
Abstract
Existing research on police recruitment is eclectic, with examples of multiple methodologies in multiple police-related settings. These methods often resemble psychological measurement of individual traits yet neglect the potential recruits’ social resources or network-based influence. More recent research has utilised social identity and social network theory to understand the route to a police candidate’s eventual recruitment, but this is underdeveloped. This literature indicates that further research utilising social identity theory could assist with understanding what was before for police recruits and whether that matters. This study explores the use of random forest machine learning to analyse one partial and two full self-report social identity measurement instruments completed by 886 police recruit applicants. It aimed to explore whether the results of these instruments completed by potential police recruits were predictive of their success in the recruitment process. The results reveal that the combined use of these validated social identity instruments offers a reliable predictive base for successful and unsuccessful applicants, with an overall accuracy rate of 86% across the model’s performance metrics. The implications from this study highlight the significance of perceived social identity in the context of police recruitment, emphasising the potential impact of using its measurement to gain improved understanding of candidate selection. Social identity measurement instruments could be incorporated into recruitment processes, allowing police departments to enhance their ability to identify individuals who are more likely to succeed at an earlier stage via machine learning. Practically, this could reduce the need for multiple, expensive recruitment stages. Theoretically, it illustrates that a police recruit’s social identity is of importance to whether a candidate is successful or not, presenting police forces with both challenges and opportunities.
Introduction
Police recruitment and socialisation are important topics within the canon of policing research, with seminal mixed method and ethnographic studies (Charman, 2017; Fielding, 1988; Van Maanen, 1973) which discuss how recruits become socialised into the policing environment. The earlier studies focused in on the process of socialisation for the recruits, discussing how world view, values, and habits were developed during training. The designated period before the recruits became officers came to be known in existing literature as anticipatory socialisation (Bennett, 1984; Conti, 2006), a term which described how police recruits develop their own shifting identity towards that of becoming a police officer. Effects of this anticipatory socialisation within the observed, recruited officers were salient as they developed through their time at the police academy; some of whom when they joined the police were already considered to have semi-developed police identities. For example, this could take the form of already used police language, decision making, or behaviours that presented more clearly in the training environment if recruits were from a police family.
This period of before is referred to as anticipatory socialisation but should instead be referred to as presocialisation (Hesketh and Stubbs, 2023b; Under Review; Stubbs & Tong, Under Review). The use of the term ‘anticipatory’ alludes to a decision having already been made to become a police officer, when more accurately, even before the decision to become an officer there can be considerable social influence present. In their study of ‘careership’, Hodkinson and Sparkes (1997) discuss how the decision to choose a career is rooted in wider social interactions over long periods, within complex relationships that exist between habitus and field (Bourdieu, 2005). In a police family, the inculcation of police values therefore may not begin at the point when the potential son or daughter decides to join the police but in fact may be generated through their social upbringing over time. This gradual growth of world view, values, language, and behaviour is built through individual and social experience and is essentially a socially mundane – and therefore largely invisible – process. If we can assume that this lengthy social learning is important to the cumulative building of police identity over time, then we can also assume that social learning is not just limited to parental or immediate family-based contexts. Existing social identities (Jenkins, 2014) may also play a part in how presocialisation is developed for the police recruit in varying degrees. A simple example of this may be that a police recruit plays football regularly in a team that contains serving police officers. The relative, figurative distance between their existing social identities and that of a police officer is mitigated through their already existing social contacts.
Existing research on presocialisation in policing is scant, but both quantitative study (Stubbs et al., 2023) and qualitative study (Hesketh and Stubbs, 2023a, 2023b; Under Review; Stubbs & Tong, Under Review) indicate that during the police recruitment period, the recruits’ policing identity is under some level of social development. Stubbs et al. (ibid) indicates that having existing social connections that were serving police officers prior to applying for the police was a significant factor in a candidate’s success, leading to subsequent questions about the strength and types of social interactions (Granovetter, 2017) that police recruits can access, and what presocialisation means for them upon recruitment. Social networks rooted in recruits’ existing social ties will build and sustain the pre-development of the police identity, values, knowledge, and even practical aspects such as communication skills. This has been studied for decades in other labour markets (Grieco, 1987; Lin et al., 1981; Lin and Dumin, 1986; Waldinger, 2005), but research in the policing space is severely limited. This study aims to illuminate some of the nature and significance of social networks and perceived social resources in that space, developing further understanding of what happens before for police recruits. It also aims to test whether aspects of that before matter for police recruitment.
Police recruitment research and the relevance of social identity
In the West, police recruitment research has gone through several iterations or trends over time. The earlier socialisation studies from Van Maanen (1973), Bennett (1984), and Fielding (1988) have found support in contemporary research from Chan (2001) and Charman (2017). These studies illustrate that there is a belief that what went before matters; Charman (ibid) describes this as the conflict between importation and socialisation. This is essentially a discussion that centres upon what a candidate for the police role brings with them and what they then learn as they begin their training. There is a heavy focus upon socialisation post recruitment in the existing literature, but this is shaped by the researcher’s ability to empirically examine observable changes during socialisation in the police academy. On the contrary, presocialisation is very difficult to measure, as it could start from birth in a police officer family or begin through sharing membership in a rugby club after finishing school. These periods are systematically non-observable, rendering empirical analysis of them very difficult. There have been enduring calls for these obscured, mundane, socialising interactions to be researched wherever possible (Holdaway and Rock, 2005). Holdaway and Rock (ibid.) make the case that without this underpinning, empirical base, real understanding of socially constructed and sustained phenomena can only be speculated upon, and underlying generative causes may remain perpetually unseen and unexamined.
As an example of empirical work in presocialisation, Conti (2006, p. 224) in his participant/observation study within United States police recruitment puts forward a set of stages as Civilian, Contestant, and Anticipatory Recruit. These United States (US) centric stages appear in the main to fit into the anticipatory section of presocialisation, as even in the Civilian phase, the candidate is still consciously consuming police-related, socially embedded content with the hope of becoming an officer. It is reasonable to say that there will also be a stage prior to that of the Civilian, one where the development of any policing-related social identity is largely an unconscious process. This is the stage where social signals are generated that allow the police as a profession to emerge as a potential employment option for the candidate; this is an unclear stage, and one which has mainly been served by the existing psychological literature with regard to police recruitment. As this model is particular to the US, much of it can be disregarded for the context of this study whilst maintaining the principle that presocialisation is possible to research empirically.
With regard to the psychological literature, the Police Personality (Skolnick, 1966, 2010) alludes directly to the psychological importation as discussed by Charman (2017). That a ‘police personality’ exists as a concept indicates that there is a something particular about the police officer. This has been borne out to some extent (Evans et al., 1992; Fenster and Locke, 1973; Hogan, 1971; James et al., 1984; Kirkcaldy et al., 1994) with research holding that there are some differences with the general population, even at the point of recruitment. This is also bolstered over time, as the discussed police personality traits become more salient longitudinally through socialisation within the policing environment (Adlam, 1982; Gould, 2000; Twersky-Glasner, 2005). More latterly, the research in this area is mainly populated by Minnesota Multiphasic Personality Inventory (MMPI)–based methods which allow a degree of cross-cultural research (Carpenter and Raza, 1987) to answer the question posed by Twersky- Glasner (2005): ‘Why are they like that?’ In this case, the ‘they’ referred to are police officers.
This focus upon importation is distinctly focused upon the subject, that is, the police recruit themselves. It neglects the wider consideration of the recruit’s social resource, social resilience, and to some extent their physical and social habits. Although the psychological literature can help us infer existing social tendencies (and therefore the potential of social contact with other officers) via traits such as extroversion in Big 5–based psychological testing (Zillig et al., 2002), the contacts themselves and the nature of that contact are measuredly absent. This results in the assertion that when considering the policing recruitment canon, the focus upon the importation of psychological based traits and tendencies is solely with regard to the existing, internal traits of the individual. It rests upon the snapshot of personality-based psychology measured at the point of recruitment being the best of what is available at point of entry. The dialogical and social interactions that assisted in generating and sustaining that psychology are therefore largely unexamined. This is despite recent systematic studies (Geuzinge et al., 2020) which show such relationships are important for resilience with regard to traumatisation and wellbeing in emergency services.
There is empirical evidence for the claim that personality is affected by socialisation, as changes have been evidenced over time during socialisation in the police environment (Gould, 2000) and more widely throughout the life course (Specht et al., 2011). This can be triangulated with those scholars that have watched such changes happen in ethnographies (Charman, 2017; Fielding, 1988; Van Maanen, 1973). This potential malleability of personality over time exists prior to police recruitment as a process and may increase over the duration of the recruits’ life – yet the social influences on this are complex and embedded within each recruits’ social landscape. It is possible that in some cases the police identity is being built from birth in some families through socially grounded, persistent influences, whilst in others it may be entirely absent. In contrast, Whitman et al. (2022) has measured the influence on prior policing socialisation to the outcome of MMPI-based tests at the point of recruitment and found minimal differences, suggesting that presocialisation may not have a strong influence on personality traits. This study exposes the weakness of using psychological personality questionnaires in isolation, and in practice, this is not the case. They are often used as a complementary or contributory stage to initial police recruitment. Questions could therefore be asked about whether other interesting variables should be measured in this context. The examination of the social impacts in terms of existing social contacts and resilience are both complementary variables worthy of study and have recently been shown to be important for resilience (Geuzinge et al., 2020). Therefore, existing literature addresses some of the impact of personality testing on police recruitment (Dantzker, 2011; Ho, 2001; Schoenfeld and Kobos, 1980), yet there is no published literature that quantitatively measures the impact of social access and resource upon police recruitment. These gaps in the literature do not support prediction for potential social impact with regard to officer performance or wellbeing. Qualitative studies such as Paes-Machado and Linhares de Albuquerque (2006) and Conti (2006) delve to some extent into presocialisation, as does Stubbs et al. and Stubbs and Tong (2023; Under Review), leaving the social landscape of police recruits open to further investigation.
An example of how this investigation may draw from police recruitment’s past in England and Wales relates to the practice of ‘home visits’ (Holdaway, 1991). These were conducted by officers of rank prior to eventual police recruitment. Officers of Chief Inspector rank and above would visit the home environment of the potential recruits and meet with family, partners, or housemates about their potential employment. Home visits allowed the senior officer to discuss the pressures of the work and the likely demand on the recruit, whilst observing the socio-cultural background that the officers were drawn from. This information would then inform the eventual hiring of the recruit. Notwithstanding the inestimable amount of bias that may be introduced at this juncture, this could be viewed as an opportunity to measure that which went before; it is an attempt that looks past psychological, or competency-based individual tests, and into areas of social interactions and support. This is currently only partially captured via competency-based interviewing (Pilbeam et al., 2012), as the candidate will be required to provide examples of when they have traversed social challenges to address the measured competency. Competency-based interviewing has received criticism from within industry because of its inflexible approach and inability to adapt to changing workplace demands (Derek-Martin and Pope, 2008).
These literature limitations highlight the need to explore methodological innovation to measure social networks, identity, resources, and behaviours in potential police recruits. Empirical examinations of existing social networks are complicated and often require qualitative interview (Best et al., 2016) to accompany a survey-based approach. The sample in this case was too high to hold separate interviews within the researched recruitment window; the resources to complete such a study would be considerable and were unavailable. It is however possible to measure social identity at scale using individual instruments from within social identity theory (Jetten et al., 2012, 2017). These are designed and tested to measure the self-reported social identities of candidates, an internal snapshot of their perceived social connections and access to social support. Current social psychology research indicates that social identity is also linked to personal wellbeing (C. Haslam et al., 2008; Jetten et al., 2012), resilience (S. A. Haslam et al., 2005), and access to social support from within your chosen social identity (Levine et al., 2005; Levine and Thompson, 2004). Social identity literature also links external police behaviours and legitimacy (Bradford, 2014), suggesting that the benefits of building and operating healthy social identities will affect not only the individual but also their potential operational efficacy. This promising literature directs future exploration of social identity in policing.
From the existing literature, it is therefore currently unknown how influential social identity is for potential police recruits, both with relation to a candidate’s relative success in the recruitment process and other previously researched factors in police recruitment such as personality. Therefore, proposed research using social identity instruments can offer a new perspective on presocialisation, exposing some of the other areas of importation that take place during police recruitment. Capitalisation of new research methods in this area will provide insight into the recruits’ social identities, which establishes a benchmark for further investigation. This would support other research into the wider nature of social tie and network usage (Granovetter, 2002) in police recruitment as discussed in Stubbs et al. (2023).
This leads to the formulation of the research questions: How does social identity function with regard to a candidate’s success in police recruitment? Is it possible to predict the outcome of the recruitment process using social identity self-report instruments?
Methods
The machine learning approach
Machine learning has technologically advanced the core functions of human resource management (HRM) and could be considered the strongest in recruitment and performance management, although this is often limited to decision tree methods (Garg et al., 2022). To extend the methodology of machine learning in HRM, this model has been built to include multiple decision trees into random forests (RFs), to shed light on the research question. Random forest (RF) is a powerful machine learning method, relying upon data to make accurate prediction with regard to future events or outcomes. However, RF methods are limited in use across police research and offer a new way to critically analyse and identify key issues throughout the public sector. Therefore, this method was selected to add insight without any prior knowledge, constraints, or incomplete data (Genuer et al., 2010). The model seeks to learn from an initially uncorrelated dataset, explore the inner relationships of that data, and then interpret the outputs accordingly (Louppe, 2014). Selection of the primary algorithm used in this case has been determined by both the research question and the nature of the data collected, as a classification model can be created and trained for future research opportunities in social identity–based police recruitment.
Capturing primary data for the model
As the foundation for data collection, several social identity themes were drawn from the literature (Jetten et al., 2012) to use as evidence-based social indicators to train the ML model. Importantly, the tools listed in the compendium do not address pre-socialised identities, so minor changes occurred to adjust the tool for better alignment. In this case, we used established instruments to collect data, and all candidates that completed the survey were at the first point in the police recruitment process (the initial application form). The initial two questions came from Doosje et al.’s work (1995), which is reliable, tested, and validated social identity measurement tool. The full tool has two questions that were removed because they directly allude to the person completing the instrument as being already within the target identity – this was not the case as recruitment was not complete at the point of the data collection. All questions utilised a Likert Scale 1-7 answer format.
The two removed questions were: • I see myself as a member of [relevant group]. • I am pleased to be a member of [relevant group].
Whilst the questions that were kept from this scale were: • I feel strong ties with members of [relevant group]. • I identify with members of [relevant group].
The second instrument used was a 2-item scale from Jetten et al. (2010), that is often used to index multiple forms of group identity at the point of transition (Jetten et al., 2012: p. 348). As the police recruits were attempting to transition policing, this tool represented an appropriate measurement of their perceived interaction with other social groups. • I am a member of lots of different social groups. • I have friends who are in lots of social groups.
The final tool that was used measured aspects of social isolation. This scale had been previously used for the purposes of screening (Reicher and Haslam, 2006) and assesses whether there are social resources for the participant to draw upon. • Do you have someone close in whom you can confide? • Do you see yourself as a loner? • Do you see yourself as a sociable person? • Are relationships important to you?
These three instruments were selected to measure whether potential police officers already saw themselves as part of the policing social identity, if they held multiple social identities, and whether they felt they had access to important social relationships that would support their resilience if successful in the recruitment process. Although this is not a complete picture of a candidate’s social relationships, it does provide a level of information that is simply not present in previous policing research.
Sampling
A recruitment window was opened in 2017 within an English Police service to select a cohort of new police officers. Although this data is 6 years old at time of publication, it is of note that internal recruitment processes have changed slightly, with a move from the College of Policing conducting an in-person assessment centre, to a similarly comprised online assessment centre due to the COVID-19 pandemic (College of Policing, 2021). The stages used either side of this centre within individual forces are similar in structure and content still, ensuring this study remains relevant. The total number of applications received was n = 2795. The window was opened for a 2-week period, during which applicants were able to complete their initial job applications online. The recruitment process followed the typical practices and patterns managed by the Human Resource department without any procedural modifications. Once the initial applications were received, contact was established with the n = 2795 applicants through email. They were provided with a link to an optional survey, clearly stating that participation in the survey was not mandatory or related to their future employment. Out of the n = 2795 applicants, there were 981 responses (35% response rate), of which there were an eventual 160 successful applicants. Out of the eventual n = 160 successful applicants, n = 141 responded to the initial contact and completed the survey, resulting in an 88% response rate amongst successful candidates. In the remaining potential recruits (n = 2635), there were n = 840 responses, representing a return rate of 31.9% for unsuccessful candidates. The respondents consisted of 34% females, 66% males, and a small number of respondents (n = 7) who chose not to disclose their gender. The overall sample after data cleaning resulted in n = 886 which is sufficient for a machine learning model to be applied.
In typical social identity–based research, the responses to the returned scales would be interrogated with regard to their results, their validity, and their reliability, using typical statistical methods. However, this would provide the researchers with the relative results of the tests for successful and unsuccessful candidates, and not their predictive validity in terms of each scales’ component importance for selecting whether the candidates would be successful. In this case, the scales were used as test and training data for the binary machine learning classification model to assess if it was possible to predict candidate success using the social identity instruments. Moreover, the use of social identity measurement as model input assisted with exploring the function of social identity in the success of police recruitment.
Building the machine learning model
From the outset, the ML model was constructed with a RF classifier to incorporate the ensemble learning power efficiencies of the primary dataset. These efficiencies reinforced the construction of multiple decision trees, where the dataset was split between training (80%) and testing (20%). The split between training and testing helped maximise the accuracy, tuning model’s inputs to the classification outputs (X_train, y_train, X_test, y_test). First attempts at building the model lacked accuracy on predictive power to classify either successful or unsuccessful candidates and there were deficiencies in the overall performance indicators of the model. Further testing was conducted and application of the model highlighted an imbalance in the outcome classifiers (Unsuccessful = 761; Successful = 250 responses); this was affecting the model predictions.
Hyper-tuning the model’s predictive power and performance
To counteract the imbalance in the classification outcomes, a machine learning technique of Synthetic Minority Over-Sampling Technique (SMOTE) was employed to balance and mitigate for any potential biases towards the majority classification. SMOTE works by the creation of a synthetic sample of the minority class, in this model, officers who were successful. SMOTE promotes oversampling of the datasets, and bagging (bootstrap aggregation) was applied to randomly selected subsets of features to mitigate against imbalanced classifications. Furthermore, the number of trees in our random forest (n_estimator) increased from 100 to 200 to enable our ML techniques a better opportunity to create a balanced and accurate model of binary classification.
Machine learning model’s performance and validity
The classification report for the final ML model in Figure 1 reflects a high-performing model with balanced precision (86), recall (86), and F1-scores (86) across two classes. The high recall score indicates the effectiveness in both not misclassifying negative instances as positive (precision) and in identifying positive instances (recall). ML model performance metrics.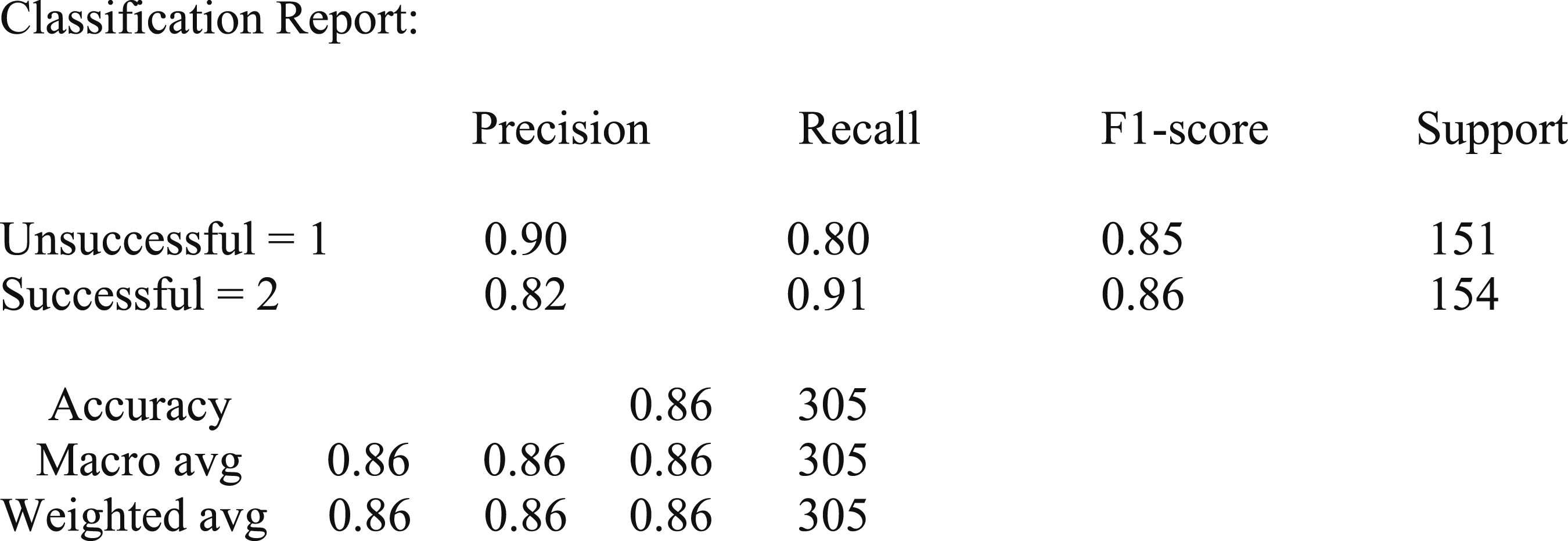
To conduct a test on the model’s performance and validation, the confusion matrix, with its metrics of 123 true positives (TP) and 136 true negatives (TN) against 28 false positives (FP) and 18 false negatives (FN), indicates a strong performance by the model in correctly classifying instances. To reinforce the confusion matrix metrics, the receiver operating characteristic (ROC) corroborates the small chance of false positives and false negatives in this model with a metric of 0.93. Furthermore, the Out-of-Bag (OOB) method measures prediction errors of the RF against one-third of the samples, on average, are left out of the bootstrap sample and not used. An OOB score of 0.87 further indicates a high predictive accuracy on unseen data during training, which has led to a robust model (Figure 2). Receiver operating characteristic (ROC) curve and Out-of-Bag (OOB) score. Feature importance and scores.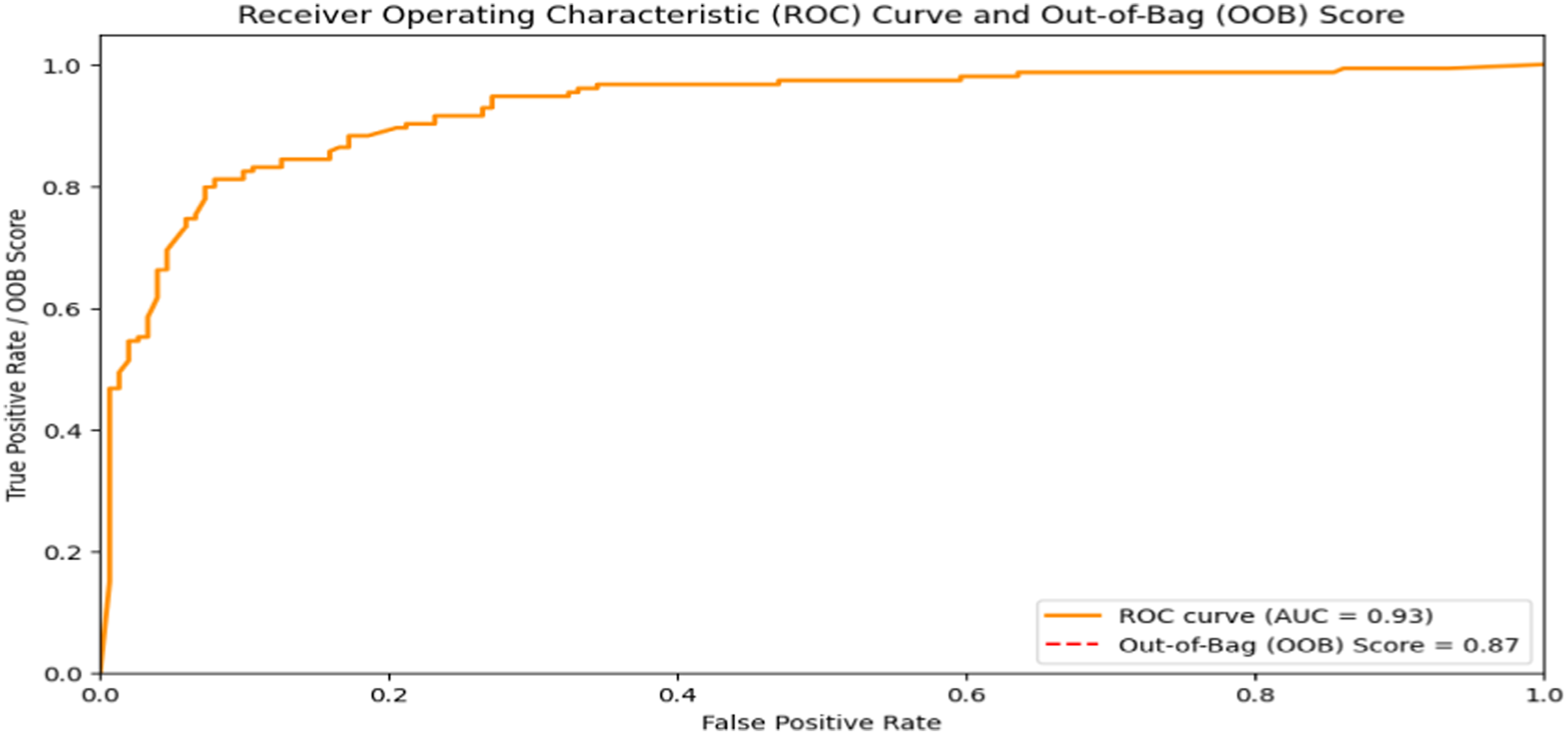
Results, analysis, and findings
Feature importance
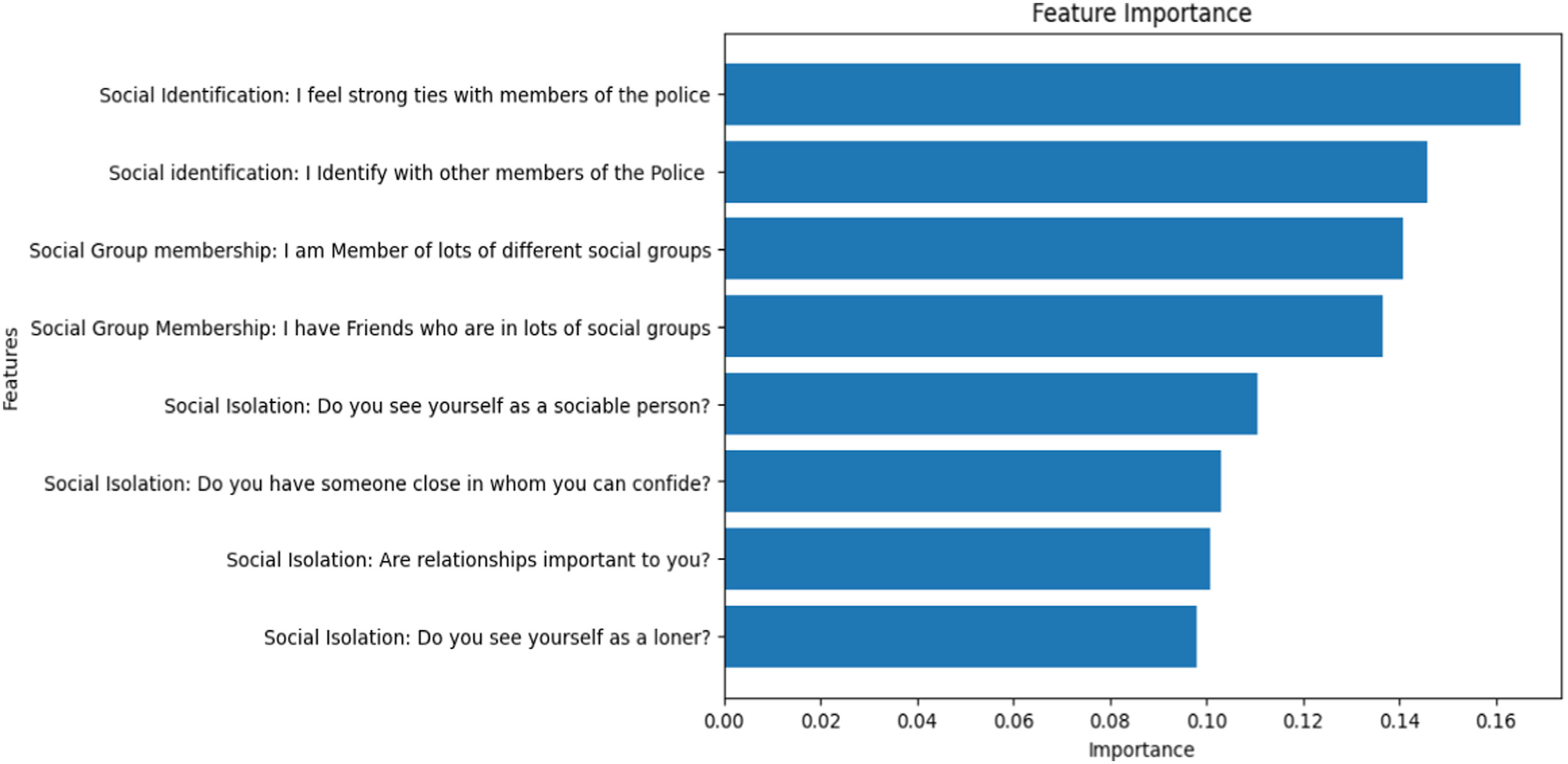
A key aspect of ML is the feature importance (nodes) results (See Figure 3), which are essential to understand how the variables or attributes influence the model outcomes. Driven by social identity, the model’s variables are reflected in their respective importance scores. These scores provide a valuable insight into how the model was shaped by the individual’s sense of social identity and availability of social resources. A prominent theme highlighted by the model was social identification, drawn from a strong performance from ‘I feel strong ties with members of the police’ and ‘I identify with other members of the Police’, which return the highest importance scores. This is Doosje et al.’s instrument (1995) and relates to whether the individual identifies strongly with the social identity. Therefore, a feeling of already being a part of the police is a significant factor when the model predicts a successful or unsuccessful recruitment outcome.
The theme of social group membership also scores high in the feature importance chart, with ‘I am a member of lots of different social groups’ and I have friends who are in lots of social groups’. This theme indicates that either the responder has access to multiple group memberships and networks, which are importance social factors when drawing on the social resources of likeminded peers. Finally, when exploring the instrument of social isolation with items such as ‘Do you see yourself as a loner?’ and ‘Are relationships important to you?’, it is clear that this instrument scores lower than the previous two of social identification and social resource. The role of isolation (0.13) with scores slightly behind social group membership (0.10) remains a somewhat important factor in the prediction performance of the model. In summary, the feature importance scores provide a quantitative measure of each feature’s contribution, which can guide feature selection, model interpretation, and interventions aimed at improving the predicted outcome. These metrics, extracted from the model highlight the importance of social identification and group memberships in the social recruitment process of the police.
Interrelationship of the features
In addition to feature importance, edges represent connection, or relationships between the features, which are drawn together by the strength and weight of the connection. The features and their connections extracted from the dataset provide valuable insights into the complex interplay between aspects of social identity and their contributions to the predicted outcome. Social identification (Doosje et al., 1995) remains strong, and there is a positive association between feeling strong ties with the police and identifying with other police members. The relatively low edge weight suggests that while these two aspects of social identification are related in the candidates, this relationship is not particularly strong.
Interestingly, the model starts to interconnect the themes of social identification and group membership with the positive association between feeling strong ties with the police and being a member of different social groups or having friends in various social groups. This relationship implies that individuals who identify with the police may also have a more extensive social network. Moreover, the interactions between social identification and social isolation may also indicate a small level of association. Similarly, the interactions between social group membership and social isolation suggest the importance of multiple social groups, sociability, and the availability of peer-to-peer support within wider social networks.
First decision tree analysis from the random forest
The first decision tree was important as an initial benchmark and an indicator of predictive features. This then informs upon the algorithmic behaviour of the model and the diversity of decision trees. In predictive modelling, a decision tree will take an input, make a series of decisions based on the criteria at each node, and arrive at a prediction (in this case, a classification into ‘successful’ or ‘unsuccessful’). The decision tree in Figure 4 has selected the most prominent feature importance to predict success based on one’s social ties, particularly with the police and other social groups. Feature interconnectivity based on importance. The model’s first decision tree. Mean value predictions per class type.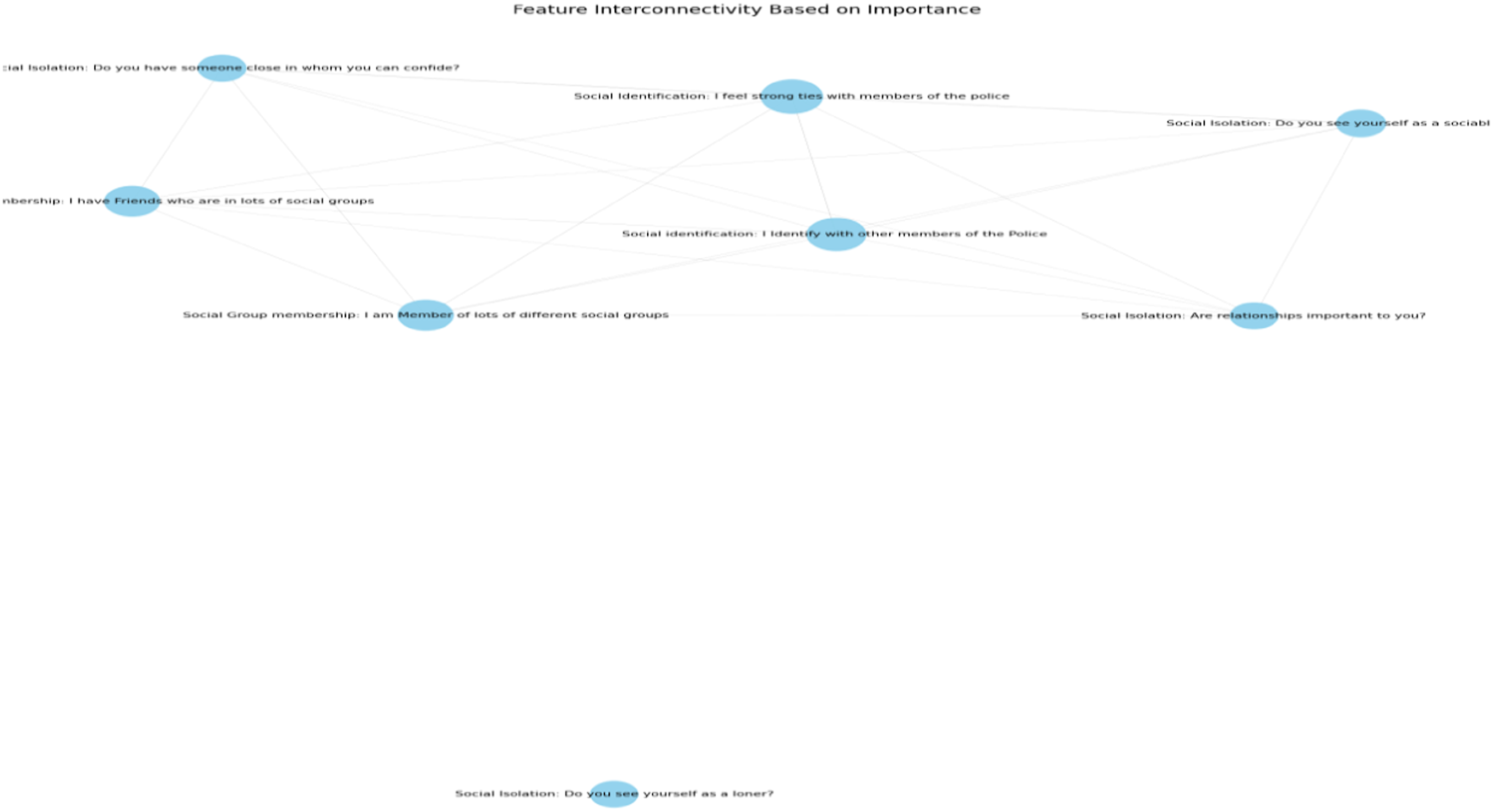
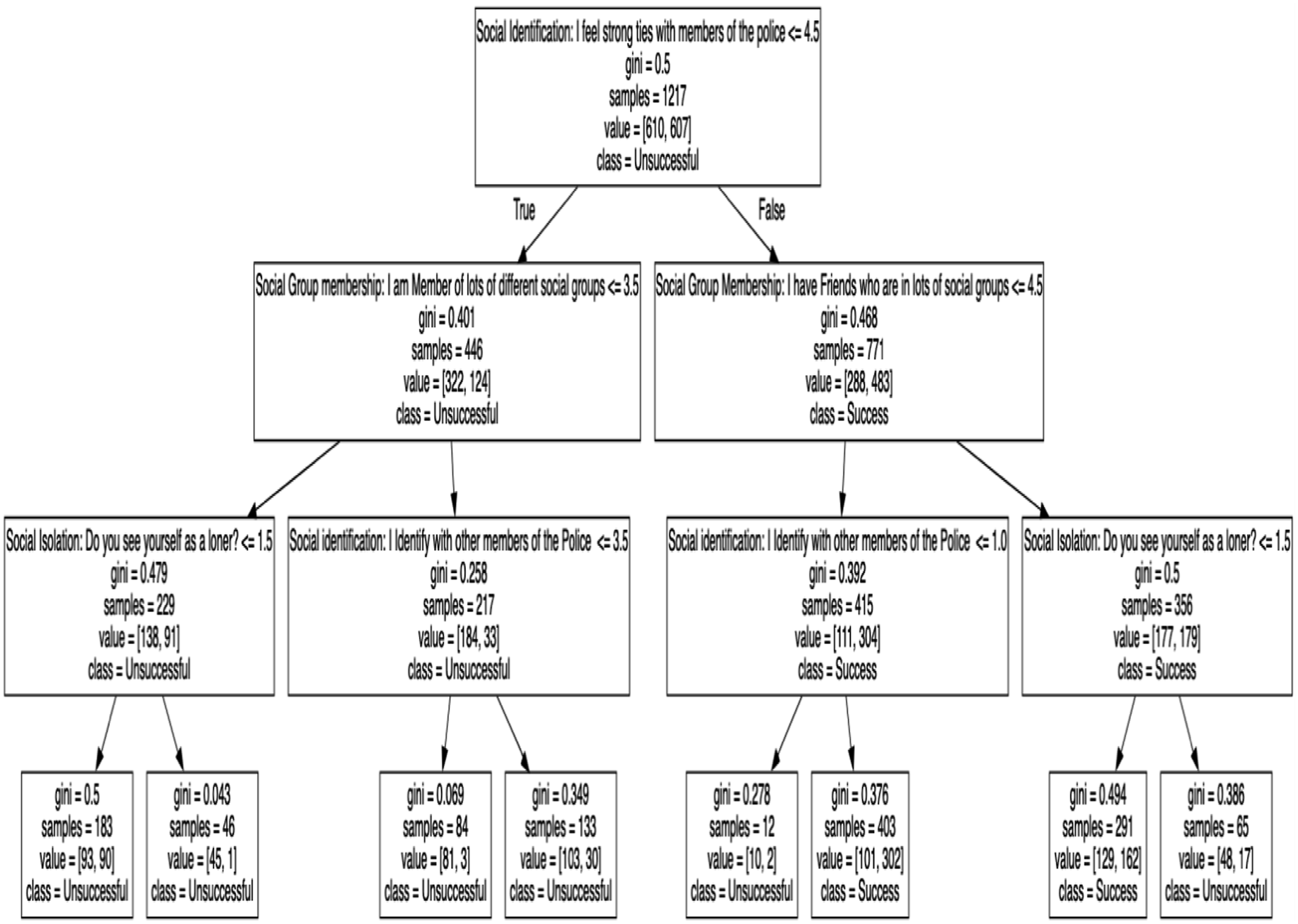
The root of the decision tree in Figure 5 starts with a question about social identification, specifically the strength of ties with members of the police force. If individuals score less than 4.5 on this scale, they fall into one branch; if they score 4.5 or above, they fall into another. This suggests that the feeling of strong ties with police members is a significant predictor for the outcome, labelled as ‘Successful’ or ‘Unsuccessful’. On the left branch of the tree, those with stronger ties to the police (less than 4.5), the tree then considers ‘Social Group Membership’, asking if the person is a member of many social groups (less than 3.5). If not, the tree further divides based on ‘Social Isolation’, particularly whether one sees themselves as a loner. This branch seems to indicate that within the context of strong police ties, broader social group membership and lower social isolation are predictive of success. On the right branch, weaker ties with Police are evident, as individuals do not feel strong ties with the police (score of 4.5 or more). ‘Social Group Membership’ is again considered, but with a different question with regard to friends in lots of social groups. If the score is less than 4.5, identification with other police members is assessed. A lower score here predicts success, while a higher score seems to predict the opposite.
The final nodes (leaves) of the tree give the ultimate classification based on the path taken through the tree. They include Gini impurity scores (a measure of how often a randomly chosen element would be incorrectly labelled if it was randomly labelled according to the distribution of labels in the subset), sample sizes, and values (which likely represent the count of samples that fall into each category). A lower Gini score indicates a purer division (better prediction). The varying Gini scores (measures inequality on a scale from 0 to 1, where higher values indicate higher inequality) at each node demonstrate how well each question separates the samples into successful and unsuccessful outcomes. For instance, nodes with a Gini close to 0 are very good at predicting the outcome, while nodes with a Gini closer to 0.5 are less predictive. Each node shows the number of samples that were considered at that point and the distribution of those samples across the possible classifications. For example, the root node has 1217 samples split into 610 ‘Unsuccessful’ and 607 ‘Successful’ classifications. As a result, the success of an individual police recruit seems to be influenced by a combination of their social identification with the Police, their broader social group membership, along with feelings of social isolation.
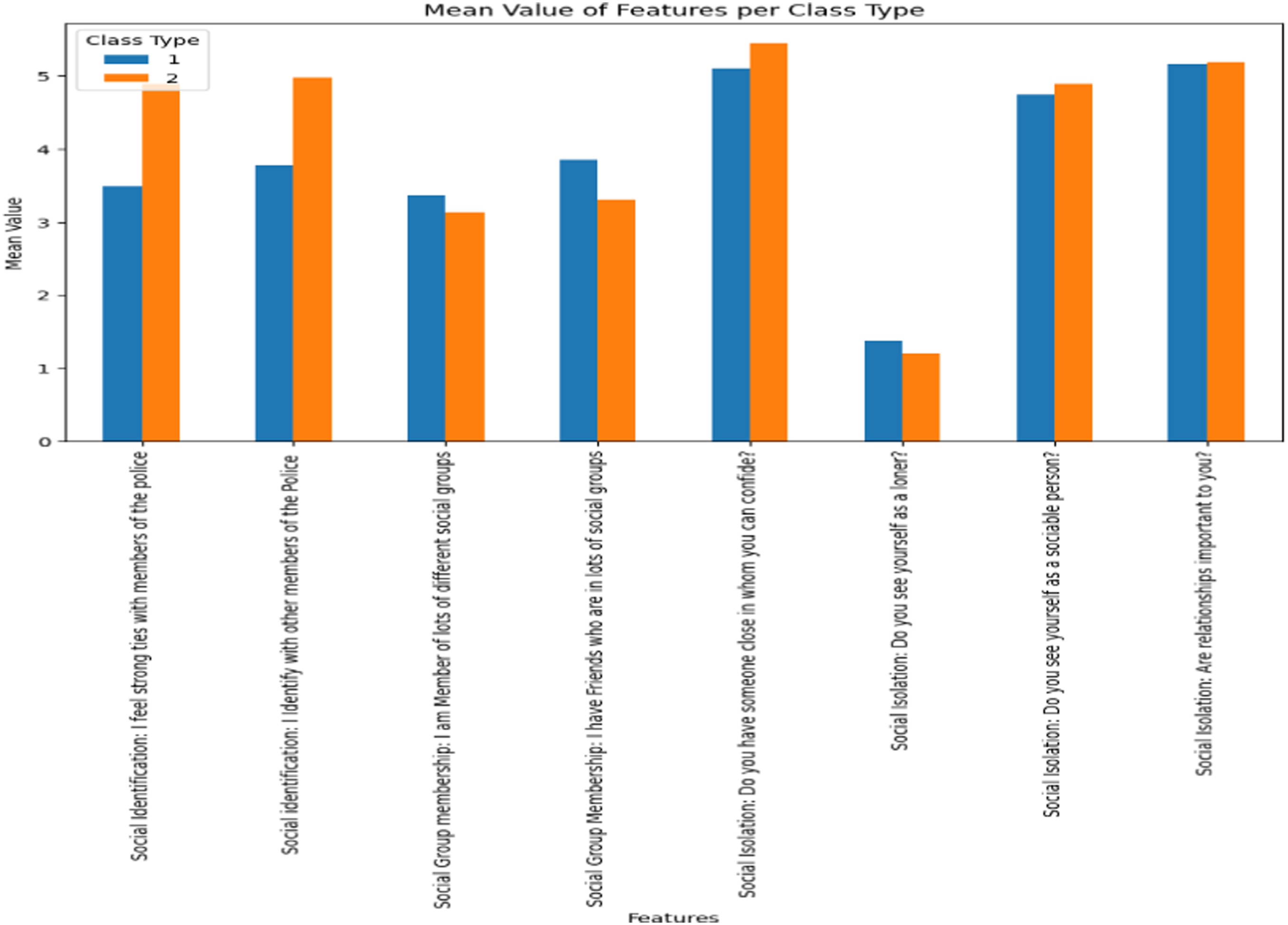
Comparative analysis of mean value class type predictions
A comparative analysis of social factors (see Figure 6) between predictive classification of unsuccessful (1) and successful (2) draws out the intricacies of social identification with the police force, the scope of social network involvement and social isolation. This comparison highlights the psychological and communal foundations that may underpin the personal attributes of the successful police recruit. Inversely, unsuccessful recruits exhibit a subdued existing identification with the police, which may suggest a potential detachment from the institution. In contrast, the ‘Successful’ cohort demonstrates a marked connection to law enforcement, a tie that could be foundational to obtaining a wider net of social support and security, both of which may be critical for successful outcomes. It is of note that this social identification was measured at the point of initial application to the police, prior to any formal acceptance from the organisation.
The social dynamics within social groups and the feelings of isolation are able to be explored in the reported successful and unsuccessful nature of the participant's social group connections; they suggest that the quantity of social ties does not directly lead to success. Therefore, the quality and depth of these connections are more evident with successful recruitment. Successful people derive significant benefits from deeper, perceived supportive relationships within their social networks. In contrast, the perception of social isolation differs greatly between the groups. Unsuccessful individuals often do not view themselves as isolated, which could indicate an overestimation of their social engagement, or a disconnect between their perceived and actual social support. Evidently, successful individuals see themselves as more independent, which reflects a sense of self-reliance backed by a few strong, meaningful social ties. This highlights that success might be more influenced by the value and support of a few substantial relationships, rather than by several superficial connections.
Discussion
Level of overall predictive value for the used social identity instruments.

Interestingly, this illustrates that the instruments did not function solely within their respective categories and instead spanned different predictive values when interrelated with other instruments. The higher levels of reliability when it comes to prediction are related to the perceived level of importance a candidate gives to relationships in their life, having a trusted social resource, and a self-awareness of their sociability. The moderate indicators rely mainly in social identification with the police profession and the candidate’s social relationship with existing groups. The lower level of predictive value is related to the self-perception of being a loner, which was low on prediction for both successful and unsuccessful candidates. The overall predictive model performs at an accuracy of 86% success utilising the above factors. This is very high level of accuracy for such a model and strongly indicates that when social identity instruments are combined in this way, they are highly predictive of police recruitment outcomes within the researched context.
These results highlight that self-reported social identity can be used for predicting a policing candidate’s success when attempting to traverse the difficulties of police recruitment. They also suggest that perceived access to social resource (Geuzinge et al., 2020) and self-perceived sociability are the most important predictive factors for candidates. Why these factors are more predictive is unclear. It could be speculated that police officer’s perceptions of their ability to interact with others are important for their perceived self-legitimacy and confidence when decision making. A police officer is repeatedly thrust into unpredictable social situations, and a self-perception of being able to deal with these social issues may have strong links with in-person performance in stages such as the SEARCH National Assessment Centre (College of Policing, 2021).
Qualitative research of the police recruitment process itself (Hesketh & Stubbs, Under Review; Stubbs & Tong, Under Review) indicates that the police recruitment process is lengthy and stressful for some candidates without available social resources, which may lay the foundations for the high predictability of this factor.
These findings also expose some areas of concern. Social identity measurement instruments result in a high predictive accuracy for a reason. Existing identification with the police may suggest that the candidates already represent the existing police demographics and world view. This could be supported by the theory of homophily (Mcpherson et al., 2001), which states that, ‘birds of a feather, flock together.’ If a candidate who is hoping to become a police officer already sees themselves as embodying the identity of a police officer, in part due to their social circumstances before they join the service, then this may place barriers on their competitors without such resources during the recruitment process. There may be many potential officers who come from backgrounds where feeling as if they are already part of the profession could carry stigma, socially and professionally (Holdaway, 1991). It may also be the case that having lower social support and being without someone who they can confide in also limits the recruitment of some very able police officers who would build their social support once they become a part of the profession itself. Longitudinal study in this area would greatly assist in understanding this area, and the measurement of social identity as a baseline along with psychological personality should be considered to widen the practical application of what could be considered as important aspects of importation in police recruitment.
These results add to the existing psychological research with regard to police recruitment and put forwards another potential avenue through which to explore potential causal variables in police officer candidate’s recruitment success.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.