
Abstract
/n/ is merging with /l/ in Cantonese, as well as in several other Chinese languages. The Cantonese merger appears categorical, with /n/ becoming /l/ syllable-initially. This project aims to describe /n/ and /l/ in Cantonese and English speech from early Cantonese–English bilinguals to better understand the status of the merger in Cantonese and its potential for cross-linguistic mutual influence. We examine early bilinguals’ (n = 34) speech using the Speech in Cantonese and English (SpiCE) corpus, focusing on pre-vocalic /n/ and /l/ onsets in both languages. Items were auditorily coded for their perceived category identity, and two acoustic measures anticipated to have the potential to differentiate /n/ and /l/ within and across languages were applied. In English, bilinguals maintained a clear contrast between /n/ and /l/ in the auditory coding and in acoustic measurements. In Cantonese, however, there were higher rates of [l] for /n/ items, in line with the merger, and [n] for /l/ items, indicating hypercorrection of the pattern. Across languages, bilinguals produced language-specific /l/s, but there were no acoustic differences between Cantonese and English /n/. The participation of Cantonese /n/ in a sound change does not appear to compromise English /n/s’ patterning, suggesting that Cantonese and English /n/ are maintained as distinct categories in the minds of early bilinguals.
1 Introduction
Diachronic sound change sits at the interface of phonetics and phonology, as variation in phonetic forms may ultimately produce broader changes in the phonological system of a given language. Understanding phonetic variation through its contextually in situ existence in spontaneous speech offers a window into how sound patterns are most typically experienced by users of language (Beechey, 2022; K. Johnson, 2004; Tucker & Ernestus, 2016). Importantly, phonetic variation need not threaten the phonological contrasts of a language, as contrast can be transphonologized (e.g., Brunelle et al., 2020) or shifted while maintaining distinctions, as is the case with push chains (Hay et al., 2015). In other cases of sound change, however, phonetic variation may indeed neutralize sound contrasts. This seems to be the case with the Cantonese /n/–/l/ merger.
In Cantonese (Zee, 1999), and several other Chinese languages (e.g., Fuzhou Min, R. Cheng & Jongman, 2019; Southwestern Mandarin, Zhang & Levis, 2021), /n/ and /l/ are merging syllable-initially. In Cantonese, this means that /n/-initial words are sometimes produced with an [l], producing two pronunciation variants for a single item: a conservative [n]-initial pronunciation and an innovative [l]-initial pronunciation. This merger is one of several other consonant mergers happening in the language (To et al., 2015). Although the Cantonese /n/–/l/ merger has been described as nearly complete in some accounts of production (To et al., 2015), others find that it is still variable in production and perception (L. S. P. Cheng et al., 2022). Speech style matters, as Cantonese speakers are typically aware of the merger and that conservative [n]-initial pronunciations are considered a prestige form (L. S. P. Cheng et al., 2022). As speech style is a long-established factor in phonetic variation (e.g., Labov, 1972), this highlights the need to examine the merger in spontaneous speech. Although prior lab-based research informs the predictions, it is important to recognize that lab and spontaneous speech behavior can differ drastically (Gahl et al., 2012). Using the Speech in Cantonese and English (SpiCE) corpus, a corpus of Cantonese and English spontaneous speech from early and proficient bilinguals (K. A. Johnson, 2021), we provide the first acoustic description of the Cantonese /n/–/l/ merger. Furthermore, ongoing sound changes represent a unique opportunity to explore the degree to which sound categories are linked across languages in early bilinguals. If sound categories are linked across languages, a change in one language should lead to a change in the corresponding sounds of the other language. On the contrary, if sound categories are not linked, change in one language should leave the corresponding segments in the other language unaffected. It is also possible that sound change decouples any pre-existing link, and that metalinguistic awareness of the change facilitates any such delinking. Although detailing the time course of any linking and delinking is not possible outside of a panel study, examining the degree of cross-linguistic influence is possible here because SpiCE is a corpus of simultaneous or early sequential bilinguals. Thus, in addition to examining the Cantonese /n/–/l/ merger in spontaneous speech, we assess the extent to which these sound categories are linked cross-linguistically by comparing an individual’s Cantonese /n/ and /l/ productions with their English /n/ and /l/ productions (Antoniou et al., 2011; Kang & Guion, 2006; Schertz et al., 2019).
1.1 The /n/–/l/ merger in Cantonese and other Chinese languages
Cantonese is a Sino-Tibetan tone language spoken across the globe in the Cantonese-speaking diaspora, but primarily in Hong Kong, Macau, and the southern Chinese provinces of Guangdong and Guangxi (Eberhard et al., 2022). Much of the work documenting the /n/–/l/ merger has focused on the Hong Kong Cantonese variety, though the merger has also been observed in particular sociolinguistic conditions in Macau Cantonese (Botha & Barnes, 2015). As mentioned, in this sound change, /n/ is produced as [l] syllable-initially. As there are /n/-initial syllables, like nou5 1 腦 “brain,” and /l/-initial syllables, like lou5 老 “old,” the sound change ultimately renders these items as homophones. Thus, an [l]-initial pronunciation like lou5 now means “brain” (due to the sound change) and “old” (the /l/-initial word), and the contrast between /n/ and /l/ is neutralized syllable-initially in production. 2 Going forward, we adopt /angled brackets/ to characterize the initial consonants as a more abstract category and [square brackets] to refer to the actual surface pronunciations or phones. In the forthcoming summaries of the work on nasal–lateral mergers in other Chinese languages, we adopt the notation (or lack thereof) that each respective study utilizes, so as not to make assumptions or claims about the (phonological) relationship between these sound categories.
The first documented observation of the /n/–/l/ merger came from Chao (1947) in the mid-20th century, who stated that “one out of four persons in Canton has no initial n and pronounces an l in words beginning with n for other speakers.” A growing body of work on Cantonese /n/ and /l/ corroborated this sound change among a larger subset of Hong Kong Cantonese talkers, clearly establishing [n] pronunciations as the “standard.” Hashimoto (1972) noted that only “standard Hong Kong Cantonese” speakers maintained the distinction between /n/ and /l/. It is worth noting, however, that various Cantonese syllabaries spanning several decades actually differ in whether certain words bear an /n/ or /l/. For instance, Zee (1999) notes that Karlgren (1926) lists the word for “oar” 櫓 as nou5, whereas Hashimoto (1972) lists the word as lou5. In addition, Karlgren (1926) lists the word for “a drop” 粒 as nap1, whereas Hashimoto (1972) lists the word as either nap1 or lap1. These differences are indicative of the change in the status of /n/ and /l/ over the course of the 20th century.
By the 1980s and 1990s, several studies observed that [l] pronunciations were more pervasive in young Hong Kong Cantonese talkers. Across two production studies with younger and older age group comparisons, Yeung (1981) observed that younger talkers produced /n/-initial words with more [l]-initial pronunciations than older talkers. This work was furthered by Bourgerie (1990), who conducted a series of sociolinguistic interviews on talkers across younger and older age groups and found that younger groups produced more [l]-initial forms than the older groups. Innovative [l]-initial pronunciations (even those for canonical /l/-initial words) were ultimately deemed “lazy” by prescriptivists who felt that these pronunciations were reflective of “lazy” younger generations who did not produce the “correct” [n]-initial forms. These pronunciation campaigns instilled metalinguistic awareness about each pronunciation variant, as [l]-initial pronunciations (among other innovative forms in other Cantonese consonantal mergers) are colloquially referred to as laan5 jam1 懶音 in Cantonese, which roughly translates to “lazy pronunciations.”
In practice, [n]-initial forms have been associated with and used in more formal contexts, whereas [l]-initial forms are used in more casual contexts. Pan (1981) recorded two groups of participants (younger university students vs. older white-collar workers) in three different speech styles differing in level of formality: (1) casual speech from a group discussion, (2) read speech from a passage, and (3) word list repetition. Pan also produced the [n]-initial pronunciation followed by the [l]-initial pronunciation (in that order) for participants and asked for their judgment on which form was the correct pronunciation, in addition to their assessment of which forms they themselves produced. For both groups of speakers, Pan (1981) observed that the percentage of [n]-initial forms increased as a function of formality of elicitation context, with the least [n]-initial forms in casual speech, and the most [n]-initial forms in word list repetition. Moreover, the older white-collar workers produced more [n]-initial forms in every speech style than the younger university students. In addition, in the word judgments, the university students reported [n] as the proper form 59% of the time, whereas the white-collar workers reported [n] as the proper form 70% of the time. Both groups self-reported using the proper form 61% of the time. In addition, Pan (1981) anecdotally noted that participants hypercorrected to [n] in the word list reading portion of the task. Participants in both young and old age groups hypercorrected to some degree, with females and participants in the older age group hypercorrecting the most. This further suggested that talkers associate the [n] forms as the “correct” or “proper” pronunciation variant, as they produce these forms even for words that are canonically /l/-initial.
By the 21st century, the sound change was described as “close to completion” in younger and older talkers by To et al. (2015), who observed that more than 90% of adults and children in Hong Kong produced a comparable number of [l] pronunciations for a canonically /n/-initial word in a single-word elicitation task. More recent work by L. S. P. Cheng et al. (2022) on speakers of Hong Kong Cantonese suggested that the social weight of each pronunciation variant may have had the effect of stalling or reversing the progression of the merger, leading to stable stylistic variation wherein the [n] pronunciation variants are used in formal registers, while [l] is reserved for more casual contexts. Cheng and colleagues found that talkers produce more [l] pronunciations overall, even for words that are historically /n/-initial, and, crucially, they observed no group-level effects of age or talker gender. A closer examination of the individual-level variation further revealed that talkers run the gamut from realizing /n/ as [l] (i.e., the direction of the sound change), to retaining the historical contrast on items (i.e., producing historical /n/ words with [n] and historical /l/ words with [l]) to hypercorrecting (i.e., producing historical /l/ words with [n]). Thus, although the results indicate some semblance of the historical contrast, there is likewise considerable individual variation that underlies this community-level finding. More broadly, L. S. P. Cheng et al. (2022) conclude that the merger between /n/ and /l/ should not be described as a change-in-progress given that there was no effect of gender or age in their study of Hong Kong Cantonese speakers. Notably, L. S. P. Cheng et al. (2022) observed that the actual percentage of [l] pronunciations for /n/ words was much lower in their study at 54% (in younger women) to 71% (in older women), compared with To et al. (2015) who observed ~94% for both children and adults. Although L. S. P. Cheng et al. (2022) acknowledge that methodological differences may account for the discrepancies across studies, they note that these differences might also point to a stalling of the merger due to community-wide recognition and association of [n] as the “proper” form from the pronunciation campaigns. In this case, the mergers may instead represent context-conditioned variation, wherein listeners adopt [n] pronunciations in more formal pronunciation registers and [l] in more casual contexts.
Several other Chinese languages also exhibit a merger between /n/ and /l/ and much of this work is published in Mandarin. R. Cheng et al. (2023) provide important summaries of this work and our discussion of the broader Chinese literature on the topic is indebted to them and their coverage. The loss of contrast in /n/ and /l/ is occurring or has occurred in many Chinese languages. As with many sound changes, particular phonological environments goad this change. In a survey of 40 varieties of Chinese languages, Tian (2009) describes the merger as more likely when preceding a low vowel and when the rhyme itself has a nasal coda; that is, disharmony is preferred. Whether the loss of the contrast is due to categorical or gradient phonetic changes has been approached with nasalance measures, which quantify the amount of nasal versus oral airflow as a means of describing the nasality of a segment. As a baseline, Shi et al. (2010) find that nasals and laterals differ substantially in their nasalance scores in Chinese languages where these sounds are not merging: 90% for /n/ compared with 20% to 40% for /l/. Chinese languages with the merger exhibit different patterns. In Wuhan, Shi and Xiang (2010) identified multiple variants based on nasalance values, with strong nasals, clear laterals, and a variant that was in between. In Chengdu, however, Shi (2015) shows that both [n] and [l] pronunciations show more nasalization than a typical lateral, though the pattern is described as a merger toward a lateral. Vowel environment was a predictor of nasalance scores in Nanjing Mandarin, with a stronger nasal in front of high front vowels /i/ and /y/ compared with other vowel environments (Shi & Liang, 2017).
R. Cheng et al. (2023) examine the merger between word-initial nasal and lateral consonants in Fuzhou Min in both production and perception. They compare productions of /n/ and /l/ words between 12 speakers of Fuzhou Min, who are expected to have the merger, with the /n/ and /l/ productions of six English speakers and 12 (standard) Mandarin speakers, groups who are expected to robustly contrast the sounds. A linear discriminant analysis demonstrated the Fuzhou Min speakers produce acoustically distinct [l] and [n], but that these do not map onto the historical (prescriptivist) association of these sounds to particular words. The change is in the direction of [l], with more items produced as [l]. R. Cheng et al. (2023) probed the contrast in two perception experiments. They conducted an AX discrimination task, which indicated the listeners were not sensitive to the contrast between [n] and [l]. Performance on a 2AFC task indicated that listeners had a bias toward responding /l/, and that their responses were somewhat nudged by different acoustic properties, though not always in the anticipated direction.
The loss of /n/ and /l/ as a phonological contrast predicts that the sounds should be perceived as more similar-sounding, as prior work indicates that allophones are perceived to be more similar than contrastive sound pairs (Boomershine et al., 2008; Huang & Johnson, 2010; K. Johnson & Babel, 2010). Nanjing Mandarin has lost the /n/ and /l/ contrast that is maintained in Standard Mandarin (Song, 2015), which is taught in schools. Younger Nanjing Mandarin listeners therefore have more experience with /n/ and /l/ being contrastive via the use of Standard Mandarin in school compared with older Nanjing Mandarin listeners. K. Johnson and Song (2016) tested whether younger listeners would perceive /n/ and /l/ as more different compared with older listeners, comparing the subjective rating of /n/ and /l/ for Nanjing Mandarin listeners with those of American English listeners, for whom /n/ and /l/ is robustly contrastive. Both groups of Nanjing Mandarin listeners and the American English listeners rated /n/ and /l/ as more similar than control pairs /r/–/l/ and /n/–/r/, though that difference was smaller for the American English listeners. Crucially, however, older Nanjing listeners rated /n/ and /l/ as more similar than the younger Nanjing listeners. Together, these results indicate that the perceptual similarity of /n/ and /l/ is indeed affected by (i) whether sounds are in a contrastive relationship and (ii) exposure to other languages—in this case Standard Mandarin—which can further warp the similarity space for allophones making them slightly dissimilar.
Finally, Zhang and Levis (2021) examine /n/ and /l/ in Southwestern Mandarin, a dialect of Mandarin with varieties that merge /n/ to /l/, merge /l/ to /n/, and maintain a contrast. Individuals from a region that maintains a contrast produced clear /n/ and /l/ differences in Southwestern Mandarin, their first language, and Standard Mandarin and English, their second and third languages, respectively. All of the individuals from regions with a merger exhibited challenges in reliably producing /n/ and /l/ in Standard Mandarin and English, though more errors were observed for English, which was individuals’ least proficient language, compared with Standard Mandarin, individuals’ second language. These results anticipate our discussion of cross-linguistic influence, as listeners’ first language (Southwestern Mandarin) affected the realization of the contrast in individuals’ later acquired languages, English and Standard Mandarin.
1.2 Cross-linguistic influence
As mentioned, utilizing the SpiCE corpus not only permits an examination of the Cantonese /n/–/l/ merger, it also allows us to investigate the extent to which these sound categories are linked cross-linguistically in early bilinguals by comparing an individual’s Cantonese /n/ and /l/ productions with their English /n/ and /l/ productions (following previous approaches, e.g., Antoniou et al., 2011; Kang & Guion, 2006; Schertz et al., 2019). In fact, a consideration of bilingualism is often unavoidable in the context of Cantonese. Census data indicates that about 75% of Hong Kong residents aged 5 and older are multilingual. Although data are not provided on what language the estimated remainder who are monolingual speak, for the 2021 census data, nearly 94% of Hong Kong residents age 5 or older are able to speak Cantonese (Census and Statistics Department, 2021). Multilingualism is thus part of the linguistic landscape in Hong Kong. The Cantonese talkers from the SpiCE corpus were recruited from diaspora communities in Vancouver, Canada. As such, they are a mix of simultaneous or early sequential bilinguals with English. All but two also speak Mandarin, and several other languages are represented in participants’ language profiles (K. A. Johnson, 2021). This is not a unique feature of the local Cantonese speech community. Individuals in the Cantonese-speaking homelands are also multilingual. In Hong Kong, for instance, although the dominant spoken language is Cantonese, many talkers are multilingual in English (a result of British colonial rule from 1842 to 1997) and/or fluent in Mandarin due to contemporary geopolitical forces. This is reflected in Hong Kong’s language policy, which recognizes Cantonese, English, and Mandarin as official languages (Matthews & Yip, 2013).
Studies on bilingual speech production have provided robust evidence for cross-linguistic influence (e.g., Baker & Trofimovich, 2005; Barlow, 2014; Flege, 1987; Fricke et al., 2016; Major, 1992; Olson, 2016; Sancier & Fowler, 1997; Schertz et al., 2019; Simonet, 2011). According to the Speech Learning Model (SLM) by Flege (1995), cross-linguistic influence is rooted in nonnative sounds being assimilated to the closest phonetic equivalent in the native language, resulting in one composite sound category that stores two sounds. The SLM framework has recently been revised as the SLM-r (Flege & Bohn, 2021) to reflect a more dynamic model that allows for continual re-organization of cross-linguistic connections across the lifespan. This acknowledges the notion that cross-linguistic influence may vary as a function of (interacting) bilingual factors, such as the age of acquisition (Guion, 2003; Kang & Guion, 2006) and language dominance (Amengual, 2018; Antoniou et al., 2011; Henriksen et al., 2021). Although early bilinguals, which is our population sample, can maintain distinct phonetic categories across their two languages (e.g., Guion, 2003; Kang et al., 2016; MacLeod et al., 2009; Schertz et al., 2019; Simonet, 2014; Sundara et al., 2006), other evidence has shown that even highly proficient bilinguals show signs of cross-linguistic influence (Flege, 1987; Schertz et al., 2019), especially under conditions that maximize cross-linguistic interaction. Amengual (2018) demonstrates both the maintenance of distinctions and variable realization in an acoustic examination of /l/ productions by Spanish–English bilinguals where language mode conditions were manipulated (Grosjean, 1998, 2008). In unilingual modes, bilinguals can show, for example, phonetic patterns that are equivalent to monolingual norms (e.g., Antoniou et al., 2010; Henriksen et al., 2021). In contrast, in bilingual/mixed modes, where both languages are activated, for example, through code-switching, bilinguals can show cross-linguistic influence in phonetic patterns (e.g., Henriksen et al., 2021). In Amengual (2018), Spanish–English bilinguals representing four different populations—individuals who were (1) foreign-born (G1.5), (2) born in the United States with either one or both parents born in Mexico (G2), (3) United States-born to parents who were also born in the United States, but with grandparents who were born in Mexico (G3), and (4) late L2 learners of Spanish—were recruited. Participants from these groups completed a production task with three language mode conditions: Spanish, English (both unilingual modes), and Spanish–English mixed (mixed mode). They observed that all speaker groups were able to establish separate lateral categories for each language in the unilingual mode; English /l/s were overall darker for all groups than Spanish /l/s. Across generations, there were also more gradient effects of language dominance. G3 speakers, who were more English dominant, produced darker /l/s than G1.5 speakers, who were less English dominant. In addition, in the mixed language mode, there was evidence of dominance-based cross-linguistic influence; bilinguals produced laterals in the nondominant language more like the laterals in the dominant language. Here again, we underscore the benefit of examining [n] and [l] from an acoustic perspective. The nature of our acoustic measures not only affords us a window into the gradience that underlies these traditionally categorical pronunciation variants but also an opportunity to embrace the individual variation across talkers, since we examine acoustic measures that are individual-specific.
Cross-linguistic influence may result in surface-level mergers, but need not. Investigations into languages undergoing sound change represent a unique opportunity to explore the degree to which sound categories are linked across the languages in early and proficient bilinguals. If sound categories are linked across languages, a change in one language should lead to a change in the corresponding sounds of the other language, or at a minimum, some level of influence in highly mixed language modes. On the contrary, if sound categories are not linked, change in one language should leave the corresponding segments in the other language unaffected. Schertz et al. (2019) tested older and younger Korean–Mandarin bilinguals across two bilingual communities. All participants learned Korean as an L1, but talkers in the older generation self-reported lower proficiency in Mandarin compared with Korean, and lower proficiency in Mandarin compared with the younger generation. The sibilant categories across both languages are undergoing a sound change affecting the laryngeal categories (Korean lenis and aspirated sounds are no longer contrastive in voice onset time) or the place of articulation (Mandarin retroflex sounds are fronted to dental pronunciations). In a production task, older talkers showed phonetic convergence across both languages, producing corresponding Korean and Mandarin sounds similarly. Younger talkers, on the contrary, showed both phonetic convergence and phonetic independence. The fronted Mandarin sibilants produced fronted Korean sibilants. However, the voice onset time distinction between Mandarin affricates was maintained for the younger group.
1.3 Current study and hypotheses
As mentioned, the Cantonese sound change has been viewed as categorical with two pronunciation variants: the conservative [n]-initial pronunciation and the innovative [l]-initial pronunciation. In this study, we examine potential gradience in the production of these sound change variants across individuals by examining the acoustic productions of [n] and [l] in Cantonese and English through the SpiCE corpus (K. A. Johnson, 2021). Thus, we build on this pre-existing work first by assessing the phonetic gradience in the sound change acoustically. Early work by Zee (1991) describes Cantonese [n] as an apico-laminal denti-alveolar nasal and Cantonese [l] as an apical (denti-) lateral approximant, differentiating these sounds in terms of nasality and tongue blade involvement. As such, we focus on acoustic measures that correlate with nasality and place of articulation.
Following Garellek et al. (2016), we use a mid-frequency spectral tilt measure—H4–H2KHz*, which is measured as the amplitude of the fourth harmonic (H4) minus the amplitude of the harmonic closest to 2,000 Hz, corrected for formant frequencies (Iseli et al., 2007)—where nasals were expected to have a greater spectral tilt than laterals.
The acoustics literature on laterals offers additional predictions. In providing a rigorous acoustic description of /l̪ l ɭ ʎ/ in Arrernte, Pitjantjatjara, and Warlpiri, Tabain et al. (2016a) ultimately propose what they refer to as a “default lateral” model. In their default lateral model, which is an articulatory configuration similar to that for /i/, with the addition of antiresonance from a side branch, they suggest that F1 is the result of the tongue forming a constriction that creates a Helmholtz resonator for the lateral airflow. F2 is the output of the back cavity resonance, whereas F3 is a front cavity resonance. They state that this is identical to the acoustic model for /i/ with the addition of the antiformant as a result of the side branch. Focusing on the same languages—Arrernte, Pitjantjatjara, and Warlpiri—Tabain et al. (2016b) describe /m n̪ n ɳ ɲ ŋ/. Across Tabain et al. (2016a) and Tabain et al. (2016b), it can be empirically observed that the F2-F1 difference is smaller between laterals than nasals. R. Cheng et al. (2023) also use F2-F1 as a complement to the predictions of acoustic theory (Chiba & Kajiyama, 1941; Stevens, 1998) to differentiate /n/ and /l/. The F2-F1 spacing also captures differences in place of articulation, which can be used to evaluate whether bilinguals use the same /n/ and the same /l/ in both languages. More velarized /l/, which we anticipate in English, will have lower F2 values, reducing the F2-F1 difference (Recasens, 2012). 3
Second, we compare whether /n/ and /l/ are linked across languages for early Cantonese–English bilinguals. If Cantonese /n/ and /l/ are linked with English /n/ and /l/, then we expect that individuals’ [n]s and [l]s across languages to be similar. That is, we would predict no acoustic differences between Cantonese and English /n/s and Cantonese and English /l/s. We also might expect English /n/s to be produced as [l]. On the contrary, if the sound categories across languages remain independent from one another, the acoustic changes induced by the merging of /n/ and /l/ in Cantonese should not affect English /n/ and /l/. Although this is perhaps overly simplistic, it highlights the framework in which we analyze sounds subject to both sound change and cross-linguistic influence.
2 Methodology
2.1 Data
The SpiCE corpus (K. A. Johnson, 2021) comprises speech from a heterogeneous group of 34 early Cantonese–English bilingual talkers (female = 17, male = 17). All talkers either learned Cantonese first or both languages simultaneously, and the vast majority reported comparable speaking and listening proficiency across the two languages. SpiCE talkers are united in their early and balanced bilingualism, but there is a high degree of variability in the geographic origins of the talkers (though mostly Canada and/or Hong Kong), and their caregivers (mostly Hong Kong and neighboring Chinese provinces). Each bilingual talker in the SpiCE corpus completed three tasks in both languages: sentence reading, storyboard narration, and a conversational interview. The analyses here include all three tasks; 7.4 of the 8.3 hours of Cantonese speech are from the interviews, and 7.7 of the 8.9 hours of English speech are from the interviews. Thus, the vast majority of the data reported here come from spontaneous speech and we characterize it as such.
As the recording sessions were casual in nature and conducted by two undergraduate student interviewers who were members of the same speech community as the participants, neither the environment nor the interlocutor was likely to have induced pressure for talkers to utilize the historical “prestigious” [n]-initial forms. Talkers were likely comfortable producing innovative [l]-initial forms in an environment with their peers. The transcripts provided with the SpiCE corpus comprise hand-corrected orthographic and force-aligned phone-level annotations. The corpus is described in greater detail in K. A. Johnson et al. (2020), and in the online documentation for the corpus. 4
2.2 Target segments and acoustic measurements
The analyses focus on pre-vocalic, word-initial /n/ and /l/ segments in Cantonese and English. Segments were not limited to complete words but could have been part words, false starts, or other disfluencies. Cantonese words were identified in the SpiCE corpus using the PyCantonese Python package (Lee, 2015), which implements a longest string matching algorithm. PyCantonese uses the Hong Kong Cantonese Corpus (HKCanCor) as the dictionary, which contains a Jyutping phonemic transcription for Chinese characters (Luke & Wong, 2015). The romanization of Cantonese words in HKCanCor therefore determines for our purposes whether a Cantonese item is /n/ or /l/ initial. Li et al. (2023) observe that compared with some other Cantonese corpora, HKCanCor does not transcribe surface-level variants, providing a single phonological transcription for each word, though it is unspecified in the HKCanCor documentation what dictionary was ultimately used for their phonological /n/ or /l/ labeling. Words were only included if there were no other nasal or liquid segments within the word. Although this criterion was included to ensure that nasality was not impacted by nasal codas (which are not realized as [l] in Cantonese), it also renders the samples more comparable across languages. Prior to collecting acoustic measurements, there were a total of 13,790 instances of /n/ and /l/ matching the criteria described above.
Because of concerns about alignment accuracy with the force-aligned data, F1, F2, and H4–H2KHz* output from VoiceSauce were averaged over the middle third of the nasals and laterals. Formants were estimated using the Snack Sound Toolkit method (Sjölander, 2004) and the default settings of 0.96 pre-emphasis, 25 ms window length, and 1 ms frameshift. H4–H2KHz* is measured in dB and is the corrected amplitude difference between the fourth harmonic and the harmonic closest to 2,000 Hz. To mitigate measurement error, tokens where the estimated average f0 for the middle third of the phone was equal to or less than 65 Hz were removed
This left 9,665 tokens for analysis: Cantonese /l/ = 1,620; Cantonese /n/ = 1,519; English /l/ = 4,724 (of which 3,677 are “like”); English /n/ = 1,802. Although a large proportion of the English /l/ tokens are represented by the word “like,” we ultimately decided against removing these tokens from the analysis as they are part of the realization of /l/ in English.
2.3 Auditory coding
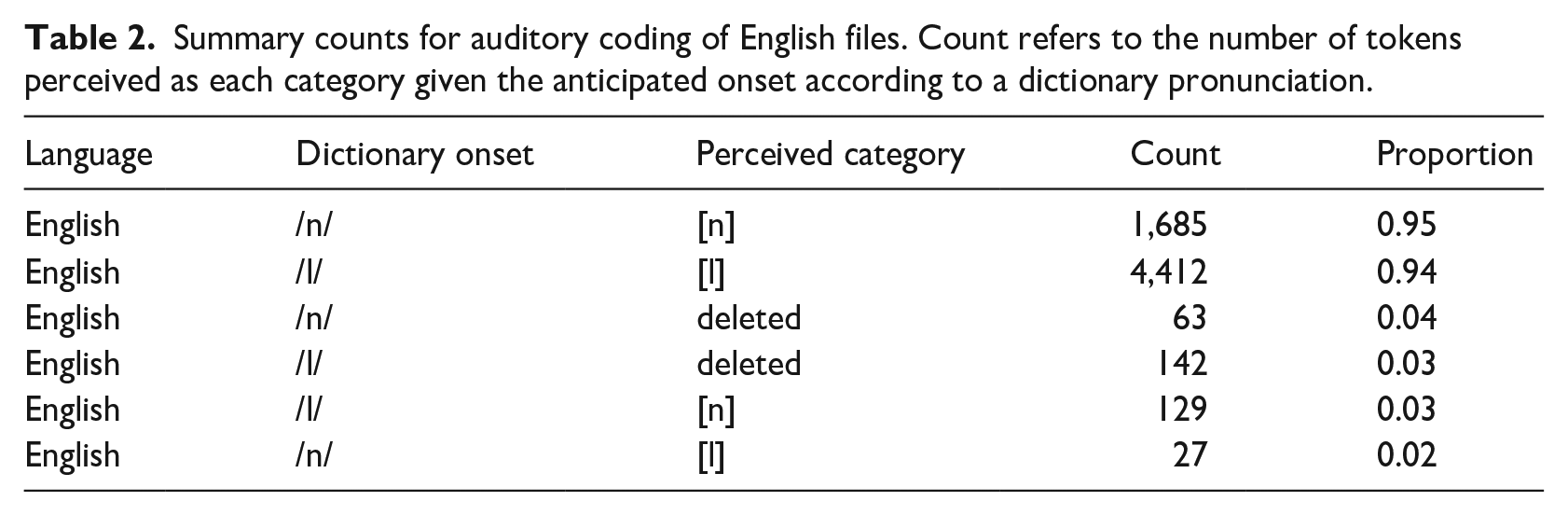
Three research assistants (RAs) without knowledge of Cantonese coded the 9,665 items that were expected to have /n/ or /l/ present in the labeled interval of a TextGrid. RAs who were not Cantonese speakers were specifically selected to avoid any lexical biases in the coding of ambiguous items in Cantonese. Tables 1 and 2 provide a summary of the auditory coding for Cantonese and English sound files, respectively. RAs coded whether a target [n] or [l] was present in the sound file, determining if it was [n], [l], or deleted. If the phone was present, RAs provided a goodness rating for the quality of the phone on a Likert-type scale of 1 to 7, where 1 is a very poor example of that sound and 7 is a perfect example of that sound. RAs also categorically coded whether the middle third of the phone labeled by the TextGrid fell within the acoustic boundaries of the target phone. One RA misunderstood the task and coded the /n/ or /l/ as deleted if it did not fall into the labeled interval; the RA was asked to recode all items on which the other two coders did not agree. Just more than 1% of the files were missed by at least one of the two RAs who completed the task as instructed (10 Cantonese /l/ words, 37 Cantonese /n/ words, 39 English /l/ words, and 20 English /n/ words), leaving 9,559 coded items.
Summary counts for auditory coding of Cantonese files. Count refers to the number of tokens perceived as each category given the anticipated onset according to a dictionary pronunciation.

Summary counts for auditory coding of English files. Count refers to the number of tokens perceived as each category given the anticipated onset according to a dictionary pronunciation.
3 Results
3.1 Categorical coding
The interrater reliability for the two RAs who followed the instructions of the coding ranged from fair to substantial (Cantonese /l/ words: n = 1,610, Kappa = 0.61, z = 31.7, p < .001; Cantonese /n/ words: n = 1,482, Kappa = 0.66, z = 32.3, p < .001; English /l/ words: n = 4,685, Kappa = 0.34, z = 29.5, p < .001; English /n/ words: n = 1,782, Kappa = 0.43, z = 23.2, p < .001).
Tables 1 and 2 report the categorical coding of the items determined by two of the three RAs agreeing on the label, organized by proportion. Starting with the anticipated direction of the sound change, Cantonese /n/ was coded as [l] in 71% of instances, as [n] or deleted in 18% and 11% of instances, respectively. The patterns for Cantonese /l/ were not dramatically different, with /l/ being coded as [l] 77% of the time, with 13% and 9% of the tokens coded as [n] or deleted. This suggests a fair bit of hypercorrection of /l/ to [n]. The English data pattern is different, with /n/ coded as [n] and /l/ as [l], 95% and 94% of the time, respectively. Deletion and the production of /n/ as [l] and /l/ as [n] are both infrequent. 5
Figure 1 illustrates the proportion of perceived [l] tokens based on auditory coding for each talker in Cantonese and English. The English data shows little by-talker variation. Across the board, talkers produce high rates of [l] for /l/-initial words but [l] is produced almost never for /n/-initial words in English. In Cantonese, however, there is considerable by-talker variation. Some talkers are relatively conservative, like VF19A, who produces relatively lower rates of [l] for /n/ words. Other talkers are more advanced in sound change like VM21 C, which produces high rates of [l] for /n/ words. Other talkers, such as VF20B, show high rates of hypercorrection such that /n/ and /l/ words are produced as [l] at similar middling rates.
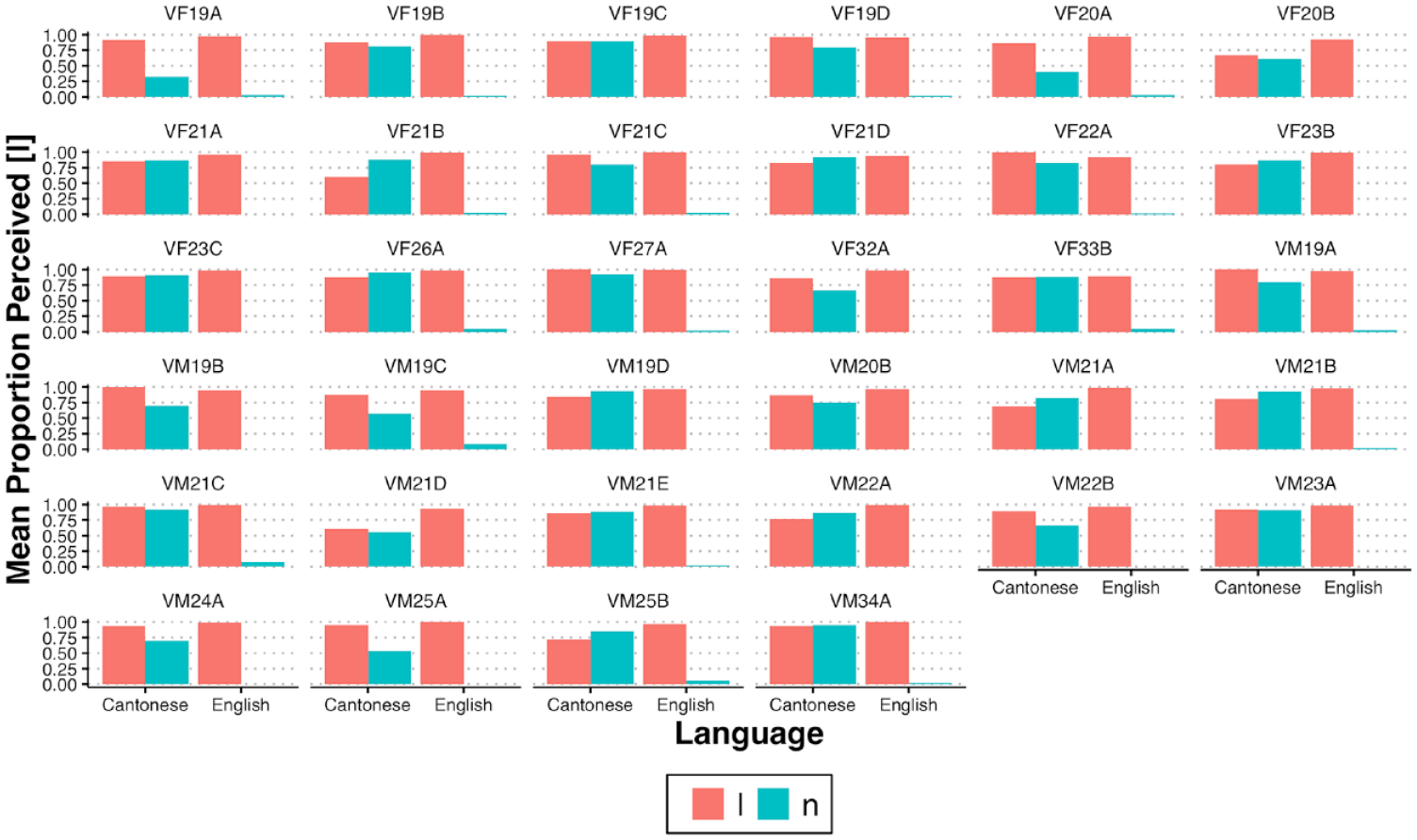
Mean proportion of perceived [l] tokens based on auditory coding broken down by talkers in Cantonese and English. The onset of the forms as indicated by the dictionary entry are represented by colors (vermillion for /l/-initial words, cyan for /n/-initial words).
To et al.’s (2015) seminal work on Cantonese consonant mergers characterized the status of mergers by focusing on single representative words (i.e., /n/-initial naam4 zai2 男仔 “boy” for the /n/-/l/ merger). Words, however, may change at different rates (e.g., Todd et al., 2019). As such, we explore the mean proportion of [l] responses for Cantonese /n/ items (see Table A1), Cantonese /l/ items (see Table A2), English /n/ items (see Table A3), and English /l/ items (see Table A4) produced more than once. These tables are provided in the appendix due to their size. Across these items at the language level, Cantonese and English are overall similar in the consistency in which /l/ is realized. Across the 66 unique Cantonese /l/ items, they are produced as [l] 97% of the time (SD = 8%). These rates are similar to the 50 English /l/ items, which are produced as [l] 96% of the time (SD = 11%). The realization of /n/ words across languages, however, is quite different. The 20 Cantonese /n/ words are realized as [l] at rates of 73% (SD = 23%), whereas the 24 English /n/ words are only realized as [l] 2% of the time (SD = 5%), or in other words, consistently realized as [n].
The proportions of [l] realizations for /n/ and /l/ items in Cantonese and English from Tables A1–A4 are further visualized in Figures 2 and 3, respectively. There are clear differences in the amount of by-word variation across languages. Within Cantonese, we see that although there is some variation among /l/ words, suggesting some amount of hypercorrection, /n/ words show substantial variation, with some items exclusively produced with [n] (no bar present at all) and others with high rates of [l]. In English, where /n/ and /l/ are not merging, the patterns are much more consistent, with /l/-initial words almost always realized with [l] and /n/-initial words almost always realized with [n].
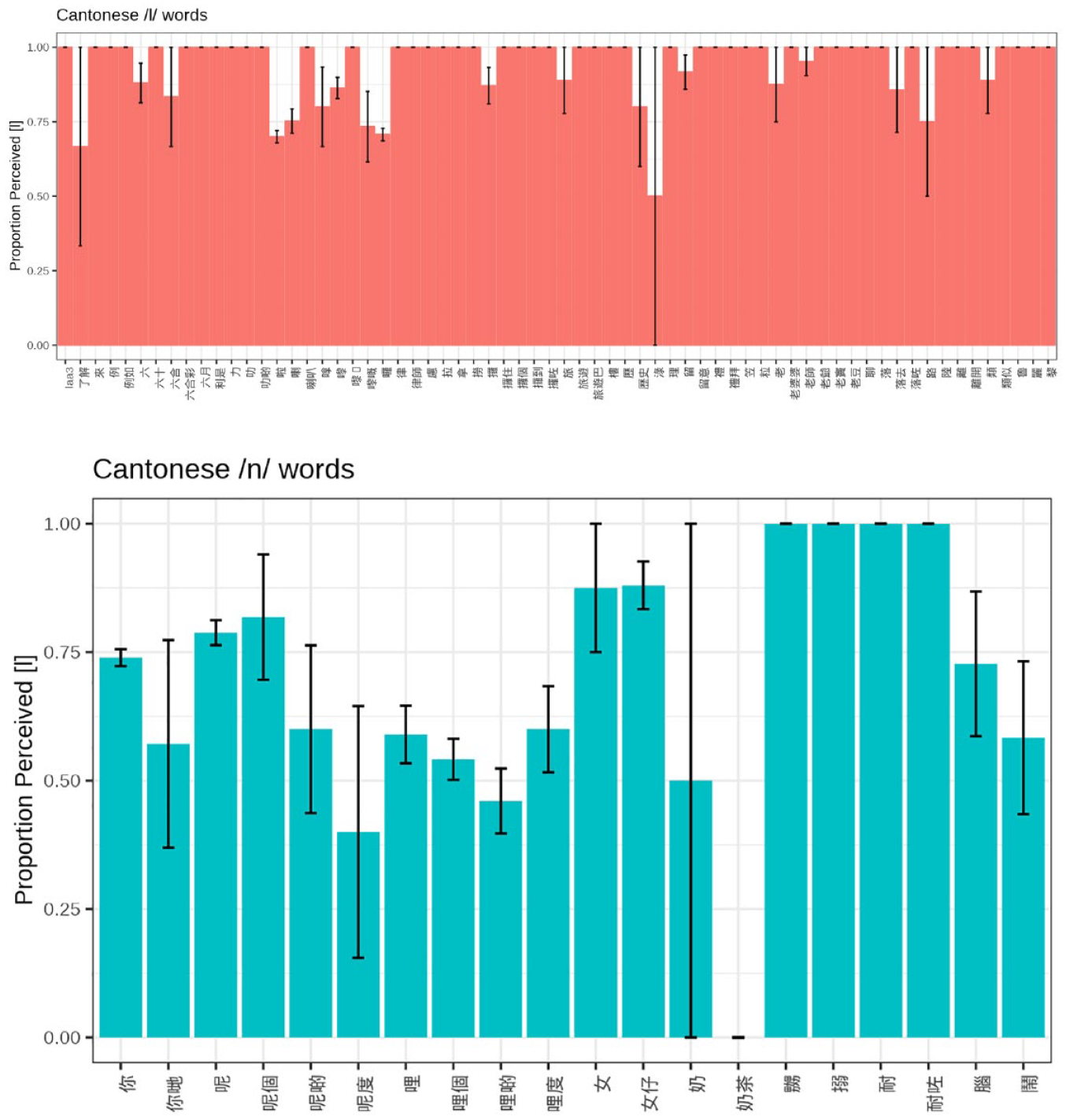
Mean proportion of perceived [l] tokens based on auditory coding broken down by Cantonese /l/ words (top) and Cantonese /n/ words (bottom). Error bars are standard errors across all talkers.
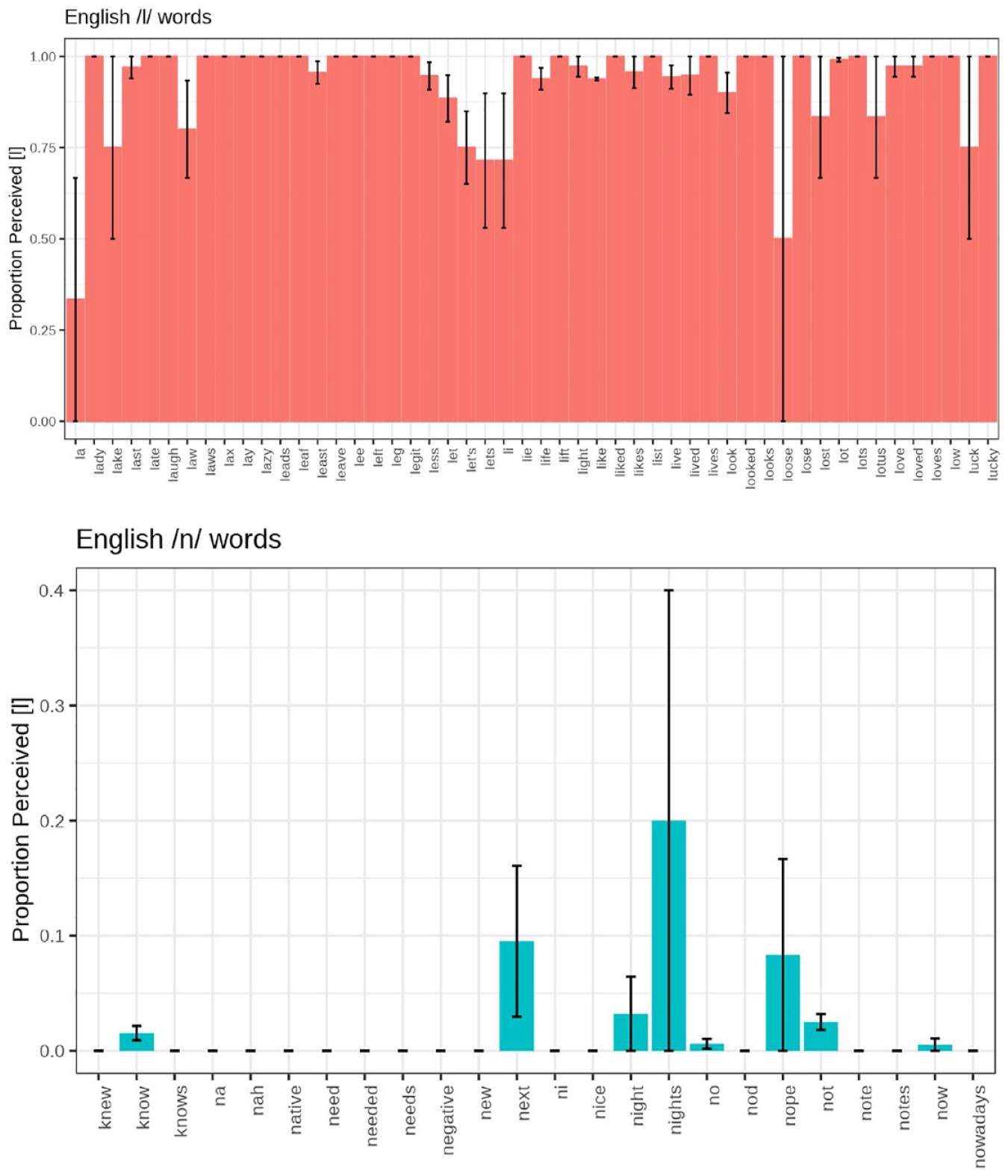
Mean proportion of perceived [l] tokens based on auditory coding broken down by English /l/ words (top) and English /n/ words (bottom). Error bars are standard errors across all talkers.
3.2 Acoustic analysis
For the quantitative analysis of acoustic data, we focus on tokens with an explicitly perceived category, setting aside the deleted tokens. These represent four conditions: /l/-initial words that are perceived as [l] (/l/ > [l]), /l/-initial words that are perceived as [n] (/l/ > [n]; hypercorrection condition), /n/-initial words that are perceived as [l] (/n/ > [l]; sound change condition), and /n/-initial words that are perceived as [n] (/n/ > [n]). As mentioned, we focus on acoustic measures shown to distinguish nasality (H4–H2KHz*) and place of articulation (F2-F1 spacing). All acoustic estimates were made using VoiceSauce (Shue et al., 2011). Figure 4 plots these acoustic measures for Cantonese and English across all four conditions. We use Bayesian data analysis, and model results are interpreted following the suggestions of Nicenboim and Vasishth (2016): when the 95% credible interval (CrI) for a given parameter excludes 0, this is considered strong evidence for an effect. The evidence for an effect is described as weak if the CrI includes 0, but the probability of direction (PD) is >0.95.
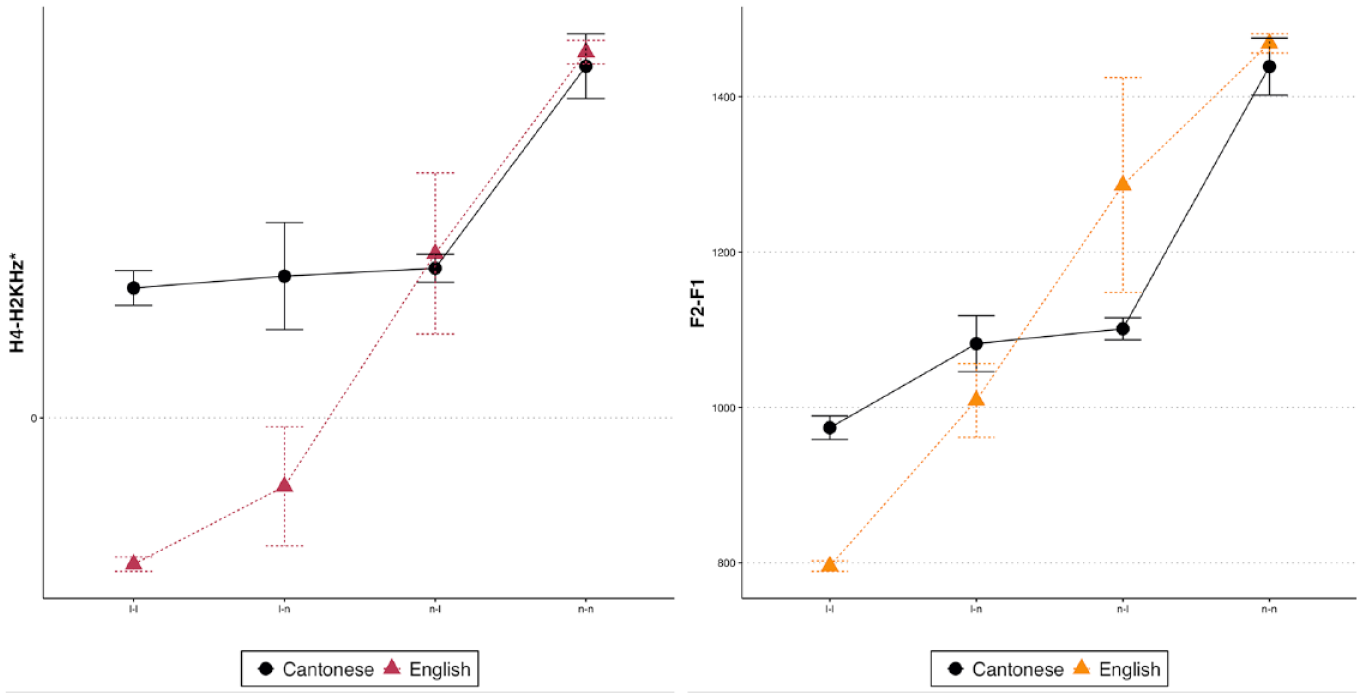
Empirical H4–H2KHz* values (left) and F2-F1 values (right) for Cantonese (dark circles) and English (vermillion triangles) items. The dictionary consonant is coded to the left of the category label, and perceived consonant is coded to the right of the category label (e.g., n-l is /n/ > [l], where /n/-initial words are perceived as [l]). Error bars are standard errors across all talkers.
3.2.1 Within-language comparisons
First, within-language comparisons were conducted for each language for each acoustic measure. We analyzed each acoustic measure using a Bayesian mixed-effects model fitted in Stan using the {brms} package (Bürkner, 2017) in R (R Core Team, 2021). The model included Condition (/n/ > [n], /l/ > [n], /n/ > [l], /l/ > [l]) treated as a forward difference coded variable. With forward difference coding, the intercept is the grand mean and all adjacent groups are compared. The model also included by-item random intercepts and by-subject random slopes for the effect of Condition. Different priors were used for the different models, and those are described in the context of each model. We used Hamiltonian Monte-Carlo sampling with four chains (each with 2,000 iterations and 1,000 warm-ups) to draw samples from the posterior distribution unless otherwise stated. In the following sections, we provide the output of each model, describing (1) the mean of the posterior distribution
Because we anticipate the acoustic measures to robustly distinguish the English consonants, we begin with the English data. For the spectral tilt measure, priors for the intercept, standard deviation, and sigma were regularizing, weakly informative priors of normal distributions with a mean of 0 and a standard deviation of 10. The class b parameter prior was a normal distribution with a mean of 0 and a standard deviation of 5. The analysis with H4–H2KHz* for English is reported in Table 3, and the empirical results are visualized in Figure 4 for this comparison and all other effects reported here. Each level is unique compared with the adjacent, increasing incrementally in nasality, according to this mid-frequency spectral tilt measure. There is strong evidence for this difference across all levels except for /l/ > [l] compared with /l/ > [n]. For this comparison, the mean of the posterior distribution is strongly negative, but the posterior distribution is wide, with the 95% CrI encompassing 0. The PD for this comparison is high, however, indicating that although the distribution is large, the probability of the mean being negative is high.
Population-level or fixed-effect predictors for the Bayesian model for the mid-frequency spectral tilt measure for English. The
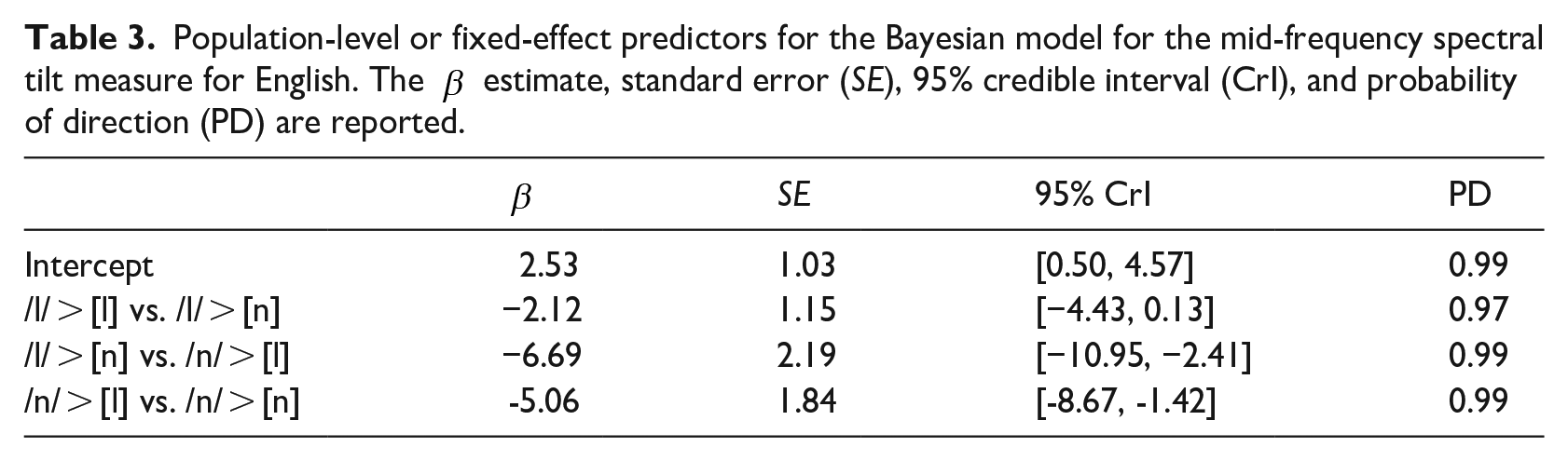
The F2-F1 model for English /n/ and /l/ is summarized in Table 4. This model had regularizing, weakly informative priors for all variables with normally distributed priors centered at 0 for all levels, and standard deviation of 100 for the intercept, standard deviation, and sigma, and 50 for class b. Like the spectral tilt measure, F2-F1 distinguishes each adjacent level. The evidence for the level-by-level difference in F2-F1 is very strong, with the 95% CrIs all far from 0 and PDs of 1. Overall, these results for English indicate that canonical [n] and [l] differ in terms of acoustic correlates of nasality and F2-F1 and that the realization of /l/ words as [l] and [n] gradient distinguish themselves from each other and the canonical endpoints.
Population-level or fixed-effect predictors for the Bayesian model for the place of articulation measure for English. The
For the spectral tilt measure, priors for the intercept, standard deviation, and sigma were regularizing, weakly informative priors of normal distributions with a mean of 0 and a standard deviation of 10. The class b parameter prior was a normal distribution with a mean of 0 and a standard deviation of 5.
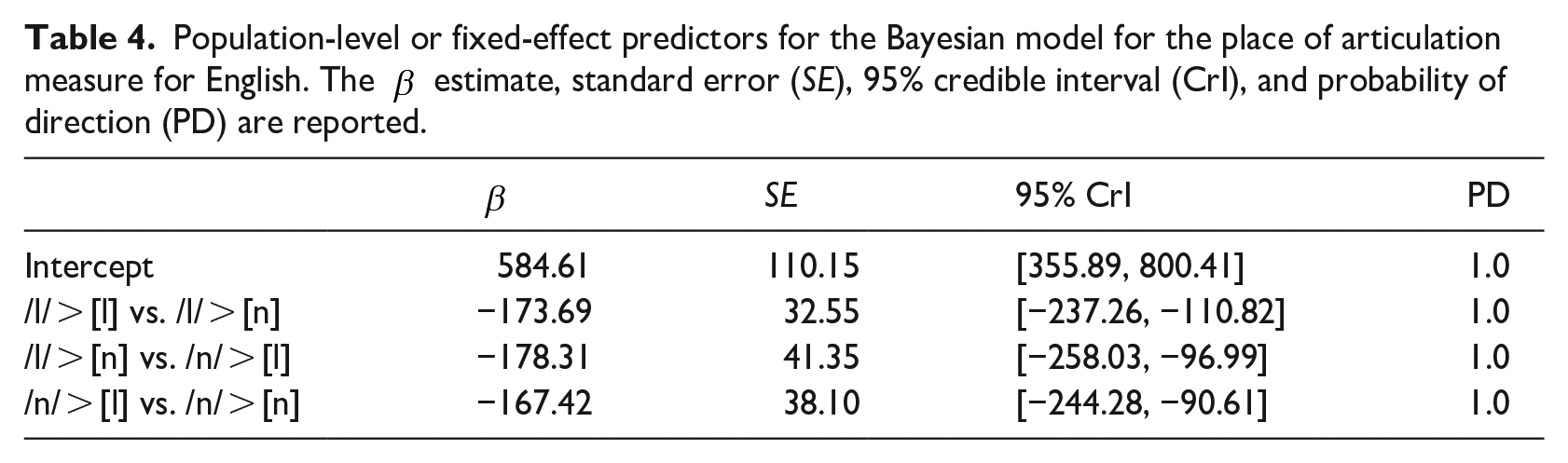
The analysis of H4–H2KHz* for Cantonese is, as expected given the sound change afoot, different. The same priors were used in this model as were used in the English spectral tilt model. The model summary is presented in Table 5. /l/ heard as [l] and /l/ heard as [n] show no evidence for a difference, and the latter shows no evidence for a difference with /n/ heard as [l]. Any item associated with /l/ or [l] overlaps substantially in the distribution of H4–H2KHz*, suggesting the same degree of laterality or, perhaps more accurately, lack of nasality. Tokens of /n/ realized as [n] are distinct, however, from the adjacent category /n/ > [l]. Only items that are historically nasal and produced as a nasal are more nasal with respect to this mid-frequency spectral tilt measure.
Population-level or fixed-effect predictors for the Bayesian model for the mid-frequency spectral tilt measure for Cantonese. The
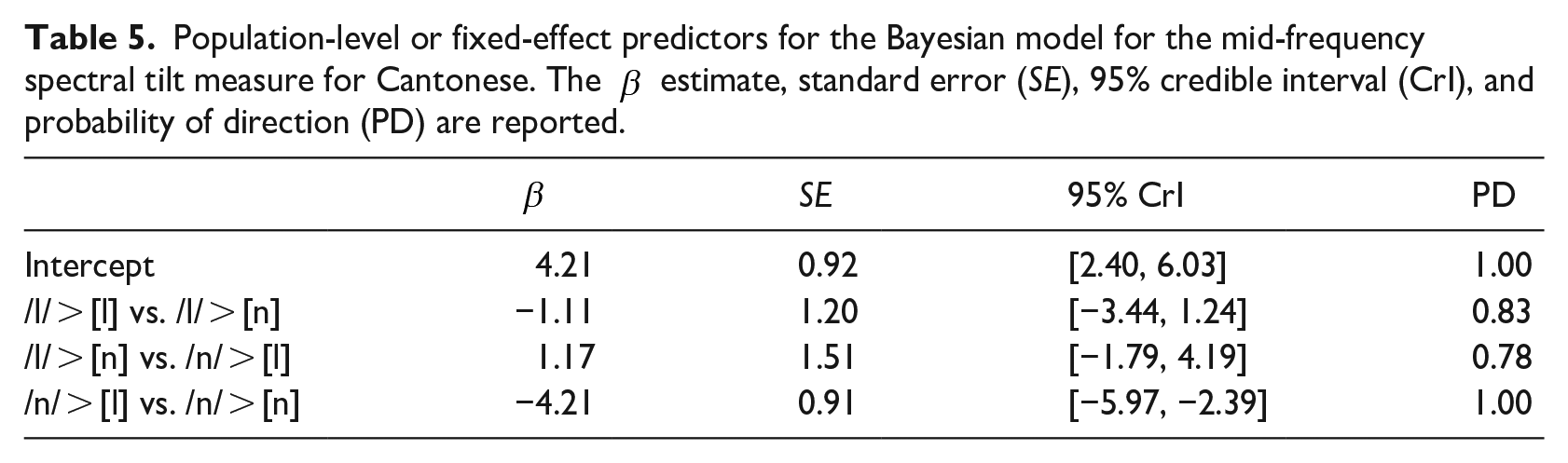
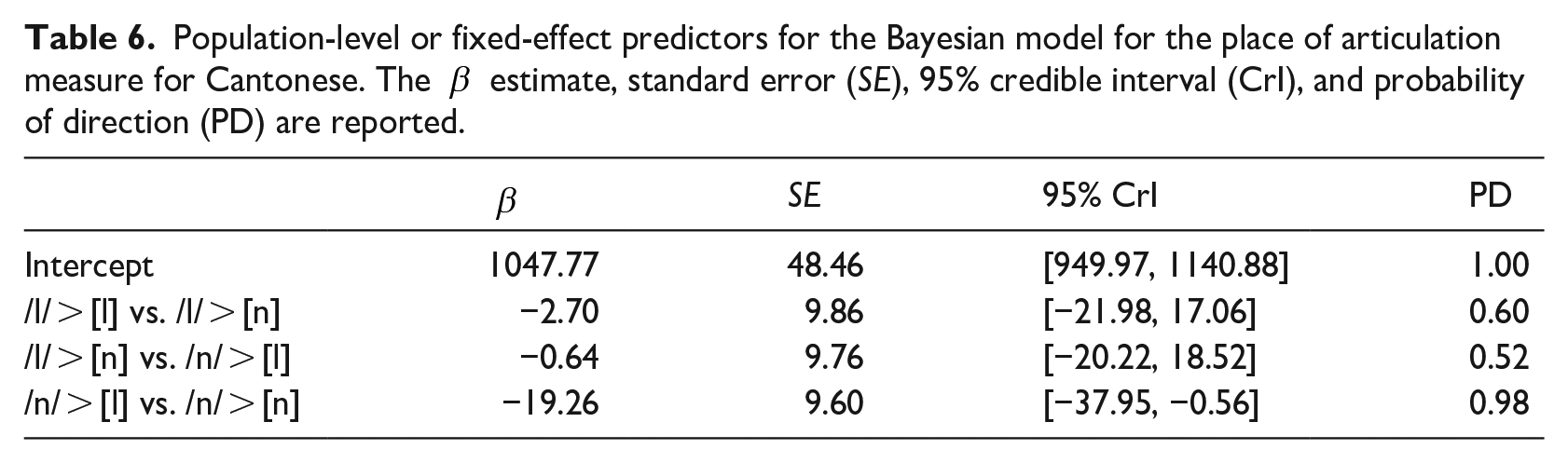
The results for the Cantonese items with respect to F2-F1 are similar. The Bayesian model, summarized in Table 6, shows no evidence for differences between adjacent levels for tokens associated with the lateral, either in terms of their dictionary form /l/ or pronunciation [l]. This model’s prior structure anticipated more variation. Again, we used regularizing, weakly informative priors for all variables with normally distributed priors centered at 0 for all levels. The standard deviation for the intercept, standard deviation, and sigma in this model was 200 and the class b standard deviation was 10. As with the H4–H2KHz* measure, however, /n/ realized as [l] and /n/ realized as [n] do show strong evidence for a difference, with the /n/ > [n] tokens showing a larger F2-F1 difference.
Population-level or fixed-effect predictors for the Bayesian model for the place of articulation measure for Cantonese. The
To summarize, in English, instances where /n/ is realized as [l] and /l/ is realized as [n] are infrequent (see Table 2), and the analyses of acoustic data suggest that these /n/ > [l] and /l/ > [n] items are unique compared with each other—there was strong evidence in the Bayesian analysis that these items differed from each other. There was also strong evidence that the /n/ > [l] items differed from /n/ > [n] items in terms of their nasality, and there was existent, but weaker evidence that /l/ > [l] items were less nasalized than /l/ > [n] items. This gradience in the phonetic realization of these categories in English suggests that /n/s perceived as [l]s and /l/s perceived as [n]s are likely speech errors that exhibit phonetic blending as a result of co-activation of both /n/ and /l/. These items /l/ > [n] and /n/ > [l] are removed from the across-language comparisons, as described in Table 7.
The coding of the four levels of laterals and nasals for the cross-linguistic comparisons.

In Cantonese, however, as summarized in Table 1, the /n/ > [n] items and the hypercorrective /l/ > [n] items are the least frequent realizations (occurring 18% and 13% of the time, respectively), but they both occur with much greater frequency than the English items deemed errors. More importantly, the Bayesian analyses of the acoustic data suggest that /l/ > [l], /n/ > [l], and /l/ > [n] are all equivalent in both the spectral tilt and formant spacing measures. We therefore call all of these surface [l]s, grouping them together in Cantonese for the cross-language comparison with English. The coding of these levels for the cross-linguistic comparisons is provided in Table 7. Next, we turn to a comparison of phones across languages to assess the degree of cross-linguistic influence on the realization of Cantonese and English nasals and laterals.
3.2.2 Across-language comparisons
In the across-language comparisons, we compare across Cantonese and English within a segment class. The two acoustic measures are approached separately as dependent measures in Bayesian mixed-effects models fitted in Stan using the {brms} package (Bürkner, 2017) in R (R Core Team, 2021). The model included language as a population-level effect; it was treatment-coded with English as the reference level. The model also included by-item random intercepts and by-subject random slopes for language. All models but the one for F2-F1 for /n/ used 2,000 iterations, with an additional 1,000 for warm-up, to draw samples from the posterior distribution. For the F2-F1 model for /n/, 4000 iterations were used after the initial model returned low bulk effective sample size values. As with our within-language analyses, in summarizing the output of each model, we provide (1) the mean of the posterior distribution
The spectral tilt model used the same priors as described above for the other voice quality models. Crucially, there was strong evidence for a population-level effect of language in the H4–H2KHz* model (Intercept:
Similarly, the F2-F1 measure also provided strong evidence for a difference between Cantonese and English [l] (Intercept:
The patterns for /n/ across languages offered a different perspective. The mid-frequency spectral tilt measure, again with the same priors as the other models with this dependent measure, does not differentiate [n] in English and Cantonese (Intercept:
3.2.3 Individual differences
Having established the group-level effects, we turn to the individual differences in the realization of these categories within and across languages. Figure 5 visualizes the structure of the individual variation across languages for the laterals in the top row and nasals in the bottom row for all of the data, including the English errors that were dropped in the previous analyses. The first column is for the F2-F1 measure, and the second column presents the H4–H2KHz* values. Each participant has a data point for Cantonese and English, which is connected by a line and visualized in a different color to facilitate the visual tracking of the lines and points. Although there are individual exceptions, the majority of individual lines for the laterals illustrate a consistent pattern—Cantonese laterals have a larger F2-F1 difference and a higher H4–H2KHz* difference. This suggests that bilinguals have a more clear realization of Cantonese /l/ than English /l/ and that the Cantonese /l/ is more nasalized or differs in voice quality compared with the English /l/. The group-level pattern for nasals is also consistent, but there are individuals who diverge from the group pattern. For nasals, it is clear that across talkers, the category variance in Cantonese is greater than in English, with individual level F2-F1 and H4–H2KHz* values spread across a wide range in Cantonese and narrowing for English. That is, the acoustic realization for items is more variable in Cantonese than in English.
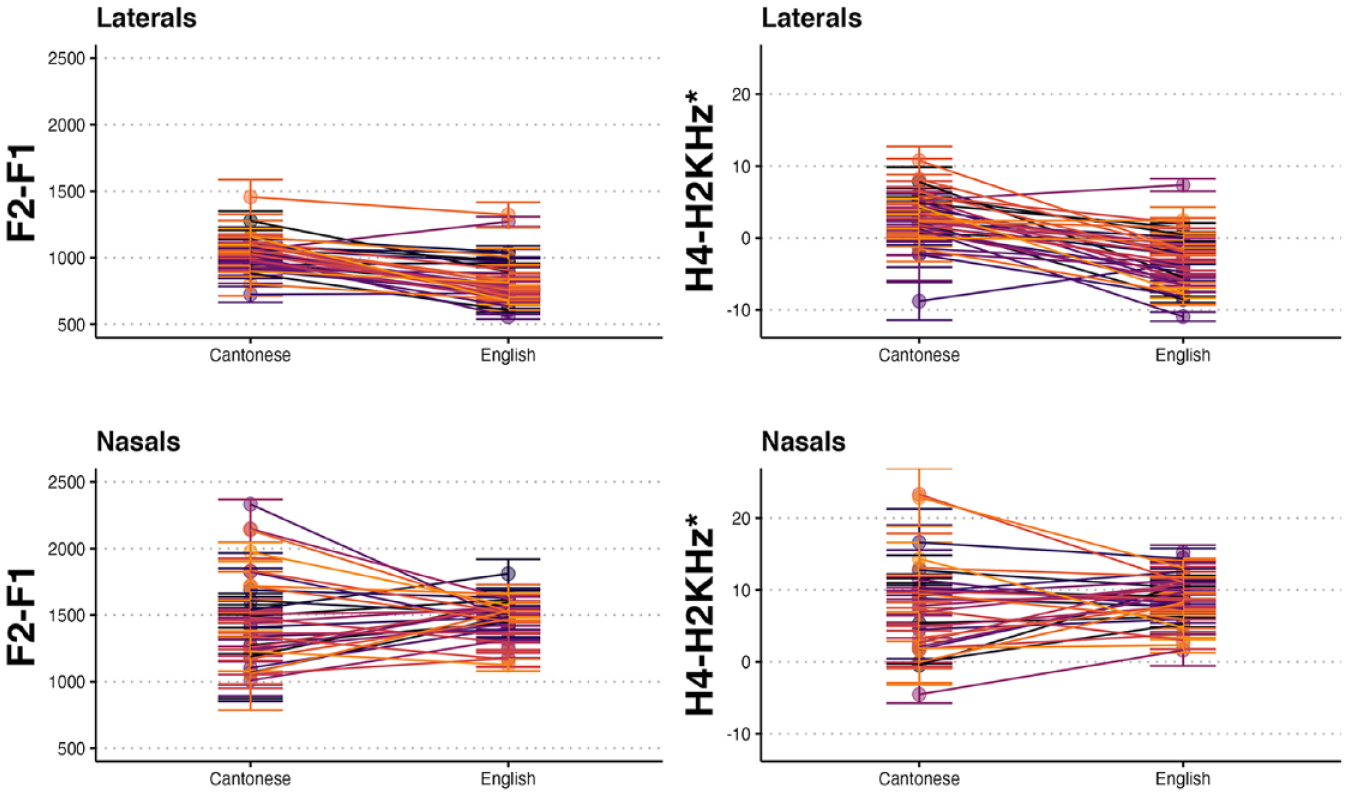
By-talker means and standard error for Cantonese and English laterals and nasals for the two acoustic measures.
Individual data are separated into four categories and faceted by the talker in Figure 6. This visualization of the individual data in this format allows for the qualitative assessment of two key points: the mean within language acoustic differences across categories and the extent to which the pattern in one language parallels the other. Starting with the latter observations, many individuals have overlapping or very close parallel (or near parallel) lines, suggesting no or minimal acoustic differences between the categories across languages. In these cases, most individuals with tightly overlapped patterns on one acoustic dimension also exhibit this overlap in the other acoustic dimension (e.g., VF21A, VF21C, VF19B, VM20B, VM21B, VM21C, VM21D, VM25A, VM25B), though not in all cases (e.g., VF19B, VF26A, VF32A, VM19C). The group-level pattern was that the Cantonese /l/ had a larger positive difference for H4–H2KHz* than English, and this is generally the case for all talkers for which there seems to be any meaningful difference, with the exception of VF22A. For F2-F1, the group-level pattern was that Cantonese had a larger difference, and this too is maintained in the individual data, with the exception here being VF33B. Although no group differences were found for /n/ across languages and the individual data are complicated by the fact that some talkers—VF21A, VF26A, and VF27A—lack the existence of any /n/ words produced as [n], there are some individuals who produce /n/s in Cantonese and English with nonoverlapping error bars, suggesting that at least some individuals have distinct phonetic realizations of Cantonese and English /n/s.
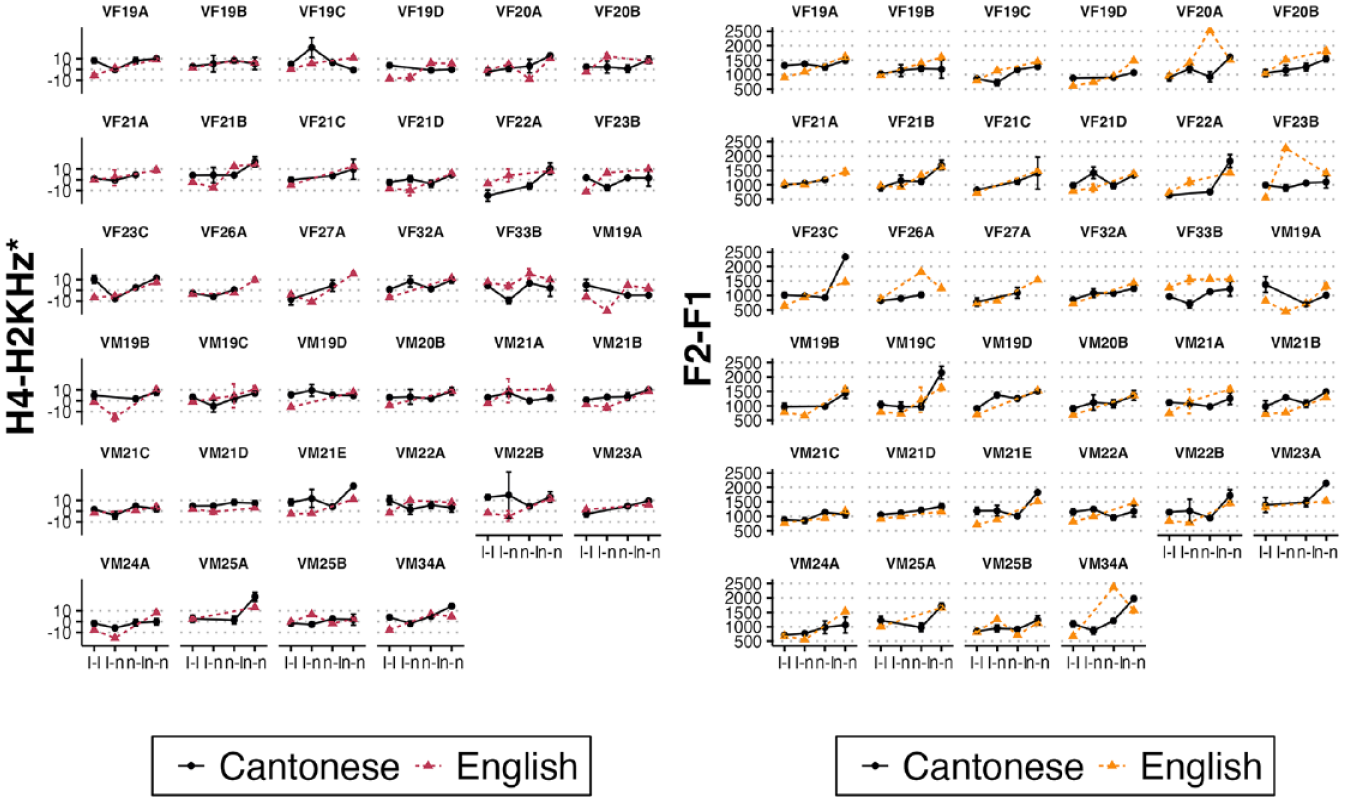
By-talker means and standard errors for the two acoustic measures across the four category types in Cantonese and English. The acoustic dimensions are on the y-axis, the category types are on the x-axis and the languages are represented in different line colors. Category type labels code the dictionary consonant on the left and perceived consonant on the right (e.g., n-l is /n/ > [l] where /n/-initial words are perceived as [l]). Some individuals lack data points for one of the x-axis categories, in which case no plot character exists for that variable.
4 Discussion
The goal of this article was to examine the /n/–/l/ merger in Cantonese using, for the most part, spontaneous speech. To this end, we used the SpiCE corpus, which is composed of read sentences, a narrated storyboard, and spontaneous speech from interviews with 34 early Cantonese–English bilinguals in Cantonese and English. The bilingual nature of the corpus affords the opportunity to establish how individuals produce /n/ and /l/ in a language that is not undergoing any merger between the two sounds, in addition to painting a picture about cross-language category maintenance, convergence, or, theoretically, divergence. Productions of words that, according to a dictionary, are /n/ or /l/ words were auditorily coded to arrive at a categorical coding of the items and then analyzed acoustically. The spectral tilt across the mid-frequencies with the amplitude measurement H4–H2KHz* was used as a proxy for nasality (Garellek et al., 2016), and F2-F1 was used both as a means to distinguish nasals and laterals (Tabain et al., 2016a, 2016b) and the place of articulation of the lateral (Recasens, 2012).
The English data provided clear benchmarks. English /n/ was robustly perceived as [n] and English /l/ as [l]—95% and 94% across all instances, respectively. This was true across all talkers (see Figure 1) and words (Figure 3 and Tables A3 and A4). In the few instances where /n/ items were auditorily categorized as [l] and /l/ as [n], those items were acoustically gradient between the clear /n/-[n] and /l/-[l] items. We interpret this as evidence that in English such items are likely speech errors.
In Cantonese, on the contrary, /n/ items were perceived as [n] only 18% of the time, with the majority of /n/ items perceived as [l] initial—71%. There was also some evidence of hypercorrection as 13% of /l/ items were perceived as [n]. The rates of /n/ and /l/ deletion were also substantially higher in Cantonese than in English (deleted /n/: Cantonese = 11%, English = 4%; deleted /l/: Cantonese = 9%, English = 3%). The rates of /n/ items perceived as [l] and /l/ items perceived as [n] were not only higher in Cantonese, they were also not different from the canonical /l/ items perceived as [l] according to the Bayesian multilevel model. This places these two intermediate categories in the described direction of the sound change—that is, realized as [l]. The intermediate productions, and the /l/ items perceived as [l], were, however, different from /n/ items perceived as [n] both in terms of H4–2KHz* and F2-F1, suggesting that Cantonese speakers do produce different [l] and [n].
In quantitative work on the /n/–/l/ merger in Cantonese, To et al. (2015) focused on the production patterns in a single elicited word, concluding that the sound change is nearly complete, with [l] being produced in
At the group-level, it is clear that /n/ and /l/ are different in English, and that there is an acoustic distinction in Cantonese between /n/ items perceived as [n] and the grouping of the canonical endpoint of /l/ for [l] with /l/ as [n] and /n/ as [l]. Cantonese talkers do produce a difference. Across languages, we query whether English and Cantonese maintain different /n/s and /l/s. Within bilinguals, the laterals for the two languages are different, both in terms of spectral tilt and F2-F1. This suggests that there is either a difference in voice quality between Cantonese and English such that Cantonese is breathier and English is more modal or Cantonese is more modal and English is creakier or Cantonese is breathier and English is creakier, or that there are inherent differences in nasality between the languages with respect to these sounds, with Cantonese being more nasal. Regardless of the interpretation, the values align with previous comparisons of Cantonese and English voice quality (K. A. Johnson & Babel, 2023). The F2-F1 difference likely reflects a darker, more velarized realization in English compared with a lighter, more apical articulation in Cantonese (Zee, 1991). The alveolar nasals, on the contrary, are not different across languages with respect to these two acoustic measures.
Turning to the individual data, there is consistency in individuals exhibiting higher F2-F1 and H4–H2KHz* in Cantonese /l/ compared with English /l/. The individual patterns for /n/ show considerable variability across talkers in the realization of the Cantonese nasals compared with the English /n/. Cross-linguistic influence in phonetic and phonological categories can shape a language at large, but the underlying mechanisms for that influence are likely supported by language influence at the individual level (K. A. Johnson & Babel, 2024; Yao & Chang, 2016). The acoustic measurements for the talker-specific realizations of /n/ and /l/ in Cantonese and English paint a complex picture. Individuals run the gamut in terms of the magnitude of the degree of difference. One aspect that may complicate the individual-level data is that there is natural code-switching in the English and Cantonese interviews. The proximity of an item to a code-switch has been shown to modulate the degree of cross-linguistic influence. Fricke et al. (2016), for example, showed that English /p t k/ exhibited more Spanish-like voice onset times in a speech that preceded a code-switch. It is certainly possible that some of the variation observed here may be due to the location of these sounds relative to a language switch, though phonetic variation in English /b d g/ voicing and final /p t k/ release rates in SpiCE are not conditioned by proximity to code-switches into English from Cantonese (K. A. Johnson & Babel, 2024).
Altogether, however, at the group-level, these data suggest that Cantonese and English /l/ are not inextricably linked in early, proficient bilinguals, but rather are realized as distinct sound categories with language-specific acoustic attributes. Although, in the current sample of early bilinguals, English and Cantonese /n/s are not acoustically distinct with respect to these measures, and the merging of /n/ and /l/ is clearly present in Cantonese, this does not appear to affect the consistency of the realization of English /n/. That is, simply because most Cantonese /n/ items are often produced as [l] does not result in English /n/ being produced as [l]. Although we do not have control data from a group of speakers who are not bilingual in a language undergoing a merger, the high rates of /n/ as [n] in the English data are sufficiently convincing on this point. This suggests, therefore, that despite the phonetic overlap in English and Cantonese [n], Cantonese and English /n/ maintain distinct categories within early Cantonese–English bilinguals.
Bilingualism is a multidimensional spectrum. There are probably as many different types of bilingualism as there are bilinguals themselves. The focus of this work was on phonetic and phonological categories in early and proficient bilinguals. Our findings that /n/ and /l/ maintain distinct profiles in Cantonese and English for this sample are likely specific to bilinguals of this general type, who established their phonetic and phonological categories in their languages early, and continue to use their languages regularly. Indeed, in a different population and as summarized above, Zhang and Levis (2021) report that individuals whose Southwestern Mandarin varieties merge /n/ and /l/ do not reliably differentiate /n/ and /l/ in their second and third languages, Standard Mandarin and English, respectively. That later learners of languages with contrastive /n/ and /l/ would initially struggle to dissimilate these sounds follows from many models and frameworks of second language sound category learning (e.g., Best & Tyler, 2007; Flege, 1995; Flege & Bohn, 2021). As an individual develops proficiency in a language, however, a contrastive /n/ and /l/ may establish a language-specific identity; the revised SLM is specifically retooled to consider the dynamic nature of linguistic knowledge (Flege & Bohn, 2021). A panel study of later learners that charts their phonetic and phonological development may be the best method to empirically chart out whether and how later learners can acquire distinctiveness in these acoustically similar categories.
5 Conclusion
In this study, we examined the production of /n/ and /l/ in spontaneous speech by early and proficient Cantonese–English bilinguals in both languages using the SpiCE corpus, providing the first acoustic characterization of the /n/ and /l/ merger in Cantonese. Both the categorical coding and the acoustic analysis of Cantonese /n/ and /l/ show that while the merger is present, with clear categorical instances in which /n/ is produced as [l], there is substantial individual and word-level variation; the merger is not complete. The contrast in English /n/ and /l/ remains robust for Cantonese-English bilinguals, suggesting that across Cantonese and English, neither the /n/’s nor the /l/’s are inextricably linked. On the group-level, Cantonese and English maintain laterals that are distinct in acoustic qualities, but acoustic differences between Cantonese and English nasals were not observed in our measurements. Qualitative assessment of individual variation, however, illustrates variation in the extent of cross-linguistic similarity of /n/ and /l/.
Footnotes
Appendix
Summary statistics for English /l/ items produced more than twice.
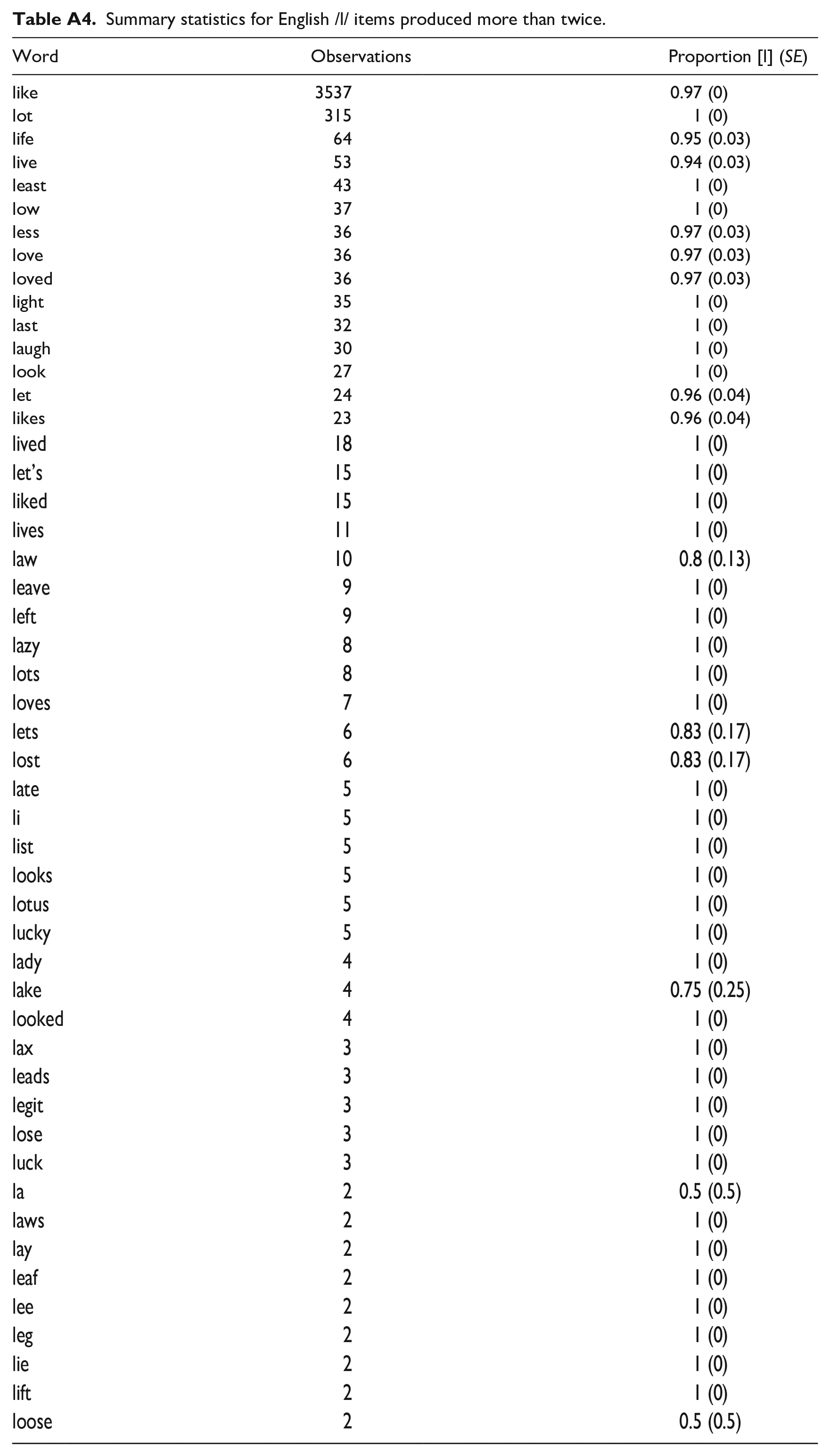
| Word | Observations | Proportion [l] (SE) |
|---|---|---|
| like | 3537 | 0.97 (0) |
| lot | 315 | 1 (0) |
| life | 64 | 0.95 (0.03) |
| live | 53 | 0.94 (0.03) |
| least | 43 | 1 (0) |
| low | 37 | 1 (0) |
| less | 36 | 0.97 (0.03) |
| love | 36 | 0.97 (0.03) |
| loved | 36 | 0.97 (0.03) |
| light | 35 | 1 (0) |
| last | 32 | 1 (0) |
| laugh | 30 | 1 (0) |
| look | 27 | 1 (0) |
| let | 24 | 0.96 (0.04) |
| likes | 23 | 0.96 (0.04) |
| lived | 18 | 1 (0) |
| let’s | 15 | 1 (0) |
| liked | 15 | 1 (0) |
| lives | 11 | 1 (0) |
| law | 10 | 0.8 (0.13) |
| leave | 9 | 1 (0) |
| left | 9 | 1 (0) |
| lazy | 8 | 1 (0) |
| lots | 8 | 1 (0) |
| loves | 7 | 1 (0) |
| lets | 6 | 0.83 (0.17) |
| lost | 6 | 0.83 (0.17) |
| late | 5 | 1 (0) |
| li | 5 | 1 (0) |
| list | 5 | 1 (0) |
| looks | 5 | 1 (0) |
| lotus | 5 | 1 (0) |
| lucky | 5 | 1 (0) |
| lady | 4 | 1 (0) |
| lake | 4 | 0.75 (0.25) |
| looked | 4 | 1 (0) |
| lax | 3 | 1 (0) |
| leads | 3 | 1 (0) |
| legit | 3 | 1 (0) |
| lose | 3 | 1 (0) |
| luck | 3 | 1 (0) |
| la | 2 | 0.5 (0.5) |
| laws | 2 | 1 (0) |
| lay | 2 | 1 (0) |
| leaf | 2 | 1 (0) |
| lee | 2 | 1 (0) |
| leg | 2 | 1 (0) |
| lie | 2 | 1 (0) |
| lift | 2 | 1 (0) |
| loose | 2 | 0.5 (0.5) |
Acknowledgements
The authors thank Ellie Yoon, Nikolai Schwarz, Gina Piñeda, and Khushi Patil for their assistance during this project. They also thank members of the Speech in Context Laboratory and audiences at Interspeech 2021 for feedback on previous versions of this project.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been financially supported by a UBC Public Scholars Initiative Award to KAJ, and an SSHRC award to MB.