
Abstract
Extraordinary amounts of fresh produce are never purchased and are discarded as waste. Reinforcement learning (RL) could serve as a means to improve business profits while reducing food waste via control of store pricing and ordering decisions. We present a discrete-event-based simulation framework for food retail which simulates wholesaler, store, and customer interactions. This simulator is critical for driving development and testing of future RL methods. It provides an efficient learning feedback system across a wide gamut of possible scenarios, which cannot be replicated from live observations or pure historical data alone. This is crucial as RL agents cannot learn robust decision-making policies without exposure to many unique scenarios. We evaluate our simulator on a demonstrative case generated from historical consumption and price data using a provided methodology for synthesizing daily demand from monthly and yearly stats. In this demonstrative case, we investigate proximal policy optimization, soft actor–critic, and deep Q networks trained with different reward formulations to decrease food waste and improve profits. These RL methods reduced food waste by 78%–92% on average on an unseen 3-year test period as compared to a baseline mimicking typical food retail waste. Compared to a second popular baseline in literature, the best performing RL algorithm was able to improve profits by up to 12.3%.
1. Introduction
Today, more than US$1 T or one-third of all food is thrown away. According to expert estimates measured as the difference between inventory delivered and inventory sold, nearly 40% of fresh products are wasted by most food retail stores. 1 Such waste is neither environmentally conscious nor sustainable, and even worse, it suggests an extraordinarily large wasted potential access to nutrition for those in need. From a business perspective, food waste negatively affects business profits and contributes to extremely tight profit margins (2.2% industry average for food retailers). Reducing food waste presents a significant opportunity toward a more sustainable future and has economic incentives for businesses.
Recent advancements in artificial intelligence (AI) offer new solutions to big societal challenges. As a motivating example, reinforcement learning (RL) methods have managed to greatly outperform expert human decision-making in complex strategic games, such as chess and Go while revealing previously unknown conceptually novel strategies. 2 Our long-term vision is to exploit RL techniques to optimize food retail operations by reducing food waste while simultaneously improving business profitability.
In food retail, consumer habits and purchasing decisions are highly influenced by various factors, including discounts, weather, seasonality, and product quality. To be profitable, a retailer makes difficult decisions when determining sale price and order/restock quantities of perishable products. Extreme discounts or insufficient orders may result in products running out-of-stock, which presents a loss in potential revenue for retailers. Therefore, overstocking of perishable products is a common business practice to prevent lost sales in the face of variable customer demand, despite the accompanying food waste. As retailers maintain significant markups compared to wholesale prices, the revenue from one product sold to consumers can often cover the loss from more than one product of waste.
Optimal replenishment policies are complex, and simple decision rules cannot be written to cover all constantly changing circumstances. This motivates looking into approximate methods.
A primary hypothesis of our paper is that an RL-driven decision-making system can greatly improve sustainability and retail profitability by decreasing food waste while avoiding understocked inventory. However, for successful application, such a system needs to provide reliable business decisions and autonomously adapt to changing environments. In particular, it must be capable of operating and reacting effectively to both expected events (e.g., holiday season) and unexpected events (e.g., pandemic, drought, and new health trend). Both types of events can affect wholesale prices of products, and consumer purchase behaviors.
Consequently, any intelligent RL system requires rigorous evaluation on a wide gamut of possible events prior to deployment in a real environment. As historical data limit the examples an RL system can learn from, simulation plays a crucial role for training and evaluating RL-based decision-making systems. Such simulation must be capable of not only properly evaluating state transitions but also be able to generate high-quality examples of situations which can be, but have not been, encountered in real prior data.
Problem statement. Adapting RL to reduce food waste and improve profitability in food retail stores requires a learning and testing environment where a myriad of events can be learned from and relevant data can be accessed. Unfortunately, existing simulators, e.g., work by Teller et al. 3 and Baydar 4 (Section 2.2), fail to provide interfaces to food waste, product deliveries, purchase tracking, and pricing/ordering control, which is a prerequisite for an RL approach in food retail.
Objectives. This paper aims to provide intelligent decision-making in food retail to reduce food waste and maintain profitability by innovatively combining RL with simulation techniques. In particular, our paper aims to (1) provide a simulation framework that can be used for the development, validation, and testing of RL methods. It also (2) offers realistic, product-specific demand functions to estimate expected purchases. Moreover, (3) the paper provides a detailed experimental evaluation of various RL algorithms in a food retail context using our simulator and demand functions.
Contributions. Our research presents novel technical contributions in the following areas:
A food retail simulator capable of simulating a food retail environment with event, seasonal, and day-to-day demand variations, revenue, food spoilage (waste), product deliveries, and product pricing.
Synthesis of realistic demand from historical data and statistics for training and testing RL agents.
Conceptual methodology for applying RL to the retail food waste problem via simulation.
Detailed experimental evaluation for strawberries, potatoes, and carrots derived from historical data compared to two baseline approaches.
This paper extends our previous work 5 by providing more realistic demand functions (Section 5), applying additional RL algorithms (Section 4.2) and carrying out a more extensive experimental evaluation (Section 6) with three perishable food products and two baseline algorithms. In addition, the formal background of RL algorithms and related work is also discussed more extensively in this article.
Significance. A highly customizable food retail simulator provides a sandbox environment to develop and test RL solutions for optimizing pricing and inventory management of perishable items. It allows an RL agent to experience, experiment, and learn from an immense number of unique realities and events which have not occurred, rather than being restricted to limited live and historical data. A methodology for generating realistic demand functions enables the application of AI techniques even for stores which have limited historical data. Furthermore, it contributes a conceptual methodology for RL application to reduce food spoilage and waste in food retail practices.
2. Background and related work
2.1. Background
Decisions in food retail stores. Successful store management requires careful decision-making to maintain profitability in a low profit margin environment. In this endeavor, food retail stores have many strategies, including adjusting product arrangement and organization to drive customer traffic to certain products within a store. However, fundamentally, the key decisions a store makes are (a) what price to set for products and (b) how many products to order from wholesale to stock inventories. These decisions are not completely independent and directly affect profits. For example, changes in product price can impact customer demand, which then requires a change in order quantity. When there is excess inventory, product discounts may be needed to avoid large sunk costs due to food waste.
Discrete Event Simulation.
Reinforcement learning. RL is a machine learning technique which seeks to learn what actions to perform in a given situation via feedback from rewards. RL problems can be represented by Markov Decision Processes
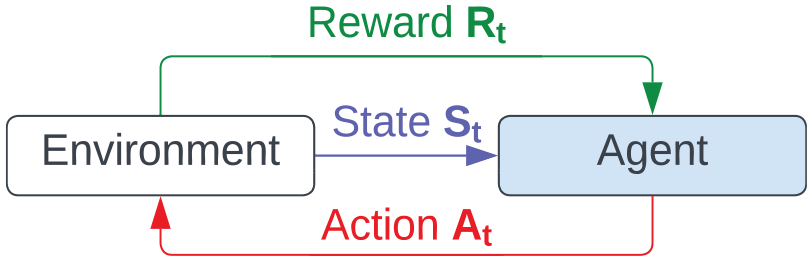
RL formulation. 5
In an RL setting, pricing and ordering decisions can be mapped to agent actions. The state of the environment can encapsulate information, such as the season and number of products in inventory. With a carefully crafted (custom) reward function and sufficient learning episodes (e.g., via simulation), an RL agent could learn a pricing policy and ordering policy used in given environment states.
Value functions in RL. Many RL algorithms seek to learn the value of particular states or state–action pairs. Intuitively, by approximately learning the value of particular states, the algorithm can also learn a policy (strategy) for actions to lead the agent to high-value states.
Soft Actor–Critic. Soft actor–critic (SAC) is an RL algorithm which seeks to maximize both cumulative reward and its policy’s entropy (or stochasticity).
8
It is a deep RL algorithm which uses three neural networks to learn three functions. The original SAC formulation used these three neural networks to learn a state value function (approximates cumulative future rewards starting at state
Proximal Policy Optimization. Proximal policy optimization (PPO) is a policy gradient method RL algorithm that maintains two policy neural networks. One designates the policy we are trying to refine and the other is the policy we last used to collect samples via actions in the environment. PPO minimizes its cost function through small update steps that avoid diverging its new policy too far from the previous policy.
10
PPO improves on trust region policy optimization (TRPO)
11
through a clipped surrogate objective,
Deep Q-learning. Deep Q-learning (DQN) is a Q-learning approach which improves on original table-based representations of the Q-function by employing a parameterizable neural network instead
12
(same as in SAC). The neural network acts as a non-linear function approximator of the Q-function, where
2.2. Related work
Related work spans the research fields of simulation and machine learning, and includes literature on sales forecasting, 13 price optimization, 14 customer behavior, 15 food waste, 3 and inventory restock policy.16,17 Our work differentiates itself from existing work by simulating a food retail environment in which RL-driven store management is possible. Moreover, most existing simulators are either (a) not available off-the-shelf or (b) cannot be tailored to the needs of food waste reduction of individual retail stores as they lack sufficient customizability to simulate specific product definitions, prices, and relevant entities. Furthermore, we conduct a food retail demonstrative case with RL techniques and reward formulations not previously explored in the food retail domain.
Simulation. Baydar 4 creates an agent-based simulation environment for a grocery store and uses optimization to determine discount amounts for particular customers to balance pricing, sales volume, and customer satisfaction. While this is a similar work discovered in our literature search, it does not factor in wholesalers, control over delivery order sizes, nor model food waste. 18 However, develop a single-store simulator for food waste relying on the Poisson distribution. This simulation is limited to need-based purchases. Customers always select the cheapest product available that meets their remaining days of freshness requirement. Welling et al. 19 provide a discrete event simulator by following the 12-step simulation development process to study lead-time-based pricing for semiconductor supply chains. Lau et al. 20 create a simulator studying the effects of inventory policy on supply chain performance with four retailers and one supplier. This simulator generates random demand and production capacities, and models retailer and supplier decisions. Christensen et al. 21 propose forecasting methods using product shelf life and validate these methods through simple simulation. To evaluate the effect of price management on food retail, 18 build a simulation of food retailers.
Customer behavior. Customer behavior focuses on understanding how an individual customer interacts with—stores, products, and brands—and applies a model to predict future actions. Initial examinations of modeling consumer purchase behavior as Stochastic Processes in the work by Rao 22 and Aaker and Jones 23 state that customer purchase behavior is stringent and not easily changed (store and brand loyalty). However, various simulations analyze when to centralize and decentralize groups of customers, as an example, through geographical information.13,24 In e-commerce platforms, constraints and additional insights are often provided to help model future customer actions. Such models handle customer behavior as a multivariate multinomial problem or a hidden Markov model.15,25
Perishable inventory management and pricing. There is a set of relevant literature in the perishable inventory management and pricing field. Nahmias 26 , Raafat 27 , and Goyal and Giri 28 provide reviews and surveys of the field. Relevant work includes the work of Goto et al. 29 who study the optimal ordering policy for the airline meal by Markov decision processes. Chen et al. 30 and Jia and Hu 31 both investigate pricing and ordering decisions for a retailer and supplier operating on perishable products. Other relevant literature includes the work of Broekmeulen and Van Donselaar 32 who develop a new replenishment policy which calculates and uses the age of inventories, and compares with a baseline which does not. This same baseline is used in the work by Tekin and Gürler Berk 33 who likewise investigate reorder control policy for perishable products.
Reinforcement learning. Rolf et al. 34 provide an extensive review of RL methods and algorithms used within the supply chain contexts, including perishable food items. For example, Chen et al. 35 develop a deep learning RL method for agri-food supply chain profit optimization. Afridi et al. 36 use simulation to develop and test a deep Q-learning-based approach to replenishment policy in vendor management inventory for semiconductors which leads to significant improvements over a baseline. Similarly, Oroojlooyjadid et al. 37 use simulation and a Q-learning-based approach for the inventory optimization problem to achieve near optimal order quantities in the beer game. Chaharsooghi et al. 38 investigate many players in the beer game supply chain controlled via multi-agent RL. Gijsbrechts et al. 39 adapt A3C deep RL for inventory management problems and match state-of-the-art heuristic and dynamic programming solutions in simulation. Finally, David and Syriani 40 propose the use of RL techniques to create DEVS models.
RL in perishable retail. Some related works regarding RL focus on perishable retail. Kara and Dogan 41 experiment with Q-learning and SARSA for waste reduction. Sun et al. 42 found that DQN can reduce the amount of spoilage for fresh product retailers. A recent work by Jullien et al. 43 approaches the food waste problem with RL and introduces a new algorithm. Our work differentiates itself by (1) building a more customizable multi-entity simulation framework, (2) developing a new methodology for demand synthesization, and (3) investigating a new demonstrative case and reward function.
3. A food retail simulator
3.1. Architecture of food retail simulator
Our discrete event simulation (DES) framework allows for RL-driven control of individual store decision-making. The user inputs stores, wholesalers, and (groups of) customers definitions and behavioral functions to initialize the simulation environment. Ideally, underlying demand functions governing customer purchase behavior are based on real food retail data (Section 5). The simulation models entity interactions on a day-by-day basis and keeps track of sequences of events.
Simulation architecture. The detailed simulation architecture and how it maps into an RL problem space can be seen in Figure 2. A store interacts with its environment and can be controlled by an RL agent. This agent performs actions given information received from the environment. Such information is provided in the form of events (e.g., a product purchase or spoilage). Such events (marked in blue) designate updates in the environmental state and store observation. Pricing and order decisions (red) can be considered as RL actions (e.g., set the product price). The environment controls when a store can perform an action. When it is the time for the agent to perform an action, an observation of the state is constructed from prior event information. The action is passed as a pricing or order event to the environment, which properly handles the outcome. These constitute observable events which the simulator can log, record, and save. Information encoded within events can be used to form (green) rewards (e.g., a measure combining profit and food waste).
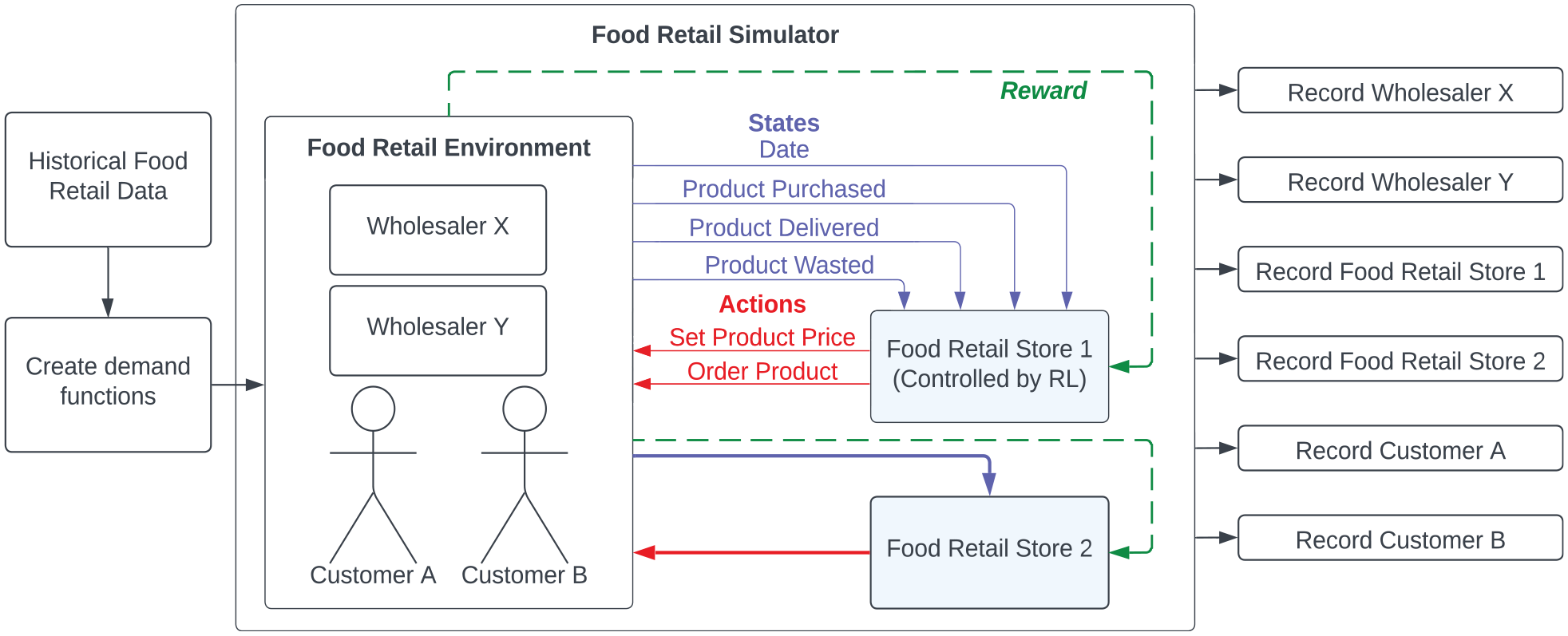
Simulator architecture with state information colored in blue, actions in red, and rewards in green. 5
By design, we specifically avoid imposing any concrete RL formulation for our targeted retail food waste problem. This prevents our solution space from being restricted to a particular definition of a reward or state representation.
As an abstraction, the simulator passes events from which rewards and observations can be formed. This highly flexible abstractions allow for experimentation with any class of RL technique (or alternative approaches) and different reward/observation definitions. The potential solution space for the food retail waste problem is expansive with many valid RL problem formulations. We present a demonstrative case with several RL algorithms and products in Section 4.
Food retail environment. Our simulation environment follows a DES framework where time increments in (discrete) daily intervals. We provide three primitive entity types. (1)
Each entity has its own underlying control function (e.g., RL in Section 3.1) which makes decisions (e.g., pricing, purchasing, and ordering) on a daily basis subject to potential constraints. The control function could be abstracted to subfunctions for individual products or aggregated to cover all products at once. As entities interact, each entity’s actions produce events which alter the state of the environment. For example, environment state changes may manifest as changes in store inventory values or food wasted.
Each entity may have defined constraints on its decision (action) space. Such constraints could include maximum price increases for designated products or limits on what days the entity can submit restock orders. This is highly configurable. For example, in Section 4, we limit restocking orders to two weekdays and prices to weekly adjustment.
Each event generated via interaction between wholesaler, store, and customer entities is well defined and appropriately consumed to trigger potential state transitions. For example, a customer purchasing a product from a store produces a purchase event which triggers a change in inventory. Generated events are validated on the fly via type and instance checking.
3.2. Methodology of food retail simulator
Simulation allows for the training and testing of RL agents across a myriad of expected and unexpected food retail events. Effective simulation must be computationally efficient and customizable. Furthermore, generated data and statistics must be safely accessible. Our simulator captures the food retail environment, correctly generates states, and acts accordingly to actions undertaken by store-controlling RL agents.
Configuration. To configure the simulation, the user defines the simulation start and end dates, the number of episodes to perform, and the number of parallel threads to use. The base configuration file (in TOML format) also supplies links to product, wholesaler, store, and customer entity definitions, their relations, and their behavior control functions. The base configuration file can serve as documentation for future simulation reruns or extensions.
DES environment for food retail. Simulation (Algorithm 1) follows a daily pattern with each day consisting of a sequence of discrete events which signal environment state changes. Six primary event types are produced and consumed:
PriceSetEvent is generated when a store agent changes the price of a product.
ProductOrderedEvent is created when a store agent places an order to a wholesaler.
ProductSoldEvent occurs from a customer purchase. The product is removed from inventory.
ProductDeliveredEvent alerts that a delivery from a wholesaler has arrived. Product added.
ProductWastedEvent is triggered when a product has reached its expiration date. Product removed.
EODEvent marks the end of the day. The date is moved forward by one day.

Algorithm 1 shows how a day is simulated. Each day follows a fixed high-level order of events.
The day begins with deliveries (Lines 2–5): a ProductDeliveredEvent is created for an arriving product. The delivered product is added to the store’s inventory using event data.
Next, expiring food is removed from a store’s inventory (Lines 6–9). A ProductWastedEvent is created which provides a link to the store and the expiring product. The store is then updated via this event, wherein it removes the product from its inventory.
The store then has the option to order more products (Lines 10–15). A store’s agent provides a list of order actions it would like to perform. These order actions are then transformed into ProductOrderEvents which update both the wholesaler from which the product is purchased and the store. These updates begin the order and delivery process and confirm to the store that the order was accepted.
Similarly, the store then makes pricing decisions (Lines 16–20). An agent generates a list of price actions. From this list, PriceSetEvents are created to record how the store changes the product price.
At this time, the store becomes open for customers to shop (Lines 21–26). A customer is selected until all customer groups have completed their shopping. This customer determines their next purchase, which then is used to form a ProductSoldEvent. This event is then used to update the store to remove the purchased product from inventory. Such implementation allows randomization of customer orders (e.g., different customers purchasing the last product leads to different behaviors).
Once the customers have completed their shopping, an EODEvent is created to update all entities that the day is over. A new day can then be simulated.
Customer behavior. Modeling customer purchase behavior is critical for food retail simulation. In our simulator, a demand function representing the desired demand for a product (i.e., quantity to purchase at a price) controls customer purchase behavior. The demand function template is flexible and allows for many possible inputs, such as product price, season/date, and product freshness. For simulation realism, it is best if such functions are derived from historical customer demand data. We generate such functions from historical statistics in Section 5.
Logger. Event-driven simulation environment updates have two key benefits: (1) they can provide simulation correctness and consistency guarantees, and (2) events provide a simple schema for logging and tracking simulations and statistics. Our simulator features a logger which calculates statistics across simulations.
Multiprocessing. Simulation runs are independent; thus, they can be parallelized. The simulator allows for multiprocessing simulations across multiple CPU cores or threads for significant simulation speedup. Rewriting the simulator in C++ can provide further runtime improvements.
Simulator design. We followed a DES framework rather than a DEVS framework when designing our simulator, as it sufficiently meets our requirements. Our primary objective is to enable RL control for store pricing and ordering decisions which does not require modeling continuous time. For this purpose, we also developed gymnasium 44 wrappers to make it easy to experiment with existing algorithms. DES allowed for quicker design, development, and testing of the initial simulator version. Furthermore, it capably handles macro (daily) information which is sufficient for exploring RL for food retail optimization.
In the future, we do plan to extend the simulation environment to a DEVS framework to model more detailed, continuous-time customer behavior (e.g., shopping or delivery at particular hours).
Software as a service deployment of the simulator is possible via a public interface, which could provide smooth integration with existing food retail solutions in the future.
4. Demonstrative case: base assumptions
As a feasibility demonstration and initial evaluation of the simulator, we run a simulation campaign. This campaign implements a synthetic grocery store derived from aggregated real data to demonstrate both how the simulator can be used and to explore some RL problem formulations and potential benefits.
4.1. Simulation scenario
We set up the simulation with the following entities and parameters. (1) One wholesaler, (2) One customer group, and (3) One store which can only order products on Mondays and Thursdays. (4) An agent controls the store-level decision-making regarding the purchase quantity of three perishable products with unique demand patterns and seasonality. The prices of products are set on Mondays, but this is not controlled by the agent.
4.2. Agent assumptions
Observations The range of observations an agent is allowed to access is listed below. We leave these general here, as the way they are implemented can have a significant effect on performance. We provide a detailed observation setup when presenting results in Section 6.
Time can be observed and represented in many ways, including daily, weekly, monthly, with continuous and one-hot-encoding schemes.
Inventory levels for each product at each time can be observed and represented numerically.
Quantities purchased by customers over a period of time can be observed and represented in an aggregated manner.
A Demand forecast for upcoming customer purchase quantities is available to the agent.
Reward Functions RL agents can be trained on various reward formulations. These rewards can be constructed via combinations of:
Sold quantities and monetary values
Order totals and monetary values
Food waste totals and monetary values
Agent Algorithms We evaluate the following algorithms:
4.3. Product assumptions
Our simulation study consists of several products which have different seasonality patterns and times to expiration.
Strawberries have a short time to expiration and a consistent summer demand peak.
Carrots have a medium time to expiration and demand is slightly more seasonal throughout the year than potatoes.
Potatoes have a long time to expiration with more constant, yet still variable demand throughout the year.
How daily demand is determined for each of these products is presented in Section 5. We consider these three different product categories for evaluating algorithms across a breadth of perishable product categories.
5. Deriving demand functions for products
This section outlines the data sources and methodology developed to generate daily demand for the demonstrative case in Section 4. As access to high-quality daily historical sales data, we investigate the following research question.
- Correctness: Daily demand aggregates to historical monthly and yearly levels for each product.
- Seasonality: Demand follows expected seasonal yearly patterns.
- Diversity: Demand patterns exhibit appropriate variation across years.
5.1. Data sources
To build realistic demand profiles for each product, we rely on the Statista database for historical statistics regarding quantities of strawberries, potatoes, and carrots sold and consumed per month and per year.
We build the potato demand function on data from yearly (2009–2019) potato sales 45 and monthly sales by month in Spain in 2020. 46 We use similar yearly and monthly data for strawberries and potatoes as well.47–50
While we merge data from different countries, all data are from the Northern hemisphere and should exhibit similar seasonal patterns. As there always exists variation in demand for a particular location, any variations between these data sources should not overwhelmingly affect realism.
5.2. Generating daily demand
Our simulation setup (Section 3.1) requires daily demand. However, the data sources are limited to the measures of total demand per year and a monthly demand breakdown for 1 year. Thus, we develop and use an interpolation method to derive daily demand for each product. This method is presented in Algorithm 2.

This process is divided into two parts: yearly to monthly and monthly to daily. The first connects yearly demand data points to monthly total sales, and the second uses the monthly totals to infer the corresponding daily demand for that year.
Yearly to monthly. As available monthly demand breakdown statistics are limited to 1 year, expected monthly totals for other simulation years must be generated. This can be accomplished by treating the monthly demand as a weighted demand concentration within the year. Furthermore, one can introduce extra variation between years by injecting random noise into the monthly parameters. In this article, we add noise to each month by sampling from Gaussian noise centered at 0, with a variance of 1/10th the monthly demand value. This maintains the general monthly seasonality shape across years with realistic quantities. This step can be seen in Lines 2–4 of Algorithm 2.
Monthly to daily. Given monthly demand totals for each simulation year, we develop a methodology to convert monthly demand to daily values via interpolation. On a high level, this methodology consists of (1) determining first-of-month sales (FOMS) basis points from the raw data, (2) interpolation to daily values, (3) Sequential Least Squares Programming (SLSQP) optimization to adjust FOMS for interpolation sales to match expected sales, and (4) shifting demand between weekdays based on customer foot traffic.
FOMS. As each monthly total is the sum of discrete daily demand across a month, one can derive a series of basis points corresponding to the FOMS by averaging two distinct approximations. The first approximation (FOMS linear interpolation) uses linear interpolation to generate a system of equations that can be solved using a least-squares approximation. The second approach (FOMS midpoint method) assumes the FOMS of a given month is the midpoint selling volume of the monthly total of the previous and following month, averaged over the total days in the month.
FOMS linear interpolation. This method starts by naively assuming linearly increasing and decreasing demands between FOM dates to get an initial set of basis starting points. This produces a solvable series of linear equations as the sum of demands between the dates can be set equal to the determined total monthly demand. This can be done by setting the FOMS for each month to a variable, e.g.,
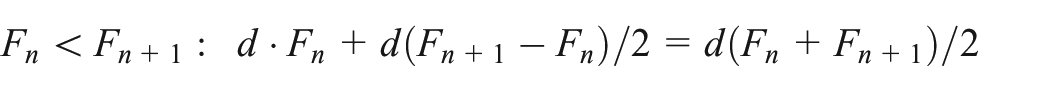
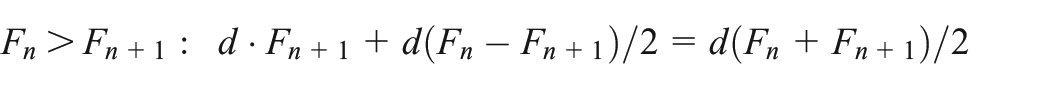
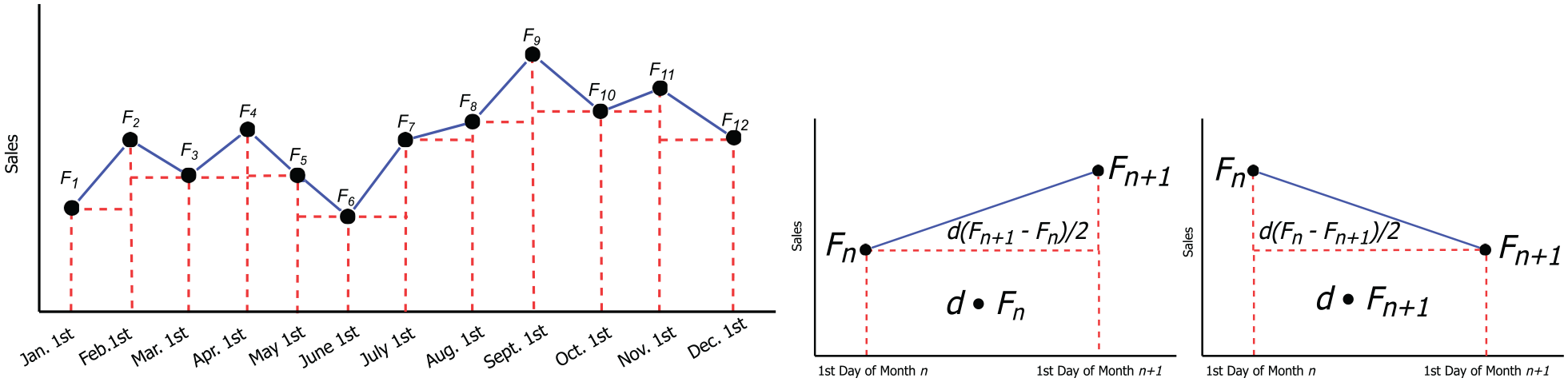
(Left) Linear interpolation between FOMS (Right) and two cases between consecutive points.
The series of equations can be rewritten as a matrix equation. However, this can result in a non-singular matrix, which prevents systematic equation solving. The solution therefore can be approximated by solving the equation via the least-squares method.
FOMS midpoint method. The second approach to finding a FOM demand value is to set it to the mean daily sales across the previous month and the present month.
The final basis points used for upcoming steps are created by finding the average of the linearly determined basis points and the midpoint method. Finding FOMS can be found on Lines 6–8 of Algorithm 2.
Interpolation. Given the set of FOMS basis points, it is possible to interpolate to daily demand. We use cubic interpolation as it preserves the continuity between months, unlike linear and quadratic interpolation, thereby improving realism. As interpolation returns a continuous demand function, each day can be sampled to return daily demand (Line 10 in Algorithm 2).
SLSQP optimization. The cubic interpolation started with a naive set of FOMS basis points determined via approximation. Therefore, there is a high probability that the resulting sum of monthly demands does not match the desired monthly totals. Therefore, an optimization loop using SLSQP is run, wherein the objective minimizes the difference between the yearly sum from the interpolated daily demands and the yearly total found in the yearly to monthly step,
Customer foot traffic. To further enhance realism, we extract usual store traffic for each day of the week from Google Maps 51 —assuming that store traffic increases linearly with purchases. Such traffic is incorporated as a weighted window from the total sum of purchases over a week (Line 14 of Algorithm 2). The final resulting demand plot for strawberries, carrots, and potatoes is shown in Figure 4. Due to high variation between days and periodicity in levels of foot traffic throughout a week, the plot looks as if it has two colors. This is merely due to the relative density between lines while plotting.
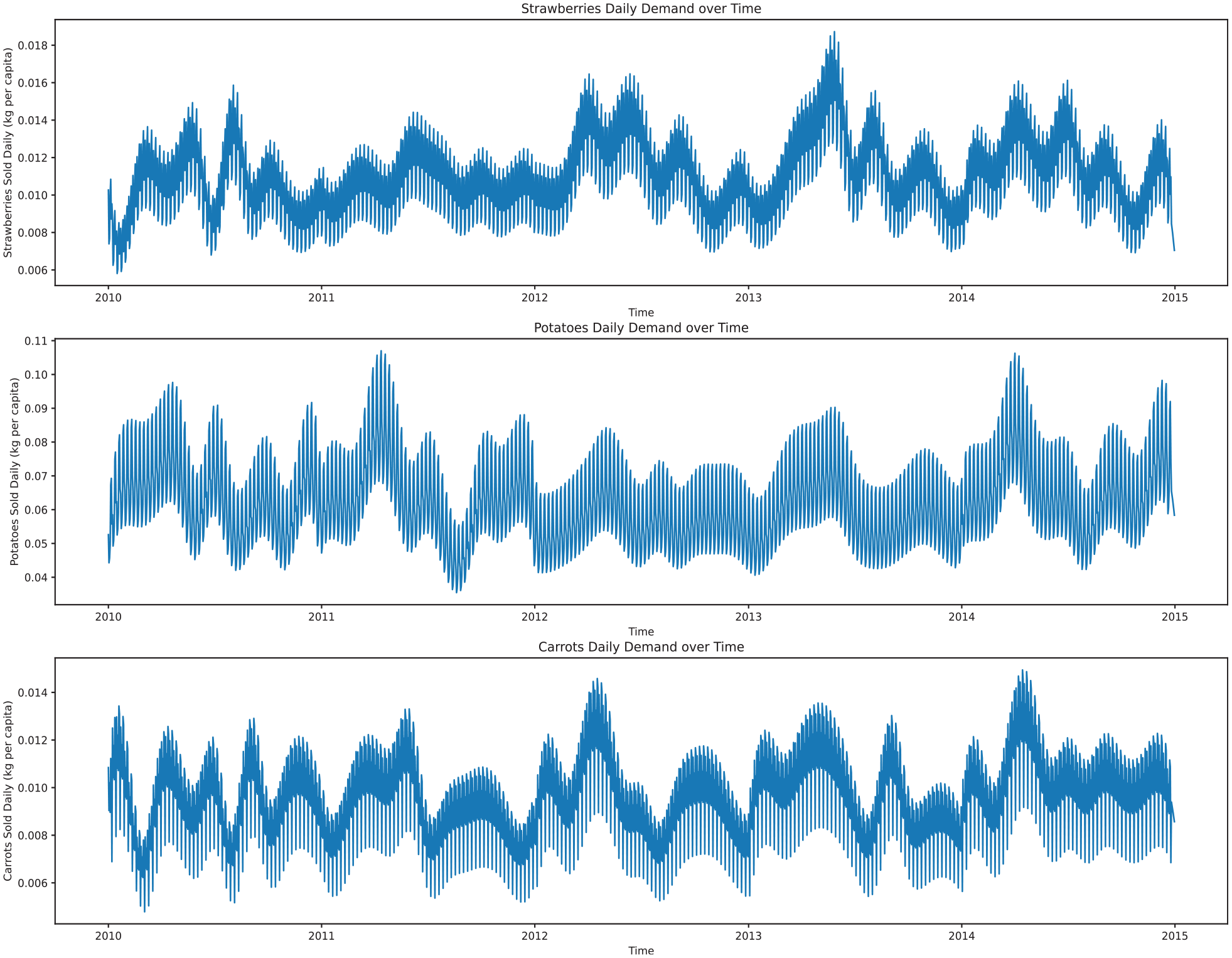
Daily demand functions per customer derived via interpolation from historical statistics.
5.3. Discussion
As an investigation of RQ1, we introduced a methodology combining interpolation and optimization to generate daily demand data from monthly and yearly historical statistics.
Correctness. The optimization solver succeeds in finding solutions where the daily demand summed across the year is effectively equal to the yearly demand total. Insignificant numerical differences can be observed due to optimization thresholds, but this error is certainly less than 1%. Monthly totals can experience more significant levels of error from an expected initialization point, but drastic differences are limited due to the selection of the basis points. Furthermore, as data are limited to 1 year of monthly sales, noise is applied to monthly values regardless, so this error can be considered as a form of extra noise or variation.
Seasonality. Clear seasonality patterns can be observed in Figure 4. Strawberries provide the clearest example with significant increases in sales volumes summer periods (mid-year). Peak volume periods shift slightly from year to year, which can be expected in reality.
Diversity. There is a clear variation in demand patterns across the years. However, in some cases, the diversity may be exaggerated. Looking at the example of strawberries, there is a month in 2010 which experiences a massive decrease in strawberry demand. Given that we have data limited to data on a monthly granularity only for 1 year, it is difficult to assess the realism of such a drop. Such drastic changes could be prevented by decreasing the amount of added noise. The cubic interpolation technique also likely produces a bias in demand curves. For the purposes of training, larger diversity in demands can lead to more robust decision-making systems, albeit likely less optimized.
6. Experimental evaluation
This section provides experimental results and discussion regarding the RL and simulation approach. We investigate the following two research questions independently of RQ1 as they directly relate to the targeted goal of food waste reduction in food retail.
6.1. Experimental setup
The entities described in Section 4.1 are initialized with the following parameters:
The wholesaler sells strawberries, potatoes, and carrots at their respective average historical weekly farm prices. 52 It takes 2 days to ship an order from the wholesaler to a store.
The customer group is a population of 10,000 whose purchases reflect the demand determined in Section 5.
The store sets the price of products according to the historical weekly average retail prices in Atlanta, USA. 52 See Figure 5.
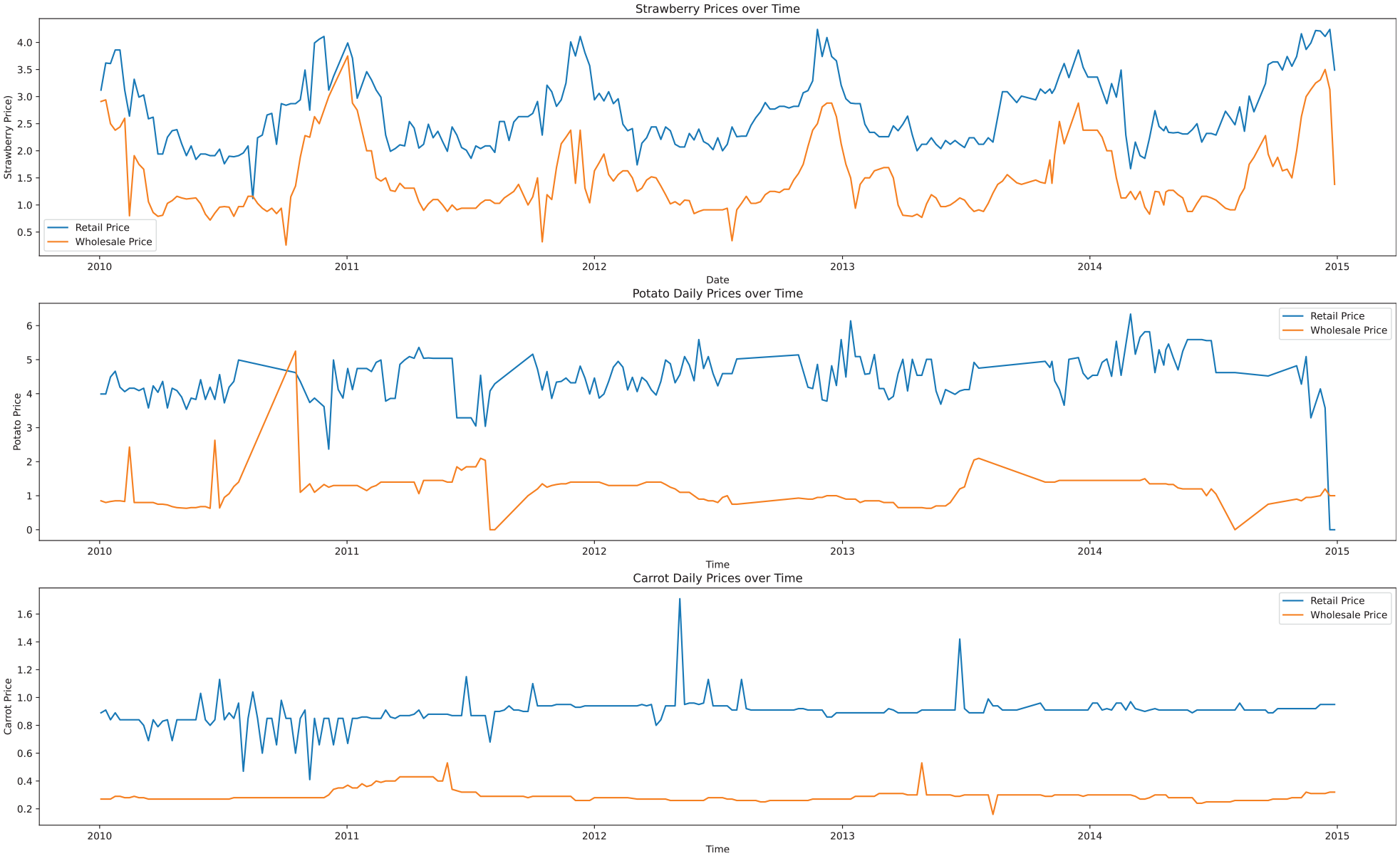
Historical wholesale (orange) and retail (blue) prices for strawberries, potatoes, and carrots.
Product expiration dates are assumed to be the following:
Strawberries have a time to expiration of
Potatoes have a time to expiration of
Carrots have a time to expiration of
These assumptions were derived from the mean time to expiration for each product type and expected intervals.
While some existing works (e.g., Broekmeulen and Van Donselaar 32 ) model customer behavior wherein the customer always purchases the freshest product, we chose not to model their behavior in this way. Many retailers have processes to push FEFO (“first expiring, first out”). Oftentimes retailers use strategies such as organizing visible inventory so oldest products remain on top or hiding fresher inventory. Some consumers also undoubtedly apply their own strategies to seek fresher products. As such, we model a uniform distribution of consumer selection likelihood from available items. All items of a particular product group get the same pricing. The simulator architecture allows for these different modeling formulations and we plan to address these in a future work where we focus on further refining product ordering and pricing strategies.
Learning. Agents are allowed to learn from simulations of days between 1 January 2010 and 1 January 2012. Up to 100k steps can be used for training with normal demand variation from Gaussian noise. Agents are trained across a range of hyperparameters and initializations. Best performing (on the training set) variants are evaluated on unseen data.
Evaluating and comparing agents. Each agent is evaluated across 1000 simulation runs taking place from 1 January 2012 to 1 January 2015. Simulation runs omit hypothetical catastrophic unexpected events (e.g., pandemic). We provide two baselines.
Actions. Each agent seeks to learn a policy to optimize an order quantity action for a given state observation. As such, each action value provided by an agent is translated into an order quantity.
Observations. All algorithm results presented in Section 6 had access to the following observations, normalized to fall within the range of
The day of the week using one-hot encoding.
The current inventory of each product as a number of items. The algorithms do not have visibility into the age or freshness of individual items.
The purchase quantity of each product over past week.
A forecast which falls within
Rewards Each algorithm is trained with both the following reward functions:
REW1 is defined as
REW2 is defined as
REW1 serves as an optimization for profit, our key optimization target.
Time dilation. RL environments (such as OpenAI gym 53 or gymnasium 44 ) typically expect that all actions are performed sequentially and that a reward from the previous action is given along with the current observation for which the next action is taken. In an attempt to mitigate the known negative effect of delays on RL techniques, 54 we introduce a “time warp” during learning (not present during testing). As delivery of products takes 2 days after an order action, we log/freeze the observations on the day an order action would be taken, but continue simulating until the order would arrive. At this point we return the reward calculated to this time, have the agent provide an action for previously observed state, and create an “instantaneous delivery.” The agent’s observability remains exactly the same, the products arrive at the exact same time, but the reward is better temporally correlated with the relevant action which should help estimating value functions.
6.2. RQ2: effectiveness of RL algorithms
Experiment results are presented in Figure 6 and summarized in Table 1.
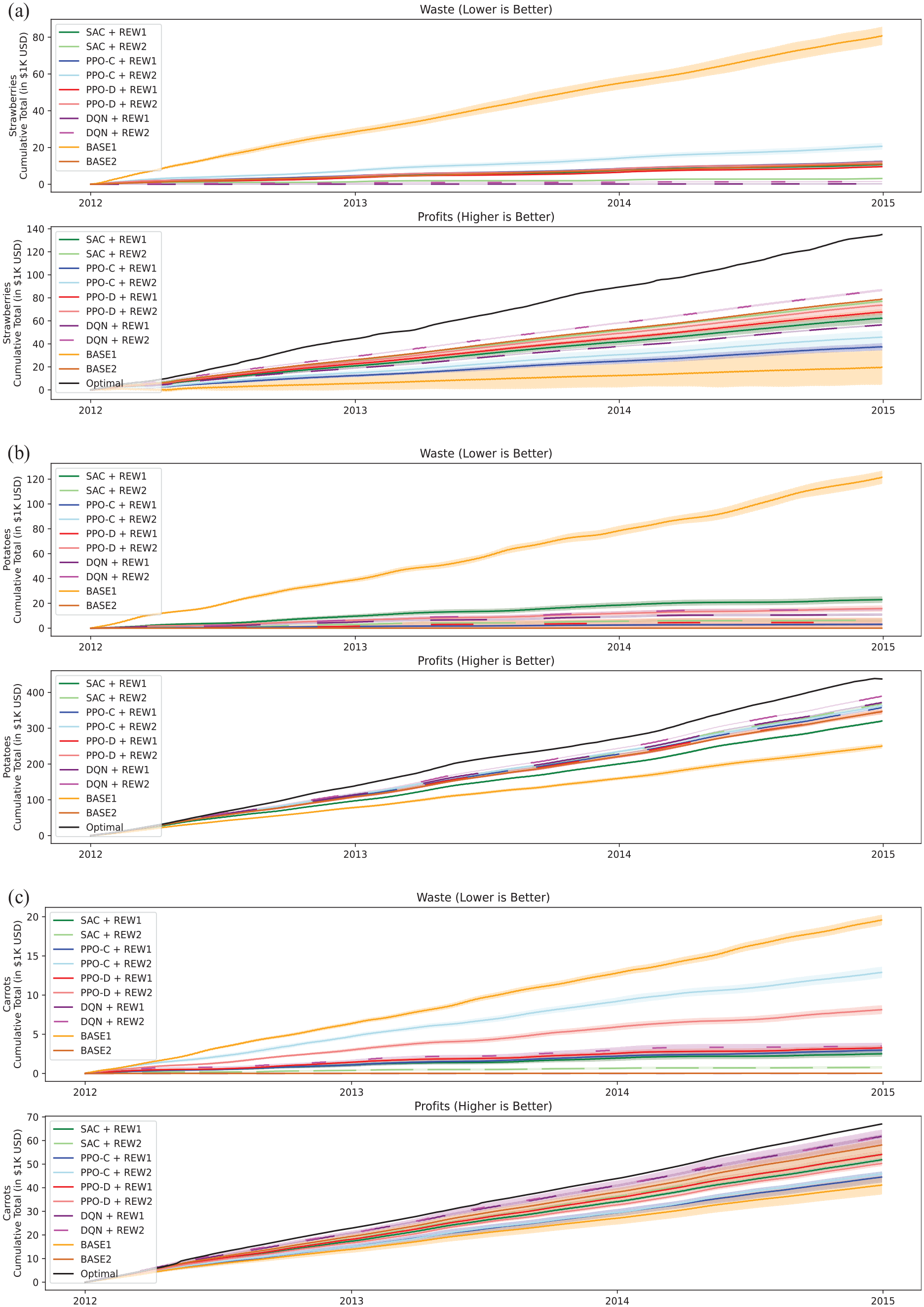
Cumulative waste (top) and cumulative profit (bottom) for (a) strawberries, (b) potatoes, and (c) carrots in USD across 1000 simulations for
Cumulative waste and profits for each RL algorithm and product compared to two baselines.
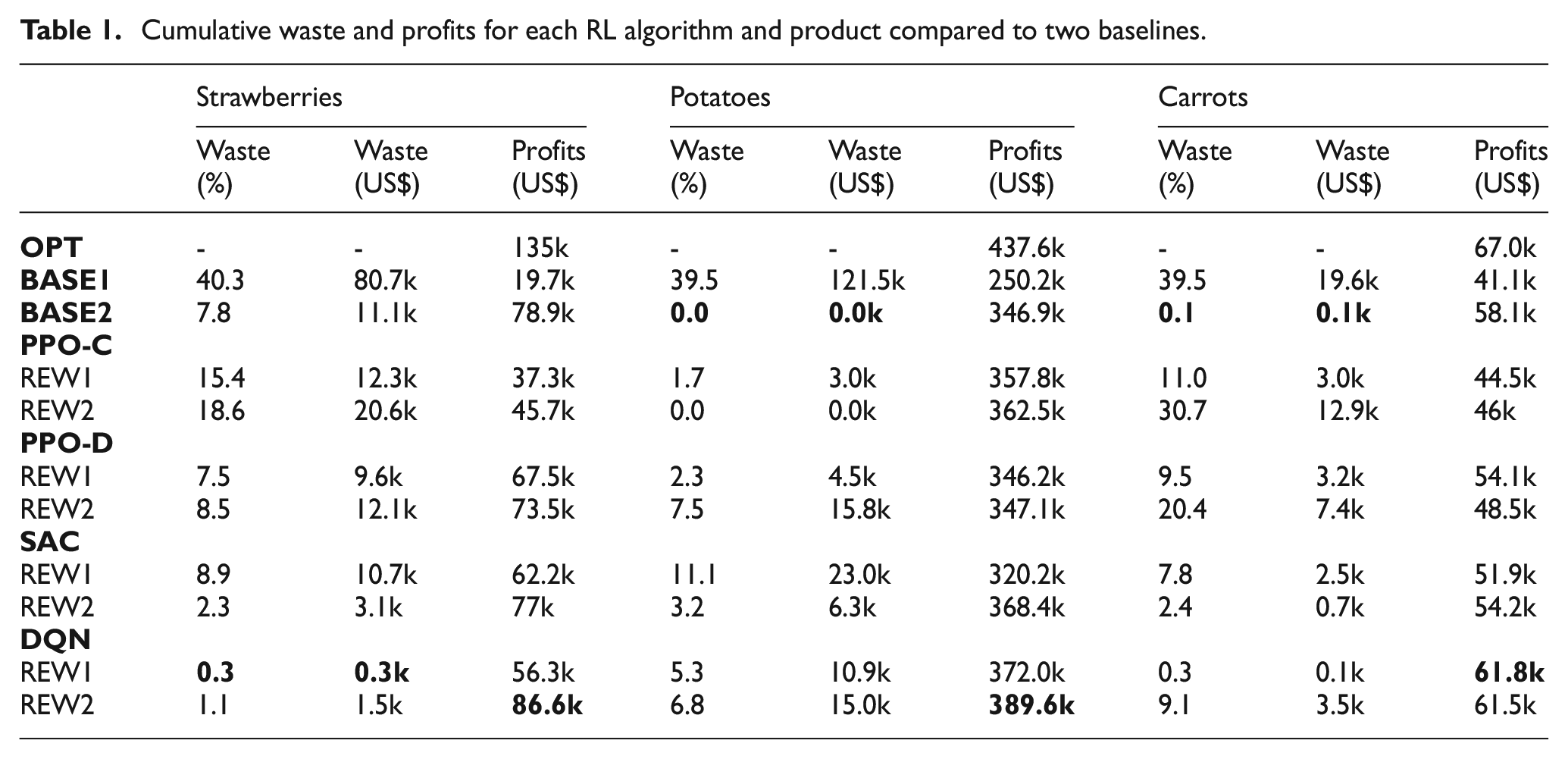
6.2.1. Experimental results
In RQ2, we investigate how effective various RL algorithms are at managing fresh grocery product ordering. Table 1 highlights that each algorithm can reduce food waste and increase profit for each product as compared to
Food waste. Each product exhibits unique demand, seasonal, and pricing characteristics.
As seen in the example of
Profit. All algorithms and reward formulations are capable of improving profitability across all three items.
Stability. Algorithms trained with REW2 typically provide better training stability than those trained with REW1. In the case of REW1, the algorithms were rewarded for reducing the amount of waste until the moment of no waste. However, REW1 can induce a reward “cliff” where decreases in order sizes can result in fewer profits due to not covering full demand while increases in order sizes can result in increased waste. This can make it difficult to appropriately adjust the policy. REW2’s more gradual reward function formulation helps prevent this case by providing a smoother gradient from the threshold to this cliff moment.
Learning curves. Not all algorithms improved at the same rate per epoch. Given the prior discussion on instability, in this paragraph, we ignore the periods where the rewards became instable and drop heavily prior to recovering. In this analysis,
6.2.2. Discussion
Demonstration. Our experimental results showcase that simulation-trained RL can simultaneously significantly reduce food waste and improve business profitability. Undoubtedly, our results could still be improved via better algorithms, rewards, and observation configurations, but this presents a clear proof-of-concept and validity in the approach.
Impact. This work confirms that AI techniques, such as RL, can provide high business impact for food retailers. The demonstrated food waste reductions and increases in profit provide clear environmental and business impact.
Limitations. For a real business scenario, additional factors may need to be incorporated into reward structures. E.g., to maintain customer satisfaction, there should always be products available (i.e., beauty stock) even though it may result in additional food waste. This is a likely reason why food waste metrics more closely align with the results of
We plan to more thoroughly investigate RL for improving business profitability in future work, now that we have a validated modular simulation framework. In this investigation, we plan to explore the scalability of an RL approach to thousands of products and to provide the RL algorithms the opportunity to adjust prices.
6.3. RQ3: simulation runtime
6.3.1. Experimental results
In RQ3, we investigate the time spent on simulation computation versus training to profile various algorithms and identify potential performance bottlenecks. An Apple M1 chip is used in our measurements.
Computation. Table 2 presents the computation time each algorithm uses to complete 100k training or inference (non-learning) steps. Times are reported as the mean of 10 non-parallelized runs wherein the algorithms are set to the default Stablebaselines3 hyperparameters. Our simple non-RL
Training and inference times (in seconds) normalized for 100k steps for each algorithm.
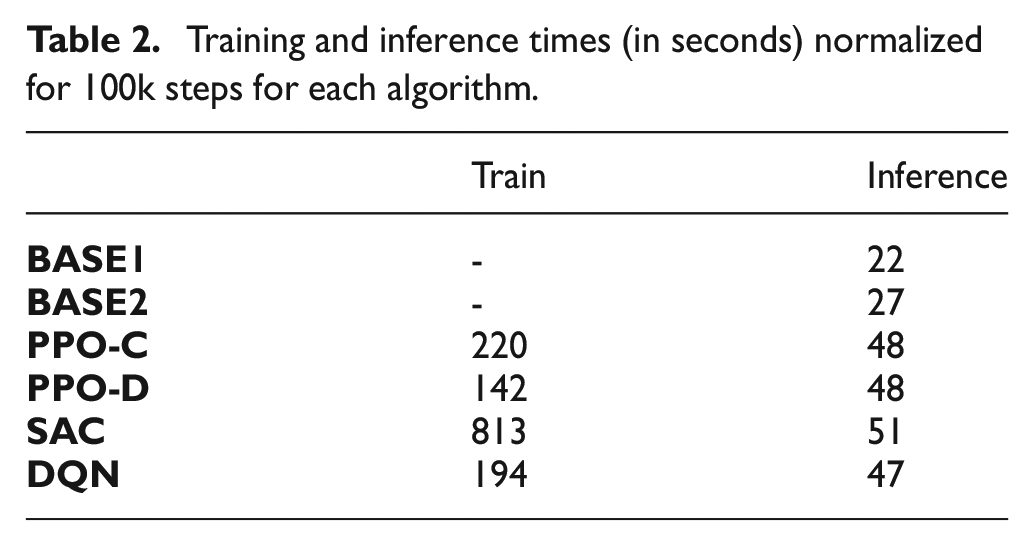
We also measure
6.3.2. Discussion
Demonstration. Our demonstrative case demonstrates that the food retail simulation framework properly handles events and can be used to train and test RL agents or other decision-making systems. Interfaces provide proper access for agents to control product prices and orders. Furthermore, food waste, product deliveries, and purchases are systematically tracked and logged. Each entity is functional; wholesalers, retailers, and customers all interact as expected and customer groups can select between available products. While the demonstrative case used synthetic demand, our framework is highly customizable and configurable which makes future transitions to real daily sales data easy.
Impact. This simulator can serve as both a testbed for research and a real food retail operations tool in the future. It can be deployed as a software service with a public interface, which would enable a smooth transition toward integrated solutions to be used by individual food retailers.
Limitations. RL agents improve with experience. Fast simulation times therefore enable quicker learning as the agent can process more experience per second of computation. While simulation takes less computation time than the RL agents, it could still be optimized to speed up learning. Presently, the simulation environment is written in python without any specialized optimizations, such as just-in-time compilation. This significantly limits the possible computation speeds achievable by the simulator architecture. To improve computation time beyond just-in-time compilation, one can rewrite parts of the simulator in C ++ and connect them to python interfaces via python wrappers. From previous experience, this can result in significant simulation speedups.
Currently, the simulation is limited to daily time steps. In the future, transitioning toward a DEVS framework could allow for finer-detailed modeling.
6.4. Threats to validity
Construct validity. In our demonstrative case, we limit threats to construct validity by initializing simulations from aggregated statistical data. While, this may not be perfectly representative for simulating a realistic food retail location, the data are derived from real sources with seeming consistency (see Section 5.1). We maintain historical average pricing and extract data from average historical demand, which we believe mitigates the threat of simulating a completely unrealistic food retail location.
Internal validity. To avoid threats to internal validity, we use implementations from a trusted library (stablebaselines3) and present the results on the backdrop of a simple baseline. Final evaluation results are the average of 1000 simulation runs to prevent lucky performance. Many metrics and simulation intermediary results are logged to prevent likelihood of inconsistent results.
External validity. The results exhibited in this paper are not guaranteed to be reproduced if the same methodology is adopted by a real food retailer. We seek to mitigate threats to external validity by leveraging data sources based on average statistics to try and create an “average” food retail store.
7. Conclusion
This paper presents a novel food retail simulation framework designed for developing and testing RL solutions for reducing food waste and improving business profitability. As relying on historical data alone is usually insufficient for training such solutions, this work provides a simulation training and test bed, where RL algorithms can be exposed to many food retail scenarios. The DES environment is highly customizable with definable wholesalers, stores, and customers which interact on a daily basis. Any entity can be independently controlled via RL agents or other control algorithms. Logs and statistics of purchases, deliveries, and food waste are all recorded to enable data analysis. We provide a simulation + RL demonstrative case consisting of strawberries, potatoes, and carrots derived from yearly and monthly statistics via a method combining interpolation and optimization. Results for PPO, SAC, and DQN demonstrate that RL methods can significantly improve on a baseline strategy which mimics industry typical 40% food waste. These algorithms reduced food waste by 78%–92% on average with 50%–340% increases in profit. Best algorithms likewise improved on profits from a second well-known baseline from literature by 11.1% on average. Such optimizations would provide true environmental and business impact.
In future work, we will extend our simulation to follow a DEVS framework to improve operations realism and prepare it for working with real food retailers. Furthermore, we will conduct a rigorous investigation across a larger number of algorithms, problem formulations, and algorithms (including multi-armed bandits with delay 54 ) to control pricing and order quantities. The goal is to evaluate the ability of such technology to be fully applied in practice and its ability to scale to thousands of retail items.
Footnotes
Funding
This research was partially supported by the Natural Sciences and Engineering Research Council of Canada Idea-to-Innovation (grant no. NSERC I2IPJ 576543-22), a TechAccelR (grant no. #243794) grant and the Invention To Impact (I-to-I) program of McGill Engine. The third author was also supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation.