
Abstract
Expert-coded datasets provide scholars with otherwise unavailable data on important concepts. However, expert coders vary in their reliability and scale perception, potentially resulting in substantial measurement error. These concerns are acute in expert coding of key concepts for peace research. Here I examine (1) the implications of these concerns for applied statistical analyses, and (2) the degree to which different modeling strategies ameliorate them. Specifically, I simulate expert-coded country-year data with different forms of error and then regress civil conflict onset on these data, using five different modeling strategies. Three of these strategies involve regressing conflict onset on point estimate aggregations of the simulated data: the mean and median over expert codings, and the posterior median from a latent variable model. The remaining two strategies incorporate measurement error from the latent variable model into the regression process by using multiple imputation and a structural equation model. Analyses indicate that expert-coded data are relatively robust: across simulations, almost all modeling strategies yield regression results roughly in line with the assumed true relationship between the expert-coded concept and outcome. However, the introduction of measurement error to expert-coded data generally results in attenuation of the estimated relationship between the concept and conflict onset. The level of attenuation varies across modeling strategies: a structural equation model is the most consistently robust estimation technique, while the median over expert codings and multiple imputation are the least robust.
Keywords
Expert-coded datasets such as the Chapel Hill Expert Survey, Electoral Integrity Project, Human Rights Measurement Initiative, and Varieties of Democracy (V-Dem) allow scholars to conduct cross-national longitudinal research on vital concepts (Bakker et al., 2012; Norris, Frank & Martínez i Coma, 2014; Clay et al., 2020; Coppedge et al., 2018). However, expert-coded data come with potential disadvantages. Experts are susceptible to different sources of error (Clinton & Lewis, 2008; Bakker et al., 2014; Marquardt & Pemstein, 2018b); such error may bias results in statistical analyses (Lindstädt, Proksch & Slapin, 2018). These concerns are particularly acute in the context of quantitative peace research. Since outcomes such as conflict onset are rare events, quantitative analyses will be sensitive to measurement error on the right-hand side. Moreover, expert perceptions of key correlates of conflict may be endogenous to this outcome.
Given these concerns, awareness of the degree to which different forms of expert error substantively matter is of great importance, as is understanding of the extent to which different modeling strategies can correct for these errors. I provide insight into these two issues by conducting a series of ecologically valid simulation analyses in which I vary expert error in the measurement of a latent concept. I then regress conflict onset on the simulated data using five modeling strategies: three strategies utilize common point estimates, while the other two incorporate measurement uncertainty.
Results from these analyses indicate that most methods roughly recover the correct relationship between the expert-coded concept and conflict onset, even when expert error is extremely high. At the same time, simulated expert error almost always results in attenuation bias, in line with standard expectations from the error-in-variables literature (Chesher, 1991; King, Keohane & Verba, 1994; Stefanski, 2000; Hausman, 2001): simulated error reduces the magnitude of the relationship between the expert-coded variable and conflict onset. However, the degree to which this attenuation occurs varies across modeling strategies: the most robust strategy is a structural equation model which iteratively estimates concept values and their relationship to conflict onset, while the median and multiple imputation are the least robust.
Measuring latent concepts with expert-coded data
As articles in this special issue illustrate, scholars can use data from a variety of sources to estimate important latent concepts (Barnum & Lo, 2020; Fariss, Kenwick & Reuning, 2020; Krüger & Nordås, 2020; Terechshenko, 2020). Individuals who have extensive knowledge about both these concepts and particular cases – henceforth ‘experts’ – can also efficiently provide information for such purposes (Marquardt et al., 2017). However, since latent concepts are not directly observable, equally expert experts are likely to have different perceptions of ‘true’ latent values. Experts will therefore disagree in their codings. While such disagreement is an integral element of expert coding, disagreement may also result from variation in expert (1) scale perception (a concept known as differential item functioning, or DIF) and (2) reliability (Clinton & Lewis, 2008; Bakker et al., 2014; Lindstädt, Proksch & Slapin, 2018; Marquardt & Pemstein, 2018b).
These latter forms of disagreement present problems for quantitative analyses that use expert-coded data, particularly in the context of peace research. To illustrate these problems, I focus on an expert-coded latent variable from the V-Dem dataset, identity-based discrimination (‘Social group equality in respect for civil liberties,’ Coppedge et al., 2018). 1 Though identity-based discrimination underlies many theories of ethnic conflict and separatism (Gellner, 1983; Gurr, 1993; Horowitz, 2000), it is difficult to observe: relevant forms of identity and discrimination vary across countries, and governments generally have little incentive to publicize the degree to which they engage in discrimination. As a result, this concept is an excellent example of an important-but-challenging latent concept for expert coding.
Differential item functioning in expert-coded data
Experts may have different perceptions of question scales. For example, the V-Dem identity-based discrimination question asks experts to use a five-point Likert scale to report the degree to which a government deprives citizens of civil liberties on the basis of membership in social groups (a term which largely aligns with ethnicity). 2 The words ‘much’, ‘substantially’, ‘moderately’, and ‘slightly’ modify the degree to which social groups enjoy fewer civil liberties in the question scale. In this example, one expert’s ‘substantially’ could easily be another expert’s ‘much’. As a result, two experts who perceive the same latent level of discrimination may report different values.
If DIF is randomly distributed across a sufficiently large number of experts, this source of expert disagreement is problematic only in that it increases uncertainty about an estimate. However, it is likely that DIF is not randomly distributed, but instead clustered by cases. Such clustering raises concerns about cross-national comparability.
Most generally, experts with similar backgrounds may exhibit similar biases (Maestas, Buttice & Stone, 2014). Since experts with expertise on a specific country are those most likely to code it, these biases may be clustered by country. More specific concerns are also possible. If a country changes from having relatively high levels of a latent variable to a lower level, experts who focus on this country may code the change as more extreme than would experts with more comparative experience (Pemstein, Tzelgov & Wang, 2015). Actors in conflict settings may use grievances – ranging from discrimination to repression to corruption – to justify their struggle, even if the true cause of conflict lies elsewhere (Fearon & Laitin, 2003). Such framing may lead country experts to perceive high levels of the concept linked to the salient grievance, regardless of the concept’s actual level.
Variation in expert reliability
Potential variation in expert reliability is also a concern. For example, V-Dem uses a network of over 3,500 expert coders. Although the project employs a rigorous procedure to select experts (Coppedge et al., 2019), there is almost certainly variation in the degree to which these coders are knowledgeable about their cases and concepts.
As with DIF, more idiosyncratic forms of variation in reliability are also possible. Reliable information about political processes may not be readily available in cases with conflict, causing experts to rely on less accurate and potentially biased sources. Civil conflict is a context that may particularly lead to expert polarization: in periods leading up to conflict a regime-sympathizing expert may code latent concepts such as identity-based discrimination as decreasing, while a regime opponent may code the same concept as increasing.
Aggregating expert-coded data
The method by which a researcher aggregates expert-coded data has important implications for the degree to which the resulting estimates are robust to DIF and variation in expert reliability. Here I focus on three aggregation techniques: (1) the normalized average; (2) the median; and (3) latent variable models, in this case a modified Bayesian ordinal item response theory (IRT) model. The primary virtue of the first two methods is that they are straightforward, with Lindstädt, Proksch & Slapin (2018) arguing that the median is a robust alternative to the more commonly used average.
The third aggregation technique has two main virtues. First, it provides estimates of uncertainty that can be readily incorporated into regression analyses, as I will discuss in the following section. Second, it can account for both DIF and variation in expert reliability. In particular, IRT models outperform both the normalized average and the median in recovering latent values when expert error is high (Marquardt & Pemstein, 2018a,b). 3
To explain how IRT models can account for variation in expert scale perception and reliability, I provide a brief overview of the standard V-Dem IRT model. 4 Equation 1 presents the partial likelihood for this model.
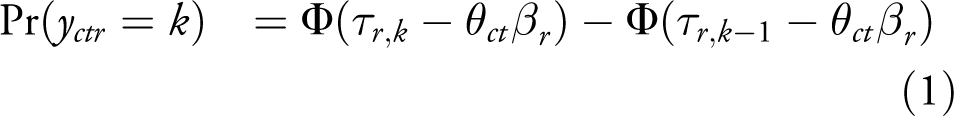
y represents the ordinal coding (values
The model accounts for variation in expert reliability through
Modeling expert-coded data in regression analyses
Since expert disagreement is an inherent aspect of expert-coded data, incorporating the resulting measurement uncertainty into regression analyses is of clear theoretical value. I illustrate this process using a very reduced Bayesian probit model, 6 in which I regress a country-year level indicator of civil conflict onset (Gleditsch et al., 2002; Pettersson & Wallensteen, 2015; Girardin et al., 2015) on different aggregations of a latent expert-coded concept with a one-year lag. The model also includes a cubic spline and country and year effects. Equation 2 presents the baseline model:
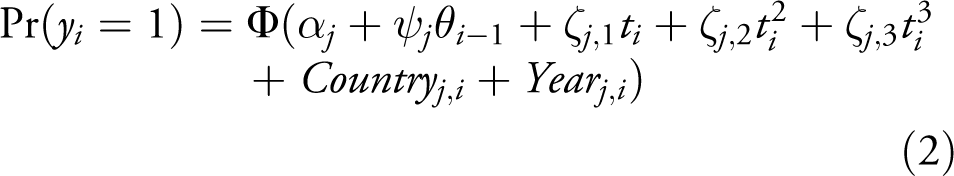
Here
The Bayesian estimation strategy allows me to incorporate measurement uncertainty about the latent concept in two ways. First, it facilitates multiple imputation using draws from the IRT model in Equation 1.
8
Specifically, I rerun the model eight times with each of 500 draws from the posterior distribution of
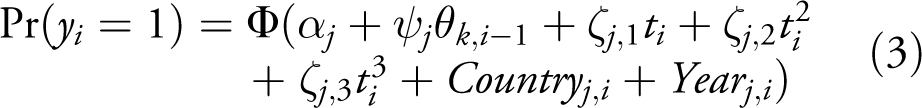
Second, I embed the IRT model within the regression equation using a structural equation model. This model iteratively estimates
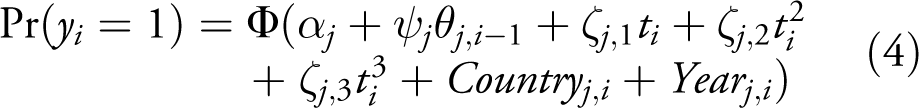
Simulation analyses of expert error
While there are clear theoretical distinctions between different aggregation techniques and modeling strategies, the extent to which they matter in an applied regression context is unclear. To put it bluntly: while we know that experts can be unreliable and have different scale perceptions, we do not know the extent to which expert-coded data can yield misleading regression results. Equally importantly, we also do not know if different modeling strategies can correct for the different forms of measurement error we expect in expert coding.
I therefore conduct a series of simulation analyses to provide insight into the sensitivity of regression analyses to different forms of expert error, using the modeling strategies described in the previous sections. 9 Note that conflict onset – the outcome in these analyses – is a rare event, occurring in only 2.8% of observations. As a result, these analyses should be highly sensitive to perturbations in the expert-coded data and thus constitute a strong test of robustness.
I use data from the V-Dem identity-based discrimination variable to create ecologically valid simulated data. Specifically, experts in the simulated datasets code the same set of observations as their real-world counterparts. I set the true values for each observation as equal to the posterior median estimate of identity-based discrimination, which means that the true relationship between the simulated concept and conflict onset is known. I then simulate different forms of error across expert coders, and use these forms of error in conjunction with the known true values to create simulated expert coding datasets. 10 I regress conflict onset on different aggregations of the simulated data, using the models in Equations 2 –4. I replicate this procedure thrice for each form of simulated error to check robustness.
Although I derive the data from a particular latent variable (identity-based discrimination), this simulation strategy means that the results should be generalizable to other expert-coded data, with several caveats. First, these analyses constitute a particularly hard test for expert-coded data. Not only is the outcome of interest a rare event, but the assumed relationship between identity-based discrimination and conflict onset is relatively weak, if consistently positive: a change from a low to high level of identity-based discrimination correlates with a .04 increase in the posterior probability of conflict onset. 11 As a result, the simulated data are likely more sensitive to expert error than they would be for a latent concept with a stronger relationship with conflict. Second, V-Dem data are relatively sparse: while a total of 1,418 experts code some subset of cases for this variable, the median observation has six coders. If the data were less sparse (i.e. more than six experts coded each observation), the analyses would be more robust to random expert error; the converse is also true (Marquardt & Pemstein, 2018b). Third, there is relatively substantial bridging in the data: the median number of additional countries which the experts who coded a given country also coded is 25, while the equivalent statistic at the observation level is 10. As a result, the data present the IRT model in Equation 1 with the potential to correct for systematic differences in scale perception and reliability across countries. As with general data density, greater bridging density would likely make the data more robust to systematic error.
Random error
The first set of simulations assume that expert error is randomly distributed across experts, matching modeling assumptions in Marquardt & Pemstein (2018b). These simulations include two levels of error for both expert reliability and DIF. The first level corresponds to a moderate level of error, while the second corresponds to a high level in which DIF spans the threshold range and a substantial proportion of experts have negative reliability. 12
Figure 1 presents posterior effect estimates from regressions that include moderate and high levels of both types of expert error, divided by modeling strategy.
13
Posterior estimate of latent concept’s effect on probability of conflict onset, simulated data with random error in expert coding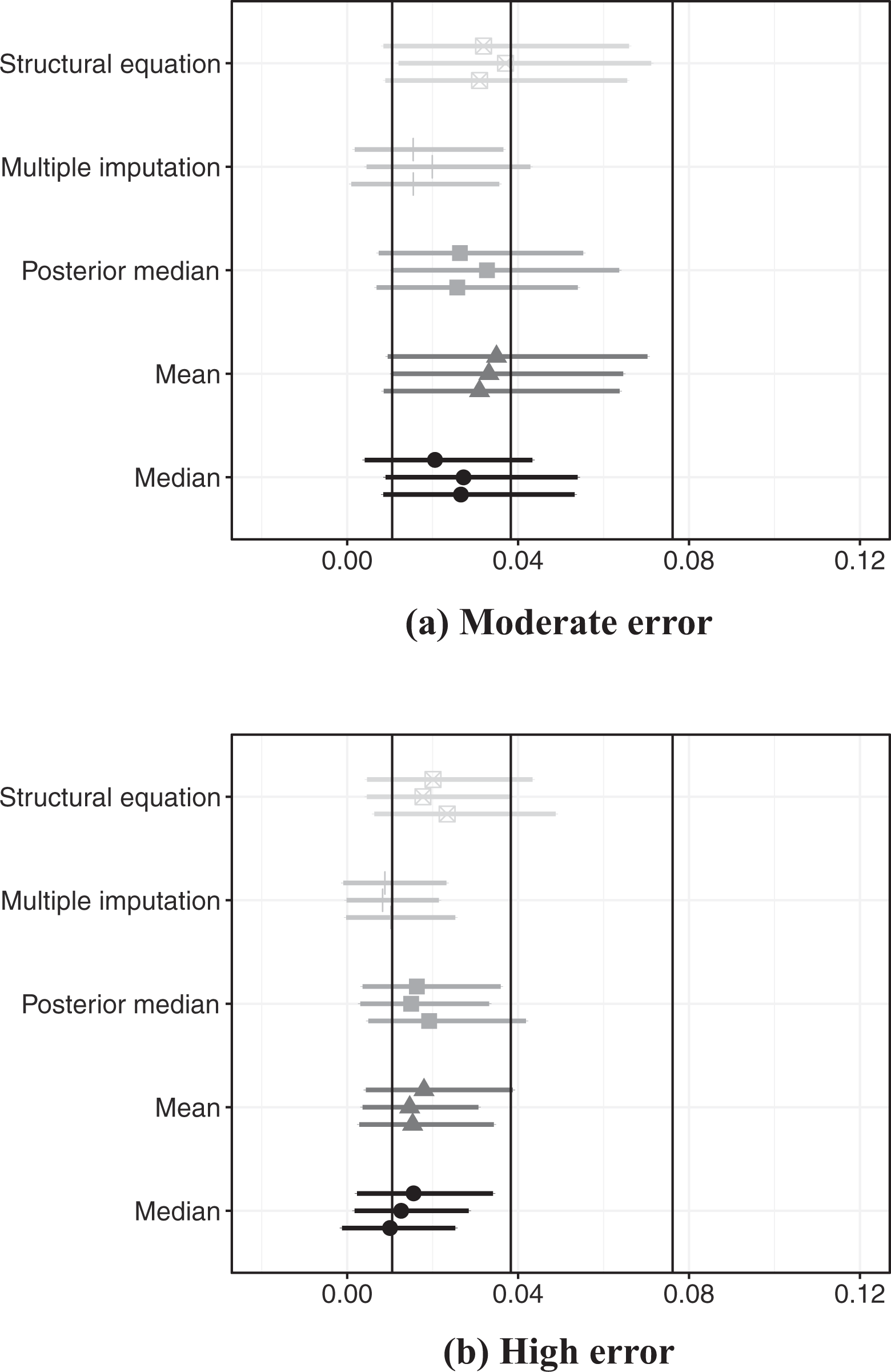
Perhaps the most important result in Figure 1 is that, even in a scenario of extremely high simulated DIF and variation in expert reliability (Subfigure 1B), all modeling strategies result in consistently positive estimates of the relationship between the latent concept and conflict onset, in line with the assumed true relationship. However, the figure also indicates that estimates from all strategies attenuate the relationship between the concept and conflict onset, even in the presence of only moderate variation in expert reliability and DIF (Subfigure 1A).
The degree to which this attenuation occurs varies across methods. The structural equation model yields effect estimates that are the closest to the true relationship, and the credible regions for all estimates that use this aggregation technique overlap with the point estimate for the true relationship. In contrast, the median and the multiple imputation techniques yield the most attenuated estimates. This result is most apparent in the context of high variation in expert error (Subfigure 1B), in which the credible regions of the estimated effect for both of these aggregation techniques do not overlap with the true effect in any simulation. The average and the posterior median perform similarly to each other: worse than the structural equation model and better than the median and multiple imputation.
Systematic error
Expert error may not be randomly distributed across experts, and such systematic error may be even more problematic than random error. I therefore create two simulated datasets in which experts who focus on countries with ethnic conflict systematically differ from other experts. 14 In the first dataset, these experts have lower reliability on average than other experts. This simulation approach is in line with the concern that experts who code certain cases of conflict may have less access to information about these cases, or are ideologically polarized and thus provide divergent codings. This approach should further attenuate the estimated relationship between the latent concept and conflict onset.
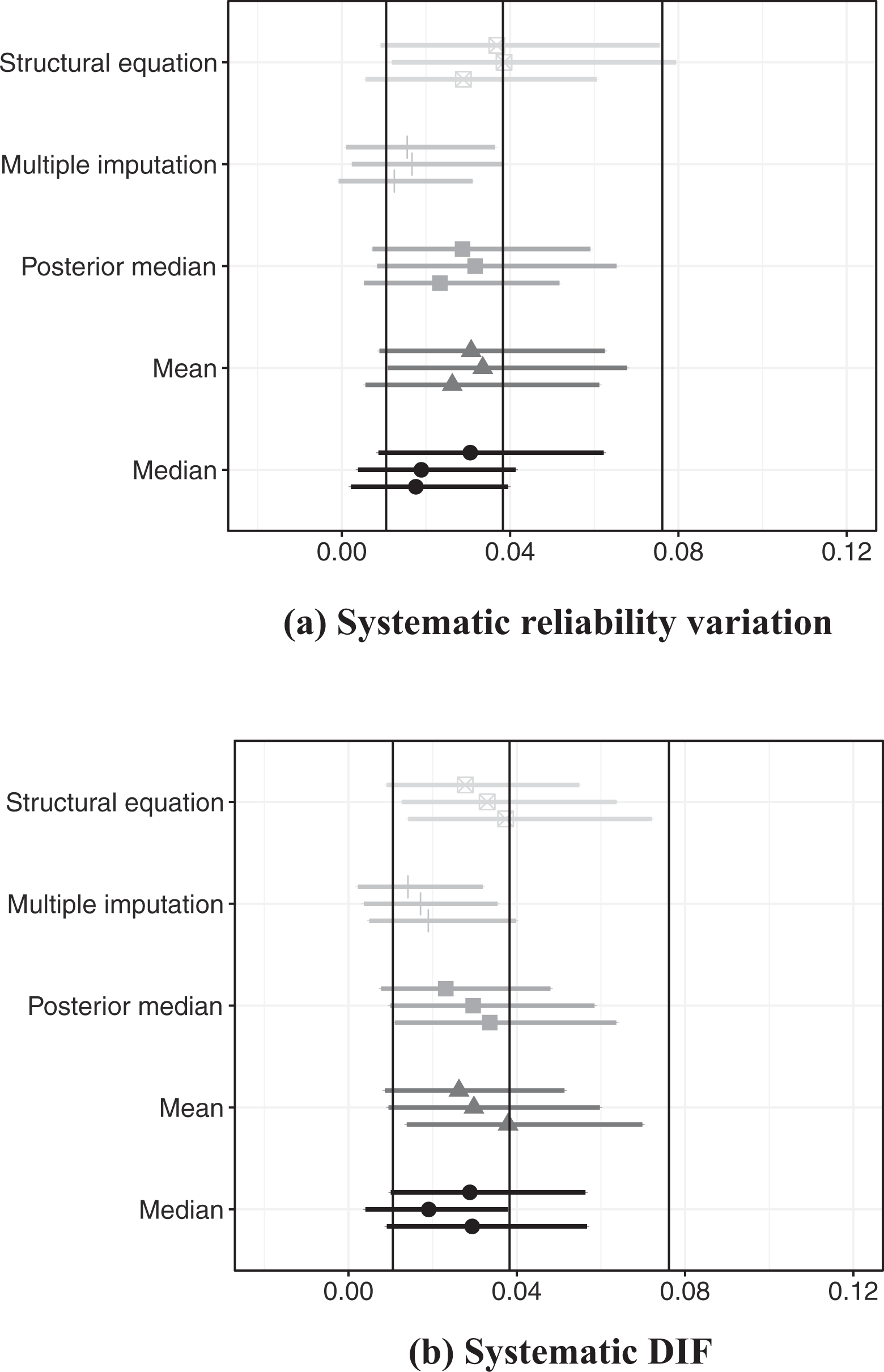
Posterior estimate of latent concept’s effect on probability of conflict onset, simulated data with systematic error in expert coding
In the second dataset, experts who code ethnic conflict tend to perceive higher levels of the latent concept. This approach models the possibility that experts who focus on cases with a particular form of conflict may systematically – and erroneously – perceive high levels of a related latent concept. This simulation strategy should artificially increase the relationship between the concept and conflict onset.
I present results from simulations with systematic variation in expert reliablity and DIF in Figure 2. 15 Subfigure 2A presents results from analyses of simulated data with systematic variation in expert reliability. The structural equation model performs very well in this context: in two simulations, the point estimates and credible regions coincide substantially with the true relationship. The mean over expert scores and posterior median also perform well in these analyses, while the relationship between the median over expert scores and conflict onset tends to have relatively more attenuation. As with previous analyses, multiple imputation yields the most attenuated relationships between the concept and conflict onset.
Subfigure 2B presents results from analyses of simulated data with systematic DIF. Contrary to expectations, there is little evidence that this form of simulated DIF artificially strengthens the relationship between the concept and conflict. Instead, the results again tend to show a generally attenuated relationship between the concept and outcome, though the structural equation model, posterior median, median and mean all perform relatively well in recovering the true relationship. Multiple imputation again provides the most attenuated estimates of the relationship between the concept and conflict.
Conclusion
The simulation analyses in this article have illustrated that regression analyses of civil conflict onset which use expert-coded data on the right-hand side are relatively robust to expert error. As a rare event, conflict onset is an outcome for which regression analyses are likely highly sensitive to expert error; the not-overwhelmingly strong relationship between the expert-coded concept and conflict onset increases this sensitivity. These analyses thus present a hard test for the robustness of expert-coded data, which the data largely pass.
Despite their broad robustness, the analyses demonstrate that expert error almost always attenuates the estimated relationship between the expert-coded concept and conflict. The level of attenuation varies based on modeling strategy. Multiple imputation consistently provides the least robust estimates. The median over expert codings is less robust than either the average over expert codings or the posterior median from an IRT model; Online appendix J also presents some evidence that the posterior median is more robust to variation in expert reliability than both the average and the median.
The most robust estimates of the relationship between the concept and conflict onset come from a structural equation model, indicating that scholars should consider using such a model in future quantitative research. To that end, the replication materials provide code and instructions for using such models.
These conclusions come with several scope conditions. First, though simulated error leads to attenuation bias in this relatively simple regression context, both the form and level of bias may change in more complicated multivariate analyses (Cochran, 1968; Cragg, 1994). Moreover, concerns about the unpredictable effects of measurement error are particularly acute in non-linear contexts (Stefanski & Carroll, 1985). Second, if the latent explanatory variable had a stronger relationship with the outcome – and the outcome were not a rare event – expert error would likely attenuate their estimated relationship to a lesser extent and could in fact amplify it if error is systematic. Third, if there were more experts-per-observation – as is the case with expert-coded datasets such as the Chapel Hill Expert Survey and the Human Rights Measurement Initiative – analyses would likely be even more robust to random expert error. Fourth, greater bridging density or more efficient use of anchoring vignettes could make the data more robust to systematic error. Future research would do well to probe these results using different outcomes, forms of expert error, and patterns of expert coding.
Footnotes
Replication data
An abbreviated replication dataset that focuses on applied analyses is available at https://doi.org/10.7910/DVN/BINH8N. The complete replication files for the empirical analysis in this article can be found at http://www.prio.org/jpr/datasets. All analyses were conducted using R; all Bayesian analyses use Stan (Stan Development Team, 2018).
Acknowledgments
I thank Ruth Carlitz, Carl Henrik Knutsen, Anna Lührmann, Juraj Medzihorsky, and Daniel Pemstein for their helpful insights. I also thank Chris Fariss, James Lo, and four anonymous reviewers for their valuable comments on earlier drafts.
Funding
I prepared the article within the framework of the HSE University Basic Research Program, with funding from the Russian Academic Excellence Project ‘5-100’. The work was also supported by the National Science Foundation (SES-1423944), Riksbankens Jubileumsfond (M13-0559:1), the Swedish Research Council (2013.0166), the Knut and Alice Wallenberg Foundation, and the University of Gothenburg (E 2013/43). I performed simulations using resources provided by the High Performance Computing section and the Swedish National Infrastructure for Computing at the National Supercomputer Centre in Sweden (SNIC 2017/1-406 and 2018/3-543).