
Abstract
Vocabulary learning strategies have been frequently viewed as a practical tool to facilitate the acquisition of words and enhance comprehension and production in communication. Previous research suggests that vocabulary learning strategies are a multidimensional construct. This study attempts to validate a vocabulary learning strategies questionnaire using rigorous validation procedures. A questionnaire with 52 items from Gu (2018) was administered to 556 university students in Taiwan. Data were analyzed using exploratory factor analysis and confirmatory factor analysis with SPSS 23.0 and AMOS 23.0, respectively. The results showed that a validated short version of the questionnaire, comprising 33 items, can be used as a measurement tool to assess strategy use and be used when administration time is limited, or the assessment of vocabulary learning strategies is part of a larger number of variables. The second-order confirmatory factor analysis revealed that Activation, Visual and Auditory Encoding, Structure Encoding, Oral Repetition and Selective Attention were the top five important strategies related to vocabulary learning. Finally, the data revealed that it is possible to obtain plausible underlying constructs for a set of questionnaire items in exploratory factor analysis, while the discriminant and construct validity cannot be established in confirmatory factor analysis.
Keywords
Introduction
Vocabulary knowledge plays an integral and indispensable role in both receptive and productive skills for effective comprehension and communication. Vocabulary learning strategies (VLSs) have been frequently viewed as learning aids that may be used by language learners to plan how to learn, memorize, retrieve and review vocabulary in the target language. Over the past few decades, there have been many studies exploring the taxonomies of VLSs (e.g. Cohen et al., 2001; Gu, 2018; Gu and Johnson, 1996; Nation, 2013; Schmitt, 1997; Zhang and Li, 2011). For example, Schmitt’s (1997) 58-item VLSs were classified into 2 broad types: discovery strategies and consolidation strategies. The former involved determination (e.g. figure out the meaning of new vocabulary items using learner knowledge of the language, contextual clues or reference materials) and social strategies (e.g. ask others for help). The latter included social, memory (e.g. association, link to prior knowledge, and imagination), cognitive (e.g. repetition, note-taking and word lists) and metacognitive strategies (e.g. selective attention and planning). The reliability of Schmitt's 58-item questionnaire was 0.91 (Zhang and Lu, 2015). Cohen et al. (2001) proposed a Vocabulary Strategy Use questionnaire, including strategies to learn new words, to review vocabulary, to recall vocabulary and to make use of new vocabulary. The reliability was tested in Paige et al.’s study (2004) and yielded 0.85. Nation (2013), on the other hand, categorized VLSs into four types: (a) planning (e.g. choosing words or strategies); (b) sources (e.g. analyzing words and inferencing); (c) processes (e.g. prior knowledge and schemata activation); and (d) skill in use (e.g. gaining in coping with input through listening, reading, speaking and writing). These VLSs were categorized in different but overlapping ways, under different names but with similar descriptions.
While these questionnaires were designed for second-language (L2) and foreign-language (FL) learners with diverse first-language (L1) backgrounds, Gu and Johnson (1996) developed a 108-item Vocabulary Learning Questionnaire (VLQ) for English as a Foreign Language (EFL) university students in China, with reliability ranging from 0.46 to 0.79 for different dimensions in the VLQ. This questionnaire has been criticized for its length, modified several times and reduced to a 62-item version (Gu, 2018). The questionnaire consists of two sections: beliefs about vocabulary learning and VLS. An exploratory factor analysis (EFA) conducted by Gu (2018) showed 15 factors extracted from the 62 items (r = 0.67 to 0.88). In addition to the beliefs about vocabulary learning, the VLSs were classified into a number of subscales: (a) metacognitive strategies (i.e. selective attention and self-initiation); (b) inferencing; (c) dictionary use; (d) note-taking (i.e. word choice and information choice); (e) rehearsal (i.e. word list, oral repetition and visual repetition); (f) encoding (i.e. visual, auditory, structure and context); and (g) activation. Selective attention refers to learners’ ability to recognize important keywords in a passage and know whether they need to remember them or not. Self-initiation concerns learners’ motivation to learn new words that are not taught or tested in class. Inferencing strategies refer to using logical development in context, guessing meanings from contexts and using background knowledge. While visual repetition focuses on memorization letter by letter and translation, oral repetition emphasizes pronouncing and saying a word aloud during memorization. Visual encoding strategies utilize a created image or pictures of words in the mind, auditory encoding strategies seek similar sounds, and structure encoding makes use of prefixes, roots and suffixes. Visualization and word parts have been regarded as fundamental mnemonic devices that help learners memorize vocabulary (O’Malley and Chamot, 1990; Nation, 2013). Specifically, Nation (2013) highlighted that knowledge of prefixes and suffixes helps learners see the relationships in word families. Finally, activation strategies concern learners’ actual use of vocabulary, such as making up one's own sentences using the newly learned words in real-life situations. Researchers have found that language learners preferred strategies involving memorization, repetition and note-taking (Gu and Johnson, 1996; Schmitt, 1997; Schmitt and Schmitt, 2020). Furthermore, studies have shown that more successful or advanced learners used more metacognitive strategies, such as inferencing, selective attention, imagining word meanings, skipping unfamiliar words and connecting words to personal or past learning experiences (e.g. Gu, 2018; Rao, 2016; Schmitt and Schmitt, 2020; Zhang and Lu, 2015).
In recent years, issues have been raised regarding difficulties of administering questionnaires with a large number of items in: (a) large-scale assessments involving different dimensions, such as structural equation modeling; and (b) longitudinal studies requiring participants to fill out the same questionnaire items multiple times (Bieleke et al., 2021; Casanova et al., 2019). Therefore, based on Gu’s (2018) latest version of the VLQ, the main goal of the present study was to validate and develop a short version and to scrutinize its properties by comparing it with the original. In this study, the multidimensionality of VLSs was tested with EFA and then confirmatory factor analysis (CFA), to evaluate the possibility of reducing the number of items in each dimension. This reduction is required to avoid redundancy in the contents of the questionnaire items and facilitate the use of these strategies in future research. After the validation of the short version, relationships among the university students’ use of VLSs, Vocabulary Size Test (VST) scores and students’ Common European Framework of Reference for Languages (CEFR) level (transformed from their English proficiency test scores) were also examined.
Methods
Participants
The participants were 556 university students majoring in arts and humanities, social science and science subjects from 3 universities in Taiwan (mean age: 21.53 years). Of the 556 participants, 33.5% were males and 66.5% were females. Wolf et al. (2013) suggested that a sample size from 30 to 460 is considered adequate for CFA. In the questionnaire, they were asked to provide the score from one English proficiency test they had taken within six months prior to the data collection. Five English proficiency tests taken were: (a) College Student English Proficiency Test (CSEPT; 340 participants); (b) Test of English for International Communication (TOEIC; 188 participants); (c) General English Proficiency Test (GEPT; 18 participants); (d) Linguaskill (6 participants), and (5) International English Language Testing System (IELTS; 4 participants). The IELTS and Linguaskill tests are developed by Cambridge Assessment English and the scores are aligned with the CEFR. The CSEPT and GEPT are criterion-referenced proficiency tests developed by the Language Training and Testing Center (LTTC) in Taiwan, with the test contents and scores aligned with CEFR level (Language Testing and Training Center, 2021). However, TOEIC is not constructed on the CEFR, but the Educational Testing Service (2021) published an official document suggesting the interpretation of TOEIC scores in relation to CEFR. Owing to the variety of English language proficiency tests taken and reported by the participants, their test scores were transformed into CEFR levels. In the present study, 34 students (6.1%) were at A1 Breakthrough, 117 (21.0%) at A2 Waystage, 293 (52.7%) at B1 Threshold, 107 (19.2%) at B2 Vantage and 5 (0.9%) at C1 Advanced level.
Instrument and VST
Gu’s (2018) VLQ (version 6.4) was designed to assess Chinese university students’ English vocabulary learning beliefs and strategy use. The participants in the present study shared the same L1 and educational level as those in Gu's study. This questionnaire was therefore adopted. Of the 62 items, 10 items belonged to beliefs about vocabulary learning, while the remaining 52 were about VLSs. Gu's measure of questionnaire items was based on likelihood, using a 7-point Likert scale, ranging from ‘extremely untrue of me’ to ‘extremely true of me’. In the present study, a 5-point, frequency-based Likert scale, including ‘almost never’, ‘occasionally’, ‘sometimes’, ‘frequently’ and ‘almost always’, was adopted.
In addition to providing their CEFR level, the participants took a VST developed by Nation and Beglar (2007) after completing the questionnaire. The VST is a multiple-choice proficiency test with short non-defining context used to measure written receptive vocabulary size. The VST samples were from the most frequent 14,000 word families of English (10 items for each 1000 level, and 140 items in total). Nation and Beglar (2007) suggested that it was not necessary to ask learners to finish all 140 items if their English proficiency was low or intermediate. Following discussions of students’ English ability with the instructors from the 3 universities, 70 items (from the first to the seventh 1000 levels) were considered adequate to test the participants. Thus, the total score would be 70 in this study. According to Nation and Beglar (2007), a test-taker's score needs to be multiplied by 100 to get their total vocabulary size. Table 1 shows the vocabulary size, frequency, and percentage from the 556 participants.
Range, frequency and percentage of the vocabulary size test scores (n = 556).

Note: The minimum score was 25, while the maximum score was 65. The vocabulary size presented in the table had been multiplied by 100.
Data Collection
To ensure research ethics and reduce the risk of potential psychological discomfort or stress for participants, an informed consent form was provided before the participants answered the questionnaire and took the VST. The VST, questionnaire and informed consent form were completed online and then submitted electronically to the researcher in their English classes in December 2020. It took approximately 25 minutes for each participant to finish the test and the questionnaire.
Data Analysis
EFA was first used to evaluate the VLS scale from Gu (2018) and to reduce the large number of interrelated variables (i.e. 10 belief and 52 VLS items) to smaller, coherent sets of variables. To conduct EFA, IBM SPSS Statistics 23 software was used. Next, CFA was used to confirm specific hypotheses concerning the latent structure underlying a set of variables (Pallant, 2020). According to Hair et al. (2018) and Fornell and Larcker (1981), three statistical indices and values used to measure and interpret the convergent and discriminant validity are: (a) standardized factor loadings (λ) > 0.50; (b) average variance extracted (AVE) > 0.50; and (c) construct (or composite) reliability (CR) > 0.60. Convergent validity assesses the extent to which observed variables of a specific latent construct share a high proportion of variance in common (Hair et al., 2018). Discriminant validity, on the other hand, measures the degree to which a latent construct and its observed variables are different from another latent construct and its respective observed variables (Bogozzi et al., 1991). The absence of cross-loading between and within different latent constructs and observed variables guarantees the discriminant validity.
IBM SPSS AMOS 23 was used to perform and measure the CFA and the model fits. To interpret the statistics, the following six common indices and values were used to measure the goodness of fit of the model: χ2/df < 3.0, goodness of fit index (GFI) > 0.90, comparative fit index (CFI) > 0.90, Tucker-Lewis Index (TLI) > 0.90, Root Mean Square Error of Approximation (RMSEA) < 0.06 and Standardized Root Mean Square Residual (SRMR) < 0.08 (Hu and Bentler, 1999; Kenny, 2015; Kline, 2016). Finally, a multivariate analysis of variance (MANOVA) was conducted to distinguish mean differences between the participants’ vocabulary size (grouped into high and low) on the dependent variables (VLSs).
Results
EFA
A total 52 items of the VLSs from the VLQ were subjected to principal component analysis (PCA) using SPSS version 23. To refine the scale and increase the total variance explained (Pallant, 2020), items with communality values that were below 0.50 and factor loadings below 0.30 were deleted. This resulted in the deletion of Questions 4, 14, 18, 28, 29, 30 and 37, leaving 45 items for the second round of the PCA with varimax rotation. Inspection of the correlation matrix revealed the presence of many coefficients of 0.30 and above. The Kaiser-Meyer-Olkin value was 0.90, exceeding the recommended value of 0.6 and Bartlett's Test of Sphericity reached statistical significance, supporting the factorability of the correlation matrix. The PCA revealed the presence of 10 components with eigenvalues exceeding 1. The 10-component solution explained a total of 65.81% of the variance. The rotated solution revealed the presence of simple structure, with all components showing a number of strong loadings and all variables loading substantially on one component.
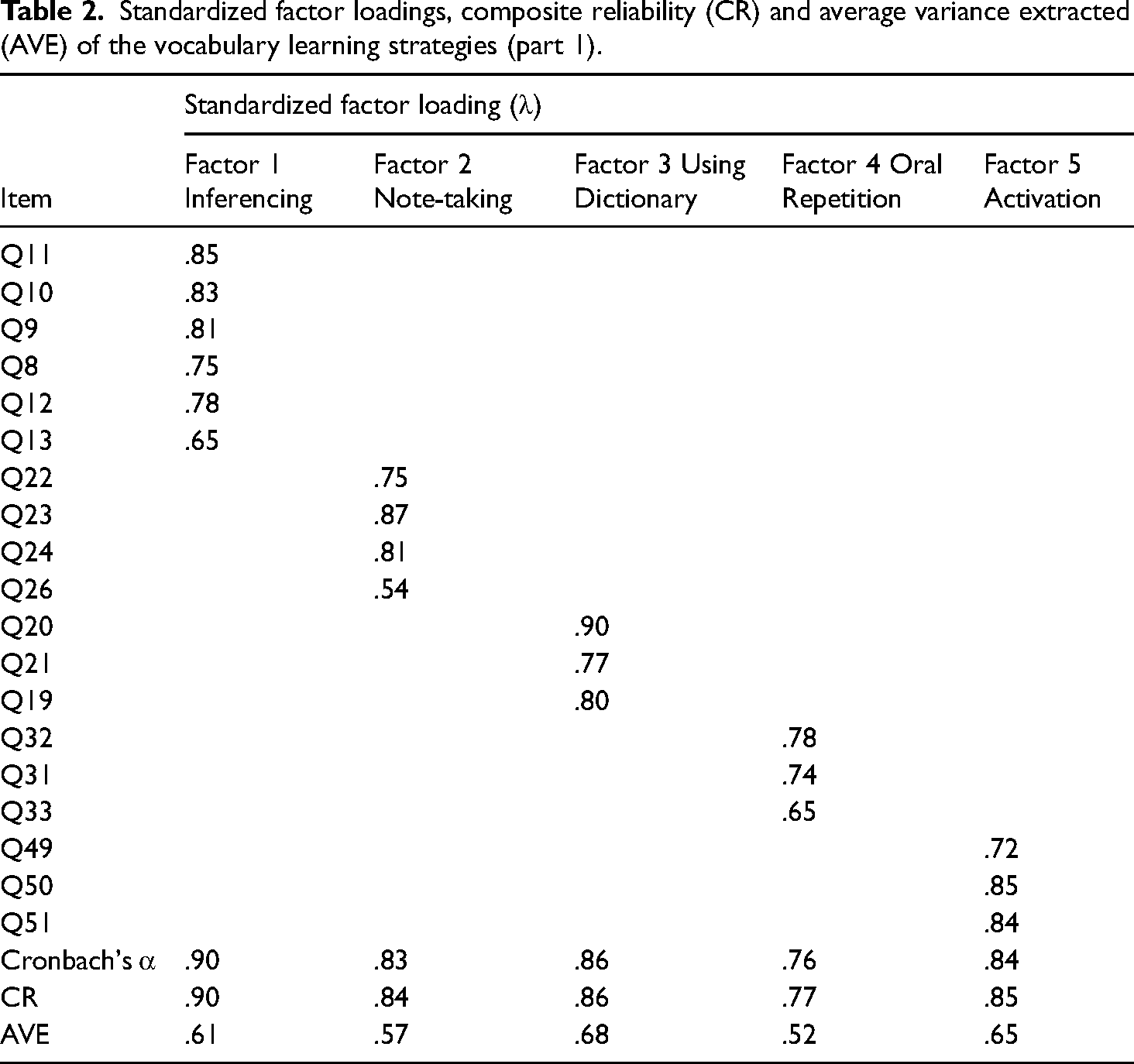
The interpretation of the 10 components followed Gu (2018): Inferencing Strategies (Factor 1), Note-taking Strategies (Factor 2), Using Dictionary Strategies (Factor 3) and Oral Repetition Strategies (Factor 4), Activation Strategies 1 (Factor 5), Visual and Auditory Encoding Strategies (Factor 6), Structure Encoding (Factor 7), Self-initiation Strategies (Factor 8), Selective Attention Strategies (Factor 9) and Visual Repetition Strategies (Factor 10). Unlike Gu (2018), who found Visual and Auditory Encoding Strategies to be two separate factors, the participants in the present study adopted and utilized the two types of strategy jointly, with one assisting the other. Similarly, Note-taking Strategies, which were divided into two sub-categories by Gu, were merged under a single dimension. Use of Word List Strategies were deleted due to low factor loadings (below 0.30) in EFA.
Another 10 items from Gu's VLQ asked about learners’ beliefs in vocabulary learning. As a ‘belief’ scale usually involves the degree of agreement, which is different from frequency-based learning strategies, EFA of the 10 belief items was conducted separately from the 52 VLS items. With two items deleted in the process of EFA, two components extracted were Beliefs in Word Memorization and Beliefs in Word Use, which were the same as Gu's taxonomy.
CFA
The 45 items of the VLSs and 8 items of the Beliefs were examined with CFA, respectively. Six items of the VLSs were deleted because the Modification Indices suggested high χ2 values, leaving 39 items. The composite reliability (CR) estimates for the nine latent constructs were above the recommended cutoff value of 0.60 and the average variance extracted (AVE) were above 0.50 (Tables 2 and 3), except for Factor 10 (Visual Repetition) and the two factors regarding the Beliefs in Word Memorization and Beliefs in Word Use. To improve the model, Visual Repetition, Beliefs in Word Memorization and Beliefs in Word Use were removed due to their low AVE and/or CR values. Also, another 3 items were dropped due to high χ2 values, leaving 33 items tested for the final model fit. The Cronbach's α for the 33 items was 0.93. All the standardized factor loading estimates ranged from 0.54 to 0.90, exceeding the recommended cutoff value of 0.50. Appendix 1 shows the questionnaire items.
Standardized factor loadings, composite reliability (CR) and average variance extracted (AVE) of the vocabulary learning strategies (part 1).
Standardized factor loadings, composite reliability (CR) and average variance extracted (AVE) of the vocabulary learning strategies (part 2).
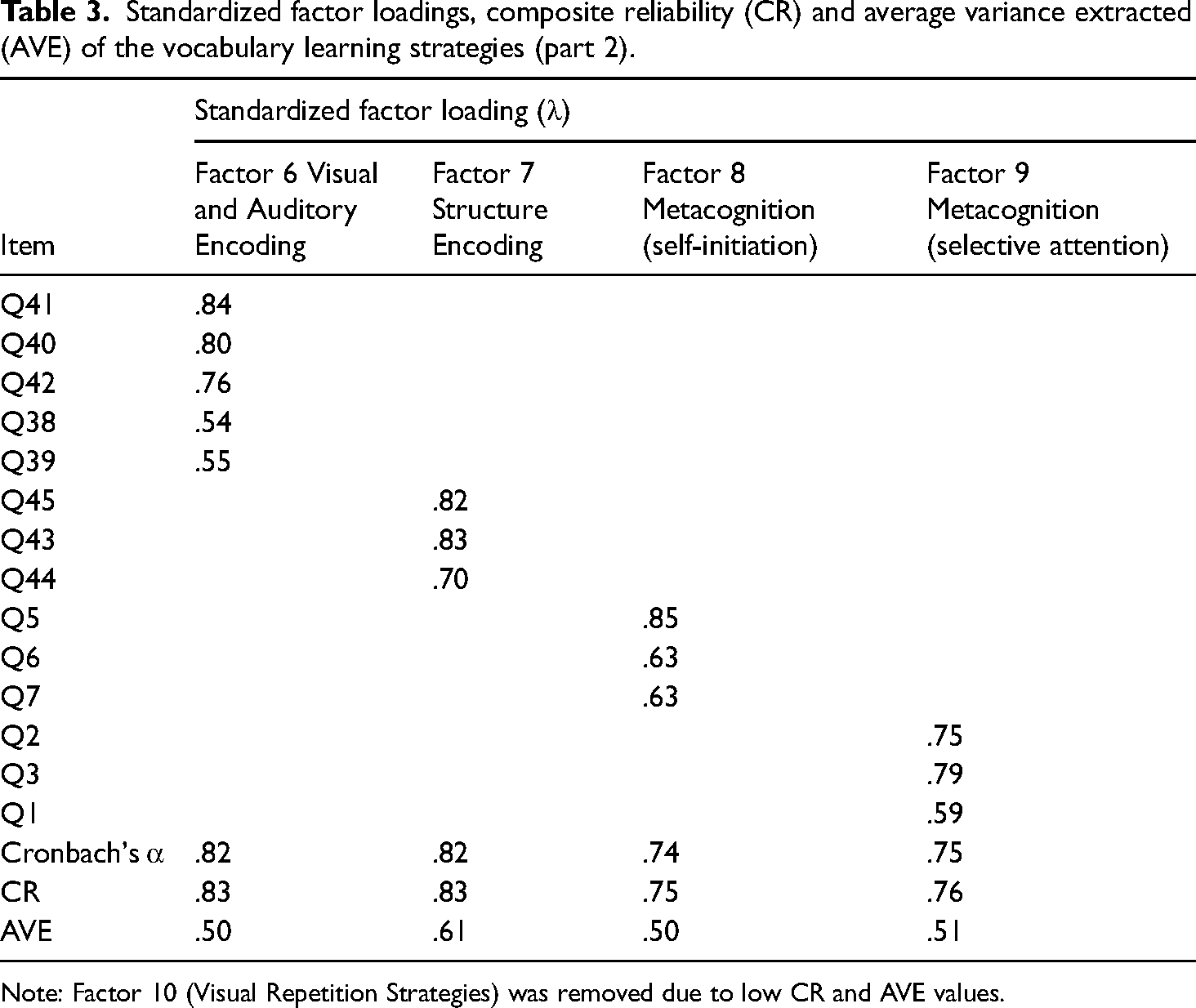
Note: Factor 10 (Visual Repetition Strategies) was removed due to low CR and AVE values.
Correlation
There were positive, moderate to strong correlations among students’ use of Inferencing, Note-taking, Using Dictionary, Oral Repetition, Activation, Visual and Auditory Encoding and Structure Encoding Strategies, r = 0.35 to 0.68, p < 0.01, with a high frequency of one strategy use associated with another (Table 4). Self-initiation Strategies, on the other hand, had a positive but weak relationship with other strategies (r = 0.12 to 0.31, p < 0.01). The VLSs were found to be positively but weakly correlated to VST scores and students’ CEFR level (transformed from the English proficiency test scores) (r = 0.09 to 0.24, p < 0.05). The VST scores and the participants’ CEFR level were positively correlated (r = 0.29, p < 0.01), suggesting that greater vocabulary size related to higher English proficiency. In particular, frequent use of Inferencing Strategies was more related to the participants’ English proficiency test scores (in the form of CEFR level) than to their VST scores. This can be attributed to the testing approaches. Cohen (1998, 2006) once noted that language strategy use could be greatly influenced by test techniques and candidates’ test-taking processes. As English proficiency tests usually involve integrative test items that require candidates’ integrated language use ability, Inferencing and Structure Encoding Strategies appeared to play more influential roles in comprehending contextualized information in the test performance. However, Inferencing Strategies played a minor part in the VST, considering the discrete point test items used.
Descriptive statistics and correlations between the measured variables (n = 556).

* p < 0.05; ** p < 0.01.
VST: Vocabulary Size Test; CEFR: Common European Framework of Reference for Languages
Model Fit Evaluation
The standardized path coefficients for the first-order model showed that the overall model fit was good: χ2 = 1089.69, χ2/df = 2.37, GFI = 0.89, CFI = 0.93, TLI = 0.92, RMSEA = 0.05, SRMR = 0.05. Similarly, the overall model fit with the second-order model was good: χ2 = 1190.57, χ2/df = 2.45, GFI = 0.88, CFI = 0.92, TLI = 0.92, RMSEA = 0.05, SRMR = 0.06 (Table 5). Figure 1 illustrates the second-order CFA model. According to Byrne (2016), the second-order CFA serves as a cross-validation of the determined factor structure. This second-order CFA model suggested the possibility of obtaining a general index of VLSs. The results also showed different weights of the first-order factors, and these might be related to the importance regarding university students’ use of VLSs in Taiwan. In this study, Activation (β = 0.80; R2 = 0.64), Visual and Auditory Encoding (β = 0.78; R2 = 0.61), Structure Encoding (β = 0.75; R2 = 0.57), Oral Repetition (β = 0.73; R2 = 0.54) and Selective Attention (β = 0.69; R2 = 0.47) were found to be the top five important strategies related to vocabulary learning, while Self-initiation (β = 0.33; R2 = 0.11) might be considered a less important VLS.
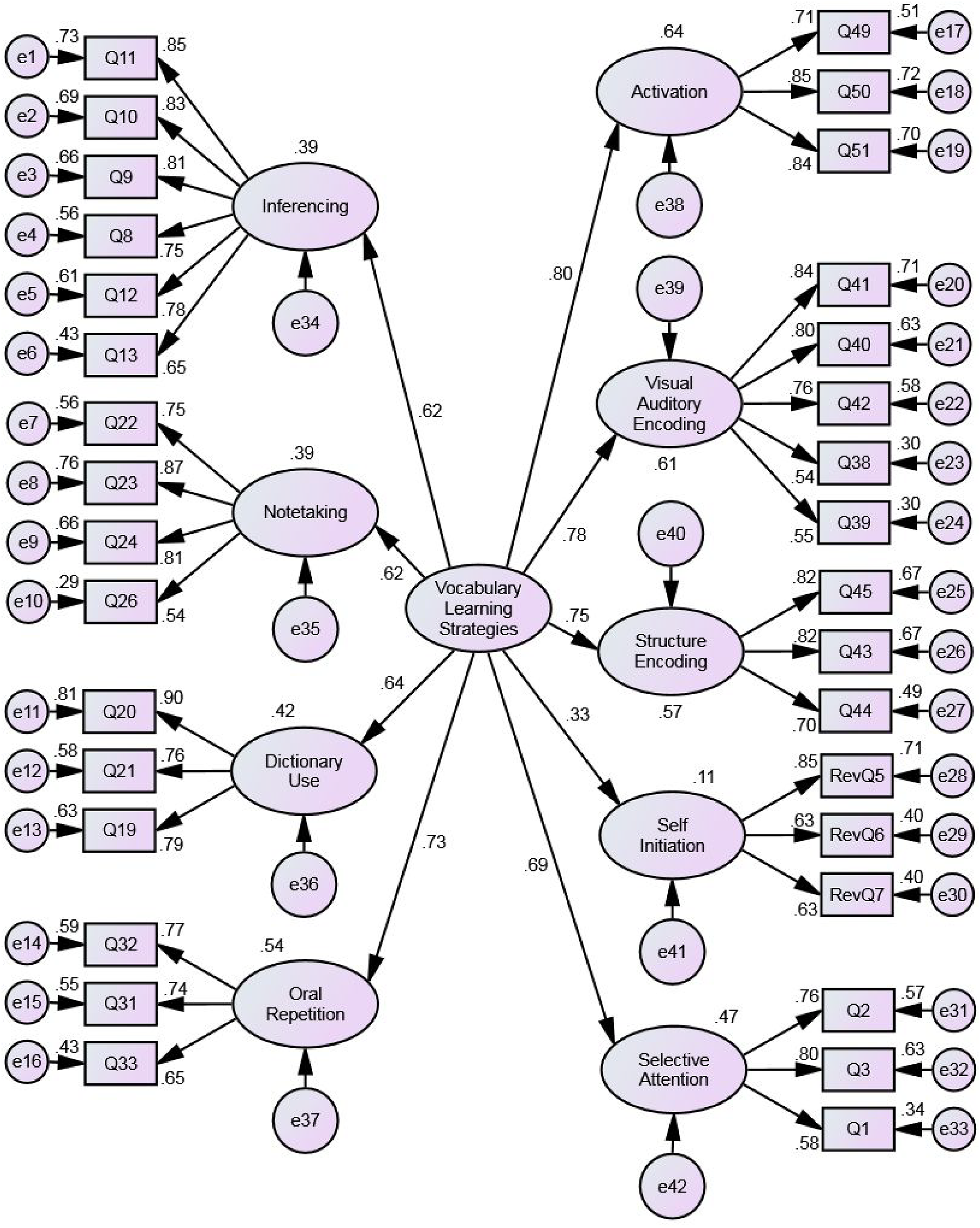
Vocabulary learning strategies – hierarchical model.
Goodness-of-fit indices for the first- and second-order confirmatory factor analysis (CFA) models (n = 556).

GFI: goodness of fit index; CFI: comparative fit index TLI: Tucker-Lewis Index; RMSEA Mean Square Error of Approximation; SRMR: Standardized Root Mean Square
MANOVA
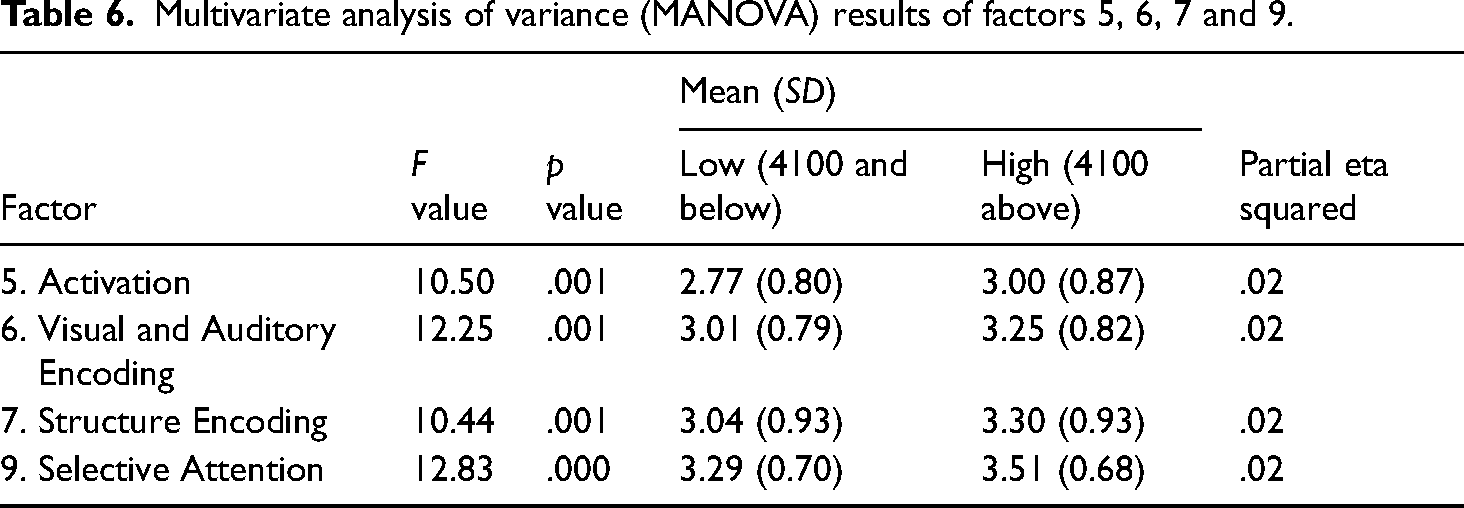
A one-way MANOVA was performed to investigate VST differences in the use of VLSs. The dependent variables were the nine factors, while the independent variable was low and high scores in the VST. The mean score of 41.09 was used as the cutoff score to categorize the participants into 2 groups: high (vocabulary size above 4100) and low (vocabulary size 4100 and below). There was a statistically significant difference between students with low and high scores on the combined dependent variables, F (9, 546) = 2.99, p = 0.002, Wilks’ λ = 0.95, partial eta squared = 0.05. When the results for the dependent variables were considered separately, four factors (Factors 5, 6, 7 and 9) reached statistical significance, using a Bonferroni adjusted α level of 0.006. An inspection of the mean scores indicated that the participants whose vocabulary size score was above 4100 used Activation, Visual and Auditory Encoding, Structure Encoding and Selective Attention Strategies more frequently than students whose score was 4100 and below. Table 6 summarizes the statistical information.
Multivariate analysis of variance (MANOVA) results of factors 5, 6, 7 and 9.
Discussion
Utilizing this comprehensive and multidimensional questionnaire of VLSs in Taiwan, this research analyzed factorial structure, especially if there was a better goodness of fit model when VLSs were considered as individual first-order factors or when they were merged in a second-order factor. The ultimate goal was to provide evidence for the construct validity of the factor structure. At the same time, it was possible to verify whether some items could be eliminated due to low factor loadings and high χ2 values, allowing for a smaller scale and reducing student time and effort in questionnaire completion. Testing the convergent and discriminant validity with standardized factor loadings, AVE and CR of the latent constructs showed that better indices were achieved in nine constructs. Both first- and second-order CFA models in the current study have yielded very good model fits. The second-order CFA helped cross-validate the determined first-order factor structure (Byrne, 2016), and the model fit suggested a general index of VLSs. This short version can be helpful in research with a large number of students and when the structural model involves other variables and scales.
Compared with Gu’s (2018) 14 factors regarding the VLSs extracted from the EFA, the CFA of VLSs in the present study yielded 9 factors, including the integration of the Visual and Auditory Encoding Strategies, the merging of the two sub-scales of Note-taking Strategies, the deletion of Use of Word List Strategies (factor loading below 0.30 in the EFA) and Contextual Encoding Strategies (high χ2 values when collapsed into Activation Strategies in the CFA), and the removal of Visual Repetition Strategies dimension (low validity with the AVE value below 0.50). Moreover, an interesting finding in this study was that the EFA and CFA revealed a reliable and valid construct with Visual and Auditory Encoding Strategies underlay the same dimension. It seemed that these two types of strategy were adopted together for vocabulary memorization. Studies from Ehri and her associates (e.g. Ehri, 2014; Ocal and Ehri, 2017; Rosenthal and Ehri, 2011) found that spellings accompanying pronunciations and meanings of new words can activate orthographic mapping, which involves the formation of letter-sound connections to link the spellings, pronunciations and meanings of vocabulary in memory. Even though the visual and auditory strategies in the present study were adopted silently in the mind rather than read aloud, the results clearly support Ehri's notion that the integration of two or more strategies (i.e. spelling, pronunciation and meaning of words) increases vocabulary memorization and vocabulary size.
From a practical perspective, the validation of the VLSs helped researchers better understand which types of VLSs were considered essential for Taiwanese university students to learn English as a foreign language. Of the top five important VLSs from the second-order CFA, the adoption of four types of strategy – Activation (e.g. use newly learned words in real or imaginary situations), Visual and Auditory Encoding (e.g. create a picture, visualize words or remember sound-alike words), Structure Encoding (e.g. use prefixes, roots, suffixes) and Selective Attention (e.g. recognize important keywords) – were related to the participants’ vocabulary size. In the MANOVA test, the participants whose vocabulary size was above 4100 word families adopted the 4 types of strategy more frequently than those whose vocabulary size was 4100 and below. In particular, only Activation Strategies imply the use of newly learned vocabulary in speech or writing, while Oral Repetition concerns the pronunciation and reading-aloud of words. Visual, Auditory and Structure Encoding and Selective Attention rely on one's internal encoding system and cognitive processing to recognize and memorize new words. Several researchers have noted that intentional vocabulary learning with a specific goal to learn and use vocabulary in interactive language tasks leads to greater and better vocabulary gains and retention (Nation and Meara, 2020; Schmitt and Schmitt, 2020). Though the VST measures receptive vocabulary size and the score provides little indication of how well these words can be used in speaking and writing (Nation and Beglar, 2007; Schmitt and Schmitt, 2020), the present study discovered a positive association between larger vocabulary size and use of Activation Strategies, which imply using vocabulary in real or imaginary situations.
Aside from the nine validated latent variables, three dimensions which failed to be validated were Visual Repetition Strategies, Beliefs in Word Memorization and Beliefs in Word Use. The low standardized factor loadings, AVE and CR values indicated a lack of convergent and discriminant validity (Bogozzi et al., 1991; Fornell and Larcker, 1981; Hair et al., 2018). Several observed variables in each of the three factors had a low proportion of standardized factor loadings. That is, the questionnaire items shared limited variances with the other items that theoretically belonged to the same factor. In other words, not all questionnaire items under a factor, say, Visual Repetition Strategies, represented the participants’ behaviors in memorizing vocabulary visually. Even though the factor loadings of the three dimensions were above 0.40 in EFA (higher than the recommended value of 0.30; see Pallant, 2020), they were still lower than the recommended cut-off point of 0.50 in CFA, and these consequently resulted in low AVE values and a lack of discriminant validity (Carter, 2016). These results clearly showed that it is possible to obtain plausible underlying constructs for a set of questionnaire items in EFA (Gu, 2018), while the discriminant and construct validity on the internal relationship between the items within a certain construct and dimensionality between different constructs cannot be established in CFA.
Conclusion
This shortened version of the VLS questionnaire showed adequate reliability and validity, proving to be an adequate instrument to assess university students’ English VLSs in Taiwan. These strategies can be reported as a whole by informing them of an overall use of strategies or can be differentiated according to specific dimensions. In addition, reducing the number of items from 52 to 33 allows for it to be included in structural models that take into account a greater number of variables.
While the results confirm that VLSs are a multidimensional construct, the study has some limitations. First, the international English proficiency tests taken by the participants were not all designed based on CEFR, which might limit our interpretation of students’ CEFR level in relation to their use of VLSs. Second, the participants were all university students in Taiwan. Generalization to other populations such as secondary school students may not be possible. Similarly, validation using samples with different L1s or cultural backgrounds may result in different factorial structures on Gu’s (2018) VLQ. More research is therefore needed.
The VLSs serve as practical tools to facilitate acquisition of words and enhance comprehension and production in communication. Drawing on the findings in the present study and other empirical studies, this study is of value in: (a) validating the VLS questionnaire and proposing a short version for future research; (b) revealing the importance of Activation, Selective Attention, and Visual, Auditory and Structure Encoding Strategies in learning vocabulary and increasing word families; (c) discovering a positive association between larger receptive vocabulary size and the use of Activation Strategies (for practicing vocabulary in speaking and writing); and (d) providing researchers with evidence that the nine VLS components should be viewed as distinct, and all of these dimensions need to be considered when assessing learners’ use of VLSs.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.
Notes
Author Biography
Mu-Hsuan Chou is a professor in the Department of Foreign Language Instruction at Wenzao Ursuline University of Languages, Taiwan. She has published research papers in Educational Psychology; TESOL Quarterly; English for Specific Purposes; Language, Culture and Curriculum; The Journal of Educational Research and Reading Research Quarterly. Her current research interests include educational psychology, language assessment, learning strategy and EFL teaching and learning.
Questionnaire items of the observed variables.

| Factor | Questionnaire items |
|---|---|
| Factor 1 – Inferencing | Q11. When I don't know a new word in reading, I use my background knowledge of the topic to guess the meaning of the new word. |
| Q10. I check my guessed meaning in the paragraph or whole text to see if it fits in. | |
| Q9. I use common sense and knowledge of the world when guessing the meaning of a word. | |
| Q8. I make use of the logical development in the context (e.g. cause and effect) when guessing the meaning of a word. | |
| Q12. I look for explanations in the reading text that support my guess about the meaning of a word. | |
| Q13. I make use of the grammatical structure of a sentence when guessing the meaning of a new word. | |
| Factor 2 – Note-taking | Q22. I make a note when I think the meaning of the word I’m looking up is commonly used. |
| Q23. I make a note when I think the word I’m looking up is related to my personal interest | |
| Q24. I make a note when I see a useful expression or phrase. | |
| Q26. I write down both the meaning in my native language and the English explanation of the word I look up. | |
| Factor 3 – Dictionary use | Q20. When I want to know more about the usage of a word that I know, I look it up. |
| Q21. I check the dictionary when I want to find out the similarities and differences between the meanings of related words. | |
| Q19. When I want to have some deeper knowledge about a word that I already know, I look it up. | |
| Factor 4 – Oral repetition | Q32. When I try to remember a word, I repeat its pronunciation in my mind. |
| Q31. When I try to remember a word, I say it aloud to myself. | |
| Q33. Repeating the sound of a new word to myself would be enough for me to remember the word. | |
| Factor 5 – Activation | Q49. I make up my own sentences using the words I just learned. |
| Q50. I try to use the newly learned words as much as possible in speech and writing. | |
| Q51. I try to use newly learned words in real situations. | |
| Factor 6 –Visual & Auditory Encoding | Q41. When words are spelled similarly, I remember them together. |
| Q40. I put words that sound similar together in order to remember them. | |
| Q42. When I try to remember a new word, I link it to a sound-alike word that I know. | |
| Q38. I create a picture in my mind to help me remember a new word. | |
| Q39. To help me remember a word, I try to ‘see’ the spelling of the word in my mind. | |
| Factor 7 – Structure Encoding | Q45. I memorize the commonly used roots and prefixes. |
| Q43. When I learn new words, I pay attention to prefixes, roots, and suffixes (e.g. inter-nation-al) | |
| Q44. I intentionally study how English words are formed in order to remember more words. | |
| Factor 8 – Self-initiation | Q5. I wouldn't learn what my English teacher doesn't tell me to learn. (Reversed value) |
| Q6. I only focus on things that are directly related to examinations. (Reversed value) | |
| Q7. I wouldn't care much about vocabulary items that my teacher does not explain in class. (Reversed value) | |
| Factor 9 – Selective Attention | Q2. I know which words are important for me to learn. |
| Q3. When I meet a new word or phrase, I know clearly whether I need to remember it. | |
| Q1. I know whether a new word is important in understanding a passage. |