
Abstract
This study investigates young school-aged children’s knowledge (at 4–7 years) of accurate English word-initial onset clusters. By this age, we expect children to be mostly accurate in producing #CC clusters (rather than repairing them with deletion or epenthesis). We ask how well can they recognize and reject cluster repair errors, in both real and nonce word tasks. The results suggest that these learners’ cluster judgment skills lag behind their cluster production abilities, and that asymmetries in error types do not overall align between the two domains. Perceptual errors are made most often when comparing clusters with epenthesis repairs, not deletion, and the cluster’s sonority profile does not directly influence error rates. After comparing these findings with similar results from adult L2 English speakers as well, we discuss the ways in which issues like recoverability, salience, and contiguity can account for our findings. We also suggest that more work on phonological knowledge and judgments in older children will provide a broader understanding of sound pattern acquisition across development.
1 Introduction
It is by now almost axiomatic in the language acquisition literature that very young children exhibit remarkable speech perception skills, which are both flexible and language-specific. At 4 to 6 months of age, infants can reliably discriminate between non-native segmental contrasts, similar to adult listeners with decades of experience perceiving such sounds (e.g., Kuhl et al., 1992; Polka & Werker, 1994; Werker & Tees, 1984). By their first birthday, children become highly focused on the sub-segmental details, allophonic distributions, and phonotactic restrictions of their native language(s) (e.g., Kuhl et al., 2006; Narayan et al., 2010), using these patterns to segment novel words and much more (e.g., Friederici and Wessels, 1993; Jusczyk et al., 1999).
All of this perceptual knowledge is clearly in advance of infants’ production abilities. As a particularly stark example: infants at 1 to 4 months discriminate between voiced and voiceless stops (Eimas et al., 1971), but this laryngeal contrast is not produced reliably until multiple years later (e.g., Macken & Barton, 1980; MacLeod, 2016). Nevertheless, there is also compelling and growing evidence for a link between perception and production abilities in very early development. The combined studies of Bruderer et al. (2015) and Choi et al. (2019) reveal one striking connection: that impeding the articulators used in a particular non-native segmental contrast, using a specially designed teether, can impair that contrast’s perception in 6 month olds. Another research program suggests that infants at this same age attend more to those segments that they themselves are beginning to pronounce (Majorano et al., 2014, and references therein).
Through the preschool years, children’s production accuracy improves significantly; while segmental accuracy may sometimes be described as near adult-like by ages 4 to 5, mastery of more complex segments especially can take until age 7 or beyond (see, for example, Dodd et al., 2003, Table 1 on later-acquired English consonants; for a cross-linguistic review, see McLeod & Crowe, 2018). At the same time, perceptual tuning must also undergo much refinement into childhood. McAllister Byun’s (2015) study of 4 and 5 year olds finds that children are much worse than adults at discriminating familiar segments via minimal pairs in an AX nonce word task—but this poor performance does not reflect a general inability to perform or understand the task, since their relative accuracy with different contrasts predominantly lines up with that of adults. In fact, fine-grained perceptual tuning of phonemic categories continues throughout childhood, even past age 12 (Hazan & Barrett, 2000) and up to age 18 (McMurray et al., 2018). During at least the preschool years, there is also evidence that children’s individual perception and production lacunae correlate—although these connections come predominantly from studies of developmental delays or disorders. The clinical literature documents many cases of children who both neutralize segmental contrasts in production and find those contrasts more difficult to discriminate than others in perception: Hoffman et al. (1985), McAllister Byun (2012), Rvachew and Jamieson (1989), Velleman (1988), Whitehill et al. (2003), and cf. Gierut (2006).
Example Stimuli and Error Variants.
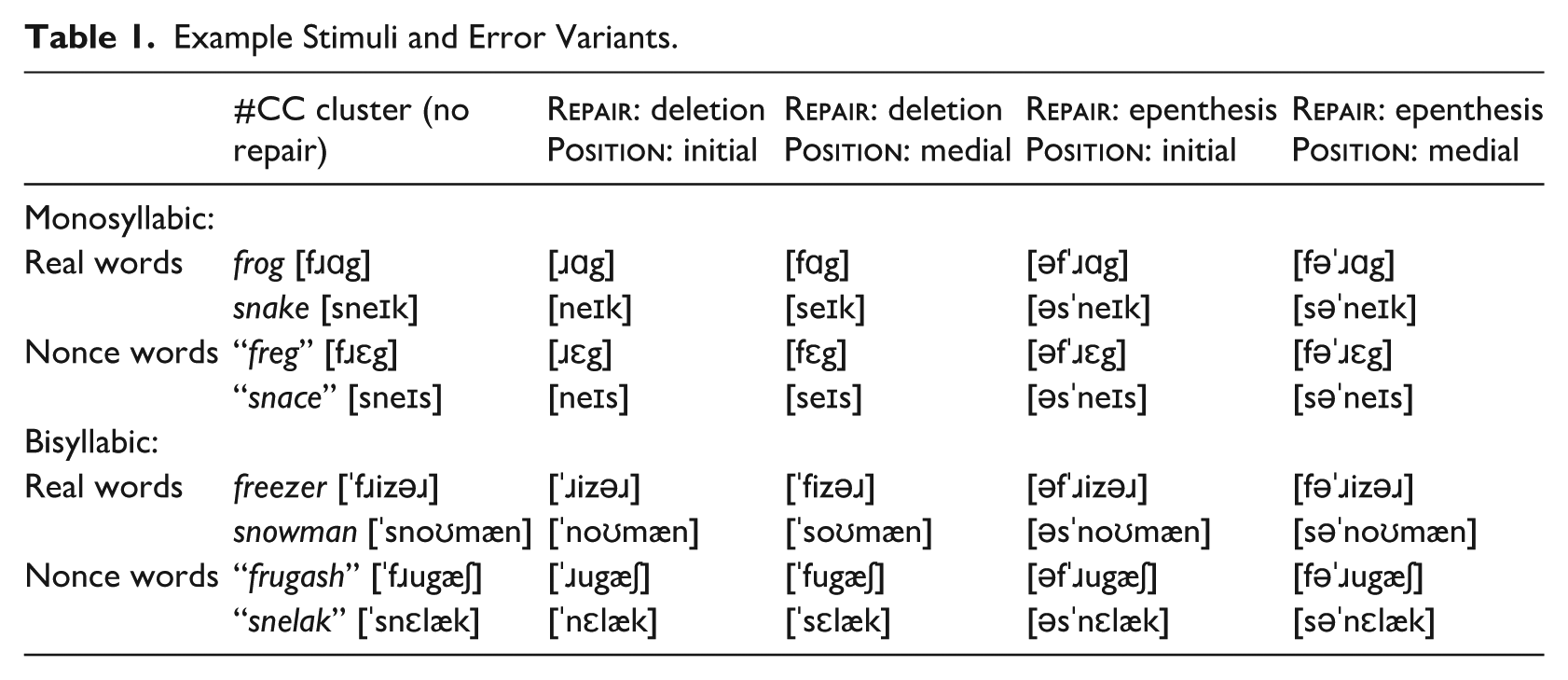
Almost all previous work on children’s later perceptual refinement focuses on linguistic units at or below the segmental level (although notable exceptions are discussed below). But at the level of larger phonological units, relating to syllable structure and phonotactics, similar learning and refinement must still be done. This article focuses on discrimination accuracy in a domain where the developmental production facts are very well studied: the acquisition of word-initial onset clusters, in terms of error repair type and position within the cluster, and the influence of cluster sonority. Our overall question is to what extent children’s accuracy at discriminating between onset clusters and singleton onsets is affected by the same factors that influence early onset cluster production accuracy.
Most children who are learning a language such as English that contains consonantal onset clusters will begin by simplifying these clusters in their early productions. The most common repair pattern is deletion, reducing a biconsonantal cluster to a singleton (e.g., Gnanadesikan, 1995/2004; Pater & Barlow, 2003). When choosing a consonant to delete, the most common strategy is to preserve the least sonorous segment (see especially discussion in Goad & Rose, 2004)—meaning in English that usually the first segment is retained and the second deleted, as in the first column in (1) below. Exceptions to this majority pattern come particularly from s-initial onset clusters, which a variety of studies have found that children treat differently, and acquire later (see, for example, Barlow, 2001; Chen & Pan, 2017; Goad & Rose, 2004; Treiman et al., 1992 and references therein). If a subset of s-initial clusters are treated exceptionally, it is most often s+stop (see the second column of (1)), reflecting a grammatical sensitivity to sonority sequencing (e.g., Ohala, 1999; Pater & Barlow, 2003; Wyllie-Smith et al., 2006); there is also considerable evidence of exceptional [s+nasal] clusters (e.g., Greenlee, 1973; Yavas & Beaubren, 2006).
(1) Onset cluster repair via sonority-sensitive deletion at age 2 (Gnanadesikan, 1995/2004):
Less commonly, some English-learning children go through a stage of medial epenthesis into onset clusters (as in 2) or segmental fusion (e.g., /sw/ → [f]); others use different strategies for selecting the surviving consonant (e.g., Goad & Rose, 2004; Pater & Barlow, 2003). For much more on onset cluster repairs in L1 acquisition, see especially Tessier (2016) chapter 3 and references therein.
(2) Onset cluster repair via epenthesis: (Pater, 1996):
On the perceptual or comprehension side, literature on the development of onset clusters is much sparser. Two notable studies have focused on English learning children’s perception of illegal onset clusters, with an eye to determining whether phonological universals influence their relative acceptability or accurate perception. Pertz and Bever (1975) asked L1 English 9 to 11 year olds and 16 to 19 year olds to judge the relative well-formedness of highly ungrammatical English onsets—for example, whether [
Another type of evidence regarding children’s interpretations of onset clusters comes from the acquisition of English spelling. Several studies have found that when children make spelling errors on word-initial consonant clusters, they most commonly omit the second consonant and not the first; Treiman (1991) found this asymmetry for 4 to 6 year olds when spelling both familiar and nonce words. These other types of evidence thus align with children’s dominant production repairs, insofar as they usually delete the second member of a two-consonant cluster, and demonstrate a sensitivity to relative sonority preferences. However, not that much is known about how children interpret the types of onset cluster simplification patterns that they themselves produce. This in turn means that we cannot build firm theories of how phonological development in production is built up from, and/or connected to, development in phonological perception, at least in these later years of childhood.
The main goal of this article is to determine how accurately 4- to 7-year-old children perceive English onset consonant clusters, compared with the same consonants as singletons, as are found in typical cluster production repairs. When listening to real words and novel words, what influences their ability to tell a CCV from a CvCV or a CV? The main factors we consider are the repair type (deletion vs. epenthesis), the repair location (initial or medial to the cluster, as defined below), and the segmental/sonority profile of the cluster, in both familiar and nonce words.
Our expectations for this study were that the children would be overall quite accurate in their onset cluster production, but we had two potential hypotheses for how their perceptual results would play out. One possibility was that children’s errors on our two acceptability tasks would be roughly aligned with typical production errors in the developmental literature (though usually made by younger children). Overall, this would mean more errors caused by deletion rather than epenthesis; more difficulty with forms that violate cluster sonority principles, at least including a reversal of error patterns for s+stop clusters, and indeed possibly for other sC clusters, compared with those with a different C1. The other possibility we hypothesized was that the dominant influences on behavior in our perception tasks would not be those which affect production. In that case, we hypothesized the opposite overall prediction about repair type—that is, repairs with epenthesis errors should cause more inaccuracy instead of deletions (see further discussion in Section 4).
To preview our findings very briefly: our participants’ perception of clusters versus singletons did not align closely with production asymmetries. The children in our study were old enough to make very few errors in production, but they did in fact make far more errors in perception, and while the repair type and position played a significant role in predicting their accuracy, the segmental profile of the clusters did not. We ultimately argue that children’s accuracy was influenced by multiple factors which are especially (or only) relevant to perception, including a particular pressure to keep input segments contiguous in the output (McCarthy & Prince, 1995). We also report a comparison of our main child population with an adult population of English speakers, drawn from the same population as our study’s children. This adult population includes English native monolinguals, native bilinguals, and advanced L2 learners of English. Their results also support the claim that these asymmetries come from general acquisition pressures on perception, regardless of learner age.
2 Method
2.1 Materials
Two sets of materials were created: 22 high-frequency English words with word-initial clusters, and 24 corresponding nonce words. Each set contained two tokens of the clusters [kl, pl, fl, fr, sm, sn, sw, sl, st, sk, pj, mj] (except that only one pj and mj-initial real word were used); one token was monosyllabic, and the other bisyllabic with initial stress. Sample words are provided in Tables 3 and 4; the full lists are given in Appendix A. The onset clusters chosen here represent all the possible two-consonant combinations by manner of articulation, with the understanding that /s/ is special compared with other fricatives—thus, they include stop+liquid, fricative+liquid, stop+glide, nasal+glide; /s/+nasal, /s/+liquid, /s/+glide, and /s/+stop. Half of the clusters were /s/-initial, which increased the chances of detecting differences in participant’s judgments of /sC/ versus other clusters.
For each word, one “accurate” cluster production and four repair variants were recorded: one with the cluster’s initial consonant deleted, one with the second (medial) consonant deleted, one with a schwa epenthesized before the initial consonant, and one with a schwa epenthesized medially between the two consonants. We label these four types by Repair
All stimuli were recorded by two monolingual speakers of North American English, one female with a pitch range of roughly 200–325 Hz, and one nonbinary person with a pitch range of roughly 100–200 Hz. Both were linguistically trained but naïve to the goals of the study. They recorded all nonce words and the real word nouns in the sentence frame “Look at that ___!.” Real word verbs, such as sleeping and swimming were recorded in the frame “Look at him/her ___!.” Speakers were instructed to place pitch accents on “Look” and the target word only so that all other words were phonologically reduced. Final stimuli were checked to ascertain that they all followed this prescription. These frames were chosen to prevent the interpretation of an initial epenthesized schwa as an indefinite article (e.g., *Look at that a frog). Utterances were amplitude normalized at 80 dB but otherwise left with natural durations and pitch contours. Epenthetic schwas in nonwords had a mean (sd) duration of 46.7 (14.5) ms in the lower voice, and 29.5 (6.8) ms in the higher voice. In the nonwords, initial schwas had a mean duration of 45.0 (14.9) ms and medial schwas had a mean duration of 34.0 (12.1) ms. In real words, epenthetic schwas had a mean (SD) duration of 69.2 (18.6) ms in the lower voice, and 48.9 (19.2) ms in the higher voice. They had a mean duration of 77.2 (15.1) ms in initial position, and 53.0 (19.8) ms in medial position.
2.2 Participants
Thirty-one children ages 4 to 7 performed three related tasks. They were recruited via flyers, social media, word of mouth, and day camps at a large western Canadian university. To be included in the study, children had to have no reported language delays or hearing difficulties, and to be primarily monolingual English speakers. Given the context of the local population, where the majority of children grow up hearing multiple languages at least in the broader community, our definition of “monolinguals” were children for whom English was reported as their first language, and whose parents or guardians reported no significant exposure to any other language. Two participants did not finish the experiment, one failed to respond correctly to the test trials (indicating they may not have understood the task well), and three additional participants turned out to be multilingual. Data from the remaining 25 children was analyzed. These children ranged in age from 51 to 87 months, with a median age of 67.5 months.
In addition, adult participants were recruited as controls. All were at least 19 years old fluent English speakers, and participated for course credit at an English-speaking university in western Canada. Anyone who met these criteria was allowed to participate for course credit. As a result, we collected data from 29 participants whose only native language was English, 29 participants who were native in English and at least one other language, and 51 participants who were advanced L2 learners of English. The 29 monolinguals served as our control group, but data from the bilinguals and advanced L2 learners is also discussed.
2.3 Procedure
Children completed three related tasks—two perceptual and one production—in a single session. Children were tested in a university lab, either on their own or in a quiet side room as part of a language day camp. Adults were tested in the same lab, and were told that the study was designed for children.
AX Nonce-word Discrimination: In this first task, children were introduced to two space aliens: Boo and Tee, still cartoon drawings displayed on a laptop computer screen. It was explained that Boo and Tee wanted to teach their names for alien objects to the children—and that they both spoke similar alien languages, but that sometimes they produced words somewhat differently from each other. Each trial had a picture of an object probably unknown to most contemporary 4 to 7 year olds (e.g., an abacus or a phonograph) in the middle of a computer screen, and the two cartoon alien figures each on one side of the object (see Figure 1). Children were asked to listen to both aliens, each naming the object (“Look at that [word]!”) and then indicate whether the two aliens had said “the same word or not.” The aliens spoke with different voices: Throughout, the tall alien Boo was assigned recordings from the lower-pitched talker (100–200 Hz), and the short alien Tee was assigned recordings from the higher-pitched talker (200–325 Hz).

Nonce-word discrimination example trial.
Children were instructed that they should ignore differences in the aliens’ voices, and were given four practice trials before they began. Practice trials did not have clusters, but had two different initial consonants (loʊp ~ foʊp) on “different” trials, and were identical on “same” trials. Two practice trials were “same” and two were “different.” Half of the trials in the Nonce-word Discrimination task were “same” trials, in which both aliens produced a word with a true onset cluster, and half were “different” trials, in which one alien produced the cluster and the other produced one of the four deletion or epenthesis variants from Table 1. These repairs were evenly distributed across “different” trials and counterbalanced across four lists, to which participants were assigned at random. Each participant saw each of the 24 items twice (once as “same” and once as “different”) for a total of 48 trials. The aliens switched sides of the computer screen between each trial, and overall both aliens produced 50% of the error variants.
We emphasize that the goal of this task was to access more high-level, phonological representations of these word forms. To this end, the task was not speeded, and children could take their time responding to each trial; the prompt asked children to judge whether they heard “the same word,” rather than whether the two strings were identical; the two aliens’ voices were judged by adults as considerably different in their F0 range, and the practice trials provided evidence that these two voices could nevertheless say “the same word.” All of this was designed to prevent children from using raw acoustic memory traces of the two strings when making their judgments—as we expect that by this age, children’s low-level phonetic representations do contain sufficient detail to distinguish between clusters and singleton pronunciations.
Real Word Production: In the second task, children were presented with new cartoon scenarios involving kids named Billy and Tammy. Each scenario was designed to elicit one of 22 nouns and verbs beginning with an onset cluster, as in Table 1 (see appendix for full list). If the child labeled the crucial object spontaneously the trial was complete; if not, the child was encouraged to click on a recorded prompt that included the object name (e.g., “Thanks for getting my
Real-word Acceptability: This task was structured similarly to the Nonce-word Discrimination task, although this time each trial began with the image of the same two aliens Boo and Tee, superimposed on one of the cartoons of familiar objects from the previous Production task (e.g., a frog or a snowman). Children were now told that the aliens were trying to learn more English. On each trial, both aliens labeled the familiar object in turn (“Look at that [word]/Look at that [word]ing!,” and the child had to indicate which one “said it best,” by pointing or naming the alien (Figure 2). In this acceptability task, there were no “same” trials: every image was paired with one alien producing the target onset cluster and the other producing one of the four repaired variants (Table 1). As in the Nonce-word Discrimination task, children were given three practice trials to direct them toward phonological representations rather than low-level acoustic information. Participants saw each of the 22 items twice, once with a deletion repair and once with an epenthesis repair, for a total of 44 trials. The position of the repair varied across repetitions as well, to make the second repetition maximally different from the first.

Example real-word acceptability trial.
All children performed these three tasks in sequence: Nonce-word Discrimination, then Real-word Production, then Real-word Acceptability. This order was chosen so that production of real words would precede the acceptability task, in which children would hear recordings of those same real words, which might influence their productions if it came later. Also, because we expected the nonce-word task to be more difficult than the real-word task, we positioned it first in the order to minimize fatigue in our participants. Four versions of each task were created, with all of the same trials but each in a different randomized order.
2.4 Data treatment and coding
Experimental sessions were audio recorded. The perceptual tasks were coded by two L1 English-speaking researchers, as to which alien the child had chosen (for the real word task) or whether they had indicated “same” or “different” (on the nonce word task). No discrepancies or difficulties were observed between coders.
Children’s productions were transcribed with a focus on the word’s initial cluster. Every target word from a single child was transcribed by one student research assistant (four RAs in total), who were all naïve to the goals of the study and had been trained in child speech transcription. Utterances were first categorized as having a consonant cluster, regardless of segmental errors (e.g., [sneɪk], also, for example, [smeɪk]), or having one of the four cluster repairs of interest to us: Initial deletion ([neɪk]), Medial deletion ([seɪk]), Initial epenthesis ([əsˈneɪk]), or Medial epenthesis ([səˈneɪk]). Transcriptions also noted any additional segmental errors or abnormalities in the child productions. To validate, one of the other RAs independently transcribed 20% of each child’s target words. Inter-transcriber reliability for cluster categorization (i.e., CC or one of the four error types) was 94%. The remaining transcriptions in dispute were resolved in consultation with a third transcriber; these disputes were usually unrelated to the cluster at hand, but involved the segmental nature of a consonant (i.e., [sl] vs. [sw] or similar).
2.5 Predictions
At the end of Section 1, we introduced our broad hypotheses and predictions about children’s perceptual abilities on our two acceptability tasks. Here, we spell them out concretely, using the materials and conditions we have now introduced.
Under the assumption that children’s perception and production are closely aligned, we first expect more errors caused by deletion rather than epenthesis: in the discrimination task, this means that children should incorrectly judge pairs as “same” more often when the cluster repair is deletion ([fɹεg] ~ [ɹεg] or [fɹεg] ~ [fεg]) compared with pairs like [fɹεg] ~ [əfɹεg] and [fɹεg] ~ [fəɹεg]. In acceptability, when choosing the “best” pronunciation, children should preferentially choose a repair variant with deletion: [ˈfizəɹ] or [ˈɹizəɹ] for “freezer,” rather [fəˈɹizəɹ] or [əfˈɹizəɹ].
(An anonymous reviewer introduces a caveat to this prediction—that since epenthesis into English onset clusters is indeed sometimes observed, and if so found later in phonological development, we might in fact expect more difficulty with epenthesis errors as well. We note, nevertheless, that deletion errors are definitely the dominant cluster repair by English-learning children.)
If aligned with production errors, we also expect our children to show sensitivity to cluster sonority. Thus, we expect children to have more difficulty noticing or rejecting medial deletion than initial deletion when the cluster rises in sonority (e.g., more “same” answers for [fεg] ~ [fɹεg] than [ɹεg] ~ [fɹεg], and more mistakes on [ˈfizəɹ] rather than [ˈɹizəɹ] for freezer). This pattern should reverse for falling sonority clusters, sp and sk (e.g., more answers of “same” for [kib] ~ [skib] than [sib] ~ [skib], and more mistakes on [ˈkijɨŋ] rather than [ˈsijɨŋ] for skiing).
Among epenthesis repairs, sonority should also matter. Medial epenthesis removes the CC cluster entirely, /CCV/ → [CV.CV], while initial epenthesis preserves the cluster, though it now spans a syllable boundary, /CCV/ →[vC.CV]. In clusters with rising sonority, that cross-syllable boundary sequence is marked (see especially Baerstch, 2002; Gouskova, 2004), but less so for falling-sonority clusters (sp, sk). In clusters with rising sonority, we expect more perceptual errors with medial epenthesis, while in clusters with falling sonority we expect equal or more perceptual errors with initial epenthesis. In nonce-word discrimination, this would mean more “same” responses to [fɹεg] ~ [fəɹεg] than to [fɹεg] ~ [əfɹεg], but equal or more “same” responses to [skib] ~ [əskib] than to [skib] ~ [səkib]. In real-word acceptability, this would mean more erroneous choices of [fəˈɹizəɹ] for freezer than [əfˈɹizəɹ], but equal or more erroneous choices of [əsˈkijɨŋ] for skiing than [səˈkijɨŋ]. We note finally that other sC clusters might similarly show differences in repair types and locations, in line with previous production evidence (especially but not limited to s+nasal clusters).
If perceptual pressures that do not affect production are the dominant influence in this task, however, we would predict substantially different results. Most broadly, we would make the opposite overall prediction about repair type—that is, repairs with epenthesis errors should cause more inaccuracy instead of deletions, since vowel epenthesis into clusters is well known to be less salient than consonant deletion from a cluster (see esp. Fleischhacker, 2001; and see further discussion in Section 4). If a pressure for input contiguity is a dominant force, as raised in Section 1, we should also expect more errors on initial repairs, both deletion and epenthesis, rather than medial ones—that is, more errors on forms like [ˈɹizəɹ, əfˈɹizəɹ] for freezer and fewer on [ˈfizəɹ, fəˈɹizəɹ].
3 Results 1
3.1 Production
Children sometimes skipped production trials, either saying a word other than the target word (bowl instead of spoon, or toad instead of frog for example), or saying nothing at all on the trial. The largest number of trials a single participant skipped was 5 out of 22. Seven participants skipped at least one trial. Recordings from five participants could not be analyzed due to technical problems.
Unsurprisingly, children were overall accurate in their onset cluster production, which is consistent with their age range (4–7 years). Out of a total 444 productions, there were a total of 24 cluster repair errors (meaning 95% accurate #CC production). Children differed from each other in their rate of production errors, but a majority of them made at least one error. Seven children made no cluster repair errors at all. One participant made five cluster repair errors, including both initial deletion errors and two of the medial epenthesis errors. All other participants made three or fewer errors.
The most predominant repair were 14 medial deletions (i.e., C2 deletion), compared with 2 initial deletions; there were 3 epenthesis errors, all medial and none initial. 2 Figure 3 shows the distribution of production errors across clusters. Clusters are arranged in order of sonority: pj being the largest sonority rise, and sk and sp being sonority falls.
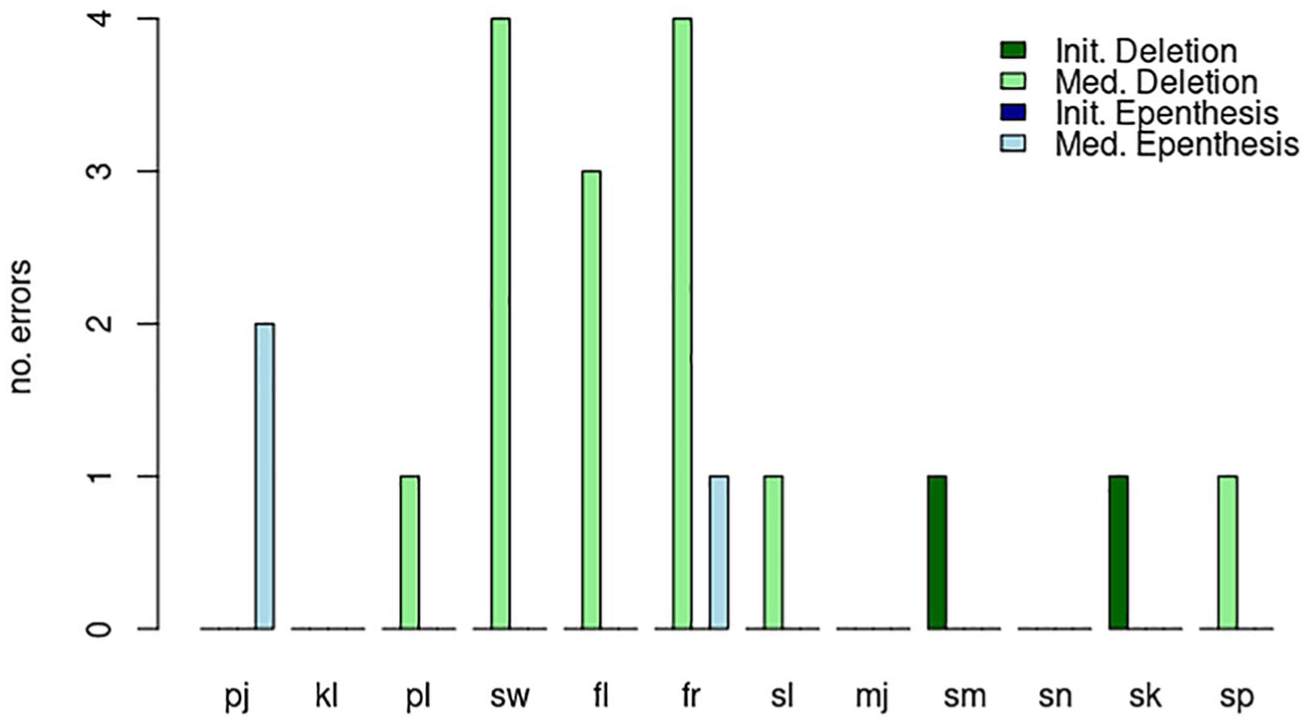
Production errors by cluster type.
Figure 3 shows no clear relationship between deletion errors and cluster sonority. The predominant repair was deletion of a C2 approximant (/l, r, w/), but the target clusters they were deleted from are generally felicitous in terms of their sonority profiles. As for epenthesis, 2/3 errors targeted “piano,” which we believe reflect an alternative pronunciation for this word which adults also accept ([pɨˈænoʊ]), rather than a true cluster repair.
Transcribers also identified 32 segmental errors within onset clusters pronunciations, which targeted four segment types: 12 /s/ errors, produced as either [ʃ], [θ] or [t]); 7 errors mapping /r/ to [w]; 9 /l/ errors, mapped to either [w], [ɫ] or a lateral fricative; 4 errors of denasalization, thus mapping /m/ → [b] or /n/ → [d]. We suspect that it is not an accident that we observed a large proportion of segmental errors on /r/ and /l/, which were also more frequent targets of cluster deletion—that is, that some of children’s deletions might be driven by segmental rather than cluster pressures.
We also examined the distribution of production errors by age of child, pictured in Figure 4. Our median age was 68 months (5;8). Children below this age made multiple types of errors, while children above or equal to 68 months old only made Medial Deletion errors (deletion of the second consonant, as in [seɪk] for [sneɪk]).
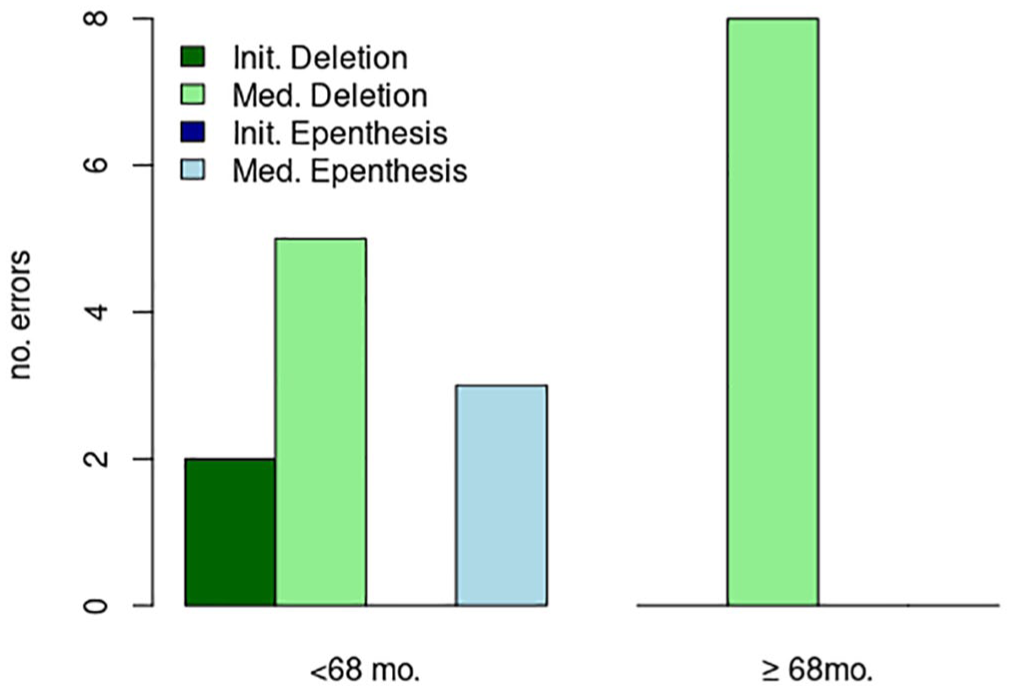
Production errors by age.
The clearest finding from our production task is that overwhelmingly, the children in our study produce onset clusters of all sonorities accurately. To the extent they make production errors, they are mostly medial deletion errors.
3.2 AX nonceword discrimination
Recall that the nonce word task had five condition types: half of the trials were “same” trials, with the aliens both producing the word-initial onset cluster; the other half were “different” trials, split across the four repair conditions, deletion versus epenthesis and initial versus medial position. In these tasks, “accuracy” refers to children’s correct classification of the two tokens as same or different.
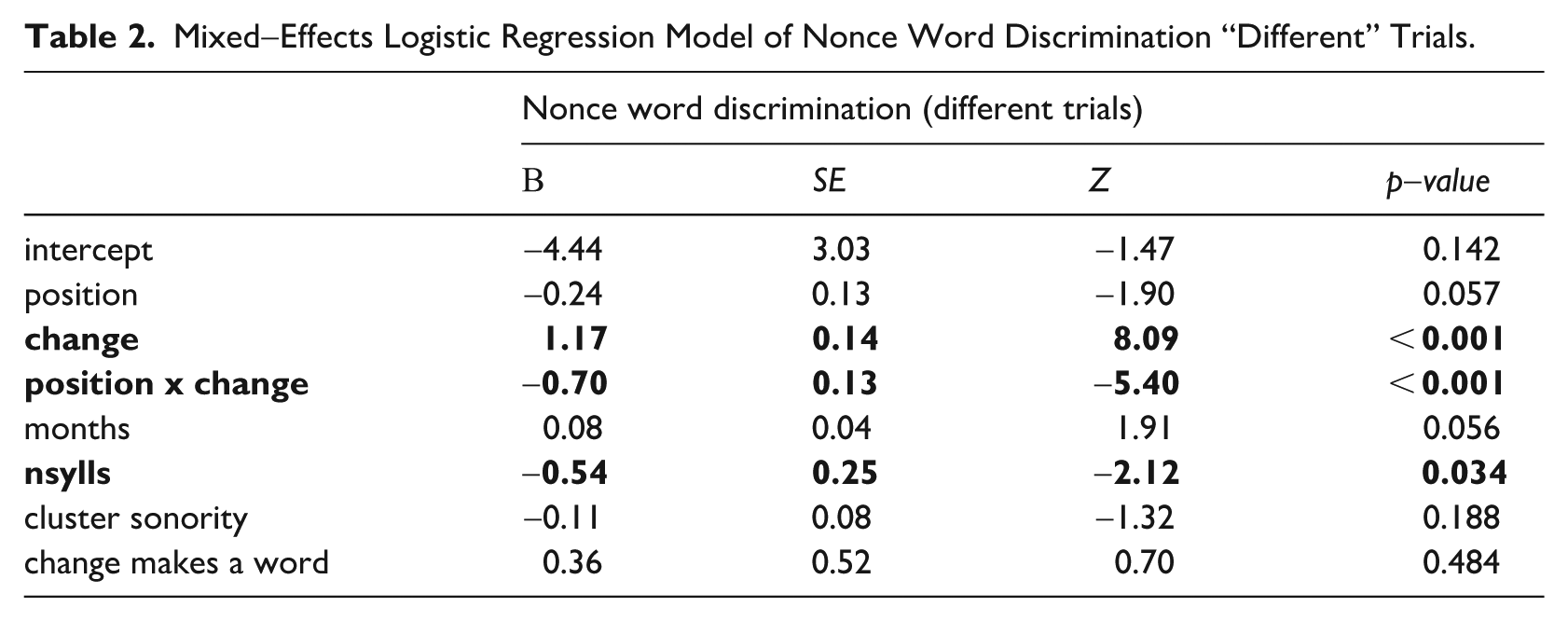
Children’s accuracy data is first summarized in Figure 5. The rightmost bar shows that children are quite accurate in judging two #CC tokens as “same,” but among the four “different” trials they show clear differences in accuracy, between both repair position and type. Error bars represent 95% confidence intervals (using the Wilson method).
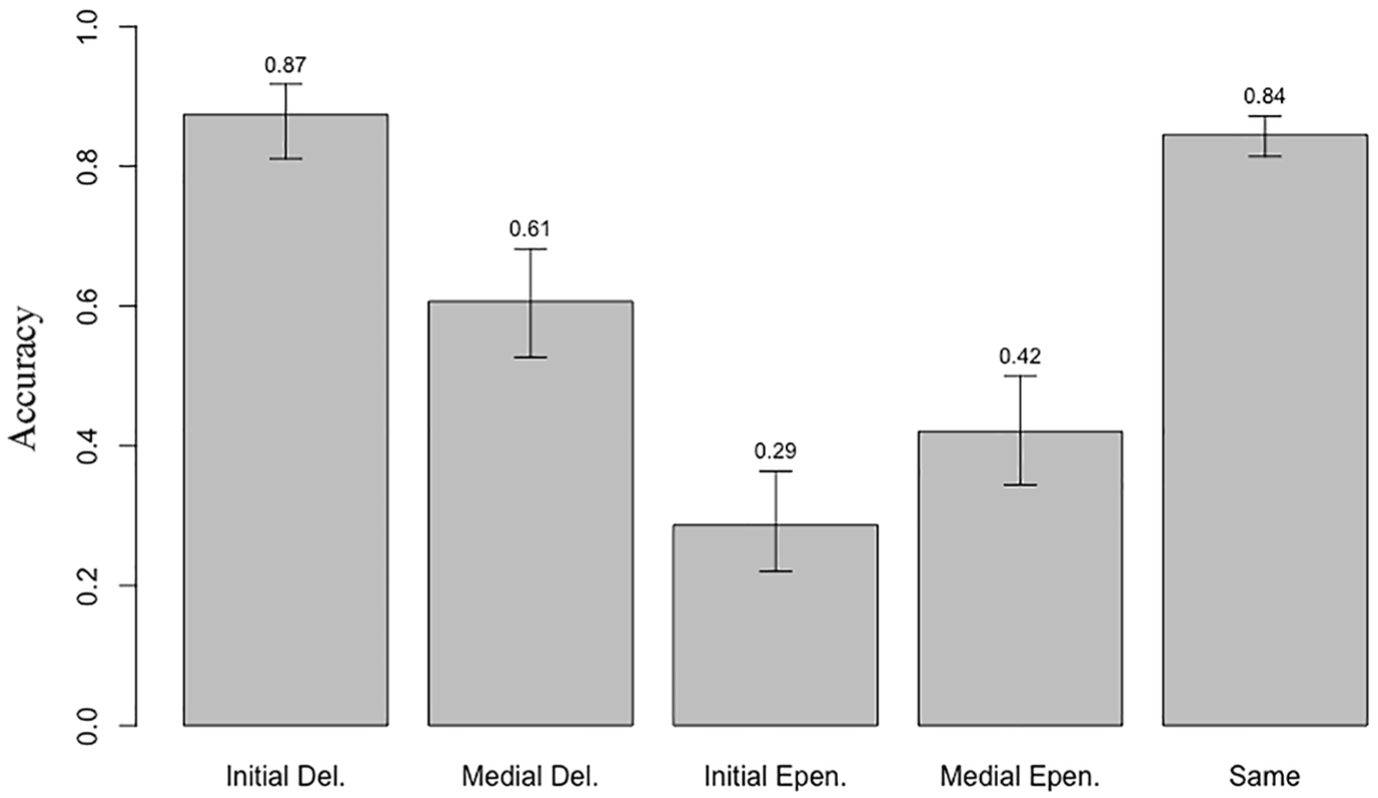
AX nonceword discrimination accuracy rates by condition (change and position).
3.2.1 Predictors
To investigate the influence of our predictors on children’s accuracy, we fitted the “Different” trials data to a mixed-effects logistic regression model in R (R Core Team, 2018). The dependent variable was accuracy, with position, change, and cluster sonority as main effects of interest. Random intercepts were included for participants, but not for items. Neither random intercepts by item, nor random slopes by participant (or item) could be fit in this case, since we had relatively few items per condition (especially when cluster sonority is taken into account), and relatively few observations per participant for each condition. Accuracy was coded as correct or incorrect, with incorrect as the baseline so that positive coefficients correspond to greater accuracy. Position and change were both sum-coded, with medial as 1 and initial as −1 for position, and deletion as 1 and epenthesis as −1 for change. Cluster sonority was a continuous variable, corresponding to the sonority difference between the first and second consonant in each cluster. We use a standard sonority scale (Jespersen, 1904): (3)
Cluster sonority was calculated as the sonority of the first segment, minus the sonority of the second. The lowest sonority difference was -1 for sk and sp; the highest was 4 for pj.
Some of our nonwords formed a word when they underwent deletion. For example, the nonword [pjʌk] forms the word “yuck” when it undergoes initial deletion, [jʌk]. Because of this, participants may have been more easily able to discriminate between [pjʌk] and [jʌk] than between pairs where neither was a word, like [sneɪs] and [neɪs]. To model this effect, if it exists, we included the variable “change makes a word,” coded “yes” for trials like [pjʌk] ~ [jʌk] and “no” (the baseline) for trials like [sneɪs] ~ [neɪs].
We also included the number of syllables (hereafter “nsylls”) in each item as a continuous variable, though it only took values of 1 or 2. We included this factor because we thought accuracy might be worse on longer words—at least in our real word task, since word length is frequently correlated with early productions of real words (see variously Jones & Brandt, 2019; Kehoe et al., 2023; Maekawa & Storkel, 2006). An anonymous reviewer rightly points out that the difference in length between one and two syllables does not appear to matter in non-word repetition tasks, where “longer” words mean at least three syllables and up (see dos Santos & Ferré, 2018, and references therein), so we might have expected less of an effect of length in our nonce word task. Finally, we also included in the model each child’s age in months (hereafter “months”). 3
3.2.2 Model fitting
We included all main effects listed above, as well as an interaction between position and change. Other interactions were considered, such as interactions between cluster sonority and position, or cluster sonority and change, as well as interactions between months and position, change, or cluster sonority, but our model did not converge with the inclusion of these interactions. Our final model structure is given in (4), and the resulting fit is given in Table 2.
(4) accuracy ~ position * change +months + nsylls + cluster sonority + change-makes-a-word + (1|Participant)
Mixed-Effects Logistic Regression Model of Nonce Word Discrimination “Different” Trials.
3.2.3 Effects
Significant effects were found for change, and the interaction between position and change. Children were more likely to correctly say “different” when the cluster was repaired with deletion ([fɹεg] vs. [fεg] or [ɹεg]), than when it was repaired with epenthesis ([fɹεg] vs. [fəˈɹεg] or [əfˈɹεg]). This effect was especially strong in initial position, meaning that the difference in accuracy between [fɹεg]~[ɹεg] and [fɹεg]~[əfˈɹεg] was greater than the difference between [fɹεg]~[fεg] and [fɹεg]~[fəˈɹεg].
Number of syllables had a significant effect on accuracy, indicating that children made more errors on the longer bisyllabic items than on the shorter monosyllabic items. Neither children’s age in months nor cluster sonority were significant predictors, nor was whether or not the cluster repair make a real word (so children were not more likely to notice repairs like [pjʌk] ~ [jʌk] than [sneɪs] ~ [neɪs]).
3.3 AFC real word acceptability task
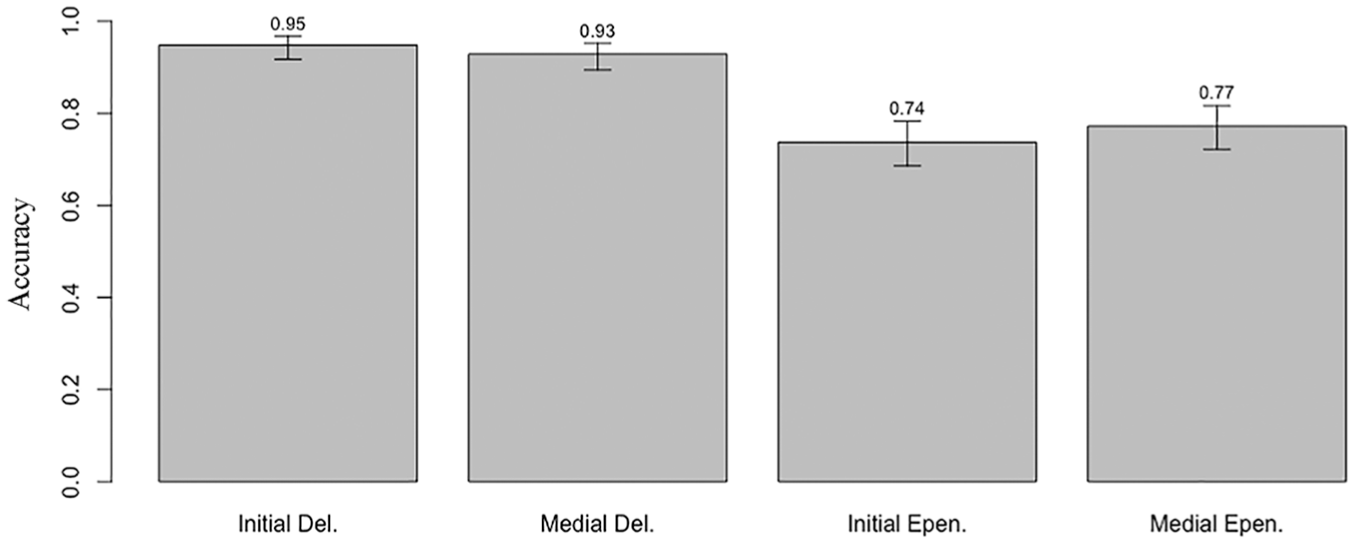
In this task, children were asked to choose which alien “said it best,” so that accuracy reflected choosing the correct pronunciation of a real word which began with a cluster and rejecting one of the four repaired variants of that word. As in the nonce word discrimination task, children’s accuracy showed clear differences between both position and change. Figure 6 shows these differences, with 95% confidence intervals as before.
Children’s real-word acceptability accuracy rates, by condition.
Overall, children were much more accurate in this real word judgment task compared with the nonceword task reported earlier; this may mean that performance is at ceiling in some conditions, so that there is less to interpret among predictors.
3.3.1 Predictors
As in the nonce word discrimination task, our dependent variable was accuracy. We considered the same predictors as well, with the same baselines: position, change, cluster sonority, syllable count, age in months (months), and whether or not the change made a word.
3.3.2 Model fitting
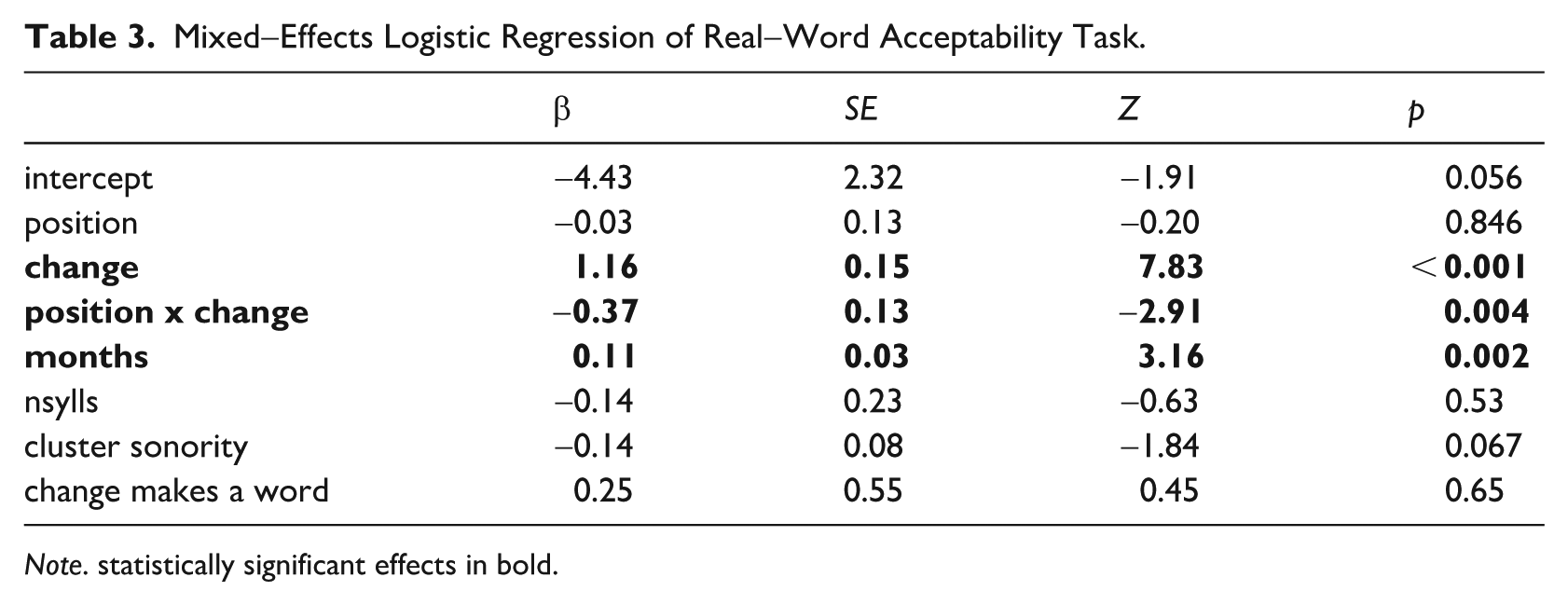
As before, we included all our main effects and the interaction between position and change. Additional interactions failed to converge. Our model structure is given in (5), and our model fit is given in Table 3.
(5) accuracy ~ position * change +months + nsylls + cluster sonority + change-makes-a-word + (1|Participant)
As in the nonce-word discrimination task, significant effects were found for change, and the interaction between position and change. Children were more likely to incorrectly choose an epenthetic repair (əˈfɹɑg, fəˈɹɑg) than to incorrectly choose a deletion repair (ɹɑg, fɑg), and they were especially more likely to do so with initial epenthesis (əˈfɹɑg) than with initial deletion (ɹɑg). We did not find a significant effect of the word’s number of syllables, or of the sonority of the onset cluster, but we did find a significant positive effect of the child’s age in months, indicating that older children gave more correct responses than younger children.
Mixed-Effects Logistic Regression of Real-Word Acceptability Task.
Note. statistically significant effects in bold.
Figure 7 shows the effect on errors of a child’s age, split up by repair condition. In all cases, younger children made more errors than older children, but this effect was numerically stronger for epenthesis errors than for deletion errors.
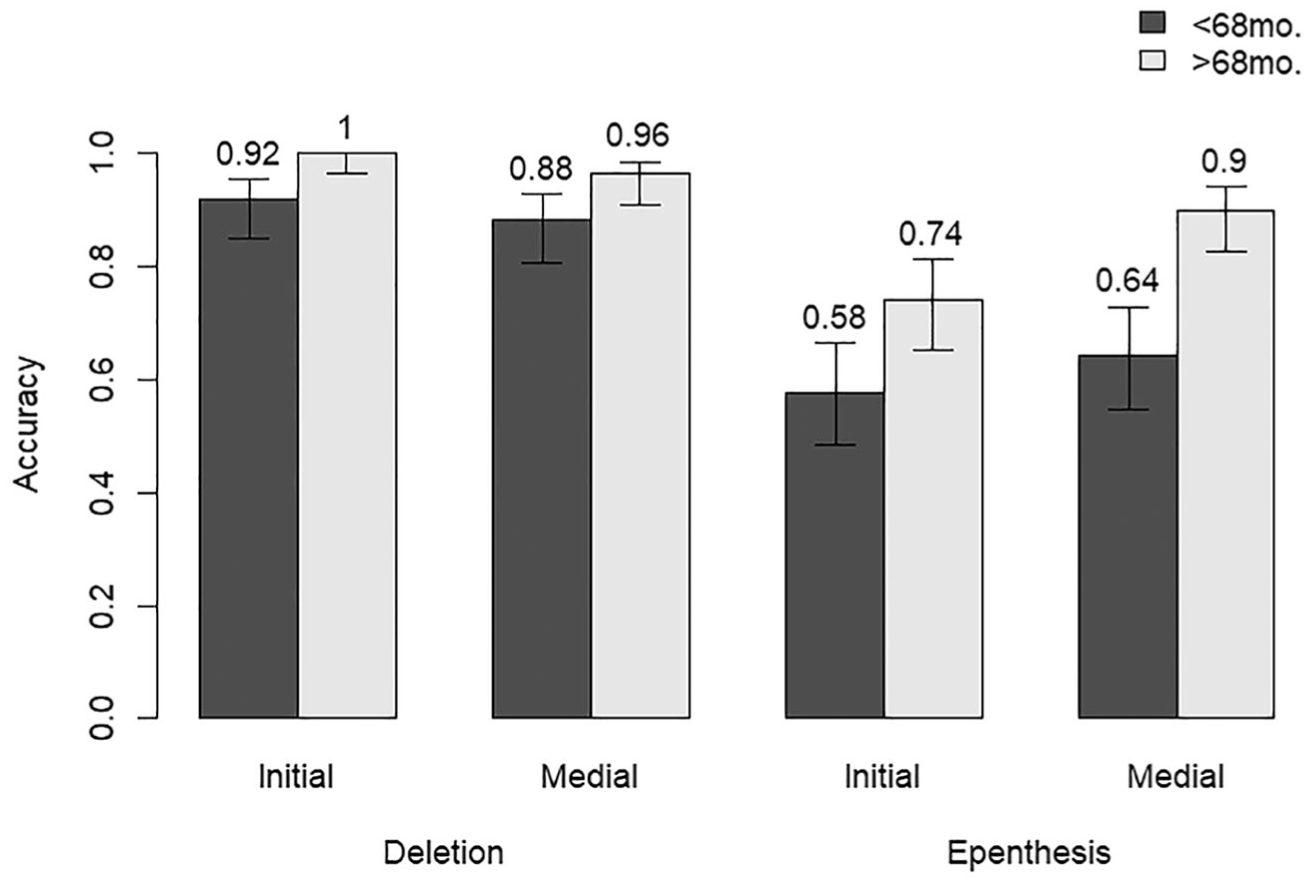
Real word errors by condition split by months.
3.4 Adult nonce word discrimination
As foreshadowed in Section 1, Figure 8 provides AX Nonce-word discrimination data from our adult participants. Three language groups were determined according to their answers on the background questionnaire: (1) L1 English monolinguals, who serve as controls for our L1 child data, (2) adult bilinguals, and (3) advanced L2 English learners. This is the only task which we report from the adult study, as accuracy rates in the production and real-word acceptability were overall near ceiling with all adult groups. (See Appendix B for further data on the adult study, including our criteria for determining the participant groups, the languages spoken by our bilingual and L2 speakers, and error rates and further analysis of adult’s real word judgments.)
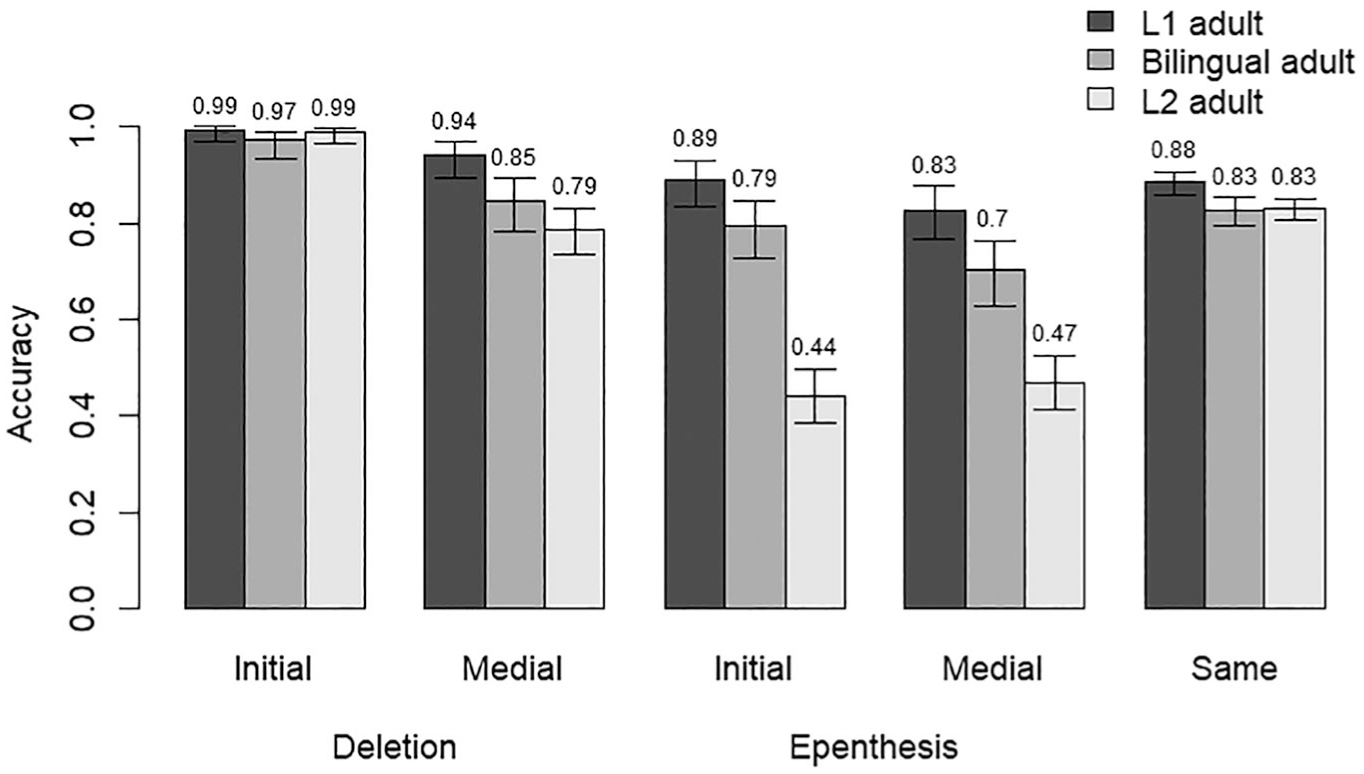
Adult nonceword discrimination accuracy rates by condition.
In fitting our regression model, we began with the same model structure that we used in the child nonword task, but added the language group factor, and allowed it to interact with position, change, and cluster sonority. The variable of age in months was not included. Our L2 speakers had a range of ages of first exposure to English, from 3 to 12 years (median 6). The model structure is shown in (6) and the fitted model is shown in Table 4.
(6) accuracy ~ position * change + language group*change + language group*pos + language group*cluster sonority + nsylls + change makes a word + (1|Participant)
Position and change are both significant predictors—initial repairs were easier to detect than medial, and deletion repairs were easier to detect than epenthesis—and their interaction is significant. As with children, syllable count was significant in that participants made more errors on bisyllabic words than on monosyllabic words. The significance of both bilinguals and L2 speakers as compared with L1 monolinguals (as baseline) shows that both bilinguals and L2 speakers made more errors overall than L1 monolinguals. Interactions between language group and either position or change were not significant, but there was a significant interaction between cluster sonority and the L2 language group, as well as a significant main effect for cluster sonority. The effect of cluster sonority was negative, meaning that L1 adult participants (the reference level of language group) made more errors on clusters with large sonority falls than on clusters with small sonority falls, or sonority rises. One possibility is that this effect is driven by pj clusters, which had the very highest sonority fall, but are somewhat marked in English and often repaired (as in [piˈænoʊ], rather than [ˈpjænoʊ]). On the other hand, the interaction between L2 language group and cluster sonority was positive, indicating that the advantage L1 speakers had on accuracy was smaller for clusters with larger sonority falls. Figure 9 illustrates how accuracy changes across cluster types for each language group.
Logistic Regression of Adults’ Nonword Discrimination Task.
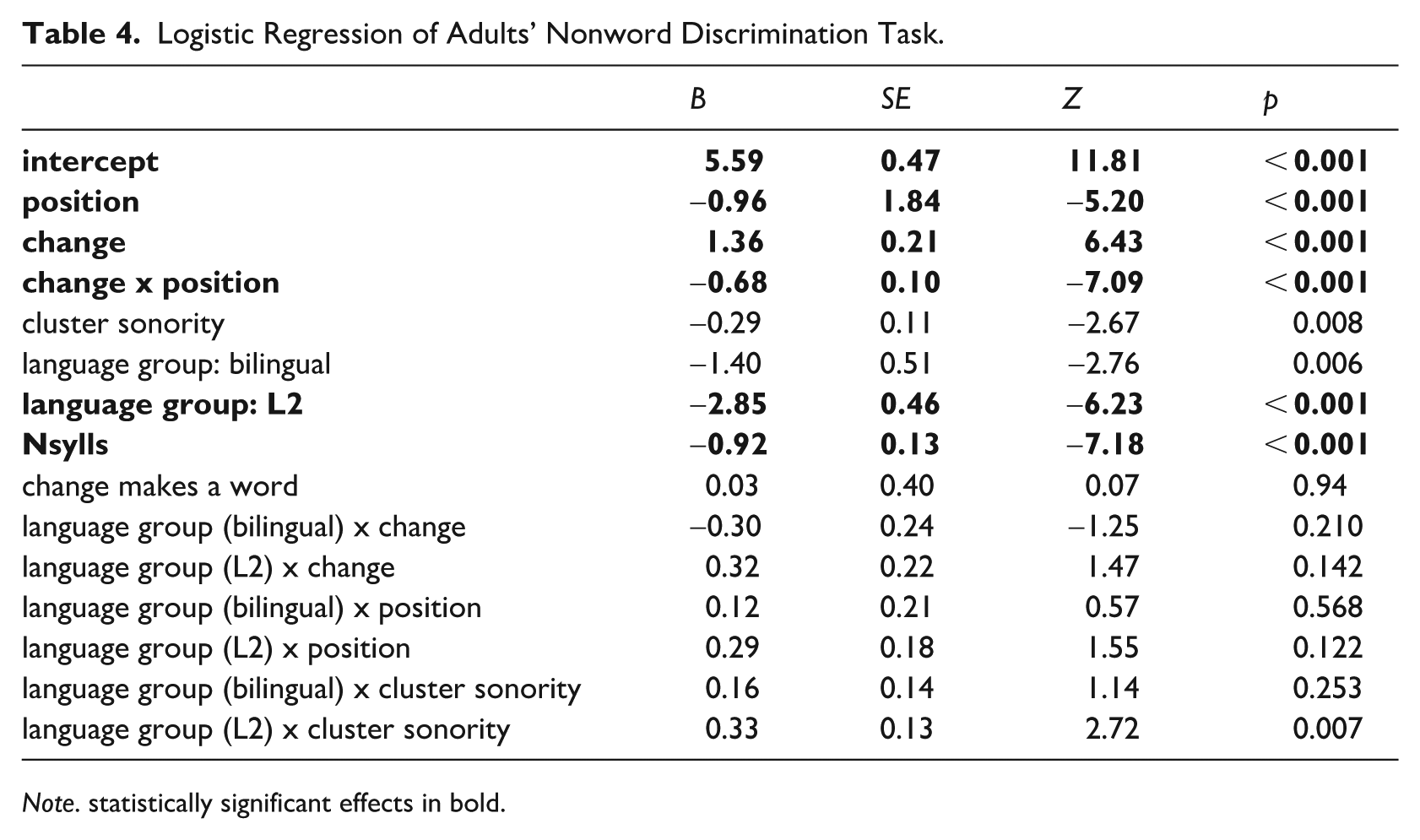
Note. statistically significant effects in bold.
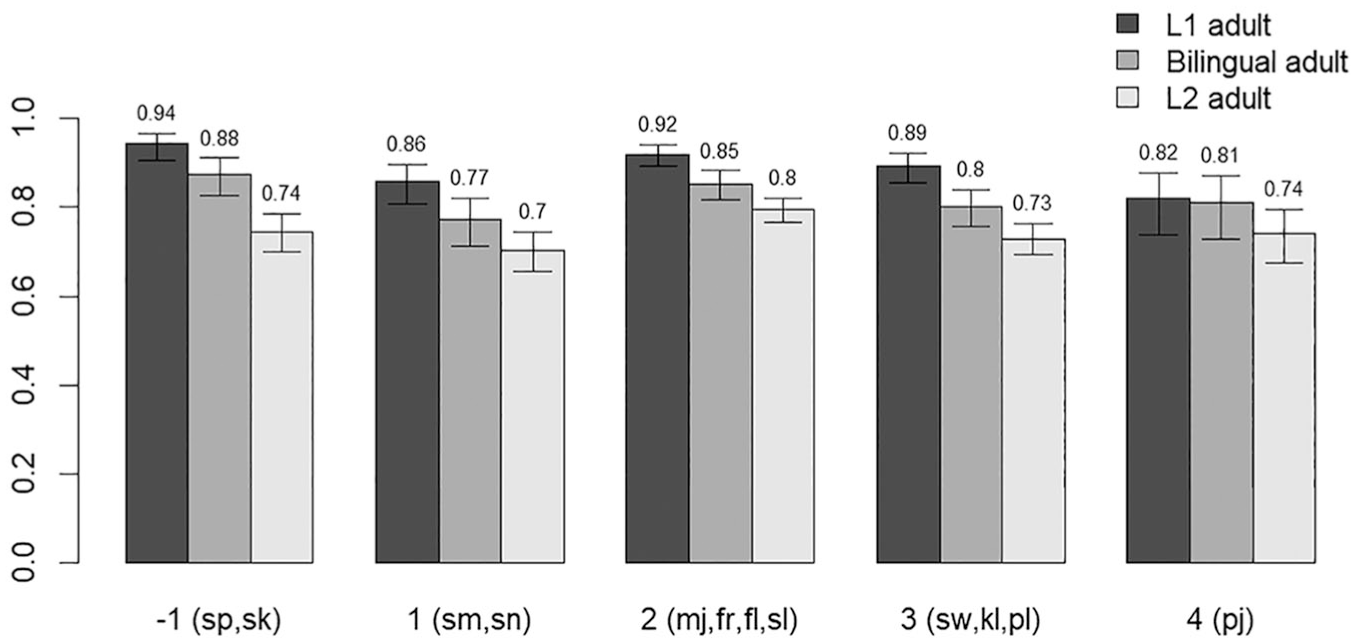
Adult nonceword discrimination accuracy rates by cluster type.
4 Discussion
In this study, 4- to 7-year-old children produced a set of familiar English words with initial onset clusters, and were asked to judge and recognize the difference between these same clusters and their potential repairs, in both real and nonce words. What we found overall was that children were quite accurate in producing clusters, but that their ability to reject mispronunciations of those clusters was considerably less accurate, particularly for nonce words. In production, the predominant though infrequent error type was medial deletion; in the judgment tasks, children made more of their mistakes with epenthesis repairs, especially initial epenthesis. The sonority profile of clusters had no significant influence on judgment accuracy for either nonce words or real words. In addition, similar results were found for adult Monolingual, Bilingual, and L2 English speakers, where again the mistakes were most often on epenthesis repairs, especially initial epenthesis.
We conclude first that this domain of onset clusters, at least as tapped by our judgment tasks, is one in which learners’ abilities to make perceptual judgments lags considerably behind their production. Second, we observe our participants’ perceptual errors did not pattern directly with typical production errors from younger children. Most obviously, they made the majority of their errors on epenthesis repairs, in both the real and nonce word judgment tasks. They also showed no sensitivity to cluster sonority, which is striking given the centrality of cluster type in many children’s production grammars. Focusing just on epenthesis, we found consistently that initial repairs were harder to reject than medial ones, which does not align with child production facts.
When considered alongside our child data, the adult participants provide evidence of a few things. First, the very high accuracy of the monolingual adult controls rules out the uninteresting possibility that our materials were flawed—if our intended true cluster stimuli sounded like they contained epenthetic segments, perhaps any listener would have a reasonable chance of perceiving an initial or medial schwa even in the /CC/ target items. Instead, when any of our adult groups did make errors, those errors patterned similarly to children’s errors. We therefore interpret this error pattern as reflecting developing knowledge of English, regardless of age.
With respect to comparison between our participants’ perceptual errors and expected production errors, the landscape for adult L2 learners is somewhat mixed. To briefly summarize a very large literature: both deletion and epenthesis repairs are observed in the production of L2 English onset clusters, although epenthesis is considerably more common (on deletion, see, for example, Eckman and Iverson (1993) for L1 Cantonese and Korean speakers; see Campbell (1998) for Finnish; on epenthesis see, for example, Carlisle (1994), for L1 Spanish speakers; Broselow (1992) for L1 Arabic speakers; for epenthesis as the dominant L2 strategy, see, for example, Paradis & LaCharité, 1997). We also note that in Mandarin, the most common first language in our L2 group, deletion and epenthesis are both observed (e.g., Walden, 2014). In Mandarin borrowings of English words, epenthesis is the predominant repair but almost exclusively in cluster-medial position—for example, “brandy” → [
4.1 Interpretations of perceptual influences
As we have already highlighted, the errors that our learners made in judging onset clusters versus singleton repairs appear to diverge significantly from the principles that govern errors in onset cluster production. Instead, the asymmetries in accuracy between error types and positions seem to be led by perception-only principles, which we now discuss in turn.
1. In our perceptual tasks, why is deletion easier to recognize and reject compared with epenthesis? We see at least two types of available explanation. One is that accuracy is predicted by the perceptual similarity of the cluster versus its various repairs, given that epenthesis as an onset cluster repair is reliably judged as more similar to the target than deletion (see Steriade (2001/2008), relying on discussion in Fleischhacker (1999) and Wingstedt & Schulman (1988); see also Flemming (2001)). This pressure has frequently been related to asymmetries in phonological learning but mostly with L2-learning adults, as well as with loanwords and borrowings (e.g., Adler, 2006; Kang, 2003; Kenstowicz, 2001). Our results would suggest that the perception grammars of
Another explanation is a preference for recoverability (e.g., Jun, 2004; Silverman, 1997; Wright, 1996): compared with a CC cluster, an epenthesis repair at least maintains all the input material, and so allows the listener to recover all the underlying content. For the specific choice between deletion and epenthesis in terms of recoverability in the acquisition literature, see especially Weinberger (1987, 1994) about L1 learning, and Abrahamsson (2003) and Alelaiwi and Weinberger (2022) about adult L2 learning.
2. Among epenthesis repairs, why is initial epenthesis harder to recognize and reject compared with medial, especially for child learners? We suggest that this is a special case of recoverability and/or similarity to target—because in addition to retaining all the target string’s material, epenthesizing a vowel before the cluster keeps all of the input segments contiguous as well, thus also preserving the transitions between the cluster’s two consonants, and from the second consonant into the first vowel (see especially Wright, 2001, and references therein). Many phonological grammars and patterns have been explained as preserving contiguity (Lamontagne, 1996), but in children’s onset cluster production its influence has been rarely observed (although cf. van der Pas, 2004).
An anonymous reviewer raises the interesting point that initial epenthesis repairs might be especially hard to reject if the learner’s grammar has parsed the target clusters as coda-onset sequences. In other words: if the target “spoon” is phonologically treated as [s.p]oon, then a repair like [əs.p]oon is rather similar to the target. This proposal about the phonological structure of initial clusters has been made especially for clusters with sonority reversals, that is, s+stop clusters, but potentially some or all sC clusters as well (see especially discussion of the theoretical options in Goad, 2011). We do not discount this possibility out of hand, for both younger children learning English onset production as well as the older children in our study.
3. Among deletion repairs, why is initial deletion sometimes easier to recognize and reject compared with medial? Unlike the above two patterns, here our perceptual results match the typical production data more closely. From the perceptual perspective, this effect reflects the well-known salience of word-initial segments, which has been well established in much of the speech processing and word recognition/access literatures (e.g., Marslen-Wilson & Zwiterslood, 1989; Norris, 1994; Shattuck-Hufnagel, 1992; Vitevitch et al., 2004 interalia). A variant of a target item which begins with the wrong first segment will be much easier to recognize as different, and/or correctly rejected.
We note that the principles in 2 and 3 do in fact conflict, between deletion and epenthesis repair patterns. The more common error we saw among deletions preserves the salient first input segment, at the expense of input contiguity; the more common epenthesis error, however, preserves contiguity at the expense of matching input and output first segments. We flag this conflict as a topic for future investigation.
Finally, the highly limited or missing influence of sonority sequencing and segmental content also emphasizes that the influences on our perceptual results go beyond those of production grammars. We especially note this with respect to learners’ poor performance in rejecting initial epenthesis errors—because if these repairs were intended to remove the complexity of an onset cluster, initial epenthesis would only help if the cluster were interpreted as a coda-onset sequence, and such a syllabification would be dispreferred on sonority grounds for all but the s-stop and s-nasal clusters. Instead, we found no effect of sonority in our child data. It should be noted, however, that we did not ultimately have enough data to fit an interaction term between cluster sonority, position, and change. Such an interaction would be the proper way to test for the influence of sonority, since it is predicted to have different effects depending on the repair type and location.
As concerns sonority, our results are very different from some previous studies which asked children to judge illegal onset clusters as did Pertz and Bever (1975) and Berent et al. (2011), both discussed in the introduction. In our task, where children were instead judging clusters and singletons that are legal in their language, segmental content and sonority considerations were unimportant. Whether this difference should be attributed to legality of the clusters, the more lexical nature of our task, or something else entirely, is worthy of further investigation beyond this study.
We also noted in Section 2 our carrier phrases for nouns (and the few verbs in the real word task) were designed to minimize the possibility of morphological parsing errors in the initial epenthesis condition. That is, if a learner perceived the initial schwa as the indefinite article “a,” rather than an epenthetic segment, they would have to parse the sentences as, for example, *“Look at that a freezer!” and *“Look at her a sleeping” which are clearly syntactically ill formed. (We do note that it might be possible for some listeners to have interpreted these initial schwas as “uh. . .” hesitations, although we would argue that the carefully-controlled fluidity of the rest of the materials makes this possibility unlikely as a full explanation for the low accuracy rates on initial epenthesis trials.)
4.2 Concluding remark
The biggest takeaway of our study, we believe, is that the later stages of fine-tuning in children’s phonological development remains a fairly understudied area—and that in some tasks, older children with solid production accuracy can still show considerable gaps in their perceptual abilities. Much may be revealed about how grammars for both perception and production are learned and later refined by considering the full trajectory of children’s acquisition process. Here, we perhaps see evidence that perceptual pressures more commonly thought to influence L2 adult learners are already driving the bulk of L1 learner’s responses as young as age four—but much more study is needed. To the extent that further studies find perceptual judgments lagging behind production accuracy in later childhood, we see a need for theoretical frameworks that can capture these later phases of development.
Footnotes
Appendix A
Appendix B
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was in part funded by SSHRC Insight Grant # 435-2015-0176, awarded to the second and third authors.