
Abstract
The Transformer-Led Policing (TLP) model, published in 2025, provided a framework for applying artificial intelligence (AI) in policing, including Generative AI (GenAI). This article introduces a matrix to support this model, providing policing with a quantitative tool that scores 12 elements required for safe AI development and implementation, including: operational validity, integration, usability, privacy, data handling, safety, stakeholder engagement, legal compliance, bias and community impact, procedural justice, ease of use, and effectiveness. By providing a means to identify strengths and weaknesses of policing applications of AI, the matrix supports informed decision-making by providing a tool to assess utility, assist project implementation and management, or act as a structured evaluation method.
Introduction
The use of artificial intelligence (AI) to support policing objectives is not a new concept; its potential was recognised more than three decades ago (Hernandez, 1990). Until recently, however, AI applications in policing were largely bespoke, designed, trained, and implemented for narrow, task-specific functions using techniques such as machine learning, natural language processing, deep learning, and neural networks (Halford, 2025a). This landscape changed dramatically in November 2022 with the public release of ChatGPT, which marked a paradigm shift toward accessible, easy-to-use, and general-purpose Generative AI (GenAI). This type of AI is built on sophisticated deep learning algorithms that have been fine-tuned by learning from vast amounts of data, often taken from the internet, to identify patterns in language that enables them to make incredibly accurate predictions (Bordas et al., 2024). These predictions can take the form of written outputs such as text, numbers or computer code which are generated by the user first entering a request or information, known as a prompt. Although outputs from GenAI may simulate what an output from a human looks like, in reality all they are doing is predicting the next word or number (Bordas et al., 2024). Regardless, their popularity has risen fast and the emergence of GenAI has triggered a rapid expansion of AI applications across all sectors, including policing.
Despite growing interest and concern around the use of AI in law enforcement, no commonly accepted model or framework existed for guiding AI adoption within policing until I introduced the Transformer Led Policing (TLP) Model in 2025 (Halford, 2025a). The TLP Model provided a structured framework for devising, discussing, and deploying AI in policing environments, capturing the operational, ethical, and organisational nuances that distinguish policing from other sectors. It offered a foundational approach applicable across design, implementation, and evaluation processes. However, while my early efforts demonstrated the conceptual utility and broad applicability of the model (Halford and Webster, 2024), the original publication did not include a supporting tool or methodological guidance to operationalise it fully.
The purpose of the current article is to introduce the TLP Matrix, an applied tool that builds upon the TLP framework by providing a structured, practical mechanism for operationalising the broader model. To achieve this, the article first revisits the key evidence-based components required of a comprehensive AI framework, establishing the foundations from which the TLP Matrix was developed. It then reviews existing AI-related matrices proposed in other sectors and outlines their methodological approaches before highlighting their limitations in a policing context. The article proceeds to detail the structure and contents of the TLP Matrix and offers guidance on its use in planning, implementing, and evaluating AI, and specifically GenAI within policing environments. Finally, it explains how results should be interpreted to support informed, long-term decision-making regarding AI adoption.
By providing a quantitative, operational tool aligned with the original TLP Model, this article enables both policing practitioners and researchers to apply the framework consistently and rigorously. It further ensures alignment with the European Union’s Artificial Intelligence Act (European Commission, 2021), which sets out the legal requirements for the deployment of AI systems, including within law enforcement, and with the United Kingdom’s National Police Chiefs’ Council (NPCC) Covenant for Using Artificial Intelligence in Policing (National Police Chiefs’ Council, 2023), which outlines the governing principles police services must follow when using AI.
The background of artificial intelligence within policing
Prior to the arrival of GenAI, single use AI was already being widely applied in the United Kingdom and other countries (Oswald and Babuta, 2019). The public response to its use is generally positive, with many believing it is justified from a ‘safety first’ perspective (Ezzeddine et al., 2023), provided it is used for protecting communities (Ezzeddine et al., 2023). Contrasting views focus on concerns it can facilitate punitive surveillance (Weisburd, 2022), while others highlight the unexpected and unintended consequences caused through negligent or uncontrolled application (Joh, 2022). I have personally highlighted the human resource implications caused by automation and augmentation of policing functions (Halford, 2025b). Other key issues include concerns it may undermine police legitimacy, magnifying embedded bias and unfairness. Aspects related to security and privacy have also been raised.
Operational application
The aforementioned issues have been identified because of literature on the application of AI in policing, which has examined a multitude of use cases. These include its ability to support decision making (Hobson et al., 2021), including those related to police bail (Elyounes, 2020). It has also been explored for its potential to assess calls for service, as well as looking for exploitation online (Babuta and Oswald, 2020; Hodgkinson et al., 2023; Joh, 2019; Simpson and Orosco, 2021; Sunde and Sunde, 2021; Testerink et al., 2019). The data analysis capabilities of AI have been demonstrated in studies that have shown its efficacy in collecting and analysing large volumes of information (Kuk, 2015), making it useful for aiding the police to more efficiently examine data obtained from smart and digital devices (Scanlon et al., 2023). AI has also been shown to be particularly effective at analysing and forecasting crimes (Berk, 2021; Guevara et al., 2018; Nissan, 2009) which helps the police better task and co-ordinate patrols (Guevara et al., 2018) leading to crime reduction improvements.
It has also shown great promise in using natural language processing techniques to analyse data and then predict potential threats or harm posed by suspects (King et al., 2020; Oswald and Babuta, 2019). Literature has also explored how AI can be used to conduct process-based functions, with significant promise displayed in studies exploring its accuracy in analysing and creating written reports and crime records (Adams et al., 2024; Adderley and Musgrove, 2001; Bengtsson et al., 2012; Potts, 2024), and more recently, the conduct of witness interviews and statement writing (Dando and Adam, 2025; Minhas et al., 2022; Walley and Glasspoole-Bird, 2025). It was even recently shown to be effective at examining the audio and visual content of police body-worn videos (Adams, 2025), indicating potential as a large-scale audit capability for police – citizen interactions that could drive improved professionalism. Similarly, its ability to support crime investigation (Fernandez-Basso et al., 2024) has been demonstrated, to the degree that it can now be used to help the police monitor racial and gender bias during interviews (Noriega, 2020) which can assist in reducing stereotyping and unfair practice.
Such studies are beginning to lend credibility to claims that the point at which AI can undertake unsupervised, process-based functions is nearing fruition (Open Data Institute, 2020; Sourdin, 2018). Despite this optimism, evidence from both traditional AI and GenAI research consistently highlights recurring challenges that continue to impede the realisation of this potential. In response, a range of models, frameworks, and matrices have been developed across sectors to guide the implementation and evaluation of these technologies.
Models, frameworks and matrices for artificial intelligence application
Broadly, a model is a theoretical representation of how a system or phenomenon operates, identifying its core components and the relationships between them. A framework, by contrast, provides a structured set of criteria or elements to guide analysis, decision-making, or implementation. A matrix is the most operational of the three and provides a structured analytical tool, typically presented as a table or grid, that outlines sector-specific criteria, risks, requirements, or decision points. Although not necessarily mathematical, matrices that incorporate quantitative indicators allow organisations to evaluate issues systematically and transparently. Together, the model explains the overarching logic, the framework organises the essential elements required to apply that logic, and the matrix translates the framework into a practical tool for real-world application.
Key considerations
A full exploration of AI’s broader conceptual models lies beyond the scope of this article. More relevant here are the key framework components required for effective implementation. Over the past decade, an expanding body of literature has proposed a range of AI frameworks that articulate these and this section briefly reiterates them to demonstrate their relevance and importance to the TLP matrix advanced in this article (For a detailed review of these see Halford 2025, which is the original article that introduced the TLP model).
First, measures to mitigate bias and unfairness are frequently identified within existing frameworks for AI (Barletta et al., 2023; Floridi and Cowls, 2019; Fukuda‐Parr and Gibbons, 2021; O’Neil and Gunn, 2020). To mitigate these concerns AI frameworks, advocate for a clear purpose, with practical utility of the technology (Reddy et al., 2021; Ruiz-Rojas et al., 2023), supported by transparency through governance, oversight and investigative scrutiny (Barletta et al., 2023; Floridi and Cowls, 2019). Security and privacy are also central tenants and includes emphasis on data protection measures to mitigate cyber-threats, maintain personal information, and prevent unjustified citizen surveillance (Barletta et al., 2023; Fukuda‐Parr and Gibbons, 2021). To ensure these issues are considered sufficiently, stakeholder engagement is often included and deemed essential in respect of security, privacy and gathering informed consent (Wirtz et al., 2022). Underpinning these features is the requirement for AI frameworks to ensure human oversight is retained to prevent unwanted and unintended outcomes (Barletta et al., 2023).
Application matrices
To ensure that these critical considerations are not overlooked when applying AI technologies, a range of matrices have been devised for different sectors to adopt and follow. The following outlines several notable examples developed within ethics, education, healthcare, and policing.
The ethical matrix developed by O’Neil and Gunn (2020) emphasises the principles of well-being, autonomy, and justice. Its purpose is to support the ethical implementation of AI by systematically incorporating stakeholder perspectives. Stakeholders include developers such as data scientists and programmers, deployers such as police or other practitioners, and affected groups including workers whose roles may change because of AI adoption. Societal stakeholders, such as the public, community groups, and marginalised populations, are also included. Stakeholder mapping is conducted through workshops and consultations to refine the list of relevant parties and ensure the ethical analysis remains up to date. The matrix itself is applied as a tabular tool in which stakeholders occupy the rows and their interests populate the columns (e.g., efficiency, accuracy, false positives/negatives). Each issue is evaluated against ethical principles and assigned a risk grading (low to high), typically colour coded for clarity. The output is a completed table that informs decisions on adaptation, governance, and deployment.
The 4PADAFE matrix, developed by Ruiz-Rojas et al. (2023), stands for Academic Project, Strategic Plan, Instructional Planning, Instructional Material Production (4P), Teaching Action (AD), Formative Adjustments (AF), and Evaluation (E). It is designed to guide the integration of “off-the-shelf” AI tools into classroom environments and improve teaching–learning processes. The associated framework consists of seven phases, including defining an e-learning plan, planning instructional activities, creating content, implementing teaching actions, making formative adjustments, and evaluating outcomes. Unlike the ethical matrix, the 4PADAFE tool does not function as a scoring matrix. Instead, it operates as a structured planning tool that offers educators a blueprint for AI adoption. Findings suggest that when applied, the tool assists teachers in using AI resources effectively to enhance learning (Ruiz-Rojas et al., 2023).
The Translational Evaluation of Healthcare AI (TEHAI) matrix, developed by Reddy et al. (2021), was created to support AI implementation in healthcare. It focuses on assessing the applicability, safety, and utility of AI technologies, emphasising functionality, ethical adherence, and real-world adoption. TEHAI comprises three main components, capability, utility, and adoption, each containing several subcomponents used to assess aspects such as data integrity, technical performance, generalisability, relevance, safety, transparency, privacy, and system integration. Within the matrix a numerical scoring system is used, with subcomponents weighted by importance; results are presented using a traffic-light style visualisation to clearly indicate strengths and weaknesses.
In 2024, INTERPOL introduced the first policing AI matrix. Working with United Nations Interregional Crime and Justice Research Institute (UNICRI) and funded by the European Union, they released an AI Toolkit (INTERPOL, 2024) designed to support law enforcement agencies in understanding and governing AI technologies. The toolkit brings together international ethical principles, human rights guidance, and practical considerations to help police services identify risks associated with AI use. Its focus is primarily on ethical safeguards, data protection, transparency, accountability, and organisational readiness, offering high-level guidance for assessing potential harms such as bias, misuse of data, or operational over-reliance on automated systems. Alongside these governance elements, the toolkit provides a risk questionnaire for grading each area between low-high risk to support decision making.
Limitations of existing tools
While each of the tools outlined provides sector-specific mechanisms for evaluating or guiding AI implementation, they have significant limitations. First, despite some being labelled as matrices, they function primarily as frameworks rather than true matrices, offering structured conceptual guidance but lacking an operational, evaluative tool that practitioners can apply systematically. Others, such as the ethical matrix prioritises stakeholder inclusion but is heavily qualitative and dependent on what emerges during engagement, meaning critical risks may be overlooked without structured evaluative criteria. The 4PADAFE tool functions as a planning tool tailored specifically to education and would require substantial modification before being suitable for policing or other high-risk operational environments. Similarly, TEHAI is designed for healthcare and, while methodologically rigorous, its specialised focus and domain-specific metrics restrict its broader relevance and ethical concerns and operational risks central to policing are not fully captured.
The INTERPOL AI Toolkit presents the only policing-oriented resource, yet it is primarily oriented toward risk awareness and ethical governance, offering narrative guidance rather than a structured, evaluative matrix. While useful for raising organisational awareness, it does not include key policing theories essential for legitimacy, implementation effectiveness, measurement of technology acceptance or other key necessities. As such, it falls short of being a method for comprehensibly assessing the feasibility of specific use cases, comparing operational benefits against risk, or evaluating organisational readiness in a systematic, measurable way. In addition to the practical limitations of the existing models, they also lack sufficient and/or transparent theoretical grounding. In this regard, although they may intentionally or unintentionally include components that consider issues related to procedural justice, technology acceptance and implementation theory, these are not systematically considered or addressed. Taken together, these limitations highlight the absence of a policing-focused matrix capable of translating AI implementation requirements into a practical, replicable, and sector-specific tool. Such gaps created the necessity for developing the original TLP model and framework and highlight that the need for an operational matrix tailored to the policing context remains.
The transformer led policing model
As an effort to begin to address these gaps, I introduced the Transformer Led Policing (TLP) Model (see Halford, 2025a), a structured approach designed to support the integration of AI, particularly GenAI, into policing. The TLP Model was informed by bringing together selected theories and frameworks from other sectors, international AI governance recommendations, and the specific operational requirements of policing. It provided both a conceptual model and a practical framework that aligned with the EU AI Act and the UK’s NPCC Covenant for the safe and ethical use of AI in policing.
The model itself is organised around a three-stage cycle, Devise, Discuss, and Deploy, which forms the overarching conceptual structure for how AI should be introduced, scrutinised, and embedded within police organisations. Beneath this sits a twelve-component framework, with four features aligned to each stage. Devise includes defining use cases, establishing measures of efficacy, setting performance thresholds, and developing structured prompts and API configurations for AI inputs. Discuss focuses on stakeholder engagement and ensuring legality, security, ethics, and public legitimacy. Deploy centres on testing, implementation, performance evaluation, and dissemination to support best practice and continuous improvement. As illustrated in Figure 1, the model is cyclical and can be entered at any point, with feedback loops designed to ensure learning, refinement, and accountability across all components. The transformer led policing model (taken from Halford, 2025a).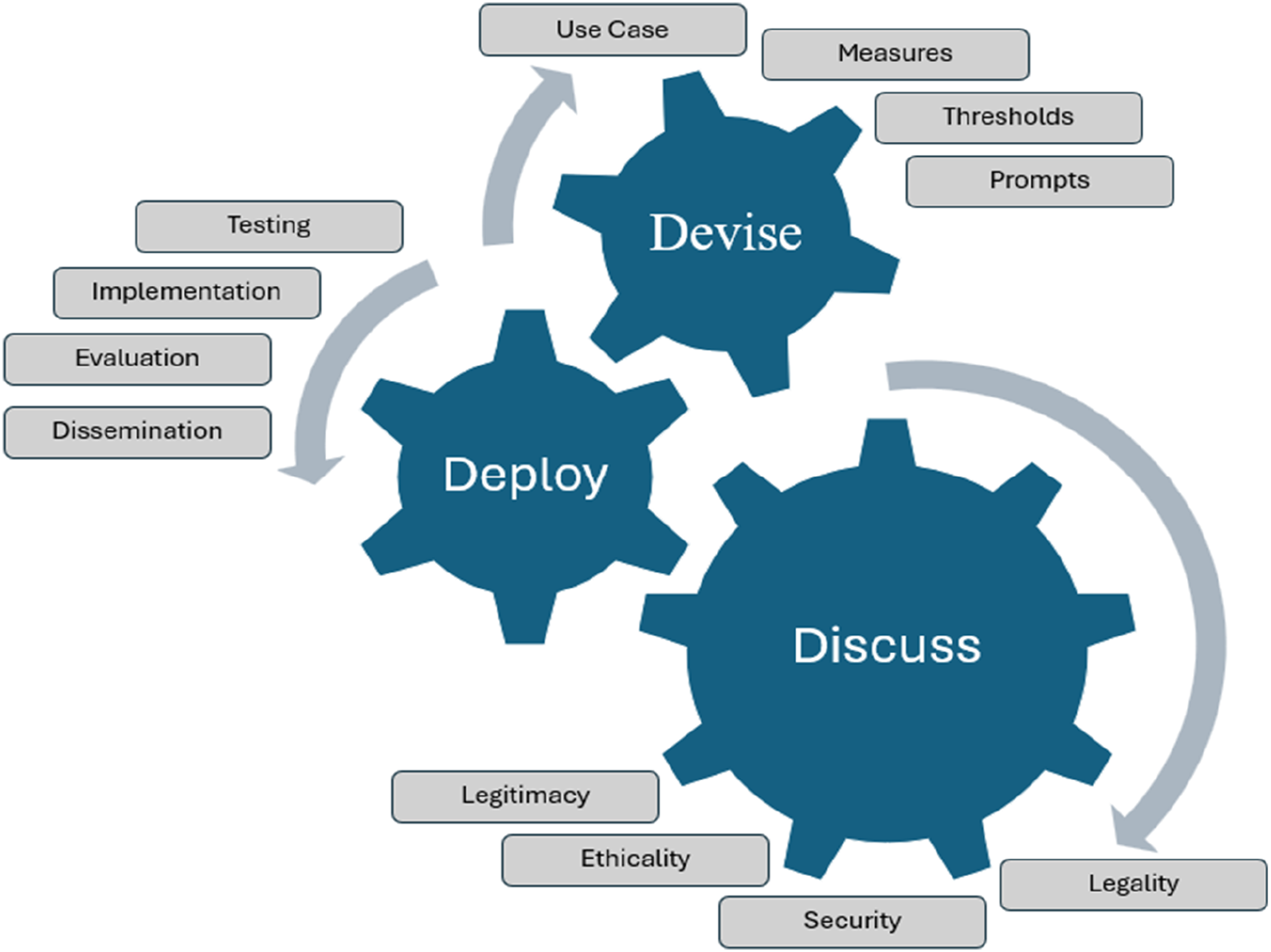
This structure translates the high-level model into a coherent set of domains that policing organisations must consider when adopting AI systems. However, while the original TLP Model provided a robust conceptual structure and an accompanying framework, it did not include a practical matrix for application, leaving agencies without an operational tool to assess readiness, feasibility, or implementation progress.
The current article
As indicated, the absence of a matrix was a notable limitation of my original article.
Addressing this gap is the primary purpose of the current one. By offering a clear and accessible method for operationalising the TLP Model, this will ensure that it can be adopted effectively within policing, thereby enhancing its ease of use and increasing its ‘perceived usefulness.’ Both constructs are essential for successful technology adoption in policing and have been central to previous implementations of digital tools within law enforcement (Allen, 2019; Lindsay et al., 2014; Kurkinen, 2013). To this end, the remainder of this article outlines the structure of the TLP Matrix and provides clear directions on how to apply it when planning, implementing, and evaluating general-purpose AI in policing environments, alongside recommendations for interpreting the results.
The transformer led policing matrix
The full TLP Matrix is provided in Appendix Table 1. It functions as the analytical tool used to score every component feature of the TLP Model’s underlying framework. For each of the three stages of the model, Devise, Discuss, and Deploy, detailed subcomponents and grading criteria have been developed to operationalise the framework. Figure 2 illustrates this structure using the “use case” element from the Devise stage. Example section from the transformer led policing matrix.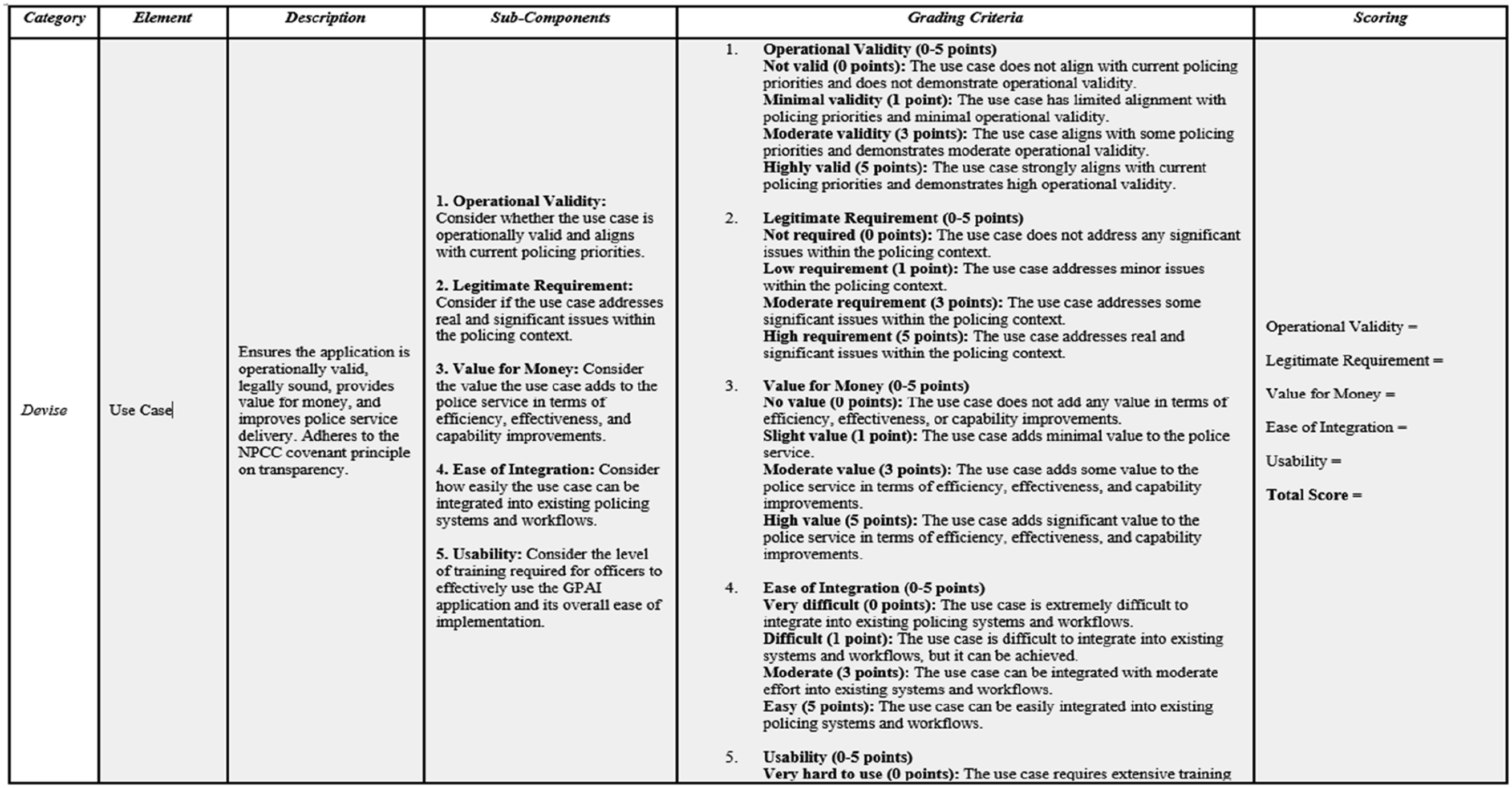
Each element of the matrix is accompanied by a descriptor and consists of between three and six subcomponents that outline the key considerations relevant to that element. These subcomponents are directly derived from the original TLP Model but have been expanded into discrete, assessable features based on corresponding theoretical frameworks that have been empirically evidenced.
For example, within the Discuss category, the subcomponents of the “ethicality” element draw on the three pillars of the public confidence in policing model (trust, procedural fairness, and presence), as described by Morrell et al. (2020). This is essential as it grounds the model in procedural justice theory in a way that existing tools do not. This is vital for the police application of AI because policing theory on legitimacy and procedural justice, emphasise that public trust and confidence are shaped less by outcomes and more by whether authority is exercised through transparent, fair and respectful processes (Bradford et al., 2009, 2014; Hough et al., 2010; Jackson et al., 2012; Tyler, 2006; Sunshine and Tyler, 2003). In this regard, procedural justice outlines four core dimensions (voice, neutrality, dignity/respect, and trustworthiness), through which citizens evaluate the fairness of police power (Lind and Tyler, 1988; Tyler, 2006). The legitimacy literature further stresses that this relationship is dialogic contingent and that legitimacy is continually negotiated between institutions and those they serve and can be damaged when practices are perceived as arbitrary, biased, opaque, or disproportionate (Bottoms and Tankebe, 2012; Jackson et al., 2012). These issues are directly relevant to AI, and particularly GenAI in policing because such systems can shape decisions and citizen-facing outcomes directly and indirectly (e.g., through risk assessments, prioritisation, triage, report writing etc.). If affected police actions are not conducted in a just and fair manner, or if governance is not procedurally robust, then legitimacy risks can scale rapidly (Bradford et al., 2014; Hough et al., 2010). Accordingly, the Discuss stage operationalises legitimacy safeguards by requiring explicit consideration of procedurally just governance conditions, such as transparency, explainability, bias and fairness, and demonstrable community value, meaning every use case is considered not just against organisational requirements, but also its legitimacy suitability. In this way, Discuss embeds the core philosophy of procedural justice literature, that it is not only what the police do, but how they do it, as a structured process for AI adoption rather than a discretionary step (College of Policing, 2024; Hough et al., 2010) by applying Morrell et al.'s. model (2020).
Likewise, the Deploy category incorporates elements derived directly from implementation theory (May, 2013). This is particularly salient in policing, where implementation success is shaped by organisational structure, leadership commitment, occupational culture, and the interpretive discretion through which officers translate innovations into routine practice (Kirby, 2013). For AI, these dynamics are decisive: even where a tool is perceived as useful, implementation may still fail, or generate unintended harms, if enabling conditions are absent or weak (Kirby, 2013). Accordingly, implementation theory is incorporated intentionally within the TLP Matrix to ensure that Deployment is treated as an organisational embedding process rather than a singular ‘go-live’ event. In this regard, implementation research consistently shows that successful integration depends on systematic attention to governance infrastructure, training capacity, operational supervision, feedback loops, and sufficient financial and human resourcing to support early adoption and sustained use at scale (May, 2013; Moullin et al., 2019), and inclusion of implementation theory ensures these are appropriately considered.
Furthermore, the subcomponents of the Evaluation element within the Deploy category are informed by the Technology Acceptance Model (TAM) (see Venkatesh and Bala, 2008). This inclusion is important in a policing context because evaluations of new programmes have historically been vulnerable to optimism bias, selective reporting, and success narratives that are weakly evidenced, or what Murray (2019) characterises as a tendency for initiatives to become “doomed to succeed.” While the growth of evidence-based policing has strengthened expectations around evaluation quality and methodological rigour (Sherman, 2015), the organisational and political pressures that shape police reform mean that biased or unobjective assessments may still occur. Embedding TAM within the TLP Matrix therefore functions as a safeguard which is required as implementation success in policing is often behavioural, as well as technical, and depends on whether officers and staff judge the technology to be useful, easy to use, and operationally integral. In this regard, empirical research on police technology adoption demonstrates that uptake is consistently shaped by the core TAM constructs of perceived usefulness and perceived ease of use across a range of policing technologies (Allen, 2019; Kurkinen, 2013; Lindsay et al., 2014; Vrielink, 2015; Abbas and Nicoletta, 2020). Incorporating these constructs into the Deploy evaluation stage should, therefore, help prevent successful deployment being claimed based on technical delivery alone, and instead requires systematic assessment of real-world utilisation, operational value, and resistance (Venkatesh and Bala, 2008). In doing so, the matrix strengthens its evidence-base by aligning implementation evaluations with observable adoption conditions and realised benefit, reducing the risk that reforms are recorded as successful through demonstrated practice, rather than subjectively biased interpretation (Murray, 2019; Abbas and Policek, 2021).
Quantitative assessment
The quantification used in the TLP Matrix should be understood as a form of structured professional judgement (SPJ), rather than as an actuarial risk assessment, algorithm or a mechanistic pass/fail scoring system. In policing and criminal justice, SPJ tools are routinely used to standardise information gathering, support consistency, and make professional reasoning more transparent, while still recognising that final decisions remain matters of individual judgement rather than numerical calculation (Hart et al., 2016). The ordinal scale used here (0–5) is therefore intended to direct attention to key governance, implementation, and operational considerations to support structured comparison across use cases. It is not intended to replace human deliberation.
To support the quantitative assessment, each subcomponent is evaluated using four grading criteria, enabling each AI use case to be examined from multiple perspectives. This design allows the matrix to be used flexibly: as a forward-looking tool to assess proposed AI applications, as a project management guide during implementation, as an evaluation framework post-deployment, or as all three in combination. Each grading criterion assigns subcomponent scores using four possible ranks, 0, 1, 3, or 5. Depending on the number of subcomponents within an element, this results in a maximum element-level score typically ranging from 20 to 30. Individual subcomponent grades are recorded in the final section of the matrix, allowing users to quickly identify low-scoring areas that may signal risks, weaknesses, or gaps requiring further attention.
Once all subcomponents within an element have been scored, the total for each category (Devise, Discuss, Deploy) is calculated out of 100. When the grading for all three categories is completed, the matrix produces an overall score out of 300, providing a comprehensive, quantitative assessment of an AI system’s readiness, implementation quality, or operational performance, depending on the context in which the matrix is applied.
At this stage it should be noted however, that scoring in this manner does have limitations and weaknesses. Scholarship on this issue therefore cautions that when organisational problems, such as implementation of AI, are rendered into simplified scores, important contextual and normative questions may be abstracted away, leading to the so called ‘abstraction trap’, in which the measured representation is treated as the conclusion (Selbst et al., 2019). In policing, the risk can become amplified because quantified tools can become embedded into compliance routines and audit systems, encouraging decision-makers to overemphasise the score rather than the underlying risk it may highlight, potentially narrowing attention (Selbst et al., 2019). Relatedly, work on black-box decision-making highlights how opaque or weakly contestable scoring and evaluation practices can shift accountability over time, as organisational reliance grows and the tool becomes treated as an authoritative judgement (Pasquale, 2015). This can undermine fairness if outputs are interpreted, or acted upon, without due care and attention (Binns, 2018; Dolata et al., 2022). For these reasons, consistent with the ethos of the matrix as an SPJ tool, I strongly advocate for multiple assessors to be utilised to enable inter-rater reliability as this will highlight disputed gradings, enable further discussion, through consensus panels for example, and ultimately increase validity of the scoring process (Hart et al., 2016). In addition, the quantitative scoring should be applied alongside a narrative justification for each element score which highlights all strengths and weaknesses.
Planning using the TLP matrix
Using the matrix as a proposal or planning tool is best suited to cases at the beginning of development. This is when the AI is still an idea and needs consideration to understand its feasibility. For example, in the United Kingdom, Thames Valley Police and the Hampshire and Isle of Wight Constabulary have recently introduced an AI chatbot called Bobbi (Hampshire and Isle of Wight Constabulary, 2025). The purpose of this AI is to respond to online non-emergency enquiries. To reach such a stage, the police service would have been required to consider many of the issues covered by the TLP model prior to its purchase and implementation being authorised at a strategic level. In this context, the TLP matrix would have been an ideal tool to assist the planning process. At the outset, it would be first necessary to complete element 1 (use case) of the devise category. This establishes if an operationally valid need exists i.e. one that falls within a policing priority. It will also identify if it meets a legitimate requirement as although a use case may be valid, it does not mean there is a need for an AI to address the issue. Furthermore, it establishes if the AI presents value for money and can be integrated and used. These factors help determine the necessity and potential of the AI. In the case of Bobbi the AI chatbot, such a case is easy to make as it potentially provides significant efficiency gains for both the police and the public, and the use of AI is a legitimate means to achieve this.
Once a use case is deemed suitable, the user can apply the remaining matrix as a proposal/planning aid by following each element and considering its subcomponent features. This will ensure that a comprehensive, transparent proposal or plan is developed that can then be fully considered prior to implementation, thereby reducing the likelihood that key issues will be overlooked.
Implementation using the TLP matrix
As done so with the public confidence in policing and technology acceptance models, within the deploy category the element that focuses on implementation has been widened to now contain subcomponent features drawn from the overarching theory, in this case, implementation theory (See May, 2013, for a full overview). This now ensures that issues related to material and human resources, stakeholder management, and overall organizational buy-in are adequately considered. The focus of this part of the matrix is to act as a ‘checklist’ to ensure an appropriate plan for implementation is in place. When being applied as an implementation tool the matrix should be used to aide project management. This can occur as a follow-on activity from the proposal/planning stage, or in cases where AI is already developed and deployment ready i.e. ‘off the shelf.’ This is achieved by using the matrix as the scaffold for project management.
For instance, implementations in organisations are commonly conducted using methods such as the Project Management Body of Knowledge (PMBOK), and PRojects In Controlled Environment Version 2 (PRINCE2) (Drob and Zichil, 2013; Karaman and Kurt, 2015). Both use planning tools including spreadsheets and Gant charts to focus implementation teams on key issues. This includes developing the business justification, integration of processes, human resource management, communications, stakeholder management, and product delivery (Drob and Zichil, 2013; Karaman and Kurt, 2015). However, these are generic overarching components and using such methods requires extensive thought regarding the individual elements and subcomponents to be mapped, planned, and executed. The TLP matrix does this for the user and can be instantly used to create project management plans, aide stakeholder mapping, and underpin Gant charts required to plan timescales, resources, and administration. This is done by using the TLP matrix directly as the project management template or ‘lifting and shifting’ its features into project management software. Either approach saves considerable time and effort and ensures the project management plan considers all relevant issues related to implementation theory, and the wider literature on AI within a policing context.
For example, again using the case of Bobbi the AI chatbot, even though this has already been implemented by Thames Valley Police and the Hampshire and Isle of Wight Constabularies, they could use the TLP matrix to guide their continued project management, even after the AI has gone live. This would then help to reduce the likelihood of the common issues that often plague large scale IT implementations from occurring. Similarly, if Bobbi the AI chatbot proves successful, the TLP matrix could be used by other police services who choose to purchase and roll out the same, or similar technology, bypassing the Devise stage of the model. In this scenario, they could simply utilise it is a pure implementation tool to support project management, and subsequently as an evaluation aid.
Evaluating using the TLP matrix
When using the matrix as an evaluation tool for AI in policing it should be used in a retrospective fashion. In this regard, it can be used in two ways. First, as with the other cases it can be used as a follow-up tool to conduct an evaluation post proposal/planning, development, and implementation. If previous stages of the matrix have already been adopted it will save considerable time and effort when conducting an evaluation as most information required will have been considered and should be readily available.
Its second use is as a tool for ad-hoc evaluation. In this capacity it is suited to cases when an AI has already been developed and implemented with no consideration of the TLP model, and an evaluation is yet to be conducted. This will enable the user to conduct a completely objective evaluation that considers all aspects of AI application within policing, ensuring no key issues are overlooked. This avoids implementations being ‘doomed to succeed’, and reported as a success, enabled through bias interpretation and reporting of results (Murray, 2019). As iterated earlier, avoiding this is essential with applications of AI in policing due to the potential for magnifying bias and unfairness.
Interpreting results
Once completed, it is important to interpret the results provided by the matrix carefully. The overall score of 300, which includes scores up to 100 for each category (devise, discuss, deploy), provides a quantitative figure that is easy to articulate and understand. For example, a score of 25 out of 300 would indicate that the AI has significant flaws across all areas. As such, continued use, or implementation would be unwise. In contrast, a score of 275 out of 300 would indicate that there is substantial evidence that the AI model has significant strengths. Both examples demonstrate how a score could be used to aid decision making. However, it is not recommended that any attainment score be set for an AI to be considered safe and appropriate to use. This decision should be made by police leaders at an organisational level after considering all evidence. The score produced should only assist this process.
To help decision makers carefully consider the AIs use case the scoring provided for each category enables identification of strengths, weaknesses and limitations of the AI, and the planning, and/or implementation that has been undertaken. For instance, consider a case where each category has been completed or considered in full and a score of 100 in the categories of devise and deploy has been achieved. This indicates that the model provides utility, can be integrated, has been tested robustly, is effective, and can be replicated and shared. However, a low score in the discuss category, 10 out of 100 for example, would indicate, dependent on the context the matrix has been used (planning, implementation or evaluation), that regardless of effectiveness, the AI model is, or may not be safe, legal, or ethical, or that these issues have not been considered at all. As result, it is unlikely to be considered legitimate by stakeholders, including the public. In such circumstances, regardless of whether the AI model is extremely effective at its intended purpose and can provide value to policing, it would be unwise to implement or continue its use until such issues are addressed or considered properly.
Furthermore, using the tool to identify weaknesses and limitations through low scores for individual elements or subcomponents also helps the user and decision makers pinpoint potentially fatal issues. For example, in an extreme case a score of 275 may appear promising. However, closer inspection may reveal a score of zero in the security element (discuss category). This indicates no consideration has been given to security stakeholder engagement, data privacy, handling and storage, data protection policies, or safety and reliability. Therefore, it would flag a potentially fatal flaw. Similarly, a score of 280, with a score of five in the security element may indicate that comprehensive stakeholder engagement has been considered or conducted, but even then, the security issues cannot or are unlikely to be overcome. Both scenarios are likely to be fatal for the AI model given the importance of security.
These scenarios highlight the importance of considering the results in full and not focusing on a ‘high score,’ which is only an indication of the AI models strengths, weaknesses, and limitations. Deployment decisions must be made at a prominent level and after full consideration of all the results. The benefit of the TLP matrix is that it provides this data in a systematic and consistent format, thereby facilitating effective and efficient strategic decision making.
Application case study
This section demonstrates how the TLP Matrix can be applied to a practical policing GenAI use case by continuing to draw on the example of the Bobbi AI virtual assistant. However, it must be stated that I was in no way involved in this project and this offers a purely hypothetical perspective presented for methodological illustration, rather than as an accurate reflection of either the AI or its implementation.
Illustrative worked example of the TLP matrix.
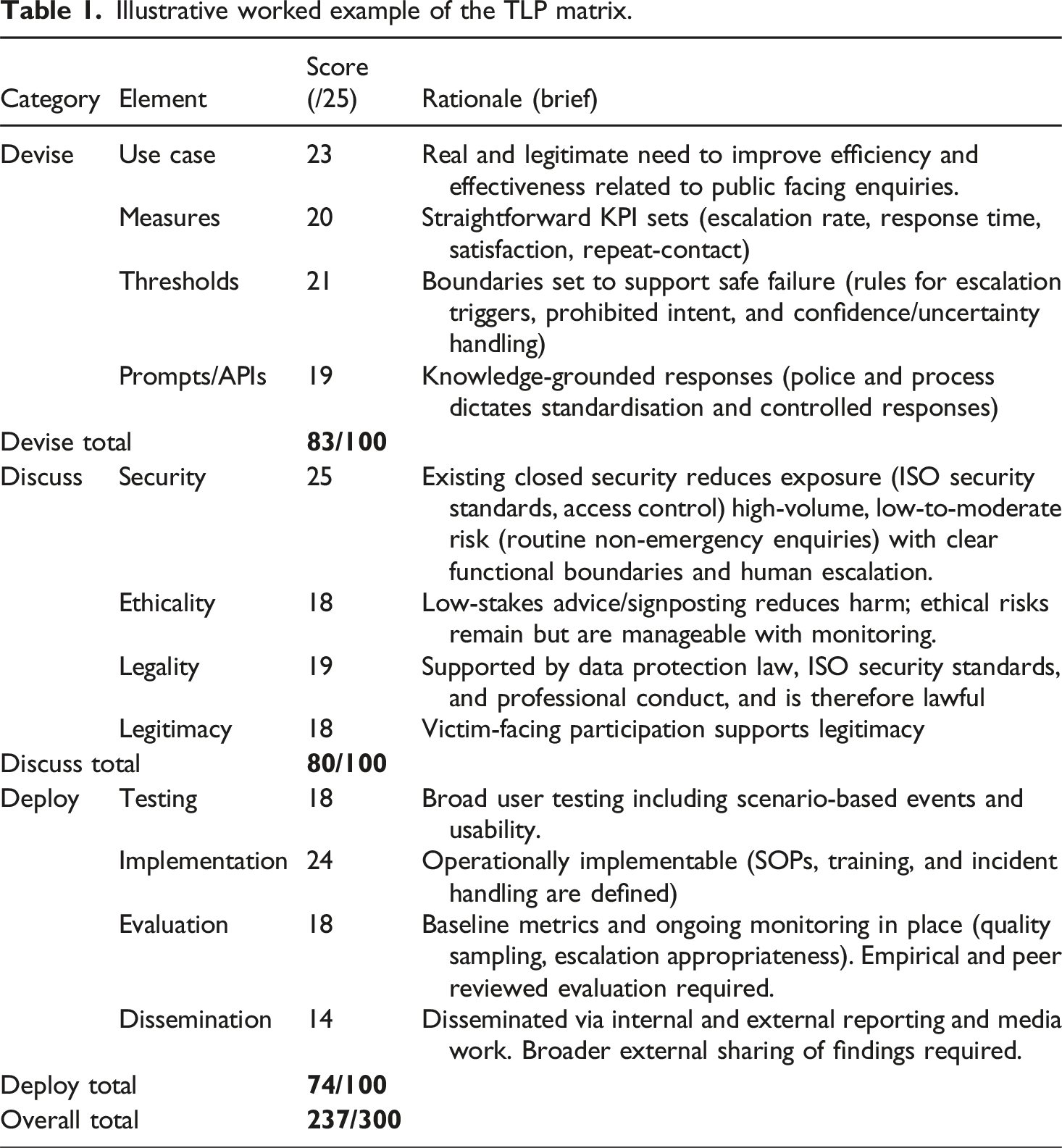
The worked example in Table 1 Illustrates under a hypothetical application of the TLP matrix, that the AI Chatbot Bobbi, would score strongly overall (237/300). This score is led by a high mark in the Devise (83/100) section, which is driven by the legitimacy of the use case, which combines a genuine business need, strong community focus, and easily identifiable metrics and thresholds of success that have clear safety measures to underpin them. Similarly, the Discuss score (80/100) indicates that the AI tool is easily governable, primarily because the principal issues of risk related to security can be met with existing and well tested structures that are internationally accredited and lawful. In this use case the ethical considerations are also less about sensitive issues, such as decision-making, and more about accessibility and speed of service, relating to existing information, which are all manageable through the escalation processes and human monitoring. Finally, the Deploy score (74/100) is also high as the testing and evaluation components can be easily conducted, quantified, and reported. Additionally, its roll out requires limited training or increased capacity, further supporting its operational feasibility and increasing its utility and overall technological acceptance. The Dissemination score highlights that it could be improved with a formally published and shared evaluation or academic examination, but overall, it is a robust use case.
Limitations and future research
The TLP matrix, while comprehensive, has several limitations. First, the scoring process is inherently subjective; what one assessor may regard as a moderate level of maturity or assurance may be interpreted by another as comprehensive. Use of inter-rater reliability methods, consensus panels and narrative reports will help mitigate or reduce such subjectivity. Second, the matrix has not yet been fully operationally tested, and its effectiveness has therefore not been empirically demonstrated. Third, the complexity of implementing the matrix may present challenges for smaller police services or research teams with limited resources, particularly given the level of stakeholder engagement advocated. Fourth, the matrix is primarily oriented towards assessing immediate and short-term aspects of AI implementation, with less emphasis on longer-term impacts, unintended consequences, and the evolution of community trust and confidence, all of which require sustained evaluation over time. Finally, as AI technologies continue to develop rapidly, there is a risk that elements of the TLP matrix may become outdated, necessitating periodic review and refinement to maintain relevance.
To address these limitations, future research should prioritise empirical application and validation of the TLP matrix through its use in devising, implementing, and evaluating real-world AI applications in policing. This should include studies examining the consistency of scoring across different assessors, as well as comparative work exploring how TLP assessments align with existing AI governance and assurance frameworks. Longitudinal research would be particularly valuable to assess how TLP scores change over time as systems move from design to deployment and beyond, and to examine longer-term outcomes such as operational effectiveness, organisational learning, and public trust. Collectively, this body of research would support refinement of the matrix, strengthen its evidential foundations, and clarify its practical utility as a governance tool for policing-related AI.
Conclusion
This article introduced the Transformer-Led Policing (TLP) Matrix as a structured framework for assessing the suitability, governance, and operational readiness of generative artificial intelligence within policing. Responding to the growing interest in the use of generative AI across law enforcement, the matrix develops and operationalises the abstract principles set out in the original article that first introduced the TLP model in 2025. It does so by providing a structured assessment process across the three interconnected domains of the model (Devise, Discuss, and Deploy) and by offering a worked example that demonstrates how the matrix can be applied to real-world AI use cases to highlight strengths, expose weaknesses, and support informed decision-making.
Importantly, the TLP Matrix is not presented as a predictive or prescriptive tool, nor as a replacement for existing governance, legal, or ethical oversight mechanisms. Rather, it is advanced as a decision-support framework designed to encourage structured reflection, transparency, and proportionality in the adoption of AI within policing. Its value lies in its ability to prompt critical questioning at each stage of the TLP model’s lifecycle, facilitate dialogue between technical and non-technical stakeholders, and provide a defensible basis for decision-making in a domain characterised by significant ethical sensitivity and heightened public scrutiny. While the matrix remains conceptual and requires empirical validation, it nevertheless offers a coherent and practical starting point for operational policing contexts. As policing organisations continue to explore both the opportunities and risks associated with generative AI, the TLP Matrix provides a flexible and adaptable framework through which innovation can be pursued in a manner that remains accountable, legitimate, and aligned with public value.
Supplemental material
Supplemental material - The transformer led policing matrix: A tool for grading suitability of general-purpose artificial intelligence models in policing
Supplemental Material for The transformer led policing matrix: A tool for grading suitability of general-purpose artificial intelligence models in policing by Eric Halford in The Police Journal.
Footnotes
Ethical considerations
An ethical exemption was provided for writing of this article by the Rabdan Academy Ethics committee.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
No data is available for this study.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.