
Abstract
Achieving accurate trajectory tracking in Active Denial System (ADS) remains a complex and pressing task, particularly for real-time tracking-and-pointing operations. In this context, we begin by examining the stringent accuracy demands of such systems and put forward an adaptive control strategy that integrates Integral Sliding Mode Control (ISMC) with an improved Double Deep Q-Network (AdaDDQN). The proposed method employs a high-dimensional state-space framework coupled with a context-aware reward mechanism, enabling the controller to adaptively fine-tune its parameters on the fly. This hybrid approach harnesses the learning flexibility of Reinforcement Learning (RL) while preserving the inherent stability of SMC. Experimental evaluations reveal that this method achieves a significant improvement—over 80% gain in tracking precision compared to traditional sliding mode schemes—maintaining the tracking error consistently within 8 mrad. Moreover, it demonstrates strong resilience against mechanical friction, external interference, and model uncertainties, ensuring both accuracy and robustness under real-world operational constraints.
Keywords
Introduction
The Active Denial System (ADS) represents a class of non-lethal directed-energy technologies that project microwave radiation toward a target using a continuous-wave transmitter operating in the 94–95 GHz range (∼0.1 THz), delivering output power between 10 and 100 kW.1–3 This radiation travels at the speed of light and induces a thermal effect roughly 0.4 mm beneath the surface of human skin—sufficient to stimulate pain receptors within seconds and trigger a strong withdrawal response. Notably, once the exposure ceases or the individual moves beyond the beam’s reach, the sensation dissipates rapidly. Due to its controllable physiological impact without lasting harm, ADS offers a compelling solution for crowd dispersion, conflict de-escalation, and minimizing collateral injury. 4
In parallel with ADS technology, the development of precise tracking and pointing platforms has become increasingly critical. These servo control systems are essential for ensuring that the microwave beam consistently targets the intended area with minimal deviation, especially under dynamic conditions. Among control strategies, robust control and Sliding Mode Control (SMC) are frequently favored due to their resilience against model uncertainties and external disturbances.5–7 More recently, Deep Reinforcement Learning (DRL) has emerged as a promising paradigm, offering real-time adaptability and enhanced perception in high-dimensional environments.8–11 Algorithms like Deep Q-Network (DQN) and Double Deep Q-Network (DDQN) have addressed stability and policy evaluation biases, paving the way for intelligent, self-adjusting control frameworks. In this context, combining the adaptability of DRL with the reliability of SMC is gaining traction as a promising direction for high-precision tracking applications.12–18 In addition to these developments, several recent works have explored advanced control strategies for complex dynamic systems. Regarding intelligent decision-making in networked environments, Cho et al. 19 proposed a resilient algorithm combining multi-agent reinforcement learning (MARL) with message-passing mechanisms to ensure robust operation of UAVs under unreliable network conditions. While such distributed learning frameworks demonstrate superior resilience, high-precision tracking tasks for servo systems often require more focused compensation for local dynamic nonlinearities; To address specific actuator nonlinearities such as dead-zones, Yuan et al. 20 developed a time-scale decoupled adaptive prescribed-time control scheme. Their method cleverly utilizes fuzzy logic to compensate for unknown dead-zones without prior knowledge, ensuring convergence within a user-specified time. Similarly, addressing the constraints of communication bandwidth and system security, Zhang et al. 21 introduced a periodic event-triggering adaptive control strategy capable of mitigating actuator attacks and exogenous disturbances in networked uncertain nonlinear systems. Although these state-of-the-art methods have achieved remarkable success in their respective domains (network resilience, dead-zone compensation, and security), controlling the Active Denial System (ADS) presents unique challenges, particularly regarding constant unmodeled loads and the trade-off between rapid convergence and steady-state precision.
Therefore, applying such techniques in real-world ADS scenarios remains challenging. Specific control performance indicators must be identified based on the unique characteristics of microwave-based systems. A meaningful control framework must not only achieve high accuracy but also operate robustly in the face of chattering, mismatched disturbances, and hardware-induced constraints. These include friction, backlash, input saturation, quantization noise, and sampling delay, all of which influence closed-loop dynamics and complicate controller design.
Moreover, while RL introduces adaptability, it also raises new concerns: function approximation errors, generalization gaps, and violations of Lyapunov stability can compromise safety. Although methods like Constrained Policy Optimization and Control Barrier Functions offer theoretical safeguards, they are often difficult to implement under strict real-time or high-disturbance conditions.
To address these challenges, this study first establishes quantitative control accuracy requirements—specifically, ensuring that the ADS tracking error remains within 10 mrad. On this basis, we propose a novel adaptive control scheme that integrates an improved DDQN (AdaDDQN) into the structure of Integral Sliding Mode Control (ISMC). The approach features a multi-dimensional state-space formulation combined with an intelligent reward mechanism, allowing for online parameter adjustment and real-time learning during tracking tasks.
At the core of the method lies a redesigned integral sliding variable, which includes cumulative error compensation and decomposes the control torque into equivalent, switching, and adaptive components. RL determines the angular velocity increments, enabling the controller to respond swiftly to rapid trajectory changes while retaining SMC’s characteristic robustness. To address chattering, the system incorporates diversity metrics, sliding variable history, and torque transformation statistics, which enhance smoothness perception and suppress excessive torque fluctuation.
Experimental validations confirm that the proposed method outperforms traditional SMC, achieving an improvement of over 80% in tracking accuracy and maintaining errors consistently within 8 mrad. Even in the presence of structural friction and environmental disturbances, the system demonstrates stable, high-precision performance.
The primary contributions of this work include:
Development of a smoothness-enhanced adaptive control framework which seamlessly integrates the adaptive decision-making of AdaDDQN with the theoretical stability of Integral Sliding Mode Control (ISMC). This hybrid framework effectively handles both unmodeled dynamics and transient disturbances.
Proposing a RL decision-making module based on AdaDDQN, capable of adaptively optimizing angular velocity adjustments and key control parameters in a multi-dimensional state space, enabling robust tracking under changing inertial and disturbance conditions.
The proposed strategy is rigorously implemented and validated on a physical ADS tracking-and-pointing platform. Comprehensive experiments demonstrate that it achieves the best performance metrics among all tested methods, maintaining the tracking error consistently within 8 mrad and fully satisfying the stringent beam coverage requirements.
Precision analysis and system modeling
Precision analysis
Given the operational demands of microwave-based ADS, achieving high-precision tracking and pointing is essential to ensure continuous, effective energy projection while minimizing unintended damage. To formalize the control objectives of such systems, this section derives quantitative tracking and pointing accuracy criteria by analyzing both the diffraction behavior of 94 GHz millimeter waves and a probabilistic hit model.
As a starting point, we consider the inherent beam divergence characteristics of the system. With the operating frequency set at 94 GHz and the antenna aperture
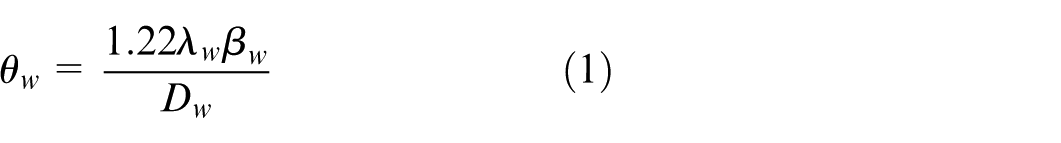
By inserting the given parameters into the Rayleigh-based formula, the resulting theoretical beam divergence is calculated to be approximately 19.5 mrad. At an operational distance of 250 m—a typical engagement range for ADS—this divergence directly limits the physical spread of the microwave beam.
To establish an accuracy threshold grounded in stable aiming probability, it is essential to distinguish between two primary error sources: static pointing error (a systematic offset) and dynamic tracking error (a random fluctuation). The latter typically appears as line-of-sight jitter with respect to the moving target and is commonly modeled using a Gaussian distribution. For the microwave beam to consistently maintain coverage over the target, this jitter must remain within a controllable range. Leveraging the statistical properties of Gaussian noise, the stable aiming probability
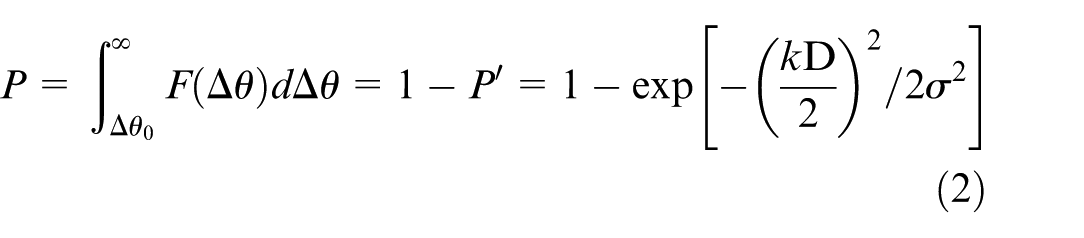
Here, the hit probability

Where
The hit probability also satisfies the condition:

Letting
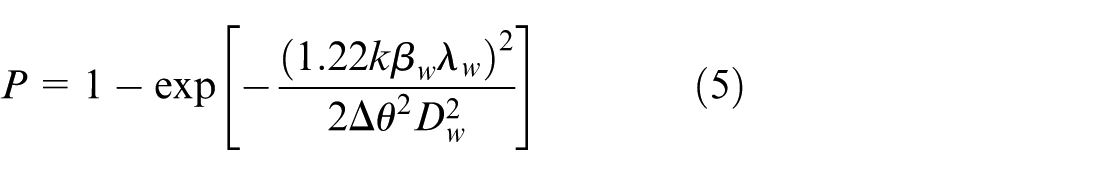
Figure 1 presents a schematic representation of the microwave beam diameter and the associated accuracy requirements, while Figure 2 illustrates how the ratio between beam divergence and line-of-sight jitter influences the tracking precision at a distance of 250 m. The analysis suggests that to achieve stable and high-precision tracking, the jitter of the microwave spot must remain within half of the beam diameter. Under this constraint, the system’s allowable tracking error must be tightly bounded. Simulation results indicate that when the tracking accuracy satisfies
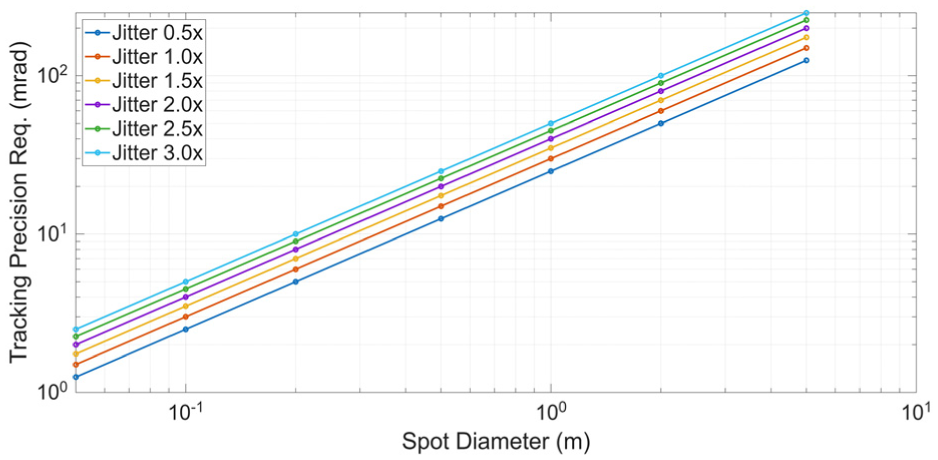
Beam divergence and tracking accuracy constraints.
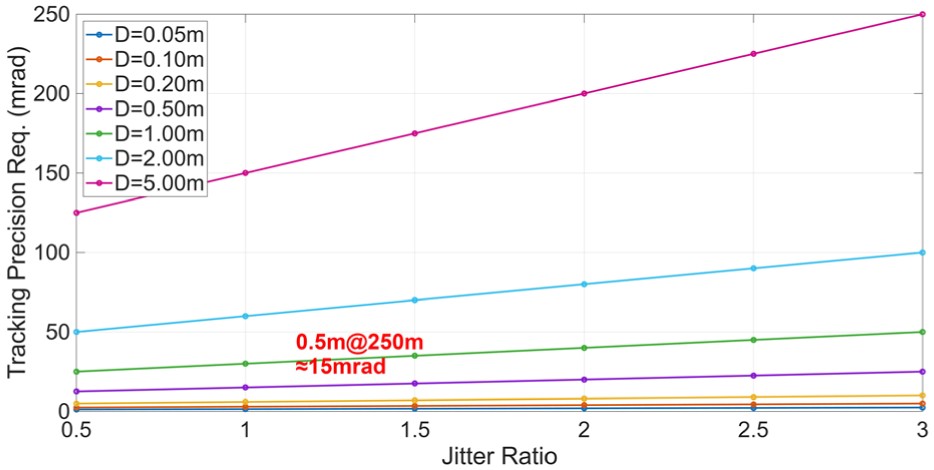
Effect of beam diameter and tracking accuracy constraints at 250 m.
In light of these findings, and considering the nonlinear disturbances introduced by platform motion at the 250 m operating range, the tracking-and-pointing system is required to meet a maximum RMSE of
System dynamics model and control objectives
To effectively manage the tracking-and-pointing control task for an ADS (Figure 3), we begin by establishing a dynamic model that captures the essential coupling behaviors of the system. The tracking platform is represented as a rigid-body mechanism with two degrees of freedom (2-DOF). Let the joint-angle vector be defined as

Dynamic model of two-axis tracking and pointing platform.
Figure 3 illustrates the structural and functional configuration of the tracking-and-pointing platform within ADS. The azimuth axis rotates around the vertical vector to control the horizontal heading, providing panoramic field coverage, while the pitch axis rotates around the horizontal vector to adjust the vertical tilt of the payload.
Based on the system’s physical properties, the corresponding mathematical formulations for its key dynamic components are defined as follows:
The positive-definite inertia matrix
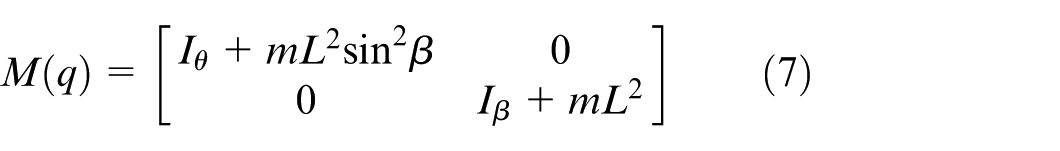
The coupling effects during rotational motion are described as follows:
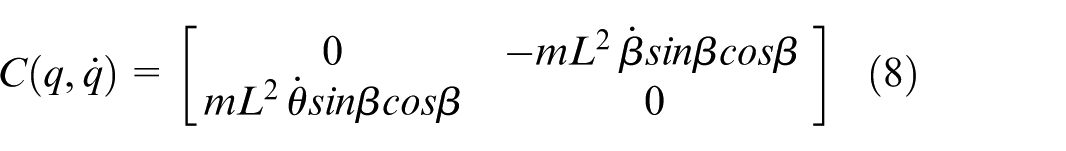
The gravitational effect

The damping matrix
The control objective is to ensure that the system meets the prescribed RMSE criteria by driving the actual state vector
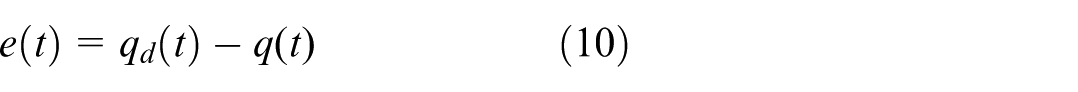
RMSE can be obtained as follows:
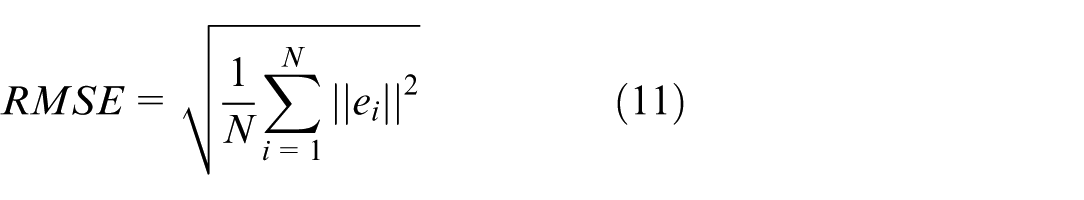
ISMC and improved RL-based adaptive optimization strategy
Construction of integral sliding variable
The ISMC is constructed by first defining a suitable sliding variable, which shapes the system’s motion to achieve the desired dynamic response. This design helps eliminate steady-state error while enhancing transient performance. The sliding variable is formulated as follows:
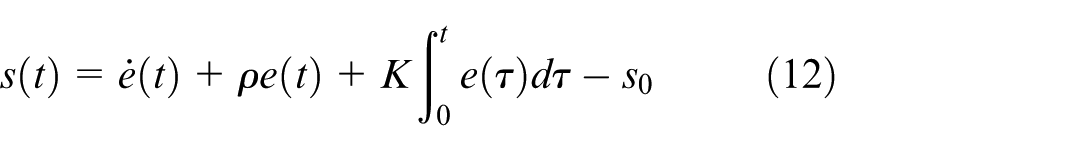
where
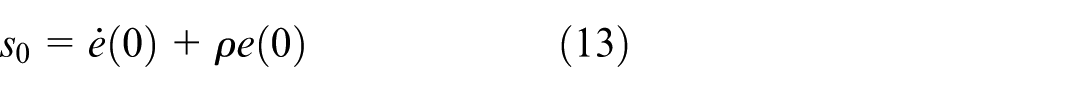
By substituting
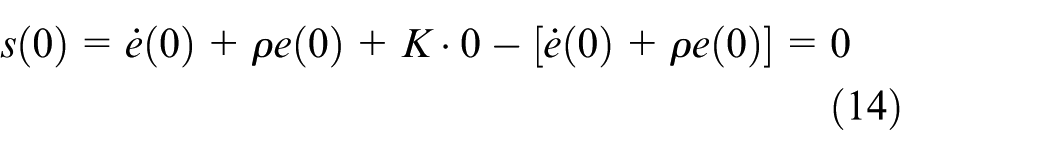
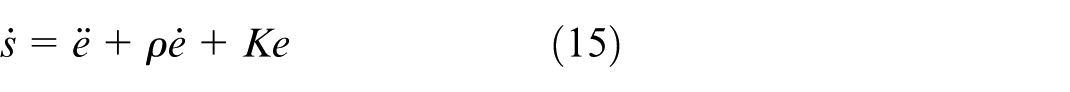
Based on the integral sliding variable, the control law is formulated to drive the system states to the sliding manifold within finite time and to ensure sustained sliding motion thereafter.
The control input τ is composed of two main components: the nominal control, which reflects the known system dynamics, and the switching control, designed to counteract external disturbances and uncertainties.
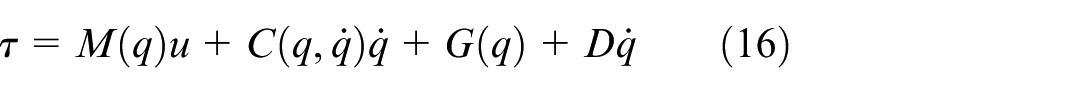
The auxiliary control component
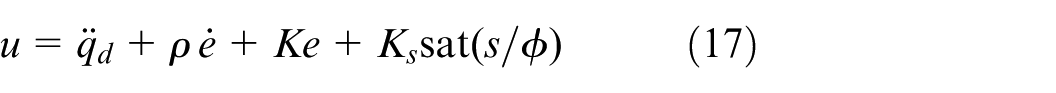
Where
Substituting the control law (equation (16)) into the system dynamics (equation (6)) yields:
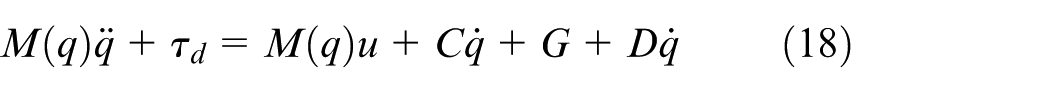
Since the nonlinear terms are compensated by the control law and the inertia matrix
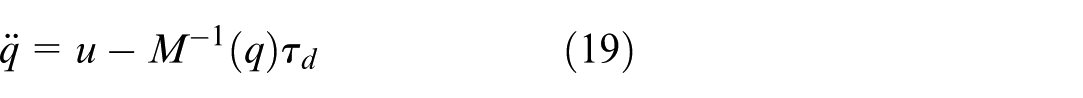
Substituting the expression for
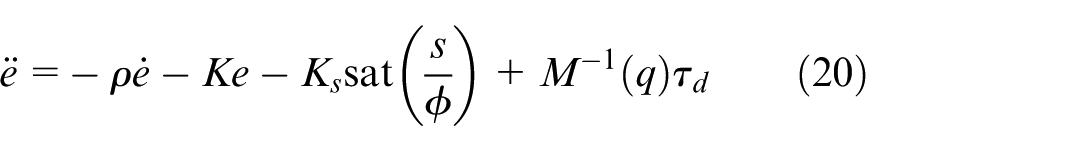
Combining this with the derivative of the sliding variable from equation (15), the decoupled sliding mode dynamics is derived as:
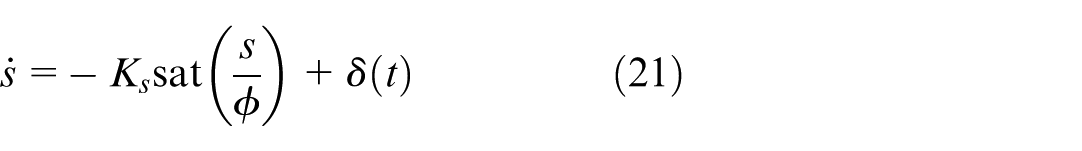
where
Adaptive optimization strategy via improved RL
Traditional sliding-mode control often depends on empirically tuned parameters, which limits its adaptability in the face of rapidly changing or uncertain environments. To address this limitation, we integrate AdaDDQN into the control framework, enabling online optimization of key parameters.
The parameter tuning process is reformulated as a Markov Decision Process (MDP), characterized by the standard five-tuple M = (S, A, P, R, γ):
State S represents the system’s current dynamic characteristics, capturing essential information for decision-making.
Action A represents the incremental adjustment applied to the control parameters.
Reward R represents the evaluative feedback that guides the learning agent toward optimal policy selection.
To improve the agent’s sensitivity to trajectory complexity and control smoothness, we design a high-dimensional state space that embeds both diversity metrics and predictive information about the system’s future behavior.
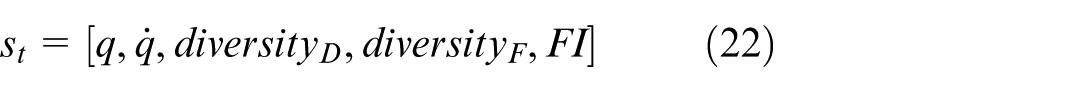
The following features are carefully designed to capture critical aspects of system dynamics and trajectory complexity:
State-space diversity (
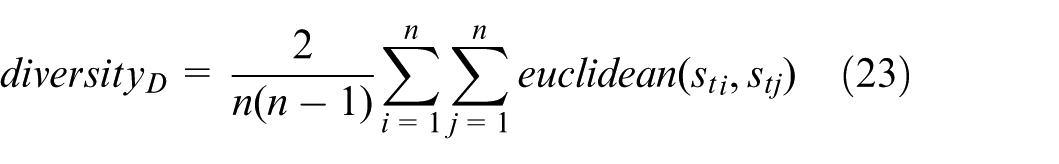
Target-space diversity (
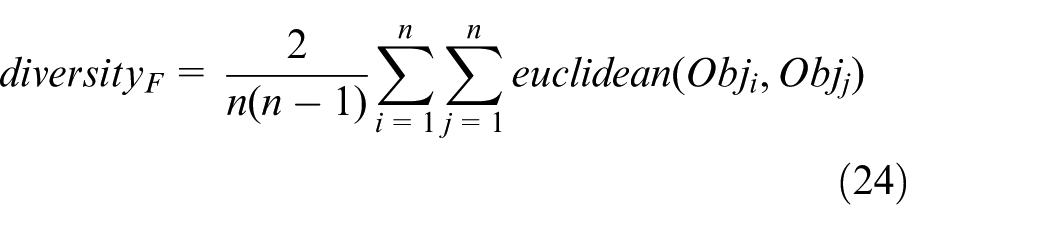
where Obj represents the normalized target vector, which can be determined as follows:

By jointly analyzing the dispersion of state samples and the complexity of the normalized target trajectory, the system gains improved resilience to distributional shifts. This, in turn, enhances the generalization capability of the policy across varying control scenarios.
The feature vector includes future-informed indicators—collectively denoted as FI—which capture predictive information about target motion and disturbance trends. The FI component is structured into three elements:
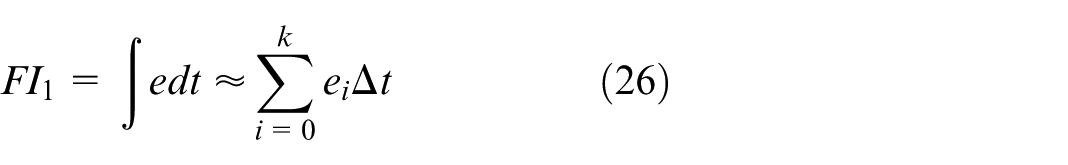

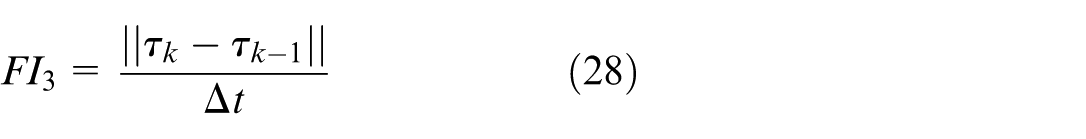
The structure of the action space is carefully designed to suit the needs of online parameter tuning in a dynamic control environment.
The action space is structured to enable real-time adaptation of control parameters, ensuring the agent can respond effectively to changes in dynamic and uncertain environments:
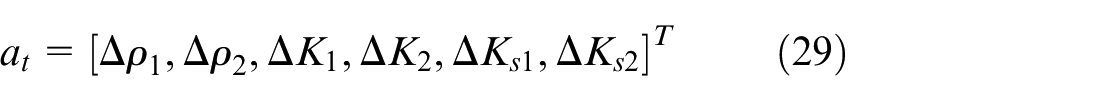
The adjustable parameters include the sliding-variable coefficients, integral gains, and switching gains, all defined separately for the azimuth and elevation control channels.
For the switching gain adjustment (
For the sliding variable parameter adjustment (
For the integral gain Adjustment (
To improve both learning stability and decision quality, the proposed AdaDDQN network leverages a Dueling DDQN architecture. This structure incorporates two key mechanisms:
DDQN introduces a separate target network to compute the estimated Q-values. By decoupling action selection from value evaluation, this approach effectively reduces the overestimation bias often encountered in standard DQN methods.
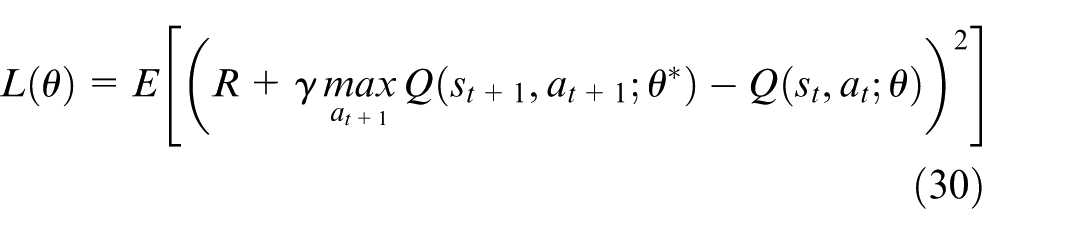
The dueling network separates the Q-value into a state-value
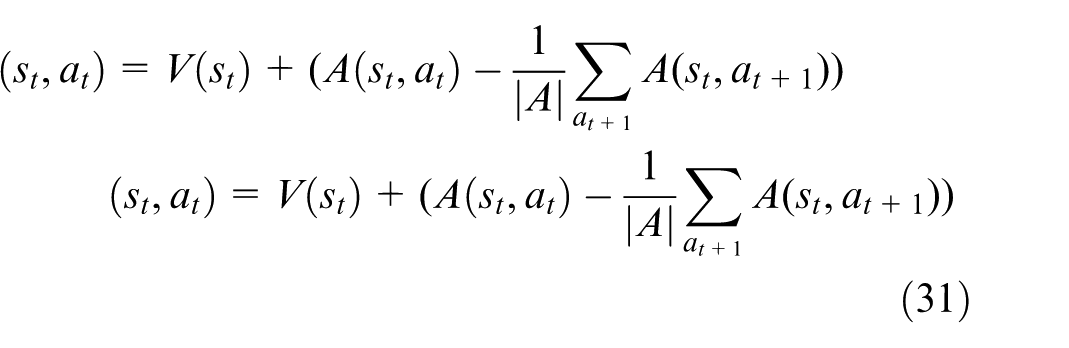
The reward function is constructed to penalize angular tracking errors while simultaneously incorporating constraints on control torque magnitude and variations. The mathematical formulation of the reward is as follows:
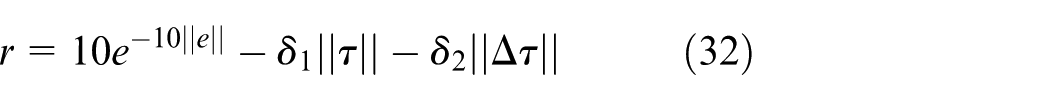
Specifically, the first term in the reward function applies an exponential penalty to the tracking error, encouraging precise alignment with the target trajectory. The second term serves as a constraint on the control energy, limiting excessive torque output. The third term discourages large control adjustments by penalizing the magnitude of changes in torque. This adjustment penalty
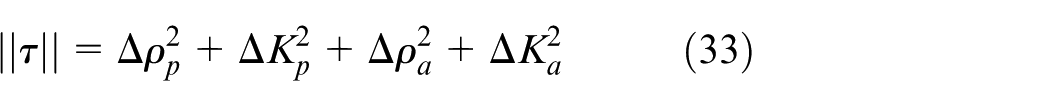
where
Stability analysis and ultimate boundedness
To rigorously verify the stability of the proposed control scheme under the influence of the RL-optimized parameters and the saturation function, we first establish the necessary assumptions and then derive the stability theorem based on Lyapunov theory.
Assumption 1 (Bounded Disturbance): The transformed disturbance term
Assumption 2 (RL Safety Constraint): Although the switching gain
Theorem 1 (Uniform Ultimate Boundedness): Consider the gimbal dynamics described by equation (16). Under Assumptions 1 and 2, and utilizing the control law with the saturation function
To formally establish this result, we construct the following Lyapunov candidate function:

Differentiating
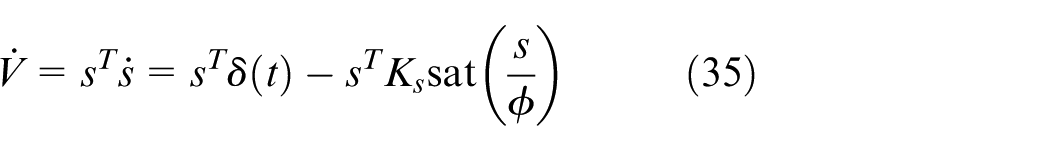
We analyze the stability in two regions based on the boundary layer thickness
Utilizing the skew-symmetric property

We analyze the stability in two regions based on the boundary layer thickness
Case 1: Outside the Boundary Layer (
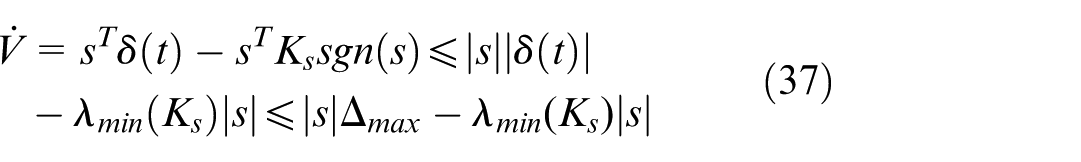
By Assumption 2, since
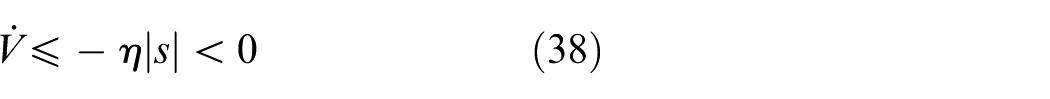
This ensures that any system trajectory starting outside the boundary layer will reach the boundary layer region in finite time.
Case 2: Inside the Boundary Layer (
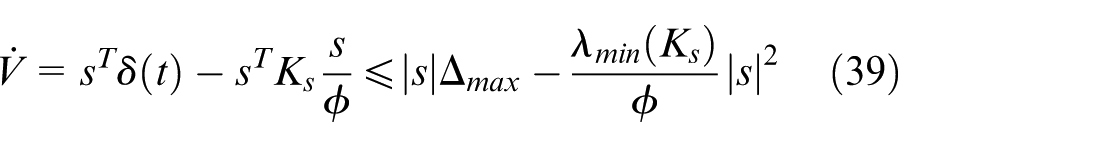
For

Consequently, the sliding variable

In the steady state, the dynamics of the sliding variable are dominated by
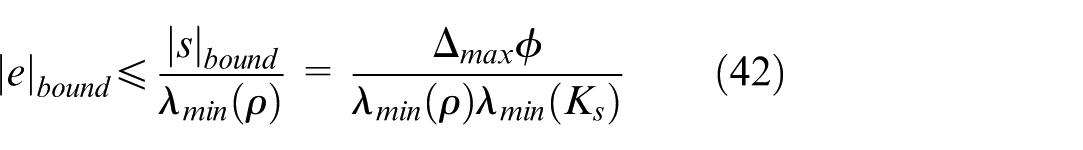
Equation (42) provides the theoretical lower bound of the tracking error. It explicitly reveals that the error bound is proportional to the disturbance magnitude
Simulation and experiment results
To evaluate the performance of the proposed adaptive ISMC, which integrates AdaDDQN, a comprehensive validation framework is established. The experimental setup includes both numerical simulations and physical hardware testing, aimed at examining the system’s tracking accuracy, response speed, and robustness in the presence of nonlinear friction, external disturbances, and structural uncertainties.
A simulation model of the two-DOF gimbal platform is constructed based on its physical configuration. The system dynamics—including the inertia matrix
Physical parameters of two-axis tracking and pointing platform.
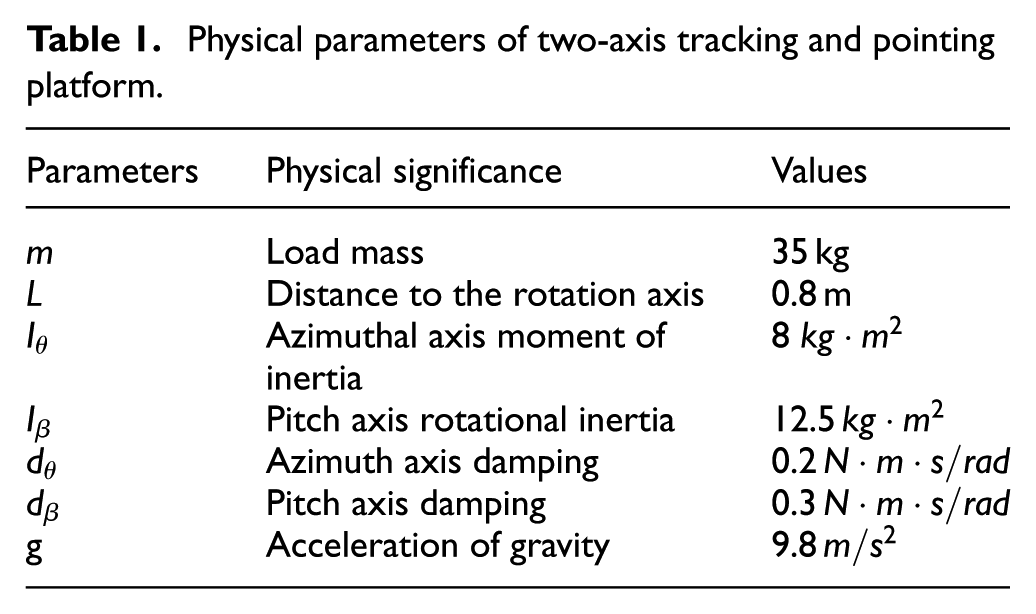
To closely replicate real-world operating conditions, the simulation environment incorporates nonlinear friction and stochastic disturbances.
Nonlinear friction modeling: A Stribeck friction model is employed to capture the key characteristics of mechanical friction, including breakaway static friction, Coulomb friction, and viscous damping. The parameters are configured as follows: maximum breakaway torque
Random torque disturbances: To emulate torque ripple inherent in motor drive systems, a zero-mean random noise is applied with an amplitude of 4% of the instantaneous motor output torque (
The simulation is conducted over an extended duration to assess the long-term performance of the proposed controller. Initial conditions include an azimuth angle offset of 0.1 rad and an elevation angle offset of −0.05 rad, with both angular velocities initialized to zero. A composite reference trajectory is applied to evaluate the system’s tracking accuracy and dynamic response under varying conditions. Figure 4 illustrates the azimuth tracking performance, where the desired trajectory is shown as a red dashed line, and the actual response as a blue solid line. During the first 1–2 s, a noticeable discrepancy is observed due to the initial misalignment and the RL agent not yet having optimized the control parameters. As learning progresses, the agent continuously refines the control strategy, leading to a gradual reduction in tracking error. After a short transient period, the actual trajectory closely aligns with the reference, demonstrating high-precision tracking. A similar behavior is observed in Figure 5, which presents the elevation (pitch) tracking results. After an initial adjustment phase, the tracking error rapidly diminishes and remains negligible throughout the remainder of the simulation, confirming the method’s robust dynamic performance across both motion axes.
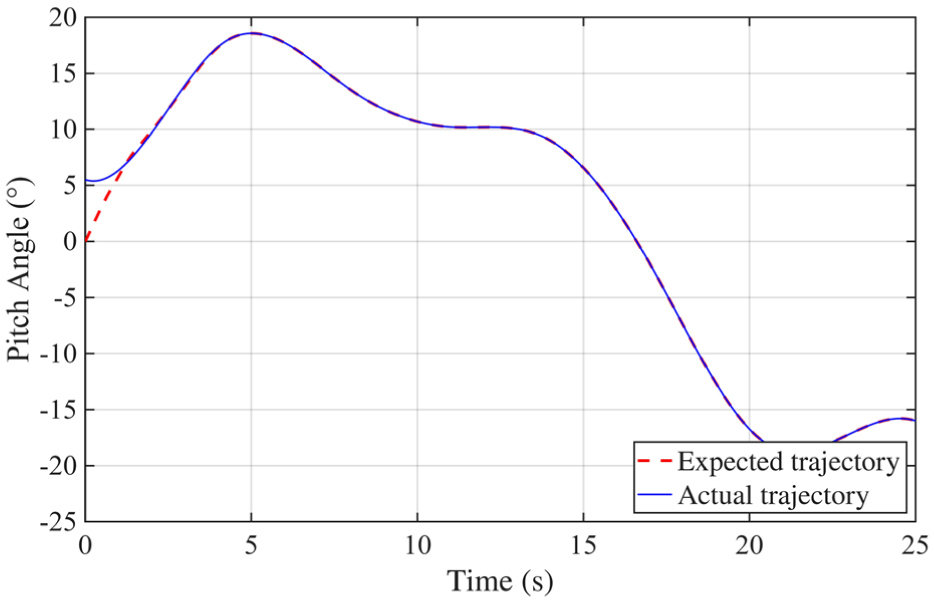
Azimuth tracking analysis results.
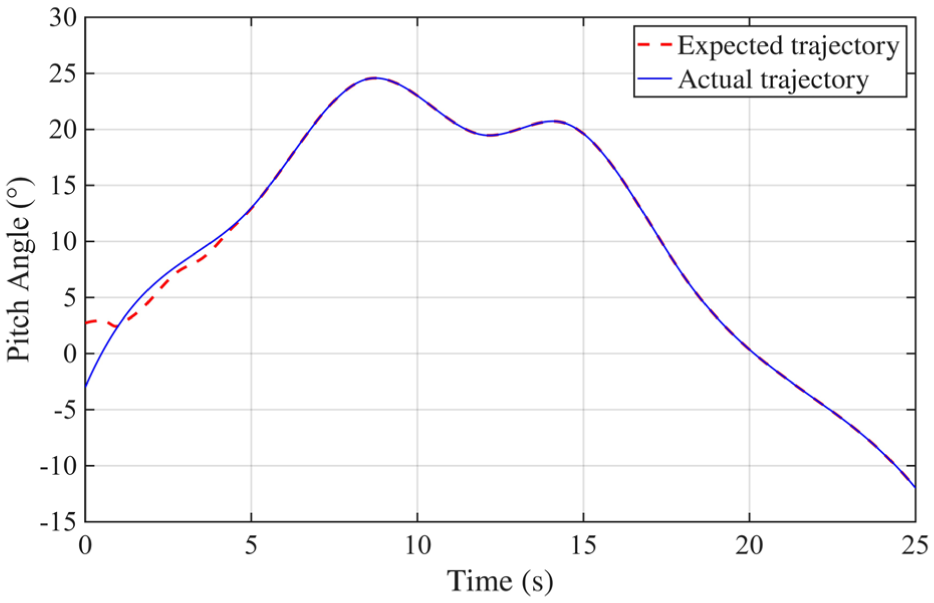
Pitch tracking analysis results.
Figure 6 presents the tracking error curves for both azimuth and elevation channels, shown in blue and red, respectively. Immediately following system activation, both error signals exhibit rapid decay. Once the initial transient subsides, the tracking errors remain consistently within the target threshold of 10 mrad. Minor oscillations are observed, primarily due to external disturbances and the system’s inherent nonlinearities. However, thanks to the synergistic effect of integral sliding-mode control and adaptive RL, these fluctuations are effectively suppressed. The RL agent’s continuous parameter tuning ensures ongoing error convergence and robust performance over time.
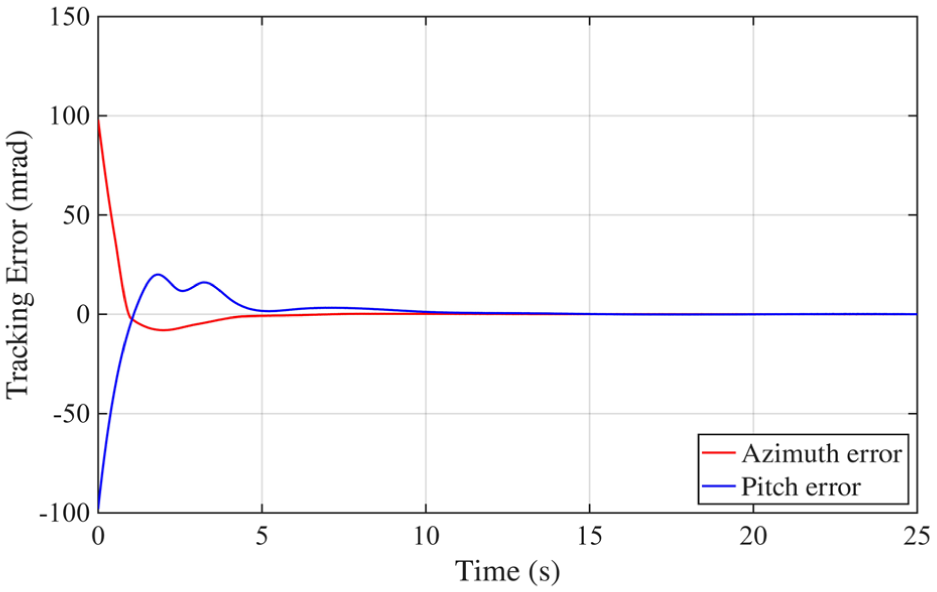
Tracking errors analysis results.
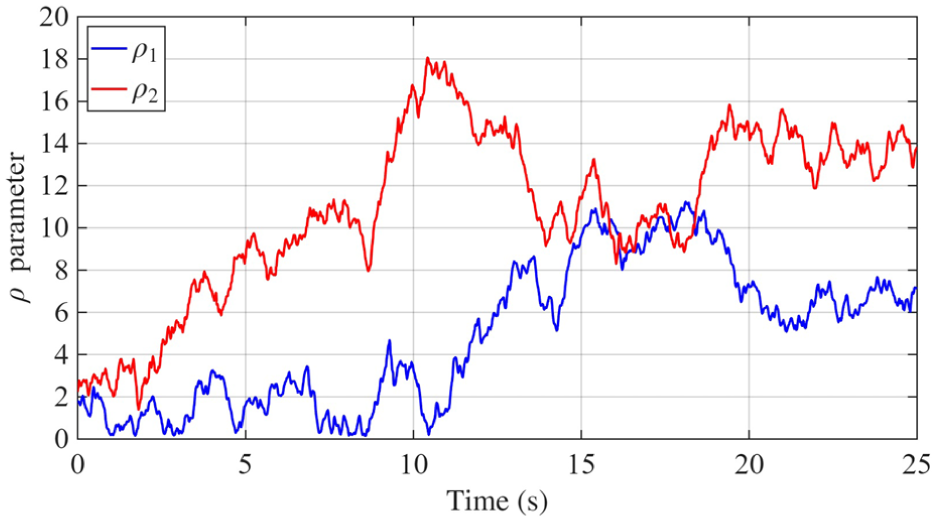
Figures 7–11 illustrate the internal dynamics and adaptive behavior of the control system. Figure 7 shows the output torque response, reflecting how the system modulates control effort under dynamic conditions. Figure 8 presents the evolution of the sliding variable, which rapidly converges toward zero, indicating the effectiveness of the sliding-mode strategy in stabilizing the trajectory. In Figure 9, the adaptive parameter
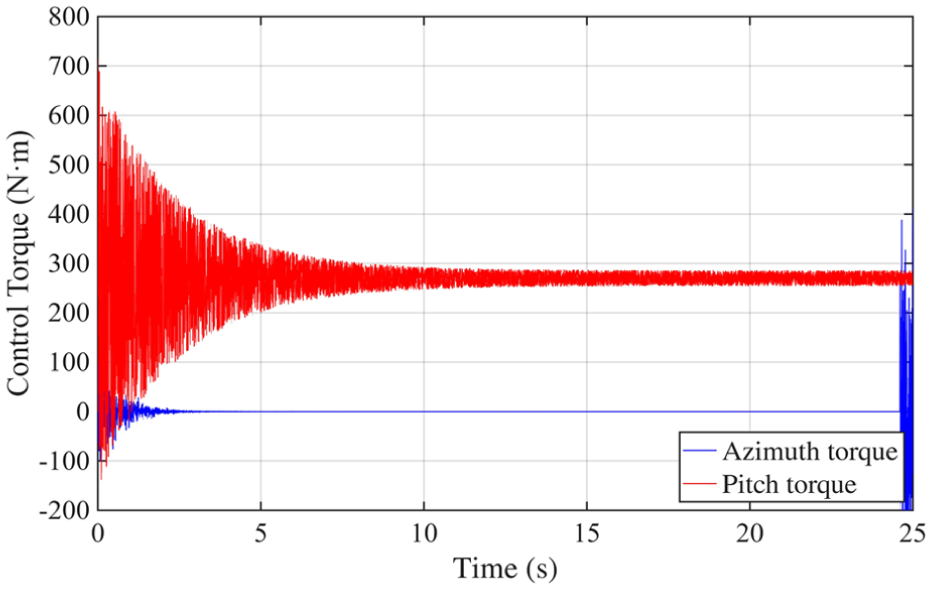
Control torque analysis results.
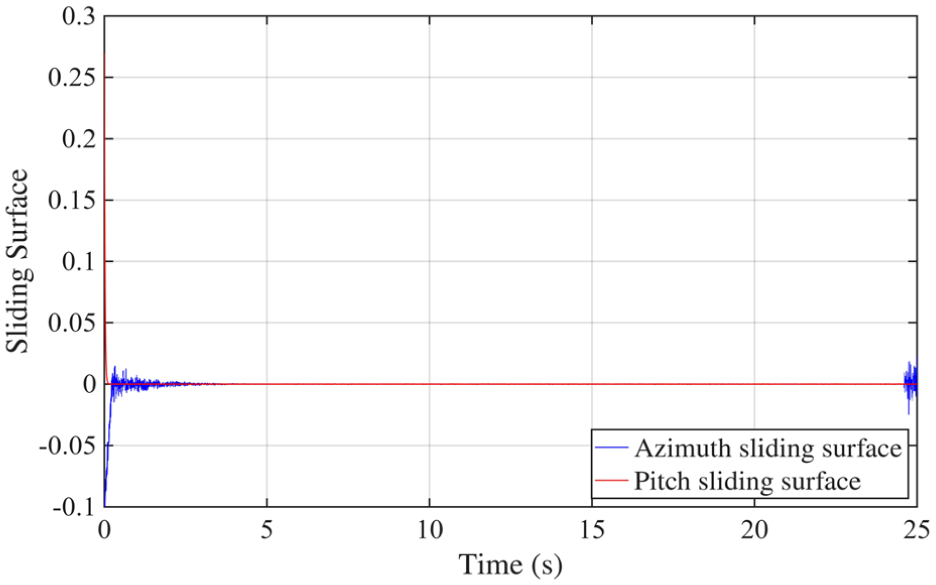
Sliding variable analysis results.
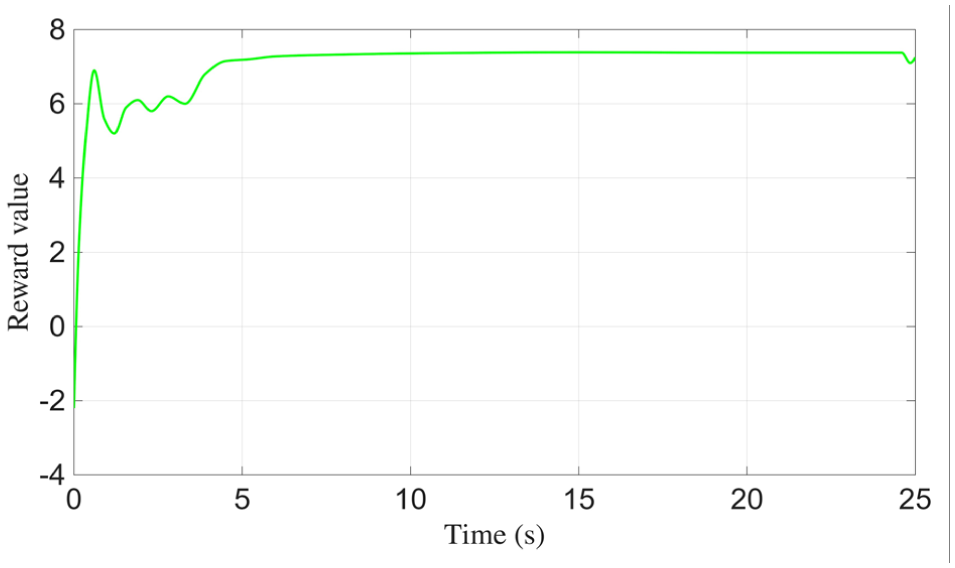
Reward analysis results.
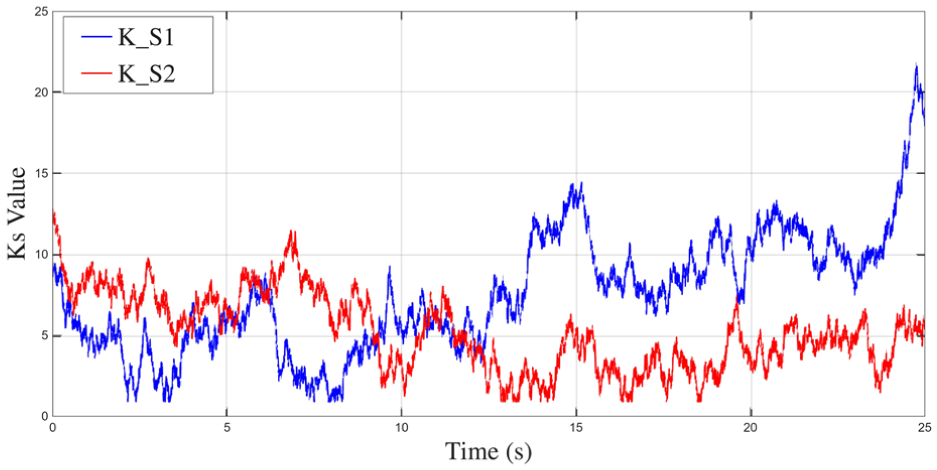
Adaptive adjustment of
Relative to conventional ISMC, the proposed approach demonstrates significantly enhanced performance across several key dimensions.
In Figure 12, the blue curve represents the proposed RL-enhanced control method, the yellow dashed line shows the desired trajectory, and the red curve corresponds to the conventional ISMC baseline. The proposed method achieves high tracking precision, with minimal deviation from the reference across the full trajectory. While the ISMC baseline performs adequately in azimuth tracking, it exhibits noticeable oscillations during the initial transient phase and slightly lower steady-state accuracy. Figure 13 reveals a more pronounced difference in the elevation channel: the ISMC baseline suffers from an observable response delay, whereas the RL-improved controller maintains close adherence to the target trajectory. This performance gap highlights the advantage of online adaptation; the RL component dynamically adjusts control parameters, enabling rapid convergence to near-optimal configurations without requiring manual tuning. In contrast, traditional ISMC relies on fixed or heuristically selected parameters, which may require iterative adjustment to suit different dynamics. The absence of delay in azimuth tracking for the ISMC baseline can be attributed to a favorable initial parameter setting, but this does not generalize across axes or tasks. Overall, the results demonstrate that the proposed RL-ISMC framework consistently delivers better tracking performance, improved stability, and faster convergence compared to the conventional ISMC approach.
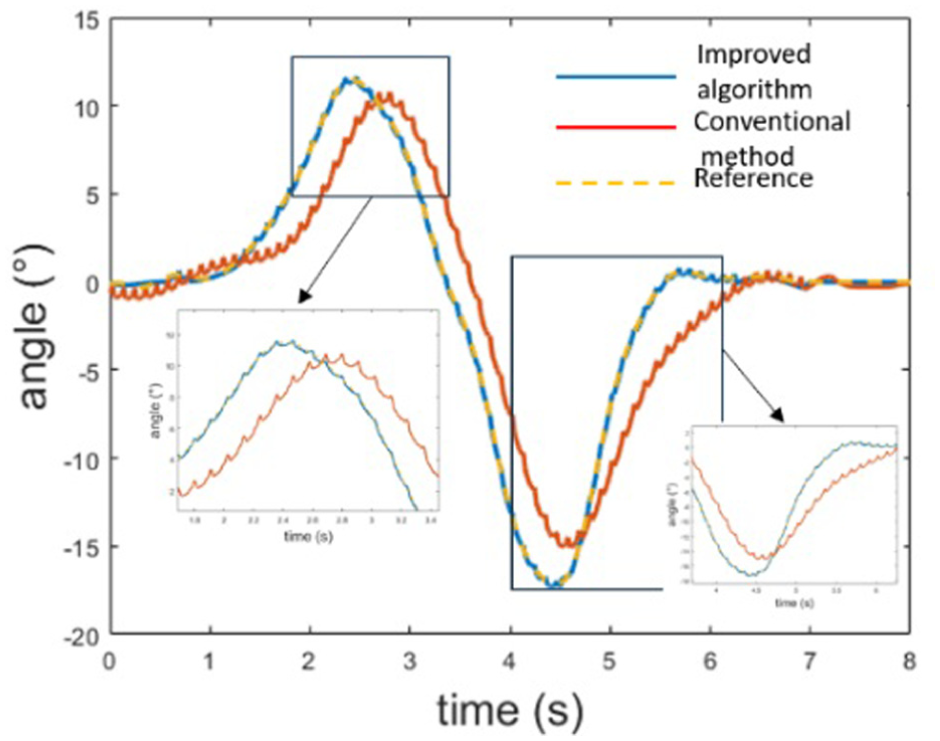
Azimuth tracking analysis results.
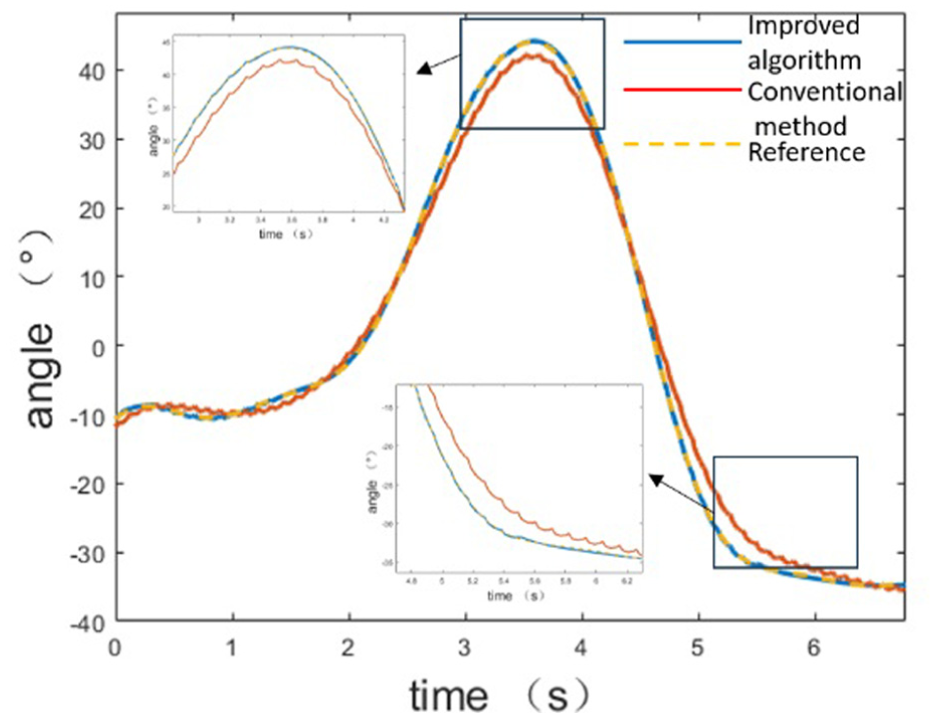
Pitch tracking analysis results.
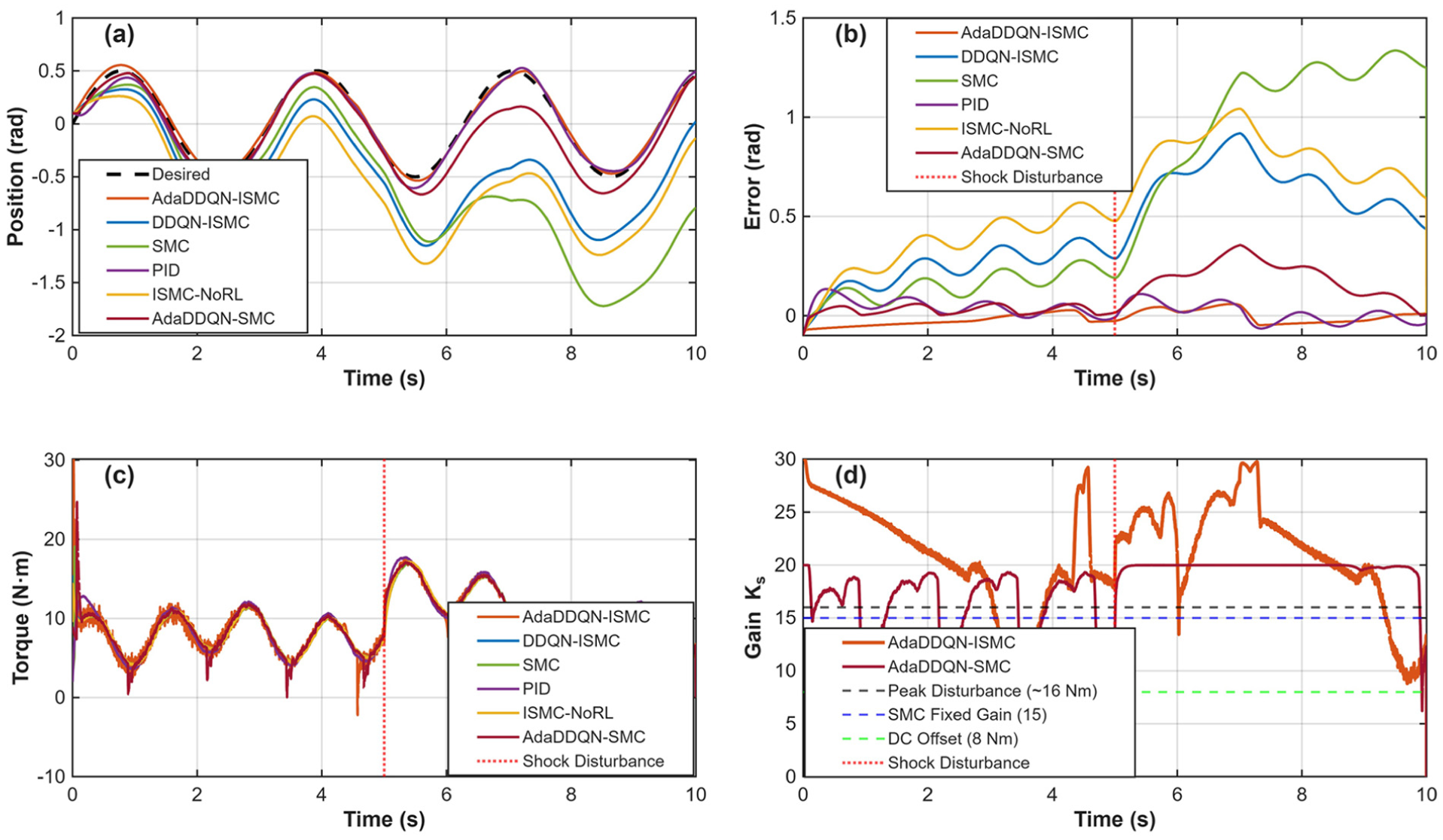
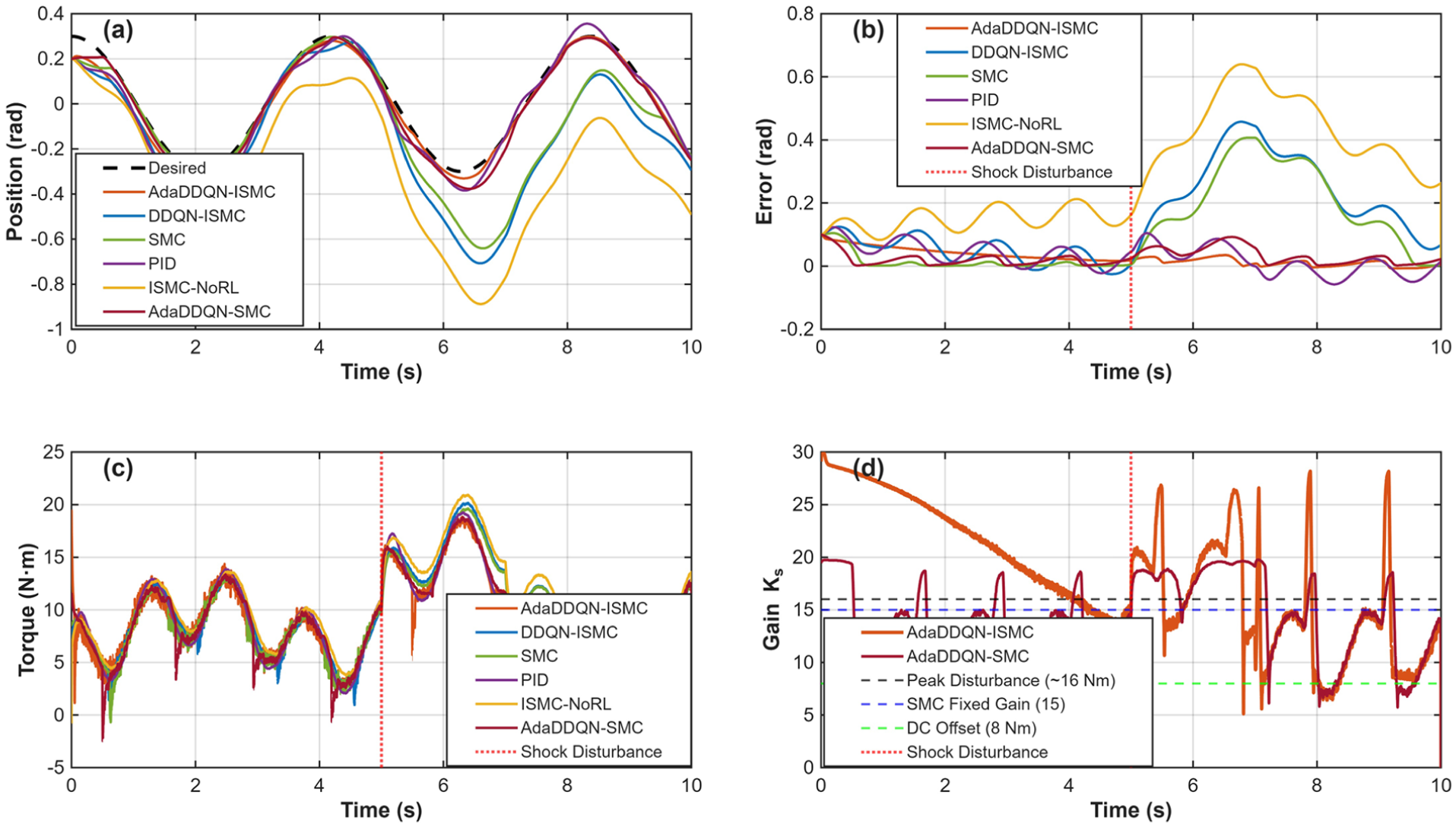
Another simulation is designed to rigorously evaluate the contribution of each component (RL adaptation and Integral Sliding Mode) under challenging, realistic conditions. The study compares six distinct control strategies to isolate the effects of the Integral term and the RL-based adaptation: The complete framework combining Integral Sliding Mode Control with adaptive RL tuning of gains (
A continuous torque bias of approximately 8 Nm was applied to simulate unmodeled gravitational moments and constant friction and a sudden shock disturbance of 5 Nm was introduced from
Figures 14 and 15 illustrate the tracking trajectories for the pitch and azimuth angles, respectively. A comparative analysis demonstrates that the proposed method exhibits the best performance in eliminating errors induced by the 8 N·m bias. Furthermore, it maintains superior tracking stability even when a shock disturbance is introduced at
Pitch tracking analysis with ablation: (a) pitch position tracking, (b) error of pitch tracking, (c) torque for pitch tracking and (d)
Azimuth tracking analysis with ablation: (a) Azimuth position tracking, (b) error of azimuth tracking, (c) torque for Azimuth tracking and (d)
Notably, the comparison between AdaDDQN-ISMC and AdaDDQN-SMC highlights the critical role of the integral term. Methods lacking an integral sliding variable (specifically SMC and AdaDDQN-SMC) failed to eliminate the steady-state error caused by the 8 N·m bias. Although the RL agent attempted to compensate by increasing the gain, the AdaDDQN-SMC method still exhibited a persistent non-zero mean error. Conversely, both the proposed AdaDDQN-ISMC and the fixed ISMC methods successfully converged to a near-zero steady-state error, confirming that integral action is indispensable for handling constant unmodeled loads.
To evaluate the proposed control method under real-world conditions, a physical trajectory-tracking experiment was conducted using a two-axis gimbal platform (Figure 16). A predefined target trajectory was issued to the system, and the gimbal executed the motion commands while onboard sensors continuously recorded its response. The reference trajectory and real-time sensor data were processed by the RL-improved ISMC algorithm, which computed the appropriate control signals for each actuator. These control outputs were then applied to drive the gimbal in real time. Once the motion was completed, the recorded position feedback was compared with the original command trajectory to assess the tracking performance of the physical system.

Experimental setup for control validation: (a) control box interior, (b) gimbal joint, (c) control box and host computer and (d) gimbal assembly.
The gimbal control system is composed of three primary components: the mechanical gimbal structure, the gimbal control box, and a host computer functioning as the upper-level controller. Within the control box, several integrated modules are responsible for core functions, including an embedded processor, a pulse signal generator, a data acquisition card, and a communication interface. The pulse generator translates control instructions into electrical pulse signals that directly drive the gimbal motors. The acquisition card continuously samples the state signals from onboard sensors and structures the data for processing. Acting as the central processing unit, the embedded motherboard receives both sensor data and control commands via the communication module. It processes incoming signals from the host, packages sensor data collected by the acquisition card, and transmits it back to the host. Simultaneously, it converts the host-generated control commands into motor control signals via the pulse generator. At the upper level, the host computer synthesizes real-time sensor feedback, the user-defined target trajectory, and predefined environmental disturbances, applying the proposed RL-based control algorithm to compute control outputs, which are then dispatched to the control box. The AdaDDQN agent is first trained in a high-fidelity simulation environment to learn the optimal policy for adjusting control parameters. The trained policy is then deployed to the physical gimbal system. During this phase, the agent operates in real-time inference mode.
During runtime, the host continuously uses the current system state and reference trajectory as inputs to generate the next-step control command. These commands are transmitted to the control box, which actuates the motors accordingly. Sensor modules then acquire the resulting gimbal motion in real time and return the measurements to the host. By comparing the feedback data with the reference trajectory, the tracking error is calculated to evaluate performance. Unlike simulation conditions, the physical setup introduces additional challenges such as stronger mechanical vibrations and unmodeled uncertainties, which can influence system behavior. The following section presents the experimental tracking results obtained under these real-world operating conditions.
In the physical testing environment, the gimbal was subjected to additional unmodeled factors including stronger mechanical vibrations and environmental disturbances not present in the simulation setup.
The results indicate that the maximum tracking error in azimuth remained below 0.01°, while the maximum error in elevation was under 0.03°, as can be seen from Figures 17 and 18. Despite the increased complexity and unpredictability of the real-world conditions, the system maintained stable operation without any signs of divergence or significant oscillation. These findings confirm the proposed algorithm’s strong robustness and its effective adaptability to hardware platforms.
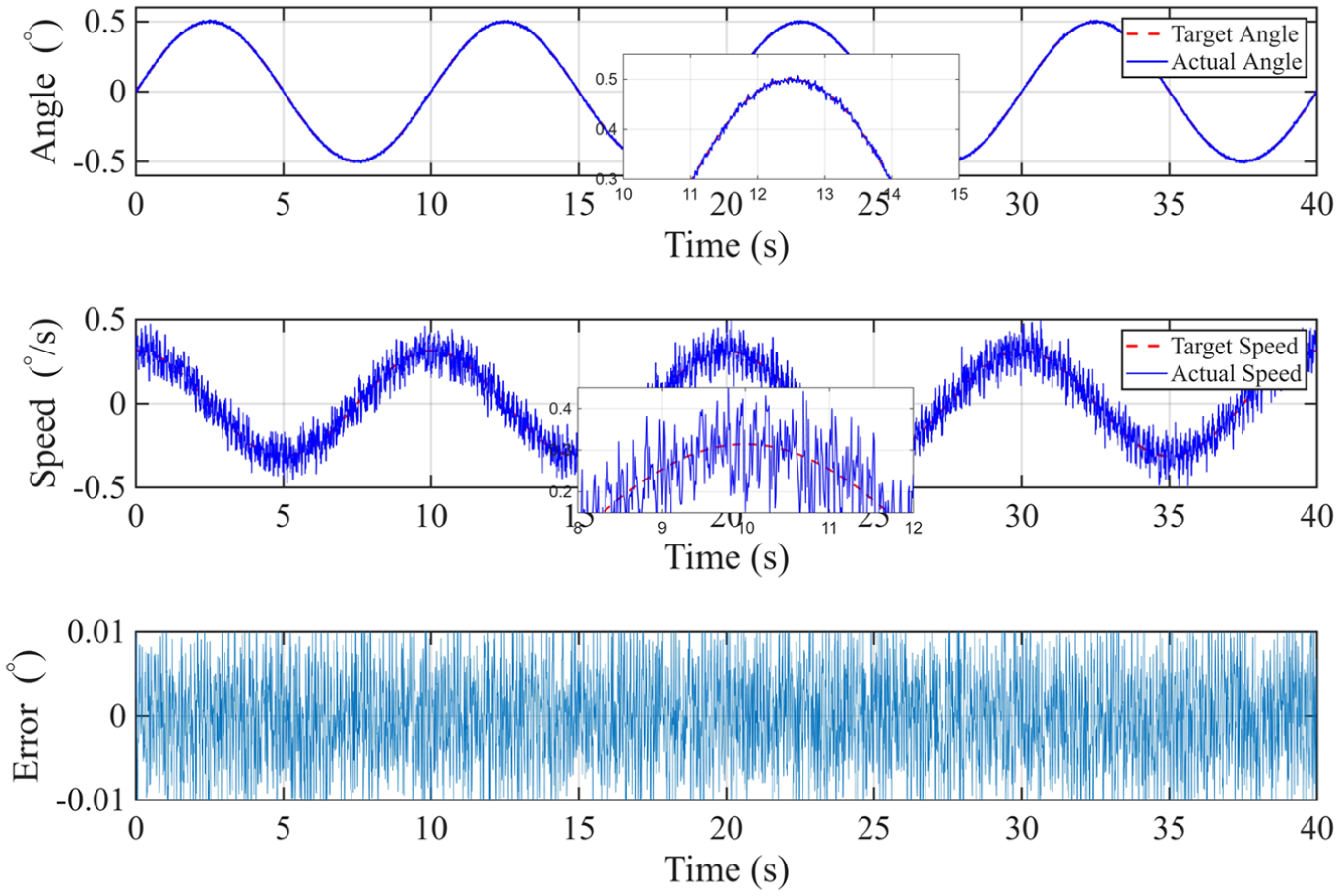
Pitch tracking analysis results.
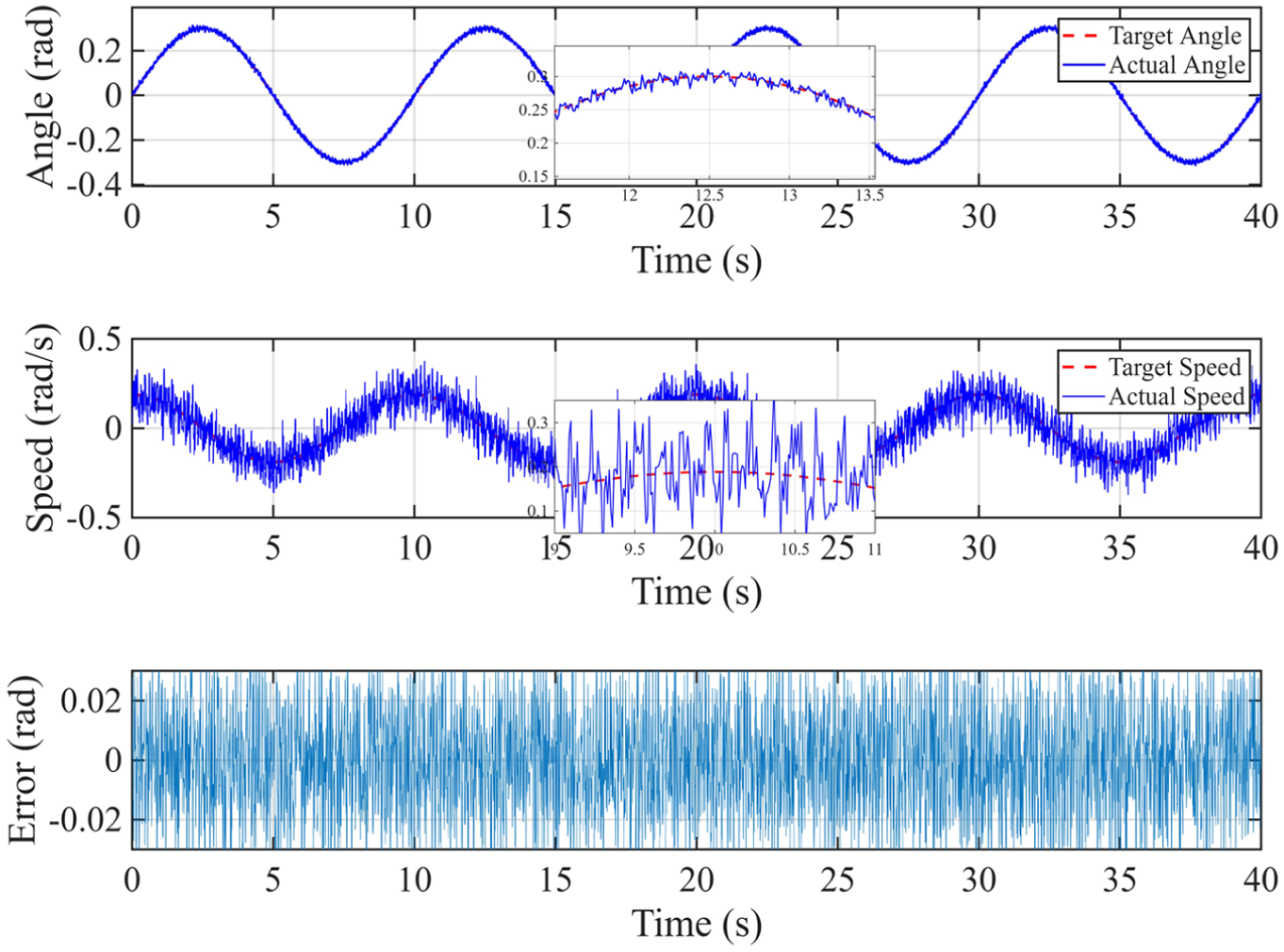
Azimuth tracking analysis results.
Discussions
The core innovation of this study lies in the seamless integration of RL adaptability with the robust control guarantees of SMC. Traditional SMC approaches often rely on fixed switching gains to handle worst-case disturbances, which can lead to excessive chattering. In contrast, the proposed method leverages an AdaDDQN agent to dynamically adjust the switching gain
Compared with conventional ISMC and the foundational design requirements, the proposed AdaDDQN-ISMC delivers measurable performance gains, validated through rigorous ablation analysis. Firstly, regarding steady-state robustness and precision, the ablation study confirms the indispensability of the integral term. Under a continuous torque bias (simulating unmodeled gravity and friction), the conventional SMC and the ablated AdaDDQN-SMC variants exhibited persistent steady-state errors, as they lacked the error-accumulation mechanism to counteract the constant load. In contrast, the proposed method leverages the integral sliding surface to completely eliminate this bias. Consequently, the system consistently maintains tracking errors below 8 mrad, exceeding the 10 mrad accuracy threshold required for effective beam coverage. Measured results further highlight this precision, showing an elevation error of only 0.01° (
Despite promising results in both simulation and hardware testing, several limitations remain. Firstly, the current evaluation is limited to the gimbal’s own nonlinear dynamics; in real-world deployment, platform-induced disturbances such as translational motion and carrier rocking (e.g. on vehicles or ships) introduce complex coupling effects. Future work will extend testing to high-DOF motion platforms to validate disturbance suppression under carrier-coupled dynamics. Secondly, while the simulation environment incorporates measured mechanical parameters, real-world factors such as aerodynamic drag and temperature-sensitive friction remain difficult to model accurately. Enhancing sim-to-real transfer through meta-RL or domain randomization is an important direction to improve generalization in unstructured environments. Lastly, the DRL model incurs non-negligible computational costs, which may challenge real-time deployment in resource-constrained embedded systems. Future research will explore network pruning, model compression, and hardware-aware policy acceleration to enable lightweight deployment in compact Active Denial devices.
Conclusions
The proposed method improves the tracking and pointing performance of microwave ADS. Experimental results indicate that the tracking accuracy increases by more than 80% compared with conventional SMC, with dynamic errors reliably constrained within 8 mrad. Hardware tests on a two-DOF gimbal platform show that the elevation and azimuth tracking errors remain below 0.01° and 0.03°, respectively—well within the threshold required to maintain beam jitter within half of the spot diameter. Validated by rigorous ablation studies, the integral sliding term effectively eliminates steady-state bias, while the RL agent—utilizing a novel torque-rate penalized reward mechanism—dynamically adjusts gains to mitigate phase lag and suppress chattering. This fusion of adaptive learning and robust control delivers reliable performance in both simulated and physical environments. According to the accuracy model, this level of precision corresponds to a target-lock probability of approximately 99.87% at an operational range of 250 m. By enabling online decision-making through RL, the approach effectively mitigates issues such as phase lag and torque chattering that commonly affect traditional controllers. This fusion of adaptive learning and robust control delivers reliable performance in both simulated and physical environments, offering a technically viable path toward enhancing the effectiveness of non-lethal directed energy systems.
Future work will focus on extending the validation of the proposed approach under more complex operational conditions. In particular, when mounted on mobile carriers such as vehicles or ships, the gimbal system experiences translational motion and rotational disturbances that introduce nonlinear coupling through kinematic interactions. To address this, further experiments will be conducted on dynamic platforms to assess the algorithm’s ability to reject carrier-induced disturbances. In addition, considering the computational load of DRL in embedded systems, we plan to investigate model compression techniques and edge computing frameworks for real-time deployment. Additional efforts will be made to examine the influence of unstructured environmental factors—including extreme temperatures, wind loading, and mechanical vibration—on control performance, with the goal of improving the system’s generalization ability and responsiveness in field applications.
Footnotes
Ethical considerations
This study is based on theoretical analysis and/or published literature, and no ethical approval was required.
Consent to participate
This study did not involve human participants, and thus no informed consent to participate was required.
Consent for publication
This study does not contain any individual person’s data in any form, and therefore consent for publication is not applicable.
Author contributions
Zongzheng Sun: conceptualization, data curation, formal analysis, investigation, methodology, software, writing–original draft, writing–review and editing.
Xinjian Niu, Jianwei Liu, Yinghui Liu: supervision, validation, project administration, funding acquisition, review and editing. Jin Han: validation, formal analysis, review and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Laboratory of Science and Technology on Vacuum Electronics.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The datasets used and analysed during the current study are available from the corresponding author on reasonable request, and all key data are already presented in the main text of the article.