
Abstract
This study examined how infants exploit an interlocutor’s eye gaze for word learning, using a novel eye-tracking paradigm. The final sample included 25 Hebrew-speaking infants aged 12 and 18 months. Infants completed three experimental phases: (a) a 2-part validation phase: (1) recognition of a familiar object (ball) among two items (ball, bottle) upon hearing its label (e.g., “Where is the ball?”), and (2) exposure to an interlocutor gazing at and talking to an unfamiliar object (rattle) without labeling it (e.g., “Look, it is here”); (b) a learning phase, in which two unfamiliar animal dolls of similar visual salience were presented, and the interlocutor labeled one doll (e.g., “Look, here is bícket”); and (c) a test phase, in which the four objects (ball, rattle, and the two animal dolls) were shown together, and infants were tested to see if they look at the target object upon hearing the learned label (e.g., “Where is bícket?”) but not upon hearing a novel label. Eighteen-month-olds followed the interlocutor’s gaze more often and attended longer to the labeled object during learning compared with 12-month-olds. In the test phase, both age groups showed word recognition, looking longer at the target object after hearing its label than at familiar or unlabeled distractors, although differences with the visually similar distractor were nonsignificant. When hearing the non-learned word, infants looked longer at the similar distractor. Infants demonstrated word–object learning based on the interlocutor’s gaze, with gaze -following abilities strengthening with age.
1 Introduction
1.1 Word-object mapping in the second year of life
At approximately 12 months of age, typically developing infants usually produce their first words and can comprehend up to about 20 words (e.g., in English: Fenson et al., 1994; Hamilton et al., 2000 in Hebrew: Gendler-Shalev & Dromi, 2022). At 19 months, English-speaking children at the 50th percentile produce about 50 words and comprehend around 200 words, a pattern highly comparable with Hebrew-speaking children at the same percentile (Gendler-Shalev & Dromi, 2022; Hamilton et al., 2000). This rapid change in vocabulary acquisition in the second year of life has been attributed to changes in the underlying processes that promote word learning (e.g., Golinkoff & Hirsh-Pasek, 2000; Hollich et al., 2000; Nazzi & Bertoncini, 2003).
The two underlying processes that have been suggested as guiding word learning in the second year of life are associative learning and social-pragmatic learning. The associative learning mechanism enables the infant to link a heard word with an object or an event presented in the infant’s immediate environment (Plunkett, 1997; Werker et al., 1998). Infants usually associate a heard word with an object that is visually salient or interesting from their point of view (Hollich et al., 2000; Pruden et al., 2006). However, because the infant’s environment usually includes more than one interesting object, identifying the labeled object might be difficult if the infant relies only on the visual perceptual salience of the object to choose the target object, that is, color, size, movement or motion (e.g., Hollich et al., 2000). Thus, according to the social-pragmatic learning account, the infant’s ability to leverage the interlocutor’s social-pragmatic cues, such as the interlocutor’s eye gaze or pointing, instead of relying solely on visual perceptual salience, can assist the infants in mapping novel words to objects and facilitates the acquisition of a broader lexicon (e.g., Hirotani et al., 2009; Houston-Price et al., 2006; Okumura et al., 2013; Paulus & Fikkert, 2014; Yurovsky & Frank, 2017). In sum, infants are involved in transactional relationships with their caretakers and gradually learn to exploit social cues for learning new words (Briganti & Cohen, 2011; Bruner, 1985; Hoff, 2006; Lee & Lew-Williams, 2023; Tomasello, 1992).
1.2 The use of the interlocutor’s eye gaze for word learning
One social cue that infants learn to use for word learning is the use of interlocutor’s eye gaze. Infants’ ability to utilize the interlocutor’s eye gaze for word learning is deep-rooted at the beginning of life. Newborns look longer at faces with open eyes than faces with closed eyes (Batki et al., 2000), and favor faces gazing directly at them, which makes eye contact possible (Farroni et al., 2002). Infants develop the ability to follow the interlocutor’s eye gaze between 3 and12 months of age (D’Entremont et al., 1997; Gredebäck et al., 2010). The accuracy and speed of the gaze-following skill improves with age during the first year of life, with 12-month-old infants demonstrating the most accurate and fastest responses relative to younger infants (Gredebäck et al., 2010).
Mutual gaze and gaze-following facilitate the appearance of joint-attention behaviors in dyadic and triadic interactions that include shared attention to an object or an event while the infant and the caregiver are attentive toward each other (see Çetinçelik et al., 2021 for a review). Numerous studies have suggested that there are positive links between periods of joint attention measured by gaze-following between infants and parents and infants’ later vocabulary development. For example, it has been suggested that both parents’ looks at their infants’ faces during object-oriented coordinated attention and infants’ sustained visual attention to an object within joint-attention interactions predict later language learning (e.g., Abney et al., 2020; Yu et al., 2019). However, the ability to use gaze cues to establish word-object associations appears only between 10 and 12 months of age (Baldwin, 1993; Hollich et al., 2000; Pruden et al., 2006).
Early word learning by means of eye-gaze cues suggests that infants’ learning is influenced by the context of the learning scene, including the interlocutor and the target objects. Research has shown that 18-month-olds differentiated between human and non-human (robotic) gaze and learned the names of novel objects only when the labels were provided by a human being (O’Connell et al., 2009). Twelve- and 18-month-olds also tended to follow the gaze of a familiar person more than that of a stranger when both were present (Barry-Anwar et al., 2017). However, in the absence of alternative cues, infants did follow a stranger’s gaze (e.g., Hirotani et al., 2009). Other studies pitted eye-gaze cues against cues of visual perceptual salience. In a seminal series of studies, Hollich et al. (2000) demonstrated age-related differences in how infants weigh visual perceptual salience versus social cues during word learning. While 19- and 24-month-olds prioritized the interlocutor’s eye gaze over an object’s visual perceptual salience when mapping words, 12-month-olds demonstrated a stronger reliance on visual salience during testing. Similarly, younger infants, such as 10-month-olds, were found to disregard gaze cues entirely when they conflicted with visual perceptual salience (Moore et al., 1999; Pruden et al., 2006). These studies lay the foundation for the emergenist coalition model, which proposes developmental changes in the weight that infants attribute to different cues for word learning throughout infancy, suggesting that the weight of social cues increases in the second half of the second year of life (Golinkoff & Hirsh-Pasek, 2000; Hollich et al., 2000).
Although evidence suggests that infants rely more on eye-gaze cues for word learning during the second half of their second year compared with the first half (e.g., Hollich et al., 2000), to the best of our knowledge, there is limited data regarding visual attention, that is, how infants visually scan the interlocutor, the target object, and other items within the scene. Most studies have not reported changes in infants’ behaviors related to looking toward the interlocutor’s face, the target object, and competing objects between 12 and 18 months of age. One study that assessed looking toward the interlocutors’ face, the target object, and the competing object found that children aged 12 to 48 months demonstrated increased looking toward the interlocutor’s face, but the study did not differentiate between 12- and 18-month-old infants (Yurovsky & Frank, 2017). Given that around 12 months of age, word learning is slow, with infants producing an average of two new words per week (Carey, 1978), whereas by approximately 18–19 months, their vocabulary expands significantly (e.g., Bloom, 1976; Clark, 1973; Gendler-Shalev & Dromi, 2022), and they begin to rely more on social eye-gaze cues (e.g., Hollich et al., 2000), it is plausible to expect changes in infants’ ability to exploit social cues, including looking toward the interlocutor’s face and/or the target object, in word learning procedures between 12 and 18 months. However, in view of limited previous research on word learning at these two ages when two salient objects are presented (Yurovsky & Frank, 2017), it is challenging to predict how infants’ word learning performance and gaze behavior may differ between 12 and 18 months of age.
1.3 Methodological constraints
Two main methods have been developed to assess language comprehension in infants. The intermodal preferential looking (IPL) paradigm is used to evaluate infants’ understanding by observing their gaze toward videos that match an accompanying audio (e.g., Piotroski & Naigles, 2011). The looking-while-listening procedure builds on this approach by providing a detailed analysis of children’s interpretation of spoken language by tracking their eye movements as they listen to sentences (e.g., Swingley, 2011). Both methods generally consist of an initial familiarization, training or exposure phase, followed by a test phase in which infants are presented with two side-by-side options. These procedures have produced highly influential results regarding young children’s developing language. However, when we examined previous studies focused on word learning, some remaining questions have been identified, particularly when word learning is based on eye-gaze cues.
In most previous studies that assessed word learning based on eye-gaze cues, during the learning phase, the interlocutor looked at and verbally addressed one object while both objects were presented on the screen, side by side (e.g., “Look, here is bicket”). This might create a confounding variable because it is not clear whether the infant learned to associate the specific word (e.g., bicket) with the object or whether the fact that the interlocutor was looking at and verbally addressing the object made it more noticeable for the infant and consequently facilitated its recognition during the test phase (e.g., Hollich et al., 2000). Also, some previous studies assessing word learning based on the interlocutor’s eye-gaze did not consistently vary the placement of the target object between learning and test phases. This inconsistency allowed infants to rely on the object’s location rather than forming a true word-object association (Hollich et al., 2000; Pruden et al., 2006 Exp. 1). While there is some evidence that 10-month-olds map words to objects rather than their spatial locations (Pruden et al., 2006, Exp. 2), it remains crucial to systematically change the target object’s location between the learning and test phases to ensure valid assessments. In addition, in most previous studies, one visually salient object and one less salient object were presented during the learning phase, and the speaker looked at and labeled the less salient object (e.g., Hollich et al., 2000; Pruden et al., 2006). Only during the second half of the second year of life did infants learn the name of the object that the speaker was looking at, whether or not it was visually salient. Since a visually salient and a less salient object were presented side by side, it is not clear whether the ability of the infants to learn words via the interlocutor’s eye-gaze cues increases with age, or alternatively, infants’ inclination to associate labels with the visually salient object decreases with age (Yurovsky & Frank, 2017). One way to answer this question is by presenting equally salient objects. Thus, to assess whether infants’ ability to learn novel words by following the interlocutor’s eye gaze increases between 12 and 18 months, a period of time in which learning procedures shift from relying mainly on visual perceptual salience to relying mainly on the interlocutor’s eye-gaze, there is a need to present two objects that are similarly salient so that the object’s salience cues and the interlocutor’s social eye-gaze cues do not compete with one another.
1.4 The present study
To address the methodological challenges mentioned above, we have carefully developed a new paradigm for word learning that utilizes an eye tracker. This approach builds on previous methodologies by introducing three distractors during the test phase: a familiar object, a similarly salient object, and a no-name distractor, which is an object that the interlocutor refers to without assigning it a name. This setup more accurately simulates everyday situations where infants must recognize a target word while the target object is surrounded by many others in various real-life contexts. The no-name distractor (presented both in the validation phase that preceded the learning phase and in the test phase) is intended to test whether infants learn the label given to the object, or conversely, simply tend to look in the test phase at whichever object was looked at and spoken to by the interlocutor.
Furthermore, to enhance the robustness of the procedure, we consistently vary the placement of the target object between the learning and test phases. In addition, we aimed to explore the potential relationship between visual attention and word learning. Previous research by Yu et al. (2019) indicated that infants’ sustained visual attention to an object at 9 months was related to their language development at 12 and 15 months. However, it is still unclear whether sustained visual attention to a target object is directly linked to immediate word learning in infants. This raises the question: How might sustained visual attention influence the immediate learning of new words during infancy?
The aim of this study was to assess the ability of 12- and 18-month-old infants to use an interlocutor’s eye gaze for word learning with multiple distractors. Implementing a procedure with multiple distractors with different characteristics more closely resembles everyday situations where infants need to recognize target words amid numerous objects. This approach allows for a more comprehensive understanding of how infants navigate and process competing stimuli in their environment. We also tested whether upon hearing a different novel word, the infants would not look at the object named in the task. We hypothesized that if children formed a specific word-object association during the learning phase, they would not associate the novel word with the previously learned target object.
The main research questions were the following:
(1) How do 12- and 18-month-old infants allocate their looking time toward the interlocutor’s face, the target object, and the competing distractor during a social word-learning task, and how does this allocation change with age? This was assessed by measuring looking time to the face, target object, and distractor during the learning phase. We hypothesized that 18-month-old infants would allocate more looking time to the target object and less to the distractor compared with 12-month-olds, indicating a shift in attention allocation during word learning with age.
(2) Do 12- and 18-month-old infants recognize a newly learned word during the test task when presented with the target word alongside three distractors? Recognition was assessed by measuring looking time at the target object compared with the distractors. We hypothesized that both age groups would demonstrate recognition of the newly learned word, with 18-month-olds showing longer looking times at the target relative to distractors compared with 12-month-olds.
(3) Will infants look at the similar distractor when a novel word is introduced during testing? If they have previously formed an association between the target word and the target object, we would not expect them to look toward the previously named target object upon hearing a different, novel word. We hypothesized that infants would show evidence of word-object mapping by increasing their looking time toward the similar distractor in response to the novel word.
(4) Is looking behavior during the learning phase associated with later recognition of the target object? This was evaluated by examining the correlation between looking time at the target during the learning phase and looking time at the target during the test phase.
2 Method
2.1 Participants
The infants were recruited from central Israel. Parents and their infants were invited to participate in a short language-learning study through social media and other outreach channels (e.g., fliers distributed in community centers and local advertisement).
A total of 38 infants started the study, of which 13 were excluded for the following reasons. Three infants were excluded during the validation phase because they did not look at the screen—two from the younger age group and one from the older group. Thirty-five infants took part in the learning phase. Of these, seven were excluded because they never followed the interlocutor’s eye gaze—four from the younger group and three from the older group. The remaining 28 infants were included in the analysis of the learning phase: 15 infants (10 girls, 5 boys) aged 11.9 to 12.23 months (M = 12.11, SD = 0.62), and 13 infants (5 girls, 8 boys) aged 17.1 to 18.6 months (M = 17.41, SD = 0.62). In the test phase, three additional infants from the younger group were excluded because they looked at the screen less than 30% of the time during the first trial. Thus, the final test-phase sample included 25 infants—12 aged 12 months (M = 12.10, SD = 0.60) and 13 aged 18 months (M = 18.2, SD = 0.62). All infants were full-term at birth with an APGAR (Activity, Pulse, Grimace, Appearance, Respiration) score of 9 or 10, and normal development and hearing as reported by well-baby clinics. They had no hearing or developmental problems based on parental reports and the newborn hearing screening at birth. They had not had an ear infection or upper respiratory infection in the last month prior to testing and on the day of testing. Hebrew was the only language spoken at home.
2.2 Stimuli and design
In this study, a cross-sectional design was employed to assess the ability of 12- and 18-month-old infants to use an interlocutor’s eye gaze for word learning. The experiment consisted of three phases, namely, the validation phase, the learning phase, and the testing phase (see Figure 1 and Appendix A). The stimuli for the validation (two parts), the learning phase, and the testing phase were video and audio that were recorded using a Panasonic HC-VX980M camera with a microphone attached to the interlocutor’s shirt in a dedicated lab for experimental video recordings at Tel-Aviv University. The four short video clips were edited using Final Cut Pro X software and combined into one sequence that was presented to the infant. The speaker in the clips was a woman who was a native speaker of Hebrew. She used the type of language typically used in child-directed-speech as if addressing an infant.
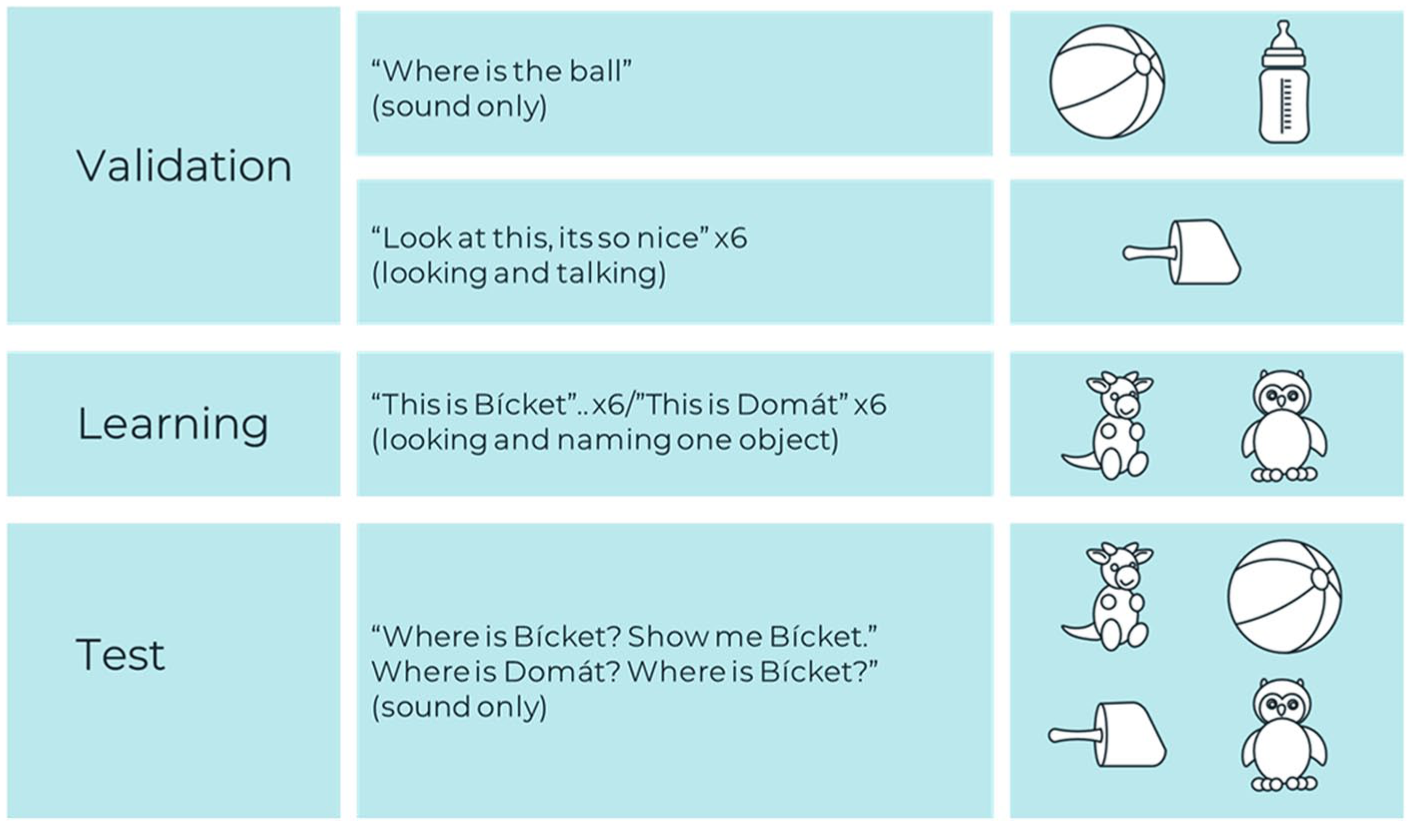
Experimental design.
The validation phase consisted of two parts. The purpose of the first part was to confirm that the infants’ gaze could be used to infer word recognition. Accordingly, in the first video, two familiar objects were presented on a table (a ball and a bottle) side by side and the infant was asked (voice only) in two trials to identify the ball (Where is the ball? Show me the ball; in Hebrew: eifo hacadur, tare li cadur). The purpose of the second part of the validation phase was to acquaint the infant with an object that the interlocutor was addressing (looking and speaking toward it) but did not provide a name for (a no-name object). Thus, in the second video, a new object (a rattle) was presented on a table. The interlocutor stood behind the table, looked straight at the camera, and in a cheerful voice said “Hello” (Shalom), then looked and spoke toward the object without labeling it six times in successive utterances; here it is (hine ze), hello (shalom), where is it? (eifo ze?), who’s playing with it? (mi mesachek ito?), I love it (ani ohevet oto), and bye-bye. Infants were excluded if they did not look at the screen.
The learning phase was designed to teach the infant a new word by having him or her follow the interlocutor’s eye gaze. The stimuli included two stuffed animals as shown in Figure 1. In the learning phase (the third video), two novel objects (the stuffed animals) were presented side by side on a table. The speaker stood behind the table between the two objects, turned her head (by 30 degrees), gazed toward one object, and labeled it by using one of two nonwords (bícket or domát). She then turned her head and gazed toward the middle. She repeated this process six times in successive utterances (see Appendix B). The choice of the names bícket and domát was made based on a previous study (Gliga et al., 2012). The word bícket has trochaic lexical stress, and the word domát has iambic lexical stress. We chose to present the nonwords as proper nouns and not as common nouns in the utterances (where is bícket? and not where is the bícket?) because proper nouns are considered easier to learn (Gelman & Taylor, 1984; Houston et al., 2005). The target word was located at the end of the utterance because the final position was found to be relatively easier for infants to segment the word (Depaolis et al., 2014; Seidl & Johnson, 2006).
Finally, the test phase was designed to assess whether the infant had learned to associate the heard word with the target object. Accordingly, in the fourth video, the target object and three distractors appeared on the screen in a 2X2 pattern (the presentation of four pictures arranged with two on top and two at the bottom of the screen), and the infant was asked (voice only) to identify the target object. The first two trials tested the learned word (e.g., where is bícket, show me bícket), one trial assessed the non-learned word (e.g., show me domát), and the last trial again assessed recognition of the learned word.
We used a non-learned word in the third trial as an indirect test of object-label word mapping. Looking at the correct target could be due to preference rather than mapping, but an absence of looks toward the previously labeled object when hearing a novel label can be taken as evidence that successful learning of the specific object-label pairing has occurred during the learning phase. In between trials, and between the different parts of the procedure, a laughing baby appeared in the middle of the screen, serving as a drift correction.
2.2.1 Selecting visual stimuli
The stimuli for the learning phase included two stuffed animals that were chosen from a set of six stuffed animals by three adults who judged them as having similar salience. The two stuffed animals included one with horns (A) and one that resembled an owl (B) as shown in Figure 1. To validate the selection of the stuffed animals, 17 adults (10 women and 7 men; mean age = 25.5 years) rated the visual salience of two stuffed animals on a 5-point Likert-type scale (1 = not visually salient, 5 = very visually salient). The mean ratings were 2.4 (SD = 0.7) for object A and 2.7 (SD = 0.5) for object B. A paired t test revealed no statistically significant difference in the visual salience ratings of the two objects, t(16) = 1.44, p = .17, suggesting that the two objects were perceived as similarly salient. In addition, 10 infants (five girls and five boys), whose mean age was 14.77 months (SD = 2.99), were presented twice with the two objects on a screen for 2 s each time. Their looking behavior was measured with the SMI RED 250 system. A paired t test confirmed no significant difference in the percentage of total looking (dwell) time directed to each Area of Interest (AOI): object A (M = 38.95%, SD = 6.47) and object B (M = 40.82%, SD = 8.89), t(9) = 0.54, p = .57. The remaining percentage of looking time reflected gaze directed outside the AOIs (e.g., background or off-screen). Accordingly, we concluded that both objects were equally salient for the infants and could serve as stimuli for the word-learning task. Also, ten 12-month-olds whose mean age was 12.8 months (SD = 1.5), were presented with the four objects (A, B, the ball and the no-name object, the rattle from the validation phase) for 4 seconds without accompanying audio. The mean percentages of total looking time across the four AOIs were balanced: A (M = 24.68%, SD = 5.64), B (M = 26.44, SD = 8.15), rattle (M = 23.13%, SD = 7.40), and ball (M = 24.95%, SD = 6.31). Here, the four AOIs accounted for nearly all looks, so percentages sum to ~100%. A Kruskal–Wallis test revealed no statistically significant differences in looking times among the items, H = 1.11, p = .78, suggesting that the distribution of attention was comparable across all objects. This indicates that no single item disproportionately captured the participants’ attention.
In addition, 10 parents of 18-month-old infants were asked whether the two stuffed animals were familiar or could be taken by their infants to resemble familiar animals, using a Likert-type scale from 1 to 5, with 1 representing not familiar and 5 representing very familiar. The mean scores for familiarity, as judged by the parents, were 1.3 (SD = 0.5) for stuffed animal A and 1.4 (SD = 0.4) for stuffed animal B, t(9) = 0.49, p = .42. The same parents were also asked whether the objects were likely to trigger preexisting labels in infants using a Likert-type scale from 1 to 5, with 1 representing not likely to trigger a known word and 5 representing very likely to trigger a known word. The mean scores for the likelihood of triggering preexisting labels were 1.3 (SD = 0.5) and 1.5 (SD = 0.3) for stuffed animals A and B, respectively, t(9) = 1.08, p = .19. These pretests confirmed that the two objects had similar salience, low and similar familiarity, as well as low and similar ability to trigger preexisting labels.
2.2.2 Video details across phases
The duration of the video in the first part of the validation phase was 9.30 s. The speech started at 2.90 s, and the target label (e.g., ball) was heard at 3.40 and 7.60 s. The dimensions of the screen were 26° in height by 44° in width, at a viewing distance of 65 cm. The measurements of the objects presented on the screen during the first part of the validation phase were 9 cm height and 6 cm width, which correspond to approximately 7.80° in height and 4.98° in width (calculated based on the screen size and viewing distance). The duration of the video in the second part of the validation phase was 28.96 s. The speech started at 0.4 s (e.g., “Hello” Shalom), with successive utterances at 4.65, 8.59, 13.35, 17.56, 21.96, 26.52 s. The measurement of the object presented on the screen during the second part of the validation phase was 4.5 cm height and 9 cm width, which corresponds to approximately 3.90° height and 7.47° width (calculated based on the screen size and viewing distance). The speech started at 4.16 (e.g., here is bícket) 9.19 s 14.80 s 19.86 s 24.97 s, and 30.47 s. The measurements of the objects presented on the screen during the learning phase were 7.5 cm height and 6 cm width, which correspond to approximately 6.50° height and 4.98° width (calculated based on the screen size and viewing distance). The duration of the video in the test phase for each target word was18.00 s. The speech started at 3.50 s (e.g., where is bícke?), and the target label was heard at 3.58, 7.28, 10.75, and 14.36 s for the target word bícket and at the 3.46 s, 7.28 s, 10.85 s, and 14.20 s for the word domát. The measurements of the objects presented on the screen during the learning phase were 9 cm height and 5 cm width, which corresponds to approximately 7.80° in height and 4.15° in width (calculated based on the screen size and viewing distance) (see Appendix A).
2.3 Apparatus
The apparatus included a control room and a test room as shown in Appendix C. The test room was quiet with blackout curtains on the walls to prevent distractions and included a 22-inch computer screen with an eye-tracking system (SMI RED 250) located at the bottom of the screen. The SMI sent infrared light and monitored the movement of the cornea at a sampling rate of 250 Hz. The eye-tracking data were accurate enough to reliably pinpoint fixations on the screen. The SMI RED 250 system provided tracking accuracy within 0.5° of the visual angle and a resolution of 20 pixels. Fixations were defined as a stable gaze within a 1° visual angle lasting at least 100 ms, while saccades were identified as rapid eye movements between fixations exceeding a velocity threshold of 30°/s. In the control room, a monitor was connected to the computer in the test room. This allowed the experimenter to run the experiment and to observe the infant’s eye gaze on the monitor.
2.4 Procedure
The procedure was approved by the Ethics Committee of Tel Aviv University and the study complies with established guidelines for working with human participants (approval no. 0006799-1). At the beginning of each session, the parent signed an informed consent form and filled out some developmental and medical questionnaires. During the eye-tracking experiment, the infant was seated on the parent’s lap in front of the monitor at a distance of 65 cm from the screen. The parent’s eyes were covered with a blindfold, and they wore earplugs to avoid influencing the infant’s behavior. The eye tracker was calibrated for each child using a 4-point calibration with a picture and the voice of a laughing baby. Next, the infants were presented with the video clips described above. The speaker’s voice was played at a sound level of 65–70 dB SPL. In each age group, half of the infants were tested with the word bícket (associated with either object A or B), while the other half of the group of infants was tested with the word domát (associated with either object A or B). While the infant was watching the video, the eye-tracking system monitored the infant’s gaze at the speaker’s face and the objects displayed on the screen. During the test phase, the four objects were presented in a 2x2 grid pattern arranged with two on top and two at the bottom of the screen, and their positions on the screen varied across trials. Five different orders were used, with different infants assigned to a different order, resulting in an overall semi-random presentation.
2.5 Data extraction and analysis
We analyzed the infants’ eye movements using the Area-of-Interest (AOI) approach. AOIs were manually defined by a human coder for the following: the two familiar objects in the validation phase, the two objects and the speaker’s face in the learning phase, and the four objects in the test phase. The infants’ looking behavior in the validation, learning, and test phases was quantified by measuring dwell time, that is, the sum of durations, from all fixations and saccades that hit the AOI in time windows of 1,600 ms similarly to some previous studies (e.g., Ellis et al., 2015). These time windows started at the onset of the second syllable of the target word (in the validation and test phase), and when the speaker started to rotate her head (in the learning phase). The looking percentage was calculated as the relative amount of time infants spent looking at a particular AOI within the 1,600 ms time window. However, the looking percentages do not always sum to 100%, as infants may also look outside the defined AOIs. To compute mean looking percentage for each age group, looking percentage were initially calculated for each individual trial, averaged at the individual-child level, and then averaged across the age group. Note that during the learning phase, we performed two analyses. The first involved counting the number of instances in which the infant followed the interlocutor’s eye gaze within a 1,600 ms time window. The second analysis assessed the mean looking percentage—that is, the percentage of time spent looking—toward the target object, face, and distractor within the same interval.
Statistical analyses were conducted using SPSS software (version 29). In the validation phase, the looking percentages were normally distributed, as indicated by z-scores for skewness and kurtosis (±2.58). Consequently, a paired t test was performed to assess differences in looking percentages between the target and non-target objects. In the learning phase, each trial was coded dichotomously (0 = did not follow gaze; 1 = followed gaze) based on whether the infant shifted attention to the target object. These values were then summed across the six learning trials for each infant, yielding a total score ranging from 0 to 6. Independent-sample t test was employed to compare 12- and 18-month-old infants. In addition, in the learning phase, the looking percentages for the face, target, and distractor were normally distributed based on z-scores for skewness and kurtosis (±2.58). In the test phase, the looking percentages to the target object and all distractors were also normally distributed, as indicated by z-scores for skewness and kurtosis (±2.58). In order to assess whether the sample size (n = 25) was sufficient to evaluate word learning in the test phase, as measured by repeated-measures univariate analyses (see below in the Results section), a post hoc sensitivity analysis was conducted using G*Power software, version 3.1.9.7. The Type I error rate was set to 0.05, with the desired power, 1 – β, set at 0.80. Effect sizes were categorized as small, f = 0.10; medium, f = 0.25; and large, f = 0.40, based on Cohen’s (1988) guidelines. The sensitivity analysis revealed that the study is adequately powered, 0.80, to detect a small-to-medium effect size, f = 0.24, with a sample size of 25 participants. This analysis further supports the interpretation that our findings reflect the infants’ learning process rather than limitations due to sample size. In addition, a post hoc sensitivity analysis including the effect of Age Group yielded f = 0.49, indicating that with the current sample size only large effect sizes could be detected.
3 Results
3.1 Validation phase
To assess whether infants show recognition of familiar words by looking at the labeled familiar object, we calculated the relative dwell time on each familiar object (ball and bottle) during the 1,600 ms analysis window of each trial. For 12-month-olds, the mean percentage of looking time directed to the target object was 36.57%, SD = 0.28, relative to the 1,600 ms window, compared with 10.57%, SD = 0.10, for the non-target object. This difference was significant, t(17) = 8.28, p < .001. For 18-month-olds, the mean percentage of looking time toward the target object was 51.71%, SD = 0.23, versus 7.26%, SD = 0.08, for the non-target object, also significant, t(16) = 6.68, p < .001. Note that we did not analyze looking behavior during the validation phase toward the object that was spoken to but not named, as this was outside the scope of our research question, which focused specifically on recognition of labeled familiar words
3.2 Learning phase
To evaluate whether infants followed the interlocutor’s eye gaze toward the target object (one of the two stuffed animals shown in Appendix A), we analyzed the number of instances each infant followed the gaze across six trials. This measure recorded whether the infant followed the interlocutor’s eye gaze and head movement toward the target in each trial out of six trials, regardless of the total looking time. For example, an infant might follow the gaze in only one out of six trials (16.67%). For the 12-month-olds, the mean number of eye-gaze-following instances was 2.07 (SD = 0.80), while for the 18-month-olds, it was 3.23 (SD = 1.64). An independent-sample t test revealed a significant difference between the two age groups, t(16.83) = 2.33, p = .03. To examine the infants’ attention to the target object, the interlocutor’s face, and the competing similar object, we measured the mean looking percentages across the six trials. Figure 2 summarizes the mean looking percentages within a 1,600 ms time window.
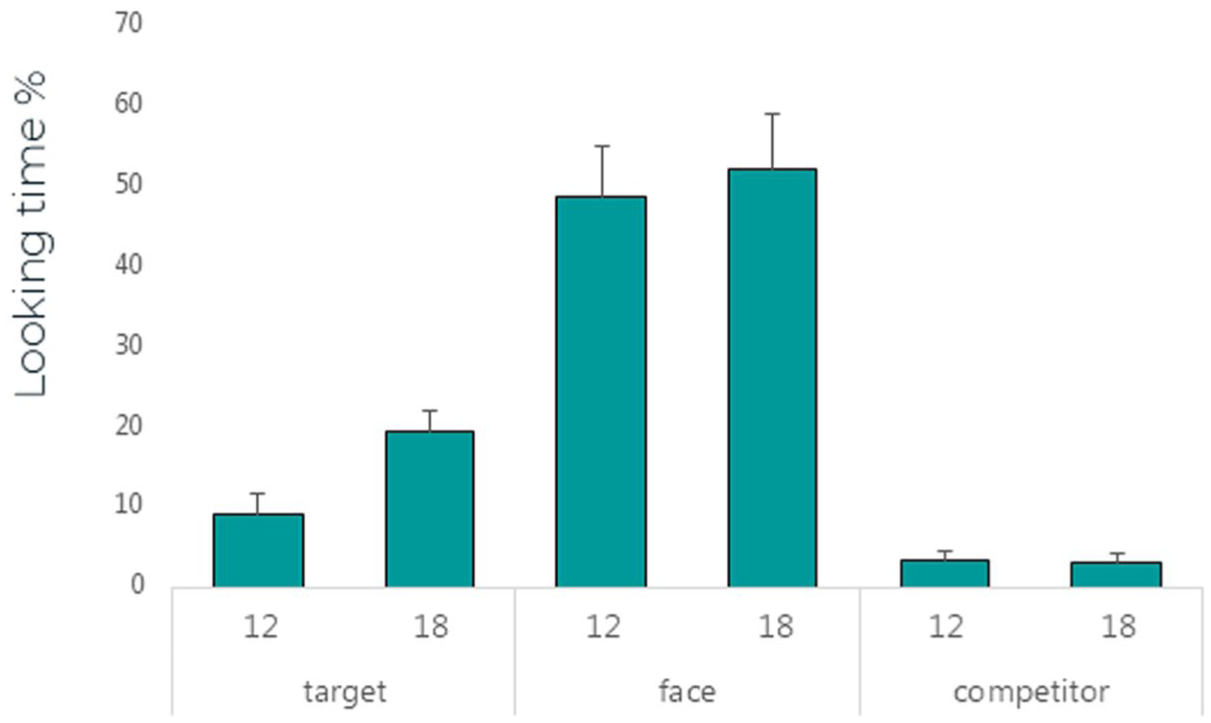
Mean looking time (in percentage) and standard error (SE) to the target object, the face of the interlocutor, and the similar competitor object in two age groups of infants in the learning phase.
Figure 2 shows that the looking percentages for the interlocutor’s face were longer compared with the looking percentages for the target object and the competing similar object for both age groups.
To assess the infants’ attention to the interlocutor’s face and the target versus the competing similar object, we analyzed the looking percentages at each AOI, which included the face, target object (the target stuffed animal), and the competing similar object (the non-target stuffed animal). For 12-month-olds, the mean looking percentage for the face was 48.8% (SD = 29.30), while for 18-month-olds, it was 52.3% (SD = 18.2). Both age groups spent a greater percentage of time looking at the target object compared with the competing similar object. Specifically, 12-month-olds spent 9.4% of their time looking at the target object and 3.5% at the competing similar object, while 18-month-olds spent 19.5% looking at the target object and 3.2% at the competing similar object.
To test whether these differences were significant we ran a two-way mixed analysis of variance (ANOVA), with AOI (target, face, competitor) as the within-group variable and Age Group as the between-group variable. The analysis revealed a significant main effect of AOI, F(2, 25) = 91.51, p < .001, η² = .88, and an interaction between AOI and Age Group, F(2, 25) = 4.76, p = .02, η² = .28. Pairwise comparisons with Bonferroni adjustment indicated significant differences between each pair of AOIs; target (M = 14.05, SD = 10.31) face (M = 50.54, SD = 24.39), and competitor (M = 3.40, SD = 3.88) for both age groups (p < .001). Specifically, pairwise comparisons revealed significant differences between target and face, target and similar competitor, and face and similar competitor (p < .001). Also, a significant difference was found between the two age groups for the target object only (p = .007). No main effect of Age Group was found, F(1, 26) = 2.35, p = .14, η² = .08.
3.3 Test phase
To assess learning of the target word (one of the stuffed animals), we conducted a mixed three-way multivariate analysis of variance (MANOVA) across the four trials simultaneously, with AOI (target object, that is, one of the stuffed animals, familiar object, that is, the ball, the non-name object, and the visually similar distractor, that is, the other stuffed animal) as the within-group variable and Age Group and Novel Object Named in Learning Phase (Object A and Object B) as the between-group variables. In the third trial, the visually similar distractor was labeled, rather than the target object. The analysis revealed no main effects for Age Group, Wilks’ λ = 0.82, F(4, 18) = 0.98, p = .44, η² = 0.18, or Novel Object Named in Learning Phase, Wilks’ λ = 0.99, F(4, 18) = .05, p = .99, η² = .01, and no interaction was found between Age Group and Novel Object Named in Learning Phase, Wilks’ λ = .91, F(4, 18) = .44, p = .78, η² = .09. A significant main effect was observed for AOI, Wilks’ λ = .15, F(12, 10) = 4.68, p = .01, η² = .85, but no significant interactions were found for AOI × Age Group, Wilks’ λ = .88, F(12, 10) = .62, p = .79, η² = .42, AOI × Novel Object Named in Learning Phase, Wilks’ λ = .47, F(12, 10) = .95, p = .54, η² = 0.53, or AOI × Age Group × Novel Object Named in Learning Phase, Wilks’ λ = 0.63, F(12, 10) = 0.49, p = .88, η² = 0.77.
Despite the relatively large effect size for Age (η² = 0.18), which suggests that age-related differences might emerge with a larger sample, the main effects for Age and for the Novel Object Named in the Learning Phase (Object A or B) did not reach statistical significance. Therefore, we conducted a repeated-measures MANOVA with AOI as the within-subject variable across all trials simultaneously. The analysis revealed a significant main effect for AOI, Wilks’ λ = 0.16, F(12, 13) = 5.68, p = .002, η² = 0.84. Subsequently, univariate analyses were conducted separately for each trial, with simple contrasts comparing each distractor to the target word.
The results of the first trial (time window 0–1,600 ms following the onset of the second syllable of the target word; see Figure 3) showed a main effect for AOI, F (3, 72) = 11.05, p < .001, η 2 = .32. Following contrast tests revealed significant differences between looking percentage for the target object versus the familiar distractor (ball), F (1, 24) = 27.88, p < .001, η 2 = .54, and the no-name distractor, F(1, 24) = 27.02, p < .001, η 2 = .53. No significant difference in looking percentage was found between the target object and the similar distractor, F (1,24) = 3.27, p = .08, η 2 = .12).
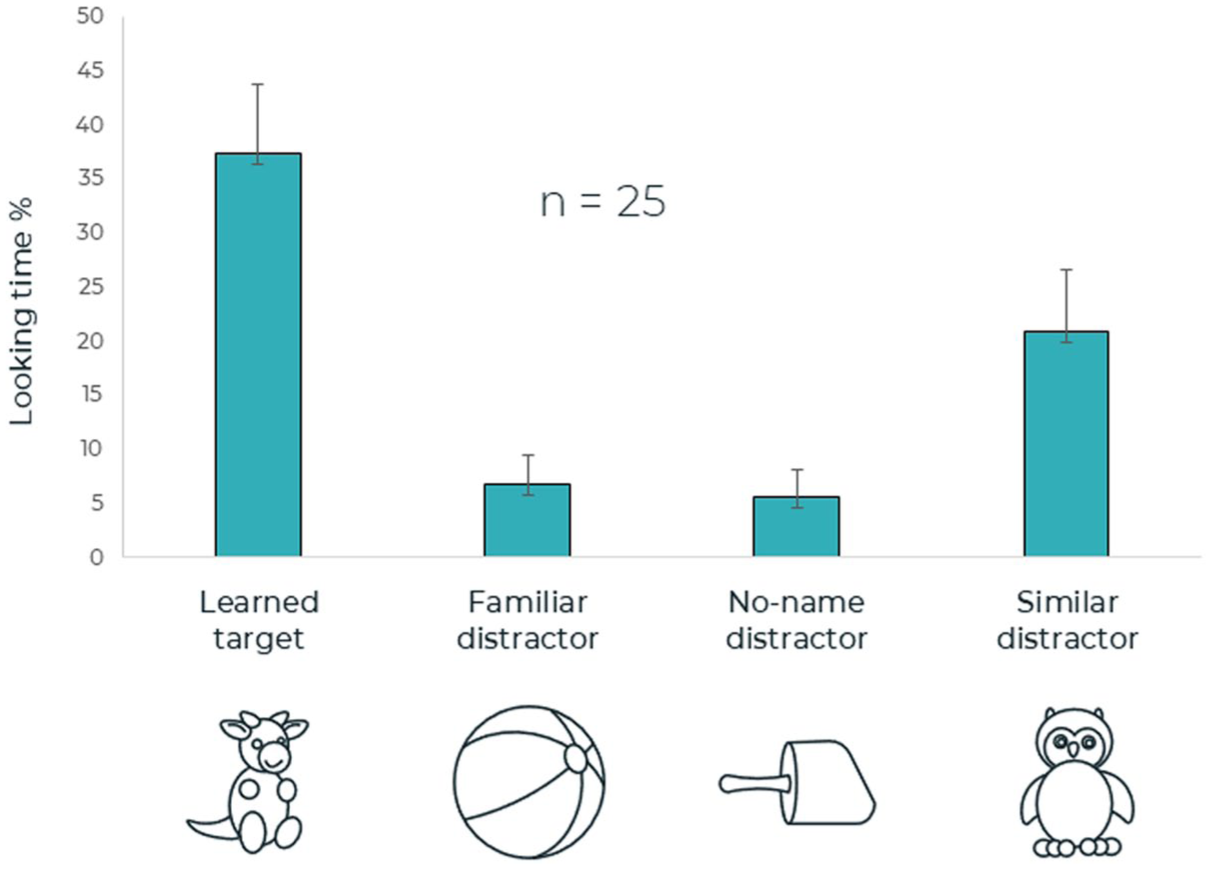
First time window of the test phase. Mean looking times (in percentage) and standard error (SE) to the learned target and three distractors (dis): familiar object, object with no name, and similar competitor.
The results for the second trial (time window 0–1,600 ms following the onset of the second syllable of the target word; see Figure 4) showed a main effect for AOI, F (3, 72) = 2.98, p = .02, η 2 = .14. The following contrast tests revealed significant differences between looking percentages to the target object versus the familiar distractor (ball), F(1, 24) = 6.18, p = .02, η2 = .21, and the no-name distractor, F(1, 24) = 7.30, p = .01, η2 = .23. No significant difference in looking percentages was found between the target object and the similar distractor (the other stuffed animal), F (1, 24) = 2.50, p = .13, η 2 = .09.
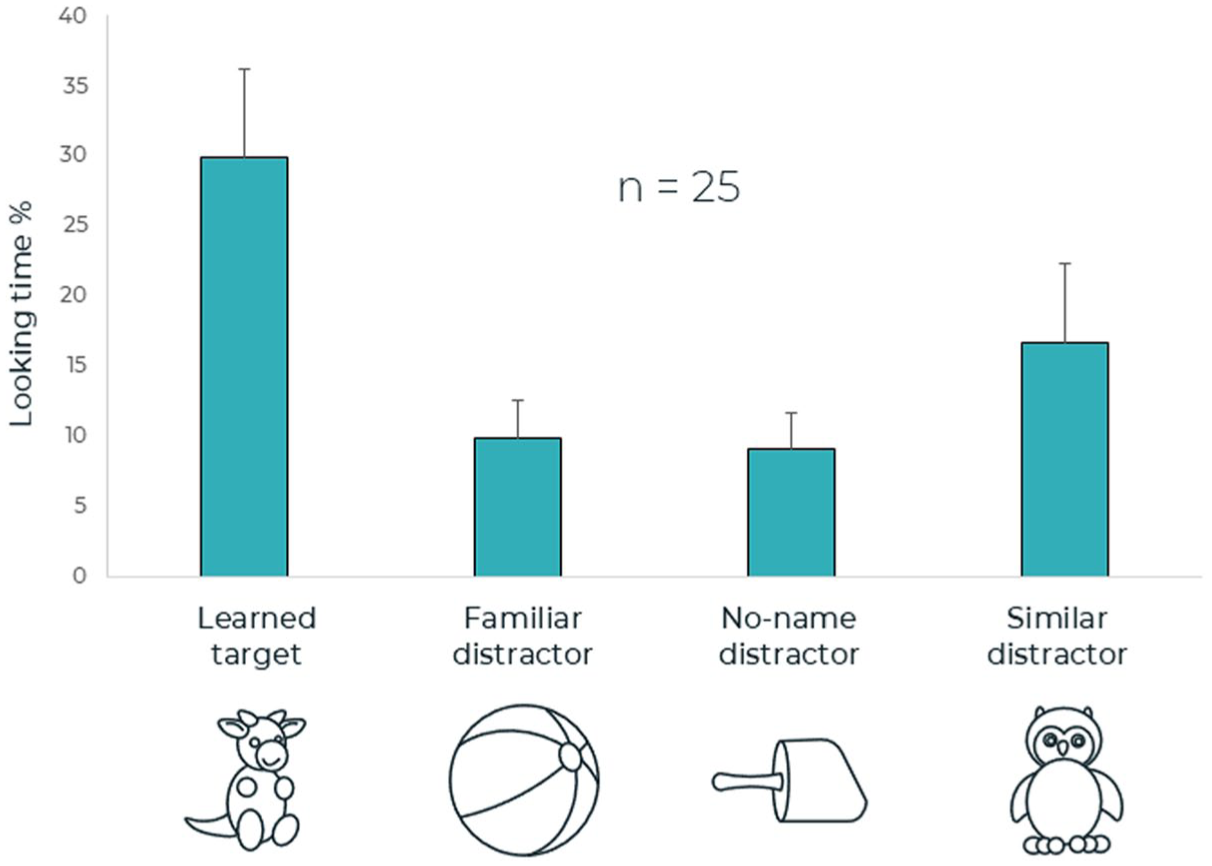
Second time window of the test phase.
The results of the third trial (time window 0–1,600 ms following the onset of the second syllable of the target word; see Figure 5) suggest a main effect for AOI, F(3, 72) = 2.98, p = .04, η 2 = .11. The following contrast tests reveal significant differences only between looking percentage to the target object versus the similar distractor (the other stuffed animal), F(1, 24) = 5.70, p = .02, η 2 = .19. Importantly, the label used in this trial was not the word learned in the learning phase (e.g., bícket) but a novel word (e.g., domát). Accordingly, a longer looking percentage was observed to the similar distractor and not to the learned target object.
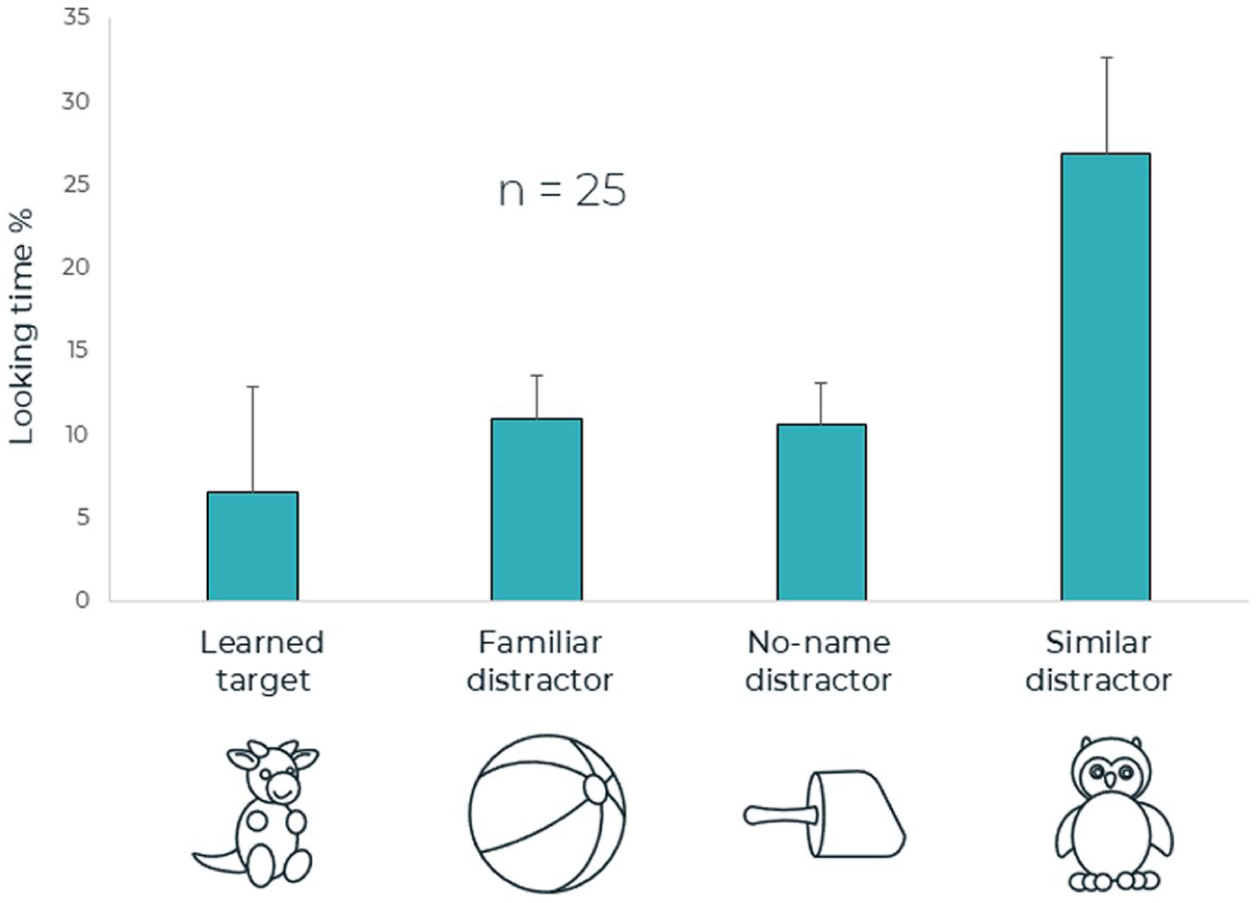
Third time window of the test phase.
The results of the repeated-measures ANOVA for the fourth trial (time window 0–1,600 ms following the onset of the second syllable of the target word) are presented in Figure 6. No main effect was found for AOI, F (3, 72) = 1.51, p = .22, η 2 = .06.
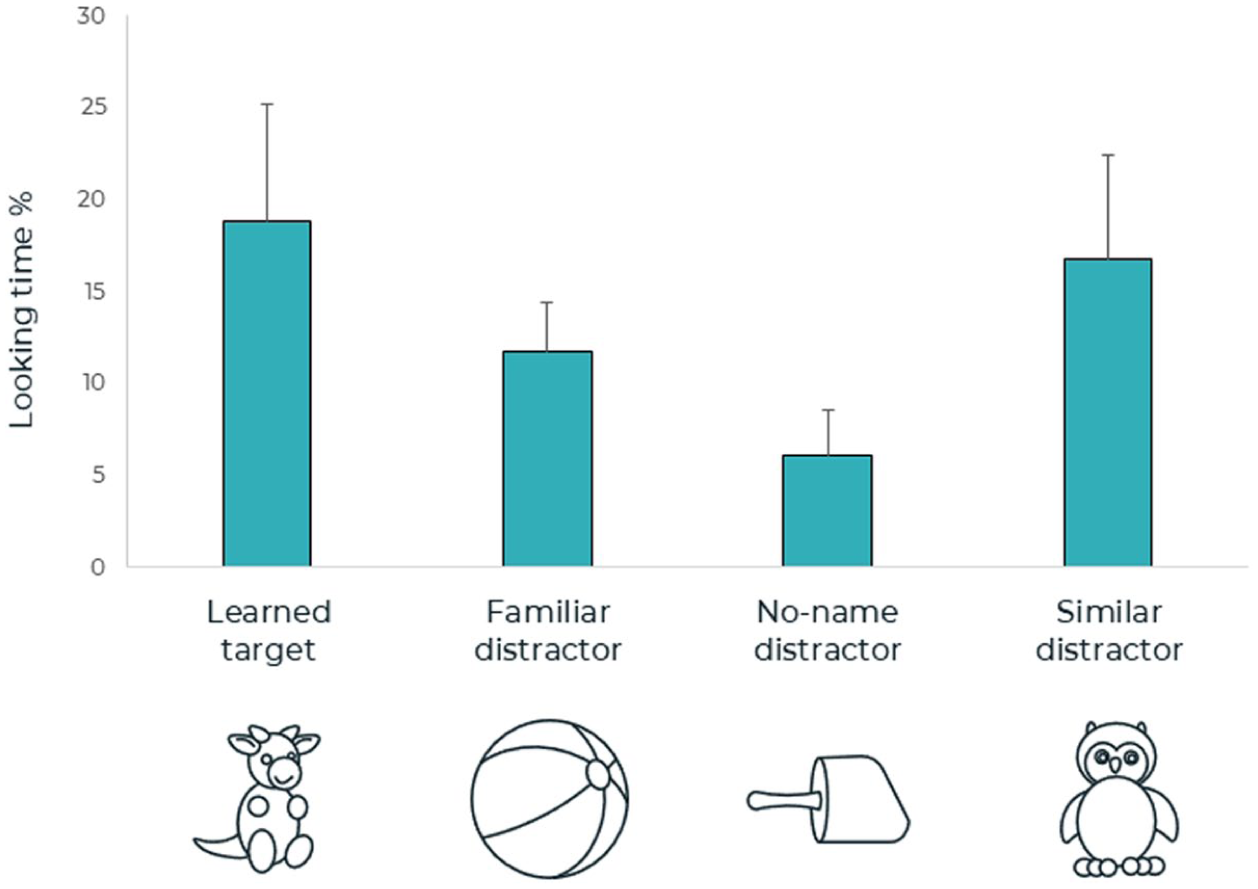
Fourth time window of the test phase.
To assess the association between looking time to the target object during the learning phase and word recognition in the test phase, a Pearson correlation was conducted between the mean looking times to the target object during the learning phase across six trials and looking time to the target object in the test phase. We selected the first trial of the test phase, as infants’ looking toward the target object was longest in this trial. The Pearson correlation suggests a significant correlation between looking percentage to the target object during the learning phase and looking percentage to the target object in the first trial of the test phase (r = .51, p = .001) as shown in Figure 7.
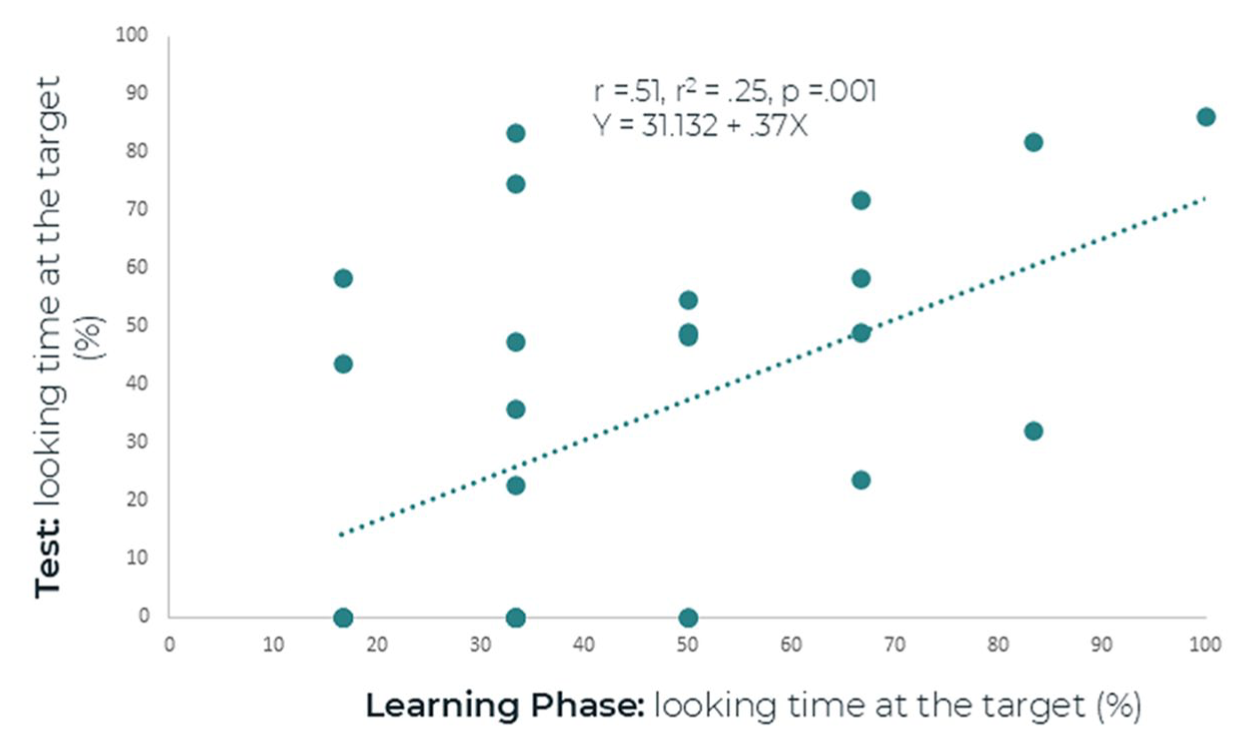
Correlation between looking time to the target object in the learning phase and in the test phase (first window).
4 Discussion
The main goal of the present study was to examine how 12- and 18-month-old infants utilize an interlocutor’s eye gaze for word learning. This was achieved using an eye-tracking paradigm that combined a learning phase (involving word teaching) with a four-alternative forced-choice testing phase. The main findings of the present study are the following: (1) There was a developmental increase between 12 and 18 months in infants’ tendency to follow the interlocutor’s head and eye gaze toward the target object, along with an increase in the duration of sustained visual attention to the target object. (2) In the test phase, there is some evidence that infants can recognize the learned target word in the presence of three distractors. Infants showed longer looking percentages to the target object in the first and second trials, but not in the fourth trial (in all of which the learned label was heard). However, the looking percentage toward the target object in the first and second trials was not significantly higher compared with the similar distractor. Therefore, it is possible that the learning of the target word was not sufficiently robust. In the third trial, after hearing a novel, non-learned word, infants did not look longer toward the previously labeled target object. Instead, they looked more toward a similar competing object, suggesting that they had formed a specific link between the original word and its corresponding object. In the remainder of the discussion, we elaborate on each finding, emphasizing its relevance within the broader context of research on word learning.
The first finding of the present study was that the 18-month-olds followed the interlocutor’s head and eye gaze toward the target object more often and demonstrated a longer looking percentage to the target object compared with the 12-month-old infants. However, the two age groups did not differ from each other in looking percentages to the interlocutor’s face or to the similar competing object. Overall, in both age groups, the looking percentage to the interlocutor’s face was the longest compared with the target object and the competing distractor. The looking percentage to the target object was longer compared with the similar distractor. Similarly, Yurovsky and Frank (2017), who tested children aged 1 to 4 years, found that children of all ages had the longest looking time to the experimenter’s face, and a shorter looking time to the target object. At all ages, the shortest looking time was to the competing distractor. Yurovsky and Frank (2017) also found that the looking time toward the target object increased with age. The present study builds on this developmental trajectory by demonstrating that 18-month-old infants showed greater looking percentage to the target object compared with 12-month-old infants. Older infants demonstrated an improved ability to follow the speaker’s head and eye gaze and to sustain their attention to the target object. Visual attention to the object in joint-attention contexts has been shown to be related to word learning (Yu et al., 2019). This finding may suggest that 18-month-old infants have some advantage in word learning compared with 12-month-old infants, although this advantage was not evident in the test phase of the present study. Taken together, these results suggest that 18-month-old infants are more attentive to the referential role of the eye gaze during word learning.
An additional finding of the present study was that at 12 and 18 months, infants associated the learned word with a specific object. The analysis of the third trial suggested that learning was specific to the learned target word. When a novel word that had not been presented in the learning phase was heard, infants did not show a looking preference to the learned target object but rather to the similar competing object. These results suggest that infants related the specific learned word to the specific object. However, since no clear recognition of the target word was found during the fourth trial, and the looking percentage toward the target object in the first and second trials was not significantly increased compared with the looking percentage toward the similar distractor, it is possible that the learning of word-object associations is still fragile and inconsistent at this age. Also, it is possible that the four-alternative forced-choice task increased the difficulty of recognizing the target word by placing greater demands on executive functions, including visual attention, cognitive flexibility in tracking changes in the target’s position on the screen, and the inhibition of non-relevant targets. This cognitive load on novel word recognition could potentially explain some of the null results observed in the test phase, where no differences between age groups were found (Devine et al., 2019; Escobar-Ruiz et al., 2024). In general, while 12- and 18-month-old infants can learn a novel word after a short exposure of six consecutive trials in which the interlocutor looks toward the object and names it, this learning may remain unstable. The recognition process can be influenced by contextual factors, including the visual similarity of the other objects in the same context.
One interesting result of the present study is that during the test phase, the longest looking percentages were toward the target object and the similar competing object. Because of the visual similarity between the target object and the competing object, we assume that infants had to look toward both the target object and the competing object to discriminate between the objects and identify the target object. These findings are consistent with a previous study on Dutch-speaking students who were presented with a target word (e.g., snake), pictures of a competing object that shared features with the concept-related visual representation of the target word (e.g., rope), and two distracting objects (e.g., couch and umbrella) (Dahan & Tanenhaus, 2005). When participants heard the beginning of the word, they tended to look toward the visual competitor (rope) rather than toward one of the distracting objects (couch) that included the same opening sound as the target word (snake) in Dutch. These findings support the notion that word-object matching involves visual features of the target object (Dahan & Tanenhaus, 2005). Alternatively, it is possible that the fact the two objects in our study belonged to the same category of stuffed-animal toys made it more difficult to recognize the specific target. A previous study showed that infants between 18 and 24 months of age had difficulty associating words with objects when the target and the distractor belonged to the same category (e.g., animals) and were perceptually similar. However, the same toddlers could identify word-object pairs when the target object and distractor belonged to different categories, regardless of whether or not they were perceptually similar (Arias-Trejo & Plunkett, 2010). In the present study, the infants’ potential categorization of the target object and the similar competing object into the same category may have introduced an additional layer of complexity in target recognition. However, this complexity also mirrors real-life word learning scenarios, where infants must often learn words for objects that are similar or belong to the same category. Further studies on the influence of visual similarity and category on infants’ word learning are required.
In interpreting the results of the present study, it is also important to acknowledge the observed discrepancy in looking times between the target, the similar distractor, and the two dissimilar objects in test trials 1 and 2. This difference suggests that the infants may not have perceived all four objects as equally relevant. However, it is noteworthy that when ten 12-month-olds were presented in a pretest with the four objects without accompanying audio, no statistical difference in looking percentages toward the objects was found. The short looking times toward the dissimilar objects in the test phase may suggest that, in real-world learning contexts, children are naturally more drawn to objects similar to the target object, rather than treating all available options as equally relevant.
The finding of the present study that infants in the test phase mapped a new word that had not been learned before to an object that had not been named before supports previous findings. When presented with a familiar and a novel object, infants as young as 17 months of age prefer to map a novel label (e.g., dax) to the novel object (Halberda, 2003; Markman et al., 2003; Mervis & Bertrand, 1994). The present study adds to existing knowledge by demonstrating that after learning a novel word through social eye-gaze cues, 12- and 18-month-old infants already map a novel word to a novel object. This finding implies that a novel learned word-object link facilitates additional word learning.
Another finding of the present study pertains to the association between looking time at the target object in the learning phase and test phase, suggesting that infants who looked at the target object for a longer time during the learning phase were better able to recognize it in the test phase. Thus, improved sustained visual attention during learning supports word learning. Recent studies also highlight the importance of sustained visual attention in word learning. Abney et al. (2020) assessed infants and their parents with head-mounted eye trackers and reported that the simultaneous combination of parents’ triadic gaze to the object and the infant’s face, and infants’ looking toward the object was associated with larger vocabulary size at 12 and 15 months. The authors highlight the importance of the parent’s attentional monitoring and the infant’s sustained visual attention for vocabulary acquisition. Yu et al. (2019) demonstrated that infants’ sustained visual attention to an object at 9 months predicted language development at 12 and 15 months. Moreover, infants’ sustained visual attention to the named object during naming predicted later vocabulary acquisition even without shared attention with the parent (Yu et al., 2019). However, to the best of our knowledge, the present study is the first to demonstrate that sustained visual attention to the target object is related to immediate learning of a novel word. Nonetheless, this finding should be interpreted with caution, as the correlation was tested only in the first trial, where looking time was highest, and may not generalize across the entire learning phase.
One limitation of the present study is the relatively small sample size. It is possible that with a larger sample, developmental differences in the recognition of recently learned words between 12- and 18-month-olds might emerge. The findings of the present study suggest that infants’ ability to follow the eye gaze of the speaker as well as their ability to sustain visual attention toward the target object increases with age. It is possible that the high variability within each age group limited our ability to detect developmental trends in word recognition, and that a larger sample size may be needed to reveal such effects. It is also possible that other possible intervening factors, such as vocabulary size and working memory in addition to age, need to be measured to better understand the influence of different developmental factors on word learning in 12- and 18-month-old infants.
Another limitation of the present study is related to the fact that we used two objects with faces (stuffed animal dolls) and two objects (toys) without faces. Thus, it is possible that the infants found the target object and the similar competing object with faces more interesting compared with the other objects. However, it is also likely that presenting four objects with faces may require extensive attention and memory resources, rendering the task too difficult for infants. In fact, our recent pilot study of 10 infants aged 24 months demonstrated that when all the objects had faces, the infants did not recognize the learned word.
In addition, another limitation is the exclusion of children who did not look at the screen or engage in gaze following. This exclusion may limit the generalizability of our findings to a broader population, particularly to infants less responsive in gaze-following behaviors. Future research should aim to explore factors influencing gaze-following engagement, to better understand how these differences impact language development across different infants.
Finally, one common limitation in infant research is the number of test trials. In this study, we included four trials during the testing phase to improve measure reliability without overburdening the infants. Three trials (the first, second, and fourth) used the same target object, distractors, and target word, while the third trial presented the same objects paired with a novel, non-learned word. This design allowed us to assess target word recognition across multiple trials, aligning with recommendations by Byers-Heinlein et al. (2022), who emphasize the importance of multiple trials for more reliable and robust findings. In addition, we used a non-learned word in the third trial as an indirect test of object-target mapping. The fact that the children did not look to the learned target when hearing a non-learned word, suggests that they had formed a specific link between the learned word and its corresponding object during the learning phase.
Despite the limitations mentioned above, the present study offers valuable insights into word learning through social cues in young infants. Presenting one target object alongside three distractors in the test phase allows for the assessment of word recognition in the presence of multiple non-target objects. This setup more closely simulates everyday situations, where infants must identify a newly learned target word while the target object is surrounded by familiar objects, unlabeled objects, and visually salient or similar items in various real-life contexts. The present study provides further evidence supporting the notion that, during the first half of the second year of life, infants can learn a novel word by using the interlocutor’s eye gaze as a cue for word learning.
Footnotes
Appendix A
Stimuli for the validation (two parts), learning phase, and testing phase.
Appendix B
Appendix C
A control room and a test room.
Acknowledgements
We are grateful to the infants and parents who participated in this study, as well as the undergraduate students from the Department of Communication Disorders at Tel-Aviv University who assisted with data collection. For access to the raw data, additional information, or questions, please contact the second author at:
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Israeli Scientific Foundation [#1724/18] and is part of the doctoral research of Ms. Zipora Yegudayev.