
Abstract
Cooperative multiagent reinforcement learning approaches are increasingly being used to make decisions in contested and dynamic environments, which tend to be wildly different from the environments used to train them. As such, there is a need for a more in-depth understanding of their resilience and robustness in conditions such as network partitions, node failures, or attacks. In this article, we propose a modeling and simulation framework that explores the resilience of four c-MARL models when faced with different types of attacks, and the impact that training with different perturbations has on the effectiveness of these attacks. We show that c-MARL approaches are highly vulnerable to perturbations of observation, action reward, and communication, showing more than 80% drop in the performance from the baseline. We also show that appropriate training with perturbations can dramatically improve performance in some cases, however, can also result in overfitting, making the models less resilient against other attacks. This is a first step toward a more in-depth understanding of the resilience c-MARL models and the effect that contested environments can have on their behavior and toward resilience of complex systems in general.
1. Introduction
Large-scale, complex rescue and military operations often operate in contested and dynamic environments, with unavailable or jammed networks. 1 The operational success and system resilience in these environments rely on ensuring that decision-making happens correctly even when the environment is perturbed. This perturbation can happen as a result of forces of nature making system parts separated from the rest, various network faults that lead to partitions, jamming (intentional or otherwise), or resource contention due to SWaP constraints.2–4 Regardless of the cause of the contention, automated and autonomous systems must make decisions with partial observability and, in some cases, within severe time constraints.
Two approaches to develop such complex resilient decision-making systems are widely used. In the bottom-up approach, the decision-making system is developed from scratch, with the end goal being the desired system-wide property. Approaches include mechanism design and game theory 5 and their closely related agent-based approaches.6–11 These approaches are in general successful in achieving the desired emergent property, but the system-wide behaviors are often not fully validated. In addition, most approaches are evaluated in small-scale scenarios and are deployed in stable environments, where a property such as resilience is not frequently considered. 12 Often there is no analysis of side effects, and thus, the full aspect of system-wide behaviors is not well understood. 13 Modeling and simulation approaches have tremendous potential to help alleviate this problem, as these complex systems can be evaluated in simulation environments before being deployed in real life. In a reuse-focused approach, previously validated systems or models are integrated to achieve a desired system-wide property. This might include the integration of various system components in a systems-of-systems design approach 14 or component-based philosophy 15 or the use of established decision-making approaches in new contexts. 4 This reuse-focused approach is appealing because it has reduced development costs and promotes a deeper understanding of the limits of using previously developed models in new environments. However, the effectiveness of the reuse-based approach relies on the existence of validated model components and on their integration without any side effects,10,13,15 and assumes that the reuse happens within the initial parameters of the initial model. Regardless of the approach used, a decision-making overlay, model, or protocol helps seamlessly integrate these system components and ensure that the desired property is met. The decision-making protocol might form the entirety of the newly developed system, might facilitate communication between model components, or might be used to reason about changing context information. There are countless decision-making approaches, 16 including game theory, 17 fuzzy logic, 18 machine learning, 19 and rule-based expert systems. 18 In this paper, we focus on multiagent reinforcement learning (RL) and understanding its resilience through a modeling and simulation framework.
The use of multiagent RL to solve decision-making problems has seen significant research interest up-take in recent years, due to the significant advances in RL and computational methods to support it. In an ever-evolving stochastic world, animals and robots alike learn from trial and error to manage, navigate, and negotiate within their environment to achieve a goal. This trial and error process with underlying cause and effect rules generates information about action consequences and the best approach to achieve a goal. 19 This in turn forms the underlying principle of RL, which leads to learning optimal actions for a given sequence of situations. 20
Multiagent RL (MARL) is a type of deep RL (DRL) that trains multiple agents to either cooperate or compete against each other. Cooperative MARL (c-MARL) models have agents that work toward a common goal. 21 Their extensive popularity has seen their application to real-world problems such as traffic management, power management, unmanned aerial vehicle control, 22 swarm robotics, autonomous driving, 23 and cellular base station control. 21
The cooperative nature of c-MARL boosts its performance when compared to classic RL agents; however, it also makes it more vulnerable to attacks. 24 Robustness is the ability of c-MARL models to make accurate decisions for a large range of inputs 21 and captures the models’ ability to generalize over unseen training data. Resilience is the ability of a c-MARL model to recover from unforeseen, disastrous events, such as loss of network capability or agent failures, including adversarial attacks. Despite their increase in popularity and varied use across diverse critical application domains, many c-MARL models are deployed in real-life environments without an in-depth understanding of their resilience and robustness, and after only being trained with simulated data. 25 A modeling and simulation approach must exist to understand their limitations, in particular concerning specific c-MARL constraints such as their difficulty in estimating team rewards, nondifferentiable models, nonstationarity, and the low dimension of feature spaces 21 as well as specific environment effects and attacks that might impact their resilience.
The state, action, reward, and transition space of c-MARL models increase the domain for adversarial attacks 26 and the dynamic and contested nature of some of the environments in which c-MARL models could be deployed can further pose significant challenges. 12 Very few works analyze the robustness of suites of c-MARL algorithms, 22 and existing work only focuses on white-box attacks that perturb the action, observation, and reward of an agent. We build on this work by assessing the resilience and robustness of four c-MARL algorithms against different types of attacks, namely, perturbation of observation, reward, action (white box), environment (gray box), and communication (black box).
In this paper, we propose the design, prototype development and experimental analysis of a modeling and simulation framework that explores the resilience of c-MARL models under different types of attacks. Our framework explores different types of white-, black-, and gray-box attacks and how their devastating impact can be mitigated with training in some cases. Our approach represents a first step in a deeper understanding of the decision-making capabilities of c-MARL models as they are operating in environments that are significantly different from those used to train these models. The contributions of this paper are many-fold:
An in-depth overview of decision-making in contested and dynamic environments, with a focus on c-MARL.
An overview of modeling and simulation perspectives on resilience and robustness.
A simulation and experimentation architecture focused on attacking decision-making algorithms operating in dynamic and contested environments.
A comprehensive analysis of the lack of robustness of various c-MARL models in the face of white-, gray-, and black-box attacks.
A study on how different training approaches can improve model resilience against various types of attacks.
2. Background and related work
We discuss in this section literature relevant to understanding resilience in complex systems, decision-making in contested environments, and the use of modeling and simulation to understand the effect of disruptive events on system behavior in a variety of application domains. We also present an overview of c-MARL and discuss several relevant models, and existing work in understanding their resilience against attacks.
2.1. Resilience in dynamic and contested environments
Dynamic environments are environments where conditions change quickly, affecting the system state and agent operation, either directly or indirectly.12,27,28 A contested environment is one where adversarial action or initial conditions leads to stale or incomplete information, or in resource-constrained environments, where resources are either limited or required by a large number of components. For example, complex rescue operations might use radio-based ad hoc networks where there is no guarantee of reliable communication but there is a need for quick and accurate decision-making. In most battle scenarios, soldiers may not have a complete view of the position or status of their platoon and thus critical decisions that affect system-wide outcomes are made with incomplete and unreliable information. In addition, within these contested networks operating in dynamic environments, there is a need for assurance of timely delivery, responsiveness and graceful degradation mechanisms that can manage the fragility of the communication networks and guarantee the system resilience.
There are many definitions of resilience, starting with its first use in a scientific context by Sir Francis Bacon in 1625, 29 followed by its use to describe the ductility of steel beams in 1858 by Rankine. 30 The broad understanding of resilience within complex systems is that it encompasses the behavior of the system before and after a disastrous event, and can be viewed, according to Francis and Bekera 31 as three capacities, namely, an adaptive capacity to the disastrous event, an absorbing capacity of the effects and consequences of the event, and a recoverability of the system to a state that was before the event, or a better state. 32 The “bouncing back” ability is considered by Gunderson’s ecological resilience definition to be measured by a threshold, with resilience defined as “the capacity of a system to absorb impacts before a threshold is reached where the system changes to a different state.” 33
Another perspective considers four aspects of the systems and operating environments that build the case for resilience, according to Tierney and Bruneau: robustness, redundancy, resourcefulness, and rapidity.34,35 A system is resilient if the occurrence of undesired incidents is minimized, and, once an incident occurs, its undesirable consequences are reduced, and the system returns to normal operation within a short time.34,36,37
From the perspective of the resilience of engineered Systems of Systems (SoS), resilience can be viewed as an inherent property of the system that is influenced by the SoS components and their behaviors, with an understanding that the resilience of a system is dynamic, and changes as the environment changes. 30 In a similar approach to the NAS definition above, 38 recognize that quality, robustness and agility are components of resilience, and identify repairability, extensibility, flexibility, adaptability, and versatility as how the system achieves robustness after a shock. In addition to these components, Haimes 39 identified also “the ability to prepare and plan for, absorb or mitigate, recover from, or more successfully adapt to actual or potential adverse events.”
One way to incorporate resilience within a system is by incorporating some of the resilience considerations described above within the behaviors and decisions of all individual system components. This could be done by designing node-specific rules or behaviors relying on the partial or complete understanding that a node has of the system context and the role this plays in the system-wide resilience.12,30,36 The node would then be able to reason over the context and prioritize information-sharing activities as it suits the mission plan and the current context. This complex systems design approach subsumes the understanding that individual nodes will make decisions both in cooperation with other nodes and in isolation, caused by various network partitions or specific attacks, and that the local node decisions are cooperative, in the sense that they lead to a complex system with a desired behavior.
2.2. Modeling, simulation, experimentation, and validation
Complex systems are ubiquitous, and, as their operations increasingly take place in contested and dynamic environments, so the need for their resilience becomes critical.36,38 Modeling and simulation approaches by their nature have become increasingly popular in the analysis of the resilience of complex systems under various attacks and environmental changes,4,40 with application domains such as energy infrastructures, 41 emergency department planning and analysis, 42 landscape ecology, 43 sociotechnical systems, 44 supply chain management,45–47 and cyber-physical systems (CPS) 48 employing modeling and simulation to study various aspects of resilience.
Keane et al. 43 proposed the use of discrete event simulation to understand the resilience of emergency departments within hospitals that are facing earthquakes. The authors use the patient waiting time as a resilience metric and propose a meta-model that considers the seismic input and the number of available emergency rooms. Many works use modeling and simulation to understand the resilience of supply chain and transportation networks.45–47 Wicher et al. 47 used a simple disruption profile to show the system’s vulnerability to simple disruptions while 46 identifying sustainability factors that can improve resilience. A review of modeling and simulation approaches to study resilience in this domain was given by Dong et al. 45
Koutsoukos et al. 48 proposed a modeling and simulation framework for the analysis of resilience in CPS, using a smart transportation system as an example. The framework proposes the realistic modeling of cyber components and introduces a test-bed for the evaluation of security of CPS, using seven white-box attacks, which assume in-depth knowledge of the system is available to attackers.
2.3. Decision-making algorithms and communication
Many approaches can be used for decision-making in contested and dynamic environments, including artificial intelligence, rule-based, heuristic, fuzzy logic, multicriteria decision-making, and machine learning. In this paper, we focus on RL and specifically on c-MARL, as discussed below.
Machine learning is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is defined as a subset of artificial intelligence. Machine learning algorithms build a mathematical model based on sample data, known as training data, to make predictions or decisions without being explicitly programmed to perform the task. A core objective of a learner is to generalize from its experience. RL—is an area of machine learning concerned with how software agents ought to take actions in an environment to maximize some notion of cumulative reward. 19
MARL is a type of DRL that trains multiple agents to either cooperate or compete against each other. c-MARL models have agents that work toward a common goal. 21 Their extensive popularity has seen their application to real-world problems such as traffic management, power management, unmanned aerial vehicle control, 22 swarm robotics, autonomous driving, 23 and cellular base station control 21 ; however, to date, there is little to no understanding of their resilience, in particular when deployed in real-life environments. 21
2.3.1. c-MARL algorithms
This paper proposes the evaluation of the resilience and robustness of c-MARL models, and the proposed framework is instantiated with four models, namely, IQL, VDN, QMIX, and QTRAN, which are discussed briefly below to highlight their different learning approaches.
2.3.2. IQL: independent learning
Tampuu et al. 20 noted that Q-learning is an approach that estimates the quality of action in a particular state of the environment. Distributed learning has its own challenges such as convergence and consistency which arise due to the impact of actions by other agents. The authors propose autonomous Q-Learning or independent Q-Learning (IQL) for each agent in the environment, where agent interaction happens only through the environment, leading to an algorithm that is decentralized, simple, fast, and consistent in results. However, IQL fails to capture nonstationarity due to changing policies of agents which theoretically does not guarantee any convergence. 49
2.3.3. VDN, QTRAN: centralized training
c-MARL problems can also be solved using a centralized training approach by combining the observations of each agent. Sunehag et al. 49 proposed a novel learned additive value decomposition network (VDN), which can be represented as follows:
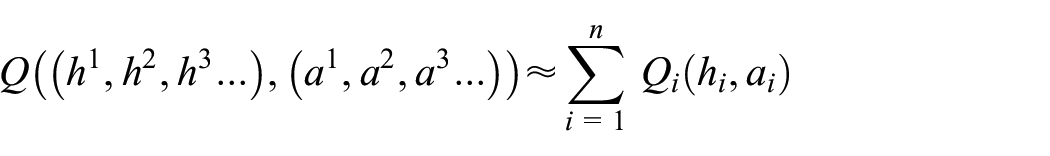
where h is the history of an agent, a is the action taken, and
2.3.4. QMIX: centralized training with decentralized execution
Centralized training with decentralized execution (CTDE), where, ..., is popular due to its ability to access additional state information and lift communication constraints. 50 In their proposal of QMIX, Rashid et al. 50 suggested that complete factorization of VDN is unnecessary and note that consistency can be achieved by applying global argmax on the global Q value, which yields the same result when applying argmax on the individual Q value obtained by the agents:
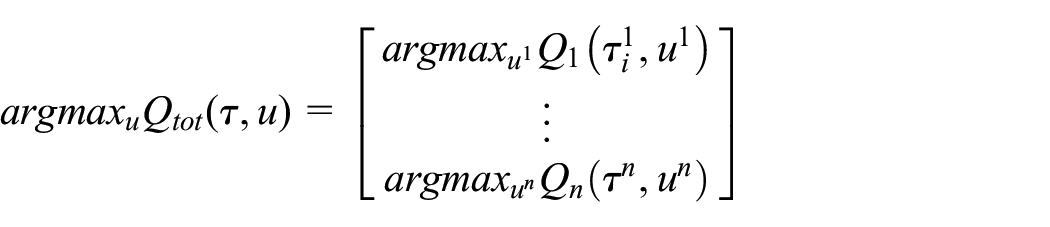
where

The authors demonstrate that QMIX outperformed both IQL and VDN in StartCraft II due to its ability to extract extra information from the state, which enables it to have finer control over the agents.
Son et al. 51 discussed the issues associated with VDN and QMIX, stating that they are able to factorize only a handful of MARL tasks due to their structural constraint in factorization, namely additive decomposability and monotonicity, respectively. Authors propose a novel factorization method QTRAN that they claim to be free from structural constraints. QTRAN transforms the joint action-value function into an easily factorizable function with optimal actions similar to other c-MARL algorithms. QTRAN does this through its interconnected deep neural network architecture which consists of individual action value networks, joint action value networks, and state value networks. The individual action value network produces action values as output by taking an action observation (history) as input for an individual agent. A joint action-value network approximates the joint Q value by taking a selected action as input and producing the Q-value of the chosen action as output. The state value network computes a scalar state value to provide flexibility to match the joint action value and individual action value network output. Without the state-value network, partial observability would limit the representational complexity. The authors demonstrate that QTRAN covers a larger array of MARL tasks than VDN or QMIX due to a more general factorization. They also showcase that QTRAN outperforms VDN and QMIX especially when the MARL challenges have nonmonotonic characteristics.
2.3.5. Importance of communication
Communication plays a crucial role in the performance of c-MARL models. Zhu et al. 52 asserted that since communication helps with coordination, it thus improves the quality of learning and therefore the model performance. In their study, Zhu et al. explored various aspects of communication and divide existing approaches into nine categories, based on the when, how, and what is communicated. Communication is required in a CTDE training framework as individual Q-values need to be collected, calculated (by the required Q-function), and distributed among agents. Zhang et al. 23 proposed that effective communication between the agents can improve the overall performance of c-MARLs. However, they argue that the existing communication approaches have excessive message exchange without any major advantage. They claim that this may lead to a reduction in performance or delay in the decision-making process. They also consider the loss of communication which can be detrimental to performance. They suggest temporal message control (TMC) to counter both issues. TMC aims to improve communication efficiency and robustness by reducing the variation in transmitted messages over time. QMIX with TMC has been shown to achieve a 23% higher winning rate in StarCraft II (SMAC) as compared to variance-based control (VBC) + QMIX. 23
Jarne Ornia and Mazo
53
presented an approach to reduce communication between agents in a multiagent learning system by exploiting the inherent robustness of the underlying Markov Decision Process. Authors create a robustness surrogate function that gives agents a conservative indication of how far their state measurements can deviate before they need to update other agents in the system. The authors propose an event-triggered control (ETC). They define a surrogate robustness indicator
2.3.6. Resilience and robustness of MARL algorithms
MARL algorithms are prone to different types of adversarial attacks, and a comprehensive review of such attacks is presented by Standen et al. 40 Ilahi et al. 26 investigated the vulnerabilities an adversary can exploit to attack DRL equipped with state-of-the-art countermeasures to prevent such attacks. All the major components of a DRL pipeline (state, action, model, and reward) can be attacked, depending on the knowledge and adversary types. 26 The knowledge adversaries might have can be divided into black box (no knowledge of the model), gray box (have some knowledge), and white box (have perfect knowledge of the model). In addition, the types of adversarial attacks depend on the part of the DRL pipeline that is under attack. When targeting the state space, the adversary can add perturbations to the environment, training data, observations, and sensory data. When perturbing the action space, the adversary can target the agents. When perturbing the reward function, the adversary can perturb the reward signal. For model-space attacks, the adversary can perturb the learned parameters of the model or might attempt to extract the learned model. The authors mention a few defenses against adversarial attacks such as adversarial training, game-theoretic approach, robust learning, adversarial detection, and defensive distillation. Unfortunately, there is no one solution for all the attacks and almost every defense mechanism needs to keep updating with novel attack patterns. 26
He et al. 54 investigated the robustness of MARL algorithms under state uncertainty. They claim that the discretization approach for solving MARL problems with continuous state and action space might not lead to optimal policy in a high-dimensional space. They note that state uncertainty can be introduced through adversarial state perturbation for high-dimensional continuous space which leads to suboptimal solutions using discrete methods, degrading the performance. They also highlight the importance of investigating heterogeneous agents in a MARL setting since the underlying development of agents’ capabilities, knowledge, and objectives is still unclear making investigation and mitigation of robustness even more challenging for such models.
Guo et al. 22 introduced MARLsafe, a robustness testing framework for c-MARL models. MARLsafe attacks state, action, and rewards one at a time. A perturbed state is introduced forcing the enemies to take erroneous actions. Action generated by the model is substituted by actions generated by an adversary and rewards are flipped at some predefined intervals. These attacks were performed on QMIX and MAPPO models resulting in a significant drop in performance. We adopt a similar approach to assess the degree of impact on different c-MARL algorithms (IQL, VDN, and QTRAN) because of their different learning approach. We also subject these algorithms to not only white-box attacks but also gray- and black-box attacks.
Another approach to attacking MARL algorithms is to train a MARL algorithm (antagonist) such that it learns the behavior of the target MARL system (protagonist), this approach is undertaken by Lin et al. 21 to assess the robustness of c-MARL models. They attack the c-MARL model in two steps, first, training a policy network with RL receiving minimum rewards for a given action, and second, using targeted adversarial examples to force the victim to take a particular action (with minimum reward). Just by attacking a single agent, in a black-box setting, their method has a negative overall team reward, the protagonist’s winning rate went from 98.9% to 0%. This demonstrates that cooperation within multiple agents in c-MARL can improve the performance against a simple RL model, but it can also become a major disadvantage considering adversarial attacks. To reduce the impact of such attacks the authors suggest that the training of agents should include an estimate of action values or reward functions for other agents and use the estimate to identify malicious agents potentially. Another possible defense involves formulating all agents as potential adversaries during MARL centralized training so that an agent can react better to adversarial actions during execution.
In the field of c-MARL, attack methods are largely unexplored. 55 Gleave et al. 56 developed adversarial attacks which introduced perturbations to the natural observations forcing the victims to take suboptimal actions. Nisioti et al. 57 and Zan et al. 55 proposed targeted attacks on the agents. Nisioti et al. 57 targeted a single agent based on its performance which was followed by a temporal difference strategy to create a robust policy. Whereas, Zan et al. 55 had a clustering algorithm to identify a group of agents which can be attacked. After identifying the group of agents a GMA-FGSM-based white-box attack is performed. A min-max approach was introduced by Li et al. 58 to improve the robustness of learned policies in a c-MARL setup. While updating an agent’s policy all the other agents were considered as adversaries. All of these attacking approaches were targeted on a single c-MARL algorithm.
Li et al. 59 introduced adversarial minority influence (AMI). AMI is a black-box adversarial attack that aims to exploit the influence agents have on each other by decomposing the shared information and using an RL agent to compute the worst action for a given situation. The authors focus on the impact of black-box attacks on the performance of an on-policy model, MAPPO, after it has been trained. In contrast, we explore the impact of such an attack on off-policy models.
2.4. Training approaches to improve resilience
Different training approaches have been shown to increase the resilience of c-MARL algorithms. Al-Nima et al. 21 attempted to improve the robustness of DRL by introducing faulty samples in the training session. They measure the model robustness by neuron coverage (NC). Al-Nima et al. 21 claimed that having a higher NC leads to better performance. They attempt to employ Genetic algorithm for Neuron coverage (GANC), i.e., genetic algorithm using neuron coverage as the fitness function. The benefit of using such an approach is that the model can generalize better and “re-training” is done only on the faulty samples. Their results show that GANC improves the performance of DRL-RT models.
Zhou and Liu 60 also suggested that a robustness testing framework for MARL models is necessary due to their wide application, state-of-the-art performance, and high vulnerability to attacks. They claim that such testing frameworks are essential to building trust in MARL models and suggest the robustness testing framework for the MARL that attacks states of Critical Agents (RTCA). RTCA is a differential evolution-based method that selects a victim (an agent) based on a team cooperation policy evaluation method to recommend the worst action possible for a given situation.
To improve the robustness of MARL algorithms, Guo et al. 61 trained a MARL model, QMIX, with a variety of attacks during the training phase. They attempt to adopt robustness training methods in a MARL setting. They investigate four such training strategies gradient-based adversary, policy regularization, alternating training with learned adversaries (ATLA), and policy adversarial actor-director (PA-AD) to improve the robustness of algorithms. They note that all the above strategies have limitations and advantages under certain conditions such as action space, observation space, the complexity of the MARL model, and the task at hand.
Phan et al. 62 and Lin et al. 21 argued that the higher the number of agents, the higher the potential for failure as each agent can succumb to hardware/software failure or adversarial attacks. To avoid this Phan et al. 62 proposed antagonist-ratio training scheme (ARTS) to address both learning and resilience in cooperative multiagent systems (MAS). In ARTS, the cooperation and competitiveness of MAS system are clubbed, where the cooperative (protagonist) MAS learns how to become resilient while achieving the target, whereas the competitive (antagonist) MAS trains to learn possible failure situations, which is later used in testing. An important aspect of the training is that the agents in the protagonist team would not know if an agent is an ally or a foe, whereas the antagonist has access to this information. ARTS combines CTDE with population-based training (PBT) which leads to a decentralized execution of individual policies. The authors showcase that the ARTS testing framework improves the resilience of MAS. However, they do indicate that the ratio of the protagonist to antagonist is crucial for optimum performance. If the ratio is high then the MAS system is not as resilient, which later affects the performance when under attack. Whereas, if the ratio is too low, the protagonists learn to behave conservatively leading to poor centralized learning. The authors also point out that the quality of the antagonist in ARTS cannot be determined as it depends on the difficulty of the domain. ARTS is tightly coupled with the type of MAS systems, the difficulty of the problem, and the ratio of the protagonist to the antagonist. Also, the quality of the antagonist in ARTS cannot be determined. It can be regarded as a black box testing suite, which makes it easy for integration but difficult to investigate the test cases executed or to add more test case scenarios.
Pinto et al. 25 noted that MARL algorithms succumb to either the gap between the simulation and the real world or to the lack of data if the training is in the real environment, both leading to failed generalization. To mitigate such issues, they suggest modeling these errors as extra forces or disturbances of the system, which, the authors note, is impossible. The authors propose robust adversarial RL (RARL), where an adversarial agent (antagonist) is trained to learn the weakness of the target agent (protagonist) through a zero-sum game. The antagonists in RARL, have “superpowers” in their action space, which allows them to create unexpected situations during the training, which can help the protagonist generalize better. During testing the authors altered a few environment features and found RARL-trained models were more robust compared with other RL algorithms.
Pan et al. 63 noted that RARL can improve robustness to some extent but does not encapsulate the variety of scenarios present in the real world, catastrophic events being one of them. Therefore, they suggest risk-averse RARL (RARARL). This approach also involves an antagonist and a protagonist. Training of protagonist policy is not only aimed at maximizing long-term expected rewards but also at the selection of actions with low-risk variance, where risk is modeled as the variance of an ensemble of the Q-value network for a given state and action.
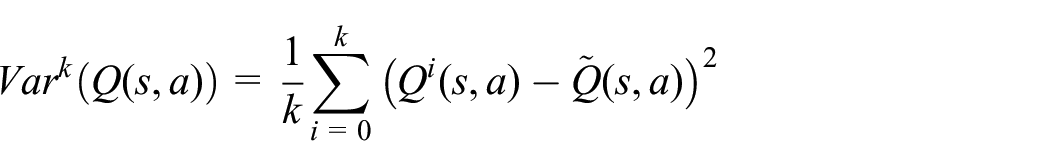
where Q (s, a) is the mean of Q values obtained from the ensemble of the k Q-value network.
The goal is for the protagonist and antagonist to select actions with low and high variances, respectively. The protagonist is made risk-averse by introducing a risk-averse term in the Q-value obtained from an action, state pair. This Q-value is essentially the difference between the original Q-value and the modeled risk (variance)
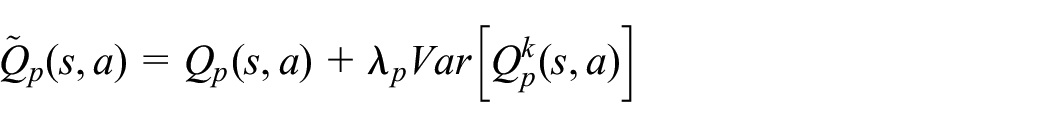
where
Similarly, the calculated Q values for the antagonist is
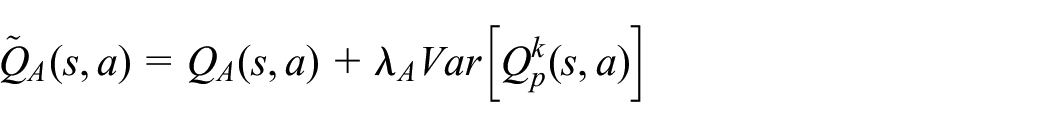
where
Unlike RARL, actions in RARARL are taken sequentially. The antagonist takes an action after the protagonist has completed a predefined or randomly defined (during training) number of steps. The Bellman equation is updated to incorporate the dynamic transition model for both protagonist and antagonist accordingly. The authors found that adding the risk term achieved better robustness under both random and adversarial perturbations.
Wang et al. 64 argued that in RARL creating a neural network-based adversary requires handcrafted reward signals which is difficult, especially if training is not a zero-sum game. Therefore, they suggest a safety falsification-based approach to improve upon RARL, which is called falsification-based RARL (FRARL). FRARL aims at finding the initial condition and input sequence with which a system violates a given safety specification. They showcase that the policy learned in safety-critical scenarios behaves much safer than those classically trained. All the above approaches rely on a trained antagonist to attack the system, and thus assume that in-depth knowledge about the system is somewhat available to the attacker. In addition, the approaches focus on resilience issues within specific models, without an in-depth understanding of the complexities of the environment, decision-making components, and context information that leads to the various algorithm vulnerabilities. To the best of our knowledge, no modeling and simulation framework exists that can evaluate the resilience and robustness of various c-MARL models under diverse conditions, and we propose a first step toward such a framework discussed below.
3. Proposed approach
Many factors that influence the resilience and robustness of a c-MARL decision-making algorithm, including the environment used, the attack type, and the whether the model has been exposed to this type of attack during training. We propose a plug-and-play modeling and simulation framework that considers these aspects, as shown in Figure 1. To evaluate the robustness of c-MARL models in various contested and dynamic scenarios, we rely on an experiment definition that provides an overview of the potential attacks, the model training, and allows us to select the environment.
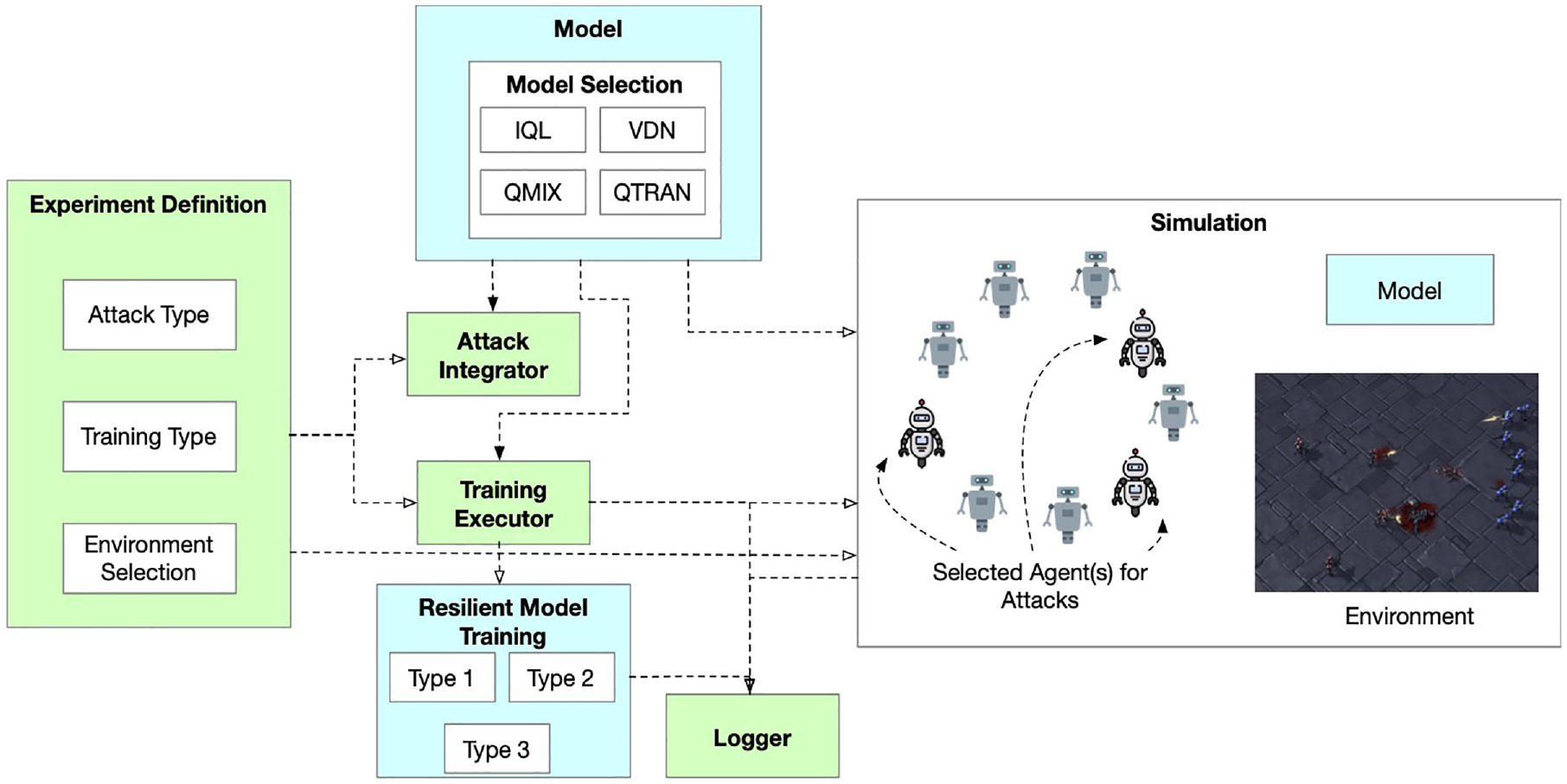
Simulation and experimentation framework for resilient c-MARL.
The Experiment Definition module interacts with the Attack Integrator and Training Executor modules to properly execute training runs. The Attack Integrator integrates the various attack types within the simulation execution. The attack types are dependent on the chosen models and also might influence the different training types.
The model selection component focuses on selecting the model to be evaluated from the various existing c-MARL models in our repository. Based on the training type definition and the specific model chosen, different types of training approaches for resiliency are selected.
The Training Executor determines what are the appropriate types of training to be used, based on the experiment definition file and the selected model types.
Finally, the simulation component selects the agents that are to be perturbed and deploys the model with its training regime within the selected environment. We discuss these in the below sections. All relevant information, which is defined in the experiment definition files, is logged by the Logger.
3.1. Adversarial attacks
As discussed above, adversarial attacks cover the perturbations introduced in the simulation within the observation, action, reward, and agent communication, to cause the agents to misbehave and the model to fail in achieving its goal. The effectiveness and usefulness of each specific attack depend on many factors, including the type and frequency of the attack and the type of training the model is subjected to.24,26 Within our proposed modeling and simulation framework, the factors that we can control to determine the resiliency of the c-MARL algorithms are the type, tempo, and locus of the attack as well as the training type, as discussed below.
Adversarial attacks can be broadly divided into white box, gray box, and black box based on their access to the c-MARL model.
3.1.1. White-box attack
White-box attacks are adversarial attacks in which the adversary has perfect knowledge of the model. The attacks which fall under this category are perturbation of action and perturbation of reward.
Perturbation of action: The attack handicaps an agent by limiting available actions for a given state. The attack proceeds by randomly removing few actions from a list of total actions available for a given state observed by that agent. Such an attack forces the model to learn policy which can be detrimental to the overall performance. Since the policy is correlated to action space through the reward signals, it becomes difficult to diagnose such an attack. 26
Perturbation of reward: Rewards help influence the policy of an agent which impacts the overall performance of the c-MARL algorithms. Adversarial attacks on rewards shape the policy which ultimately leads to the learning of faulty behavior. After a fixed internal the sign of reward signal obtained by an agent for a given action is flipped from positive to negative or vice versa.
3.1.2. Gray-box attack
Gray-box attacks are adversarial attacks in which the adversary has some knowledge of the model and has limited access to the model. The attack which falls under this category is the perturbation of observation. What specific observation is perturbed depends on the choice of the environment. For the chosen StarCraft II environment discussed below, the observation perturbation refers to the enemy location.
Perturbation of enemy location: An adversarial attack on the observation is achieved by adding perturbations to the environment or by intercepting and altering the flow of values between the environment and the agent, also known as man-in-the-middle adversary attack. 26 We adopt the man-in-the-middle attack where we perturb the incoming observation and pass on the perturbed observation to the c-MARL models. For the StarCraft II environment, for an agent under attack, the location of the enemy unit was perturbed with a deviation of 5e-7 along its y-axis.
3.1.3. Black-box attack
Black-box attacks are adversarial attacks in which the adversary has no knowledge or access to the model. Since our modeling and simulation framework focuses on resilience in contested and dynamic environments, we focus on communication loss as it is a frequent occurrence in such environments, where it can occur because of sensor malfunction, limited communication bandwidth, or jamming of communication channels. In addition, communication helps with coordination which inherently improves the performance of c-MARL models. 52
Our framework perturbs communication was perturbed to varying degrees.
100% Communication loss: Every request for observation of the state is ignored by the agent under attack.
50% communication loss: Every other request for observation of the state is ignored by the agent under attack.
25% Communication loss: Every fourth request for observation of the state was ignored by the agent under attack.
3.2. Training approaches
To assess the impact on robustness of different training approaches, our framework introduces three types of training:
Type 1 training: No perturbation introduced in this training.
Type 2 training: Perturbation is added from the start of the training.
Type 3 training: Perturbation is added after 100,000 timesteps have passed during the training. This allows the model to train without perturbation ensuring that the model does not overfit the noise.
The perturbation of enemy location (gray box) and 100 % communication loss (black box) were selected for training and testing since they are more realistic.
3.3. Environment
There are many environments where c-MARL models can operate. These environments are hoisted within platforms such as OpenAI Gym (Gymnasium), OpenSpiel, and PettingZoo. A prototype of our framework considers StarCraft II, as it is very similar to a military operation, where the concepts of resource contention and attacks can be modeled. StarCraft II is a real-time strategy game that provides units with complex micro-actions that they have to execute to win a battle. StarCraft II has a stochastic environment and partial observability, which enables learning of complex interactions. 65 It is well suited for MARL due to its multiagent problem with units competing for influence and resources. Its partial observability comes from the unit limitation of that unit’s range of sight. The availability of vast and diverse action space makes it an ideal training and testing environment for RL, as the Combined action space of the agents has roughly 108 possibilities. 65
Our framework integrates the StarCraft II Learning Environment (SC2LE), where each learning agent controls an individual army unit. The objective of the army unit, which is controlled by the learning agents, (or allies), is to defeat the enemy units to win the game. The action space of agents compromises of move (direction), attack (enemy id), stop, and no operation. The agent movement is possible in four directions north, south, west, and east. An attack is only possible if the enemy is within the shooting range. Agents receive a joint reward based on the total damage done to the enemy units. Twenty points are awarded for killing an opponent and 200 points for winning a game. The rewards are normalized to ensure that the maximum cumulative reward achieved is 20. Figure 2 shows a training step in SC2LE.
Training step on a 3-m map, StarCraft II Learning Environment (SC2LE).
4. Experimental analysis
We instantiate our framework with all three attack types on four different c-MARL models, namely, IQL, VDN, QMIX, and QTRAN. These models were chosen as they represent some of the most popular c-MARL algorithms. In these experiments, to facilitate a better understanding of the robustness of these models under different attack types and training regimes, we focus the attacks on a single agent. With different attacks targetting multiple agents, the effects will be compounded and the robustness and resiliency of the models will be more significantly affected.
We first show the results from white-, gray-, and black-box attacks. Our simulations then explore the effects of different training approaches on the robustness of these models. As a measure of robustness, we look at the average number of wins (closer to 1 is better), losses (closer to 0 is better), dead allies (closer to 0 is better), and dead enemies (closer to 3 is better) on a StarCraft II 3 m map. The StarCrafII 3 m map was chosen for its simplicity: it contains more than two agents and thus is significantly more complex than most analyses on c-MARL models (which usually include two agents), but it is sufficiently simple to allow us to obtain insights into the behaviors of the models under attack. It is also important to highlight that the models displayed similar behaviors regardless of the type of the map.
All the training is done on 3-m map of the SC2LE environment which contains 3 marines on either side, and the results present an average of 10 runs. Training is done for 100,000 timesteps and 350,000 timesteps for different perturbations. Two timesteps are selected to investigate if perturbations have any impact on the selected metrics and the behavior of the selected c-MARL algorithms. Each algorithm is trained for 350,000 timesteps to ensure that all the algorithms were achieving a performance of more than 90% success. Testing was done on 3 m map for 20 episodes and 2000 timesteps per episode. The difficulty level for both training and testing was set to 2 on a scale of 0 to 7.
4.1. Adversarial attacks
We simulate different types of attacks and evaluate the model robustness.
4.1.1. White-box attacks
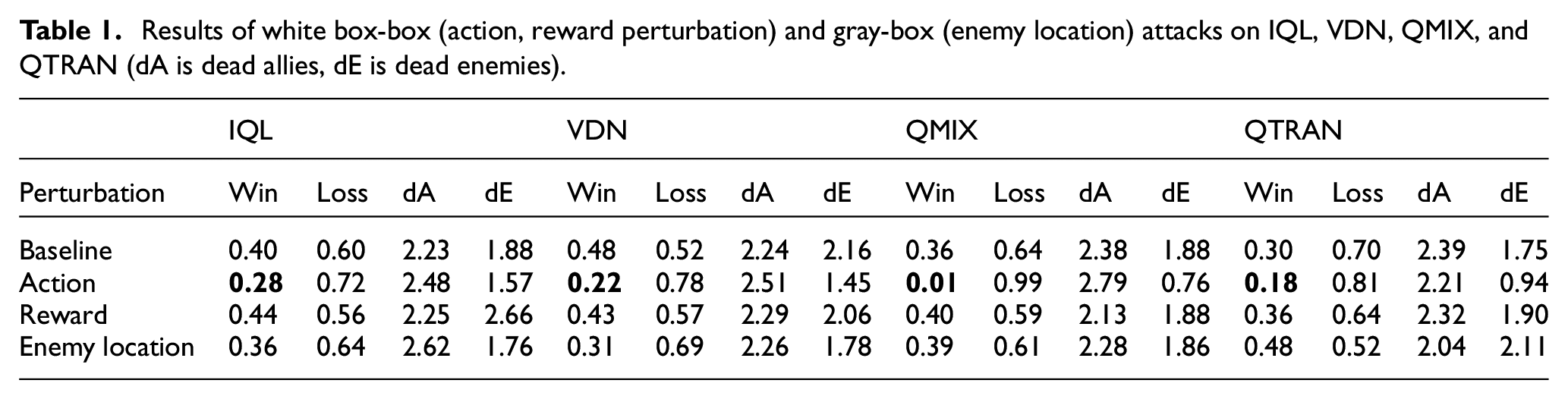
We evaluate each algorithm under white-box attacks and present the results in Table 1.
Results of white box-box (action, reward perturbation) and gray-box (enemy location) attacks on IQL, VDN, QMIX, and QTRAN (dA is dead allies, dE is dead enemies).
4.1.2. Gray-box attack
Table 1 showcases that the perturbation of observation did not have much impact on the resilience metrics. In fact, QMIX and QTRAN were able to mitigate the attack due to their capability to extract more information from a given state. In contrast, IQL and VDN did worse than their baseline due to their different learning approach.
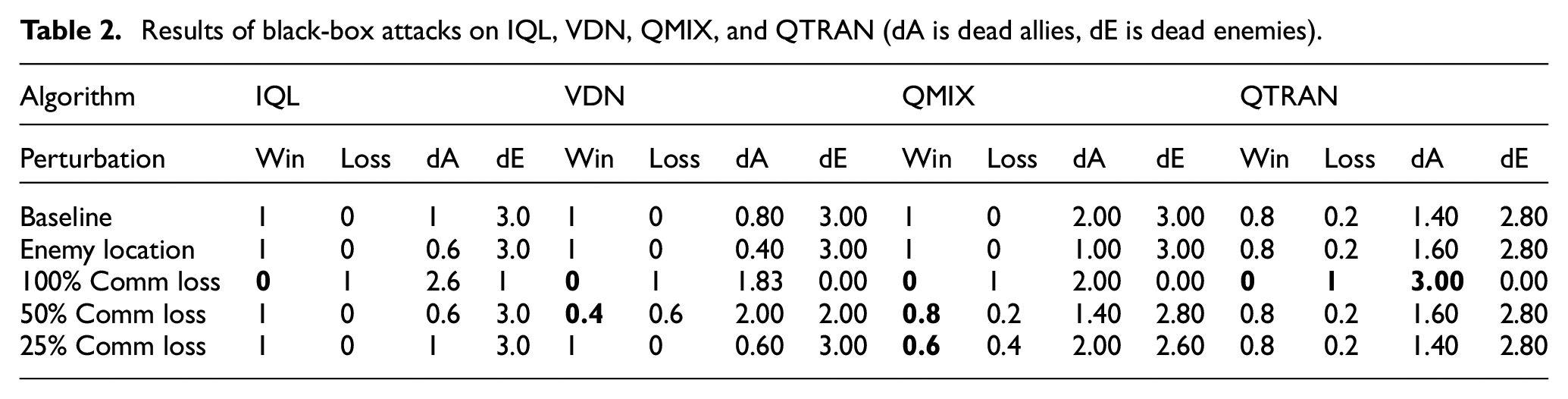
4.1.3. Black-box attack
As expected, the communication loss of 100% had the worst impact on all the algorithms, as shown in Table 2. A perturbation of 50% communication loss results in roughly 20% performance drop for QMIX and QTRAN, along with a 60% drop for VDN. As QMIX, QTRAN and VDN are CTDE, communication loss will impact the performance of all the agents. VDN and IQL remained unaffected by 25% communication loss suggesting that VDN and IQL are resilient to at least a 25% drop in communication. Furthermore, the independent learning nature in IQL led to it being unaffected by 50% communication loss.
Results of black-box attacks on IQL, VDN, QMIX, and QTRAN (dA is dead allies, dE is dead enemies).
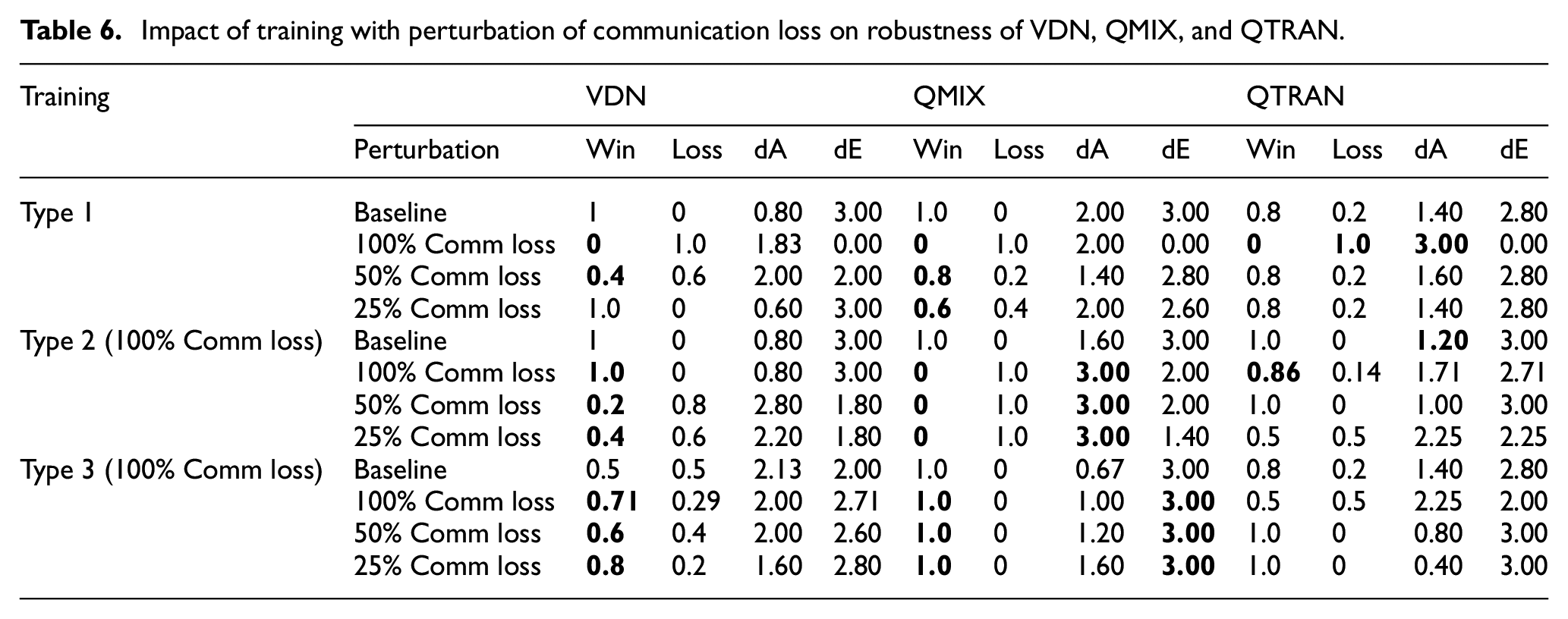
4.2. Training approach
We now focus our analysis on the impact of different training approaches on the robustness against gray- and black-box attacks, by simulating models with the three different types of training discussed in Section 3. The results of this analysis are shown in Tables 3–6.
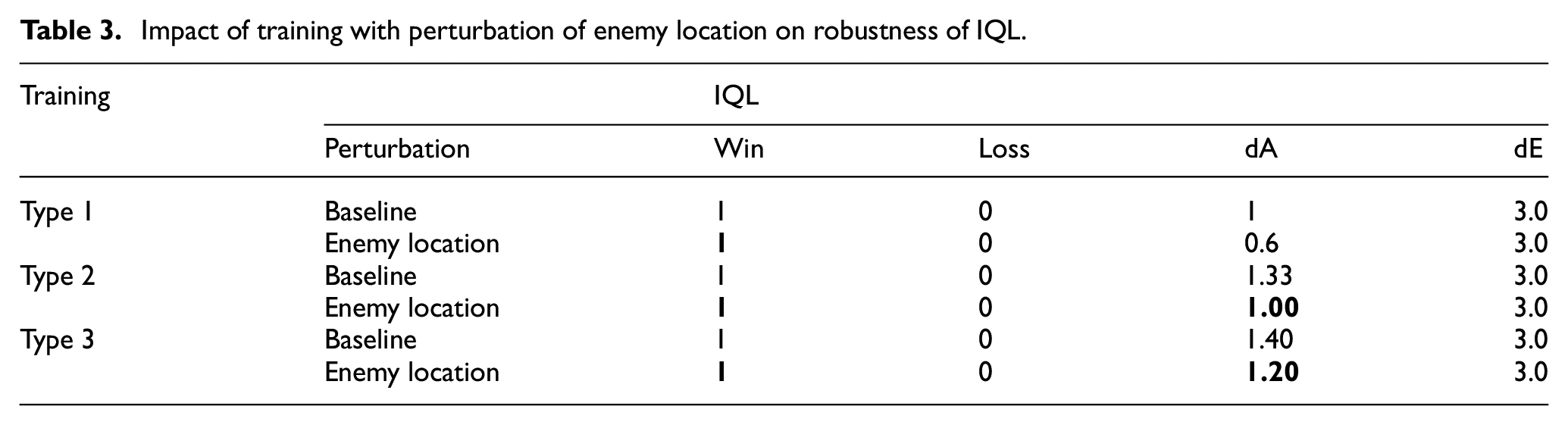
Impact of training with perturbation of enemy location on robustness of IQL.
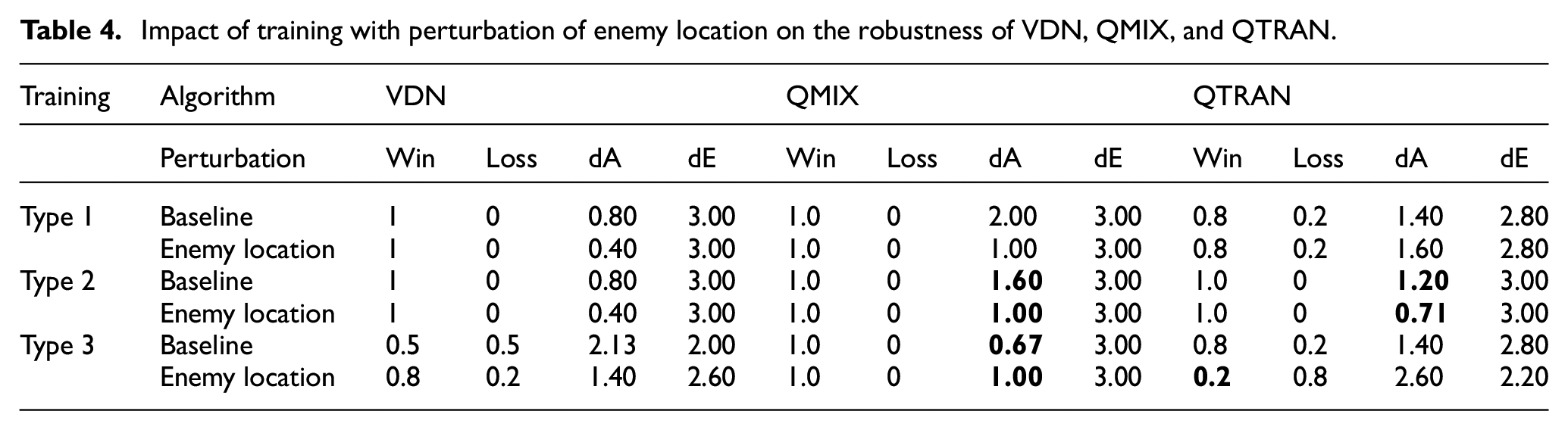
Impact of training with perturbation of enemy location on the robustness of VDN, QMIX, and QTRAN.
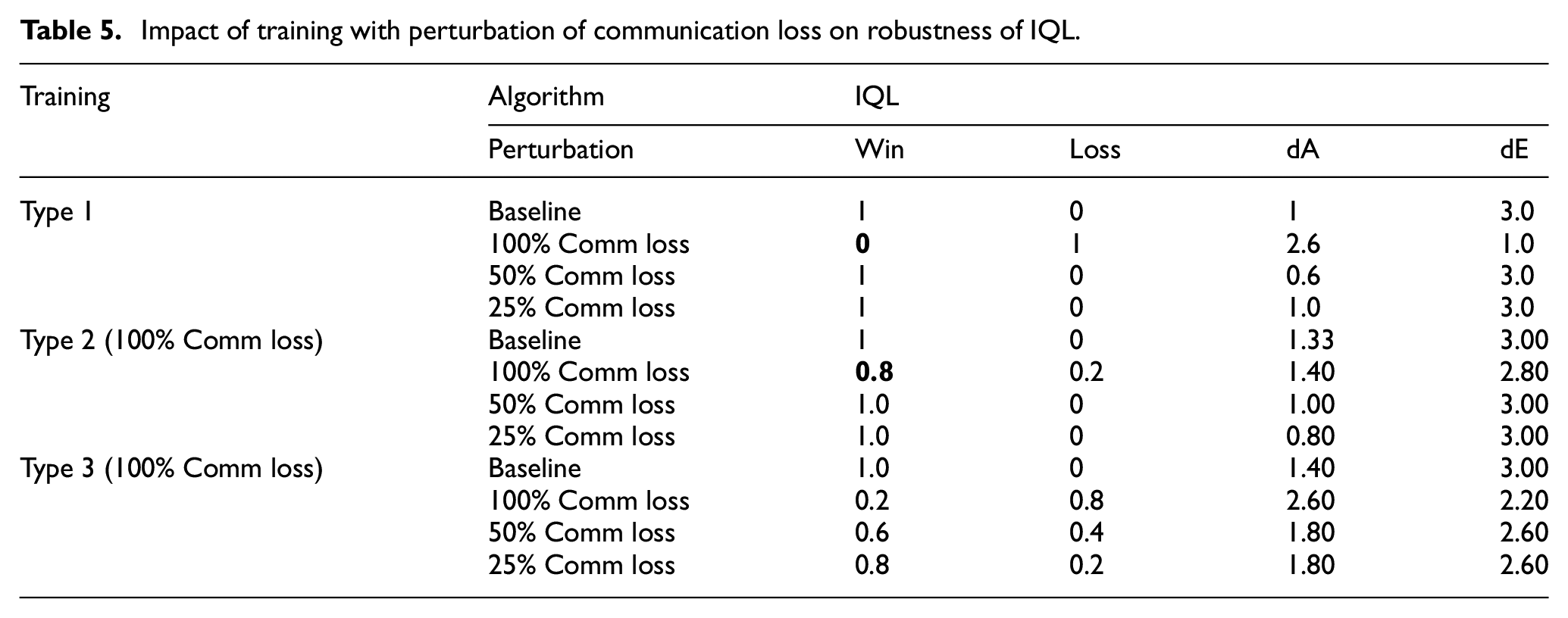
Impact of training with perturbation of communication loss on robustness of IQL.
Impact of training with perturbation of communication loss on robustness of VDN, QMIX, and QTRAN.
4.2.1. Training with perturbation of enemy location
As shown above, IQL is robust against perturbation of enemy location and as such the different training types will have no effect on this behavior (Table 3). Nevertheless, the Type 2 and Type 3 training approaches enable IQL to win all the episodes with lower casualties than Type 1 training. This suggests that even though IQL can maintain its performance under such attacks, training it with adversarial examples improves the policy by reducing its own damages.
The experimentation with VDN, shown in Table 4, had similar results for both Type 1 and Type 2 training. However, it did worse for Type 3 training. This could be due to the training approach of introducing perturbation after 100,000 steps, as this allowed only limited remaining time for VDN to update its policy.
QMIX outperforms other algorithms by winning all the episodes under different training approaches while under perturbation of enemy location as can be seen from Table 4. We can also see that Type 2 and type 3 training approaches improved the policy by reducing its losses, while delivering the same performance.
For Type 1 and Type 2 training approaches, QTRAN did well. The Type 2 training approach had the best performance and the least casualties. However, in Type 3, QTRAN did significantly worse, suggesting that QTRAN requires more time or a more diverse adversarial sample for Type 3 training.
4.2.2. Training with perturbation of communication loss
Table 5, shows that IQL’s performance for Type 1 training dropped to zero under 100% communication loss. However, it was able to do better under the Type 2 training approach, where it had an 80% win rate for 100% communication loss. The Type 3 training approach did not do well at all, regardless of the different degrees of communication loss.
VDN did not perform well under Type 1 training with 100% and 50% communication loss, as seen from Table 6. However, the Type 2 and Type 3 training approaches were able to mitigate the impact of communication loss. The model with Type 3 training demonstrates a better generalization. The lower performance of the model with Type 3 training might be due to the lower training time available after the perturbation is introduced.
QMIX and QTRAN both are severely impacted by communication loss when trained by Type 1 approach. This indicates the high vulnerability of QMIX and QTRAN against such attacks. Type 2 training approach improves the performance of QTRAN but not for QMIX because of the difference in their learning approach. However, both the algorithms did well under communication loss when trained with the Type 3 training approach. QMIX not only won all the games but was also able to kill all the enemy units while safeguarding its own units, especially for test scenarios involving communication loss. The ability to extract information along with Type 2 or Type 3 training helps both QMIX and QTRAN against communication loss.
5. Discussion
In this section, we discuss the impact on robustness of selected algorithms when a single agent is under different types of attacks (white-, gray- and black-box). We also discuss the impact of different types of training on the robustness of these algorithms. Overall, IQL did fairly well across different adversarial attacks, due to its independent learning nature. The simplicity of the training objective might also be a contributing factor for its performance.
5.1. Adversarial attacks
The white-box attack that perturbed the action space, had the worst impact on all models. QMIX was the most vulnerable to perturbation of action due to limited action space which resulted in poor decomposition of decentralized policies from the centralized training platform. QTRAN closely follows QMIX when considering vulnerability to perturbation of action followed by VDN and IQL. The behavior of QTRAN under perturbation of action is showcased in Figure 3, where a red unit, ally, flees from the fight due to its policy. QTRAN learns that running away is more rewarding than standing on the spot and doing nothing (no operation) since during training, under similar conditions, the action for shooting might not be available. IQL was the least impacted by this attack because each agent learns independently and the overall performance is not normalized. Perturbing the rewards did not have much impact on the algorithm performance. This might be due to the interval of flipping the reward signal. The longer the interval between the switch lesser is its impact on the performance. The length of the interval for flipping the reward can be determined heuristically. Different algorithms would have different intervals due to various factors such as the complexity of the task or the learning nature of the algorithm. Another aspect which makes the algorithms immune to such an attack is the formulation of joint action values which normalize the impact of flipping the rewards for an agent or the agent attacked operates independently, like in IQL. Figure 4 shows the sequence of steps taken by the Red Team (allies) while testing it with perturbation of reward. It is observed that the red units move to and fro before engaging with the enemy. This happens because the policy of the agent prefers moving away from enemies. Eventually, the allies engage with the enemy showcasing that the agents have received enough positive rewards during training to learn that damaging/killing enemy units is more beneficial than moving around.
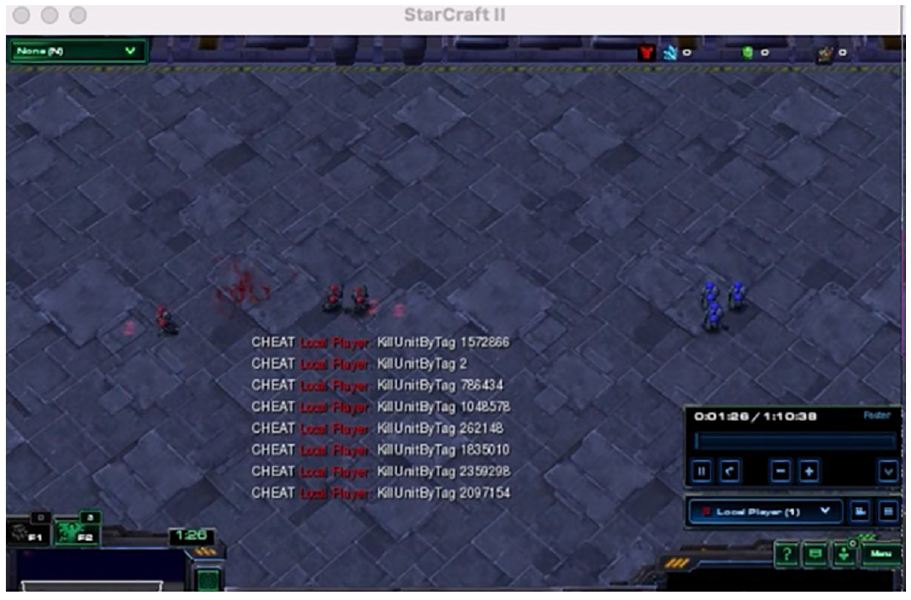
QTRAN under white-box attack (perturbation of action).
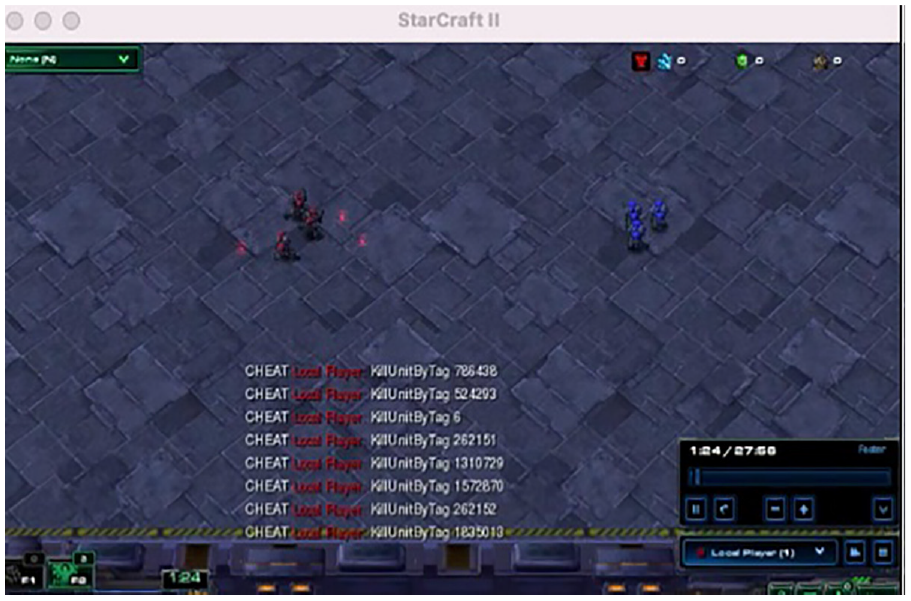
Sequence of action (clockwise starting from top left) for perturbation of reward (IQL).
The gray-box attack perturbing of enemy location did not have a significant impact on performance. This might be due to the small displacement introduced to the enemy location. QMIX and QTRAN were able to mitigate the attack due to their capability to extract more information from a given state. In contrast, IQL and VDN did worse than their baseline due to their different learning approach. There were, however, different effects on the number of allies lost. All the algorithms lost more allies than the baseline under this attack.
All the c-MARL algorithms, especially QMIX, succumbed to black-box attacks (communication loss). 100% communication loss for a single agent gravely impacts the performance of all of the c-MARL algorithms. It can be seen from Table 2 that all the test episodes were lost. 50% communication loss also has adverse effects especially for VDN followed by QMIX. For VDN, the drop in performance was by 60%. However, QTRAN was not affected as much by 50% communication loss. Furthermore, IQL was unaffected by 50% communication drop as well showcasing its ability to withstand 50% communication loss due to its independent learning nature. Perturbation of 25% communication loss did not have much impact on the IQL, VDN, and QMIX but did affect QMIX and lowered it is performance by 40%. This shows that IQL, VDN and QTRAN are robust when the communication loss is lower or equal to 25%.
5.2. Impact of various training approaches
The baseline values in Table 2 indicate that all the algorithms are performing well on the given task except QTRAN which has a performance ceiling of 80%. This suggests that QTRAN will require a longer training time. Therefore, for most of the algorithms trained without any perturbations and under ideal conditions, it is safe to assume that they would do well.
Since our simulations show the gray-box attack did not have much impact on the performance of any of the models, as expected training them with such perturbation did not have much impact on the performance either, with the new policy being able to achieve similar performance as the baseline but with less damage. For instance, the Type 2 and Type 3 training approaches enable IQL to win all the episodes with lower casualties than the Type 1 training. This suggests that even though IQL can maintain its performance under such attacks, training it with adversarial examples improves the policy by reducing its own damages. VDN had similar results for both Type 1 and Type 2 training. However, it did worse for Type 3 training. This could be due to the training approach where the learning time is limited after the perturbation is introduced. QTRAN with the Type 3 training also struggles with this problem.
100% communication loss for a single agent gravely impacts the performance of all of the c-MARL algorithms. It can be seen from Table 2 that all the test episodes were lost. However, our simulation framework allows us to experiment with different training approaches, and as such after training the models with the 100% communication loss they did better, with few of them even maintaining their performance (Tables 5 and 6). This success, unfortunately, has a grim effect of over-fitting. However, the over fitting issue is seen to be mitigated by the Type 3 training approach only for some models. For instance, QMIX was unable to recover even after it had gone through Type 3 training with communication loss. This shows the reduced resilience of QMIX in these kinds of attacks.
As expected, a white-box attack had devastating consequences regardless of the type of perturbation. We found that communication loss at all levels (small, medium, high) was devastating to various degrees on all models, and that training with this particular black box attack was not always successful. Type 2 training was able to mitigate this impact, however, while over fitting. QMIX and VDN showed the most improvement when trained with Type 3 training. This is because the training approach allowed the algorithms to develop a policy for an ideal situation before the perturbation was introduced. QTRAN did not perform as well as QMIX and VDN; however, Type 3 training did improve its performance significantly. One of the reasons for this might be that QTRAN requires a longer training time. It is possible that QTRAN might be a better performer than VDN and QMIX in a more dynamic environment with complex actions due to its ability to capture extra state information and transform the joint action-value function into an easily factorizable function. 51 In contrast, the algorithm with the least improvement was IQL. This is because of its independent learning, where each agent worked individually toward a common goal.
Finally, it is important to highlight here that this study focused on a simple map, to allow for an in-depth analysis of the studied algorithms. Our preliminary analysis of more complex maps show that the impact of attacks is similar, and that the algorithms behave in a similar manner as within these experiments. One avenue that is to be explored in the future is the extension of the framework to consider attacks on more than a single agent, either in the form of a group attack or of multiple individual agent attacks.
5.3. In-depth understanding of resilience
Our analysis has shown that several of the c-MARL models in our study had reduced resilience under specific attacks and training scenarios within the tested environment. Specifically, QTRAN struggled in all scenarios regardless of its training type, but did show improvements with Type 3 training under a white-box attack.
Our proposed framework represents a first step in understanding the resilience of c-MARL models under different types of attacks, and it focuses on how the various models are affected by simple but disastrous changes within the environment. This represents a single data point within the evaluation of a decision-making algorithm, with more in-depth understanding facilitated by two aspects. First, there is a need to define more varied attack scenarios that target more than one agent. This could be achieved by using knowledge extracted from a subject matter expert and the use of model-driven engineering approaches to define, run, and store simulation experiments and their results.66,67
Second, there is a need to better understand the time component of the effects of an attack, and inherently of resilience, but performing a more in-depth analysis of the system behavior. Our current approach is limited by the metric used for resilience, in that it does not have a temporal component (e.g. allies do not come back to life after being killed), making a temporal analysis difficult. There is a need for system behavior focused metrics to quantify resilience, and in this complexity theory might provide some answers. For example, metrics such as system entropy, complexity, and self-organization have been linked to desired emergent behavior in past work.10,27,36 With the formulation of resilience as a fluctuation in available knowledge about other components, information theory approaches 68 could be used to further expand understanding.
6. Conclusion
In this paper, we propose a modeling and simulation framework that analyses the resilience of c-MARL models operating in contested and dynamic environments. Our plug-and-play approach allows for the definition of white-, gray-, and black-box attack scenarios on agents within a c-MARL model, operating in a battle-like environment. The initial prototype and experimental analysis considers four c-MARL models, namely, IQL, VDN, QMIX and QTRAN, which were selected due to their different approaches to learning. In this first iteration, the framework addresses attacks on single agents with more complex attacks on agent groups a topic of future work.
Our results show that even the compromise of a single agent can dramatically impact performance. Our analysis looked at a small StarCraft II map and introduced white-, gray-, and black-box attacks. Models were trained under various conditions and for differing lengths of time to better evaluate their performance. Our evaluation of training strategies looked at introducing perturbations throughout the scenario or after a certain time period has started. This work presents a first step toward the in-depth evaluation of c-MARL resilience. Our future work involves first more in-depth evaluations with larger scenarios with more than one agent under attack while operating in a more complex and dynamic environment, and exploring heterogeneous agents. Second, we will explore the use of model-drive engineering to define simulation experiments, attacks and system configuration, and complex systems theories to understand the impact the long-term impact on the system resilience of various configurations and attacks.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.