
Abstract
Reliability of a system defines the likelihood that a system would operate as expected for a predefined length of time. There have been numerous notable efforts to model systems with the goal of analyzing their reliability and possibly quantifying it. Simulation as a technique has shown a great capacity to address the challenge of quantitatively evaluating system’s reliability. Traditionally, expert knowledge has been the gold standard for modeling and analyzing system reliability. However, the prevalence of data that stems from systems of interest, enabled through the easily available Internet of Things devices, coupled with simulation, presents a potential to change the way reliability of systems is being evaluated. Namely, data provides an opportunity for both automated modeling and continuous reliability assessment of systems through simulation. This article presents an overview of reliability modeling and simulation for cyber-physical systems, highlighting opportunities arising from data availability and its integration with expert knowledge. We use case studies from our research to illustrate these opportunities and advancements.
1. Introduction
Reliability is a fundamental metric that quantifies the likelihood of a system performing its intended function over a specified period of time, i.e., the likelihood that the system fails after a specified point in time. Reliability holds significant importance, particularly in safety-critical systems, as it closely relates to the overall safety. Although an unreliable system may not automatically be deemed unsafe, an unsafe system is inherently unreliable. The reason for this distinction lies in the fact that not all system faults pose a risk to human safety. In a formal sense, reliability is typically quantified using the following definition or formula:
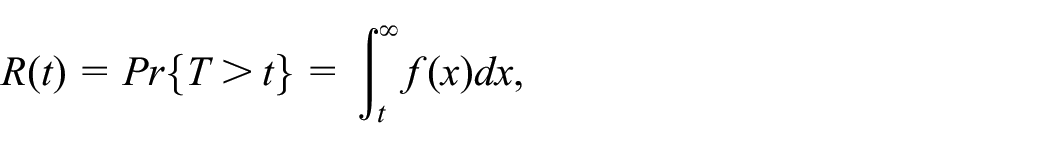
where
Modeling and simulation (M&S) have long been used to study the behaviors of systems. In particular, M&S enable evaluation of different scenarios for their impact on the overall reliability of a system.4,5 Using simulation with appropriate reliability-centered models, we can explore how various operational conditions, changes in system configurations, repair and maintenance strategies, or new components impact system performance and reliability. This analysis helps in identifying potential vulnerabilities, components of high importance, beneficial repair and maintenance strategies, thus, supporting decisions to improve system’s reliability.
This article provides an overview of reliability M&S for cyber-physical systems (CPS), highlighting the opportunities created by the availability of extensive data and the integration of expert knowledge with data-driven techniques. In this context, we also present case studies from our research to illustrate these developments and suggest potential future directions.
The rest of the case is structured as follows: In Section 2, we provide background on reliability M&S and an overview of the related state of the art. Section 3 describes emerging trends in Reliability M&S, followed by the presentation of the two corresponding case studies in Section 4. Finally, a summary and outlook of the paper are provided in Section 5.
2. Background and state of the art
Reliability M&S are fundamental techniques used for assessment and enhancement of the performance and dependability of complex systems. In today’s interconnected and technology-driven world with ever-increasing complexity of systems, ensuring reliability of systems and components is a paramount concern across diverse industries, including aerospace, automotive, telecommunications, and manufacturing. Reliability M&S provide valuable tools for comprehending, predicting, and optimizing the reliability characteristics of these systems.
Reliability modeling encompasses the development of models that capture behaviors, failure patterns, performance attributes, and their interdependencies of systems or components. Reliability models enable engineers and researchers to analyze systems’ reliability and availability, estimate failure rates, and identify critical areas for improvement. However, the quantitative assessment can be greatly supported by simulation, which enables execution of these models to study their behaviors under different assumptions. By simulating the operation and behavior of a system over time, reliability simulation allows for the evaluation of different scenarios, identification of vulnerabilities, and optimization of maintenance and repair strategies. Furthermore, simulation enables introduction of different types of uncertainties in an algorithmic manner as opposed to only mathematical, thereby facilitating more realistic models and assessments.
A key advantage of reliability M&S lies in its ability to address complex systems where analytical solutions may be challenging or impractical. With advancements in computational power and modeling techniques, it has become feasible to model and simulate intricate systems with a high degree of accuracy and fidelity. In addition, the integration of data-driven approaches and Digital Twins has further enhanced the capabilities of reliability M&S by incorporating real-time data and capturing the dynamic behavior of systems in operation.6,7
In the following, we provide an overview of the most significant Reliability M&S approaches, followed by an overview of the three main aspects of reliability adhering to CPS.
2.1. Reliability M&S
M&S provide valuable tools for evaluating the performance and reliability of complex systems. Some significant examples of how M&S have been applied for reliability analysis are described as follows.
One of the most popular and most used simulation paradigms for reliability M&S is Discrete-Event Simulation (DES). In systems, the interactions between physical processes and computational elements introduce complexities that can affect system reliability. DES allows modeling of these interactions in a discrete manner, capturing events, such as component failures and repairs, that occur at specific points in time. These events are then captured in the models that represent reliability-relevant systems’ behaviors. Through the calculation of reliability metrics, such as mean time to failure (MTTF) and availability, DES facilitates the quantitative evaluation of system’s reliability.
In the work by Ram, 8 an extensive overview of the recent research in M&S for reliability engineering is provided. The book covers topics, such as the performance evaluation of complex engineering systems, the modeling of non-exponential distributions in reliability analysis, optimal software rejuvenation policies, multivariate analysis for reliability modeling, and more. The book, furthermore, provides insights and case studies to bridge the gap in knowledge pertaining to engineering applications.
Another example of using DES for reliability evaluation is the RAMSAS (Reliability Analysis by Modeling and Simulation) method, which is a model-based approach for system reliability analysis. 9 This method can be integrated into various phases of the system development process, complementing other well-known techniques, such as Failure Modes, Effects, and Criticality Analysis (FMECA), Fault Tree Analysis (FTA), and Reliability Block Diagram (RBD). RAMSAS has been applied in different application domains, including avionics, automotive, and satellite systems,10,11 to improve modeling of both intended and dysfunctional system behaviors.
More specifically and more recently, Chiacchio et al. 12 introduced a simulation framework called Stochastic Hybrid Fault Tree Automaton (SHyFTA) for designing and analyzing dynamic reliability problems in real industrial applications. SHyFTA combines deterministic and stochastic models using shared variables, particularly using Dynamic Fault Trees (DFT) for modeling complex dependable systems. Furthermore, Pourhassan et al. 13 propose a simulation-based approach for generalized reliability assessment. The proposed model accommodates stochastic degradation processes and randomly occurring shocks across two-state, multistate, and continuous degradation scenarios, with customizable time to failure distributions and shock densities. Two case studies in a sugar plant and an example from literature demonstrate the model’s validity and applicability.
2.2. Three aspects of reliability in CPS
CPS, being complex systems, consist of multiple interconnected aspects, influenced by external factors. Numerous potential issues can arise, each associated with the different aspects of CPS and having their own distinct nature. Three key aspects, namely hardware, software, and human interaction, significantly impact the reliability of a CPS. Despite their distinctiveness, it is crucial to consider all these aspects collectively since they exert mutual influence on one another. It is worth noting that these aspects are essential for understanding the system’s reliability, but they do not encompass all the factors relevant to reliability that is often intertwined with security and safety. In the following, we provide a brief overview of hardware, software, and human reliability in CPS, exemplifying on the successful use of M&S for each reliability aspect. For a more in-depth overview of the concrete models and methodologies being used for reliability assessment for each of these three aspects, we refer the reader to our extensive review article. 14
In hardware reliability, diverse modeling approaches are employed to evaluate and predict the performance and dependability of hardware components and systems. These modeling techniques aid in understanding failure mechanisms, analyzing failure probabilities, and designing robust hardware. To analyze the interconnectedness of faults in components and systems that may result in system failure, Fault Trees (FTs)15–17 can be employed. Other common modeling approaches in hardware reliability encompass Failure Modes and Effects Analysis (FMEA), which systematically identifies and prioritizes potential failure modes; 18 RBD, a graphical method representing complex system reliability; 19 Markov Models, useful for analyzing system reliability and availability; 20 DES, which models uncertainty and variability; 21 Physics of Failure (PoF) Models, employing physics-based principles to understand failure mechanisms; 22 Dynamic Reliability Models, accounting for changes in system states and interactions over time; 23 and the emerging use of Artificial Intelligence and Machine Learning techniques for data-driven decision-making in hardware reliability.24,25 By integrating these modeling approaches, a comprehensive understanding of hardware reliability is achieved, enabling robust design and maintenance decisions.
In the context of hardware reliability assessment, various simulation methodologies have been used extensively. For example, DES has been used to evaluate FTs 16 and RBDs. 19 Monte Carlo simulation is used in the work by Ruijters and Stoelinga 17 to evaluate FTs and in the work by Distefano and Xing 26 to evaluate RBDs. Finally, Lazarova-Molnar et al. 15 use proxel-based simulation 27 to determine the instantaneous availability of basic FT components and the entire system.
Hence, to enhance the reliability of software, it is crucial to prioritize it right from the initial stages of development, including the requirements specification phase. The sooner reliability is incorporated, the greater its potential. Common practices employed to enhance software reliability encompass processes, such as debugging, early error detection, swift recovery, dynamic and static analysis, and evolution.
Compared with hardware reliability, software reliability is also linked to many unquantifiable factors, such as programmers’ skills or software project management skills. In the case of hardware, the skills of workers that build the hardware also matter, so the design aspect is common for both hardware and software. However, in software, there is no wear out. Therefore, most of the reliability in software is tackled through certifications and quality assurance methods, 29 and there is very little in terms of widely accepted software reliability assessment methods. One such attempt is presented in the work by Shi et al. 29 where the authors propose systematic software reliability prediction approach based on software metrics.
Various approaches have considered and successfully used simulation for software reliability assessment. For instance, Tausworthe and Lyu 30 discuss several simulation approaches for evaluating software reliability. In a study by Gokhale and Lyu, 31 simulation procedures are developed to assess the influence of individual components on application reliability in the context of fault detection and repair strategies. Finally, Gokhale et al. 32 use DES to model the failure behavior of a terminating application, considering both instantaneous and explicit repair scenarios.
As far as approaches to include human uncertainty in the overall reliability assessment of CPS, the efforts are not plentiful. In one of them, Bessani et al. 35 present a model to include operator’s responsiveness together with machines’ faults and failures to evaluate the reliability of a system. Furthermore, Fan et al. 36 present a platform and associated methodology to effectively generate accident scenarios by modeling human–machine interaction errors using model-level fault injection, followed by simulation to produce dynamic evolutions of accident scenarios. These are notable efforts toward providing accurate and holistic, and therefore useful, reliability measures of CPS. In that context, Bolton et al. 37 recently introduced a novel method for generating human errors based on the task-based taxonomy of erroneous human behavior. In this case, the authors show how the method can be used with formal system modeling and formal verification with model checking to prove whether or not potentially unanticipated erroneous behavior could contribute to system failures.
Further notable recent attempts of addressing human behavior in the context of reliability of CPS have been presented in literature.38–40 These efforts address critical aspects of system reliability and safety in different domains. Che et al. 38 focus on load-sharing man–machine systems and analyze the impact of machine degradation, human errors, and random shocks on system reliability. Che et al. 40 introduce an FT-based approach for aviation risk analysis, with a specific emphasis on mental workload overload, proposing safety recommendations to enhance aviation system dependability. Although Zheng et al. 39 introduce Systems Analysis for Formal Pharmaceutical Human Reliability (SAFPH), a next-generation human reliability analysis tailored for the pharmaceutical industry, which aims to comprehensively understand human actions and decision-making in pharmaceutical processes to improve safety and reliability. These research efforts contribute valuable insights into their respective fields, and offer methods and strategies to address human and technical factors influencing system dependability.
Several researchers employ simulation for human reliability assessment. For instance, Angelopoulou et al. 41 introduce a human reliability assessment simulation model that accounts for performance shaping factors influencing human work within complex Industry 4.0 systems. Another approach, presented by, Musharraf et al. 42 uses a Bayesian method to improve human reliability assessment by leveraging data generated in a simulator. In addition, an extensive overview of simulation approaches to human reliability assessment is presented in the work by Boring. 43
3. Emerging trends in reliability M&S
Evaluation of systems has undergone a significant transformation with the increasing availability of data. This transformation has been particularly accelerated by the development of the Internet of Things (IoT), which not only provides new opportunities for analyzing system reliability but also allows for the validation of existing approaches. Traditionally, reliability analysis heavily relied on expert knowledge, and this remains essential, especially for safety-critical systems, where the occurrence of faults can have catastrophic consequences. One prominent example that requires extensive expert knowledge is the design of FTs for aviation system reliability, as highlighted in the work by Netjasov and Janic. 44
It is, however, important to note that a considerable portion of systems used in manufacturing and other domains is not safety-critical. In these cases, the impact of faults and failures is primarily measured in terms of financial costs rather than posing risks to individuals or the environment.
Overall, while expert knowledge continues to play a vital role in ensuring system reliability, advancements in the IoT have opened up new possibilities for analyzing and validating reliability approaches. This is particularly relevant in non-safety-critical manufacturing systems, where the focus shifts toward minimizing financial implications resulting from faults and failures. The availability of data has indeed become a game changer in system evaluation, shaping the way we approach and improve system reliability.
In the following, we elaborate two emerging advancements in the reliability M&S. Namely, we first introduce the concept of data-driven reliability modeling, followed by the approach to combine and enhance data-driven models with expert knowledge in a systematic way. For both advancements, in the subsequent section, we provide illustrative case studies.
3.1. Data-driven reliability modeling
The conventional approach to reliability modeling, which heavily depends on expert knowledge, exhibits various limitations. As systems grow in complexity, it becomes increasingly challenging to maintain them effectively and identify vulnerabilities that can impact their reliability. In addition, a rising number and variety of failures add further complexity to the systems. Expert knowledge, while invaluable, can become a bottleneck as systems become increasingly complex. 6
Another shortcoming of conventional reliability modeling is the static nature of the models, which fail to account for changes in a system over time. As physical systems undergo modifications, manually developed models can quickly become outdated and require updating. This manual model updating process becomes labor-intensive and tedious, particularly in systems where frequent changes in system topology and configuration occur.
Finally, conventional reliability models are typically developed for a specific system and its particular configuration. As a result, these models do not generalize well to other systems, limiting their applicability beyond the specific context for which they were developed.
Considering the challenges and limitations regarding conventional reliability modeling, it is crucial to address these issues by adopting an approach that involves dynamically generating accurate reliability models for systems characterized by high complexity. This need is particularly significant when it comes to short-term decision-making processes, where up-to-date and accurate models are essential for informed and effective decision-making. 45
Data-driven reliability modeling addresses this need by leveraging real-world data collected from the operation of a system. Compared to conventional modeling approaches, data-driven reliability modeling offers several advantages. It facilitates a more accurate representation of real-world system behavior, as it takes into account the variability and complexity that may not be captured by manually developed models. Moreover, data-driven models can adapt and learn from new data, enabling continuous improvement and updating of reliability assessments as more data become available.
The availability and ease of collecting data is the key driver behind the development of data-driven reliability modeling techniques. Recent advancements in the context of Industry 4.0 have facilitated the effective gathering of data through the use of IoT devices. These data play a crucial role in supplementing expert knowledge and constructing more accurate reliability models. 6 Various types of data can be collected and used in data-driven reliability modeling, including the following:
To fully harness the potential of the collected data, the development of new and sophisticated approaches to extract insights from them that is relevant for reliability modeling is essential. For example, sensor data are typically collected in the form of time series without explicitly capturing fault occurrences. Consequently, there is a need for approaches that prioritize event detection, enabling the extraction of fault occurrences and other relevant events from the time series data. Moreover, the development of accurate root cause analysis methodologies becomes crucial to extract event dependencies and model them effectively. 46
Figure 1 illustrates the feedback loop that can be facilitated through data-driven reliability assessment, where model generation is the key component. Based on a system of interest, data such as event data, sensor data, operational data and contextual data are collected. It is important to note that data-driven reliability modeling is particularly suitable for systems that are not safety-critical, as the collection of data in such scenarios is safe and feasible. In safety-critical systems, collecting data for reliability analysis would be impractical due to the potential risks to human lives associated with failures.
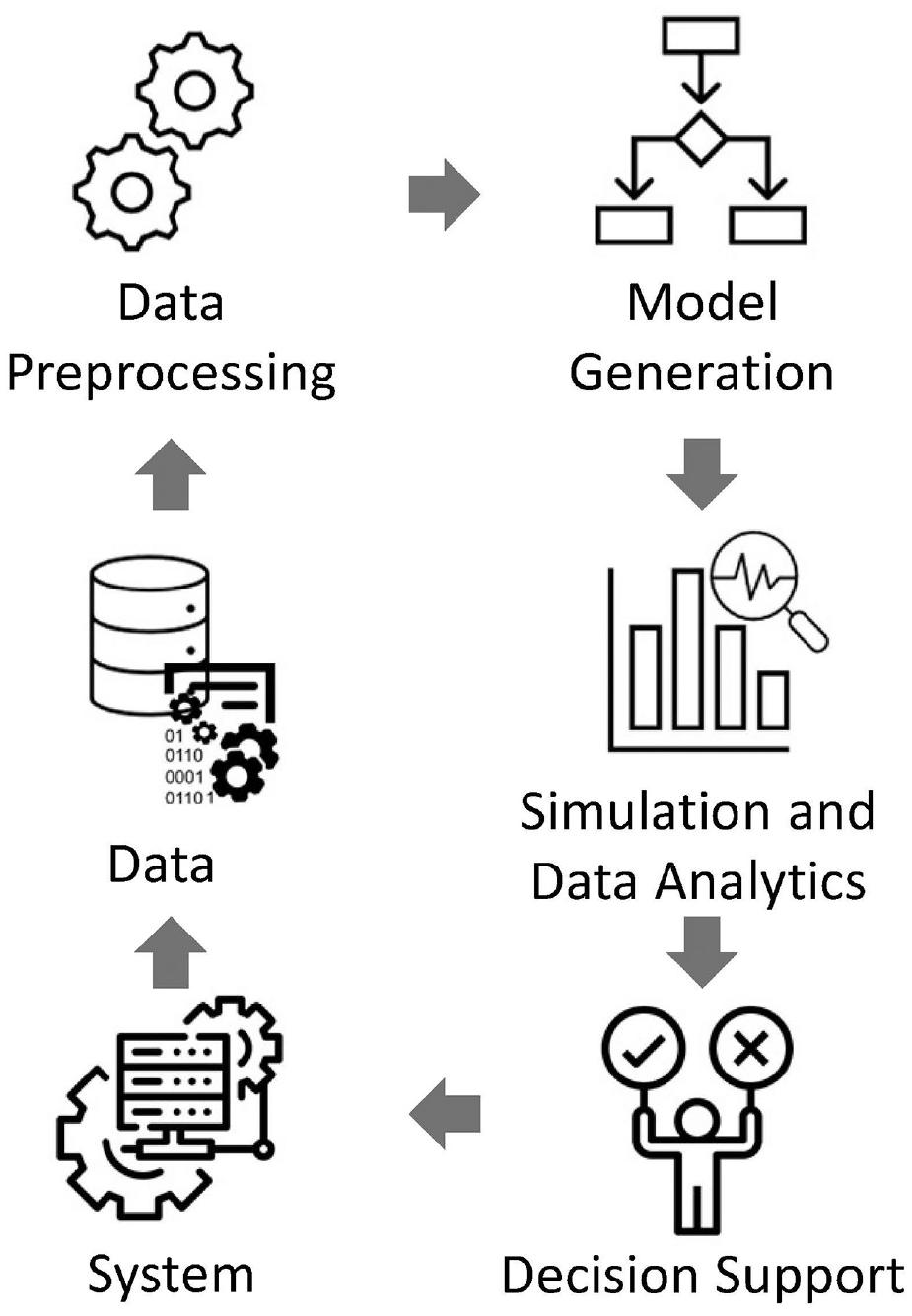
Data-driven reliability assessment process (adapted from the work by Lazarova-Molnar and Mohamed 46 ).
Once collected, the data undergo preprocessing to ensure its usability for data-driven reliability modeling. This preprocessing phase involves tasks, such as event detection in sensor data and transforming the data into a format suitable for model generation methods. Next, the preprocessed data are used to generate reliability models. Once a reliability model is derived, simulation and data analytics techniques are used to support decision-making processes. These decisions may regard, for example, system configuration, purchasing decisions, or maintenance scheduling.
Several contributions propose methods for data-driven reliability modeling. For example, Lu et al. 47 propose a Bayesian approach to model the reliability of manufacturing systems based on data. Alsina et al. 25 use machine learning techniques and manufacturing component data to predict reliabilities. Zou et al. 48 introduce a novel data-driven stochastic manufacturing reliability model that captures production dynamics and identifies the causes of persistent production failures in both deterministic and stochastic scenarios. Lugaresi and Matta 49 employ Process Mining for automated manufacturing system discovery and digital twin generation. In our work, Friederich and Lazarova-Molnar, 50 we propose an approach for data-driven reliability modeling of smart manufacturing systems using Process Mining and stochastic Petri nets (SPNs). In addition, in another contribution, 15 we present an approach for data-driven FTA based on time series data of a system.
In summary, data-driven reliability modeling is a promising research direction for addressing the limitations of conventional approaches using real-world data, facilitating accurate modeling, and supporting informed decision-making in complex systems.
3.2. Fusing data and expert knowledge for reliability model extraction
Disregarding the cognitive abilities and expert knowledge of humans results in significant information loss, which can only be partially offset by the expensive endeavor of collecting extensive data. However, advancements in system designs, data collection technologies, blockchain-based data storage, and access frameworks have rendered the reliance solely on expert knowledge for model building obsolete.
Combining expert knowledge with data has been a common practice in fields such as machine learning, artificial intelligence, and decision-making. The goal is to leverage the expertise of domain specialists or subject matter experts along with the information contained in data to improve the quality and accuracy of predictions, models, or decision-making processes.
One common approach to combining expert knowledge with data is through the use of expert systems or knowledge-based systems.51–53 These systems integrate expert knowledge, typically represented as a set of rules or a knowledge base, with data-driven techniques to solve complex problems. Expert systems have been used in diverse domains, such as medicine, 54 finance, 55 and engineering, 56 to assist with diagnosis, decision-making, and prediction tasks.
Another approach is Bayesian statistics, which allows for the incorporation of prior knowledge or beliefs into the analysis of data.57,58 Bayesian methods provide a framework for updating prior beliefs using observed data to obtain posterior beliefs. By combining prior knowledge with data, Bayesian inference can yield more accurate estimates and predictions.
Recent advancements in machine learning, such as deep learning and neural networks, have also explored ways to incorporate expert knowledge into data-driven models. One common approach is transfer learning, where knowledge from one domain or task is transferred to another related domain or task.59,60 This allows models to benefit from pre-existing expertise and generalization capabilities.
Furthermore, the field of explainable AI (XAI) has gained attention, aiming to combine expert knowledge with data to provide interpretable and understandable models. Explainable AI techniques allow experts to contribute their domain knowledge, verify model behavior, and ensure ethical considerations are taken into account.61,62
Considering some of the popular types of reliability models, i.e., FTs and Petri nets, there are basically two aspects in which data and expert knowledge can be fused: building the structure of a model, also known as qualitative analysis, and identifying the associated parameters or the quantitative analysis. In classical Simulation, both the structure and the parameters of the system of interest are fully characterized by experts. In Table 1, the areas in which data-driven methodologies and human cognitive capabilities can be combined are illustrated. When only expert knowledge is used for both qualitative and quantitative aspects, it is referred to as “Classical Simulation” (Table 1). If the information source is limited to data without incorporating expert knowledge, the approach is termed “Data-driven simulation.” The gray cells in Table 1 highlight the areas where the fusion of data and expert knowledge can enhance accuracy and leverage all available information from both data and human cognitive abilities.
Areas in which data and expert knowledge can be fused.
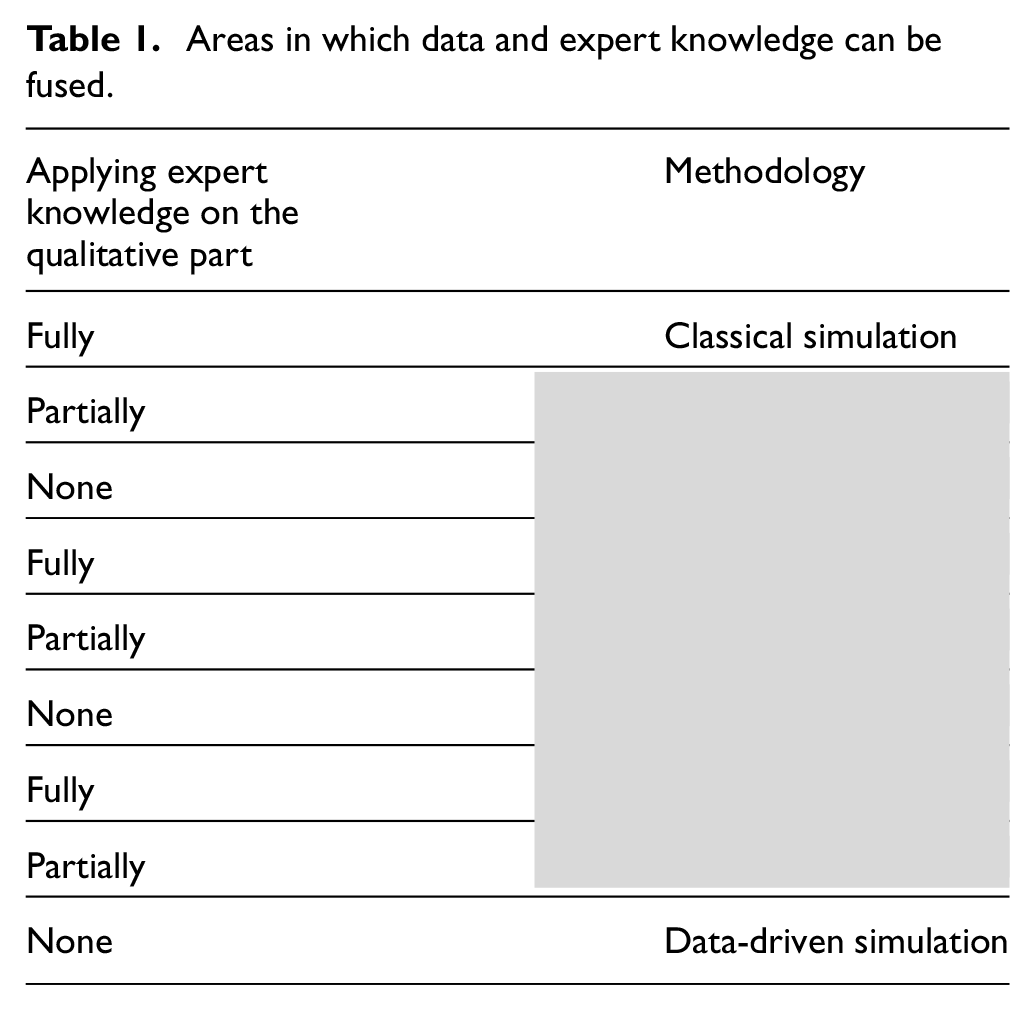
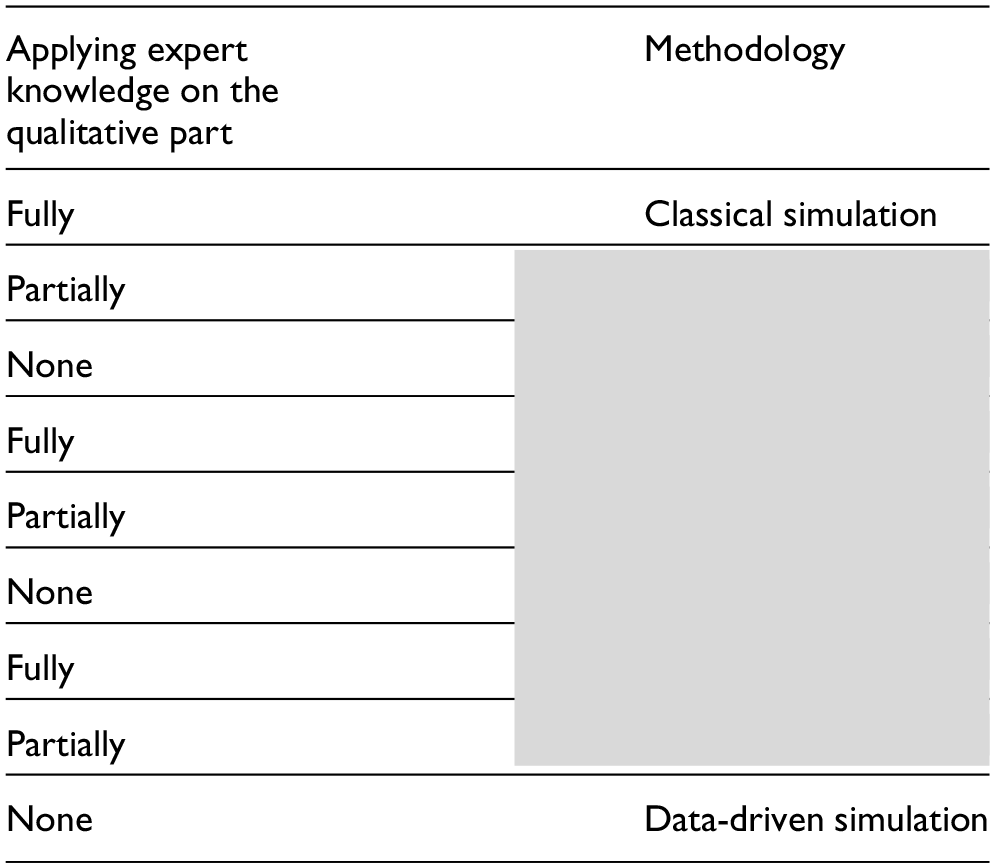
There have been studies in risk and reliability analysis to make use of experts’ knowledge. Traditionally, only Bayesian statistics were applied to take experts’ opinions into account because probability is the only language in which uncertainty can be consistently expressed. This process requires the use of prior distributions for reporting expert opinions.63,64 Data availability has had its influence on reliability analysis, and Bayesian approach, especially Bayesian Networks, is the perfect framework to use both data and expert’s knowledge. 65 However, most of the existing research on reliability assessment makes use of the experts’ opinion only in quantitative analysis, i.e., to estimate model’s parameters (red fields in Table 1).
In our previous study, 66 we point out the gap in availability of systematic methods for fusing data with expert knowledge for the purpose of qualitative and quantitative reliability analysis of CPS. In this study, we introduce a systematic way of converting human’s knowledge into formal statements that can be easily combined with data-extracted facts for data-driven FTA. Different types of statements from experts can be recorded in various ways. Some examples are as follows:
Whenever components A and B fail (regardless of the rest), the whole system fails;
Whenever components A and B fail (not sure about the other components), the whole system fails to function;
Component A fails approximately once every 2 years;
Component A is highly reliable and rarely fails.
The first two examples concern qualitative analysis, while the last two examples inform us about the quantitative part of the model. Some of the methods that can help with converting these statements into computer understandable language are black lists and white lists67,68 for the qualitative analysis, and Fuzzy set theory 69 and Bayesian statistics 63 for the quantitative analysis.
In the light of fusing data and expert knowlegde, it is important to mention the concept of cognitive digital twins (CDTs). Namely, CDTs, that can be also used for reliability M&S, aim to integrate a human dimension in classic digital twins. With this, CDTs reveal a promising evolution of the current digital twins concept toward a more intelligent, comprehensive, and full lifecycle representation of complex systems. 70 CDTs are essentially dynamic data-driven simulation models that do not only integrate real-time data for updating the model but also fuse it with human knowledge, which is seen as an important factor in designing, updating, optimizing and validating the model.
4. Case studies
To build up on the previous section, here we present two case studies from our research to illustrate both presented emerging trends in the field of Reliability M&S. In both case studies, we automatically extract reliability models that are subsequently simulated, showcasing how the whole Reliability M&S process can be automated. The first case study illustrates a purely data-driven approach to reliability modeling using SPNs, whereas in the second case study, we illustrate the concept of seamlessly fusing data and expert knowledge for FT Modeling and Analysis.
4.1. Case study 1: Data-driven reliability assessment of production systems
In this section, we present a case study that demonstrates the application of data-driven reliability assessment to a production system. To do so, we first describe the case study system and the data we extracted from it, followed by the data-driven model generation and validation process. Finally, we use the generated model to aid decision-making in maintenance staffing.
The presented data-driven reliability assessment approach is novel, as it not just uses data for typical M&S tasks, such as model parameterization, calibration, validation, or sensitivity analysis. In such approaches, an initial, manually derived model is usually assumed. Instead, our approach uses data to generate an explicit simulation model using process mining and statistical techniques. By generating a model from data, the model becomes very flexible and can quickly be calibrated/regenerated under changing conditions.
4.1.1. Case study system and extracted data
Figure 2 provides an overview of the case study system, which is a flow production line commonly found in manufacturing systems. The production line is fully automated and consists of five resource components: a manufacturing execution system (MES), two automated guided vehicles (AGVs), and two assembly cells. Both assembly cells work concurrently, performing the same assembly operation. The MES controls the production process by initiating new production orders, directing them to either Assembly Cell 1 or 2, and marking orders as completed. When a new production order is initiated and assigned to one of the assembly cells, the AGVs transport the raw material to the designated cell.
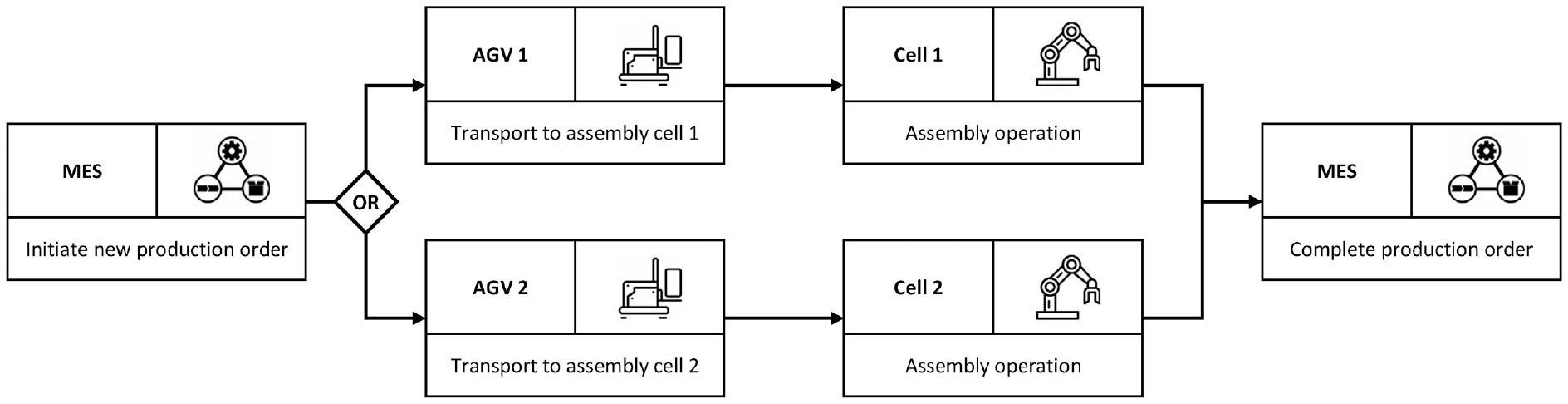
Overview of the case study system.
The AGVs and the assembly cells are susceptible to failures, while the MES is always fully operational. In the event of a production resource failure, the resource stops operating and a repair crew is dispatched to repair the malfunctioning resource. The maintenance policy in place is purely reactive. The AGV has an unlimited buffer and a capacity of one, while both Assembly Cells 1 and 2 have a finite buffer and a capacity of one.
To simulate streaming data and conduct experiments, we developed a simulation model based on the described case study system. We used this simulation model to generate synthetic data in form of event logs, which capture the production process, and state logs, which record the operational state changes of production resources. The data captured by these logs will later be used to generate a simulation model.
Event logs can be extracted from information systems, such as MES, enterprise resource planning (ERP), or supply chain management (SCM). Each entry in the event log captures the execution of an event, including the timestamp, order identifier, the production resource involved in the corresponding activity, and the event type (i.e.,
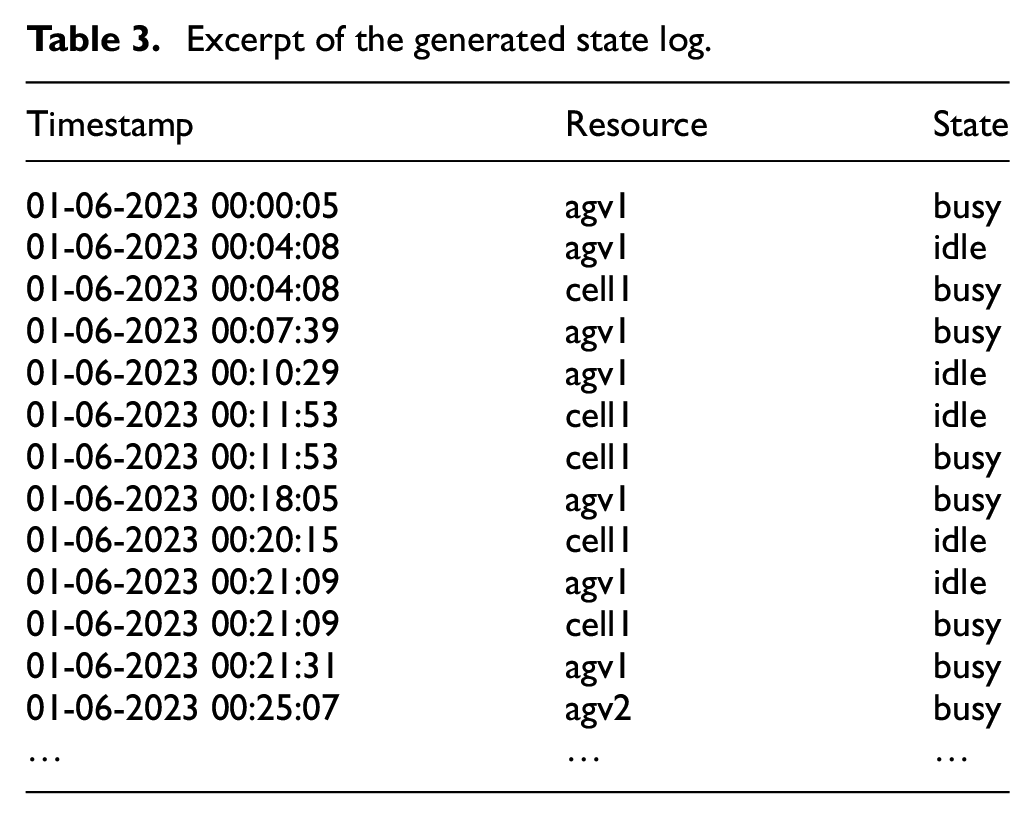
State logs, however, can be extracted from control systems, such as programmable logic controllers (PLC) or supervisory control and data acquisition (SCADA). Each entry in the state log captures the operational state changes of a resource at a specific time, including the timestamp, the production resource changing its state, and the new state the resource transitioned to (i.e.,
The event and state log that we used to generate the reliability model capture the production of 4431 orders more than 1-month time span. Excerpts of the event and state logs are displayed in Tables 2 and 3, respectively.
Excerpt of the generated event log.

Excerpt of the generated state log.
4.1.2. Reliability model generation
This section describes the generation of a reliability model based on the event and state logs, using our approach proposed in the work by Friederich and Lazarova-Molnar. 50 Our approach combines process mining and statistical analysis to generate a reliability model using SPNs as the modeling formalism. The class of SPNs considered can be defined as follows:

where:
Each transition
To generate the reliability model, we first extract a manufacturing process model and then integrate it with fault models for production resources.
The extraction of the manufacturing process model uses the information captured by the event log and involves the following four steps:
Identification of a Petri net that represents the material flow within a production line using process discovery algorithms. The material flow is the path that production orders follow through the system. 49
Determination of transition types (i.e., timed or immediate). Timed transitions correspond to the arrival of new production orders or to resources activities.
Estimation of probability distributions for timed transitions and extraction of weights for immediate transitions.
Extraction of resource capacities and buffers.
The extraction of the fault models for production resources uses the information captured by the state log and involves the following two steps:
Creation of necessary places and transitions from a fault model template.
Estimation of resource failure and repair distributions.
Finally, the fault models are integrated into the manufacturing process model using inhibitor arcs preventing the corresponding resource activity timed transition from firing.
Figure 3 depicts the generated reliability model obtained through the described model generation process. We successfully extracted and parameterized the manufacturing process model and the resource fault models. For each timed transition, the corresponding distribution function including parameters is shown. For each immediate transition, the corresponding weight is displayed. Furthermore, the capacity of one for both assembly cells, and their finite buffer sizes, have also been extracted. This data-driven reliability model can now be used to simulate and analyze the case study system.
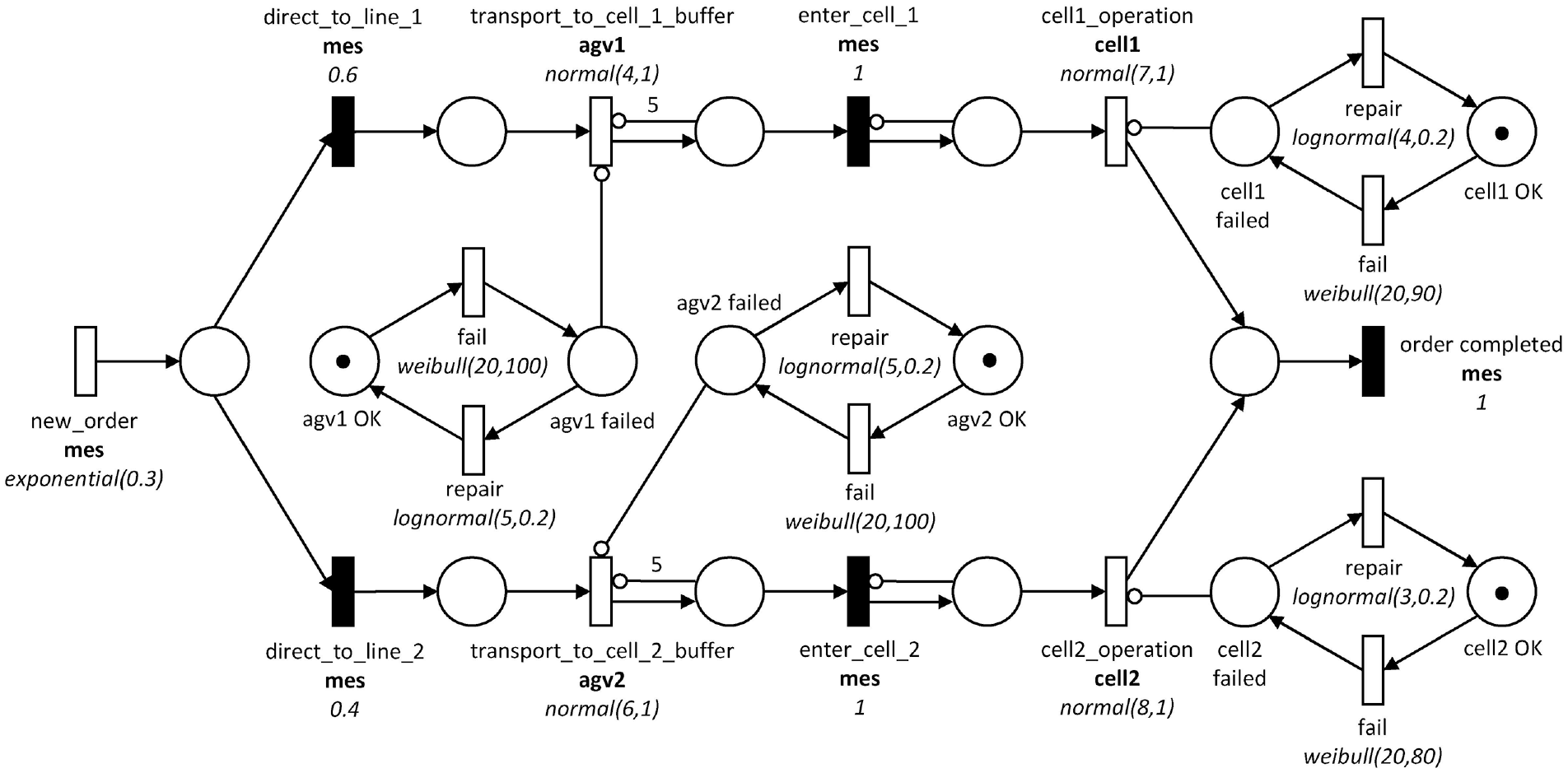
Generated reliability model of the case study system.
4.1.3. Simulation and validation of the generated model
We simulate the generated reliability models using DES. DES is a popular method for simulation of SPNs due to its versatility and efficiency in simulating complex systems. 71 In DES, the simulation time is divided into discrete-time intervals, and events are triggered based on the state of the system and the occurrence of random variables. This approach allows for the modeling of stochastic systems with a high degree of realism, as it can capture the effects of randomness and variability in the system. DES is particularly useful in simulating SPNs, as it can effectively handle the probabilistic transitions and random variables that are inherent in these network models. 72
Validation is an essential step to ensure that the generated reliability model accurately reflects the behavior of the real-world system being modeled. For this case study, we use quantitative validation, which is typically conducted using either input–output transformations (IOT) or historical input data (HID). In the case of IOT, only the output from the actual system is compared to the output generated by the reliability model, without taking into account real data for the input random variables. However, when using HID, both the output and input data from the actual system are incorporated into the evaluation. 71
We use the following two key performance indicators (KPIs) to compare the real system with the generated reliability model:
To assess the similarity between the outputs of the real system and the reliability model, we calculate confidence intervals using the t-distribution. By comparing the KPI of the real system and the confidence interval of the reliability model, we can determine if their outputs are statistically different or not, and thus whether the reliability model accurately captures the behavior of the real system. To do so, let
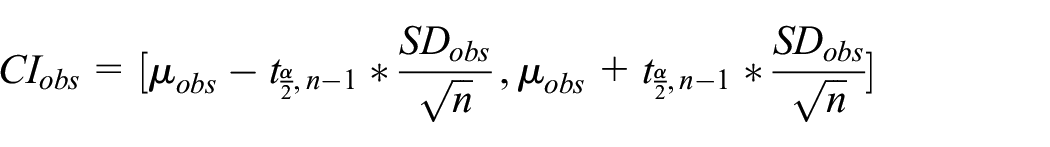
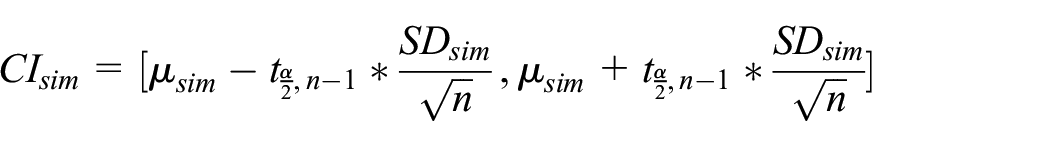
where
Figure 4 illustrates the validation results for our extracted reliability model using IoT and 100 simulation replications at a confidence level of 95%. We validate the model using the same data that were generated from, and an unseen dataset capturing the production system at another month. As depicted, the confidence intervals of the model and the real system overlap for both KPIs, representing the production volume over one day and the total downtime of all production resources over one day. Consequently, we can assume the generated model to be valid for the system under study.
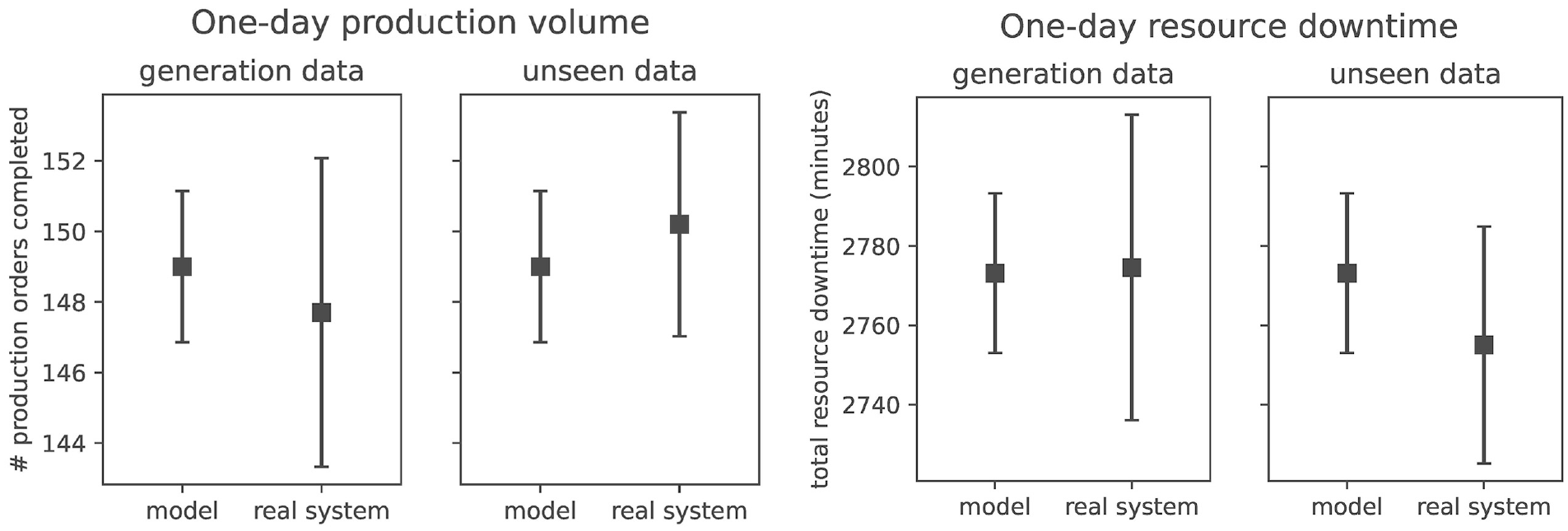
Validation results.
Model Application and Decision Support: The generated and validated data-driven reliability model can now be applied to support various decisions regarding, for example, resource maintenance or system configuration. To apply the model, adjustments may be needed, such as modifying distribution functions for timed transitions, modifying firing probabilities for immediate transitions, or adding new model components. After the modifications, the model is simulated to assess the impact on the system. Similar to the validation process, this involves selecting an appropriate KPI that can be used to compare the model before and after modifications have been applied.
To demonstrate the application of the previously generated and validated reliability model, we consider the following scenario. The production manager wants to analyze how reducing the repair time for production resources will affect both the total resource downtime and the production volume. Based on this analysis, the production manager can make informed decisions, such as investing in better training for existing repair crews or determining the need for additional repair crews.
We test this scenario by adjusting the distribution functions of the repair transitions of the production resources in the SPN. Specifically, we decrease the duration of the repair activities by a factor ranging from 1 to 3 with a step of 0.1. A reduction factor of 3 implies that the repair activities are performed three times faster compared to the original configuration. Mathematically, the reduction factor
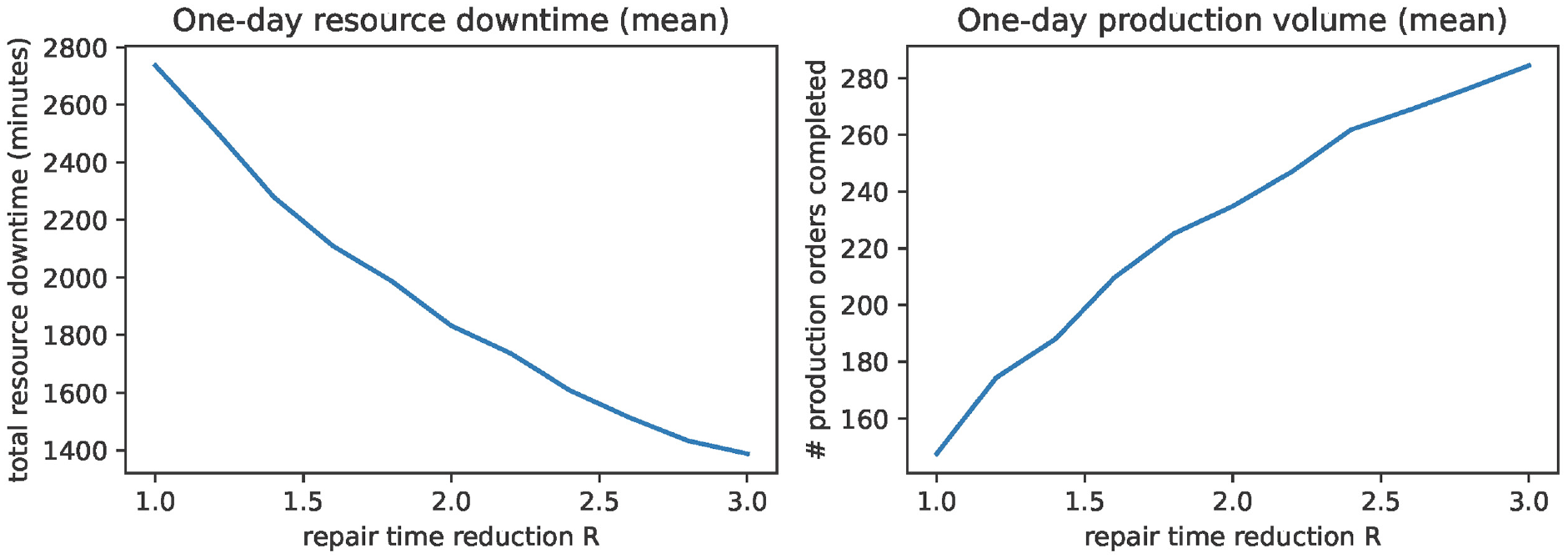
Effect of reducing the repair time duration of production resources.
4.2. Case study 2: Hybrid learning of FTs
Classical way of analyzing FTs, relies extensively on expert knowledge, and while this is essential for some systems, FTA can benefit substantially from data-driven M&S techniques. In this section, we present a methodology to learn FTs from both data and expert knowledge, which we call hybrid learning of FTs. The highlights of this case study can be summarized as follows:
Introducing a systematic way of converting human’s knowledge into formal statements that can be combined with facts extracted from data;
Fusion of data and expert knowledge is considered in different levels, for M&S of the system;
Applying hybrid learning of FTs for a multistate repairable FT.
To showcase and assess how availability of expert knowledge and data can affect the performance and accuracy of a system’s reliability measures, we start by an introduction to FTA through a multistate FT case study taken from the research literature on FTs.
73
Multistate FTs have the same structure of regular FTs, except that the components or the system may have more than two functioning levels. In other words, the state space of the system and its components may be represented by
Reliability and maintainability distribution functions of the basic events of the FT in Figure 6.

A fault-tolerant multiprocessor (FTMP) consists of two processors
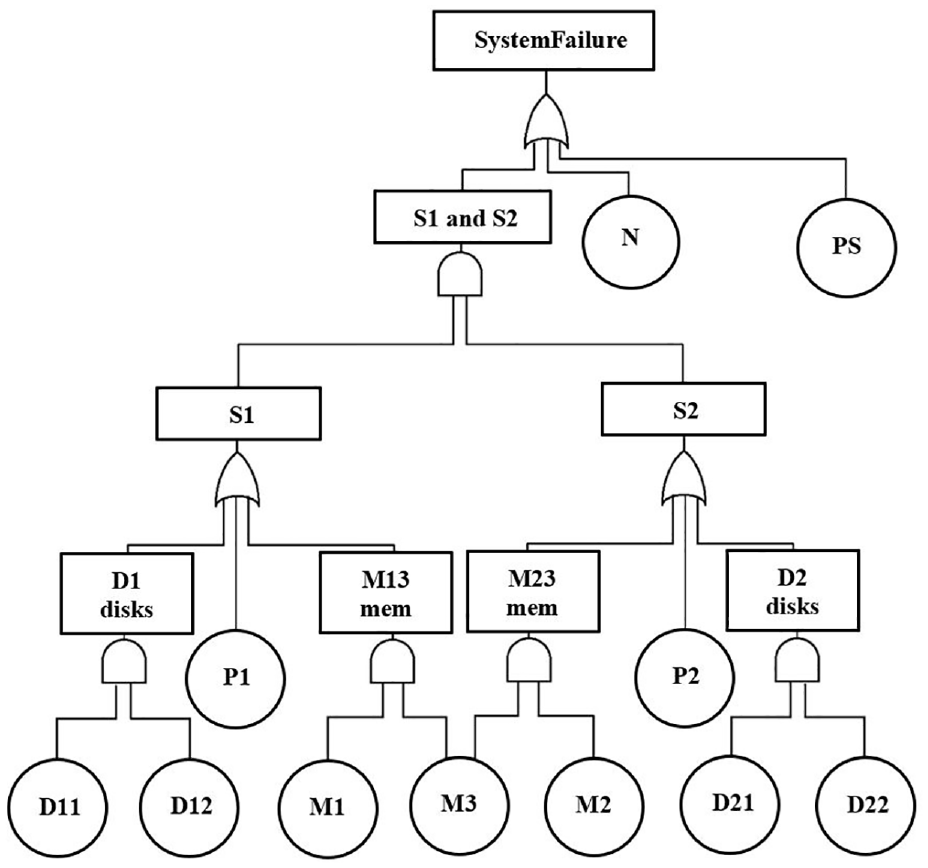
A fault tree of an FTMP system with a multistate component
2 × 2 confusion matrix that depicts all four possible outcomes in classification.

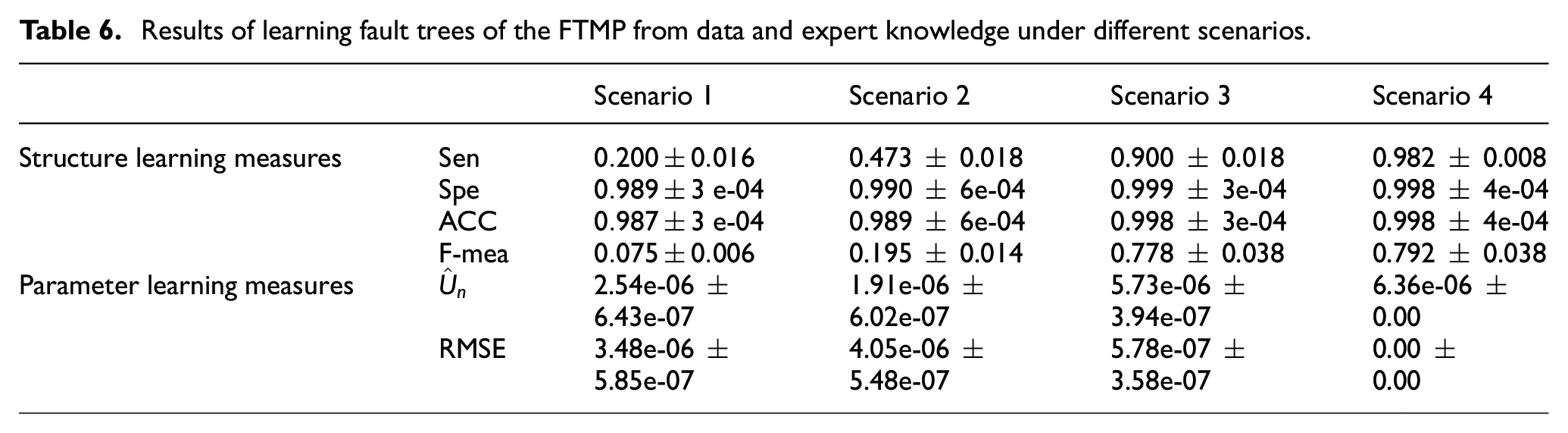
Results of learning fault trees of the FTMP from data and expert knowledge under different scenarios.
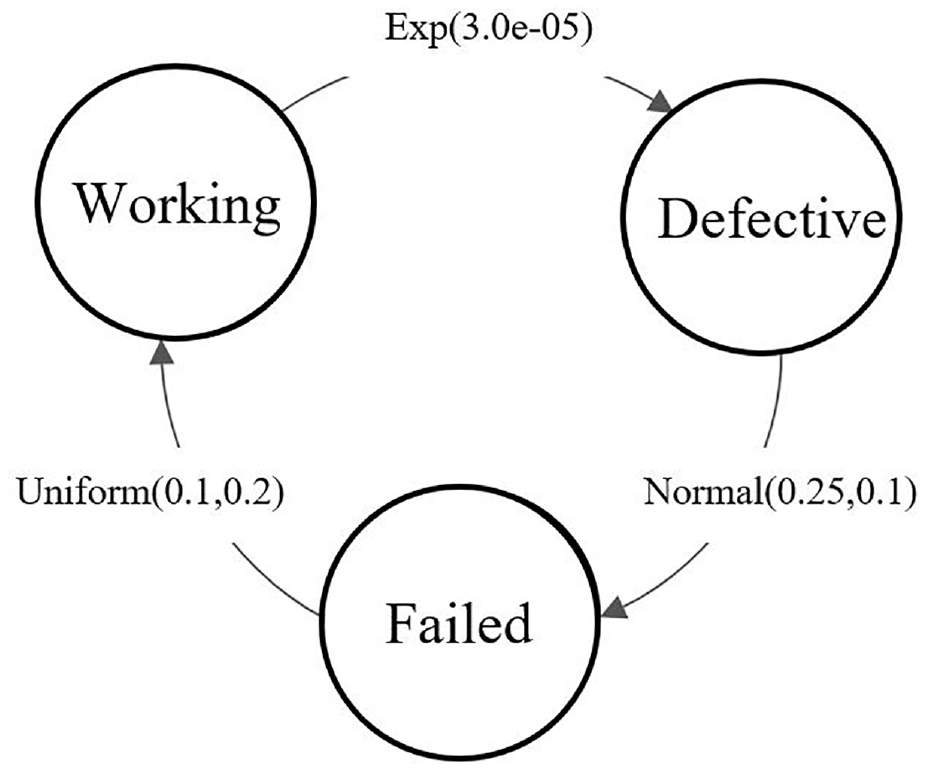
State change diagram for the multistate component PS.
There are two aspects of FTA:
Qualitative Analysis:
Cut sets indicate which combinations of component failures lead to system failures. A minimal cut set (MCS) is a cut set of which no subset is a cut set. For example, in the sub-tree of FTMP displayed in Figure 8,
where
Quantitative Analysis:
In quantitative analysis, one objective is to measure how reliable the system of interest is. Assuming that the failure rates and the time it takes for them to be repaired are independent and are governed by probability distribution functions, then quantitative FTA starts with estimating the failure and repair probability distribution functions. Often times, in FTA, exponential or Erlang distributions are considered for modeling time-to-failure or time-to-repair associated with basic events, and domain experts specify the parameters of these distributions, e.g., an exponential distribution with a rate of 0.5.
Once the FT has been fully extracted and characterized, both in structure and parameters, reliability or unavailability of the system can be calculated.
As shown in Table 1, expert knowledge and data can be fused for both structure learning and parameter learning.
In this case study, we implement the methodology presented in the work by Niloofar and Lazarova-Molnar 66 by extracting MCSs of FTMP, from time series data of faults received from this system, and then combine this information with the statements from experts to estimate the system reliability.
The set of minimal cut sets for the FT from Figure 6 has 11 elements:
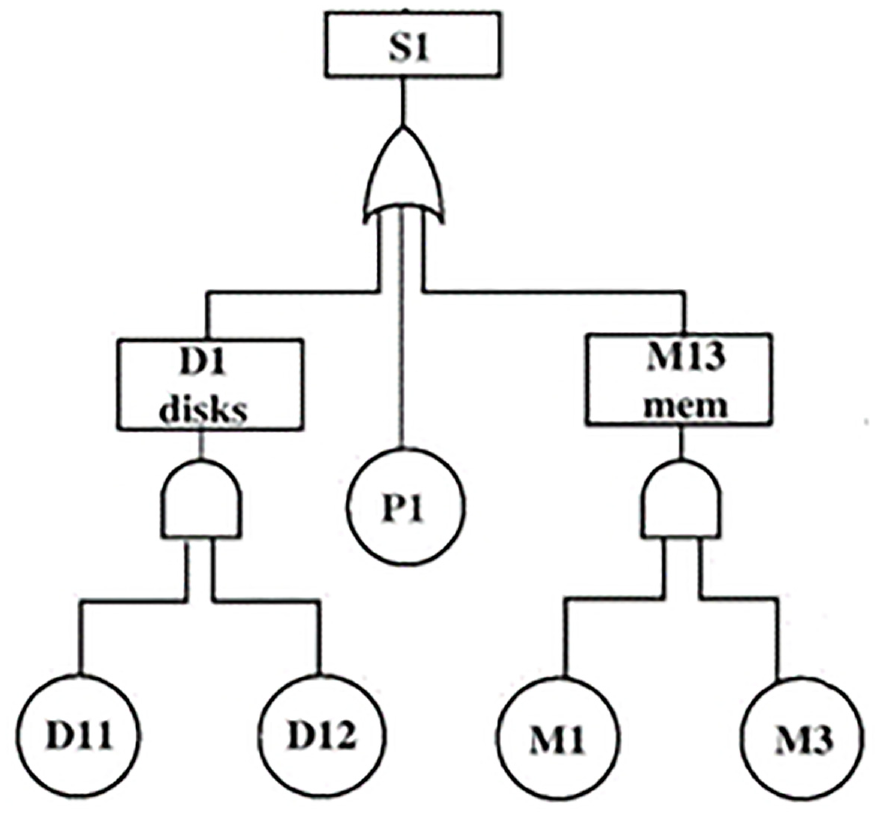
A sub-tree of the FTMP fault tree from Figure 6.
The hybrid FTA methodology consists of the following steps:
Generating time series data by simulating the original (ground truth) FT of Figure 6 with parameters in Table 5 and Figure 7;
Learning/Reconstructing the FT from the time series data simulated from the original FT and prior knowledge from the expert, under different scenarios;
Calculating the performance measures obtained from the hybrid learning of FT.
For this case study, we consider the following four scenarios:
No knowledge from experts and 20% data availability;
20% knowledge from experts and 20% data availability;
No knowledge from experts and 90% data availability;
90% knowledge from experts and 90% data availability (expert’s knowledge and data might overlap).
By 20% or 90% availability of knowledge from experts, we mean 20% or 90% of MCS are derived from expert knowledge. For instance, in the FT of Figure 9, if 1 out of 3 MCSs is derived from expert knowledge, it means ca. 33% expert knowledge availability.
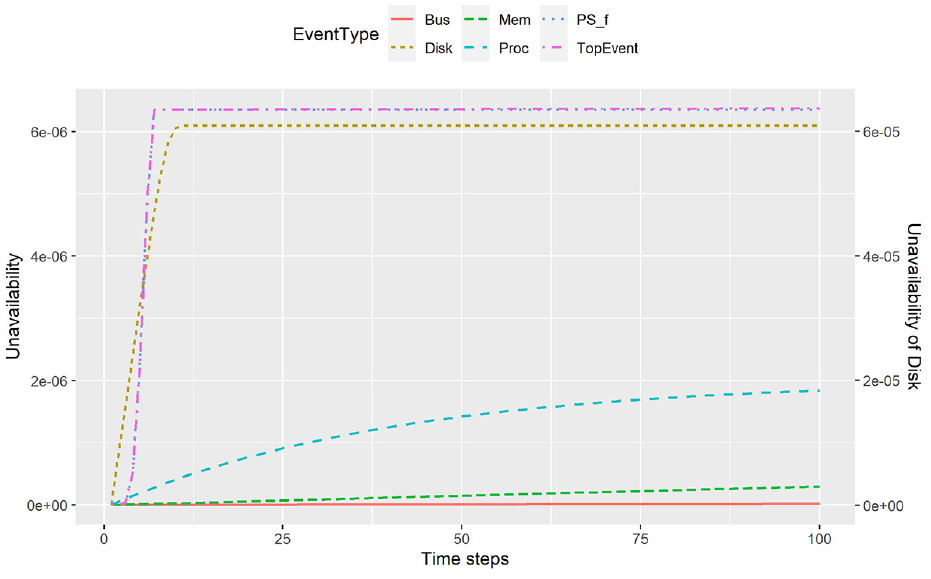
Instantaneous unavailabilities for the fault-tolerant multiprocessor from Figure 6.
Systematic Fusion of Data and Expert Knowledge: To benefit the most from the human prior knowledge of the system, we need to find a way to transfer this information into statements that can be seamlessly fused with data.
For the qualitative analysis of the FTMP system of Figure 6, let us assume that we have a piece of expert knowledge in the following form: “whenever events
For the quantitative analysis, information received from experts can be implemented as prior probability distribution functions (
For instance, assume an expert believes that an item fails twice a year. This belief from the expert can be converted to an exponential distribution with a failure rate of
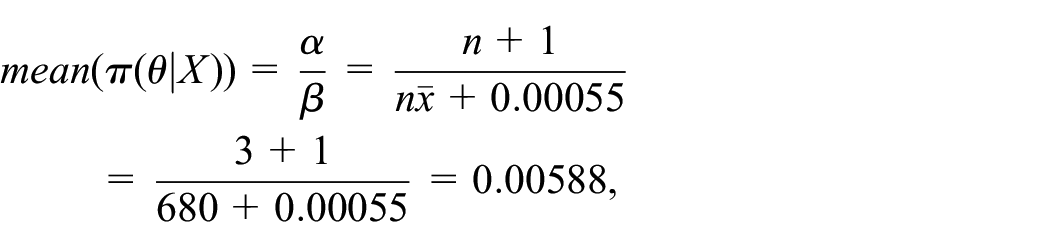
where
Performance Evaluation: To compare the reconstructed FT structure with that of the original FT, we use the 2 × 2 confusion matrix of Table 5 that depicts all four possible outcomes.
In this confusion matrix, TP represents the number of sets that are both in the MCS of the reconstructed FT and the original FT (correctly identified sets). FP is the number of sets in the MCS of the extracted FT which are not in the MCS of the true FT (incorrectly identified sets). FN is the number of undetected sets, and finally, TN is the number of sets which are correctly undetected. Using the confusion matrix, we calculate the sensitivity (Sen), specificity (Spe), and accuracy (ACC) and F-measure (F-mea):

Larger values of above-mentioned measures indicate higher performance in structure learning.
When the structure of the FT is extracted from the data/expert knowledge, the unavailability of the system can be calculated using proxel-based simulation. Since unavailabilities are calculated as transient solutions for each time step, we have a vector of instantaneous unavailabilities calculated for the extracted FT
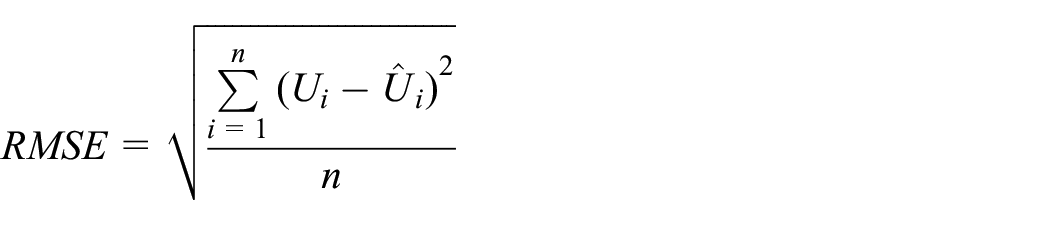
Better estimation of unavailability leads to a smaller distance between
Summary of Experimental Results: In this case study, we assume that expert’s availability of knowledge for the FT parameters, which are the probability distribution functions, is complete and partial knowledge only concerns the structure of the FT. Hence, the structure is learnt through fusion of data and expert knowledge.
We observe that as we enhance the algorithm with a prior knowledge of the system, the measures reported in Table 6 also improve. The true unavailability of the system is
5. Conclusion
Reliability M&S is gaining in importance with the ever-increasing complexity of systems that surround us. The conventional approach to reliability modeling heavily relies on expert knowledge, which poses limitations as systems grow in complexity. In this article, we provide an overview of the use of M&S for reliability analysis of CPS, with the aim of pointing how new technologies that enable easy collection of large quantities of data from systems can impact and transform the traditional ways of doing it. With this, we outline and describe the emerging trends in reliability modeling, mostly through the data-driven and hybrid modeling that fuses data and expert knowledge. Learning reliability models from data leverages real-world data collected from systems to improve accuracy and adaptability of extracted models. It is, however, important that in the whole process, we do not neglect the knowledge that we already have about these systems.
The systematic fusion of data and expert knowledge has the potential to play a significant role in enhancing reliability modeling. While data-driven approaches provide valuable insights, incorporating human expertise and cognitive abilities is essential. Combining expert knowledge with data-driven techniques allows for more efficient and more accurate model extraction, and improved predictions and decision-making. This integration can be achieved through approaches, such as expert systems, Bayesian statistics, transfer learning, and explainable AI.
To illustrate the new trends in reliability M&S, and based on our research developments, we presented two case studies. The first case study illustrates the data-driven reliability assessment of productions systems, where the extracted models are described using SPNs. The second case study focuses on the fusion of data and expert knowledge to extract reliability models in form of FTs.
These advancements offer significant potential for addressing the limitations of conventional reliability modeling. By leveraging data and expert knowledge, researchers and practitioners can enhance the accuracy, adaptability, and decision-making capabilities of reliability models. Furthermore, these advancements are very beneficial in terms of the utilization of Digital Twins technologies, which rely on having models updated with changes in the real systems. By developing approaches that automate simulation model extraction, be it using solely data or incorporating human expertise, we enable Digital Twins, in this case reliability-centered Digital Twins.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.