
Abstract
In natural conversations, words are generally shorter and they often lack segments. It is unclear to what extent such durational and segmental reductions affect word recognition. The present study investigates to what extent reduction in the initial syllable hinders word comprehension, which types of segments listeners mostly rely on, and whether listeners use word duration as a cue in word recognition. We conducted three experiments in Dutch, in which we adapted the gating paradigm to study the comprehension of spontaneously uttered conversational speech by aligning the gates with the edges of consonant clusters or vowels. Participants heard the context and some segmental and/or durational information from reduced target words with unstressed initial syllables. The initial syllable varied in its degree of reduction, and in half of the stimuli the vowel was not clearly present. Participants gave too short answers if they were only provided with durational information from the target words, which shows that listeners are unaware of the reductions that can occur in spontaneous speech. More importantly, listeners required fewer segments to recognize target words if the vowel in the initial syllable was absent. This result strongly suggests that this vowel hardly plays a role in word comprehension, and that its presence may even delay this process. More important are the consonants and the stressed vowel.
1 Introduction
Research on speech comprehension has focused on the comprehension of carefully pronounced, laboratory speech. In everyday conversations, however, words are generally realized much shorter and with less articulatory effort than in laboratory speech (an introduction to the phenomenon of acoustic reduction is provided by Ernestus & Warner, 2011). For example, the English word “ordinary” can be pronounced like [’ɔnri] and, likewise, the Dutch word natuurlijk “of course” may be reduced to [’tyk]. Reduced pronunciations are ubiquitous in spontaneous speech. To illustrate, Johnson (2004) found that, in American English, segments are changed or missing in 25% and complete syllables are missing in 6% of the word tokens. Similarly, in Dutch, segments are changed or missing in 48% of the word tokens and complete syllables are missing in approximately 19% of the word tokens (Schuppler, Ernestus, Scharenborg, & Boves, 2011). 1 The present study investigated how reduced word pronunciation variants are recognized and whether this can be assessed by means of an adapted version of the gating paradigm.
Several studies have already investigated how listeners recognize reduced word pronunciation variants. Research by Pollack and Pickett (1964) was the first to show that the intelligibility of words excised from fluent speech is increased by adding surrounding context. In line with this, Ernestus, Baayen, and Schreuder (2002) found that listeners had difficulty recognizing highly reduced pronunciation variants out of context (ca. 50% correct) and when these variants were presented together with minimal phonetic context (the neighboring vowels and intervening consonants; ca. 70% correct). Within sentence context, listeners did not have any difficulty recognizing these reduced variants (more than 90% correct). These findings indicate that listeners need some information from the sentence context to recognize highly reduced word pronunciation variants. Consequently, experiments investigating how listeners recognize reduced word pronunciation variants can only yield ecologically valid results if they present the variants in their context.
Listeners can base their predictions of omitted reduced words on the preceding context as well as on the following context. Van de Ven, Ernestus and Schreuder (2012) showed that participants can better guess the identity of an omitted reduced word if they are presented with both the preceding and following context rather than just the preceding context. The relevant semantic/syntactic information is not restricted to the meanings of directly surrounding words, but may also include the larger (discourse) context (e.g., Nieuwland & Van Berkum, 2006). Furthermore, the context may contain informative acoustic cues, as was also shown by Van de Ven and colleagues. They found that participants better predicted omitted reduced words if they heard rather than read the context.
Context alone, however, is insufficient to recognize reduced variants, as shown by Janse and Ernestus (2011) and van de Ven et al. (2012). Janse and Ernestus (2011) presented participants only with orthographic transcriptions of the preceding and following context of reduced word pronunciation variants, or participants also heard the reduced variants (in a separate experiment; the context was again presented visually). Listeners could not identify most target words on the basis of the written context alone (only 13% of the items were guessed correctly by at least a third of the participants), but the auditory presentation of the target words significantly increased participants’ performance (90% correct). Apparently, context only becomes highly informative once listeners have heard the reduced variants. This raises the question, which acoustic information from the reduced variants is, above all, informative.
Many studies suggest that even if listeners hear reduced words in their natural context, their recognition is slower than the recognition of well-articulated words. Nearly all these studies present reduced variants in isolation (e.g., Ernestus & Baayen, 2007; Ranbom & Connine, 2007; Tucker, 2011; Tucker & Warner, 2007; van de Ven, Tucker, & Ernestus, 2011). There are, however, two clear exceptions. Results obtained by Brouwer, Mitterer, and Huettig (2012) came from several eye-tracking experiments in which participants heard fragments of conversational speech and saw orthographic representations of words on a computer screen (i.e., the printed words version of the visual world paradigm). Participants were instructed to click on the printed word that matched a word in the fragment; if they did not hear any of the words on the screen (which was the case for all target trials) they had to click in the middle of the screen. The results suggest the recognition of reduced pronunciation variants is inhibited compared to the recognition of unreduced variants. These findings are unexpected since everyday conversations are full of reduced words. This raises the question whether the printed words version of the visual world paradigm can be used for investigating the comprehension of reduced words. The words’ orthographic forms represent their full pronunciations, and participants may therefore expect these pronunciations. As a consequence, they may recognize words more slowly when they are realized as reduced variants. Further, presenting orthographic information while listeners hear (casual) speech also leads to questions concerning ecological validity because listeners are normally not presented with orthographic transcriptions of what they will hear.
An EEG study by Drijvers, Mulder, and Ernestus (2016) shows that gamma oscillations only increase when listeners hear reduced rather than unreduced word pronunciation variants in mid-sentence positions. The authors interpret this result as suggesting that it is more difficult for listeners to activate the semantic network when hearing reduced instead of unreduced pronunciation variants (in line with van de Ven et al., 2011). The target words were presented in read-aloud sentences, and were cross-spliced. The effect of reduction might have been absent if the reduced words had been presented in their natural contexts.
The present study aims at contributing to the understanding of how listeners identify reduced words in their natural contexts. We do so by focusing on three questions. First of all, we investigated which segments are used by listeners to recognize reduced word pronunciation variants. Second, we assessed to what extent word token duration contributes to the recognition of reduced pronunciation variants. The third question of our study was whether the gating paradigm (Grosjean, 1980) can be adapted for studying how listeners understand reduced pronunciation variants in their context.
The present study focused on the recognition of reduced words with unstressed initial syllables, which are likely to be reduced (e.g., the Dutch verb form verlaten [fər’latən] 2 “leave” may be realized like [’flatə]). Since this reduction is located (far) before the word’s uniqueness point, it may increase uncertainty about the word’s identity during the word recognition process. For example, the reduced variant ([’flatə]) of the Dutch word verlaten is initially very similar to the Dutch word flater “blunder,” which may be realized like [’flatə]. One may therefore predict that listeners are better at recognizing words with unreduced rather than reduced initial syllables, in line with the literature showing that reductions hinder comprehension (see above). On the other hand, however, if the first unstressed vowel is missing, listeners hear more segments known to be especially relevant for word recognition: they hear subsequent consonants and the stressed vowel earlier. The absence of the first vowel may consequently increase the relevance of the following segments as cues to recognize reduced pronunciation variants.
Segments may be completely absent or may leave acoustic traces that listeners can pick up on. For example, Manuel (1992) showed that listeners can distinguish between English “sport” and “support” pronounced without the schwa, based on the duration of the aspiration of the following /p/. 3 Another example is provided by Zimmerer and Reetz (2014), who found that, in German, if the word-final /t/ is missing in final /st/ clusters, the duration of the preceding /s/ tends to be longer (Zimmerer, Scharinger, & Reetz, 2011, 2014), and listeners use this subsegmental cue to reconstruct the missing /t/. Likewise, the absence of the initial vowel in reduced pronunciation variants may leave beneficial cues for the listener. This would be another reason why listeners may not be hindered by such reductions, and these reductions may even enhance the recognition of these variants. In fact, reduction in these cases actually leads to more information in the same stretch of time.
Another potential cue for the word’s identity is its duration. Listeners may use the duration of a reduced word, relative to the durations of (segments in) surrounding words (to estimate speech rate; Nooteboom & Doodeman, 1980), to deduce its number of syllables/segments. If the listener is (unconsciously) aware of the possible pronunciation variants of a word (for instance, because some of them are lexically stored, e.g., Ranbom & Connine, 2007), the duration of the word may thus form a cue to the intended word. Previous research has shown that listeners take word duration into account and that they build expectations that even influence the number of words and word boundaries they perceive (e.g., Dilley & Pitt, 2010). Because of all these cues, listeners may not be hindered by reductions in initial syllables in words presented in context, in contrast to what has been found so far for words presented in isolation, or in experiments that are not ecologically valid for some other reason.
We tested the recognition of reduced word pronunciation variants in a gating task. In a typical gating task, participants hear incremental portions of a target word (i.e., the gates), and for each gate (usually 50 ms longer than the previous one) they need to identify the target. Using this technique, Grosjean (1980) has shown that listeners can recognize carefully pronounced words already before their acoustic offsets and, in many cases, even before their uniqueness points. Furthermore, when these words are embedded in context, listeners need even less acoustic information.
We expect that the gating task is highly suitable for investigating the processing of spontaneous speech. Although some authors criticized the gating paradigm for not being a true on-line paradigm, Tyler and Wessels (1985) showed that this paradigm is equally sensitive to the real-time processes involved in spoken word recognition as other on-line paradigms. Moreover, Bruno, Manis, Keating, Sperling, Nakamoto, and Seidenberg (2007) suggested that the gating task is highly suitable for measuring phonological processing because it is independent of a phonemic level of representation, as is the case in other tasks (e.g., categorization or phonological awareness tasks). Further, the task can indicate how much acoustic information is required to recognize a word (e.g., Grosjean, 1996).
We are not the first to use the gating paradigm with spontaneous speech instead of connected, laboratory speech. Bard, Shillcock, and Altmann (1988) presented participants with utterances extracted from a corpus of spontaneous speech that were gated in increments of one word. They found that for 21% of the words listeners did not only need the preceding context and the word itself, but also the following context to recognize the word. Apparently, listeners also need the following context to recognize words when they are presented within spontaneous rather than laboratory speech (see also van de Ven et al., 2012, discussed above). The findings of Bard et al. may (partly) be due to the frequent occurrence of reductions in spontaneous speech.
We created a version of the gating paradigm where the gates are aligned with the edges of consonant clusters or vowels. This approach is highly suitable for studying the contributions of the different segments in the word to the recognition of reduced pronunciation variants because we could control the segments participants heard in each gate. We placed gate boundaries (1) at word onset; (2) at the end of the first realized consonant (cluster); (3) at the end of the first realized vowel; and (4) after the second realized consonant (cluster; see Cutler & Otake (1999) for a similar approach, using the gating paradigm to study the role of pitch-accent information in spoken word recognition). Note that gate 2 may not only contain more segments if the initial unstressed vowel is absent but may also be longer. We address this multicollinearity with statistical modeling, as we explain in Experiment 1.
We report three auditory gating experiments, in Dutch. Listeners were presented with the natural preceding and following context (since both are relevant, see Bard et al., 1988) of reduced word pronunciation variants (henceforth “target words”), and some acoustic information from these variants themselves (except for the baseline condition). The materials were extracted from a corpus of spontaneous speech.
In Experiment 1, we investigated the role of the first realized consonant or consonant cluster (henceforth “consonant cluster,” for the sake of convenience). The experiment consisted of two parts. In part one (gate 1), participants heard the preceding and following contexts, separated by a square wave. In the second part of the experiment (gate 2), participants heard the preceding contexts and the initial consonant clusters of the target words, followed by a square wave and the following contexts. Each part contained half of the target sentences, and each sentence only occurred once throughout the experiment (the same holds for subsequent experiments reported in this study).
The initial consonant cluster of a given target word consisted of only the onset consonants from the citation form if the first unstressed vowel was present, whereas it consisted also of consonants from the coda and/or the onset of the following stressed syllable from the citation form if the first unstressed vowel was absent (henceforth “merged clusters”). For example, the Dutch word principe “principle” with the citation form [prɪn’sipə] was realized like [pə’sipə] in one token and like [’psipə] in a different token from the experiment, and the participants in the second half of Experiment 1 either heard the segments [p] or [ps] of these target words, depending on which pronunciation variant they heard (each token was only presented once throughout the experiment). Almost half of the target words contained merged initial clusters. As illustrated in the example (where [r] appears missing), in many initial unstressed syllables with reduced vowels, consonants were also reduced.
This experimental design allowed us to make two comparisons. First, we could compare the conditions with and without the initial consonant cluster (gate 1 vs. gate 2), which would show the contribution of this consonant cluster to the recognition of reduced pronunciation variants. Second, we could compare tokens with simple initial consonant clusters (e.g., [p] from [pə’sipə]) to tokens with merged initial consonant clusters (e.g., [ps] from [’psipə]), which allowed us to investigate the effects of missing vowels on the word recognition process.
In Experiment 2, we investigated whether listeners can make use of word duration as a cue to word identity. This experiment was identical to Experiment 1, except that the duration of the square wave (combined with the duration of the initial consonants in the second half of the experiment) now equaled the duration of the target word.
Finally, Experiment 3 investigated the role of the consonants and vowels from the second, stressed syllable in the recognition of reduced target words. This experiment also consisted of two parts, and the duration of the square wave was fixed. In part one (gate 3), participants heard the context, and the reduced target word up to and including the first vowel. This vowel was either the vowel from the first, unstressed syllable (e.g., the first schwa in [pə’sipə]) or the vowel from the second, stressed syllable (e.g., [i] in [’psipə]). This part allowed us to compare the contribution of the vowel and consonants from the unstressed initial syllable with the contribution of the initial consonants and stressed vowel in the absence of the unstressed vowel.
In part two (gate 4), listeners heard the context and the target words up to and including the consonant cluster immediately following the first vowel. For example, for the Dutch word principe “principle” listeners heard [pə’s] and [’psip] for the realizations [pə’sipə] and [’psipə], respectively. This part shows to what extent hearing these additional consonants influences participants’ performance.
For all experiments, we also investigated how the acoustic information from reduced realizations of words interacts with the contextual predictabilities of these words given their context. Van de Ven et al. (2012) observed that contextual predictability as indicated by word trigram frequency becomes less important when more acoustic cues are present. We hypothesize that the contribution of contextual predictability becomes smaller if a larger portion of the reduced word is presented.
In short, we report a series of experiments using an adapted version of the gating paradigm that allows us to investigate the contribution of segmental and durational information to the recognition of reduced pronunciation variants in their natural context (rather than in clearly articulated laboratory speech). We compared reduced pronunciation variants with and without the initial unstressed vowel being present. The segmental information and the average durations of the segment sequences provided in gates 1–4 for tokens with and without the first unstressed vowel being present are summarized in Table 1.
An overview of the segments provided in gates 1–4 (top line), and their average durations (bottom two lines), for tokens in which the first unstressed vowel was acoustically present or absent (exemplified by two tokens for the target word principe: [pə’sipə] and [p’sipə].
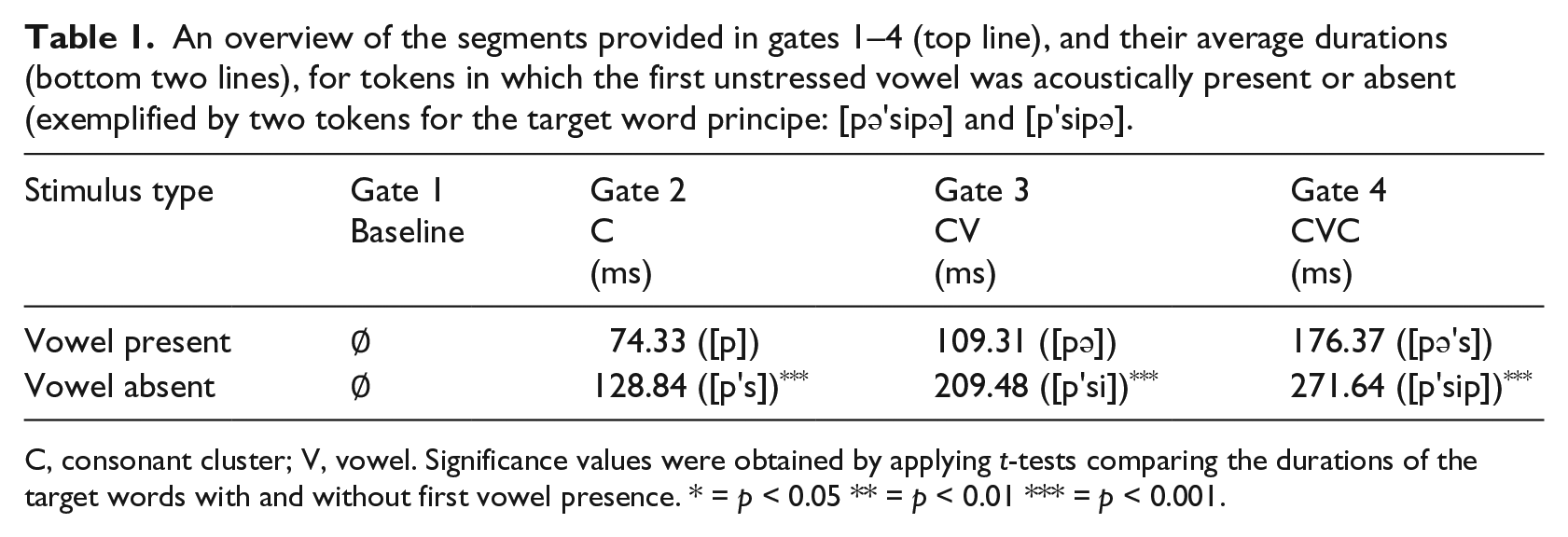
C, consonant cluster; V, vowel. Significance values were obtained by applying t-tests comparing the durations of the target words with and without first vowel presence. * = p < 0.05 ** = p < 0.01 *** = p < 0.001.
2 Materials and methods
2.1 Experiment 1
2.1.1 Participants
Twenty native speakers of Dutch were paid to take part in the experiment. They did not report any hearing loss, and most of them were undergraduate students (the same holds for all subsequent experiments).
2.1.2 Materials
The materials were extracted from the Ernestus Corpus of Spontaneous Dutch (Ernestus, 2000), which consists of casual conversations between 10 pairs of Dutch native speakers, recorded in a soundproof booth. We selected as our target stimuli 38 high-frequency multisyllabic Dutch word types with unstressed initial syllables, all starting with a consonant in their citation form. Many of these word types were content words, or they at least contributed substantially to the meaning of the utterance. In addition, we selected 20 different Dutch word types, including words with word-initial stress and monosyllabic words, as filler items, to introduce more variation in the experiment.
For each target word type, we selected two tokens on average (one token for 23 word types, two tokens for nine word types, three tokens for two word types, and four tokens for four word types). The stimuli were produced by 20 different speakers in total; the distribution of tokens across speakers is shown in Table 2.
An overview of the distribution of tokens across speakers for the stimuli used in this study.

If the first unstressed vowel was present, all consonants in the initial (but not the coda) consonant cluster were nearly always present, too. We tried to select as many tokens with simple as with merged initial consonant clusters (i.e., clusters consisting of more than the onset consonants from the full forms). Since, for most word types, we could not find a token with a simple cluster and a token with a merged cluster, we varied these two cluster types across (rather than within) word types. Further, we selected 1.5 tokens for each filler word type on average.
We extracted these tokens embedded in their prosodic phrases (mean preceding context: 5.46 words, range: 2 to 18 words; mean following context: 4.12 words, range: 1 to 15 words). None of the extracted speech fragments contained overlapping speech or loud background noises.
We verified the intelligibility of the resulting 73 possible target and 30 possible filler tokens, embedded in their contexts, in a control experiment, because we only wanted to include tokens that could easily be recognized in context. Following the procedure described in van de Ven et al. (2012), we presented 20 native speakers of Dutch with the full sentence fragment (e.g., Kan je op verschillende [’fsχɪln] manieren doen. “You can do that in
For the main experiments, we selected those stimuli that were easy to understand in their contexts (more than 75% correct in the control experiment). In total, the main experiments contained 63 target tokens (again representing 38 word types) and 30 fillers, produced by 20 speakers. We include the orthographic transcriptions of the 63 target tokens in the Appendix.
Subsequently, we carried out a second control experiment to assess how easily the filler and target tokens could be recognized in isolation. This experiment was identical to Control Experiment 1, except that the words were presented in isolation. Participants (who did not take part in Control Experiment 1) recognized the target tokens in 69.24% of the trials on average (range: 0%–100%), which indicates that listeners require context to recognize these reduced pronunciation variants, in line with previous research (e.g., Bard et al., 1988; Ernestus et al., 2002; van de Ven et al., 2012).
Two transcribers, naive to the purpose of the experiments, determined which segments were present in the speech signal. They disagreed on the presence/absence of consonants in the first syllable and on the presence/absence of vowels in the first syllable in 12.7% and 15.87% of the target tokens, respectively. Whenever there was a difference between the two transcriptions, a third transcriber (the first author) determined the correct transcription. A phonetic transcription of the materials, which provides insight into the degree of reduction of the target and filler tokens, is provided in the Appendix.
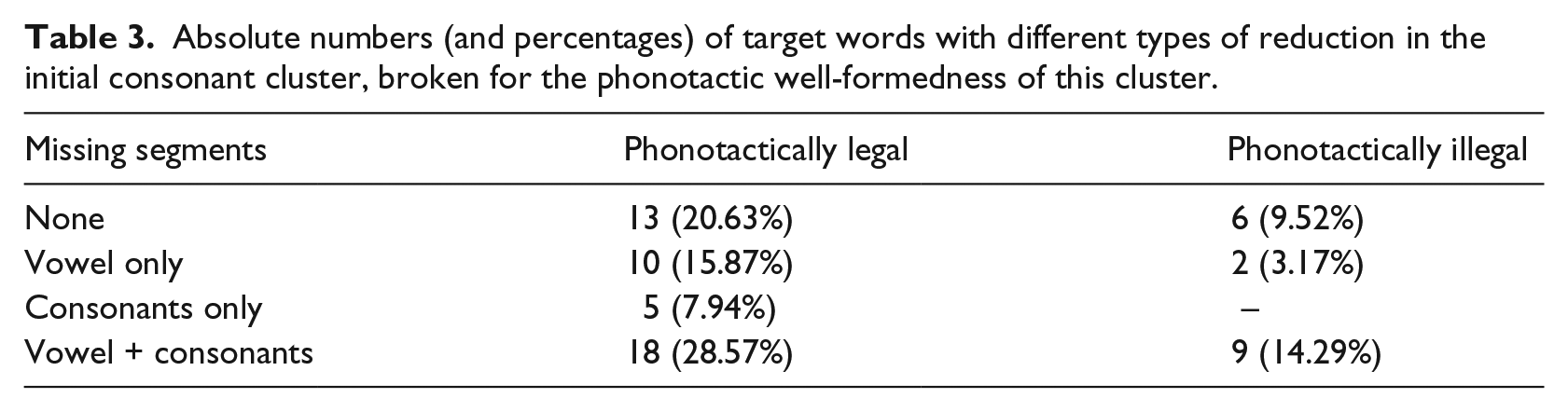
The descriptive statistics for the reduction in the initial consonant cluster are shown in Table 3. Vowels were missing in the initial syllable (and thus in the initial consonant cluster) in 39 target tokens (61.90%), for instance, in [prɪn’sipə] realized like [’psipə]. Spectrograms and transcriptions of two tokens of principe, one realized with and one without the first unstressed vowel, are provided in Figure 1. Missing vowels lead to phonotactically illegal consonant clusters in 11 target tokens (17.46%, e.g., [vər’kopt] realized like [’fkopt]). We included more tokens with legal than with illegal initial consonant clusters because legal initial consonant clusters may incur higher processing costs for the listener, as suggested by Spinelli and Gros-Balthazard (2007).
Absolute numbers (and percentages) of target words with different types of reduction in the initial consonant cluster, broken for the phonotactic well-formedness of this cluster.
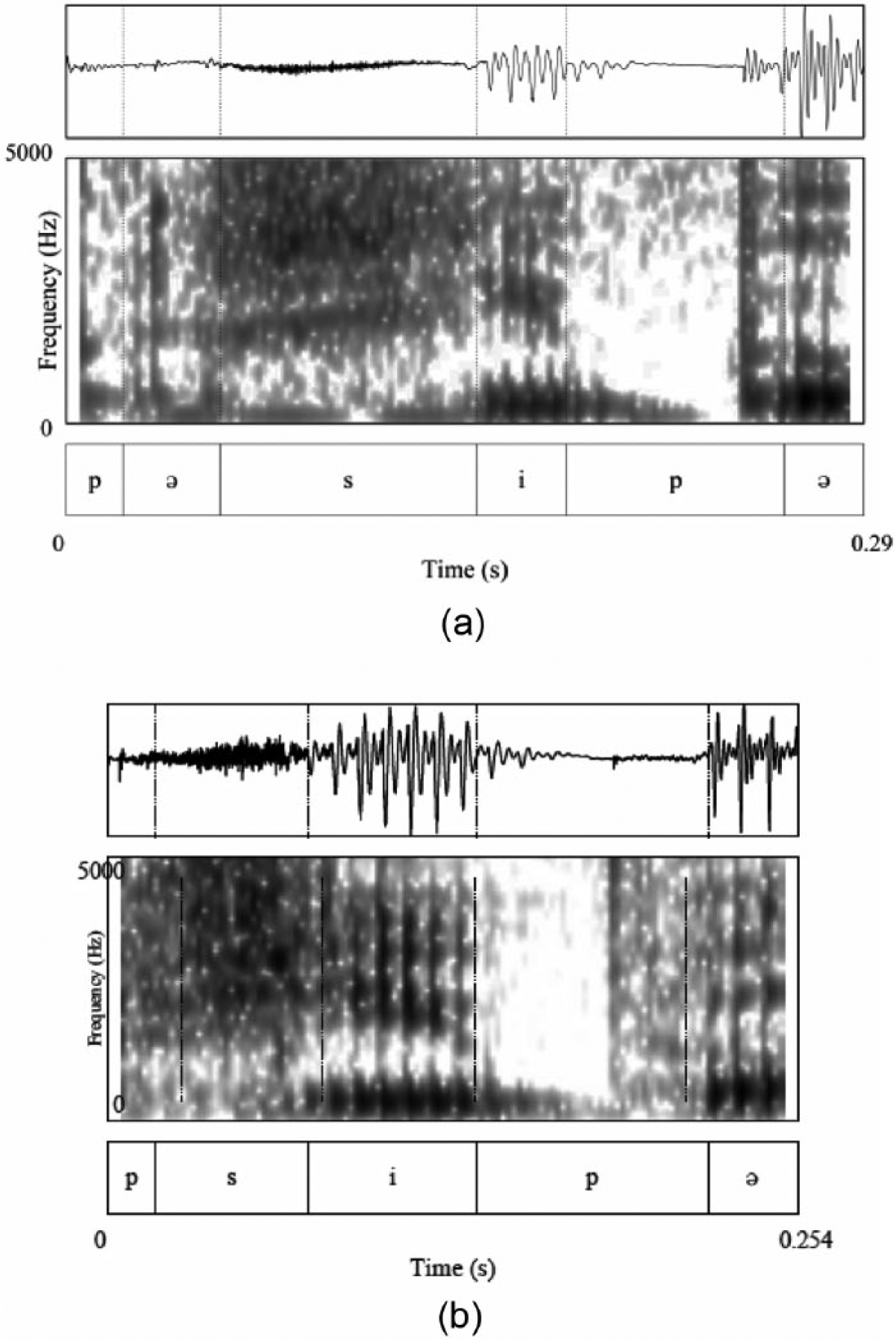
Spectrograms and transcriptions for two tokens of the word principe “principle.” (a) with the first unstressed vowel; (b) without the first unstressed vowel.
We determined the gates for our main experiment based on the locations of the segment boundaries in the phonetic transcription. Whenever there was a difference between these locations set by the two transcribers, the same third transcriber determined the correct boundary location. The average discrepancy between the locations of the segment boundaries of two transcribers equaled 2.11 ms.
Experiment 1 presented two different gates. Gate 1 consisted of only the preceding and following context of the experimental items, separated by a square wave. Gate 2 also contained the initial consonant cluster (which was the merged cluster in 62% of the tokens). Here, nine target tokens contained two consonants (14.29% of all target tokens), 14 target tokens contained three consonants (22.22% of all target tokens), and eight target tokens contained four consonants (12.70% of all target tokens).
Truncated speech sounds highly unnatural and may lead listeners to perceive an inserted labial or plosive consonant (Pols & Schouten, 1978), especially when the truncated speech is followed by silence. This is less the case if the truncated speech is followed by a square wave (Warner, 1998), and in our experiments we therefore used a square wave (rather than silence) to indicate the original location of the target word. We used a 500 Hz square wave, which consisted of an onset of 5 ms with gradually increasing amplitude and 500 ms with a fixed amplitude of 52 dB. The intensity of the sound fragments (without the square wave) was normalized to 70 dB.
As for the control experiments, the experiment consisted of 20 blocks. Each block contained the speech materials of one of the 20 speakers and was preceded by the same familiarization phase as in the control experiments. The blocks and trials within blocks were again randomized across participants, and each speaker block started with two filler tokens. Participants heard the materials of a particular speaker in either gate 1 or gate 2. After 47 of the 93 trials, the current speaker block was completed with gate 1, and the trials of the subsequent speakers were presented with gate 2. As a consequence, part one contained more target tokens than part two (33 vs. 30 target tokens on average).
2.1.3 Procedure
In both parts, participants were instructed to orthographically transcribe the target words while seated in a sound-attenuated booth, and while wearing headphones. The experiment was self-paced.
2.2 Experiment 2
2.2.1 Participants
Twenty native speakers of Dutch were paid to take part in the experiment. These participants did not take part in any of the other experiments.
2.2.2 Materials
The materials were identical to those of Experiment 1, except that the duration of the square wave now equaled the duration of the reduced word (in gate 1) or the duration of the word minus the duration of the initial consonant cluster (in gate 2). We used a minimum duration of 20 ms because a pilot experiment indicated that for shorter durations listeners have difficulty locating the square wave. The minimum duration of 20 ms meant that, in gate 2, the combined duration of the square wave and the initial consonant cluster for three fillers was longer than these reduced filler tokens themselves.
2.2.3 Procedure
The experimental procedure was identical to that of Experiment 1, except that participants were now told that the duration of the square wave equaled that of the missing word in gate 1, and of the part that was missing in gate 2.
2.3 Experiment 3
2.3.1 Participants
Twenty native speakers of Dutch were paid to take part in the experiment. These participants did not take part in any of the other experiments.
2.3.2 Materials
Each stimulus used in Experiment 1 was extended to include the first realized vowel for gate 3 and this vowel as well as the second consonant cluster for gate 4. For example, for the target word principe “principle” pronounced like [pə’sipə], participants heard [pə] in gate 3 and [pəs] in gate 4. On the other hand, for a different token of this target word, pronounced like [’psipə], participants heard [’psi] in gate 3 and [’psip] in gate 4. This meant that two tokens of the target word manier (both realized like [’mni]) were presented in full in both gates 3 and 4 (3.17% of the trials), while an additional 22 target words (38.10%) were presented in full in gate 4 (e.g., [’mir] for the target word manier “manner” and [’χɑt] for the target word gehad “had”).
Our phonetic transcriptions showed that 13 target stimuli contained merged second consonant clusters (20.63%). For example, the Dutch word verschillende [vər’sχɪləndə] “different” was realized like [’fsχɪln] and in gate 4 participants then also heard the consonants immediately following the second unstressed vowel in the word’s citation form. In 40 target stimuli (63.49%) consonants were missing in the second consonant cluster. For example, the Dutch word vanzelf “by itself” [vɑ
2.3.3 Procedure
The experimental procedure was identical to those of Experiments 1 and 2.
3 Results and discussion
3.1 Experiment 1
A transcriber labeled participants’ responses as correct or incorrect. 4 Participants produced 430 correct and 830 incorrect responses for the target words. Descriptive statistics indicated that listeners experienced difficulty guessing the target words on the basis of just the context (26.02% correct) or the context combined with the first consonant cluster (43.19% correct). Nevertheless, listeners performed better when presented with some acoustic information about the target words (average correctness increased by 17.17%). More acoustic information for these target words was required to correctly identify these words.
We analyzed the correctness of participants’ responses (correctness; in the analysis of the present and subsequent experiments) by means of generalized linear mixed-effects regression with the logit link function (Jaeger, 2008), using the statistical package lme4 (Bates, Maechler, Bolker, & Walker, 2015), and starting with the maximal random effects structure (Barr, Levy, Scheepers, & Tily, 2013). We included random effects for participant, target type (e.g., the Dutch word principe or manier), and target token (e.g., the first or second token of the Dutch word principe). We tested the significance of the random intercepts, random slopes, fixed effects and interactions of fixed effects by means of χ-squared tests comparing nested models. For the fixed effects, we also examined the p-values obtained from the model summary, and relied on the most conservative p-value if there was a difference between the two. Variables were removed if they did not attain significance at the 5% level. We first determined the fixed-effects structure, and subsequently whether the inclusion of random slopes improved the model fit. In a first analysis, we investigated whether participants gave significantly more correct responses after hearing the initial consonant cluster.
We entered several fixed predictors. Most importantly, we included gate (gate 1 vs. gate 2). We also incorporated as predictors the likelihoods of the target words given the preceding and following words in the sentences. We determined the words’ bigram frequencies with their preceding or following words on the basis of the Spoken Dutch Corpus (Oostdijk, 2002). 5
Finally, we included the control variable trial number (trial number within each gate), in order to capture effects due to learning or fatigue. The results of the mixed effects model are shown in Table 4.
Results for the statistical analysis for Experiment 1.
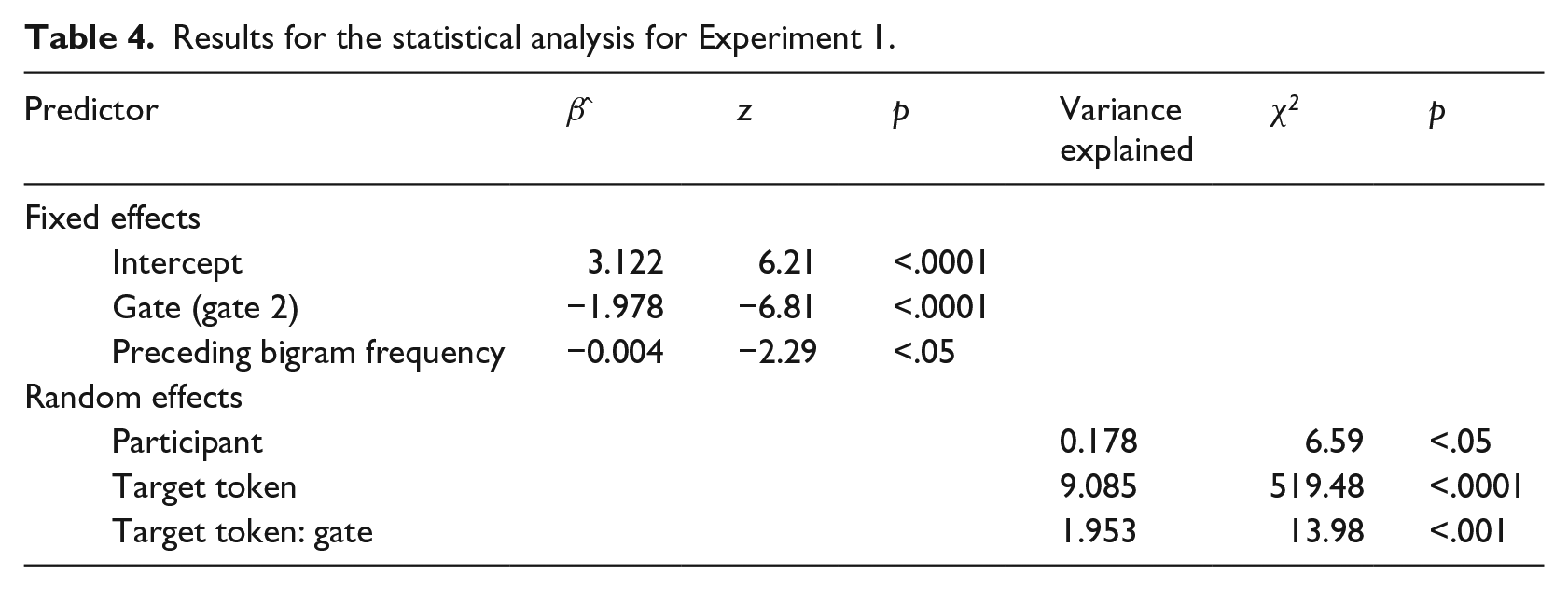
We found the main effects of gate and preceding bigram frequency, indicating that participants performed better if they heard the initial part of the target word (gate 2) and if the target word had a higher bigram frequency with the preceding word. The random slope of the variable gate for token type further indicated that the effect of adding the initial consonant cluster varied significantly across tokens. More specifically, we found that seven target tokens had strong positive slopes (β ̂ > 1) for gate 2 and thus listeners did not benefit much from hearing the first realized consonants and vowels for these target tokens. Four of these tokens also had strong positive intercepts (β ̂ > 1), indicating that these tokens were harder than the other tokens. On the basis of a visual inspection, it appears that the surrounding context of these target tokens allowed a relatively large number of semantically and syntactically legal alternatives, although this did not imply a relatively low bigram frequency of the preceding word with the target word or the target word with the following word. For example, de manier waarop “the way in which” contains a highly frequent bigram (de manier “the way”), but there are also many alternative answers for de… waarop resulting in highly frequent bigrams. On the other hand, there were three target tokens with strong negative slopes (β ̂ < −1), and for these tokens participants apparently benefited greatly from hearing the initial part of the target word in gate 2. Subsequently, we conducted a post hoc analysis to investigate the effects of the presence of the vowel in the initial syllable in gate 2. As mentioned in the Materials section, there was a relation between the presence of the first vowel and the presence of the complete initial consonant cluster; the same holds for segments in subsequent syllables, which is relevant for later experiments. Detailed analyses (for all main experiments reported in this study) showed, however, that the presence of the first unstressed vowel was a better predictor of the correctness of the responses than was the presence of the first complete consonant cluster of the unstressed syllable. Importantly, the presence of the vowel in the initial syllable affected the duration of the second gate (and subsequent gates; see Experiment 3) in the experiment. To make sure that the effects of vowel presence were not merely due to differences in duration between the stimuli presented with simple and merged consonant clusters, we included stimulus duration as a variable in the analysis.
Given that first vowel presence and stimulus duration were highly correlated, we had to orthogonalize these predictors before we could proceed with the analysis. Since orthogonalization reduces the predictive power of residualized predictors (Wurm & Fisicaro, 2014), the to-be-residualized predictor, which is least predictive, had to be determined in an objective manner. We used the following procedure to determine which of the two predictors was to be residualized (in all models that included both predictors in this paper). First of all, we fitted a separate regression model on participants’ responses with stimulus duration as predictor and another model with first vowel presence as predictor. These models included any other (uncorrelated) significant predictors (in this case preceding bigram frequency) and interactions. Importantly, we did this separately for each gate, because stimulus duration increased incrementally with each gate, whereas first vowel presence was always constant. We then compared the Akaike Information Criterions (AIC) of the two models (i.e., for stimulus duration and preceding vowel presence) and ranked them accordingly. This ranking determined which predictor was residualized. For all experiments reported in this study, we found a better fit for the model containing first vowel presence than for the one containing stimulus duration. Hence, for all models that contained both predictors, stimulus duration was residualized from first vowel presence, and stimulus durationresid was used to replace stimulus duration in the analyses.
Importantly, we found a significant effect of first vowel presence, t(1,592) = −3.37, p < .001, but not of stimulus durationresid. This finding shows that participants benefited especially from hearing the consonants following unstressed vowels in the full forms rather than from hearing just longer stretches of speech.
We also investigated participants’ incorrect responses. For this purpose, the same transcriber first marked whether the incorrect response was contextually appropriate, that is, if it could fit within the syntactic structure of the sentence, and whether the resulting sentence made any sense. For example, the response papier “paper” was labeled contextually inappropriate for the sentence Met die slaapzakken ook in het verleden wel
Further, the transcriber marked the correctness of the word’s first segment, second segment (if the first segment was correct), third segment (if the first and second segment were correct), the word-final segment, and the number of syllables. A segment was labeled as correct if its pronunciation matched that of the word’s citation form(s). For example, in certain regions of the Netherlands, voiced fricatives are frequently pronounced as voiceless, and therefore if a participant’s answer for the target word [vər’kopt] verkoopt started with an “f,” the first segment of this answer was labeled as “correct.”
The descriptive statistics for the incorrect responses are provided in Table 5 (the total number of incorrect responses equals 100%). These descriptives suggest that, in the case of an error, participants could better identify the first segments of the word’s citation form in gate 2 than in gate 1, which is as expected, since participants heard these segments in gate 2, whereas they did not in gate 1. Moreover, participants could better identify the first segments of the word’s citation form in gate 2 if they heard a merged consonant cluster. In both cases, however, listeners could not always recognize the initial consonants or did not always use this segmental information.
Percentage of contextually appropriate incorrect responses, and percentages of correct first segments, final segments, and number of syllables for the incorrect responses in Experiment 1, broken down by the gate and whether the initial unstressed vowel was realized.
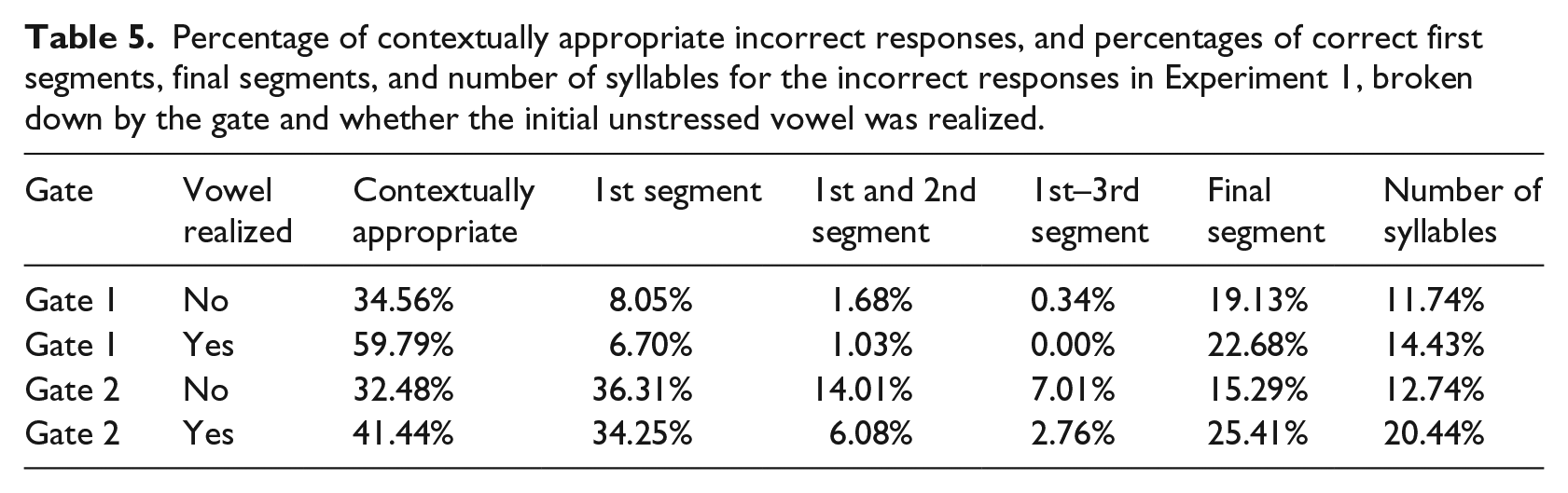
Further, participants provided more contextually appropriate responses for target words with simple than with merged consonant clusters, and this difference was smaller in gate 2 than in gate 1. Possibly, participants had more difficulties understanding the contexts of target tokens with merged consonant clusters, since highly reduced word tokens tend to occur in acoustically reduced contexts. This effect was smaller in gate 2, probably because any effects of reduction in the context become smaller as participants hear more acoustic information from the target words, for instance due to compensation for coarticulation.
Finally, 22.49% of the incorrect responses were semantically and syntactically possible and shared their first segments with those of the reduced target words. Apparently, Dutch allows multiple word candidates on the basis of the context and the word’s first segments. For example, for the sentence Ik had vandaag weer een auto geleend. “
To summarize, our results show that listeners had difficulties guessing the target word on the basis of the context alone or on the basis of the context and the initial consonant cluster. Importantly, performance was better if words started with merged consonant clusters, in gate 2, and this effect was not simply due to longer durations of these consonant clusters compared to simple consonant clusters. This finding indicates that hearing additional consonants outweighs the absence of the first unstressed vowel in word recognition.
Listeners apparently need more information from reduced pronunciation variants than the initial consonants, which could be more segmental information, or perhaps the durations of the words, as mentioned in the Introduction. Experiment 2 investigated whether listeners are able to use word duration to recognize words more easily.
3.2 Experiment 2
A transcriber labeled the responses, using the same criteria as for Experiment 1. Participants produced 335 correct and 925 incorrect responses for the target words (see Table 6).
The percentages correct for target words in Experiment 2, broken down by whether the initial unstressed vowel was realized, and by gate.
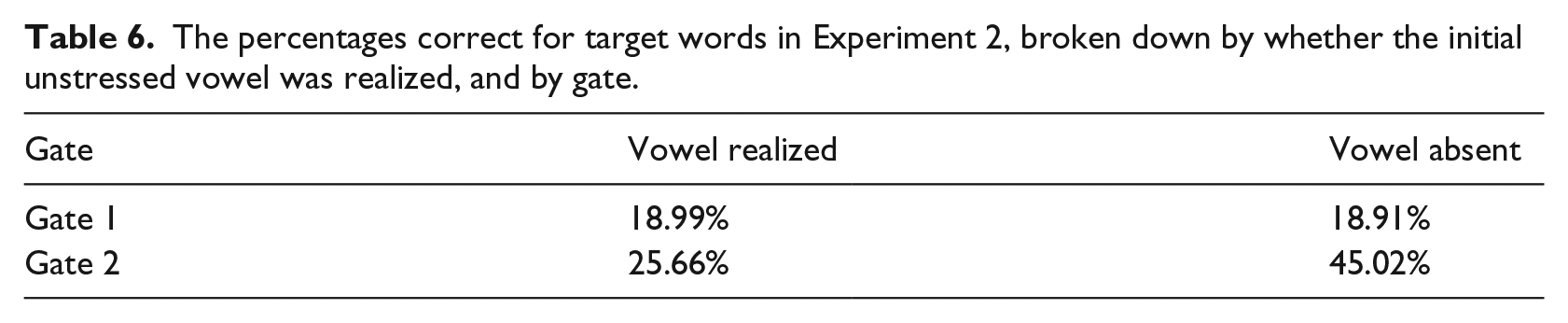
We fitted a regression model for the combined data set of Experiments 1 and 2, so that we could compare their results. We included the same random and fixed variables as for Experiment 1, in addition to experiment (Experiment 1 vs. Experiment 2). The results are provided in Table 7.
Results for the statistical analysis comparing Experiments 1 and 2.
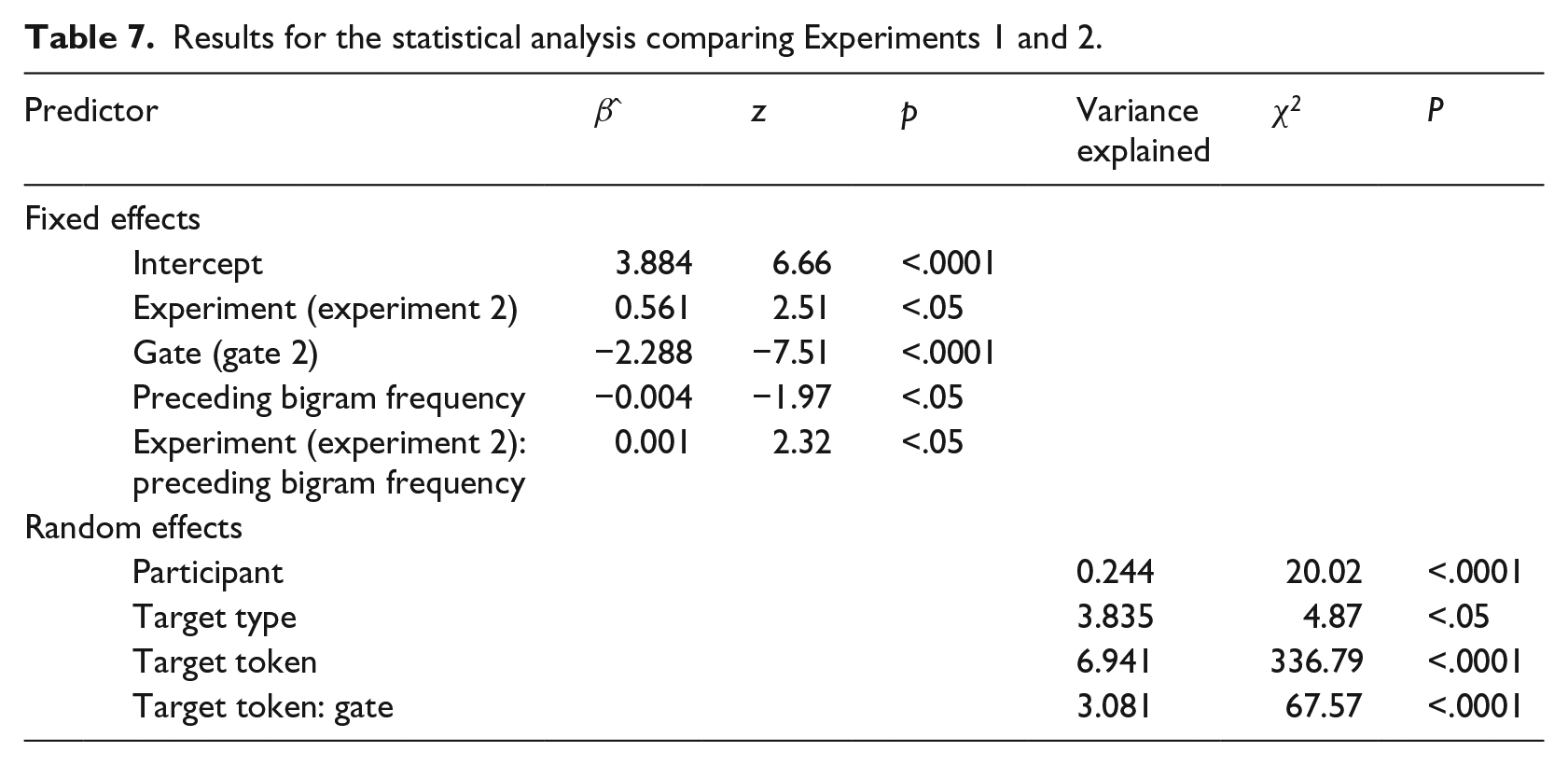
Importantly, we found a main effect of experiment, indicating that participants who heard the durations of the target words performed worse than those who did not. Durational information thus did not make the task easier, but appeared misleading.
Interestingly, we also found an interaction between experiment and preceding bigram frequency. This result indicates that the effect of preceding bigram frequency was restricted to Experiment 1. Apparently, participants focused less on context when also provided with durational information.
Subsequently, we fitted an additional model for gate 2 of both experiments, in which we included first vowel presence and stimulus durationresid as predictors, following the same procedure as for Experiment 1.
Importantly, we found an effect of first vowel presence t(1,1186) = −2.05, p < .05, yet no effect of stimulus durationresid. Thus, this effect of first vowel presence was not simply due to durational differences between merged and simple initial consonant clusters.
Why did participants perform worse if they were provided with additional, durational information to rely on? Listeners appear generally to be unaware of the reductions that occur in spontaneous speech (e.g., Kemps, Ernestus, Schreuder, & Baayen, 2004) and consequently participants may have tried to match the durations of the square waves to the durations of words’ citation forms. Since the target words were all segmentally and durationally reduced, participants may consequently have preferred candidates that are shorter than the citation forms of the target words.
We converted participants’ orthographic responses into phoneme sequences, and subsequently compared the lengths of the responses in phonemes (henceforth response length) in Experiments 1 and 2. Long vowels were counted as one phoneme (a decision that did not affect the outcome of the comparison). Since the lengths were not distributed normally, we converted response length into a binary variable by applying a median split: We labeled responses as “long” if they contained more than five phonemes; otherwise we labeled them as “short.” We then fitted a generalized linear mixed-effects regression model with the logit link function for the dependent variable response length, including the same random variables as for the analysis of the correctness of the responses. We found a significant main effect of experiment β = 0.477, F (1, 2518) = 8.20, p < .01, indicating that participants provided shorter responses in Experiment 2 than in Experiment 1 (4.92 vs. 5.31 phonemes on average).
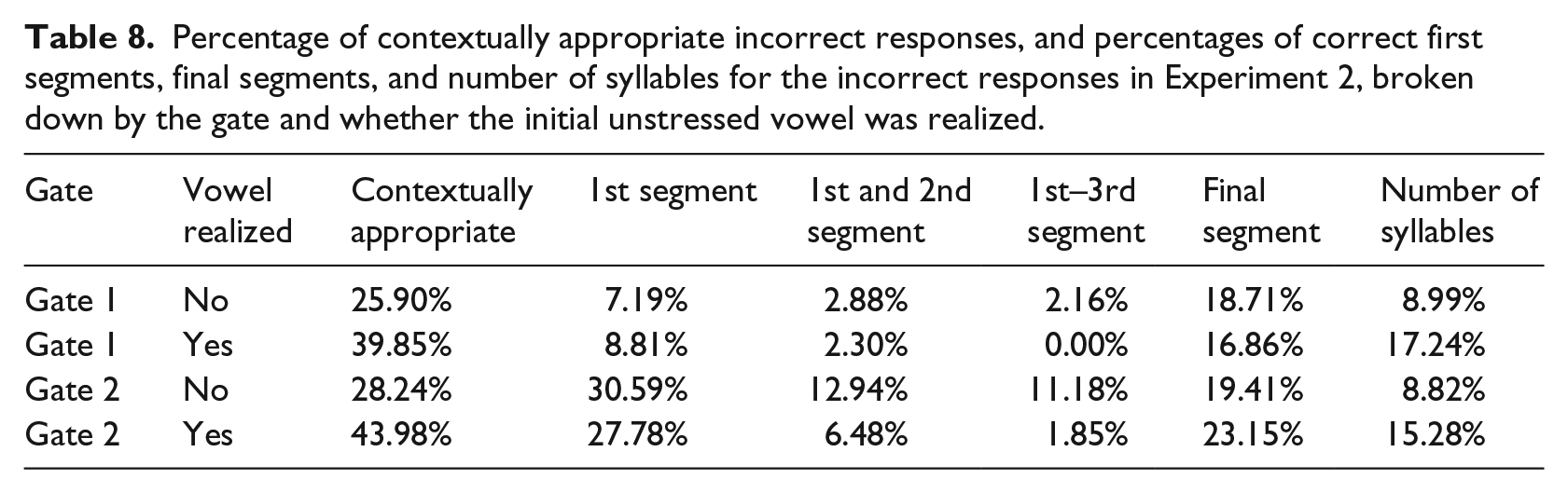
The descriptive statistics for the incorrect responses are provided in Table 8 (the total number of incorrect responses equals 100%). These descriptives were largely similar to those of Experiment 1. One important difference may be noted, however. The difference between simple and merged consonant clusters in terms of participants’ recognition of the first segments in incorrect responses appeared smaller than in Experiment 1.
Percentage of contextually appropriate incorrect responses, and percentages of correct first segments, final segments, and number of syllables for the incorrect responses in Experiment 2, broken down by the gate and whether the initial unstressed vowel was realized.
To conclude, listeners are misled by the durational information from reduced pronunciation variants if this durational information is provided separately from other acoustic information. These results are in line with the hypothesis that listeners are unaware of the reductions in spontaneous speech, and therefore cannot use word duration by itself to recognize these reduced pronunciation variants.
So far, we have established the contribution of the initial consonant cluster and of word duration to the recognition of reduced pronunciation variants. In Experiment 3, we investigated the contributions of the first realized vowel and of the subsequent consonant or consonant cluster (henceforth the “second consonant cluster,”) to the recognition of these variants.
3.3 Experiment 3
Participants produced 745 correct responses and 515 incorrect responses for the target words (see Table 9). First, we investigated the contribution of the first vowel to the recognition of reduced pronunciation variants by comparing the results for gate 2 from Experiment 1 to those for gate 3 from Experiment 3, with a regression model, including the dependent variable correctness and the same fixed and random effects as for Experiment 1. The results are provided in Table 10.
The percentages correct for tokens in which listeners either heard the unstressed or stressed vowel from the target words in gates 3 and 4.

Statistical results for gate 2 and gate 3 in Experiments 1 and 3 respectively.
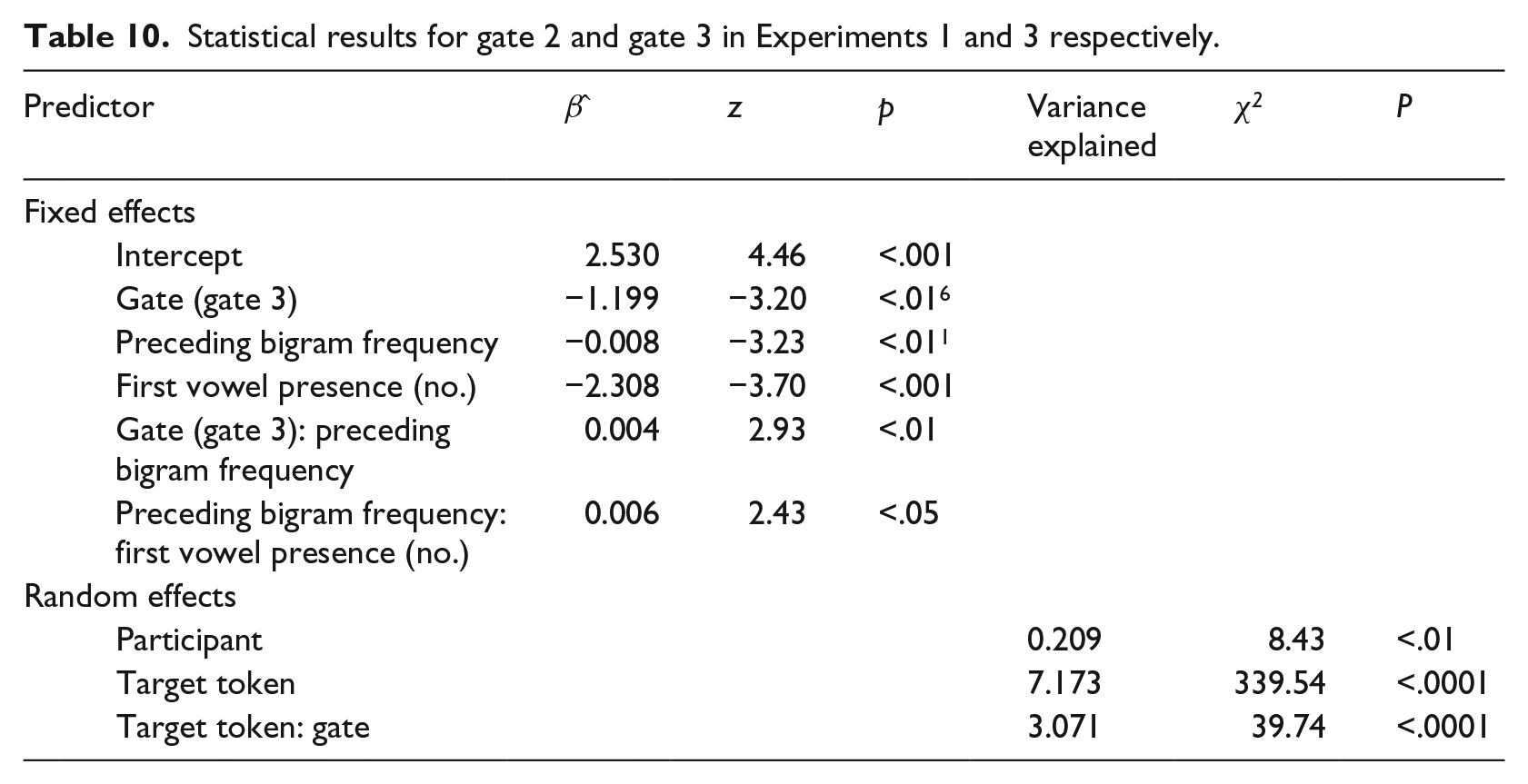
Importantly, we found a main effect of first vowel presence and two-way interactions between preceding bigram frequency and gate and between preceding bigram frequency and first vowel presence. These interactions indicated that listeners better recognized target words if they heard the vowel in addition to the initial consonant (i.e., in gate 3), and if they heard a merged consonant cluster (in both gates) and a vowel from the stressed rather than the unstressed syllable (in gate 3), and these effects were larger for target words with low bigram frequencies with their preceding words. There was no effect of stimulus durationresid.
The random slope of the factor gate for target token indicated that the main effect of gate, which had a beta estimate of −1.20, was reversed or completely absent for 13 target tokens (20.63%); thus, for these target tokens, the beta estimates were maximally 1.95 (range of beta estimates for these tokens: 1.21 to 3.15).
Subsequently, we fitted a regression model for the complete data set of Experiment 3 in order to determine the effect of the consonant cluster following the first vowel in the stimulus. We included the same random and fixed variables as for Experiment 1, in addition to the fixed variable complete auditory form (whether the reduced target word was presented in full). Given that complete auditory form was correlated with gate (participants heard more acoustic information in gate 4 than in gate 3), and neither of the two was numeric, two separate models were fitted containing only one of these two predictors. Subsequently, we selected the best model on the basis of the AIC and the Bayesian Information Criterion (BIC). This model comparison showed a substantially better fit for the model containing gate (AIC difference = 58.60, BIC difference = 58.60).
The results of the analysis are provided in Table 10. We found a three-way interaction between gate, first vowel presence, and preceding bigram frequency. In addition, the random slope of the factor gate for target token showed that the main effect of gate was absent for one target token (i.e., the slope estimate for this token equaled 1.47), and the random slope of the factor first vowel presence for participant indicated that the main effect of first vowel presence was, despite a significant amount of variation, not completely absent for any of the participants. In order to interpret the three-way interaction, we split the data by gate. Post hoc analyses (for the two gates separately) revealed an interaction between first vowel presence and preceding bigram frequency for gate 3 t(1,659) = 2.44, p < .05, yet no such interaction for gate 4 (only main effects of first vowel presence and preceding bigram frequency).
Hence, while participants’ benefit from hearing a merged consonant cluster in the absence of the first vowel depended on the target words’ bigram frequencies with their preceding words (gate 3), there was no such dependency in gate 4. Since we did not find any effects of stimulus durationresid, this main effect of first vowel presence cannot purely be attributed to the durations of the gates.
Finally, we investigated participants’ incorrect responses in Experiment 3. The descriptive statistics are provided in Table 11. The results show that listeners often did not recognize the first three segments of the reduced target word at all. Further, unlike the incorrect answers for Experiments 1 and 2, participants’ incorrect responses more frequently contained the correct initial segment if the first unstressed vowel was present. Apparently, listeners could identify more segments after hearing more following segments, but they nevertheless could not identify the target words in these cases (Table 12).
Statistical results for Experiment 3.
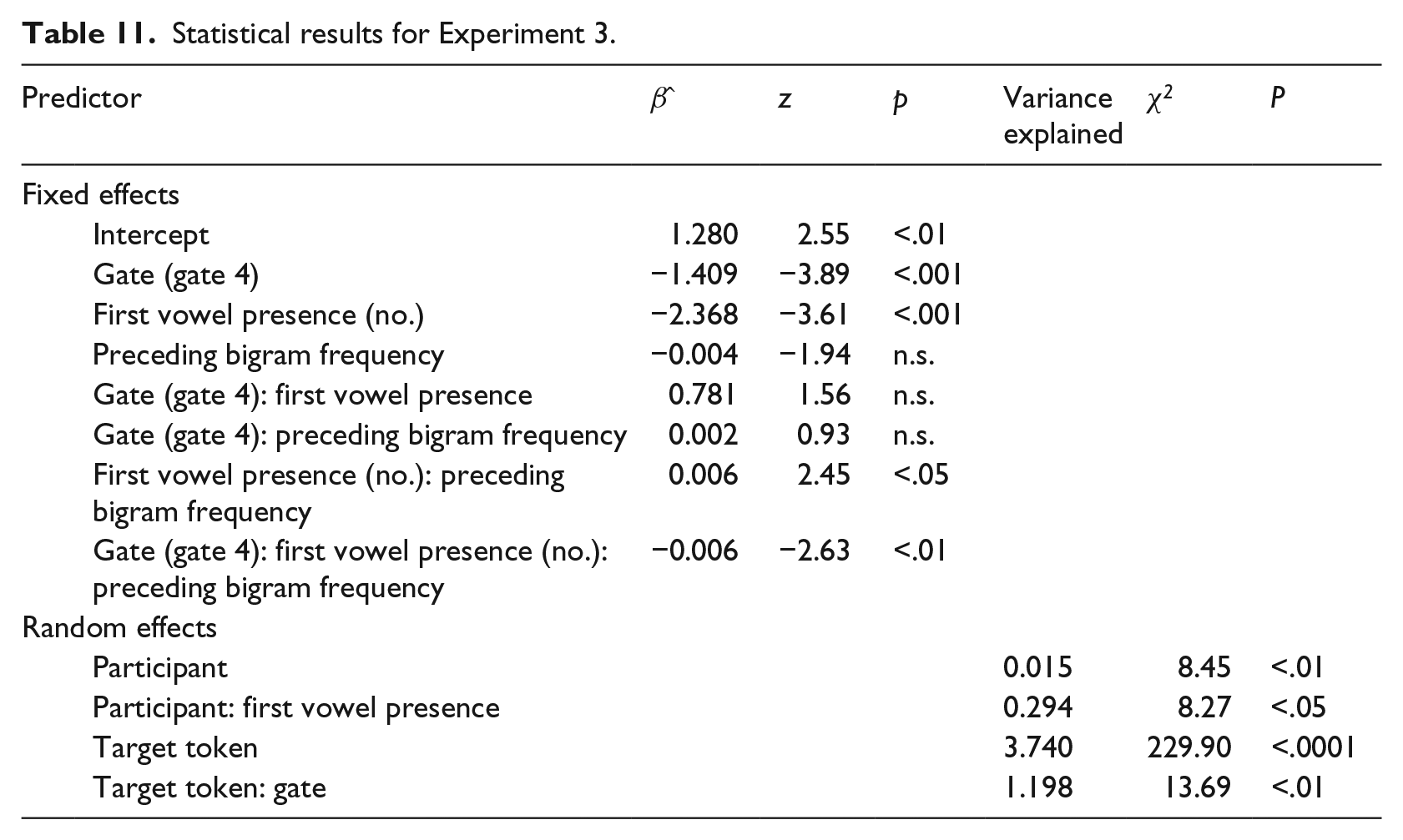
Percentage of contextually appropriate incorrect responses, and percentages of correct first segments, final segments, and number of syllables for the incorrect responses in Experiment 3, broken down by the gate and whether the initial unstressed vowel was realized.
To summarize, listeners better recognized target words if they heard the vowel from the stressed syllable and the first, unstressed vowel was missing than if they heard the vowel from the initial, unstressed syllable. This suggests again that the possibly disturbing absence of a vowel may be compensated for by information from the stressed vowel and additional consonants becoming more readily available. In addition, phonetic residues from the unstressed vowel may play a role. This effect was larger for words with low bigram frequencies with their preceding words. Finally, we found that the role of bigram frequency information decreased as listeners heard more segments of the target words.
4 Discussion
Listeners need both the context and acoustic information from reduced word pronunciation variants to recognize these variants (e.g., Janse & Ernestus, 2011; van de Ven et al., 2012). The present study investigates which types of acoustic information listeners rely on most. We addressed three questions, namely: (1) which segments are especially important for listeners to recognize reduced word pronunciation variants; (2) what is the contribution of word token duration to the recognition of reduced pronunciation variants; and (3) whether the gating paradigm (Grosjean, 1980) can be adapted for studying how listeners understand reduced pronunciation variants in their context. We focused on target words with reduced unstressed initial syllables because missing vowels in the initial syllables are likely to create ambiguity and increase uncertainty during the recognition process (e.g., the Dutch words verlaten “leave” and flater “blunder” with the citation forms [fər’latən] 6 and [’flatər] may both sound like [’flatə]).
In an adapted version of the gating paradigm, participants heard fragments of spontaneous speech always consisting of the context preceding the reduced target word, some segments of this target word (except for the baseline condition, gate 1, in which listeners heard only the context), a square wave, and the following context. By aligning the gates with the boundaries of consonant clusters (rather than using gates with fixed durations), we controlled the types of segments that participants heard in each gate. This allowed us to investigate the role of these segments. Importantly, by comparing simple and merged consonant clusters we could investigate the role of the first unstressed vowel in the recognition of reduced pronunciation variants. Merged consonant clusters contained more segments and could contain subphonemic cues signaling the missing vowels. Hence, the question arises whether listeners are hindered (or, on the contrary, aided) by the absence of the initial unstressed vowel, if we take into account the durational differences.
Each participant heard two out of four gates. They only heard the context in gate 1. In addition to the context, they heard the initial consonant cluster of the target word in gate 2, the initial consonant cluster and the first realized vowel of the target word in gate 3, and the initial consonant cluster, the first realized vowel, and the second consonant cluster of the target word in gate 4.
We found that participants’ performance improved with every gate (percentages correct for gate 1: 26.02%; gate 2: 43.19%; gate 3: 51.13%; gate 4: 68.07%). Importantly, the performance for gates 2–4 was higher for merged than for simple consonant clusters. This shows that the full presence of unstressed vowel is less important than the presence of additional consonants. This result may partially be explained by research indicating that, at least in carefully pronounced speech, consonants play a larger role in word recognition than vowels (e.g., Bontatti, Peña, Nespor, & Mehler, 2005; Cutler, Sebastián-Gallés, Soler-Vilageliu, & van Ooijen, 2000; Mehler, Peña, Nespor, & Bonatti, 2006).
Importantly, our study is the first to indicate that reductions may actually benefit the listener. This result contrasts with previous findings suggesting that reductions inhibit word recognition (e.g., Ernestus & Baayen, 2007; Ranbom & Connine, 2007; Tucker, 2011; Tucker & Warner, 2007; van de Ven et al., 2011), lead to relatively high cognitive demands (Drijvers et al., 2016), and delay spreading of activation to semantically related words (e.g., Drijvers et al., 2016; van de Ven et al., 2011). These previous findings nearly all come from experiments testing listeners’ comprehension of reduction in read-aloud isolated words or in words embedded in short (e.g., Ernestus & Baayen, 2007; Ranbom & Connine, 2007; Tucker, 2011; Tucker & Warner, 2007; van de Ven et al., 2011) or more elaborate (Drijvers et al., 2016) read-aloud sentences. This may explain these divergent findings, especially since previous research has shown the importance of natural contexts (e.g., Ernestus et al., 2002; Janse & Ernestus, 2011). Only Brouwer et al. (2012) tested the comprehension of reduced words in their natural contexts, as in the present study. They used a printed words version of the visual world paradigm, which may have activated the words’ citation forms. Possibly, these orthographic representations are responsible for the inhibition that these authors found for reduced forms.
The present study also investigated the role of durational information in the recognition of reduced words. In Experiment 2, the duration of the square wave (gate 1), or its duration combined with the duration of the initial consonant cluster (gate 2), equaled that of the reduced target word. Surprisingly, listeners found this durational information misleading, and they made more errors and gave shorter words as responses in Experiment 2 than in Experiment 1, where the duration of the square wave was fixed. In line with Kemps et al. (2004), this finding shows that listeners are unaware of the reductions that occur in spontaneous speech, and, because the target words were short, they therefore expected them to contain few segments in their citation forms.
In all three experiments, we tested the contribution of local semantic/syntactic contextual information, operationalized as bigram frequencies, to the recognition of the reduced target words. Theoretical models of word recognition predict that listeners can use contextual information to narrow down their lexical search space (e.g., van Berkum, Brown, Zwitserlood, Kooijman, & Hagoort (2005) or enhance semantic integration (van Petten & Kutas, 1990)). We found a gradually decreasing effect of preceding bigram frequency as a function of how much participants heard of the target words. This finding shows that listeners rely less heavily on probabilistic information based on the context to recognize these reduced variants if more acoustic information from the word is available, even for a reduced word (with e.g., shorter segment durations, spectral reduction). Hence, reduced segmental information seems to outweigh probabilistic contextual information in recognizing reduced pronunciation variants, in line with van de Ven et al. (2012).
These results are expected. They show that listeners predominantly rely on their acoustic input. Contextual information mostly facilitates the word recognition process. It only determines the outcome if insufficient acoustic information is available. If contextual information played a larger role, listeners would not be able to understand unexpected words/information.
We obtained these results by operationalizing local semantic/syntactic contextual information as bigram frequencies. We could have operationalized contextual probability differently, for instance by means of a visual cloze task. We believe that a different operationalization would have produced the same result because bigram frequency well reflects semantic/syntactic contextual information and because the result reflects the fact that listeners are able to understand unexpected information.
Participants’ incorrect responses also provide information about the recognition process. These responses mainly show that, when provided with just the initial consonant cluster, participants could better identify the segments of the cluster when it was merged, as a result of vowel reduction, than when it was a simple cluster. However, since merged clusters also typically contained more segments and were therefore probably more noticeable, it is difficult to draw strong conclusions based on this finding. Moreover, participants could frequently come up with contextually appropriate alternatives for our target words with the same initial segments, which testifies the importance of hearing the complete realization of reduced pronunciation variants.
Finally, this study demonstrates that the gating paradigm (Grosjean, 1980), designed for studying the comprehension of laboratory speech, can also be used for studying the comprehension of highly reduced pronunciation variants in conversational speech. In our version of the gating paradigm, we placed gates at the end of segment boundaries, thereby controlling for the number of vowels and consonant clusters listeners heard. Since we statistically controlled for the confound between vowel reduction and gate duration, we could use the gating paradigm to study the influence of vowel reduction on the recognition of reduced words.
Preferably, future studies follow up on our study in order to investigate whether the same results are also found with different experimental paradigms. This holds for all studies using only one experimental paradigm. Furthermore, one disadvantage of our version of the gating experiment is that (part of) the target word is replaced by noise, which decreases the task’s ecological validity.
5 Conclusions
The present study shows that the gating paradigm can be effectively adapted to investigate the effects of initial vowel reduction on the recognition of reduced pronunciation variants embedded in natural contexts. The results show that acoustic cues in reduced words override probabilistic cues based on preceding context, and that reductions may enhance word recognition if this means that subsequent segments from the stressed syllable become more readily available.
Footnotes
Appendix
This Appendix contains orthographic transcriptions of the materials and phonetic transcriptions of the target words used in the present study. We have underlined the target words in the orthographic transcriptions.
Ze hadden ons gevraagd of wij de allerlaatste keer in die boot wilden roeien en
“They had asked us to row that boat for the last time and
En een jaar
“And the year
Hij heeft
“
Het was precies
“It was exactly
En daar zit nu ook de hele
“And the whole
Ja, bij jullie
“Yes, in your
Het ging dan meer om
“It was then more like a
En dan de
“And then update the
Ik heb een tijd
“I have
Of heb jij ook te maken
“Or have you also
Ik heb ook een periode van een jaar ofzo
“I have also
Want ik heb nooit het idee
“Because I have never
De mensen van wie je normaal
“The people who normally
Een grote partij in te slaan en dan heel
“Stock a large amount and then offer them at a very
Straks staan ze allemaal tegen die [χə’kop] tenten aan te loeren.
“Soon they will all be looking at those
Dat was de tweede keer dat we op
“That was the second time that we were at
Je betaalt exact
“You pay exactly
Waarom we voor een
“Why we opted for an
Nee, maar het is toch de
“No, but it is still the
Maar dat was al op die
“But that was already guaranteed in that
Maar goed, dan wordt het toch op een of andere
“But well, that will still be recorded in some
Moet natuurlijk dat geld op de een of andere
“Of course that money had to be administered in a certain
Maar hij leest op dit
“But at the
In Amsterdam duurt het op dit
“In Amsterdam it takes very long at this
Maar waar wordt dit
“But what is this
Als ik iets koop dan moet het maximaal een
“If I buy anything then it has to be maximally a
In het verleden heb je vrij forse
“In the past you bought quite large
Ik kan eh in
“I can eh in
De dingen die je meet zijn in
“The things that you measure are in
Ik voel me daar in
“In
Boeken die er in
“Books that in
Met die slaapzakken ook in het verleden wel
“With those sleeping bags in the past there were also problems actually.”
Nee dan wil ik toch echt 25
“No then I really want to have a 25
Dan kan ik daar wel eh twintig
“I think I can get eh a 20
Maar dat vind ik een slecht
“But I consider that a bad
Hij is weer met een ander Europees
“He is working on a different European
Echt het idee van op
“Really the idea of maybe renting a car during the
Ik had
“
Dat het opeens
“That suddenly it goes
Op die
“On that
Ik zal het
“I will tell the
Het moraal van het
“The moral of the
Jij was niet op de
“You were not present at Jet’s
Ik vind een
“I think a
Hij had toch wel eh een
“He did have a eh
Dat ze een grote kans hebben om eh het
“That they run a larger risk to eh go
Want jij
“Because after all you
Mijn oma heeft
“
Maar dit jaar ga ik niet het risico lopen, want
“However, this year I will not run that risk, because
Van hoe hoe dat afscheid
“Of how how one
Kan je op
“You can do that in
Corpus dat bestaat uit materiaal van
“Corpus that consists of materials from
Ik vind wel een heleboel
“I like a lot of
Steekproef te nemen van
“To take a sample of
Dus ik kan meer
“So I can better
Gewoon het idee dat je niet af en toe even kan praten over je werk vond ik heel
“Simply the thought that you cannot occasionally talk about your work, I considered very
Ik moet ze ook netjes houden, want anders is het voor jou
“I also need to keep them tidy, because otherwise it is very
Nou hij
“Well he has been
Het ging die ene persoon dan ook
“It concerned that one person who
Je komt weleens langs en
“You occasionally pass by and you are
En jullie hebben
“And you have
Net
“
Te vieren
“To celebrate it
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a European Young Investigator Award from the European Science Foundation and by an ERC starting grant (284108), both to the second author.