
Abstract
The emotional state of pilots during high-pressure light missions is crucial for aviation safety. However, traditional monitoring methods suffer from lagging and subjective defects. Over recent years, multimodal physiological signal-based emotion recognition has drawn substantial focus, stemming from its complementary data that can capture real-time emotional dynamics. However, existing methods face three critical limitations: (1) insufficient modeling of non-stationary physiological signals that contain both short-term fluctuations and long-term trends; (2) high computational complexity caused by high-dimensional cross-modal fusion features, leading to overfitting and poor practical deployment; (3) inadequate preservation of cross-modal correlations during fusion. To address these gaps, we develop a framework for emotion recognition via multimodal fusion. Firstly, we design the MS-TimesNet network, which extracts time-space joint features from EEG signals through parallel multi-scale convolution layers and periodic phase transformation, enhancing the modeling capability of non-stationary time series. Secondly, we introduce the low-rank multimodal fusion (LRF) method to decompose multimodal feature tensors into low-rank matrices, reducing redundancy while preserving cross-modal correlations. Moreover, we incorporate the bidirectional long short-term memory (BiLSTM) network to derive temporal characteristics from peripheral physiological signals, and dynamically assign weights to critical emotional features via a self-attention mechanism, thus boosting the model’s generalizability. Experiments conducted on the DEAP dataset reveal that our approach attains classification accuracy values of 94.52% and 94.36% for the arousal and valence dimensions, respectively, markedly outperforming state-of-the-art models including TACOformer and Husformer. Ablation experiments validate the contribution of each module (MS-TimesNet, LRF, self-attention) to performance improvement, confirming the effectiveness of multi-scale modeling and low-rank fusion. The proposed framework achieves low computational complexity with 16.8 million trainable parameters and 8.3 GFLOPs. This study provides a high-precision and low-complexity method for personnel emotion recognition, which has important practical value for monitoring of emotions.
Introduction
In aviation missions, pilots are required to maintain prolonged concentration in high-pressure environments while simultaneously confronting complex decision-making scenarios. Their mental state and physical condition play a pivotal role in flight safety.1,2 Due to prolonged exposure to high-intensity workloads, variable environmental conditions, and time-sensitive mission requirements, pilots frequently operate under sustained tension and fatigue. Such emotional fluctuations and cognitive variations may adversely impact flight operations, thereby elevating accident risks.3,4 Consequently, real-time monitoring of pilot emotional states and early warning of potential risks have emerged as a critical issue requiring urgent resolution in aviation safety research.5–7
Traditional methods rely on subjective questionnaires or behavioral observations, which suffer from limitations such as latency and susceptibility to subjective biases. 8 In contrast, physiological signals like EEG,9–11 ECG,12–14 GSR,15,16 and EOG17,18 can objectively reflect individual neural activity and physiological states, providing a new technical path for real-time monitoring of emotional changes. Research based on the valence–arousal (VA) two-dimensional emotional model 19 quantifies the positive-negative polarity (valence) and activation level (arousal) of emotions, providing a theoretical framework for mapping emotions to physiological signals.
Over recent years, studies focusing on emotion recognition utilizing physiological signals have achieved notable advancements. In single-modal analysis, many researchers prefer EEG-based emotion recognition20–23 due to its close correlation with multiple brain regions involved in emotion generation 24 and its ability to reflect emotional regulation through prefrontal EEG activity. 25 For instance, Lawhern et al. 26 designed a typical EEGNet, which directly extracts spatiotemporal information features from EEG signals through convolutional networks, achieving end-to-end emotion classification. Furthermore, emotion recognition approaches leveraging alternative physiological signals have demonstrated considerable efficacy.27,28 However, EEG signals are easily affected by electromyographic noise 29 and eye movement artifacts, and significant inter-subject differences in EEG patterns limit model generalization ability. 30 Similarly, ECG signals reflect emotional stress levels through heart rate variability (HRV), but its sensitivity to emotional valence is low, making it difficult to distinguish between positive and negative states. 31 The limitations of single-modal physiological signals, which are easily affected by environmental noise and individual differences, make it challenging to fully capture the dynamic changes of complex emotions. Multi-modal fusion technology can integrate complementary information from multiple sources of physiological signals,32–34 providing new solutions to address the aforementioned issues. Existing methods primarily include data-level fusion, 35 feature-level fusion, 36 and decision-level fusion. 37 For example, Shen et al. 36 proposed a tensor correlation fusion framework for emotion recognition based on multimodal physiological signals, which attempts feature-level fusion by learning linear correlations based on covariance tensors and constructing optimization solutions to obtain collaborative representations, inputting them into a classifier to achieve emotion recognition. However, the computational complexity of multi-modal physiological signal fusion networks grows exponentially with the number of modalities, 38 making it difficult to deploy in practice. Additionally, traditional time series models like LSTM 39 and GRU 40 can capture temporal dependencies but lack the ability to extract multi-scale dynamic features of non-stationary physiological signals, such as short-term fluctuations of EEG waves and long-term trends of waves. Thus, multi-modal physiological signal-based emotion recognition confronts the following core challenges:
Non-stationary time series feature extraction: Physiological signals exhibit significant time non-stationarity, 41 necessitating the design of multi-scale modeling methods to capture long-term trends as well as short-term fluctuations.
Cross-modal correlation modeling: Inter-modal interactions encompass both common features and complementary features. 42
Computational efficiency and model generalization: High-dimensional fusion features can lead to overfitting, necessitating optimization of feature representations through low-rank decomposition or attention mechanisms. 43
Addressing the aforementioned challenges, this study presents a multi-modal fusion-based emotion recognition approach, with the goal of realizing high-accuracy recognition of emotional states. By leveraging the multi-scale time modeling capabilities of MS-TimesNet, we extract features from EEG signals and peripheral physiological signals (including EOG and EMG), and integrate them with low-rank multi-modal fusion and self-attention mechanisms to achieve accurate classification of emotional states. Analysis of comparative experimental results reveals that our approach attains a classification accuracy of 94.52% and 94.36% in the arousal and valence dimensions, respectively, significantly outperforming existing models (such as Husformer and TACOformer). Additionally, ablation experiments verify the contribution of each module (MS-TimesNet, LRF, self-attention) to performance improvement, demonstrating the effectiveness of multi-scale time series modeling and low-rank fusion strategies. The key contributions of the approach proposed in this work are summarized as follows:
We propose a multi-modal fusion framework that integrates an MS-TimesNet network. Through the parallelization of multi-scale convolutional layers and TimesNet’s periodic phase transformation, it extracts combined spatiotemporal features derived from EEG signals, thereby strengthening the modeling capacity for non-stationary time series dynamics.
We develop a low-rank cross-modal fusion approach via the integration of the low-rank multi-modal fusion (LRF). This method decomposes feature tensors from signals such as EEG, EOG, and EMG into low-rank matrices, reducing computational complexity while preserving cross-modal correlations.
We present an adaptive feature enhancement method that employs bidirectional long short-term memory (BiLSTM) networks to derive temporal dependencies from peripheral physiological signals. Furthermore, we employ a self-attention mechanism for dynamically weighting critical emotional features, thereby boosting the model’s noise robustness.
The subsequent parts of this paper are arranged as follows. Section 2 surveys relevant studies associated with the approach put forward in this paper. Section 3 details the network architecture and computational procedures. Section 4 describes the experimental processes. Finally, Section 5 includes discussions and conclusions concerning the proposed approach.
Related work
Recently, research on emotion recognition using multimodal physiological signals has made progress, highlighting the importance of feature extraction and fusion strategies.
Deep learning-driven multimodal emotion recognition
In recent years, optimization studies on deep learning algorithms within multimodal emotion recognition have centered on innovations in network architectures and cross-modal collaborative modeling. The hierarchical fusion convolutional neural network, through the design of differential kernel parameters, captures local and global features in multiple convolutional layers, significantly enhancing the joint representation ability of physiological signals.44–46 The multimodal decomposition bilinear pooling method and its optimized versions can effectively improve the performance of cross-modal fusion.47,48
In the field of temporal sequence modeling, the multimodal diverse spatio-temporal network can effectively capture spatio-temporal features across various modalities. On the AFEW dataset, it remarkably boosts performance to attain a recognition accuracy of 71.54% for basic emotion recognition. 49 The self-attention mechanism has been widely used for cross-modal correlation modeling. For instance, the unimodal feature extraction network (UFEN) employs a multi-head attention module, which enables the extraction of cross-modal complementary features and mitigates the influence of inter-modal emotional representation asymmetry, thereby enhancing emotion classification accuracy effectively. 50
To tackle the issue of modal heterogeneity, deep canonical correlation analysis projects language, audio, and visual modalities onto a shared latent space via non-linear mappings, with its efficacy for cross-modal emotional representation validated on the MOSI dataset and MOSEI dataset. 51 In addition, the dynamic convolutional recurrent neural network and the multi-task learning framework verify the effectiveness of task collaboration for implicit emotion recognition by jointly optimizing emotion classification and feature reconstruction tasks.52,53
Despite the advancements in deep learning-driven multimodal emotion recognition, existing methods still exhibit prominent limitations. They lack effective multi-scale modeling capabilities for non-stationary physiological signals, failing to simultaneously capture short-term fluctuations and long-term trends. Additionally, excessive network complexity leads to high computational costs that hinder practical deployment, and cross-modal collaborative modeling often overlooks signal heterogeneity, resulting in suboptimal fusion performance.
Feature extraction and fusion technologies for multimodal emotion recognition
Multimodal fusion technologies have been extensively studied to integrate complementary information across distinct modalities. Within fusion paradigms, decision-level multimodal fusion initially performs independent classification for each modality, then integrates the respective outcomes. Ebrahimpour and Hamedi 54 utilized a decision template algorithm to perform decision-level fusion among multiple classifiers for the identification of handwritten digits. Hao et al. 55 utilized convolutional neural networks (CNNs) and support vector machines (SVMs) as base classifiers to process speech and facial images, and adopted a blending algorithm relying on a meta-classifier for fusion, achieving an accuracy of 81.36% in multimodal emotion recognition. However, decision-level fusion often loses fine-grained information and fails to capture deep cross-modal associations—this underscores the value of feature-level fusion, which integrates early-stage features for better inter-modal complementarity and is now the mainstream. Zadeh et al. 56 proposed a tensor fusion network (TFN) that models inter-modal interactions via unimodal feature outer products, showing that dynamic inter-modal feature extraction aids emotion recognition. Zhang et al. 46 proposed a hierarchical fusion convolutional network that fuses weight-combined global features with manually extracted statistical features at the feature level, yielding 84.71% accuracy on the DEAP dataset. Panda et al. 57 extracted unimodal features via multiple methods, performed feature fusion, and tested the fused features on multiple classifiers, achieving 86% accuracy on the gender-inclusive CREMA-D dataset. Nevertheless, existing feature-level fusion methods often have high computational complexity due to exponential growth in fused feature dimensions. To address this, we propose the low-rank multimodal fusion (LRF) method, which diminishes redundancy by decomposing the fusion tensor into low-rank matrices—optimizing efficiency while retaining key cross-modal correlations.
Current feature-level fusion methods suffer from exponential growth in feature dimensions, which induces high computational complexity and overfitting risks, while struggling to balance the preservation of cross-modal correlations and redundancy reduction. In contrast, decision-level fusion loses fine-grained feature information and cannot model deep inter-modal interactions. These inherent drawbacks of existing fusion technologies limit the accuracy and generalization of emotion recognition systems.
Method
As shown in Figure 1, the proposed multi-modal fusion emotion recognition algorithm mainly includes constructing a 3D EEG frequency-space feature map, proposing a multi-scale MS-TimesNet model, extracting peripheral signal features using Bi-LSTM, achieving low-rank multi-modal fusion, introducing a self-attention mechanism, and emotion classification detection. The algorithm is designed to deeply excavate latent features in EEG signals and peripheral physiological signals, thereby boosting the accuracy and robustness of emotion classification.
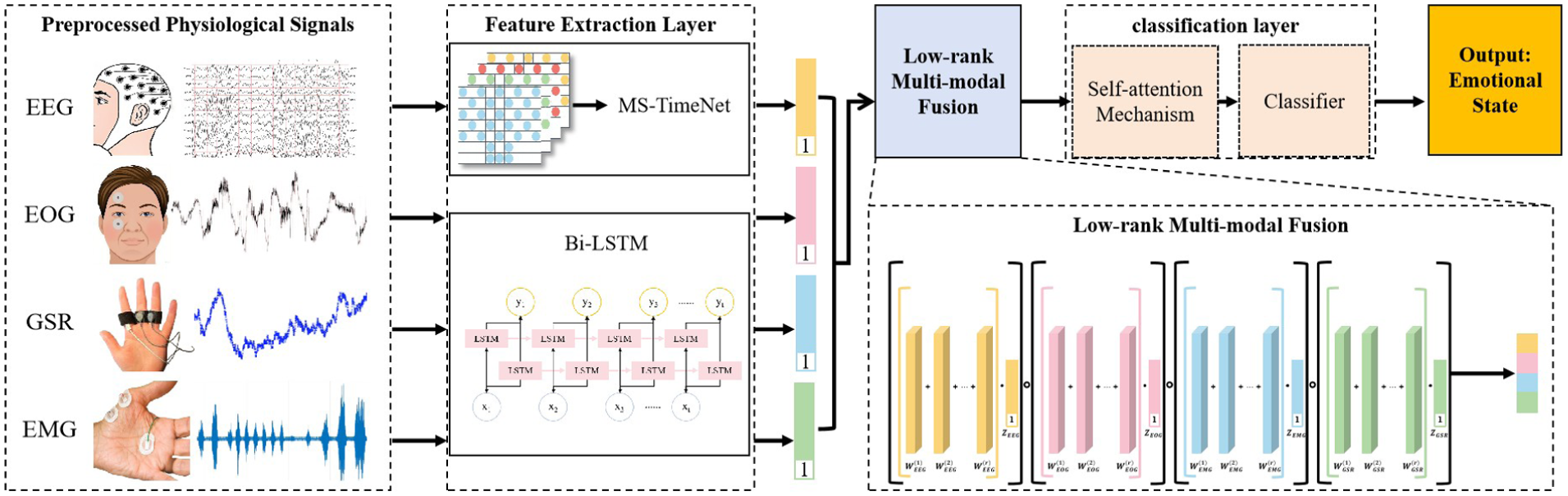
Multi-modal physiological signal emotion recognition framework.
Overall framework of the model
Firstly, the raw signals are subjected to preprocessing, which includes feature extraction and format conversion. For EEG signals, given their multi-channel configuration and frequency-domain properties, 58 a 3D EEG spatial-frequency feature map is built to capture both frequency-domain and spatial information of the signals.
To effectively capture the intricate temporal interdependencies within EEG signals, this study adopts the MS-TimesNet model. Via multi-scale temporal modeling, it can grasp the dependent features of the signals across varying temporal granularities. For peripheral physiological signals (such as EOG, EMG, GSR), since they are typically single-channel signals, in this paper, the Bi-LSTM model is used to extract the time series features and explore the potential patterns within them.
Subsequently, the low-rank multi-modal fusion approach is utilized to merge the features of EEG signals and peripheral signals, synthesize key information across modalities, and preserve potential correlations. By utilizing the fused features, we introduce the self-attention mechanism to further enhance the model’s ability to focus on crucial features, and the emotion classification task is finally accomplished through the fully connected layer.
EEG signal preprocessing and feature construction
Traditional time-domain-based feature extraction methods often fail to fully utilize the spatial information between different electrode positions. The emotion recognition task requires comprehensive consideration of the temporal variation, frequency characteristics, and spatial distribution of the signals. Therefore, feature extraction relying solely on the time dimension can no longer fully reflect the complexity of EEG signals.
Compared to other peripheral physiological signals such as EOG, EMG, and GSR, EEG signals possess distinct characteristics that make them the core modality for emotion recognition. They directly reflect cerebral neural activity, enabling capture of unconscious emotional responses that peripheral signals cannot access—peripheral signals primarily reflect surface physiological or muscle reactions rather than the neural origin of emotions. EEG signals also exhibit ultra-high time resolution (in ms) to track rapid emotional fluctuations, especially in high-pressure flight scenarios, whereas peripheral signals have slower response dynamics. Additionally, EEG signals contain rich frequency-domain information (theta, alpha, beta, gamma bands) that correlates with specific emotional states, a level of fine-grained differentiation not as prominent in other signals which mostly provide holistic arousal information. However, EEG signals are highly susceptible to external interference and exhibit stronger non-stationarity than peripheral signals, making targeted feature extraction essential.
These inherent characteristics of EEG signals—including multi-channel configuration, frequency-domain specificity, and spatial distribution of electrodes—necessitate a feature construction approach that integrates space and frequency dimensions to fully exploit their discriminative potential.
To address this limitation, this paper proposes a feature construction approach based on space and frequency. Figure 2 illustrates the detailed generation procedure of this feature.
Data segmentation: To enable effective processing of EEG signals, the pre-processed EEG signals are first split into non-overlapping segments of Ts length based on a fixed time window. Each segment will be labeled with the corresponding original emotional state label, which ensures that in the subsequent analysis process, a clear association is established between the signal of each time period and the corresponding emotional state. Further, to improve the resolution of the time-domain features, these non-overlapping Ts segments are further divided into 2 T small segments each with a length of 0.5 s. This step can capture the short-term dynamic changes of EEG signals more finely, especially the rapid changes of emotional fluctuations.
Signal filtering: EEG signals contain various frequency components, and these components are closely related to different cognitive and emotional states of the brain. Drawing on the physiological characteristics of these frequency components, we disaggregate EEG signals into multiple separate frequency bands to facilitate detailed frequency-domain analysis. Table 1 summarizes the main frequency modes of EEG signals and their corresponding EEG activity states. The higher the frequency of the signal, the usually higher the individual’s consciousness level and cognitive activity. For example, when an individual is in a highly alert or tense state, their EEG signal will exhibit activities with higher frequencies. To achieve this frequency band division, we adopted the Butterworth filter. The Butterworth filter exhibits a smooth passband response, is straightforward to design, and easy to implement, 58 making it widely employed for frequency band segmentation of EEG signals. Using this filter, the EEG signals were divided into four main frequency bands, including 4–8, 8–13, 13–30, and 30–50 Hz.
Feature extraction: In each data segment, we quantify the complexity and nonlinear dynamics of the signal by calculating the differential entropy (DE) feature. The differential entropy feature can effectively reflect the information complexity in the EEG signal, and by reducing the error caused by high-frequency noise in filtering, improve the stability of the feature and the accuracy of extraction. In addition, we used the average differential entropy value of the baseline data to correct the extracted differential entropy, thus further reducing the influence of systematic bias and improving the model learning performance.
Feature transformation: As shown in Figure 3, to better characterize the EEG features across different frequency bands, we map these features onto the spatial layout of the 2D electrode array, forming a 3D feature representation. This transformation not only visually illustrates the spatial distribution of different frequency bands but also integrates temporal and frequency-domain information, 59 thereby providing a more comprehensive feature hierarchy to support subsequent analyses.
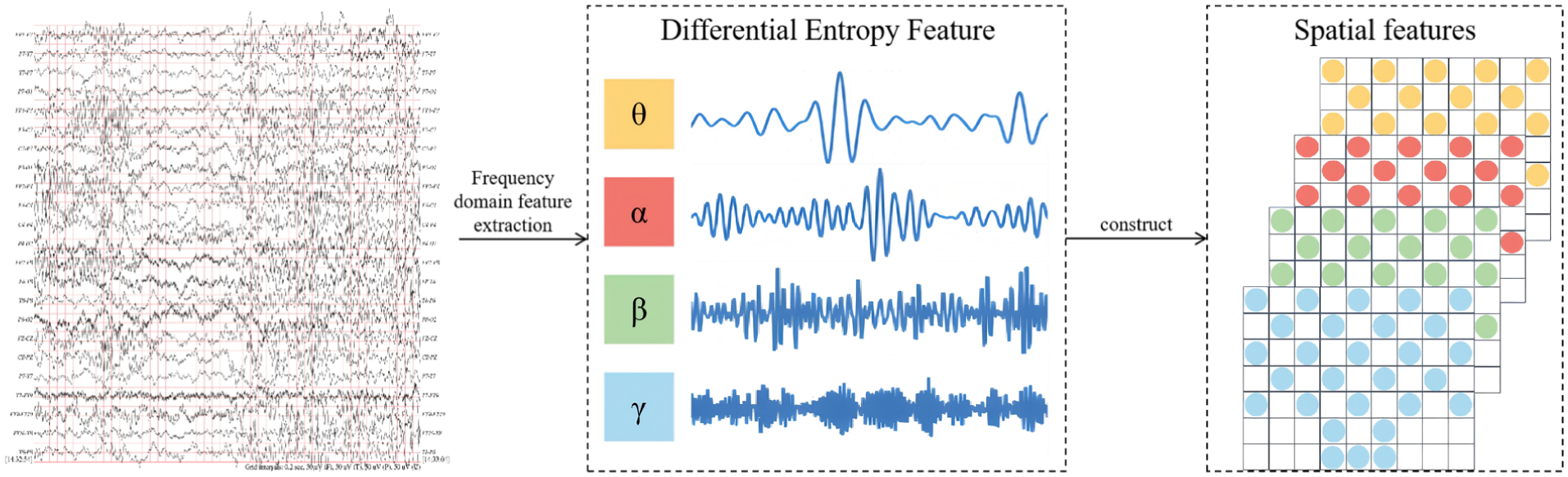
Detailed diagram of EEG signal construction for frequency-space features.
Frequency modes and corresponding characteristics of electroencephalogram.


Electrode mapping matrix in electroencephalogram.
MS-TimesNet network
The general architecture of the MS-TimesNet network is depicted in Figure 4, which comprises a multi-scale convolutional layer and the TimesNet network layer. The multi-scale convolutional layer mainly serves to derive integrated spatial and temporal information from 2D EEG signals, whereas the TimesNet network layer encompasses a data transformation layer, a feature extraction layer, and a feature fusion layer.
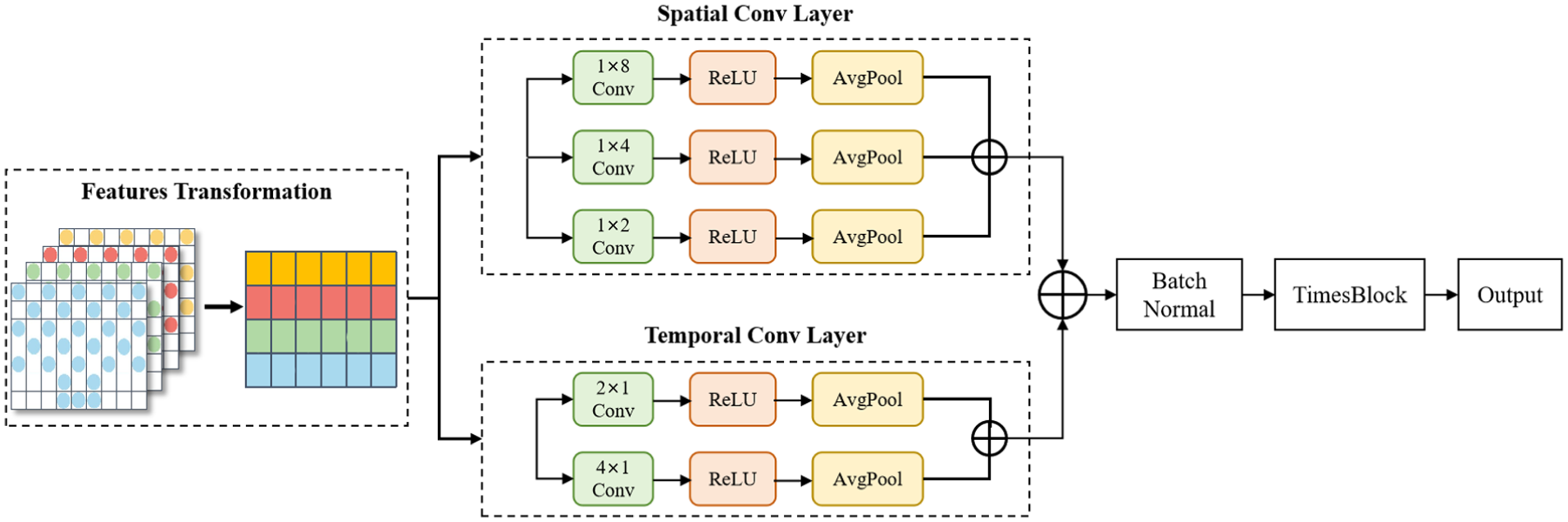
Framework diagram of MS-TimesNet.
For holistic extraction of spatiotemporal dynamic features from projected EEG characteristics, the network employs a parallel architecture integrating multi-scale temporal and spatial convolutional layers. Given the prominent temporal characteristics of EEG signals, 1D convolution has been demonstrated to be highly effective in handling such time-series data. This method facilitates efficient capturing of dynamic changes along both temporal and channel axes, thereby boosting the accuracy and flexibility of feature extraction. As a result, the multi-scale temporal convolution module utilizes 1D kernels of varying scales to model temporal features.
Multi-scale temporal convolutional layer
This layer aims primarily to capture how EEG signals change in the temporal dimension. To this end, a variety of small-scale 1D convolution kernels are used, among which. This design enables more accurate capture of both short-term dynamic fluctuations and long-term trend variations in EEG signals, while simultaneously boosting the model’s adaptability to diverse temporal patterns.
Let the input be the two-dimensional DE feature
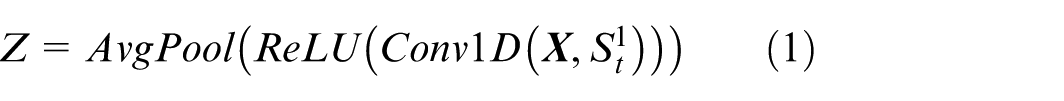
where S indicates the convolution kernel’s size,
Multi-scale spatial convolutional layer
Parallel to the temporal convolution, the multi-scale spatial layer serves to capture spatial features of EEG signals across channels. Employing a 1D convolution kernel with dimensions
where S denotes the convolution kernel’s size,
After the extraction of the temporal feature

TimesNet network layer
TimesNet innovatively projects 1D time-series data into 2D space for analysis. By folding 1D time series according to multiple periods, multiple 2D tensors are generated. The rows and columns of each 2D tensor denote temporal variations within and between periods, respectively, enabling effective capture of 2D changes in the time-series signal. The TimesNet module comprises a data transformation layer, a feature extraction layer, and a feature fusion layer, which enables efficient extraction and fusion of features from multi-scale information.
In the layer dedicated to data transformation, the dimension of the fused

where FFT denotes the Fast Fourier Transform to find the transformation between periods; Amp() represents calculating the amplitude,
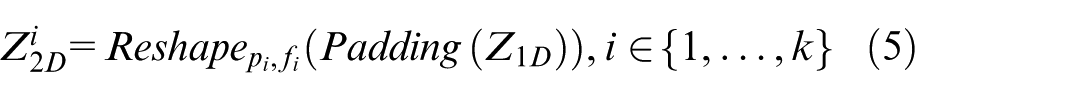
where
Within the feature extraction layer, leveraging the two-dimensional tensors derived from the data transformation layer, the Inception network performs feature extraction. The Inception network structure is shown in Figure 5. By using multi-scale convolution kernels to simultaneously aggregate the temporal changes within and between periods, deep features can be extracted from each two-dimensional tensor.
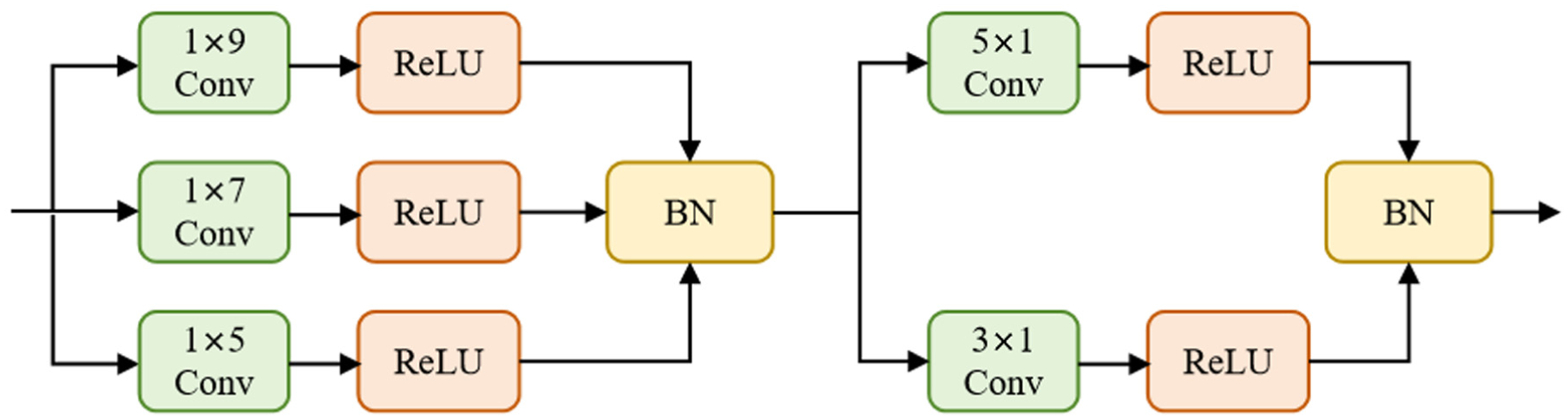
Framework diagram of the Inception block.
The processed result is:
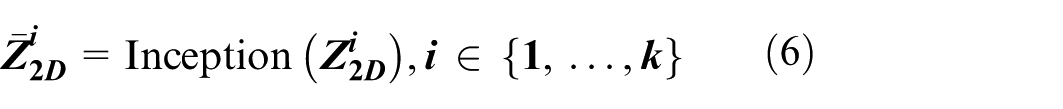
Finally, the learned two-dimensional tensor
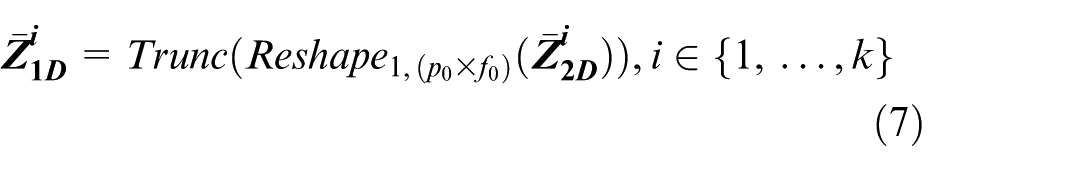
Since from the 1D space to the 2D space,
Within the feature fusion stage, concerning the outputs from the feature extraction layer, that is, k 1D representations
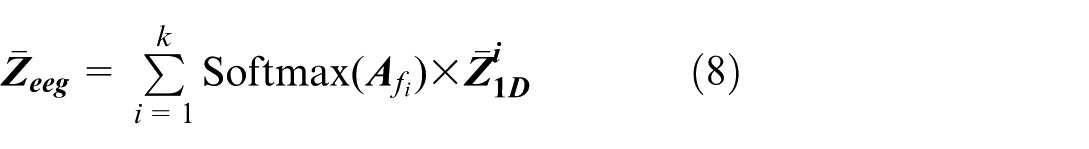
where after
Extracting emotional features from peripheral physiological signals
To enhance the accuracy of the emotion recognition model, we incorporated the differential entropy features of peripheral physiological signals (e.g. EOG, EMG, GSR) by leveraging the characteristics of electroencephalogram (EEG) signals. As time-series data, peripheral physiological signals exhibit inherent sequential correlations during emotional arousal. We employed the bidirectional long short-term memory (BiLSTM) network to capture the temporal dependencies of these signals, since emotional dynamics are manifested through continuous temporal changes in physiological indicators—this necessitates the simultaneous modeling of past signal trends and subsequent variations, thereby improving the classification performance via fusion with EEG features.
The selection of BiLSTM is driven by three key advantages that align with our research objectives. First, BiLSTM’s bidirectional propagation mechanism enables full capture of both forward and backward temporal dependencies in signals, which is critical for capturing transient emotional fluctuations reflected in peripheral physiological data. Second, BiLSTM effectively alleviates the gradient vanishing and exploding issues inherent in traditional time-series models, thereby ensuring stable training even when processing long-sequence peripheral signal data. Third, BiLSTM retains moderate computational complexity, which aligns with the low-complexity requirement of our overall framework.
BiLSTM is shown in Figure 6. In the DEAP dataset, the signals collected on channels 33–37 are two EOGs, two EMGs, and one GSR, respectively. Assuming that
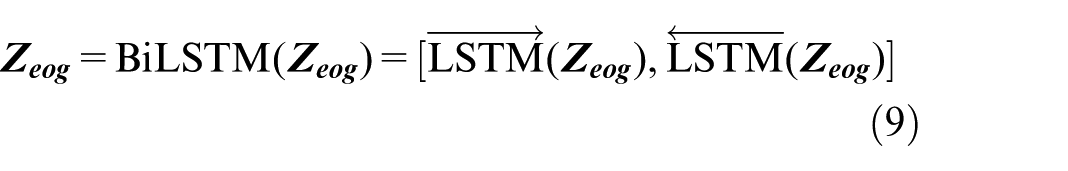
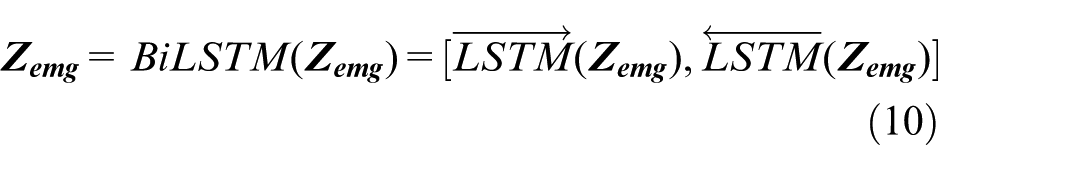
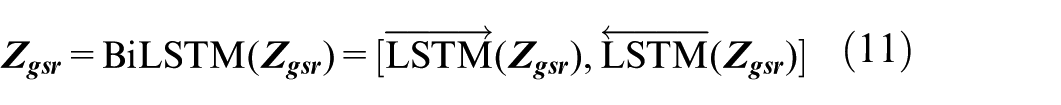
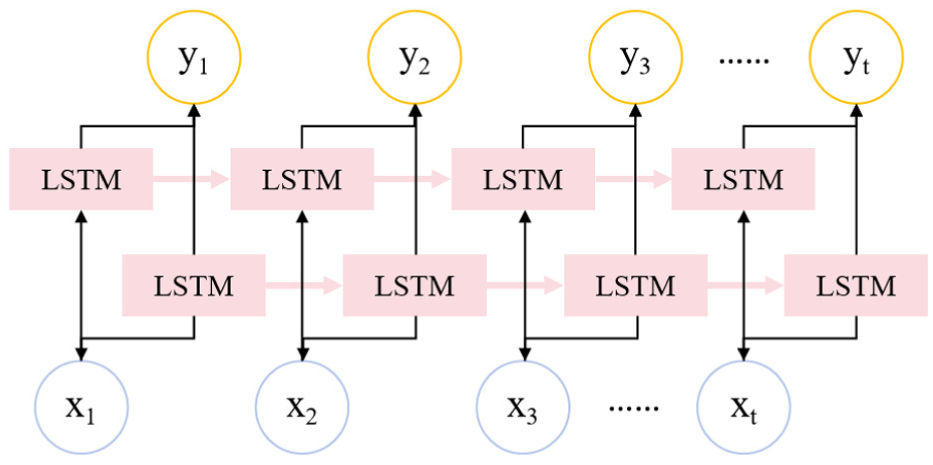
Structure diagram of bidirectional LSTM.
Low-rank multimodal fusion and self-attention mechanism
To integrate the peripheral modal signals more effectively and enhance the features of the electroencephalogram (EEG) signals, this paper adopts the low-rank multimodal fusion technology to extract the common and complementary features among various modalities. Using this method, the feature representations of each modality are fused into a unified feature matrix:
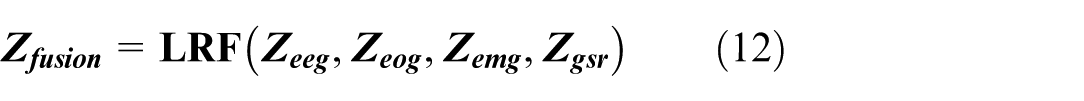
To provide comprehensive input for subsequent modeling. Subsequently, the fused features are processed through the self-attention mechanism to capture nonlinear relationships and long-range dependencies, and finally, the enhanced feature representation

Classifier
The classifier is mainly composed of a fully connected layer and Softmax. Input the final feature vector
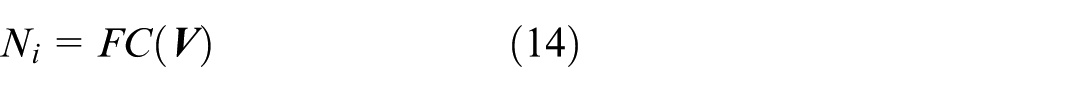
Finally, input N i to the Softmax classifier for emotion recognition:
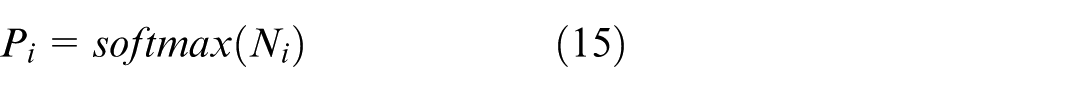
where Pi represents the probability that the EEG image segment Xn belongs to a certain type of emotion.
Loss function
While in training, the standard cross-entropy loss function serves as the supervision signal to gauge the difference between the predicted class distribution and the ground truth labels. The loss function is defined as:
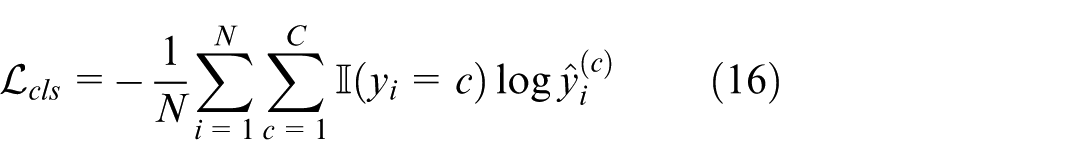
where N is the total count of training samples, C is the number of categories,
Experiments
Dataset and evaluation method
Dataset
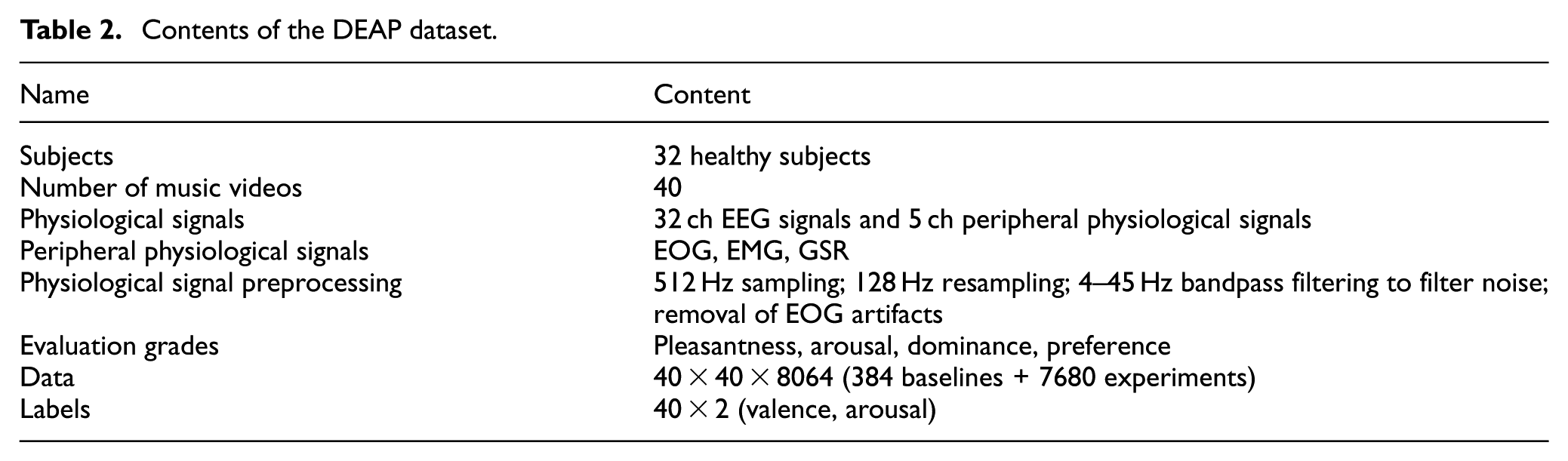
The algorithm presented in this study was validated using the DEAP dataset. This dataset serves as an open-source repository for multimodal human emotional states, capturing and recording EEG, ECG, and other peripheral physiological signals. EEG data were acquired via an EEG cap designed per the 10–20 international electrode placement standard, encompassing 32 scalp electrode channels. The specifications of the DEAP dataset are summarized in Table 2.
Contents of the DEAP dataset.
This paper elects to perform experiments on the two dimensions of arousal and valence, and investigates the binary emotion classification task. The score threshold for each dimension is 5. Scores <5 are classified as low levels, and scores above 5 are set as high levels. Among them, the binary classifications are low arousal (LA), high arousal (HA), low valence (LV), and high valence (HV).
Implementation details
The hardware configuration used in the experiment is 24 GB of running memory, the GPU graphics card is NVIDIA GeForce GTX 4090, and the operating system is 64-bit Win11. The ten-fold cross-validation method is employed to evaluate the classification performance of each subject in the DEAP dataset. Specifically, the experimental samples is evenly split into ten subsets, where one subset acts as the test set and the other nine as the training set. This process is iterated ten times until every subset has served as the experimental test set. The model parameters are listed in Table 3.
Model hyperparameter settings.

Evaluation metrics
This study mainly uses accuracy as the evaluation index, which is defined as follows:
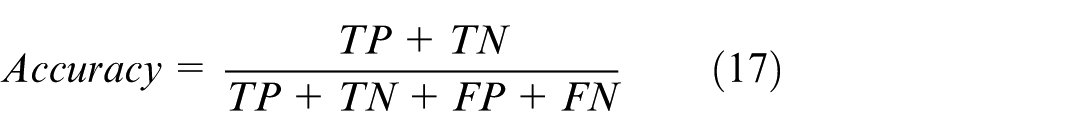
where TP is the number of positive cases of low arousal/negative emotion correctly identified by the classifier, TN is the number of negative cases of high arousal/positive emotion correctly identified by the classifier, FP is the number of cases misjudged as positive cases, and FN is the number of cases misjudged as negative cases.
Accuracy denotes the proportion of samples correctly classified by the classifier relative to the total sample count, which directly reflects the classifier’s performance but fails to fully capture the model’s efficacy, particularly in scenarios with class imbalance. Accordingly, the F1 score is additionally employed as a complementary metric. This metric synthesizes precision (Pre) and recall (Rec), and is particularly adept at addressing class imbalance or varying cost penalties. The formulas for calculating precision and recall are as follows:
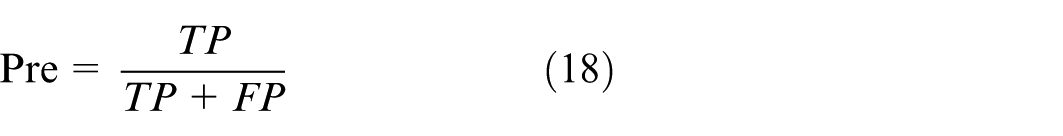
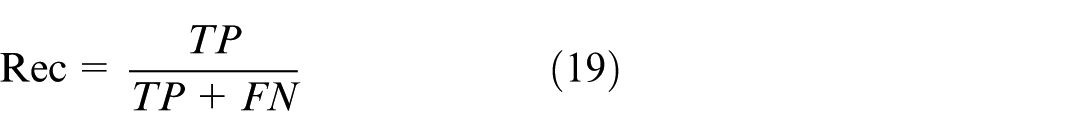
A notable merit of the F1 score is its capacity to more sensitively detect misprediction cases across varied categories. The calculation formula is:
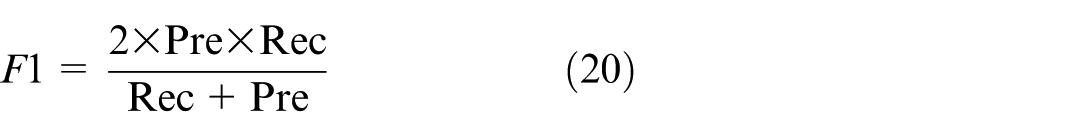
Furthermore, a confusion matrix is incorporated to offer granular insights into model performance. It not only demonstrates the overall classification accuracy but also clearly pinpoints false positives and false negatives in each category. Via this matrix, a refined grasp of the model’s performance across different categories is enabled. All aforementioned metrics are employed herein to validate the model’s efficacy in emotion classification tasks.
Via the evaluation protocols outlined above, a holistic assessment of the model’s efficiency and precision was conducted. This serves to verify that the model not only delivers robust overall performance but also retains efficiency and precision when handling specific emotion categories.
Model experiment
In this experiment, a 0.5-s time window was employed to segment EEG signals. Ultimately, the EEG data for each subject was partitioned into 40 × 120 (4800) samples, yielding a total of 153,600 samples. The experimental data was then split into training and test sets. The detailed experimental design comprises three components: subject-independent experiments, subject-dependent experiments, and experiments involving different combinations of modality.
Subject-independent experiment
In this experiment, we used a subject-independent setup to verify the model’s generalization ability across various subjects. As illustrated in Figures 7 and 8, as the number of training iterations increases, the recognition accuracy of the arousal dimension rises notably and stabilizes after roughly the 60th iteration, finally hitting around 94.79%. Concurrently, the loss value continues to decrease and gradually stabilizes during the corresponding iteration process. This result indicates that as iterations deepen, the model achieves good convergence in the arousal dimension, demonstrating excellent performance and stability.
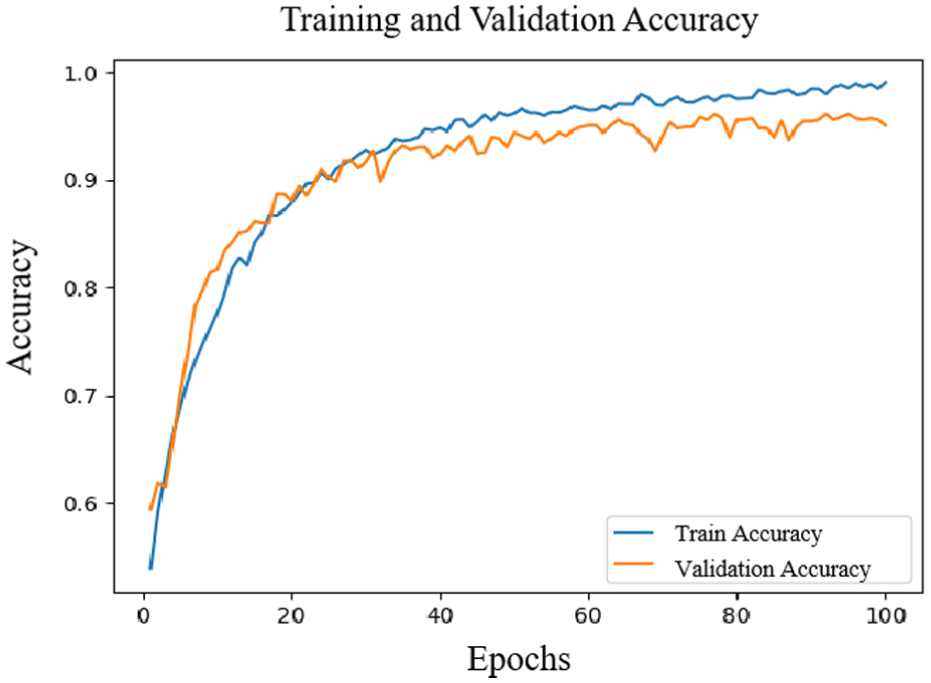
Accuracy change in the arousal dimension.
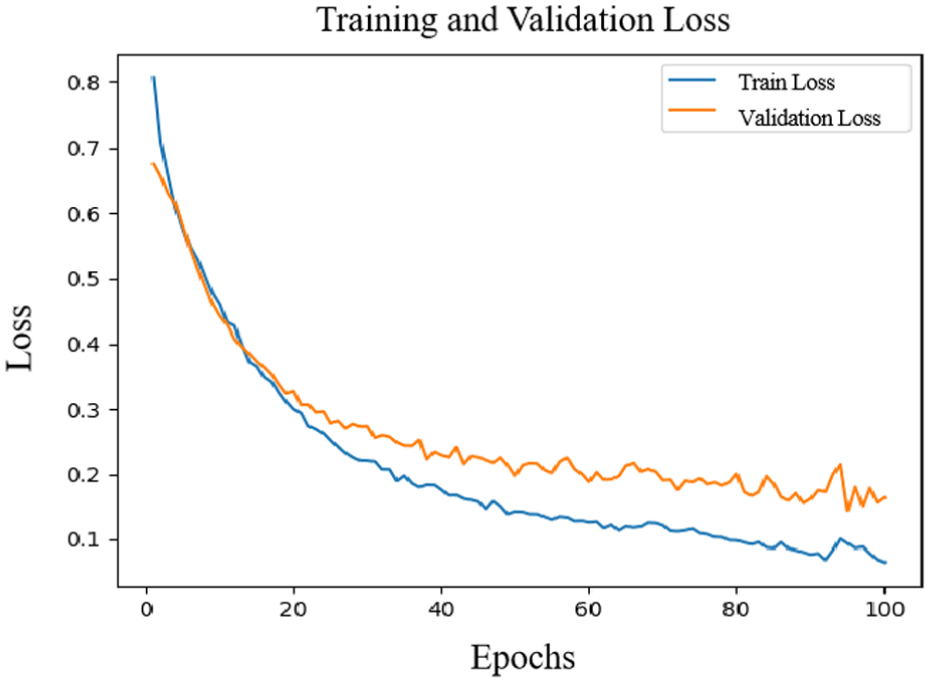
Loss rate change in the arousal dimension.
Similarly, Figures 9 and 10 show the training results of the valence dimension. After 40 iterations, the accuracy and loss rates of the valence dimension tend to be stable, and the final accuracy is 94.36%. This further highlights the model’s stable efficacy in emotion classification, especially as it retains high accuracy with training data from diverse subjects.
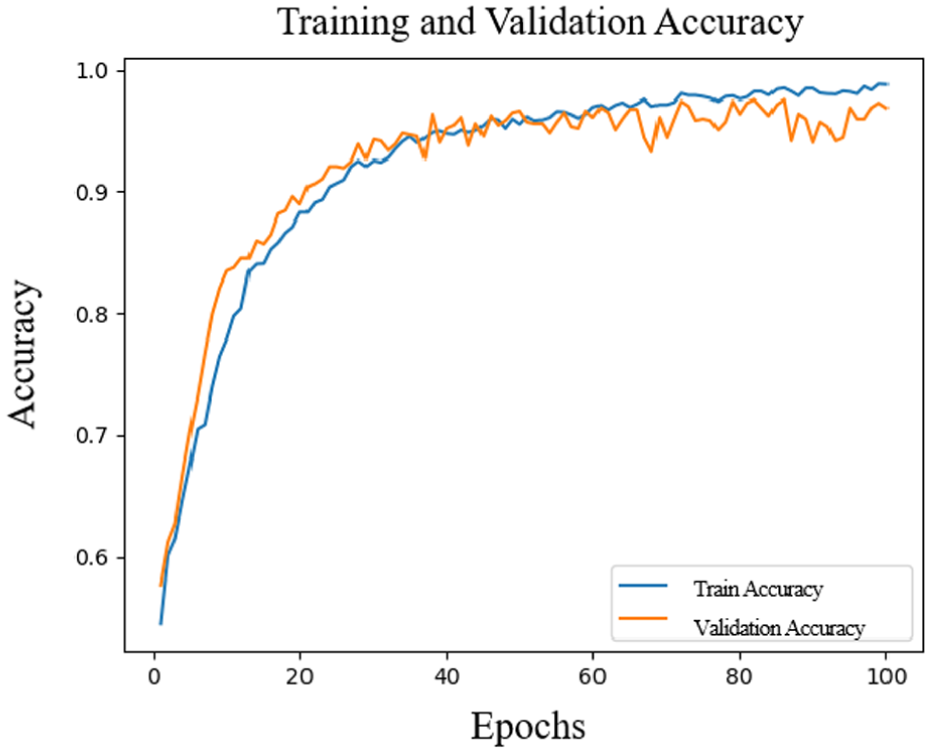
Accuracy change in the valence.
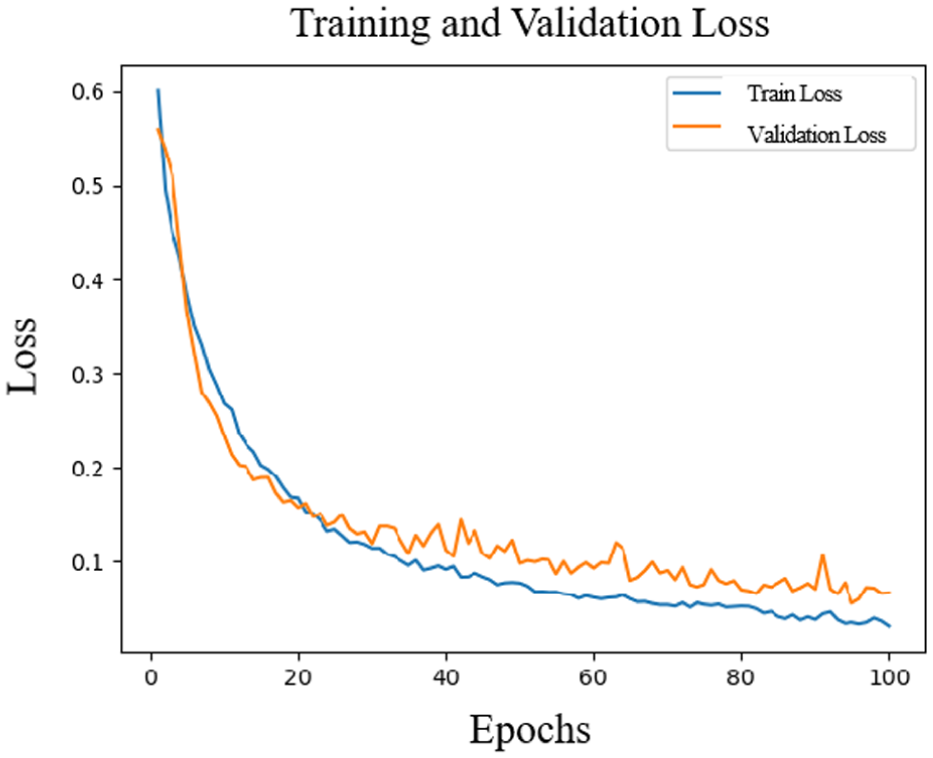
Change in the loss rate of the valence.
Overall, from these charts, it can be seen that as the training proceeds, the accuracy of the model continues to rise, and the loss rate continues to decrease, indicating that the model effectively converges during the training process and shows good generalization ability on the independent test set. In order to evaluate the classification effect more comprehensively, Figures 11 and 12 show the confusion matrices of the arousal and valence dimensions, further revealing the classification performance of the model in each category.
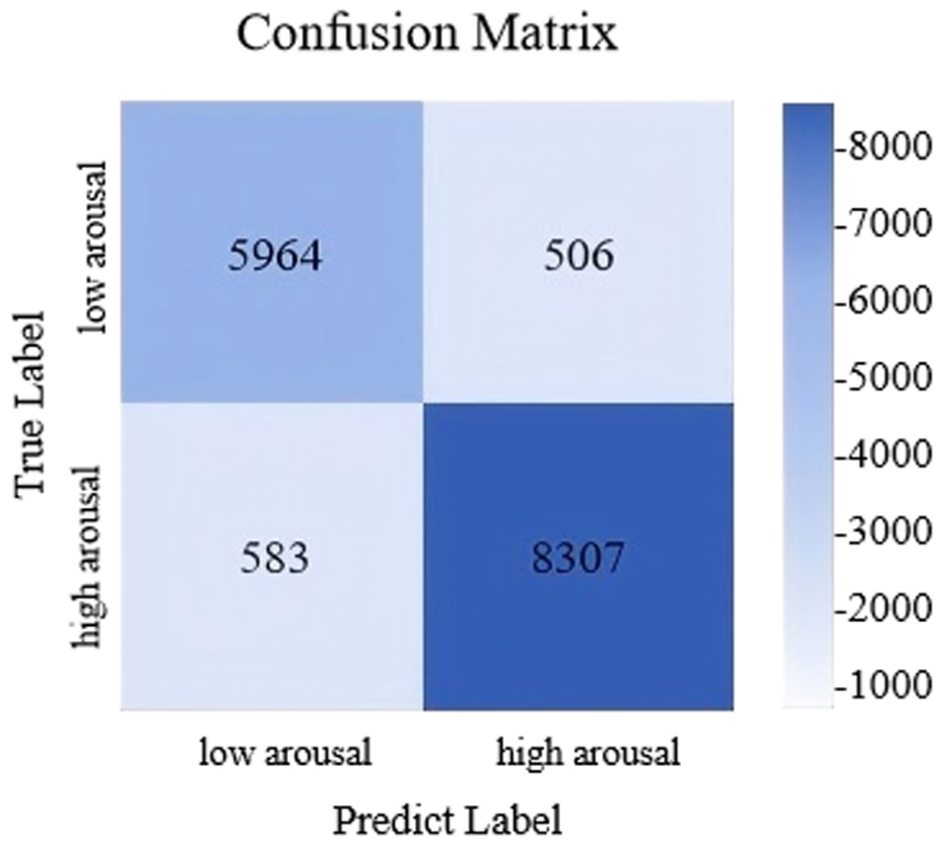
Confusion matrix of classification results of arousal.
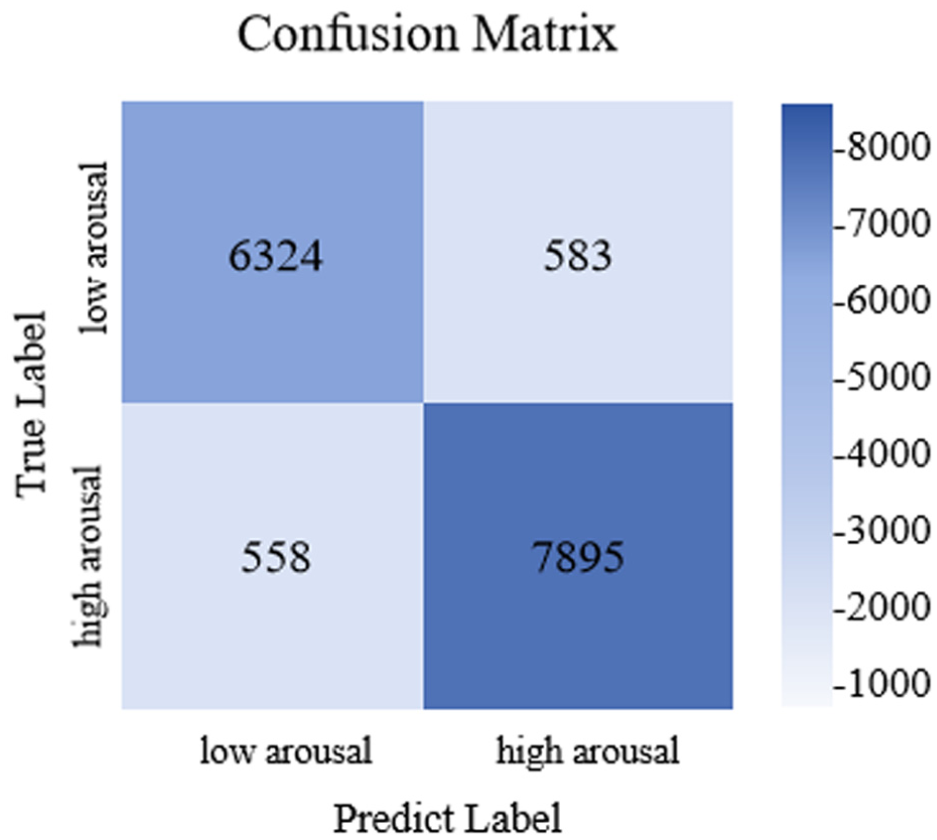
Confusion matrix of classification results of valence.
This experimental finding confirms that under subject-independent conditions, the model exhibits strong emotion recognition capability and can be effectively generalized to classification tasks on unseen data.
Figure 11 presents the confusion matrix for classification results in the arousal dimension, showcasing the model’s classification performance across various arousal level categories. From the matrix, it is evident that the model correctly classified 5964 low-arousal samples and 8307 high-arousal samples. However, there were notable misclassifications: 583 high-arousal samples were misclassified as low-arousal, and 506 low-arousal samples were misclassified as high-arousal. Such errors may stem from inter-sample feature similarity, individual variations in emotional expression, or data noise. Nonetheless, overall, the model demonstrates strong classification performance for the arousal dimension.
Figure 12 displays the confusion matrix corresponding to classification results in the valence dimension, showcasing the efficacy of the model in classifying emotions. From the matrix, it is clear that the model accurately identified 6324 negative emotion samples and 7895 positive emotion samples, which verifies high precision in differentiating positive and negative emotions. Nevertheless, notable misclassifications existed: 1089 samples were incorrectly allocated to other emotion categories. These inaccuracies stem from the complexity of emotional expression and inter-category similarity among emotions. Overall, the model delivers satisfactory classification performance in the valence dimension, though there is room for further optimization.
Subject-dependent experiment
The objective of the subject-dependent experiment is to assess the performance variations of the model and response disparities across the same subject cohort under varying conditions, with an emphasis on examining performance fluctuations in the arousal and valence dimensions. Through this experiment, we can further explore the adaptability of the model to individual differences and provide a basis for subsequent optimization, with the experimental results shown in Figures 13 and 14.
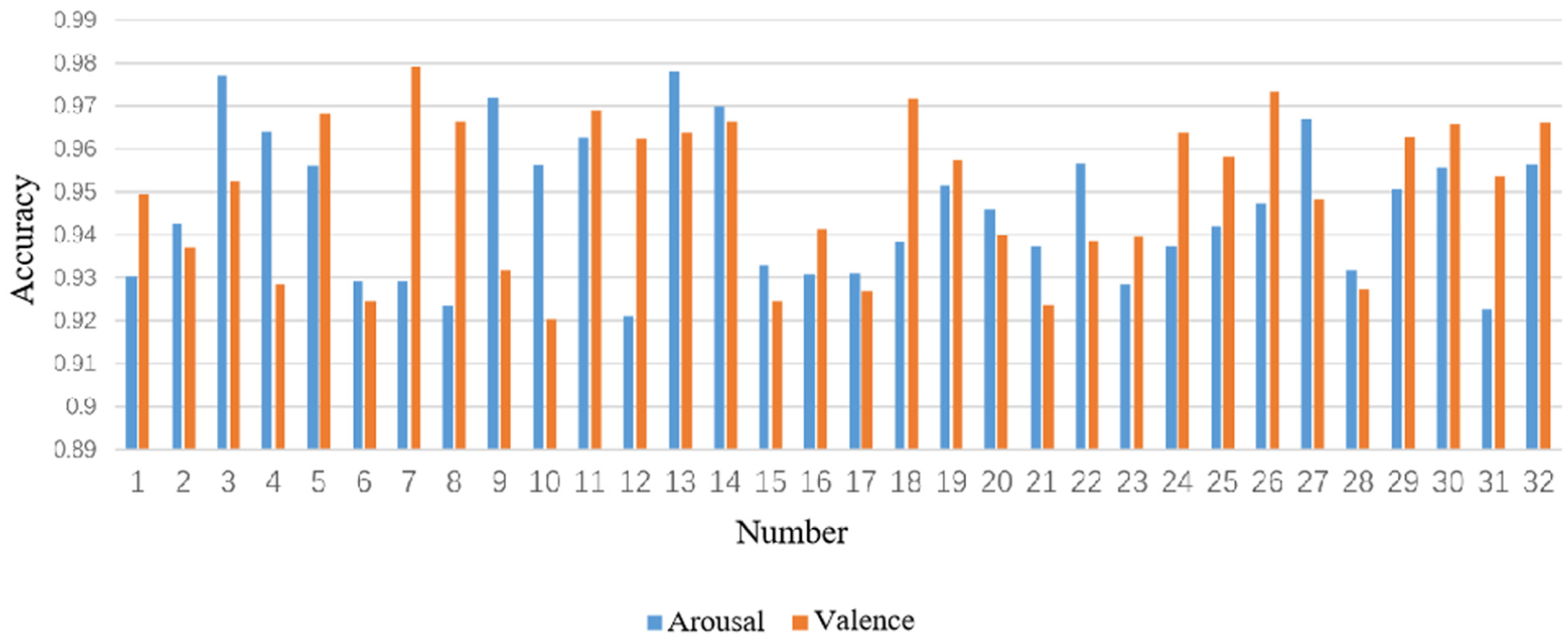
Accuracy of subjects in arousal and valence classification.
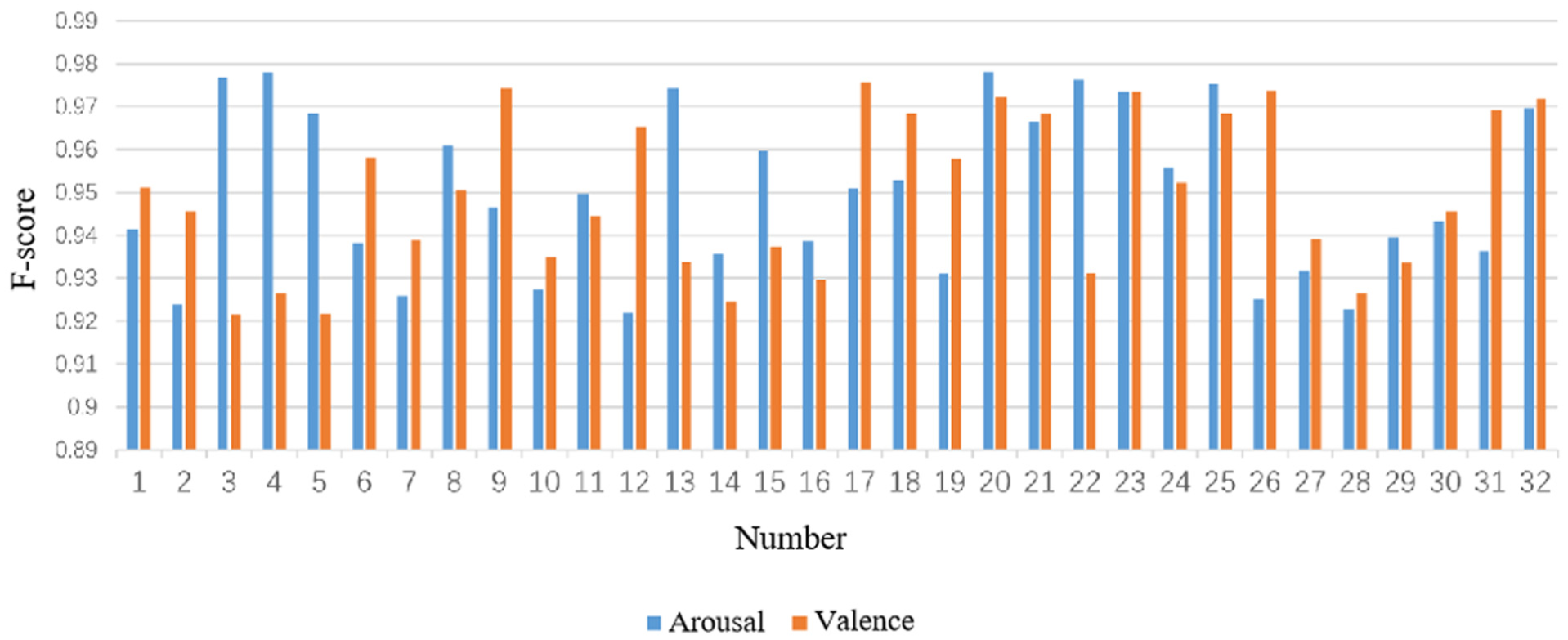
F1 score of subjects in arousal and valence classification.
Specifically, in terms of the accuracy rate in the arousal dimension, the average accuracy rate of 32 subjects was 95.89%, and the standard deviation was 1.72%. Among them, the accuracy rates of six subjects numbered #2, #22, #26, #30, #31, and #32 were lower than 95%. In terms of the F1 score of arousal, the average score was 95.7%, and the standard deviation was 1.6%. Among them, the F1 scores of seven subjects numbered #2, #22, #26, #30, #31, #32, and #33 were lower than 95%.
In terms of the accuracy rate in the valence dimension, the average accuracy rate of 32 subjects was 94.99%, and the standard deviation was 1.73%. Among them, the accuracy rates of five subjects numbered #2, #5, #8, #13, and #26 were lower than 95%. The F1 score in the valence dimension averaged 94.6%, and the standard deviation was 1.7%.
Among them, the F1 scores of eight subjects numbered #2, #5, #8, #13, #18, #26, #30, and #32 were lower than 95%.
The observed performance variability stems from three key individual differences: First, inherent variations in physiological signal patterns. Subjects with lower accuracy exhibited more pronounced EEG non-stationarity and weaker cross-modal correlations between EEG and peripheral signals. Second, divergent emotional response mechanisms. Some subjects had less discriminative physiological reactions to emotional stimuli, resulting in ambiguous feature representations. Third, individual differences in data quality. Residual EOG artifacts such as eye blinks persisted in specific subjects even after preprocessing, interfering with valid feature extraction.
These findings underscore the impact of individual heterogeneity on model performance. Future work will adopt personalized adaptation strategies such as subject-specific fine-tuning to enhance robustness across diverse populations.
Overall, the model performed well in most subjects, with the accuracy rate and F1 score mostly exceeding 95%. Although the performance of a few subjects was lower than 95%, the results of these subjects still remained at a relatively high level, indicating that the model has strong robustness and stability in the emotion classification task.
Experiments of different modality combinations
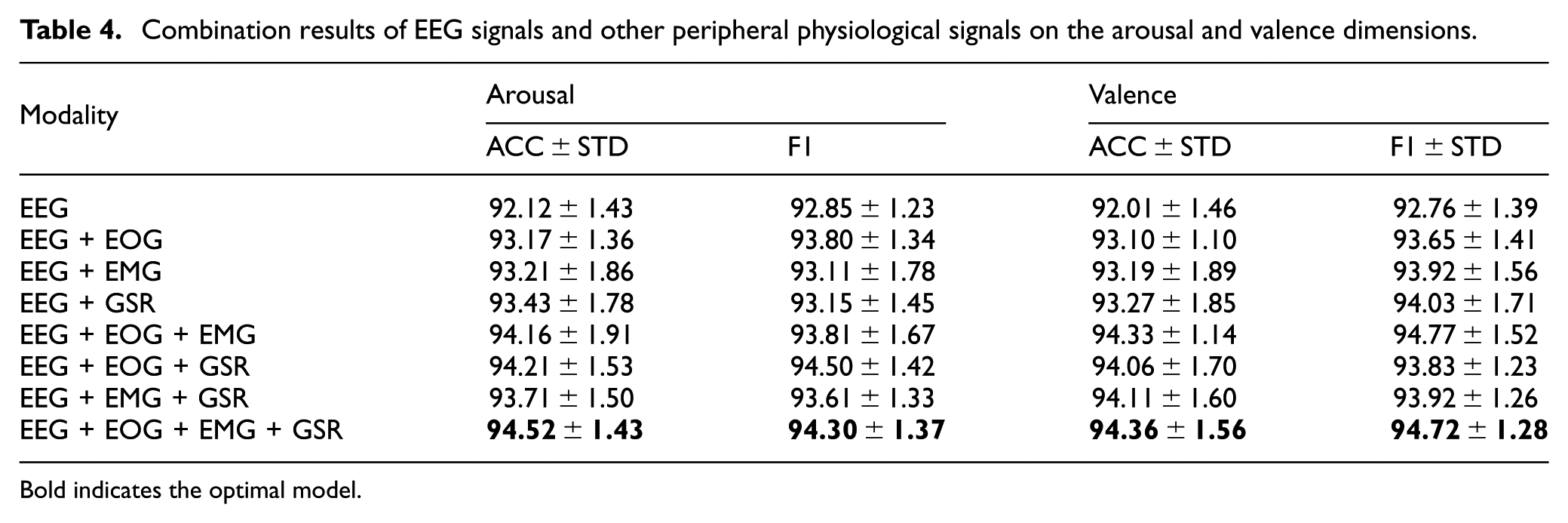
For the purpose of exploring how diverse modality combinations affect emotion recognition performance, this study compared combinations of EEG signals and other peripheral physiological signals (including EOG, EMG, GSR). Table 4 presents the experimental results for different modality combinations across the arousal and valence dimensions. Results indicate that when EEG signals are used in isolation, the model’s accuracy values on the arousal and valence dimensions stand at 92.12% and 92.01%, respectively, with corresponding F1 scores of 92.85% and 92.76%. With the integration of EOG and EEG signals, the model exhibits enhanced performance: accuracy on the arousal dimension attains 93.17%, while that on the valence dimension stands at 93.10%, with associated F1 scores of 93.80% and 93.65%, respectively. Likewise, following the inclusion of EMG and GSR signals, the model demonstrates varying degrees of enhancement across multiple evaluation metrics.
Combination results of EEG signals and other peripheral physiological signals on the arousal and valence dimensions.
Bold indicates the optimal model.
Especially when simultaneously integrating EEG, EOG, EMG, and GSR signals, the accuracy rate of the model on the arousal dimension increased to 94.52%, and the F1 score was 94.30%; on the valence dimension, the accuracy rate was 94.36%, and the F1 score was 94.27%. These results indicate that combining multi-modal signals can notably boost emotion recognition performance, especially in the arousal dimension, and the combined signals yielded optimal outcomes for improving accuracy and F1 scores.
Therefore, it can be concluded that the combined use of EEG signals and peripheral physiological signals can effectively improve the accuracy and stability of emotion recognition. Especially after integrating multiple modalities, the model shows a stronger ability of emotion classification.
Comparison of different research methods
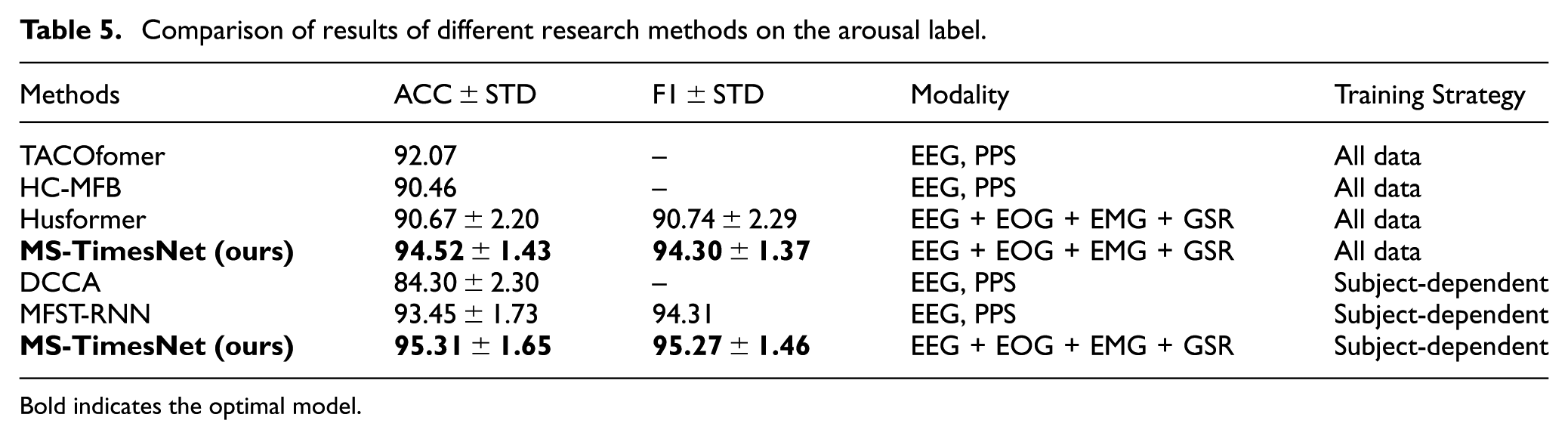
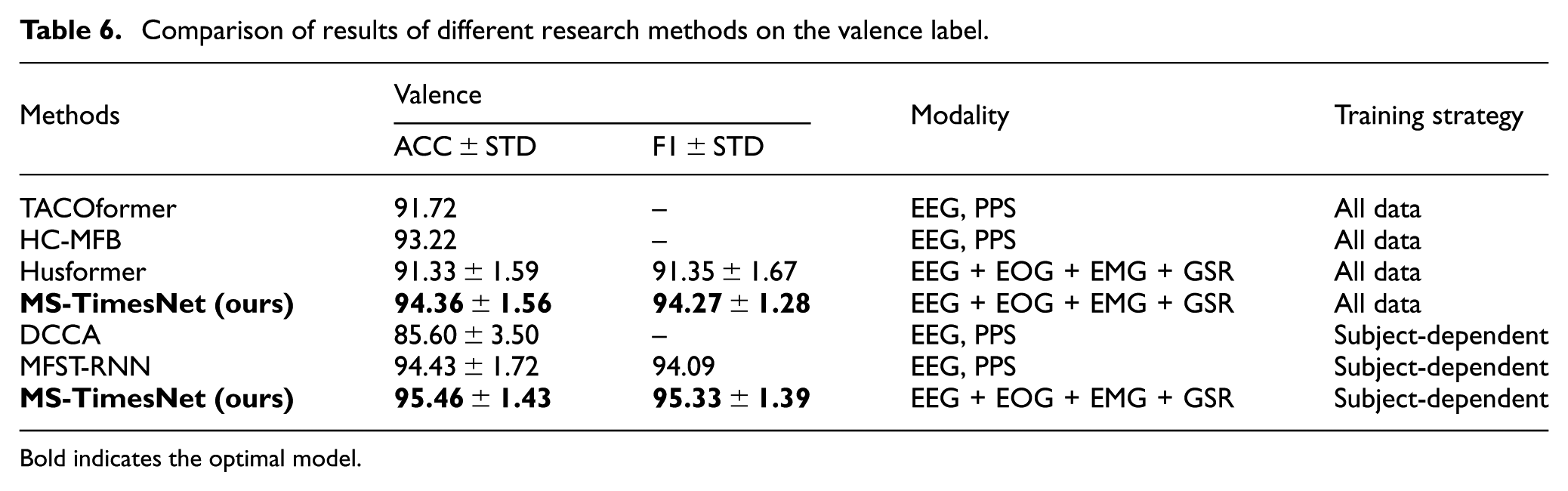
Tables 5 and 6 show the comparison of classification results of different research methods on the arousal and valence labels. In the classification task of the arousal dimension, the model using this method performed well in both accuracy (ACC) and F1 score (F1), reaching 94.52% and 94.30%, respectively. Compared with other methods, the performance of this method is significantly better than models such as TACOformer, HC-MFB, and Husformer. Especially in the subject-dependent experiments, the classification accuracy (95.31%) and F1 score (95.27%) of this method in the arousal dimension exceeded all other comparison methods.
Comparison of results of different research methods on the arousal label.
Bold indicates the optimal model.
Comparison of results of different research methods on the valence label.
Bold indicates the optimal model.
In the classification task of the valence dimension, this method also demonstrated excellent performance, with an accuracy rate of 94.36% and an F1 score of 94.27%. Compared with other methods, such as TACOformer and Husformer, this method performed more prominently in the valence dimension, and in the subject-dependent experiments, this method performed the best again, with both the accuracy rate and the F1 score reaching 95.46% and 95.33%.
Thus, in contrast to other state-of-the-art techniques, this approach has exhibited notably better performance in emotion recognition tasks across the two emotional dimensions (arousal and valence). By integrating EEG signals with peripheral physiological signals (such as EOG, EMG, GSR) and employing sophisticated feature extraction and fusion strategies, the model’s accuracy and stability in emotion recognition tasks across all dimensions have been effectively improved.
Ablation experiment
To evaluate the contribution each module makes to emotion recognition performance, ablation experiments were performed in the present study. Table 7 shows the changes in accuracy (ACC) and F1 score (F1) of the model in the arousal and valence classification tasks under different module combinations.
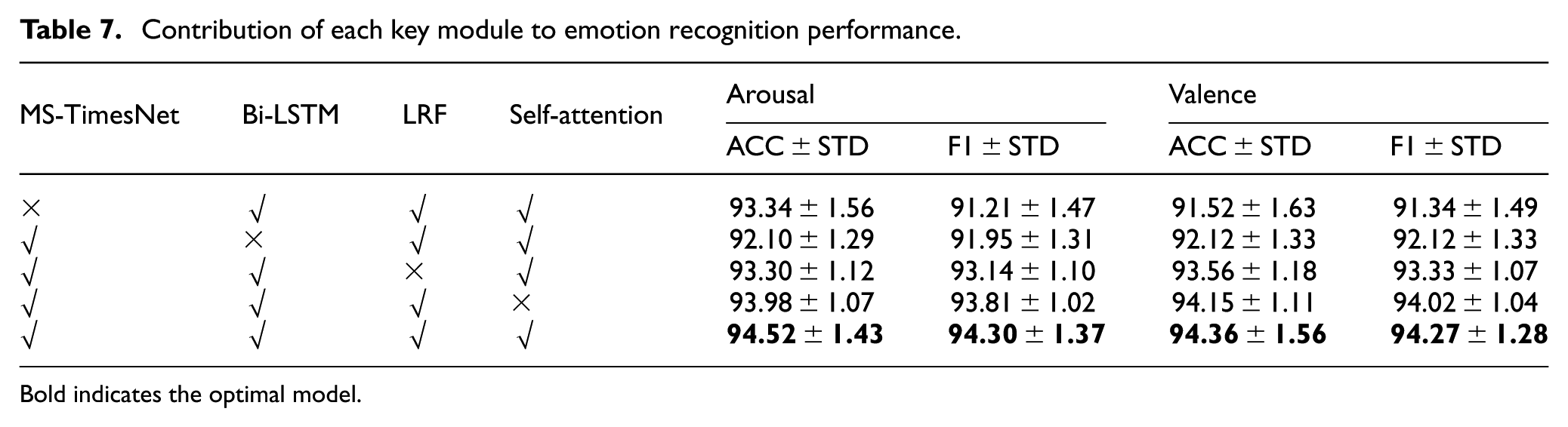
Contribution of each key module to emotion recognition performance.
Bold indicates the optimal model.
As depicted in the table, MS-TimesNet, Bi-LSTM, LRF, and Self-Attention constitute the core modules of the emotion recognition model in the present study. To verify the effectiveness of each module, we performed comparisons between the performance of models excluding a specific key module and those integrating all key modules. Experimental findings indicate that:
Models lacking any key module fare worse than the complete model, which suggests each module is vital to enhancing model performance.
Among different modified versions, the model with MS-TimesNet removed performs the worst, followed by the model with Bi-LSTM removed, while the models with LRF and Self-Attention removed perform relatively close. This indicates that MS-TimesNet and Bi-LSTM are the most effective modules, followed by LRF and Self-Attention.
These results indicate that the MS-TimesNet, Bi-LSTM, LRF, and Self-Attention modules each play a unique role in the model. Especially, the LRF module can still maintain high emotion recognition accuracy while reducing the complexity of the model, further verifying its effectiveness in model optimization.
Discussion
In this section, we analyze the contributions, limitations, and practical implications of the three innovative design strategies underpinning our proposed MS-TimesNet-based multimodal fusion emotion recognition framework. This framework achieves 94.52% and 94.36% accuracy in the arousal and valence dimensions on the DEAP dataset, respectively, outperforming models such as TACOformer and Husformer. Its superior performance stems precisely from these three innovative design strategies.
First, the MS-TimesNet architecture addresses the critical challenge of EEG non-stationarity through a parallel integration of multi-scale temporal–spatial convolutions and periodic phase transformation. This design uniquely captures both short-term fluctuations and long-term trends, which are indispensable for decoding dynamic emotional states.
Ablation experiments conclusively validate its core role: removing MS-TimesNet results in the most significant performance degradation (arousal: 93.34%; valence: 91.52%), confirming that multi-scale temporal-spatial modeling is pivotal for extracting discriminative EEG features.
Second, the low-rank multimodal fusion (LRF) method resolves the trade-off between information integrity and computational efficiency. By decomposing cross-modal feature tensors into low-rank matrices, LRF retains critical inter-modal correlations, such as the interplay between EEG-derived brain activity and EOG/EMG signals reflecting facial muscle tension. Modality combination experiments further demonstrate that fusing EEG with EOG, EMG, and GSR yields optimal results, underscoring the irreplaceable complementary role of central and peripheral physiological signals in emotion expression.
Third, the synergistic integration of BiLSTM and self-attention mechanisms enhances the model’s robustness against noise and individual variability. Specifically, BiLSTM effectively captures temporal dependencies within peripheral signals, while the self-attention mechanism dynamically weights emotionally salient features to mitigate noise-induced errors. This adaptability is validated in subject-dependent experiments: across 32 subjects, the model achieves an average Arousal accuracy of 95.89% with a standard deviation of 1.72%, thereby demonstrating strong generalization across individual physiological differences.
Notably, this framework directly addresses the key limitations of existing methods: it mitigates the inefficiency inherent in high-dimensional fusion through LRF, enhances multi-scale dynamic modeling of non-stationary signals via MS-TimesNet, and strengthens noise tolerance by means of adaptive feature weighting. These innovations collectively enable high-precision emotion recognition while maintaining low computational complexity, which represents a critical advantage for real-world deployment.
Several limitations of this study warrant acknowledgment. First, the DEAP dataset, collected under controlled music-induced conditions, differs substantially from the high-stress, task-oriented environments of real-world flight missions; thus, future validation with in-flight physiological data is imperative to establish ecological validity. Second, although the LRF method reduces computational complexity, further optimization for edge-device deployment remains necessary to meet the stringent latency constraints of aviation scenarios. Third, individual performance variability (e.g. in subjects #16 and #28) underscores the need for personalized adaptation strategies—such as transfer learning—to address inter-individual physiological differences.
Conclusion
In this paper, we propose a multimodal fusion emotion recognition framework with high accuracy and low computational complexity. Quantitative evaluation confirms the framework has 16.8 million trainable parameters and 8.3 GFLOPs, supporting its feasibility for deployment in resource-constrained scenarios. To address signal heterogeneity, we perform feature extraction across different modalities: for EEG signals, we fully account for their time-frequency and spatial characteristics, while preserving the time-frequency features of peripheral physiological signals (e.g. GSR, EOG, EMG). To explore inter-modal correlations, we adopt the LRF method to fuse emotional features from each modality, thereby strengthening cross-modal associations. Furthermore, this study verifies the complementary role of EEG signals and peripheral physiological signals in emotion classification, which significantly enhances the accuracy of emotion recognition. Given the development requirements for low-cost, high-information-objectivity emotion detection systems, multimodal physiological signal fusion-based emotion recognition, as an efficient and cost-effective solution, can effectively improve emotion recognition accuracy. It provides a novel technical pathway for monitoring of pilots’ emotional changes and early warning of potential risks, holding great significance for the field of aviation safety.
Footnotes
Consent for publication
The corresponding author gave consent for the publication of the identifiable details.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Authors are thankful to the supported by the Joint program of the National Natural Science Foundation of China and Civil Aviation Administration of China (no. U1733118).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The use of this data is completely restricted for research and educational purposes. The use of this data is forbidden for commercial purposes.