
Abstract
We present an implementation of DIANA, a computational model of spoken word recognition, to model responses collected in the Massive Auditory Lexical Decision (MALD) project. DIANA is an end-to-end model, including an activation and decision component that takes the acoustic signal as input, activates internal word representations, and outputs lexicality judgments and estimated response latencies. Simulation 1 presents the process of creating acoustic models required by DIANA to analyze novel speech input. Simulation 2 investigates DIANA’s performance in determining whether the input signal is a word present in the lexicon or a pseudoword. In Simulation 3, we generate estimates of response latency and correlate them with general tendencies in participant responses in MALD data. We find that DIANA performs fairly well in free word recognition and lexical decision. However, the current approach for estimating response latency provides estimates opposite to those found in behavioral data. We discuss these findings and offer suggestions as to what a contemporary model of spoken word recognition should be able to do.
1 Introduction
The question of how a listener understands the meaning of what is being said is central to the field of speech perception and spoken word recognition. After decades of research, it is clear that the process of spoken word recognition is very complex. The sheer number of moving parts affecting the processing of speech make it very difficult to keep track of all of them—let alone create precise predictions about particular situations—using a verbal model “stored” in one researcher’s mind. Computational models, however, allow (or rather, force) researchers to formalize their theories and generate measures or estimates that can be directly compared to behavioral data (see, for example, Perfors et al., 2011; Scharenborg & Boves, 2010; Tan et al., 2021 for similar arguments). Importantly, they allow researchers to observe the interplay of multiple relevant factors at the same time. By switching models, model characteristics, or model parameter values, we effectively change our assumptions about the process of spoken word recognition. We can observe the consequences of alterations regarding any of a number of major points of contention in the field. For example, we can test the adequacy of different prelexical representations, compare the performance of a model with and without top-down effects (or even fine-tune the impact of top-down information), pit against each other different ways of competitor activation and retention, and so on. Overviews of models of spoken word recognition and how they attempted to solve these various problems are given in the works of Magnuson et al. (2012); McQueen (2007); Protopapas (1999); Scharenborg and Boves (2010); and Weber and Scharenborg (2012).
A crucial step in the process of spoken word recognition is isolating characteristics of the speech signal that act as reliable cues of its content. This particular problem has proven difficult due to lack of invariance, leading to a long debate and numerous explanations of how this process unfolds. Still, most abstract models of spoken word recognition, which are the focus of the present paper, sidestep the problem of analyzing the acoustic speech signal and “instead use an artificial, often-hand crafted, idealised discrete (prelexical) representation of the acoustic signal as input” (Scharenborg & Boves, 2010, p. 144).
The main reason for eschewing the acoustic signal were technical limitations that all first- and second-generation models of spoken word recognition faced, not lack of understanding of its importance. Topics ranging from acoustic-phonetic invariance to prosodic cues were central in the development of the Lexical Access From Spectra (LAFS) model proposed by Klatt (1979). The acoustic-phonetic representation in bottom-up approaches to spoken word recognition is also discussed by Pisoni and Luce (1987) as they overview what are mostly considered first-generation models of spoken word recognition, and also the Cohort model (Marslen-Wilson & Tyler, 1980; Marslen-Wilson & Welsh, 1978) and TRACE (McClelland & Elman, 1986b). Where the more recent, second-generation models of spoken word recognition are concerned, TRACE I is built around the acoustic signal being used as input, but TRACE II, the model that was actually implemented, employed acoustic pseudofeatures instead (McClelland & Elman, 1986b; Strauss et al., 2007). Similarly, Shortlist (Norris, 1994) used phoneme strings as input, but Shortlist B (Norris & McQueen, 2008) made a step toward representing their variability better using sequences of phoneme probabilities calculated over time slices, which were obtained from a diphone gating study with human listeners. (Despite the differences in model input, note that both TRACE and Shortlist can provide information over time, i.e., as the signal unfolds.) One consequence of using pseudo-acoustic input is difficulty of establishing a direct comparison between model output and human performance, that is, forming a linking hypothesis (see, for example, Magnuson et al., 2012; Tanenhaus, 2004).
However, although many of the technical limitations have since been alleviated, most abstract models of spoken word recognition continue to settle for pseudo-acoustic input. Even the more recently developed time-invariant string kernel (TISK; Hannagan et al., 2013; You & Magnuson, 2018) model uses phonemes as input, assuming that the process of phoneme recognition had already been successfully completed. This issue becomes even more acute when we take into account other domains within the broader field of speech perception. Classic models of speech perception focused on finding invariant acoustic cues in the speech signal, although these largely investigated recognition of individual speech sounds (for an early speech perception model focusing on lexical access, see Klatt, 1979). Some of the earliest implementations of episodic models of speech perception also used actual sound recordings (Johnson, 1997). More recently, researchers have managed to computationally extract features or categories from the acoustic signal using unsupervised learning (see, for example, Lee et al., 2015; Schatz et al., 2021). Similarly, studies show that information collected from spectra can be used to successfully categorize speech sounds (e.g., McMurray & Jongman, 2011; Stevens & Blumstein, 1978). A large body of research has continued to focus on using actual phonetic input to describe and model a number of phenomena in speech perception, such as categorical perception (Kronrod et al., 2016), perceptual recalibration (Norris et al., 2003; Theodore & Monto, 2019; Xie et al., 2021), unsupervised and supervised adaptation (Clayards et al., 2008; Kleinschmidt & Jaeger, 2016), or foreign-accent adaptation (Hitczenko & Feldman, 2016; Tan et al., 2021); for a summary of recent progress, see Kleinschmidt and Jaeger (2015) and Kurumada and Roettger (2022).
Still, even if we restrict our discussion to the abstract models of spoken word recognition that mostly rely on the activation–competition process to determine what the target word is, there are notable exceptions to the trend of avoiding acoustic input (although these models of spoken word recognition do not always investigate or explain how low-level acoustic features influence the process of spoken word recognition). Two early examples are SpeM and Fine-Tracker (Scharenborg, 2008, 2009; Scharenborg et al., 2005), while the other two examples are the most recent additions to the group of models of spoken word recognition, the discriminative lexicon approach to spoken word recognition (Baayen et al., 2019) and EARSHOT (Magnuson et al., 2020). Fine-Tracker maps the acoustic signal to a set of articulatory features, and it is capable of simulating durational and fine-phonetic detail effects captured in behavioral experiments (see, for example, Andruski et al., 1994; Salverda et al., 2003). The discriminative lexicon approach extracts frequency band summary features (Arnold et al., 2017) that are strings describing a particular frequency band of a temporal chunk of the signal in terms of its initial, final, median, and maximum amplitude. Both approaches are promising, but may require additional fine-tuning, as is the case with Fine-Tracker (see Scharenborg & Merkx, 2018), or additional testing, in case of frequency band summary features. EARSHOT uses spectrographic input and a two-layer neural network architecture to connect the said input to pseudo-semantic vectors. Initial model accuracy in word recognition does show promise, but further model testing is necessary. Besides an inspection of the hidden units that showed similarities to human neural responses, EARSHOT’s output has for now only been compared to the results of the visual world paradigm study performed by Allopenna et al. (1998) and previous simulations of that study using TRACE.
To the best of our knowledge, the only other model to also implement the acoustic signal as input is a process-oriented model, DIANA (ten Bosch, Boves, & Ernestus, 2015). Similarly to other notable models of spoken word recognition, DIANA is an activation and competition model. The current setup uses speech corpora to develop acoustic models (AMs), which are then used to calculate phone activations in novel acoustic signals presented to DIANA. What sets DIANA apart in comparison to models like Fine-Tracker, the discriminative lexicon approach, and EARSHOT is that it acts as an end-to-end model of spoken word recognition that is a computational approximation of (1) a general perceptual decision-making framework with a linking function for recognition and estimation of response latency, (2) which is based on word activation and competition principles most models of spoken word recognition agree on, and (3) extends it to take raw acoustic inputs (shared with, for example, EARSHOT). Importantly, all of these features are an integral part of the model in the case of DIANA, so that the user does not have to rely on multiple different theoretical or computational models (or to choose from multiple different specifications of, for example, decision-making) to simulate a behavioral task. DIANA is built upon the computational modeling of an interpretable interaction between two human cognitive functionalities (namely, activation and decision) in such a way that it can take acoustic input (thus supporting ecological validity) while being able to predict overt outcomes (such as response latency). In DIANA, estimated response latencies are the result of underlying processes, rather than the focus of explicit modeling. Among all current computational models of spoken word recognition that can handle audio input, it is the only one that includes an explicit decision component. This decision component overlaps with computational approaches of human decision-making, such as diffusion models and ballistic accumulation models (see, for example, Ratcliff et al., 2004). In the case of DIANA, the drift is nonlinear and hypothesis-dependent.
In the present paper, we first give a more detailed description of DIANA and previous simulations of the auditory lexical decision and word repetition experiments performed using this model. We then motivate the present simulations, presenting the goal of the current study. The central part of the paper describes the simulations we performed and discusses the findings to both develop DIANA and further scrutinize the process of spoken word recognition.
1.1 DIANA
A coarse visual representation of DIANA’s components and parameters is given in Figure 1 (adapted from ten Bosch, Boves, Tucker, & Ernestus, 2015). The first major component is the activation component: The model takes the speech signal as input and uses existing automatic speech recognition AMs (described in detail in later sections) to activate subword units, which are phones in the current setup, and words in the mental lexicon represented as phone strings. This aspect of DIANA was partly inspired by an observation made by Norris and McQueen (2008). In Shortlist B, the direct connection between the model and the input audio is lost due to the use of intermediate phone-phone confusion probability tables instead of the acoustic signal itself. That step was justified by stating that Shortlist B aims at modeling a part of the cascade from audio to word and that it was not clear how humans perform this step. To create a full end-to-end model, one has to bridge that gap in some way. One of the possible implementational options to close this gap is to use speech decoding techniques that (necessarily) operate from real audio, such as, for example, those developed in research on automatic speech recognition. Importantly, automatic speech recognition is not a panacea to solve the problem of how humans make the connection from audio to phone-like or word-like symbols. Instead, speech decoding techniques can be used as a proxy to compute activations of symbolic representations based on their bottom-up support from the (sub-symbolic) audio. The model can also weigh the activations using top-down information, such as word frequency. The impact of top-down information is controlled by changing the parameter
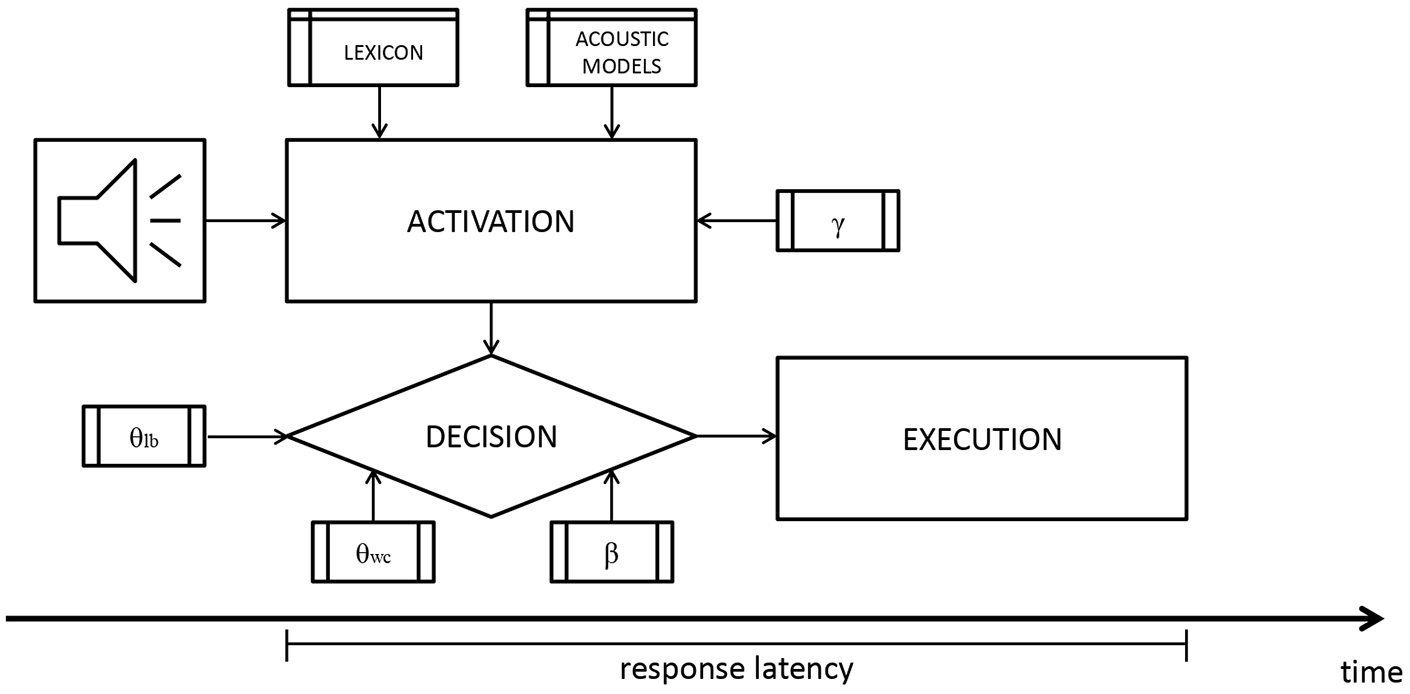
DIANA takes the acoustic signal as input and has three components (activation, decision, and execution). Word activation depends on the input signal, the acoustic models, and the impact of top-down information adjustable by changing the parameter
The decision component operates in parallel with the activation component, reassessing whether a winner can be found at each time step. As words in the lexicon gain activation, they compete without lateral inhibition. Conceptually, DIANA follows the approach used in the Cohort model (Marslen-Wilson & Tyler, 1980; Marslen-Wilson & Welsh, 1978) to determine plausible candidates. Under this simplifying assumption, candidates that do not match with the input will be discarded as the signal unfolds. Note, however, that in the cohort model early mismatches are heavily penalized as they depend on the strict and correct identification of individual phones. In DIANA’s current implementation, the match between the signal and the internal representations is probabilistic (as in Shortlist B) and early mismatches do penalize the word score, but do not necessarily exclude these words from competition. Activation changes and competition unfolds until a winner is selected based on the difference in activation between the leading candidate and the runner-up. This difference is determined by an adjustable threshold
Finally, the third major component of the model is the execution component. The execution happens after the decision has been made and represents the time taken to actually respond (e.g., press a button). Usually, this time is set to 200 ms in our implementation of DIANA. This estimate of the execution time is based on existing measures of response times (RT) in different tasks (see Kosinski, 2008, for a review). Note, however, that increasing or reducing the execution time is a linear transformation that would not impact the correlation between model estimates and some existing behavioral measure. The more important question is whether an approximation that is a fixed number can represent the variability in human reaction time well—not all humans react equally fast. Since the intent of the model is to represent general tendencies in human behavior and since it is unclear how a distribution of execution times can be modeled, we employ the standard approach and use a fixed number.
Besides these integral processes of activation, decision, and execution, DIANA’s other elements could be replaced. For example, the analysis of the acoustic signal can be performed in many different ways or the representation of the lexicon could be made to match TRACE or the Distributed Cohort Model (Gaskell & Marslen-Wilson, 1997, 1999, 2002). The current setup can then be viewed as a task architecture focusing on the process of spoken word recognition, primarily, in word repetition and auditory lexical decision tasks (but see ten Bosch, Giezenaar, et al., 2016, for a simulation of L2 listener errors in comprehension of reduced word forms in a sentence dictation task). We provide more technical detail about the current task architecture of DIANA when we describe the setup of our simulations.
The simulations of word repetition and auditory lexical decision task using DIANA were performed almost exclusively in Dutch. The first such instance (ten Bosch et al., 2013) modeled auditory lexical decision responses to 613 disyllabic monomorphemic Dutch words made by 20 participants. The model showed comparable error rates to human participants as its accuracy was 96% for the “word” (participant average: 94%) and 93% for the “not a word” (participant average: 95%) response. Model estimates of when the decision should be made also correlated quite well with tendencies in participant response latency. The average correlation between the model estimates and each of the human participants separately was
In a subsequent report describing a simulation of participant performance in a word repetition task using the same stimuli, ten Bosch et al. (2014) explain the lack of between-participant correlation using the notion of “local speed effects” (Ernestus & Baayen, 2007). Local speed effects explain the tendency of response latencies to a certain stimulus to correlate with response latencies to a number of previous stimuli. It is assumed that these correlations are a product of, for example, learning, fatigue, or shifts in attention (see also Phaf et al., 1990, for an early example of a computational model taking participant attention into account). Since the variation induced by these factors can be treated as noise in comparison to long-term effects, such as general cognitive abilities, their effect should be attenuated, especially considering that a computational model of spoken word recognition is not susceptible to similar effects. Therefore, ten Bosch et al. (2014) took into account response latencies to five preceding stimuli when estimating the “true” response latency to a stimulus, similarly to taking into account previous RT in statistical modeling (see also ten Bosch et al., 2018). The number of relevant preceding stimuli was selected to achieve maximum participant-to-participant correlation in response latency. After local speed effects have been attenuated, the correlation between participants and the correlation of DIANA to the average participant response latency both increased. The highest correlation between DIANA and the average participant response latency recorded for this word repetition task dataset was
The same procedure that removed local speed effects was used in a later study (ten Bosch, Boves, & Ernestus, 2015) that again simulated participant responses to 613 Dutch words in the word repetition task. This time, however, different model parameters were also varied, showing that word frequency plays an important role in approximating participant response latencies, that the model should not just take the word with the highest activation score as the winner but also should add extra choice time if there is a close competitor at word offset, and that a word should in general have a substantial advantage to be selected as the winner. Applying these rules increased the average correlation between DIANA’s estimates and actual participant response latencies to
DIANA was also implemented outside of Dutch, albeit only once (ten Bosch, Boves, Tucker, & Ernestus, 2015). The dataset included responses from 10 to 12 native and non-native listeners of English to 1,200 words. The results of the simulation still showed satisfactory performance of DIANA, with the correlation between model estimates and average participant response latency in an auditory lexical decision task being
1.2 The present study
One of many advantages of studies with very large item and/or participant sample sizes, often called megastudies (see Balota et al., 2012), is that they enable testing how well model estimates correspond to human performance by providing a behavioral database for comparison. The results of these comparisons are necessary for further model development. An extensive overview of existing megastudies is given in the work of Keuleers and Balota (2015), while a more recent list is available at http://crr.ugent.be/archives/2141.
Most large studies investigate responses to visually presented, written stimuli. The number of existing databases and their sizes are smaller for the auditory domain. Still, such databases are instrumental in the development of many models of spoken word recognition. One of the first larger databases was created by Luce and Pisoni (1998) and the data gathered in this study were used in the development of the capitalize Neighborhood Activation Model (see also Luce, 1986). Another example is the study conducted by Smits et al. (2003), as the collected data were used in the development of Shortlist B (Norris & McQueen, 2008). Biggest Auditory Lexical Decision Experiment Yet (BALDEY; Ernestus & Cutler, 2015) collected responses to 5,541 Dutch content words and pseudowords from 20 young native Dutch listeners and was instrumental in testing DIANA (ten Bosch, Boves, & Ernestus, 2015, 2016).
Massive auditory lexical decision (MALD; Tucker et al., 2019) is a still ongoing project designed to provide an even larger database of responses to isolated words presented in the auditory modality, with the goal of complementing the existing databases in the visual domain, such as the English Lexicon Project (Balota et al., 2007). One of the purposes of building a large database of MALD responses is to test existing computational models of spoken word recognition. The goal of the present study is to implement DIANA in English and test how well it matches participant performance in an auditory lexical decision task using MALD data. Although correspondence to actual participant behavior is only one of the criteria for estimating adequacy of models of spoken word recognition (see Scharenborg & Boves, 2010, for an extended discussion), an acceptable fit is still necessary for a model to be considered credible.
DIANA aims to be language-independent and, in our simulations, we want to investigate the challenges of implementing DIANA for the first time—the way any researcher would be using it for a language in which DIANA has not yet been tested. Therefore, although DIANA was already tested in English on a smaller scale (ten Bosch, Boves, Tucker, & Ernestus, 2015), we develop new AMs from spontaneous speech corpora, completing the entire process a researcher in any language would have to undertake to implement DIANA for their own purposes. These AMs are adapted for a single speaker, the same speaker that MALD participants listened to in the auditory lexical decision experiment. This approach restricts the model input variability to the variability present between segments produced by the same speaker in different words, not between different speakers. Once the AMs are created, we test DIANA’s performance in recognizing words in novel speech signals by calculating between-word competition as a function of time, and, most importantly, by simulating the lexical decision task. In addition, we compare model estimates to actual participant performance in MALD on a large scale and test model adequacy in that way. Original data accompanied with DIANA and statistical analysis scripts are available as supplementary material at https://doi.org/10.7939/r3-jdpa-dn72.
2 Behavioral experiment
As we noted in the introduction, we compare DIANA model estimates to human performance in the MALD project database (Tucker et al., 2019). We use the first version of the dataset (MALD1) available at mald.artsrn.ualberta.ca. In the present paper, we provide only the necessary information about the MALD experiment and the word and pseudoword recordings. More details about the stimuli and procedure are available in the work of Tucker et al. (2019).
2.1 Sample
The MALD1 dataset includes responses from 231 native monolingual English listeners (180 females, 51 males; age M = 20.11, SD = 2.39). All participants were recruited from the University of Alberta, receiving partial course credit for their participation.
2.2 Stimuli
Stimuli recordings were made by one 28-year-old male speaker of western Canadian English. The speaker was recorded reading isolated words and pseudowords on a computer monitor. He was instructed to produce the words written in their standard spelling as naturally as possible. Pseudowords were presented in their International Phonetic Alphabet (IPA) phonemic transcription and the speaker was instructed to read them as if they were words. All word and pseudoword recordings are available as separate wave files and have been aligned using the Penn Forced Aligner (Yuan & Liberman, 2008).
The recording procedure and post-processing of the stimuli yielded 26,800 words and 9,600 pseudowords used in the experiment. The words were split into 67 sets, and the pseudowords were split into 24 sets. Each word and pseudoword set contains 400 unique items. A total of 134 pairings of one word and one pseudoword set were made (i.e., each word list was paired separately with two different pseudoword lists), creating 134 balanced 800-item lists used in the behavioral experiment.
The simulations described in the following sections have many steps and there was small word/pseudoword loss between these steps for various technical reasons (mostly recording errors, mismatches between item lists, or missing MALD1 RT data). In the interest of clarity and brevity, we do not document all of these losses in the paper because they are minor and because we always maintain a high standard of hundreds or thousands of items used. We do provide the exact number of items used for critical simulations and comparisons to MALD data. Detailed information about the simulation process can be found in our supplementary materials, and following the scripts allows more detailed tracking of item loss.
2.3 Procedure
The participants were seated in a sound-attenuated booth for the experiment. A single 800-item list of stimuli was presented using the E-Prime experimental software (Schneider et al., 2012). Stimuli order was randomized. After a visual fixation cross lasting 500 ms, a word or a pseudoword was presented over headphones and the task for the participants was to decide whether the signal was a word of English or not by pressing the “yes” or “no” button on the button box. Responding during stimulus presentation would interrupt it and the experiment would proceed to the next trial. If no response was made within 3 seconds, the following trial was presented. The participants had the option of returning for another session and a new experimental list up to three times. Some participants, therefore, completed more than one list (but never the same word or pseudoword set), and a total of 284 responses to experimental lists were recorded.
3 Simulation 1—AMs
The first goal of Simulation 1 was to follow the process of setting up DIANA from scratch. We developed our own AMs and compared their performance with the performance of existing AMs for English in a free word recognition test. We do not compare model estimates to participant data in this simulation.
3.1 Simulation setup
Acoustic models can be trained using careful (read) speech corpora, such as TIMIT (Garofolo et al., 1993) or LibriSpeech (Panayotov et al., 2015), which was used in the development of Montreal Forced Aligner (McAuliffe et al., 2017). AMs can be also trained using spontaneous speech corpora, such as SCOTUS (Yuan & Liberman, 2008), which was used in the development of the Forced Alignment and Vowel Extraction (FAVE; Rosenfelder et al., 2014) suite. We used two unpublished spontaneous speech corpora as a baseline for creating AMs. The WCE spontaneous speech corpus contains telephone call recordings made by 11 speakers, while the Corpus of Spontaneous Multimodal Interactive Language (CoSMIL) contains conversation recordings of eight pairs of speakers. We decided to use WCE and CoSMIL to train AMs for three reasons. First, many languages do not have extensive support in terms of previously available speech corpora. Using our own corpora, we show that an independent researcher could create a spontaneous speech corpus for their language of interest and use it to create AMs for DIANA. Second, the speakers in WCE and CoSMIL speak the western Canadian variety of English, same as the MALD speaker. Third, human listeners are more often exposed to spontaneous, conversational speech than to careful enunciations. It is best when a model of spoken word recognition can be presented with the same input as the human listener; in our study, both are presented with MALD items in the test phase. However, we also wanted to represent the kind of “practice” human listeners receive as faithfully as possible, so that we used spontaneous speech in the training phase.
In our implementation of DIANA, similar to previous implementations, we trained the AMs using automatic speech recognition training in the Hidden Markov Model Toolkit (HTK; Young et al., 2006). HTK is a modular open source system for speech decoding. The process of creating the AMs described below is time-consuming. In ideal circumstances, starting from a few hundreds of hours of speech, this process may be completed in several days with computational time included. However, the amount of time will vary depending on a number of factors, one of them being familiarity with the technicalities involved. This estimate does not include the process of creating and organizing acoustic recordings and compiling reference data about this material.
WCE and CoSMIL recordings were separated into brief speech intervals, and we further split the longer transcribed intervals to create speech chunks shorter than 10 seconds. We excluded speech chunks that entirely consisted of silent pauses, laughter, or other non-speech noise. In total, just over 9 hours of speech were isolated and split into 20,086 speech chunks each shorter than 10 seconds. We downsampled the speech chunks to 16 kHz, and excluded 31 speech chunks due to potential sound clipping.
The first step in the training procedure takes the speech chunk input and creates estimates for all transcribed units (in this case, phones) as three-state hidden Markov models (HMMs), while the acoustic characteristics of phones are represented by Gaussian mixture models (GMMs). An HMM is a classical, elegant, and computationally feasible solution for representations that correspond to time varying signals, such as words and syllables. An HMM is a network (often a linear sequence with self-loops) of nodes or “states”; each state in an HMM is then associated with a statistical distribution of a collection of very short speech sounds (e.g., all transients into an /a/, stable portions of an /u/, spectral properties of the burst of a /t/). Those statistical distributions can be modeled by a GMM or by other statistical models (nowadays, deep neural networks have become more widely used; see Abdel-Hamid et al., 2014). Allophonic variation is encoded in terms of deviations from acoustic trajectories matched by an HMM and individual Gaussians in a GMM may carry a short stretch in such an allophonic trajectory. The HMM is then a truly representational structure, while the Gaussians or the deep network is a mathematical construct used to associate the audio signal with the HMM states. The HMMs themselves do not have a cognitive status, but they act as an operational computational unit that simulates the activation between audio and representational units. The modeling power of an HMM depends on its topology (linear, or multiple paths in parallel, number of nodes per path, and the number of statistical distributions used to link the acoustical statistics with each node). The number of Gaussians per node is indirectly related to the number of allophones.
Speech chunks from conversational speech corpora often included two or more connected words. Therefore, we expanded the created AMs to also include estimates for short pauses in speech, that is, we created the so-called “sp models” (for more information, see Young et al., 2006).
Increasing the number of GMMs per state may reliably reduce error rate in word recognition (Vertanen, 2006), so in the second step of creating the AMs, we increased the number of GMMs per HMM state from 1 to 2, then 4, 8, 16, and finally to the usually recommended 32 GMMs. The currently employed monophone system assumes that phones are context-independent. In reality, they are not, so with larger training material triphone models can be created to take into account phonetic context. We kept our models simple due to our limited training material, and also because HTK is just a technical mechanism to bridge audio on one hand and activations of words as items in a dictionary on the other.
The third and final step in creating the AMs was speaker adaptation. In this step, recordings from the MALD speaker (the speaker that the model will be tested on) are introduced to realign AM estimates. This process enables the AM to perform substantially better when recognizing speech recorded by a particular individual. Besides being a technical necessity, speaker adaptation is also cognitively relevant; inter-talker variability is high (see, for example, Kleinschmidt, 2019; Magnuson et al., 2021) and humans too show improved performance upon adapting or being exposed to particular speakers or speaker groups (see, for example, Bradlow & Bent, 2008; Eisner & McQueen, 2005; Xie et al., 2021).
Using a portion of speakers’ recordings for training purposes limits the amount of material remaining for the test phase. Considering that the amount of material from the same speaker used in a behavioral experiment may be small to begin with, we wanted to test how much material is required to create adequate AMs. Starting with the “sp model” described above, we created separate speaker-adapted models differing in the number of MALD word recordings used for adaptation. Pseudoword recordings were not used in training. The smallest adaptation set included only three MALD word lists with a total of 1,200 words. Larger adaptation sets were created in increments of three (six lists, nine lists, 12 lists, etc.) up to 45 MALD word lists with a total of 18,000 words. Each list includes approximately just under 4 minutes of speech.
We compared speaker-adapted models in their ability to recognize the input signal from a list of candidates comprised all 26,000 MALD words. In other words, all MALD words were used as the lexicon and we used six MALD lists (46–51) as test (input) material. In the current implementation of DIANA, the activation component analyzes the acoustic input by converting it into vectors of mel-frequency cepstral coefficients (MFCCs), while the acoustic characteristics of every phone in the lexicon, as we stated above, are represented by GMMs specifying the distribution of MFCC vectors for the three states in an HMM that each phone has. MFCCs are built upon the characteristics of the human auditory pathway (critical bands, energy compression) and are since the nineties the dominant audio representation in many analyses based on audio (and speech in particular, Rabiner & Juang, 1993) as well as in computational psycholinguistics. The MFCC representation is a representation of the audio signal in terms of a sequence of low-dimensional vectors. The MFCC vector contains a number of coefficients, each representing an aspect of the spectrum of a small portion of the speech signal. The MFCC vector sequence is computed using a sliding window—an analysis window of 25 ms is standard, as it is considered long enough to cover both steady and transient portions in the speech signal—with a window shift of 10 ms. The number of MFCCs mentioned in the literature may differ: while certain studies mention the use of 12 coefficients, other studies mention 13. Often 12 MFCCs (c1, . . ., c12) are combined (augmented) with log(E) (i.e., log energy) resulting in log(E), c1, c2, . . ., c12, while studies using 13 MFCCs always refer to the additional use of the “zeroth coefficient” (c0) which is also a measure of energy, resulting in c0, c1, . . ., c12. The matching is performed using a Bayesian framework that is often employed in conventional automatic speech recognition. Briefly, the probability that a certain sequence (word) is observed given the acoustic signal depends both on the probability that such an acoustic signal would be created for that sequence (this first factor is related to the AM) and on the probability that such a sequence would occur at all (this second factor is related to the language model and captures effects of expectations based on, for example, frequency of previous occurrence). Therefore, the activation values are scaled log probabilities. Calculations are performed for every 10 ms of input, as per the HTK default settings. Since the goal was to assess the quality of the AMs, activation values were not weighted by word frequency (γ = 0). Furthermore, we did not use the decision component of DIANA; we simply observed whether the correct, target word has the highest activation value.
To further assess AM quality, we also compared our AMs based on spontaneous speech corpora with FAVE AMs (Rosenfelder et al., 2014), likewise adapted for the MALD speaker. In addition, one may be concerned whether the obtained model performance is a consequence of which MALD lists were used for training and which for testing. For that reason, we created another set of AMs based on CoSMIL and WCE which were adapted on MALD lists 67–23, again in steps of three lists (i.e., the model adapted on three lists used lists 67–65, the model adapted on six lists used lists 67–62, etc.), and tested the performance of these models on MALD lists 22–17.
Finally, we created n-best lists to show the top candidates and their activations at word offset. These lists allow us to see whether the competitors considered alongside the word with top activation are sensible, and also inspect the cases in which the wrong winner is selected. We created 20-best lists, that is, observed top 20 candidates for every target word. The choice of the number of candidates considered was arbitrary and made to ascertain that no important candidates will be omitted, and also to allow feasible computation and data manipulation. The number of retained candidates is comparable to those used in established measures, such as orthographic Levenshtein distance 20 and phonological Levenshtein distance 20 (OLD20 and PLD20; Yap & Balota, 2009; Yarkoni et al., 2008).
3.2 Results
Free word recognition results are presented in Figure 2. We can see that free word recognition accuracy is relatively low when models unadapted to the MALD speaker are used. In this initial step, the FAVE model performs slightly better than our own models. Adapting the AMs on more MALD words leads to a large improvement in free word recognition at first, but this effect is reduced for adaptations performed on more than nine MALD word lists, especially for models based on WCE/CoSMIL. AMs created based on WCE and CoSMIL (circles) slightly outperform those based on FAVE AMs (triangles), but this difference becomes smaller as more words are added and disappears when the adaptation is performed on 40 MALD word lists or more. AMs trained and tested using a different set of MALD word lists (squares) show that the obtained free word recognition accuracy (circles) is not an artifact of the training/test set used; in fact, these models even have slightly higher accuracy. As another point of comparison, the AMs used by ten Bosch, Boves, Tucker, and Ernestus (2015) in the pilot DIANA simulations of MALD data had an accuracy of 82% when 500 words were tested with a lexicon of 36,000 word competitors.
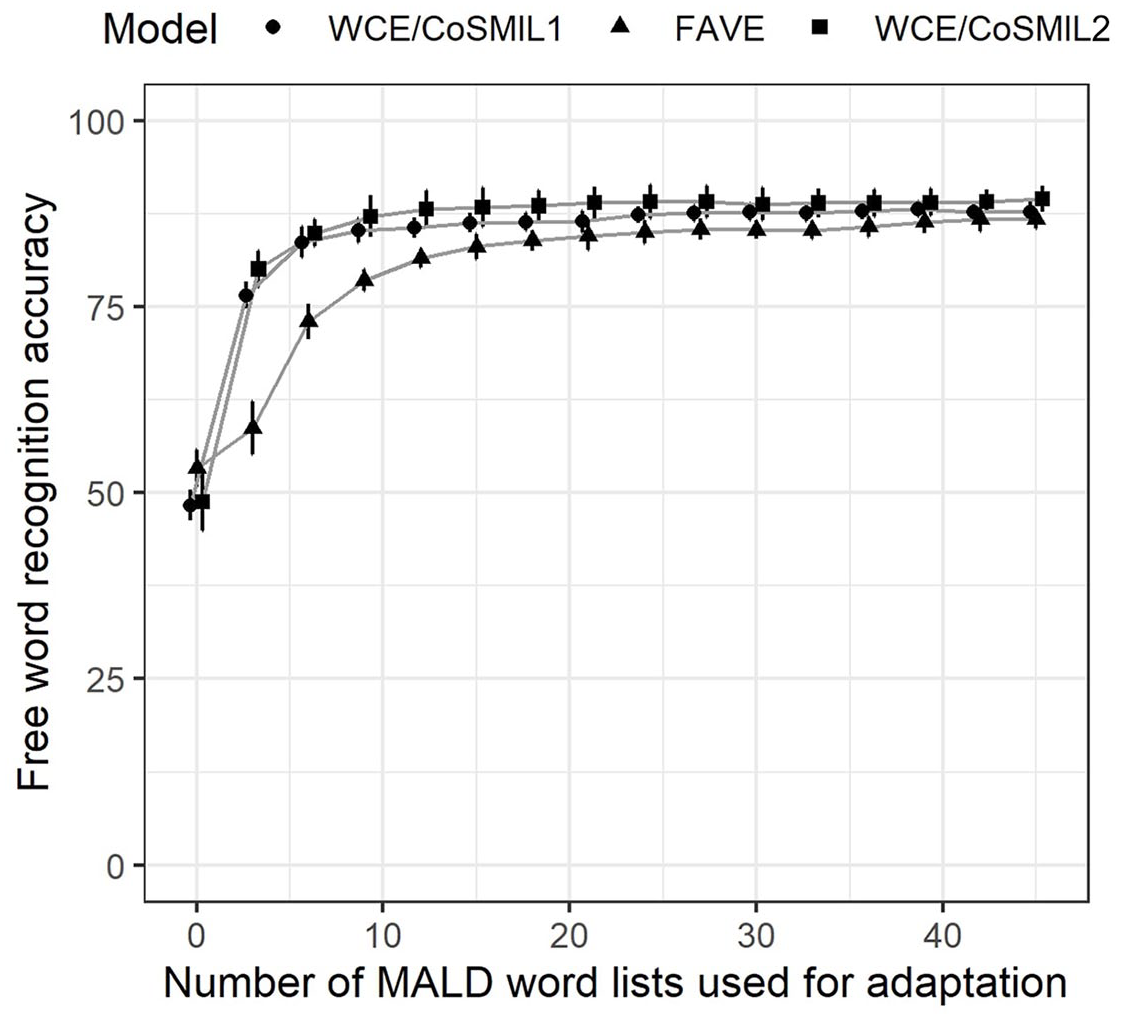
Accuracy in free word recognition on six MALD word lists. The number of MALD word lists used for speaker adaptation is given on the x-axis. Average recognition accuracy and confidence intervals across six MALD word lists used for testing are given on the y-axis. The legend distinguishes between models based on WCE and CoSMIL and adapted on MALD word lists 1–45 (circles), models based on the FAVE AM and adapted on MALD word lists 1–45 (triangles), and models based on WCE and CoSMIL and adapted on MALD word lists 67–23 (squares).
We selected the model adapted on (MALD word lists 1–30), henceforth referred to as AM30, for all subsequent simulations. The difference in average accuracy between AM30 and the AM adapted on 45 MALD lists is only 1%. The model adapted on 33 MALD lists is the first model where we see a slight decline rather than an increase in free word recognition accuracy, indicating that any additional realigning may be volatile. The model still offers a bit more (1.4%) than the model adapted on 15 MALD word lists, as well as a smaller difference in accuracy across the six test lists. Choosing AM30 as the model to be used leaves 37 MALD word lists available for testing purposes.
We also used AM30 to extract 20-best candidates for the target words in the six MALD test lists. We noted sensible competitors in all cases, regardless of whether the correct word was selected as the winner or not. Table 1 shows the winning word and the top 3 competitors for target words tales and proceed. For the first word, the string of phones was correctly recognized although the target word shares the same activation level as its heterographic homophone tails. The correct word was selected as the winner because it appears earlier in an alphabetized list of words. (Note that weighing activation using word frequency would change activation values of the homophones so the more frequent homophone would be selected as the winner; regardless, in later simulations we treat a win by any of the homophones to the target word as correct.) High activations of rhyme competitors pales and hails indicate that the model is considering candidates with initial phone mismatches. The remaining candidates not shown in Table 1 for the word tales, in order of decreasing activation, were fails, sales, sails, bales, trails, veils, nails, ails, jails, rails, wails, whales, feels, Brailles, males, and scales. The word proceed was incorrectly recognized as precede by a very small difference in activation, indicating that small differences in vowel characteristics may be difficult for the model to tease apart. Other close competitors include words that have the same lemma as the target word, while the remaining candidates were preceded, perceived, proceeding, preceding, poppyseed, airspeed, proceedings, preseason, and concede (in some cases, the output presents fewer than 20 candidates as there are not as many suitable options).
Activation of Top 4 Candidates at Word Offset for Two Example Words.
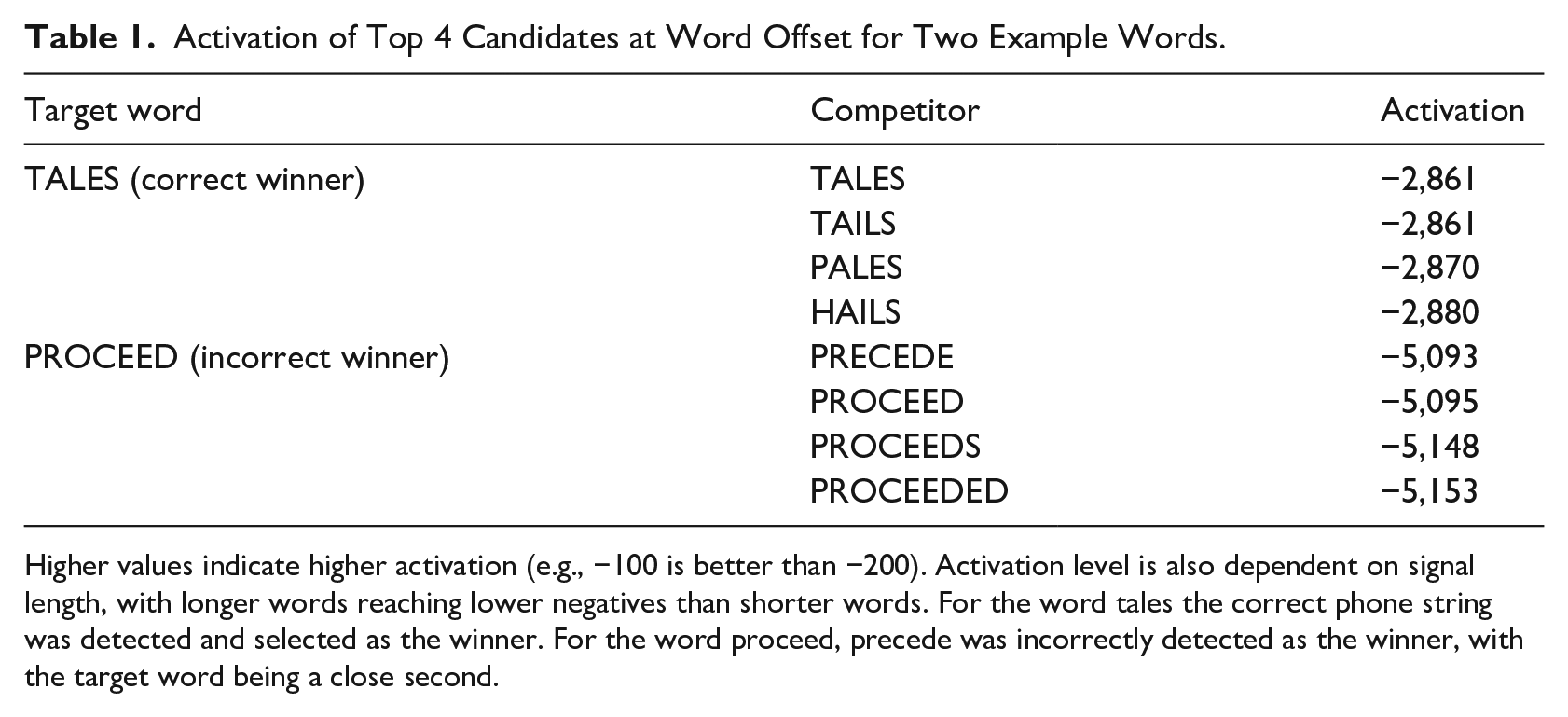
Higher values indicate higher activation (e.g., −100 is better than −200). Activation level is also dependent on signal length, with longer words reaching lower negatives than shorter words. For the word tales the correct phone string was detected and selected as the winner. For the word proceed, precede was incorrectly detected as the winner, with the target word being a close second.
Out of 2,403 words considered, only 14 were not one of the top 20 candidates for their signal: bow, curb, dear, tongues, desirous, boors, brazier, juggle, bairn, beer, betrothed, croquette, mowing, and priority. We found no errors in the recordings of these words and no commonalities between them, except perhaps that they all begin with an oral or a nasal stop. The 20 closest candidates for these words still seemed sensible, at least based on a subjective assessment made by the authors. In all other cases, even when the correct word is not selected as the winner, it is at least a close competitor. In 59% of the remaining cases the correct word is the runner-up and in 88% it is within the top 5 competitors. A closer (manual) inspection of errors showed that some of them were made because there is a heterographic homophone among the competitors, such as in urns and earns or genes and jeans. Other errors mainly occur due to uncertainty whether there should be an initial stop or not (e.g., breast winning instead of arrest and aiding winning instead of bathing), due to omitting the final stop (individualize instead of individualized), or due to the wrong vowel being activated (cake instead of kick). Complete information on 20-best lists can be found in our supplementary material.
3.3 Discussion
Setting up the HTK AMs required for DIANA simulations was relatively successful. It seems that approximately 9 hours of transcribed and labeled spontaneous speech is sufficient to create AMs that will, after speaker adaptation, perform on par with certain existing AMs. Where speaker adaptation itself is concerned, we selected the model trained on 30 MALD word lists (AM30), that is, we used slightly less than 2 hours of careful speech from the MALD speaker. It also seems that similar results in free word recognition can be obtained with the equivalent of 40 minutes of speech (approximately, 10 MALD word lists).
Currently, DIANA certainly requires more adaptation to a particular speaker than a human listener does. Humans are capable of understanding even those speakers they have never heard before despite the fact that the speech signal is highly varied between speakers (see, for example, Johnson & Sjerps, 2018; Kleinschmidt, 2019; Magnuson et al., 2021; Peterson & Barney, 1952; Weatherholtz & Jaeger, 2016). Still, DIANA performs well without years of experience humans have with speech, and it seems that the amount of required recording material for training is not unfeasibly high.
Free word recognition accuracy never exceeded 93% in any of the AMs for any of the test lists—we see that free word recognition accuracy is roughly between 85% and 90%. This is a result that could perhaps be improved using a larger, more varied training set or by providing the AM with transitional probabilities between segments. However, the competition process included 26,000 competitors for every word and even when a mistake was made, the target word was often among the closest competitors. Therefore, we decided to use AM30 in subsequent DIANA simulations of the auditory lexical decision task.
4 Simulation 2—lexical decision
When simulating the auditory lexical decision task, DIANA’s task architecture treats the process as containing two distinct decisions—(1) the decision of whether the signal is a word or a pseudoword and (2) the decision of which word is the winning candidate and when it is selected as the winner. In Simulation 2, we use DIANA to simulate the first decision: whether a signal is a word or a pseudoword. We also compare DIANA errors to MALD1 participant errors.
4.1 Simulation setup
The end result of the activation process in DIANA is a string of phones (one or more) that align with the acoustic input to some degree. When a lexicon of words is presented for the model to choose from, the model only uses strings of phones that exist in the lexicon (i.e., that are stored as words) as valid options. In those cases, the signal is placed in a kind of a Procrustean bed, as it is forced to align with the presented options. The best of these options, that is, the word whose string of phones best matches the acoustic input, will have the highest activation. We have seen this in Simulation 1 as one word is selected as the winner for having the highest activation, while other candidates have lower activation values. We refer to this kind of activation as word activation.
However, there may be a string of phones that would fit the acoustic signal better than any of those present in the mental lexicon. This can be tested using a language model that does not include a mental lexicon with a list of word candidates. Instead, it only contains phones, and, optionally, probabilities of moving from one phone to the other. In our simulation, we treated all possible phone transitions as equally probable. Note that this is not likely the case for real listeners, as they show a tendency to learn and use phonotactic constraints or transitional probabilities in behavioral tasks (e.g., Bailey & Hahn, 2001; Warker & Dell, 2006). When there is no mental lexicon of words, there is no Procrustean bed for the signal to forcefully fit; the model simply chooses the string of phones that yields highest possible activation level. We refer to this activation as free phone activation.
Since free phone activation is the highest activation obtainable for a particular acoustic input (given existing phone AMs), word activation can never exceed free phone activation. Words form a subset of the set of all word-like, phonotactically licensed phone sequences: even if a particular word activation is indeed optimal for a signal, free phone activation would simply yield that same phone string (the same word) and match the activation level registered. Conversely, if the signal does not have a perfect match with any of the words in the lexicon, forceful attempts to adapt to one lead to imperfect matching and therefore lower word activation levels, while free phone activation would still come up with the optimal string of phones and would remain high.
DIANA uses this difference between word activation and free phone activation to perform lexical decision. The decision whether a signal is a word or a pseudoword is made by comparing the best possible activation of a word candidate present in the mental lexicon (best word activation) to the best possible activation achieved if any phone sequence is allowed (free phone activation). The larger the difference in word activation and free phone activation, the less the signal resembles the given word (though keep in mind that the same result in word activation and free phone activation does not necessarily mean that the model recognized the correct, intended word). When a pseudoword is presented to the model, free phone activation should be significantly higher than word activation for any word in the mental lexicon, simply because phone strings comprising pseudowords are not present in the mental lexicon. Words, in turn, should have similar free phone and word activations. This should yield two distinct distributions of differences between free phone and word activation, forming a group in which the difference is 0 or close to 0 (words) and a group in which the difference is larger (pseudowords).
Ideally, there would be no overlap between these two groups of stimuli, allowing the model to perfectly distinguish between them. However, this would require AMs that perform perfectly, in addition to all word and pseudoword recordings having very careful enunciations of every phone in the word that align well with the AM. Instead, DIANA employs a threshold θ lb that specifies the difference between free phone activation and word activation that is small enough for a signal to be considered a word. This threshold is adjustable and we investigate what value leads to best accuracies in word and pseudoword classifications. We test what word vs. pseudoword accuracy levels are registered for a range of θ lb values and compare them to those recorded in human responses.
Besides calculating free phone activation and introducing pseudowords, we made additional changes in comparison to Simulation 1. We performed the simulation on all MALD words from lists 31 to 67 (i.e., all lists that were not used in adapting the model AM30, a total of 14,800 words) and on all MALD pseudowords. Instead of using all of the MALD words as the lexicon of candidates, we created separate lexicons for every word and pseudoword. Since DIANA conceptually endorses a Cohort-like competition (Marslen-Wilson & Tyler, 1980; Marslen-Wilson & Welsh, 1978), the lexicon included all short words (three phones or fewer) and all words that share the first three phones with the target word. The competitors were selected from the Carnegie Mellon University Pronouncing Dictionary (CMU; Weide, 2005). This procedure yielded lexicons of approximately 25,000 words mostly comprised words with three phones or fewer. In other words, the intention was to limit the competitor list under the assumption that the first three phones would be correctly recognized as the signal unfolds, but expand the number of close competitors by including more similarly sounding words.
We noticed in Simulation 1 that sometimes the wrong word is selected as the winner because the target word had a heterographic homophone in the lexicon (as in the urns vs. earns example mentioned previously). Using the entire CMU dictionary to create separate lexicons of competitors for each target word introduced many such heterographic homophones. To avoid this issue, we treated all cases in which a homophone of the target word was selected as the winner to be accurate, given that homophones have identical activations in DIANA and that in an auditory task where single words are recognized both are technically correct.
The activation scores for words were still left unaffected by word frequency weighted by the parameter
4.2 Results
For word recordings, the maximum difference between word and free phone activations was 371.87, recorded for the word depopulation. Mean difference in activation was 29.64, while the median was 16.93. A total of 3,303 words (22.26%) had the activation difference of 0, meaning that free phone activation perfectly matched word activation. For pseudoword recordings, the differences between word and free phone activations were expectedly higher. The highest difference was 1,482.45 and it was recorded for the pseudoword /εkmɪsieɪskləɹoʊsiz/, which the model fitted as Izzy’s—competitors with more than three phones beginning with /εkm/ were rare and not similar to this pseudoword. The mean difference in activations for pseudoword recordings was 222.34 and the median was 184.38. Still, 337 pseudowords (3.5%) had the activation difference value of 0, meaning that the model incorrectly interpreted them in a way that perfectly matched with a word in the lexicon.
Figure 3 shows the distribution of word and free phone activation differences for word and pseudoword recordings. We set the x-axis limit to activation difference of 500 to make the distribution in the lower values more visible, but the long tail of differences continues for pseudoword recordings up to 1,482.45. In the case of words, as the activation difference increases, the number of words with that difference between word and free phone activation decreases; most words tend to have a small difference between word and free phone activation. For pseudowords, this trend can also be noted, but with a much smaller slope, as the distribution is, especially toward the lower hundreds, nearly uniform.
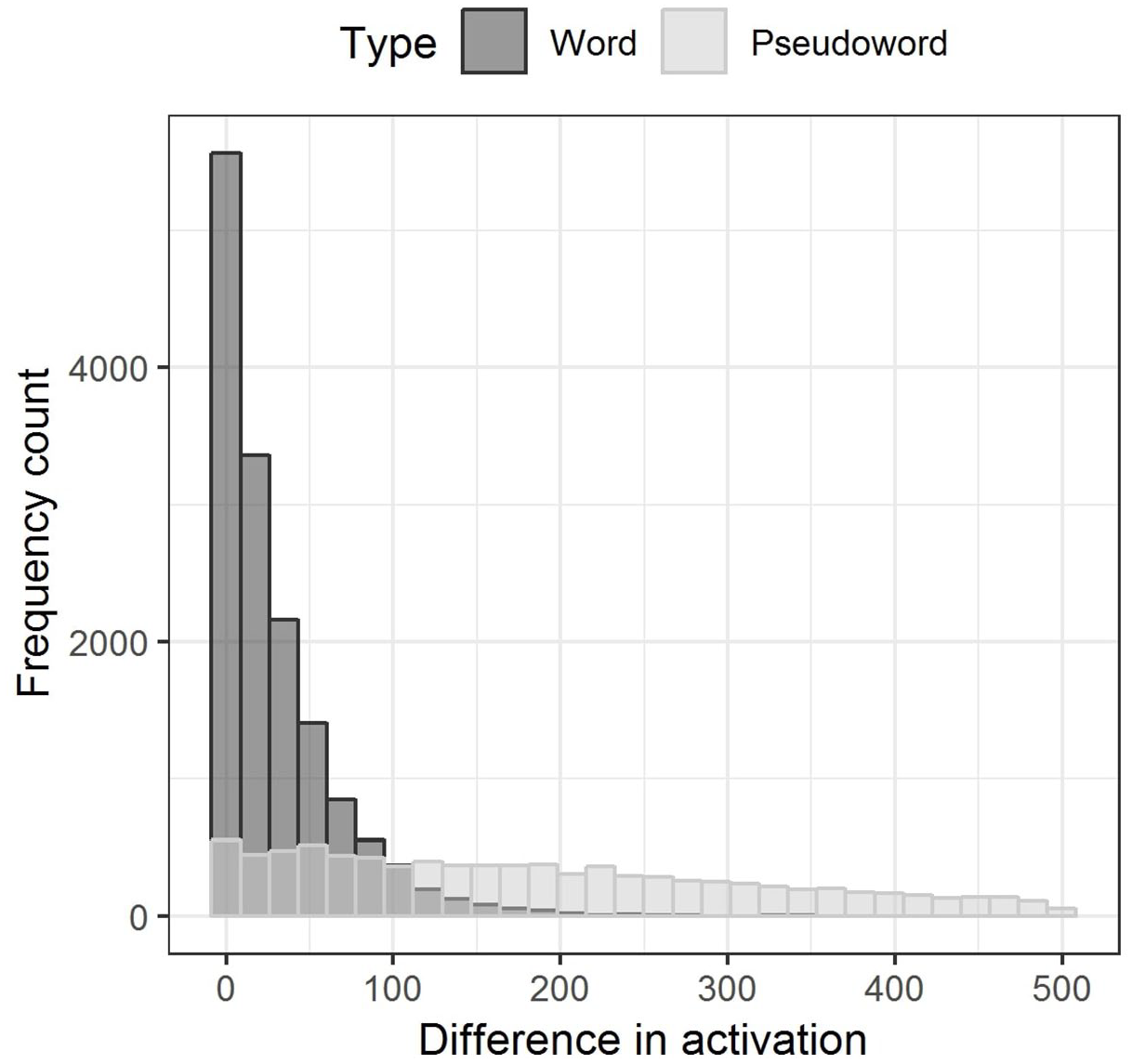
Histogram of differences in word activation and free phone activation for MALD words (lists 31–67) given in dark gray and MALD pseudowords given in light gray. The x-axis is limited to activation difference of 500, but the same trend continues to the maximum activation difference recorded which is 1,482.45.
We then examined the ratio of “word” versus “pseudoword” responses and model accuracy in predicting whether the input signal is a word or a pseudoword as a function of
The percent of “word” responses increases as the θ
lb
increases. When θ
lb
is 0 only 13.01% of the stimuli are selected as real words. With θ
lb
of 150, the percent of “word” responses in all stimuli rises to 70.44%. Figure 4 shows this relationship and also includes three points of special interest on the curve. These points mark the quartiles of the percent of “word” responses in all experimental sessions in MALD1. The middle half of MALD1 sessions (the interquartile range) are found between points Q1 (48.12% “word” responses) and Q3 (54.83% “word” responses). These results indicate that in most sessions MALD1 participants had a fairly balanced response regime, making roughly an equal number of “word” versus “pseudoword” responses. Since DIANA aims to simulate general tendencies in participant behavior, it seems that
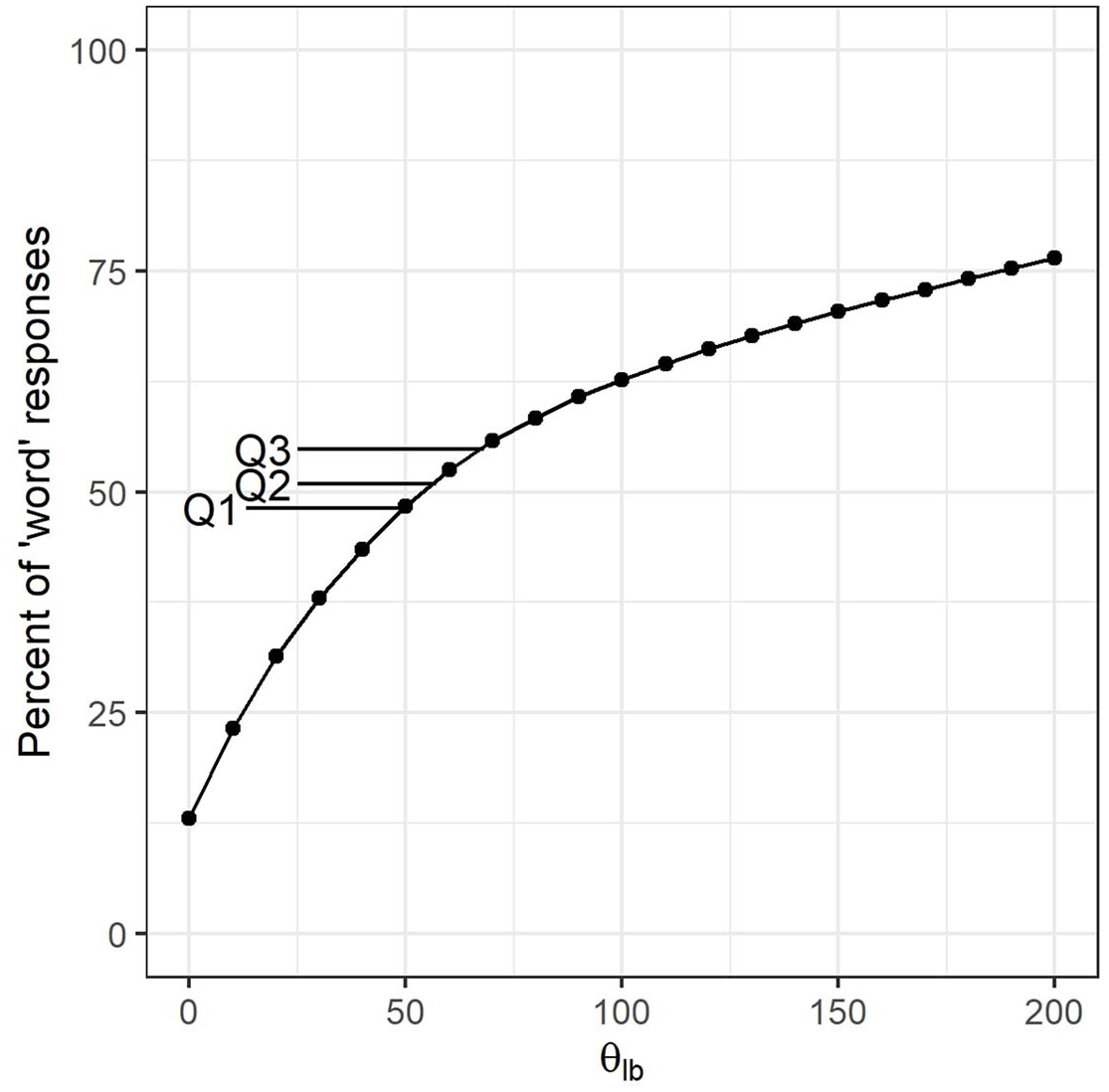
The relationship between threshold θ lb and the percent of “word” responses DIANA makes. Points Q1, Q2, and Q3 are added for comparison and represent quartiles of the percent of “word” responses in MALD1 sessions.
DIANA’s accuracy in classifying words versus pseudowords is also dependent on θ lb . As the threshold rises, so does the percent of word signals correctly recognized as words. At the same time, the number of false alarms increases, as more and more pseudowords are mistakenly taken for words. Figure 5 shows how accuracy for words and pseudowords changes as a function of θ lb and again includes quartiles from MALD1 sessions for comparison. We see that in our current setup DIANA inevitably performs worse than an average MALD1 participant, as it cannot have a performance higher than the value of Q1 for both words and pseudowords. Since the focus of our simulations was responses to words and since we wanted to match the participants’ balanced response regime, we settled for θ lb value of 70. With this threshold value the model made 55.65% of “word” responses and had an accuracy of 87.92% when responding to words and 76.44% when responding to pseudowords.
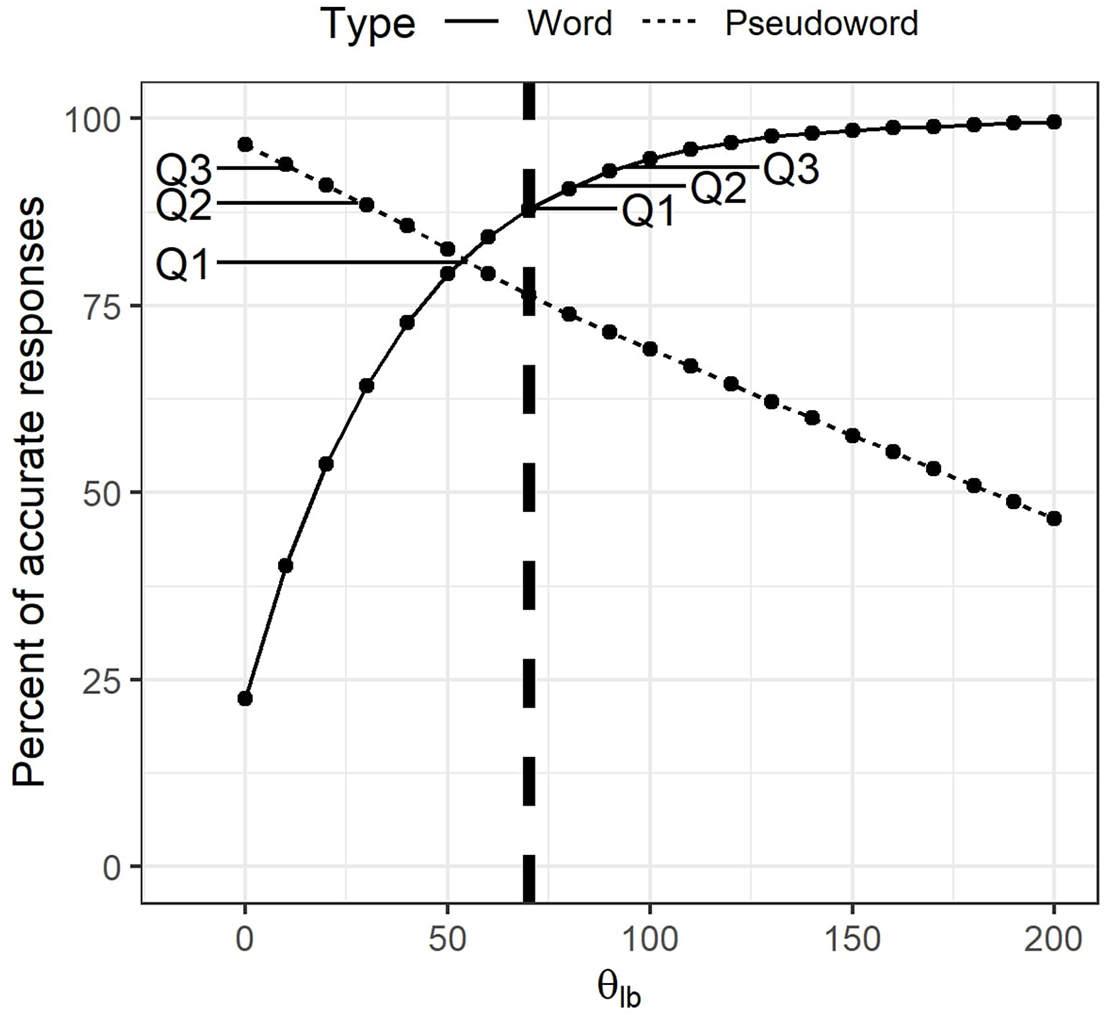
DIANA’s accuracy in lexical decision for words and pseudowords as a function of threshold θ lb . Points Q1, Q2, and Q3 connected to word and pseudoword curves represent quartiles from MALD1 session data. The vertical dashed line marks the value of θ lb selected as optimal in the present simulations.
Cross-tabulation of lexical decision and winner selection accuracy at word offset showed that 78.46% of word items were both selected as a word by the lexical decision process and the target, correct word won at signal offset. In 10.57% of the cases, the correct word was the winner based on word activation, but the word activation was still smaller than free phone activation by more than 70, so these signals were incorrectly flagged as pseudowords. In 9.45% of the cases, the signal was accurately selected as a word (the difference between word and free phone activation was less than 70), but the wrong word had the highest activation at word offset. Only 1.52% of word recordings were both mistakenly marked as pseudowords and the wrong word had the highest activation at word offset. Words tend to be misinterpreted as another word rather than a pseudoword if they are shorter in duration (Welch’s unequal variances t test:
As noted in Simulation 1, longer recordings reach lower negative activation values. One concern that we had is whether higher differences between word activation and free phone activation would simply be a product of longer signals and a higher opportunity of mismatch between the two. Figure 6 shows that this is indeed the case, but mostly for pseudowords
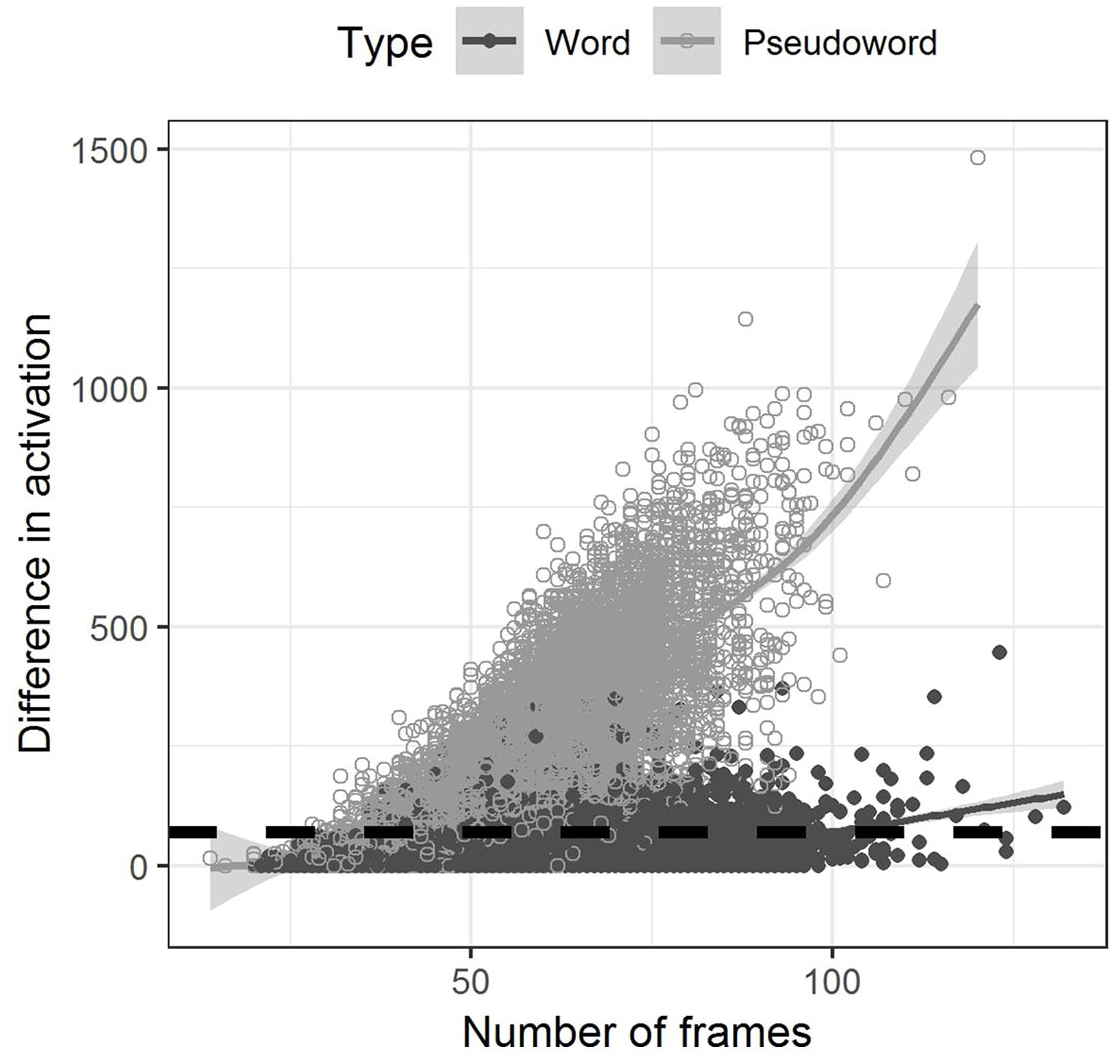
The relationship between the number of frames (duration) of a stimulus and the difference between word and free phone activation for that stimulus presented separately for words and pseudowords. The black dashed line marks the selected difference value of θ lb = 70. The eventual score a hypothesis (phone string) receives is based on the summation of local scores that are associated with individual MFCC frames—in principle, the longer the stimulus, the larger the deviations will be between the scores of competing candidates.
We do not see such a strong correlation between duration and accuracy in MALD1 participants. There is no correlation between word duration and the proportion of correct responses to that word
4.3 Discussion
The goal of Simulation 2 was to test DIANA’s approach to modeling lexical decision, that is, the word/pseudoword decision all human participants make in an auditory lexical decision experiment. Specifically, we wanted to establish the best value of the threshold θ lb which determines whether a stimulus will be recognized as a word by DIANA. We found that the approach can distinguish between the two types of stimuli fairly well, although the model in our current setup does perform somewhat worse than an average MALD1 participant. It is important to note that DIANA’s response accuracy could be increased by selecting an unrealistic response strategy—in our case, by increasing the number of “word” responses the model makes. However, this is a poor approach if the goal of the simulation is matching participant behavior. The goal of cognitive simulation is to explain a process, such as spoken word recognition in humans using plausible solutions, not to maximize model performance.
Where words are concerned, although we changed the lexicon of candidates, tailoring them for every target stimulus, word recognition accuracy remained as high as in Simulation 1. However, in a portion of cases, a pseudoword has higher activation than the target word. In addition, among correct lexical decisions, there are cases in which the wrong word had the highest activation. Both of these kinds of errors in DIANA’s word recognition stem from the same root cause—relatively low activation of the target word.
The reasons for making mistakes are only partly shared between DIANA and human participants. Both can “mishear” the signal, taking a pseudoword for a word, a word for a pseudoword, or mistaking the word for some other word. However, participants also make mistakes because they do not know a word, whereas DIANA has all the MALD/CMU words stored in its lexicon. In addition, a human participant can simply lose attention and press the wrong button (Prins, 2012; ten Bosch et al., 2019), whereas DIANA always performs on the same level. In the current simulation, DIANA’s performance fully depends on the quality of the AMs, the characteristics of the incoming novel acoustic signal, and the available competitors in the mental lexicon.
In the case of pseudowords, we note a trend in which longer pseudowords are more accurately categorized by DIANA. We explain this finding in terms of cumulative activation and lexicon structure. There are more opportunities for longer pseudowords to mismatch with an existing word. In addition, the number of plausible word candidates is smaller for longer pseudowords and with that so are the odds of the pseudoword signal being mistakenly taken for an existing word. Still, due to imperfect AMs, we see that certain short pseudowords are mistaken for words using the threshold θ lb = 70.
Although a similar relationship between pseudoword duration and accuracy exists in the MALD1 data, it is much less pronounced. But why are not MALD1 participants benefiting (as much) from more opportunities for mismatch and fewer plausible word candidates when listening to longer pseudowords? We argue that, unlike our current DIANA setup, MALD1 participants are aware of the morphological and even semantic characteristics of pseudowords, making certain long pseudowords more word-like to a human listener. MALD pseudowords were created from actual words of English by replacing a third of their subsyllabic constituents with another phonotactically licit and probable segment, yielding pseudowords with some apparent morphological complexity (Tucker et al., 2019). One example is the pseudoword /εnspeɪzd/ that was correctly classified in only 36% of occurrences in MALD1 sessions. Morphologically, this word may resemble a combination of en plus spaced, as in, for example, encircled (although we do note that the final sounds are voiced in the pseudoword, unlike in the word spaced /speɪst/). Another example is the pseudoword /trænzvɑɹmɪŋ/. Although there are differences in comparison to existing words, such as transforming, or a potential “word” transwarming, the prefix trans and the suffix ing in conjunction with the central part of the word that sounds like existing words are likely the reason why this pseudoword was correctly responded to in only 27% of its MALD1 trials. DIANA is not sensitive to this kind of similarity and the top word competitor to /εnspeɪzd/ is the word inspires, while the top competitor for the pseudoword /trænzvɑɹmɪŋ/ is tensiometer. Furthermore, processing written pseudowords is not free of item-level frequency or semantic effects, as pseudowords do not necessarily have a frequency of 0 and as form-meaning patterns learned from words can extend to pseudoword processing to yield pseudoword positions in a semantic space (Cassani et al., 2020; Hendrix & Sun, 2021).
5 Simulation 3—response latency
The goal of Simulation 3 was to test how well DIANA’s estimates of when a word is recognized match general tendencies in participant response latency from MALD1 data.
5.1 Simulation setup
Statistical modeling of participant response latencies collected in auditory lexical decision tasks ordinarily only considers trials in which the participant responded correctly. Our approach to estimating response latency using DIANA was the same, as we only considered the words that were correctly classified as words in Simulation 2 for response latency estimation in Simulation 3. However, when a participant makes the correct lexical decision to a word in a behavioral task, we cannot know whether they actually accessed the correct, target word or some other word. DIANA, in turn, outputs information about the winning word. The researcher needs to decide whether words that were correctly classified, but incorrectly recognized will be included in the simulation.
We conducted separate simulations and considered both possibilities. The results were not qualitatively different in any way. The results of the simulation using all the words that were correctly classified as words in Simulation 2 (even if the wrong word won) are presented in the supplementary material. In the remainder of the text we present the results of the simulation in which we only considered the words that were both correctly recognized at word offset and treated as words (not pseudowords) by DIANA in Simulation 2. This number was further reduced by approximately 100 words to the final number of 11,465 words when the simulation results were merged with MALD1 data due to missing or skewed data or technical issues in item matching. We used the same lexicons of competitors to these target words as in Simulation 2. However, in Simulation 3 we calculated word activation using a gating procedure. We split all word recordings into 20 ms frames. Model estimates were made upon addition of every new frame. Since the process is computationally demanding and since the initial stages of word competition are uninformative, we only observed the activation of top 20 candidates in the last 300 ms of the sound signal. In effect, the gating procedure allows us to estimate candidate activation and observe the activation–competition process as the signal unfolds. In addition, DIANA’s decision component can make a decision at every selected point in time during the signal presentation.
The activation at the final phase of the gating procedure (word offset) is identical to the activation used in the lexical decision simulation from Simulation 2. We already determined the value of the lexical decision threshold θ
lb
based on the difference in free phone and word activation when the entirety of the signal was available to the model. The majority of responses in auditory lexical decision experiments are made after signal offset, and our reasoning was that one viable strategy for the listener would be to make the best possible decisions when all of the information is available. In addition, varying all parameters in DIANA at the same time would create too many combinations for feasible computation and analysis of results, so we determined θ
lb
independently from
We followed similar reasoning when determining plausible values for parameter

We assessed which values of parameter
The decision of which word is the winning candidate in DIANA is regulated by a threshold θ wc determining the required difference in activation between the leading candidate and the runner-up. Since there are many heterographic homophones in the dictionary that will have identical activation (e.g., tails and tales), we only considered non-homophone competitors when we determined the difference between the leading candidate and the runner-up. We calculated this difference at every step in the gating procedure. When determining the range of acceptable values for threshold θ wc , we again used MALD1 responses as a benchmark. Increasing θ wc increases the required difference between the top candidate and the runner-up for a winner to be selected, and therefore increases the number of word signals which do not have a clear winner before word offset. A very low value of θ wc will in turn yield many winners before word offset—which can also lead to many wrong competitors being selected as winners based on early activation. We decided to adjust the value of θ wc so that the percent of words that win before word offset is roughly equal to the percent of word responses that happen before word offset in MALD1 data. When determining this percent for MALD1, we added 200 ms to word duration to take into account the time required to execute the response, as assumed by DIANA.
In this simulation, we only selected words that were correctly recognized at signal offset in Simulation 2 (but see the supplementary material for the alternative option). However, a wrong word may be the leading candidate prior to signal offset, especially considering that top-down information now affected competitor activation. Therefore, we also tested which word is the leading candidate at the time frame when the winner is selected.
When a winner is selected prior to word offset, DIANA takes the time at which it was selected and adds the aforementioned 200 ms for execution. In the case when the required difference between the top candidate and the runner-up (controlled by threshold θ wc ) is not attained at stimulus offset, a controllable parameter β estimates the added time for the final winner decision. The time needed to decide on the final winner depends on the number of remaining plausible competitors, that is, all the words with an activation difference of less than θ wc from the top candidate. However, when simulating the lexical decision task, DIANA assumes that the listener is at this stage also considering viable phone strings which are not present in the mental lexicon. In other words, pseudowords are also competing with real words, increasing the perplexity of the decision at signal offset. Unlike for highly activated word competitors, we cannot obtain the activation values for all potential pseudowords. The number of pseudoword competitors at word offset is approximated by raising 3 to the power of the number of phones of the target word. The formula for estimating choice reaction time then follows the Hick–Hyman law (Hick, 1952; Hyman, 1953) by calculating the logarithm of the total number of remaining word and pseudoword competitors weighted by parameter β (Equation 2). Choice reaction time is finally added to the total duration of the signal, in addition to the 200 ms required for execution.

We note that this formula is a rough estimation in itself that also assumes that these non-word competitors are still plausible competitors at stimulus offset. Also note that the plausible pseudoword competitors retained using this formula would likely highly outnumber the remaining word competitors, especially for longer target words and if phoneme recognition is precise so that most word competitors are excluded as implausible. However, the formula is based on a deeper conceptual idea about the (virtual) role of pseudowords during decoding. DIANA is based on the idea that the total reaction time that is the empirical outcome of a lexical decision experiment is composed of three parts: (1) the time it takes for the stimulus to unfold and to build activations, (2) the time it takes to make a decision based on these activations, and (3) some additional time (here assumed constant) for the signal to travel from the motor cortex to the finger muscles along the neural pathway. The contribution from (1) is dependent on the stimulus, and primarily on stimulus duration. Contribution from (2) is directly related to Hick’s law, which says that the time it takes to make a decision is approximated by the expression
With acceptable ranges for parameter
5.2 Results
We first tested how word recognition accuracy at signal offset changes when top-down frequency effects are introduced to the model. We tested
We then assessed plausible ranges for threshold θ
wc
by comparing the percent of decisions made before word offset in DIANA and MALD1. When making this comparison, we decided to take into account only the percent of correct responses made before word offset per MALD1 session (to remind, a MALD1 experimental session includes a single participant completing a single 800-stimulus MALD1 list). This was done for two reasons. First, the correlation between the percent of responses made before word offset with 200 ms added for execution time and the percent of correct lexical decisions made to word stimuli was very low in MALD1 sessions
Figure 7 shows how the number of winner selections that happen before word offset decreases as the required difference in activation between the top competitor and the runner-up (θ
wc
) increases. This relationship is nearly identical for all considered levels of
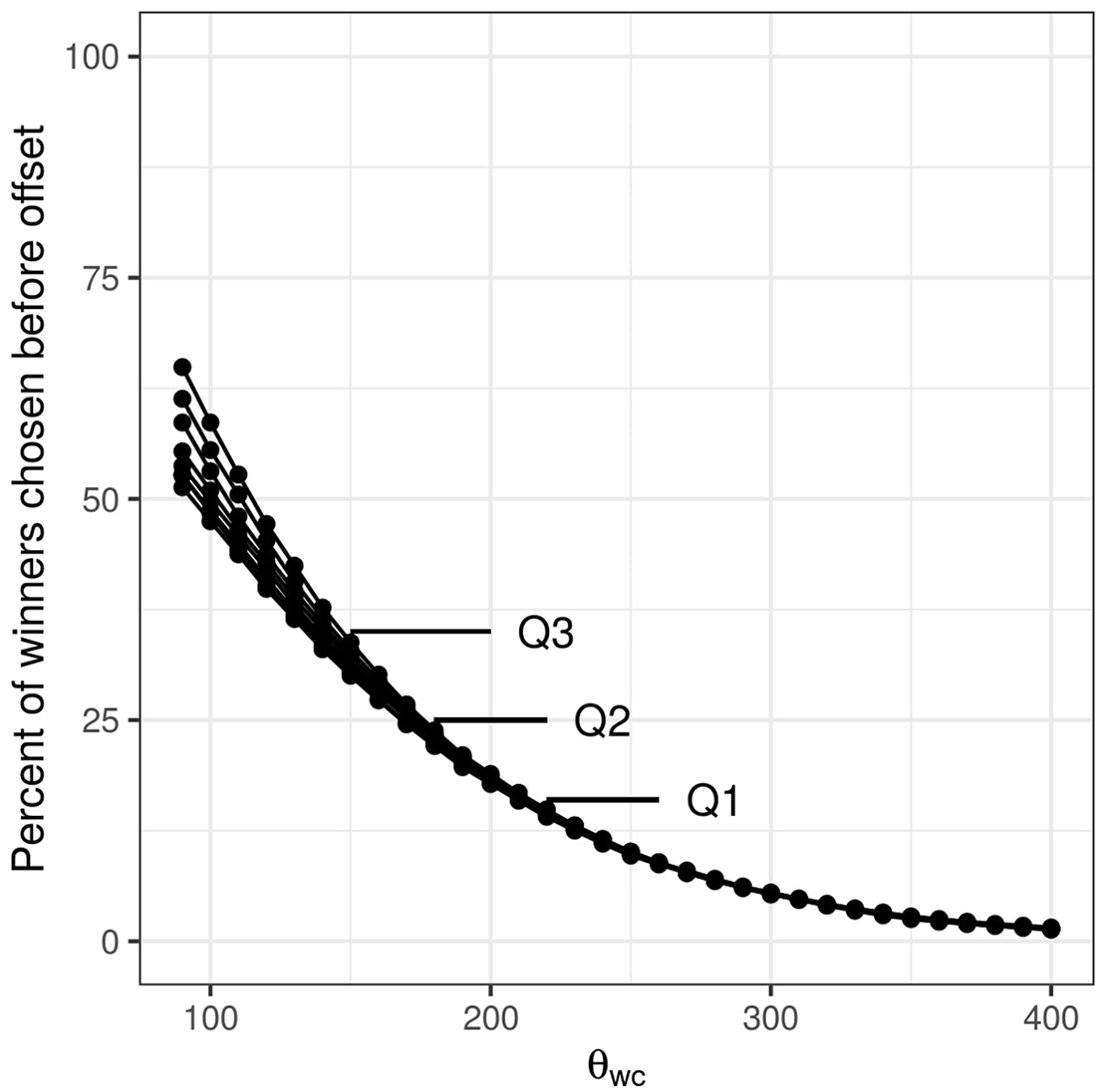
DIANA’s percent of decisions made prior to word offset as a function of threshold θ
wc
. Separate lines are drawn for different parameter
However, making a decision prior to word offset also introduces the risk of choosing the wrong word as the winner: at some point during the activation–competition process, a candidate may get highly activated and win, even though the remainder of the signal would reduce its activation. (Remember that we previously excluded all the words that were incorrectly recognized in Simulation 2, so all words are correctly recognized at word offset.) Therefore, we tested how accuracy in selecting the right word as the winner changes as a function of θ
wc
. Figure 8 shows that the number of wrong selections for responses prior to word offset decreases as θ
wc
increases. When the model is more conservative in selecting the winning word and fewer words are recognized before word offset, there is less of a chance that the wrong word will be selected as the winner. Frequency again plays only a minor role when the value of θ
wc
is high. However, for θ
wc
of 150, the range of correctly recognized words ranges between 77.78% (
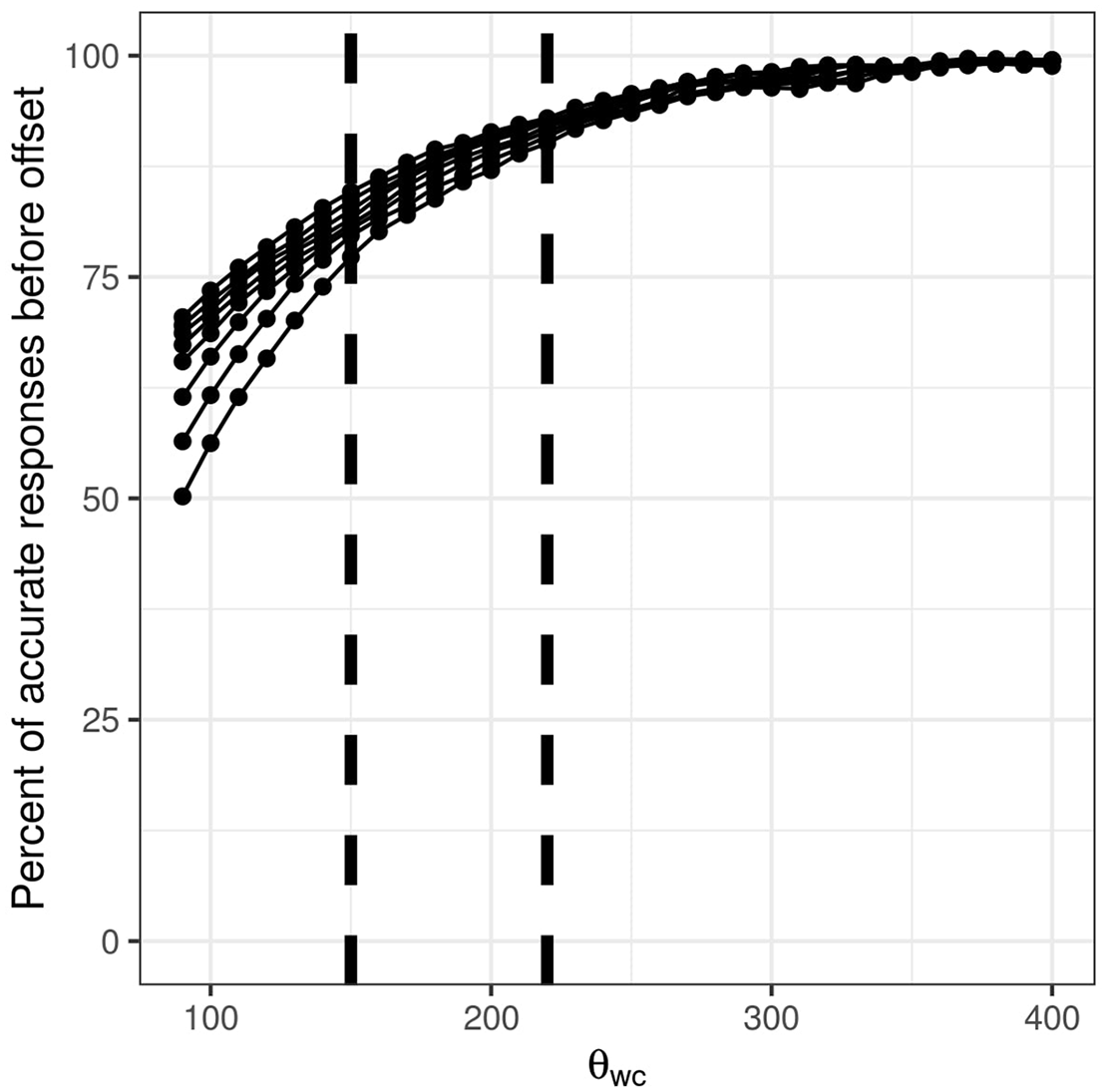
DIANA’s percent of accurate responses prior to word offset as a function of threshold θ
wc
. Separate lines are drawn for different parameter
We considered θ
wc
values between 140 and 240 in steps of 20 for estimating response latency in DIANA. We excluded very early DIANA estimates of a word winning (before 420 ms pass with 200 ms for response included) as unrealistic. We also excluded words that were RT outliers in MALD1 data. As stated above, the final number of words used to correlate DIANA’s response latency estimates with response latency from MALD1 data was 11,465. DIANA estimates of when the target word should be selected were compared to de-trended MALD1 data from Sessions 31 to 67. As before,
To adjust plausible levels of β, we assessed the final response latency estimate in milliseconds provided by DIANA and observed whether this duration fits within the general time frame of responses in MALD1. Figure 9 shows how the average response latency estimate by DIANA changes as a function of β (ranging from 0 to 100 in steps of 10) for different levels of
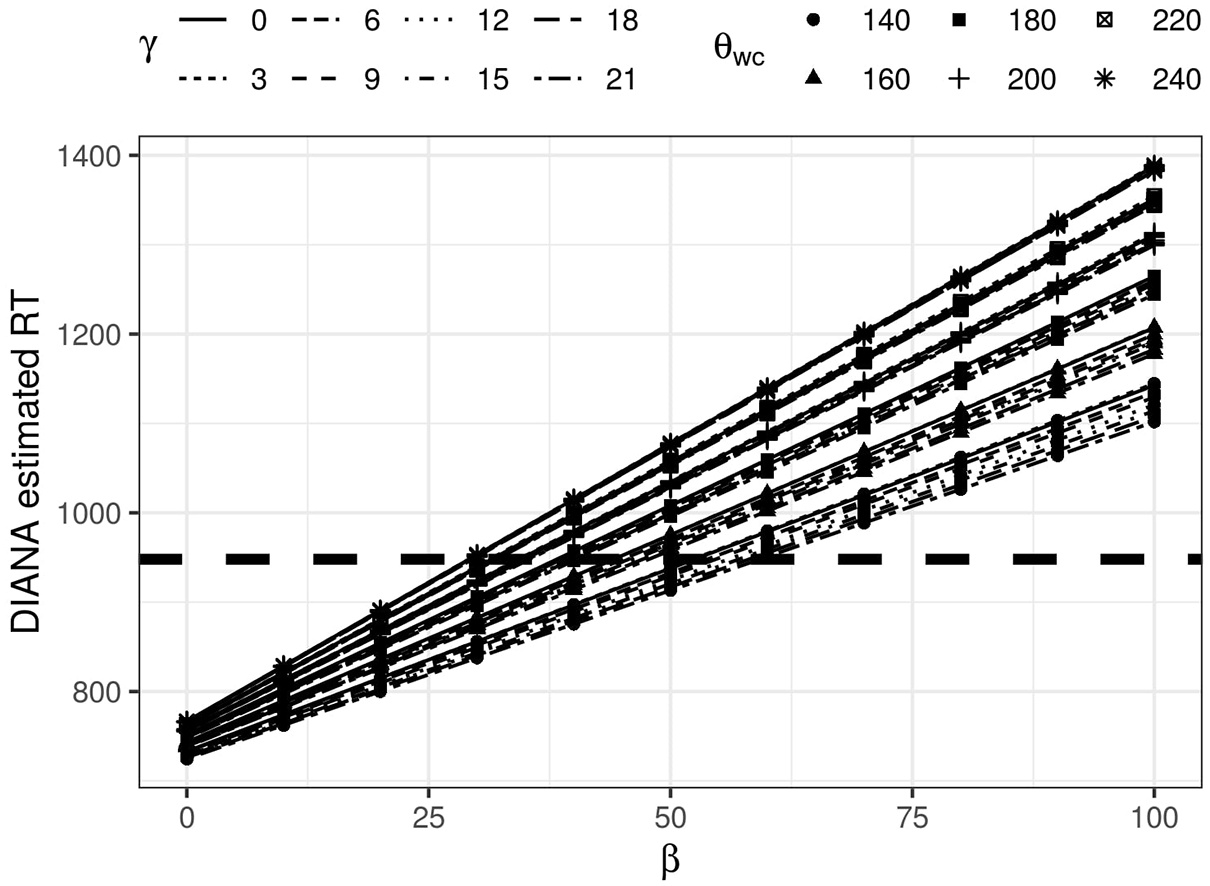
DIANA’s estimated RT as a function of parameter β for different values of
However, for the range of β values between 25 and 60, we noticed that the correlation between logged DIANA’s estimated RT and participant de-trended RT (dRT) decreases as β increases. We decided to use a broader range of β values to better explore this trend. Figure 10 represents the change in the correlation between DIANA and MALD1 response latency for values of β ranging from −50 to 100 in steps of 10. Different lines stand for different
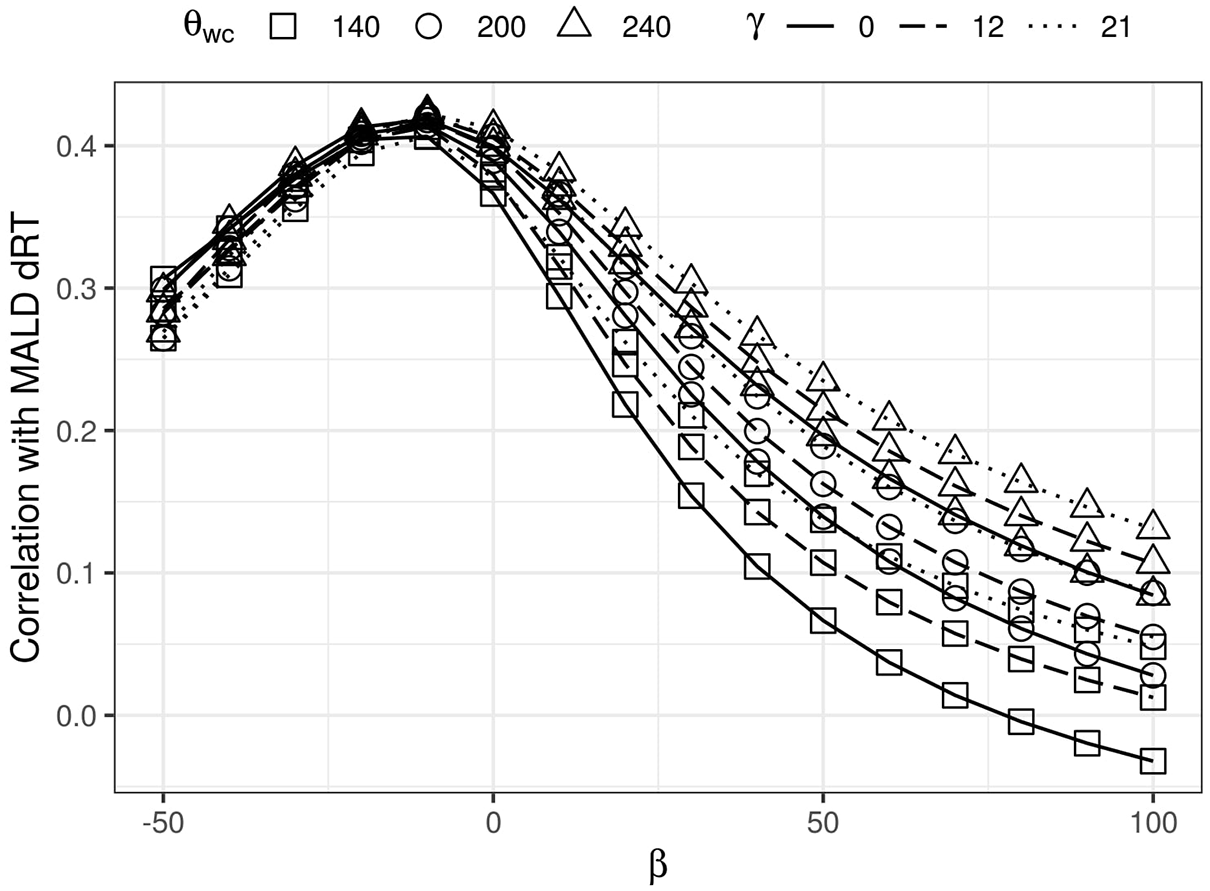
Correlation between DIANA estimates and MALD1 dRT as a function of parameter β for different values of
5.3 Discussion
The goal of Simulation 3 was to simulate participant response latency when responding to words in the auditory lexical decision task. We used words that were correctly classified as words and correctly recognized in Simulation 2 (although note that the results do not change if all the words that are correctly classified are used; see the supplementary material) and adjusted the values of parameters γ and β and threshold θ wc to calculate DIANA estimates of participant response latency. Crucially, we developed parameter and threshold values that lead to plausible model behavior by comparing model performance to human performance.
Increasing
Varying the threshold θ wc leads to conceptually similar results. A lower threshold leads to an increased percent of wrong word selections prior to word offset, where some of the decisions are made implausibly early. In addition, all correlations of MALD1 participant response latency with DIANA estimates favored the highest θ wc we used (240), which indicates that better matching with participant RT is achieved if more decisions are made after the entirety of the word signal had been presented to the model.
DIANA also includes a parameter θ
wc
, which weighs the formula accounting for choice reaction time—once the signal has reached its end, the model calculates added time needed to make a decision between the remaining plausible candidates. DIANA assumes that in the lexical decision task (but not word repetition task) the set of plausible candidates at word offset includes the remaining word competitors whose activation is within the threshold θ
wc
from the activation of the leading candidate. The correlations obtained with MALD1 response latency were moderate, reaching the value of
Simulating MALD1 response latency data show a shortcoming of DIANA in the sense that the transformation from choice entropy to choice RT is not precise enough. This could indicate that either Hick–Hyman’s law is not applicable in its full form, or that the computation of the entropy is not precise enough—for example, due to the quite rough estimation of the number of pseudoword competitors at stimulus offset. We offer a more thorough discussion of the theoretical implications of these findings in the following section.
6 General discussion
In this study, we used DIANA (ten Bosch, Boves, & Ernestus, 2015) to simulate participant performance in an auditory lexical decision task. In three simulations, we (1) created new AMs for western Canadian English, (2) simulated the lexical decision, and (3) correlated DIANA’s estimates of when the winning word is selected with general tendencies in participant responses from the MALD project (Tucker et al., 2019). The results of these simulations can be used to guide future development of models of spoken word recognition and inform the theory regarding the process of spoken word recognition.
6.1 Model input
In Simulation 1, we show that setting up DIANA in a new language is possible even without existing AMs: we used our own, relatively small, in-house spontaneous speech corpora to make new AMs. This process is labor-intensive, as it requires recording and annotating a speech corpus, training AMs, and recording enough additional material by the speaker whose recordings are used in experiments to adapt these AMs. Although possible, it would be time-consuming for an independent researcher to take DIANA as an off-the-shelf model even with existing AMs, given that speaker adaptation must be performed regardless. We provide the AMs we developed and adapted for the MALD speaker as part of our supplementary materials. These adapted AMs should allow researchers to perform DIANA simulations using MALD recordings as material.
DIANA is not isolated with regards to model setup complexity. SpeM and Fine-Tracker (Scharenborg, 2008; Scharenborg et al., 2005) require similar preparatory work. Shortlist B (Norris & McQueen, 2008) depends on a large database of listener responses to gated diphones, which is likely the reason this model has only been implemented in Dutch. For comparison, using instantiations of the TRACE model, jTRACE (Strauss et al., 2007) and the TISK model (You & Magnuson, 2018), requires installations that can be completed in a matter of hours. However, the additional work yields a crucial advantage: DIANA deals with actual acoustic input (but see Norris & McQueen, 2008, for criticism of spoken word recognition models based on automatic speech recognition).
One consequence of a good representation of the variability in the acoustic signal is that DIANA performs well in free word recognition. Accuracy in selecting the correct word as the winner from a corpus of approximately 26,000 words was between 85% and 90%. This level of word recognition accuracy is much higher than those we obtained using TISK, where lexicons with close competition never yielded word recognition accuracy higher than approximately 30% (Nenadić & Tucker, 2020, but note that the competitor structure was different in TISK simulations). DIANA also exceeds the accuracy recorded in the initial tests of the EARSHOT model, which was 67% when novel items from trained-on speakers where presented to the model (Magnuson et al., 2020). Shortlist and SpeM never exceeded 75% recognition accuracy in free word recognition, although it is important to note that these values were obtained for spontaneous speech recordings and multiple speakers (see Scharenborg et al., 2005). At the same time, DIANA was tested using a larger lexicon. Shortlist and SpeM were tested on 10,509 utterances representing 2,398 unique lexicon entries, while EARSHOT used a lexicon of 1,000 words. Word recognition accuracy using the discriminative lexicon approach yielded accuracy of up to 25%, although that simulation analyzed word recordings isolated from spontaneous speech and human participants generally did not perform better on the same material (Arnold et al., 2017). Finally, our AMs work on par with the AMs based on the FAVE suite (Rosenfelder et al., 2014). Even higher accuracy may be obtained with improved base AMs or extended model adaptation. A high standard of model performance in terms of input (free word) recognition is crucial for simulations that involve large word sets—that is, for any simulation that aims to be more than a proof of concept using a toy example.
Another important advantage of using the acoustic signal as input is that candidate activation is dependent on the characteristics of the sound signal, not on preconceptions about which words should sound similar (see, for example, Hawkins, 2003, for an extended discussion). For example, TRACE (McClelland & Elman, 1986b; Strauss et al., 2007) relies on acoustic pseudofeatures to determine phoneme identity. A phoneme always has the same pseudofeature values, meaning that every occurrence of a phoneme is always the same (barring some pseudofeature overlap of neighboring phonemes that accounts for coarticulation, see also Salverda et al., 2014). DIANA, in turn, can analyze any number of unique recordings of the same word, each time generating a different activation–competition pattern. Besides providing much better estimates of what words the signal actually resembles most, this allows researchers to explore and simulate phenomena that were not part of our simulation, such as subphonemic, acoustic effects (e.g., Andruski et al., 1994; Marslen-Wilson & Warren, 1994), effects of prosody (e.g., Kemps et al., 2005; Salverda et al., 2003), or effects related to processing reduced variants of a word (Dilley & Pitt, 2010; Ernestus & Baayen, 2007; Ernestus & Warner, 2011; Tucker, 2011; Tucker & Ernestus, 2016). Although DIANA’s AMs are currently necessarily adapted for a particular speaker, models that use actual acoustic input have the potential of also probing at inter-speaker or inter-group differences (see, for example, Kleinschmidt & Jaeger, 2015; Liu & Jaeger, 2018; McMurray & Jongman, 2011; Theodore & Monto, 2019; Theodore et al., 2020; Xie & Jaeger, 2020), as was recently attempted with the EARSHOT model (Magnuson et al., 2020).
6.2 Competitor selection
We noticed that even toward the end of a signal, many competitors had high activation despite initial mismatch with the target word. For example, pales and hails are the highest activated competitors for the recording of word tales. This model performance is in contrast to the Cohort-like competition endorsed by DIANA, but is in line with human performance. Listener flexibility when analyzing an ambiguous initial part of a signal to make it match with its later parts is the baseline for the well-established Ganong (1980) effect. The fact that listeners maintain more than just categorical information from preceding signal was also shown in various studies utilizing the visual world paradigm (see, for example, Allopenna et al., 1998). Although we deal with isolated word recognition in our simulation, it is worth mentioning that these effects apparently extend even beyond word boundaries (see, for example, Burchill et al., 2018; Connine et al., 1991; Falandays et al., 2020; Szostak & Pitt, 2013). A recent experiment using magnetoencephalography also supports the claim that subsequent contextual information influences the perception of preceding segments as subphonemic detail is preserved in the auditory cortex and reanalyzed as additional signal becomes available (Gwilliams et al., 2018).
Models of spoken word recognition in general attempt to include this kind of flexibility in word recognition and not discard a candidate based on differences in early phonemes the way it was done in the original Cohort model (Marslen-Wilson & Tyler, 1980; Marslen-Wilson & Welsh, 1978). Cohort II (Marslen-Wilson, 1987; Marslen-Wilson et al., 1988) was specifically adapted to be able to recognize the correct word despite initial mismatch (see also Weber & Scharenborg, 2012). TRACE (McClelland & Elman, 1986b) also retains candidates even if there is some initial mismatch, as besides cohorts (words sharing the first two phonemes with the target word), the model also considers rhymes (words sharing the last two phonemes with the target word) and embeddings (words that are fully embedded in the target word) to be close competitors to a target word. The authors of Shortlist B (Norris & McQueen, 2008) also make a point of that model successfully recognizing words despite some (initial) mismatch with the target.
Although DIANA’s current implementation allows creation of lexicons including as many as 36,000 words, this implementation still cannot deal with lexicons the size of the entire CMU dictionary (approximately 135,000 words). Therefore, the initial set of plausible competitors needed to be decided by the researcher. DIANA, conceptually, endorses a Cohort-like competition so we created separate lexicons in Simulations 2 and 3 to include all words with up to three phones and all words that share the first three phones with the target word. The assumption behind this procedure was that DIANA should resolve initial inconsistencies for longer words and that only the closest of competitors will matter toward word offset. However, since the AMs and the enunciations of every segment in MALD recordings are not perfect, we have seen in Simulation 1 that DIANA made mistakes in recognizing the correct word due to, i.a., initial stop elision. The approach currently endorsed by DIANA, which we used to preselect competitors, seems to be faulty as it disqualifies words that could have won instead of the target word. In addition, even if the model successfully resolves initial inconsistencies, that does not mean that competitors with initial mismatch are not some of the closest competitors to the target word. By pre-excluding competitors based on initial phone mismatch we inevitably affected both the potential winner of the activation–competition process and the structure of close competitors (which may be relevant for response latency estimation).
Then how should we select which competitors should be included in the limited lexicon of competitors created for every target word? It is important to note that competitor selection depends on the task the model of spoken word recognition is simulating. An example is the visual world paradigm where limiting the lexicon to include only the competitors that are visually presented on the screen may be justified (see, for example, Allopenna et al., 1998), although Dahan et al. (2001) show evidence that a close competitor to the target word may be activated and compete even if it is not visually presented. In many other tasks—such as the word repetition or the auditory lexical decision task with unrestricted stimulus selection—the constraints of competitor selection are even laxer as any word in the lexicon could be activated if a fitting acoustic signal is presented. If we continue to think of close competitors to words in terms of the phonemes they share, using competitor selection criteria from TRACE (McClelland & Elman, 1986b) seems like a better approach. Note that the criteria from TRACE encompass word neighbors from the Neighborhood Activation Model (Luce & Pisoni, 1998) and word cohorts from the Cohort model (Marslen-Wilson & Welsh, 1978).
Still, it is possible (although not too probable) for a word competitor to be highly activated and not belong to any of these three groups of TRACE competitors, especially prior to word offset. This issue may be solved through brute force, that is, by the sheer size of the lexicon that the current implementation of DIANA can handle. The number of TRACE close competitors extracted from the CMU dictionary for 442 English words ranges from 17 to 2,243, with the average of 605 close competitors (Nenadić & Tucker, 2020). DIANA, in turn, can handle quite sizable lexicons. Therefore, we propose using the competitor selection approach from TRACE but also capitalizing on DIANA’s capacity for large lexicons by selecting 30,000 words that have the lowest phone edit distances from the target word. This approach is yet to be tested, but all cohorts, rhymes, and embeddings should be present in these 30,000 selected competitors—in fact, it should be true that most of the words that are not within 30,000 most similar competitors to the target word (based on phonemic transcription) are indeed not very similar to the target word. One downside of that approach is that it is more computationally demanding to use large lexicons of 30,000 words than to build smaller, targeted lexicons.
However, relying on categories such as the phoneme, as we have previously noted, misses a lot of variability present in the fine-phonetic detail and stemming from reduction or other pronunciation variants in words. The close competitors could instead be determined using similarity in the acoustic signal, rather than generalized categories. For example, with our MALD word set, we could calculate acoustic distances between word recordings and use those to form sets of competitors for each word (Kelley, 2018). An even better alternative would be to calculate acoustic distances between many recordings of many words—although this would require a very large (truly, representative) set of word recordings—and use those as a benchmark.
We also note that the necessity of preselecting competitors in a model of spoken word recognition has been at least as much a question of its technical implementation as it has been of its theory. If a model always considers all the options stored in the mental lexicon, there would be no need to discard a candidate before the activation–competition process has even started. Our implementation of DIANA relied on the HTK (Young et al., 2006) and the lexicon limitations we had were a matter of technique: the model could be implemented using, for example, KALDI (Povey et al., 2011), allowing for better performance and a much more fine-grained view of unfolding activations. The lexicon size could also be dramatically increased to hundreds of thousands of words, removing the issue of candidate preselection. Technical limitations and novel advances will certainly continue to shape models of spoken word recognition and in part determine which questions regarding their architecture are considered relevant.
6.3 Lexical decision
DIANA’s lexical decision accuracy was fairly high. The model uses a simple but powerful solution of comparing the best possible activation of a word in the mental lexicon with the best possible activation of any phone string. Note, however, that DIANA and the human participant have different causes of errors, both in free word recognition and lexical decision. For the computational model, the only cause of error is a poor match between the acoustic signal and the existing AMs, leading to a misinterpretation of the input. Listener errors may have other causes besides issues in interpreting the acoustic signal. For example, a human may not have the target word stored in their mental lexicon (i.e., the person may not know a word), may not be able to retrieve the target word at that particular time, may miss portions of the signal, or simply press the wrong button.
We note two specific issues in the current approach. The first issue is that pseudoword accuracy highly depends on signal length. We will address this finding in more detail below, when we consider the representation of the mental lexicon in DIANA. The second issue is that word frequency does not affect the outcome of the lexical decision, while MALD1 and other lexical decision data generally show that word frequency predicts response accuracy. As we said above, some of the correlation between accuracy and word frequency in behavioral experiments is certainly due to the fact that lower frequency words are known by fewer participants. In addition, perhaps signals of low frequency words require a higher threshold of attention due to less practice with that signal; it is easier to get confused and make a mistake for a word one does know if that word is encountered rarely. Given high-performing AMs, future simulations could include a parameter that would estimate the probability of a word being responded to as a pseudoword based on that word’s frequency (or other characteristics that prove relevant).
6.4 Estimating response latency
The central aim of our simulations was to simulate the time needed to make a response from the onset of the signal. Effect of word frequency, regularly registered in statistical analyses of behavioral responses, was found to be almost negligible. It is important to note that the current implementation of the frequency effect in DIANA is not as straightforward as it may appear. In statistical modeling of auditory lexical decision data, word frequency is ordinarily included as a predictor of response latency to that word. In DIANA the impact of frequency is instead best described as an interaction between a word’s frequency and the frequency of its close acoustic competitors (cf. Vitevitch & Luce, 2016). If a high-frequency target word has a high-frequency runner-up, then the activation difference between the two will remain dependent on acoustic activation alone and the winner may be selected rather late. In contrast, a high-frequency target word that has no high-frequency competitors will become the sole plausible candidate much sooner. Statistical analyses of participant responses should investigate whether this sort of frequency relationship between top acoustic competitors is a better predictor of human response latency than using solely the frequency of the target word.
Another reason for low impact of word frequency is due to the model estimating that it is better to wait until word offset, as higher values of θ
wc
are favored (i.e., a larger difference in activation between the leading candidate and the runner-up is required for a winner to be selected), where
In line with participant data, we found that optimal values of parameter
6.5 Future directions and concluding remarks
Besides the above-mentioned adaptations that may be performed on the DIANA’s auditory lexical decision task architecture, we discuss two more important aspects of models of spoken word recognition that could be a part of future DIANA developments. First, the current representation of the mental lexicon in DIANA ignores a very important characteristic of words—their meaning and contexts in which they are used. This ties directly to our interpretation of how the mental lexicon is organized and accessed. Currently, DIANA represents the mental lexicon as a list of unconnected strings of phones (words), focusing on form alone. Under this setup, recognizing a word is in no way affected by the word’s meaning beyond its frequency of occurrence, which is the case in most (abstract) models of spoken word recognition.
However, effects of word meaning in spoken word recognition, even when words are presented in isolation, extend beyond frequency of occurrence (e.g., Goh et al., 2016; Sajin & Connine, 2014; Tucker et al., 2019). In addition, we have seen in Simulation 2 that a representation of the mental lexicon that stores information on form and frequency alone leads to lexical decisions to pseudowords being mostly guided by direct acoustic mismatch, making long pseudowords very easy to discard for DIANA. Human participants, however, do not have this sort of certainty when responding to long pseudowords, given that these pseudowords share, for example, morphological characteristics with existing English words (see also Hendrix & Sun, 2021, for a detailed discussion of factors affecting pseudoword processing in the visual modality).
Therefore, we argue that not just DIANA, but any model of spoken word recognition would benefit from a representation of the mental lexicon that does not consider word form (and frequency) only. This is not a novel notion. The authors of both Cohort (Marslen-Wilson & Tyler, 1980; Marslen-Wilson & Welsh, 1978) and TRACE (McClelland & Elman, 1986a, 1986b), for example, recognize the impact semantic or contextual factors can have on processing (but see also Gaskell & Marslen-Wilson, 1997, 2002). However, primarily due to technical limitations, such factors remained underdeveloped. Many of these technical limitations are now alleviated and certain models of spoken word recognition attempt to expand on the representation of the mental lexicon. The Distributed Cohort Model (Gaskell & Marslen-Wilson, 1997, 1999, 2002), EARSHOT (Magnuson et al., 2020), and the discriminative lexicon approach (Baayen et al., 2019) represent units in the mental lexicon as semantic vectors. These vectors are correlated, creating a network of word meaning. Similar solutions could be implemented in DIANA in the future, by altering DIANA’s lexicon and the information it holds or even by grafting a solution from another model to DIANA’s existing task architecture.
The second development direction we discuss is estimating when the model (and therefore the human listener) should make a “pseudoword” decision. Most models of spoken word recognition do not mention or simulate the process of responding to a signal that is not present in the mental lexicon, although this is an important situation that occurs even outside of the laboratory, for example, when the listener is presented with unknown or foreign words. We envision an approach similar to the one used to determine that the input is a word: a threshold that marks the difference between free phone activation and word activation needed to discard the input as a pseudoword. This threshold would be higher than the threshold used to determine that the signal is a word, creating a zone of uncertainty between the two thresholds where DIANA would wait for more information. This waiting could continue until signal offset. At signal offset, an elegant solution would be to calculate the added choice reaction time using the same formula as in words.
The value of this “pseudoword” threshold would likely have to be high. Otherwise, too many “pseudoword” decisions would occur before pseudoword signal offset, contradicting the behavioral data showing that responses to pseudowords tend to be slower than responses to words (Tucker et al., 2019). It seems that human listeners prefer to wait until more information is provided even in the cases when there may be an early point of disambiguation that should disqualify the signal as a word. We believe this is because they allow for a possibility that something was pronounced in a strange manner, that they misheard something, or that they are simply coming up short in their search through the mental lexicon and that they need a bit more time and information to find the word to which the signal corresponds. The more the pseudoword deviates from words stored in the mental lexicon, however, the bigger the chance that it would be discarded before signal offset, so an exception to this general rule could be very unlikely strings of segments and especially speech signals that break the phonotactic rules of the language—nonwords (cf. Ziegler et al., 1997)—though such stimuli do not occur in MALD and other standard auditory lexical decision studies.
Despite many challenges that the current implementation of DIANA faces, we believe that DIANA is very promising. DIANA successfully uses the acoustic signal as input and has no binding limitations in terms of language it can be used for (as long as AMs exist or can be created) or the lexicon size that can be implemented. Furthermore, we hope that DIANA will be applied to other behavioral tasks. This could also show how robust the current task architecture actually is, that is, whether the performance in these tasks can be described using the same processes as those used for auditory lexical decision and word repetition or not. The development of the field of spoken word recognition depends on its models being tested against various behavioral data and improved based on the findings. We argue that the primary frontier for current models of spoken word recognition is to simulate spoken word recognition phenomena using realistic conditions (e.g., realistic input and realistic competitor sets) and be adaptable enough to simulate data from a plethora of different behavioral experiments used in the field.
Supplemental Material
sj-pdf-1-las-10.1177_00238309221111752 – Supplemental material for Computational Modeling of an Auditory Lexical Decision Experiment Using DIANA
Supplemental material, sj-pdf-1-las-10.1177_00238309221111752 for Computational Modeling of an Auditory Lexical Decision Experiment Using DIANA by Filip Nenadić, Benjamin V. Tucker and Louis ten Bosch in Language and Speech
Footnotes
Acknowledgements
The authors thank Terrance M. Nearey and Matthew C. Kelley for their help in shaping this study.
Authors’ note
Prior publication: An earlier version of some simulations in this paper was presented at Interspeech 2018 (DOI: 10.21437/Interspeech.2018-2081).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was funded by the Social Sciences and Humanities Research Council of Canada: Grant #435-2014-0678.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.