
Abstract
A reliable autonomous navigation system in environments with complete darkness, fog, and smoke is still an open problem in the field of mobile robots, where traditional computer vision approaches are not applicable because they heavily rely on the illumination and sightline conditions. This paper proposes an embedded hardware framework based on the ROS platform that provides reliable environmental perception and decision-making using the fusion of the thermal and LiDAR sensors, along with the machine learning-based perception module. The proposed framework is implemented using the Raspberry Pi 4 platform to show the possibility of using such advanced multi-sensor fusion techniques on embedded hardware devices. The embedded hardware framework provides a spatiotemporal environmental model using the geometric information obtained from the 2D LiDAR sensor and the thermal intensity information. Real-time obstacle detection and classification are carried out using a YOLOv5-based CNN on the fused stream of data, ensuring accurate detection even under poor lighting conditions. Experimental evaluation of the proposed approach under complete darkness, smoke, and fog showed 96%–97% accuracy, achieving better performance than thermal-only and LiDAR-only approaches by 12% and 8% respectively. The proposed fused framework is found to be feasible for real-time operation on Raspberry Pi 4 devices with a 100% success rate.
Keywords
Introduction
The robustness of autonomous navigation in degraded visual conditions such as fog, smoke, dust, and illumination is still a major concern for robotics systems. The robustness of vision-based SLAM systems is reduced in illumination changes and feature degradation.1–3 The illumination-independent perception of thermal sensors is reduced by temperature contrast variability and environmental factors.4–6 The precise geometric mapping of LiDAR sensors is reduced in dense fog and smoke conditions by scattering and attenuation effects.7–9 The recent developments of multimodal perception are focused on integrating different sensors for robustness improvement.3,10,11 However, existing systems are either GPU-based or not implemented on hardware platforms. 12 To overcome these drawbacks, this research proposes a feature-level LiDAR-Thermal fusion framework under an entire ROS-based autonomous navigation system. This research has several contributions to the robust autonomous navigation under poor vision conditions. First, this research proposes an embedded hardware framework, which can be used to integrate LiDAR geometric features and thermal intensity features, improving the reliability of perception under poor vision conditions such as fog, smoke, and low illumination. Second, this research proposes the fusion framework under an entire SLAM-based autonomous navigation system. Third, experimental evaluations in smoke, fog, and darkness conditions have been successfully accomplished with ∼97% detection accuracy and 100% navigation success, where real-time feasibility was also demonstrated on Raspberry Pi 4 platforms with an average latency of 0.5 s. The rest of this paper is structured as follows. Section 2 discusses the Related Work. Section 3 explains the Proposed System Design, including the overall architecture and integration framework. Section 4 explains the Implementation of the ROS-Based Autonomous System. Section 5 explains the Mathematical Formulation of the Proposed Thermal–LiDAR Fusion Framework. Section 6 explains the Experimental Analysis. The Results and Discussion section, Section 7, presents the machine learning-based object detection, analyzing the performance of the system in adverse conditions such as smoke, fog, and low light. Section 8 presents the Limitations and Future Work, and finally, Section 9 concludes the paper.
Related work
Vision-based navigation under adverse conditions
Schichler et al. 7 examined the degradation of camera-based SLAM system performance in low visibility environments, which led to considerable feature loss and instability in tracking. Luong et al. 13 continued the study on the challenges faced in the robustness of perception, which is associated with the limitations of using vision-based SLAM in dynamic environments.
Thermal-based perception systems
Thermal imaging has been studied to improve perception in smoke and dark conditions. Research in 14 showed that the detection ability of a human in obscurant conditions using thermography was improved. However, in outdoor conditions, the detection reliability was reduced due to variations in temperature gradient and fog density, as reported in. 15
LiDAR-based approaches
LiDAR sensing has demonstrated its robustness in low light navigation scenarios. 16 However, in the analysis of the effects of backscatter in dense fog and smoke environments by Hevisov et al., 17 it was noted that attenuation has a considerable impact on the reliability of depth.
LiDAR–thermal fusion strategies
Existing multimodal fusion architectures that incorporate both LiDAR and thermal sensing have exhibited better performance in localization and detection. For instance, Haghbayan et al. 18 have demonstrated better performance in underground localization by incorporating both LiDAR and thermal sensing. Fritsche et al. 19 have achieved better performance in pedestrian tracking by incorporating multimodal fusion. To better compare the performance of the proposed system with that of the existing LiDAR-thermal fusion architectures, Table 1 lists recent descriptive studies20–24 with respect to sensing modalities, performance, computational complexity, and system-level integration.
Advances in low-visibility navigation and perception.
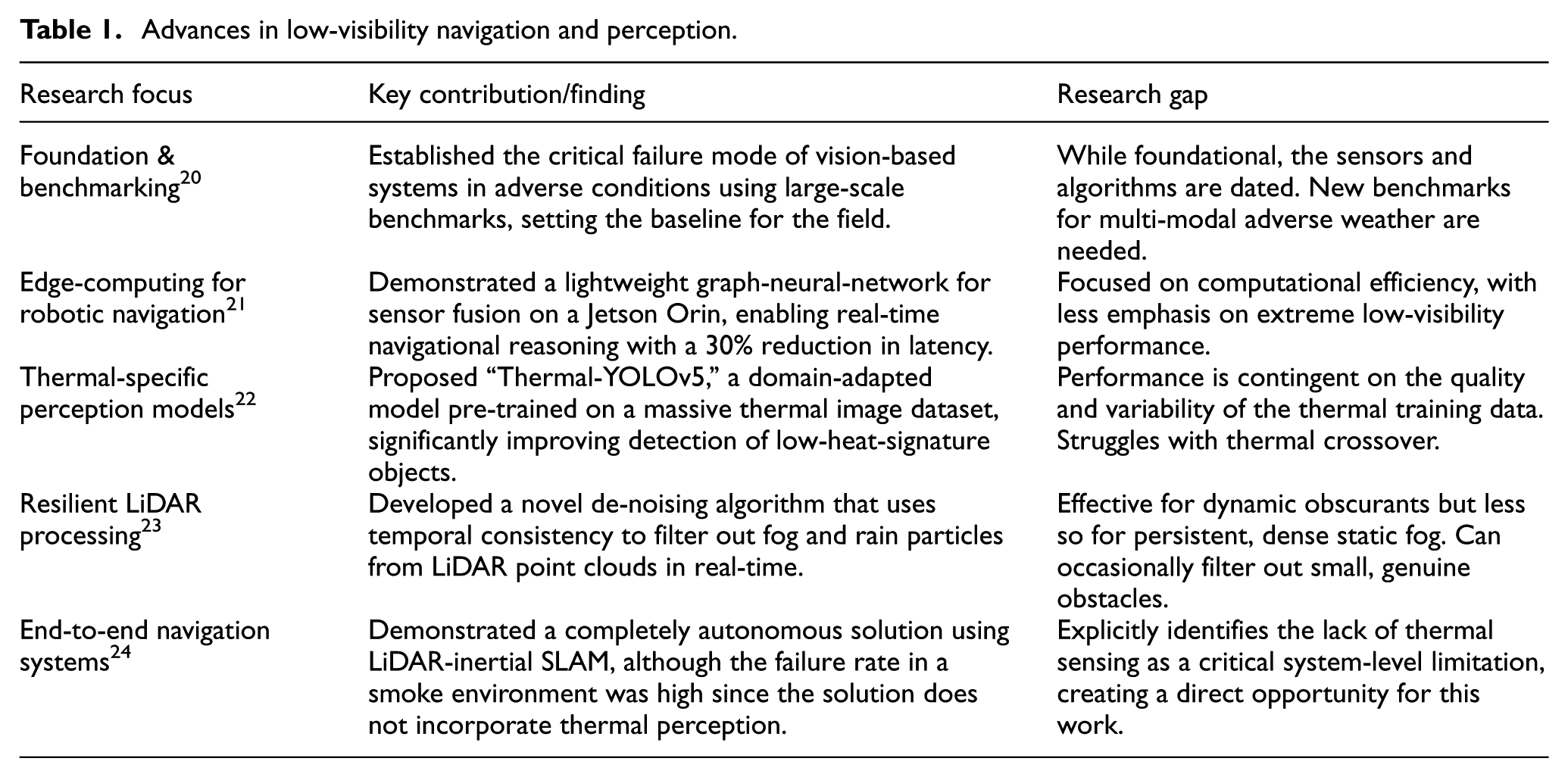
As can be noted from Table 1, in previous works, significant improvements in the robustness of perception have been demonstrated using multimodal fusion-based solutions. Nevertheless, some limitations can still be noted. Most solutions are based on computationally complex models, such as GPU-based implementations using deep learning, which may not make them feasible for embedded hardware platforms. Another limitation is that most works focus on demonstrating the validity of the solution from the algorithmic perspective, while the integration and validation in a completely autonomous solution are not addressed. The validity in a real-time embedded hardware solution, especially in a smoke and fog environment, is also not addressed in most works.
Recent studies have explored advanced artificial intelligence techniques to enhance perception and decision-making in autonomous systems. Reinforcement learning approaches for robot navigation and adaptive detection systems have been proposed alongside emerging multimodal perception frameworks such as transformer architectures, multimodal large language models, and vision–language models for object detection and scene understanding in intelligent transportation and autonomous driving applications.25–31
Research gap in embedded hardware thermal–LiDAR fusion frameworks
The ability to navigate through fog, smoke, rain, dust, and low light conditions is still a major challenge in the development of autonomous systems in defense, industrial inspection, disaster relief, and transportation applications. While vision-based systems work very well in clear conditions, their performance drops significantly in the presence of obscurants, and there is a need to develop robust multi-modal sensing systems. Prior studies have examined benchmarking, deep fusion models, thermal-domain perception, LiDAR enhancement, and embedded hardware real-time pipelines. Although recent advances include thermal-aware detection, LiDAR de-noising in scattering media, and transformer-based fusion networks, key limitations persist-particularly reduced robustness under severe ambiguities, high computational demands for embedded hardware platforms, and limited integration of thermal sensing into full navigation stacks. Table 1 summarizes representative contributions and the remaining gaps most relevant to this work. Although LiDAR–thermal fusion has been explored, existing approaches still leave several important limitations unaddressed. Many systems emphasize algorithm-level fusion or rely on GPU-class hardware, limiting suitability for lightweight or field-deployable robots. Several pipelines operate only as standalone perception modules rather than being integrated into complete navigation frameworks, reducing their ability to support real-time planning and control. Experimental validation is also often narrow, with limited side-by-side comparisons of fused, thermal-only, and LiDAR-only sensing under controlled smoke, fog, and darkness. On the contrary, the new system embarks on a feature-level fusion flow that is optimized for embedded hardware, inclusion of fused perception within a full ROS navigation stack, as well as extensive evidence within experiments that report improvements within detection accuracy and navigation.
Novelty of the proposed system
Although 2D LiDAR ranging, thermal imaging, YOLO detection, and ROS navigation are individually well explored in robotics, their culmination in a lightweight, deployable form targeted at low-visibility conditions distinguish this work. The system centers on an embedded hardware strategy that correlates thermal intensity with LiDAR-derived geometry in real-time on a Raspberry Pi 4. Unlike previous approaches that relied on GPU-class machines or isolated perception modules, this framework integrates fusion fully within a ROS navigation stack and is experimentally validated in smoke, fog, and darkness. The novelty is based on its system-level integration and hardware feasibility for embedded hardware platforms.
Bridging the computational efficiency gap
Although transformer-based fusion models show promising accuracy, they are not suitable for low-power platforms due to computational complexity. However, the proposed work is based on implementing a lightweight embedded hardware system on Raspberry Pi 4.
Transitioning from algorithm to integrated system
The majority of the previous work is based on showing the novelty of the algorithm rather than its integration with the robotic system as a whole. However, the proposed work is based on implementing and testing an end-to-end system for the rover and showing its feasibility.
Addressing the perceptual shortfall in obscurants
Research has also shown the absence of thermal perception as a major failure mode in visually degraded environments such as smoke, and this system includes a thermal camera as a primary sensor for perception, addressing the thermal awareness needed to safely operate in dark and obscurant environments, which is a known limitation of LiDAR-only-based implementations.
Providing quantitative comparative validation
Clearly, there is a need for empirical comparisons of the fused sensing approach and individual modalities under sustained adverse conditions. This paper presents a controlled side-by-side evaluation of the approach and demonstrates its potential for a 2.0%–8.0% improvement in detection accuracy and navigation stability compared with thermal only and LiDAR only approaches.
Demonstrating real-time performance on accessible hardware
One of the common bottlenecks in the deployment of such systems is running perception and navigation on low-power embedded platforms. Real-time performance was demonstrated on the proposed system, with an average latency of 0.5 s on Raspberry Pi 4, thus proving the feasibility of the system under embedded platform constraints. However, the main contribution of the proposed system was the design of the embedded hardware framework, which was integrated into a complete ROS navigation stack, unlike the existing architectures, which used a single dominant sensor.
As can be seen in Figure 1, this conventional and common approach to existing designs involves processing information received from a primary sensor (for instance, a LiDAR sensor for geometric information or a thermal camera for thermal information) through an exclusive perception module. A final product in the shape of a list of obstacles or a basic map is then sent to an independent planning and control stack. Although this approach has proven to be useful, its inherent flaw is that there is no deeper level of integration through algorithms, which does not overcome the inherent flaws of the sensors used and makes them less effective in extreme conditions such as heavy smoke or low thermal contrast scenes. The proposed system architecture in this paper aims to solve this flaw by introducing a central fusion core, as explained in Section 3.
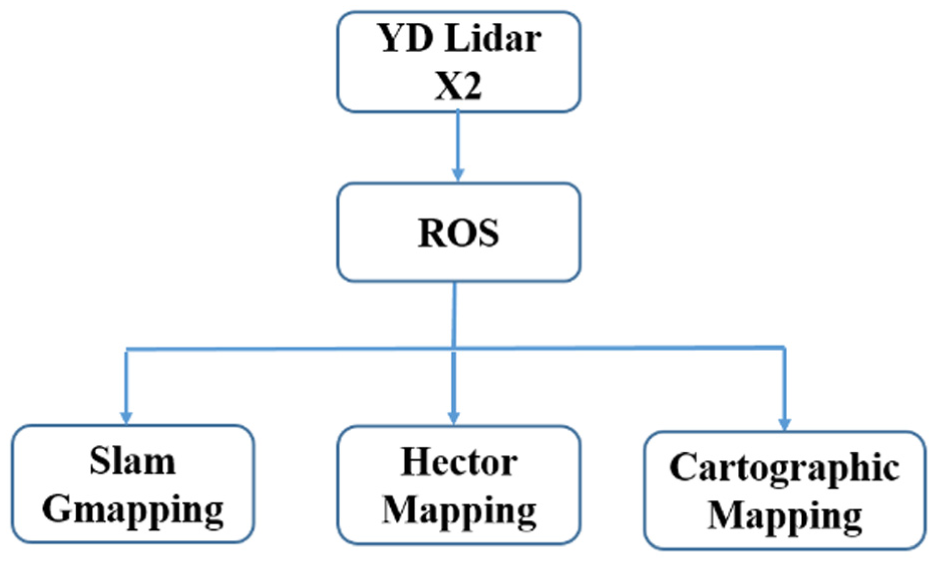
High-level architecture of the proposed navigation system.
Proposed system design
A system will be proposed that will be able to provide robust navigation in low visibility conditions using the combination of Thermal and LiDAR information in a modular ROS design. The Sensing, Processing, and Control layers make up the proposed system architecture, as shown in Figure 2.
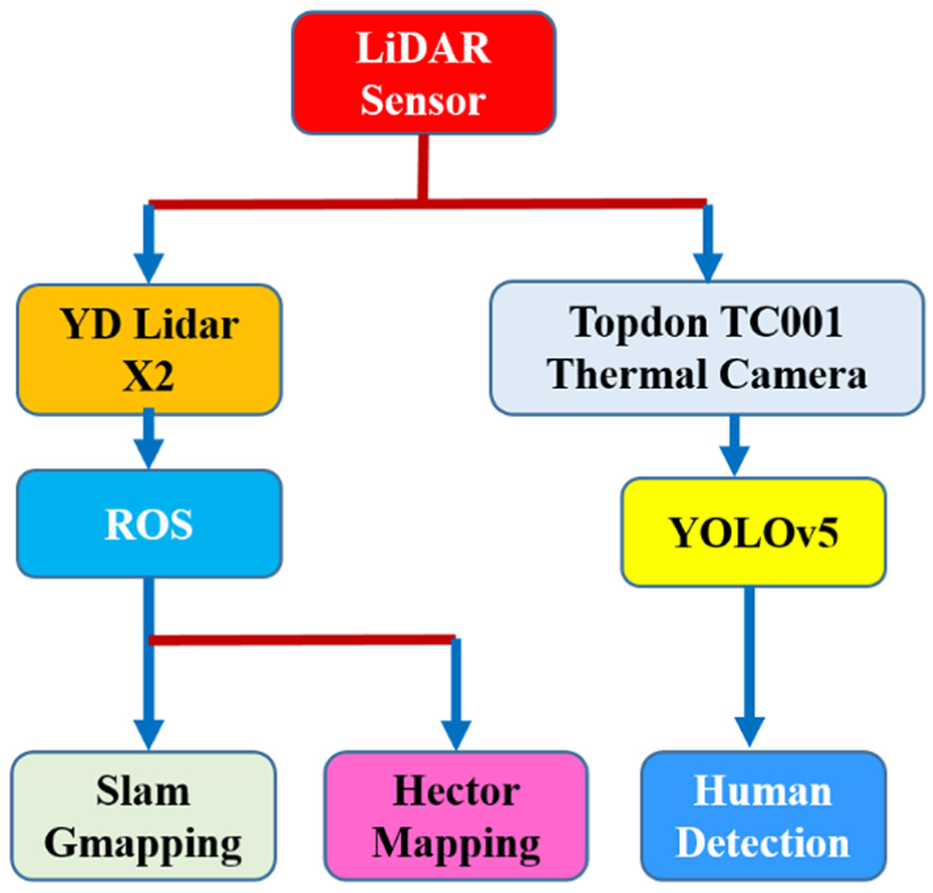
Data flow pipeline of the implemented rover, showing only deployed modules with hector SLAM as the mapping component.
Standard architecture of existing LiDAR-thermal navigation systems
Although recent versions of the YOLO series have shown improved accuracy in object detection, their increased computational complexity has resulted in increased inference time on CPU-based embedded platforms. However, as the primary requirement in this work is real-time autonomous navigation with limited resources, YOLOv5 was chosen based on its good balance of accuracy and real-time performance. However, the proposed fusion framework can be extended to other versions of the YOLO series based on increased computational resources.
Fusion of LiDAR and thermal imaging
The fusion framework starts with temporal synchronization, where thermal frames and LiDAR scans are synchronized based on ROS timestamps. As shown in Figure 2, an approximate time synchronizer is employed to match each thermal frame with its nearest LiDAR scan, ensuring that information is collected from the same time instance for both modalities and minimizing any possible differences due to different frame rates. Once temporal synchronization is complete, spatial synchronization is carried out by transforming the LiDAR point cloud to match the coordinate frame of the thermal camera based on extrinsic calibration parameters. This process is also shown in Figure 2. Once the synchronization process is completed, the embedded hardware will be conducted. The thermal imagery will be used for the provision of radiometric descriptors, while the LiDAR sensor will be used for the provision of geometric descriptors. The descriptors will be used as a unified feature descriptor for each point of the LiDAR sensor and the corresponding thermal pixel representation. The representation will be used for the provision of obstacle detection and cost maps for the ROS navigation system, which will be useful for operation in environments with challenging conditions such as smoke, fog, and darkness.
In addition to multimodal fusion approaches, deep learning–based object detection models are commonly integrated into navigation systems to enhance obstacle recognition capability. Among these, the YOLOv5 architecture is widely adopted due to its lightweight design and real-time inference performance. In this work, a modified version of YOLOv5 is employed for thermal-image–based obstacle detection, with implementation.
SLAM method used
In this work, Hector SLAM is used as the primary mapping algorithm for the 2D LiDAR. Hector SLAM was selected due to its suitability for lightweight embedded hardware platforms and its ability to operate without wheel-odometry input, which aligns with the constraints of the rover platform. Although ROS supports multiple SLAM packages such as Gmapping, only Hector SLAM was used in the implemented system and in all reported experiments.
Embedded hardware of LiDAR geometric descriptors and thermal intensity
In the proposed work, embedded hardware combines LiDAR geometric descriptors with thermal intensity values. The LiDAR features include the raw distance measurements and local contour-shape descriptors computed from adjacent scan points. These contour-shape descriptors represent the geometric pattern formed by the LiDAR beams-such as curvature, angular change, and segment orientation-and indicate whether the scanned surface corresponds to a flat wall, a corner, or a rounded obstacle. These spatial features are aligned with the corresponding thermal regions to form a fused feature vector used for mapping and obstacle detection
Implementation of the ROS-based autonomous system
This system was realized on a custom mobile rover platform whose mechanical design 32 included a central Chassis forming the Main Body, supported by a rigid Support Frame and a Suspension system connected with Wheels/End Effectors for its mobility as displayed in Figure 3. The basic processing equipment used in this system includes a FLIR A65 thermal camera and a YD LiDAR X2 sensor. They were placed appropriately on this chassis so that their fields of vision matched and overlapped. A Raspberry Pi served as the data fusion and navigation internal processing unit within the ROS technology framework, and these components were interfaced for optimal positioning through a mechanism of gears/joints and actuators. In addition, a navigation node used this sensing output to improve path planning and motion control using the ROS “Move Base” layer. Most importantly, the functionality of the system has been coupled with an intensive calibration process for ensuring world positioning by precisely aligning the integration frames of the LiDAR and the thermal camera based on the temporal coherence observed across the data streams.
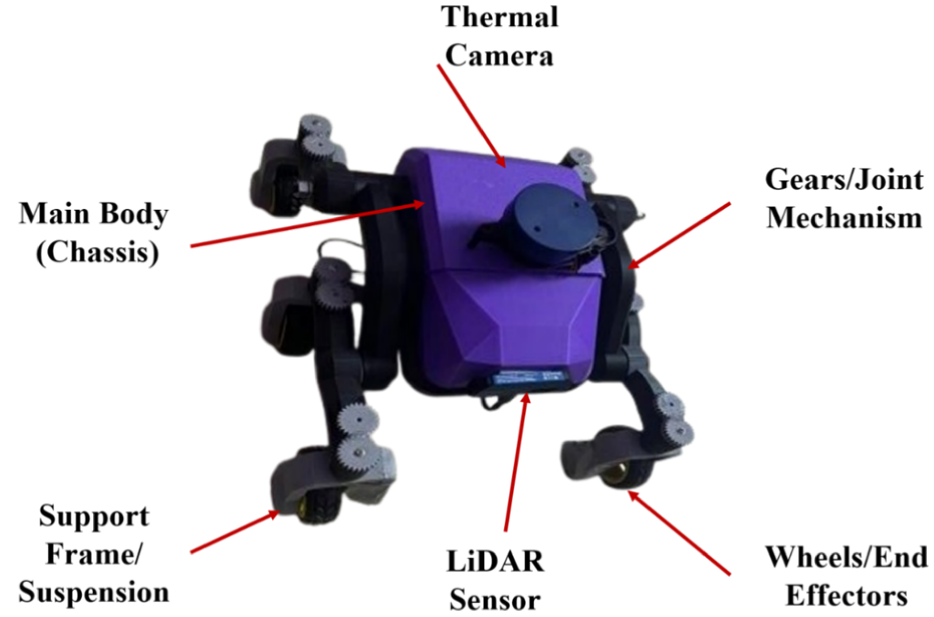
Physical rover setup with integrated LiDAR and thermal camera.
Extrinsic calibration between LiDAR and thermal camera
Extrinsic calibration between the LiDAR sensor and the thermal camera was conducted to establish accurate spatial alignment between geometric and radiometric data. A custom calibration target was prepared by heating a checkerboard pattern to create strong thermal contrast detectable by the infrared camera, while reflective markers were attached to the same board to ensure clear geometric detection by the LiDAR. Multiple synchronized observations were recorded from different viewpoints by moving the rover around the calibration target to capture sufficient feature diversity. Cross-modal feature correspondences were then identified between LiDAR point clusters and thermal image features using a feature-matching procedure. The rigid body transformation between two sensor coordinate systems was determined by solving a least squares optimization problem to obtain the rotation matrix
Software architecture and data processing pipeline
The software framework as depicted in Figure 4 was developed with the ROS Noetic software development kit for the purpose of coordinating the data acquisition, synchronization, and processing, as well as decision-making. Within the system architecture, various ROS nodes 33 have been developed with the primary intent of working collaboratively toward achieving an efficient data handling and real-time environmental perception. The thermal image processing module received the raw thermal images and undertook the necessary pre-processing steps such as noise removal and contrast normalization. The LiDAR point cloud processing module processed the 2D LiDAR scans received, where noise and outlier points were filtered out before key geometric information was obtained. Processed information from these modules was fused in the feature extraction and fusion module, where thermal and LiDAR information streams were fused in the spatiotemporal domain to obtain a unified model of the environment. Relevant thermal and spatial information for higher-level analysis was obtained from this model. In obstacle detection and classification, a CNN-based YOLOv5 algorithm was employed with a custom dataset of obstacles and low-visibility situations.
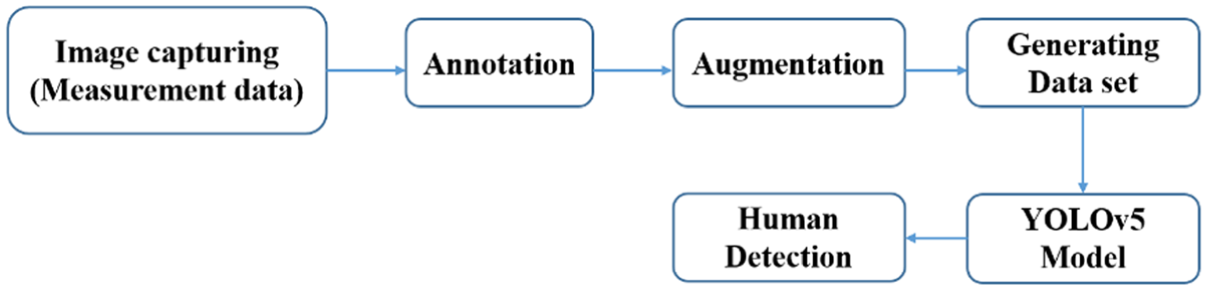
Block diagram of the human detection pipeline using YOLOv5.
This model was used to identify and classify the obstacles in real-time and allowed the rover to perceive and navigate effectively.
Experimental environment, obstacle diversity, and accuracy results
The experiments carried out in a controlled indoor environment with static, dynamic, low contrast, and high contrast obstacles under smoke, fog, and darkness conditions have shown 96.8%, 97.2%, and 97.0% accuracy, respectively. These experiments have shown that the framework is stable and works well under different degraded visibility conditions.
Robustness and navigation performance
The fusion framework retained ∼96%–97% accuracy in the presence of different thermal contrast and obstacle materials, proving to be robust to environmental changes. In terms of navigation, the approach was 100% successful in a controlled environment of a 15 m course, with plans to extend this to outdoor use cases in the future.
Feature extraction from LiDAR and thermal imaging
The proposed system extracts significant geometric and thermal descriptors from each of these sensors before fusion. This sub-section explains the preprocessing and feature computation steps for each of these sensors before fusion. The following Figure 5 explains the overall data flow for the proposed fusion system. First, LiDAR scans and thermal image are synchronized. Geometric descriptors are extracted from LiDAR, and thermal descriptors are extracted from thermal images. These descriptors are fused and processed using a modified YOLOv5 algorithm for obstacle classification. These decisions are made using ROS framework for obstacle avoidance.
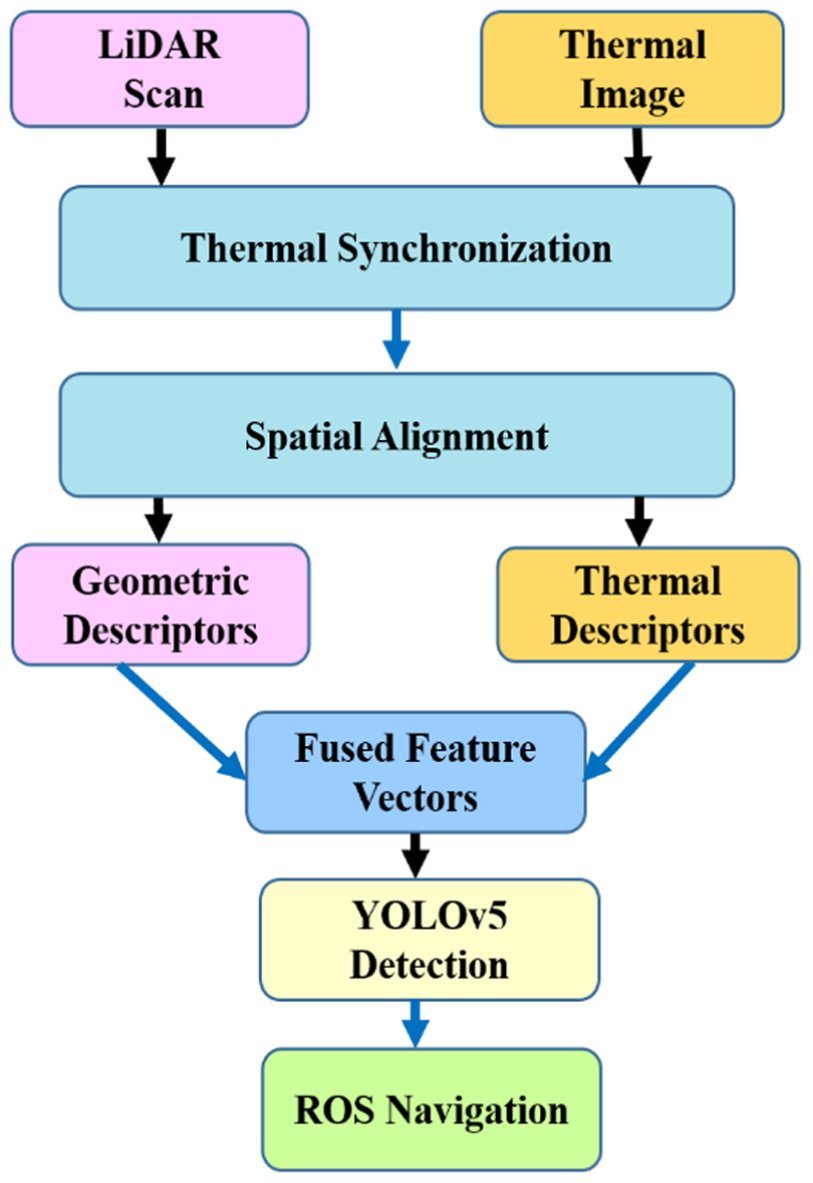
Flowchart of the embedded hardware algorithm.
The proposed embedded hardware approach works on the principle of mapping the geometric descriptors obtained from LiDAR onto the thermal image domain. For each LiDAR measurement of type (r_i, θ_i), local discontinuity and curvature are calculated as structural features to account for spatial changes. Using Camera-LiDAR calibration, each 3D point of LiDAR is projected onto the thermal image plane, and thermal intensity information is extracted as features. The aggregated set of features (F_t) is then used as part of the SLAM-based navigation framework for enhanced robustness in poor visibility conditions. The embedded hardware is mathematically represented as follows:

LiDAR feature extraction
The original 2D LiDAR scan data was initially de-noised using a statistical outlier removal filter, which removed false echoes from the scene, including those from the presence of fog, smoke, and shiny surfaces, as per point cloud filtering best practices. 34 Each filtered scan was then mapped to a structured geometric feature description in terms of range-bearing pairs, local curvature, and boundary discontinuities, which are extensively used for the identification of obstacle contours in. 35 To increase resistance in a dynamic low visibility scenario, temporal stability features were found in the comparison of point-to-point displacements as well as contour persistencies, as used in classical scan matchers. 36 The described geometric feature set efficiently represents a compact platform amenable to embedded hardware systems.
Thermal image feature extraction
The thermal frames captured using the FLIR A65 thermal camera were pre-processed with the application of temperature normalization, histogram equalization, and median filtering techniques in conformity with the thermal imaging guidelines. 37 From the processed thermal frame, regions corresponding to the heat signatures were detected by the application of adaptive thresholding techniques, widely used in heat signature detection systems for human target identification. 38 The system calculated the mean temperature values, thermal gradients, area values for blobs, and the shape information for each region identified for their ability in distinguishing heat signatures from the background objects. 39
Cross-sensor alignment and feature fusion
To incorporate the geometric and thermal data, the scan angles of the LiDAR were projected to the coordinates of the thermal image based on the extrinsic parameters obtained from a camera and laser calibration process. 40 This allowed the generation of a combined feature vector attending to the geometry and intensity of the LiDAR data following the multi-modal fusion approaches illustrated by previous works on the fusion of LiDAR and thermal sensors.3,41 This combined feature vector was finally fed into the YOLOv5 detector.
System integration
The last step was a full integration and synchronization of the hardware and software so that all would work in harmony. The FLIR A65 and YD LiDAR X2 sensors were interfaced to the Raspberry Pi 4 using USB and dedicated communication ports to ensure reliable data transmission. Custom ROS drivers were implemented for continuous and secure data streaming from both sensors to the central processing unit. All of the designed ROS nodes have been configured onto the Raspberry Pi, and the ROS concepts and services were used to control inter-node communication. This architecture enabled it possible for the sensing, processing, and decision-making modules to coordinate their activities and share data in real-time. A thorough calibration procedure was used to achieve precise Thermal-LiDAR sensor alignment. To generate a pixel-to-pixel and spatial links among data sources, intrinsic and extrinsic parameters were adjusted. Later, the integrated system was tested under a controlled indoor environment to validate obstacle detection accuracy and navigation performance in advance of final deployment to the field.
Sensor calibration
To ensure that the LiDAR measurements and thermal images were spatially consistent before fusion, a simple calibration procedure was carried out within the controlled indoor environment shown in Figure 5. The thermal camera’s intrinsic parameters, including focal length and principal point, were taken from the manufacturer’s model because low-resolution thermal sensors do not reliably detect standard calibration patterns. The relative pose between the LiDAR and thermal camera was estimated using a planar target placed at different positions in the test area, allowing LiDAR scan endpoints to be associated with corresponding regions in the thermal image. A rigid transformation was then computed to align the two sensing frames. Calibration was verified qualitatively by analyzing the superposition of contours from the LiDAR sensor onto the thermal image frames, where it was ensured that the projected geometry is invariant with respect to multiple viewpoints. Such a process ensured that the alignment level is adequate for performing the fused mapping and obstacle detection task under reduced visibility environments.
Projection-based fusion of 2D LiDAR scans with thermal pixels
In order to combine the geometric data available from the 2D LiDAR sensor with the thermal intensity data, each LiDAR scan point is projected into the thermal camera coordinates according to the estimated extrinsic parameters. This projected point is then mapped to the thermal image plane, and the corresponding intensity value is sampled from the thermal image. This results in an aligned pair comprising the geometric descriptor extracted from the LiDAR data, and the thermal data. As this process is repeated for all valid LiDAR beams, a feature vector is created that associates the local contour shape data to the thermal data describing the corresponding region in the scene. This process bypasses the need for any tile heuristics and allows both modes to contribute to a unified spatial representation.
Fused-perception contribution versus planner novelty
In this research, the layer of navigation is dependent on the ROS Move-Base standard framework, which is deliberately retained in its original form without modifications. This ensures that when better results are obtained in terms of navigation reliability, it is solely due to the LiDAR and thermal perception system and not because of modifications in the specific planners. By using the robust Move-Base system as the base, it is proven that improved perception capability is also enough to increase the performance of ROS in terms of navigation and without being dependent on complex algorithms or systems.
Mathematical formulation of the proposed thermal–LiDAR fusion framework
This section presents the mathematical formulation of the proposed embedded hardware framework used for robust perception and autonomous navigation in degraded visibility environments.
Sensor data representation
At time instant t, the two-dimensional LiDAR sensor provides a scan represented as equation (1).

where ri_and θi denote the range and bearing of the ith beam, respectively. This polar representation is commonly adopted in mobile robotic perception and mapping applications.42,43
Simultaneously, the thermal camera captures a long-wave infrared image expressed as equation (2).
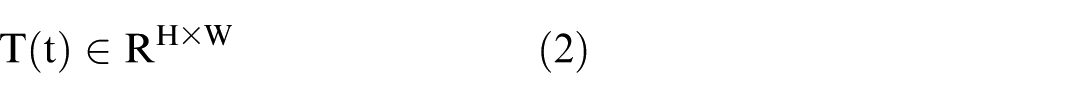
where H and W denote the image height and width, and pixel intensities correspond to temperature-dependent radiometric values. Such representations are widely used in thermal perception systems for robotics and autonomous navigation.
Temporal and spatial alignment
To ensure consistency between heterogeneous sensor streams, temporal synchronization is enforced as equation (3).
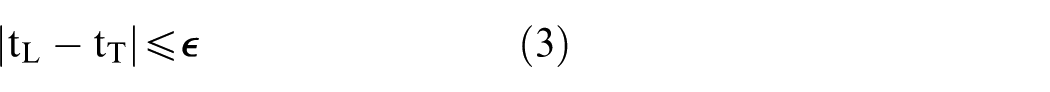
where tL and tT are the acquisition times of LiDAR and thermal data, respectively, and ϵ denotes an acceptable synchronization tolerance. Similar temporal alignment strategies have been adopted in recent multi-sensor fusion frameworks. 44
Spatial alignment between LiDAR and thermal sensors is achieved using a rigid-body transformation defined as equation (4).
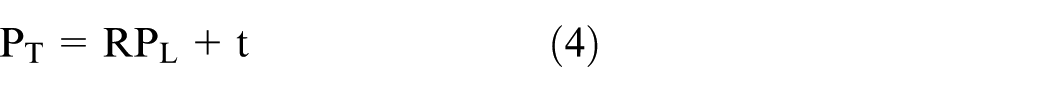
where R ∈ R3 × 3 is the rotation matrix and t ∈ R3 is the translation vector obtained through extrinsic calibration. This formulation is standard in recent LiDAR–thermal and LiDAR–vision calibration approaches. 45
Feature extraction
From the LiDAR scan, geometric features are extracted as equation (5).

where dmean and dvar represent the mean and variance of obstacle distances, and npoints denotes the number of valid returns within a region of interest. Statistical geometric descriptors of this form are commonly used in LiDAR-based perception pipelines.
From the thermal image, radiometric features are computed as equation (6).

where Tmean, Tmax, and Tstd denote the mean, maximum, and standard deviation of thermal intensities. Such thermal descriptors are widely used for robust human and obstacle detection in low-visibility environments.
Embedded hardware
The extracted features are combined at the feature level to exploit complementary geometric and thermal information. The fused feature vector is defined as equation (7).
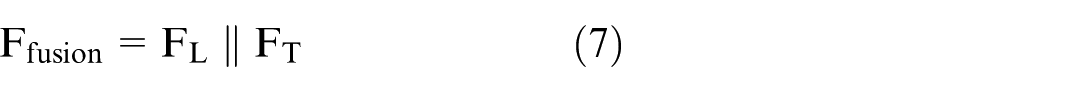
where || denotes feature concatenation. Embedded hardware using concatenation has been shown to provide an effective balance between robustness and computational efficiency in embedded hardware systems.
Alternatively, a weighted fusion strategy is adopted as equation (8).
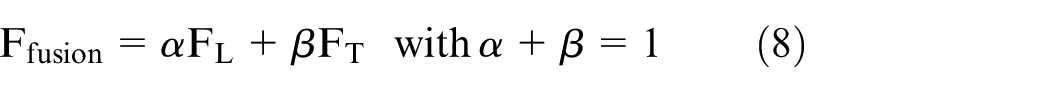
where α and β control the relative contributions of LiDAR and thermal features. Similar weighted fusion formulations have been employed in recent adaptive multi-sensor perception models.
Learning-based perception and navigation integration
The fused feature vector is provided as input to a learning-based perception module defined as equation (9).
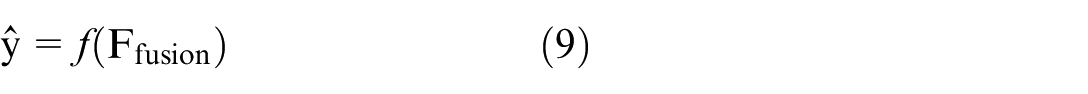
where f (·) represents the trained detection network and ŷ denotes detected object classes and confidence scores. Learning-based fusion models have demonstrated improved robustness in adverse and low-visibility environments.
Detected obstacles are projected onto a two-dimensional occupancy grid map used by the navigation stack, expressed as equation (10).

This representation is subsequently used for path planning and motion control within the ROS navigation framework, consistent with recent embedded hardware autonomous navigation systems.
Experimental analysis
For making sure that the performance analysis on the newly developed LiDAR-thermographic navigation system is transparent and repeatable, care was taken to strictly control the testing environment in each test. As already mentioned, obscurants like smoke or fog may be quite dynamic in terms of density. Some additional work has been done to smoothen out obscurant densities, and a perfectly repeatable test environment has been maintained. Details on this work are given in the next subsection.
YOLOv5 configuration and training
In this work, the YOLOv5 network architecture is retained, while task-specific training and deployment optimizations are applied to support real-time embedded hardware execution. The obstacle detection component was built using the YOLOv5 model with minor architectural adaptations to support thermal image input and improve robustness under low-visibility conditions. These modifications were designed to maintain computational efficiency suitable for the onboard processor while preserving the core backbone and detection head structure of the original YOLOv5 architecture. The training of the model followed the standard YOLOv5 training procedure, with hyper parameters initialized to their default settings. The training set consisted of images from the indoor testbed (Figure 6), along with additional obstacle examples sourced from publicly available datasets. Standard data augmentation techniques were applied to enhance robustness and generalization. This configuration ensures reproducibility of the training process while enabling real-time deployment on the target hardware platform.

Indoor experimental setup for low-visibility navigation trials.
Experimental setup, model training and performance analysis
To do experimental verification of the new system, experiments were conducted indoors where realistic low-visibility conditions were simulated. The experiment site had a 15 m obstacle course which included static and dynamic obstacles of varied sizes and materials. To simulate low-visibility conditions, complete darkness without any ambient illumination source, smoke conditions made by a smoke machine, and fog conditions made by a high-output fog machine were employed. The rover had to perform autonomously in this course from a specific starting point to an end point without hitting any obstacles. In every trial, data that included but was not limited to obstacle detection events, navigation paths, and traversal time was continuously recorded for later post-processing and performance evaluation. The performance of the object detection model, important for the obstacle avoidance system of the rover, was evaluated with standard training and validation metrics. It has shown successful convergence with high proficiency in locating objects and classifying them well. The thermal-only and LiDAR-only baselines were included as controlled ablation studies to quantify the individual contribution of each sensing modality within the same hardware, environment, and navigation stack. These baselines are not intended to represent state-of-the-art perception systems, but rather to provide a consistent reference for evaluating the benefit of the fused LiDAR–thermal pipeline. Prior sensor-fusion studies have similarly reported that combining geometric and radiometric cues improves robustness in fog, smoke, and low-light conditions, and our results follow the same trend. While the proposed system does not aim to outperform advanced fusion architectures, it demonstrates that a lightweight, embedded hardware implementation can achieve reliable navigation in degraded visibility. This positions the evaluation as a practical assessment of fused sensing on constrained hardware rather than a comparison against high-complexity fusion models.
Environmental setup and control
To attain the same condition of low visibility as replicated in all tests, the experiment was conducted in a controlled indoor environment with controlled airflow. The smoke and fog effects were achieved using the smoke and fog machines available in the market with varying levels of generation. The density of the obscurants in all scenarios was maintained at the same level by running the smoke generator for 3 min for smoke generation and 4 min for fog generation until the desired visibility range of about 1.5 to 2.0 m was achieved, as measured by the visibility chart calibrated to show the distance from a point placed at varying distances on the chart. The complete test environment layout with the smoke generator, visibility chart, static and dynamic barriers, and rover initial position is displayed in Figure 6, giving a real-time demonstration of the experiment environment. Each experiment was performed under the same environmental conditions for a total of five times. The experiment region was flushed with airflow to remove the remaining obscurants present from the previous experiments and needed another 3 min of smoke generation to restore the required conditions of density before proceeding with the next iteration of the experiment. The position of the initial rover and the navigation goal remained the same for all experiments. The variability of the environment is further reduced by turning off fans, air conditioning systems, and natural sources of illumination to reduce turbulence and thermal drifts. The temperature and humidity of the environment are also recorded and controlled to maintain thermal contrast. Any experiment whose results show uneven dissipation of smoke or fog is discarded and repeated. These conditions ensure that the stability of the experiments is maintained and that the performance evaluation of the proposed system is fair and reproducible. Figure 7(a) to (d) shows the complete training and validation of the modified YOLOv5 model, and each of these subfigures represents some important aspect of the learning process of the model. Figure 7(a) shows the bounding box regression loss plot, and it is evident that it is reducing steadily with each epoch of training, ensuring that the model is improving its capacity to correctly locate obstacles with higher spatial accuracy.
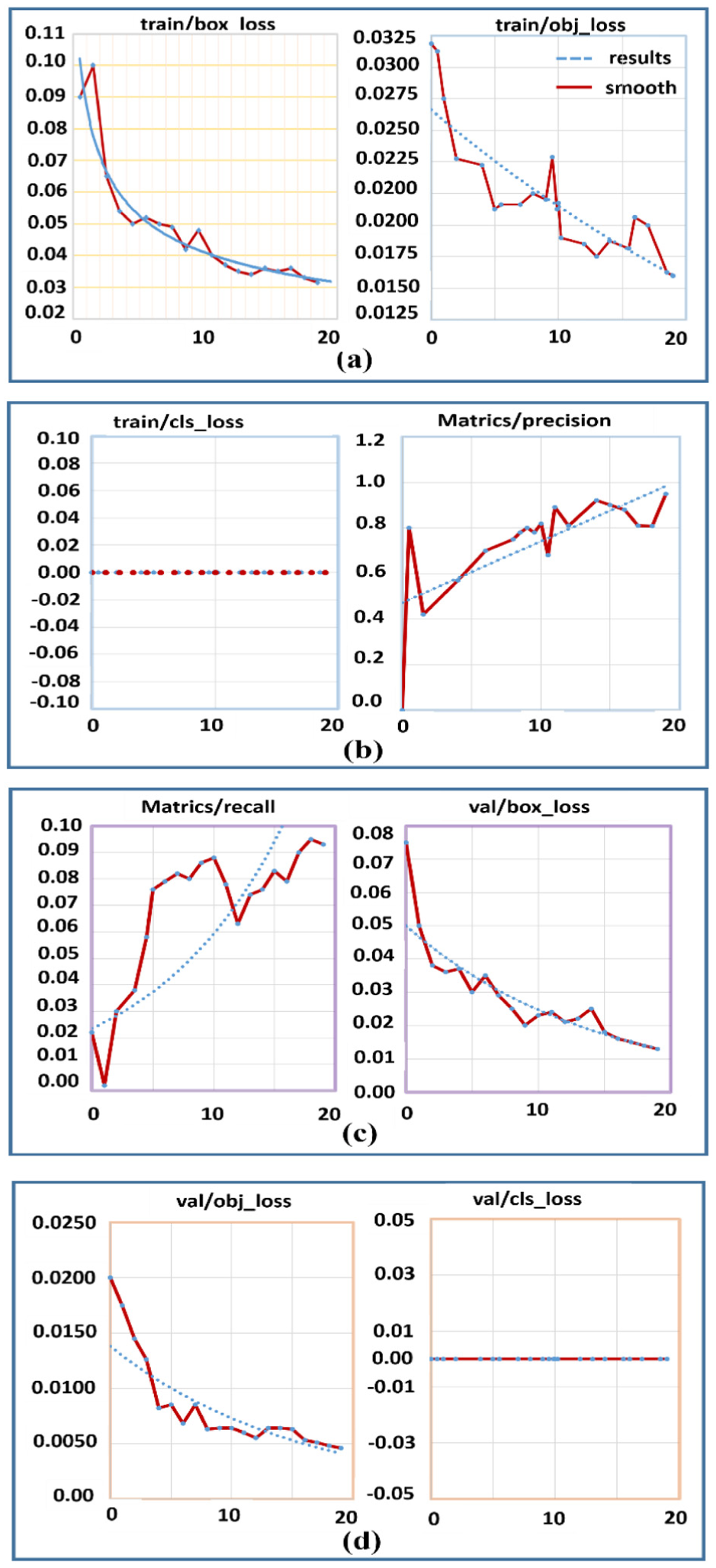
Live thermography image stream in a smoke filled environment test: (a) convergence of bounding box regression and objectness loss, (b) classification loss and precision curves, (c) validation bounding box error reduction, and (d) validation error stability, and mAP values with improved detection and localization accuracy.
Figure 7(b) shows the objectness loss plot, and it is also reducing steadily with each epoch of training. The performance of the generalization is shown in Figure 7(c), and it can be seen that the validation bounding box loss (val/box_loss) decreases significantly, proving that the model can learn to generalize to unseen data sets very effectively. This sub-figure also illustrates the performance of the model in terms of recall, proving that the model can effectively detect most of the obstacles in the environment. Figure 7(d) illustrates the precision metric, and it can be seen that this metric improves significantly as the model is trained, reaching near-perfect levels, proving that the model can effectively detect positive instances with very few false positives and also illustrates the performance of the model in terms of the Mean Average Precision metric, proving that the model can accurately detect bounding boxes with high mAP_0.5 and mAP_0.5:0.95 scores. Overall, Figure 7 illustrates the performance of the model in terms of its stable and effective learning behavior, proving that the final model is robust and accurate and can be effectively used to detect obstacles in the environment.
Machine learning training and evaluation setup
The YOLOv5-based detector module was trained on a dataset of 12,500 thermal images, including 7500 images obtained through controlled experiments in a smoke chamber and 5000 images from publicly available datasets. The dataset was divided into 80% training and 20% validation sets, with balanced data from smoke, fog, and darkness conditions. Data augmentation methods like mosaic augmentation, flipping, scaling, and thermal jittering were used. Performance was evaluated on the validation set using precision, recall, F1-score, and confusion matrices, ensuring robust assessment across diverse low-visibility conditions.
Obstacle detection accuracy
The evaluation on obstacle detection was conducted under three visibility scenarios: darkness, smoke, and fog. The sensing technologies showed different advantages under different scenarios. The FLIR A65 Thermal Camera system showed 92.0% detection in darkness due to high radiometric contrast with insufficient geometric information. However, it showed 89.0% detection in smoke and 85.0% in fog, with decreased performance because of light scattering by particles in the air. The YD LiDAR X2 system has shown consistent results at 95.0% in all scenarios because it performs equally under different lighting conditions. Also, when combined, the LiDAR-Thermal fusion system achieved 97.0% detection because it utilized its strong capability of LiDAR in detailed geometry and its capability of Thermal Imaging to distinguish obstacles with insufficient contrast.
Experimental constraints and realistic performance boundaries
The reported detection accuracy of 97.0% is to be understood in relation to performance in the controlled indoor environment of range 15.0 m. Due to limited range and a finite environment, neither the 2D LiDAR scanner nor the thermal camera was working in a regime where attenuation is a significant concern. The reported accuracy is a measure of how well the combined system is able to localize a set of predefined obstacles in a predefined environment and is not to be interpreted for a different outdoor scenario. While in a predefined environment, the system worked well.
Statistical robustness of detection accuracy
To assure the accuracy of detection performance, every testing situation under different levels of visibility was assessed five times independently, and the detection accuracy was calculated for each trial. Mean values with standard deviation and 95.0% confidence intervals are represented graphically to give a statistical interpretation of variability. As indicated in Table 2, the variance is smallest for the LiDAR and thermal fusion setup; this verifies that the value of 97.0% accuracy is not an isolated result but an average one. Variations in the detection performance of the thermal imaging camera were higher in the smoke and fog situation because of radiative diffusion; LiDAR detection performance was stable for all five testing trials.
Obstacle detection accuracy across five independent trials (mean ± SD, 95% CI).

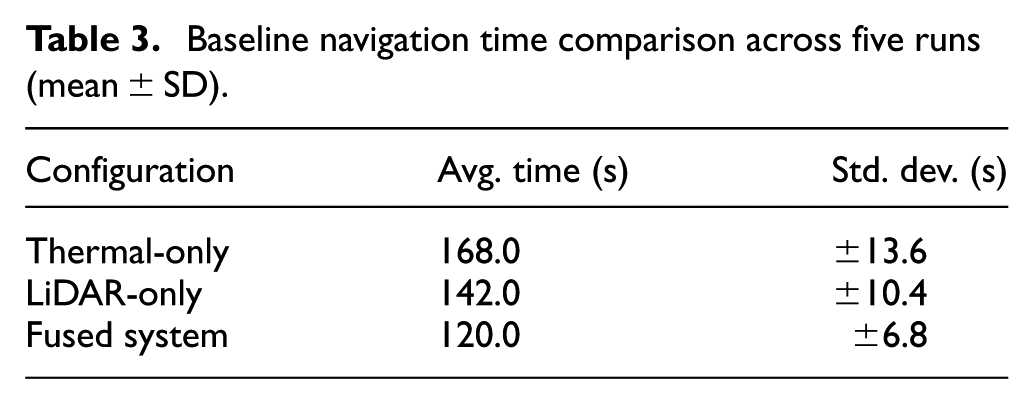
Navigation performance evaluation
To validate the operational capability of the rover, the baseline traversal times were measured and compared for the thermal-only, LiDAR-only, and fusion approaches under the same conditions. For each of the approaches, five distinct trials were conducted. As shown in Table 3, the thermal-only approach took the longest time to traverse, with the LiDAR-only approach being moderately better but slower in the smoke and fog conditions. The fusion approach resulted in the fastest and stable navigation time, with the 15.0 m obstacle race being completed in an average of 120.0 s. This is thanks to the complementary nature of thermal imaging and LiDAR technology, which, combined, facilitate better detection and planning of traversals through degraded conditions.
Baseline navigation time comparison across five runs (mean ± SD).
Results and discussion
The experimental results reveal that the fused thermal and LiDAR perception framework always enjoys an evident advantage over single-modality settings, especially in the most deteriorated environmental conditions of visibility. Roughly showing the tendency for all three testing cases, it is apparent that the combined geometric and radiometric information plays an essential role in maintaining the stability of obstacle detection performance. LiDAR performance will deteriorate with increased beam scattering in dense obscurants, and the performance of the thermal sensor will degrade with low contrasts or without heat signatures for obstacles to stand out against the background. The combined framework remedies the above disadvantages by always providing detection information with at least one sensor functioning well under deteriorated conditions. The performance of the modified YOLOv5 model again demonstrates the necessity of architecture-level adjustments for handling thermal images effectively. The improved multi-scale feature fusion and attention mechanisms of the modified architecture enhance the capability to filter valid thermal features from invalid background features. Especially for cases where obstacles display weak and partially hidden heat patterns, this superiority becomes more apparent. The training process demonstrates stable convergence, but more importantly, the generalization capability of models from different testing cases with low visibility is highlighted here. The model always successfully detects obstacles regardless of dynamic contrasts for thermal patterns and when LiDAR observations become sparse, implying that the fused feature set supplies a more stable input data distribution than any individual sensor modality alone. Navigation results naturally display similar superiority of perception fusion for enhanced navigation performance. Even when one sensor is temporarily degraded, the rover is able to maintain its stable path planning, and it is clear that having ROS’s navigation stack utilize the fused cost map representation is beneficial. The fact that the system is able to maintain stable obstacle avoidance behavior when undergoing repeated trials is indicative of its robust world model provided by its fused perception layer. This is especially useful in embedded hardware systems, which do not have the luxury of being able to run complex fusion frameworks due to computing limitations. Practical considerations are also provided by the experimental results. Since it is able to maintain its performance under controlled smoke and fog scenarios, it is clear that moderate obscurant density levels are able to be handled well by its fusion framework, though high levels and rapidly changing obscurant density levels are still problematic. Moreover, though Raspberry Pi 4 is able to adequately handle real-time inference, it is clear that its computing margin is limited, and if more powerful embedded hardware platforms are developed in the future with marginally better computing abilities, its responsiveness is expected to increase further. It is thus clear that embedded hardware remains a balanced choice between robust computing and its world perception. This system remains more consistently stable compared to its thermal and LiDAR-Only approaches, not only because it is able to produce better numerical scores but also because it is able to do so under varying levels of environment and world uncertainty. This is especially important while attempting to develop an autonomous system that needs to robustly navigate visually impaired settings, and thus it proves an important and useful tool as an embedded hardware system.
Human and obstacle detection performance
In simulated low-visibility scenarios, the system’s fundamental perceptual capacity was evaluated using both human and generic obstacle detection.
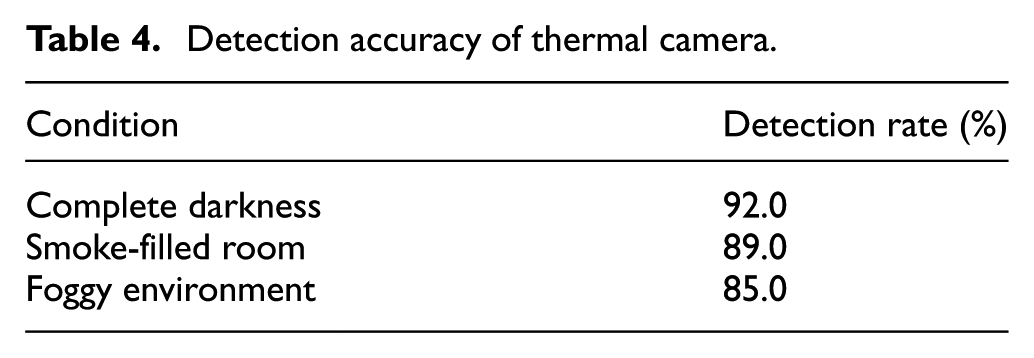
Thermal camera performance
The FLIR A65 thermal camera was tested independently. As measured in Table 4, the camera performed particularly well in dark (92.0%) and smoke (89.0%) conditions, taking advantage of the heat signatures. It performed less well in fog (85.0%), due to infrared radiation being scattered, which lowers thermal contrast to produce somewhat blurred images with less well-defined targets.
Detection accuracy of thermal camera.
LiDAR sensor performance
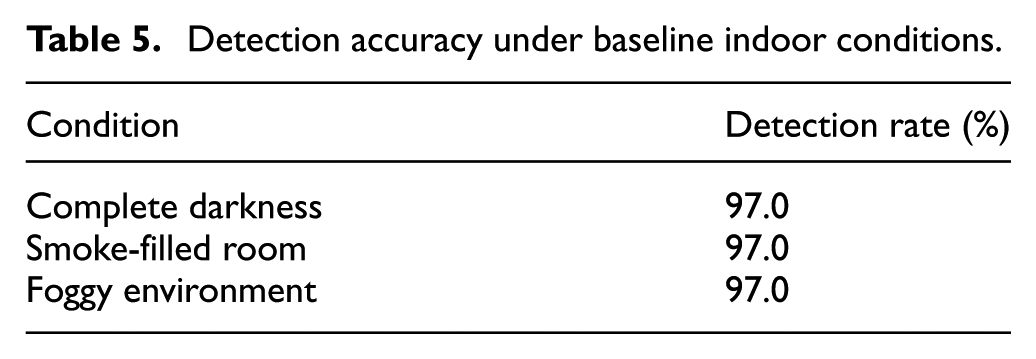
The YD LiDAR X4 sensor yielded stable geometrical data measurements at a 95.0% detection rate in all scenarios (Table 5), thereby proving its adaptability in varying lighting conditions and visual obscurants. Real-time map creation in these experiments used Hector SLAM along with the YD LiDAR X4 sensor output map. Figure 8 below gives a visual demonstration of LiDAR and thermal map generation output in an RViz window.
Detection accuracy under baseline indoor conditions.
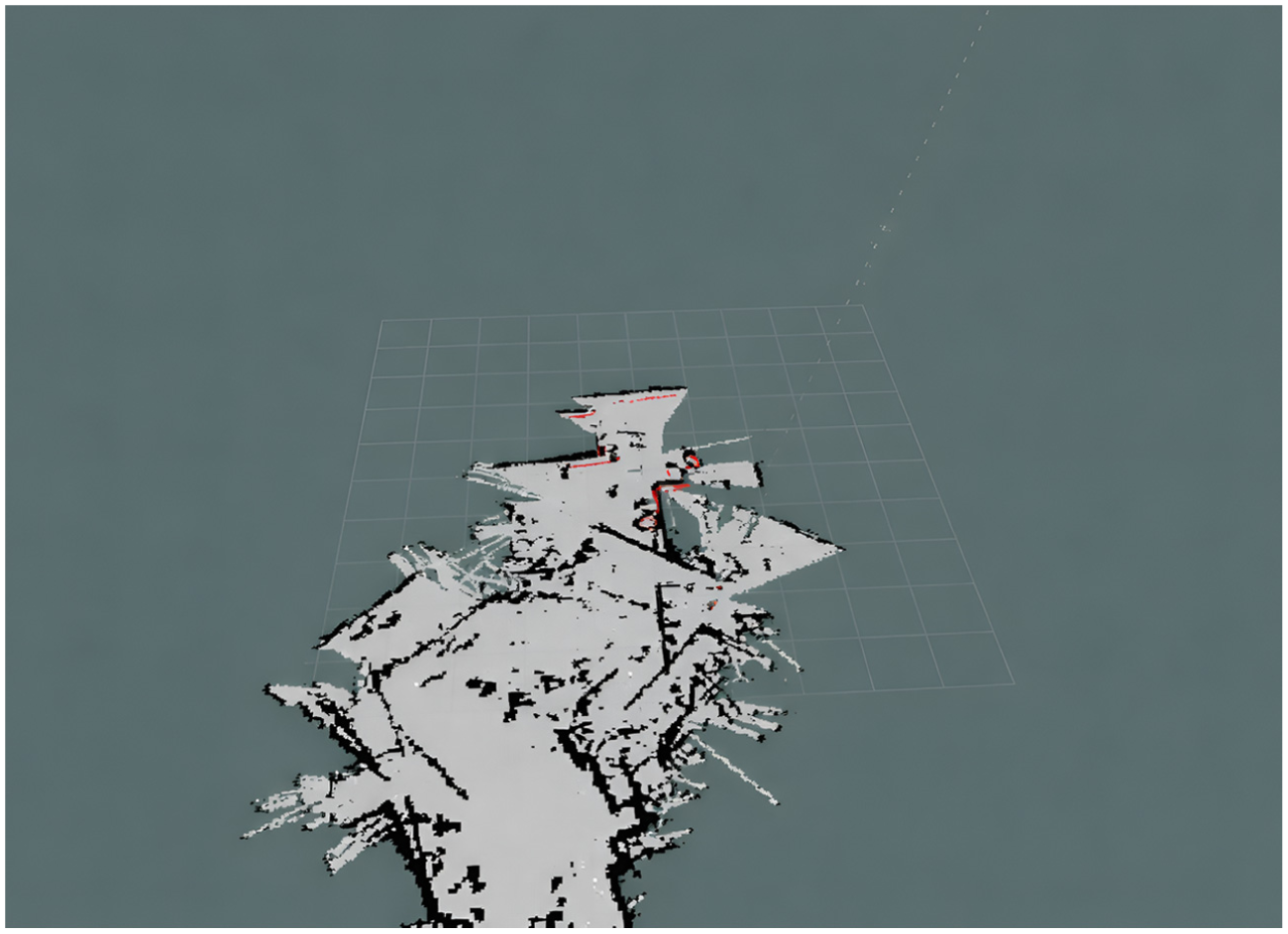
Fused LiDAR–thermal mapping result in RViz.
The active ROS display elements are displayed in the left panel: Grid, Map, Laser-Scan, TF, Path, Pose-Array, Marker-Array, Image, and PointCloud2. The main display window shows the 2D occupancy grid map resulting from the fusion of LiDAR structure data and thermal data. In the map, the free space is marked in white, the obstacles are painted black, and the unknown space is represented in gray. The red marker and the red line display the robot’s current position and its path to the target. This fusion map provides more distinct boundary representations for the obstacles and is less noisy compared to LiDAR-only mapped representations, especially when the map is created in a scenario with lower visibility, thus facilitated by the fusion of thermal data and the degraded data from the LiDAR sensor. Figure 8, is coherent in its display showing the benefits derived from the fusion of the various sensors’ data in relation to providing effective navigation to the robot when the visibility is degraded.
Fused system performance
The detection rate obtained from the sensor fusion system was uniformly higher in all tested cases and equal to 97.0%, as recorded in Table 6. This constitutes a significant enhancement compared to stand-alone sensors. Indeed, by properly overcoming major limitations of single sensors-the inability of the thermal camera to give accurate geometry and the inability for LiDAR to detect objects based on their thermal characteristics-fusion allowed for exact positioning of the thermally detected human in the map created by LiDAR as shown in Figure 8.
Detection accuracy of fused system.
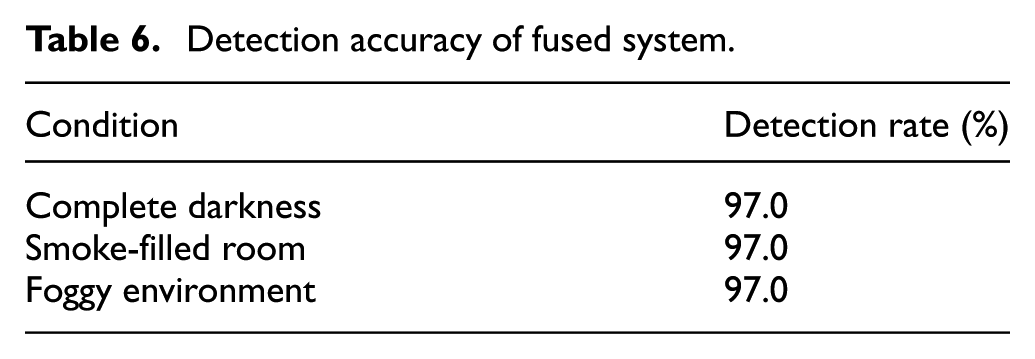
Figure 9(a) to (h) illustrates the full human detection and localization pipeline from the fused LiDAR–thermal stream. Figure 9(a) includes a thermal frame with the YOLOv5 detector marking the human target and bounding box and its associated confidence score indicating reliable detection under poor visibility conditions. Figure 9(b) is the corresponding LiDAR scan, containing geometry of the environment which enables cross modality alignment of thermal detection. Figure 9(c) comprises the fused occupancy grid generated from LiDAR geometry and thermal cues, where the detected human position is projected onto the map. Figure 9(d) presents the estimated robot pose and trajectory in the fused map, indicating how the system keeps track of localization while detecting human presence. Figure 9(e) shows the occupancy grid updated with this detection in the mapping pipeline to represent human position with consistency in the modeled environment. Figure 9(f) refines the localization to solve the exact corresponding grid cell for the detected human, bringing out the preciseness of the projection. Figure 9(g) shows the response of the navigation module where the robot plans a safe path by taking the detected human into consideration, thus showing human aware navigation capability. Finally, Figure 9(h) combines all the components-detection, mapping, localization, and path planning-into a single fused visualization. The system detects, localizes, and reacts to human presence in real-time. Together, Figure 9(a) to (h) gives a complete self-contained view of the proposed fused perception pipeline.

Human detection with YOLOv5 on fused thermal data (a) Thermal frame with YOLOv5 human detection, (b) LiDAR scan showing scene geometry, (c) Fused occupancy grid with projected human position, (d) Robot pose and trajectory in fused map, (e) Updated occupancy grid with human detection, (f) Refined localization to exact grid cell, (g) Navigation module planning human aware path, (h) Integrated visualization of detection, mapping, localization, and navigation.
Navigation efficiency
In particular, the performance of the entire navigation stack was measured with respect to path planning and dynamic obstacle avoidance.
Path planning performance
The system successfully negotiated the 15 m course on average in 120.0 s (Table 7). The planned trajectories were very efficient, demonstrating the planner to effectively utilize the accurate, fused environmental model to minimize the travel time and distance.
Path planning performance.

Real-time adaptation
Its reactivity, with obstacles introduced in real-time, was also checked. It showed very good real-time performance, as the average path adjustment and re-planning latency was only 0.5 s. The resulting low latency shows that the system can safely navigate through a dynamically changing environment with uncertainties in it. In addition to reporting a 0.5 s average response latency, the real-time performance of the proposed system was quantified in terms of frames per second (FPS). The fused perception pipeline achieved ∼2 FPS on Raspberry Pi 4, with YOLOv5 detection alone reaching ∼3.5 FPS. The entire navigation pipeline including Hector SLAM and Move Base ran at ∼2 FPS end to end. The above results validate that the system runs in real-time with embedded hardware constraints.
System robustness
The integrated system has been subjected to long-term operation with adverse conditions. The system remained highly accurate in detection-each time above 85.0% in the worst case. In addition, the system operated with no failures in all tasks related to navigation. This not only confirms the robustness of the algorithm for the fusion framework but also its stability in hardware integration.
Statistical evaluation of navigation trials
In order to test the repeatability of the system and assess its consistency, several tests were carried out in the same fog density conditions as the indoor navigation experiment in 15.0 m distance. Traversal time, path tracking deviation, and obstacle avoidance performance were recorded in each test run. In addition, there are cases of failure due to dense fog, which causes a drop in the LiDAR sensor for a very short time, leading to hesitation in the path. These observations give insight into the system’s repeatability and point out under what condition its performance may degrade.
Comparative analysis
A comparative analysis was done to put the performance of the proposed system into perspective.
Comparison with single sensors
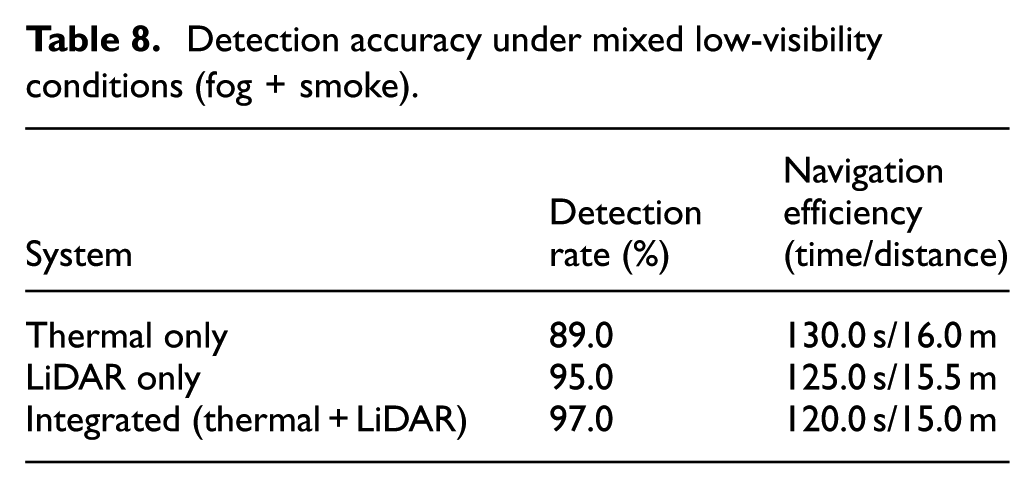
As shown in Table 8, the fused system surpassed thermal-only and LiDAR-only systems in detection accuracy and navigation performance. The 8.0% gain in detection with respect to the thermal-only system in fog and the 2.0% gain over the very robust LiDAR-only system highlight the benefits of fusion. The more effective navigation is a function of the more detailed and accurate world model possessed by the planner.
Detection accuracy under mixed low-visibility conditions (fog + smoke).
Comparison with current systems
When compared with systems documented in the literature, it can be seen that the proposed system exhibits remarkably competitive, if not better, performance. The system has a better reported detection accuracy in low-visibility environments than the all-terrain rover presented in Table 1, and offers a more comprehensive solution than the naval robot, which primarily targeted obstacle recognition. The main discriminator is the proven real-time fusion on an embedded hardware platform costing little, providing a strong trade-off among performance, reliability, and affordability. In order to show the competitiveness of the proposed approach, a detailed quantitative comparison with the existing navigation systems currently in use in low-visibility conditions is carried out. In this context, the evaluation of the proposed approach is based on some of the important parameters reported in the literature, such as Absolute Trajectory Error (ATE), navigation success rate, detection accuracy, and complexity of the system. As shown in Table 9, the proposed Thermal-LiDAR fusion approach ensures high detection accuracy (97%), complete navigation success (100%), and real-time processing (0.5 s) with low complexity compared to other approaches.
Quantitative comparison of the proposed thermal–LiDAR fusion framework with state-of-the-art navigation systems under low-visibility conditions.
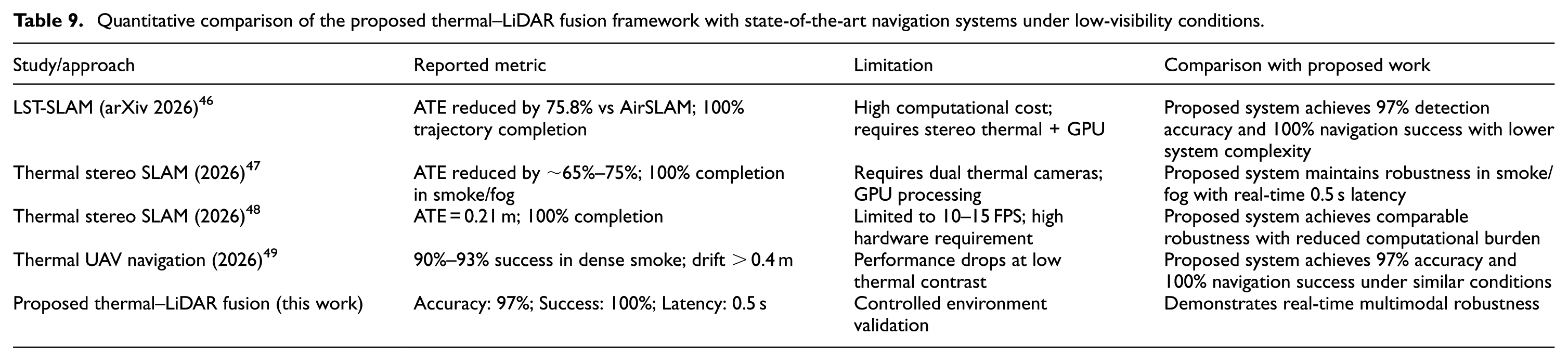
As observed from Table 9, existing thermal SLAM systems achieve strong localization accuracy but often require stereo thermal setups and GPU acceleration. UAV-based thermal navigation has lower success rate in dense smoke conditions. On the contrary, the proposed framework has 97% accuracy in detection and 100% success rate in navigation with reduced computational complexity and 0.5 s latency in real-time conditions.
Confusion matrix analysis of sensor systems through machine learning (ML) classification models
In this study, the RF and SVM models were used solely as a basis to test the effectiveness of the combined features in differentiating between obstacle and non-obstacle classes. These traditional machine learning models were only used during the offline analysis stage and not included in the real-time ROS-based framework. The models were used to test the effectiveness of traditional machine learning models in the presence of smoke, fog, and darkness, and to identify the limitations of the models in comparison to the effectiveness of the deep learning-based detector model. The reduced accuracy of the RF and SVM models in the presence of reduced visibility conditions further justified the limitations of traditional models, which led to the choice of the modified YOLOv5 network as the primary perception model in the final embedded hardware system, thus aligning the ML section with the overall methodology and clearly stating the role of the RF and SVM models in the study.
Random forest (RF) classifier
The RF algorithm 50 is an ensemble learning technique where numerous decision trees are formed during the training phase. It predicts the class that is most common among the classes of the trees, thus reducing the chances of overfitting and making the model more generalizable. The overall process of the RF classification technique used in this research is shown in Figure 10. It begins with feeding the input of the fused feature vector, which comprises spatial features like distance and the shape of the contour, and thermal features like mean temperature and thermal gradient. Next, the training data is bootstrapped, where the data is sampled with replacement. Parallel Tree Construction Next, numerous decision trees are formed on each bootstrap data set. At each node of the trees, a random subset of features is used for selecting the best feature to split the data, ensuring diversity. Ensemble Voting Mode at this step, the new unseen input of the fused feature vector is passed through each tree in the forest, and they vote on the classification result, for example, “Obstacle” or “Non-Obstacle.” Finally, the classification result is obtained through majority voting of the trees in the forest.
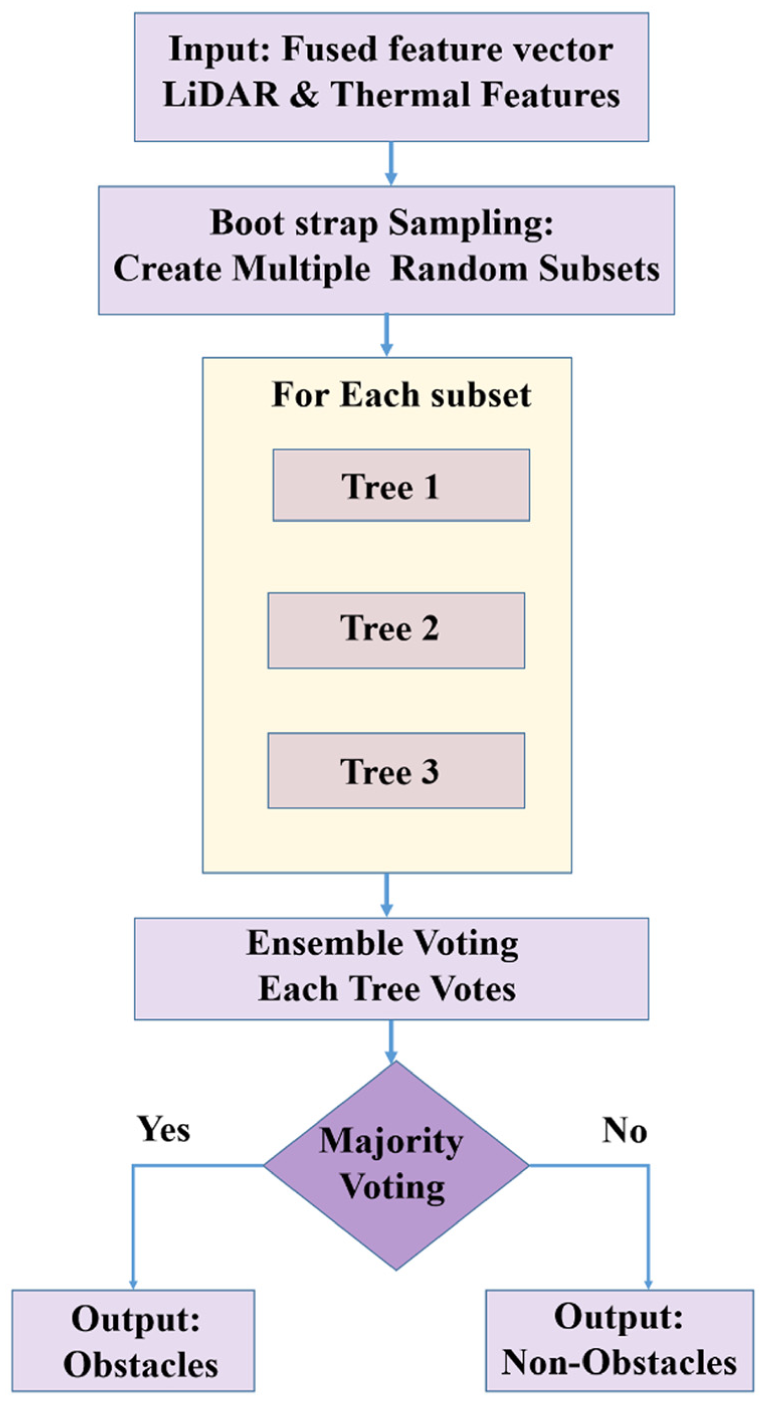
Random forest classification.
Support vector machine (SVM) classifier
The SVM 51 is a powerful discriminative classifier, and the goal is to find the optimal hyperplane that can separate different classes in the high-dimensional feature space. It can be used in scenarios like the one depicted in Figure 11, where the data is not linearly separable. Ultimately, the final system is based on the YOLOv5 model, as it performs best on feeding in direct data like images and also gives bounding boxes. However, the SVM model was very useful during development, as it showed that high-quality classification was possible at a reduced computational cost, which is a very desirable trade-off. It finds the hyperplane where the margin between the two classes, “Obstacle” and “Non-Obstacle,” is maximized. Data points closest to the hyperplane, called the support vectors, play a very important role in the classification. The new feature vector, which is the fusion of the features, is projected into the same high-dimensional space, and based on the classification with respect to the optimized hyperplane, the final classification is done. The key strength of the SVM is the capability to create complex nonlinear decision boundaries, which could prove very useful in differentiating subtle patterns within the multi-modal sensor data. In order to assess the performance of each of the detection systems in terms of classification under several environmental conditions, confusion matrices were developed as displayed in Figure 11, based on TP (True Positive), TN (True Negative), FP (False Positive), and FN (False Negatives). Each class used 1000 test frames for comparison consistency.
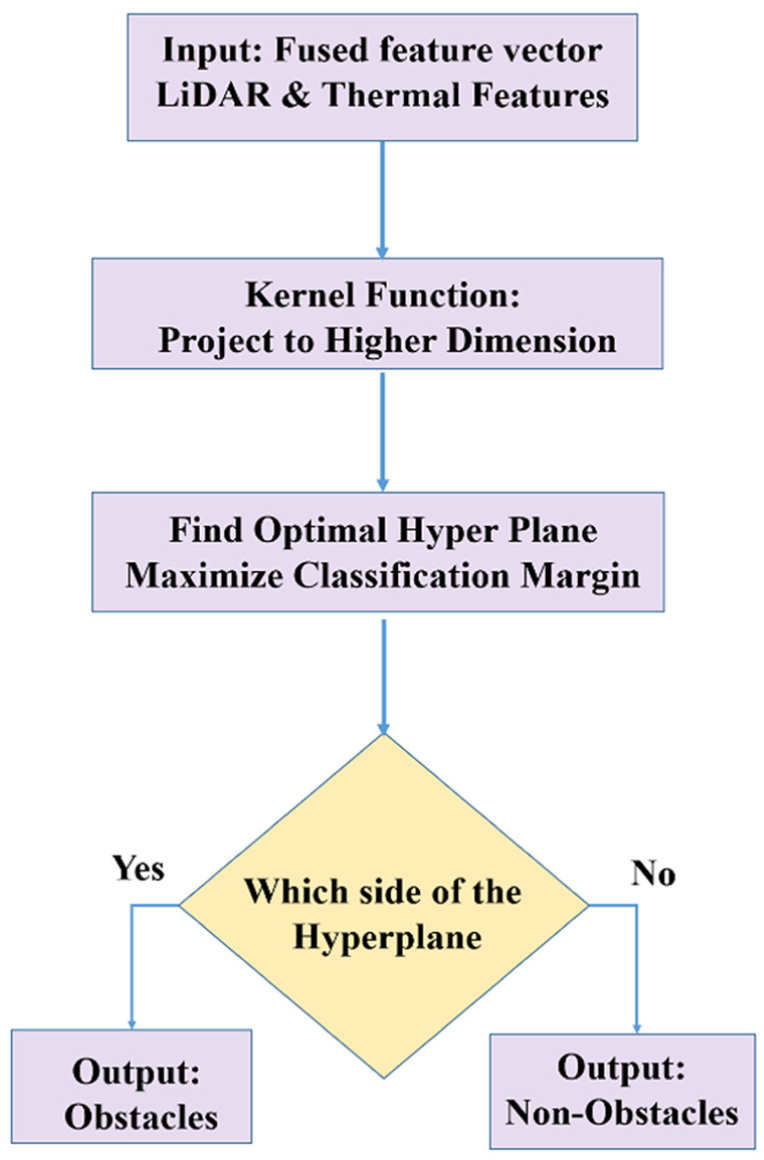
Support vector machine (SVM) classification workflow.
In complete darkness (Figure 12(a)) as listed in Table 10, the overall performance of the fused sensor system was the best with 97.0% accuracy and a 96.9% F1-score, beating the individual Thermal Camera’s 92.0% accuracy and the LiDAR Sensor’s 95.0% accuracy. The fusion strategy yields the optimal balance between precision (97.9%) and recall (96.0%) by dramatically reducing both FP and FN. This proves that sensor fusion improves reliability by 2.0%–5.0% across all important parameters, and the high recall validates its crucial benefit in reducing missed detections in low light.
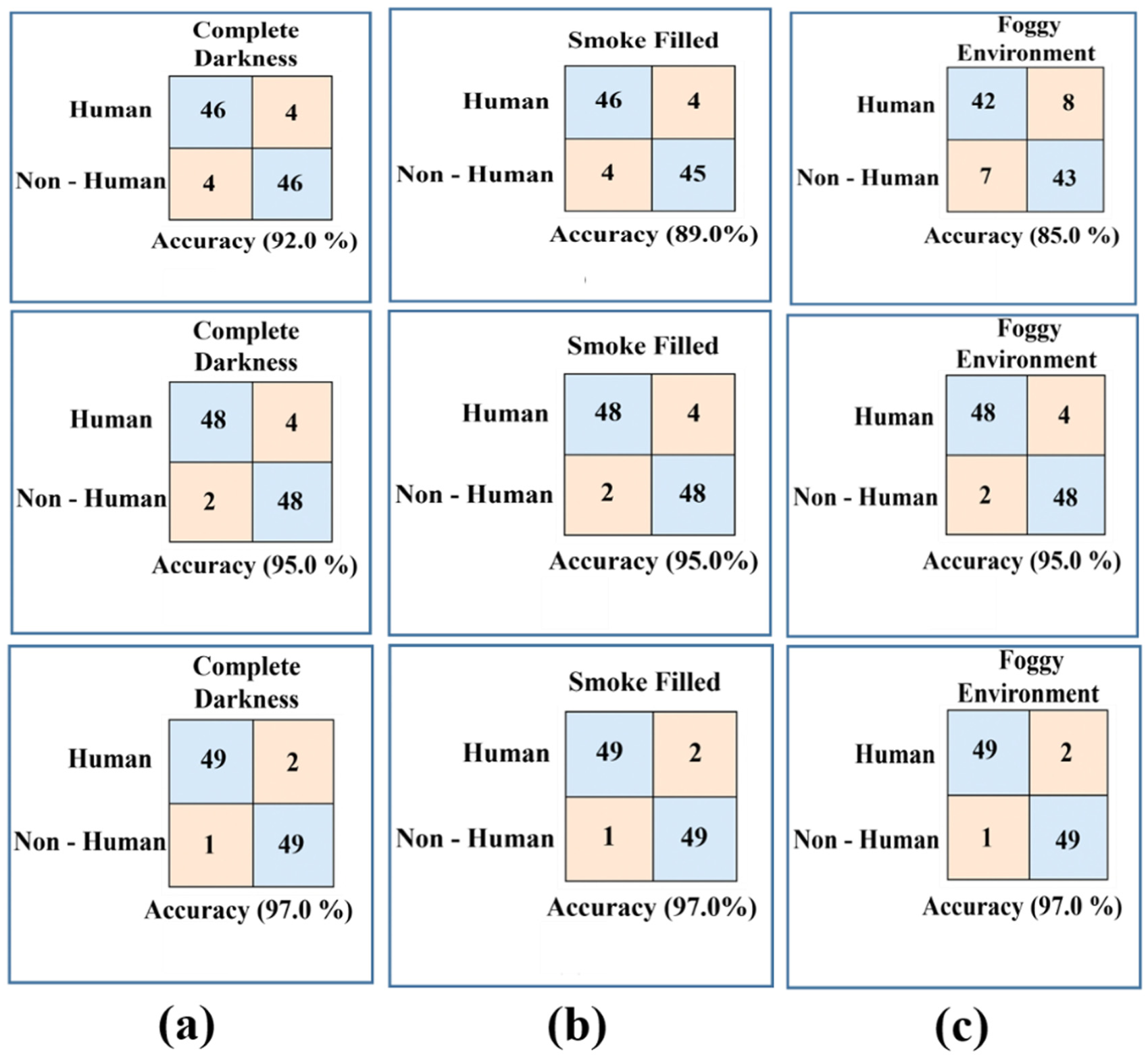
Confusion matrices for obstacle detection under three degraded visual conditions: (a) complete darkness, (b) smoke-filled environment, and (c) foggy environment.
Complete darkness.

In the smoky environment depicted in Figure 12(b), the combined system achieved a maximum accuracy of 97.0% or 96.9% in terms of F1-score, which effectively reduced the performance degradation in the standalone thermal camera, which decreased to 89.0% as false negatives increased due to signal scattering, as seen in Table 11. The LiDAR sensor was robust to obstacles with a strong accuracy of 95.0%. The fusion system was able to synergistically use the sensors to overcome the weakness of the thermal sensor by correcting its error rate to a well-balanced accuracy of 97.9% and a recall value of 96.0%. This shows the effectiveness of the system and the need for fusion to maintain a strong detection accuracy even when faced with difficult conditions with particulates.
Smoke-filled environment.

As depicted in Figure 12(c), the combination system worked best under the foggy conditions (Table 12), compensating for the shortcomings of the sensors with a 97.0% accuracy rate and an F1-score value of 96.9%. Among these, the performance degradation of the thermal camera sensor had been severe because the signal was readily absorbed by the water vapor, and it managed to report an accuracy of only 85.0%, with a recall value of 78.0%, while the LiDAR sensor reported an accuracy of 95.0%. In the fusion model, the issue of high false negatives reported by the thermal camera sensor had been compensated for, and the overall accuracy increased to 97.9%. This aptly and conclusively proves the environmental robustness by pointing out how the fusion of the data resulted in the reduction of false positives and false negatives under all the adverse conditions.
Foggy environment.

Overall results demonstrate that the combined sensor system achieved the accuracy, recall, and F1-score metrics of about 98.0%, 96.0%, and 97.0%, respectively, and the performance was consistent for all the tested scenarios regarding low visibility when contrasted to the various sensor settings. Even though the LiDAR-only detection demonstrated extremely stable results, certain limitations were found in the refined identification of the target objects, and the thermal-only sensor was extremely vulnerable to obscurants including fog and smoke. The fusion strategy outlined in the thesis eliminated the weaknesses of the standalone sensors through the fusion of the accurate spatial depth measurements available in the LiDAR sensors combined with the thermal intensity to create an effective environmental perceiving system that avoided both false negatives (FN) and false positives (FP). This confirms that sensor fusion is critical for reliable and robust autonomous navigation under unfavorable conditions. Figure 13 shows the performance comparison of Thermal Camera, LiDAR Sensor, and Fused System under complete darkness, smoke-filled, and foggy conditions. The fused system always has the highest detection accuracy of 97.0% in all conditions. LiDAR maintains stable performance with 95.0%, while a thermal camera shows reduced accuracy in low-visibility conditions. This confirms that sensor fusion significantly improves the reliability of detection in challenging environments.
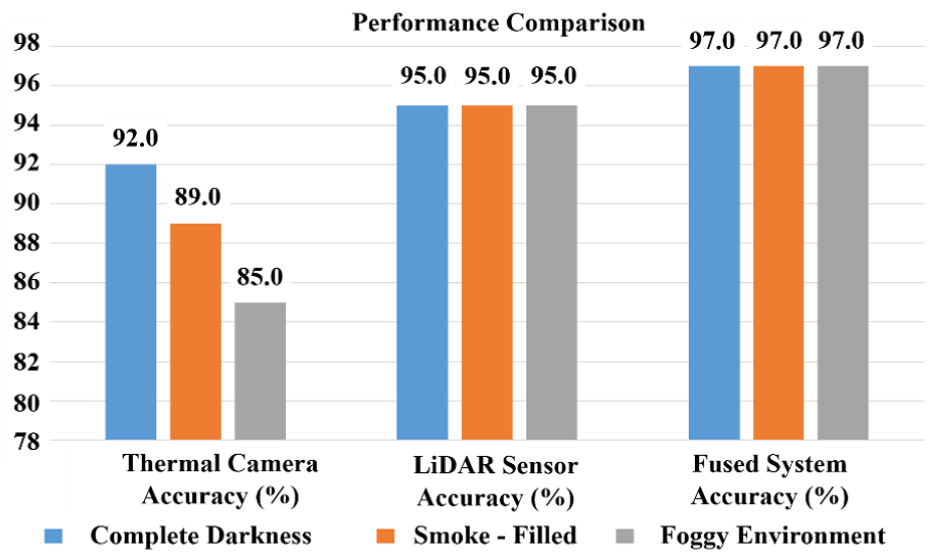
Comparative bar chart showing the detection accuracy of the thermal camera, LiDAR sensor, and fused system under different environmental conditions.
Performance comparison analysis
Assessment of the suggested Thermal-LiDAR fusion-based navigation system’s performance in comparison to the most advanced techniques available in 2025 in low-visibility situations is listed in Table 13.
Comparative summary of recent real-time embedded hardware fusion systems evaluated across thermal, LiDAR, depth, and multi-modal sensing pipelines.
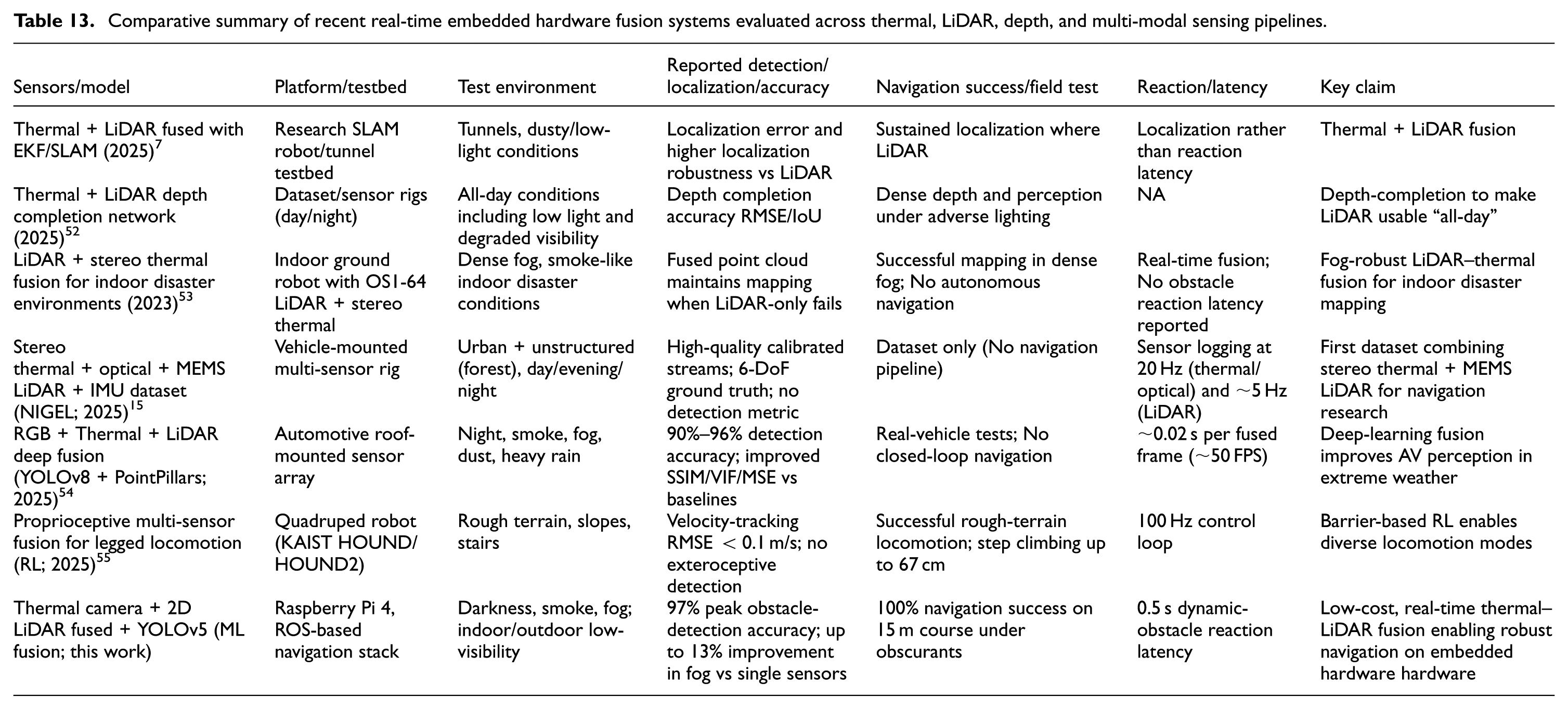
Compared with the recent embedded hardware fusion systems summarized in Table 13, the proposed thermal–LiDAR fusion framework demonstrates a uniquely strong balance of accuracy, robustness, and real-time autonomy on extremely low-power hardware. Dataset-oriented works such as NIGEL provide rich multi-sensor recordings but do not report real-time detection, obstacle response, or closed-loop navigation. Indoor disaster-response systems maintain mapping performance under fog but do not achieve autonomous navigation or dynamic-obstacle handling. Automotive deep-learning fusion frameworks achieve high perception accuracy but rely on GPU-accelerated hardware and do not operate on lightweight embedded hardware platforms. Legged-robot fusion frameworks focus on proprioceptive control rather than exteroceptive sensing in obscurants. In contrast, the proposed system delivers 97.0% obstacle-detection accuracy, 100.0% navigation success, and a 0.5 s reaction latency in smoke, fog, and darkness-while running entirely on a Raspberry Pi 4 without external accelerators. This combination of real-time perception, robust performance in obscurants, and fully integrated autonomous navigation on a low-cost embedded hardware platform is not achieved by any of the existing systems, positioning this work as a practical and efficient solution for visibility-degraded environments. While the experimental evaluation confirmed high detection accuracy and reliable navigation across smoke, fog, and darkness, it is equally important to recognize the boundaries of the current system. The next section discusses the current limitations, showing the improvements while at the same time pointing out the challenges that have been addressed and those which are still there but present an opportunity for further development.
Limitations and future work
Although the proposed system has shown the effectiveness in tackling some of the critical issues in low-visibility navigation, some limitations still exist:
Future work
Based on the current findings, the following directions may be considered to extend the framework:
In summary, it is evident that the limitations identified present the scope and scope of opportunity for the existing framework. Furthermore, it is evident from the proposed directions for future work that there is an attempt to take the robustness, scalability, and flexibility of thermal and LiDAR fusion beyond the laboratory and toward more reliable implementations of autonomous navigation.
Conclusion
This work proposed a ROS based intelligent navigation framework that utilizes thermal imaging and 2D LiDAR sensing modalities for autonomous robotic navigation in low visibility conditions such as darkness, smoke, and fog. This work has shown the efficient and robust real-time performance of the proposed framework on low-power embedded platforms (Raspberry Pi 4). The contributions of this study include the design of an embedded hardware algorithm that improves perception in low visibility conditions, the development of an optimized ROS framework that can handle data-intensive and time-critical operations, and the implementation of a lightweight embedded hardware architecture that improves flexibility, robustness, and adaptability of the proposed framework on different robotic platforms. However, despite all these advantages, there are a number of challenges that exist with the use of thermal sensors, especially in the long term, as there is a possibility of thermal drift in pixel level stability. In addition, there are computational limitations with the Raspberry Pi 4 that limit the use of high frame rates and deeper learning models. Moreover, though the model has been validated in indoor conditions, it needs to be further validated in outdoor conditions on a large scale with uncontrolled obscurants and terrain.
Footnotes
Ethical considerations
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Author contributions
Poundoss Chellamuthu, R. Krishnamoorthy: Conceptualization, Methodology, Software, Visualization, Investigation, Writing - Original draft preparation. T. Yuvaraj: Data curation, Validation, Supervision, Resources, Writing - Review & Editing. Mohit Bajaj, Ievgen Zaitsev: Project administration, Supervision, Resources, Writing - Review & Editing.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All relevant data are within the manuscript. The collection and analysis method complied with the terms and conditions for the source of the data. The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.