
Abstract
Complexity, accuracy, and fluency (CAF) as measures of language proficiency have been used extensively in assessing second language production in English language studies related to task-based language teaching. The present review adds the following critical elements to the existing body of literature: (i) Provides synthesis and critical analysis of various measures of CAF used in empirical studies and reveals the variation with which the three constructs have been used; (ii) Lays down the most appropriate CAF measures for beginners, intermediates and advanced learners for a valid and robust assessment of oral production in English as a second and foreign language.
Introduction
The conceptualization of second language proficiency and its assessment is a pivotal topic in the field of language testing, developing extensively over the years with diverse contributions from the researchers and practitioners (Alderson, 1991; Amirian et al., 2017; Bachman, 1990, 2000; Bachman & Palmer, 1996; Canale & Swain, 1980; Davies, 1990; McNamara, 1996; Spolsky, 1985). Extensive research work has emanated myriad models of language proficiency with varied interpretations, resulting in the ambiguous nature of the measurement of language proficiency (Piggin, 2012). It was with the advent of task-based approach that language performance was conceptualized in terms of complexity, accuracy, and fluency (Bui & Skehan, 2018), and it was Skehan (1995, 1996) who came up with the three dimensions together (Wartan, 2019). These three dimensions fit well to explain the “Trade-off hypothesis” 1 given by Skehan (1998). The “trade-off hypothesis” asserts that when learners are engaged in communicative tasks, their mental resources are unable to give equal attention to all three dimensions, and therefore, improvement in all three dimensions may not occur simultaneously. CAF measures are also used to explain and test Robinson (1995, 2001) “Cognition Hypothesis,” which focuses on task complexity and sequencing of pedagogic tasks while retaining task complexity. Task complexity augments accuracy and complexity, promoting interaction.
Complexity, accuracy, and fluency has been utilized widely in the realms of Second Language Acquisition (SLA) and English as a Foreign Language (EFL) for assessing skill in oral and written production as “major research variables” (Housen & Kuiken, 2009; Rausch, 2017). Over the years, various constructs and sub-constructs of CAF have been utilized in studies, and these have been critically scrutinized in previous studies to generate a plausible rationale behind their usage. Given that there is a lack of consensus among researchers regarding the definition of manifold measures of CAF, it limits the “comparability, reliability, and validity” of the constructs (Housen et al., 2012). Furthermore, as the standardization of every metric of CAF is not feasible (Michel, 2017), employing CAF measurements in research investigations becomes difficult.
With a broad spectrum of CAF sub-constructs for assessing second language proficiency, valid measures have to be selected judiciously as the use of “all the measures every time” is arduous (Pallotti, 2009). In this regard, a synthesis of the measures used by previous researchers can aid in a better understanding of the metrics to be used. Some researchers have accomplished synthesis of CAF measures in previous studies with a focus on planning conditions (Suzuki, 2017) and task types with task conditions (Skehan & Foster, 2008). The present study focuses on synthesizing the CAF measures used in the past two decades, particularly studies on oral proficiency. This synthesis aims to extract the metrics that were used more than others and understand the researchers’ perspectives regarding the choice of particular metrics. Secondly, the study intends to explore the most suitable measures according to the proficiency level of the learners as it has been indicated time and again that second language speakers may face difficulty in attending to both form and meaning (Skehan, 1998, 2009), particularly the low proficiency speakers (Lambert et al., 2017).
CAF and Their Sub-Constructs
There are many sub-constructs used in previous studies to assess accuracy, fluency, and complexity.
Complexity
Generally speaking, complexity is “the extent to which learners produce elaborated language” (Ellis & Barkhuizen, 2005, p. 139). In measuring complexity, both syntactical complexity and lexical variety are considered the most germane sub-components of language complexity (Skehan, 2009). Both these sub-components have multiple metrics, which contribute to the “complexity,” and notably, in second language acquisition research, syntactic complexity is an “intensively measured component whereas lexical, morphological and phonological forms of complexity have been investigated much less” (Kuiken et al., 2019, p. 162–163).
Measures of lexical complexity
Second language research studies have developed different tests for measuring lexical richness (Read, 2000), and it is usually measured with “diversity, sophistication, and density” (Read, 2000; Wolfe-Quintero et al., 1998). Lexical complexity is measured with different metrics (type token, Guiraud’s index, D index). Furthermore, Bulté and Housen (2012) proposed “to add compositionality (i.e., the number of formal and semantic components of lexical items)” while Jarvis (2013) “identified six sub-components of lexical diversity: rarity, volume, variability, evenness, disparity, and dispersion.” These sub-constructs of lexical complexity make it challenging to present “an all-encompassing picture” of second language data (Michel, 2017), which also applies to accuracy and fluency.
Lexical diversity
It is a measure of complexity that assesses the variety of words produced. The most common way of assessing lexical variety is by finding the “type-token ratio (TTR), which is the number of word types divided by all word tokens” (Vercellotti, 2012). This measure is influenced by text length. As it has been considered unstable for short texts (Gregori-Signes & Clavel-Arroitia, 2015), other measures of lexical complexity were used in subsequent studies such as D-measure and Guiraud’s Index.
Lexical density and lexical sophistication
Another index of measuring lexical variety is lexical density. It is the “lexical items or content words packed into the grammatical structure” (Halliday & Martin, 1993). Lexical sophistication is also another index of measuring lexical variety (Read, 2000) indexed by the value of Lambda using the tool P-Lex (Meara & Bell, 2001; Bell, 2003). The Lambda value is the degree of rare and “advanced words” used by learners. Skehan and Foster (2008) proposed the use of lexical density (to be measured as D) and lexical sophistication as both these measures, according to Skehan and Foster (2008), encapsulate the different aspects of lexical performance. P-Lex is text external and works best if “task specific word lists” is created (De Jong & Vercellotti, 2016; Meara & Bell, 2001). It points out the “number of hard words in each 10-word segment (Vercellotti, 2012).”
General measures of syntactic complexity
Syntactic complexity as a multidimensional measure includes “sentential, clausal and phrasal complexity” (Lahmann et al., 2019). There are generalized and specialized measures of complexity, and researchers believe that general measures are better for measuring the complexity of language since they allow for comparisons between studies (Tonkyn, 2013, as cited in Inoue, 2016).
Clausal subordination
Foster and Skehan (1996) preferred generalized measures as more “sensitive indices of task performance.” According to Foster and Skehan (1999, p. 228), the number of clausal subordination is “a reliable measure in various experimental contexts and are correlated with other complexity measures,” and therefore, complexity should be measured as the amount of subordination per communication unit. Dembovskaya (2009) reported on the reliability of the clausal subordination measure. Many studies have calculated subordination, which is defined as the “percentage of subordinate clauses in the total number of clauses.” (Wigglesworth, 1997, as cited in Inoue, 2016).
Other measures of syntactic complexity
Norris and Ortega (2009) suggested that studies should incorporate the following measures of complexity—(a) length-based variables (such as words per chosen unit) as an overall measure of syntactic complexity, (b) subordination-based variables, (c) variables of phrasal complexity (i.e., clause length) (d) coordination-based variables (i.e., amount of coordination).
Accuracy
Accuracy as “freedom from error” (Skehan, 1996) includes sub-constructs such as percentage of error-free clauses, errors per AS unit, errors per 100 words, target-like use of verbs, plural, and tenses. Accuracy is a “straightforward and internally consistent construct” (Housen & Kuiken, 2009; Pallotti, 2009), and yet it is not as simple as conceptually it seems. As accuracy is assessed by how much a second language performance “deviates from the norm” (Housen et al., 2012; Pallotti, 2009; Wolfe-Quintero et al., 1998), it is difficult to define the “nature” of the norm. It is debatable whether accuracy norms or criteria should be based solely on native target language norms or certain non-native norms that are “acceptable in some social contexts” (Ellis, 2008; James, 1998; Polio, 1997) is a point of concern. This ambiguity within accuracy makes it difficult to apply its definition strictly to second language performance. When it comes to accuracy, “more is not better,” as (Sanell, 2007), as cited in Pallotti, 2009) discovered that advanced second-language French learners employed a phrase that was regarded erroneous by standard French norms but commonly used for “sociolinguistic comfort.” This creates an ambiguous situation in which determining an appropriate definition of accuracy will be challenging.
Fluency
Fluency is “the production of language in real time without undue pausing or hesitation” (Ellis & Barkhuizen, 2005). Fluency can be analyzed by measures of—(a) silence (breakdown fluency), (b) reformulation, replacement, false starts, and repetition (repair fluency), (c) speech rate (e.g., words/syllables per minute), and (d) automatization, through measures of length of run (Koponen & Riggenbach, 2000). Skehan (2003), Tavakoli and Skehan (2005) categorized fluency sub-components into speed fluency, breakdown fluency, and repair fluency.
The varying sub-constructs of CAF make the three dimensions multidimensional and multi-componential (Housen & Kuiken, 2009). Furthermore, CAF measures are interrelated with one another in non-linear ways, as Skehan (2009) characterized the interplay between the three measures using the Trade-off Hypothesis theory and Levelt (1989) speech production model. According to Housen et al. (2012), CAF does not develop “collinearly,” but the “distinct dimensions” may interact and interrelate in a variety of ways. As a result, utilizing CAF to assess and measure language is an intricate and challenging task (Michel, 2017). It is critical to investigate all three variables in a study rather than individual measures to grasp the intricacy and interconnectedness of CAF (Larsen-Freeman, 2009).
Research Questions
With the co-existence of different “definitions and interpretations” of the measures of CAF (Housen & Kuiken, 2009), it becomes essential to understand the interaction among the measuring variables. Therefore, the present review has been undertaken to explore the perspectives of researchers in terms of the suitability of certain measures and also put forward certain measures apt for assessing the oral production of second language learners. Thus, the study seeks to provide insights into the following research questions: (a) What are the sub-dimensions of Complexity, Accuracy, and Fluency applied in previous studies? (b) To what extent the varied sub-dimensions of CAF are suitable for assessing second language learners? (c) Which measures of CAF will be appropriate for analyzing the oral production of learners, specifically for beginners, intermediate, and advanced language learners?
Methodology Implemented for the Present Review
The included studies were selected as per the inclusion and exclusion criteria.
Search Strategy of Studies
The journal databases of Scopus, Web of Science, SAGE Journals, Science Direct, Springer links, Taylor and Francis Online, ERIC, and ProQuest were searched for research articles and thesis, using relevant keywords. In the databases, the following search term combinations were entered: “complexity, accuracy, and fluency as measures of assessing the English language,” or “CAF for assessing tasks,” or “assessing oral performance in task-based studies,” and “accuracy as a measure,” or “components of accuracy;” “fluency as a measure,” or “components of fluency” and “complexity measures” or “components of complexity.” More similar articles were found by searching the reference lists of all the related articles. Finally, 36 studies were selected (31 research papers and 3 doctoral dissertations, 1 Master’s dissertation, and 1doctoral thesis) from 1999 to 2019 (see Figure 1). As CAF gained prominence since the mid-nineties, the review included studies from the 1990s. The selected empirical studies focused on assessing task-based lessons with complexity, accuracy, and fluency measures. Flow diagram illustrating the review selection process.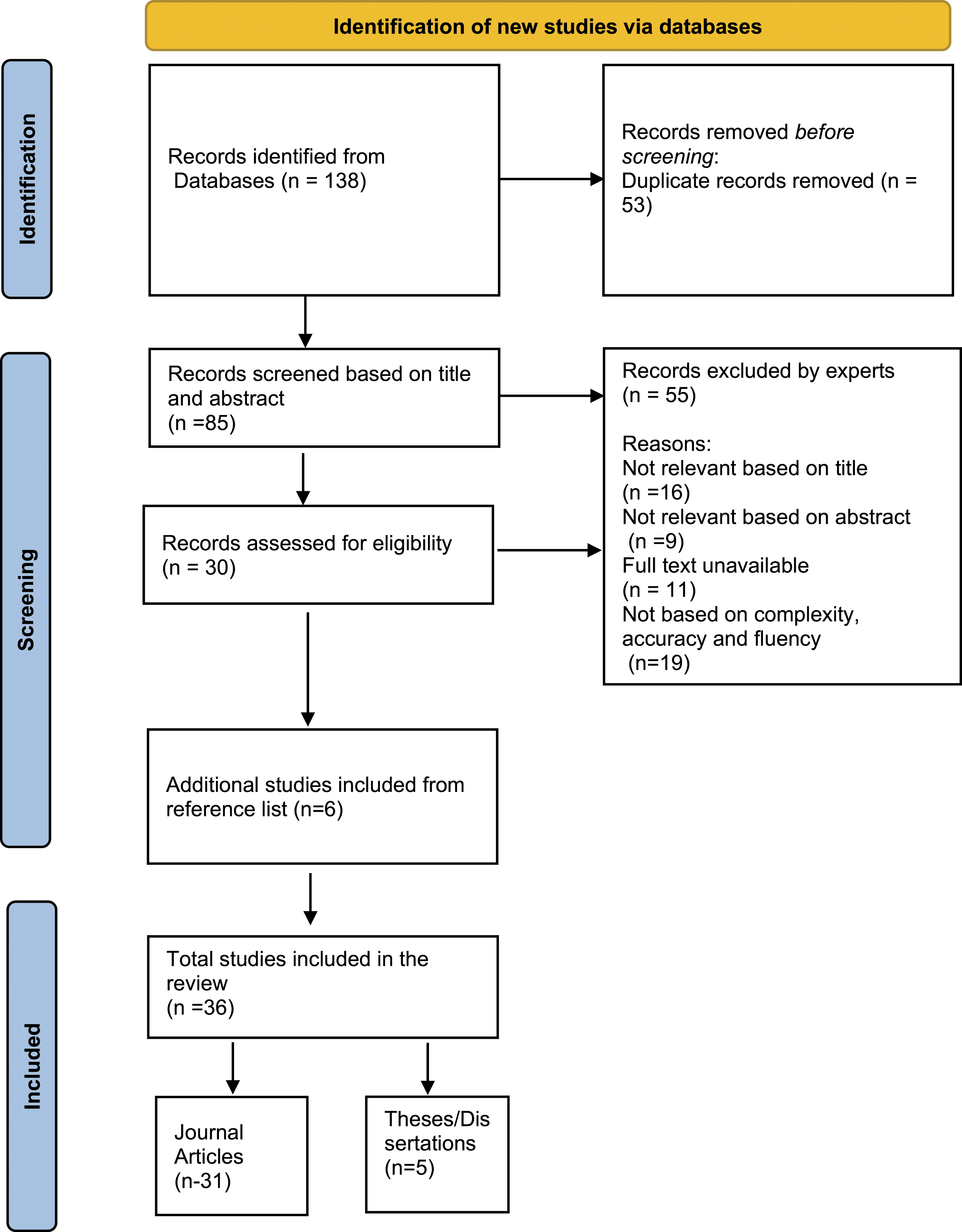
Inclusion and exclusion criteria
The included studies dealt with Task-based language teaching and the assessment of oral language output with the three constructs-complexity, accuracy, and fluency. Studies that dealt with all three components (CAF) or even just one or two of them were included as well. The articles published in journals from 1999 to 2019 and published/unpublished thesis and dissertation were included. Only quantitative studies dealing with speaking skills were included, where the measures of CAF were empirically tested. Furthermore, only those articles and theses that were public and accessible through Open access portals and authors’ university access were included; as a result, not all studies could be included. Studies based on the teaching of languages other than the English language were excluded, and studies based on language skills other than speaking were excluded. Qualitative studies and metanalysis were not included in the present review.
The studies were coded and selected by the two authors. Their interrater agreement at the initial screening based on title and abstract was strong. At the time of abstract screening, disagreements over including other languages for CAF were resolved. The authors evaluated each article independently with a series of yes/no questions based on some predetermined elements such as study design, use of language assessment measures, and outcomes (Appendix 1). The interrater reliability coefficient was strong at each stage. The included empirical studies were categorized and analyzed under the following headings-
a) Name of author and year of study; b) Sub-components of Complexity; c) Sub-components of Accuracy; d) Sub-components of Fluency.
Results
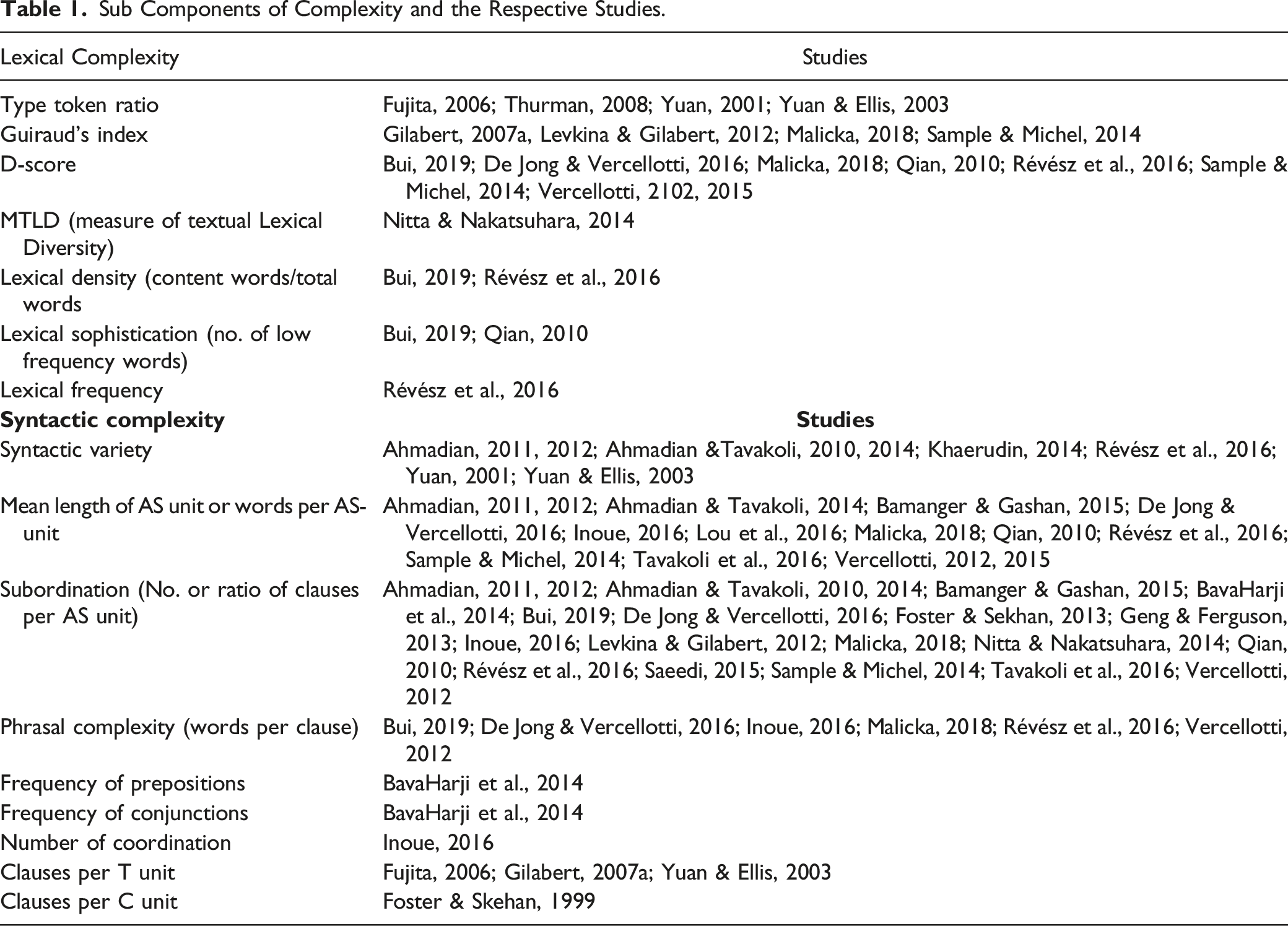
Sub Components of Complexity and the Respective Studies.
Subcomponents of Accuracy and the Respective Studies.

Sub Components of Fluency and the Respective Studies.

Measures of Lexical and Syntactic Complexity
The subcomponents of lexical and syntactic complexity as used in previous research works are summarized (Table 1).
Lexical complexity
Lexical diversity
The review found that the type-token ratio was used by some researchers
Lexical density and lexical sophistication
Out of the studies reviewed, very few works had used lexical density (e.g., Bui, 2019; Révész et al., 2016) and lexical sophistication (e.g., Bui, 2019; Qian, 2010). Lexical frequency was used by Révész et al. (2016). P-Lex was used for assessing lexical sophistication in the studies. Vercellotti (2012) indicated that P-lex lacks robustness as it is topic-specific, and all topics may not incur difficult words. Moreover, repetition of one difficult word several times may be counted and considered as difficult, even in the absence of a wide variety of words in the text.
Out of the lexical measures of density, diversity, and sophistication, Daller et al. (2007, as cited in Qian, 2010) pointed out that lexical sophistication and lexical diversity is highly related to language development and assessment. Likewise, Bui (2019) discovered that the two lexical sub-constructs mentioned above are unrelated and thus appropriate metrics. D measure and Guiraud’s index have been used for lexical diversity more than other measures (e.g., Malicka, 2018; Sample & Michel, 2014), indicating its effectiveness.
Syntactic complexity
General measures
Subordination appears to have been used in studies where the majority of the learners were in the lower intermediate, upper-intermediate, and advanced levels (Ahmadian & Tavakoli, 2010; 2014; Ahmadian, 2011; 2012; De Jong & Vercellotti, 2016; Fujita, 2006; Foster & Skehan, 2013; Geng & Ferguson, 2013; Inoue, 2016; Révész et al., 2016; Vercellotti, 2012) suggesting that this measure may be more appropriate for intermediate and advanced learners. Khaerudin (2014) employed another grammatical measure, syntactical variety, to find the number of verbs, as proposed by Yuan and Ellis (2003) because subordination as a measure failed to yield results for beginner-level learners.
Inoue (2016) used the four measures for measuring complexity following Norris and Ortega (2009)—words per unit for syntactic complexity, subordination-based variables, phrasal complexity, coordination-based variables. Inoue (2016) found that for measuring complexity, appropriate tasks need to be selected after piloting as his study reported that subordination was unexpectedly more in a less complex task which went against the established norm that complex tasks elicit complex language. Hence, Inoue (2016) suggested proper selection of tasks for measuring subordination.
The choice of syntactic measures may determine the research outcomes in terms of complexity concerning other variables like accuracy (Bui, 2019). Vercellotti (2012) suggested that grammatical complexity may be best measured using the three sub-constructs: length of AS unit, length of clauses, and the ratio of finite clauses to AS units. The present review showed that many studies employed clauses per AS unit (Ahmadian, 2011; 2012; Ahmadian & Tavakoli, 2010; 2014; Bamanger & Gashan, 2015; De Jong & Vercellotti, 2016; Foster & Sekhan, 2013; Geng & Ferguson, 2013; Inoue, 2016; Levkina & Gilabert, 2012; Malicka, 2018) and words per AS unit (e.g.,Ahmadian, 2011, 2012; Ahmadian & Tavakoli, 2014; Bamanger & Gashan, 2015; De Jong & Vercellotti, 2016; Inoue, 2016; Lou et al., 2016; Malicka, 2018; Qian, 2010; Révész et al., 2016; Sample & Michel, 2014; Tavakoli et al., 2016; Vercellotti, 2012, 2015).
Specific measures
The frequency of conjunctions and prepositions are specific complexity measures that have been used in a few studies (BavaHarji et al., 2014; Yuan & Ellis, 2003). In the study by BavaHarji et al. (2014), the learners were primarily beginners and used simple short sentences before the experiment, so the number of conjunctions and prepositions was appropriate to understand the development level of learners’ oral production in terms of complexity.
Measures of Accuracy
The sub-components of accuracy are mentioned in Table 2.
General measures of accuracy
Previous researchers have dealt with the accuracy of spoken discourse in varying ways. General measures include errors per 100 words, errors in total AS units, percentage of error-free clauses. Researchers have used several general accuracy measures, particularly the percentage of error-free clauses (Ellis & Barkhuizen, 2005; Skehan & Foster, 1999).
Errors per 100 words
Errors per 100 words also have been used as a measure of accuracy (Inoue, 2016; Malicka, 2018; Nitta & Nakatsuhara, 2014; Révész et al., 2016). Vercellotti (2012) pointed out that using errors per 100 words spares the researcher from segmenting discourse into T-units or AS-units. However, Vercellotti (2012) also emphasized that the “100 words segment have no psycholinguistic reality” while idea units and AS units do have some reality. It may be pointed out that while accuracy may be assessed with errors or error-free clauses, the question about the time limit for producing 100 words remains unclear. Beginners may find it difficult to produce 100 words, and the task requiring 100 words may be performed in less than 100 words. In such a circumstance, the appropriate remedy for assessment is uncertain.
Error-free clauses vs. Errors per unit
Researchers have also employed total errors per AS unit (e.g., Gilabert, 2007b; Inoue, 2016; Levkina & Gilabert, 2012; Malicka, 2018; Sample & Michel, 2014) as using errors as a benchmark reduces the probability of being subjective. If errors per AS unit or per clause are being used, then the definition of erroneous sentence and errors in syntax, morphology, tenses, lexical, etc., have to be decided beforehand. According to Skehan and Foster (1999), error-free clauses are appropriate for experimental design. As a result, many studies have used the percentage of error-free clauses as a measure of accuracy (Dembovskaya, 2009; Yuan & Ellis, 2003), where error-free clauses are divided by the total number of clauses and multiplied by 100 (Abdi et al., 2012; Ahmadian & Tavakoli, 2014; Ahmadian, 2011; Bamanger & Gashan, 2015; BavaHarji et al., 2014; De Jong & Vercellotti, 2016; Fujita, 2006; Shafaei et al., 2013; Thurman, 2008; Vercellotti, 2012, 2015). According to Skehan and Foster (2008), the disadvantage of this measure is that if the speakers use many short sentences, the scores may be inflated; to avoid this inflation, they proposed that all clauses be ranked in length, with a set criterion (usually 70% correct use), and the maximum length that meets the criteria be considered as “clause length accuracy score.”
Vercellotti (2012), in her work, used both error-free clauses as well as error-free AS units, and both resulted in high correlation, which led to the conclusion that only clause level accuracy would be adequate for assessment. Another problem in using an error-free AS unit, which Vercellotti (2012) faced, was that the learners were not proficient in producing lengthy error-free AS units. So, she concluded that error-free clauses would be sufficient to measure accuracy, and only if learners are of good proficiency level then error-free AS units can be used. Another variation of this measure is “errors per AS unit” as Bygate (2001) has emphasized that the use of errors per unit gives a clear picture of accuracy; hence, some studies used this measure (Gilabert, 2007b; Inoue, 2016; Malicka, 2018). Inoue (2016) used three measures: errors per AS unit, errors per 100 words, and percentage of error-free clauses, and concluded that errors per 100 words was the best fit for his study, where the learners’ levels ranged from basic to intermediate. Inoue (2016) pointed out that the differences in the denominator with clauses and words caused variation in the results when different measures were used.
Self-Repair
Though self-repair is a measure of fluency in terms of reformulations, it has been employed in a few studies as a measure of accuracy (Ahmadian & Tavakoli, 2014; Gilabert, 2007a; 2007b) since it demonstrates students’ awareness of forms and their efforts to be accurate (Kormos, 1999). Cognitively demanding tasks lead to more self-repairs (Gilabert, 2007b), so this measure may be used to see how much the learners are aware of their errors which will be more applicable for intermediate and advanced learners.
Specific measures of accuracy
Specific measures include correct verbs, articles, tenses, etc. Specific measures like verbs (Ahmadian, 2011; Ahmadian & Tavakoli, 2010; 2014 BavaHarji et al., 2014; Khoram & Zhang, 2019) or articles (Ahmadian, 2012) cannot capture the overall accuracy of learners, and quite likely, lexical flaws may go unnoticed in this process. A specific measure of accuracy is suitable in works where focused tasks and focused forms are used. Tasks are designed carefully to elicit the target forms. However, in loosely structured and unfocused tasks, general measures are more suitable as Ellis and Barkhuizen (2005, p. 151) recommend a general measure of accuracy, such as “percentage of error-free clauses or number of errors per 100 words.” In addition, general measures seemed to be more appropriate for assessing the accuracy of learners from different backgrounds (Vercellotti, 2012).
Measures of Fluency
Speech rate
There are variations in the way fluency word count and syllable count have been employed in previous studies. Most of the studies used word count in 1 minute or 60 seconds (Geng & Ferguson, 2013; Lou et al., 2016; Qian, 2010; Sample & Michel, 2014) and some used syllables per 60 seconds-both pruned and unpruned speech (Ahmadian, 2011; Ahmadian & Tavakoli, 2010; 2014; Malicka, 2018; Tavakoli et al., 2016); few used only pruned speech (Gilabert, 2007a; Levkina & Gilabert, 2012; Saeedi, 2015). BavaHarji et al. (2014) measured fluency and other constructs for “90 seconds,” explaining that most learners were beginners and were nervous initially, resulting in many pauses and repetitions. Therefore, they adopted the measure for 90 seconds for reliable results. 2 minutes of oral production was measured by Thurman (2008), which shows that there is no particular reason for selecting 1 minute or more than 1 minute as the time limit for testing the fluency of the learners. Nonetheless, it was found that most of the measurement was done with a time length of 1 minute. Bui and Huang (2016) preferred the tallying of frequency-based measures by adopting the standardized textual length approach (occurrence per 100 words/syllables) to the temporal length approach.
Instead of silence measures, De Jong et al. (2012) recommend utilizing the phonation time ratio, which is defined as “the percentage of time spent speaking as a percentage proportion of the time taken to produce the speech sample.” Likewise, Vercellotti (2012) and De Jong and Vercellotti (2016) used the phonation time ratio. Vercellotti (2012) considered speech rate and articulation rate irrelevant for her study as both metrics did not capture the length and number of pauses which is supposedly one of the essential markers of dysfluency. Pruned speech is recommended by Bui and Huang (2016) because it provides accurate speech rates and is sensitive to subtle changes in task characteristics and task conditions. Thus, most researchers prefer pruned speech (Ahmadian, 2011; 2012; Ahmadian & Tavakoli, 2010, 2014; Bui & Huang, 2016; Lambert et al., 2017; Fujita, 2006).
Pauses and silence as breakdown fluency
According to Ellis (2003), fluency can be measured in terms of the “number of pauses” (i.e., a break of 2.0 seconds or longer either within a turn or between turns). The previous studies vary in their use of the duration of pauses and the type of pauses (filled and unfilled pauses) that they took into their calculations. Some studies defined pause as a silence that is over 0.2 seconds long (De Jong & Perfetti, 2011; Nitta & Nakatsuhara, 2014; Vercellotti, 2012, 2015), some as 250 milliseconds (Révész et al., 2016) within an utterance, while some set 0.4 seconds or 1 second as their criterion (e.g., Skehan & Foster, 1997). A few researchers utilized pauses that were shorter in duration (e.g., Tavakoli & Skehan, 2005; Wigglesworth & Elder, 2010). However, pauses in speech should not be attributed simply to a lack of fluency (Freed, 2000, p. 256). Because little pausing is deemed normal in the first language, occasional pauses in the second language speech can be considered. Huensch and Tracy-Ventura (2016) investigated the fluency of first-language Spanish, French, and English speakers. They discovered that the first language English speakers paused a lot because English as a language has an expansive syllable inventory, which means there are more phonemes within each syllable, resulting in more pauses while speaking. Also, they have found in their study that first language fluency usually influences second language fluency, so individual differences are bound to be there.
While some studies have measured the number of pauses, few have calculated the length of pauses, such as Vercellotti (2012). Some have calculated filled pauses and unfilled pauses or either of them. Some studies have emphasized mid-clause pauses as more appropriate to assess fluency for non-native speakers Foster & Skehan, 2013; Skehan & Foster, 2008) as not much difference has been noticed in the end clause pauses in both first and second language speakers (De Jong, 2016; Tavakoli, 2011). However, mid-clause pausing is more common in less proficient second-language speakers. Skehan and Foster (2008) further pointed out that there is a difference between native and non-native speakers in pausing and in the pattern of pause location. Non-native speakers’ pauses become more prominent in unpredictable places, whereas native speakers pause as well, but it is less noticeable. De Jong et al. (2012) also reiterated that individual differences hold true for native and non-native speakers with regard to fluency. Thus, pauses have been interpreted in various ways, and the length of pauses helps to understand the fluency attained by learners over time, whereby long pauses may reduce with adequate oral practice.
Repair fluency measures
Repair fluency reflects “adjustments and improvements” which learners make in their performance (Foster & Skehan, 1999). This comprises reformulation whereby the learner rephrases syntax, morphology, or word order; replacement is a change of vocabulary while speaking; repetition is repeating of words or string of words, and false start is abandoning the utterance and starting afresh (Foster et al., 2000). Nitta and Nakatsuhara (2014) view that, unlike breakdown fluency, repair fluency may not necessarily indicate dysfluency because learners repairing their language can be a sign of improvement. Repair fluency has been used in many studies with good effect (Abdi et al., 2012; Bamanger & Gashan, 2015; Bui, 2019; Bui & Huang, 2016; De Jong & Vercellotti, 2016; Foster & Skehan, 1999, 2013; Lou et al., 2016; Malicka, 2018; Qian, 2010).
Discussion
Most Appropriate Measures of Complexity, Accuracy, and Fluency
The review of studies as presented in the results section indicated the varied sub-constructs used by researchers in the studies, and researchers discovered that some measures were more effective than others. As a consequence of the findings, which revealed the most commonly used and relevant CAF measures, the current study proposes measures that may be utilized to assess beginners, intermediates, and advanced learners.
Most appropriate measures of complexity
Based on the measures found in previous studies, general measures appear to be the most appropriate because they allow for comparison between studies (Foster & Skehan, 1996). In contrast, Norris and Pfeiffer (2003) claimed that specific measures such as target grammatical items could measure complexity more robustly than a general measure. It seems, however, for assessing beginners, complexity by coordination may be more suitable (Norris & Ortega, 2009), while phrasal complexity may work well with more advanced second language learners (Ortega, 2003). Some increasingly used measures may be selected for intermediate and advanced learners, such as words per AS unit, clauses per AS unit, phrasal complexity (Norris & Ortega, 2009; Vercellotti, 2012). For assessing lexical variety, D score and Guiraud’s index (Révész et al., 2016) may be used as the type-token ratio has limitations of being affected by text length.
Lexical complexity may not be used as a measure for assessing beginners, as Skehan (2009) stressed that native speakers’ complexity might be “unidimensional,” with lexical and structural complexity being hand in hand. However, for the second language, non-native learners, the two areas may not be integrated, and focusing on lexis may lead to poor performance in other areas. Therefore, depending on the objective of the study and the learners’ proficiency level, researchers ought to use their discretion while selecting the measures for oral complexity.
Most appropriate measures of accuracy
For measuring accuracy, a general measure of “percentage of error-free clauses” is appropriate if the tasks are loosely structured, and unfocused tasks are employed. Depending on the learners’ competence level and the tasks they are assigned, “errors per 100 words” might be used as a general measure of accuracy. Specific measures may be used for focused tasks as the accurate number of tenses, verbs, etc. General measures such as “percentage of error-free clauses” should be used along with specific measures. For beginners, identifying their specific areas of accuracy concern and working solely on those would be preferable, and specific metrics could be quite useful. At the same time, both specific and general measures may provide a comprehensive view of the accuracy level for intermediate and advanced learners. As Michel (2017) said, global accuracy measures may assist in assessing accuracy across “different languages, populations, and tasks.” However, it may not be apt for capturing slight differences in high proficiency learners. Michel (2017) said that specific measures might capture the slight changes. This indicates that combining both general and specific measures can yield an effective result.
Attaining accuracy in a foreign language is no mean feat; hence, while assessing the beginner’s, researchers need to be less stringent and use their discretion. As Pallotti (2009) noted, weighing learners’ errors is not an easy task, and Foster and Wigglesworth (2016, p. 112) stated that “anyone who has worked on assessing accuracy in L2 data will know this only too well; some degree of personal judgment has to be invoked occasionally.”
Most appropriate measures of fluency
De Jong et al. (2012) emphasized that for beginners’, articulation rate was the best predictor and for intermediate learners mean length of the run was the best predictor of fluency. Therefore, based on the critical analysis of the studies measuring fluency, the indices that may be appropriate for the beginners and low intermediate language learners are: Articulation rate (Tavakoli et al., 2016), number of mid clauses pauses per 100 words (Skehan & Foster, 2008; Foster & Skehan, 2013), Reformulations (repair fluency) per 100 words (Foster & Skehan, 2013).
Mean length of run (De Jong et al., 2012); pruned speech rate; repair fluency including false starts, reformulation, replacement and repetition, number of mid-clause pauses (Bui, 2019; Foster & Skehan, 2013) are appropriate for upper-intermediate and advanced language learners.
The duration of pauses for beginners and intermediate learners may be different. Beginners may be assessed for longer pauses as short pauses may be found more in their speech. Thurman (2008) avoided this measure altogether in his study as Japanese students learning English as a second language were beginners, and they were used to pausing between words. Harumi (2002, as cited in Thurman, 2008) stated that Japanese students are silent in English language classes as they lack confidence and have time management issues. This is true for most second language learners. Therefore, mid-clause pauses may be an appropriate measure for capturing the breakdown fluency of non-native learners (Skehan & Foster, 2008).
Skehan and Foster (2008) pointed out that repetition is found more in non-natives, and even planning time does not seem to reduce repetition, which is otherwise beneficial to native speakers. Therefore, instead of using repetition for assessing the fluency of beginner and intermediate learners, it may be used effectively for advanced learners. With studies assessing fluency with different repair measures and breakdown fluency measures, it seems that fluency may be assessed by using the measures of pauses and number of utterances in a given time; however, it should not be assessed at the cost of accuracy. Incomprehensible words spoken fluently may not serve the purpose of learning a language. Therefore, the amount of leniency in assessing fluency should rest with the researcher’s discretion.
Educational Implications
The findings of this study have ramifications for both English language teachers and institutions where English is taught as a second language including the teacher education courses/institutions. The goal of teaching a second language should be to make students feel at ease in the language. Language assessment is critical for teachers to identify the effectiveness of the course they are teaching as well as the language areas in which the students need to improve. Teachers cannot employ CAF constructs in classrooms because there is a traditional testing system in place. However, after an interactive session, the teacher may utilize distinctive fluency, accuracy, and complexity subconstructs to assess the students to see if the tasks and lessons helped them improve their language fluency, accuracy, and complexity. Teachers will be able to design better tasks and activities by using these evaluations, and they will be able to focus on the specific subconstruct that requires attention. Thus, if teachers and educational institutions are aware of the constructs of language proficiency, they can use them to monitor the students’ language proficiency and adapt their language curriculum for the desired improvements in students.
Summary and Conclusion
A limitation of this review that needs to be acknowledged is that it includes only those studies that were accessible in the database. Yet, the empirical studies selected and reviewed were of a wide range, which has provided an understanding of the manifold nature of CAF and its sub-components. The present study critically presented the different perspectives of researchers on the effectiveness of certain measures and concluded that CAF measures must be finalized based on learners’ proficiency levels. For instance, a beginner’s achievement in the second language initially should be based on words or syllables being uttered, with repetition and pauses measured subsequently. The present review further deduced that there is no fixed way of analyzing second language production using CAF, though undeniably, it remains a “scientifically valid and informative” (Pallotti, 2009) way of measuring language production.
Another finding of this review was that researchers preferred using more than one sub-component of each construct as they indicated that more than one sub-component would give an impartial result. Emphasis was on using both general and specific measures to obtain impartial results. The wide array of sub-constructs for assessing accuracy, fluency, and complexity gives flexibility to the researchers to select the sub-construct most suitable for their settings and participants, and this is one of the advantages of employing CAF measures. Another advantage is that it is one of the best ways that language practitioners have found to quantify language production. This quantification aids in understanding the extent of development in the language areas of accuracy, fluency, and complexity. CAF is used as dependent variables in relation to planning and tasks, and it helps the researchers decide on the type of tasks and planning that may aid in developing CAF with the least trade-off effects. The limitation of using CAF for assessing oral language production is that it requires expertise and proficiency for assessing the students’ oral proficiency. Assessing with CAF may be “fast and reliable” with “computerized tools” (Michel, 2017) and the use of technology. However, in different countries and regions where second language accents and pronunciation are unlike native speakers, the computerized tools may not be the best methods, and manual calculations for a large sample can be tedious.
The present review was limited to studies with oral proficiency; therefore, future reviews on the sub-constructs of CAF used in written proficiency will be an additional insight into the most appropriate measures of language performance according to task modality. Further studies with a distinct focus on the language performance of learners with different proficiency levels would aid in gaining insight into the most suitable measures for assessing second language learners.
Footnotes
Acknowledgments
The first author wishes to thank her guide and mentor, Professor Santoshi Halder (Second Author) for the step-by-step guidance and her valuable inputs.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.