
Abstract
Maximum Power Point Tracking (MPPT) control is a critical component in photovoltaic (PV) systems, ensuring optimal energy extraction under fluctuating environmental conditions. This study presents a ground-breaking artificial intelligence (AI)-driven MPPT control method that operates without the need for pre-training or extensive data collection. Departing from conventional techniques, this approach minimizes trial-and-error processes, significantly reducing system disruptions and energy losses. The proposed control mechanism dynamically adapts to real-time variations, including component degradation and hardware modifications, making it a versatile and resilient solution for diverse PV systems. This method removes the need for setup or calibration. It greatly cuts production costs. It also reduces system complexity. Plus, it lessens the reliance on extra electronic components. The system demonstrates exceptional responsiveness and operational simplicity, outperforming traditional intelligent control methods in terms of efficiency, reliability, and ease of implementation. These advantages position it as a highly promising solution for enhancing energy management in PV systems across a wide range of environments and configurations.
Keywords
Introduction
In recent years, the development of artificial intelligence (AI) has experienced remarkable growth. Inspired by human behavior, AI relies on algorithms capable of adapting to and solving unforeseen problems while improving through experience. The behavior of AI is grounded in rigorous mathematical principles. Generally, problems can be categorized into two main types: regression and classification. These two categories, or a hybrid combination of both, enable the resolution of a wide range of challenges. 1
AI has emerged as an effective solution for controlling complex systems, minimizing errors related to unforeseen issues, and managing systems where nonlinear responses pose significant challenges. Nonlinearity in systems is a major challenge. One solution is building a large database covering all possible scenarios. Another option is using search algorithms. However, recent advancements in algorithms based on trial-and-error learning principles offer promising solutions. In this context, AI serves as a solution where the system learns from its own experiences. 2
In this study, we present AI as a solution where the system learns from its experiences. We demonstrate how AI can be applied to enhance control systems by reducing errors and adapting to complex, nonlinear environments. The emergence and diversity of AI algorithms provide an opportunity to improve numerous control structures in terms of performance, accuracy, and speed. In this research, we address advanced learning challenges associated with the use of artificial intelligence.
The primary difficulty in using AI lies in the learning phase, which requires prior data collection a process that can be complex and demand specific requirements. 3 To overcome this challenge, we have developed a hybrid approach combining two algorithms: one intelligent and the other non-intelligent, both based on the trial-and-error principle. These two algorithms operate simultaneously and complement each other.
This hybrid approach, akin to bagging, enhances control by enabling continuous adaptation and constant improvement. This control method remains reliable even when system characteristics change.4,5
In this research, we adopted the k-Nearest Neighbors (k-NN) algorithm for maximum power point tracking (MPPT) without requiring a prior learning phase. This control technique is advantageous as it eliminates the need for initial data collection. Learning occurs in real-time during the system’s normal operation, allowing our controller to be more general and adaptable, accounting for changing factors such as component aging.
The k-NN algorithm works by identifying the closest data points (or neighbors) in a multi-dimensional space, enabling efficient real-time tracking of the maximum power point. This dynamic method continuously adjusts system control, adapting to environmental variations and changes in system characteristics. As a result, our solution offers enhanced robustness and flexibility, ensuring high performance even under changing conditions.6,7
Our innovative approach aims to reduce disruptions caused by trial-and-error processes while maintaining optimal system performance. By eliminating the need for a prior learning phase, we avoid performance drops that may occur when parameters change. Furthermore, this type of controller is more versatile and reliable, applicable to a variety of systems without being limited to specific cases.
K-Nearest Neighbors
The k-Nearest Neighbors (k-NN) algorithm is based on the principle that if an object shares similar characteristics with a reference object, the two objects are considered similar. Mathematically, this principle is applied in a multidimensional space where the similarity of characteristics is quantified numerically.7,8
In a multidimensional space, each characteristic of an object is represented by a dimension. For example, if we have three characteristics, our space will be three-dimensional. To determine the similarity between two objects, we measure the distance between their corresponding points in this space. Commonly used distance metrics include Euclidean distance, Manhattan distance, and other distance measures tailored to the specific problem. 9
A crucial aspect of the k-NN algorithm is the consideration of feature weights. This means that certain characteristics may have a greater impact than others in determining similarity.
Thanks to its proximity-based approach, the k-Nearest Neighbors (k-NN) algorithm is capable of effectively solving both classification and regression problems. This means that the algorithm can not only group objects into distinct categories (classification) but also predict continuous values (regression) based on input data. The k-NN algorithm has demonstrated its performance and robustness in various practical applications, whether for categorizing objects or estimating numerical values. 7
K-NN for classification
The k-Nearest Neighbors (k-NN) algorithm is particularly effective for classification tasks, assigning a class to a new object based on the classes of the k nearest objects in a multidimensional space. The process begins by defining the feature space, where each object is represented as a point. For a new object to be classified, the algorithm calculates the distance between this object and all reference objects in the training dataset, using metrics such as Euclidean distance or Manhattan distance, depending on the problem’s specifics. The k nearest reference objects is then selected, and the new object is classified according to the majority class of these k nearest neighbors. If classes are weighted, the weights can give more importance to closer neighbors.
The k-NN algorithm is non-parametric, making no assumptions about the data distribution, which makes it flexible and adaptable to different types of data. However, it is sensitive to the quality and quantity of training data, and a high-quality dataset significantly improves its performance. Although k-NN is intuitive and easy to implement, its computational cost can increase with larger datasets, as it requires calculating distances to all reference points. 9
In summary, the k-NN algorithm is a powerful tool for classification, offering a simple and effective method for assigning classes to new objects based on their proximity to reference objects. Its adaptability and ease of use make it a popular choice for various machine learning tasks.
K-NN for regression
The k-Nearest Neighbors (k-NN) algorithm is also highly effective for regression tasks, where it predicts a continuous value for a new object based on the values of the k nearest objects in a multidimensional space. Each dimension in this space represents a specific feature of the object. The process begins by defining the feature space, where each object is represented as a point. For a new object requiring prediction, the algorithm calculates the distance between this object and all reference objects in the training dataset. The k nearest reference objects are then selected, and the predicted value for the new object is determined by evaluating the neighboring objects surrounding the target object in this multidimensional space.8,10
More specifically, the prediction is made by deducing the target object’s value from the values of the nearest reference objects in each dimension. This means that each descriptive parameter of the object is treated as a dimension in the space, and the final value is computed by combining the contributions from each dimension. 10
It is important to note that some parameters may have a lesser impact on classification or regression. Consequently, it is crucial to assign appropriate weights to different parameters to reflect their relative importance. By adjusting these weights, the k-NN algorithm can improve its ability to classify objects and predict values by accounting for the relative significance of various features.
In summary, the k-NN algorithm is a powerful tool for regression, offering a simple and effective method for predicting continuous values based on proximity to reference objects in a multidimensional space. Its flexibility in handling feature weights and its intuitive approach make it a valuable choice for regression tasks in diverse applications.
Photovoltaic (PV) system: Principle, operation, and influential factors
The performance of a photovoltaic (PV) system depends on several interdependent factors that influence its ability to efficiently convert solar energy into electricity. Among these factors, weather conditions and the management of the extraction current play essential roles. Weather conditions, such as sunlight intensity, temperature, and physical obstructions, directly affect the amount of solar energy captured by the panels. Meanwhile, the extraction current, which represents the energy drawn to power connected loads, must be carefully regulated to avoid energy losses or overloads. A thorough understanding of these two aspects allows for the optimization of PV system design and operation, ensuring maximum energy production and extended component lifespan.11,12
Effect of weather conditions on a photovoltaic (PV) system
Weather conditions directly influence the energy production of a PV system. The intensity of solar radiation is the primary factor: the stronger the sunlight, the greater the number of photons reaching the photovoltaic cells, increasing electron generation and the current produced. However, phenomena such as cloud cover or atmospheric pollution reduce light intensity, decreasing energy production.13–15
Temperature also plays a critical role. Although increased sunlight boosts production, high panel temperatures reduce their efficiency. This is because photovoltaic cells have a negative temperature coefficient: as temperature rises, the output voltage decreases, affecting overall power output. For example, a 10°C increase above the standard temperature (25°C) can reduce efficiency by 4%–5%. 13
Finally, factors such as dust, snow, or shading can obstruct the panel surface, limiting light absorption and reducing energy production. These phenomena require regular maintenance to ensure optimal performance.
Effect of extraction current on a photovoltaic (PV) system
The extraction current, or load current, represents the electrical energy drawn from the PV system to power connected devices. Its impact on energy production is critical for system efficiency.
If the extraction current is too low, some of the energy generated by the panels remains unused, leading to energy losses. This often occurs when the connected load is insufficient or poorly sized. Conversely, an excessively high extraction current can overload the system, reducing output voltage and increasing Joule losses (heat dissipated in cables and components). This can also damage electronic components, shortening their lifespan.
To optimize the extraction current, techniques such as Maximum Power Point Tracking (MPPT) are used. MPPT dynamically adjusts the current and voltage to maintain the system at its optimal operating point, maximizing energy production. For example, in cases of varying sunlight or temperature, MPPT recalculates the ideal extraction current in real time to adapt the load to the available power.13,15
MPPT control: concept and physical phenomena
MPPT (Maximum Power Point Tracking) control is a crucial technique for optimizing energy production in photovoltaic (PV) systems. Its goal is to maintain the system at its maximum power point (MPP), where the combination of voltage and current produces the highest possible electrical power. This concept is based on understanding the physical phenomena that govern the behavior of solar panels under varying environmental and load conditions.
Physical phenomena behind MPPT control
Solar panels generate energy through the photovoltaic effect, where photons from sunlight excite electrons in a semiconductor material, creating an electric current. However, the power produced by a solar panel is not constant: it depends on the voltage and current, which vary based on sunlight intensity, temperature, and the connected load.
The current-voltage (I-V) characteristic of a solar panel shows a nonlinear relationship between current and voltage. This curve features a unique point called the maximum power point (MPP), where the product of voltage and current is maximized. This point changes dynamically depending on external conditions.14,15
Without MPPT control, a PV system often operates away from its maximum power point, leading to significant energy losses. For example, if the connected load imposes too low a voltage, the current produced will be high, but the power will be suboptimal. Conversely, too high a voltage reduces the current, also limiting power output. 14
Types of MPPT controls
MPPT controls are divided into two main categories: traditional controls and intelligent controls. Each approach relies on distinct principles and specifications to locate and maintain the maximum power point (MPP) in a photovoltaic (PV) system. Below is a detailed explanation of the principles and specifications of each type. 14
Traditional controls
Traditional controls, such as Perturb and Observe (P&O) and Incremental Conductance (IC), rely on simple algorithmic methods. They slightly perturb the system’s voltage or current and observe the impact on power to gradually adjust the operating point. These methods are easy to implement, making them popular for residential and commercial applications. However, they can oscillate around the maximum power point (MPP) and lack precision under rapidly changing sunlight or temperature conditions. Their robustness is limited in complex environments, such as partial shading or rapidly changing weather.14,15
Intelligent controls
Intelligent MPPT controls use advanced techniques, often based on artificial intelligence (AI) or machine learning, to predict and dynamically adjust the MPP. These methods, such as Artificial Neural Networks (ANN), Fuzzy Logic, or Genetic Algorithms (GA), adapt in real time to environmental variations and system characteristics. They offer superior precision and speed, even in complex or nonlinear conditions. For example, ANNs can predict the MPP based on sunlight and temperature, while Fuzzy Logic uses linguistic rules to robustly adjust voltage and current. Although these controls are more complex to implement, they ensure optimal energy efficiency and long-term adaptability.14,15
System configuration selection
The choice of the system’s structure is a crucial step to ensure a rigorous evaluation of the performance of our innovative real-time learning-based MPPT control. We have selected an architecture that highlights the effectiveness of our approach, considering key criteria such as simplicity, representativeness, and the ability to accurately reflect the dynamics of the photovoltaic system. Thus, we have opted for a configuration consisting of a photovoltaic panel, a DC-DC converter, and a load, allowing for precise analysis of the system’s behavior under different sunlight and temperature conditions. The chosen structure is described in detail, and we justify our choices in the following section.
Choice of photovoltaic panel for MPPT control evaluation
Our system integrates a photovoltaic panel as an energy generator. Since a single photovoltaic cell produces very limited power, it is essential to combine multiple cells to obtain usable power. This grouping not only achieves a useful power level for real-world applications but also ensures a better representation of the photovoltaic system’s behavior under different operating conditions.
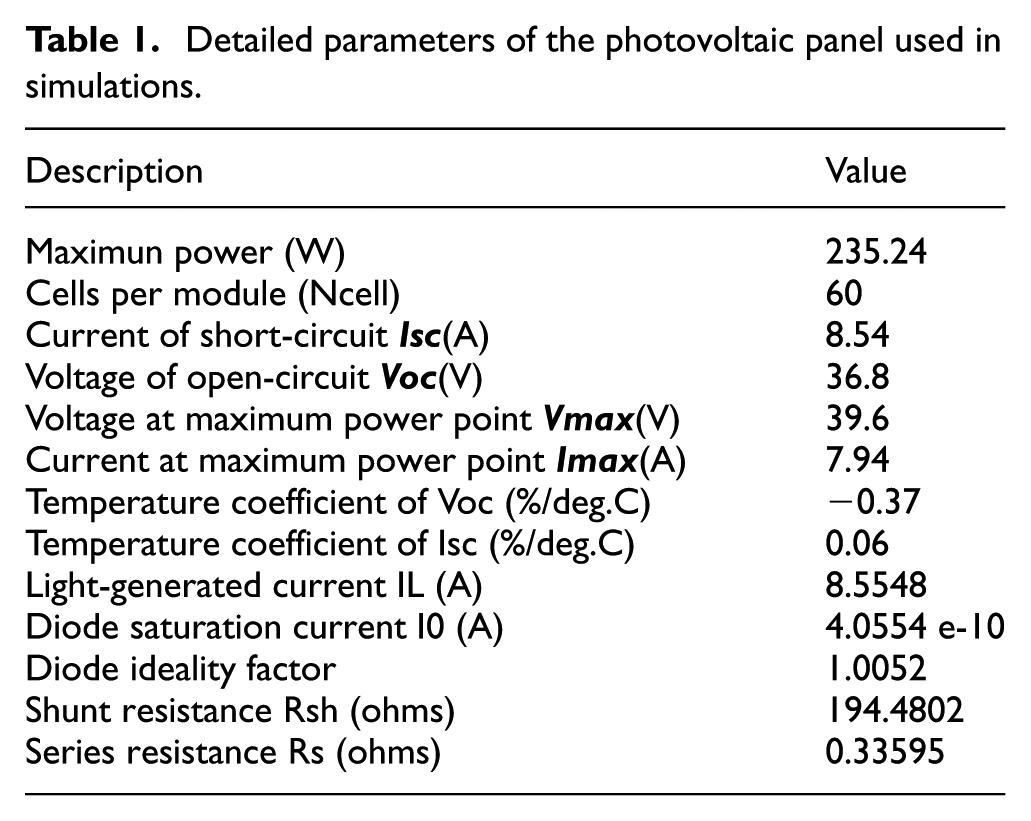
In our study, we have selected a photovoltaic panel with a power rating of 235 W, a value that allows us to evaluate the performance and responsiveness of our MPPT control accurately. It is important to emphasize that our algorithm is designed to be applicable to any type of photovoltaic panel, making the specific choice of model secondary. However, to ensure relevant and representative tests, it was essential to choose a sufficient power rating, capable of demonstrating the effectiveness of our approach.
The detailed parameters of the photovoltaic panel used in our simulations are presented in the following Table 1.
Detailed parameters of the photovoltaic panel used in simulations.
Choice of DC-DC converter for maximum power point tracking (MPPT)
An essential component for the implementation of our innovative MPPT control is the use of a DC-DC converter, which provides an adaptive interface between the photovoltaic panel and the load. Its primary role is to modify the apparent resistance seen by the photovoltaic panel to ensure optimal operation at the maximum power point.
The apparent resistance, denoted as

where
If the apparent resistance is not properly adjusted, the panel may operate at a suboptimal point, resulting in energy loss. Therefore, a well-sized DC-DC converter is essential to ensure efficient extraction of photovoltaic energy. 16
Justification for the choice of boost converter
In theory, any type of DC-DC converter (Buck, Boost, Buck-Boost, Cuk, SEPIC, etc.) can be used to implement an MPPT algorithm, as long as it is properly sized according to the system’s requirements. However, in our study, we have chosen to use a Boost converter (voltage step-up converter) for several practical reasons:
The Boost converter meets both the needs of real-world loads and the requirements of AC conversion systems. Indeed, many photovoltaic applications require a voltage higher than that directly delivered by the panel, whether to power resistive loads, motors, or to ensure good efficiency during AC conversion via an inverter. The Boost converter allows for a controlled increase in voltage, ensuring optimal compatibility with different types of loads and facilitating system integration into hybrid or grid-connected architectures.
Although other converters such as the Buck-Boost could be considered to offer more flexibility by both stepping up and stepping down the voltage, 17 our choice of the Boost converter is based on its suitability for current energy needs and its simplicity of implementation in a photovoltaic conversion context.
Thus, even though any properly sized DC-DC converter could be used, the choice of the Boost converter naturally arises in our study to ensure optimal compatibility with real loads and maximize the efficiency of the MPPT system.
Operating principle of a boost converter in an PV system
The Boost converter is a fundamental component in PV systems. It serves as an adaptive interface between the photovoltaic panel and the load, enabling the maximization of energy extracted from the solar generator. Unlike a direct connection, the converter dynamically adjusts the operating conditions of the panel to ensure it always operates at its maximum power point, regardless of variations in irradiation, temperature, or load.16,17
On the hardware side, the Boost converter consists of several key elements. It includes an inductance that stores energy during the conduction phase, a switch (often a MOSFET transistor) controlled by a pulse-width modulation (PWM) signal, a diode that enables energy transfer to the load while preventing current reversal, and finally, a capacitor that stabilizes the output voltage. These components work in coordination to efficiently convert the input voltage to a higher output voltage (Figure 1).
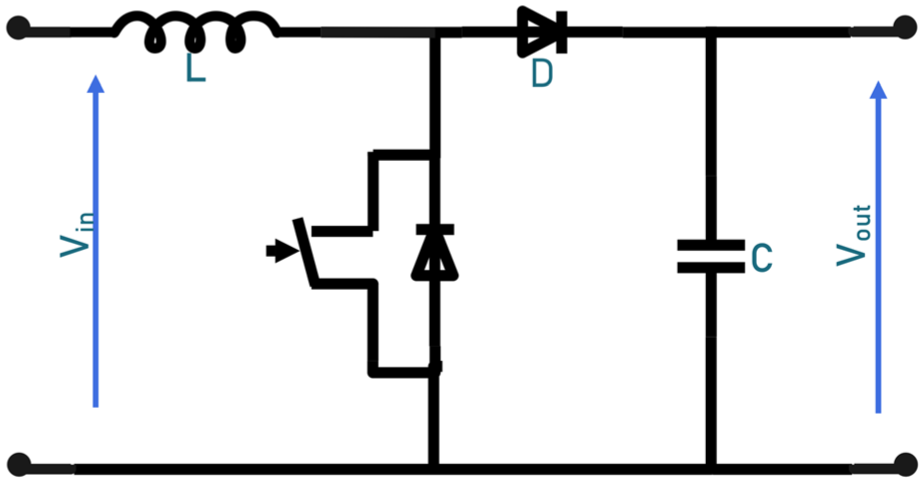
Boost converter circuit.
The operation of the Boost converter relies on two successive phases controlled by a PWM signal:
By modulating the duty cycle (D) of the PWM control, the output voltage

where
Modification of the apparent resistance seen by the panel
The Boost converter modifies the apparent resistance seen by the PV panel, which is crucial for the MPPT algorithm. The electrical resistance “seen” by the panel can be expressed as follows:
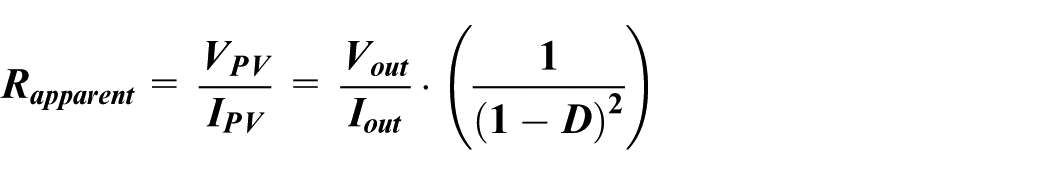
This equation shows that the duty cycle (D) control directly influences the equivalent load applied to the panel. By adjusting this ratio, the converter affects the equivalent load that the panel “sees,” which helps steer its operating point toward maximum power. This variation in the apparent resistance is at the core of the MPPT principle, as it allows the panel to adapt in real time to fluctuations in environmental conditions and load requirements.16,18
Sizing of the boost converter
Importance of proper sizing of boost converter components
Proper sizing of the Boost converter components is essential for ensuring stable, efficient, and reliable operation of the photovoltaic system. Each element plays a specific role in regulating voltage and current, as well as in the system’s response time to variations in environmental conditions. A poorly sized component can severely affect overall performance: oversizing can slow down the response dynamics, add weight to the system, increase costs, and cause unnecessary passive losses. On the other hand, under sizing can lead to significant voltage or current ripples, malfunctions, overheating of components, or even premature degradation. 18
In a PV system, the variability of irradiation and temperature imposes particular demands on the converter’s adaptability. Although the input capacitor
Worst-case design approach
In a photovoltaic system, the electrical parameters of the panel (voltage, current, power) continuously vary depending on weather conditions, including solar irradiation and temperature. This variability makes the sizing of the DC-DC converter particularly challenging, as the components must be able to operate stably and safely even in extreme conditions. To ensure this robustness, a “worst-case design” approach is applied, which involves sizing the converter components based on the extreme (maximum or minimum) values the system might encounter.
Variability of PV parameters
In a photovoltaic system, the electrical quantities output by the panel, such as voltage (V), current (I), and power (P), are not constant. They continuously vary based on environmental conditions, including solar irradiation and ambient temperature. For instance, higher irradiation generally increases the generated current, while higher temperature tends to reduce the output voltage. Thus, the input voltage to the converter (Vin) can fluctuate between the open-circuit voltage
Application of the worst-case design for sizing
To properly size the converter, we consider the following:
Duty cycle D (Boost converter duty cycle)

For
This duty cycle is crucial for sizing the other components.
Calculation of the inductance L
We size the inductance

With:
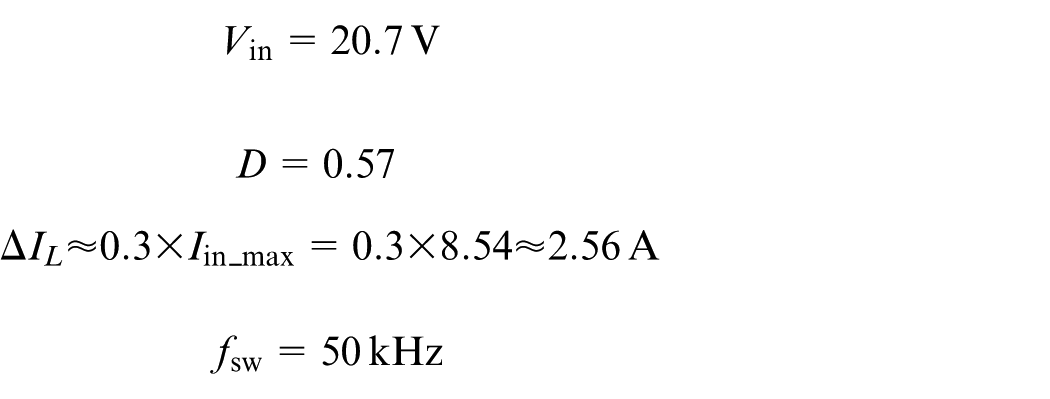
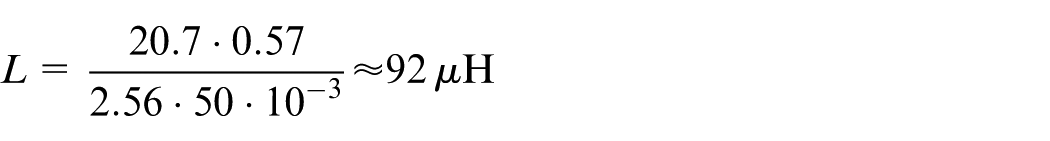
Output capacitor
This capacitor absorbs current variations toward the load while maintaining a stable output voltage.

With:
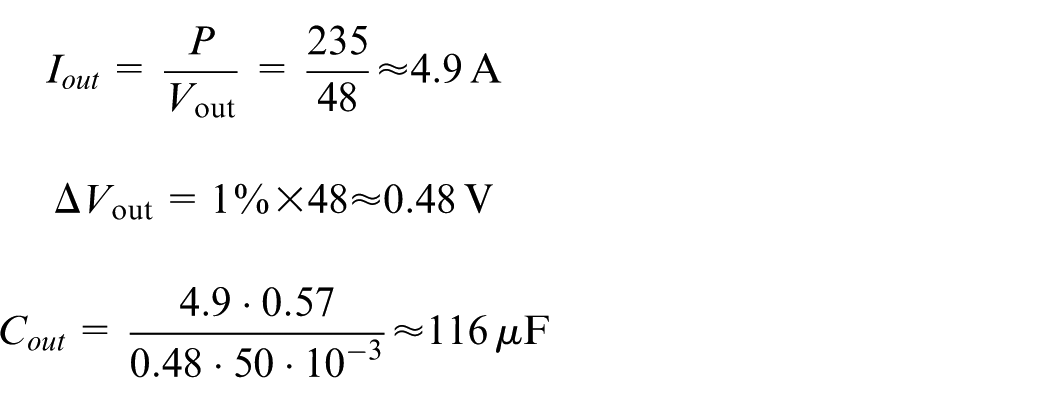
Input capacitor
This stabilizes

With:

Choice of load: Justification for using a resistive load
In the context of our study and to model the response of the MPPT control system clearly and objectively, we chose to use a purely resistive load. This choice is primarily based on the linearity of this type of load, which allows us to observe more directly and accurately the effects of the control on the system’s dynamics. Unlike inductive or capacitive loads, the resistive load neither filters nor dampens voltage and current variations. Therefore, any observed disturbance in power or dynamic behavior of the system can be attributed solely to the control, making it easier to evaluate its performance. In this sense, the resistive load serves as a rigorous test case that highlights the quality of the regulation of our control without any external influence or passive compensation.
Choice of precise control for data collection
The quality of the data used for training an intelligent model depends closely on the precision with which these data are collected. In our case, it is essential to use a control method capable of generating very reliable duty cycle values, as these values serve as the reference for further learning. An inaccurate or poorly estimated duty cycle could skew the learning process and degrade the overall model performance. For this reason, we have ruled out methods based on approximations or regression models, as even the most advanced regressions introduce some degree of uncertainty, which, although sometimes negligible, is still present.
It is in this context that we turned to “test and error” type algorithms, recognized for their reliability and their ability to converge quickly to the maximum power point (MPP) with great precision. These methods explore the search space by directly observing the variation in power in response to a change in duty cycle, making them particularly suited for accurate data collection. We have selected the four most representative approaches in this category, detailed below:
PSO (Particle Swarm Optimization) PSO is an algorithm inspired by the collective behavior of birds or schools of fish. Each candidate solution (particle) explores the search space by following two main directions: its own best-known position and the best-known position of the entire group. In the context of MPPT, each particle represents a potential value of the duty cycle, and the goal is to maximize the extracted power. PSO is known for its fast convergence and ability to avoid local minima, making it an excellent candidate for precise data collection.
GWO (Grey Wolf Optimizer) GWO is an optimization algorithm based on the social hierarchy and hunting tactics of grey wolves. It models behaviors such as encircling, hunting, and attacking prey, here represented by the MPP. GWO classifies solutions into four types of wolves (alpha, beta, delta, omega), each playing a specific role in the convergence toward the optimal solution. Its ability to balance exploration and exploitation well makes it a robust tool for extracting reliable data, even under variable conditions.
Perturb & Observe (P&O) P&O is one of the simplest and most classic methods for MPPT. It is based on a basic principle: slightly perturb the duty cycle and observe the change in power. If the power increases, the perturbation continues in the same direction; otherwise, it is reversed. Despite its simplicity, this method can be very accurate when properly tuned, especially under stable conditions. It remains a reference for initial data collection.
Incremental Conductance (IncCond) The Incremental Conductance algorithm relies on analyzing the slope of the power-voltage curve. It uses the derivative
These algorithms, although based on different principles, share a fundamental commonality: their ability to dynamically assess the system’s behavior without relying on predefined models.
Comparison and justification for the choice of reference algorithm
From a comparative perspective, each “test and error”-based algorithm has strengths and limitations, particularly depending on the environmental variation conditions and the characteristics of the load or system. To select the most suitable algorithm for precise data collection, a reasoned elimination process was applied.
The PSO (Particle Swarm Optimization) and GWO (Grey Wolf Optimizer) algorithms stand out for their ability to quickly converge to the maximum power point (MPP), especially in cases of significant and sudden environmental variations (such as in wind systems). Their principle is based on partitioning the search space into several regions, within which the algorithm searches for the optimal solution by dynamically adjusting intervals. This strategy is effective for rapidly exploring a wide range of values, but it becomes less optimal when the new MPP is very close to the previous one, as unnecessary additional calculations are made, slowing down the process in environments with gradual variations, such as photovoltaic systems subject to gradual changes in irradiation or temperature. Moreover, the algorithmic complexity of these methods makes them less attractive for lightweight and real-time implementations. Therefore, PSO and GWO are better suited for wind systems, where variations are sudden and unpredictable.
The Perturb and Observe (P&O) algorithm, although effective at quickly detecting small variations and adjusting the maximum power point (MPP), has limitations in maintaining MPP stability in photovoltaic systems under gradual conditions. Its constant perturbation principle leads to permanent oscillations around the MPP, which can be problematic in linear configurations, but becomes advantageous when coupled with inductive or capacitive loads. These types of loads, which present nonlinear behavior due to their ability to store energy in magnetic or electric fields, cause delays in the system’s response and fluctuations in voltage and current. In this context, the continuous exploration method of P&O becomes useful, as it dynamically adapts the operating point to the micro-variations generated by these reactive loads. However, for our control, where MPP stability and precise data collection are critical, this characteristic of continuous oscillation is counterproductive. Indeed, it does not guarantee the stable and coherent response required for reliable data collection, which leads us to discard the P&O algorithm in favor of more suitable approaches.
On the other hand, the Incremental Conductance (IncCond) algorithm proves to be the most suitable choice for our application. Its operation relies on a differential analysis of the power-voltage curve, through the calculation of the derivative
Thus, considering stability, precision, responsiveness, and ease of implementation, the Incremental Conductance algorithm stands out as the best candidate for our real-time data collection system, serving as the reference for the learning of our intelligent MPPT control.
MPPT control without a learning phase
Our innovative control strategy is based on a hybrid approach that combines two methods: the traditional Incremental Conductance (IncCond) and the intelligent k-Nearest Neighbors (k-NN) algorithm. This hybridization, of the bagging type, leverages the strengths of both methods while mitigating their respective drawbacks. The goal is to create a robust and adaptive solution for Maximum Power Point Tracking (MPPT) in photovoltaic (PV) systems, reducing oscillations and improving energy efficiency.
Operation of the hybrid control system
At the system’s startup, the IncCond control is activated to collect real-time data while the system generates electricity. This initial phase builds a dynamic database that captures variations in voltage, current, and power based on environmental conditions (sunlight, temperature) and system characteristics. Although IncCond relies on iterative perturbations, it is effective in establishing a solid and adaptive reference base.
Once the database is sufficiently enriched, the k-NN control is gradually integrated. Unlike IncCond, which uses iterative tests to locate the MPP, k-NN employs a predictive approach based on data similarity. By identifying the closest data points in a multidimensional space, k-NN predicts the MPP without requiring continuous perturbations. This gradual transition helps reduce oscillations around the optimal point and enhances system stability.
Advantages of the hybrid approach
This hybrid approach offers several key benefits. First, it combines the adaptability of IncCond, which performs well under varying conditions, with the speed and precision of k-NN, which minimizes disturbances and optimizes energy efficiency. Second, it enables continuous performance improvement: as the system operates, the database grows, and the k-NN control becomes increasingly accurate and responsive.
Finally, this hybridization eliminates the need for a prior learning phase, which is often required by pure intelligent methods. It ensures a smooth transition from a traditional model to an intelligent one, while minimizing implementation costs and complexities.
Design of a database and data processing
Data collection
A crucial step for our algorithm is the progressive creation of a database, intended for future use. This database is built gradually, particularly in situations where the available data is insufficient to effectively predict the duty cycle that manages the maximum power point (MPP). In such cases, we use the Incremental Conductance (IncCond) algorithm, which is based on the trial-and-error principle, to search for the optimal duty cycle.19,20
It is important to note that the IncCond algorithm requires a variable amount of time to find the optimal duty cycle, as this time depends on previous conditions, which are often random. The data collection strategy relies on a rigorous observation of system stability before recording values into the database. Specifically, data is only recorded when the power generated by the system stabilizes (i.e. when the derivative of power with respect to time,
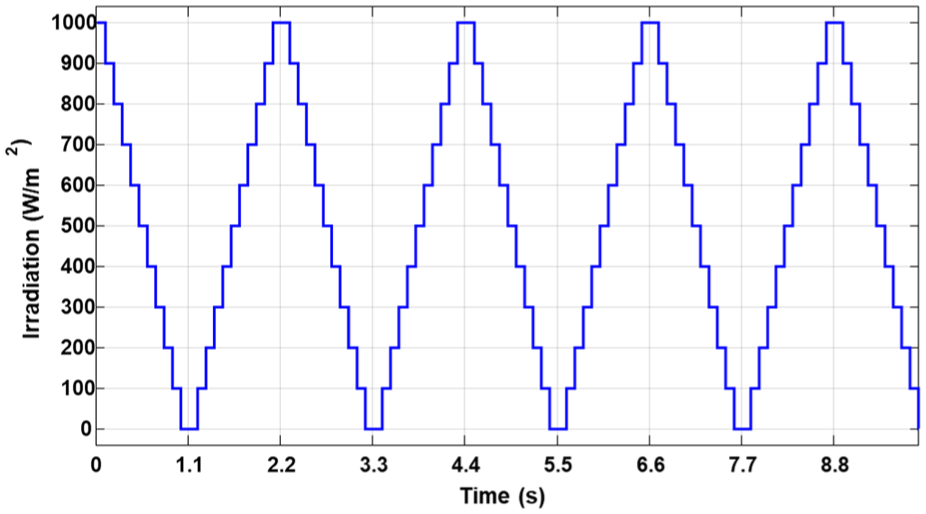
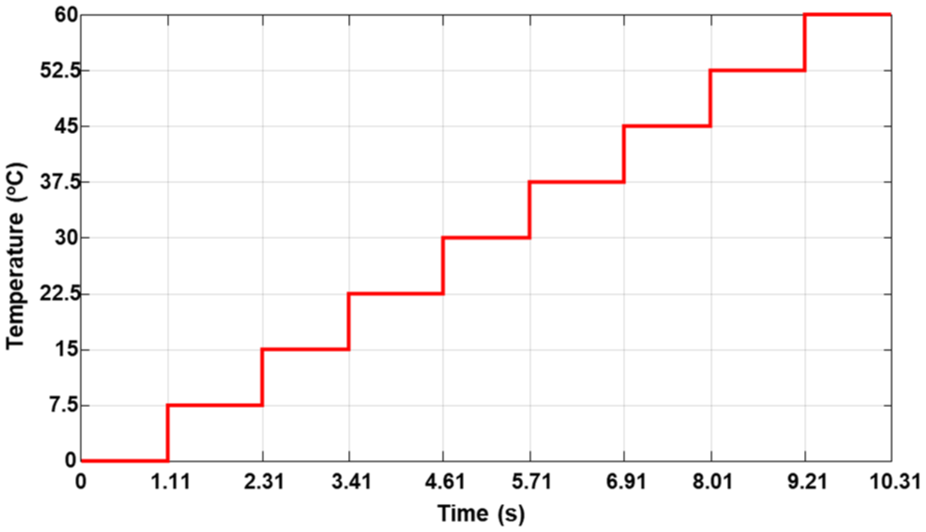
To validate this method, we tested our strategy’s ability to collect and build a database using the Simulink tool. We implemented the algorithm in a functional block and then simulated the system under various changing weather conditions, including variations in irradiation (illustrated in Figure 2) and temperature (illustrated in Figure 3).
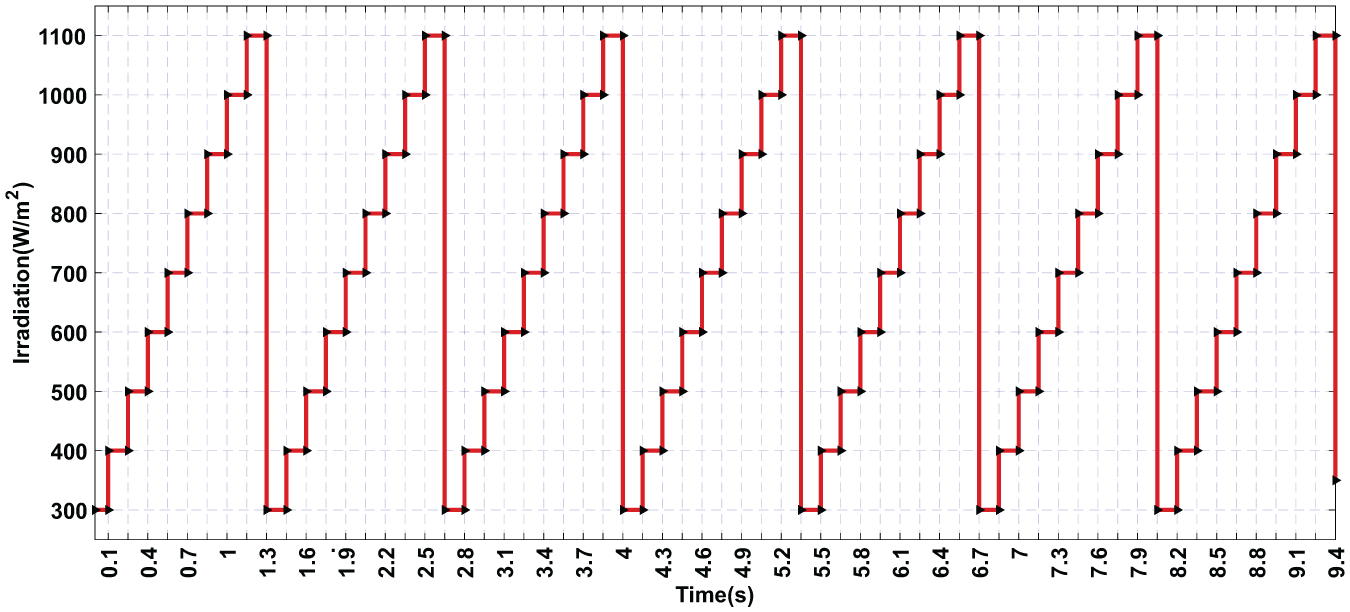
Variation of solar irradiation over time simulated changes in irradiation levels used to test the data collection strategy under dynamic environmental conditions.
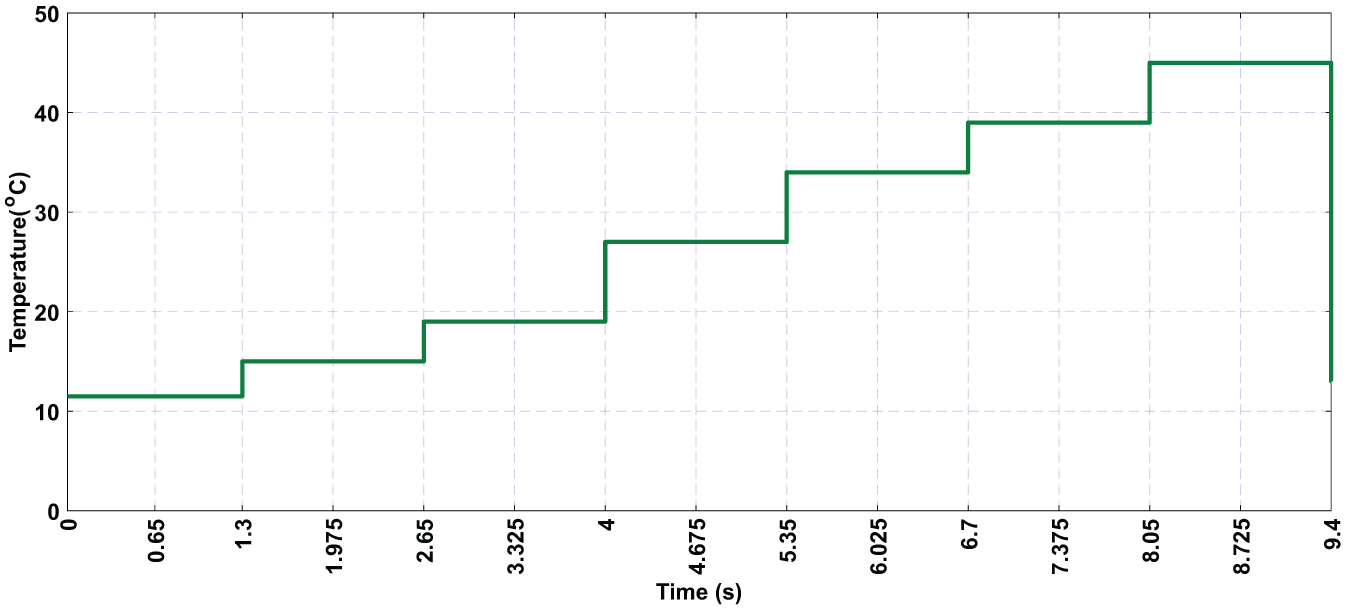
Variation of temperature over time simulated temperature fluctuations used to evaluate the system’s response and data collection accuracy under varying thermal conditions.
Figure 4 below illustrates that the IncCond algorithm, integrated with the data collection strategy, is capable of effectively adapting to fluctuations in environmental conditions while building a robust database to enhance the system’s long-term performance.
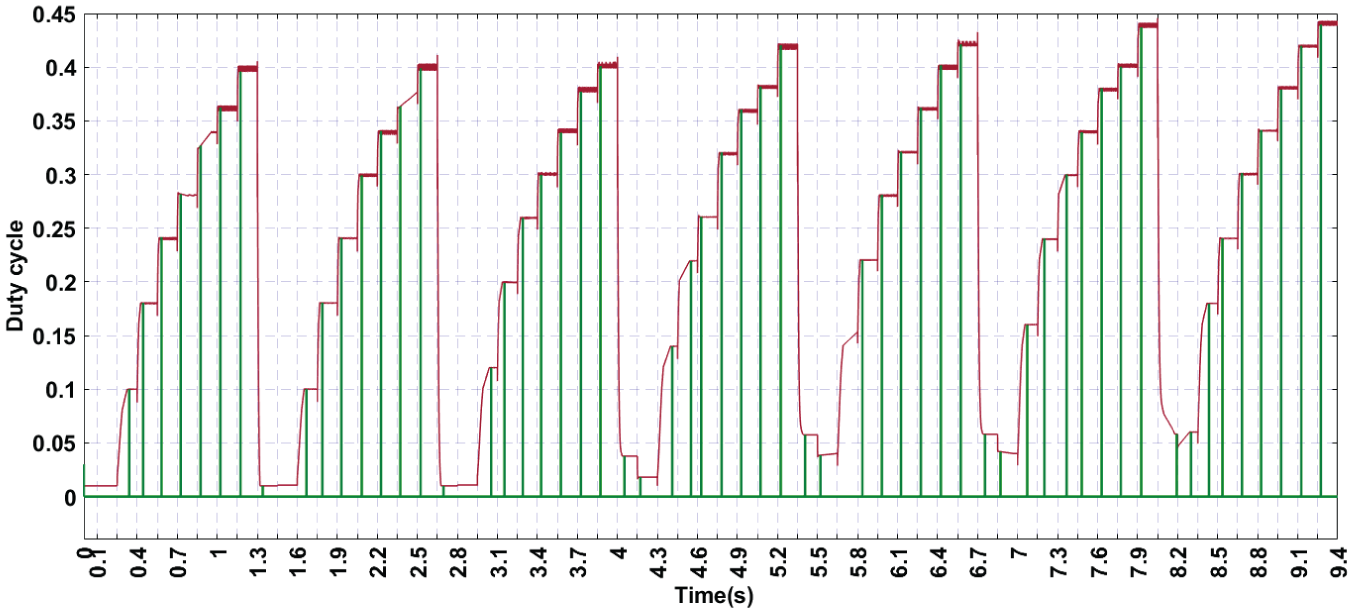
Evolution of the duty cycle and data recording—illustration of the duty cycle (red curve) adapting to weather variations and the moments of data recording (green curve) after MPPT stabilization.
This figure highlights the ability of our algorithm to identify and record the optimal duty cycle, which is essential for maximizing the energy efficiency of the photovoltaic (PV) panel. The duty cycle, represented by the red curve, evolves in response to variations in weather conditions, particularly irradiation and temperature. These variations directly influence the optimal operating point, requiring precise and rapid adjustments to maintain maximum performance.
The blue curve illustrates the moments when the system records the duty cycle in the database. This recording occurs only after the maximum power point (MPPT) has been identified by the algorithm. This capture signal marks the reliability of the recorded data, ensuring that the duty cycle aligns with the actual operating conditions.
However, as shown in the figure, there is a delay between changes in weather conditions and the recording of the new duty cycle. This delay is due to the time required by the Incremental Conductance (IncCond) algorithm to detect and confirm the stability of the maximum power point. This stability is evaluated using the criterion
This methodical approach guarantees increased accuracy in data collection. The observed delay, although inevitable, is a necessary compromise to avoid erroneous recordings and maintain a reliable database. By progressively enriching this database with precise values, the system enhances its long-term performance, reducing the time and effort required to identify the MPPT in similar scenarios.
Description of the hybrid MPPT control algorithm
Our control strategy, based on a bagging-type hybridization of the (IncCond) and (k-NN) algorithms, enables seamless switching between the two algorithms depending on specific conditions. It is essential to understand the underlying logical operation of the system’s control. This algorithm was designed to optimize (MPPT) under varying weather conditions. It relies on intelligent decision-making, grounded in the analysis of available data from a pre-existing database and, when necessary, the application of real-time learning and adjustment methods. The goal is to ensure a smooth transition between different stages, effectively leveraging available data when it exists or recalculating critical parameters if conditions are not covered.
The diagram below provides a clear and structured representation of the algorithm’s logical flow, highlighting decision points, associated actions, and the continuous integration of new information for ongoing system improvement (Figure 5).
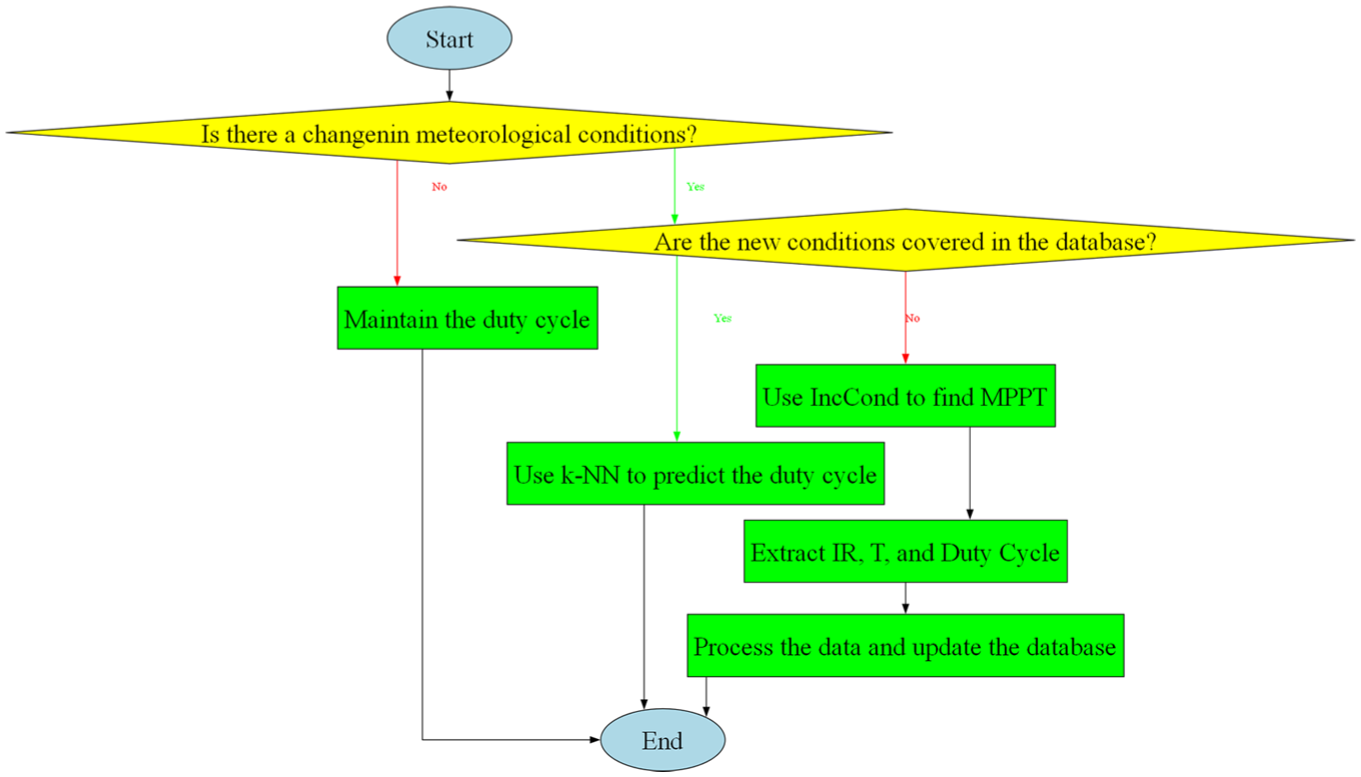
Logical flow of the hybrid MPPT control algorithm—illustration of the decision-making process, algorithm switching, and continuous data integration for optimal system performance.
Database design
To ensure the reliability and performance of our control system, it is essential to effectively structure the processing and organization of data collected during system operation. Rigorous data management not only ensures optimal performance but also reduces system complexity and prevents overfitting. This involves a thoughtful selection of the data to be retained, focusing only on what is necessary to minimize storage requirements and guide the algorithm accurately and efficiently.
To ensure effective subsequent regression, data processing must consider the following constraints:
Avoid Redundancy: The system should not collect closely related data that conveys the same meaning. This reduces unnecessary redundancy, simplifies the model, and improves data processing efficiency.
Use Real Measurements: The database should be developed using real measurements rather than predictions. This approach avoids complex errors associated with incorrect predictions, ensuring that the collected data accurately reflects real conditions.
Proper Data Spacing: Data should be well-spaced to cover a wide range of scenarios. Proper spacing captures the diversity of operating conditions, enhancing the model’s ability to generalize and make accurate predictions.
Regular Data Updates: Regular updates to the database are essential. When a new, better-dimensioned and better-located data point is received, it should replace the old one. This continuous updating allows the system to adapt and improve based on new information, maintaining the model’s accuracy and relevance.
Preference for Imperfect Data Over No Data: It is preferable to have imperfect data rather than no data at all. Even imperfect data can provide useful insights for system operation and contribute to model improvement.
In the context of (MPPT) using the (IncCond) method, it is crucial to evaluate whether the obtained data can enrich the database and enhance its performance. This evaluation checks if the data is relevant enough. The goal is to predict the optimal duty cycle directly and accurately in future cases. If successful, it would remove the need for trial-and-error methods. If the collected data demonstrates potential for improvement, particularly by enhancing the k-NN algorithm’s ability to deduce the optimal duty cycle effectively under similar conditions, it should be integrated into the database. The goal is to build a well-structured and uniformly distributed data matrix capable of covering the entire operating range of the system. 19
The matrix designed for optimal propagation includes irradiation values ranging from 0 to 1100 W/m2, with an interval of 40 W/m2. For temperature, it covers a range from 0°C to 60°C, with a step of 2°C. This configuration ensures comprehensive and precise coverage of irradiation and temperature variations, enabling better system adaptation to diverse operating conditions. This optimal database can be represented by the following Figures 6 and 7:
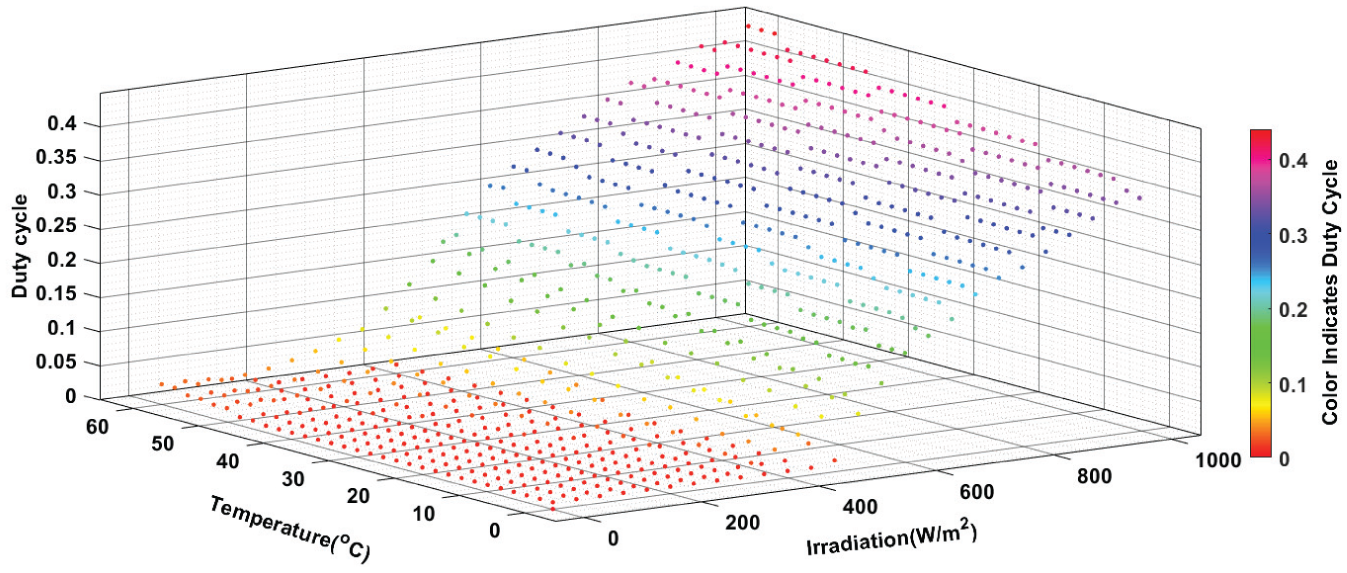
3D View of data propagation, showing the distribution of irradiation, temperature, and duty cycle values across the operating range.
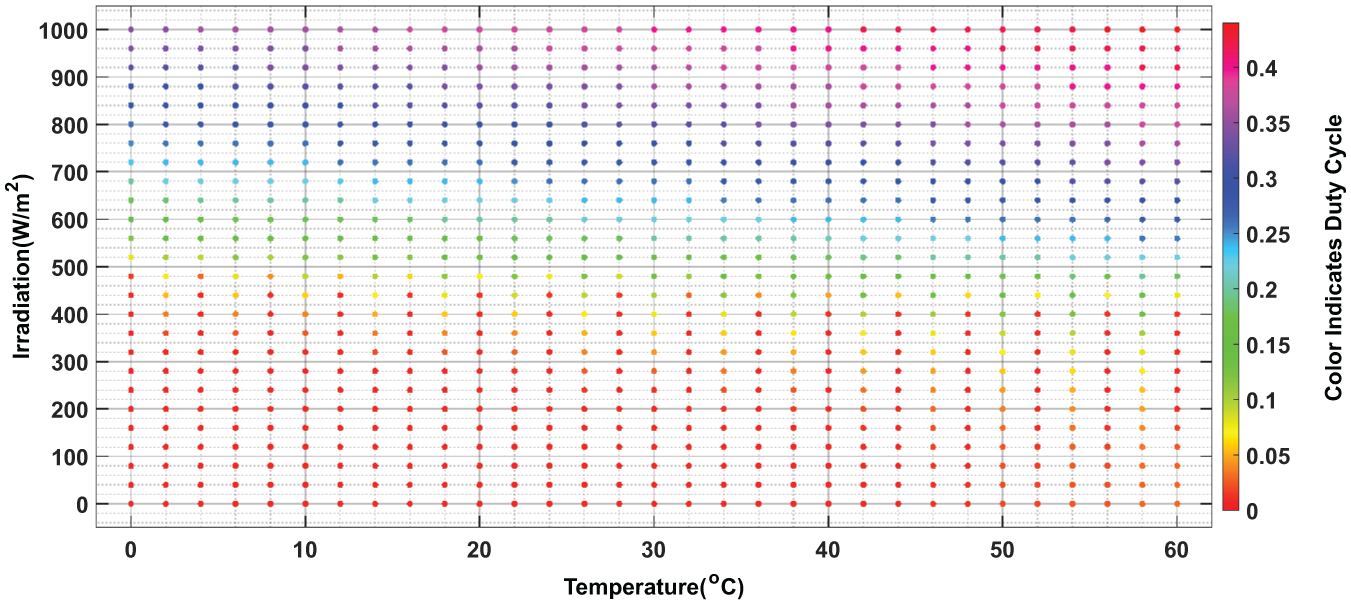
2D View of irradiation and temperature distribution, illustrating the relationship between irradiation and temperature values across the operating range of the system.
These figures provide a clear visualization of how the data is structured and distributed, ensuring comprehensive coverage of the system’s operating conditions and facilitating accurate predictions for maximum power point tracking.
However, due to the random nature of the collected data, the ideal values offering the best propagation are often rare. To overcome this limitation, the system records the available data that most closely approximates the ideal conditions, thereby maximizing the propagation and reliability of the matrix. This approach ensures high performance and accuracy, even in the presence of non-optimal data, by fully leveraging the collected information to provide effective and robust coverage of the operating range.
The algorithm, capable of developing the database and ensuring its reliability over time while adhering to the previously mentioned constraints, is illustrated in the following algorithm:

General concept of the algorithm
This algorithm implements a continuous improvement strategy for the MPPT control database using the k-NN approach. It is based on the principle of progressive optimization rather than simply selecting the best data. The core idea is that a less representative data point is still preferable to having no data at all, while constantly striving to improve the overall quality of the database. When a new dataset arrives, the algorithm assesses whether it can improve upon the data already stored at the optimal location. If the new data offers better propagation capability, it replaces the old data. However, the algorithm doesn’t just discard the replaced data. Instead, it intelligently attempts to reposition these older data points in neighboring locations where they could still be useful, adhering to the principle that partially representative data is better than an informational void.
Optimization and redistribution methodology
The method operates through a sequential process divided into three main phases, corresponding to the key stages of the algorithm. The localization and direct insertion phase (steps 1–3) identifies the optimal location for the new data and proceeds with immediate insertion if the location is vacant, thereby avoiding unnecessary comparisons. The comparative evaluation and replacement phase (steps 4–5) is the core of the improvement strategy: it compares the propagation ability of the new data with that of the existing data at the optimal location, performs replacement if an improvement is detected, and systematically explores neighboring locations to optimize distribution. This phase applies the principle of intelligent redistribution by first searching for empty neighboring slots for the new data if it cannot replace the optimal point, then evaluating potential replacements in the vicinity. Finally, the displaced data management phase (steps 6–7) ensures that no potentially useful information is lost by repositioning the replaced old data into appropriate neighboring locations, thereby ensuring progressive and optimal densification of the database without leaving exploitable empty spaces.
MPPT control using k-NN
The primary objective of MPPT control using the k-NN algorithm is to predict the optimal duty cycle
Step 1: Locating neighboring points in an organized database
The first step involves locating the 4 nearest neighbors of the target point
For a target point
-
-
-
The organization of the database with fixed steps for
Additionally, although the database is approximately propagated, it is sufficiently dense to ensure that each target point
Step 2: Calculating Euclidean distances to neighboring points
Once the 4 neighboring points are identified in the database, the next step is to calculate the Euclidean distances between the target point
For each neighbor
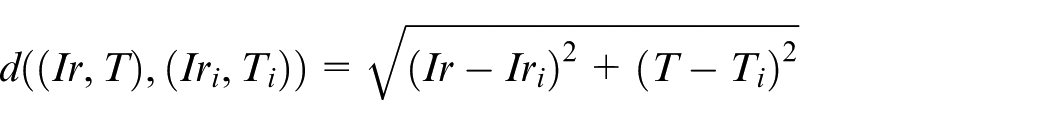
For the 4 neighbors
Euclidean distances represent a measure of proximity in the meteorological condition space
Step 3: Determining weights using inverse distance
After computing the Euclidean distances between the target point
The method used is inverse-distance weighting, which means that closer neighbors are given more importance since their meteorological conditions are more similar to those of the target point.
The weight

where:
-
Step 4: Calculation of the predicted duty cycle
The duty cycle

Where:
-
-
This MPPT control method offers an optimal balance between precision, adaptability, and robustness. By combining a well-structured and propagated database with weighted interpolation techniques, it effectively predicts the duty cycle under various meteorological conditions without requiring intensive real-time computations. Systematic validation ensures reliable performance, even in situations where the data does not precisely cover new conditions. Thus, this approach not only improves the speed and stability of MPPT tracking but also reduces reliance on traditional algorithms while optimizing energy extraction, which is crucial for modern photovoltaic systems.
Evaluation and justification
Our control strategy is based on an innovative principle aimed at maximizing the performance of photovoltaic (PV) systems by dynamically adapting to variations in meteorological conditions, such as irradiation and temperature. Each change in these parameters triggers an evaluation of the target zone’s coverage in the database. If the zone is already covered, the algorithm uses existing data to directly predict the optimal duty cycle using supervised learning methods, such as k-NN. Otherwise, the control activates an iterative process: the Incremental Conductance (IncCond) algorithm determines the maximum power point (MPPT), and the collected data (irradiation, temperature, and duty cycle) are integrated into the database while adhering to proximity and propagation constraints.
This process ensures a progressive and structured construction of the database, enabling not only effective coverage of the entire operating range of the system but also optimal utilization of available information to accurately predict the optimal parameters. This approach is essential in a big data processing context, as it promotes intelligent data organization while maximizing its utility.
This innovative control strategy was tested using the MATLAB 2023a simulation software. We modeled a photovoltaic (PV) energy production chain controlled by the duty cycle variation of a DC-DC converter. This modeling aims to explain the power regulation phenomenon and illustrate the operating principle of the control. The detailed and structured model is represented by the following Figure 8.
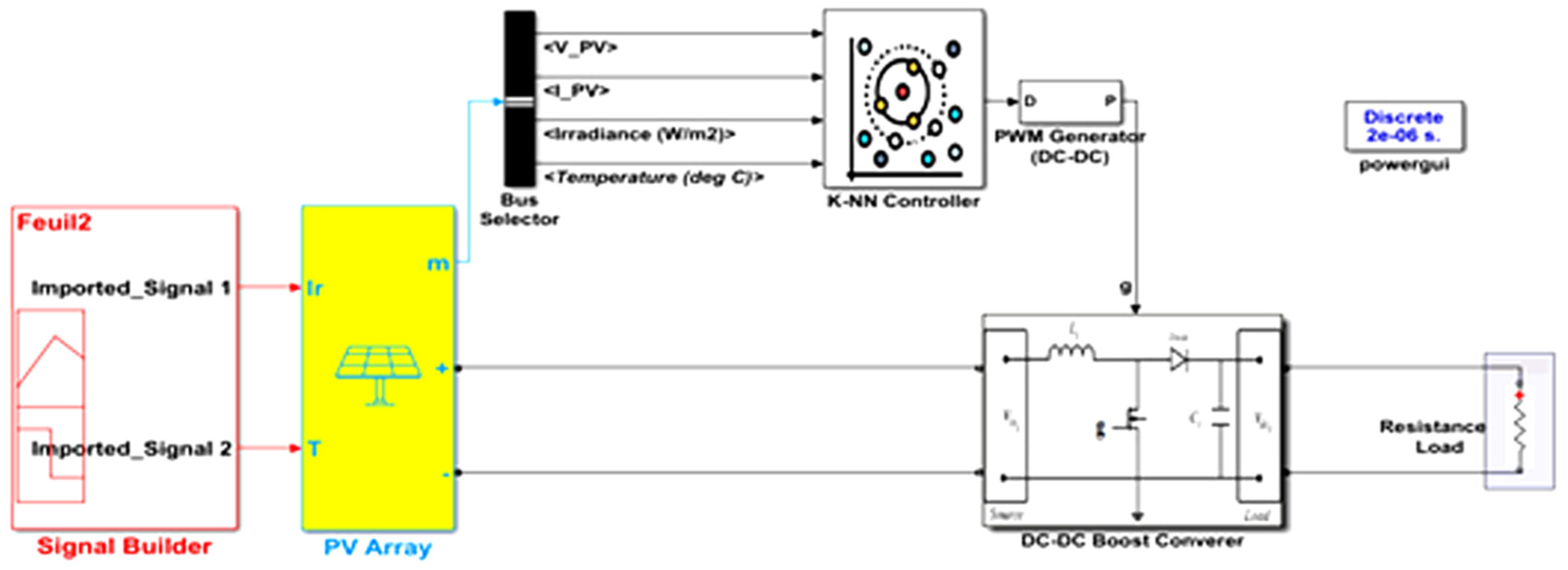
Simulation model of the PV energy production chain. A detailed representation of the PV system controlled by a DC-DC converter.
This figure provides a clear visualization of the system’s structure and the interaction between its components, facilitating a better understanding of the control strategy’s implementation and performance.
Scenario 1: Initial construction of the database
To clearly demonstrate the performance and reliability of our innovative Maximum Power Point Tracking (MPPT) control algorithm, we designed several experimental scenarios that cover the full dynamic behavior of the photovoltaic system.
The first scenario represents the initial construction phase of the database, where the database is completely empty. In this situation, our control algorithm is exposed to an unknown environment and must autonomously build and populate the database while strictly adhering to predefined consistency constraints.
To evaluate this behavior, we subjected the system to a series of carefully selected meteorological conditions (irradiance and temperature). The goal is to observe how the control mechanism collects, validates, and stores meaningful data in real time. This initial phase is critical, as it lays the foundation for future predictions—the quality and spatial coverage of the database built at this stage directly affect the effectiveness of the MPPT strategy in subsequent scenarios.
These variations are illustrated in the two figures (Figures 9 and 10) below:
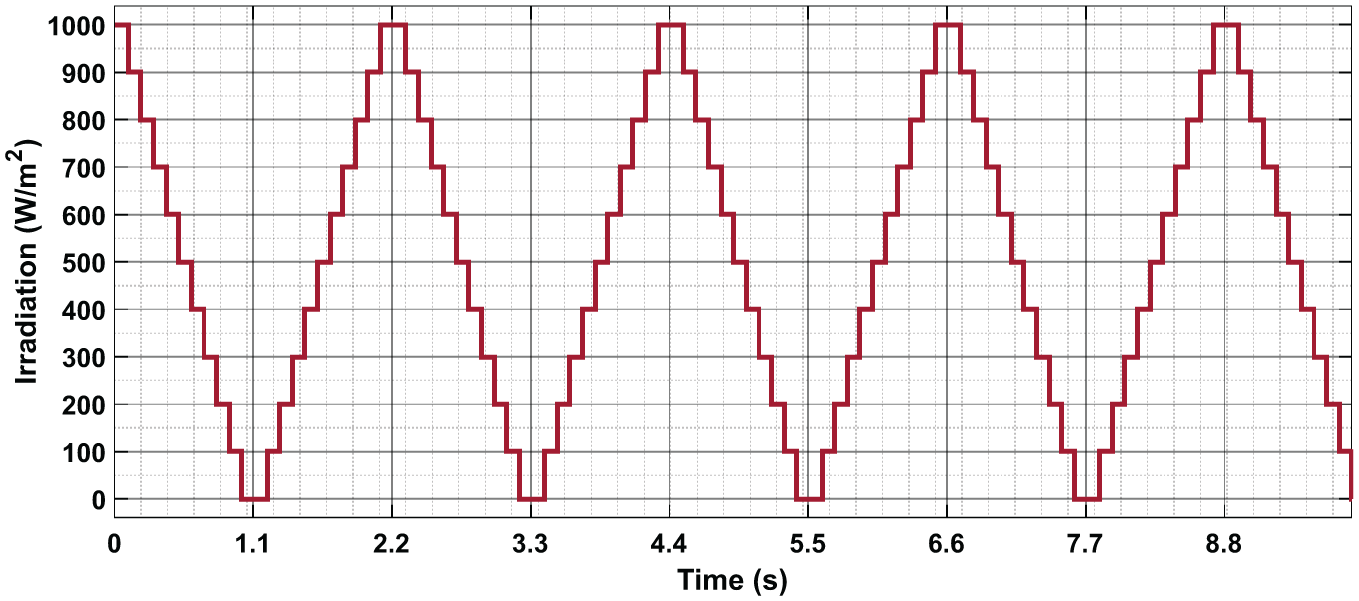
Irradiance profile applied during initial database construction.
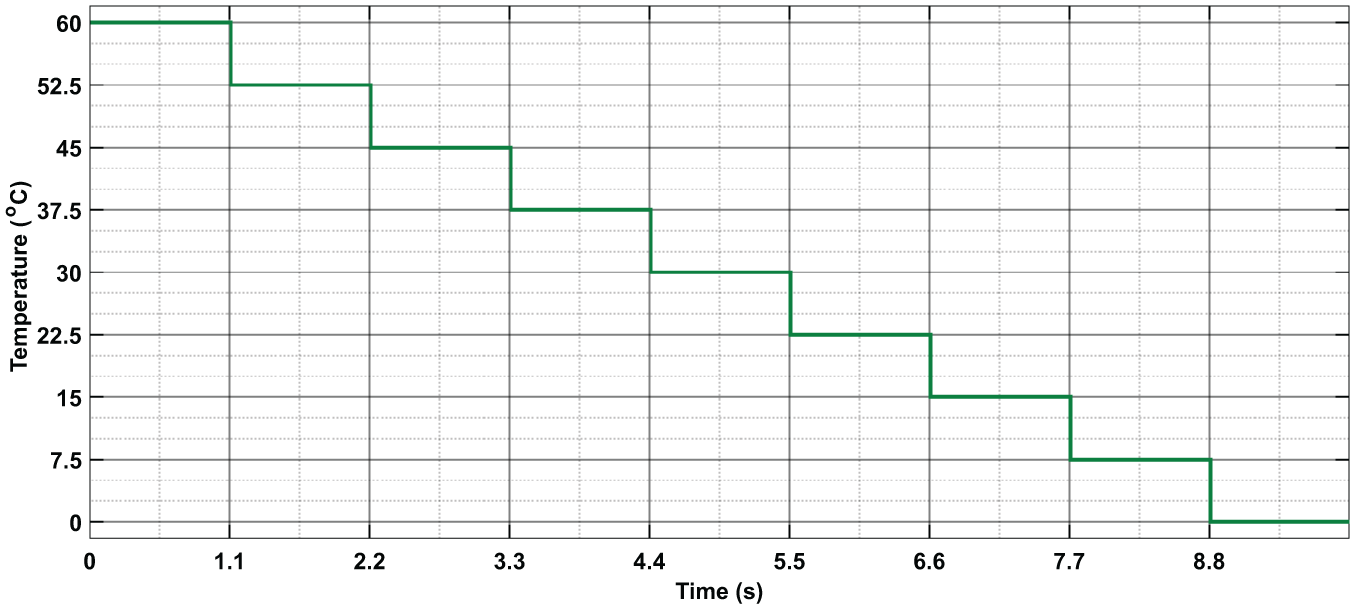
Temperature profile applied during initial database construction.
In this scenario, once the system identifies the maximum power point (MPP) under current environmental conditions using the Incremental Conductance (IncCond) algorithm, it captures a data set composed of irradiation (W/m2), temperature (°C), and duty cycle.
Afterward, the algorithm determines the optimal storage location within the database for this data set. This decision is based on a strategic spatial organization, designed to ensure that each data entry can be easily accessed and efficiently reused in future MPPT control scenarios—especially when employing the k-NN algorithm.
Figure 11 below illustrates this mechanism through a 2D representation of the database. The
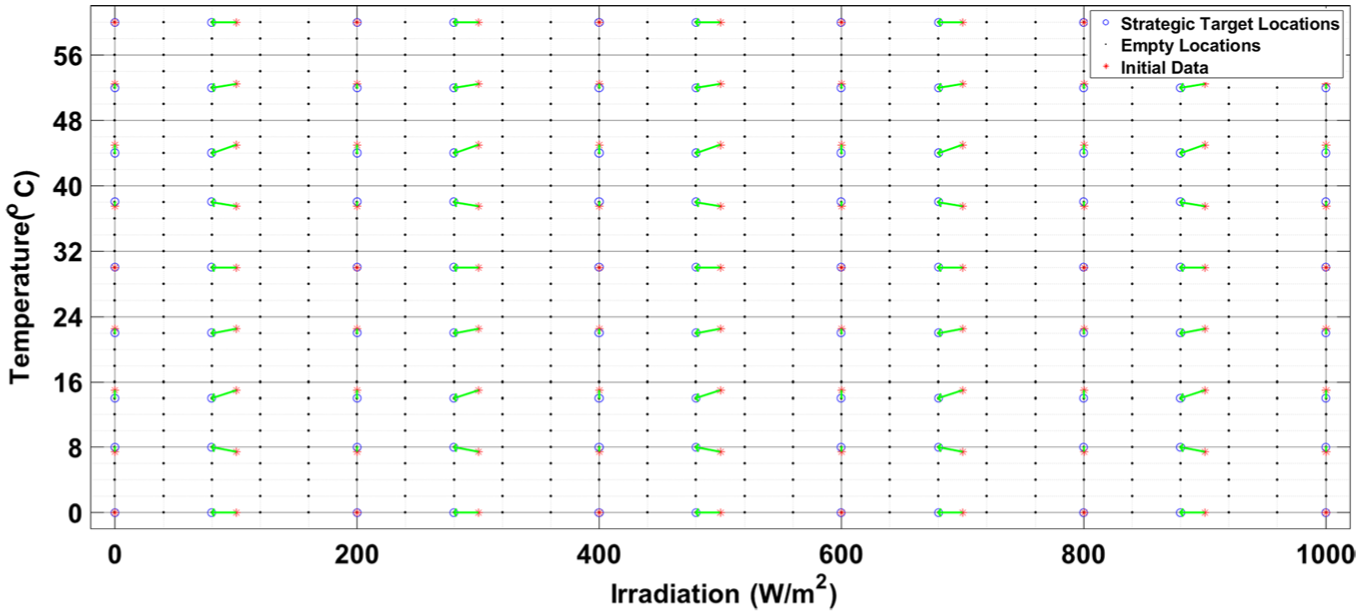
Strategic allocation of captured data points in the MPPT database grid.
Rather than storing data randomly, the system builds the database strategically anticipating future needs and ensuring quick and reliable access to high-quality data points. This organization not only improves the efficiency of real-time search and retrieval, but also enhances the accuracy of MPPT control by ensuring that relevant neighboring points are optimally placed within the environmental condition space.
The data captured during this scenario can be represented in the three-dimensional space illustrated in Figure 12, to better visualize the structure and distribution of the database. Each point corresponds to a measured set consisting of irradiance, temperature, and the associated duty cycle.
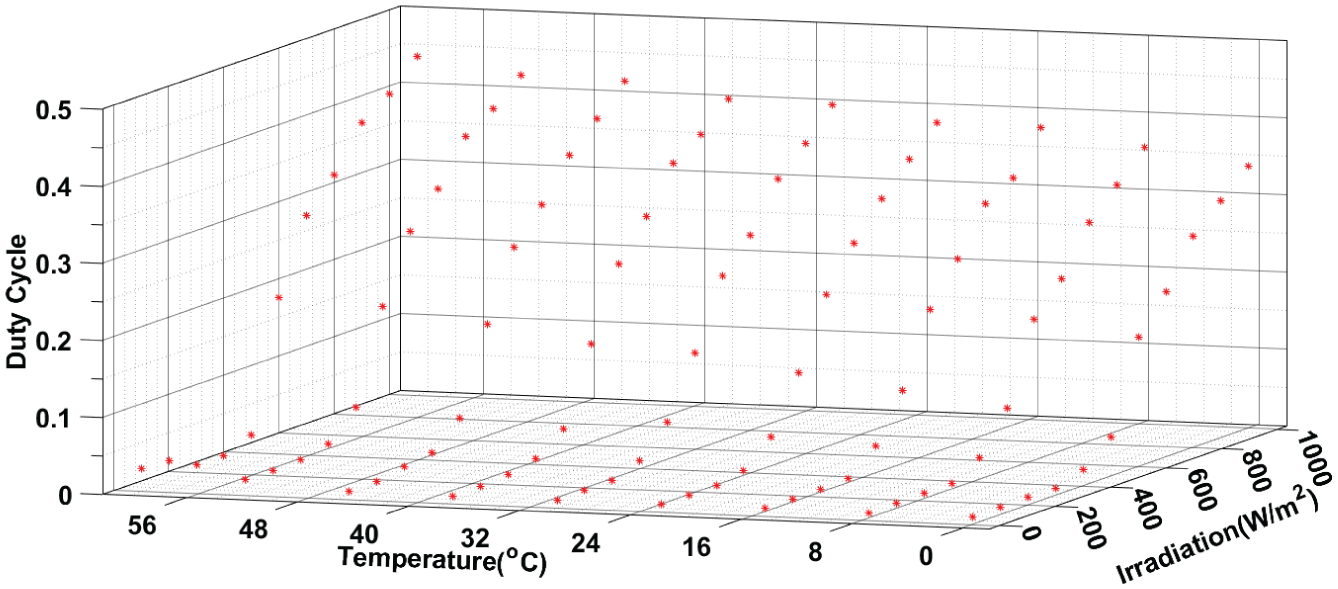
3D Visualization of database evolution. A three-dimensional representation of the database’s progressive construction.
Second scenario: Intelligent database update
Following the evaluation of the initial database construction phase, we now proceed to a second scenario designed to test the system’s ability to perform intelligent updates. The objective is to analyze how the database responds when it is already partially populated and new data recorded under weather conditions similar to previously stored entries is introduced.
In this case, the system is exposed to slight variations in irradiance and temperature, close but not identical to the data from the first scenario. This situation creates a storage conflict, as the optimal storage locations are already occupied by prior entries.
Figures 13 and 14 illustrates the evolution of irradiance and temperature, allowing us to assess the efficiency of the database update process.
Applied irradiance conditions testing DB update capability.
Temperature conditions evaluating intelligent DB update.
A key focus of this study involves the intelligent management of storage conflicts within the database system. When inserting new meteorological data, the system systematically evaluates whether the optimal storage location determined by maximum propagation criteria is already occupied. If occupied, it implements a sophisticated decision-making algorithm based on propagation quality metrics: if existing data demonstrates suboptimal propagation characteristics, it may be overwritten by new entries with superior diffusion properties. Conversely, when resident data is already optimally positioned, the system activates alternative strategies—either storing the new information in an available secondary location or executing partial database reorganization by relocating existing entries to optimize overall structure. This dynamic mechanism maintains consistently high database performance while adapting to environmental fluctuations. The accompanying figure demonstrates these priority criteria in action during database updates, clearly illustrating replacement scenarios, secondary storage allocation, and optimized reorganization processes. The system’s ability to make these nuanced decisions ensures data integrity while maximizing propagation efficiency across varying weather conditions.
Figure 15 highlights the adaptive capability of our intelligent system to dynamically manage its database during the transition from the first to the second scenario. It illustrates the smart reorganization strategy implemented by our algorithm to optimize the quality of coverage within the meteorological space.
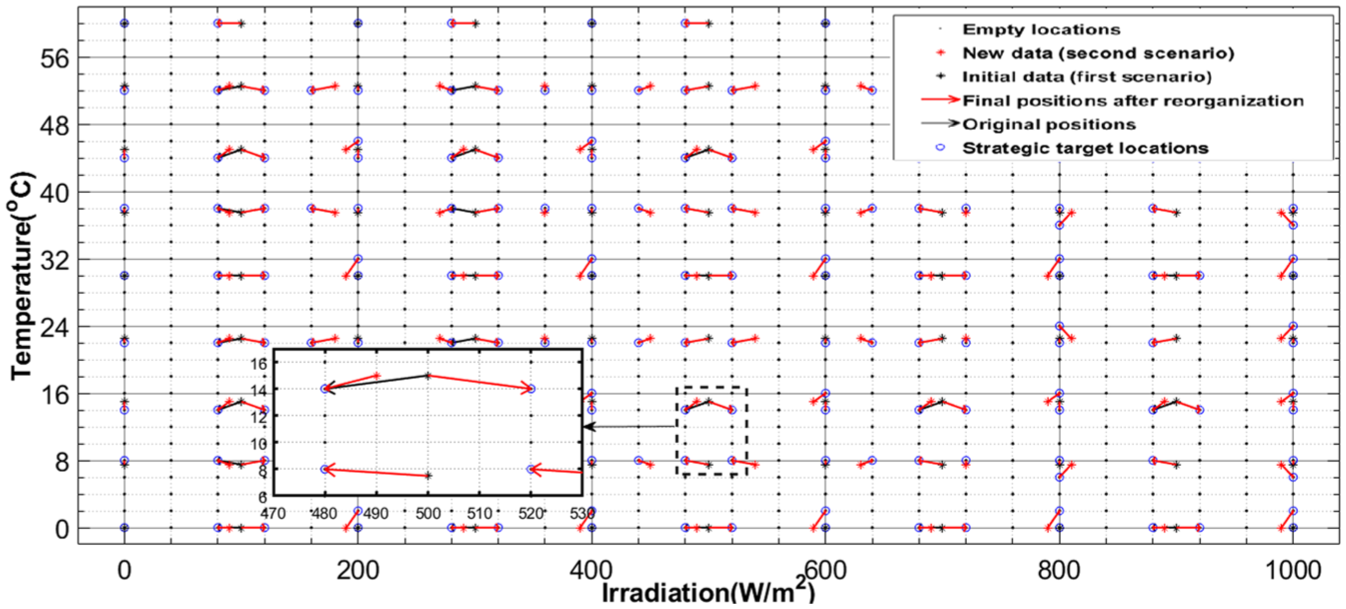
Adaptive reorganization of the database between two meteorological scenarios.
Data entries in the database are represented by
This innovative approach is based on a logic of continuous improvement. Unlike traditional systems that passively accumulate data, our algorithm takes a proactive approach: it constantly reassesses the informational value of each data point and adjusts its placement accordingly. This ensures that the database remains compact yet highly effective, reinforcing key zones and enabling more accurate and faster estimation of the maximum power point.
Through this technique, our system does more than simply respond to changing environmental conditions it learns, organizes, and optimizes its knowledge in real time, thereby enhancing the reliability and responsiveness of MPPT tracking.
Strategic preparation of the database
Before moving on to the actual third scenario (dedicated to evaluating the performance of our intelligent control system), a crucial step involves finalizing and consolidating the database built during the first two phases (initialization and updating). This preparation phase is essential, as it ensures the availability of a sufficiently rich, diverse, and representative dataset to test the robustness and effectiveness of the system under realistic conditions.
The database obtained at this stage consists of a mix of data: some points are ideally positioned to ensure effective propagation when using the KNN method marked with “*,” while others, inserted in suboptimal or less strategic locations, are also marked with “*.” This distribution directly reflects the random nature of meteorological conditions, over which we have no control, but which significantly influence the quality and structure of the database.
This three-dimensional representation (Figure 16) allows for a clear visualization of the density and coverage quality of the database across the axes of irradiance, temperature, and the appropriate duty cycle required for the PV system to produce maximum power.
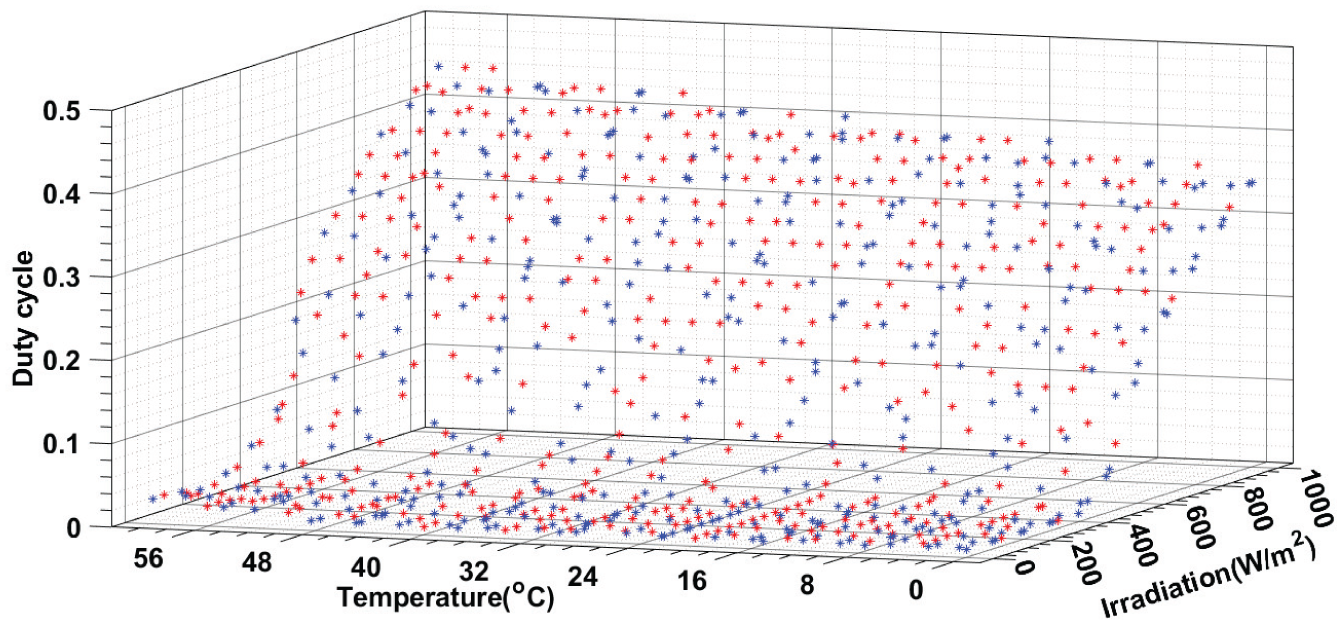
3D Visualization of the consolidated database.
This 2D map (Figure 17) illustrates the propagation quality of data points distributed across the Temperature–Irradiance plane. It highlights both well-propagated points, which exert strong local influence, and less well-propagated ones with more limited impact. All of these data, derived from realistic conditions, will serve as the reference base for the k-Nearest Neighbors (k-NN) algorithm to estimate the Maximum Power Point (MPPT). The chosen mesh, deliberately heterogeneous, reflects natural environmental variability and allows us to assess the robustness of our approach under realistic conditions. This configuration will serve as the foundation for evaluating, in the following section, our innovative MPPT control strategy based on the k-NN principle.
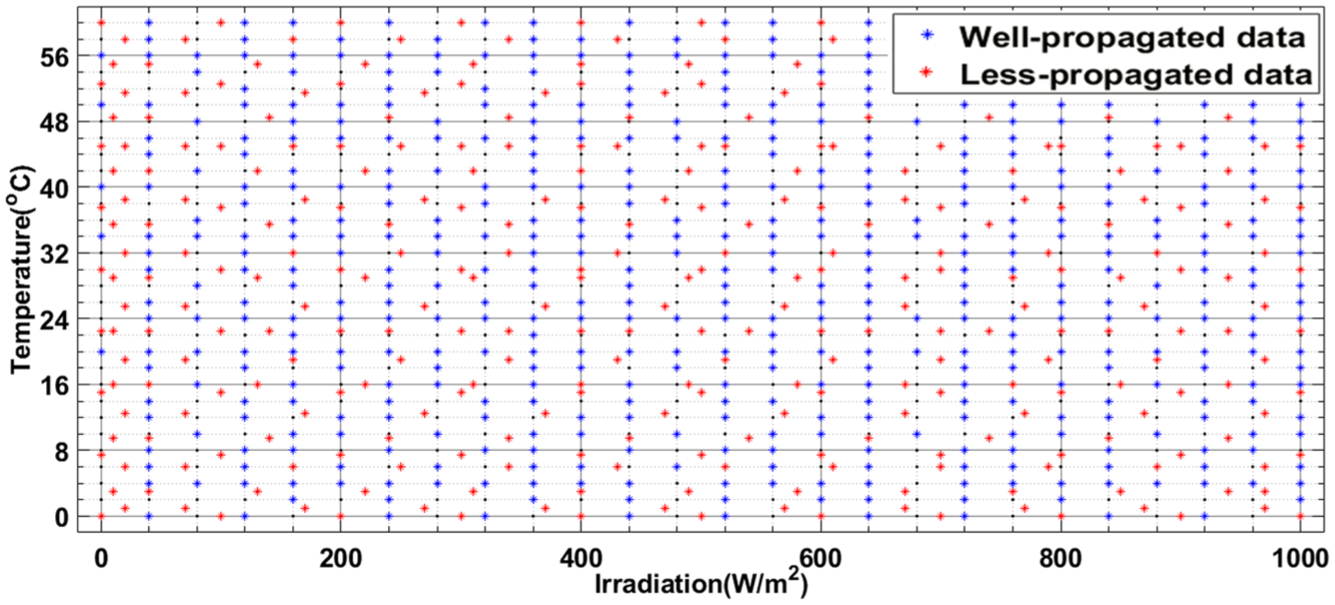
2D Map of data distribution by propagation quality.
Real-time MPP estimation using optimized k-NN algorithm
Our system has demonstrated its ability to dynamically construct and organize a real-time database, and this phase aims to evaluate the performance of the intelligent control system in an operational real-world context. The objective is to verify how the algorithm successfully extracts the Maximum Power Point (MPP) from stored data using the k-Nearest Neighbors (k-NN) method. To achieve this, we simulated new meteorological conditions, such as temperature and irradiation, within an area well-covered by the existing database. The algorithm accurately identifies the most relevant neighbors for each new data point, ensuring precise MPP estimation.
The k-NN principle relies on the spatial proximity of data, which requires a well-structured database with optimally distributed data points. Our database is designed to facilitate efficient nearest-neighbor searches through effective data organization, even in areas with variable density. Although data distribution may not always be perfect, their arrangement enables rapid identification of relevant regions. Thus, despite potential heterogeneity, the algorithm effectively finds conditions most similar to new entries by leveraging previously recorded measurements.
The effectiveness of this approach is ensured by an intelligent hashing system that strategically locates each data point within the database. This mechanism is reinforced by advanced techniques for handling storage conflicts and performing continuous updates, guaranteeing real-time data integrity and consistency. Thanks to this optimized architecture, the algorithm can precisely determine the nearest neighbors while maintaining high performance without requiring additional complex computations. This operational robustness is essential for ensuring reliable performance of the intelligent control system in real-world operating conditions. Figure 18 illustrates our system’s remarkable capability to quickly identify relevant neighbors, demonstrating the effectiveness of our method across various practical scenarios.
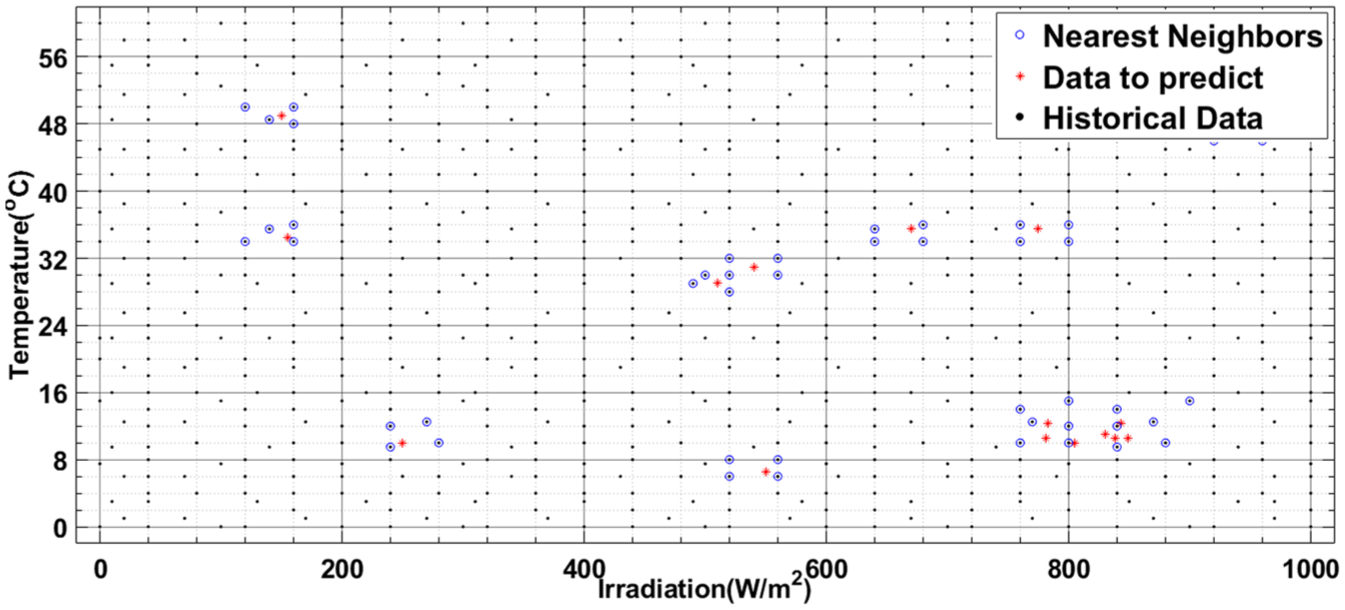
Efficient neighbor identification using an optimized structured database.
The figure illustrates the interpolation process performed by our algorithm, highlighting its operation and comparative advantages. Three significant marker types are visible: dots (“.”) represent historical data stored in the database from previous scenarios; red star (“*”) indicate new operating points to be evaluated, corresponding to unprecedented meteorological conditions (temperature and irradiation) for which the optimal duty cycle must be predicted; finally, blue circles (“o”) represent the k-nearest neighbors selected to perform this estimation.
Our method relies on a sophisticated weighting approach that significantly improves interpolation accuracy. As clearly shown in Figure 18, this technique provides immediate and precise results compared to traditional methods. Rather than treating all neighbors as equivalent, we assign each one a weight inversely proportional to its Euclidean distance from the target point. This strategy ensures that the closest (and therefore most relevant) neighbors have greater influence on the optimal duty cycle calculation. Specifically, the resulting duty cycle is obtained through a weighted average of the four nearest neighbors’ values, enabling fine adaptation to local system characteristics.
The comparison presented in Figure 19 strikingly reveals our approach’s effectiveness. On one hand, our k-NN method provides immediate, precise estimation without requiring any preliminary testing phase. On the other hand, the incremental conductance (incCond) method, while rigorous, clearly shows its limitations in convergence time. This traditional technique requires multiple successive adjustments, as evidenced by the visible oscillations in the incCond curve, before reaching the optimal solution. Our k-NN based solution, conversely, immediately achieves stable results matching the final values obtained by incCond after convergence, thus demonstrating its superiority for real-time applications.
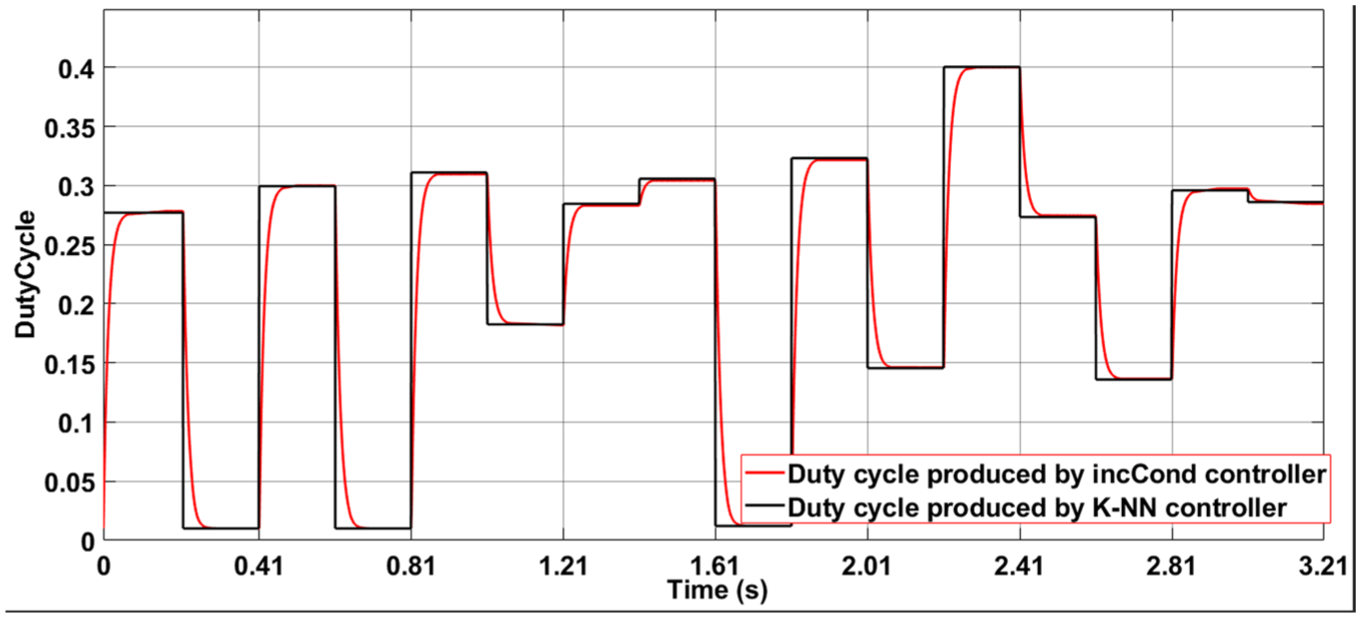
Duty cycle comparison: k-NN method (instantaneous) versus IncCond (iterative) under different meteorological conditions.
Performance comparison of IncCond and k-NN controls
As part of the evaluation of the performance of Maximum Power Point Tracking (MPPT) control algorithms, two distinct figures were presented. These figures illustrate the evolution of power output using the Incremental Conductance (IncCond) control and the k-Nearest Neighbors (k-NN) control after the database design, respectively. The objective is to compare these two approaches to highlight their strengths and limitations in the context of photovoltaic energy management.
Figure 20 shows the evolution of power over time when using the Incremental Conductance (IncCond) control. Initial fluctuations are observed, which are characteristic of this method, as it relies on successive perturbations to locate the maximum power point (MPP). Once the MPP is reached, the power stabilizes around an optimal value, demonstrating the control’s ability to extract available energy. However, oscillations around the MPP can lead to efficiency losses, especially in the case of rapid changes in environmental conditions. This figure highlights the limitations of the IncCond control, particularly its sensitivity to perturbations and relatively slow response time.
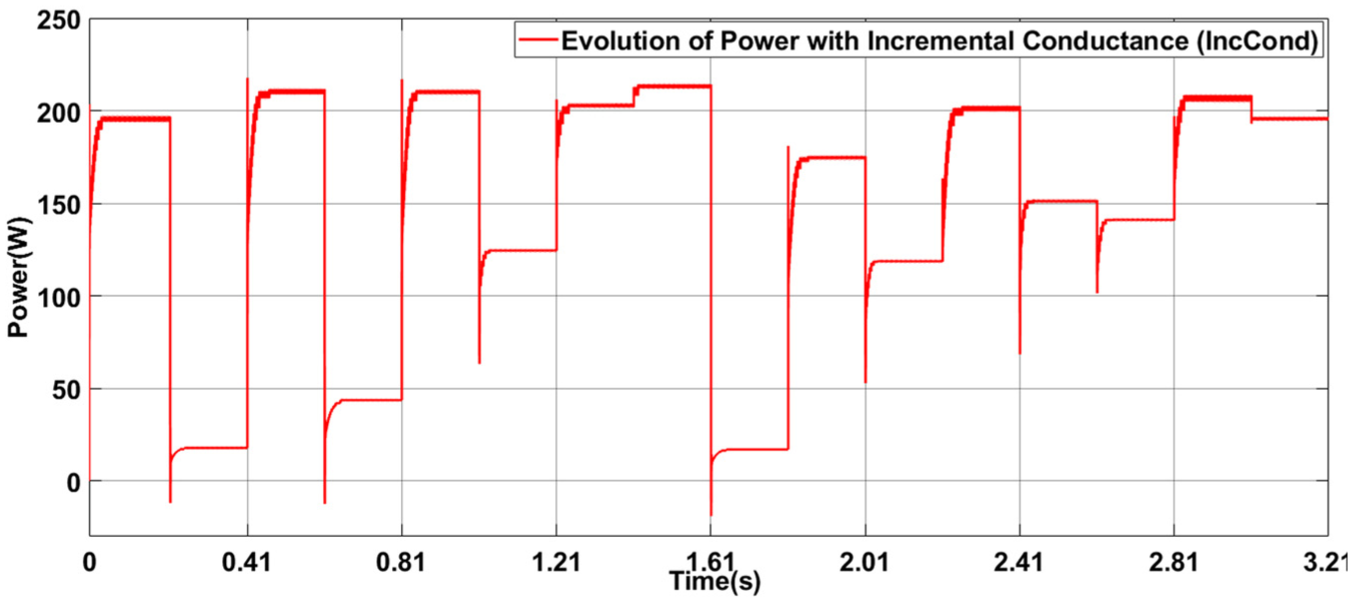
Evolution of power with incremental conductance (IncCond) control illustration of power fluctuations and stabilization using the IncCond method for MPPT.
Figure 21 presents the evolution of power over time when using the k-Nearest Neighbors (k-NN) control after the database design. Unlike the IncCond control, the k-NN control demonstrates a faster and more stable response, with fewer fluctuations around the MPP. This is due to k-NN’s ability to directly predict the optimal duty cycle based on historical data, without requiring successive perturbations. The power quickly reaches its maximum value and remains stable, even in the presence of environmental variations. This figure highlights the advantages of the k-NN control, particularly its precision and speed, which significantly improve the system’s efficiency.
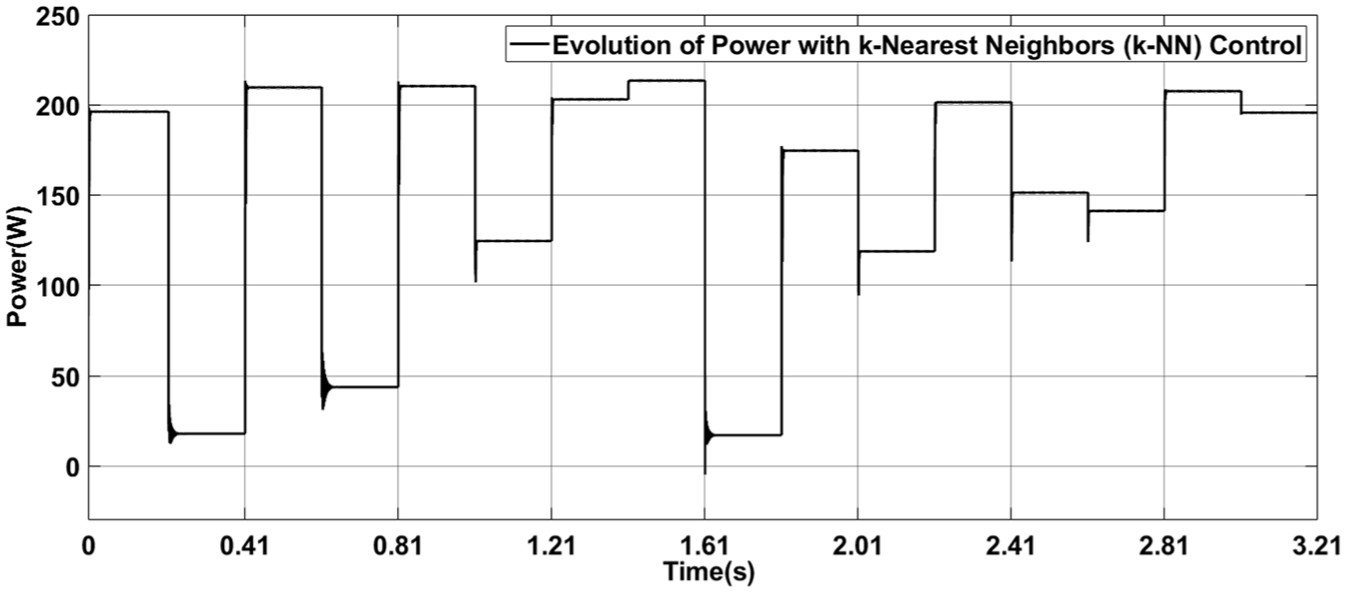
Evolution of power with k-nearest neighbors (k-NN) control after database construction demonstration of rapid and stable power extraction using the k-NN method.
The IncCond control is effective for locating the MPP but is prone to oscillations and efficiency losses due to its iterative nature. In contrast, the k-NN control, after the development of a robust database, offers a faster and more stable response, reducing disturbances and optimizing power extraction. These two figures clearly demonstrate the advantages of the k-NN control, which combines precision and adaptability for optimal performance in dynamic conditions.
Comparative analysis between our innovative control method (k-NN) and a neural network (NN) for duty cycle regression
As part of the evaluation of our hybrid k-NN/IncCond control method, a comparative study was conducted with a neural network approach—an established method known for its effectiveness in solving nonlinear regression problems, such as in our photovoltaic system. This comparison highlights the respective performances of the two approaches in terms of regression accuracy and adaptability.
For this analysis, a neural network model with two hidden layers, each containing 10 neurons, was developed using MATLAB’s Machine Learning and Deep Learning tools. The network architecture was specifically designed for our case study, with two inputs corresponding to the key parameters irradiance and temperature thus characterizing the instantaneous state of the PV system.
The neural network training process employed the Levenberg-Marquardt algorithm, a recommended first choice for supervised learning problems due to its excellent performance, despite a relatively higher memory footprint. The dataset used for training was the same as the one used to construct the initial database for the k-NN method, ensuring fair comparison conditions. The evaluation was carried out on a set of meteorological conditions different from those used during training, thereby testing the generalization capability of both methods.
Figure 22 shows the regression errors associated with each method across a series of test cases. The red bars represent the prediction errors of the k-NN method, while the green bars correspond to those of the neural network. This comparative visualization provides a quick insight into the performance differences between the two approaches, particularly in terms of accuracy and robustness when facing new scenarios.
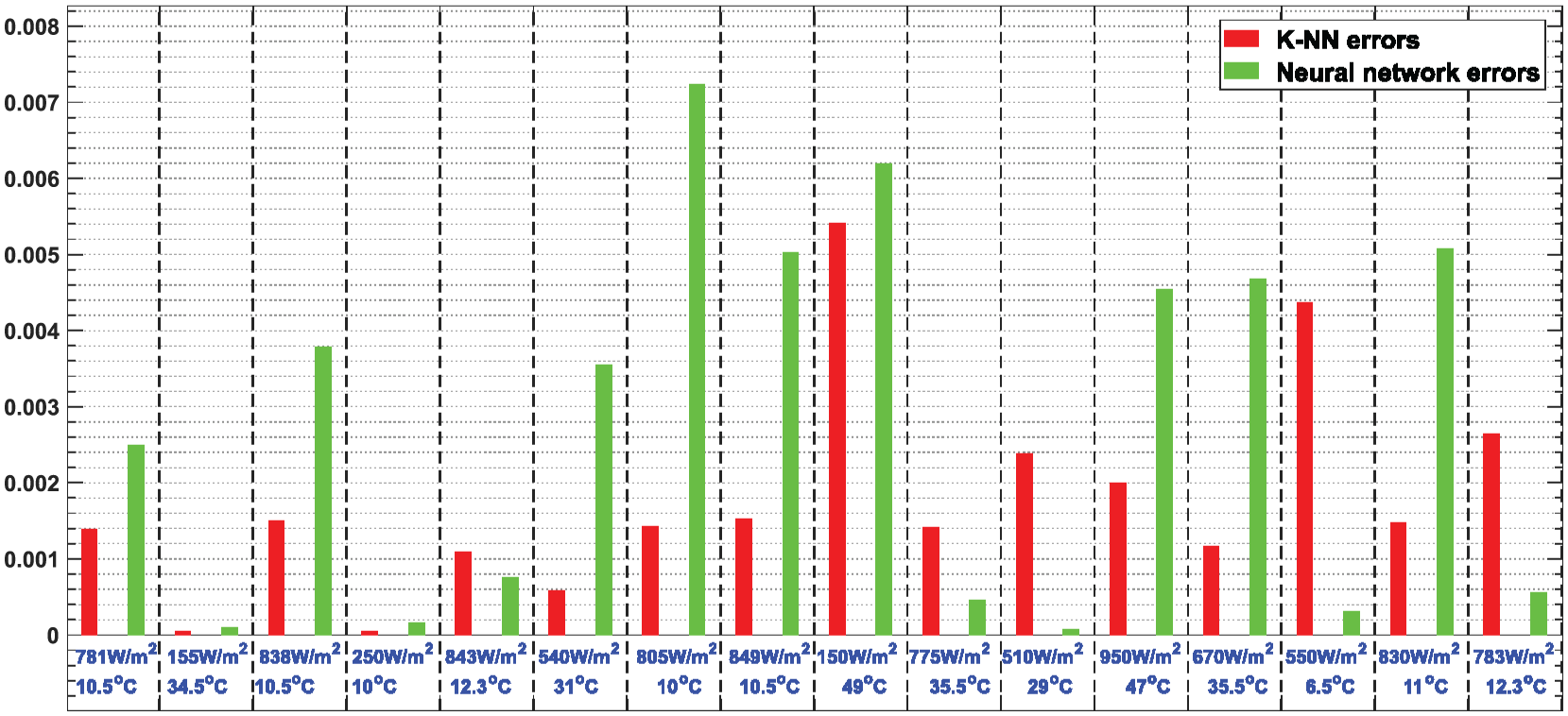
Comparison of prediction errors: k-NN-based control versus neural network.
The results demonstrate that both approaches offer a high level of overall accuracy, with relatively low errors across all test cases. However, a more detailed performance analysis clearly highlights the superior effectiveness of our control strategy. The mean squared error (MSE) achieved with the k-NN method is 0.00178, compared to 0.0028 for the neural network. Additionally, the maximum absolute error recorded by our control approach does not exceed 0.0054, while that of the neural network reaches 0.0066.
These results are particularly significant, as they confirm that our control method despite requiring no prior training manages to outperform a neural network that has been fully trained on a comprehensive and optimized dataset.
To better highlight the technical advantages of our innovative MPPT control algorithm based on k-NN, we present a comparative table against a traditional Neural Network (NN) approach. This comparison focuses on key aspects such as learning requirements, adaptability, memory usage, and practical deployment, allowing a clear evaluation of the strengths of each method in photovoltaic (PV) systems (Table 2).
Comparative table (NN) against K-NN without a prior learning phase.
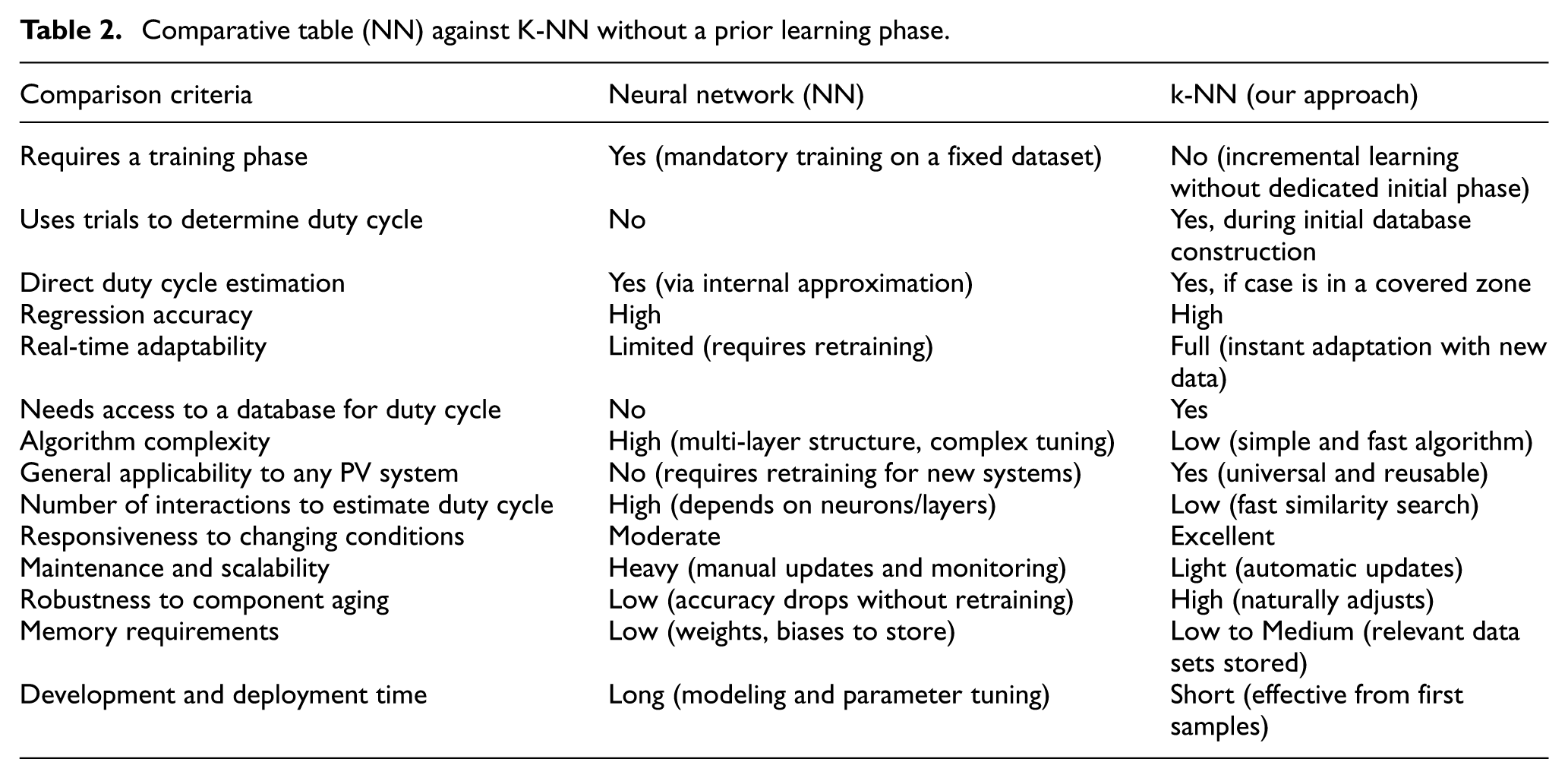
Computational cost and algorithmic simplicity
Our algorithmic approach is distinguished by its exceptional simplicity and low computational cost, making it ideally suited for low-performance microcontrollers or FPGA platforms with limited resources. Designed to operate efficiently on devices with just a few kilobytes of RAM, the system uses an optimized data representation that requires only minimal storage space demonstrating its practical feasibility on resource-constrained embedded platforms.
Unlike traditional methods such as neural networks, which require numerous weighted multiplications and costly nonlinear functions, our k-NN-based algorithm deliberately avoids complex mathematical operations. Instead, it relies solely on basic arithmetic operations (additions, subtractions, simple divisions, and comparisons) and straightforward conditional logic (if-then structures). The most demanding operation Euclidean distance computation is efficiently handled using Heron’s method, requiring only a limited number of clock cycles.
This algorithmic simplicity, combined with efficient memory management, enables a structural implementation in which the majority of operations are executed within just a few clock cycles. As a result, the system is highly responsive and well-suited for real-time MPPT applications in embedded environments, whether on low-power microcontrollers or lightweight FPGA architectures.
Behavior under partial shading conditions and multidimensional extensions
The behavior of the algorithm under partial shading conditions with dynamic changes can be significantly enhanced through an extension to a three-dimensional (3D) database using the same algorithmic principles. This 3D approach incorporates three key parameters: irradiance, temperature, and the percentage of partial shading, enabling a comprehensive characterization of the photovoltaic system’s state. The feasibility of this extension relies on the use of 3D Euclidean distance, which remains computationally simple and can be executed.
This three-dimensional distance enables the direct identification of the optimal duty cycle by selecting the k-nearest neighbors within the space defined by the three parameters, thus offering increased precision under complex shading scenarios.
The major innovation of this extension lies in the introduction of
This adaptive prioritization approach preserves the algorithm’s fundamental simplicity while offering enhanced flexibility to optimize performance for specific operating scenarios. As a result, the system becomes even more robust in the face of variable environmental conditions and dynamic partial shading phenomena.
General conclusion
In this work, we proposed an innovative approach to Maximum Power Point Tracking (MPPT) in an intelligent photovoltaic system by combining artificial intelligence techniques with a simple and efficient hardware structure. Our control strategy is based on the k-Nearest Neighbors (k-NN) algorithm, designed to learn in real time, dynamically adapt to environmental conditions, and provide high energy efficiency even under highly variable weather scenarios.
We began by rigorously defining our system: a photovoltaic generator coupled with a DC-DC converter and a resistive load. This configuration was selected based on linearity, analytical clarity, and implementation simplicity, ensuring objective and precise evaluation of the MPPT control performance.
To build a reliable initial database, we assessed several trial-and-error-based MPPT algorithms (P&O, PSO, GWO, IncCond), and ultimately selected the Incremental Conductance (IncCond) method due to its superior performance in terms of stability, accuracy, and simplicity. The initial database was then dynamically enriched by recording only operating points that met a strict stability condition (dp/dt ≈ 0). An intelligent update and reorganization mechanism ensured that the database remained compact, coherent, and effective.
Our adaptive management strategy analyzes the propagation quality of the data and, if necessary, replaces or relocates less relevant data to reinforce poorly covered regions. This self-optimization capability allows the database to remain pertinent and efficient for real-time decision-making.
To validate the quality of the database and the effectiveness of our approach, we introduced advanced visualization tools, including a 2D propagation map and a 3D representation of data points. These visualizations confirmed the density, diversity, and homogeneity of the data mesh, demonstrating the adaptability and relevance of the constructed database.
In the later phase of our work, we conducted a direct comparison between the Incremental Conductance algorithm and our k-NN-based MPPT control. This comparison highlighted the significance of gradually transitioning from trial-and-error methods to regression-based approaches, particularly in terms of faster determination of the optimal duty cycle and improved quality of the extracted power. This transition enables our system to become more intelligent and efficient over time, as it continuously improves through real-time data acquisition and regression.
The seamless handover between the two algorithms (IncCond → k-NN) is made possible by an adaptive architecture that performs learning and inference in real time. Specifically, when the operating point lies within a well-covered zone, the control uses k-NN regression to directly and quickly determine the duty cycle. If the point lies outside the covered region, the IncCond algorithm is triggered to compute the optimal point, while enriching the database for future use. Thus, learning and regression occur simultaneously without the need for prior training or successive trials.
The k-NN algorithm, applied to this dynamic database, enables a highly efficient MPPT control. Its operation is based solely on simple arithmetic operations (subtraction, comparison, addition), making it lightweight, fast, and ideally suited for embedded systems such as FPGAs. Unlike neural networks (NN), which require a prior training phase, complex calculations (sigmoid, matrix multiplication), and powerful hardware, our k-NN control is simple, adaptive, and readily deployable. Although our approach requires access to the database, it is significantly less complex and requires fewer interactions to reach the optimal duty cycle.
We compared our control strategy to a neural network (NN)-based MPPT trained with the same dataset. While both approaches delivered good performance, our controller proved more precise and stable, achieving a lower Root Mean Square Error (RMSE) of 0.00178 compared to 0.0028 for the neural network, and a lower maximum error (0.0054 vs 0.0066). Furthermore, the k-NN controller requires no training phase, adapts to any photovoltaic system, needs fewer iterations to find the optimal point, and is fully compatible with real-time FPGA implementations.
In summary, the key advantages of our k-NN-based controller include:
High regression accuracy, matching or surpassing that achieved with neural networks;
Fast reactivity, due to direct regression in covered regions;
Algorithmic simplicity, facilitating implementation on FPGAs or microcontrollers;
Real-time adaptability to changing environmental conditions and component aging;
Generalized robustness, allowing usage across various PV systems without reconfiguration;
Low to medium memory requirement, thanks to an optimized dynamic database;
Evolutionary process, ensuring continuous improvement of the database without explicit training.
This work demonstrates the feasibility and relevance of a lightweight yet powerful AI-based approach for MPPT in photovoltaic systems. It opens promising avenues for intelligent control, energy optimization, and embedded integration. Potential future directions include multi-objective optimization, adaptation to large-scale PV networks, and full hardware implementation on FPGA platforms for real-world validation.
Footnotes
Author note
All work was conducted using institutional resources and the personal efforts of the authors.
Ethical considerations
The research conducted in this study adheres to the highest ethical standards. It does not involve human or animal subjects, nor does it require ethical approval from an institutional review board. All data and methodologies used are purely technical and related to energy management systems.
Consent to participate
This study does not involve human participants, patient data, or any form of clinical trials. As such, informed consent or patient consent is not applicable to this work.
Author contributions
All authors have contributed equally and transparently to the development of this work.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data underlying this article will be shared on reasonable request to the corresponding author.
Trial registration number/date
This research represents the first registration and publication of this work. No prior registrations or publications related to this study have been made.