
Abstract
Adapting one’s speaking style is particularly crucial as children start interacting with diverse conversational partners in various communication contexts. The study investigated the capacity of preschool children aged 3–5 years (n = 28) to modify their speaking styles in response to background noise, referred to as noise-adapted speech, and when talking to an interlocutor who pretended to have hearing loss, referred to as clear speech. We examined how two modified speaking styles differed across the age range. Prosody features of conversational, noise-adapted, and clear speech were analyzed, including F0 mean (Hz), F0 range (Hz), energy in 1–3 kHz range (dB), speaking rate (syllables per second), and the number of pauses. Preschoolers adjusted their prosody features in response to auditory feedback interruptions (i.e., noise-adapted speech), while developmental changes were observed across the age range for clear speech. To examine the functional effect of the modified hyper-speech produced by the preschoolers, speech intelligibility was also examined in adult listeners (n = 30). The study found that speech intelligibility was higher in noise-adapted speech than in conversational speech across the preschool age range. A noticeable increase in speech intelligibility for clear speech was observed with the increasing age of preschool talkers, aligning with the age-related enhancements in acoustic prosody for clear speech. The findings indicate that children progressively develop their ability to modify speech in challenging environments, initiating and refining adaptations to better accommodate their listeners.
1 Introduction
For effective communication, which is critical to learning and development, children need to acquire the ability to adapt their speech to meet their interlocutors’ communicative needs in everyday communication, especially in difficult communicative environments. However, it is unclear if young children can change their speaking styles by exaggerating acoustic prosody cues to eventually enhance speech intelligibility for their listeners. Adult talkers speak in a way that is intelligible to the listener by modifying their speaking styles in difficult communicative environments. According to Hyper- and Hypo-articulation Theory (H&H theory, Lindblom, 1990), adult talkers dynamically adjust their speech production at a minimal cost between the hyper- and hypo-speech continuum as communicative demands change. Hyper-speech occurs when talkers adapt their speech in response to challenging conditions, including the presence of environmental noise (noise-adapted speech) or talking to listeners who have difficulty understanding them (clear speech). Perceptually and acoustically modified speech production is successfully performed when talkers equip themselves with the ability to identify interlocutors’ communicative needs. If talkers notice listeners’ additional needs to understand them, they naturally adapt their speaking style (i.e., hyper-speech) to promote successful communication in challenging communicative environments.
Previous findings revealed that in adult talkers, compared to conversational speech (i.e., hypo-speech), both noise-adapted speech and clear speech (i.e., hyper-speech) are characterized by more salient acoustic features (Cooke, King, et al., 2014; Godoy et al., 2014; Hazan & Baker, 2011; Smiljanić & Gilbert, 2017a; Tuomainen et al., 2021; Van Engen et al., 2012). Both hyper-speaking styles are commonly characterized by showing a slower speaking rate, increased vocal pitch (F0 mean), exaggerated pitch (F0 range), louder vocal intensity, and greater energy in medium frequencies. Distinct acoustic characteristics of speech modification between noise-adapted speech and clear speech were also reported (Gilbert et al., 2014; Godoy et al., 2014; Smiljanić & Gilbert, 2017a). For example, Smiljanić and Gilbert (2017a) examined conversational and clear speech in quiet and noise. They found a significant energy enhancement in 1–3 kHz, from conversational to clear speech, but this enhancement was only observed in quiet conditions, not in the presence of noise. In their descriptive result in Table 1 (Smiljanić & Gilbert, 2017a, p. 3086), the energy in 1–3 kHz was already greater for both conversational and clear speech in noise than for clear speech in quiet. In addition, more pauses were observed in conversational to clear speech compared to the number of pauses in quiet to noise (Smiljanić & Gilbert, 2017a). Based on these findings, the current study also examined acoustic features, including the number of pauses and energy in 1–3 kHz, in addition to F0 measures and speaking rate, to investigate whether preschooler-aged children demonstrate similar distinct differences in acoustic features between noise-adapted and clear speech.
Demographic Information About Children.
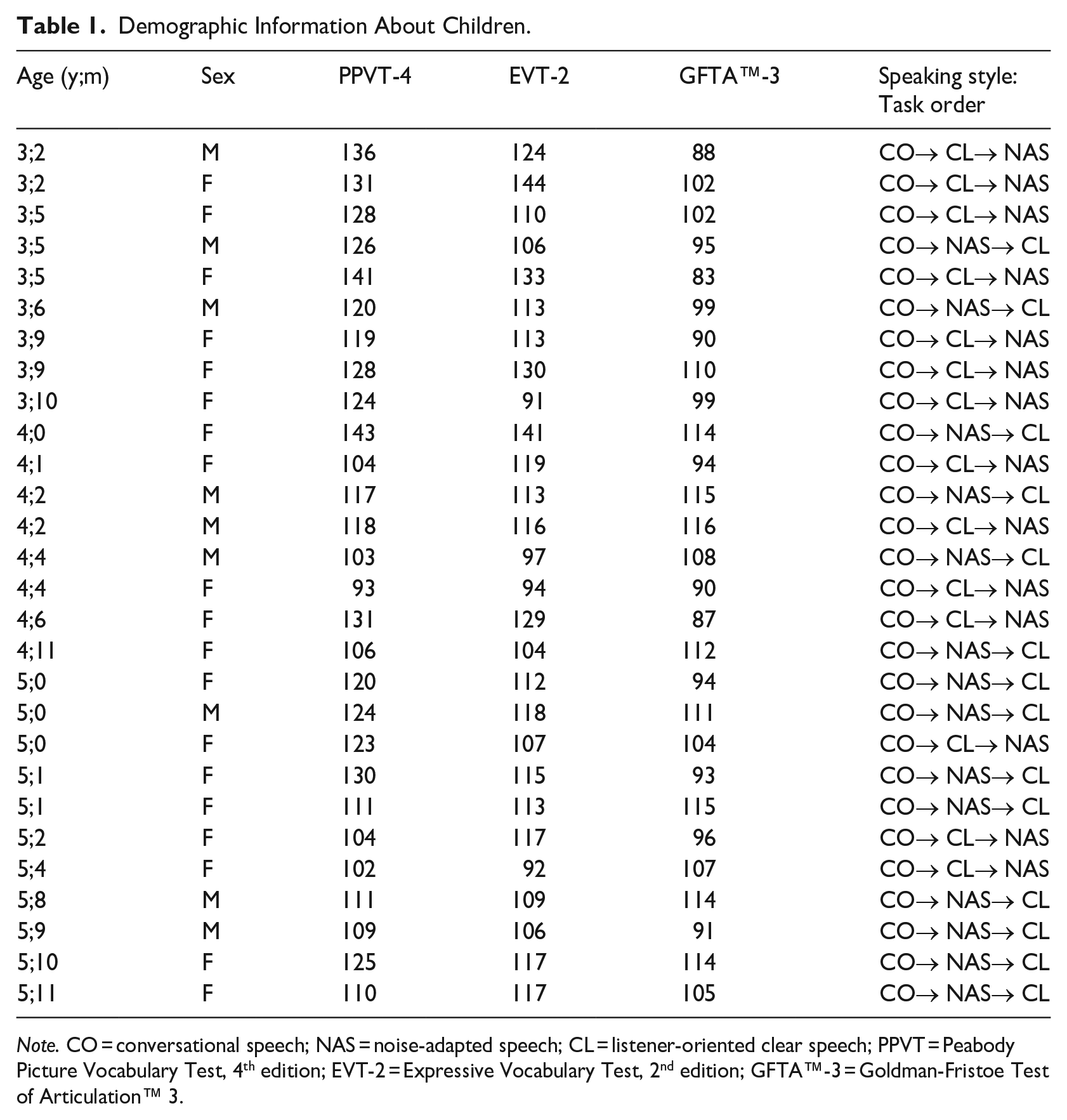
Note. CO = conversational speech; NAS = noise-adapted speech; CL = listener-oriented clear speech; PPVT = Peabody Picture Vocabulary Test, 4th edition; EVT-2 = Expressive Vocabulary Test, 2nd edition; GFTA™-3 = Goldman-Fristoe Test of Articulation™ 3.
The difference between the two hyper-speaking styles can be ascribed to specific communication challenges, such as environmental-related and interlocutor-related challenging communicative situations (Cooke, King, et al., 2014; Smiljanić, 2021). In the presence of background noise, talkers increase their vocal effort to compensate for the auditory interference, a phenomenon known as Lombard speech (Lombard, 1911). Noise-adapted speech is often considered a reflexive and involuntary response to noise as talkers increase their vocal effort without full conscious or voluntary control due to the auditory disruption in hearing their own speech (Tuomainen et al., 2021). The partially involuntary speech modification, noise-adapted speech, was observed in preschool-aged children. Specifically, children between the ages of 3 and 5 demonstrated increased vocal intensity when exposed to background noise (Garber et al., 1980; Siegel et al., 1976). On the other hand, clear speech is a more voluntary form of speech modification than noise-adapted speech. In clear speech, talkers increase their vocal effort to make their speech easier for their interlocutors to understand, even in the absence of auditory interference. Without actual disturbance of aural perception, the ability to account for the listener’s need is required to perform clear speech for effective communication. Typical adult talkers are conscious of how their listener perceives their speech to recognize if interlocutors can identify their speech signals or messages without direct exposure to the communicative challenge (Hazan & Baker, 2011). Perceptually and acoustically modified speech production is successfully performed when talkers equip themselves with the ability to identify interlocutors’ communicative needs (Cooke, King, et al., 2014; Hazan & Baker, 2011; Smiljanić & Gilbert, 2017a; Van Engen et al., 2012). Smiljanić and Gilbert (2017a) found that clear speech involves more frequent pauses, suggesting that incorporating these pauses may facilitate lexical access and reduce cognitive efforts for their listeners (Smiljanić, 2021). However, the extent to which clear speech involves more frequent pauses was much smaller in children (ages 11–13 years) than that in adult talkers.
During preschool, children undergo active and intricate developmental changes in speech-motor control (Green et al., 2000; Lee et al., 1999) and socio-cognitive ability to identify others’ perspectives and common ground with interlocutors (Graham et al., 2017). Substantial changes in speech-motor control become apparent as children integrate new sounds into their phonological system and expand their vocabulary size at around age two (Green et al., 2000, 2002; Nip et al., 2009). Prosody in speech production, characterized by suprasegmental acoustic features, starts developing in early childhood, but the refinement of prosody skills continues into adolescence (Wells et al., 2004). Regarding socio-cognitive development, it is widely recognized that socio-cognitive abilities typically emerge around the age of 4, often without formal instruction (Korkmaz, 2011). The capacity to grasp the perspectives of others is necessary for speech adaptation, particularly when responding to an interlocutor’s communicative needs. As children begin to develop this ability, they may demonstrate the skill to adapt their speech. For example, even at the age of four, children slow their speaking rate when talking to infants, a form known as infant-directed speech (Weppelman et al., 2003). In addition, a pragmatic skill, known as communicative repair strategy, typically manifests toward the end of a child’s second year of life (Alexander et al., 1997; Forrester, 2008). Therefore, it is imperative to investigate speech-modification development, such as changes in global acoustic features, during this dynamic and actively evolving preschool age range.
Earlier studies have revealed that Lombard speech (i.e., noise-adapted speech) among young children is achieved through increased vocal intensity (Garber et al., 1980; Siegel et al., 1976). As expected, even in their early years, children make vocal adjustments in an effort to enhance audibility, responding to interruptions in auditory feedback. However, our understanding of acoustic enhancements beyond vocal intensity, such as the heightened fundamental frequency (F0) for noise-adapted speech in preschoolers, remains limited. Moreover, there is a noticeable lack of studies examining the distinct elements of noise-adapted speech compared to clear speech in young children. Despite the importance of investigating speech modification development in preschoolers, only a handful of studies explored this area, and findings were inconsistent (Redford & Gildersleeve-Neumann, 2009; Syrett & Kawahara, 2014).
Syrett and Kawahara (2014) examined preschoolers’ ability to modify their speech as clear speech during a word-teaching task with a puppet. When teaching words to the puppet, the preschoolers exhibited slowed speech tempo, increased vocal intensity, and raised F0 mean and F0 range compared to the picture-naming task. In addition, they expanded their vowel space for the teaching context compared to the picture-naming context. They also examined adults’ perception of preschoolers’ clear versus conversational speech. Although adults were able to distinguish between the two speaking styles, the intelligibility of clear speech versus casual speech was not quantified. In a parallel investigation, Redford and Gildersleeve-Neumann (2009) explored speech modification in preschoolers through picture naming and natural conversations with caregivers. Children were instructed to produce clear speech by using their “big boy/girl” voice to ensure clear speech. In contrast to conversational speech during play with caregivers, clear speech exhibited acoustic enhancements, including a prolonged duration of vowels. However, pitch changes in clear speech exhibited variations based on chronological age. Three-year-olds produced higher pitch in clear speech than in conversational speech, whereas 4- and 5-year-olds exhibited the opposite trend, contrasting with findings in adult talkers. Although these two studies identified certain distinctive speaking styles in preschoolers, these two studies reported inconsistent results. Furthermore, it is crucial to highlight that the evaluation of adult perception in these studies did not directly address the measurement of speech intelligibility.
Children aged 8 years and older demonstrated hyper-speech modifications that, while not identical to those of adults, were quite similar (Hazan et al., 2016; Smiljanić & Gilbert, 2017a; Tuomainen et al., 2021). In response to background noise, children, particularly those aged 8–12 years, showed intensive vocal efforts, implementing acoustic enhancements such as increased pitch, greater energy, and a reduced speaking rate. Notably, their vocal efforts in noisy conditions were even greater than those of young adults and adolescents (Tuomainen et al., 2021). In contrast to noise-adapted speech, children may not be as effective as adults in using these communication strategies to benefit a conversational partner, even though they can modify their speech and exhibit suprasegmental features similar to adults. Hazan and colleagues (2016) revealed that children aged 9–14 years could adapt clear speech to accommodate their listeners by increasing pitch and mid-frequency energy and decreasing speaking rate. However, there were age-related differences in their adaptations regarding their F0 range; younger children within this range did not extend their F0 range for clear speech, whereas older children did. Similarly, Smiljanić and Gilbert (2017a) discovered that children aged 11–13 years could modify their speaking styles in response to challenging communicative situations such as background noise and addressing a listener with low English proficiency. Despite this, the acoustic enhancements in suprasegmental features made by children were smaller than those observed in adults. In addition, Smiljanić and Gilbert (2017b) reported that the improvement in speech intelligibility for hyper-speech produced by children was less pronounced than that produced by adult talkers.
In summary, different communicative challenges and cognitive development would affect the degree of vocal effort and speech enhancement. In the current study, our primary aim was to meticulously examine and compare prosodic enhancements within two distinct speaking styles: noise-adapted speech and clear speech in preschoolers. We anticipated preschoolers would enhance acoustic features in noise-adapted speech and clear speech; however, the acoustic enhancement in clear speech without direct auditory feedback interruptions would not be as evident as in noise-adapted speech with direct auditory feedback interruptions. We specifically hypothesized that acoustic enhancements in clear speech would become more prominent as preschoolers grew older but might not be as evident in younger preschoolers. On the other hand, the ability to modify speech in noise-adapted conditions would be consistently demonstrated within 3–5 years of age. In Experiment 2, we explored determining the actual impact of these acoustic modifications on enhancing speech intelligibility for adult listeners. Earlier research findings suggested that the modified speech produced by children has the potential to enhance speech intelligibility despite variations in their prosodic enhancements. We hypothesized that intelligibility improvement would align with the expected acoustic enhancement.
2 Experiment 1: acoustic features of the modified speaking styles
Experiment 1 aimed to explore whether preschoolers modified their speaking styles in responding to the two communicative challenges—background noise (i.e., noise-adapted speech) and a listener having hearing loss (i.e., clear speech) by augmenting acoustic features of their speech. The acoustic features included F0 mean, F0 range, energy in 1–3 kHz, speaking rate, and the number of pauses. Furthermore, we examined the differential developmental changes in prosody features between noise-adapted and clear speech. Speech recordings from natural conversations using a “spot the difference” task with diverse conversational partners were collected to scrutinize the acoustical distinctions in hyper-speech compared to hypo-speech (i.e., conversational speech) in preschoolers.
2.1 Methods
2.1.1 Participants
Twenty-eight typically developing preschool children (19 girls, 9 boys) participated in this cross-sectional study. They were all English-speaking preschoolers raised by English-speaking caregivers. The age range of the children was from 3 years 2 months to 5 years 11 months. All children passed a hearing screen at a 25-dB hearing level at octave frequencies between 500 Hz and 4,000 Hz in both ears except one child. This particular child exhibited a 30-dB hearing level in one frequency for an ear. The child experiences no difficulties in engaging in daily conversations and communication in various environments, as reported by a caregiver and the child. Table 1 provides a comprehensive overview of the children’s demographic information, encompassing age, gender, standard scores on vocabulary tests, and an articulation test for individual preschoolers. In addition, the experiment task order for the three different speaking conditions is outlined in Table 1. Ethical approval was obtained from the Texas Tech University Health Sciences Center (TTUHSC) Institutional Review Board. Written informed consent was obtained from the parent or guardian of each child.
2.1.2 Procedure
Child-caregiver dyads visited the TTUHSC Speech Production Lab twice, with the second visit occurring within 2 weeks of the first. Each visit lasted approximately 100–120 min. During the first visit, caregivers completed a case history questionnaire detailing the child’s developmental milestones. Following this, children underwent a hearing screening before participating in a picture-naming task. The picture-naming task involved introducing pictures corresponding to the target words to familiarize them. Both hearing screening and the audio-recording tasks took place in a sound-treated booth to ensure optimal audio quality. The primary experimental task, “spot the difference” (see description in the following section), was then administered to capture the child’s natural conversational speaking style. After completing the conversational speaking condition, children engaged in the “spot the difference” activity a second time to elicit either clear speech or noise-adapted speech under challenging communicative scenarios. The order of these modified speaking styles was counterbalanced across participants (see Table 1).
On their return visit, children participated in “spot the difference,” employing the alternative speaking style not previously used. For instance, if the clear speaking style was recorded during the first visit, then the noise-adapted speaking style was elicited during the second visit. Following the main experiment task, children completed standardized tests to assess the child’s expressive vocabulary (Expressive Vocabulary Test, 2nd edition [EVT-2]; Williams, 1997), receptive vocabulary (Peabody Picture Vocabulary Test, 4th edition [PPVT-4]; Dunn & Dunn, 2007), and articulation ability (Goldman-Fristoe Test of Articulation™ 3 [GFTA™-3]; Goldman & Fristoe, 2015).
2.1.3 Task materials
During the recordings, children performed a “spot the difference” task (Baker & Hazan, 2011) with a communication partner (i.e., a research assistant) to elicit conversational speaking (CO) and both noise-adapted speaking and listener-oriented clear speaking styles. The “spot the difference” task was adapted from the “Diapix task” (Baker & Hazan, 2011; Van Engen et al., 2010). In the original setup, two participants observed slightly varied versions of the same scene and communicated their observations. Primarily designed for adults and older children, the task aimed to elicit the use of specific words or phrases. Since the current study focused on much younger children, we crafted an adapted version. In this study, a research assistant acted as a facilitator to encourage the production of the target words while a child saw both pictures simultaneously and found the differences between the two pictures.
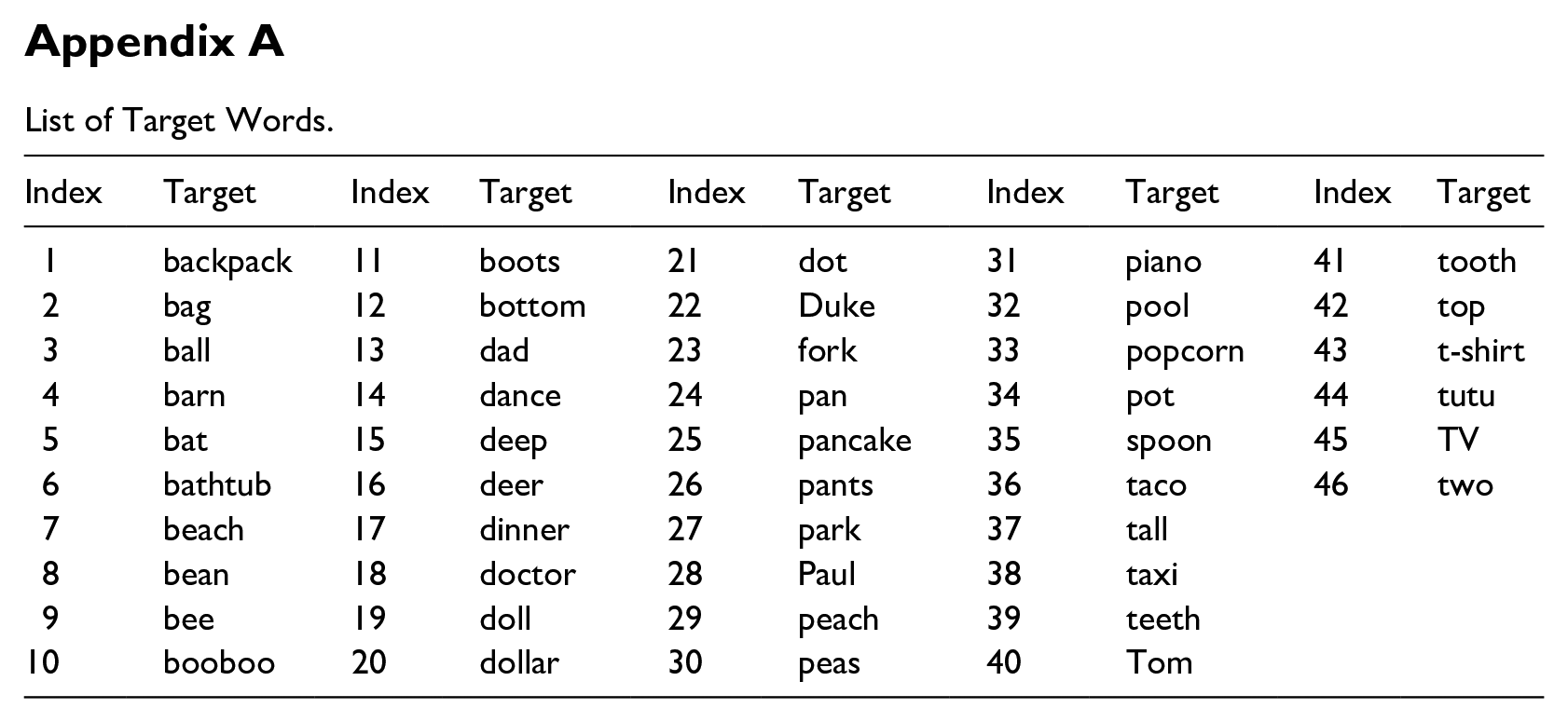
Figure 1 illustrates an example of a pair of pictures for the “spot the difference” task. To engage young participants, we crafted 15 hand-drawn pairs of colored scenes, each designed to prompt the production of 46 target words. We purposefully created scenes that shared many identical features. The only differences in the scenes were the items/objects identified as target words. For example, if the target word is a ball, one scene features a green ball, while another scene includes a purple ball. This design was used to stimulate the production of target words naturally. Each pair encompasses 2–6 subtle differences, contributing to an engaging and stimulating task. The 46 target words, such as “bat,” are identified as the “differences” in the scenes, providing a structured yet engaging framework for language stimulation in our study. Appendix A provides a complete list of target words for the “spot the difference” task.

Paired beach scenes for the “spot the difference” task, crafted to elicit target words: “ball,” “bat,” “beach.”
2.1.4 Experimental tasks for the three speaking styles
2.1.5 Recordings and data preprocessing
Audio recordings were made in a sound-treated booth using Audacity (Audacity Team, 2020) at a sampling rate of 44.1k Hz using a DPA microphone, single-ear omnidirectional headset microphone, which was mounted on one side of the child’s cheeks. An audio interface, Focusrite Scarlett 2i2, was used to convert audio signals from the microphone into a digital format. Speech recordings were segmented by utterance level and transcribed with the International Phonetic Alphabet (IPA) by using Phon (Rose & MacWhinney, 2014), a specialized software program designed for building and analyzing linguistic databases.
A research assistant, the second author, reviewed all utterances segmented by other research assistants to ensure a reliable analysis. After that, the first author reviewed 20% of each recording to pursue agreement on the segmentation of the utterances. Subsequently, 7,097 utterances containing target words were selected after excluding those unrelated to the main tasks. An utterance was defined as a spoken response following the interlocutor’s turn during a conversation. If there was a silent period of approximately 1 s within an utterance, it was divided into segments before and after the silent period. An utterance can consist of a single word or a complex sentence. For example, for the target word “bean” with a long response, a child said, “In that picture, there’s red beans and in that picture there’s blue black,” and with short responses, a child said, “beans” or “dark beans.”
2.1.6 Acoustic measures
F0 mean, F0 range, energy in the 1–3 kHz range, speaking rate (syllables per second), and the number of pauses in each utterance were analyzed for the prosodic features of the preschoolers’ speech production. The mean value of fundamental frequency, F0 (Hz), was calculated on individual utterances using the “pitch” function in Praat, with a time step of 100 pitch values per second. F0 range (Hz) was computed by determining the difference between the lowest and highest F0 values for individual utterances. Energy in the 1–3 kHz range (dB) was measured by averaging the long-term spectrum energy between 1 kHz and 3 kHz across each utterance. The above procedures were conducted using Praat software (Boersma & Weenink, 2001). The speaking rate was computed as the number of syllables divided by the duration of the utterance in seconds, providing the speaking rate reported in syllables per second. Utterance duration (seconds) was calculated by subtracting the length of pauses from the total length of each utterance. A pause was defined as a period of silence lasting ⩾200 milliseconds, with silence being defined as sound levels below 25 dB. Finally, the number of pauses was counted for each utterance containing more than one word. To refine the dataset further, any samples deviating significantly from the norm were identified as outliers based on an upper and lower limit of 2.5 standard deviations for all acoustic measures.
2.2 Analysis
The trajectory of various human developmental changes throughout the lifespan is unlikely to follow a linear function. For this reason, numerous prior studies have adopted group comparisons, such as children versus adults. However, when a study narrows its focus to a specific timeframe within the lifespan, developmental changes can be effectively approximated as a linear function (Little, 2013). This study focused on a limited segment of lifespan, specifically preschoolers aged between 3 years 2 months and 5 years 11 months, with 33 months interval, assuming a linear developmental trend within this range. To capture this developmental continuity, a continuous linear model across age was employed rather than relying on the conventionally categorized group variable. This analysis mitigates the potential loss of significant information (MacCallum et al., 2002). Group analysis was only applied to illustrate the consistency across data in Experiment 1 and Experiment 2. The children were divided into three age groups, including nine 3–year-olds (3;2 to 3;10 [years; months]), eight 4-year-olds (4;0 to 4;11), and eleven 5-year-olds (5;0 to 5;11). This categorization allows for the presentation of descriptive statistics, facilitating a comparison of acoustic outcomes between the two samples to show descriptive statistics comparing samples for Experiments 1 and 2. Descriptive statistics for Experiment 1 are shown in Table 2, and those for Experiment 2 can be found in Table 5.
Descriptive Statistics by Three Speaking Styles and Age Groups in Experiment 1.
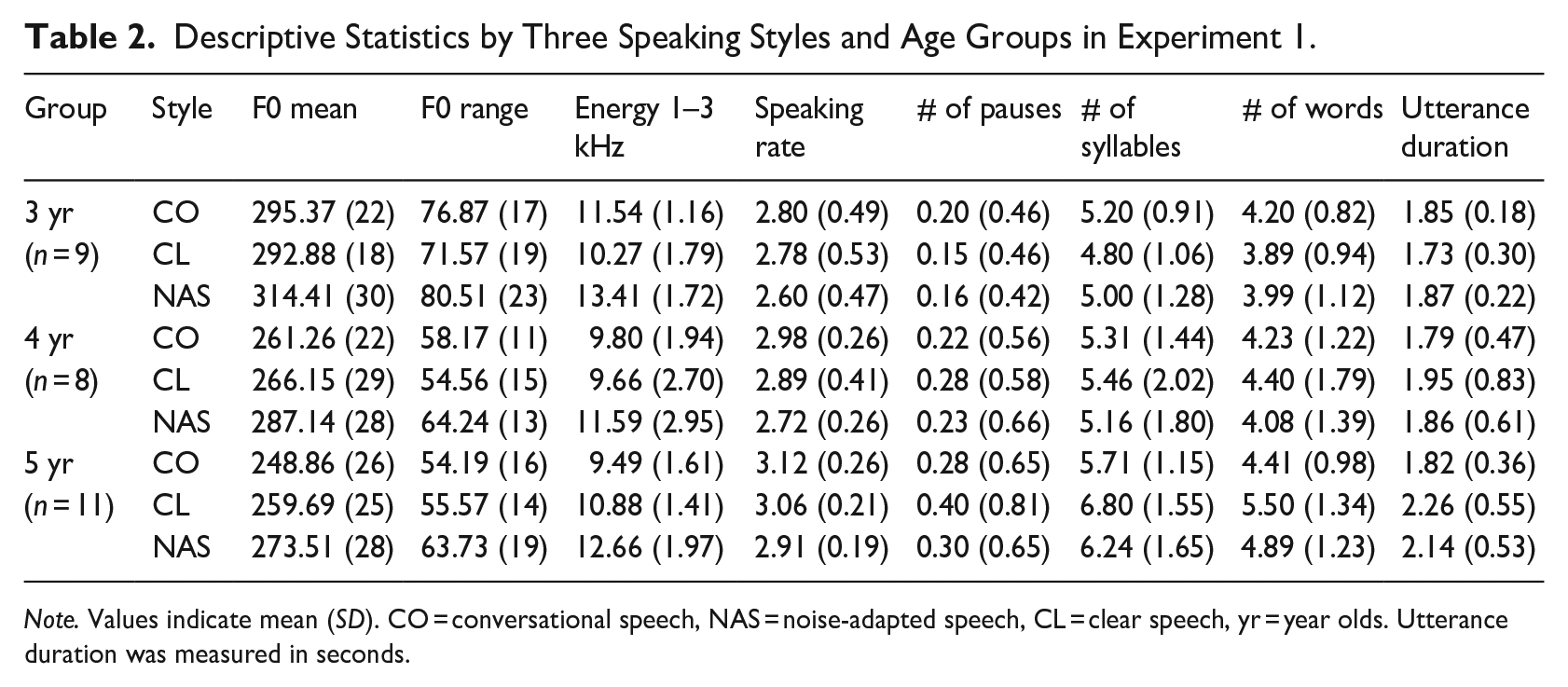
Note. Values indicate mean (SD). CO = conversational speech, NAS = noise-adapted speech, CL = clear speech, yr = year olds. Utterance duration was measured in seconds.
In this study, F0 mean, F0 range, energy in 1–3 kHz, and speaking rate were separately analyzed with the mixed-effects linear regression models using the lme4 package, and the number of pauses was analyzed by the mixed-effect negative binomial model using the glmmTMB package in R (4.2.1; R Core & Team, 2013). The final model for each acoustic measurement was selected using the following steps, which modify variables in fixed effect. The age in months, speaking style (i.e., conversational speech, noise-adapted speech, clear speech), their interaction, and the number of syllables (as a covariate) were evaluated. If the number of syllables was not significant using a Type III Wald chi-square test at α = .05 level, the model was refitted without the covariate. Following the guidelines by Barr et al. (2013), we incorporated maximal random slopes in the models to control for Type I error. For the models examining F0 mean, F0 range, energy in 1–3 kHz, and speaking rate, the random structure contained participant as a random intercept and speaking style as a random slope. However, the number of syllables was excluded as a random slope due to convergence issues for these four acoustic outcomes. When modeling the number of pauses, none of the potential models with random slopes converged; thus, the final model included only participant as a random intercept.
In order to avoid multicollinearity, the number of syllables was included in the statistical models to represent utterance length due to the high within-subject correlation (repeated-measures correlation, Bakdash & Marusich, 2017) with the number of words and utterance duration; the number of syllables and the number of words, r(7068) = .94, p < .001; the number of syllables and utterance duration, r(7068) = .84, p < .001. The variables of the number of syllables and the age in months were centered at the mean of 5.61 and the median age of 52 months, respectively, for the meaningful intercept.
If the interaction effect was significant in the final model, the interaction was further examined in the post-analysis (two-tailed tests) using contrasts of the three speaking styles at ages 38, 52, and 71 months with Bonferroni correction. The selection of 38 months for the youngest age, 71 months for the oldest, and 52 months as the midpoint was chosen to ensure an understanding of the significant interaction effects in this study. When the interaction effect was not significant at α = .05 level, prediction plots depicting the interaction between age and speaking style were still presented at the mean number of vowels or words. This was done to illustrate the trends in expected outcomes in the clear speaking condition across the different ages of children. The model parameters were reported with t, adjusted degree of freedom, and p-values using the Satterthwaite’s method. As a measure of the goodness-of-fit of the final model, Nakagawa’s conditional Rc2 (both for the fixed and random effects) and marginal Rm2 (only for the fixed effects) were reported (Nakagawa & Schielzeth, 2013).
2.3 Results
To present the overall results for each acoustic outcome, Table 2 displays the descriptive statistics, including the mean and standard deviation for each acoustic feature and utterance measure, categorized by age group and speaking style. Appendix B details the five acoustic outcomes for each preschooler, arranged sequentially from the youngest to the oldest.
2.3.1 F0 mean
The final model for F0 mean was performed on 6,944 utterances, including age in month (χ2 = 13.78, df = 1, p < .001), speaking style (χ2 = 38.51, df = 2, p < .001), their interaction (χ2 = 1.12, df = 2, p = .571), and the number of syllables (χ2 = 67.13, df = 1, p < .001) with Rc2 = .466 and Rm2 = .170. The fixed-effects model parameters are presented in Table 3. The model revealed that children produced lower F0 as their ages increased, consistent with the general human development pattern. The interaction effect was not significant at α = .05 level. In noise-adapted speech, the mean of F0 was significantly higher than that of the other two speaking styles, regardless of age (NAS-CO = 23.13, SE = 3.69, p < .001; NAS-CL = 18.41, SE = 4.74, p < .001). In contrast, the F0 mean in clear speech did not differ from that of conversational speech (CL-CO = 4.72, SE = 3.49, p = .528). Figure 2(a) illustrates the tendency of F0 mean across the three speaking styles over children’s age by the final model with interaction. The individual dots show the mean of F0 mean for each child by each speaking style, with the vertical bars representing the 95% of confidence intervals. While the slope of the F0 mean for clear speech did not differ statistically from that of conversational speech, the F0 mean for clear speech tended to be higher, on average, as children’s age increased compared to conversational speech. Regarding the significant main effect on the length of utterances, children produced a higher F0 mean for the longer sentence.
Model Parameters for Fixed Effect for F0 Mean, F0 Range, Energy in 1–3 kHz, and Speaking Rate Models.
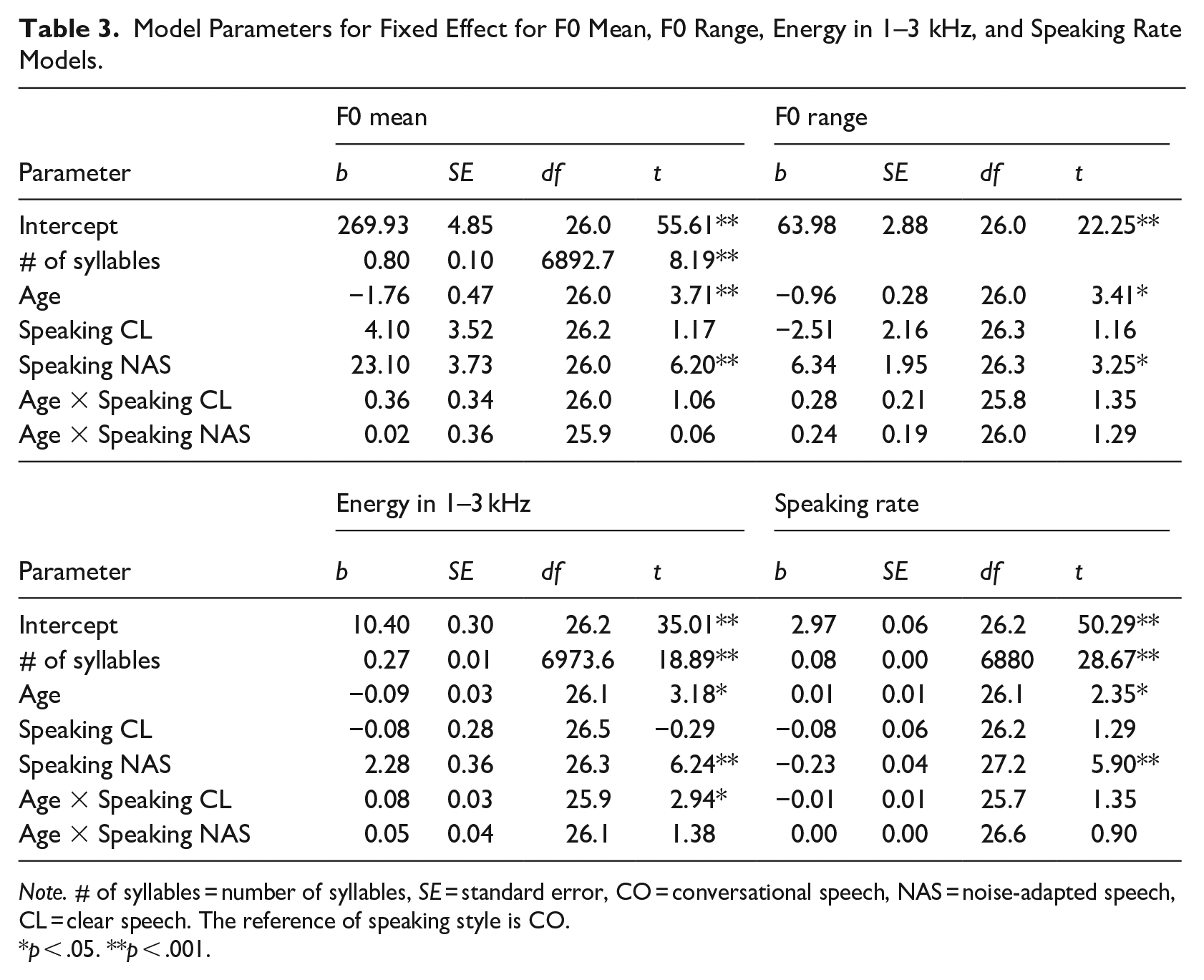
Note. # of syllables = number of syllables, SE = standard error, CO = conversational speech, NAS = noise-adapted speech, CL = clear speech. The reference of speaking style is CO.
p < .05. **p < .001.
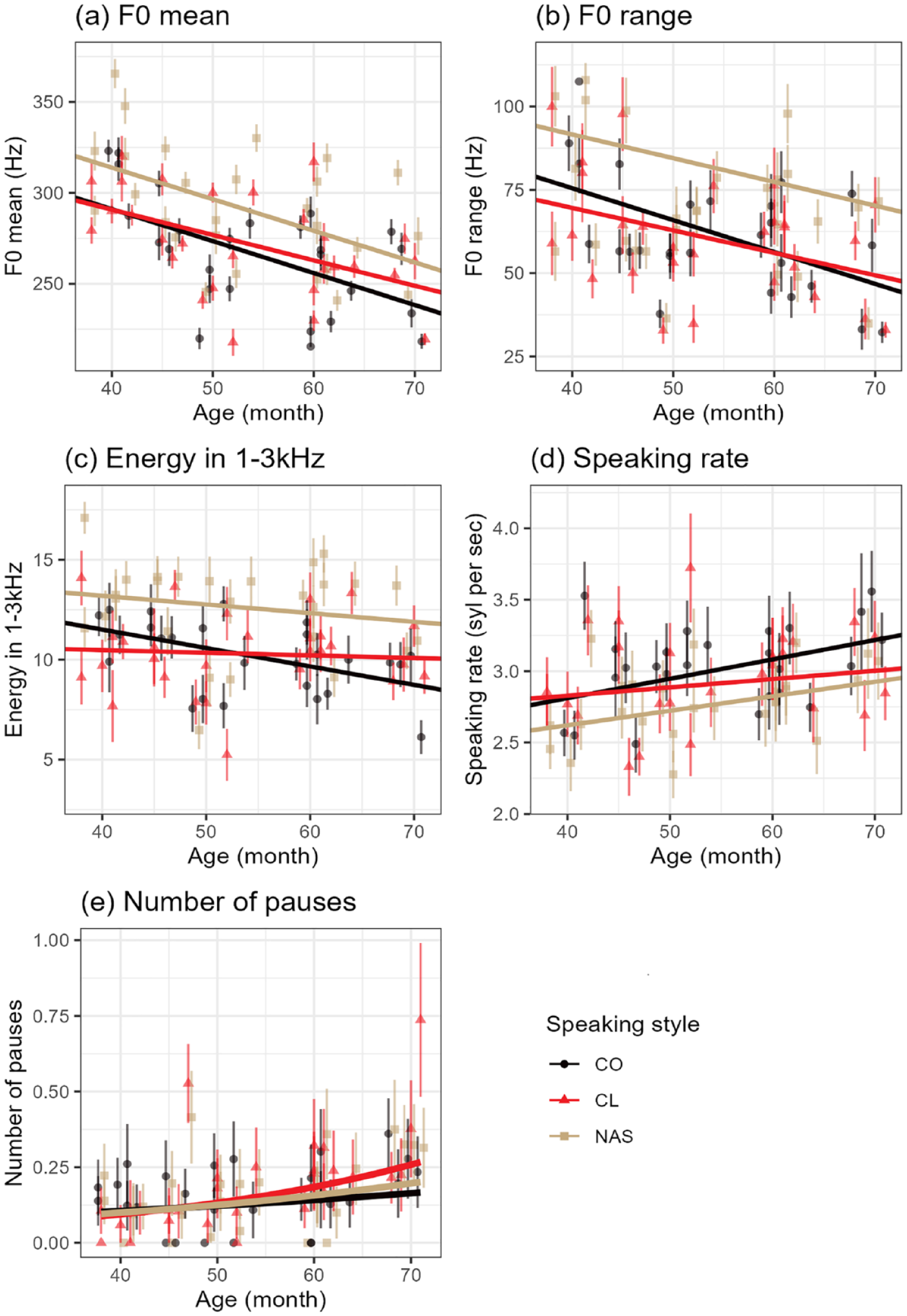
Model predictions with interaction effects and mean outcomes by children and speaking styles. The solid lines indicate the model predictions with interaction effects computed at the mean number of vowels or words. Points represent the mean outcomes for each child and speaking style, with vertical lines showing 95% confidence intervals of the mean outcomes. Interaction effects in (a), (b), and (d) were not significant at α = .05 level. CO = conversational speech, NAS = noise-adapted speech, CL = clear speech. Interaction effects in panels (a), (b), and (d) were not significant at α = .05 level. Colors: black = CO, red = CL, tan = NAS.
2.3.2 F0 range
The final model for the F0 range was evaluated on 6927 utterances with significant age (χ2 = 11.62, df = 1, p < .001), speaking style (χ2 = 18.23, df = 2, p < .001), and their interaction (χ2 = 2.44, df = 2, p = .295) variables, with Rc2 = .221 and Rm2 = .052. The model parameters are reported in Table 3. Similar to F0 mean, the overall F0 range decreased as children aged. Regardless of age, children used a wider range of F0 in noise-adapted speech than in the other two styles (NAS-CO = 6.71, SE = 1.93, p < .001; NAS-CL = 8.77, SE = 2.2, p < .001). The interaction effect was not significant at α = .05 level, indicating that the slopes of the three speaking styles did not differ statistically across the age range. As shown in Figure 2(b), the decrease in the F0 range for clear speech tends to be less pronounced than for conversational speech as age increases. However, the overall difference in F0 range between the clear and conversational speaking styles remains relatively small across the age spectrum.
2.3.3 Energy in the 1–3 kHz range
The variables for the fixed effects in the final model for mean energy in 1–3 kHz were identified as age (χ2 = 10.13, df = 1, p = .001), speaking style (χ2 = 42.90, df = 2, p < .001), their interaction (χ2 = 9.06, df = 2, p = .011), and the number of syllables (χ2 = 356.88, df = 1, p < .001), with Rc2 = .196 and Rm2 = .092 using 6911 utterances. The model parameters and contrasts of the interaction are reported in Tables 3 and 4, respectively. The interaction plot is displayed in Figure 2(c). The model indicates that the mean energy in 1–3 kHz gradually decreased as children’s age increased in all speaking conditions. The mean energy in the noise-adapted speech condition was significantly greater than that in conversational speech at all preschooler ages and clear speech at 38 and 52 months. At 71 months, there was no difference between noise-adapted and clear speech in terms of the mean energy in 1–3 kHz. On the other hand, the tendency to decrease the mean energy in conversational speech was significantly larger than it was in clear speech. At 38 and 52 months, the gap was not significantly different, but children aged 71 months produced reduced energy in 1–3 kHz in the conversational speech condition compared to the clear speech condition. Regarding the length of speech, as the length of a word or sentence increased, the mean energy in 1–3 kHz slightly increased.
Pairwise Comparison by Speaking Styles at 38, 52, and 71 Months in Experiment 1.
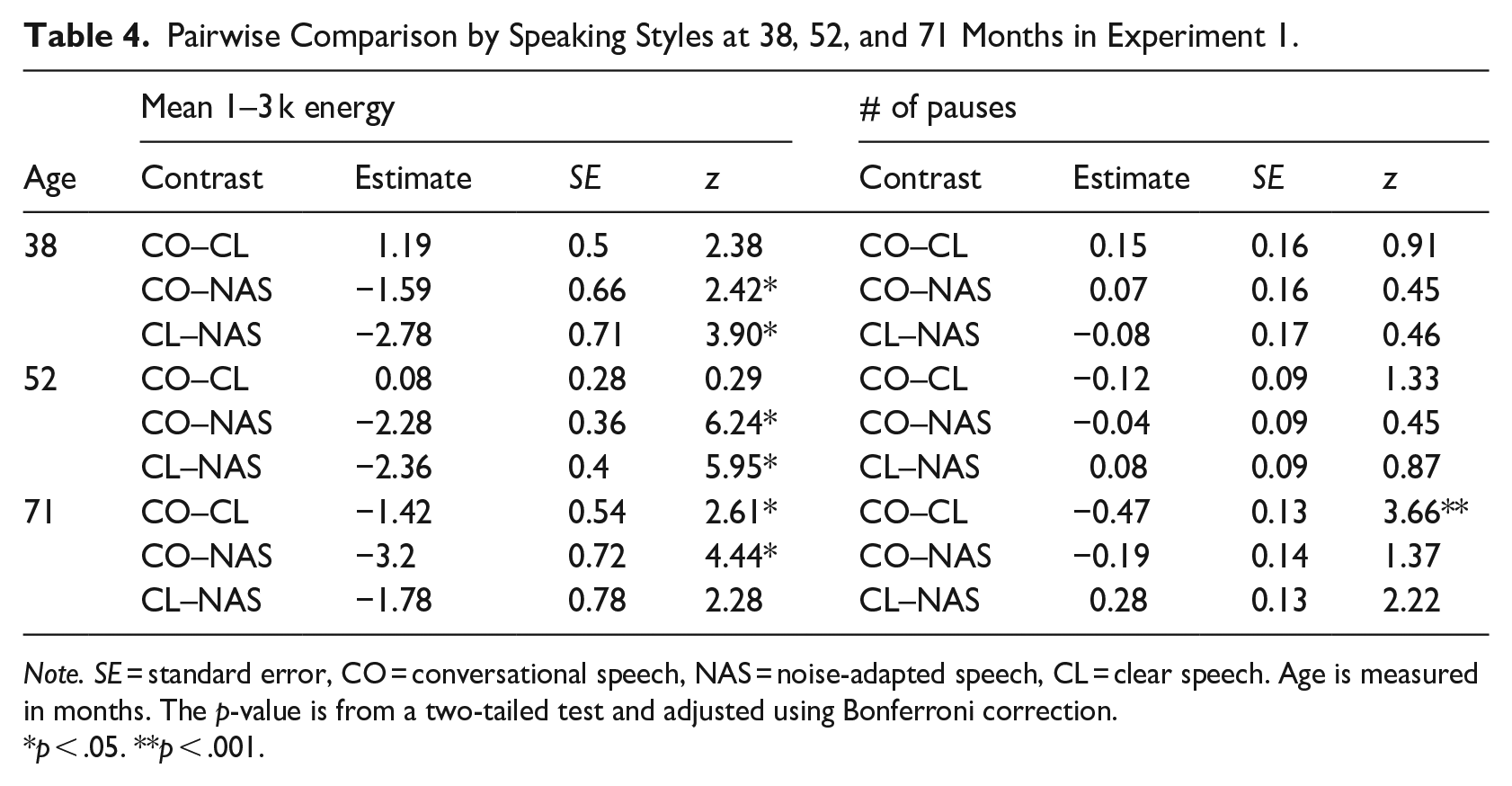
Note. SE = standard error, CO = conversational speech, NAS = noise-adapted speech, CL = clear speech. Age is measured in months. The p-value is from a two-tailed test and adjusted using Bonferroni correction.
p < .05. **p < .001.
2.3.4 Speaking rate
The speaking rate (syllables per second) was modeled by age (χ2 = 5.53, df = 1, p = .019), speaking style (χ2 = 37.53, df = 2, p < .001), their interaction (χ2 = 1.92, df = 2, p = .383), and the number of syllables (χ2 = 833.11, df = 1, p < .001), with Rc2 = .205 and Rm2 = .128 using 6977 utterances. The model parameters are reported in Table 3. Overall, the speaking rate increased as children aged in all speaking conditions. Preschoolers always produced speech slower in noise-adapted speech than in the other two conditions regardless of age (CO-NAS = 0.24, SE = 0.04, p < .001; CL-NAS = 0.15, SE = 0.05, p = .016). The interaction effect was not significant at α = .05 level, which indicates that the slopes of the three speaking styles were not statistically different. Figure 2(d) displays although the slope of speaking rate for clear speech was not statistically different from that for conversational speech, the model with interaction demonstrates the tendency of a relatively slow increase of speaking rate in clear speech compared to conversational speech as children aged. The effect of the number of vowels was similar to other acoustic outcomes: preschoolers spoke a long sentence faster than a shorter sentence.
2.3.5 The number of pauses
The final model for the number of pauses in each utterance was identified with dispersion parameter = 0.24 using 5286 utterances, containing age (χ2 = 1.85, df = 1, p = .174), speaking style (χ2 = 1.82, df = 2, p = .402), their interaction (χ2 = 6.55, df = 2, p = .038), and the number of words (χ2 = 241.91, df = 1, p < .001), with Rc2 = .194 and Rm2 = .097. This model had only three significant coefficients in fixed effect, b = −2.65, SE = 0.12, z = −21.27, p < .001 for intercept, b = 0.02, SE = 0.01, z = 2.49, p = .011 for the interaction of age × clear speech to the reference of conversational speech, and b = 0.11, SE = 0.01, z = 11.74, p < .001 for the number of words as a covariate, and all other coefficients were not significant at α = .05 level. The interaction plot is presented in Figure 2(e) at the mean number of words. The model had no significant main effect but the interaction, meaning that the log of the expected number of pauses in clear speech increased by 0.02 as children’s age increased by 1 month, while noise-adapted speech and conversational speech were constant over age, after adjusting the number of words in each utterance. The significant interaction effect was further analyzed at the ages of 38, 52, and 71 months (see Table 4). Preschoolers aged 38 months to 52 months did not produce different numbers of pauses in each utterance in all speaking styles, and significantly more frequent pauses in clear speech than in conversational speech were observed in preschoolers aged 71 months.
2.4 Discussion
Preschool-aged children exhibited acoustic enhancement for noise-adapted speech, responding to auditory feedback interruptions (i.e., noise-adapted speech). They elevated F0 mean, F0 range, and energy in 1–3 kHz while reducing the speaking rate for noise-adapted speech compared to conversational speech across all preschool ages. The findings indicate a multifaceted modification in vocal characteristics for noise-adapted speech among preschool-aged children, complementing earlier observations of Lombard speech augmentation in vocal intensity (Garber et al., 1980; Siegel et al., 1976). These outcomes also parallel earlier research on talkers in noisy environments from older children to elderly adults (Smiljanić & Gilbert, 2017a; Tuomainen et al., 2021). This alignment strengthens the understanding that similar vocal adaptations and speech characteristics occur across different age ranges and communicative contexts in challenging auditory conditions, even though the degree of speech adaptation varies across the age group.
Regarding listener-oriented clear speech, we found significant developmental changes in mid-frequency energy (1–3 kHz) as preschoolers aged. Younger preschoolers (3–4 years old) did not show significant enhancement in mid-frequency energy for clear speech compared to conversational speech, but they exhibited less energy compared to noise-adapted speech. Older preschoolers (5 years old) produced greater mid-frequency energy compared to conversational speech, but no significant difference was found between the two hyper-speech styles. The energy in the 1–3 kHz range is crucial for speech intelligibility, containing important cues for phonetic identity. An increase in this mid-frequency often reflects a greater vocal effort to enhance speech intelligibility (Hazan et al., 2016; Tuomainen et al., 2021). Thus, older preschoolers demonstrated the potential to adapt their speech by increasing vocal effort, at least by enhancing the mid-frequency, to accommodate their listeners.
The ability to produce hyper-speech, especially responding to the challenge posed by a communication partner, largely depends on developing socio-cognitive abilities such as perspective-taking (Lindblom, 1990). Within this preschooler age range, socio-cognitive skills are actively evolving, and younger preschoolers may not fully grasp their interlocutor’s needs (Korkmaz, 2011). Clear speech, tailored for listener comprehension, requires a more sophisticated socio-cognitive ability than speech adapted for background noise (Godoy et al., 2014). Interestingly, even younger preschoolers in noisy environments exhibited increased mid-frequency energy, a higher pitch, a wider pitch range, and a slower speaking rate. This indicates that despite ongoing developmental changes in their vocal structures and speech-motor systems (Green et al., 2000; Lee et al., 1999; Redford, 2019), young children can enhance certain acoustical features with auditory feedback interruption. However, additional cognitive demands reveal the limitations of their capacity to modify speech for listener comprehension effectively.
Our observations indicate that as preschoolers age, the acoustic features of clear and noise-adapted speech, including increased mid-frequency energy, appear to converge. Although the interaction effects between age and speaking style on F0 mean, F0 range, and speaking rate were not statistically significant, distinct developmental changes were noted. Specifically, the differences between these hyper-speaking styles diminished as children aged, indicating a progressive refinement in the ability to meet their listeners’ communicative needs. Despite potentially different underlying mechanisms, the extent of enhancement in suprasegmental features was comparable by the end of the preschool years. This finding aligns with earlier research in adult talkers, which demonstrated that both clear speech and noise-adapted speech share acoustic enhancements such as higher pitch, a larger F0 range, a slower speaking rate, and increased energy (Gilbert et al., 2014; Godoy et al., 2014; Smiljanić & Gilbert, 2017a).
Notably, older preschoolers exhibited distinct strategies when modifying their speech, particularly in clear speech, incorporating more pauses than noise-adapted or conversational speech. This use of pauses, a key feature that differentiates clear speech from noise-adapted speech (Smiljanić, 2021; Smiljanić & Gilbert, 2017a), potentially facilitates language comprehension by giving listeners more processing time. Recent research (Guo & Smiljanić, 2024) further suggests that clear speech might aid linguistic processing through exaggerated prosodic cues at boundaries. These findings underscore the intricate linguistic underpinnings of clear speech development, revealing older preschoolers’ growing capacity to adapt their speech to effectively address the communicative demands of their audience. The developmental changes in mid-frequency energy and pause patterns suggest an ongoing refinement of speech-modification strategies. However, the current findings on global acoustical enhancements did not fully distinguish qualitative aspects of speech enhancement.
In addition, upon visual inspection of the data, various clear speech strategies were observed among the older preschoolers (see Appendix B). For instance, K001, the oldest participant in the study, primarily increased energy in the 1–3 kHz range, decreased speaking rate, and added more pauses in the clear speech condition than in the conversational speech condition. In contrast, some 5-year-olds (e.g., K009 and K013) did not exhibit notable adjustments across the acoustic outcomes. While adult speakers typically demonstrate a consistent tendency in clear speech modifications, such as increasing mid-frequency energy and fundamental frequency (Hazan et al., 2016; Smiljanić & Gilbert, 2017a), children may not yet consistently modify their speech in response to communicative challenges. This variability underscores the nuanced progression of speech development, suggesting that while general trends exist, individual differences and ongoing developmental changes among young children greatly shape their communicative adaptation.
The absence of acoustic enhancements for clear speech in younger preschoolers may be attributed to their limited understanding of the experimental task and the potentially unsettling nature of the communicative situations. During the clear speech condition, the facilitator (i.e., a research assistant) provided occasional prompts, such as “Remember, she cannot hear you well,” while the communication partner made clarification requests like, “I couldn’t hear you well, what did you say?” to simulate common communication barriers. This setup was intended to evaluate the preschoolers’ ability to adapt their speech in response to the challenges faced by the listener. However, the clarification requests from the unfamiliar communication partner could unsettle younger preschoolers, leading them to use reduced prosodic features in this challenging communicative situation. This complexity might explain the lack of certain acoustic enhancements in their clear, listener-oriented speech. In contrast, older preschoolers might be less affected by the unfamiliar communicative context. Rather, they began recognizing the experimental intent and cues to change speaking styles. They might have increased their vocal effort or altered their speech patterns in response to the experimental setting, even without fully understanding the listener’s specific communicative challenges and needs. This suggests an emerging ability to adjust their speech in response to situational prompts, reflecting developmental progress in their socio-cognitive and communicative skills.
We initially hypothesized that all acoustic enhancements in clear speech would become more pronounced as preschoolers aged. Contrary to our expectations, neither pitch usage nor speaking rate showed significant differences between clear and conversational speech across this age range. However, there was a significant age effect across all speaking styles, with a decrease in F0 mean and F0 range and an increase in speaking rate as preschoolers aged. This developmental trend aligns with findings from studies on older children, which demonstrate continued maturation of prosodic features into adolescence (Hazan et al., 2016; Smiljanić & Gilbert, 2017a). The ongoing maturation of pitch and speaking rate in early childhood may obscure subtle differences between speaking styles. In addition, the variability in pitch during interactive conversations, as reported by Kallay et al. (2022), could further complicate the detection of acoustic modifications in clear speech. Although these discrete developmental changes did not reach statistical significance, visual observations suggested distinct patterns in clear speech compared to other speaking styles. For instance, clear speech showed a shallower decline in F0 measures and a more gradual increase in speaking rate, implying that older preschoolers may begin to refine their prosodic features to better accommodate their listeners. Nonetheless, these changes should be interpreted cautiously due to the lack of statistical significance between clear and conversational speech by age.
The lack of significant difference in pitch usage and speaking rate between clear and conversational speech could be attributed to incomplete hypo-speech production. Preschoolers may exhibit a less-pronounced reduction in hypo-speech during the conversational speaking context. According to Lindblom’s (1990) concept of hypo-speech, which proposes minimized articulatory movements and increased co-articulation for efficient speech production, these adaptations appear less evident in preschoolers than in adults. This discrepancy is likely due to their immature speech mechanisms, which do not yet fully differentiate hypo-speech from hyper-speech (i.e., clear speech). To support this finding, Redford and Gildersleeve-Neumann (2009) also reported that preschoolers, particularly younger ones, exhibited a higher pitch for casual speech than for clear speech contexts. They noted that in their experimental setting, where caregivers and children engaged in play with toys, casual speech occurred mainly in a playful atmosphere, which is not the same as the context of casual speech in adult talkers. In our study, the conversational speech tasks were administered by a graduate student assistant who, despite previous interactions with the children for hearing screenings and picture-naming tasks, remained relatively unfamiliar to them. Moreover, the conversational speaking condition was consistently presented first in our protocol, potentially influencing the children’s speaking style due to their unfamiliarity with the experimental setup. Despite efforts to foster a relaxed and child-friendly environment, these unaccustomed experimental conditions may not lead to typical conversational speaking styles in preschoolers.
3 Experiment 2: speech intelligibility of modified speaking styles
The purpose of Experiment 2 was to explore whether the modified speaking styles produced by preschoolers consistently enhance speech intelligibility as perceived by typical adult listeners. The experiment measured keyword identification to analyze developmental patterns in speech intelligibility across the age range of preschool talkers.
3.1 Methods
3.1.1 Participants
Thirty adult listeners between the ages of 19 and 23 (mean age: 20.7) were recruited from the TTUHSC and Lubbock, Texas, geographic area. All participants were female students in the Department of Speech, Language, and Hearing Sciences at TTUHSC. All listeners reported that they primarily spoke English. They filled out the Center for Epidemiologic Studies Depression (CES-D) scale (Radloff, 1977). Eight participants showed high depressive symptoms based on CES-D. However, we did not find any significant differences between the individuals with and without high depressive symptoms (χ2 = 0.37, df = 1, p = .54). All listeners passed pure-tone audiometric hearing screening and had no self-reported speech or language disabilities. Written informed consent was obtained from each participant before the experiment. All experimental procedures were approved by the institutional review board at TTUHSC.
3.1.2 Stimuli selection
The stimuli were initially selected from a pool of three- to seven-word utterances that contained target words. Utterances with fewer than five words, including interjections (e.g., uh, um, ah, etc.), were excluded. The initial list compromised 2441 utterances. From this list, 10 utterances per speaking style were randomly extracted for each child using R, representing the speaking rate predicted by the model. For instance, a phrase like “two bees” from a child’s clear speech was chosen as a stimulus because it exhibited the representative acoustic feature of the speaking rate for the specific clear speaking style. Subsequently, three student assistants independently selected three utterances per speaking style for a child to ensure the exclusion of ungrammatical sentences or phrases. Finally, the first author made the ultimate selection of three utterances from the choices made by the three student assistants. A total of 252 utterances (3 utterances × 3 speaking styles × 28 preschooler-talkers) were utilized as stimuli for the speech intelligibility experiment. Keywords of individual utterances can be duplicated, ranging from 1 (unique keyword) to 15 (15 times repeated keyword) with a median of 2. The five most repeated keywords were “has,” “piano,” “taxi,” “beachball,” and “not.” To account for the priming effect, a variable named “Repeat-order” was added to a regression model representing the repeating sequence of each unique keyword in the presenting order. Since stimuli were randomly presented to each listener, the priming effect was expected not to be correlated with other main and interaction effects. In addition, to ensure the acoustic features of the selected utterances in Experiment 2 were comparable to those in Experiment 1, the mean and standard deviation of five acoustic measures were calculated for each age group and speaking style (see Table 5). The two datasets exhibited consistent means across the four acoustic features and showed comparable trends, except for the number of pauses (refer Table 2 for Experiment 1 and Table 5 for Experiment 2). The difference in the number of pauses likely resulted from the constraint on utterance length to 3–7 words in Experiment 2.
Descriptive Statistics by Three Speaking Styles and Age Groups in Experiment 2.
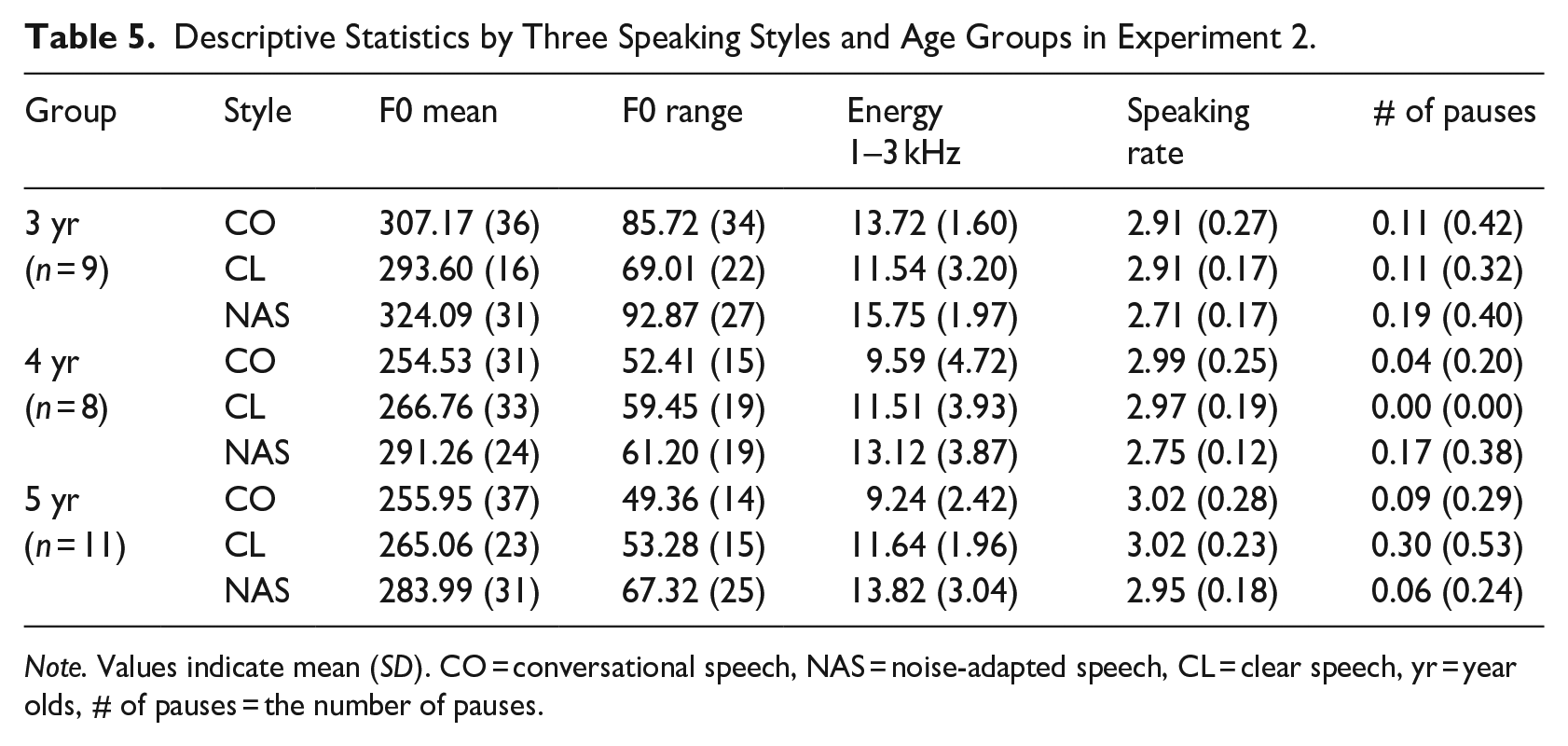
Note. Values indicate mean (SD). CO = conversational speech, NAS = noise-adapted speech, CL = clear speech, yr = year olds, # of pauses = the number of pauses.
A total of 252 utterances were equated to a 60-dB sound pressure level (SPL) by average root-mean-squared amplitude. SSN was generated by filtering white noise to the long-term average spectrum from the concatenated file of 252 utterances. Target utterances were digitally mixed with SSN maskers at a signal-to-noise ratio (SNR) of 0 dB SPL. The SNR level was determined through piloting to avoid ceiling and floor effects. Each of the stimulus files consisted of 500 ms of noise, followed by the speech plus noise, and ending with 500 ms of only noise. The noise preceding and following the speech stimuli was equivalent to the level of the noise mixed with the speech. All manipulations of audio stimuli were performed by using Praat.
3.1.3 Tasks
The keyword-identification task was conducted to assess speech intelligibility. This task, widely used to quantify speech intelligibility in the presence of background noise, offers an objective measure as opposed to relying on a scaling system (Flipsen, 2008; Smiljanić & Gilbert, 2017b). During the experiment, participants wore headphones and listened to audio stimuli derived from recordings of preschooler-talkers. Their instructions were to listen to each sentence and accurately type what they heard on the computer. The experimenter adjusted the volume to a comfortable listening level, and instructions were presented on a computer monitor using E-Prime 3.0. The experiment comprised 258 trials, including six practice items. Following the practice phase, participants proceeded to the experimental trials, which were presented in a randomized order, and each appeared only once. Participants were given unlimited time to type the target sentences and could advance to the next trial at their discretion. Responses were scored based on the number of correctly identified keywords. Keywords with added or omitted morphemes were scored as incorrect.
3.2 Results
Mixed-effect logistic regression was used to analyze speech intelligibility using the glmmTMB package in R. The keyword identification (i.e., correct or incorrect) was the dichotomous dependent variable. The model contained fixed effects of speaking styles, child-talkers’ age in months, their interaction, and repeat order of each unique keyword (See 3.1.2. Stimuli selection). The random-effect structure consists of three variables: (1) by-listener random intercept and random slope for repeat order, (2) by-child-talker random intercept and random slopes for repeat order and speaking style, and (3) by-keyword random intercept only. In R syntax, this is expressed as: (1 + repeat_order | listener) + (1 + repeat_order + speaking_style | child-talker) + (1 | keyword). All the variables of the fixed effect were significant as measured by Type III Wald Chi-square tests: age, χ2 = 2.00, df = 1, p = .157; speaking style, χ2 = 9.83, df = 2, p = .007; interaction between age and speaking style, χ2 = 7.84, df = 2, p = .020; and repeat-order, χ2 = 32.96, df = 1, p < .001. The goodness-of-fit of the model was evaluated as Nakagawa’s Rc2 = .630 and Rm2 = .043. Model parameters and contrasts at talkers’ ages of 38, 52, and 71 months using one-tailed tests and Bonferroni correction are reported in Tables 6 and 7, respectively. Figure 3 depicts the predicted probability of keyword identification by the model over the child-talkers’ age. Appendix C provides individual preschoolers’ mean intelligibility scores for the three speaking styles. Overall, keyword-identification accuracy across all speaking styles improved as the preschool talkers aged. However, the rate of improvement varied among speaking styles. Between the ages of 38 and 52 months, listeners did not show a significant improvement in identifying keywords in clear speech compared to conversational speech. In contrast, keyword identification was significantly better in noise-adapted speech than in conversational and clear speech. As the children aged, the accuracy of keyword identification in clear speech enhanced more rapidly than the rate observed in conversational speech. By 71 months of age, intelligibility in clear speech was significantly higher than that in conversational speech. Meanwhile, as the accuracy of keyword identification in conversational speech improved with age, the difference between conversational and noise-adapted speech diminished. At 71 months of age, listeners’ performance in noise-adapted speech was no longer significantly better than that in either conversational or clear speech. Repeat order, representing the priming effect, was statistically significant. As the number of repeat orders of unique keywords increased, the probability of correctly identifying the keywords increased by 10%.
Model Parameters for Fixed Effect of the Intelligibility Task in Experiment 2.
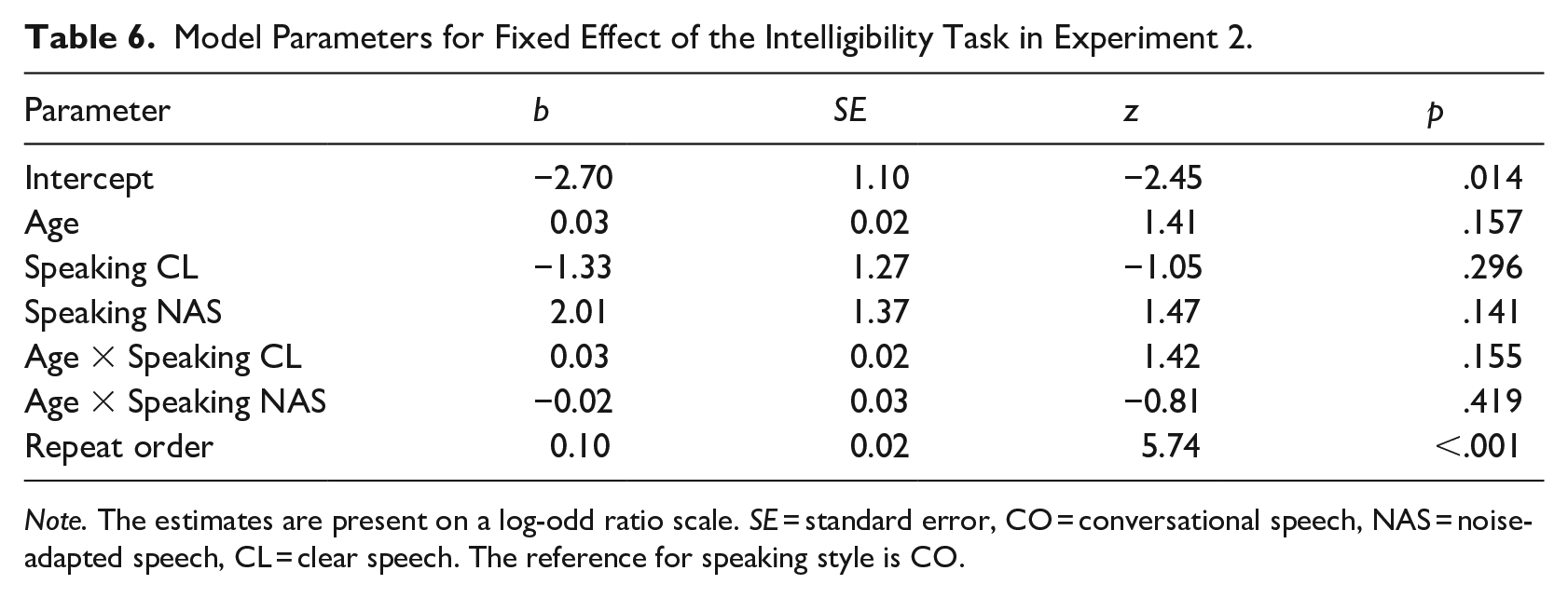
Note. The estimates are present on a log-odd ratio scale. SE = standard error, CO = conversational speech, NAS = noise-adapted speech, CL = clear speech. The reference for speaking style is CO.
Pairwise Comparison by Speaking Styles at 38, 52, and 71 Months in Experiment 2.
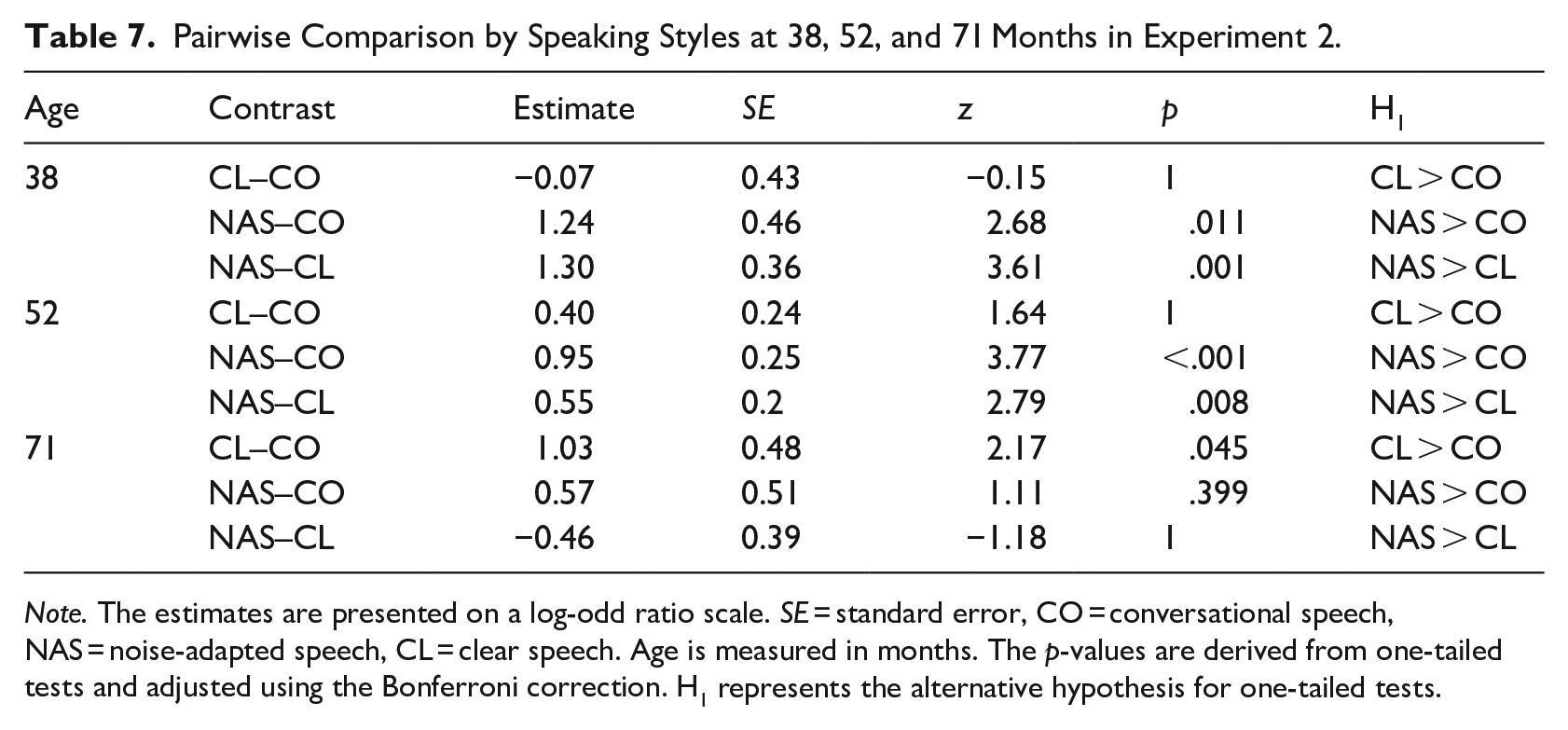
Note. The estimates are presented on a log-odd ratio scale. SE = standard error, CO = conversational speech, NAS = noise-adapted speech, CL = clear speech. Age is measured in months. The p-values are derived from one-tailed tests and adjusted using the Bonferroni correction. H1 represents the alternative hypothesis for one-tailed tests.
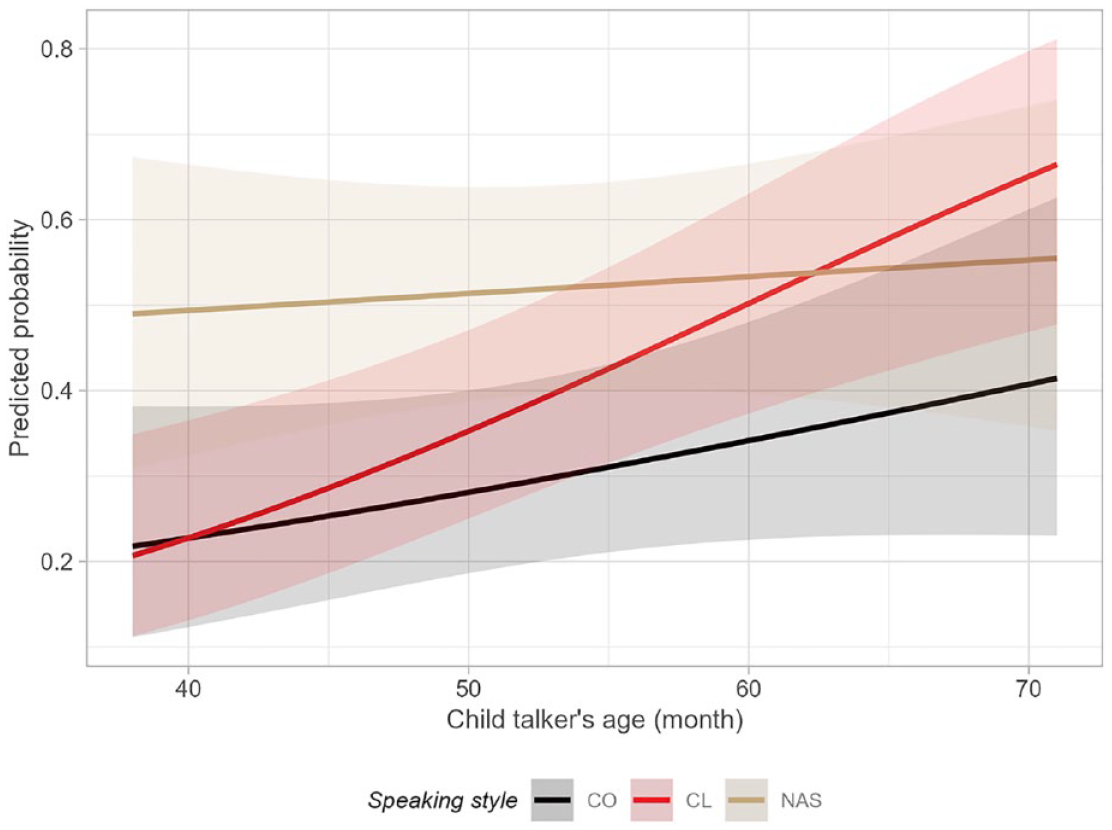
Predicted probability of correctly identifying keywords across the three speaking styles over child talkers’ age in months at the mean repeat order with 95% confidence intervals. CO = conversational speech, NAS = noise-adapted speech, CL = clear speech. Colors: black = CO, red = CL, tan = NAS.
3.3 Discussion
Listeners identified keywords more accurately in noise-adapted speech than in conversational speech produced by younger preschoolers. This indicates that even at an early age, children adjust their speech in response to auditory feedback disruptions, leading to improved intelligibility as perceived by adult listeners. These findings align with previous research demonstrating that noise-adapted speech from older children and adults enhances intelligibility for adult listeners (Cooke, Mayo, & Village 2014; Godoy et al., 2014; Smiljanić & Gilbert, 2017b). The relatively reflexive vocal adjustments observed in young children (Garnier et al., 2010; Tuomainen et al., 2021) further suggest that adaptive speech mechanisms emerge early and contribute to enhanced listener comprehension in noisy environments. While the intelligibility enhancement of noise-adapted speech over conversational speech was somewhat reduced and did not reach statistical significance in older preschoolers, it still remained higher overall than that of conversational speech (see Appendix C for individual intelligibility scores). The absence of significance in the post hoc comparisons could be due to the large standard error, underscoring the need for more extensive data collection to capture a comprehensive picture of speech intelligibility enhancement. Nonetheless, the observed trend of higher intelligibility in noise-adapted speech than in conversational speech suggests that preschoolers actively and effectively adjust their speech in response to noise, enhancing its intelligibility.
Consistent with the age-dependent differences in acoustic enhancement for clear speech observed in Experiment 1, a noticeable increase in speech intelligibility for clear speech was evident as preschoolers aged. Compared to conversational and noise-adapted speech, clear speech more explicitly demonstrated developmental changes in intelligibility. Unlike noise-adapted speech, where younger preschoolers showed intelligibility improvements in response to auditory feedback interruptions, younger preschoolers did not exhibit such enhancements in clear speech. This suggests that younger preschoolers have a limited ability to proactively adjust their speech to meet listeners’ communicative needs. In contrast, older preschoolers demonstrated a more deliberate effort to improve their speech intelligibility. The development of this ability is likely linked to the emergence of socio-cognitive skills, such as the ability to understand others’ mental states, which typically emerge during the preschool years. These findings may support a connection between socio-cognitive abilities and speech development (Ebert, 2020; Milligan et al., 2007).
Previous studies on older children and adult talkers have shown that intelligibility improvements are greater in noise-adapted speech than in clear speech (Smiljanić & Gilbert, 2017b). However, our data on older preschoolers did not reveal a similar pattern, as there was no evidence of greater enhancement in noise-adapted speech compared to that in clear speech. While certain acoustic features such as F0 mean, F0 range, and speaking rate were more prominent in noise-adapted speech than in both conversational and clear speech (as revealed in Experiment 1), noise-adapted speech had much fewer pauses than the other speaking styles, especially in the utterances used for Experiment 2. In this study, the primary prosodic feature distinguishing clear speech from noise-adapted speech was the use of pauses. The number of pauses likely plays a crucial role in speech intelligibility in this experimental setting. Given that the SNR in Experiment 2 was set at 0 dB SNR, all speaking styles were likely audible to listeners. For example, previous studies used negative SNRs, including –5 dB SNR (Smiljanić & Gilbert, 2017b; Yi et al., 2021) and −4 to −9 dB SNR (Tuomainen et al., 2019). At the 0 dB SNR used in our study, further intelligibility improvements may depend more on the number of pauses or some other acoustic features we have not examined. The limited scope of our dataset makes it difficult to isolate the specific acoustic factors that most strongly contribute to these intelligibility improvements. Further research is necessary to identify the key acoustic features driving these differences and to gain a deeper understanding of the developmental trajectory of speech modification in preschoolers.
4 General discussion
This study investigated how children aged 3–5 years enhance suprasegmental features in response to two distinct communicative challenges, comparing three speaking styles: noise-adapted speech, listener-oriented clear speech, and conversational speech. Results revealed that preschoolers adjusted their speaking styles when confronted with background noise and demonstrated some developmental changes in speech modification when communicating with a partner who struggled to understand them. In addition, their prosodic enhancement for both challenges functionally and effectively increased speech intelligibility, underscoring the functional role of these enhancements in challenging communicative contexts. Speech intelligibility is a functional indicator of oral communication competence reflecting the talker’s ability to convert the language to a physical signal and the listener’s ability to perceive and decode the signal to recover the intended meaning of the talker’s message (Hodge & Whitehill, 2010). It has been well established that noise-adapted and clear speaking styles improve speech intelligibility by increasing acoustic-articulatory outcomes in various populations, even though the intelligibility enhancement of clear speech varies depending on the listener groups and contexts (Bradlow et al., 2003; Cooke, King, et al., 2014; Ferguson & Quené, 2014; Smiljanić & Bradlow, 2009; Smiljanić & Gilbert, 2017b; Van Engen et al., 2014; Yi et al., 2019, 2021).
An interesting finding in our current study is that, despite ongoing speech development and certain phonemes yet to be acquired in the preschool age range, children utilized prosody features to improve speech intelligibility functionally. Expanding on previous studies of Lombard speech, which identified speech modifications in young children characterized by heightened vocal intensity (Garber et al., 1980; Siegel et al., 1976), our novel finding of other prosodic features such as speaking rate and pitch changes can also be modified, actively contributing to enhanced speech intelligibility for their listeners. The reflexive and involuntary aspects of noise-adapted speech might exert a greater influence on modifying specific prosodic features of their voice, particularly in younger preschoolers. This careful inference is drawn from the findings in which younger preschoolers, around 3 years old, exhibited limited and inconsistent prosodic modifications while delivering a listener-oriented clear speech in the absence of auditory feedback interruption. However, it is important to note that noise-adapted speech does not constitute a completely automatic response to ambient noise. Instead, it incorporates components of communicative intent (Garnier et al., 2010; Tuomainen et al., 2021). In our study, the interlocutor for the child talkers wore headphones to simulate a scenario where the listener, like the child talkers, was also interrupted by background noise. It is imperative not to overlook the role of communicative intent in driving speech modifications under noisy conditions.
During preschool years, children undergo active developmental changes in speech perception (Yurovsky et al., 2017), speech-motor control (Green et al., 2000; Lee et al., 1999), and socio-cognitive ability to identify others’ perspectives and common ground with interlocutors (Graham et al., 2017; Korkmaz, 2011). The capacity to comprehend the perspective of others has an impact on the advancement of speech modification, particularly in the context of responding to a communicative challenge posed (i.e., clear speech). In the current study, it has become evident that children gradually gain the capability to adapt and modify their speaking styles in response to the communicative needs of their interlocutors as they advance in their cognitive and linguistic growth. These findings contribute to the growing body of evidence linking socio-cognitive skills with speech and language development (Ebert, 2020; Milligan et al., 2007). Early social interaction skills that children develop during preschool years are foundational in shaping the relationship between environmental concepts and emerging vocal forms (Oller, 2000). At as early as 4 years old, children begin the process of self-monitoring by using external perceptual feedback to identify any discrepancies between their spoken output and the desired speech target (Redford, 2019). This self-monitoring capacity, which relies on auditory feedback, evolves alongside socio-cognitive abilities such as perspective-taking (Redford, 2019; Symons, 2004) and plays a crucial role in shaping speech-modification abilities. However, the present study does not directly address the influence of socio-cognitive development on speech-modification skills or vice versa (Ebert, 2020; Milligan et al., 2007). Future research should further explore the relationship between socio-cognitive abilities, particularly the theory of mind development, and its impact on refining speech modification. This line of inquiry could provide valuable insights into how children’s growing ability to understand and anticipate the communicative needs of others enhances their capacity to modify speech in an adaptive, listener-oriented manner.
The current study focused on only prosodic enhancement to investigate speech modification abilities in preschoolers. The lack of segmental-level acoustic analysis constrains our exploration of the differences between noise-adapted speech and clear speech, especially concerning articulation-development aspects of speech adaptation. The distinct mechanism between the two hyper-speaking styles was explored in adult talkers as noise-adapted speech increases spectral energy in the formant range, thereby enhancing audability, while on the other hand, clear speech expands the vowel space, leading to improved articulation (Godoy et al., 2014; Smiljanić, 2021). Preschoolers produced longer vowels and were more dispersed in the vowel space when children talked to a puppet to teach words (Syrett & Kawahara, 2014). This suggests preschoolers can adapt their vowel production to meet different communicative needs. To comprehensively investigate the qualitative aspects of speech enhancement between noise-adapted and clear speech, future studies should incorporate segmental levels, considering both perceptive and acoustic levels of articulation. Parameters such as vowel duration, voice onset time, and articulation errors could provide valuable insights, enabling a detailed comparison between noise-adapted speech and clear speech at the segmental level.
We purposefully excluded clear speech responses to clarification requests from the interlocutor (e.g., “what?,” “uh?” etc.) to include only spontaneous listener-oriented clear speech. While providing clarification requests was unnatural, these requests fostered and maintained a challenging communicative situation that promoted a clear speech context. Within this context, preschoolers demonstrated improved speech intelligibility for their listeners without direct instruction to speak clearly, loudly, or slowly (Tjaden et al., 2014). Children actively refine and develop speech intelligibility during this developmental period despite considerable variability (Hustad et al., 2021). A meaningful next step could involve comparing acoustic features of responses following clarification requests with those of spontaneous responses, promoting a more comprehensive understanding of speech-modification development (Brinton et al., 1986; Forrester, 2008).
In this study, we acknowledge the limitations posed by the sample size and the use of cross-sectional data. Future investigations would benefit from a longitudinal panel study with a larger sample size to deepen our understanding of the developmental trajectory of speech modification. In addition, as our listeners were all college students from the Department of Speech, Language, and Hearing Sciences, future studies should include a more diverse range of listeners to improve the generalizability of the results. Despite these limitations, the observed speech-modification strategy in young children holds promise for clinical applications, suggesting a potential holistic therapeutic approach to enhance speech intelligibility. Future research efforts, incorporating larger and more diverse participant samples, could contribute to a more comprehensive understanding of the applicability and effectiveness of this observed strategy in various contexts within clinical settings.
Footnotes
Appendix
List of Target Words.
| Index | Target | Index | Target | Index | Target | Index | Target | Index | Target |
|---|---|---|---|---|---|---|---|---|---|
| 1 | backpack | 11 | boots | 21 | dot | 31 | piano | 41 | tooth |
| 2 | bag | 12 | bottom | 22 | Duke | 32 | pool | 42 | top |
| 3 | ball | 13 | dad | 23 | fork | 33 | popcorn | 43 | t-shirt |
| 4 | barn | 14 | dance | 24 | pan | 34 | pot | 44 | tutu |
| 5 | bat | 15 | deep | 25 | pancake | 35 | spoon | 45 | TV |
| 6 | bathtub | 16 | deer | 26 | pants | 36 | taco | 46 | two |
| 7 | beach | 17 | dinner | 27 | park | 37 | tall | ||
| 8 | bean | 18 | doctor | 28 | Paul | 38 | taxi | ||
| 9 | bee | 19 | doll | 29 | peach | 39 | teeth | ||
| 10 | booboo | 20 | dollar | 30 | peas | 40 | Tom |
Acknowledgements
The authors thank the parents and kids who made this experiment possible and the TTUHSC team members who helped recruit participants.
Authors’ note
Partial reports of the data were presented to the 46th BUCLD (online, November 2021), 184th ASA (Chicago, May 2023), and 2023 Workshop Prosody and Beyond (Seoul, June 2023).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research received financial support from the seed grant provided by the School of Health Professions, Texas Tech University Health Science Center.