
Abstract
The experimental study of artificial language learning has become a widely used means of investigating the predictions of theories of language learning and representation. Although much is now known about the generalizations that learners make from various kinds of data, relatively little is known about how those representations affect speech processing. This paper presents an event-related potential (ERP) study of brain responses to violations of lab-learned phonotactics. Novel words that violated a learned phonotactic constraint elicited a larger Late Positive Component (LPC) than novel words that satisfied it. Similar LPCs have been found for violations of natively acquired linguistic structure, as well as for violations of other types of abstract generalizations, such as musical structure. We argue that lab-learned phonotactic generalizations are represented abstractly and affect the evaluation of speech in a manner that is similar to natively acquired syntactic and phonological rules.
1 Introduction
When trained on an artificial language in the laboratory, participants form generalizations about its sound structure, similar in type to the generalizations that all speakers form about the sound structure of their native language. When these generalizations concern how speech sounds can be combined to form words, the patterns are referred to as phonotactics. Phonotactic generalizations, especially if simple, can be formed after even a very small amount of exposure (less than half an hour) to an artificial language (see Culbertson, 2012; Moreton & Pater, 2012a, 2012b for reviews). Learning of the generalizations in the lab is typically implicit—participants cannot describe the patterns they know—just as knowledge of natural language phonotactics is implicit. Participants are consistently able to apply these implicit generalizations to novel test words, and in some cases even to novel sounds (Cristiá et al., 2013; Cristiá & Seidl, 2008) and novel contexts (Myers & Padgett, 2014). In this paper, we use neurophysiological measurements to examine how lab-learned phonotactic patterns affect speech processing. In particular, we address which of the phonological effects on event-related potentials (ERPs) that have been reported for natural languages arise for phonological learning that occurs during a single experimental session.
In the current study, participants learned words from an artificial language through a word-picture matching task. Although participants were not made aware of it, training words were all consistent with a phonotactic pattern; the consonants in CVCV words either always matched in voicing (Agree group) or never matched in voicing (Disagree group). During testing, participants rated familiar and novel items on how likely they were to be from the language they were learning. Test items included trained words (Studied), novel words that fit the phonotactic pattern of the trained words (Novel-Fit), and novel words that violated it (Novel-Violate). The design decisions were motivated both by what is known about phonotactic learning from artificial languages (Moreton & Pater, 2012a, 2012b), and, as described below, what is known about ERP indices of the effects of implicit phonological knowledge on speech processing.
Isolating the effects of natural language phonotactic knowledge on speech processing is challenging—sequences of speech sounds in pseudo-words that match and violate natural language phonotactics are necessarily different from one another in their acoustics and typically differ in how similar they are to meaningful words in the language. Artificial language learning offers the opportunity to avoid these confounds by comparing ERPs elicited by physically identical stimuli that match and violate a recently learned phonotactic pattern.
As is true of other domains, there is no single ERP marker of phonological processing. Instead, patterns of ERP effects depend on which phonological and non-phonological processes are invoked as participants engage in a specific task. At least three distinct phonological ERP effects have been reported: an early negativity in response to speech sounds that are inconsistent with highly predictable words and nonwords (Phonological Mapping Negativity [PMN]), a difference in the amplitude of a negativity that peaks around 400 ms after word onset (N400), and a Late Positive Component (LPC) that has recently been linked to violations of native-language phonotactics after a long history as “an index of detection for any anomaly in rule-governed sequences” (Núñez-Peña & Honrubia-Serrano, 2004, p. 130). We discuss each of these phonological ERP effects, in turn, including a description of how we examined these potential ERP effects for phonotactic patterns learned from an artificial language.
1.1 Phonological mapping negativity
The PMN is observed in response to speech segments that violate expectations set up by a highly constraining sentence context (Connolly et al., 1990, 1992; Connolly & Phillips, 1994; van den Brink et al., 2001). For example, in a sentence like “The piano was out of cake,” the [k] in cake elicits a negativity at 150–300 ms after onset compared with segments that meet phonological expectations despite violating lexical expectations (e.g., “The gambler had a streak of bad luggage.” from Connolly & Phillips, 1994). We do not expect to find a PMN in this study, however. Although phonotactics can set up expectations for upcoming phonemes (Massaro & Cohen, 1983), violations of these expectations do not seem to elicit a PMN (Lee et al., 2012). Rather, previous studies that have found ERP effects of phonotactic well-formedness have generally found effects appearing much later than the PMN window: in the N400 or P600 windows, discussed below.
1.2 Phonological effects on N400 amplitude
In general, nonwords elicit a larger N400 than words (Bentin et al., 1985; Chwilla et al., 1995; Holcomb et al., 2002; Ziegler et al., 1997), and both words and nonwords with many phonological neighbors elicit larger amplitude N400s than items with fewer neighbors (Holcomb et al., 2002; Hunter, 2016; though see also Hunter, 2013). These effects are straightforward under the hypothesis that the N400 size reflects ease of lexical access. Nonwords, with no lexical entry at all, present greater lexical access difficulty than real words, and words with many neighbors are more difficult to access because those neighbors act as competitors, slowing the eventual successful recognition of the word (or recognition that it is not a word). Congruently, stimuli that are phonologically implausible as words, including printed consonant strings (Bentin, 1987; Bentin et al., 1999; Ziegler et al., 1997) and reversed spoken psuedowords (Holcomb & Neville, 1990; Obrig et al., 2016), elicit smaller N400s than words and phonologically acceptable psuedowords. This reduction in N400 amplitude is interpreted as abandoning attempts at lexical and semantic processing.
Stimuli which are almost plausible as words, but which contain a phonotactic violation, sometimes elicit a smaller N400 than phonotactically legal nonwords (M. Friedrich & Friederici, 2005; Rossi et al., 2011), in line with the idea that a phonotactic violation would cause listeners to abandon lexical access. However, in other work, nonwords with phonotactic violations elicit a larger N400 than phonotactically legal nonwords. For example, illegal consonant clusters like “bnick” in English would elicit a larger N400 than legal clusters like “blick” (Obrig et al., 2016; Ulbrich et al., 2016; White & Chiu, 2017). Wiese et al. (2017) found a similar effect for final clusters (“blisk” vs “bligk”).
In the present study, we expect to find a difference in N400 size between novel words which are part of the training (and which thus constitute a mini-lexicon for the artificial language), and novel words which are not part of training. Among untrained novel words, predictions are unclear. We do not expect to see abandoning of processing for nonwords which violate our lab-learned pattern, as all stimuli in our study are plausible as English words. In addition, our pattern of consonant agreement in CVCV words is not very similar to the consonant cluster patterns tested in previous studies. To isolate the effects of the lab-learned pattern from participants’ previous phonological knowledge, we sought a pattern that neither conflicts with, nor is supported by, English phonotactics or universal phonotactics (Moreton, 2008, 2012).
As previous phonological effects on N400 amplitude do not offer clear predictions of similar effects in the current study, it was important to include measures of word learning that could be directly compared with measures of phonotactic learning. Specifically, N400 amplitude should be reduced for items presented during both training and testing (Studied items). If phonotactic learning results in novel items that fit the pattern being processed as more word-like than novel items that violate the pattern, then implicit learning of the pattern, as indexed by a comparison of the response to Novel-Fit and Novel-Violate items, should also modulate N400 amplitude.
Importantly, patterns across the lexicon, such as the number of phonological neighbors, do not have to be extracted and stored as abstract generalizations to affect processing (Albright & Hayes, 2003; Ullman, 2001, 2005). Instead, those patterns could affect processing because attempts at lexical access bring up more phonologically similar representations, or result in automatic spreading of activation among phonologically similar representations. We disagree with the interpretation of N400 amplitude as reflecting the earliest stages of lexical access, based on both its timing and lack of sensitivity to important factors such as lexical frequency (Dimigen et al., 2011; Dufau et al., 2015; Kretzschmar et al., 2015). However, in the current study, effects of phonotactic learning on N400 amplitude could reflect the different relationship between novel items that do and do not fit the learned pattern and Studied words that were recently added to the lexicon. As such, N400 effects would be interpreted as differences in how listeners process novel items that are more and less similar to recently learned words, rather than as evidence that the phonotactic pattern was cognitively encoded.
1.3 Late positive component
The third time window in which phonological effects have been observed on ERPs, 500–1,500 ms after word onset, is the LPC. For example, there is a constraint against having identical consonants as part of an onset cluster and as the coda in German and English (e.g., speak is an acceptable word, but speap and skeak are not). In a comparison of ERPs elicited by words, nonwords that fit this natural language phonotactic pattern, and nonwords that violated it, Domahs et al. (2009) report a larger positivity 1,130–1,380 ms after onset of nonwords that violate the constraint. Furthermore, in a review of ERP studies of second language acquisition, McLaughlin et al. (2010) included data from native Finnish speakers and native English-speaking adult learners of Finish. Native Finnish stems and suffixes comply with vowel harmony, such that if the first vowel in a word is a back vowel (/u, o, a/) all subsequent vowels are either also back or are neutral. The same is true of front vowels (/y, ø, æ/). Visually presented nonwords that violate this natural language phonotactic pattern elicit a larger LPC than nonwords that comply with it, in both native Finnish speakers and more advanced second language learners. The results of these two experiments are particularly relevant to the current study as they involve phonotactic patterns that govern nonadjacent phonemes. There is also evidence that the phonotactics governing consonant clusters and described as influencing N400 amplitude sometimes affects LPC amplitude. For example, both non-existence in the language and being ill-formed according to the sonority sequencing principle result in a larger LPC (Ulbrich et al., 2016), which is further modulated by listeners’ training with the sounds (Wiese et al., 2017). Other data suggest LPC amplitude is sensitive to listeners being aware of the difference in onsets of prime-target pairs, such that the effect is absent for non-native speakers who engage in perceptual repair of illicit /pt/ onsets (Wagner et al., 2012).
Although the interpretation of phonological effects on LPC amplitude has not been identical across studies, similar effects in other aspects of language processing and in other domains suggest they relate to evaluation of abstract structural relationships. A late positivity with similar timing and distribution has been observed for a range of syntactic violations, including agreement, phrase structure, subcategorization, and constraints on long-distance dependencies (see Gouvea et al., 2010; Morgan-Short et al., 2012, for overviews). In this context, the LPC has been labeled the P600 (Osterhout & Holcomb, 1992) or the Syntactic Positive Shift (Hagoort et al., 1993). LPC’s have also been found for violations of musical structure (Patel et al., 1998; see Carrión & Bly, 2008 for an overview), and for rule violations in arithmetic tasks (Núñez-Peña & Honrubia-Serrano, 2004). In the current study, observing an LPC in response to Novel-Violate compared with Novel-Fit items would provide evidence not only of implicit learning of the phonotactic pattern instantiated in the words presented during training, but also that this new phonotactic knowledge affects speech processing in the same manner as other “knowledge-based structural integration” (Patel et al., 1998, p. 51).
1.4 The present study
In the present study, we examined the laboratory learning of a pattern between two consonants in a CVCV word. Half of our participants learned a voicing agreement pattern, in which both consonants always exhibited the same voicing, and the other half of our participants learned a voicing disagreement pattern, in which the two consonants in a word always disagreed in voicing. These patterns were chosen because they have been used previously in the artificial grammar learning literature (Moreton, 2008, 2012) and can easily be learned in a lab setting. Furthermore, though patterns like these are found in other natural languages, English does not exhibit either of them as an absolute rule, or as a statistical tendency (Moreton, 2008).
In previous literature on artificial grammar studies, and on our patterns in particular, artificial phonology is generally learned very quickly, in as little as 10 min (Finley, 2017; Moreton, 2012). Participants are typically trained for several trials, then tested on a small number of test trials which are balanced: half follow the pattern in the training, and half do not. Because the test stage is typically quite short, participants have no opportunity to then “un-learn” the pattern in the artificial grammar by being exposed to forms that violate it. In an ERP study such as this one, however, a large number of trials are required in the testing phase to accurately observe differences between conditions. To keep participants from un-learning the pattern, we adopted a blocked structure for the experiment, with testing blocks interleaved with continued training blocks.
2 Method
2.1 Participants
Participants were 24 (9 females, 15 males) native speakers of English, between the ages of 19 and 33 years. This sample size provides power of 0.92 to detect an N400 effect that is half the size of that reported for words and pseudo-words that differ from words by a single feature on a medial consonant (C. K. Friedrich et al., 2006). It provides power more than 0.99 to detect an LPC effect of the size reported for the comparison of phonotactically legal and illegal German nonwords (Domahs et al., 2009). Data from two additional people were collected but excluded because one expressed explicit knowledge of the phonological generalization and the other showed excessive high-frequency noise in the electroencephalogram (EEG), likely caused by muscle tension. All participants reported being right-handed, having no neurological problems, and not taking psychoactive medication within a year of the study. Participants provided informed consent and were compensated for their time at a rate of $10/hr.
2.2 Stimuli
To ensure that any differences in ERPs elicited by Novel-Fit and Novel-Violate words reflected learning rather than physical differences in the stimuli or number of English phonological neighbors, the same tokens were used in each category for an equal number of participants. For the same test items to match the learned phonotactic pattern for some listeners and violate it for others, the training items for half of the participants had consonants that agreed in voicing and for the other half, consonants that disagreed in voicing (Table 1). Within the group of participants trained on one phonotactic pattern, the same test items were presented during training and testing (Studied) for some and only at testing (Novel-Fit) for others. Each training block, and each testing block, consisted of the same items throughout the experiment.
Counterbalanced Test Items.
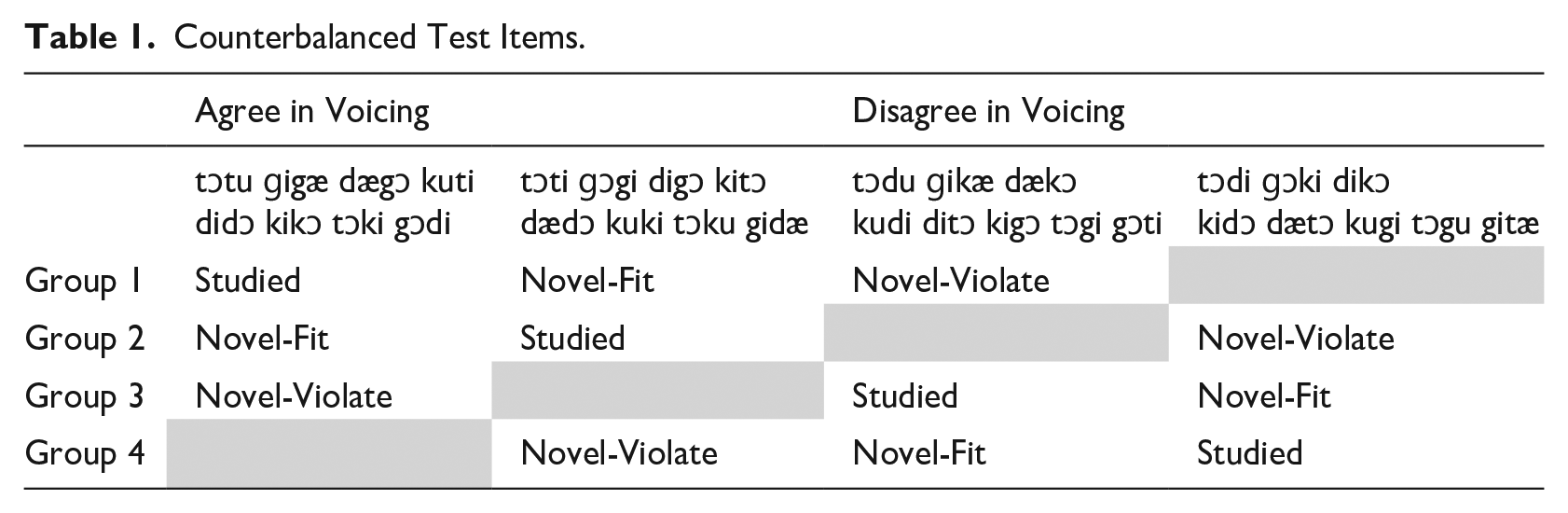
The phonotactic patterns and stimulus space were drawn from Moreton (2008, 2012) and included four stops [d,g,t,k] and four vowels [i,æ,u,ɔ]. We constructed 24 items with consonants that agreed in voicing (e.g., [didɔ], [tɔku]) and 24 with consonants that disagreed in voicing (e.g., [dækɔ], [kugi]). Not all of the items are shown in Table 1; some were presented during training, but not during testing. Vowels were chosen for the words to avoid patterns of co-occurrence with one another or with consonants within the lexicon of the constructed language. The words that followed each phonotactic pattern were equally likely to start with a voiced or voiceless consonant and with velar or alveolar place of articulation. Vowel features were also controlled in each position. Items that are also English words (e.g., duty, gaudy) were excluded.
The words were pronounced by a 26-year-old linguistically trained male native speaker of English. The speaker pronounced the words with stress on the initial syllable and a full vowel in the second syllable in the frame sentence “It was X said Tim.” The sentences were recorded to 32 bit / 44.1 kHz digital format. The words were segmented from the sentences using the offset/onset of noise for the surrounding sibilants as criterion. The peak amplitude of all items was normalized to their mean, and a 10-ms sinusoidal fadeout was applied to the end of each recording to eliminate potential effects of trimmed formants.
Words averaged 367 ms (SD = 34) in duration with the second syllable beginning 136–245 ms after the first (M = 191, SD = 29). All sounds were presented over a pair of M-Audio StudioPro3 loudspeakers with EPrime software running on a PC with a Creative Audigy 2 ZS sound card. Both loudspeakers were located directly above the computer monitor. Sounds were presented at 65 dB SPL (A-weighted) as measured from the location of participants’ heads.
The images used in the word-picture training task were color photographs of a common concrete object (e.g., puppy, ship, shoe) that participants would be expected to describe with a single English word. Images were cropped to leave minimal background behind the objects. Pictures were then resized such that four pictures shown at the same time along with their response labels (1–4) filled the space available on the computer monitor.
2.3 Procedure
Instructions for both training and testing were given at the beginning of the session. For training, participants were told they would be learning some of the words in a made up language by matching the spoken words to pictures of the objects the words refer to. They were warned that their initial responses would be guesses, but that seeing the correct answer after every response would help them to learn the words. Participants initiated a training block by pressing any button on a response pad. Each training trial began with the appearance of a fixation cross on the computer monitor. One of the 16 training words was presented from the loudspeakers 700–1,200 ms (randomly selected from a rectangular distribution) later. The fixation cross remained on the screen for 500 ms after the offset of the word and was then replaced by pictures of four objects. Each object was labeled with a number (1–4) that corresponded with a button on the response pad. Participants pressed a button to indicate the meaning of the word they had heard. Immediately following any button press, the correct picture was shown in the center of the computer monitor for 1,000 ms and the word was played again, so that the participant heard each training stimulus twice per trial. In each training block, all 16 words were presented five times in random order (80 trials per block).
During testing, participants were asked to rate how likely it is that each word is part of the language they were learning. They were told that some of the test words had been heard during training and were clearly part of the language. They were instructed that even though they had not learned a meaning for most of the test words, some of them were part of the same language and some were not. They were encouraged to use all four response buttons rather than only the one labeled “unlikely a word” and the four labeled “very likely a word.” Participants began each test block by pressing any button. At the beginning of each trial, the fixation cross was shown on the computer monitor. One of the test words was presented over the loudspeakers 700–1,200 ms later. The fixation cross remained on the screen for 1,000–1,500 ms after the word onset and was then replaced by the response prompt “Likely a word?” with the labeled scale. Participants were told not to respond until after the response prompt appeared so that ERPs in the first 1,000 ms after test word onset would be uncontaminated by motor responses; variability in the timing of the response prompt was used to reduce anticipatory effects related to the change in visual input and execution of response. A test trial ended after any response was given. In each test block, all 24 words (eight each of Studied, Novel-Fit, and Novel-Violate) were presented once in random order.
The training-then-testing sequence was presented five times for a total of 400 training trials and 120 test trials (40 of each type). For all trials, participants were asked to refrain from blinking, moving their eyes, or moving any other part of their body, including moving a finger to press a button, whenever the fixation cross was shown on the screen. The fixation cross was on the screen for 700–1,200 ms before and 636–745 ms after the onset of training words, and 700–1,200 ms before and 1,000–1,500 ms after the onset of testing words. Participants were encouraged to make any needed movements while the pictures (training) or response prompt (testing) were shown. Participants were asked to continue from each training block to the following test block without pause; they were encouraged to take breaks after each test block. At the end of the experiment, participants were asked if they had noticed anything about the language they learned and if they had developed any strategy to distinguish between words that were and were not in the language.
EEG was recorded continuously throughout the training and test trials (250 Hz sampling rate, 0.01–100 Hz bandpass) from 128 electrodes (EGI, Eugene, OR). During recording, all measurements were referenced to the recording in the center of the scalp (Cz) to achieve rejection of common-source noise before amplification. Scalp impedances at all electrode sites were maintained below 50 kΩs. Segments of EEG from 100 ms before to 1,000 ms after the onset of test words were examined. Trials with artifacts from blinks or eye-movements, motion, or muscle tension were excluded from analysis. Eye blinks and movements were detected using electrodes placed directly above, directly below, and at the outer canthus of each eye. For each participant separately, a maximum peak-to-peak amplitude for segments of EEG data was selected that excluded all trials with visible blinks or eye-movements. These thresholds were between 150 and 250 µV. An additional maximum peak-to-peak amplitude criterion (250 µV for all participants) was applied to recordings from all 128 electrodes to exclude trials that included high amplitude deflections from movement of electrodes on the scalp or muscle activity close to the recording surface. EEG from remaining test trials was averaged by condition (Studied, Novel-Fit, Novel-Violate) across all blocks. The number of trials ultimately included in the averages differed across participants, with the smallest number being 31 trials in a condition. The mean number of trials per participant was 37.8 for Studied, 37.6 for Novel-Fit, and 37.8 for Novel-Violate. As a final processing step, ERPs were re-referenced to the average of the left and right mastoid recordings. As such, ERP amplitude at all other electrodes is relative to what was recorded at the same time over the mastoids. The selection of this reference was made to facilitate comparison with other ERP studies of speech processing.
2.4 Analysis
Percent correct on the word-picture matching task employed during training will be reported but not analyzed. The goal of this task was to present the training words a sufficient number of times to induce implicit learning of the phonotactic pattern rather than to measure anything about acquisition of the word-picture pairings. As a behavioral measure of word learning, ratings of Studied and Novel-Fit items presented during testing were submitted to a repeated-measures t test. As a behavioral measure of phonotactic learning, the same thing was done to ratings of Novel-Fit and Novel-Violate items. As participants were required to delay pushing a button to indicate their rating of test words until the response prompt appeared 1,000–1,500 ms after the onset of a test item, response times are unlikely to provide information about processing time and are not analyzed.
Measurements were made on ERP waveforms collected at 100 of the 128 electrode sites such that electrode position could be included as multiple factors in statistical analyses. Although the scalp distributions of the PMN, N400, and LPC could be predicted from previous studies, it was possible that the use of artificial languages and the specific phonotactic pattern could influence the distribution of these effects. Therefore, we elected to include data from across the scalp and describe the observed distributions rather than only examining data from locations where effects were largest for other experimental conditions in other studies. Specifically, measurements from four electrodes (approximate positions shown in Figure 1) were averaged together in a 5 (anterior, anterior-central, central, posterior-central, posterior or ACP) × 5 (left, left-medial, medial, right-medial, right, or LMR) grid. Average amplitude measurements were taken 150–300 ms after onset of the second consonant in words (PMN), 400–700 ms after word onset (N400), and 600–1,000 ms after word onset (LPC). The baseline for the PMN measure was the 100 ms before onset of the second consonant; for N400 and LPC measurements, the baseline was the 100 ms before onset of the word. To index the effects of implicit phonotactic learning on speech processing, PMN, N400, and LPC data were each entered in their own 2 (Word Type: Novel-Fit, Novel-Violate) × 5 (ACP electrode position) × 5 (LMR electrode position) repeated-measures analyses of variance (ANOVAs). Greenhouse–Geisser corrected p-values (and uncorrected degrees of freedom) are reported. Significant (p < .05) interactions of Word Type and electrode position factors were followed by ANOVAs conducted on data collected at subsets of electrodes.
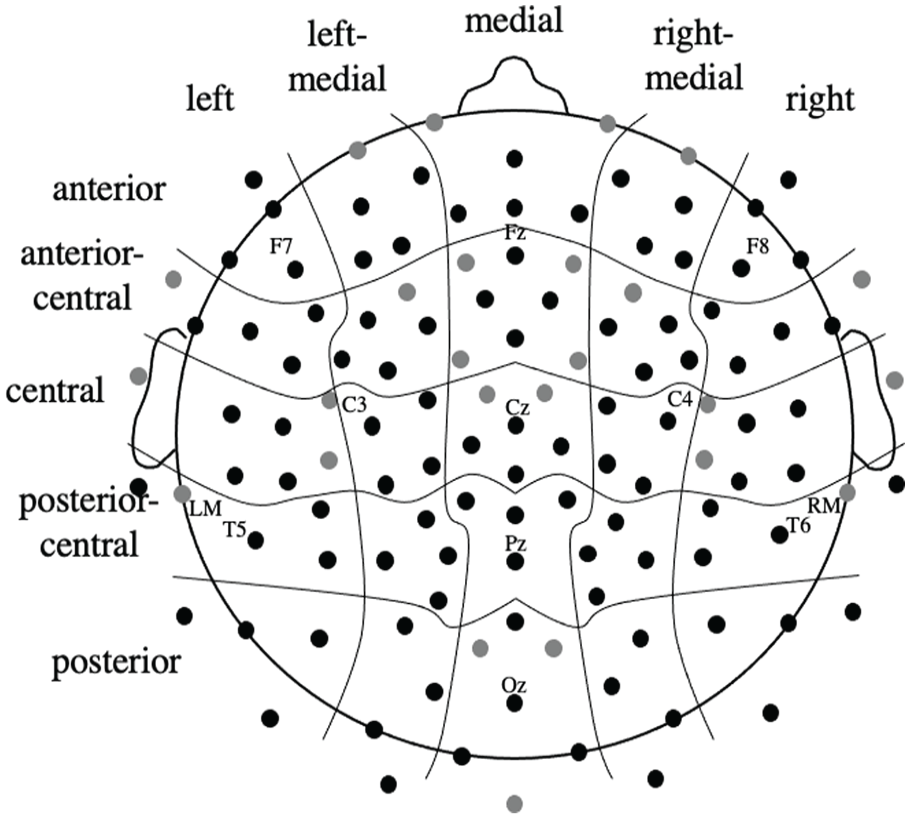
Approximate position of scalp electrodes and electrode-position factors included in ANOVAs.
3 Results
3.1 Behavioral measures
Participants began to learn the meanings of the novel words quite quickly, demonstrating accuracy above chance even in the very first block of the experiment (Figure 2). This is expected behavior if participants are creating a mini-lexicon for the artificial language, with the Studied items as lexical entries.
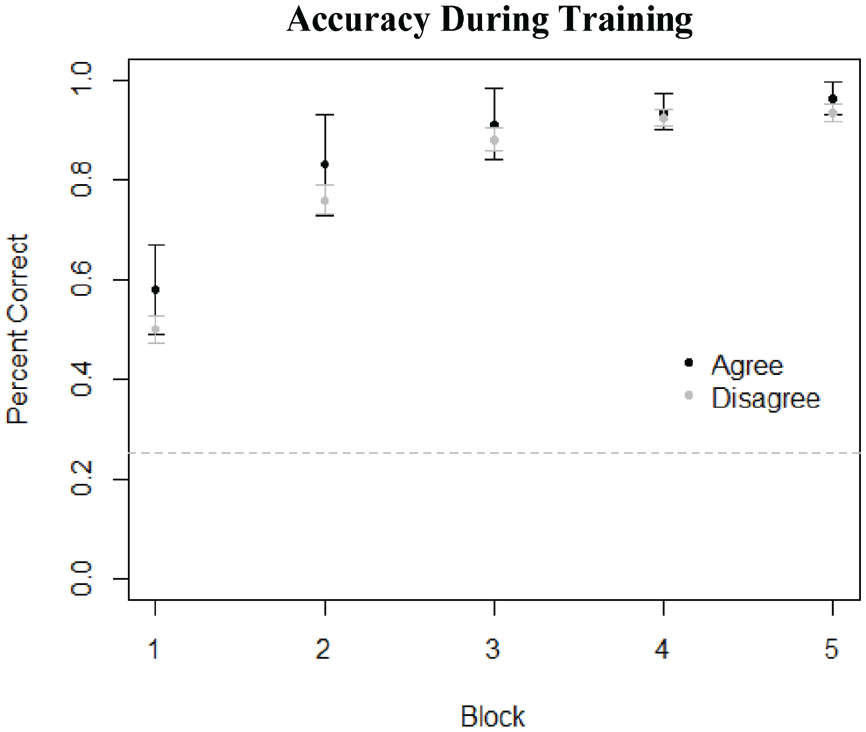
Accuracy of meaning-item pairing during training. As participants had to choose the correct meaning out of four pictures, chance performance is at 0.25, indicated by the dashed line. Black points are from the voicing agreement group, and gray points are from the voicing disagreement group.
Including Studied words as part of the testing procedure has the advantage of providing measures of word learning taken under conditions identical to those for the measures of phonotactic learning. 1 During testing, participants rated the Studied words as more likely to be in the language that they were learning (M = 3.72, SD = 0.18) than Novel-Fit items (M = 2.71, SD = 0.29), t(23) = 14.77, p < .001. Despite participants being unable to describe the pattern that governed Studied words, 2 they rated Novel-Fit items (M = 2.71, SD = 0.29) as more likely to be in the language they were learning than Novel-Violate items (M = 2.21, SD = 0.26), t(23) = 7.98, p < .001. These ratings are pictured in Figure 3.
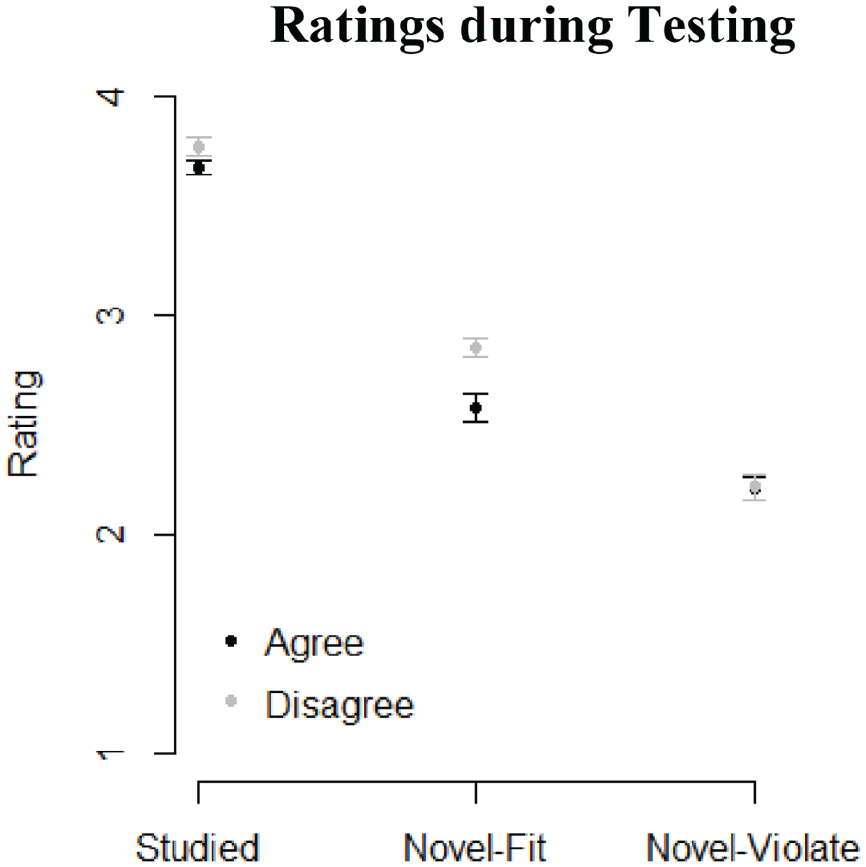
Ratings of Studied, Novel-Fit, and Novel-Violate items averaged over all testing blocks. Black points come from the voicing agreement group, whereas gray points come from the disagreement group.
The basic pattern of ratings across the three types of nonwords did not vary over the course of the experiment (Figure 4). However, the difference in ratings between Studied items and both Novel-Fit and Novel-Violate items widened across blocks. The voicing agreement pattern showed slightly different time course than the disagreement pattern, though interestingly it is only the Novel-Fit items that are rated differently across groups. This finding does not indicate that voicing agreement as a pattern was learned better, or faster, as there is no consistent difference between groups in how the Novel-Violate items were rated.
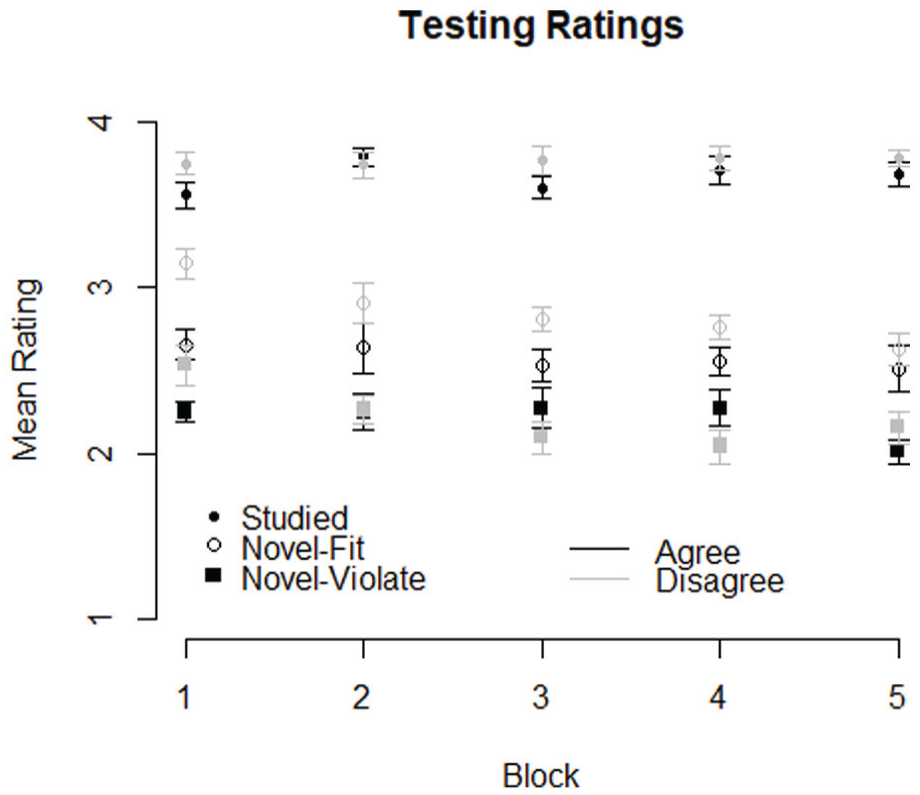
Average ratings of each nonword type across testing blocks.
An omnibus ANOVA with Condition (Studied, Novel-Fit, and Novel-Violate), Pattern Type (Voicing agreement, Voicing disagreement), and Block found a main effect of Condition, F(2, 44) = 298.99, p < .001, and Block, F(4, 88) = 5.72, p < .001. An interaction between Condition and Block was also significant, F(8, 176) = 3.55, p = .005. There was a significant interaction between Pattern Type and Block, F(4, 88) = 3.43, p = .017, but no main effect of Pattern Type, nor interaction between Pattern Type and Condition.
3.2 ERP measures
ERPs recorded during training revealed an N400 that decreased in amplitude over the course of the experiment. There was a main effect of block across all electrode locations, F(4, 92) = 2.952, p = .037, η2 = .025. The negativity was larger for block 1 (M = −1.38 µV, SE = 0.30) than in the other four blocks (M = −0.81 µV, SE = 0.29). This result is consistent with participants’ accuracy over blocks in reporting the trained meanings of the Studied words (Figure 2).
During testing, Studied words elicited a smaller N400 than Novel-Fit words over central and posterior-central regions, F(1, 23) = 6.67, p = .017, η2 = .036. In the same time, window over posterior-central and posterior regions, Studied words also elicited a larger positivity than Novel-Fit words, F(1, 23) = 11.9, p = .003, η2 = .065. Although these two effects go in the same direction (Studied more positive than Novel-Fit), the waveform morphology differs between central regions, where the difference is short and peaked, versus posterior regions where the difference in waveforms lasts longer. The posterior-central region exhibits a combination of both. We believe the posterior positivity is an example of a P300, a component typically elicited by less probable items, or by task-salient items. Because of the structure of the Testing blocks, Studied words were task-salient. Recall that the task was to indicate how likely the word was to be part of the artificial language. As participants knew Studied words to be part of the artificial language, they could rate them very highly, and with confidence (see Figure 4), relative to Novel words of both types. Studied words were also less probable than Novel words, accounting for one third of all testing trials. These two effects are illustrated in Figure 5.
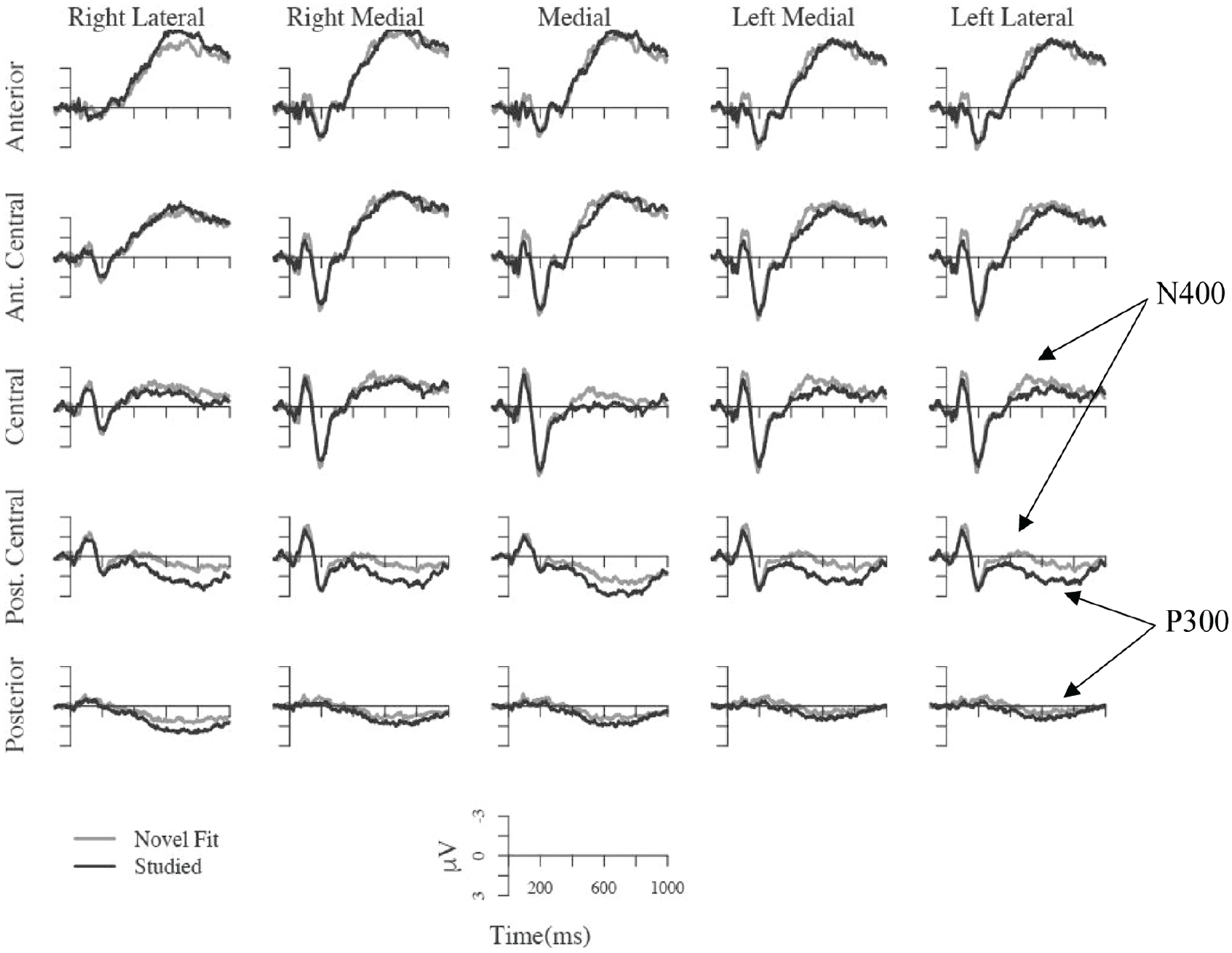
ERPs time locked to the onset of Novel-Fit and Studied items presented during testing. Each waveform shows data averaged across four adjacent scalp electrodes as shown in Figure 1. The vertical line indicates word onset. A larger negativity for Novel-Fit compared with Studied items can be seen at central and posterior-central electrodes, and a positivity for Studied compared with Novel-Fit items can be seen at posterior-central and posterior electrodes.
As Novel-Fit and Novel-Violate items were presented in an identical manner within an experimental session, and were identical tokens across participants, any differences in the ERPs elicited for these categories provide evidence of phonotactic learning. The first possibility we tested was that the new phonotactic knowledge would influence predictions about the second consonant based on the first consonant resulting in a PMN in response to speech sounds that violated the pattern. However, there was no evidence that ERPs 150–300 ms after onset of the second consonants differed for Novel-Fit and Novel-Violate items (In an omnibus ANOVA, ps > .50).
The second possibility we considered was that the different phonological relationships of Novel-Fit and Novel-Violate items to the Studied words that were recently added to the lexicon would result in differences in processing. In this case, learning would be expected to modulate N400 amplitude. However, there was no evidence of a difference in response to Novel-Fit and Novel-Violate items in the N400 time window (In an omnibus ANOVA, ps > .38).
To test the possibility that Novel-Violate items elicited a larger LPC than Novel-Fit items, mean amplitude 600–1,000 ms after word onset was examined. This time window falls after the offset of all test items, but before the onset of the response prompt. There was an interaction of Word Type and anterior-to-posterior electrode position on mean amplitude in this time window, F(4, 92) = 3.042, p = .042, η2 = .007. Over posterior-central and posterior regions (Figure 6), Novel-Violate items elicited a larger positivity than Novel-Fit items, F(1, 23) = 5.55, p = .027, η2 = .074. 3
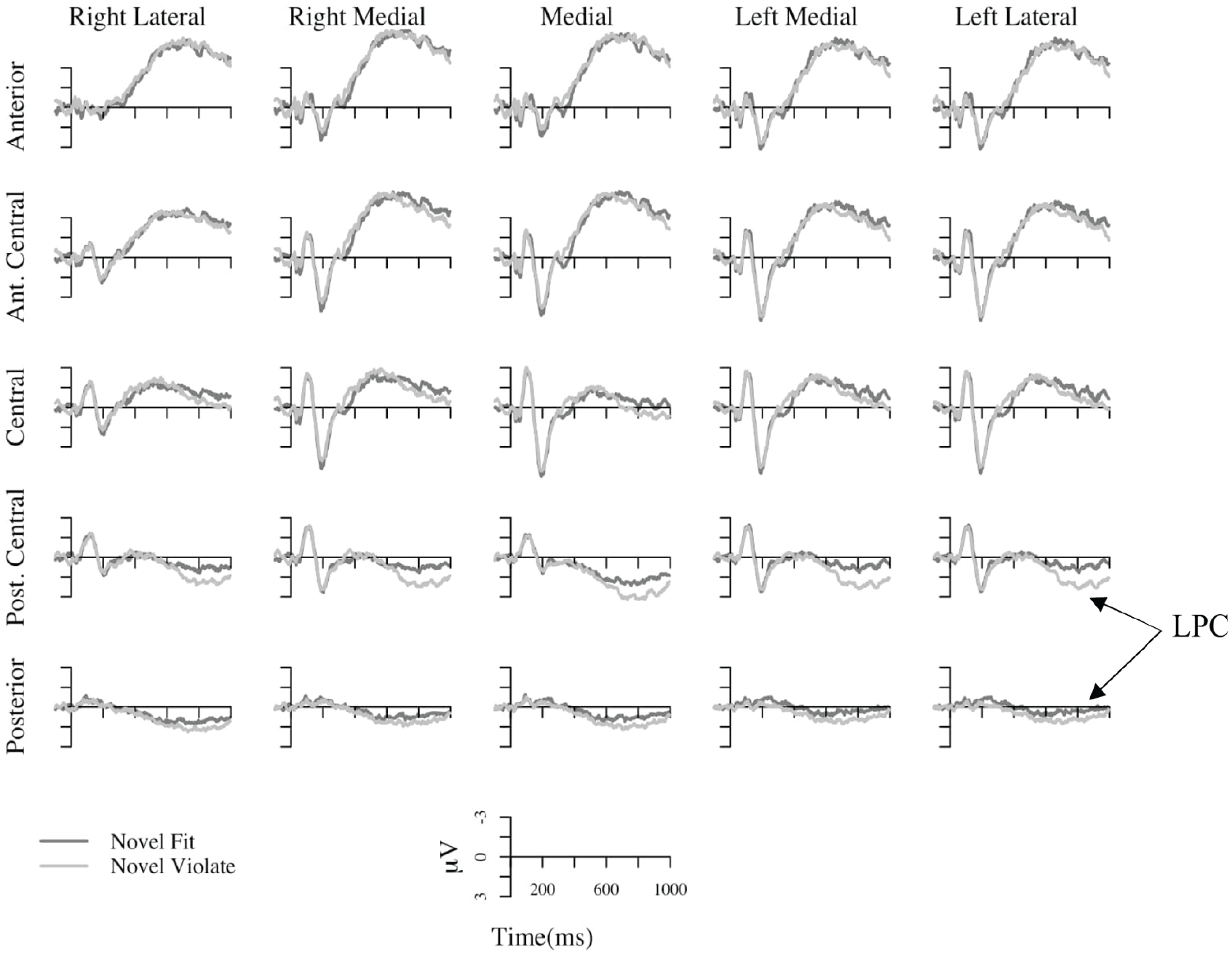
ERPs time locked to the onset of Novel-Violate and Novel-Fit items presented during testing. Each waveform shows data averaged across four adjacent scalp electrodes as shown in Figure 1. The vertical line indicates word onset. Novel-Violate words elicited a larger Late Positive Component (LPC).
All three conditions are shown together in Figure 7, using four example electrodes—two from the posterior-central region, and two from the posterior region. Here it is easy to see visually the difference in timing between the two positivities observed. Studied items exhibited a positivity relative to Novel-Fit items in the N400 window of 400–700 ms after the stimulus onset, whereas Novel-Violate items are more positive than Novel-Fit items only in the LPC window of 600–1,000 ms after stimulus onset.
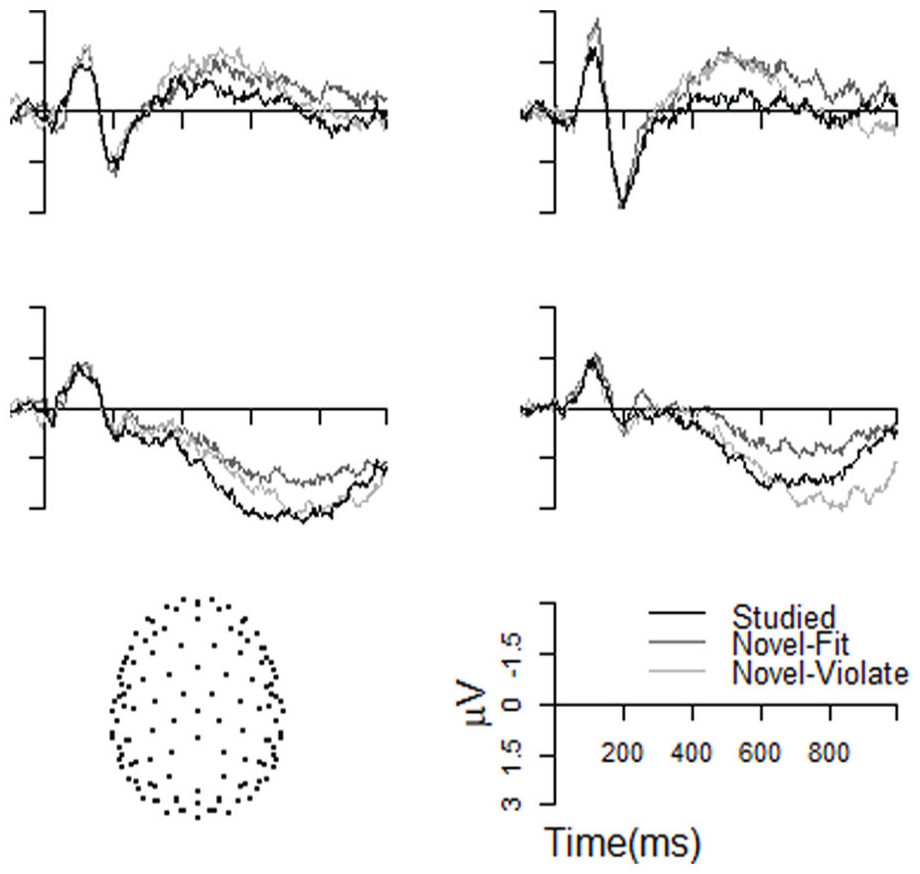
Example ERPs time locked to the onset of items presented during testing. Each waveform is data from a single electrode, with locations as indicated on the bottom left. At the two posterior-central electrodes (top) Studied items elicited a smaller N400 than both types of Novel items. The two posterior electrodes (bottom) show an earlier positivity (P300) for Studied relative to both types of Novel items and an LPC for Novel-Violate relative to Novel-Fit.
The differences in responses to Novel-Fit and Novel-Violate items for individual participants are shown in Figure 8. Individuals differ somewhat in how much they rate Novel-Fit items better than Novel-Violate, but all do except one whose difference is close to 0. There are larger differences in the size of the LPC between individuals, with a few participants exhibiting no LPC at all, or a change in the opposite direction. In the PMN and N400 time windows, participants exhibit differences distributed around 0, corresponding to the lack of effects seen above in the ANOVA analyses.
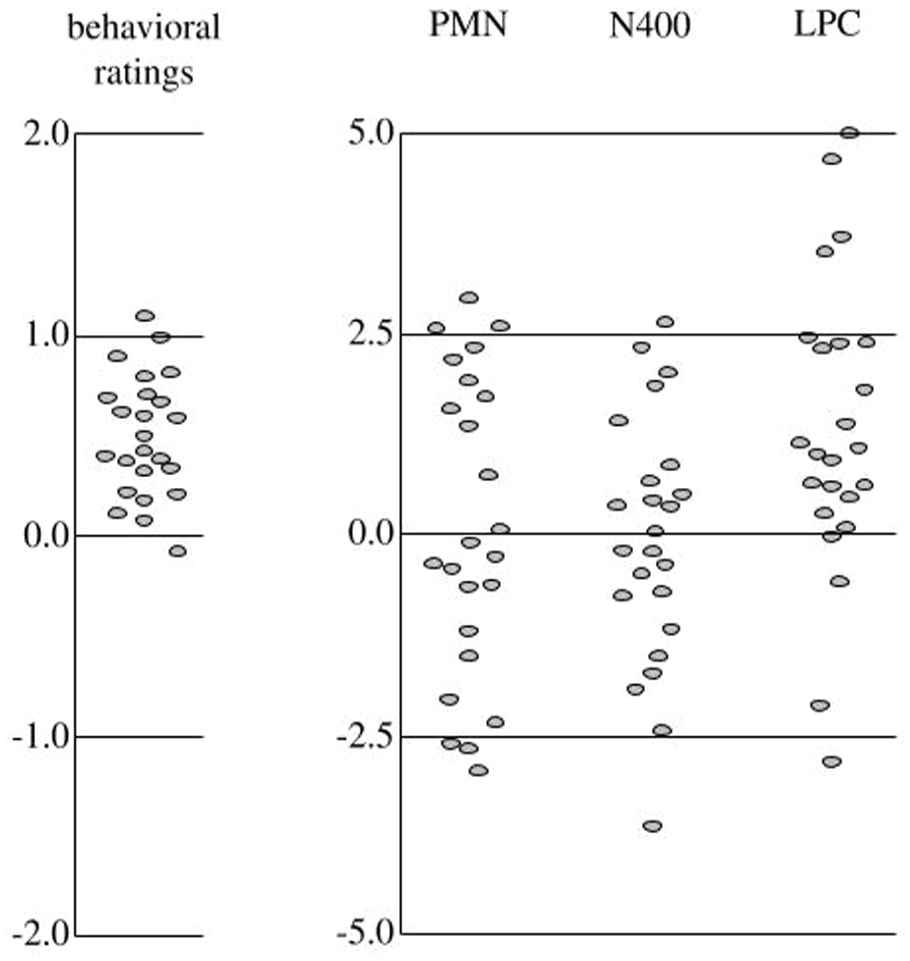
Differences between Novel-Fit and Novel-Violate. Each oval is data from a single participant.
4 Discussion
Participants showed evidence of having learned a novel phonotactic pattern, a dependency between the voicing of two stop consonants within words, through exposure to the pattern as part of a word-picture matching task. Novel items that fit and violated the implicitly learned phonotactic pattern elicited different ratings and different ERPs. The specific pattern of ERP effects, a larger LPC in response to words that violated the phonotactic pattern, shows that the phonotactic representations acquired during a single experimental session with an artificial language affects processing in a similar manner as natively acquired natural language phonotactics (Domahs et al., 2009; McLaughlin et al., 2010) and other implicitly learned structural representations (Núñez-Peña & Honrubia-Serrano, 2004; Osterhout & Holcomb, 1992; Patel et al., 1998).
A positivity was also observed between Studied and Novel-Fit items, which we believe to be a P300. This domain-general component is elicited in response to subjectively salient or task-relevant stimuli, such as infrequent stimulus types (Donchin, 1981), or stimuli which require a response (Duncan-Johnson & Donchin, 1977). In our testing session, Studied items were the minority, making up one third of the stimuli. In addition, Studied items required a qualitatively different type of response than untrained items, as participants only had to remember the item from training, and did not have to judge it based on its sound pattern.
Although it has been argued that late positivities like our LPC are also instances of the P300 (Sassenhagen et al., 2014), we believe our data show two distinct components. Our P300 is elicited by Studied items relative to Novel-Fit items, and begins early, in the N400 time window (400–700 ms). Our LPC is elicited instead by Novel-Violate relative to Novel-Fit items, and does not begin until the later time window, 600–1,000 ms after stimulus onset. One possibility would be that Studied items elicit a P300 based on their salience as trained items with meaning, whereas Novel-Violate items elicit a P300 based on their salience as violators of the trained phonological pattern. However, this hypothesis does not explain the timing difference between the two effects. 4
Notably, the effect of phonotactic knowledge on speech processing reflected by the LPC is extremely late, more than half a second after word onset. The absence of early ERP effects does not constitute evidence for the absence of phonotactic effects on early perceptual and cognitive processing. However, other types of phonological effects are sometimes evident earlier in ERP waveforms. Specifically, following contexts that set up strong expectations of hearing specific speech sounds, a word or nonword that violates those expectations elicits a PMN 150–300 ms after onset (Connolly et al., 2001; Connolly & Phillips, 1994). Furthermore, the types of syntactic violations in sentences that reliably elicit LPC effects typically also elicit an earlier left anterior negativity (LAN; Coulson et al., 1998; Friederici et al., 1993; Osterhout & Mobley, 1995). There are multiple possible reasons why the early phonological effects observed in other studies may have been absent for the current experiment. First, constraints on which phonological features or set of phonemes are probable may not affect speech processing in the same way as constraints on which specific phoneme is likely to be heard. Directly comparing feature and phoneme constraints in an artificial language paradigm would address this hypothesis. Second, phonological expectations may affect processing in different ways when based on phonological context and lexical context. It is not clear what advantage there would be for speech processing to distinct uses of predictions from different sources. Furthermore, both spoken sentences and images of objects are sufficiently similar sources to observe a PMN. However, the data in the current experiment do not rule out this possibility. Third, the specific type of phonotactic pattern might matter for the latency of the earliest ERP effects, with patterns that govern adjacent phonemes at least sometimes resulting in earlier effects (Obrig et al., 2016; Ulbrich et al., 2016; Wiese et al., 2017) than patterns that govern nonadjacent phonemes (Domahs et al., 2009; McLaughlin et al., 2010). Artificial language paradigms will also be important in addressing that possibility as adjacent and nonadjacent phonotactic constraints in natural languages are likely to differ in the extent to which they invoke perceptual repair processes. Finally, it is also possible that amount of learning will determine whether early ERP effects are evident, as it has in some studies of acquisition of second language syntax (Morgan-Short et al., 2012). However, the lack of early ERP effects in the most similar studies of natural language phonotactics (Domahs et al., 2009; McLaughlin et al., 2010) makes this possibility less likely.
We considered the possibility that implicit phonotactic learning from an artificial language would affect N400 amplitude. Novel words that violated the phonotactic pattern could have elicited a larger N400 because they were less similar to recently heard words (Coch et al., 2002; Praamstra et al., 1994; Rugg, 1984) and less phonologically similar to recently learned words (Obrig et al., 2016; Ulbrich et al., 2016). In contrast, the novel words that violated the phonotactic pattern could have elicited a smaller N400 because they were treated as phonologically implausible as words (M. Friedrich & Friederici, 2005; Holcomb & Neville, 1990; Obrig et al., 2016) or because they have fewer phonological neighbors (Holcomb et al., 2002; Hunter, 2016). No effect of phonotactic learning on N400 amplitude was evident in the data. The lack of an N400 effect in the current study could be taken as evidence that naturally-acquired and lab-learned phonotactic patterns affect processing in different ways. However, there is also a convincing and growing body of evidence that N400 amplitude does not index early stages of lexical access (Dimigen et al., 2011; Dufau et al., 2015; Kretzschmar et al., 2015). As such, it is problematic to interpret the larger N400 in response to nonwords that include clusters that violate the sonority sequencing principle (Obrig et al., 2016:; Ulbrich et al., 2016; White & Chiu, 2017; Wiese et al., 2017) as phonotactically ill-formed sequences requiring greater effort in the earliest stages of lexical access. It is still possible that the early abandonment of any processing for sequences that are not sufficiently word-like (M. Friedrich & Friederici, 2005; Holcomb & Neville, 1990) could result in the absence of an N400, and that learning in the current study was not sufficient to trigger that early rejection process.
Instead, as was true in the two studies of natural language phonotactic patterns that are most similar to the artificial language pattern in the current study (Domahs et al., 2009; McLaughlin et al., 2010), novel words that violated the pattern elicited an LPC. The LPC that is typically observed in response to syntactic violations in sentences and labeled a P600 (Barber & Carreiras, 2005; Coulson et al., 1998; Friederici et al., 1993; Osterhout & Mobley, 1995) has been interpreted as reflecting reanalysis of the structure of sentences that do not easily match up with an initial parse. There are multiple reasons to think that the syntactic LPC is related to explicit evaluation or repair of unexpected sequences. For example, the effect is greatly reduced or absent in experiments that employ a large proportion of the same type of syntactic error (Hahne & Friederici, 1990) or when participants are instructed to watch a silent movie while listening to the sentences (Hasting & Kotz, 2008). It is possible that, in the current study, the LPC in response to novel words that violated the recently learned phonotactic pattern was dependent on requiring participants to explicitly judge whether test items sounded like words in the artificial language. Both the late onset of the LPC and observed similar effects across domains (Carrión & Bly, 2008; Domahs et al., 2009; Morgan-Short et al., 2012; Núñez-Peña & Honrubia-Serrano, 2004; Osterhout & Holcomb, 1992; Patel et al., 1998) suggest that LPC amplitude might reflect the additional processing involved in evaluating how different in structure a stimulus is from the representations that are used to understand more common structures.
The gold-standard of ERP experimental design is to present identical stimuli in conditions that only differ psychologically—the Hillyard principle (Luck, 2014, p. 134). The current study meets that standard by presenting the same tokens in all testing conditions (Studied, Novel-Fit, Novel-Violate) and varying what participants heard during the training procedure. That same approach is not possible with natural language phonotactic patterns as identical sequences of speech sounds will not match the learned phonotactic patterns of some listeners and violate only the phonotactic knowledge of other listeners, even with different native-language groups. The same potential confound exists for comparing ERPs for the group of participants who learned the agreeing-in-voicing pattern and the group who learned the disagreeing-in-voicing pattern. However, it is worth noting that with twelve participants in each group, there was no evidence that word learning, phonotactic learning, or the effects of phonotactic learning on processing differed for the two phonotactic patterns. This pattern of results is consistent with similarities in the learning of long-distance assimilation and dissimilation dependencies found in other studies (see Moreton & Pater, 2012a, 2012b, for a review; though see Guevara Rukoz, 2015).
There is a large body of evidence showing that listeners can demonstrate knowledge of natural language phonotactics when evaluating novel words (e.g., Altenberg & Cairns, 1983; Bailey & Hahn, 2001; Frisch et al., 2000). Investigations of how that phonotactic knowledge is represented, and how those representations affect processing have been more challenging. Although ERP measures are a promising approach to addressing those questions, applying the measures to natural language phonotactics has resulted in a broad range of results with ERP effects that differ in distribution, timing, and even polarity. Untangling the relationships among how phonotactic patterns are acquired, the contexts that result in listeners using specific phonotactic representations, and distinct types of phonotactic patterns on how phonotactics affect processing may not be possible with natural languages. Fortunately, phonotactic generalizations can also be acquired quickly in the laboratory with exposure to an artificial language (Cristiá et al., 2013; Cristiá & Seidl, 2008; Culbertson, 2012; Moreton & Pater, 2012a, 2012b; Myers & Padgett, 2014). With artificial languages, it is possible to manipulate all of the factors that are thought to potentially influence how phonotactic representations affect speech processing. The current study takes a major step in that direction by showing that the effects of learning a phonotactic pattern from an artificial language on evaluating and processing novel words are similar to those of acquiring natural language syntactic and phonological rules, as well as structural patterns in other domains.
Footnotes
Acknowledgements
The authors would like to thank Elliott Moreton, as well as the UMass Neurocognition and Perception Laboratory, the UMass Sound Workshop, and audiences at RUMMIT, LabPhon, and the LSA for valuable feedback and discussion. The views expressed in this article are solely those of the authors and do not necessarily reflect those of the MITRE Corporation, or any other organization with which the authors are associated.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based on work supported by NSF Graduate Research Fellowships to R.D.S. and C.M.C under NSF DGE-0907995 and to B.H.Z. under NSF 1451512. The design of the experiment and writing of the paper were supported in part by NSF grants BCS-424077 and BCS-1650957 to the University of Massachusetts Amherst.