereby enhancing the system's capacity to accurately detect defects. When the SAFM is omitted, performance metrics indicate a noticeable decrease of around 1.64%, 10.49%, and 4.03%, as shown in Table 2, underlining the vital role the SAFM plays in optimizing defect detection. The CAM module, on the other hand, is crucial in foregrounding semantically rich defect information while suppressing less relevant data, leading to more precise defect detection and localization. Without the CAM, performance metrics dip by approximately 0.86%, 2.33% and 1.8%, further emphasizing the importance of the CAM in bolstering the model's performance.
Experimental results illustrate that both the SAFM and the CAM significantly contribute to the efficacy of the SLB. When these modules are incorporated, the TSUBB-Net sees substantial improvements in

Effect of semantic localization branch (SLB) defect localization. The first line indicates the original image, and the second line indicates the defect location of SLB positioning.
Feature fusion module
The FFM in our proposed model optimizes the usage of texture and semantic information, yielding superior defect detection results. While the TRB effectively exhibits defect information post texture reconstruction, as shown in Figure 10(b), it also exhibits a higher false detection rate due to the intricate textures inherent in industrial samples, leading to a lower

Influence of the feature fusion module (FFM) in TSUBB-Net: (a) original input image; (b) defect map detected by the texture reconstruction branch; (c) defect map detected by the semantic localization branch and (d) final defect map after the FFM.
The combination of texture and semantic data serves to compensate for the individual limitations of the TRB and SLB. When these branches operate in isolation, either noise is misinterpreted as defects (in the case of the TRB) or the complete shape information of defects is lost (in the case of the SLB). However, when texture and semantic information are amalgamated via the FFM, a significant increase in
Analysis and discussion
Selection of the
value
Within the framework of the TRB, the number of clusters
Background reconstruction validation
To accurately assess background reconstruction, we utilized mean absolute error (MAE) and SSIM metrics. The former provides an indication of image accuracy, while the latter evaluates visual quality. Our results demonstrated that lower and higher
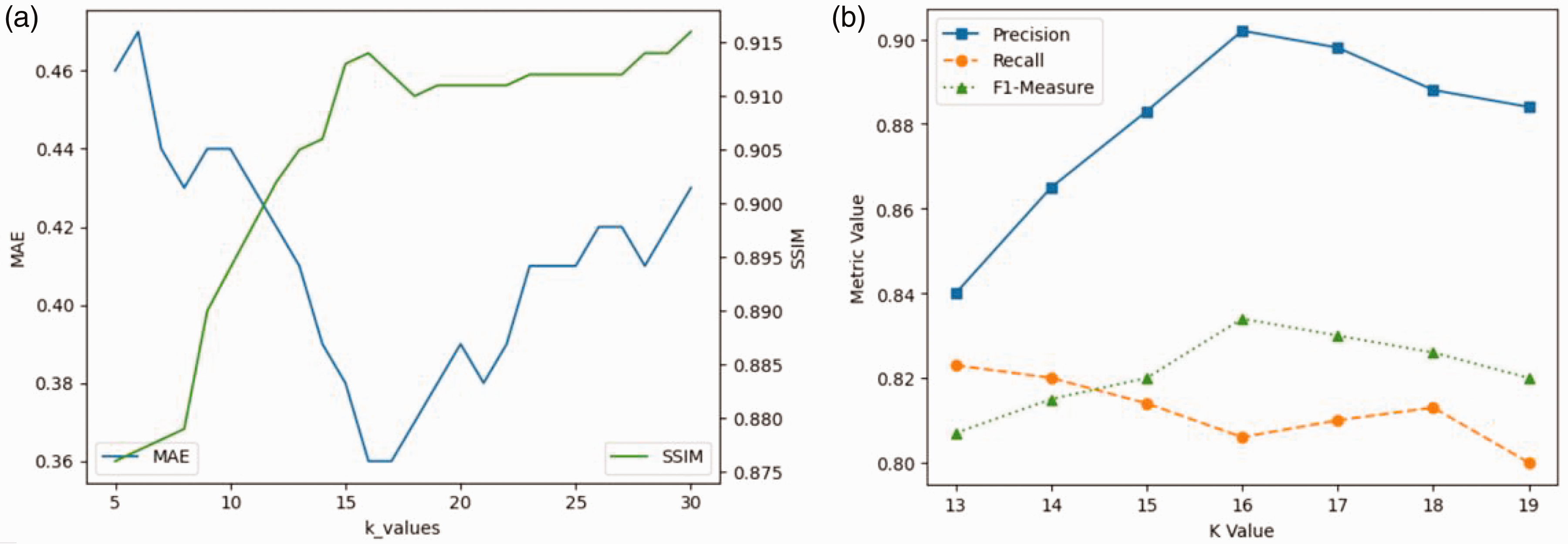
Influence of the number of clusters
Inspection verification
The selection of the ideal cluster number
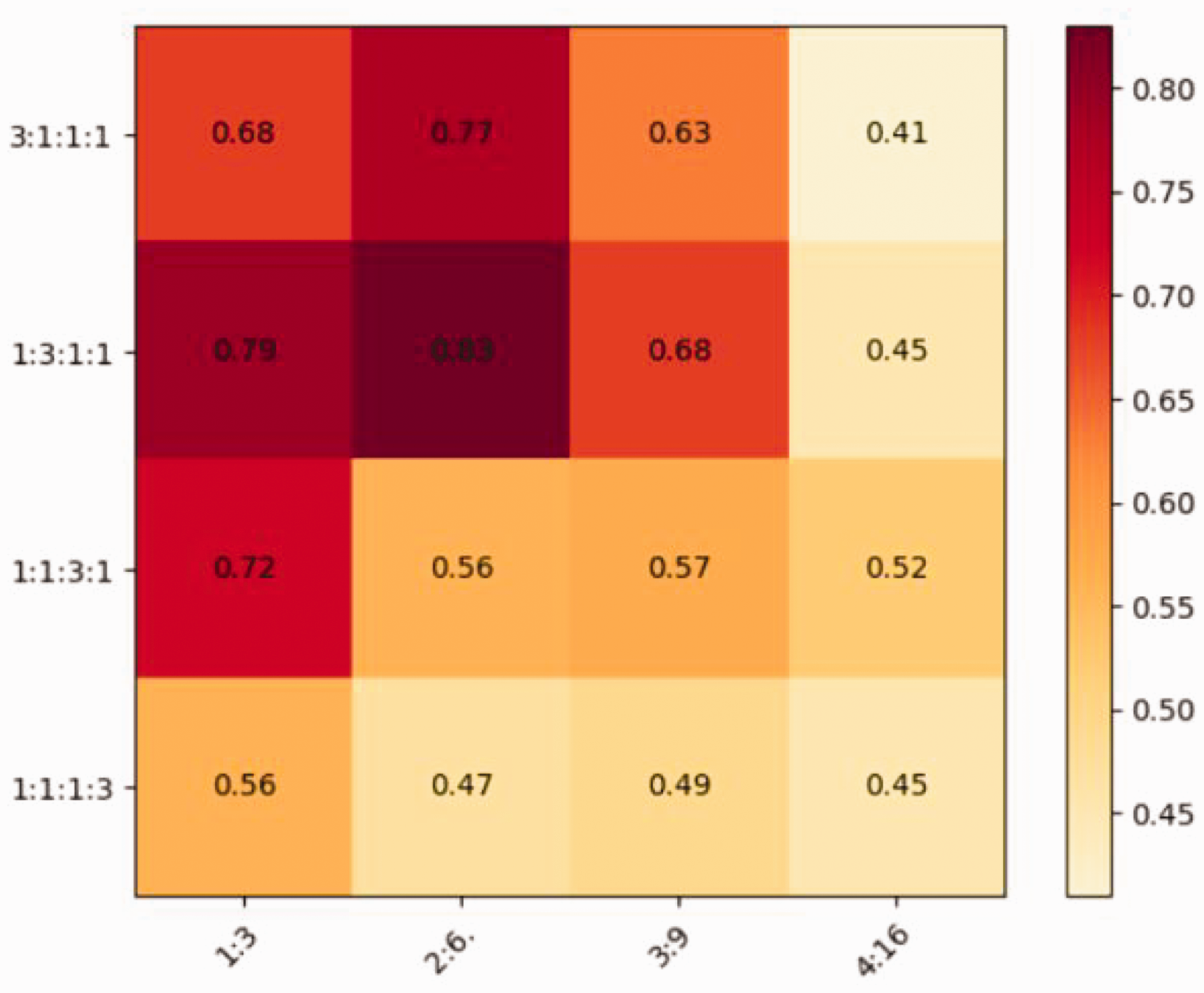
FEN and FDN ratio settings
The FEN and FDN play a critical role in representing feature information of textile images, where they are employed to extract feature maps with four levels of receptive fields directly from the entire input image, thereby maximizing the representation of internal information. The stacked block ratio and specific number in the FEN and FDN determine the quality of texture background reconstruction. Our experiments with ConvNeXt,
23
a model with a 1:1:3:1 stacked block ratio, serve as a baseline for comparison. We vary the ratios to 3:1:1:1, 1:3:1:1, 1:1:3:1, and 1:1:1:3 to optimize model performance. We assess

Defect maps at various scales: (a) original input image; (b)–(e) defect maps across different scales and (f) final defect map.
Conclusions and future work
In this paper, we propose a novel bilateral-branch network structure, known as TSUBB-Net, which efficiently amalgamates texture and semantic information. This is intended to handle the diverse and complex irregular texture structures inherent in textile images, while mitigating the influence of image acquisition quality on defect recognition. Our model resourcefully employs multiple TSUBB-Net subnetworks of varying scale levels to reconstruct the background image. Each layer undergoes clustering of texture units in the bilateral-branch network and integrates context-semantic information to maximize the utilization of textile feature information. Experimental results show that the TSUBB-Net framework can achieve the best performance compared to the current state-of-the-art methods. Within the purview of this research, we observe that TSUBB-Net encounters difficulties in extracting defect information from elongated textures, a factor that curtails its efficacy. Addressing this limitation will be a focus of our future research.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Shanghai Sailing Program (no. 22YF1401300), Cultivation Project of Discipline Innovation (XKCX202313), the Fundamental Research Funds for the Central Universities (2232021D-32,2232021A-10), National Natural Science Foundation of China (nos. 61806051, 61903078).