
Abstract
We examine the use of multiple subphonemic differences distinguishing homophones in production and perception, through a case study focusing on the distinction between two polysemous senses of the English word “sorry” (apology vs. attention-seeking). An analysis of production data from voice actors revealed significant and substantial durational differences between the two meanings. Tokens expressing an apology were longer than attention-seeking tokens, and the situational intensity of the context also independently affected duration. When asked to identify the meaning in a two-way forced-choice task after hearing each token spliced out of its context, listeners were above chance (64.7% accuracy) in identifying the intended meaning, and their responses were significantly correlated with the duration, intensity, and intonation contour (but not mean F0) of the productions. In a second perception task, listeners heard tokens of “sorry” that had been systematically manipulated to vary in duration, intensity, and intonation contour, with responses indicating that each of these dimensions played an independent role in listeners’ judgments. The results highlight the importance of broadening the scope of research on the use of subphonemic detail during lexical access and considering a wider range of lexical and non-lexical factors that condition variability on multiple acoustic dimensions, in order to work toward a more accurate picture of the systematic variability available in the input and tracked by listeners.
1 Introduction
1.1 Overview
Homophones, 1 by definition, are expected to be pronounced identically; however, they can be characterized by small but systematic differences in their phonetic realization. For example, the more frequent members of a given homophone pair tend to be of shorter duration than their less-frequent homophone twins (e.g., English “fair” is on average shorter than the less-frequent “fare”) (Gahl, 2008; Lohmann, 2018b). A variety of factors, including lexical frequency, underlying phonological representation, and contextual predictability, have been shown to condition systematic variation in homophones, and this variation occurs across multiple acoustic dimensions, as will be reviewed below. Furthermore, listeners can, in some circumstances, identify the intended meaning at greater-than-chance levels, and listeners’ responses have been found to be independently influenced by specific acoustic properties of the sound, such as duration (e.g., Bond, 1973; Warner et al., 2004). These sorts of findings suggest not only that subphonemic differences corresponding to the different meanings or senses must be perceptible in the signal, but also that the relevant information must be encoded in listeners’ speech perception systems at some level of representation and/or processing.
This case study provides an in-depth investigation of listeners’ use of multiple phonetic cues (duration, intensity, and pitch) in differentiating between two meanings of the English word “sorry”: an apology (i.e., “Sorry! I didn’t mean to hurt you,” henceforth
1.2 Subphonemic variation in production of homophones
Previous investigations of subphonemic variation in homophones have primarily focused on durational differences. Higher-frequency words are, all else being equal, produced with shorter word durations than lower-frequency words, and this is also the case with pairs of homophones (at least for content words; studies involving only function words have not found similar effects, e.g., Jurafsky et al., 2002). In the first large-scale study on this topic, Gahl (2008) examined the durations of 344 homophonous but heterographic word pairs (e.g., “fair” vs. “fare”) in the Switchboard corpus of American English telephone conversations, and found that higher-frequency items were shorter in duration than their lower-frequency counterparts. This result persisted after controlling for factors including speaking rate, contextual predictability, and syntactic category (see Lohmann, 2018b, for a re-analysis and confirmation of this result). Similar patterns were found in a comparison of children and adults (Conwell, 2018) and in Mandarin (Sherr-Ziarko, 2015). The generalization also holds in homographic homophones, as demonstrated by Lohmann (2018a), who examined the durations of 63 homographic noun–verb pair homophones (e.g., “cut” (N) vs. “cut” (V)) in the Buckeye Corpus of spontaneous speech.
Durational differences across members of homophone pairs have also been shown to be conditioned by other factors, including the morphological status of the word (Seyfarth et al., 2018), the underlying phonological form of the word (“incomplete neutralization,” Port & O’Dell (1985) among many others), and orthography (Warner et al., 2004). Additional factors systematically affecting duration that have not been tested specifically with homophones could also be expected to play a role as well (e.g., contextual predictability: Seyfarth, 2014; Tang & Shaw, 2020). Bell et al. (2009), in a corpus study of conversational English, showed that three separate factors—frequency, contextual predictability, and repetition—all contribute independently to durations of spoken words, even though they are all correlated.
Though duration is the most well-studied property, similar influences might be expected on other acoustic dimensions, particularly those which, like duration, are heavily influenced by the extent of articulatory reduction. A few studies have given evidence for other types of differences: Wright (2004) shows that properties of the lexical neighborhood affect spectral characteristics of vowels, with “easy” lexical items (i.e., those with low neighborhood density and high relative frequency) showing systematically less dispersion in the F1-F2 space than “hard” lexical items, and Tang and Shaw (2020), using a large telephone corpus of Mandarin Chinese, show that contextual predictability has significant effects on maximum pitch and intensity, dimensions related to prosodic prominence.
While all of the phonetic patterns discussed so far are at least indirectly attributable to the extent of articulatory reduction (with shorter durations, smaller pitch range, lower intensity, and less vowel space dispersion), there are many other sources of phonetic variability that could result in systematic differences across members of a homophone pair. For example, if the two meanings tend to be produced in different prosodic environments, they would show different distributions along many phonetic dimensions in the input, particularly for suprasegmental features like F0 or duration. There are a wide range of factors systematically affecting both the phonological (e.g., whether a word is accented or not) and phonetic detail (e.g., F0 alignment and range) of prosody, including discourse status, or topic structure (e.g., whether a topic is given or new; see Hirschberg, 2002, and references therein). Furthermore, intonational patterns may be idiomatically related to certain usages or meanings (Calhoun & Schweitzer, 2012).
Another potential source of differences in a homophone pair is another type of context: the emotion or affect used for each meaning. There is a large body of literature documenting the acoustic correlates of emotion (e.g., Williams & Stevens, 1972; Sauter et al., 2010, among many others; see Bachorowski & Owren, 2008, for a review). One example is work done by Banse and Scherer (1996), who recorded 12 actors asked to portray 14 different emotions in meaningless utterances consisting of non-words. They performed detailed acoustic analyses involving dimensions hypothesized to be relevant to emotion, including multiple measures of F0, intensity, speaking rate, and spectral measures corresponding to voice quality (e.g., spectral tilt). Almost all of the 29 features were statistically significant in explaining some of the emotion-based variance, with pitch and intensity measures capturing the most variance, and discriminant-based classification accuracy was well above chance (40% accuracy given a choice of 14 emotions, with chance being 1/14, or 7%). Relatedly, Ohala (1983) proposes that a biologically based “frequency code” underlies cross-language (and cross-species) regularities in use of higher F0 to signal more submissive, less assertive stances. While the acoustic correlates of emotion or attitude are far from deterministic, it is well established that there are some regularities, and if there are systematic differences in the contexts in which two members of a homophone pair are used, then it follows that there will also be systematic differences in their pronunciation.
Given the many factors at play simultaneously, it is likely that any given pair of words will differ along multiple dimensions for multiple reasons. In a case study, Drager (2011) examined variation across different grammatical uses of the word “like” in a corpus of sociolinguistic interviews in a New Zealand high school. Quotative “like” (as in, “I was like ‘yeah, okay’”) had on average more monophthongal vowels, shorter initial-consonant-to-vowel ratios, and higher mean pitch than when it was used as a discourse particle or a lexical verb. Differences in intonational patterns were proposed to underlie the pitch differences: “Impressionistically, lexical verb like seemed to be produced in conjunction with a dip in the intonation contour, whereas quotative like rarely was and was sometimes part of a rising contour that raised more steeply after the verb” (Drager, 2011: 702). The different lemmas tend to occur in different prosodic positions, and while Drager argues that prosody is unlikely to account for all of the variation found in the dataset, it does likely have some effect. Though only focusing on a single wordform, this case study demonstrated that a given pair of homophones will be characterized by differences across multiple acoustic dimensions. Whether listeners track these sorts of differences, which dimensions are tracked by listeners, and whether the tracking is different depending on the conditioning factor (e.g., lexical frequency, prosody, emotion) are open questions.
1.3 Listeners’ use of acoustic variation in the perception of homophones
The presence of the systematic acoustic variation discussed above brings up the question of whether listeners make use of this information to inform their perceptual strategies. Listeners have been found to distinguish between the two members of homophone pairs at above-chance accuracy, although these effects tend to be very small, indicating that the cues are far from deterministic. For example, Sanker (2019) showed that listeners were significantly above chance in identifying members of a homophone pair that had been spliced out of sentences (e.g., “a doe is a deer” vs. “a dough is a mixture”) in a forced-choice task. However, accuracy was only very slightly above chance (50.8%), and this effect only held for words that had been produced in a contextually predictable sentence, and not in a different condition where the words were produced in isolation.
Listeners have also been shown to be sensitive to incomplete neutralization: Port and O’Dell (1985) showed that German listeners identified minimal pairs differing in underlying final consonant voicing, like “rat” and “rad” (which are both phonologically devoiced word-finally, such that the broad transcription of both is [ʁɑt]), at 59% accuracy. Looking at the same phenomenon in Dutch, Warner et al. (2004) found that listeners performed above chance in identifying the intended production, but only for stimuli drawn from certain speakers—specifically, those who showed greater durational distinctions between final underlying voiced versus voiceless consonants—suggesting that these durational differences were in fact what listeners were using to inform their decisions. The idea that these sorts of phonetic differences may have only limited usefulness for listeners is supported by the fact that the word-final voicing distinction, which is represented orthographically, is a common source of spelling mistakes in Dutch (Sandra et al., 2001). Finally, there may be cases where these sorts of cues are not used by listeners at all. In Mandarin, Tone 3 (low) is pronounced similarly to Tone 2 (rising) in certain phonological contexts, but systematic phonetic differences indicate that this T3/T2 neutralization is incomplete: however, listeners do not reliably distinguish the two categories (Zhang & Peng, 2013).
Prosodic variation has also been shown to be useful to listeners. For example, listeners differentiate short words from longer words containing them (e.g., cap vs.
Finally, the prosody and/or affective tone of an utterance may influence lexical selection or processing. In a study by Nygaard and Lunders (2002), listeners heard words spoken in happy, sad, or neutral voices and were asked to transcribe them. Critical stimuli were members of homophone pairs in which one member had emotional connotations and the other did not (e.g., sad die vs. neutral dye). Listeners were more likely to transcribe the emotional token when it was heard in an emotionally congruent tone of voice, indicating that the emotional information was integrated at some level of linguistic processing, influencing lexical selection.
Taken together, there are a large number of studies demonstrating listeners’ sensitivity to the different types of subphonemic variation discussed above. It is important to remember that many of these effects are very small, inconsistent, or task-dependent. Particularly given the fact that positive results are more likely to be published (“publication bias,” e.g., de Bruin et al., 2015), it should not be concluded that listeners are always able to use this information. Instead, which sources of variation and which acoustic dimensions are tracked by listeners remains an open question.
1.4 Implications for representation, storage, and processing
The examination of subphonemic differences between different meanings of homophones in production, and listeners’ sensitivity to those differences in perception, has been of interest in large part because of its relevance to models of lexical representation. Systematic phonetic variability is pervasive in speech, governed by “contexts” such as the properties of the speaker, the interlocutor, the social/discourse/pragmatic context, and the syntactic/prosodic/semantic context. Since any two meanings are likely to be used in systematically different contexts, they will likely show different distributions of phonetic properties in production. How this variation is tracked, stored, and used by listeners is a question that has implications for the architecture of the lexicon and the structure of the speech processing system.
As discussed above, listeners are sensitive to subphonemic differences in meanings and use it to inform perception, at least in some situations, and this indicates that distinct information must be linked to each meaning. However, this link could take different forms. First, each of the two meanings could be directly linked to separate phonetic representations, either in the form of acoustic “exemplars” or as a summary of distributional statistics of the acoustics. In this situation, listeners would determine the meaning by evaluating the incoming signal against the two possible pronunciations. Alternatively, both meanings could be linked to the same phonetic representation, but each meaning has distinct information about the context in which it tends to be produced. These contexts are in turn linked to general phonetic regularities which also form part of listeners’ knowledge. In this case, the link between meaning and pronunciation is indirect and modulated by context: the phonetic information would suggest a certain context to listeners, and knowledge of the context would in turn inform the decision about the meaning of a word.
There is convincing evidence that both abstraction and acoustic specificity play a role in phonetic representations (e.g., McQueen et al., 2006; Ernestus, 2014; Pierrehumbert, 2016), and teasing apart the relative contributions is not possible with a case study. However, if listeners can make use of phonetic differences, it is necessary for there to be independent representations of meanings at some level. If they are not separately specified phonetic representations, but rather shared, then it is necessary that the relevant contexts are tracked independently and stored separately for the different meanings. There is evidence that homophones (with unrelated meanings) and polysemes (with related meanings) are represented differently by listeners: specifically, there is psycholinguistic evidence that while the different meanings of a homophone pair have independent semantic representations, the different “senses” of polysemes may fall under the same representation (Rabagliati & Snedeker, 2013; Rodd et al., 2002). If senses do share a representation, it is difficult to see how either option above (separate pronunciations or separate meanings) could be stored.
1.5 The current study
We present a case study examining listeners’ use of multiple phonetic cues in distinguishing between two meanings of “sorry”: when it is used as an apology versus when it is used as an attention-seeking mechanism (
Which, if any, acoustic characteristics distinguish the
Do listeners accurately perceive the difference between the two uses of “sorry,” when hearing isolated tokens removed from their original context?
Which phonetic cues do listeners use when making their judgments, and what is their relative reliance on each cue?
We address these goals in a series of three experiments. In Experiment 1, we analyze productions of “sorry” recorded by voice actors in contexts designed to elicit the two different meanings in different levels of situational intensity, and examine the patterning of several acoustic cues shown to be relevant to homophone distinctions and affect/emotional distinctions in previous work: duration, pitch, and intensity. In Experiment 2, we test listeners’ accuracy in identifying the intended meaning of tokens of “sorry” produced in Experiment 1 and spliced out of their context. We also look at the correlation of listeners’ responses with the acoustic properties of the stimuli to begin to establish which of the cues, if any, might play a role in listeners’ decisions. Based on significant correlations between listeners’ responses and multiple acoustic dimensions in Experiment 2, Experiment 3 examines listeners’ perception of tokens of “sorry” that have been systematically manipulated across three dimensions, to assess whether these cues play an independent role in perception and to quantify listeners’ relative reliance on each cue. Prior to running the experiment, we did not have specific hypotheses about the use of individual cues. However, given the fact that apologies are likely to be said in more submissive, less assertive attitudes, we might expect them to have higher F0 and lower intensity than
If listeners associate the two senses with different phonetic realizations, it indicates two things. First, the different representations of the polysemous “sorry” must be independent at some level of processing, regardless of whether they are linked to distinct pronunciations, and/or associated with distinct contexts, which in turn are associated with systematic phonetic patterns. Second, listeners must be sensitive to this acoustic detail and actively make use of it during speech perception. An additional contribution of this study is to examine perception of tokens systematically manipulated along multiple dimensions, as compared to perception of naturally produced tokens, where the dimensions may covary. This allows us to evaluate the extent to which listeners use each of these dimensions independently.
2 Experiment 1—Production
2.1 Overview
The purpose of Experiment 1 was to provide stimuli for perception experiments, as well as to examine the question of which phonetic cues, if any, distinguish productions of the word “sorry” used as an
2.2 Methods
2.2.1 Participants, materials, and procedure
Two male and two female American English voice actors recruited from fiverr.com (a platform for freelance workers) were paid to take part in the experiment. Eighteen scenarios containing the word sorry were used for the production study. Table 1 shows six sample scenarios, and the full set is provided in the supplementary material. Each of these 18 scenarios fit into one of six general situations, half of which included someone apologizing, and the other half of which included someone needing to say “excuse me.” From each of these general scenarios, three specific situations, varying on a three-tier scale of “situational intensity,” were created, resulting in the total of 18 scenarios. For example, the
Six of the scenarios used in the production experiment. The “context” was read silently, while the two lines of dialogue, including the target sentence, spoken by “Alex,” were read out loud.
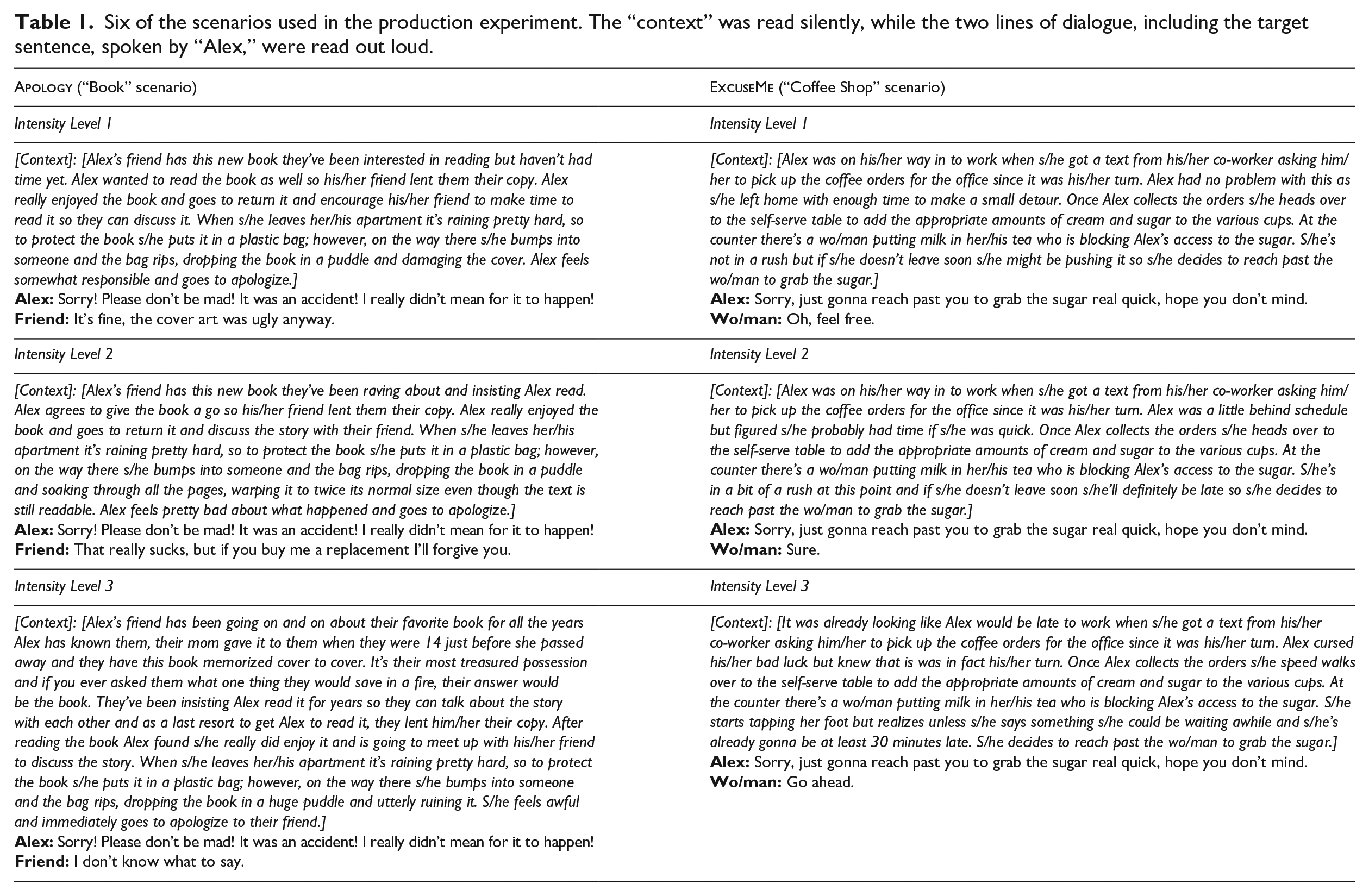
The script given to the participants included all scenarios. As shown in Table 1, each scenario included a first paragraph to provide context, which was not read aloud, followed by two lines of dialogue, which the participants were asked to read aloud. The first line of dialogue (spoken by the character named Alex) was the sentence containing the target word “sorry,” and it remained identical, including in punctuation, across each of the three intensity levels within each base scenario group. In all sentences, “sorry” was in utterance-initial position, followed by either a stop or affricate (this was done to facilitate clean splicing of the word for use in the subsequent perception experiments). The order of scenarios was pseudo-randomized such that no scenarios of the same base group, or of the same intensity, appeared immediately next to one another.
Participants were sent the script described above and given instructions about the recording procedure. Recordings took place in a quiet environment using personal audio-recording equipment. Participants were instructed to read the context silently to themselves, then to read both lines of dialogue out loud using their regular voices. They were asked not to whisper; this instruction was included in an attempt to avoid breathy voice, which could pose problems for pitch measurement and/or manipulation. Participants recorded two repetitions of the 18 dialogues from the scenarios above, resulting in 144 tokens of “sorry” in context (18 scenarios x 2 repetitions x 4 actors).
In addition to these “contextual” dialogues containing the word “sorry,” participants were also asked to record 20 instances of “sorry” in isolation, 10 as if they were apologizing, and 10 as if they were saying “excuse me.” They were asked to indicate orally when they switched from one set to the other and to feel free to vary the mood however they saw fit. No further specific instructions were given. Five tokens of each Sorry Type from each speaker were chosen for the analysis.
2.2.2 Annotations and measurements
We focused on phonetic dimensions shown in previous work to be relevant to phonetically differentiating between homophones, and/or differentiating expression of emotion: pitch (mean and contour) (ex: Bänziger & Scherer, 2005; Sauter et al., 2010), duration (Gahl, 2008; Lohmann, 2018a; etc.) and intensity (Pereira & Watson, 1998).
All annotations and measurements were done using Praat (Boersma & Weenink, 2018). First, the following landmarks were manually annotated: fricative onset (marked by the onset of frication in /s/), fricative offset (marked by the beginning of visible formants in the vowel following /s/), and word end (the end of stable F2).
F0 (in Hz) was measured at seven time points (0%, 10%, 25%, 50%, 75%, 90%, 100%) across the periodic portion of the word (i.e., everything except the initial fricative). In order to minimize measurement errors, we first determined speaker-specific floors and ceilings based on manual inspection of the data and used these as the basis for automatic pitch measurements. Visible outliers were checked and manually corrected.
Mean intensity (in dB) was measured across the full word.
One additional source of variability that we thought might be relevant was the intonation used to produce the target word. Based on initial inspection of the data, tokens varied in whether they had a final rising or falling contour. Examples of each of these is given in Figure 1, and the corresponding audio files are available in the supplementary materials. Data were coded based on the perceptual judgments of a native speaker of English familiar with the ToBI (Tones and Break Indices) system (Beckman & Ayers, 1997). Final rise tokens fell into the HLH% or LH% categories, and final fall tokens were HLL% or LL%, but were coded into a binary choice of final rise versus final fall for ease of analysis. A second annotator with no knowledge of the study provided independent judgments, and there was 76% agreement. Only tokens which were consistently annotated (n = 140) are included in the intonation contour plots and analyses below.
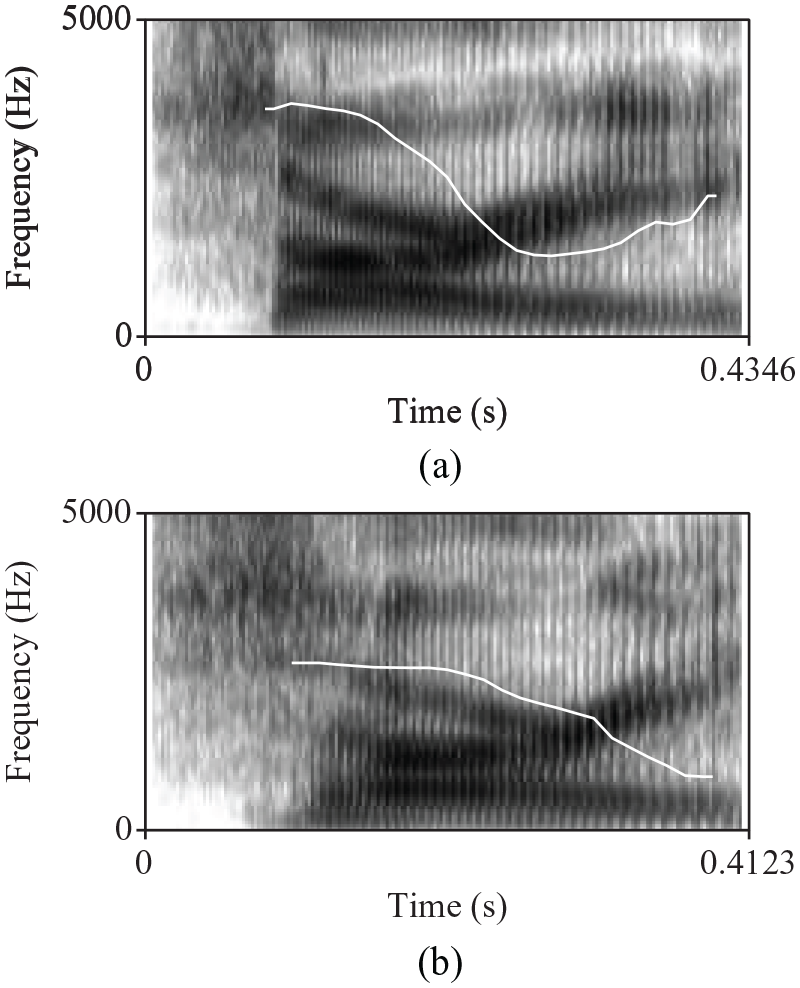
Spectrograms overlaid with pitch contours (white line) for a final rising (a) vs. falling (b) contour. Both of these were productions of an
Based on the landmarks and measurements above, we use the following measures as dependent variables in the statistical analyses below:
Total word duration: fricative onset to word end;
Mean F0: the average across the seven points measured;
Mean intensity;
Pitch contour: final rise versus final fall.
2.2.3 Statistical analysis
Our primary question for the production experiment was to determine whether there are phonetic differences between the two types of “sorry” (
2.3 Results
This experiment sought to determine whether “sorry” as an apology is phonetically distinct from a “sorry” meaning “excuse me,” and if so, which phonetic cues distinguish them. We examined four dimensions that were expected, based on previous work, to be potentially relevant: word duration, mean F0, intensity, and pitch contour. 184 tokens were analyzed (144 “contextual” tokens plus 40 spoken in isolation). Tokens for which more than half of the pitch contour was undefined (n = 9) were omitted from the F0 analysis. We discuss results for each dimension in turn in the following paragraphs. Graphs of all dimensions are provided in Figure 2, and statistical results in Table 2. For continuous dimensions, the graphs show the overall distribution of all tokens (violin plots) for each Sorry Type, as well as speaker-specific means and 95% confidence intervals. For the graph showing the binary variable pitch contour, the proportion of tokens produced with a final rising (vs. falling) tone for each speaker is given.
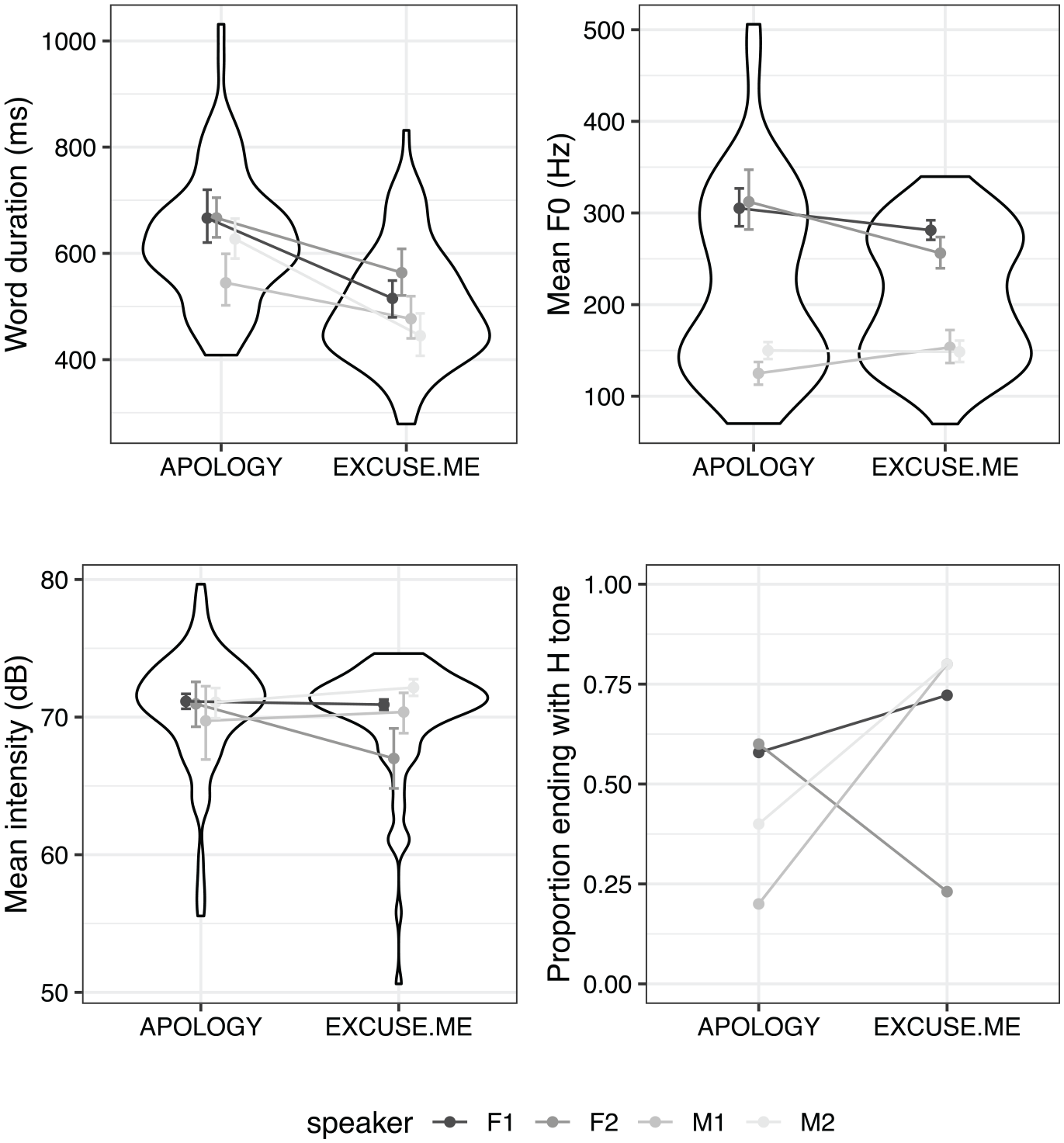
Graphs of values for each acoustic dimension measured in the production study for tokens intended as
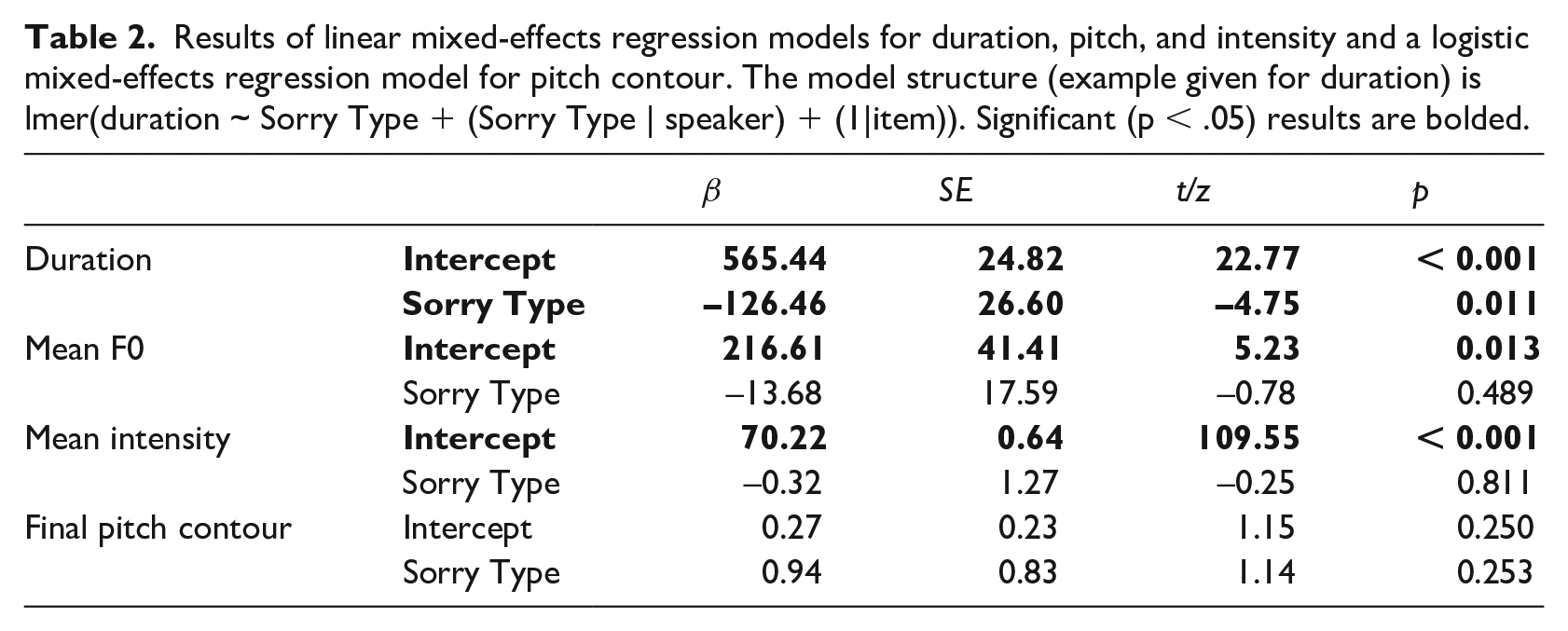
Results of linear mixed-effects regression models for duration, pitch, and intensity and a logistic mixed-effects regression model for pitch contour. The model structure (example given for duration) is lmer(duration ~ Sorry Type + (Sorry Type | speaker) + (1|item)). Significant (p < .05) results are bolded.
Duration: The first panel of Figure 2 shows the distribution of duration values for
Mean F0: The second panel of Figure 2 shows the distribution of mean F0 values across Sorry Types. There is no clear difference, nor is there a consistent pattern across speakers. This is reflected in the statistical results: while
Mean Intensity: The third panel of Figure 2 shows the distribution of mean intensity values across Sorry Types. There is again no consistent pattern, and this is again reflected in the statistical results; numerically,
Pitch contour: As shown in the final panel of Figure 2, the speakers differed in their distribution of pitch contours across the Sorry Types, with three speakers producing more final-rising-tone tokens for
2.3.1 Situational intensity
Although not our primary question of interest, we examined whether the degree of situational intensity influenced each acoustic dimension. In order to test this, we created four models, one for each dimension, which differed from the models described above in that (1) the 40 tokens produced in isolation were omitted from analysis, and (2) the model structure included an additional predictor variable of Situational Intensity, as well as its interaction with Sorry Type. Situational Intensity was simple-coded as a three-level factor, with Level 1 as the reference level. The only significant effects were found in the model for duration: as above, there was a main effect of Sorry Type, showing longer durations for
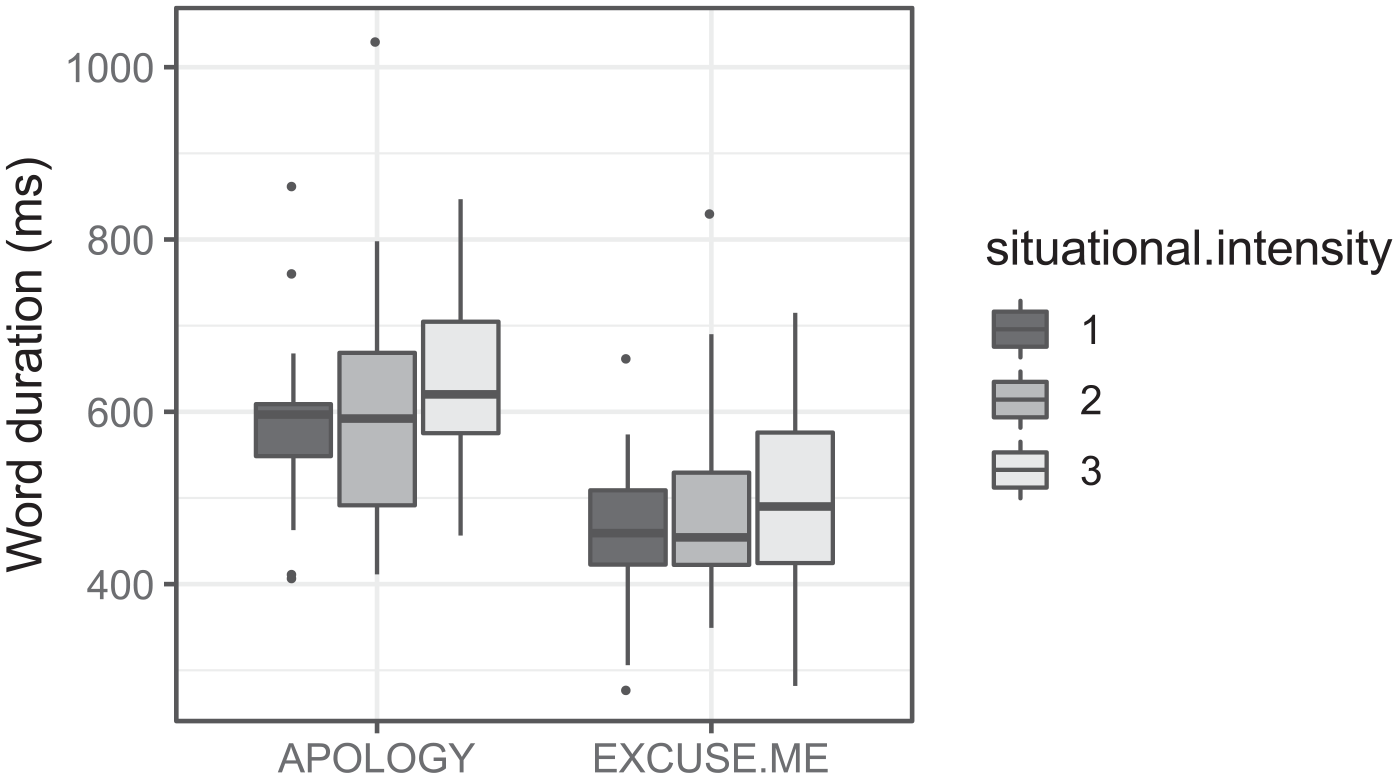
Distribution of durations by Sorry Type and Situational Intensity (for contextual “sorry” tokens only).
2.4 Production: Interim summary
The results above show that
This is a very small-scale study; therefore, we do not intend to try to interpret these findings as general to a larger population, but rather wanted to provide an overall analysis of the productions that form the basis of the perception experiment. Nevertheless, we can make some observations. First, we found a significant effect of duration, consistent across all speakers. Second, while the other three dimensions were not significant, looking at the by-speaker results suggests that this lack of significance may have different underlying causes for the different dimensions. For intensity and mean F0, none of the speakers showed clear differences, but for pitch contour, we found fairly robust differences within each speaker, but different strategies across speakers. A larger sample size is necessary to determine whether this observation is correct.
3 Experiment 2—Perception of “sorry”
3.1 Overview
In this experiment, listeners completed a forced-choice identification task, classifying tokens of “sorry” produced by voice actors in Experiment 1 as either an
3.2 Methods
3.2.1 Participants
47 listeners residing in Ontario, Canada (7 males and 40 females, age range 18 to 69, mean age 27.5) participated in this experiment. All had learned English as a child (before the age of 10).
3.2.2 Materials
Target stimuli consisted of the 184 tokens of “sorry” analyzed in the production study. These were made up of 144 contextual “sorry” tokens, spliced out of the first line of dialogue shown in Table 1 (recall that the “sorry” was always utterance-initial and followed by a stop or affricate such that the target word was surrounded by silence), as well as 40 tokens produced in isolation.
In addition to these target stimuli, the experiment contained four practice trials and 18 filler trials. Both the practice and filler trials were full sentences with context making it explicit whether the speaker was intending an
3.2.3 Procedure
The experiment was run using PsychoPy (Peirce, 2007). Participants were given headphones and were seated in either a soundproof booth (Toronto) or a quiet room (Ottawa). Before the experiment, participants were given an oral explanation of the nature of the experiment. They were first given examples of how the word “sorry” could be used in different ways: to apologize for something, or to get someone’s attention in order to get by (i.e., in place of “excuse me”). Then, they were told that they would be listening to multiple repetitions of the word “sorry” in isolation and asked to decide whether it sounded more like an apology or “excuse me,” indicating their choice via keypress. Short written instructions were also provided at the beginning of the experiment.
The experiment consisted of four practice trials, followed by the 184 target items, randomized by participant, interspersed at regular intervals with the 18 filler trials. The relevant response keys (“a” for
3.2.4 Analysis
We coded listeners’ responses (
3.3 Results
3.3.1 Accuracy
Figure 4(a) shows the percentage of time participants accurately classified tokens as
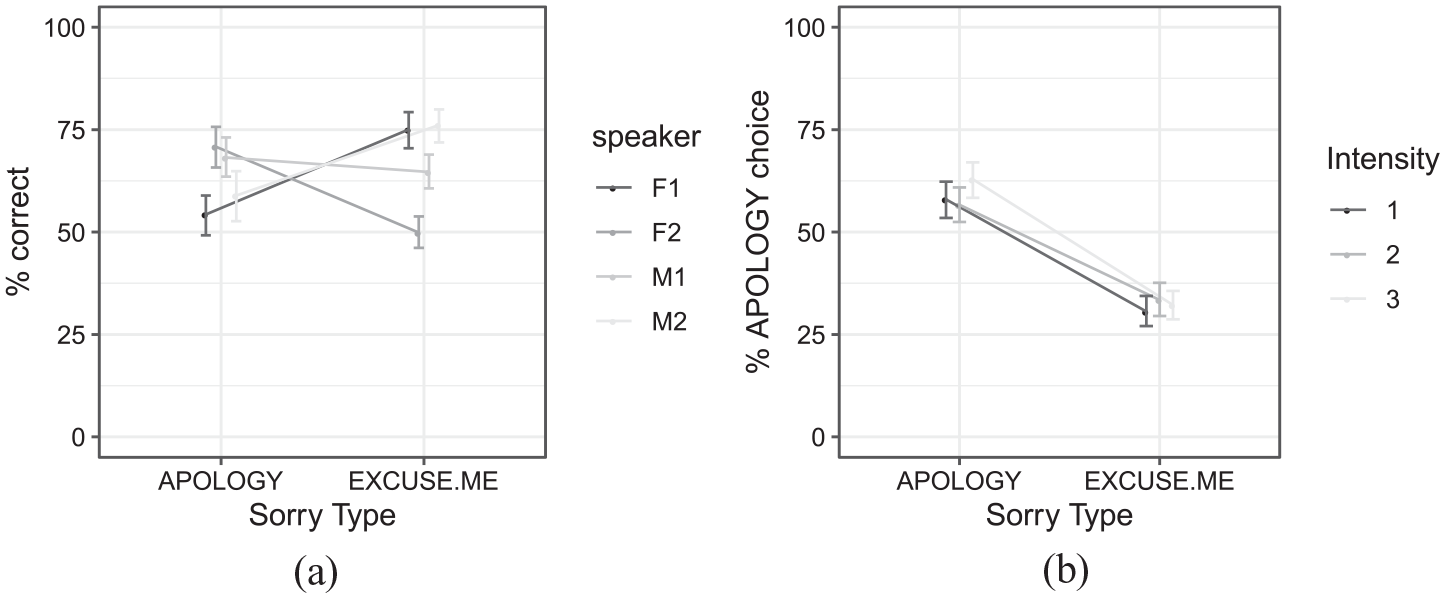
(a) Percentage correct (i.e., listeners’ choice matched the speaker’s intention) identification of “sorry” tokens, broken down by the intended meaning (
Sorry Type: We tested whether listeners performed significantly above chance, and whether performance varied by Sorry Type and speaker. We used a mixed-effects logistic regression model with Accuracy as the response variable and Sorry Type as a fixed predictor (sum-coded, reference level
Situational Intensity: In order to test whether Situational Intensity affected listeners’ responses, we ran a model with only the Contextual stimuli, since the tokens produced in isolation did not have a value for Situational Intensity. The model predicted listeners’ choice of
In sum, listeners were above chance in classifying
3.3.2 Correlations between responses and acoustic properties
We now turn to the question of which cues listeners use when differentiating between the two Sorry Types, returning to the four acoustic values (duration, mean F0, mean intensity, and pitch contour) described in the production study. For the perception analysis, we used normalized F0 values, scaled to z-scores for each speaker, instead of raw values, since we expect listeners to normalize by speaker. Figure 5 shows how often listeners classified each token as an
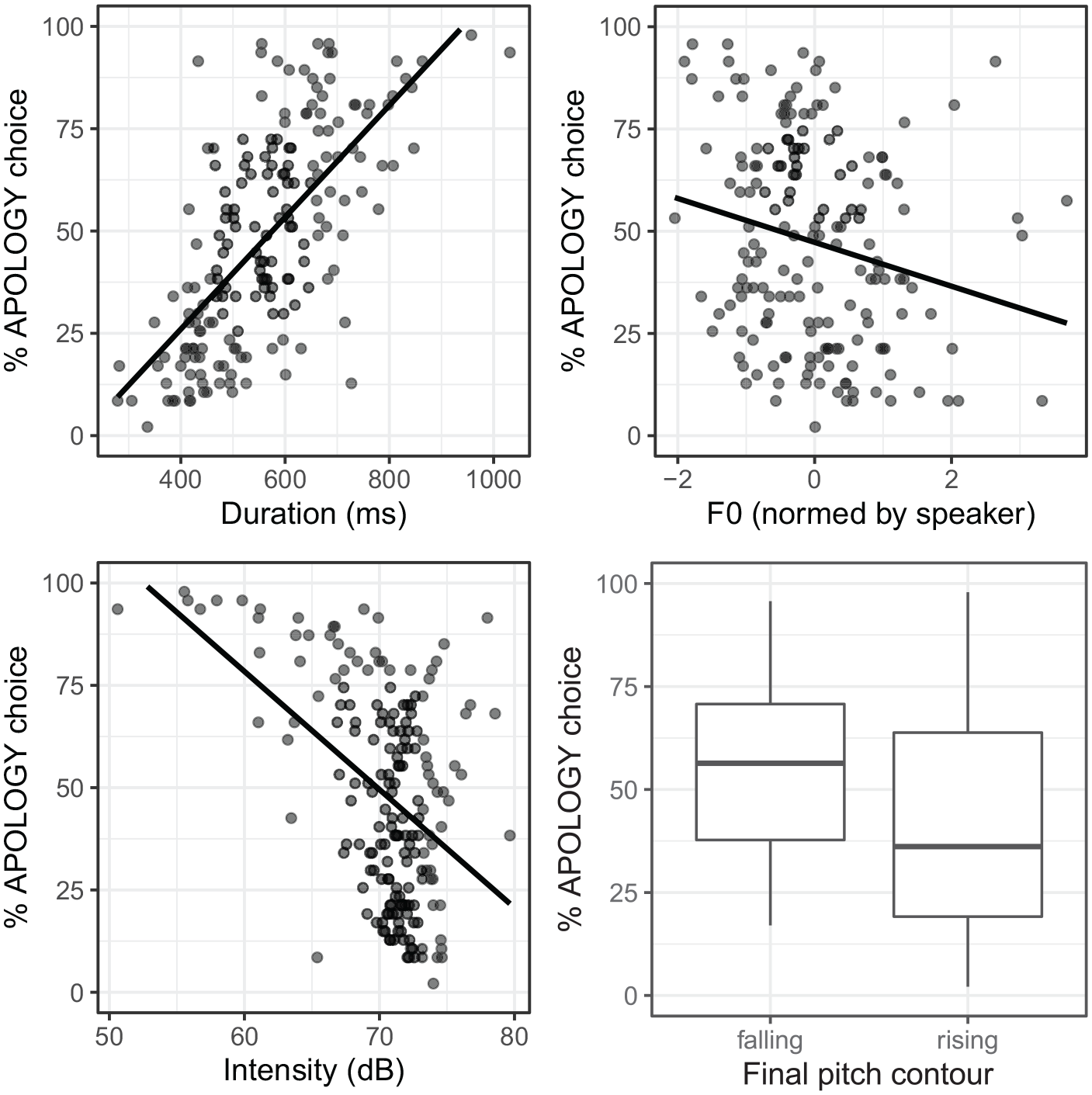
Percentage
The patterns in Figure 5 suggest that listeners are more likely to perceive tokens as indicating an apology when they are longer in duration, lower in F0, lower in intensity, and characterized by a falling (vs. rising) pitch contour.
In order to determine whether these patterns are significant, we used logistic regression models predicting listeners’ responses from each dimension. Prior to the regression analysis, we examined the interdependencies between the dimensions, testing whether all pairwise relationships were significant using linear regression models, with an alpha-level of 0.05. Three of the six pairwise comparisons showed a significant relationship (F0~intensity: t = 8.56, p < .001; F0~pitch contour: t = 2.59, p = 0.010; duration~intensity: t = −3.64, p < .001) while the other three did not (F0~duration: t = −0.93, p = 0.355; duration~pitch contour: t = −1.06, p = 0.288; intensity~pitch contour: t = 1.19, p = 0.235).
We then analyzed the relationship between acoustics and listener responses using four separate logistic regression models, one for each dimension, parallel to the production analysis. For each model, the binary response variable was participants’ choice of
Results of logistic mixed-effects regression models predicting
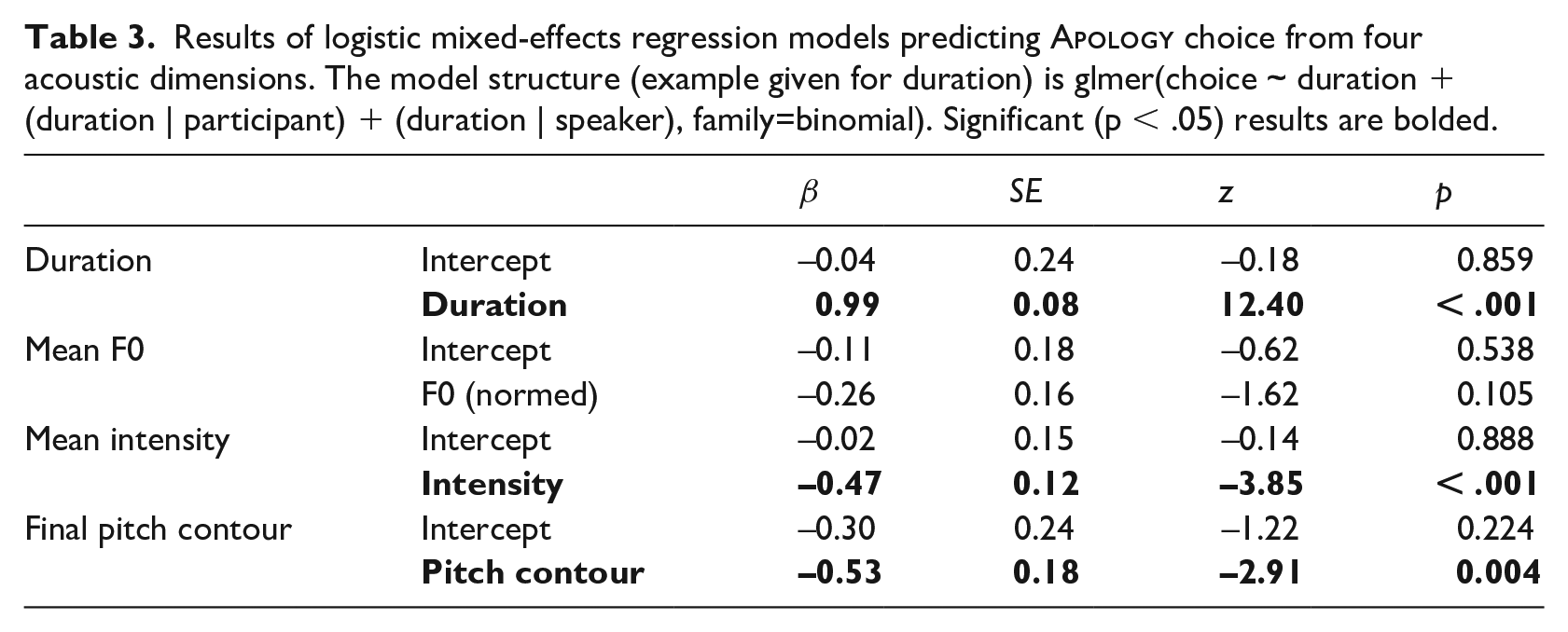
The estimates for each main effect represent the change in log odds of an
These results suggest that multiple acoustic dimensions may inform listeners’ decisions about the meaning of “sorry.” Given that these dimensions were correlated with one another in the natural productions, it is not possible to make claims about the independent role of any single dimension; for example, since duration and intensity are correlated, it could be that listeners are only using duration, but not intensity, with the apparent use of intensity being an artifact of the fact that lower-intensity tokens (which were more likely to be classified as
4 Experiment 3—Perception of systematically manipulated tokens of “sorry”
4.1 Overview
The results of Experiment 2 showed that listeners’ perception of a speaker’s intended meaning of “sorry” is affected by one or more of the acoustic dimensions measured in Experiment 1. The goal of this experiment was to tease apart the independent role of these dimensions: which cues are used, and what is the relative reliance on each cue? We approach this question by examining listeners’ perception of “sorry” tokens that have been systematically manipulated to vary along each dimension.
4.2 Methods
4.2.1 Participants
47 listeners residing in Ontario, Canada (17 males and 30 females, age range 18 to 73, mean age 27.2) participated in this experiment. All participants had learned English as a child (before the age of 10).
4.2.2 Materials
The stimuli for this experiment again consisted of individual tokens of “sorry” in isolation. Stimuli were created from 12 baseline tokens that had been used as stimuli in Experiment 2. These baseline tokens were subsequently manipulated on the three acoustic dimensions found in Experiment 2 to play a role in predicting listeners’ responses: duration, intensity, and pitch contour.
Baseline tokens: Baseline tokens, a subset of the stimulus set of Experiment 2, were selected to serve as the basis for subsequent manipulations. To increase generalizability and to allow for the fact that there are almost certainly other dimensions beyond those we were manipulating that affect listeners’ perceptions, we selected 12 baseline tokens, three from each of the four speakers in Experiment 1. In order to maximize the range of variability in the natural tokens, we chose the token from each speaker that had elicited the highest, lowest, and most ambiguous
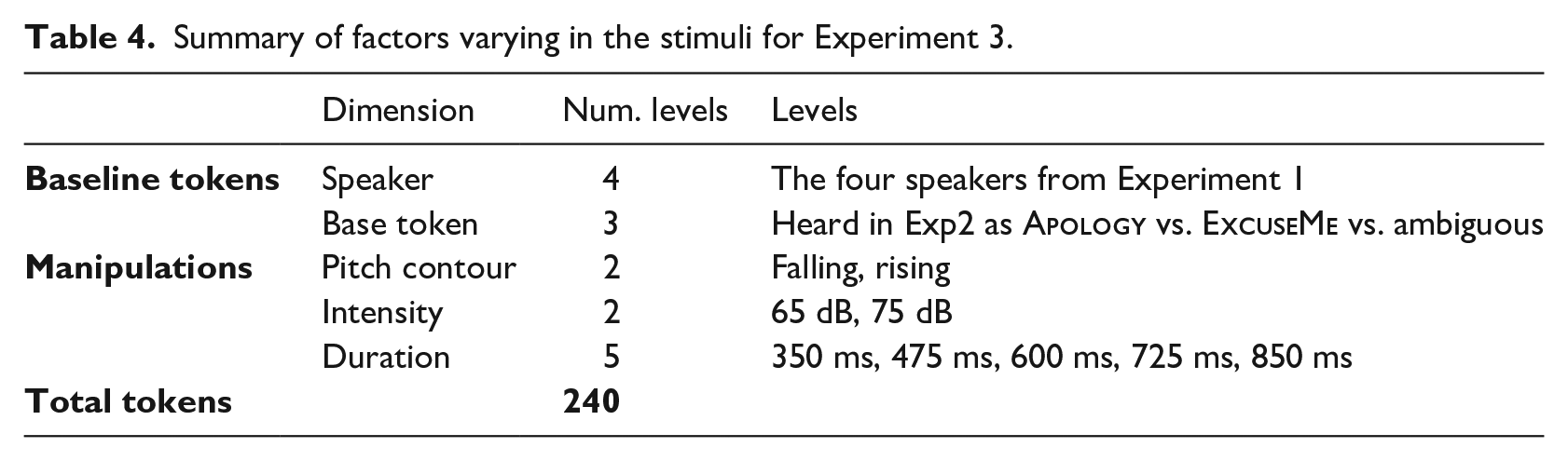
Summary of factors varying in the stimuli for Experiment 3.
Pitch contour manipulation: We created two stylized pitch contours, one with a falling and one with a rising tone. These two contours (which approximate HLH% and HLL% contours in the ToBI system, Beckman & Ayers, 1997), were chosen as models for manipulation because they were the most common contours seen in the data. The parameters for the stylized contours were chosen by trial and error, with the goal of creating contours that (1) approximated the patterns seen in the production data and (2) sounded natural to native speakers of English. An example of the manipulation is shown in Figure 6.
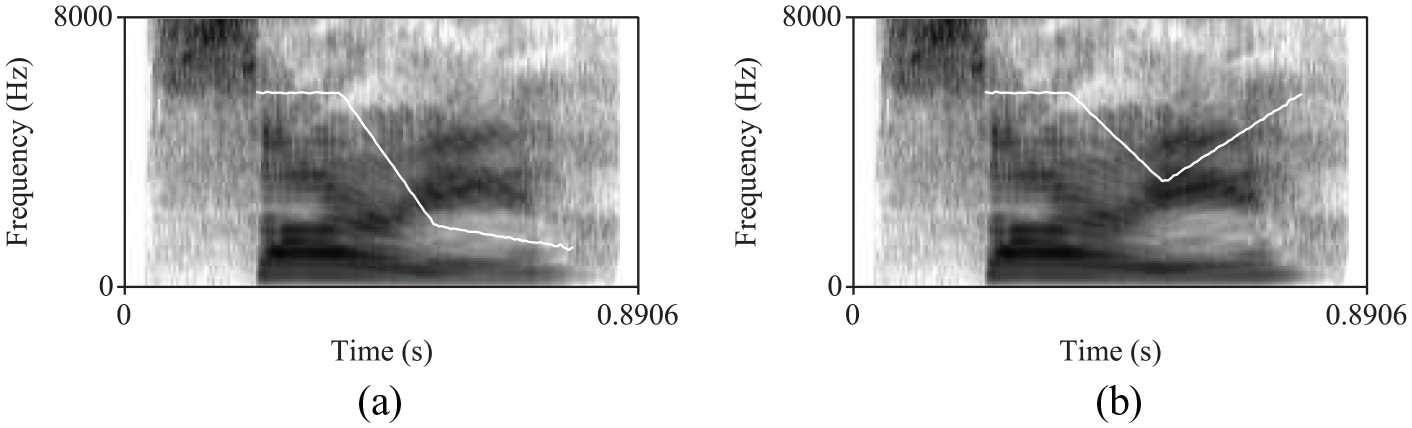
Examples of falling (a) and rising (b) stylized pitch contours. The visible pitch range is 150 to 400 Hz (audio files available in the supplementary materials).
Pitch contour manipulations were done using the “Manipulation” interface in Praat. Each stylized pitch contour was created by setting pitch points at three landmarks: the first at the end of the first vowel of “sorry,” the second at the onset of the second vowel, and the final one at the end of the word. Contours are shown in Figure 6. For the falling contour, the pitch point fell eight semitones from the first to the second landmark, then fell an additional two semitones to the third landmark. For the rising contour, the pitch point fell five semitones from the first to the second landmark, then rose five semitones to the third landmark. Identical contours were superimposed on all baseline tokens, but the raw pitch values were speaker-specific: the first landmark was always set as the speaker’s average F0 value at the 10% point across the full production dataset. The pitch contour manipulation resulted in two pitch files for each of the 12 baseline tokens (24 stimuli).
Intensity manipulation: Using the “Scale Intensity” function in Praat, we created two levels of intensity: 65 and 75 dB for each of the previously manipulated tokens, resulting in 48 tokens. These values were chosen to be centered around 70 dB and to allow for a perceptible difference in volume while remaining within a natural-sounding range so as not to be overly salient or distracting.
Duration manipulation: Since results from both Experiments 1 and 2 suggested an important role for duration, we chose to create a five-step continuum to allow for more precision in the analysis. The endpoints were set at 350 ms and 850 ms, based on the range of duration in the production dataset (after removing some apparent outliers). Using the PSOLA-based manipulation algorithm in Praat (Moulines & Charpentier, 1990), we manipulated each of the previously created 48 tokens to have each of the five duration values (350, 475, 600, 725, and 850 ms), resulting in a final total of 240 stimuli.
4.2.3 Procedure
The procedure was identical to that of Experiment 2, except the 240 manipulated tokens were used as target stimuli in lieu of the 184 naturally produced target items from Experiment 2. As in Experiment 2, 18 filler trials consisting of complete sentences with context were interspersed at regular intervals, and the order of the 240 target tokens was randomized by participant.
4.2.4 Analysis
We used a logistic mixed-effects model to model listeners’ response (
4.3 Results
Listeners’ responses as a function of each manipulated dimension are shown in Figure 7, and statistical results are given in Table 5. As shown by the non-significant intercept in the model, there was no overall bias for
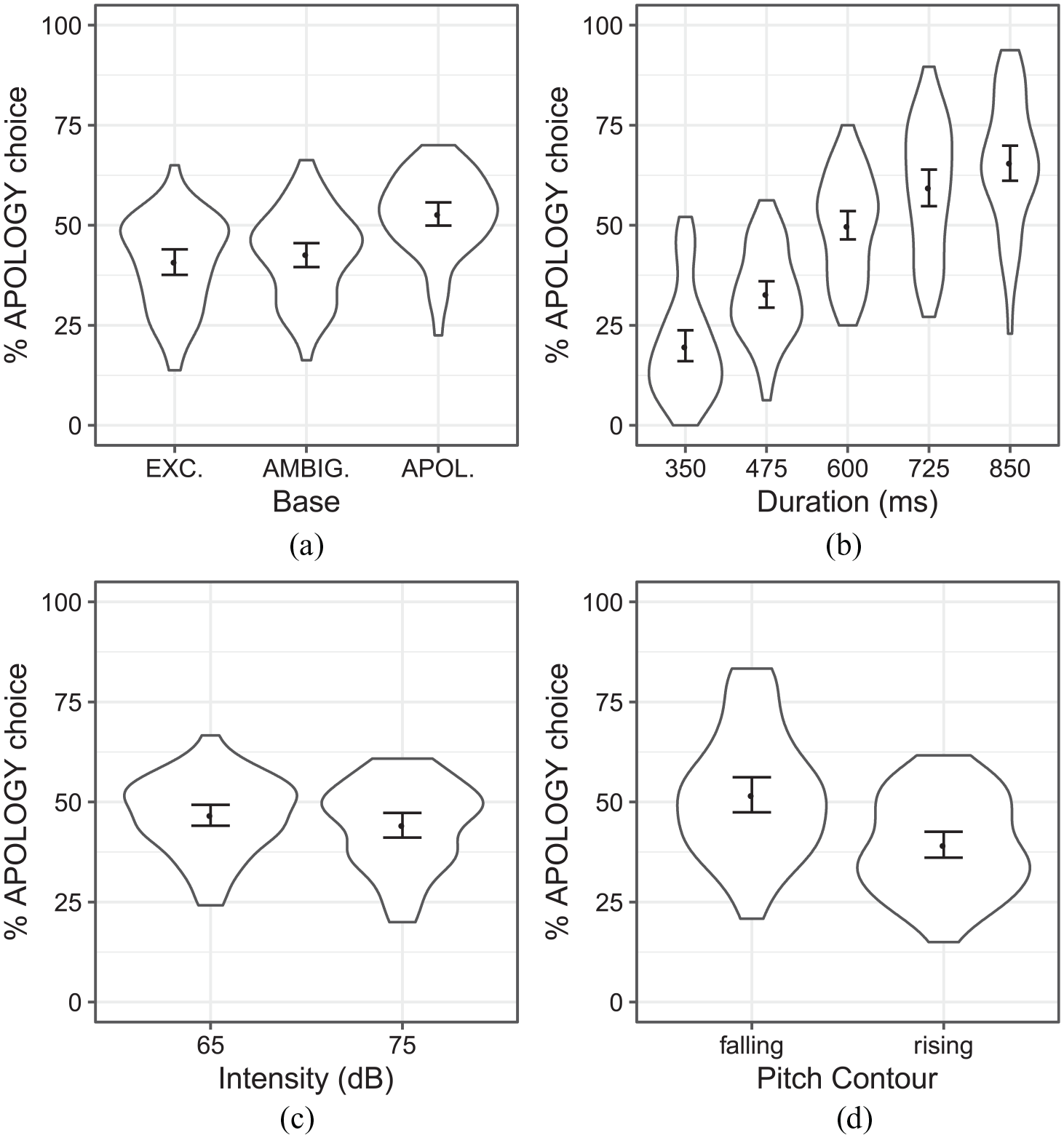
Listeners’ choice of
Results of logistic mixed-effects regression models predicting
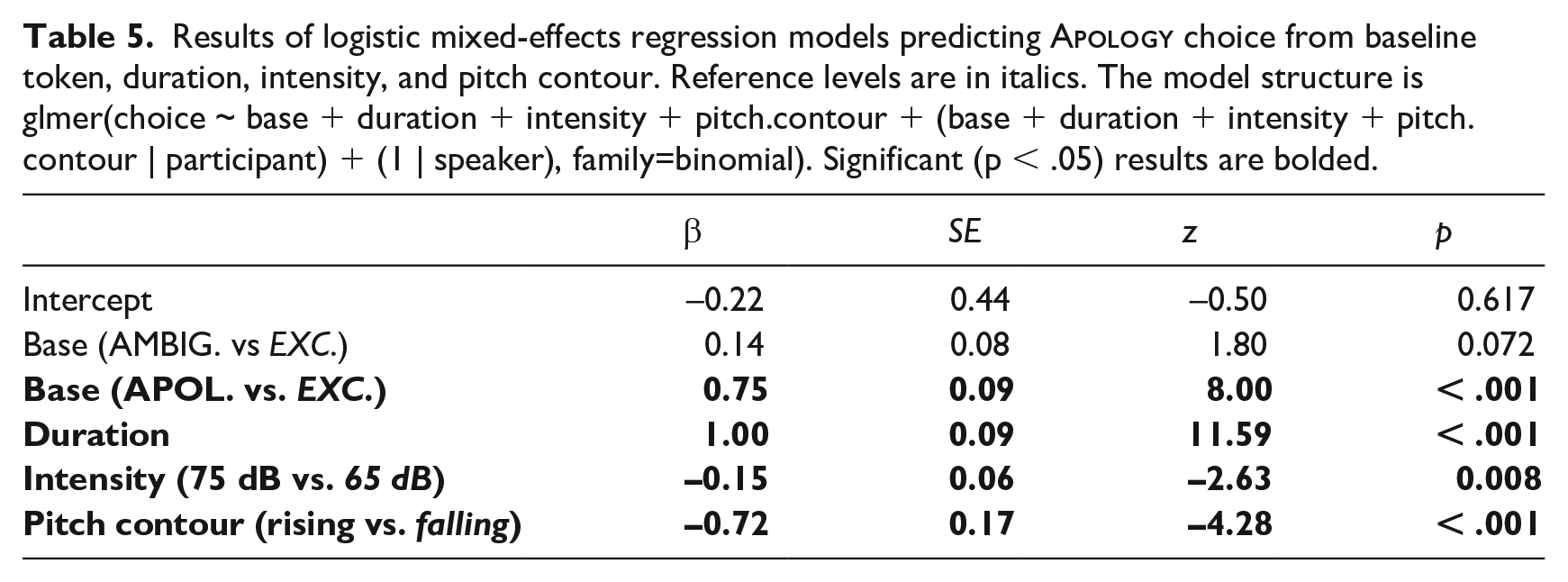
Base token: As shown in Figure 7, listeners were more likely to identify tokens created from baselines that elicited more
Duration: Reflecting the results of Experiment 2, as well as the production study, there is a remarkably systematic relationship between duration and listeners’
Intensity: As in Experiment 2, tokens with lower intensity (i.e., softer tokens) elicited more
Pitch contour: As in Experiment 2, tokens with a falling contour were more likely to be considered as an
Overall, significant differences were found for all factors tested, and paralleled the results found in Experiment 2. This suggests an independent role for each of these dimensions: tokens that were longer in duration, lower in intensity, and with a final falling pitch tended to be classified more often as
We also wanted to assess the relative importance of these cues in predicting listeners’ responses. While the question of how to quantify cue use is complex (see Schertz & Clare, 2020, for discussion), one metric for how predictive a cue is in this sort of paradigm is simply by assessing the difference in predicted responses across the range of each dimension. These differences are summarized in Table 6. Based on this metric, duration is the most predictive of the factors examined in this work, followed by pitch contour, followed by difference in base token, followed by intensity (which only elicited a 3% difference in responses). However, it should be kept in mind that this can only be interpreted within the stimulus set used in this experiment. With different parameter values (e.g., a larger difference between the two intensity values), the apparent “use” of the cue could differ.
Comparison of differences in percentage
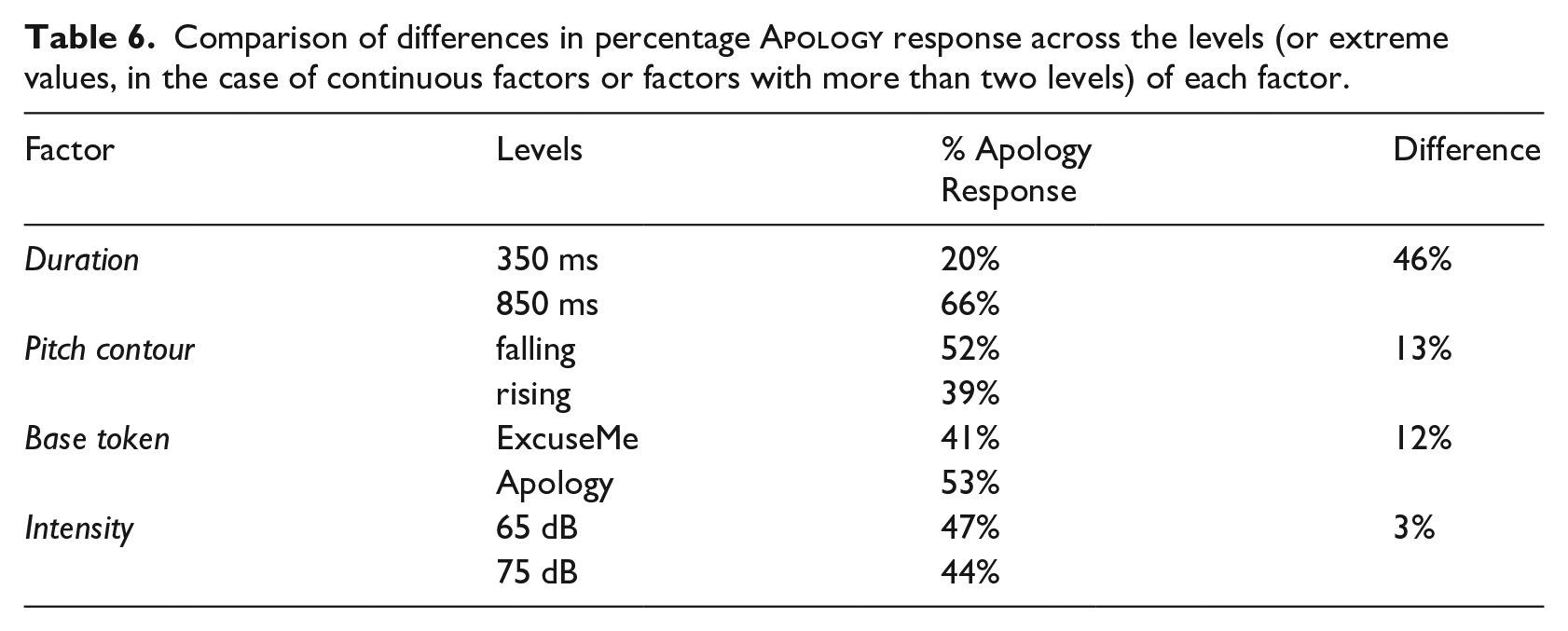
Overall, the results of Experiment 3 strengthen the findings of Experiment 2, suggesting that multiple cues inform listeners’ perception of Sorry Type: using manipulated stimuli that varied orthogonally on the dimensions of interest, this experiment provided evidence for an independent role for each of these dimensions. Specifically, tokens showing longer duration, lower intensity, and falling pitch are more likely to be classified as apologies, and that, at least in the acoustic space of the stimulus set, duration exerts the greatest influence. Furthermore, the baseline token played a role, with tokens created from baselines that had been perceived as
5 Discussion
5.1 Summary of results
This work examined the use of multiple acoustic dimensions to cue different meanings of the word “sorry” in production and perception. In Experiment 1, tokens of “sorry” produced by voice actors differed in duration based on whether they were in the contexts suggesting an
While listeners’ use of duration reflected the distribution of durations in the production dataset, two of the other cues (intonation contour and intensity) were found to influence listeners’ judgments, despite the fact that there was no significant difference in the values of these two dimensions across the two Sorry Types in production. On the surface, this may appear to be a case of acoustic cues being used in perception even when they are not informative in production (e.g., Warner et al., 2004). However, we think it is more plausible that these cues are indeed informative in the input, but that our production study simply did not have enough power, or was not representative enough, to reflect the true input. Our sample size was quite small, and given the usually very small size of subphonemic differences, we expect that a larger sample size would be necessary to detect an effect. Furthermore, we used a nonrepresentative sample of talkers (voice actors) and a non-naturalistic production setting (asking actors to read a script), such that it is difficult to assess the extent to which this reflects the distribution of productions that listeners would hear in real life. Further studies using corpus work, or more naturalistic production experiments with larger, more representative samples of speakers, are necessary to answer questions about the relationship between the distribution of cues in the input and listeners’ use of these cues in perception.
5.2 Use of individual cues
In the following sections, we discuss the findings for each acoustic dimension in the context of previous work, and we lay out potential explanations for their use.
5.2.1 Duration
Given the many factors shown to influence duration, it is perhaps unsurprising to find a durational difference between the two forms in production, with
We also found systematic durational variability within each meaning as a function of situational intensity. The fact that higher-intensity situations (with identical utterances) elicited longer durations provides evidence that factors unrelated to lexical statistics or prosodic structure must play a role, and it suggests that emotion/affect exerts an independent influence on production.
5.2.2 Pitch contour
There were no statistically significant differences between the pitch contours of the two Sorry Types in production, but this lack of result needs to be interpreted with particular caution for several reasons. First, our analyses were based on perceptual judgments using the ToBI coding system. These judgments can differ substantially across coders, even in “best-case” scenarios with highly trained coders and clear speech (e.g., Syrdal & McGory, 2000). We only reported tokens that were agreed-upon by our two coders, which reduces the amount of data (although the results were the same when using the full dataset of each coder individually). Second, the different speakers in our study showed different patterns, with three of the four speakers showing more falling tones for
While it is not possible to make strong generalizations about how this contrast is realized in production, we did see a clear influence of intonation contour in both perception experiments, with final falling tone eliciting more
It might seem surprising that the overall F0 level (mean F0) was not found to play a role in either production or perception, given the fact that it has been a relatively consistent feature found to vary based on emotion (Banse & Scherer, 1996, among others). Furthermore, we might expect
5.2.3 Intensity
Intensity was found to play a small but significant role in both perception experiments, with lower intensity eliciting more
5.3 Implications for models of speech perception and processing
Listeners’ systematic use of multiple phonetic dimensions to differentiate two polysemous uses of “sorry” (
It is clear from our results that the two senses of “sorry” must be independent at some level of representation. However, this study cannot provide a definitive answer to how sense-specific phonetic information is represented and linked to the two meanings. The fact that listeners differentiate the two senses based on acoustic information could be explained straightforwardly by each sense having an independently specified phonetic representation (e.g., a separate phonetic prototype or exemplars associated with each sense). Under this view, listeners’ choice of
The findings that listeners use a given dimension is consistent with either of these scenarios. More broadly, an accurate model of speech perception likely includes both components as a means to represent pronunciation variation. As discussed in Pierrehumbert (2016), there is evidence that (at least some) subphonemic detail must be able to be stored independently for (at least some) lexical representations. However, more abstract knowledge of phonetic patterns also influences lexical decisions. For example, Shatzman and McQueen (2006) found that listeners used duration information to distinguish short versus embedded novel words (e.g., “bap” vs. “
5.4 Lessons from a case study
As discussed in the sections above, there are several plausible explanations for the effects found in this work. It is likely that differences in prosodic phrasing play a large role across several of the dimensions examined here; this was not one of our primary considerations when designing the study, but its importance was highlighted by reviewers of an initial version of this work. For example, an
The effects found in this case study were quite large in comparison to previous work. For example, consider the 126 ms average difference between
There are multiple possible reasons for the relatively large effects found here. First, the studies about durational differences cited above were examining homophonous contrasts which differed along scalar variables (e.g., frequency, contextual predictability) or which were actually expected to be phonologically neutralized. In contrast, the senses of “sorry” used in the current study are commonly used in social routines. Their frequency and the social context of their use may form the basis of a robust contrast in production, and/or greater sensitivity to these differences by listeners; indeed, these are the types of words proposed by Calhoun and Schweitzer (2012) to be the most likely to have lexicalized or idiomatic intonational contours. If so, this would account for the particularly strong listener judgments. Second, as discussed at the beginning of this section, there are multiple factors, including prosodic regularities, emotion/affect, and lexical statistics, that could potentially play additive roles. Determining the relative roles of each of these factors is only possible through larger-scale studies examining multiple words; however, the strength of the effects in the current work highlights the importance of examining word-specific effects in these larger-scale studies. This is crucial because a particularly robust contrast for a single word could skew group-level effects, but also because examining the properties of words which have stronger/weaker differences could shed light on which factors are most important.
Finally, our findings from Experiment 3 show an independent contribution of different acoustic dimensions, and the pattern of responses to the five-step duration continuum indicates a gradient use of this cue (the other dimensions only had two levels, so we are unable to make observations about gradience). This suggests that dimensions are stored and tracked independently. The question of which dimensions are tracked, and the details of their use, is another factor that needs to be considered in models of speech perception.
5.5 Limitations and future directions
This case study of a single word pair allows for simultaneous investigation of listeners’ use of multiple acoustic dimensions, and for a comparison of perception of naturally produced and manipulated tokens. The results highlight the fact that listeners rely on several acoustic dimensions to inform their perception of these words, and while the design of this study does not allow for a definitive answer about why these cues are used, it is plausible that the regularities underlying the use of these cues stem from both lemma-specific and general contextual factors.
Any affective/emotive elements of the utterances produced in our production study are simulated, due to the fact that they are based on reading of scripted productions by voice actors. We make the assumption, following Banse and Scherer (1996) and many other researchers, that these utterances contain properties of “real-life” speech, and we believe that this assumption was supported by the findings that listeners did indeed identify the intended meanings at above-chance levels. Nevertheless, as with any laboratory-based study, we do expect that there will be systematic differences between lab-based and spontaneous productions. In this case, we might expect phonetic distinctions to be exaggerated, because of the read speech, because of the use of voice actors, and because the word of interest was likely clear to them. In the future, corpus work could be used to test to what extent the patterns found here are reflected in naturalistic speech.
As with any case study, this is a starting point for formulating and testing more general hypotheses about models of speech processing and cue use. One question, in terms of the perception–production interface, is how faithfully cue use mirrors input distributions. This has been examined quite frequently in terms of perceptual cue-weighting for phonetic categorization (see Schertz & Clare, 2020, for discussion), the question being to what extent the relative informativity of various cues in distinguishing two members of a phonetic contrast predicts listeners’ relative reliance on these cues in perception. Expanding the scope of this inquiry to lemma-level lexical contrasts can help provide information about the level on which listeners are computing input statistics, and how these statistics are used. A second, related question is which factors underlie the use of these cues. As discussed above, in the perception of a given word meaning, listeners likely draw on both lemma-specific knowledge (i.e., information encoded in the lexical entry) and their knowledge of the contexts in which the word meaning is likely to occur, as well as the phonetic regularities associated with those contexts. The range of potential “contexts” is vast, encompassing syntactic, prosodic, discourse, and emotional domains. The extent to which listeners track statistics along these dimensions, and whether they do it in similar ways for different contexts, has, to our knowledge, been largely unexplored.
Moving forward in these areas will require work on two methodological fronts: first, corpus work and/or larger-scale elicitation-based production studies should be done to get a better idea of the distribution of cues in the input as a function of a broader range of factors. Second, perception patterns should be explored in controlled experimental work using comparable methodologies as previous work to tease apart and quantify the relative roles of word-specific versus abstract information, considering a broader range of contexts over which listeners might generalize (e.g., emotion/affect). While these are broad and complex questions, answering them will help build accurate and computationally viable models of how information is stored and used.
Footnotes
Acknowledgements
We would like to thank Yoonjung Kang, the Associate Editor Holger Mitterer, and two anonymous reviewers for helpful comments on earlier drafts of this work. We would also like to thank Olivia Marasco for help with prosodic annotations.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was conducted with the financial support of the Joseph Armand Bombardier Canada Graduate Scholarship, awarded to Caitlyn Martinuzzi by the Social Sciences and Humanities Research Council of Canada.