
Abstract
Composite materials, such as Carbon Fiber Reinforced Plastics (CFRP), are widely used across industries due to their exceptional mechanical properties and lightweight nature. With increasing interest in hydrogen storage applications, a comprehensive understanding of CFRP’s microstructure is crucial. However, there remains a critical gap in effectively linking microstructural characteristics to multiscale simulation models for improved tank design. This study presents a detailed analysis of CFRP microstructure using micro-section image analysis. Advanced artificial intelligence techniques, including transfer learning with VGG16 and XGBoost, are employed to detect fibers and matrix-rich regions. Notably, the model achieves an impressive Area Under the Receiver Operating Characteristic (AUC) of 0.89, providing strong quantitative validation. Furthermore, the experimentally determined fiber volume fraction of 0.59 closely aligns with the predicted value of 0.589, demonstrating the model’s accuracy. The investigation extends to analyzing fiber distribution using statistical features such as Voronoi polygons and kernel density estimation. Through dimensionality reduction via t-SNE and clustering, distinct patterns in CFRP’s microstructure are identified, offering deeper insights into its complexity. Finally, an explainable artificial intelligence (XAI) framework is implemented using a surrogate model to map the decision-making process to microstructure characteristics. The surrogate model achieves an F1-score of 0.90, reinforcing the reliability of the approach. This research provides valuable insights into the distinct categories in CFRP’s microstructure, particularly relevant for utilization in multiscale numerical methods.
Keywords
Introduction
The imperative transition toward a sustainable and decarbonized environment has fueled a growing global demand for hydrogen as a clean fuel source. The realization of hydrogen-powered propulsion systems necessitates advancements in storage technologies, placing a particular spotlight on the development of efficient and reliable hydrogen storage systems in critical fields such as aerospace and automotive.The storage of hydrogen is challenging as it requires holding it at significantly high pressure (350 − 750 bar). 1 Due to its superior weight-to-strength ratio and better mechanical, thermal, and chemical characteristics, CFRP has proved to be a suitable candidate for this application.
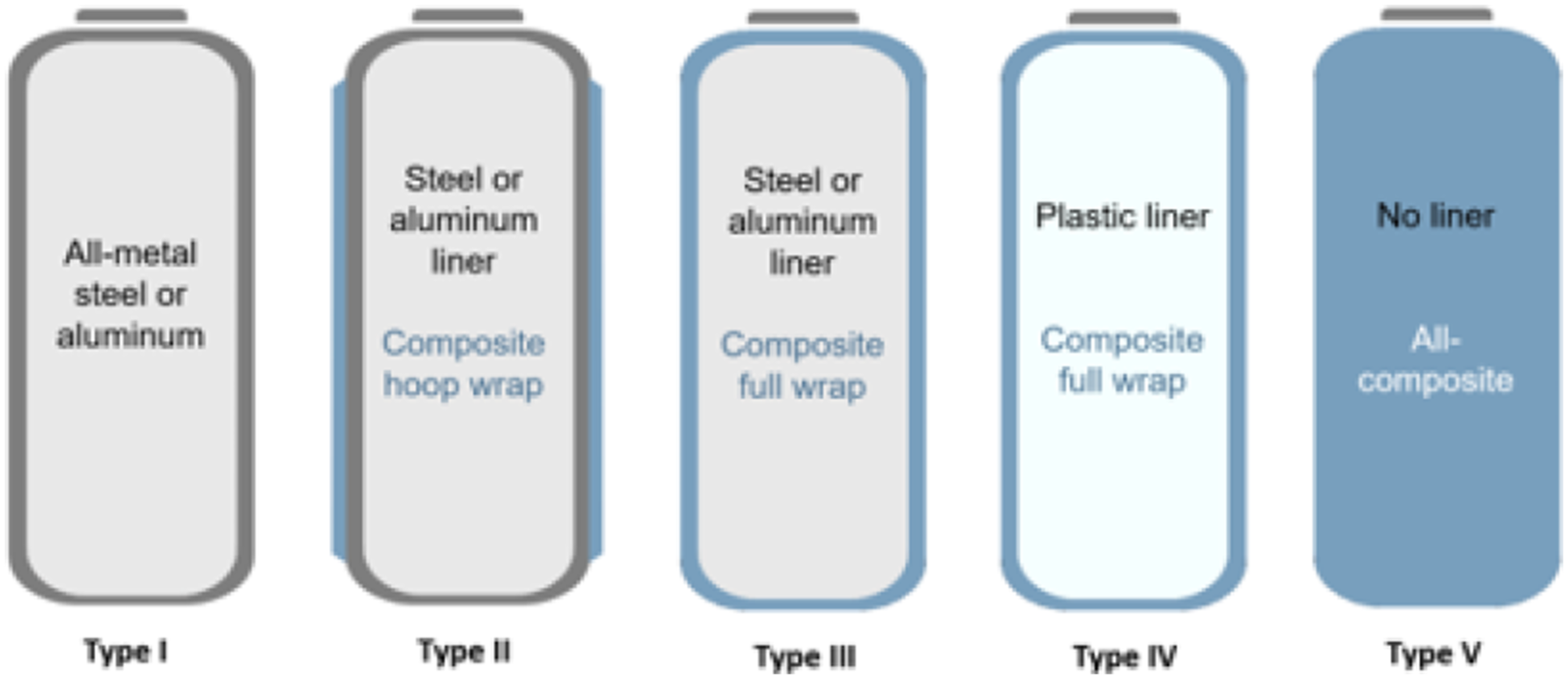
Hydrogen storage systems can be categorized as shown in Figure 1. Composite over-wrapped pressure vessels, such as Types 2 to 4, utilize CFRP to sustain structural loads. The state-of-the-art storage tank used in commercial applications is a type 4 tank, despite of advanced type 5 design. These tanks consist of an inner polymer liner to restrict gas permeation and a CFRP over-wrap to bear mechanical loads.
3
Manufacturing techniques such as filament winding
4
and automated fiber placement (AFP)
5
are commonly employed for their fabrication. A schematic describing types of storage tanks for hydrogen.
2
Advancements in CFRP-based structures have demonstrated improvements in storage efficiency and weight reduction. 6 However, gaps in understanding failure mechanisms at different length scales pose challenges in their overall application. Evidently, micro-cracks in the CFRP can combine to crack networks and lead to leakage and influence structural integrity at higher levels.7,8 Therefore, a high-fidelity multi-scale approach is required, where microstructural insights inform meso- and macro-level models for accurate material behavior predictions, particularly in areas such as burst pressure and leakage analysis.
Several studies9,10 have highlighted the significant influence of fiber arrangements on fiber-matrix bonding, which ultimately dictates crack initiation and propagation. This phenomenon is primarily attributed to the property mismatch at the fiber/matrix interface, leading to a stress concentration around the fibers and often resulting in inter-facial failure 11 and advocating the importance of the fiber distribution. Additionally, the intricate manufacturing process and functional environment, characterized by varying temperature steps, can give rise to numerous matrix cracks, particularly in materials intended for applications such as liquid hydrogen storage, which undergo cryogenic thermal loads. These thermal stresses induce differential expansion between the matrix and fibers, given the substantial difference in their coefficients of expansion of more than two order. 12
The application of thermal loads leads to matrix embrittlement, consequently affecting the region with higher resin packing density and resulting in higher unidirectional (UD) strengths. 13 However, this also correlates with an increased occurrence of micro-cracks due to purely thermal loads. 14 The continuous occurrence of such inter-facial failure and thermally induced matrix cracking may lead towards the contribution of a through-thickness crack. 15 Further thermal and mechanical loading may help join multiple micro-cracks to form a network.16–19
In conclusion, the distribution of fibers within carbon composites significantly impacts the formation of micro-cracks especially the under cryogenic loading. 20 Non-uniform distribution can lead to stress concentrations, and weak points, which may lead to higher crack density and eventually a leakage through thickness crack. 21
Traditionally, micro-level FEM analysis employed simplified periodic fiber
22
arrangements within single fiber unit cell models. However, these models fall short of representing the skewed distribution of fibers observed in real-life scenarios as in Figure 2. Several research used different approaches by utilizing modified versions of random fiber generation with specific fiber volume fraction.23–26 However such studies are not free from problems. Random fiber generation can lead to increased computational complexity due to the need to generate and analyze a large number of different configurations.
27
This could potentially slow down the simulation process, especially for complex geometries or materials. While random fiber generation can provide useful insights into the behavior of CFRP composites, it may not accurately predict the real-world performance of the material, as the random nature of the fiber distribution may not fully represent the actual fiber distribution in a real composite material.
28
More advancements can be seen in the works of
29
and,
30
where the authors have devised several methods to analyze microstructure by detecting fibers and using this information for generating a realistic representative volume element (RVE). However, these methods encounter challenges in characterizing a single RVE that can faithfully represent the diverse architecture of fiber distribution. Different microstructure demonstrating varied fiber distribution.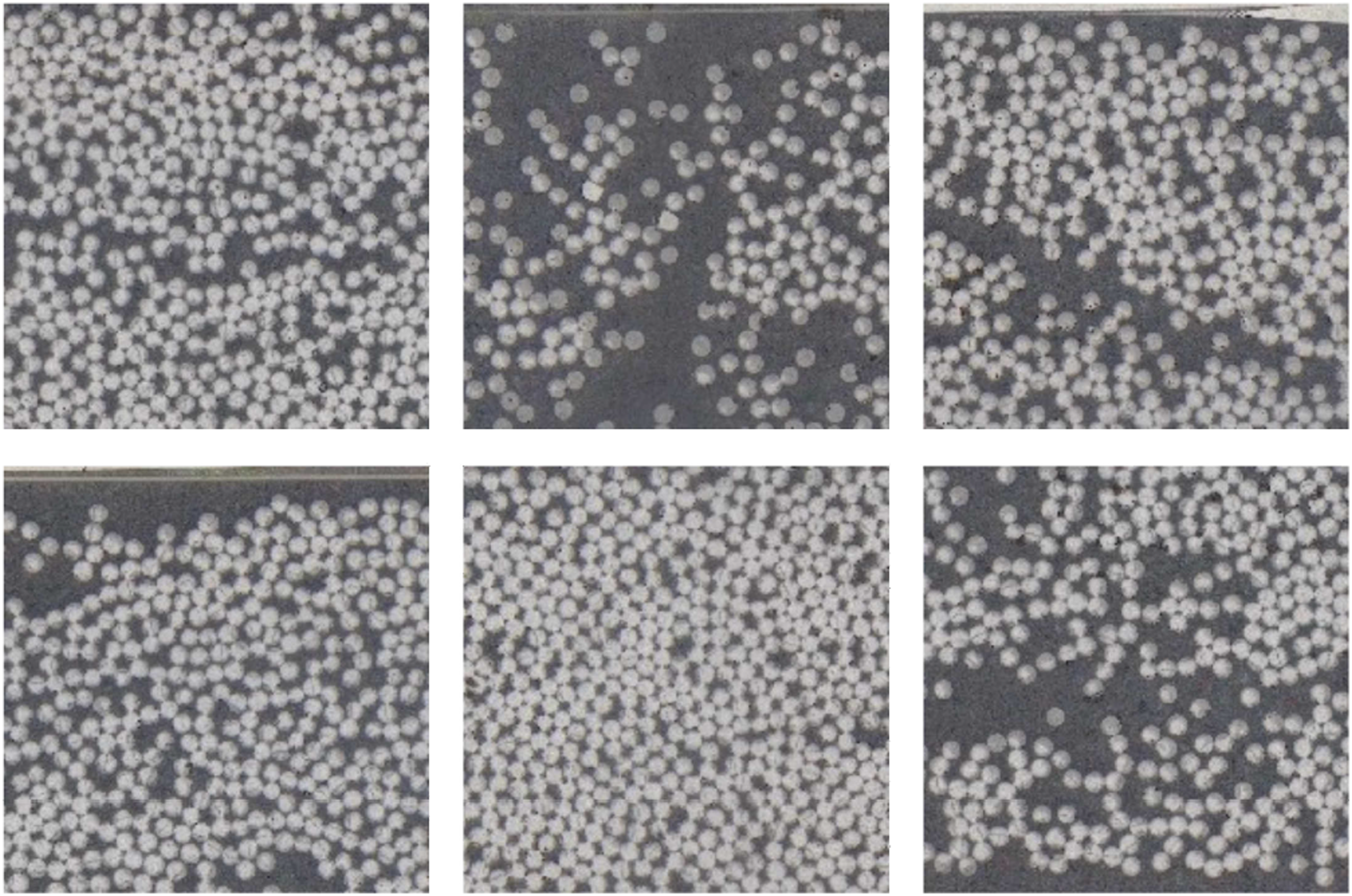
Despite these advancements, there remains a lack of frameworks that both capture realistic microstructural diversity and systematically link it to higher-scale material behavior predictions, particularly for leakage in hydrogen tanks. This study addresses this gap by developing an XAI-based methodology that bridges microstructural characterization and multiscale modeling needs.
Machine learning has emerged as a powerful tool to address these challenges by extracting meaningful insights from complex datasets and improving predictive accuracy. In 31, authors developed a Gaussian Process Regression (GPR) model utilizing drilling parameters such as cutting speed, drill size, and feed rate. Their study demonstrated that the GPR model provided stable and accurate predictions of the delamination factor, highlighting both the complexity of analyzing CFRP materials and the potential of machine learning in extracting meaningful insights from complex datasets. Similarly, in 32, author developed Multivariate Linear Regression (MLR) and GPR models based on mixture proportions, including the EVA:starch ratio, glycerin content, and NaHCO3 content. Their study demonstrated that these models produced predictions closely matching experimental values. The authors suggest that these approaches can aid in designing mixture proportions and identifying statistical correlations between components and mechanical properties in starch-based foams. This underscores the value of machine learning in uncovering numerical relationships between input parameters and performance metrics, as well as its broader applicability in analyzing complex material systems.
Building on these advancements, this work introduces a novel XAI framework capable of accurately characterizing a finite set of distinct microstructure types. By combining advanced machine learning techniques with interpretable decision-making, the framework provides deeper insights into the fundamental patterns governing fiber distribution. This enhanced understanding supports material design, optimization, and performance prediction. Additionally, the explainability of the surrogate models strengthens user confidence, establishing the framework as a reliable tool for informed decision-making.
The remainder of the presented paper is organized as follows. Section 2 describes the manufacturing of specimens and micro-section extraction to supply data for fiber distribution analysis. In Section 3, a brief overview of the existing methods to detect fibers and their shortcomings are discussed. Further, a detailed description of the employed methods to detect fibers, statistical properties to describe the microstructure and later its characterization is presented. Section 4 offers a detailed insight into the results and performance evaluation of the machine learning models. Section 5 deals with the eXplainable Artificial Intelligence framework using surrogate models and their result interpretation and performance evaluation. Lastly, Section 6 presents a summary of the presented work with an outlook.
Experiment and data
Manufacturing and testing
The specimens were manufactured using unidirectional CFRP prepreg provided by Hexcel (HexPly 8552/35%/134gsm/IM7), with a nominal cured ply thickness of 0.125 mm. Two types of plates were produced, each with a nominal thickness of 2 mm but differing in stacking sequence: namely, [0,90]8s and [02, 902]4s.
The layup was performed manually, followed by vacuum bagging and curing in accordance with the manufacturer’s recommended cycle. After curing, small 15 × 15 mm samples were extracted by milling (as illustrated in Figure 3) and subsequently embedded in resin for microscopy. A Schematic describing the specimen opted for microscopy.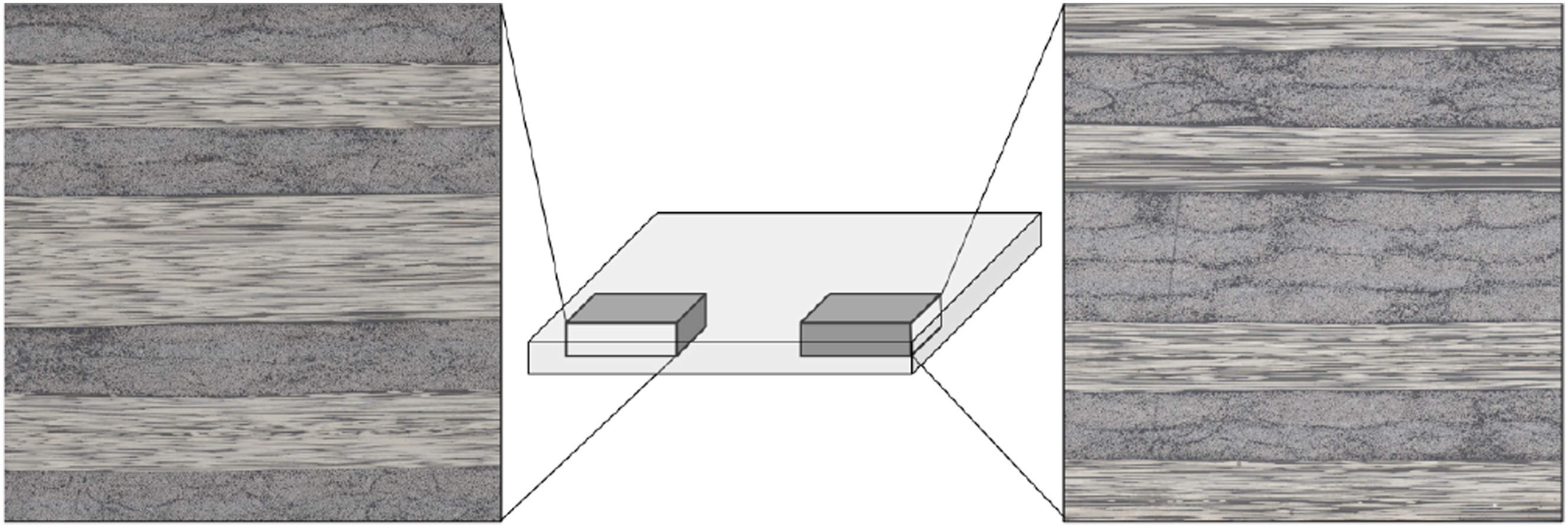
Digital microscopy
To capture the fiber distribution within the composite laminate, microscopy experiments were conducted on a specimen at a 50x zoom level with a resolution of 0.67 micron. This allowed for detailed imaging of the laminate’s cross-section, highlighting the arrangement and spatial distribution of the fibers. The obtained images were stored for further analysis, enabling the characterization of the fiber distribution and subsequent evaluation of its impact on composite performance.
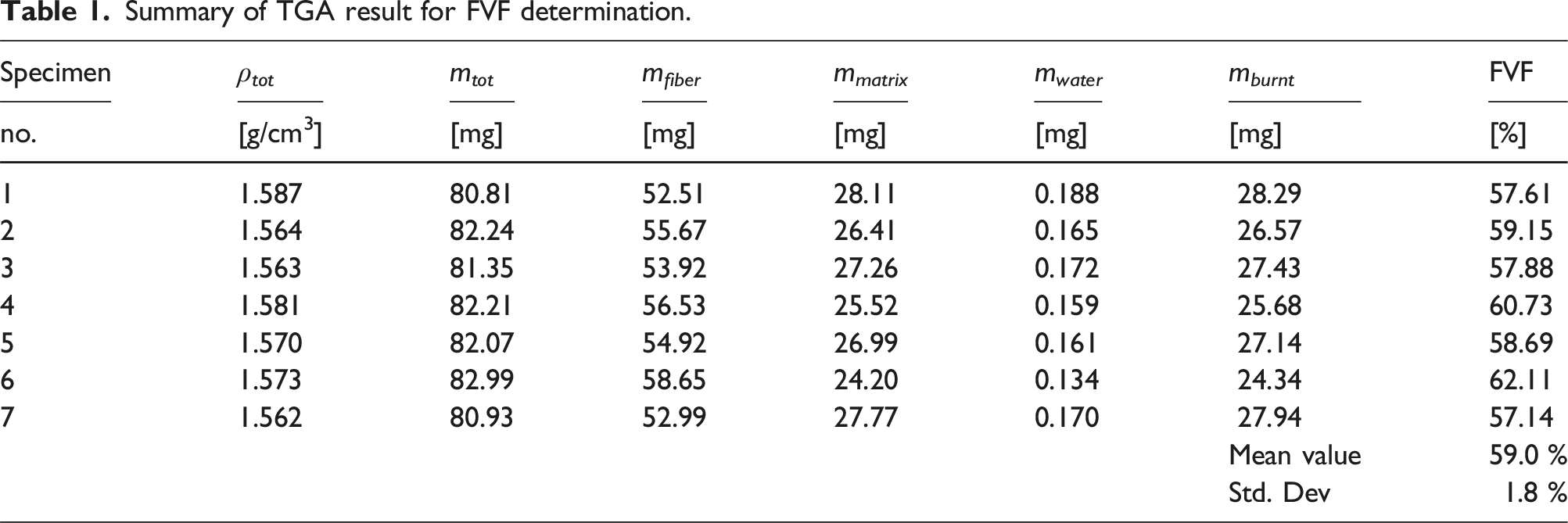
Experimental determination of fiber volume fraction
Determination of the fiber volume fraction (FVF) is done by thermogravimetric analysis (TGA) by DIN 16459:2021-06. The specimens are 7 × 7 mm in size and 2 mm in thickness. The decomposition of the matrix to determine mass loss is carried out under synthetic air with reduced heating rates to prevent uncontrolled combustion with a sharp increase in heat flow in the measuring cell. The process consists of four steps: heating of the specimen to 140°C at a heating rate of 20°C/min; isothermal holding step at 140°C, heating to 450°C at 10°C/min and an isothermal holding phase of up to 230 min. The fiber volume fraction is calculated using the mass m and density ρ of the fiber and specimen, respectively:

Summary of TGA result for FVF determination.
Methods
In this section, a brief review of existing image analysis methods is done to explore the possibilities to study fiber distribution. Later a framework is introduced to segregate the fibers from the matrix bulk material and the coordinates are studied to draw further conclusions.
Conventional methods for fiber detection
Hand labeling
A systematic analysis is used to derive the spatial fiber distribution from the acquired images. The complete microscopy image was cropped into smaller snapshots (as in Figure 4(a)), each measuring 125 x 125 micron square. These smaller snapshots allow a focused examination of localized fiber arrangements within the laminate. An open-source Python plug-in named Label-studio
33
is employed to detect the fibers within these snapshots. This plug-in facilitated the manual identification and labeling of the fibers present in each snapshot. For illustration, in Figure 4 an original snapshot (a) of size 125 x 125 micron with its hand-labeled fiber annotation (b) is depicted. Micro-section images, (a) Original snapshot from micro-section, (b) Hand-labeled image using Label-Studio, (c) Pixel thresholding result, and (d) Fiber detection using Hough Transformation.
The annotations are later exported as images and used for training and testing machine learning models. However, this manual detection process proved tedious and time-consuming, requiring significant effort to accurately identify and label each fiber.
Pixel thresholding
Pixel thresholding is a basic image processing technique used to segment an image into distinct regions based on pixel intensity values. It involves setting a threshold value and classifying each pixel as either foreground or background based on its intensity compared to the threshold. The results of pixel thresholding are depicted in Figure 4(c). Due to the intricate specimen preparation process and image artifacts, it is difficult to rely only on the pixel intensity as a metric to segment fibers. Further, a unique threshold for all the snapshots for a wide range of specimens can be a non-trivial task, therefore other image analysis techniques are investigated.
Hough transformation
The Hough circles transformation 34 is a popular image processing technique to detect circles in digital images. It is an extension of the Hough line transformation and is particularly useful for identifying circular shapes, such as objects, patterns, or structures.
The Hough circles transformation involves converting an image from the Cartesian coordinate system to the Hough parameter space. In this parameter space, each circle is characterized by three parameters: the x and y coordinates of its center and its radius. Consequently, every pixel in the image contributes to the generation of a circular equation in the Hough parameter space. However, the performance of the Hough circles transformation is strongly sensitive towards parameters such as the threshold for peak detection, which need to be appropriately set based on the specific application and image characteristics. It is also limited to detecting only perfect circles, which could be a setback as micro-section images are not exempt from noise. Moreover, the computational efficiency of Hough transformation gradually decreases with increasing amount of noise and image size (Figure 4(d)).
Problems and limitations
Due to the limitations and laborious nature of manual fiber detection, alternative image analysis techniques are explored to streamline the fiber distribution analysis process. Initially, methods such as Hough circles and pixel thresholding were implemented to automatically detect fibers. However, these techniques presented challenges, as they required the adjustment of multiple parameters and often produced faulty fiber detections, further extending the analysis time. For instance, pixel thresholding requires a unique threshold for a successful segmentation of the fibers from the bulk material. However, it is non-trivial to assign a threshold for every micro-section image. Further, the presence of noise makes it even more challenging as it increases the false detection.
A comprehensive framework may enable more effective analysis of fiber distribution within manufactured specimens. Together with a robust numerical model, a deeper understanding and improved prediction of micro-crack formation and propagation can be obtained. This type of analysis is particularly important for preserving the structural integrity of cryogenic tanks, where micro-cracks may pose serious risks.
Machine learning framework
The machine learning framework proposed in this study consists of multiple steps, as illustrated in Figure 5. First, raw microscopy images undergo preprocessing before being fed into a VGG16 deep convolutional neural network, which serves as a feature extractor. The high-quality features obtained from VGG16 are then used to train an XGBoost model to generate a binary map, where fiber pixels are labeled as 1 and the matrix as 0. Next, DBSCAN clustering is applied to the binary map to group fiber pixels based on their proximity and density, effectively distinguishing individual fibers. The coordinates of these fibers are then analyzed to study their spatial arrangement using statistical methods such as Voronoi polygons and kernel density estimation. These statistics enables us to quantify fiber distribution in-terms of their sparsity and density. These statistics are discussed in detail in section 3.3. The resulting high-dimensional spatial features are subsequently reduced to a more manageable 2D or 3D representation using t-SNE. Finally, K-means clustering is employed to identify distinct microstructure groups. Complete machine learning framework for microstructure clustering. Step-1: Optical microscopy to record fiber distribution; Step-2: Deep learning model for feature extraction; Step-3: XGB model for semantic segmentation from VGG16 features; Step-4: DBSCAN clustering to clusters fiber pixels into distinct fibers; Step-5: Extract spatial detected fibers using Voronoi polygona nd Kernel density estimation; Step-6: Dimensionality reduction and clustering in lower dimension for microstructure clustering.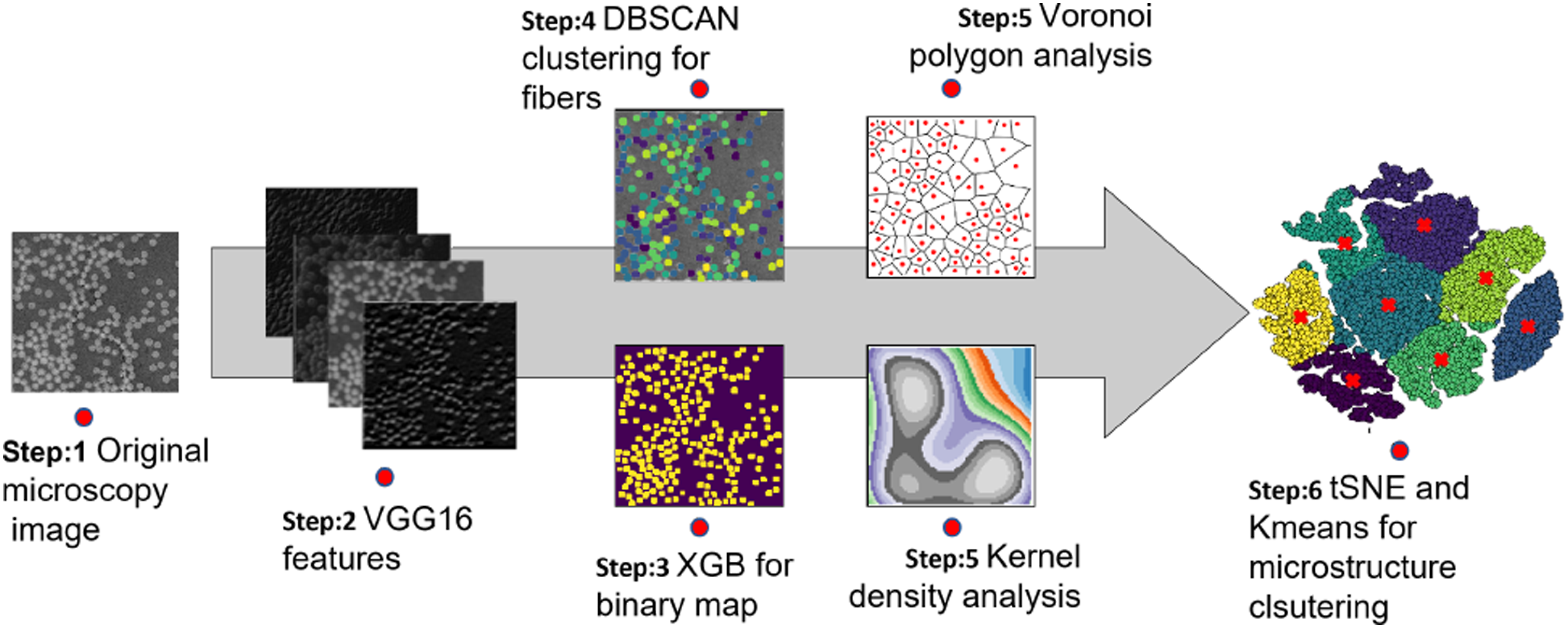
Deep convolutional neural networks for feature extraction
VGG16 35 is a deep convolutional neural network (CNN) architecture that has proven effective in various computer vision tasks, including image classification. It consists of 16 convolutional layers, hence the name VGG16, followed by fully connected layers. It is known for its simplicity and uniformity in architecture, with all convolutional layers having a 3 × 3 filter size and a stride of 1, and all max-pooling layers using a 2 × 2 window with a stride of 2. This uniformity allows for straightforward implementation and easy interpretation of the network.
The VGG16 architecture with an ImageNet 36 backbone has been pre-trained on a large-scale dataset. This pre-training process enables the network to learn general features from a diverse range of images, making it a powerful tool for transfer learning. The utilization of the pre-trained VGG16 network with an ImageNet backbone allows the extraction of relevant information from the cropped images of the composite laminate, leveraging the learned features. The original images (as in Figure 4(a)) were inputted into the VGG16 network, and the convolutional layers were utilized to capture hierarchical representations of the image features.
To focus on the discriminative features specific to our composite laminate images, we decided to chop the VGG16 network right after the feature extraction (as in Figure 6) from the convolutional layers. This allowed us to retain the high-level features extracted by the convolutional layers while discarding the fully connected layers responsible for classification. Bypassing the cropped laminate images through the modified VGG16 network, we obtained a set of feature vectors representing the extracted features. These feature vectors captured the essential information about the spatial arrangement and characteristics of the fibers within the laminate. Such features with label data from label-studio were used as training and testing data for a subsequent machine learning model, eXtreme Gradient Boosting (XGBoost). A schematic representing the presented machine learning framework for microstructure characterization.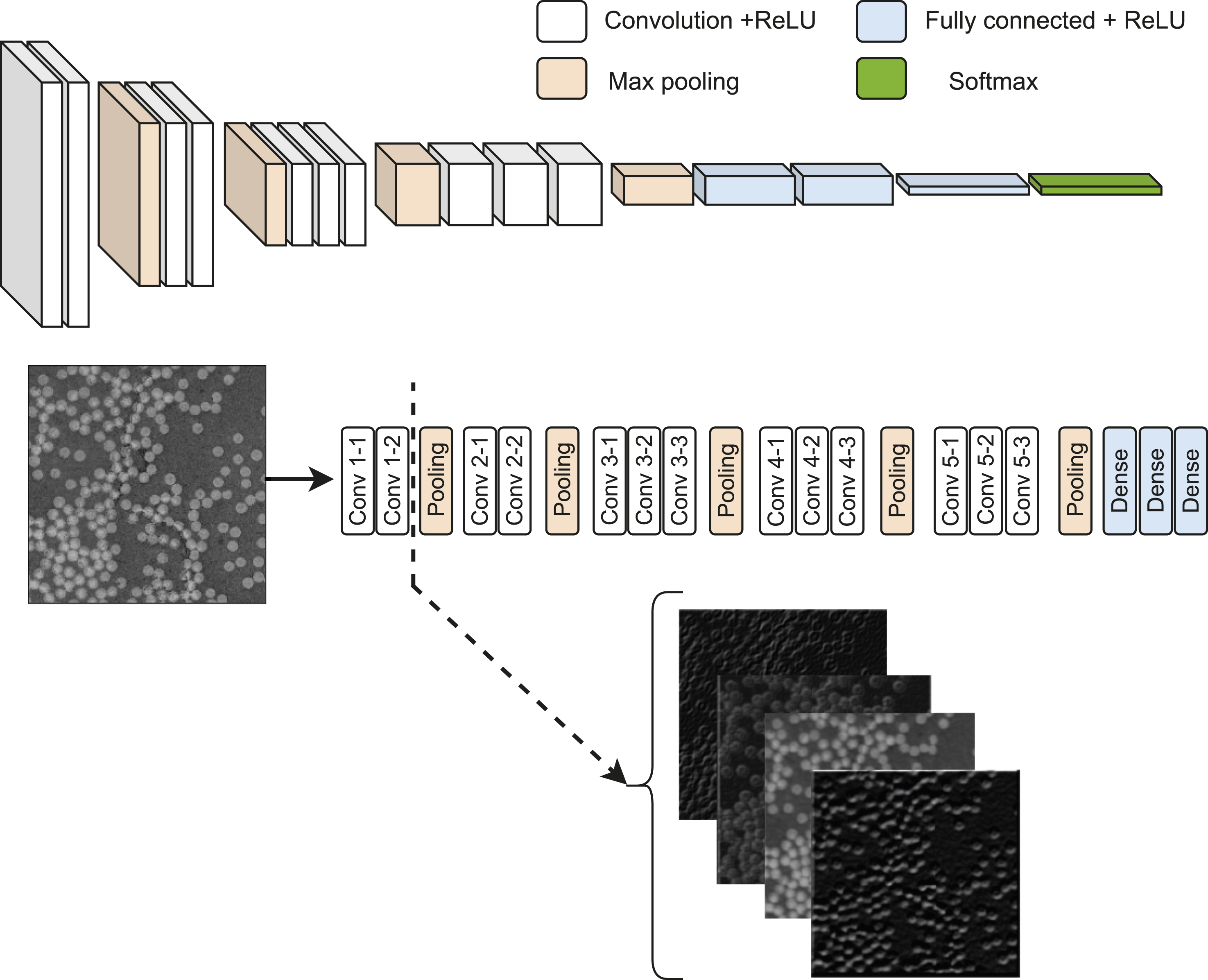
Fiber detection using eXtreme gradient boosting
XGBoost 37 is a powerful machine-learning algorithm that has gained significant popularity in both academic research and practical applications. It is known for its exceptional performance in various classification tasks. XGBoost is an ensemble method that combines the predictions of multiple individual models, called decision trees, to make accurate predictions.
As a classifier, XGBoost uses training data with known labels to build a collection of decision trees. Here the features from the VGG16 model combined with the manual labeling with label-Studio is used as such dataset. During training, the algorithm learns to iteratively improve the weak learners (decision trees) by minimizing a specific loss function (log loss). Each subsequent tree is built to correct the errors made by the previous trees, resulting in a strong and accurate ensemble model, see Figure 7. A schematic diagram of XGBoost comprised of ’k’ number of trees.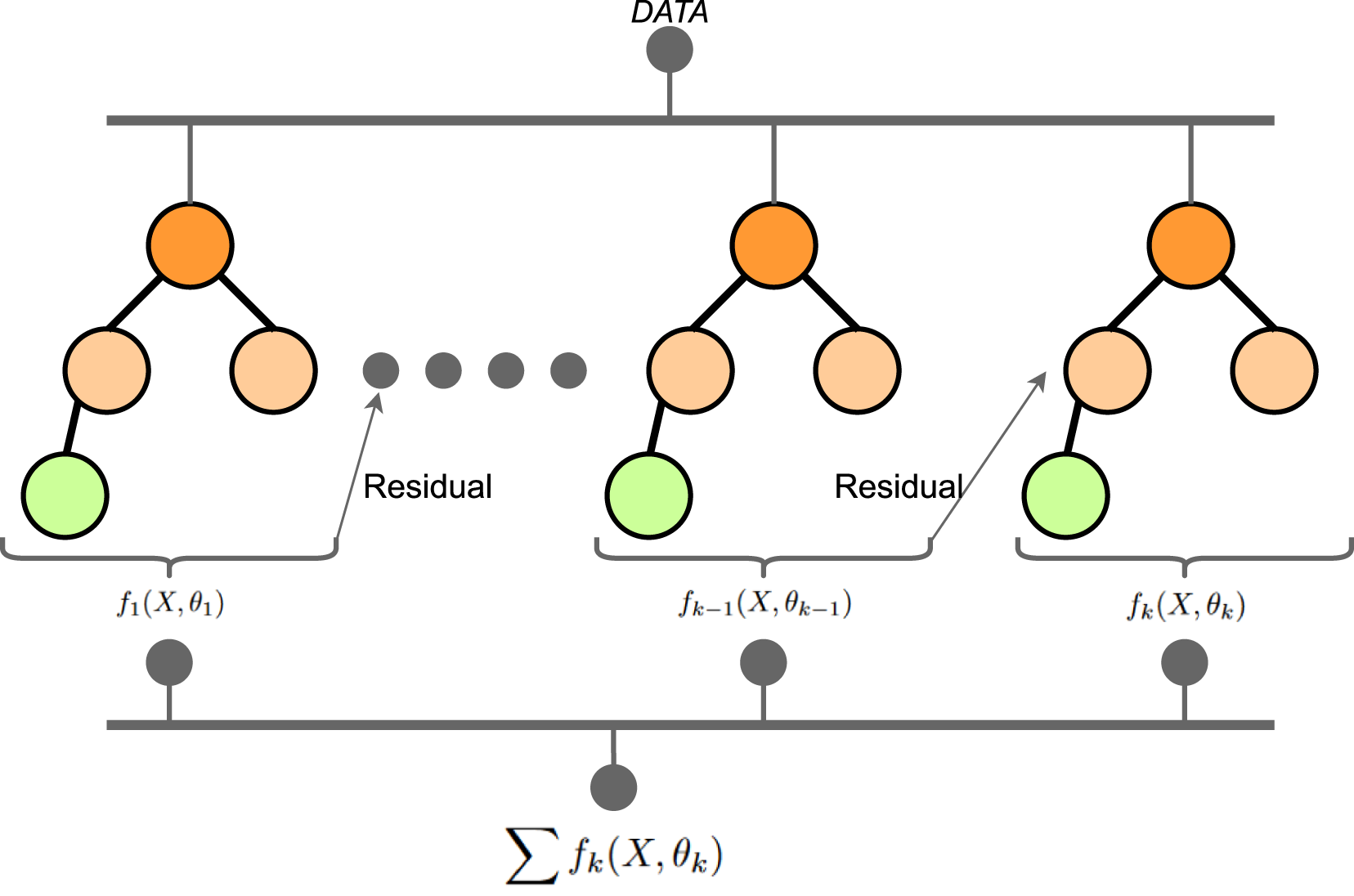
XGBoost incorporates several key techniques that contribute to its effectiveness as a classifier. It uses a gradient boosting framework, where each new tree is trained to minimize the gradient of the loss function concerning the ensemble predictions. Additionally, XGBoost implements regularization techniques to prevent overfitting, such as by controlling the complexity of individual trees or adding penalties to the objective function. For a given dataset containing ’m’ features and ’n’ data instances, the objective function for a tree ensemble model may be written as equation (2). Here L is a differentiable convex loss function, Ω is the penalty term for the model such that, Ω = γT + 1/2λ‖w‖2. T is the number of leaves in the tree, w is the weight of the leaf, γ and λ are the regularization parameters helping the smooth learning of the weights and reducing over-fitting.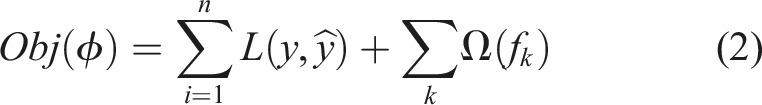
For a gradient boosting scheme, the ensemble model is trained in an additive manner and greedily adds f
t
, which can improve the learning significantly using equation (2).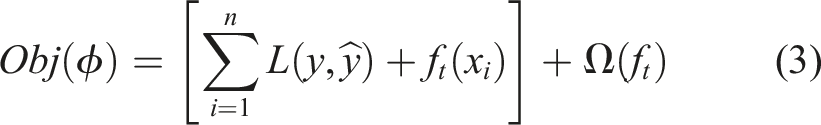
A second-order approximation is used to quickly optimize the objective function using Taylor-Series expansion and the equation (3) can be elaborated as follows. Here the 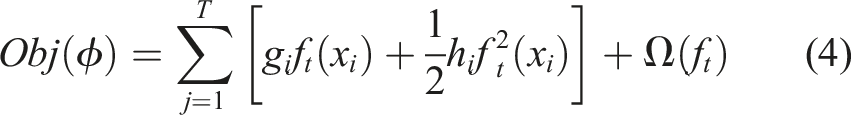
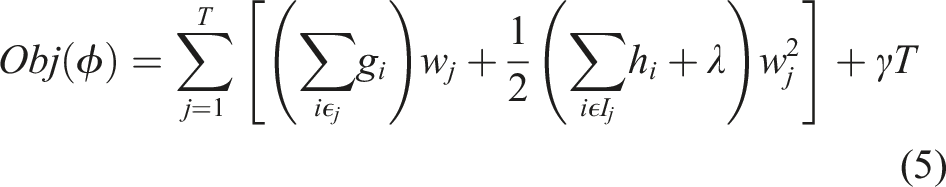
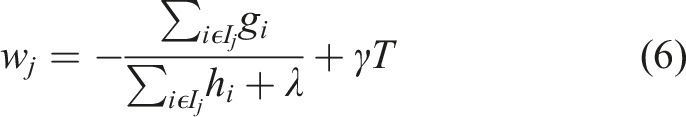
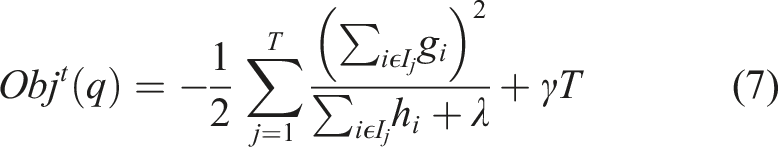
However, it is impossible to compute a separate loss function for all the different tree structures, therefore a greedy algorithm is used to get the best objective function. This greedy algorithm starts with a single leaf and iteratively adds the branches to the structure of the tree. By setting I = I
L
+ I
R
, where I is nodes/leaves for the left and right side for the corresponding sub-scripts, the generalized loss function can be for the split may be written as in equation (8).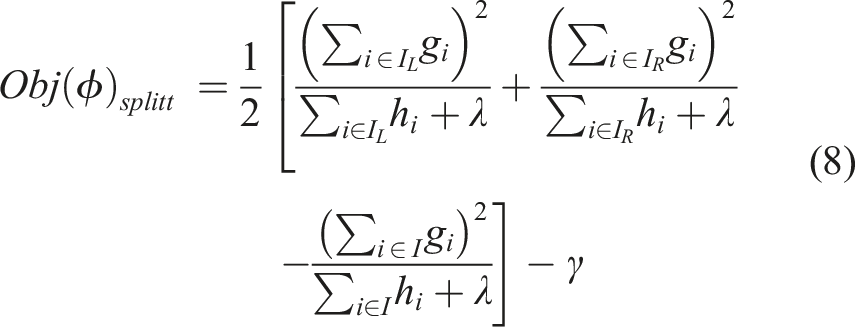
Furthermore, XGBoost offers various hyper-parameters that can be tuned to optimize its performance for specific data sets. These include parameters related to the tree structure, regularization, learning rate, and more. The algorithm’s flexibility and scalability make it suitable for large-scale problems and high-dimensional data sets.
In the work, this XGBoost model was used to detect fiber pixels from a set of features from the VGG16 model. A stratified 80:20 train-test split was used to ensure balanced representation of different microstructure categories. To prevent overfitting, early stopping was applied with a patience of 10 rounds, using log-loss on a validation set (20% of the training data) as the evaluation metric.
The semantic segmentation result from the XGBoost algorithm yields a binary image see Figure 8, where 1 represents a pixel classified as fiber and the rest as 0 representing matrix. However, to completely understand the fiber distribution, one must get the fiber centers rather than the location of all the pixels classified as fibers. Therefore a well-known non-linear clustering algorithm was employed to cluster the pixels into distinct fibers. A schematic depicting feature maps from VGG16 model predicted into fibers using XGB model.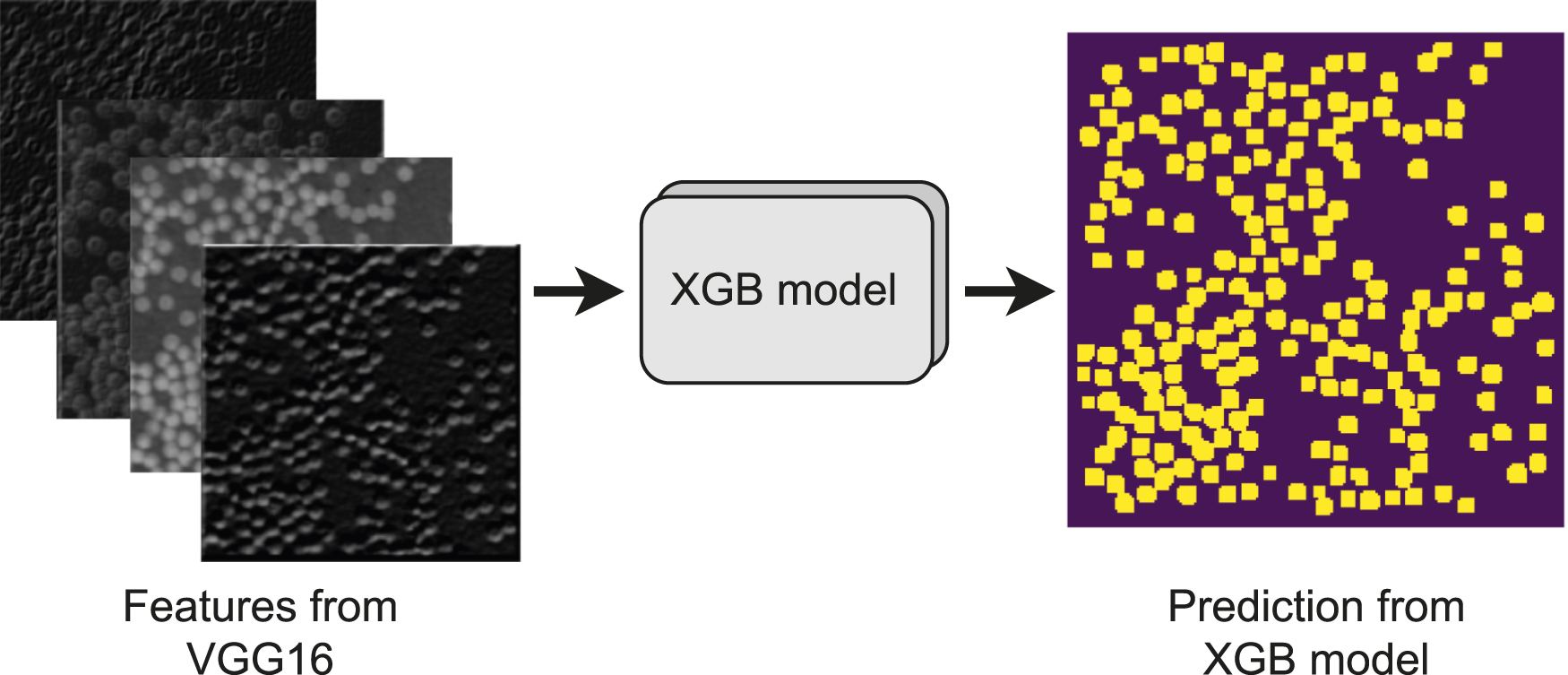
Clustering using DBSCAN
As mentioned earlier, a Density-Based Spatial Clustering of Applications with Noise (DBSCAN) 38 groups the neighboring pixels into a cluster. It is a density-based clustering algorithm commonly used for unsupervised learning tasks. Unlike traditional clustering algorithms that assume clusters have a specific shape, DBSCAN can discover clusters of arbitrary shape and effectively handle noisy data points. Here all the pixels classified as fibers from XGBoost are clustered into distinct fibers based on their density and spatial location.
As a clustering algorithm, DBSCAN does not require prior knowledge of the number of clusters (number of fibers in the presented case) in the data. Instead, it defines clusters as dense regions of data points separated by areas of lower density. The algorithm categorizes each data point (pixel in this case) into one of three categories: core points, border points, and noise points, using two user-defined parameters: the minimum number of points (minPts) and the epsilon radius (Eps). Core points are data points that have a sufficient number of neighboring points (minPts) within a specified distance (Eps). Border points are located within the epsilon radius of a core point but do not have enough neighbors to be considered core points themselves. Noise points, on the other hand, have neither enough neighbors nor fall within the epsilon radius of a core point (see Figure 9). DBSCAN operates by starting with an arbitrary data point and expanding clusters by connecting neighboring core points. It continues to grow a cluster until no more core points are found within the epsilon radius. This process repeats for other unvisited points until all data points have been assigned to a cluster or marked as noise. A schematic representing core points which has MinPts number of pixels in its Eps radius, border points, and noise/outliers.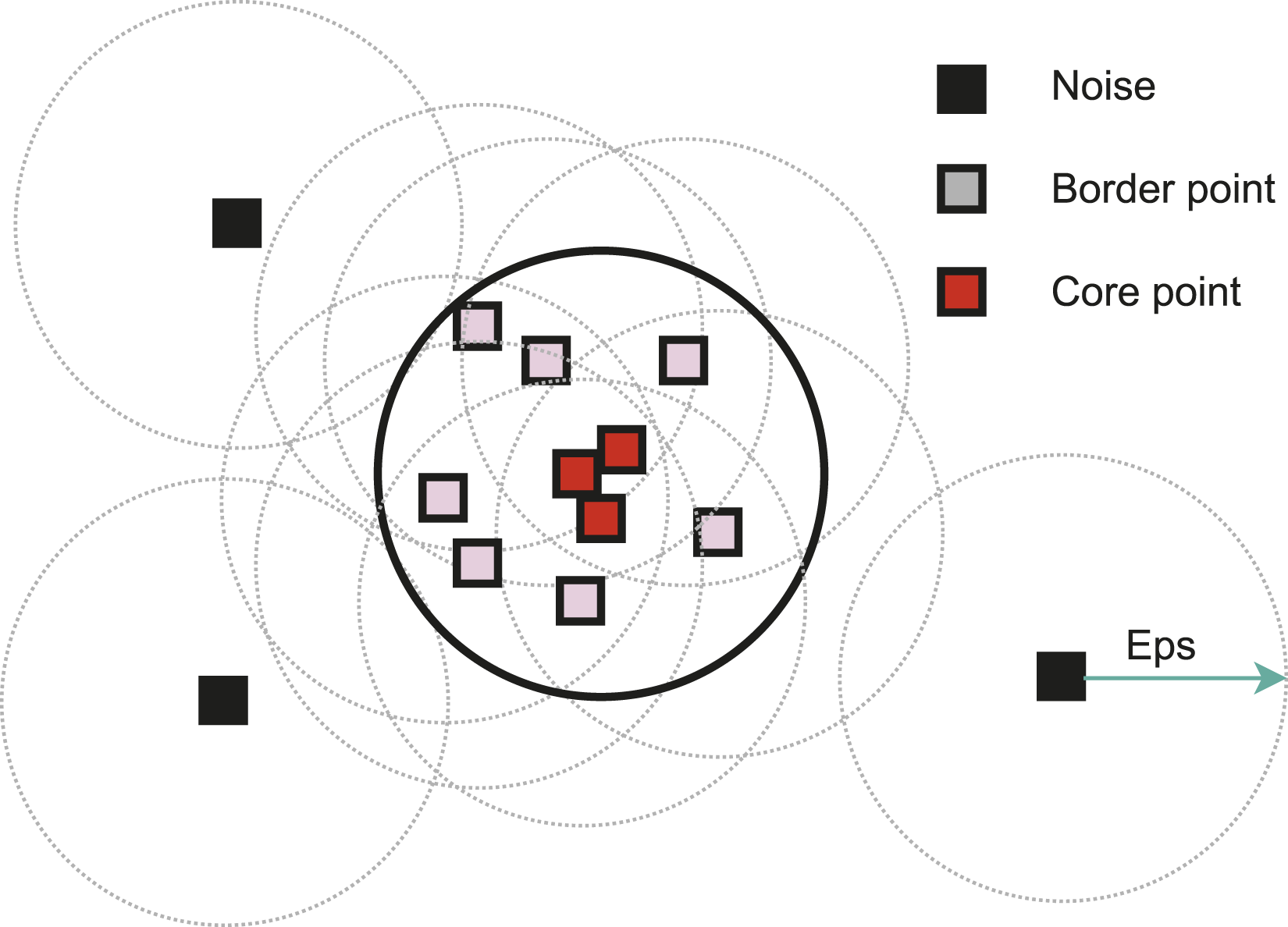
DBSCAN’s performance is dependent on two primary parameters: epsilon (Eps), which defines the radius around each data point, and the minimum number of points (MinPts) required to form a core point. These parameters influence the granularity and quality of the clusters discovered by the algorithm. Tuning these parameters appropriately is crucial for obtaining meaningful clustering results. This final step of the complete framework yields information such as the number of fibers detected (see Figure 10) in the given picture and the coordinates of each fiber center in the given domain. However, to get a complete understanding of the fiber distribution, further steps must be taken to analyze the fiber coordinates. Individual fibers detection from XGB binary map using DBSCAN.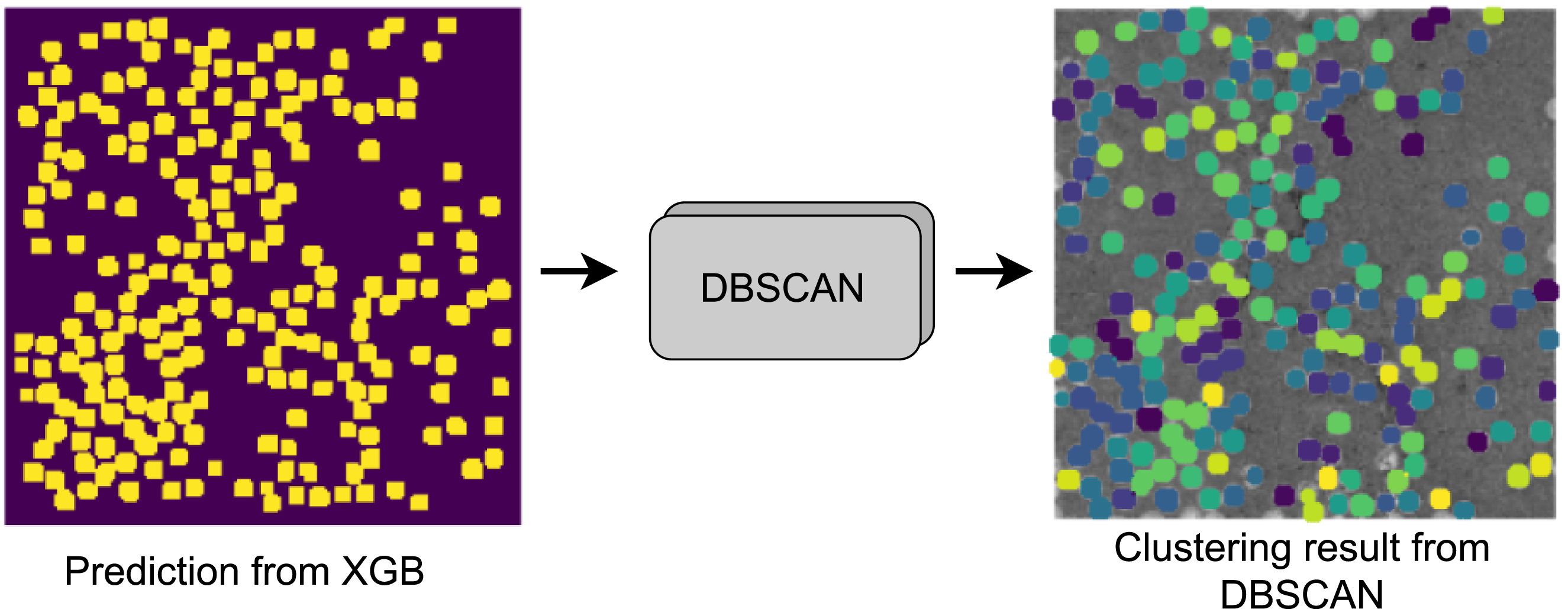
The clustering results from the DBSCAN algorithm, as depicted in Figure 10, reveal that several partially present fibers are not detected due to the algorithm categorizing them as noise. However, it is noteworthy that such fibers are indeed present in the neighboring microstructure and are accurately detected.
Quantification of homogeneity of fiber distribution
The non-linear clustering described in the previous section results in the clustering of the neighboring pixels into distinct fibers/clusters. Such clusters are later analyzed to obtain their centers as fiber centers. This information is crucial for understanding the fiber distribution and consequently tightness and looseness in the fiber packing.
Researchers have used several methods to describe a 2D spatial distribution which can help to quantify the homogeneity like Voronoi polygon analysis, 39 K-Ripley function, 28 and kernel density estimation. 40 Authors have used the mean Voronoi polygon area to quantify the gaps in the microstructure of carbon composites. Similarly, 41 used the K-reply function to obtain the quantification for the fiber distribution.
In this work, similar methods like the Area fraction method, kernel density estimation function, and Voronoi polygon analysis were used to study the fiber distribution and quantify the microstructure based on the tightness and looseness of the fiber packing.
Area fraction method
The area fraction method is used to calculate the fiber volume fraction in a given domain or material. It is commonly employed in composite materials, where fibers are embedded in a matrix. It estimates this value by measuring the fraction of the total cross-sectional area covered by the fibers in our case pixels of fibers in a representative sample. This can be readily computed using the results from the DBSCAN algorithm using equation (9).
The fiber volume fraction from an image of a microstructure can be determined using two distinct methods. The first method involves a straightforward approach: counting the number of fiber pixels and dividing it by the total number of pixels in the given microstructure. The second method entails calculating the matrix volume fraction by dividing the non-fiber pixels by the total pixels in the image and subsequently subtracting this fraction from 1 to obtain the fiber volume fraction. It is worth noting that these methods may yield divergent results due to the presence of noise. To mitigate this potential discrepancy, the pixels classified as noise by the DBSCAN algorithm are disregarded in the calculations of the fiber volume fraction.
Voronoi polygon
Voronoi polygons, 42 also known as Voronoi cells or Dirichlet cells, are regions in a plane associated with a set of points. Each polygon encompasses all the points within its boundary that are closer to its central point than to any other point in the set. In fiber distribution analysis, Voronoi polygons partition space around individual fibers, providing a spatial representation of the regions of influence for each fiber within a composite material.
In this framework, Voronoi polygon representation is used to study the distribution of the detected fibers. Figure 11 shows two different microstructures with significantly different fiber distributions with their respective Voronoi polygon representation. The analysis reveals that larger gaps in the microstructure are reflected as larger polygonal areas in the Voronoi representation. These larger polygons indicate regions rich in resin within the microstructure, which are likely to contribute to permeation and leakage.15,43 A figure depicting different microstructures and spatial statistics such as Voronoi polygons and kernel density estimations. (a) Original microstructure - 1 (b) Original microstructure - 2 (c) Original microstructure - 3 (d) Original microstructure - 4 (e) Voronoi polygon - 1 (f) Voronoi polygon - 2 (g) Voronoi polygon - 3 (h) Voronoi polygon - 4 (i) Kernel density - 1 (j) Kernel density - 2 (k) Kernel density - 3 (l) Kernel density - 4.
Kernel density function
In evaluating fiber distribution in a given domain, the Kernel Density Estimation (KDE) of a microscopy image involves estimating the probability density function of the pixel intensities associated with the fibers. KDE is a non-parametric method widely utilized in image segmentation, pattern recognition, and anomaly detection,44,45 which can be computed for an image using equation (10). This study is used to identify the underlying density function of the fiber intensities, enabling the detection of not only the regions where fibers are tightly packed but also the number of peaks in the kernel density function revealing the number of high-fiber density regions and their spatial distribution.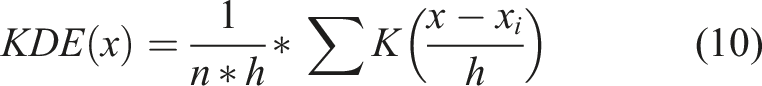
Here the kernel density function of an image is computed with the number of pixels in the image(n), bandwidth also known as smoothing parameter(h), i th pixel intensity, and Gaussian kernel function(K).
By applying KDE to the image, statistical parameters, such as the mean kernel density, can be derived, offering a quantitative assessment of the fiber distribution within the analyzed microstructure. Figure 11 presents various examples of microstructures with differing fiber distributions, alongside their corresponding KDE functions. The KDE accurately identifies regions with high fiber density, with peaks in the KDE indicating areas where fibers are closely packed. These densely packed regions are likely to contribute to stress concentration, thereby promoting the initiation and propagation of micro cracks. 20
Microstructure clustering based on fiber distribution
The results from the preceding machine learning step provide precise coordinates for all identified fibers, forming a fundamental basis for in-depth analysis of fiber distribution. From these coordinates, we extract critical quantitative descriptors such as Voronoi polygon areas, kernel density estimations, and fiber volume/area fractions. To effectively characterize various types within the microstructure, we employ higher-dimensional clustering techniques.
However, conventional clustering algorithms like K-means 46 often encounter computational challenges and diminished efficacy in high-dimensional spaces due to the curse of dimensionality, which complicates the definition of meaningful distances and the identification of significant clusters. To address these issues, we utilize advanced dimensionality reduction methods that transform complex, high-dimensional data into more manageable 2D and 3D representations. This transformation not only enhances clustering performance by mitigating computational constraints but also facilitates improved visualization and interpretation of microstructure types.
t-SNE for dimensionality reduction
t-SNE, which stands for t-distributed Stochastic Neighbor Embedding,
47
is a dimensionality reduction technique commonly used for visualizing high-dimensional data in lower dimensions while preserving the pairwise similarities between data points. In the presented work, it is employed for dimension reduction for pattern recognition applications using quantitative information from the Voronoi polygon, kernel density estimation, and fiber volume/area fraction.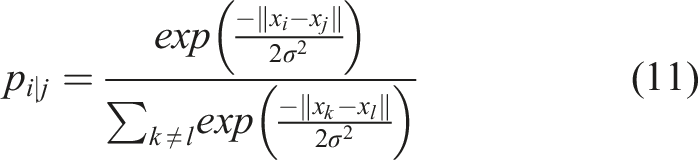
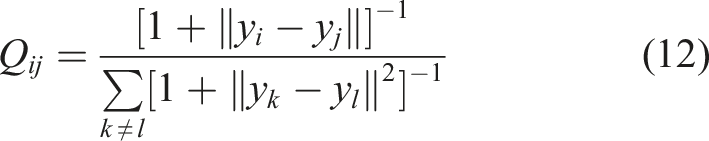

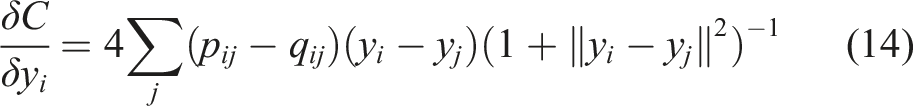
The ultimate goal of this activity is to reduce the high dimensional data into comprehensible 2D and 3D, allowing us to use clustering algorithms effectively to identify the underlying microstructure patterns, and also suitable for visualization.
Microstructure categorizing using K-means
K-means is a popular clustering algorithm that divides a dataset into a specified number of clusters. It aims to minimize the sum of squared distances between data points and their respective cluster centers. In the presented work, it plays a crucial role in categorizing the microstructure based on fiber packing. It partitions the data into distinct clusters, enabling us to identify and analyze different fiber patterns within the composite material. The transformed data from t-SNE into 2D and 3D are subsequently used for identifying the distinct categories of microstructure with different fiber patterns. This transformation enhances the categorizing quality and provides clearer visual insights, making it an integral component of our analysis.
Initially, cluster centroids are randomly placed in the data space. Through iterative steps, each data point is assigned to the nearest centroid based on Euclidean distance, forming clusters using equation (15).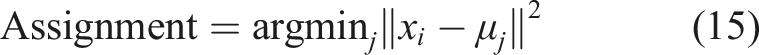

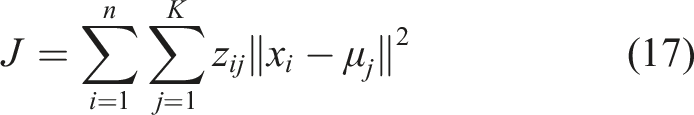
The centroids are then recalculated by averaging the data points within each cluster. This assignment-update cycle continues until convergence, usually when centroid positions stabilize or a predefined number of iterations is reached. K-means minimizes the sum of squared distances between data points and their respective centroids, effectively grouping similar data points.
The simplicity and efficiency of K-means clustering make it well-suited for this application, enabling effective categorization of microstructures based on fiber packing and dispersion. Each cluster formed by K-means reveals a distinct fiber distribution pattern, with differences highlighted by variations in the gaps between fibers and regions where fibers are densely packed.
Results and discussion
This section takes a detailed look at the results and conclusions from the methods described in section 3. The machine learning framework used to detect fibers is tested with advanced techniques, and the results are carefully analyzed and discussed.
Machine learning model evaluation
The machine learning framework detailed in Section 3 effectively detects fibers within a given microstructure. However, it is equally crucial to assess the accuracy of the trained models. In classification machine learning models, conducting post-hoc analysis on the trained model is essential. For this purpose, a testing dataset, unseen by the model during training, is employed to evaluate the model’s performance based on accurate and erroneous fiber pixel identifications. In this section, we introduce and provide a detailed explanation of the results obtained using various post-hoc methods, including the confusion matrix (CM) and receiver operator characteristics (ROC). 48 These methods offer valuable insights into the model’s classification performance and ability to distinguish between fiber and non-fiber regions within the microstructure.
There are several metrics to evaluate the performance of the trained model, like root mean square error used by, 49 and Mean Absolute Error (MAE) used by 50 for evaluating the model to predict the tensile strength of polymer/ CNTs nanocomposites. However the methods used in the present work like CM and ROC are more suited for classification based model.
In the second phase of our framework, an unsupervised machine-learning model is utilized to group fiber pixels into distinct clusters/fibers. The evaluation of this clustering process employs the Silhouette score, which prioritizes the creation of dense and well-separated clusters representing distinct fiber distribution patterns.
Classification model analysis
A CM is a tabular representation of the performance of a classification model that shows the predicted and actual labels for a data set. It provides a comprehensive summary of the model’s predictions and their agreement with the ground truth hand-labeled dataset. The confusion matrix consists of four main components: true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
The FP and FN errors represent the type-1 and type-2 errors in statistics, respectively. In a standard CM, a strong diagonal suggests improved ML model performance on the test data. In Figure 12(a), diagonal members represent the instances when the model predicted the class correctly, and off-diagonal values represent the miss-classified data instances. Confusion matrix and receiver operator charactersitics for XGB model trained to detect fiber pixels from the bulk. (a) Confusion matrix (b) Receiver operator characteristics.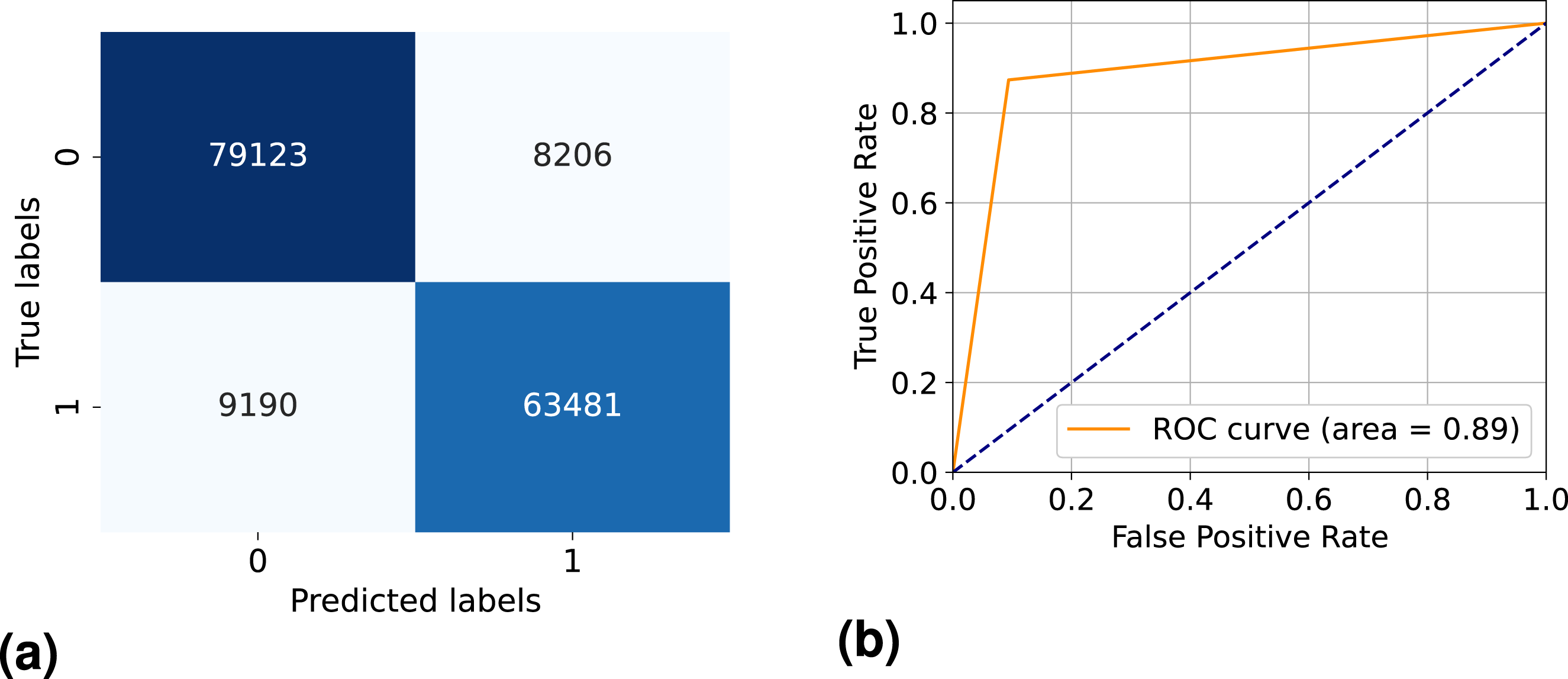
For a successfully trained model, a CM with a strong diagonal indicates that the model’s predictions align well with the ground truth labels. This diagonal dominance signifies accurate classification across various classes, showcasing the model’s proficiency in making correct predictions.
However, relying solely on the diagonal of the CM as a metric for model evaluation is inadequate. Therefore, based on the components of the CM true positives, true negatives, false positives, and false negatives, several metrics can be derived to comprehensively evaluate the performance of a classification model.
Indeed, different metrics obtained from the elements of the confusion matrix, such as precision (equation (18)) 0.88, recall (equation (19)) 0.87 and F1-Score (equation (20)) 0.88,
51
were adopted: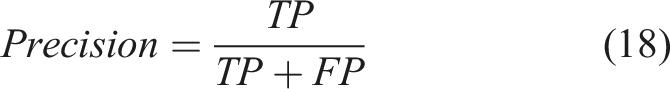

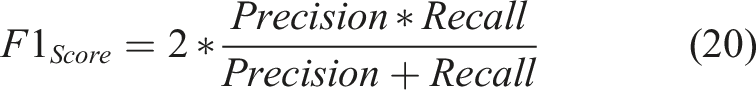
The higher values of these derived units from the confusion matrix advocate for the better-performing model, showcasing its ability to accurately classify fiber pixels from the bulk.
The AUC-ROC is a metric commonly used for binary classification problems. It represents the area under the ROC curve, which plots the true positive rate (recall) against the false positive rate.
In this study, the model achieved an AUC score of 0.89 (see Figure 12(b)), demonstrating its effectiveness in distinguishing between fiber and matrix pixels using VGG16 features. This indicates that the model performed well, accurately identifying true positives while keeping false positives low.
Clustering evaluation
The Silhouette score 52 is a metric commonly used to evaluate the quality of clusters produced by unsupervised machine learning algorithms, DBSCAN in the presented case. It provides a measure of how well-separated the clusters are and how similar the data points within the same cluster are to each other compared to data points in other clusters. The Silhouette score ranges from −1 to 1, where 1 represents that the data point is well matched to its cluster and poorly matched to neighboring clusters, while a score close to −1 indicates that the data point may have been assigned to the wrong cluster.
In the presented work, the Silhouette score is used to assess the quality of clustering performed to create distinct clusters from fiber pixels with an average score of 0.98. A visual representation of clusters from DBSCAN is shown in Figure 13(b). A figure depicting the results from DBSCAN clustering. (a) Prediction form XGB (b) Clustering from DBSCAN.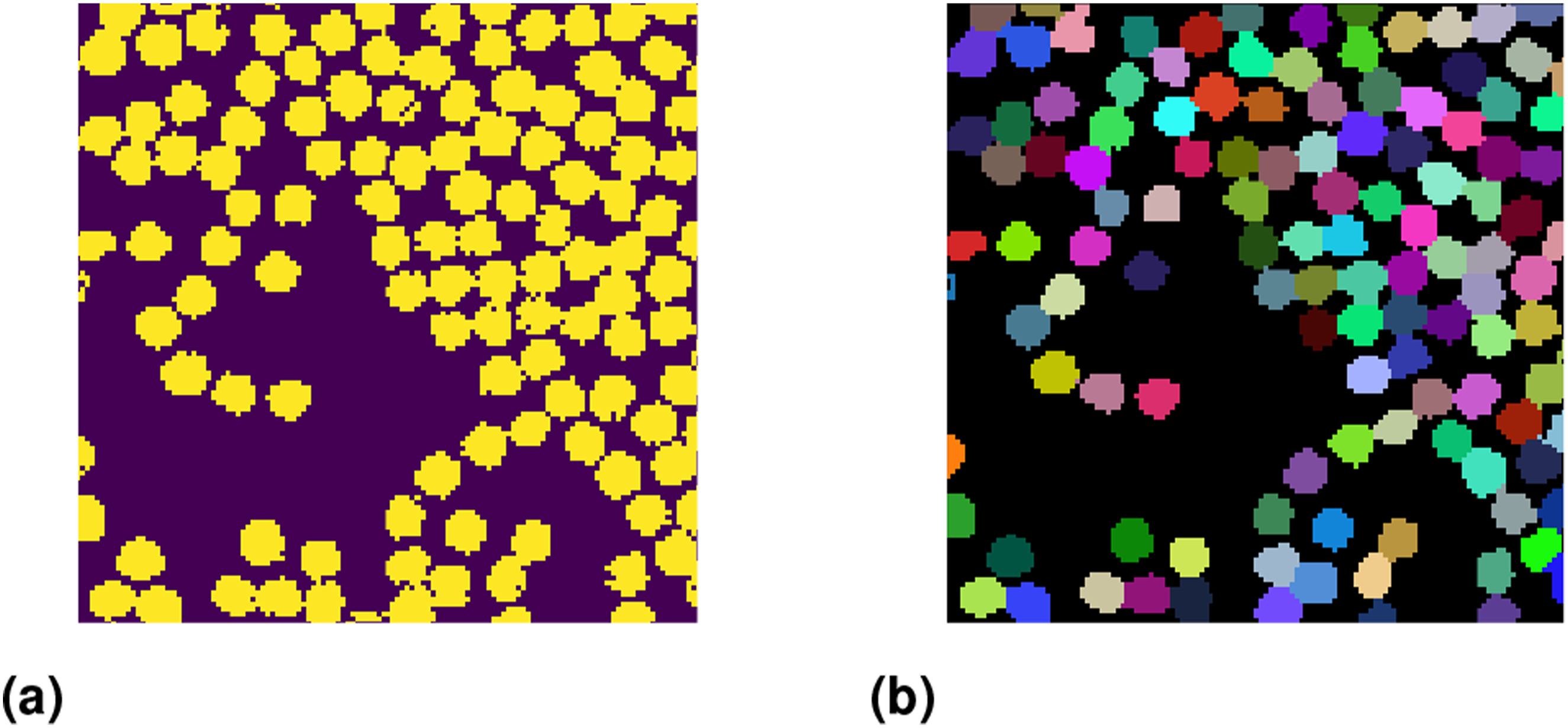
Comparison of fiber volume fraction
In section 2.3, a comprehensive method was employed to determine the FVF experimentally. Similar information can be deduced using the results from the presented machine learning framework.
Fiber volume fraction can be readily computed using microstructure image analysis using XGB segmentation. The pixels in the microstructure image are classified as fiber pixels and total pixels in the microstructure can be used as equation (9) for FVF evaluation.
Fiber volume fraction analysis on micro-strcture.
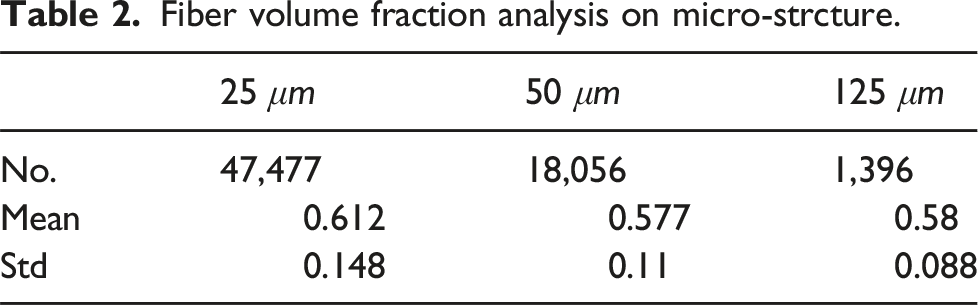
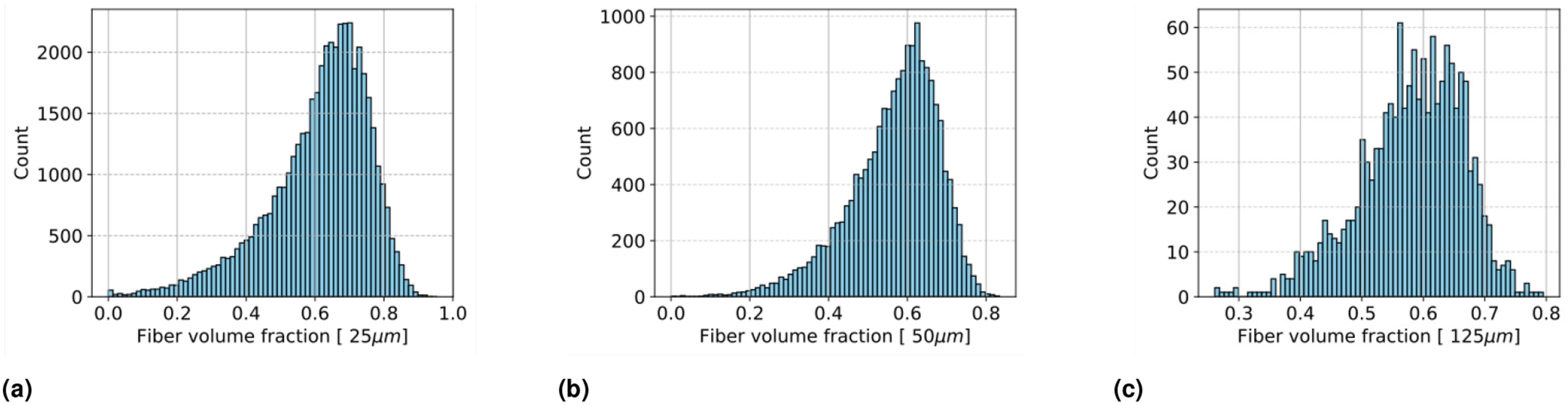
Fiber volume fraction analysis using microstructure images: (a) Fiber volume fraction distribution for 25 μm, (b) Fiber volume fraction distribution for 50 μm, and (c) Fiber volume fraction distribution for 125 μm.
The FVF obtained from the proposed method (0.589) and the TGV (0.59) analysis closely matches the material’s datasheet, demonstrating the method’s high accuracy. The FVF of the analyzed specimens falls within the expected range, meaning the fiber distribution did not significantly impact the material’s behavior at the macro level but had a notable influence on its micro-level behavior.15,20
Evaluation for homogeneity based quantification
Results of voronoi polygon
The statistical analysis of polygon areas offers valuable insights into the spatial arrangement and uniformity of fibers within composite laminates. A smaller mean polygon area serves as an indicator of a more uniform and desirable distribution, signifying that each fiber occupies a consistent and well-defined space. Conversely, a larger mean polygon area suggests uneven spacing and clustering of fibers, potentially leading to structural vulnerabilities and diminished mechanical performance as described in Ref. 53.
In Figure 15(d), a microstructure of 125 μm is shown with its Voronoi polygon representation Figure 15(f). It can be deduced that the fiber is close to evenly spaced represented by similar-sized polygons as shown in Figure 15(c). Voronoi polygon analysis, (a) Cell size 125μ m with low fiber count (d) Cell size 125μ m with high fiber count (g) Cell size 125μ m with medium fiber count ;(b) Voronoi polygon representation of low fiber count (e) Voronoi polygon representation of high fiber count (h) Voronoi polygon representation of medium fiber count; and (c) Polygon area distribution for low fiber count (f) Polygon area distribution for high fiber count (i) Polygon area distribution for medium fiber count.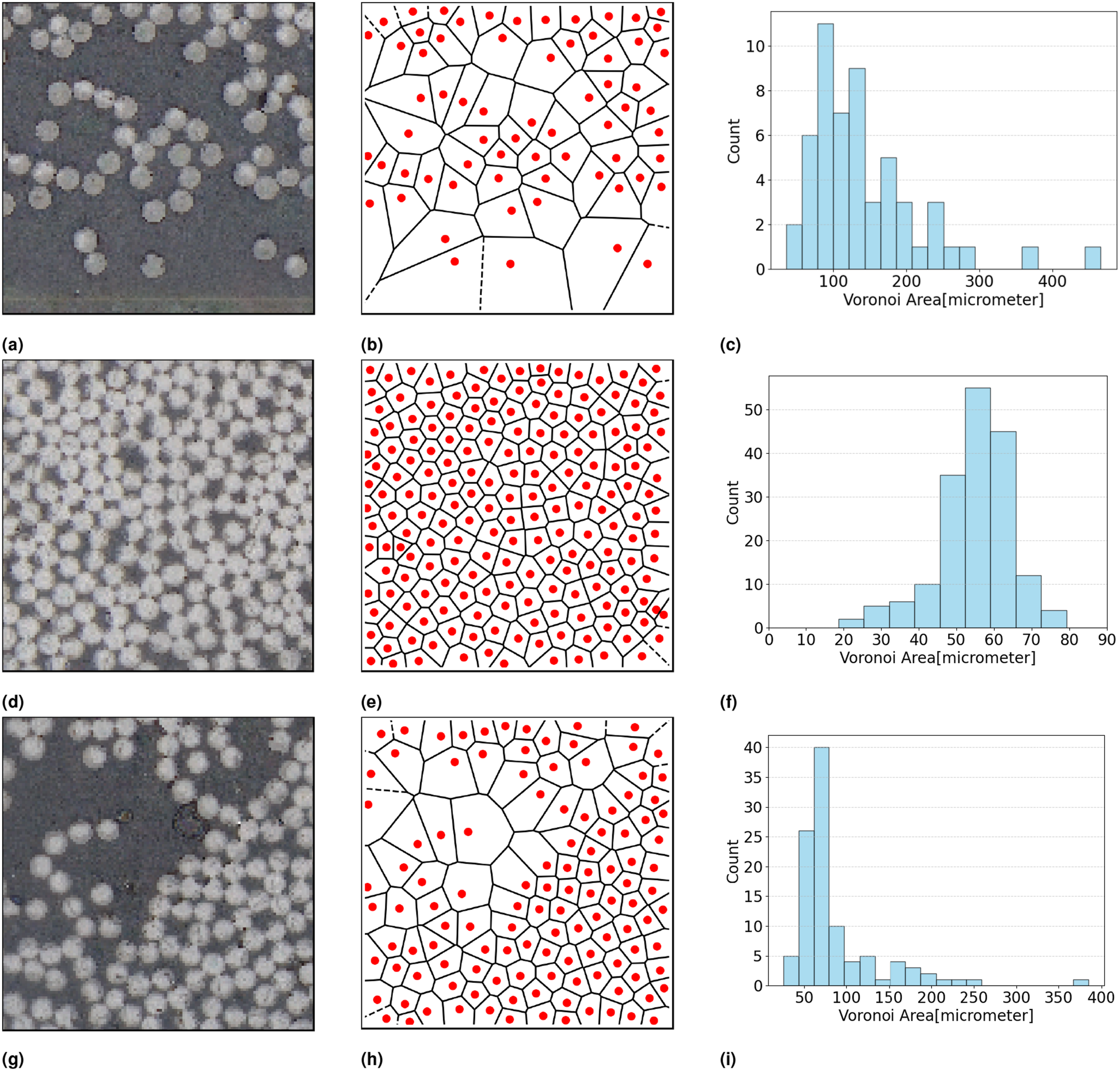
Other statistical characteristics reveal further information regarding the microstructure using Voronoi polygon areas. The smaller mean Voronoi area, see Figure 15(f) 55.54 μm, represents the tightly packed fiber arrangement in the given microstructure. Conversely, the higher mean Voronoi polygon area 141.04 μm represents the larger gaps as in Figure 15(c). Moreover, additional statistical measures, such as the standard deviation of Voronoi polygon areas, reveal the extent of variance in gaps between the fibers.
Further, higher-order statistics, including skewness and kurtosis, provide a deeper understanding of the distribution. Skewness assists in identifying whether the domain features more areas with tight fiber arrangement areas (left-skewed) with a few isolated less fiber regions as in Figure 15(c) or fewer such areas (right-skewed) as in Figure 15(f). Furthermore, kurtosis characterizes the tail of the Voronoi polygon areas. Higher kurtosis indicates a heavier tail, signifying a higher number of outlier sparse regions with very few fibers. Such regions are responsible for a possible increased rate of permeation. 22
Results of kernel density function
Similarly, a thorough statistical analysis of the kernel density estimation function may reveal deeper insights into the fiber packing. For instance, higher kernel density estimation infers regions with higher fiber density, and vice versa. It also reveals the number of peaks signifying the number of regions where the fibers are tightly packed.
As shown in Figure 16, 2D kernel density estimation of three different microstructures with their 1D distribution are shown. The mean and standard deviation of such function tell us about the high fiber density areas. Furthermore, exploring additional statistics, such as the standard deviation of the KDE, reveals variations in fiber density across the examined domain. Higher-order statistics, such as skewness and kurtosis, provide deeper insights into the distribution. (a) Original microstructure image with low fiber count;(d) Original microstructure image with high fiber count;(g) Original microstructure image with medium fiber count;(b) kernel density representation with low fiber count;(e) kernel density representation with high fiber count;(e) kernel density representation with medium fiber count;(c) kernel density distribution with low fiber count;(f) kernel density distribution with high fiber count;(i) kernel density distribution with medium fiber count.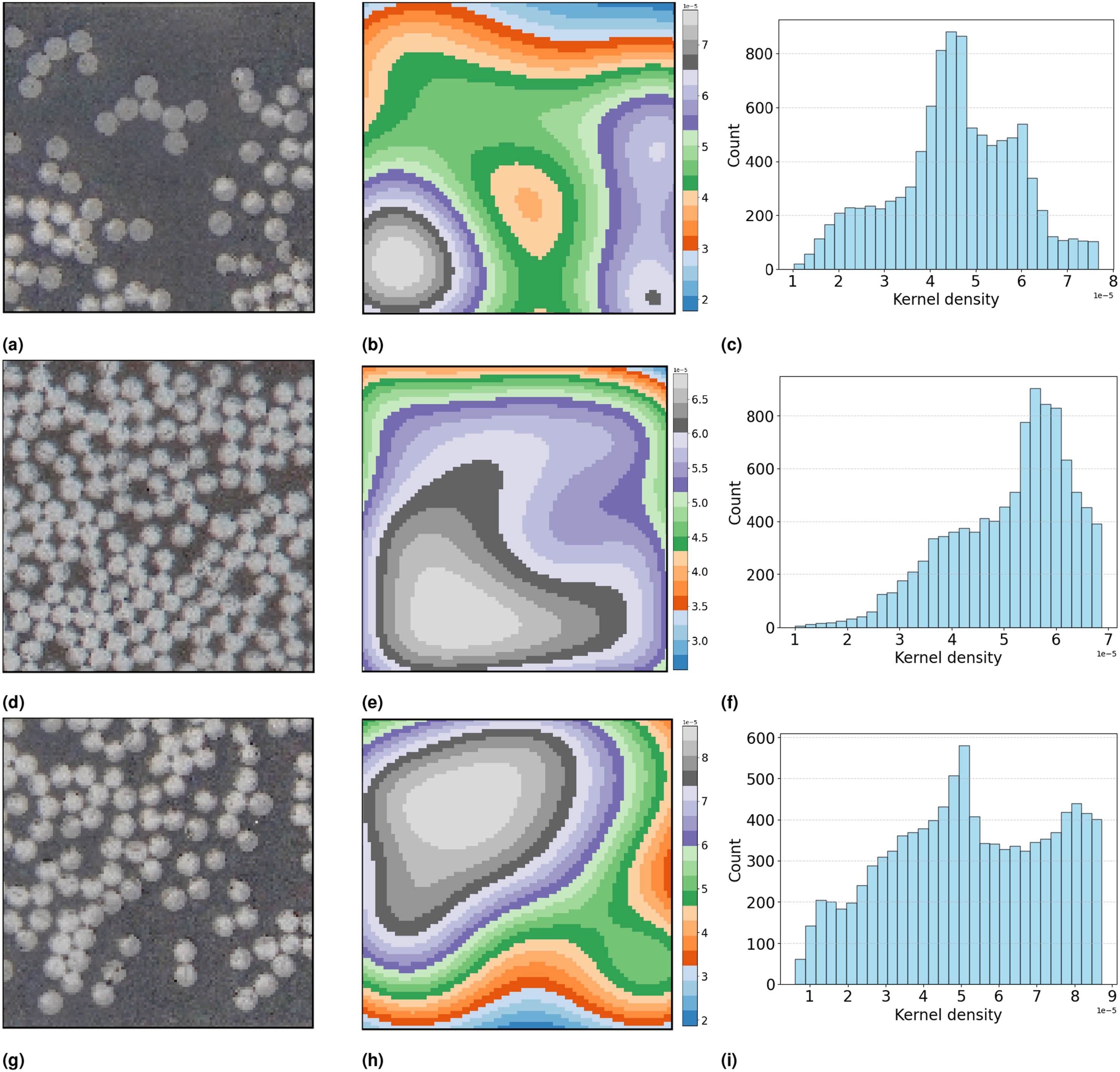
Skewness is particularly useful in determining the symmetry of fiber distribution. For example, a right-skewed distribution indicates a higher concentration of fibers in certain areas, which could lead to localized stress concentrations. 21 Conversely, a left-skewed distribution suggests that such areas are sparse.
Additionally, kurtosis characterizes the tail of the KDE. Higher kurtosis value implies that there are more extreme outliers regions of abnormally high fiber density with are potential to create nucleation sites for matrix cracking. 43
Dimensionality reduction and clustering
The micro-section images are cropped into smaller domains of different sizes, which are analyzed by the VGG16, XGB, and DBSCAN models to detect the fibers. The spatial distribution of the fibers is analyzed using statistical analysis like Voronoi polygon and kernel density estimation.
Spatial statistical analysis like Voronoi polygon area statistics and kernel density analysis provides extensive information regarding the fiber distribution pattern. Further, to circumvent the rotational invariant property of microstructure, area moment of inertia was employed. These statistics together with the fiber volume fraction sum up to 9 (4-Voronoi polygon statistics; 4-KDE statistics; and FVF) features representing a microstructure.
In higher-dimensional feature spaces, such as the 9-dimensional space representing microstructures, the complexity of the data increases, and it becomes challenging to visualize and interpret meaningful patterns directly. Clustering algorithms like K-means struggle with high-dimensional data due to the curse of dimensionality, 54 where distances between points become less meaningful as the number of dimensions increases.
To circumvent this issue and facilitate the clustering of microstructures, the dimensionality reduction method, t-SNE, is used for visualizing high-dimensional data in lower-dimensional spaces while preserving local structures and capturing non-linear relationships, which will be used to draw meaningful patterns in the microstructure.
Results of t-SNE
t-SNE is a dimensionality reduction technique, traditionally used for visualizing high dimensional data55,56 in lower dimensions while preserving the pairwise similarities between data points.
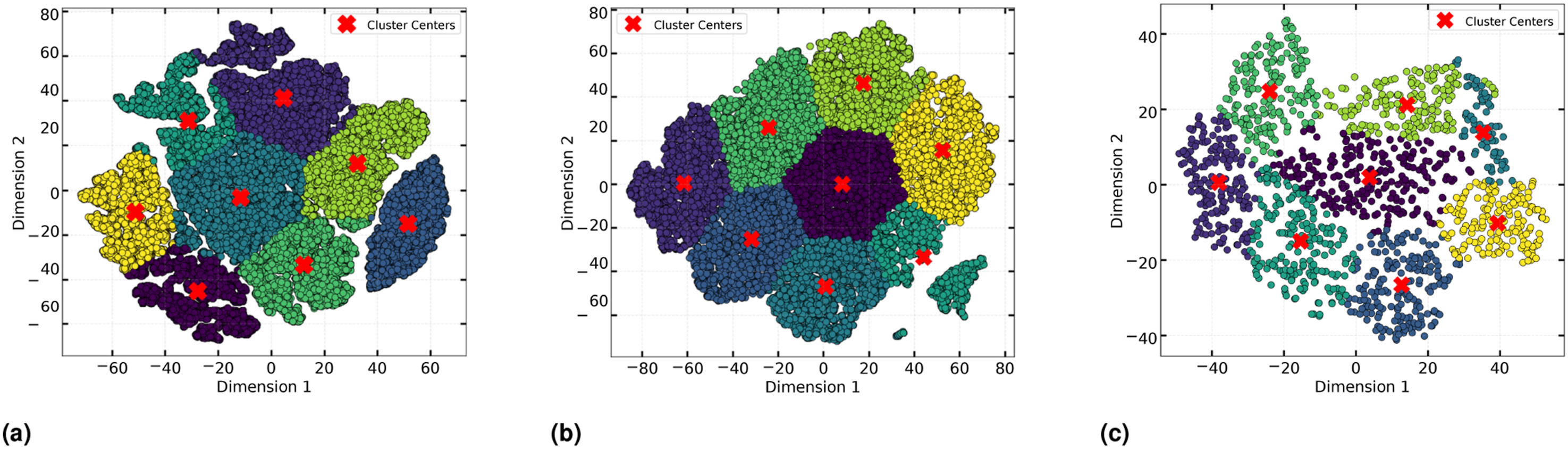
A 2D t-SNE dimensional representation is shown in Figure 17. Each point in this distribution represents a distinct microstructure. All such points are analyzed using K-means to create distinct clusters. Different colors represent the distinct clusters with cluster centers marked as red crosses. A similar analysis was conducted on microstructures of varying sizes, specifically those with dimensions of 125 μm, 50 μm, and 25 μm (see Figure 18). 2D t-SNE representation with 8 clusters using K-means, with one example shown from few clusters. 2D dimensionality reduction using t-SNE and K-means clustering results, (a) 25 μm ,(b) 50 μm, and (c) 125 μm.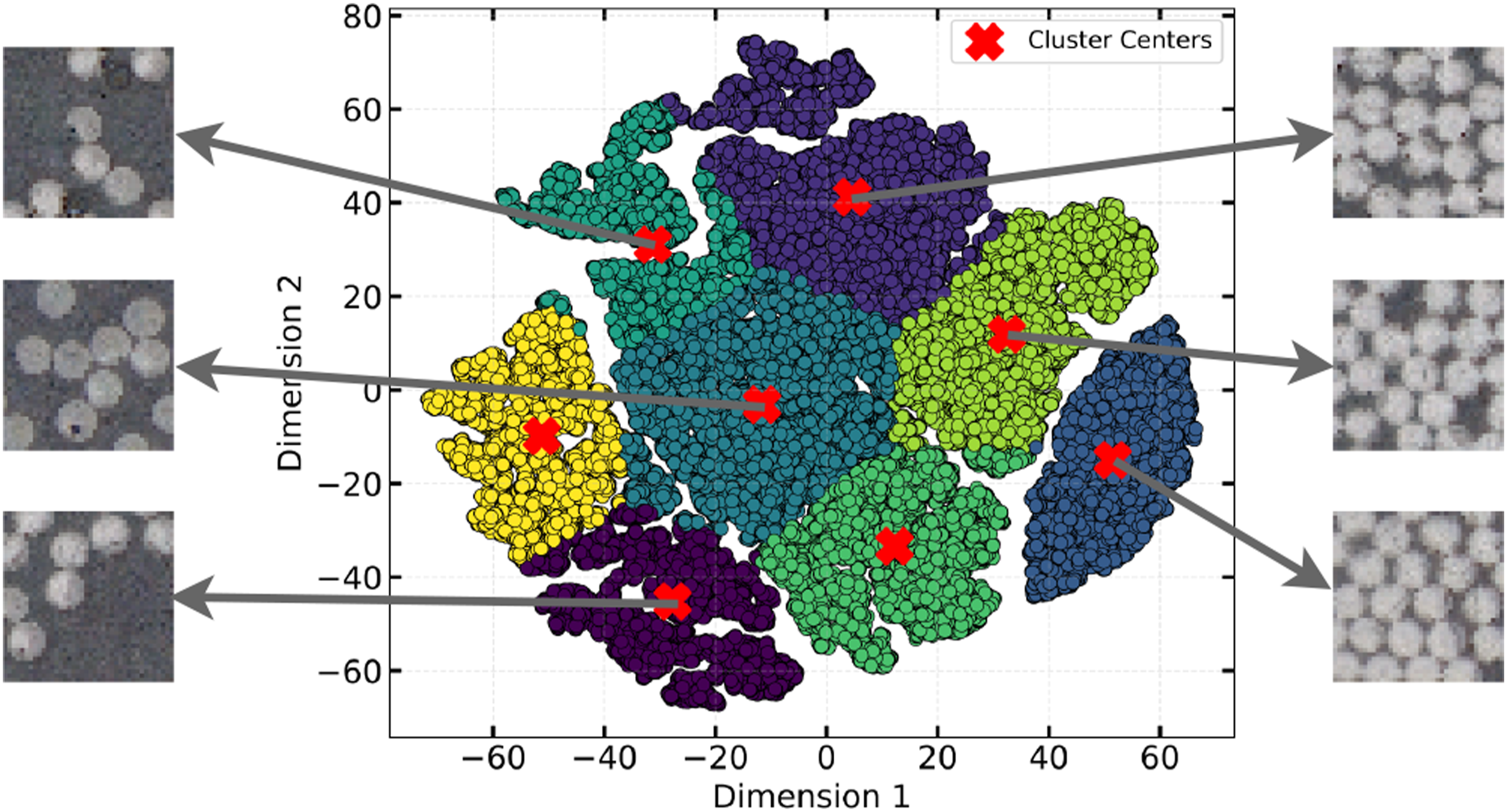
For better comprehensibility of the clusters, t-SNE representation of the microstructures was also performed in 3D. Analogously in 3D as well, K-means was used to group the different microstructures into distinct clusters, which are represented with various colors in Figure 19. 3D t-SNE representation with 6 clusters using K-means for all the 3 cell sizes; (a) 125 μm, (b) 50 μm, (c) 25 μm.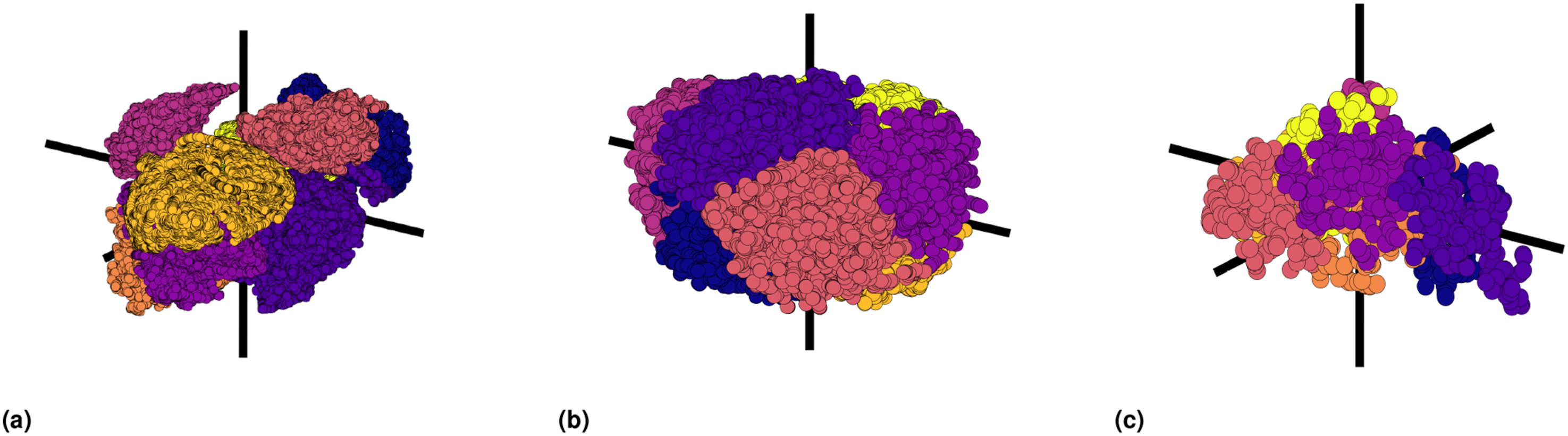
Results on K-means
Following dimensionality reduction, K-means clustering was applied to both the 2D and 3D datasets. However, K-means requires the value ”k (number of clusters)” apriori to create clusters. This crucial task of determining the optimal number of clusters (k) was performed by employing a well-known method termed an ”elbow plot”. It involved executing the k-means algorithm for a range of cluster numbers and plotting the within-cluster sum of squares (Equation (17)) against the number of clusters. The ”elbow point”, where the rate of decrease in the within-cluster sum of squares slows down, was identified as the optimal number of clusters. Later the ”k” at the elbow point was employed again to perform the final clustering. This process was repeated for both the dimensions (2D and 3D ) across three domain sizes 125 μm, 50 μm, and 25 μm. The elbow plots for this experiment are shown in Figure 20. A figure depicting the results from DBSCAN clustering. (a) Normalized elbow plot for 2D with 25 μm, 40 μm, and 125 μm, (b) Normalized elbow plot for 3D with 25 μm, 40 μm, and 125 μm.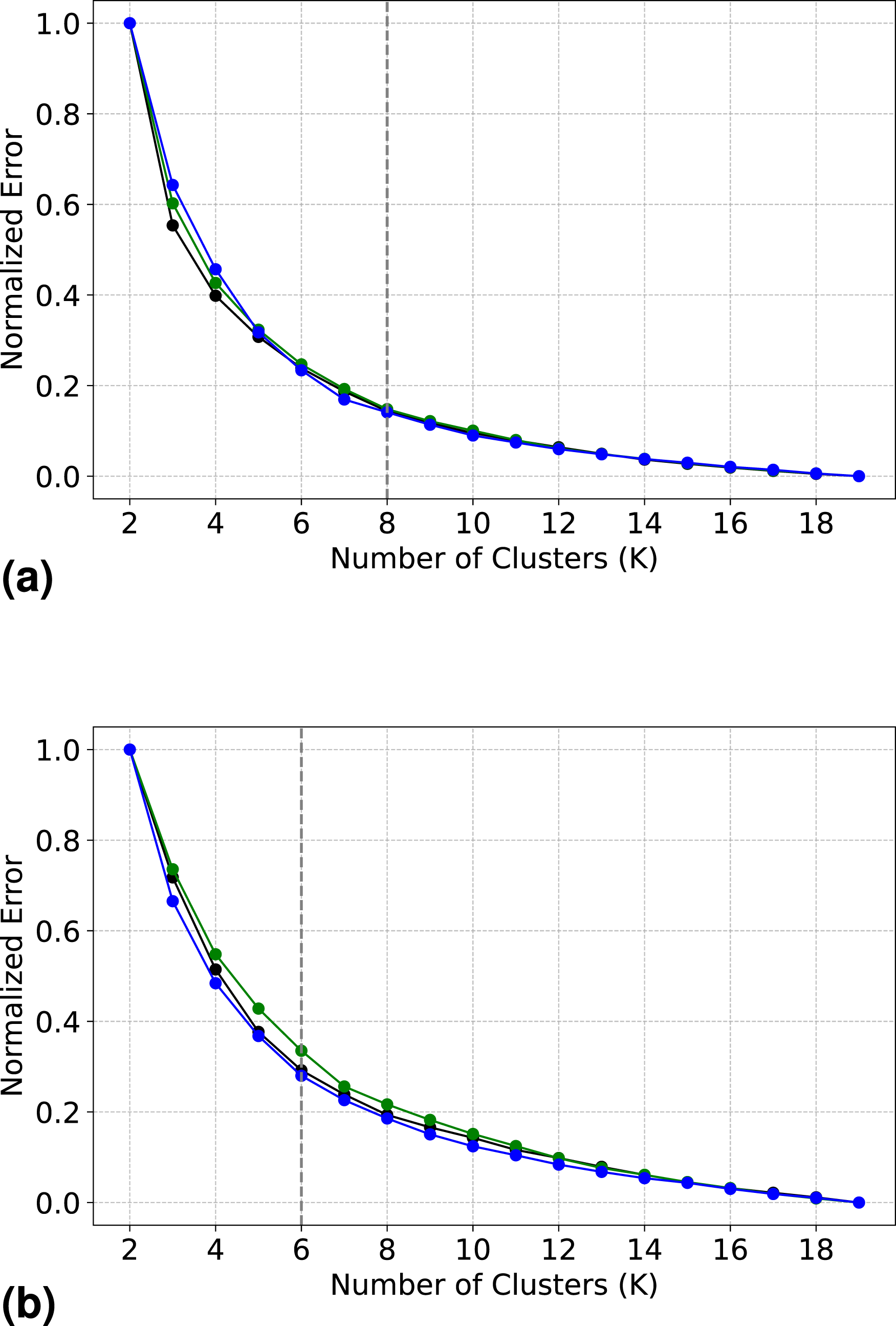
This process results in a finite number of distinct microstructure types within the laminate, defined based on features extracted from microsection images. These features, such as Voronoi area, KDE, and FVF, enable us to categorize different microstructures and help us to understand the fiber packing patterns.
These classifications are not just useful for characterizing the micro-level behavior of the material; they also play a key role in multiscale simulations. In such simulations, these distinct microstructure may be used as RVEs to model the material’s behavior across different scales—from the microscopic interactions between fibers and matrix to the macroscopic response of the entire laminate.
Explainability using surrogate model
AI has become a powerful asset in materials science, enabling fast and accurate predictions of key material properties such as electronic, magnetic, and elastic characteristics, as well as formation energy and band gaps. 57 This capability allows for the efficient screening of vast material search spaces to identify candidates with desirable properties. Deep learning models, including graph neural networks, capture complex structure-property relationships directly from data, enhancing predictive accuracy. Moreover, AI accelerates the discovery and design of novel materials by uncovering critical structural and chemical features, offering a data-driven approach to materials informatics. In this rapidly advancing field, XAI is increasingly essential to ensure the reliability, interpretability, and trustworthiness of AI-driven predictions.58,59
Post-hoc analysis of a machine learning model may offer insights into its performance on a specific dataset, but it often lacks interpretability regarding individual predictions. Additionally, challenges such as data incompleteness, lack of representation, and data leakage—where training data may inadvertently leak into the testing set—can further complicate analysis.
Therefore, it becomes crucial to understand ”why a model makes a specific prediction”, providing insights into its decision-making process and inner workings. Explainability serves to instill ”Trust”, ”Accountability”, and ”Bias Identification” in the model’s predictions. 60
Surrogate model
In the intricate process of micro-section clustering, we leverage the non-linear dimensionality reduction technique t-SNE, followed by K-means clustering, to derive meaningful patterns. The complexity of this approach poses challenges for conventional XAI frameworks for interpretability, which can be defined as the ability to trust a prediction and ultimately trust a model.
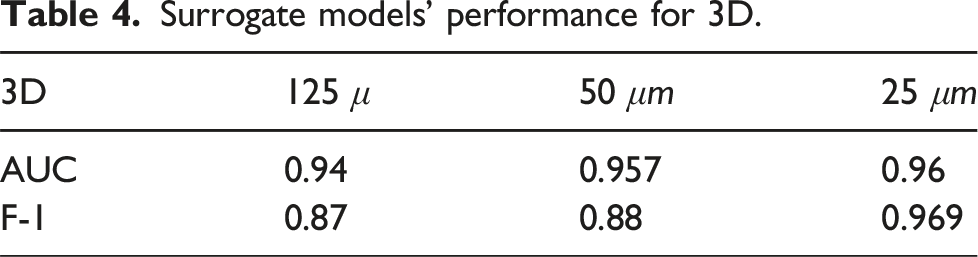
Surrogate models’ performance for 2D.

Surrogate models’ performance for 3D.
SHapley additive exPlanations for model explainability
Model explainability has become a vital focus in machine learning research, driven by the increasing need to understand and trust the decisions made by complex, often opaque models. To address this challenge, various interpretability techniques have been developed, including model agnostic methods such as SHAP (SHapley Additive Explanations)60,61 and LIME (Local Interpretable Model-Agnostic Explanations), 62 as well as inherently interpretable models like decision trees and linear regression. 63 In parallel, advancements in deep learning interpretability such as feature visualization and attention mechanisms 64 have contributed to a better understanding of neural networks and other black-box models.
Recent studies have applied XAI tools, particularly SHAP, to enhance interpretability in material science and structural engineering contexts. For instance, Ke et al. 65 utilized SHAP to interpret the predictions of a CatBoost model for CFRP–steel epoxy bond strength, enabling a quantitative understanding of each feature’s contribution to model outputs and thereby simplifying the decision-making process. Similarly, Yossef et al. 66 employed SHAP to analyze the influence of material properties such as E1, E2, G12, G23, and v12 on composite strength, identifying the longitudinal modulus (E1) as the most critical feature. In another application, Zhao et al. 67 used SHAP to interpret an XGBoost model predicting Compression-After-Impact (CAI) strength in carbon/glass hybrid laminates. Their SHAP-based analysis quantified the effect of impact parameters and revealed the complex, non-linear relationships.
These studies demonstrate the growing utility of SHAP in revealing the inner workings of machine learning models applied to composite material systems, offering domain experts a transparent pathway to interpret predictions and extract physically meaningful insights.
In the presented work, the inner workings of the surrogate model presented previously is explained using SHAP. The input features like kernel density enstimation, voronoi polygon statistics and fiber volume are correlated with micro-structure clustering by tSNE.
SHAP is based on cooperative game theory and provides a way to fairly distribute value among a group of contributors. In the context of model explainability, SHAP values assign a contribution to each feature in a prediction, indicating how much each feature contributes to the model’s output. For machine learning, each feature is considered a player, and the value to be distributed is the difference between the model’s output and the average output. The Shapley value of a feature is the average contribution of that feature to all possible combinations of features.
The SHAP method follows three conditions for interpretability. Firstly, the condition of Missingness dictates that the SHAP value of a missing feature is inherently assigned a value of zero. This ensures that the absence of a particular feature does not impart any contribution to the model’s output. Secondly, the principle of Additivity holds, compelling the model’s output to be the sum of the contributions from individual features. This additive property reinforces the interpretability of SHAP values, as the overall model prediction is comprehensively decomposed into the impact of each feature. Lastly, Consistency is maintained, signifying that if the marginal contribution of a feature increases or remains constant due to alterations in the model, the corresponding Shapley value will exhibit a corresponding increase or maintain its current level. These conditions collectively contribute to the reliability and interpretability of the SHAP method.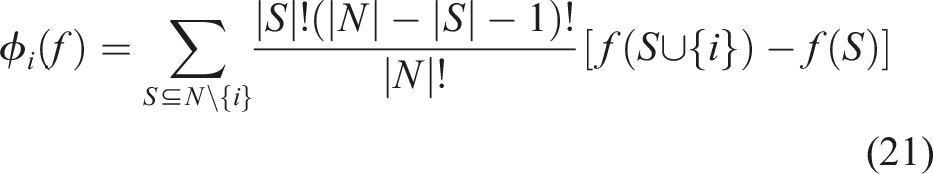
In equation (21),S ⊆ N \{i} represents all possible subsets S of the features in N excluding the feature i. |S| is cardinality ,number of elements, in subset S, and |N|: The total number of features. The global contribution of a feature can be calculated by averaging the shapely value for each feature in the dataset as in equation (22)
Global interpretation of a machine learning model can be achieved through the analysis of feature importance, which offers insights into how each feature influences the model’s predictions. Using equation (22), we compute the contribution of each feature across different microstructure types, with the results visualized in Figure 21. Feature importance plots using SHAP values for different surrogate models. (a) Surrogate model for 2D mapping with 25 μm, (b) Surrogate model for 2D mapping with 50μm, (c) Surrogate model for 2D mapping with 125 μm, (d) Surrogate model for 3D mapping with 25 μm, (e) Surrogate model for 3D mapping with 50 μm, (f) Surrogate model for 3D mapping with 125 μm.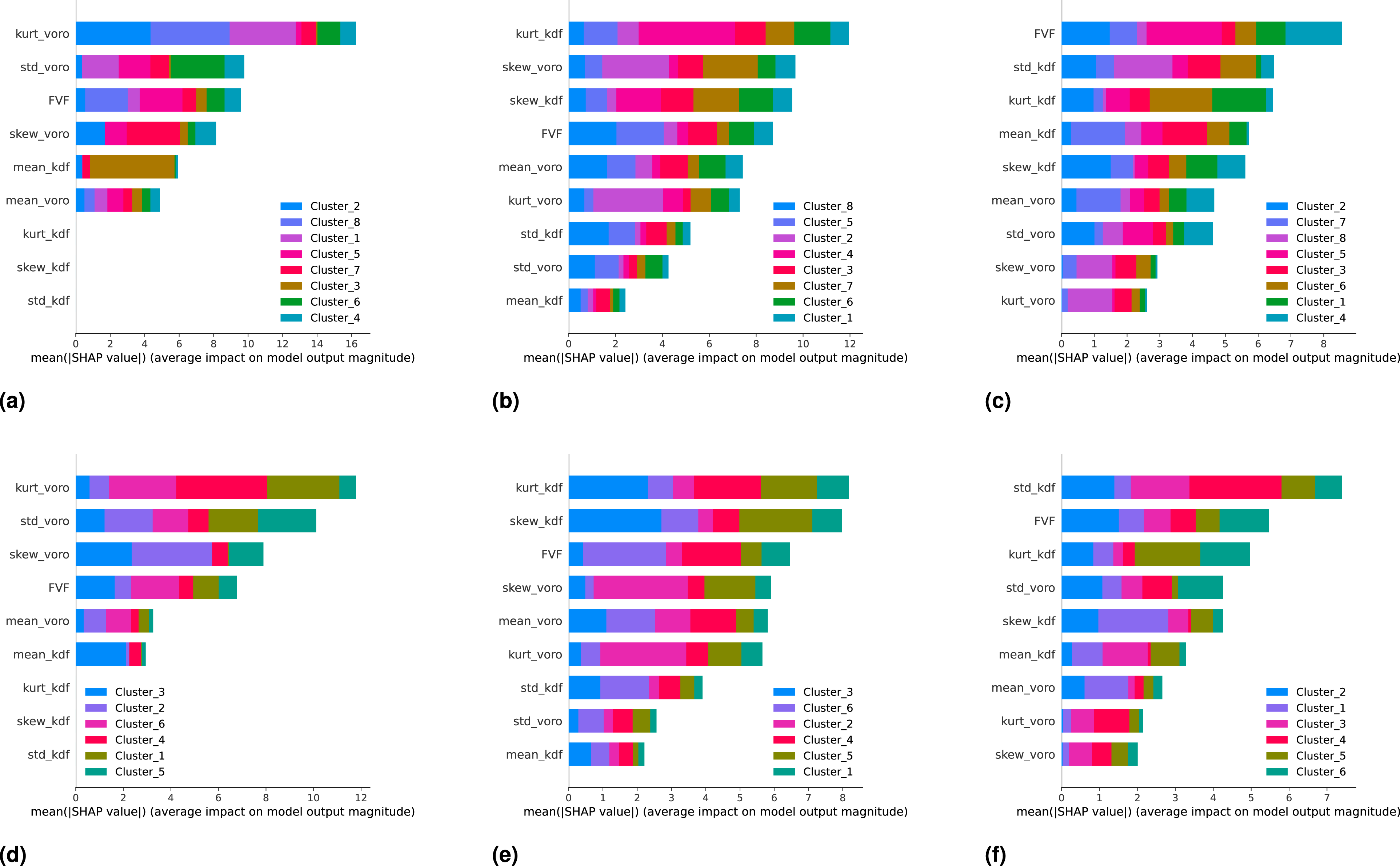
In this feature importance plot, features are ranked in descending order based on their contribution to the model’s predictions. The length of each bar indicates the strength of that contribution, while the colors represent the impact of the feature on specific microstructure classes. This plot provides not only a global overview of the model’s behavior but also reveals how individual features drive the classification of particular microstructure types.
From Figure 21, we observe that the top five contributing features kurtosis and standard deviation of Voronoi polygon areas, FVF, mean kernel density estimation , and mean Voronoi area, offer practical insights into the physical behavior of the microstructures. A high kurtosis of Voronoi areas suggests the presence of outlier regions with very large or very small fiber free zones, which are often linked to stress concentrations and early matrix cracking. Similarly, a high standard deviation implies uneven fiber spacing, resulting in local stiffness heterogeneity and potential zones of damage initiation. The FVF, as a direct measure of fiber content, pushes the classification toward denser microstructure clusters, typically associated with greater load bearing capacity. The mean KDE quantifies local fiber concentration; lower values may indicate loosely packed regions, which are relevant to resin rich zones and permeability. Finally, the mean Voronoi area complements the KDE by representing the average spacing between fibers larger values indicate sparser fiber networks. These interpretations enhance the physical understanding behind the SHAP based rankings and reinforce the surrogate model’s explainability.
As the domain size decreases, the relative importance of features such as KDE diminishes, as seen in Figure 21. This is due to the reduced likelihood of encountering fiber packing anomalies in smaller domains. While KDE effectively captures variations in fiber density in larger domains important for modeling stress concentrations and potential cracking these features become less distinguishable at smaller scales, reducing their influence on the classification outcome.
This shift in feature importance underscores a key limitation of using RVEs. Small RVEs often fail to capture critical microscale phenomena, such as fiber-matrix interactions and the initiation or propagation of matrix cracks.27,28,68 In contrast, larger RVEs better represent these interactions and the spatial variability in fiber packing, thereby allowing more accurate modeling of mechanical behavior.
Conclusion and outlook
The paper introduces a data-driven approach to analyze and categorize microstructures, focusing on identifying key microstructural features using advance XAI methods and spatial statistics.
Using microstructure clustering, this study highlights distinct fiber distribution patterns, which are then correlated with failure phenomena such as permeation, matrix cracking, and crack propagation based on existing literature.
While this work primarily focuses on microstructural characterization, the insights gained could potentially aid in quality assurance for CFRP manufacturing.
Key points and findings from the paper can be summarized as follows: • Existing methodologies for fiber detection and RVE generation for multi-scale approaches in CFRP are discussed, highlighting their limitations; • A well-known DCNN, VGG16, is employed as a feature extractor to capture fiber distribution patterns from micro-section images. A hand-labeled mask, together with the extracted features, was used as training and testing data for a state-of-the-art tree-based model, XGB, to detect fibers in a given microstructure image with an accuracy of 89%; • A sophisticated spatial clustering technique (DBSCAN) is employed to group fiber pixels into distinct fibers, and their coordinates were analyzed using advanced statistical techniques such as Voronoi polygon statistics and kernel density estimation to extract meaningful insights into fiber distribution; • These statistical features together with FVF were further processed using dimensionality reduction (t-SNE) and clustering (K-means) to identify rational patterns and group similar microstructures; • An XAI framework was implemented using the SHAP method, applied in the context of XGBoost-based surrogate models across different scales and dimensions; • All trained surrogate models were evaluated using various ML model evaluation techniques, including confusion matrix, F-1 Score, and ROC curve analysis with AUC; • The extracted microstructure patterns provide a basis for quality assurance in CFRP manufacturing by offering an automated method to detect irregularities in fiber distribution, which can impact mechanical performance. By identifying deviations from optimal fiber arrangements, this approach enables real-time monitoring and defect detection, ensuring consistency in production; • These identified microstructure patterns also serve as a foundation for multiscale modeling, where representative microstructural clusters can be integrated into higher-scale simulations. This facilitates a more accurate prediction of material behavior at macro-scales by incorporating real-world microstructural variations;
While the proposed approach provides valuable insights, some limitations must be addressed. The reliance on hand-labeled masks introduces potential subjectivity, and the generalization of the models to other materials or imaging conditions requires further validation. Additionally, the clustering results are sensitive to parameter tuning in t-SNE, which may affect the robustness of the approach in different datasets. Lastly, though correlations between microstructure patterns and failure mechanisms are identified using existing literature, a quantitative validation of these relationships with experimental data and numerical simulations remains an area for further exploration.
By systematically addressing the complexities of microstructure patterns, this work contributes to the current state of knowledge in building micro-scale FE models. The data-driven and XAI approach used in this study not only enhances the understanding of microstructural behavior but also lays the groundwork for future research in integrating machine learning-driven microstructure characterization into multiscale modeling frameworks. A key next step is to utilize the identified RVE patterns in numerical simulations to establish correlations between spatial features and material properties. Additionally, this approach can be extended to a data-driven multiscale framework, enabling a more accurate representation of intricate failure phenomena and improving predictive modeling of composite materials
Footnotes
Acknowledgements
We acknowledge their support in making this research possible.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funding for this project was provided by the Federal Ministry for Economic Affairs and Climate Action of the Federal Republic of Germany (BMWK) under the project CryoCrack - Berechnungskonzept zur Bewertung der Bildung von Leckagenetzwerken in kryogenen CFK-Wasserstofftanks, Förderkennzeichen 50RL2230A.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.