
Abstract
Collaborative filtering is a kind of widely used and efficient technique in various online environments, which generates recommendations based on the rating information of his/her similar-preference neighbors. However, existing collaborative filtering methods have some inadequacies in revealing the dynamic user preference change and evaluating the recommendation effectiveness. The sparsity of input data may further exacerbate this issue. Thus, this paper proposes a novel neighbor selection scheme constructed in the context of information attenuation to bridge these gaps. Firstly, the concept of the preference decay period is given to describe the pattern of user preference evolution and recommendation invalidation, and thus two types of dynamic decay factors are correspondingly defined to gradually weaken the impact of old data. Then, three dynamic evaluation modules are built to evaluate the user's trustworthiness and recommendation ability. Finally, A hybrid selection strategy combines these modules to construct two neighbor selection layers and adjust the neighbor key thresholds. Through this strategy, our scheme can more effectively select capable and trustworthy neighbors to provide recommendations. The experiments on three real datasets with different data sizes and data sparsity show that the proposed scheme provides excellent recommendation performance and is more suitable for real applications, compared to the state-of-the-art methods.
Keywords
Introduction
The constant growth of web technologies results in the information overload problem. A vast amount of information is uploaded and downloaded on websites.1,2 Although it may increase the total amount of information that users are interested in, it is not an easy task to find this information in a rapid-increasing data environment. 3 Therefore, the recommender system is put forward as a perfect tool that helps users find their desired items. It analyzes users’ implicit or explicit data to filter information and provide personalized suggestions about products or items. Due to its excellent applicability, the recommender system has been applied to various online business fields to increase the percentage of sales and adjust the marketing policy. 4
Among all the techniques used in the recommender system, collaborative filtering (CF) is the most known one that can handle a huge amount of user behavior data. Especially, fewer requirements of domain-related feature extraction ensure CF's superiority in processing unstructured data. Mainly, model-based CF and memory-based CF approaches are two categories of representative CF approaches. In the former, a model is trained from user data using transfer learning and other techniques.5–13 Then, the built model is used for predictions. During the prediction process, there is no need to access user data again, which is the main advantage of the model-based approach. However, long training time and many parameter settings are trouble problems. When user data updates, the model-based approach may need to train the model again.6–12 In the latter, the similarity between users or items is calculated to select similar users (neighbors) and perform recommendations to the target user. Especially, Pearson correlation coefficient (PCC), Constrained PCC (CPCC), Cosine-based similarity (COS), Jaccard, Mean squared difference (MSD), and JMSD are the widely used similarity calculation methods for memory-based CF.14–17 Unlike model-based CF, most memory-based CFs work with a single main parameter (K-number of the neighborhood) and provide immediate responses without trial and error, which is simple and intuitive.18–20 Thus, most online business fields prefer to deploy memory-based recommender systems to filter items for customers.
21
However, although memory-based CF is widely used and has been further improved, there are still some unresolved problems:
Co-rated items problem Some similarity measures do not consider the number of co-rated items. This results in some users who are similar to the target user on very few items and can get a high similarity score. Symmetry problem In most similarity measures, similarity scores between a pair of users are symmetrical. This results in users with different capabilities of providing recommendations being assigned the same score. Extra item problem Many methods only pay attention to the similar ratings on co-rated items of pair of users and ignore the number of different items. This may lead to the scarcity of the number and variety of recommendations. Time problem User preferences may change in the time domain, which affects the recommendation accuracy. Lacking consideration of the time factor may contribute to unreasonable neighbor matching. The interest of users may vary with time, and the recommendation may invalidate. To better dynamically evaluate the user capabilities, the concept of the preference decay period is first given to describe preference evolution and recommendation invalidation. Based on this concept, two dynamic decay factors are defined. The impact of old data is gradually attenuated by these two factors, which helps accurately predict target user preferences. A novel neighbor selection scheme is proposed to select capable and trustworthy neighbors and improve the recommendation accuracy. It contains three modules: a fuzzy evaluation module filters inappropriate users in advance based on the comprehensive ability evaluation; a trust evaluation module in combination with the dynamic forgetting factor captures the neighbors’ recent preferences to evaluate dynamically their trustworthiness; a recommendation evaluation module evaluates the recommendation capability of neighbors by calculating the number of their effective recommendations. The experiments on three real datasets are conducted with different sparsity. Experimental results show that the proposed scheme provides higher accuracy than the state-of-the-art memory-based methods and is more suitable in real applications.
Furthermore, these four problems are more serious in the data sparsity environment. In order to solve them, this article proposes a novel neighbor selection scheme to better predict item scores for the specific user. Initially, the concept of the preference decay period is first given to describe the pattern of user preference evolution and recommendation invalidation. Two kinds of dynamic decay factors are defined correspondingly to gradually attenuate the impact of old data. Besides, three evaluation modules, such as the fuzzy evaluation module, the trust evaluation module, and the recommendation evaluation module, are built to select capable and trustworthy neighbors for the target user. By estimating the calculation amount of each module, a neighbor selection strategy divides the two-layer selection structure and decides the corresponding module of each layer. The main contributions of our paper can be summarized as follows:
The rest sections are organized as follows: Section 2 reviews the related work, Section 3 explains the motivation of this paper, Section 4 describes the proposed method, Section 5 presents the experimental results, and Section 6 provides a conclusion.
Related works
CF algorithms
There are two types of collaborative filtering most widely used, i.e. memory-based and model-based collaborative filtering methods. In memory-based CF methods, the user-rating matrix is used to calculate similarity directly to find similar-preference users. model-based CF methods construct a user model that predicts user preferences and then apply it to generate recommendations in the online environment.
The most popular techniques used in the model-based CF approach can be divided into clustering,5–7 co-clustering,8,9 matrix factorization,10–13,22,23 mixtures models,24,25 and transfer learning approaches.26,27 Model-based CF methods have their unique advantages in handling large-scale datasets because once the model has been established, rating predictions can be provided fast without massive online computation.5–10 However, to maintain good performance, model-based CF methods need to train the model regularly. And each training needs to iteratively calculate the user rating behaviors, which is time-consuming.24,25 In addition, there still is a problem in that the call and calculation of massive data often cause information loss in the modeling process, which leads to prediction failure and inapplicability of the model.6–12
Among memory-based methods, COS, PCC, CPCC, Jaccard, MSD, and JMSD are the most popular methods, which are given in Table 1. Due to their universality and practicability, many extension methods are proposed. In, 28 a multi-level collaborative filtering method is proposed to analyze the number of common ratings and PCC scores and then enables users to get a higher similarity score when the metric exceeds a certain threshold. Li et al. 29 compute user/project similarity by a novel weighted adjusted cosine similarity method based on a novel weight calculation algorithm, which improves the accuracy of the rating prediction. In, 30 a new approach that contains a hybrid similarity measurement can achieve better prediction accuracy and effectively reduce memory and time. A new item-based collaborative filtering approach, proposed in, 18 not only uses triangle similarity measures to calculate the rating vectors between users but also adopts a multi-level recommendation approach to dynamically adjust parameters. In, 19 the authors take the categories of interests into account to extract tree structures of rated items and then compute the similarity value based on the relevant rating information, which handles data sparsity and high dimensionality problems. Singh et al. 20 aim to determine the number of neighbors for each target item more reasonably based on the Bhattacharyya Co-efficient similarity measure. In the above methods, many effective user similarity calculations are proposed from different aspects to increase the recommendation accuracy.
Similarity measures frequently used in memory-based CF.

However, many existing methods rarely consider the number of common items between a pair of users. The time factor and the discordant capability of a user in recommending items for other different users are often ignored.28,29 These issues may lead to the specific user matching some neighbors who cannot provide reliable recommendations. More importantly, the data sparseness issue makes these problems more complex, which may cause a great amount of computation or a decrease in the accuracy of recommendations.
User trust evaluations
With the emergence of social networks, many researchers introduce trustworthiness among users into CF methods. Some social and trust-based recommender systems compute trust values for alleviating sparsity based on the transitivity rules. 31 To improve the performance of trust-based recommender systems, some methods are proposed to incorporate users’ social network trust relationships, especially combining explicit and implicit relationships to build trust models.32–35 In, 36 by introducing a specific reliability measure, the authors propose a method to find the most important users based on Pareto dominance and confidence concepts. Duricic et al. 21 recognize the importance of the trust network and build a trust network based on the regular equivalence, and then a similarity matrix is generated to select the k-nearest neighbors and make recommendations. Chen et al. propose a new CF method that integrates users’ implicit social information to improve recommendation precision. 37 These methods have improved recommendation accuracy by incorporating social or trust information into the recommendation process, which also brings a problem where users’ social relationships or behaviors are difficult to extract. When lacking social information, some methods may have difficulty in practical application for many recommender systems. Therefore, many researchers further discuss this problem and present some methods that relieve the sparsity of social networks or reduce dependence on social information. In, 38 a novel method is proposed to incorporate trust into the CF recommendation process, which does not highly rely on social information. Lee et al. 39 propose a hybrid approach that combines the k-nearest neighbors and the matrix factorization methods to enhance the ability to judge the user's trust for the target user. These studies show that selecting trustworthy neighbors based on social networks or trust evaluation methods can truly improve recommendation accuracy. However, data sparsity is still a problem for most of these studies, which reduces the prediction accuracy as well as sometimes introduces high computational complexity.
Besides, the time factor is the key factor that affects the recommendation accuracy of the trust-based collaborative filtering method. Liu et al. 40 pay attention to the change in user interests and analyze users’ sequential preferences at regular intervals. Wang et al. 41 manage to introduce the time factor into the opportunity model to predict a user's purchase behavior in the time domain. In, 42 the authors propose a time function to trace each user's interest change. In, 43 the tag-time information in combination with rating information is used to calculate the similarity between users or items. Zhang et al. 44 propose a novel method to forget users’ previous behaviors and calculate similarity layer by layer to improve recommendation accuracy. Tong et al. propose a novel algorithm that integrates the time factor and the trust value to improve the accuracy of rating prediction. 45 By considering the impact of the time factor on the user similarity calculations, these studies have increased the diversity and accuracy of recommendations to varying degrees. However, they involve less discussion about the influence of the time factor on recommendation capability. This may contribute to too few recommendations being provided for the target user or some recommendations do not satisfy the latest preferences of the target user.42–44
Motivation
Most existing similarity measures exist some inevitable problems, such as the co-rated items problem, the symmetry problem, the extra item problem, and the time problem. In this section, we use six frequently used similarity measures (i.e. COS, PCC, CPCC, Jaccard, MSD, and JMSD) to demonstrate these problems. The user-item rating matrix used for illustration is shown in Table 2. There are five users and six items in this matrix and the rating value ranges from 1 to 5. The user similarity calculated by six similarity measures is shown in Figure 1. The detailed description of the problem is as follows.
Co-rated items problem

The values of user similarity based on different methods.
An example of a user-item rating matrix. (“-” represents that the item is not given).

Pseudo-code of the neighbor selection strategy.

Co-rated items play an important role in six similarity measures. However, the number of co-rated items is ignored in the COS, PCC, and CPCC, which may contribute to the wrong result, particularly for small numbers of common ratings. Take PCC for example, 2. Symmetry problem 3. Extra items problem 4. Time problem
For all six similarity measures, their similarity value matrixes are symmetric, i.e.
The number of extra items can reflect the user's recommendation ability to a certain extent. From Table 1, we can easily find that COS, PCC, CPCC, and MSD have no consideration for this. And Jaccard and JMSD consider the number of non-co-rated items as a negative factor. Take Jaccard for example,
The purpose of the recommendation system is to push recommendations in time. User preferences may change in the time domain, which affects the recommendation accuracy. Thus, the time factor is critical when calculating the similarity. None of the above six similarity measures consider it.
The motivation of our method is to address these four problems in a data sparsity environment. Thus, the proposed method introduces three evaluation modules and a new neighbor selection strategy to improve the efficiency and accuracy of recommendations. It fully considers key factors to evaluate neighbors and avoid useless calculations. Details of our method are shown in the following sections.
The proposed method
To solve four important problems discussed in Section 3, the proposed method first analyzes the same characteristics between human memory and preference change. Then, the concept of the preference decay period is given to describe preference evolution and recommendation invalidation. Based on this concept, two dynamic decay factors are defined to gradually attenuate the impact of early ratings. With the information attenuation, three evaluation modules are constructed to calculate users’ comprehensive ability, trust value, and recommendation capability, respectively. Besides, a novel neighbor selection strategy is presented to specify the evaluation order and define the fitness of the user. Finally, the proposed scheme uses the evaluation module and the selection strategy to identify capable and trustworthy neighbors. The structure of the proposed scheme is shown in Figure 2. In Figure 2,

Structure of the proposed neighbor selection scheme.
Preference attenuation
User preference information contained in each rating may attenuate as time goes by. In this section, we discuss the principle of preference attenuation in detail to describe the change in trust and recommendation ability. For a user, it is easy to divide his/her preferences into two types: short-term preferences and long-term preferences. The short-term preferences are formed by popular things, e.g. hot movies and fashionable clothes, which change frequently and quickly; The long-term preferences are formed by users’ interests, e.g. users give high marks to sci-fi movies for a long time, which are stable and consistent. Another thing with similar classification criteria is human memory. Human memory can be divided into long-term memory and short-term memory from the perspective of memory results.
46
Long-term memory is a memory that can be kept from a few days to a few years. Compared with long-term memory, short-term memory has a shorter storage time for information, and its storage capacity is also very limited. In a recent study, a mathematical formula for human memory is proposed, which meets the characteristics of human memory.
47
We can find that preferences change has similar characteristics to human memory in terms of information change trends. Thus, based on the concept and formula of human memory, we put forward a hypothesis about preference attenuation: when we take the user's preferences at a certain moment as the standard, the total amount of preference information will lose as user preferences change. Specifically, the preference information attenuation will have a trend of stability in the short term, rapid decay in the medium term, and slow decay in the later period. Thus, the preference attenuation is divided into three stages: instantaneous decay phase, short-term decay phase, and long-term decay phase (i.e.

The preference attenuation curve.
In Figure 3, the x-axis and the y-axis represent time and preference information,
Two dynamic decay factors
In this section, two dynamic decay factors (i.e. dynamic forgetting factor and dynamic invalidation factor) are introduced to quantitatively describe the attenuation rate of preference information. Firstly, dynamic decay factors are based on the time domain, which is divided into multiple parts with the time stamp (i.e. time windows). Every rating is put into the corresponding time window. When a user gives a rating at 

Dynamic forgetting factor
Dynamic forgetting factor describes the forgetting rate of user preference. According to whether consistent with the target user preferences, a user's preferences can be further divided into consistent preferences and inconsistent preferences. We assume that the quality of the recommendations will be improved when these two types of preferences adopt different forgetting rates. Especially, in real life, the person who always shares stable preferences with us is more trustworthy. Users’ inconsistent preferences should be less affected by the time factor to punish users with fluctuating preferences. Therefore, Consistent/inconsistent forgetting factors (i.e. marked as 

Dynamic invalidation factor
The change in user preference may lead to the invalidation of earlier recommendations. Therefore, referring to the preference attenuation principle, the recommendations in the short-term decay phase are effective. When these recommendations fall into the short-term decay phase or long-term decay phase, they will lose effectiveness gradually. Thus, the dynamic invalidation factor is calculated in equation (5), where 
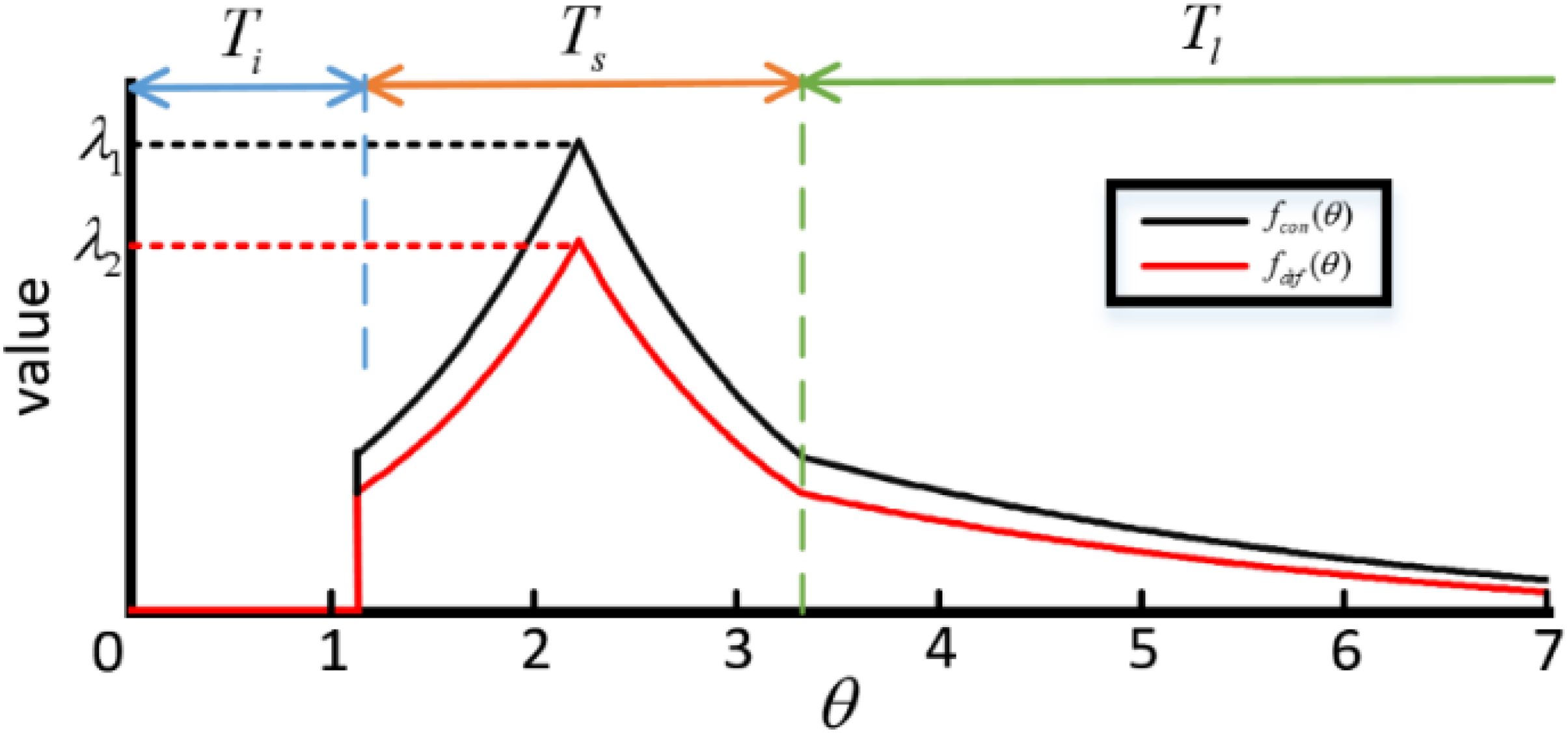
The curve of two forgetting factors.
As a summary, to describe the user preference change and recommendation validity, we give the concept of the preference decay period and two dynamic decay factors to forget users’ previous preferences and recommendations. The dynamic forgetting factors determine the forgetting rate of preferences contained in rating on co-rated items; The dynamic invalidation factor determines the invalidation rate of recommendation. Besides,
Three evaluation modules
Trustworthiness reflects the similarity among the target users and their neighbors and shows the validity of the recommendations; Recommendation capability represents the number of effective recommendations that neighbors can provide. In this section, the user's dynamic trustworthiness and recommendation ability are evaluated. The evaluation depends on three evaluation modules combined with dynamic decay factors: the fuzzy evaluation module, the trust evaluation module, and the recommendation evaluation module. These evaluation modules not only solve the four problems in Section 3 to improve the recommendation accuracy. The following sections introduce these three modules in detail.
Fuzzy evaluation module
The purpose of the fuzzy evaluation module is to roughly assess the user's comprehensive ability. Specifically, the comprehensive ability of a user (i.e. marked as 
Trust evaluation module
The trust model is an effective method to evaluate the similarity and consistency of preference between two users. Trustworthy users are defined as users who have similar ratings with the specific user on common items. A user with a higher trust score can provide more credible recommendations. Besides, due to the dynamic nature of preference, the time factor is critical in the trust evaluation. Thus, in this section, the trust evaluation module adopts a revised beta trust model that combines two dynamic forgetting factors to dynamically evaluate users’ trustworthiness.
In our model, for co-rated items of the specific user u and user e, the rating offset follows the beta distribution. Depending on the value of each rating offset, user e can be judged whether his/her preference on this item is consistent or inconsistent with the target user u ‘s preference. However, the basic beta trust model can only make a Boolean judgment on a rating behavior, which does not apply to abundant-data-type recommendation systems. Therefore, we expand the basic beta trust model and assume that the preferences of a rating contain both a consistent portion and an inconsistent portion. Each portion of preferences is quantified as a continuous value, ranging from 0 to 1.
More important, to catch the latest preferences easier, the previous preferences will be forgotten by introducing dynamic forgetting factors. As a result, the consistent portion and inconsistent portion of the preferences contained in a rating can be marked as 

Furthermore, user e may have multiple co-rated items in the time window 

To let recent ratings take higher weights in the evaluation, the model is set to forget users’ previous preferences when calculating the overall amount of user preferences in the current time window. Especially, the overall amount of two portions of preferences (i.e. 


Recommendation evaluation module
In the real application, enough effective recommendations from neighbors can effectively alleviate the degradation of recommendation accuracy caused by sparse data. Thus, the amount of the users’ effective recommendations is taken as the criterion to judge the recommendation capability of neighbors. In this section, the recommendation evaluation module is built to dynamically evaluate the user recommendation capability. Since the recommendations may invalidate with the user preference change, the recommendation evaluation process introduces the dynamic invalidation factor. The total number of user e 's extra items in the time window 


Neighbor selection strategy
In existing single-layer neighbor selection methods, there are two kinds of neighbor selection methods that are most widely used. One is to calculate similarity scores and select a certain number of neighbors(i.e.
For multiple-layer neighbor selection methods, the weighting scheme is often used. It assigns different weights to the output of each module to calculate the similarity between the two users. Although the weighting scheme can get a good recommendation result by setting a suitable weight value, it takes a lot of time and computing resources. To address the limitations of these three categories of neighbor selection methods, a mixed neighbor selection strategy combined with three evaluation modules is proposed to choose capable and trustworthy neighbors quickly and accurately. The whole process of neighbor selection can be divided into two steps, as shown in Table 3. In the first step, the fuzzy evaluation module selects the top 

Experiments
In this section, the experimental evaluation of our proposed scheme takes place and the results are based on three real datasets. The evaluation is performed on an Intel i9-9900 K 3.6 GHz, 32 GB of RAM, and Windows 10. All the algorithms were implemented in the Python programming language.
Experiment data set
For rating predictions, there are three datasets with different data sizes, MovieLens-100k, MovieLens-20 M, and Netflix-20 M, which are adopted in our experiments. MovieLens-100k dataset is a real and widely used dataset that contains 1682 movies, 943 users, and 100,000 ratings. The MovieLens-20M dataset contains 27,000 movies and 138,000 users with 20 million ratings. Netflix-20M dataset contains 4499 movies and 470,758 users with 24,053,764 ratings. All rating values are on a scale of 1 to 5. Each rating contains specific information about the user id, item id, and rating time.
To test the effectiveness of the proposed evaluation modules, the training and testing data should be pre-processed based on the rating time of every rating. The data processing steps are as follows: (1) all user ratings are ordered as a sequence according to the time, in which the newer user ratings are more forward. Then the top 30% of the ratings are defined as testing data, and the remaining part is defined as training data. To match the real online recommendation situations, the latest rating time in the training data is defined as the current time, (2) Furthermore, users who provide testing data are defined as a testing user group and users who provide training data are defined as a training user group. (3) The users who have no rating in the training data need to be excluded from the testing user group because these users have no information at the training stage to let us select neighbors for them. Conversely, the users in the training user group can be selected as appropriate neighbors even if they cannot provide testing data, so they are all preserved.
Evaluation metrics and methods
To demonstrate the effectiveness of the proposed method, it is compared with the existing memory-based and model-based methods like PCC-CF, CPB-CF,
6
ML-CF,
28
DT-CF,
44
TLSVD,
22
and MF-CF.
23
In our method, the rating prediction of a certain item i for a user u is calculated in equation (19). The predicted rating score can be obtained by multiplying neighbors’ relevant ratings by corresponding weights.





The effect of the model parameters
In this section, we discuss how different parameters affect the performance of our proposed scheme. The parameters in the proposed scheme, such as time window length
In the first experiment, for the different number of neighbors, different ε values with a scale of 1 to 2 are tested to obtain the minimum MAE. The experiment sets

Impact of parameter
In Figure 5, we can see that a larger number of neighbors makes our proposed scheme more effective for a certain
In the second experiment, we set

Impact of different decay phase lengths on MAE.
In Figure 6, we can see that the minimum MAE is always obtained when
In the third and fourth experiments, we focus on studying the effect of

The MAE results and best rate factors of different
Figure 7 is shown that the optimal
The fourth experiment is based on the third experiment, in which we study the more complex case where
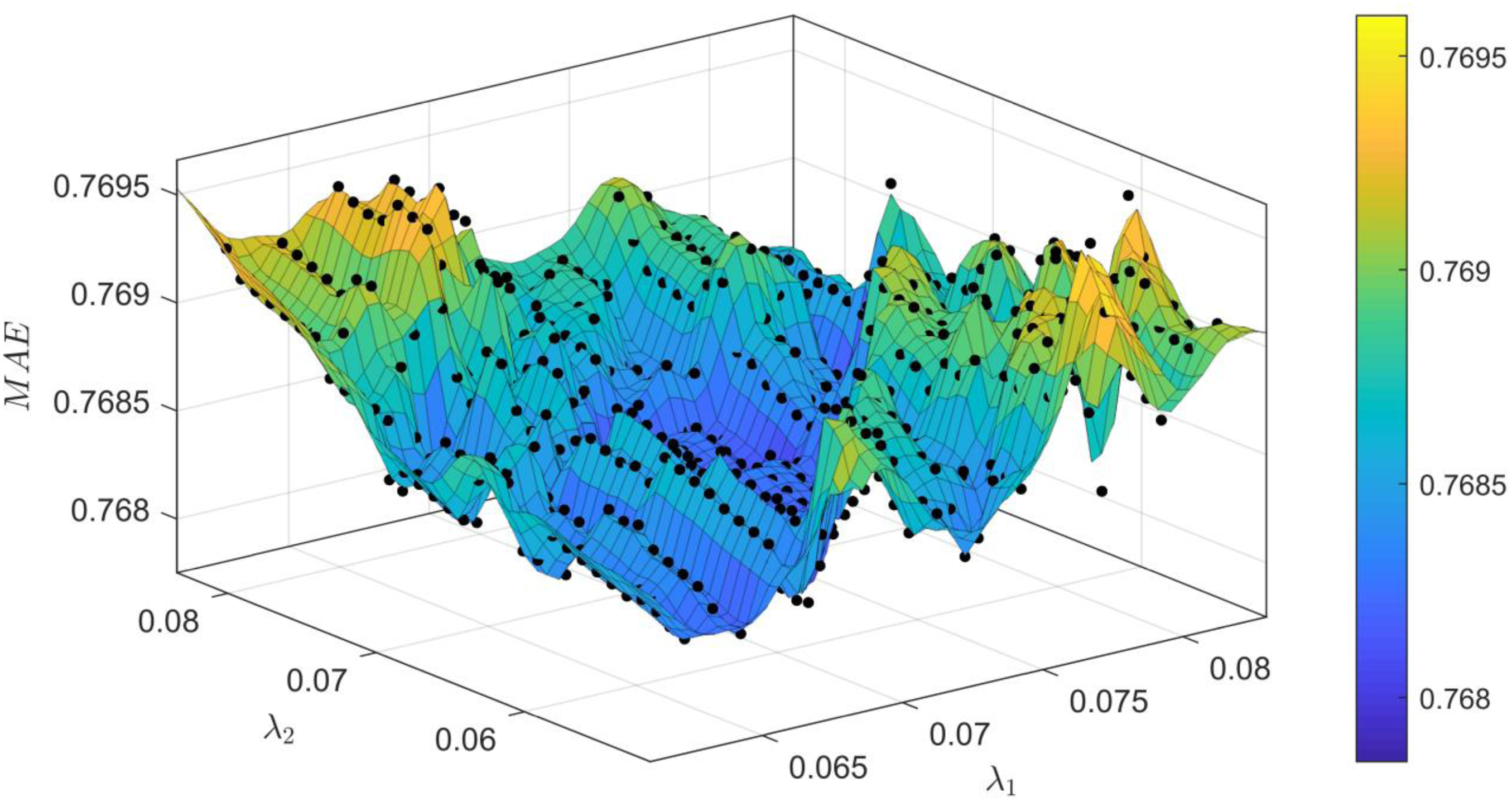
Impact of parameter
Figure 8 is shown that when the
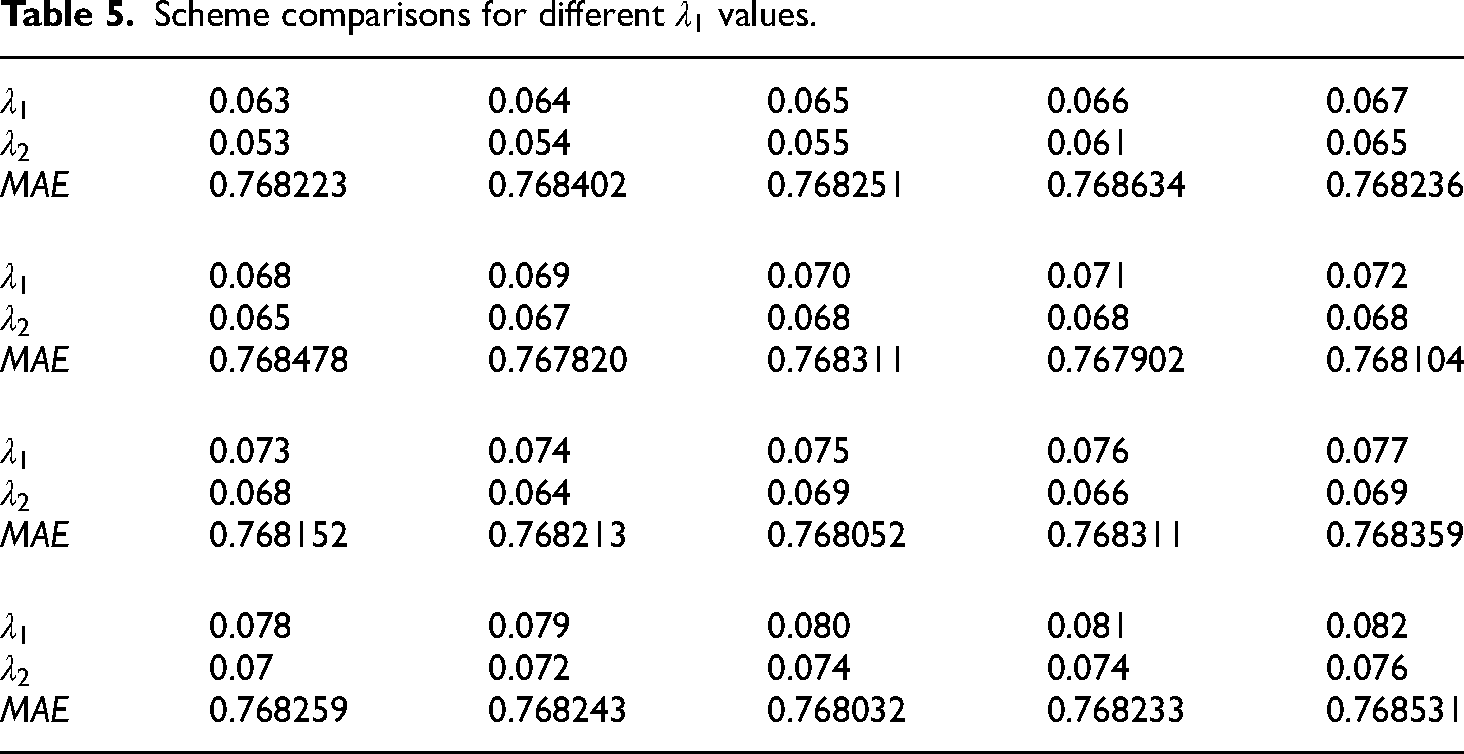
Scheme comparisons for different

Table 4 shows that for different
Scheme comparisons for different
The last experiment adopts the optimal parameters in previous experiments, in which we study the performance of our proposed method influenced by different dynamic invalidation factor values. The MAE results for different

Impact of parameter
In Figure 9, we can observe that a smaller MAE can be obtained by setting an appropriate
Comparative experimental results
In this section, the proposed method is compared with recent CF methods on MovieLens and Netflix datasets. The performance analysis of various recommender methods for these three datasets is shown in Tables 6–8. From the tables, it can be seen that the result of most methods on Netflix is better than that on MovieLens. This is due to that the data sparsity has a major impact on finding similar neighbors or items and finally influences the recommendation performance. The similar results of MovieLens-100k and MovieLens-20M also support this conclusion. Besides, in terms of MAE and RMSE, our approach achieves better recommendation performance than most memory-based CF methods and is slightly behind with two state-of-the-art SVD methods on three datasets. The other metrics, Precision, Recall, and F1-score, have similar trends. The reason is that our method can easily find the finds the best reliable neighbors considering their properties in data-sparse environments, which is a huge advantage for other memory-based CF methods. However, our method is still weaker than the latest model-based CF algorithm in some metrics due to the limitation of the mechanism. This is the direction for future improvement of our method.
Performance of various methods on MovieLens-100k dataset (K = 20).

Performance of various methods on MovieLens-20M dataset (K = 25).

Performance of various methods on Netflix-20M dataset (K = 40).

To further assess the recommendation performance with different K values and data sparseness, we adopt the MovieLens-100k dataset as a typical for the analysis. Figure 10 shows the experimental results of all methods with different K values. From the figure, it is easily observed that all metrics of all methods are decreasing as the K value becomes larger, which indicates that An increase in the K value will lead to an increase in prediction accuracy and affect the other recommendation performance to some extent. Compared to the state-of-the-art methods, our method achieves excellent performance whatever the K value is set. Reasonable K values can help our method find more reliable neighbors. Figure 11 exhibits the performance of all methods with different data sparsity, where

Performance comparisons for different K values. (a) MAE; (b) RMSE; (c) Precision; (d) Recall; (e) F1-score.

Performance comparisons on data with
Conclusions
To increase the recommendation precision, a novel neighbor selection scheme that can properly reveal the user interests change and evaluate the timeliness of recommendation is proposed. This method can more effectively select capable and trustworthy neighbors with less computation in the context of information attenuation. In our method, the concept of the preference decay period is given to describe the pattern of user preference evolution and recommendation invalidation. Two dynamic decay factors are defined to implement the information decay process and gradually weaken the impact of old data. Besides, three dynamic evaluation modules are built to evaluate the user's trustworthiness and recommendation ability. A hybrid selection strategy is presented to combine three modules and construct two neighbor selection layers. Through these two neighbor selection layers, our method can provide accurate recommendations for the target user. The experiments on three real datasets with different data sizes and data sparsity show that the proposed scheme provides excellent recommendation performance, compared to the state-of-the-art methods. In real applications, our method can be useful for helping users find their desired items in various online environments and is easier to deploy in the recommender system. In the future, we plan to combine our approach with the model-based approach to further improve recommendation performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Pioneer and Leading Goose R&D Program of Zhejiang (2022C01051), Natural Science Foundation of Zhejiang Province (LY23E050011, LQ22E050005), and Sichuan Science and Technology Program (2022YFQ0114).
Author biographies
Kerui Hu is received the B.Eng. degree in the School of China University of Mining and Technology, Xuzhou, China, in 2018. He is currently a Ph.D. candidate in the School of Mechanical Engineering, Zhejiang University, China. His research interests include data mining and collaborative filtering.
Lemiao Qiu is received the Ph.D. degree from the Department of Mechanical Engineering, Zhejiang University, Hangzhou, China, in 2008. He is currently an Associate Professor at the Department of Mechanical Engineering, Zhejiang University, China. His research interests include computer graphics, data mining, and production informatization.
Shuyou Zhang is currently a Distinguished Professor and a Ph.D. Supervisor at the Department of Mechanical Engineering, Zhejiang University, China. His research interests include computer graphics, data analysis, and product digital design.
Zili Wang is received the Ph.D. degree from the Department of Mechanical Engineering, Zhejiang University, Hangzhou, China in 2018. He is currently Research Associate at the Department of Mechanical Engineering, Zhejiang University, Hangzhou, China. His research interests include computer-aided design and data analysis.
Naiyu Fang received the B.Eng. degree in the School of Mechanical Engineering from Dalian University of Technology, Dalian, China, in 2019. He is currently a Ph.D. candidate in the School of Mechanical Engineering, Zhejiang University, China. His research interests include computer graphics, data analysis and virtual try-on.
Huifang Zhou received the B.S. degree in School of mechanical engineering from Shandong University, China, in 2017. She is currently a PH.D. candidate in the School of Mechanical Engineering, Zhejiang University, China. Her research interests include engineering optimization, product configuration design and machine learning algorithms.