
Abstract
Dynamic job shop scheduling problems with multiple order disturbances present significant challenges in manufacturing systems. This paper proposes a novel approach using Independent Proximal Policy Optimization (IPPO), a multiagent deep reinforcement learning algorithm, to address these challenges. We introduce a five-channel two-dimensional image to represent system states and design a reward function that minimizes both total tardiness and makespan. Experimental results across 72 diverse production scenarios demonstrate that our IPPO-based approach outperforms traditional deep reinforcement learning algorithms and dispatching rules in most cases. The proposed method shows strong optimization and exploration capabilities, offering a promising solution for complex, multiobjective scheduling in dynamic manufacturing environments.
Keywords
Introduction
Production scheduling is crucial for ensuring quick adaptation to market changes, managing efficient production processes, and accommodating diverse enterprise requirements. Most scholars have focused on the static job shop scheduling problem (JSSP). 1 However, real-world production environments are subject to uncertain disturbances, such as random arrivals, cancellations, and due date changes, which can affect the normal execution of the original scheduling plan 2 ; therefore, conducting in-depth research on dynamic production scheduling issues involving multiple order disturbances is essential to ensure a timely response to these disturbances and to meet the current production needs of enterprises.
Recent research on dynamic scheduling with multiple order disturbances primarily uses heuristic algorithms3–6 and dispatching rules. 7 Zhang et al. 8 proposed a hybrid intelligent algorithm that combined genetic and tabu search algorithms for production scheduling under dynamic order arrivals and equipment breakdowns. Gao et al. 9 proposed an improved two-stage artificial bee colony algorithm for the dynamic scheduling problem under uncertain disturbances of new order arrivals and variable processing time. In addition, the method of dispatching rules has been researched extensively by some scholars. Sharma et al. 10 developed nine dispatching rules to address the stochastic dynamic JSSP (DJSSP) that took into account setup times dependent on sequences. Teymourifar et al. 11 proposed a gene expression programming method combined with a simulation model to extract effective dispatching rules for dynamic production scheduling problems. The majority of research on order disturbances currently focuses on single, one-time disturbances, rather than researching on comprehensive study of multiple disturbances on a larger scale. In terms of algorithmic approaches, heuristic algorithms have high computational accuracies but at a cost of long computation times; conversely, dispatching rule-based methods offers fast computational speeds, but finding a generalized dispatching rule adaptable to most scenarios remains a significant challenge.
Deep reinforcement learning (DRL) algorithms have been widely used for dynamic production scheduling because of their robust perception and decision-making capabilities. Wang et al. 12 applied the Proximal Policy Optimization (PPO) algorithm to address the DJSSP under machine breakdowns and job rework, where the system state was represented by a set of three-channel two-dimensional images. Yuan et al. 13 introduced the PPO algorithm to tackle the JSSP, employing the Invalid Action Mask technique to reduce the search space. Huang et al. 14 developed a method that combines a Graph Neural Network with the PPO algorithm to solve the distributed production scheduling problem. Wu et al. 15 examined the DJSSP with uncertain processing times and proposed a DRL method based on PPO and hybrid priority experience replay for training the agent. Han et al. 16 proposed a combination of CNN and DRL for the production scheduling problem and designed three two-dimensional matrices to simulate the system state.
Order disturbances, as significant dynamic disruptions, have been extensively studied. Yang et al. 17 investigated intelligent scheduling with dynamic job arrivals and the reconstruction of reconfigurable flow lines using DRL. Luo 18 proposed a DQN algorithm to address the production scheduling problem under dynamic job arrivals. Liu et al. 19 established a hierarchical and distributed architecture to tackle the dynamic flexible JSSP with constant job arrivals. Wang et al. 20 presented the PPO algorithm to solve the DJSSP with random job arrivals. Zhao et al. 21 proposed a PPO algorithm based on an attention strategy network to address the JSSP with dynamically arriving jobs. Experimental results indicate that the proposed algorithms exhibit superior performance.
In summary, DRL has yielded notable results in dynamic production scheduling; however, its application in scenarios involving multiple order disturbances remains underexplored. Regarding research methodologies, the PPO algorithm has been widely applied in production scheduling, it directly optimizes action policies without the need to compute the state's value, making them more suitable for production scheduling problems characterized by path optimization properties. Additionally, the PPO algorithm employs a mechanism to limit the magnitude of policy updates, which addresses issues related to training stability and efficiency. However, this algorithm tends to be less exploratory and may fall into local optima. The Independent Proximal Policy Optimization (IPPO) algorithm22,23 is a multiagent DRL approach based on PPO, where each agent collaborates during training while collecting data independently. This greatly enhances the diversity and irrelevance of the training data, balancing the stability and exploratory nature of training, and is better suited for dynamic scheduling problems involving multiple order disturbances.
This paper explores a DRL method based on IPPO to address the DJSP under multiple order disturbances. The main contributions of this study are as follows: (1) the introduction of the multiagent DRL algorithm IPPO to tackle scheduling problems. Although many DRL algorithms have been applied to production scheduling issues, most suffer from training instability or insufficient exploration. This paper presents IPPO, a novel multiagent algorithm that has not been previously explored in this context; (2) proposal of a solution for multiobjective dynamic scheduling problems under multiple order disturbances; and (3) comprehensive analysis and comparison of experimental results across various parameter settings and scenarios.
Independent Proximal Policy Optimization scheduling framework
In this paper, an IPPO algorithm is proposed to address the DJSSP under multiple order disturbances. The IPPO algorithm is a multiagent DRL approach, where each agent consists of two Actor-Critic (AC) networks: one is involved in the new policy and the other maintains the old policy. The structure of both AC networks is identical, with CNN layers and fully connected layers. To address the issue of the dynamic image size changes caused by multiple order disturbances, a Spatial Pyramid Pooling (SPP) 24 layer was added between the last convolutional layer and the first full connection layer to ensure consistent output size from the CNN. The application of IPPO algorithm in production scheduling involves a Semi-Markov Decision Process (SMDP), where agents continuously interact with the production environment for offline training, and then the trained agents solve various problems online. The DRL framework is divided into two phases: offline training and online application, as illustrated in Figure 1.

Scheduling framework with Independent Proximal Policy Optimization (IPPO).
In the offline training phase, the IPPO algorithm trains each individual agent separately using a parameter-sharing mechanism. Each agent collects data using the old policy network, calculating the advantage function and system state value, and stores this data in a common storage queue. During training, these data are extracted for model training. The IPPO algorithm mainly trains and updates the parameters of the AC network containing the new policy and simultaneously transmit the new policy network's parameters to the old network's parameters.
The online application phase mainly utilizes the offline-trained model to solve new problems. Although the agent needs a long time for offline training, once completed, the optimal result of the new problem can be obtained in a very short time. Requiring only simple calculations, without needing to recalculate for a long time like traditional heuristic algorithms.
Independent Proximal Policy Optimization for scheduling
Problem formulation
The multiobjective dynamic scheduling problem in intelligent workshops under multiple order disturbances can be described as follows: the production system has N orders to be processed on M machines, where each order comprises
The notations and indices used for problem formulation are listed in Table 1.
Notations and indices for problem formulation.

The mathematical description of the multiobjective dynamic scheduling problem is presented in equations (1)–(6):





Equation (1) is to minimize the total tardiness and makespan, where
Principles of IPPO
The PPO is a policy-based reinforcement learning algorithm derived by improvement based on the trust region policy optimization algorithm.
25
The PPO achieves performance improvement by constraining the distributional variance between new and old policies, thus ensuring monotonic policy updates. Moreover, it addresses the challenge of low data utilization in the traditional policy gradient algorithm by employing small-batch updates. The PPO has two main variants, which differ in their approach for restricting changes between new and old policies: the PPO-penalty version and the PPO-clip version. This study focuses on the PPO-clip version, which employs a clipping function to limit the extent of policy changes. It prevents algorithmic instability stemming from excessive policy changes. The objective function is represented using equation (7):
Essentially, the PPO-clip algorithm limits the differences between the new and old policies within a range of
The IPPO algorithm is a multiagent DRL framework that represents an application of the PPO algorithm in the multiagent domain. As opposed to single-agent algorithms, multiagent algorithms facilitate the achievement of common objectives through collaborations among a group of agents. The IPPO algorithm is a decentralized extension of the PPO algorithm in the context of multiagent systems, where each PPO agent has its own AC network, enabling independent training and updates. The policy network of each agent in the IPPO algorithm is optimized using the objective function described in equation (8):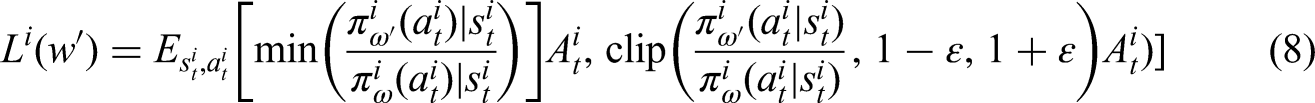


where
Transformation between scheduling problems and algorithm design
Deep reinforcement learning requires three critical components to be designed in its application: system state, action space, and system reward.
System state feature description
The design of system state features in this study is primarily based on literature. 16 Three global feature channels have been established to represent the system state features, while more sensitive local system state features have been overlooked. To enhance the accuracy of system state representation, this study optimizes and upgrades the production system state features to include two global channels and three local channel features. All channels consist of two-dimensional matrices, where rows represent operations and columns represent orders. The first global feature channel is the operation channel to be processed, with its initial values set to the processing times for all operations. Once an operation is completed, the corresponding position in this channel is updated to 0. The second global feature channel is the completed operation channel, initially set to 0; it is updated to the processing time once an operation is finished. The first, second, and third local feature channels represent the remaining processing time for the current processing operation, the processing time for the operation in the queue to be processed, and the waiting time for the operation in the queue to be processed, respectively.
Figure 2 illustrates the evolution of system state across each channel in a 3 × 3 job shop scheduling. In the initial state
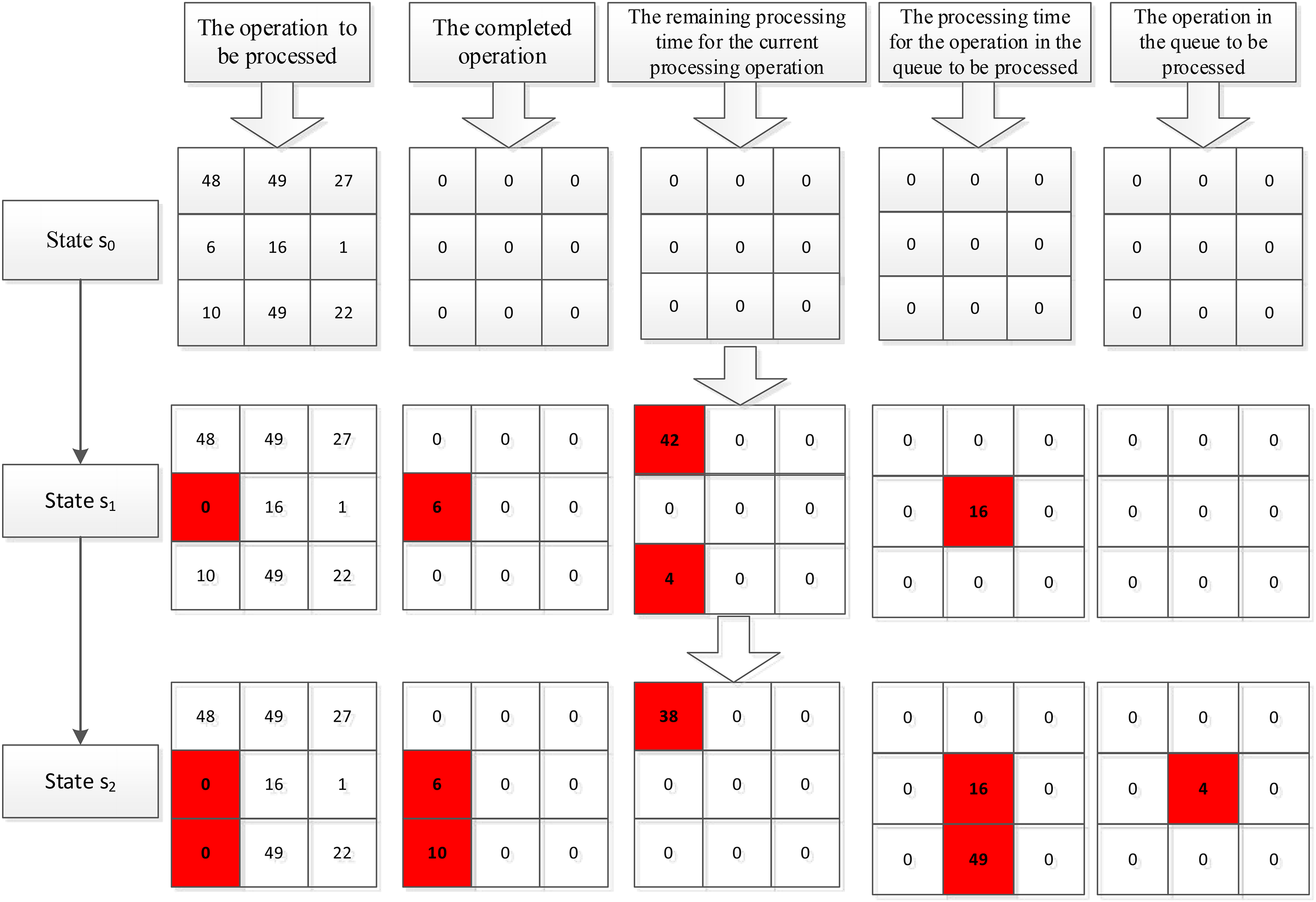
System state transition process.
It should be noted that to enhance the feature extraction performance of the neural network, this study utilizes a 4-frame integration to represent the state of the production system, which serves as the input of the CNN.
Action space
In DRL algorithms for production scheduling, the action space consists of production dispatching rules. In this study, 16 production dispatching rules were selected as the action space for the DRL algorithm. These are listed as follows: shortest processing time (SPT), longest processing time (LPT), least work remaining, most work remaining, shortest subsequent operation (SSO), longest subsequent operation (LSO), shortest remaining operation except current, longest remaining operation except current, first in first out, earliest due date, minimum sum of current and subsequent operation (SPT + SSO), maximum sum of current and subsequent operation (LPT + LSO), minimum ratio of current operation to total operations (SPT/TWK), maximum ratio of current operation to total operations (LPT/TWK), minimum product of current operation and total operations (SPT × TWK), and maximum product of current operation and total operations (LPT × TWK). The diversity of dispatching rules is increased to enable the agent to fully learn the ability to selecting dispatching rules adaptively.
Reward function
For the multiobjective scheduling problem, this paper considers two objective functions: minimizing the total tardiness and minimizing the makespan. The reward function for minimizing the total tardiness is expressed as follows:
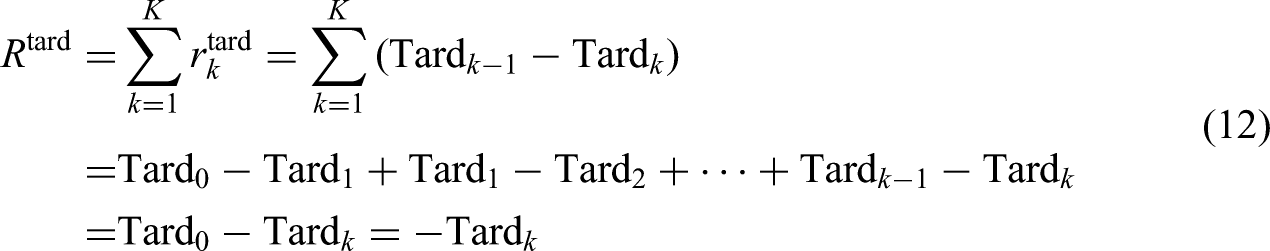
In the above formula,
The reward function with the minimum makespan is expressed as follows:

Independent Proximal Policy Optimization algorithm process
The execution process of the IPPO algorithm follows an SMDP with decision-triggering events such as the completion of an operation on any machine, the arrival of a new order, order cancellation, changes in order due dates, and so on. The algorithmic procedure is illustrated in Algorithm 1:
IPPO Algorithm

Algorithm 1 shows the entire scheduling execution process. It starts with parameter and variable initialization and undergoes training for EP_MAX loops, eventually achieving adaptive action selection capabilities across different states. Each training loop comprises data collection and parameter training phases. Lines 4–16 describe the data collection process of each agent. Starting from the initial state
Simulation experiment and results
In this section, the data generation method outlined in Luo 18 is adopted to randomly generate multiple sets of training, validation, and testing data under various scenarios. The parameters utilized for generating simulation data are listed in Table 2.
Parameter settings in different scenarios.

In Table 1, the due date for order i is calculated using formula
Network structure and parameter settings
In this study, the IPPO algorithm employed an AC network architecture, where both the actor policy network and the critic value network of each agent share a structural identity. Each network comprises two CNN layers, one SPP layer, and two fully connected layers. The CNN layers have kernel sizes of 4 × 4 and 2 × 2, with strides of 2 and 1, respectively, and output channel numbers of 40 and 80. The first fully connected layer has 512 nodes, while the number of nodes in the second fully connected layer of the actor–network corresponds to the size of the action space. The second fully connected layer of the critic network contains 1 node, which is responsible for the output of the system state value. The CNN convolutional layers use the tanh activation function, while the fully connected layers use the ReLU activation function. The neural network parameters are trained and updated using the Adam optimizer. Since the system state space, action space, and optimization objectives of each agent are identical, a parameter-sharing strategy is adopted to reduce training complexity. Specifically, different agents share the same set of network parameters, making the training more stable.
In the training process of the IPPO, parameter configuration plays a crucial role. This study validated the sensitivity of parameters in a production scenario characterized by five machines, 10 order disturbances, a due date tightness of 1.0, an average time interval of order disturbances of 100, and weight coefficients of 0.5 for both total tardiness and makespan in the multiobjective functions. Primary validations were conducted on the training batch size, entropy coefficient, number of training per dataset, and the learning rate. A total of 2000 training episodes were carried out, and the results are depicted in Figure 3.

Validation results of each hyperparameter: (a) training batch, (b) entropy coefficient, (c) number of training per dataset, and (d) learning rate.
The horizontal axis in Figure 3 represents the number of training episodes, while the vertical axis i the value of the objective function. It can be observed that the optimal performance is achieved with a batch size of 16, an entropy coefficient of 0.02, 10 training iterations per dataset, and a learning rate of 0.0001.
Based on the aforementioned experimental results, the following parameters were finally determined for training the IPPO algorithm model, as shown in Table 3.
Setting of IPPO hyperparameters.

Training process of IPPO algorithm
Independent Proximal Policy Optimization aims to train a model with extensive generalization ability, and the trained model is tested using test data. This study classifies production scenarios based on the weight coefficients of multiobjective functions, the number of machines, and the time interval between the order disturbances. For each scenario, 12 groups of training and validation data were randomly generated. The model employed eight agents and underwent 2000 training episodes. Validation data were used to assess the performance of the model after each episode, and the optimal model was selected based on the validation results. Lastly, 30 sets of test data were randomly generated to evaluate the trained model. Figure 3 illustrates the training process with a total tardiness weight of 0.7, makespan weight of 0.3, five machines, order disturbance time interval of 100, 10 disturbances, and a due date tightness of 1.0.
Figure 4(a)–(c) shows the variation process of the total objective value, variation of the rewards, and changes in the objective values of the validation data, respectively. The trend of the training curves for the reward value and the total objective value was closely aligned and exhibited a high degree of correlation.

Training process of Independent Proximal Policy Optimization (IPPO) algorithm: (a) average total objective value, (b) average reward value, and (c) average validation value.
Comparison of experimental results
To validate the effectiveness and generalization capabilities of the IPPO model, a comprehensive comparison was made between the IPPO algorithm and the classical PPO algorithms, considering 16 dispatching rules. Test data were randomly generated according to the parameter settings in Table 1. A total of 72 diverse production scenarios were designed for algorithmic comparisons, accounting for factors such as the number of machines, time interval between order disturbances, number of order disturbances, due date tightness, and weight coefficients of the multiobjective functions. Under each production scenario, 30 sets of data were randomly generated, with weight coefficients for total tardiness and makespan set to three scenarios: 0.3 and 0.7; 0.5 and 0.5; and 0.7 and 0.3, respectively. Tables 4–6 show the test results, with optimal values highlighted in bold for each dataset. Because of the large amount of test data, only the integer part of the data was displayed, with optimal values highlighted in bold for each dataset.
Test results with weight coefficients of 0.3 and 0.7.

Test Results with Weight Coefficients of 0.5 and 0.5.

Test results with weight coefficients of 0.7 and 0.3.

These results demonstrate the excellent performance of the IPPO algorithm in different scenarios, indicating that this algorithm has learned to adaptively select actions based on different system states. Compared with the PPO algorithm, the IPPO algorithm demonstrates superior performance across various scenarios, showcasing its robust generalization capabilities and proficiency on selecting optimal actions in diverse system states. Furthermore, the IPPO algorithm can integrate multiagent structures and a shared experience pool mechanism, enhancing its exploratory capacity. However, it was observed that the IPPO algorithm does not yield favorable results in all scenarios; this is primarily due to the potential in the design of the system state, action space, and reward function. The test results also clearly showed that finding a single dispatching rule that consistently performs well in different environments is challenging.
Discussion
From the above analysis, it is evident that the trained IPPO model is the most efficient, consistently yielding the best results in the majority of scenarios. First, the optimal hyperparameters were elected through parameter sensitivity experiments. Subsequently, the SPP layer was incorporated into the network structure for model training, taking into account the unique characteristics of multiorder disturbances. The performance of the trained model was then compared in detail with PPO and traditional dispatching rule. The IPPO model consistently demonstrated superior performance across most scenarios.
The effectiveness of the algorithm proposed in this paper can be attributed to several key factors. The five-channel system state incorporates both global features and critical local features. As illustrated in the training curve in Figure 4, the designed reward function aligns perfectly with the scheduling objectives. Second, to address the challenge of numerous parameters and the difficulty of training associated with DRL algorithms, a parameter sharing strategy is implemented, significantly reducing the training complexity. Third, the IPPO algorithm operates as a multiagent algorithm, where agents collaborate primarily through an experience-sharing mechanism, by leveraging shared experiences among multiple agents, the collaboration and exploration among them substantially decrease the correlation of training data, thereby enhancing the agents’ training efficacy. This innovation effectively resolves the inherent limitation of traditional PPO algorithms, which, although stable during training, frequently exhibit inadequate exploratory prowess. However, the large state space in dynamic scheduling problems, combined with minor changes in adjacent system states extracting the same eigenvalues, resulting in unstable training and a tendency to converge to local optima. The multiframe joint representation is used in this study to express the system state, which improve the training stability.
It is evident that the DRL algorithm does not yield favorable results in all scenarios. This is primarily due to the potential in the design of the system state, action space and reward function. In large-scale and complex dynamic scheduling problems, the state space is vast, making it crucial to identify a general and accurate method for representing the system state. Additionally, a well-defined and high-quality action space can significantly enhance the algorithm effectiveness.
Conclusion
This study introduces an IPPO-based approach for solving DJSSPs under multiple order disturbances. Our method, utilizing a novel state representation and reward function design, demonstrates superior performance across a wide range of production scenarios compared with traditional PPO algorithms and dispatching rules. The proposed approach shows strong optimization and exploration capabilities, offering a promising solution for complex, multiobjective scheduling in dynamic manufacturing environments. However, limitations exist such as the computational complexity of the method for very large-scale problems and the ability to address more complex production environments.
Future work should focus on addressing more intricate production disturbances, such as uncertain processing times and machine failures, and on improving the scalability of the approach for larger manufacturing systems, especially on improving the design of system states, action spaces, and reward functions in complex production environments.
Footnotes
Conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.