
Abstract
In recent years, hazardous chemical incidents have occurred frequently, resulting in significant human casualties, property damage, and environmental pollution due to human or natural factors. Accurately mining the lessons learned from accumulating incident reports and constructing the knowledge graph for hazardous chemical incident management can assist managers in identifying patterns and analyzing common attributes, thereby preventing the recurrence of similar incidents. This article addresses the challenges of dispersed textual information, specialized vocabulary, and data formats in hazardous chemical incidents. We propose a novel entity-relation extraction model called CPBA-CLIM (content-position-based attention-cross-label intersect matching) to provide an accurate data foundation for constructing the hazardous chemical incident knowledge graph. The content-position-based attention module, based on content-position attention, incorporates contextual semantic information into the combined encoding of bidirectional encoder representations from the transformer's content and position to obtain dynamic word vectors that align with the thematic context of the text. Additionally, the cross-label intersect matching strategy evaluates the rationality of entity–relation interactions in sets containing potential overlaps, reducing the impact of entity–relation overlap on triplet extraction accuracy. Comparative experimental results on public datasets demonstrate the model's outstanding performance in overlapping triplets. Qualitative experiments on a self-constructed dataset integrate our model with ontology construction techniques, successfully establishing a knowledge graph for managing hazardous chemical incidents. This research effectively enhances the degree of automation and efficiency in knowledge graph construction, thus offering support and decision-making foundations for hazardous chemical safety management.
Keywords
Introduction
In recent years, the rapid development of the chemical industry has significantly propelled global economic growth, shaping modern lifestyles worldwide. 1 However, due to the harmful chemical properties of certain substances, accidents such as explosions, fires, poisoning, corrosion, and radiation incidents may occur during their production, storage, transportation, and usage, posing potential risks to human health, wildlife, and the environment. 2 Chemical accidents often result from the interaction of various hazardous factors. Therefore, comprehensive safety knowledge is crucial for effectively managing hazardous chemicals. The field of chemical safety encompasses a wealth of safety regulations and accident reports, providing valuable information and resources. For instance, the Hazardous Chemical Incident Report published by the Ministry of Emergency Management of the People's Republic of China includes various direct causes of incidents. Additionally, documents such as the Regulations on the Safety Management of Hazardous Chemicals (State Council Decree No. 591) and the Comprehensive Governance Plan for Hazardous Chemical Safety (State Council [2016] No. 88) issued by the State Council outline various safety management standards. However, traditional methods of chemical safety management lack the means to transform them into reusable forms, hindering the full utilization and extraction of the dispersed, valuable, and applicable knowledge stored in different documents.
Emerging intelligent application technologies, such as knowledge graphs, 3 provide more comprehensive and intelligent means for safely managing hazardous chemicals. These technologies further strengthen regulatory agencies’ supervisory and response capabilities, significantly enhancing the overall level of safety management. For example, knowledge graphs extract entities, relationships, and attributes from text or databases, representing elements such as hazardous substances, the environment, equipment, and regulations as nodes and edges. 4 This systematic representation offers a comprehensive relational view, deepening the understanding of frequent interconnections related to hazardous substances. It provides comprehensive knowledge support for overall hazardous material management, risk assessment, and emergency response. 5 Various intelligent applications in hazardous chemical management rely on extracting valuable information from large volumes of text and data. 6 This information extraction is the foundational data for establishing and operating these systems.
However, hazardous chemical safety faces challenges due to dispersed textual information, specialized vocabulary, and potential ambiguity in data formats and sentence expressions. These issues give rise to uncertainty in knowledge representation and inference when constructing a knowledge graph in this domain. Currently, most research relies on static word vectors, such as Word2Vec, to represent inputs.7,8 Although static word vectors partially capture the semantic associations between words, they lack contextual semantic information, impacting the accuracy of hazardous chemical safety knowledge management.
Furthermore, an analysis of incident report texts reveals frequent instances of overlapping multiple entities and relationships within sentences. This overlap can hinder the effectiveness of information extraction and lead to missed or erroneous detections. For example, as depicted in Figure 1, the incident entity “poisoning incident” serves as the subject for the time entity “November 25, 2022,” the company entity “Hengsheng Nord High-Tech Company,” and the casualty entity “3 fatalities and 1 injured person.” Additionally, the company entity is also the subject of the location entity. This example demonstrates the presence of multiple overlapping entities and relationships. Current research attempts to address this issue by employing innovative approaches to extract the three elements of entities and relationships. For example, Chen et al. 9 proposed a novel feature engineering method to improve entity-relationship extraction performance. Jiang and Cao 10 introduced an unknown heterogeneous graph attention network to enhance semantic analysis and fusion between entities and relationships, thereby improving entity–relationship extraction. However, when these models encounter complex relationships, although they can partially address the problem of triple element overlap, they still struggle to achieve accurate extraction and matching when multiple overlapping triplets exist within a single sentence. Utilizing these models undoubtedly poses challenges in constructing a knowledge graph for hazardous chemical incident management. They fall short of meeting the precision requirements for understanding accident scenarios and their causes.

Example of entity–relationship overlap in hazardous chemical incident reports.
Based on the abovementioned issues, this article introduces CPBA-CLIM (content-position-based attention-cross-label intersect matching), a hazardous chemical safety incident entity-relation extraction model. The model utilizes natural language processing and knowledge graph mining techniques to extract information triplets from hazardous chemical safety incident reports. It stores them in a graph database for constructing incident knowledge graphs and performing key information statistics.
The main contributions of this article can be summarized as follows:
Introducing a dynamic word vector encoding module based on position and content. This module utilizes composite vectors containing word content and positional information to capture contextual semantic information, thereby representing the semantic features of each word in the input layer. This approach addresses the challenges of dispersed textual information and specialized vocabulary in hazardous chemical safety. Proposing an entity and relation decoding module based on the cross-label intersect matching strategy. This module evaluates and matches the rationality of interactions between entities and relationships from the predicted sets generated by the model. The aim is to extract triplets in sentences with various overlapping elements accurately. Conduct comprehensive experiments on public and self-constructed datasets, including comparative, ablation, and qualitative analysis. The results demonstrate the model's excellent handling of overlapping triplet sentence elements. Using the proposed model, we constructed a knowledge graph for managing hazardous chemical accidents based on ontology strategies. We have completed applications such as safety accident profiling and accident information retrieval.
Related work
Data-driven approaches in hazardous chemical safety management
The hazardous chemical safety situation is currently severe, characterized by “high temperature, high pressure, flammability, explosiveness, toxicity, continuous operation, and extensive chain length.” 11 Once incidents occur, they severely threaten people's lives and cause enormous socio-economic losses. In recent years, various advanced technologies have been applied in hazardous chemical safety management. 12 In computer science, with the advent of the big data era, the trend is to use multi-source data for comprehensive analysis. Knowledge graphs, driven by data-driven approaches, 13 have shown significant advantages in data management and representation by collecting and acquiring historical data and utilizing data mining or machine learning methods to extract useful information from a large amount of raw data.
Data-driven research in hazardous chemical safety involves several aspects. For example, based on learning from historical data, there are studies on the adjustment of environmental and conditional decision variables in the design and optimization of chemical processes. Sharma et al. 13 applied intelligent algorithm techniques to the adjustment of chemical process units and proposed an improved optimization algorithm to solve dynamic optimization problems in chemical engineering. In the research of process detection and fault diagnosis, scholars have studied the IPSO-optimized SVM-BOXPLOT method 14 for intelligent identification of abnormal operating conditions in the production process of hazardous chemicals. Regarding quality prediction and control, Lui et al. 15 corrected product quality defects by establishing a soft measurement model to improve product quality. For example, based on fuzzy neural network algorithms, 16 a device for product quality prediction is constructed to enhance product quality.
Application of knowledge graphs in hazardous chemical safety management
Knowledge graphs, intuitive tools for organizing and managing knowledge, have gradually found rich applications in various fields. For example, Moon et al. 17 developed a semantic retrieval system that allows users to retrieve incident-related information according to their needs using knowledge graph-based information retrieval applications. It enables the retrieval of safety risk factors, incident emergency response measures, and more. Combining various machine learning techniques, Zhang et al. 18 classified the causes of incidents in safety incident reports, providing technical support for summarizing incident lessons for safety professionals. Lee et al., 19 using dependency syntax analysis and other techniques, automatically detect potential risk clauses and propose an automatic extraction model for contract risk knowledge, significantly improving management efficiency.
In hazardous chemical safety regulation, there is a large amount of unstructured data, 20 such as incident reports, various safety regulations, and other data information. These data can provide decision support for hazardous chemical safety management. However, this knowledge is scattered in fragmented materials, and traditional safety management needs to utilize this information more thoroughly. Zheng et al. 12 established a knowledge graph for managing hazardous chemicals by ontology design and entity recognition, aiming to overcome the information gap between dispersed databases and improve the management of dangerous substances. Wu and Liu 21 proposed a risk knowledge question-answering model in hazardous chemicals based on relevant knowledge graph technology, which meets the needs for safe storage and management of hazardous chemicals. Establishing a knowledge graph in hazardous chemical safety can facilitate quick retrieval, statistical analysis of various incident case information, and safety regulations knowledge and help improve hazardous chemical safety management.
Unstructured data information extraction technologies in knowledge graphs
Word vectors, as the first-step input for building knowledge graphs, directly affect the accuracy of knowledge graph construction. 22 According to the different generation methods, word vectors can be divided into static and dynamic. Static word vectors are pre-computed before training, where each word is represented by a fixed-length vector that remains unchanged throughout the graph construction process. Dynamic word vectors, 23 on the other hand, adjust the vectors dynamically to represent word semantics based on specific tasks and contexts. Therefore, compared to static word vectors, dynamic word vectors can reflect contextual information and, to some extent, address issues such as polysemy and word sense disambiguation. As a result, dynamic word vectors can better adapt to different tasks and domains. In recent years, various dynamic word vector models have emerged, such as the generative pre-trained transformer model, 24 neural network-based bidirectional encoder representations from the transformer (BERT) model, 25 graph-structured gross domestic wellbeing model, 26 and time-attribute network Deep Convolutional Transformational Autoencoders Networks (DCTANs) based on the dynamic random state-space framework. 27 These dynamic word vector models can improve the accuracy of graph construction to a certain extent. However, text in hazardous chemical safety is highly specialized, and the data format needs to be more cohesive, with many entity words being uncommon. Finding a more suitable word vector representation model is crucial to improving the accuracy of building the hazardous chemical safety knowledge graph.
On the other hand, relation extraction is also a core task in building knowledge graphs, aiming to extract relationship triplets from unstructured natural language text. With the development of neural networks, researchers have gradually focused on relation extraction models in complex scenarios. 28 Some scholars 29 follow the pipelined method to complete relation extraction models: first, identify entities in the text sequence, then use relation classification methods to distinguish the relationships between entities. Although the pipelined approach can achieve relation extraction functionality, its obvious drawback is that the accuracy of the first module directly affects the effectiveness of the second module and the overall accuracy of relation extraction. Some researchers have proposed joint entity and relation detection models to address this issue. Zheng et al. used a Seq2Seq model with a coping mechanism to address overlapping relationships. 29 Fu et al. 30 proposed the binary tree structure from graph theory was introduced into the network to handle overlapping triplets.
In summary, previous research has made significant progress in hazardous chemical safety. In hazardous chemicals driven by data-driven approaches, emerging intelligent applications such as knowledge graphs provide a more comprehensive and intelligent means of managing hazardous chemical safety. This strengthens the supervisory and response capabilities of regulatory authorities. However, due to the unique characteristics of relevant texts in hazardous chemicals, the accuracy of knowledge graph construction in this domain needs further improvement. This is primarily manifested in two aspects: (1) The information in the field of hazardous chemical safety is scattered, and the vocabulary is highly specialized, with many entity terms being uncommon. Finding a more suitable word vector representation model is crucial for enhancing the accuracy of constructing hazardous chemical safety knowledge graphs. (2) Text data in hazardous chemicals often include sentences with multiple overlapping relationships. The current widely used information extraction models exhibit suboptimal accuracy when faced with complex sentences containing multiple overlapping relationships. Therefore, there is a need for a relationship extraction model that is more suitable for hazardous chemical safety to extract more accurate entity relationships.
In response to these challenges and limitations, this article presents a CPBA-CLIM model for constructing a knowledge graph in hazardous chemical safety. The model utilizes an end-to-end encoding–decoding framework, including a dynamic word vector (content-position-based attention (CPBA)) encoding module based on position and content and an entity and relation decoding module based on the cross-label intersect matching (CLIM) strategy. Finally, a knowledge graph in hazardous chemical incident management is constructed, enabling applications such as incident profiling, incident information retrieval, and incident statistical analysis.
Methods
Problem formulation and framework
Problem formulation
This paper addresses the challenges of entity relationship extraction in reports on accidents involving hazardous chemicals, including issues such as dispersed information, specialized terminology, and overlapping data relationships. An information extraction model is proposed to tackle these challenges. The model is capable of accurately extracting entity relationships in the form of triplets from a large number of unstructured documents. This provides a reliable data foundation for building knowledge graphs in hazardous chemical accident management and enhances the automation and efficiency of knowledge graph construction, offering essential support and decision-making basis for managing hazardous chemical safety.
Define the entity set as E and the relation set as R.
Define the set of textual sentences in hazardous chemical safety management as
Define the entity-relation triples as
Given a sentence
The above entity relationship extraction results, represented as T =
Framework
Based on hazardous chemical safety incident reports and incorporating natural language processing and knowledge graph techniques, this paper proposes a feature extraction model called CPBA-CLIM for encoding and decoding hazardous chemical safety incidents. The hazardous chemical incident management system is constructed through ontology-based knowledge graph-building techniques. The research framework is illustrated in Figure 2.

The overall structure of the paper's method.
The model determines the static word vectors before input and does not change with the semantic context during training. In the field of hazardous chemical safety, textual data is often complex and contains a large number of domain-specific terms and abbreviations. For example, in incident reports, there are many domain-specific terms, such as chemical names and company names, which often include common vocabulary, such as “a carbon monoxide poisoning,” “sulfide alkali workshop,” and “Petrochemical Company.” Therefore, the true meaning of a token is closely related to its contextual semantics. Consequently, in data processing, it is necessary to quantitatively encode the data based on the contextual semantics, adapting to the domain-specific vocabulary and knowledge representation, thereby improving the accuracy and robustness of the model.
The quantification of contextual semantics involves two factors: the content information of the word concerning its context and the position it occupies in the text sequence. This module proposes a dynamic word vector encoding model based on content and position to address this issue and accurately extract relevant triplets from hazardous chemical safety textual data. The structure of the CPBA module is shown in Figure 3.

Structure of the content-position based attention (CPBA) module.
Assuming the length of the input text sequence is N, and the position of a token in the sequence is i,
Therefore, in this article, we define the attention weight of a word as follows:

According to the definition of an attention model, the formula for calculating dynamic word content attention weights is as follows:

Similarly, the formula for calculating positional attention weights is as follows:




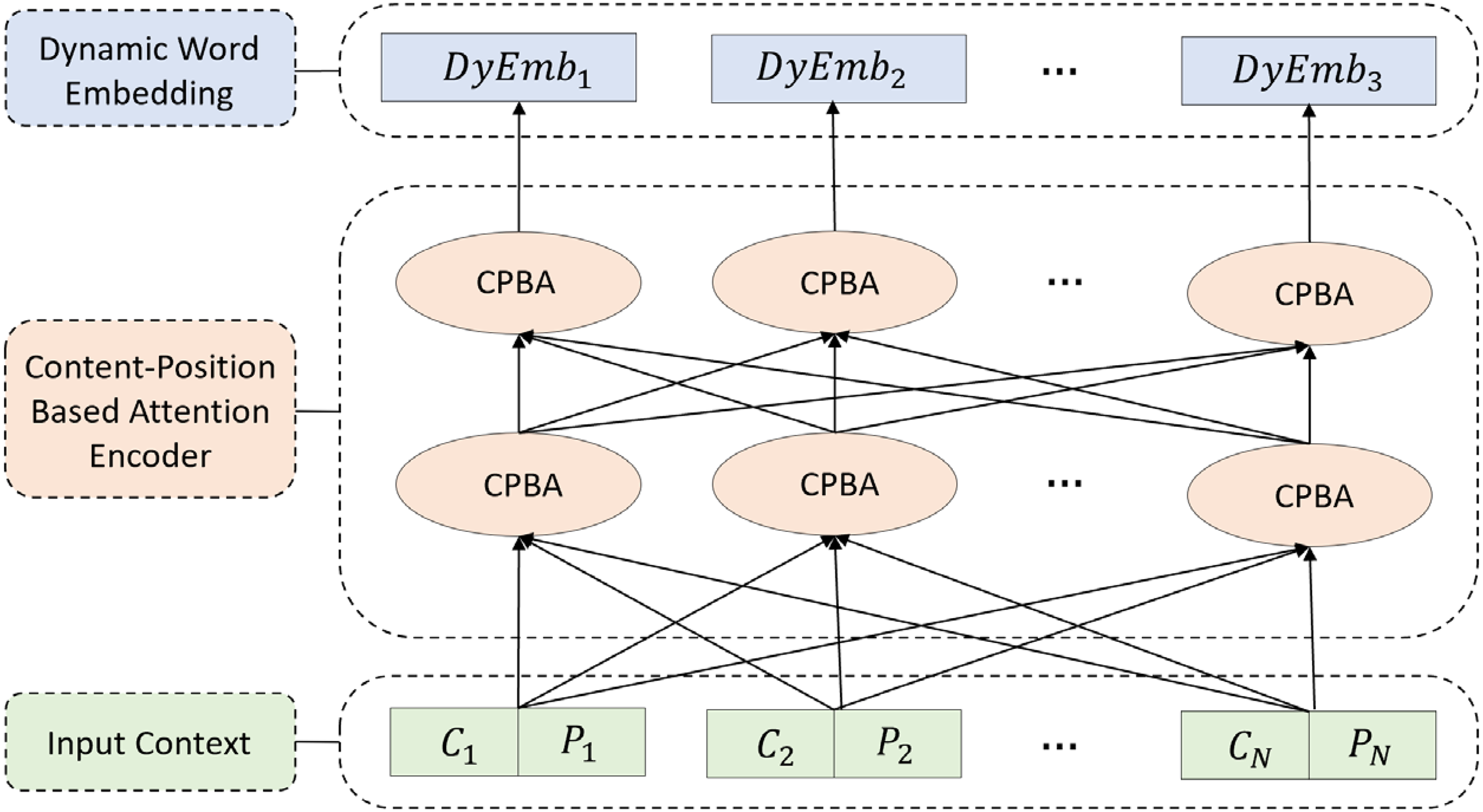
Content-position-based attention encoder.
Decoder module based on the CLIM strategy
Given a sentence
Based on the embedding

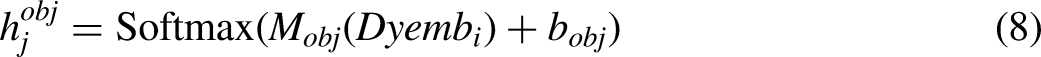
Based on two sets

After completing all sequence labeling,
Based on the table-filling mechanism, a CLIM strategy is proposed to address the issue of overlapping entity relationships and to accomplish the task of matching relationships between entities and extracting the final relationship triples. The core idea of the cross-label merging strategy lies in extracting all entity pairs and entity–relation pairs that involve the determined relationship, denoted as
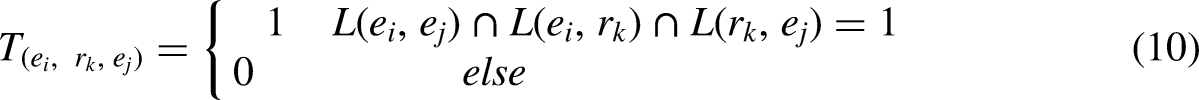
By combining the table-filling concept with the powerful deep correlation-capturing ability provided by Transformer layers, the specific calculation formula for



Finally, based on the entity and relationship label judgments matrix, the matching between entities and relationships is performed to obtain all the triples. The algorithm implementation for the matching strategy is as Algorithm 1.
Entity–relation matching strategy.

The decoding strategy first identifies entity groups corresponding to the same relation from the entity–relation and relation–entity labels. Then, it verifies the validity of the identified entity groups based on the entity–entity label matrix. As a result, it matches all the desired relation corresponding triplets. The above decoding method considers complex sentence structures that involve overlapping relationships, such as entity pair overlap (EPO) and single entity overlap (SEO), and can accurately match all possible entity and relation triplets.

Construction of the ontology in hazardous chemical accident management
Due to the diverse types of hazardous chemicals and the variety of accident scenarios, constructing a knowledge graph that can continuously evolve becomes particularly crucial. Such a knowledge graph can better support the prevention, management, and response to hazardous chemical incidents. Ontology, as the cornerstone of the knowledge graph, plays a crucial role by eliminating semantic barriers between different data sources, ensuring consistency and accuracy in knowledge representation. By carefully defining entity types, properties, and their relationships, ontology provides a standardized semantic framework for the knowledge graph, laying a solid foundation for subsequent knowledge management, queries, and reasoning.
This section presents a rule-based approach to construct an ontology for hazardous chemical accident management. The aim is to provide a standardized semantic framework for mapping the predictions of the CPBA-CLIP model to the knowledge graph. Through such construction, we ensure the sustainability of the knowledge graph for hazardous chemical incident management. This process establishes a robust foundation for future updates and the evolution of the knowledge graph. It enables it to adapt to dynamic changes in hazardous chemicals and provide persistent support for practical application scenarios.
The overall architecture for defining ontology construction rules is illustrated in Figure 5.

The architecture of rules for the construction of the hazardous chemical incident management ontology.
In this study, we adhered to the following design principles in establishing the class hierarchy. Firstly, based on human prior knowledge, we considered professional terminology and general classifications in hazardous chemical incident management. Secondly, we integrated entities and relationships extracted by the CPBA-CLIM model, ensuring close relevance between the ontology and actual data/model calculation results. Lastly, combined with the requirements analysis of safety management in the hazardous chemical domain, we ensured that the ontology structure authentically reflects users’ needs in their practical work.
According to the design above principles, the class hierarchy is designed as follows:
Five top classes: These top-level categories define the framework of the entire classification or ontology, representing the most extensive and abstract concepts indicative of the overall scope of the domain. This study identified five top-level classes: organization, equipment, chemical, person, and incident. Addition of subclasses: The addition of subclasses aims to provide more detailed support for describing each top-level class. In this study, top-level categories were further divided into three hierarchical levels of subclasses, ensuring the rationality of the hierarchy. The lowest-level subclasses represent the most specific entities.
The class hierarchy of the ontology we constructed to manage hazardous chemical incidents is illustrated in Figure 6. This structure provides an overall framework and a specific and orderly knowledge organization format for practical applications.

The class hierarchy structure of the ontology for hazardous chemical incident management.

The interclass relationships of the ontology for hazardous chemical incident management.
Experiments
Experimental settings
To intuitively verify the ability of the proposed model to handle complex textual scenarios with entity and relation overlap and accurately extract entity–relation triplets, the experimental setup is as follows:
Firstly, this article selected two significant publicly available datasets, NYT
32
and WebNLG,
33
for experimentation. This selection aims to provide a comparable benchmark for our model's performance, facilitating result comparison with current strong baseline and state-of-the-art models, thus accurately assessing the model's accuracy. Secondly, after validating the model's capability to process complex texts, we qualitatively analyzed the model's performance. We used hazardous chemical incident reports as input data for the model and extracted entity-relation triplets from these reports. These triplets were stored as < entity, relation, entity > to visually evaluate the model's ability and performance. Finally, to further demonstrate the practical value of the model, this section stored the extracted entity and related data from the incident reports in a Neo4j graph database. We constructed an ontology-based knowledge graph of hazardous chemical incident management and implemented application functionalities such as incident information retrieval and statistical analysis.
Datasets
Schema example of self-built dataset hazardous chemicals incident report (HCAR).

Data splitting and evaluation metrics
This study employs a standard data-splitting method 31 to divide the dataset into training, validation, and testing sets during the model evaluation process. This was done to provide a training foundation for the model's performance that aligns with current research standards and facilitates a fair comparison with the baseline model to assess model performance. Additionally, given that one of the research objectives in this experiment is to evaluate the accuracy of extracting overlapping entity–relation triplets, we also conducted additional statistics on the distribution of triplets under different overlapping scenarios in various datasets. The statistical results are presented in Table 2:
Statistics of the experimental datasets.

SEO: single entity overlap; EPO: entity pair overlap; SOO: subject object overlap.
This experiment follows the evaluation method employed by Fu et al.
30
It is considered that the model correctly extracts a relationship triplet, denoted as 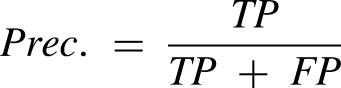
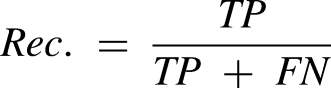
The F1 score is the harmonic mean of precision and recall, serving as a comprehensive measure of the model's performance. Its formula is given by
Based on the mathematical descriptions of the three metrics mentioned above, precision evaluates the accuracy of the model's positive predictions, with higher Prec. values indicating more accurate model judgments for positive instances. Recall assesses the model's ability to correctly identify all true positive instances, with higher Rec. values indicating greater comprehensiveness in capturing the most true positive instances and fewer instances missed. The F1 score provides a comprehensive evaluation by considering both precision and recall.
Implementation details
The model is implemented based on the PyTorch framework. The Adam optimizer
34
is used for model optimization. The learning rate is set to 3 × 10−5. The model is trained with a batch size of 24 for 100 epochs. The size of the attention heads,
To compare the performance with other models, the maximum length of input sentences is set to 128. The encoder model utilizes a pre-trained language model, BERT-base, with 108 M parameters. Additionally, the CPBA model is implemented to measure the model's accuracy and efficiency. The training and validation are executed using two NVIDIA GeForce RTX2080Ti GPUs.
Ten strong models, including SOTA models, are selected as benchmark methods for the comparative experiments. These methods specifically address the issue of entity relation overlap. NovelTagging 10 and TPlinkerBERT 35 employ improved sequence labeling techniques to solve the triplet overlap problem. CopyRE 31 and GraphRel 30 are end-to-end information extraction models. CasRelBERT 36 learns a mapping function from subject entities to object entities to accomplish triplet extraction tasks. GRTEBERT 37 utilizes graph neural networks to capture complex dependency relationships by mapping entities and relations to nodes and edges of a graph, respectively. PRGCBERT, 38 EmRel, 39 and OneRelBERT 40 are joint relation extraction models that employ different strategies for the joint training of entity relations.
Experimental results
This section will present the experimental results of our model compared to other baseline methods on publicly available datasets, including overall results and results in complex scenarios.
Overall results
Table 3 presents the results of our model compared to other baseline methods on two publicly available datasets. Considering that the encoder module of most mainstream tasks is based on pre-trained BERT, this experiment uses both pure BERT and an additional CPBA as the encoder module to obtain experimental results. Table 3 compares the efficiency of the models on the NYT and WebNLG datasets. The table shows that regardless of whether CPBA or BERT is used as the encoder, our model outperforms most mainstream baseline models in precision (Prec.), recall (Rec.), and F1-score. Furthermore, comparing the two encoders in our model suggests that the CPBA encoder achieves higher accuracy than the pure BERT encoder due to its incorporation of contextual semantics.
Comparison (%) of the proposed method with the baseline tasks on the NYT and web datasets.

Prec.: precision; Rec.: recall; F1: F1 score; BERT: bidirectional encoder representations from the transformer.
Complex scenarios results
To evaluate the performance of our model in handling sentences with different overlap patterns and varying numbers of triplets, we conducted further experiments on the NYT and WebNLG datasets. Since handling overlap patterns is closely related to the decoder module and most baseline tasks use BERT as the encoder module, we used a pre-trained BERT model as the encoder in this section. The experimental results are summarized in Table 4.
F1-score (%) on sentences with overlapping patterns and triple numbers.

SEO: single entity overlap; EPO: entity pair overlap; SOO: subject-object overlap; BERT: bidirectional encoder representations from transformer.
According to the results in Table 4, our model performs remarkably well in the overlapping scenarios. The model achieves optimal results in SEO scenarios on two datasets and EPO scenarios in the NYT dataset. In other scenarios, it also maintains suboptimal results. Additionally, in experiments with different numbers of triplets, the model achieves optimal experimental results when the number of triplets is 2, 3, and ≥ 5 in the NYT dataset and when the number of triplets is 2, 4, and ≥ 5 in the WebNLG dataset. It also maintains a top-three ranking in other cases. Therefore, this experiment confirms the model's ability to perform triplet extraction tasks in hazardous chemical accident scenarios.
It is worth noting that in our self-constructed dataset HCAR, the SEO overlap pattern has a significant proportion, accounting for 56.5% of the experimental samples. Therefore, this experiment also proves the capability of our model to perform well in hazardous chemical incident scenes, specifically in the task of triplet extraction.
Application instance of CPBA-CLIP model in the knowledge graph
Applying an entity-relation extraction model in hazardous chemical incident management overcomes the challenge of low information utilization in incident reports within the hazardous chemical domain, effectively enhancing the automation and efficiency of knowledge graph construction. This section uses the CPBA-CLIM model developed in this paper to identify the necessary entities and inter-entity relationship data from the self-constructed dataset HCAR. Then, following the methodology rules for constructing a knowledge graph based on the Hazardous Chemicals Incident Management Ontology already given in the “Construction of the ontology in hazardous chemical accident management” section, the data will be stored in a Neo4j graph using the LOAD CSV method. The knowledge graph construction for hazardous chemicals accident management is completed by storing the data in the Neo4j graph database using the LOAD CSV method.
The resulting knowledge graph for hazardous chemical incident management is presented in Figure 8. For ease of analysis and considering the limitations of information presentation due to image size, the paper displays only seven classes of entities and six classes of relationship data, including Incident Type (INC), Incident Time (TIME), Incident Location (LOC), Injured Personnel (INJ), Fatality (FAT), Economic Loss (ELOSS), and Incident Cause (CAUSE). Five classes of relationship data include TIME_to_INC, LOC_to_INC, INJ_to_INC, FAT_to_INC, ELOSS_to_INC, and CAUSE_to_INC.

Example of a knowledge graph for hazardous chemical incident management.
The example of the knowledge graph for hazardous chemical incident management demonstrates that the model's results effectively showcase the entity–relation extraction outcomes, particularly for SEO scenarios. The extraction performance of the model for SEO, EPO, and subject object overlap (SOO) scenarios, which was conducted through statistical analysis, is presented in Table 5. The “Total” column represents the number of triplets in the dataset with a specific overlap type. At the same time, “RecCnts’’ indicates the number of triplets extracted by the model for that overlap type. The analysis reveals that the model achieves an extraction rate exceeding 91% for all overlapping scenarios. It demonstrates the model's capability to accurately capture crucial information from unstructured data, such as hazardous chemical incident reports.
Statistics of extracted overlapping entity–relation triples in the HCAR dataset.

SEO: single entity overlap; EPO: entity pair overlap; SOO: subject-object overlap.
Statistical analysis is an essential requirement in the analysis of hazardous chemical incidents. Once an accurate hazardous chemical incident report is established, different statistical analyses can be performed according to specific needs. Figure 9 illustrates three commonly used types of retrieval statistics, including the statistical codes and examples of visual presentations. These types include incident time, location, and incident-type statistics. It is worth noting that achieving a combined statistical analysis of incident information is possible by controlling the retrieval conditions through codes.

Example of hazardous chemical incident information statistics.
According to the knowledge graph of hazardous chemicals safety management based on accident reports, the data analysis of instances is as follows: The dataset HCARD contains 868 accidents. When examining the incident data from 2011 to 2022, there is a notable 22.4% reduction in accidents in 2022 compared to 2011. At first glance, the data trend suggests that the chemical industry is becoming safer.
In terms of accident types, explosive accidents are the most prevalent, accounting for 487 cases, followed by leakage and poisoning accidents (292 cases) and fire accidents (184 cases). Asphyxiation accidents represent a smaller proportion at 5.9% (40 cases). Additionally, the majority of accidents, 75.9%, occur in processing areas, with storage areas accounting for 14.7%. According to related searches, 80% of accidents in storage areas are associated with explosions, highlighting a critical need for preventative measures in these locations.
Analyzing hazardous chemical types reveals that hydrogen sulfide is the primary cause of accidents, contributing to 11.2% of cases (77 accidents), predominantly resulting in poisoning. Carbon monoxide ranks second with 5.3% (36 cases), followed by hydrogen at 4.7% (32 cases). It is worth noting that nitrogen, while not classified as hazardous, is implicated in 4.1% of incidents (28 cases) due to its high concentration in enclosed spaces leading to asphyxiation.
Compared with hydrogen sulfide and carbon monoxide, natural gas (2.9%, 25 cases) and petroleum vapor (3.5%, 24 cases) are more prone to causing explosions, accounting for 52 incidents.
The graph data structure of the hazardous chemical incident management knowledge graph facilitates a more precise and intuitive understanding of incidents. For instance, retrieving causes of leakage and poisoning incidents from the past five years enables analysis to identify patterns and common attributes, contributing to proactive measures in preventing similar incidents in the future.
There is a wealth of textual information on hazardous chemical safety, with incident reports providing detailed records and summaries of hazardous chemical accidents. These reports offer valuable empirical data for chemical safety management, facilitating a profound understanding of the underlying causes of accidents. Effectively extracting and analyzing this information, and transforming it into a graph data structure to build a domain knowledge graph, provides managers with more accurate and intuitive insights into events. This, in turn, supports improving management systems, equipment, and training based on scientific evidence.
However, traditional methods face challenges in fully utilizing and extracting dispersed knowledge stored in different files. In this context, the CPBA-CLIM model developed in this study addresses the challenges of entity relationship extraction in hazardous chemical accident reports, along with a statistical analysis approach based on knowledge graphs, demonstrating significant innovation and advantages. This research provides an accurate data foundation for constructing knowledge graphs in hazardous chemical accident management.
The CPBA-CLIM model proposed in this study and the method of building ontology-based knowledge graphs using information extracted through the mapping model represents both a technical innovation and a tool for managers to gain insights into the deep-seated causes of accidents.
For instance, conducting statistical analysis of information related to hazardous chemical accidents stored in graph data structure form (as discussed in the “Application instance of CPBA-CLIP model in knowledge graph” section, point (2)) helps reveal patterns in accident occurrences, discover hidden common attributes, and derive valuable lessons. Furthermore, connecting multiple entity nodes such as accident types, storage locations, types of hazardous chemicals, and accident causes to form a graph structure can assist relevant personnel in understanding whether a leakage incident in a specific area is related to certain environmental factors in that area (e.g. hydrogen sulfide easily causing poisoning accidents in storage (11.2%), with improper personnel operations leading to leaks (28%) or failure to wear personal protective equipment correctly (13%), etc.).
This multidimensional correlation may be challenging to capture with traditional statistical methods. Therefore, the approach presented in this paper records accident data and provides various retrieval and statistical means for managers to have a data foundation for accident analysis. This helps them understand the multidimensional characteristics of hazardous chemical accidents, comprehend the fundamental causes, and formulate safety strategies and preventive measures more effectively. Ultimately, it contributes to preventing similar incidents in the future.
Summary of experiments
To simultaneously assess the model's generalization capabilities and performance in specific application scenarios and to enable a more effective comparison with other baseline models, we conducted experimental evaluations of the proposed methods on public and self-constructed datasets in the experimental section. The outcomes indicate that our proposed methods perform exceptionally well in extracting text features and managing overlapping triplets. The detailed summary is as follows:
The experiments on public datasets provide a comparable benchmark for the performance of the proposed model against strong baseline models, achieving F1 scores of 93.2% and 94.7% on the NYT and WebNLG datasets, respectively. The model also exhibits extraction rates of entity–relationship overlaps above 91% in complex contextual situations. The extraction results on the self-built dataset further validate the model's effectiveness in scenarios involving specialized vocabulary and overlapping entity relationships. The qualitative analysis demonstrates the model's ability to provide data support for constructing a hazardous chemical incident knowledge graph based on extracted triple data from reports. In the final part of the experiment, we demonstrated the application value of the CPBA-CLIM model in hazardous chemical incident management. The application of this model not only improves the utilization rate of report data and the efficiency of knowledge graph construction but also provides insights through data analysis. This assists relevant personnel in taking more effective preventative and responsive measures in similar scenarios in the future.
However, we also acknowledge certain limitations of the model, such as a noticeable decrease in the completeness and accuracy of information extraction in complex sentence structures or extreme cases. Therefore, the robustness of the model when handling more challenging textual scenarios remains an area of concern. Future work will focus on addressing these limitations and improving model performance. Specifically, we plan to expand the scope of the dataset by incorporating additional materials, such as regulations and standardized documents related to hazardous chemical safety management, to cover a broader range of scenarios and enhance model generalization. Furthermore, ongoing efforts will be dedicated to refining the model's architecture to better adapt to various text structures.
Conclusion
In conclusion, this article presents the CPBA-CLIM model. It effectively tackles the challenges of entity relationship extraction in hazardous chemical incident reporting, including scattered text, specialized terminology, and overlapping data relationships. The CPBA-CLIM model innovatively combines content-position attention with BERT encoding for dynamic contextual analysis in hazardous chemical incidents. Its CLIM strategy efficiently addresses entity–relation overlaps, enhancing triplet extraction accuracy. Our experimental results on public and self-constructed datasets confirm its superior performance in text feature extraction and handling complex scenarios, including overlapping triples. Finally, by applying the CPBA-CLIP model to constructing knowledge graphs, we demonstrated its application value in hazardous chemical incident management. It provides technical support for intelligent services in hazardous chemical safety management. Future work will expand the dataset and refine the model architecture to enhance its ability to process complex texts and adaptability to different textual scenarios.
Footnotes
Acknowledgements
The authors would like to acknowledge the support provided by Aerospace Hongka Intelligent Technology (Beijing) Co., Ltd.
Authors’ contribution
Wanru Du and Quan Zhu: study conception and design; Wanru Du, Quan Zhu, Xiaoyin Wang, Xiaochuan Jing, and Xuan Liu: data collection; Wanru Du, Quan Zhu, Xiaochuan Jing, Xiaoyin Wang, and Xuan Liu: analysis and interpretation of results; Wanru Du, Quan Zhu, and Xiaoyin Wang: draft manuscript preparation. All authors reviewed the results and approved the final version of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Author biographies
Wanru Du is a PhD candidate in Systems Engineering. Her area of research is systems engineering, machine learning, and data mining.
Xiaoyin Wang is a professor of Computer Engineering. Her area of research encompasses artificial intelligence and natural language processing.
Quan Zhu is a master's student in Computer Engineering. His area of research is data mining and sentiment analysis.
Xiaochuan Jing is a professor of Systems Engineering. His area of research is knowledge engineering and artificial intelligence.
Xuan Liu holds a PhD in Systems Engineering. Her area of research is behavior recognition and safety engineering.