
Abstract
This paper considers dual-rate systems, where the output is measured at a relatively slow rate while the control signal is adjusted at a faster rate. The output sampling time is an integer multiple of the input sampling time. The paper examines dual-rate inferential control systems, which consist of a fast model, a slow model, and a switch. Missing output samples are estimated using the fast single-rate model. The single-rate control algorithm is then implemented at the fast-sampling rate. The fast-sampling discrete-time model is derived from the plant’s continuous-time model using the first-order hold (FOH) element. A discrete LQ regulator is proposed for this plant model, with a prescribed degree of stability (all closed-loop eigenvalues are within the range 0 < λ < 1 in magnitude). The matrix gain is calculated offline, and an online method for calculating the regulator gain is provided. The regulator gain is calculated using policy iteration, specifically Hewer’s algorithm. Finally, it is demonstrated that the presented inferential control system remains effective in the presence of multiplicative unmodeled dynamics. The main contributions of the paper are: (i) Designing the LQ regulator with a prescribed degree of stability using reinforcement learning (RL) (generalized policy iteration); and (ii) Considering the robust stability of the inferential control system in the presence of multiplicative unmodeled dynamics using the lifting technique.
Introduction
There are industrial processes that use digital control with sampled input and output values at different sample time intervals.1,2 These are known as multi-rate systems. Standard control techniques cannot be used in these circumstances, leading to significant interest in these systems.3,4
Kranc proposed the switch decomposition method for controlling multi-rate systems. This method involves transforming multi-rate systems (specifically dual-rate systems) into single-rate systems. The method has been further developed under the name “lifting technique,”5–7 which is now a standard tool for transforming periodically time-varying systems into time-invariant ones. This technique is particularly important for state-space models.
Additionally, a dual-rate model that uses all available data (fast input and slow output data) can be derived using the polynomial transformation technique. 8 When stochastic disturbances have a non-Gaussian distribution, this method is used for the recursive identification of stochastic systems with unmodeled dynamics. 9 However, these transformation strategies require identifying more parameters. This issue was addressed by employing an accelerated stochastic approximation approach and the Bayesian information criteria, which allowed for identifying a fast model with fewer parameters. 10
In chemical processes, dual-rate systems are often used11,12 and dual-rate techniques have recently been introduced in filtering theory. 13 Inferential control is an effective method for controlling dual-rate systems.14,15 This method first estimates the missing output samples using a fast single-rate model. Then, it applies a single-rate regulator at the same fast sampling rate.
The paper assumes that the plant has a known continuous-time state-space model. The plant’s fast discrete-time model is derived using the first order hold (FOH) element. 16 A linear quadratic (LQ) regulator can be designed for this model. 17 The paper 18 proposes designing an LQ regulator, in the continuous time, to ensure that all poles of the closed-loop system lie in the left half-plane, Re{s} < −α, with α > 0 chosen by the designer. This approach provides greater tolerance for time delays and nonlinearities.
In this paper, we address the design of an LQ regulator with a specified degree of stability for discrete-time systems. The criterion ensures all closed-loop eigenvalues have magnitudes less than λ∈ (0,1]. The design procedure is typically completed offline.
We propose an online method for designing LQ regulators with a specified stability level, building on current active research 19 and documented in relevant monographs.20–24 This iterative procedure solves the algebraic Riccati equation, forming the basis for LQ regulator gains, using generalized policy iteration derived from control theory principles.25,26 Generalized policy iteration optimizes control laws iteratively until converging to optimal solutions for various dynamical systems and cost functions. Recursive feasibility, robust stability, and near-optimality properties are explored using policy iteration. 27 Recent advancements in online policy iteration algorithms for optimal control in continuous-time systems with input constraints are discussed in. 28 The intersection of reinforcement learning with adaptive control is explored in. 29 Research references30,31 address LQ regulator design under unknown linear system dynamics.
Reinforcement Learning (RL) is a broad area. Reference 32 explores RL based on differential games. Optimal control applications in industries using RL are discussed in Reference. 33 Reference 34 examines RL’s impact on decision-making under uncertainty. Reference 35 describes a multi-agent system based on RL. Stochastic approximation algorithms and algorithms such as temporal-difference learning and Q-learning are detailed in Reference. 36 Further developments in RL are also discussed.36,37
The problem considered in this paper falls under model-based RL algorithms using adaptive dynamic programing. To the best of the authors’ knowledge, this problem has not been addressed in the literature.
The paper examines the robust stability of a closed-loop system controlled by the proposed LQ regulator, considering the presence of unmodeled dynamics in the form of multiplicative uncertainty. Through the use of the lifting technique, 38 it demonstrates that dual-rate systems exhibit superior performance compared to fast-rate systems.
The main contributions of the paper are: (i) design of LQ regulators with the prescribed degree of stability for linear discrete-time fast rate model based on FOH and the design of reinforcement learning LQ regulators based on generalized policy iteration; (ii) consideration of robust stability of inferential systems in the presence multiplicative unmodeled dynamics using lifting techniques.
Problem formulation
Consider a single-input, single-output, single-rate system shown in Figure 1.

The single-rate system.
In Figure 1. P c represents a continuous linear time invariant (LTI) plant, H h represents a zero-order hold (ZOH) and S h is an ideal sampler. Both, H h and S h , operate with the sampling period h. Here, we introduce equivalent discrete time model for P c
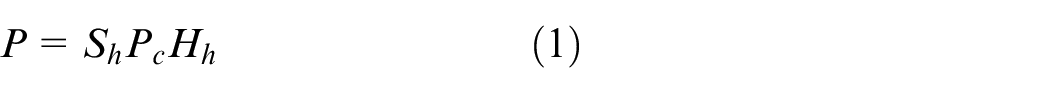
The standard discrete time control system is then shown in Figure 2.
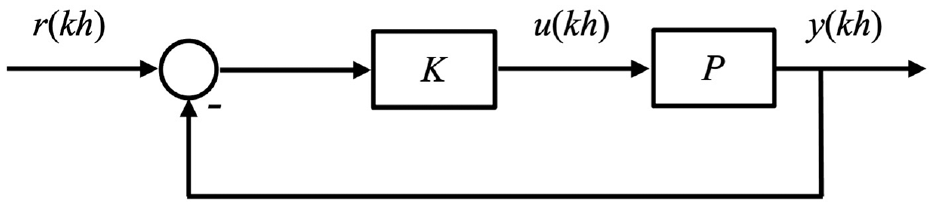
The discrete time single-rate control system.
In Figure 2, K represents a controller. In practical scenarios, sampling the output as fast as the input is often impossible due to physical sensor constraints. Therefore, in Figure 1, S h is replaced with a slower sampler S hp , where p ≥ 2 is an integer. The following figure illustrate this situation.
The input-output data are:
(i) {u(kh): k = 0, 1, 2, ….} at a fast rate,
(ii) {y(khp): k = 0, 1, 2, …} at a slow rate.
As a result, the intermediate output samples y(khp + j), for j = 1, 2, 3, …, p − 1, are not available. The dual-rate measurement is represented by the pair {u(kh), y(khp)}. The control system in this scenario is structured as shown in the figure below.
In Figure 4,
It’s important to note that S hp is equivalent to S h followed by periodic switch S. Therefore, Figure 3 can be modified accordingly in the following figure.

The dual-rate systems.
The signal
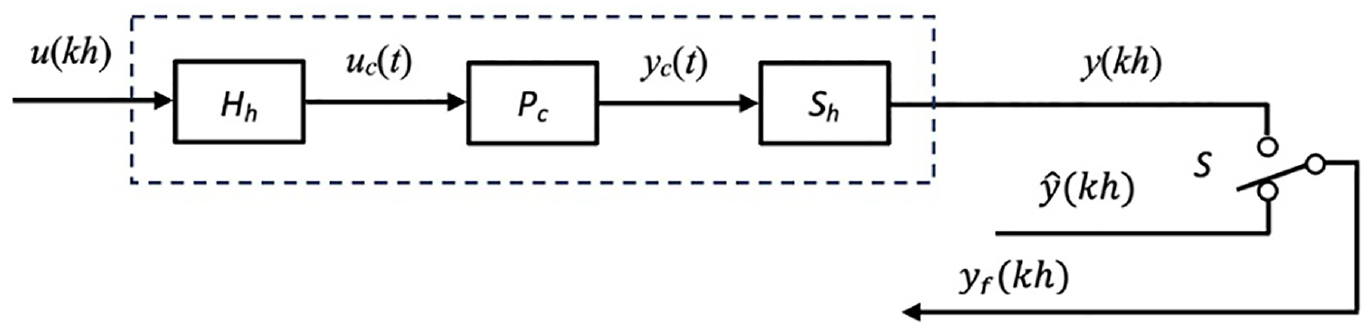
Finally, inferential control in Figure 4 consists of a fast-rate plant model, a fast single-rate regulator, and a periodic switch S.

The sampled-data inferential control system.
From Figure 5, without unmodeled dynamics, it follows that
Modified dual-rate system.
Fast model of the plant based on FOH method
Suppose the continuous time model of the plant P c in state-space form is:

In the next section, we will derive the discrete-time model
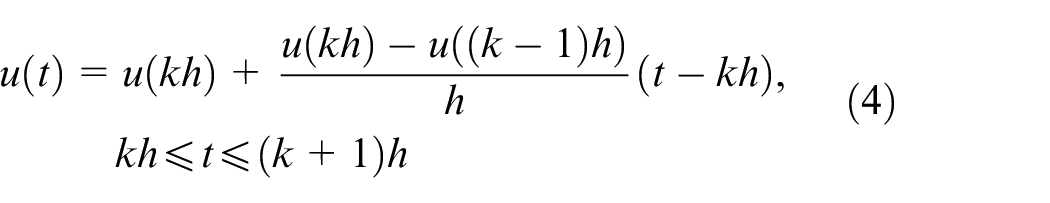
By using instantaneous sampling, the sampler generates a discrete-time sequence:
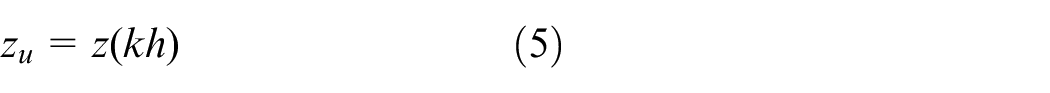
The FOH dynamic is presented in the Figure 6.
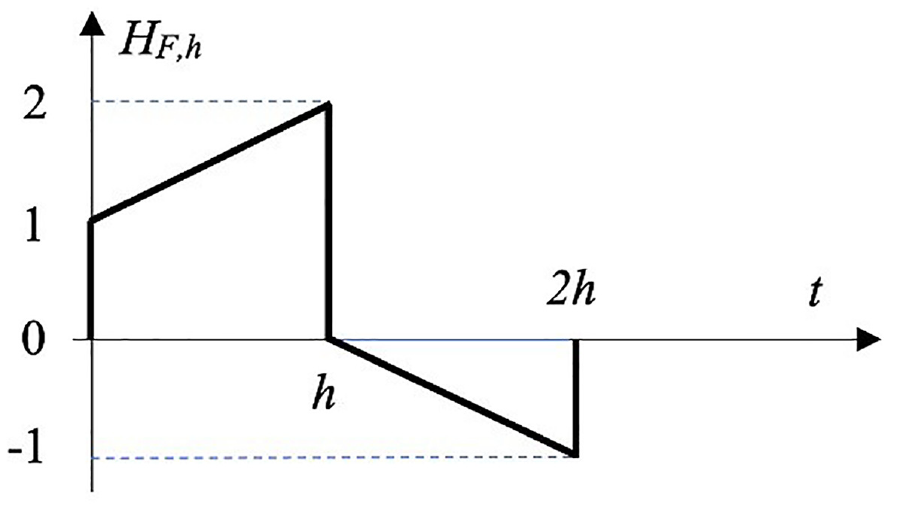
Impulse response of FOH.
The fast model
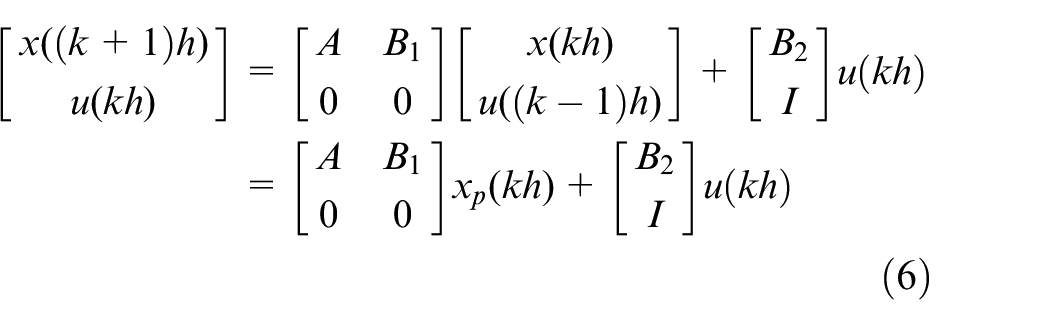
where

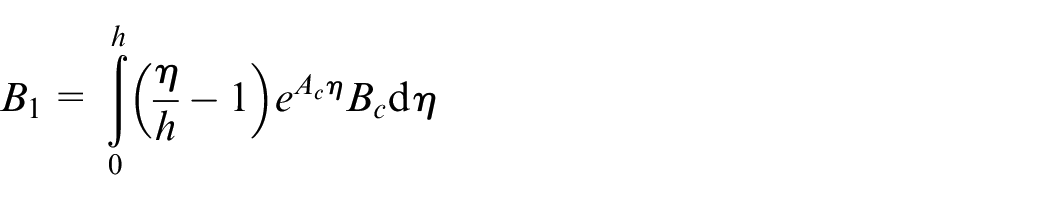
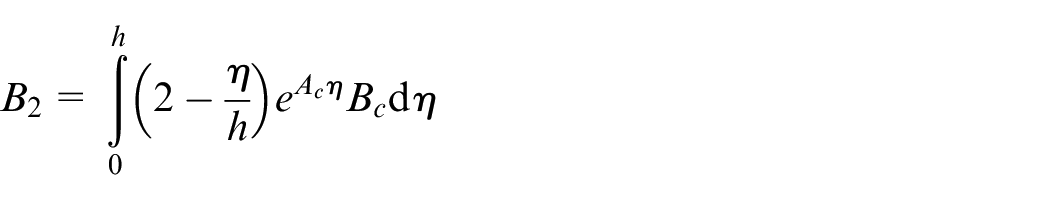
Finally, we can obtain the next block diagram for the FOH and system (6)
LQ with prescribed degree of stability for fast discrete time model
Now, we introduce a criterion for regulator design with constraints in equation (7). This criterion ensures that all closed-loop eigenvalues have magnitudes less than λ∈ (0,1], known as the closed-loop pole constraint. For system (6), the performance index is:
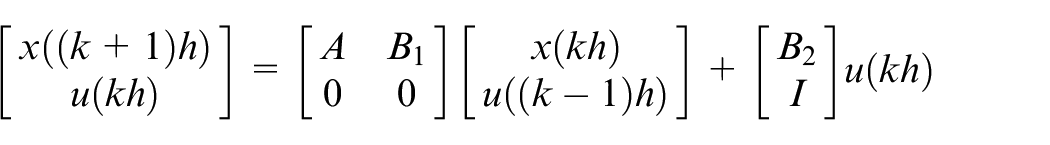
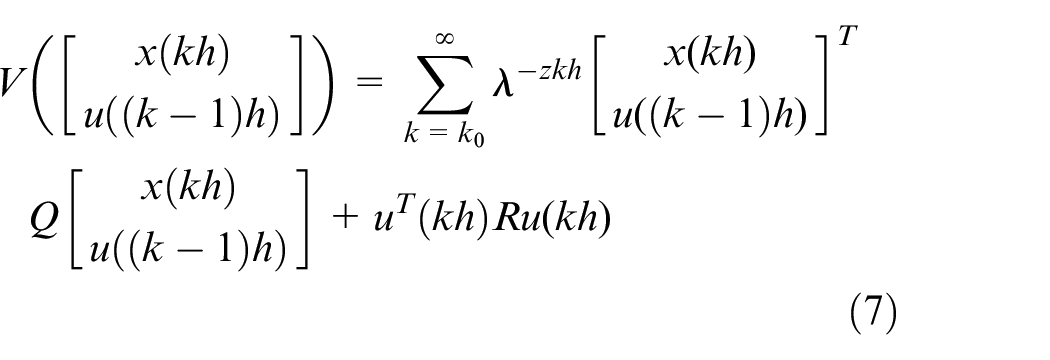
The following theorem is now developed.
1)
2) Let H be any matrix so that Q = HHT. The pair
3)
4)
5) Degree of stability for system (6) is λ∈ (0,1].
Then,
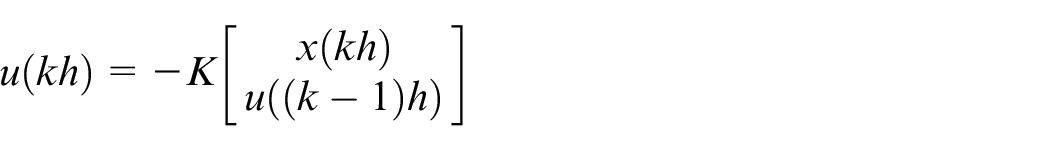
where:
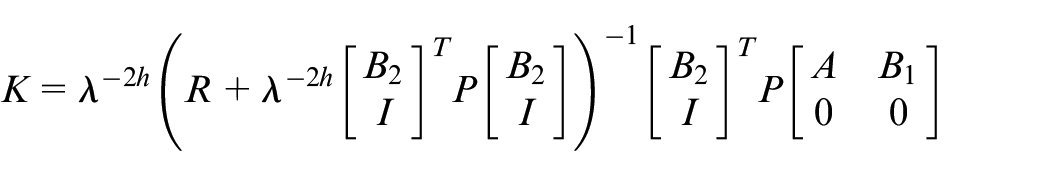
and matrix P is a solution of the next algebraic Riccati equation:
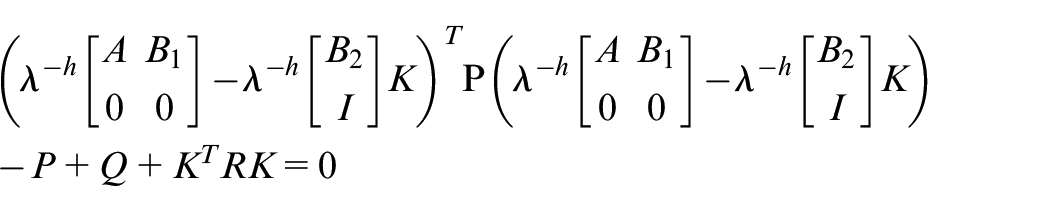
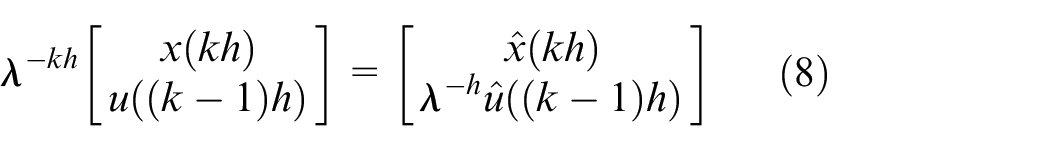

From relations (7)–(9) follows that:
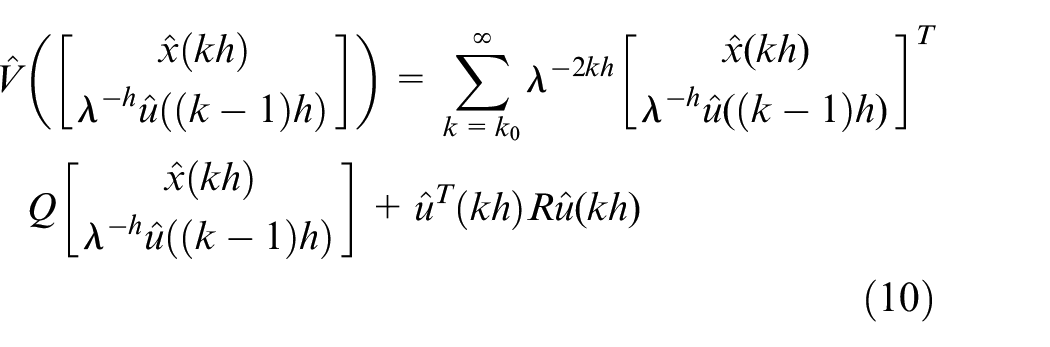
From equations (6), (8), and (9) we have:
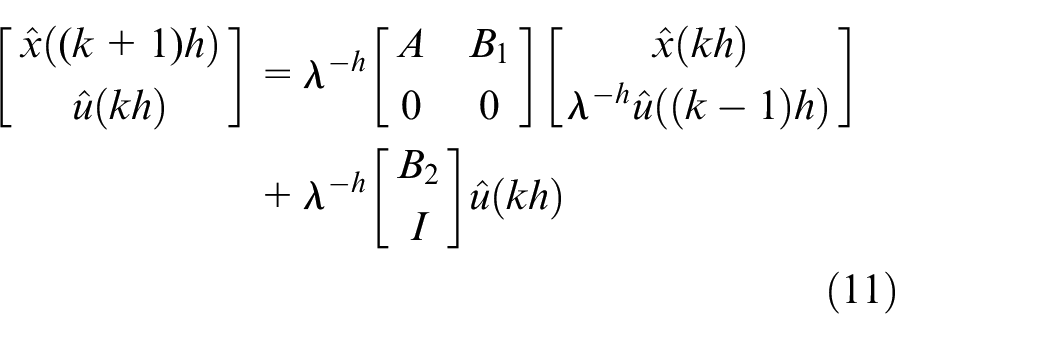
owing the fact:
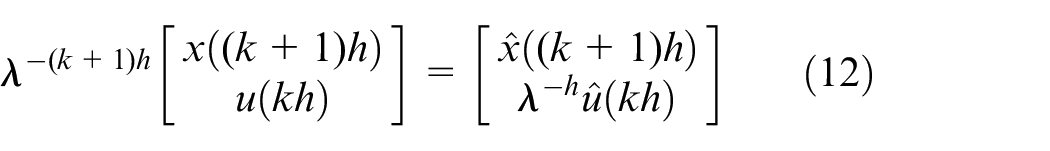
The optimal performance index has a form:
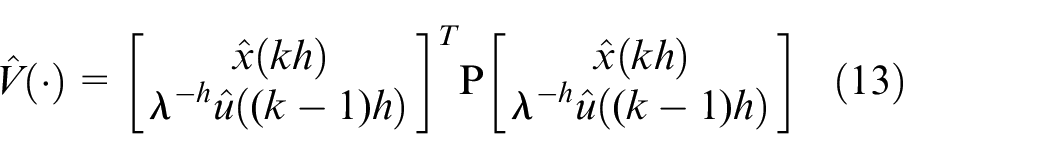
where P is symmetric matrix.
The Bellman equation for our case is:
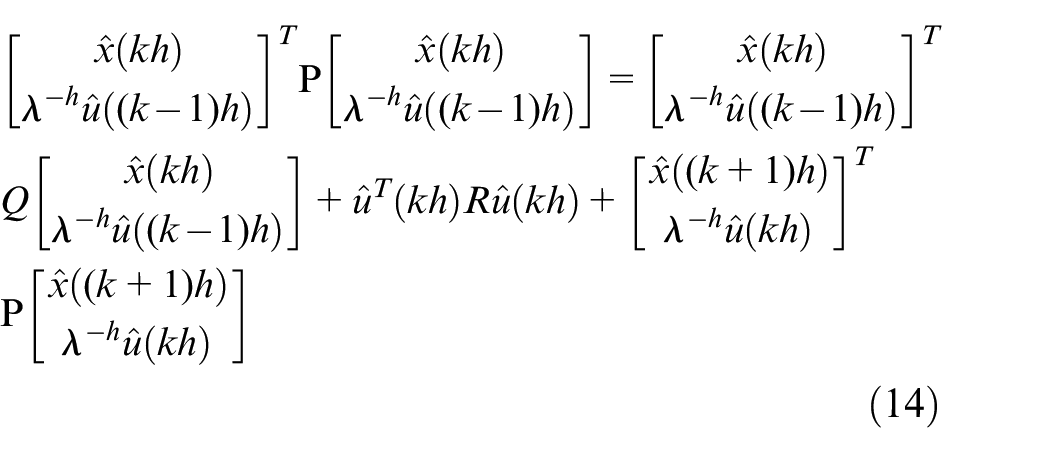
For last term in relation (14), by using relation (11), one can get:

According to (13) we have:
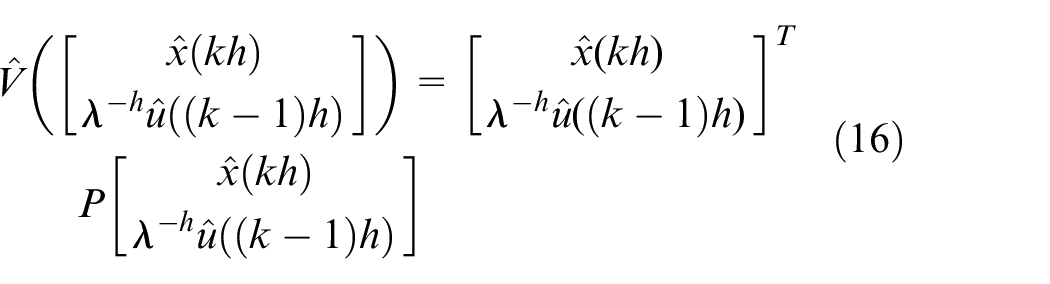
From (14), (15) and (16) it follows that from:
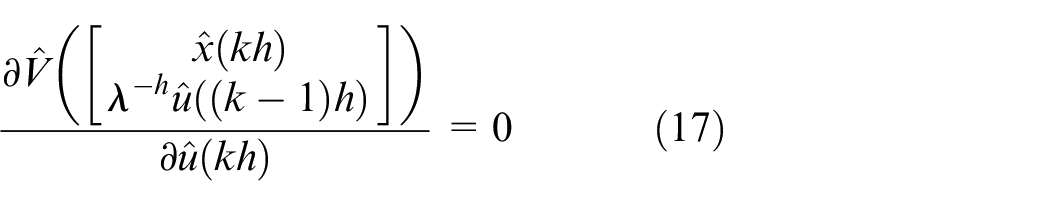
we have:
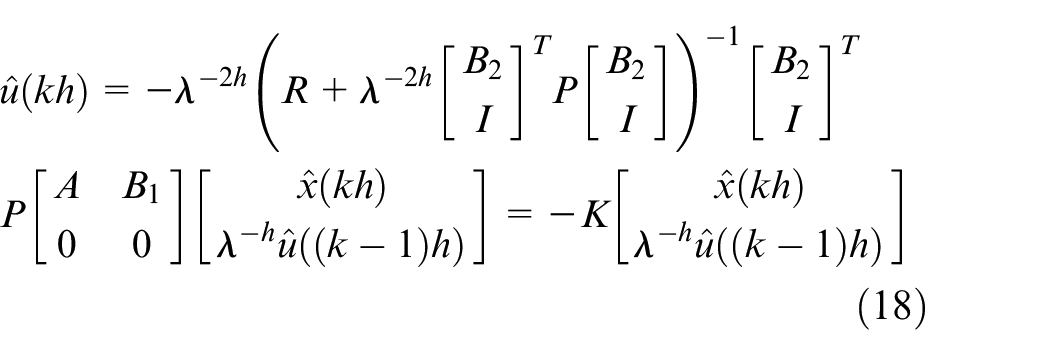
where:
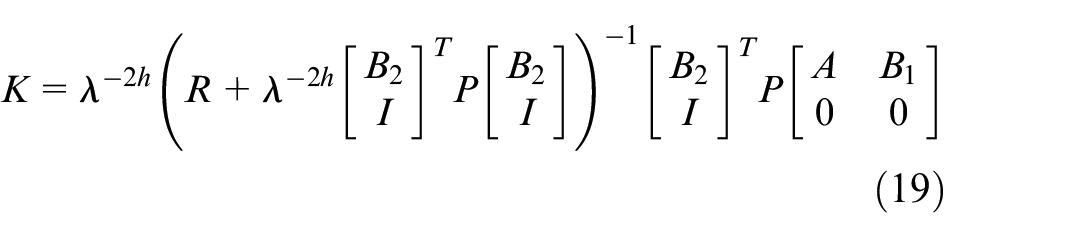
By using (14) and (18) one can get equality:
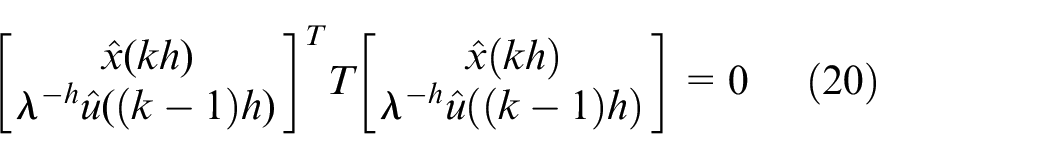
Since this must hold for all state the matrix:
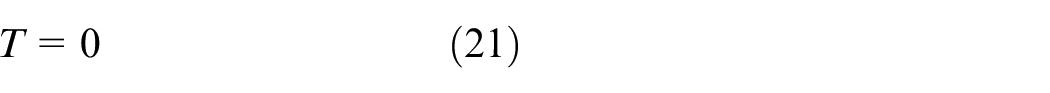
In our case, matrix T has a form:
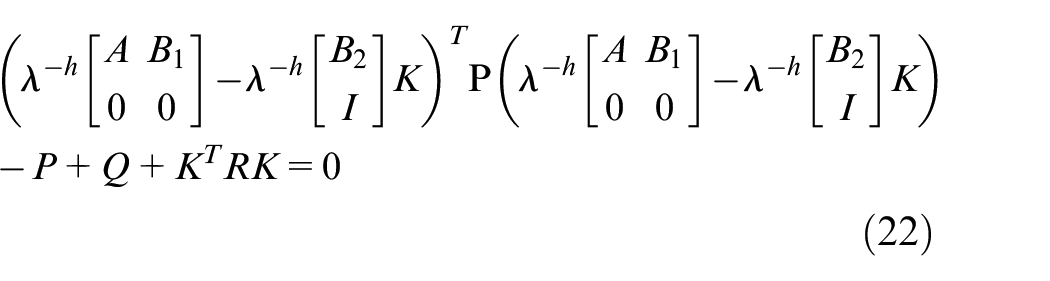
If we put (19) into (22) after arranging the formula one can get:
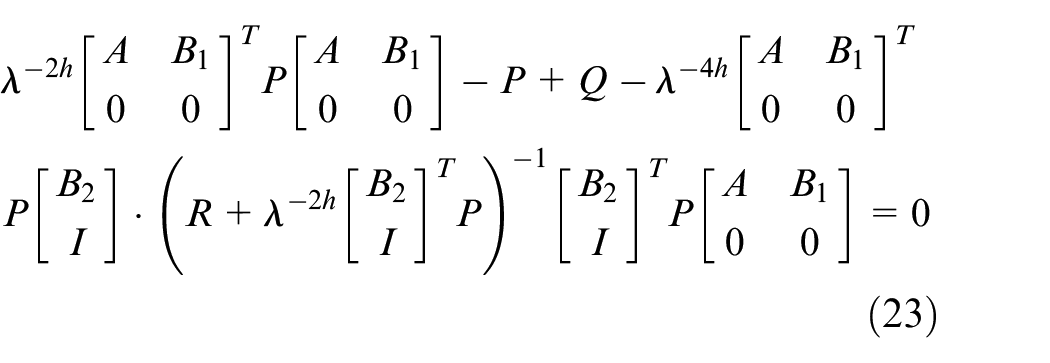
Based on relations (8), (9), (18) and (23) it follows the proof of the theorem.
LQ regulator design is described by Algorithm 1.
Choose the matrices
For P, solve algebraic Riccati equation (23).
Determine the regulator’s gain K (relation (19)).
It is possible to see that the procedure for regulator design is off-line.
Robust stability of dual-rate systems
In this section, we consider robust stability of the dual-rate system. It is supposed that Assumption 1 is not valid. We treat
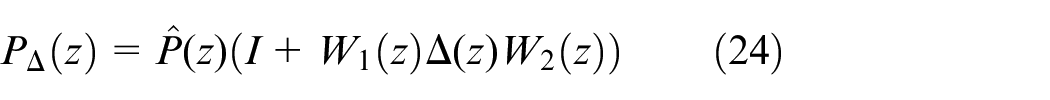
where
The standard technique for analysis and design of multi-rate systems is lifting. 38 The lifting technique transforms periodically time-varying systems into time-invariant systems. Let u(kh) be a discrete-time signal defined on the set {0, 1, 2, …}.
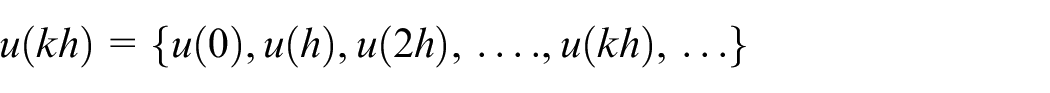
The lifting operator L is the map from
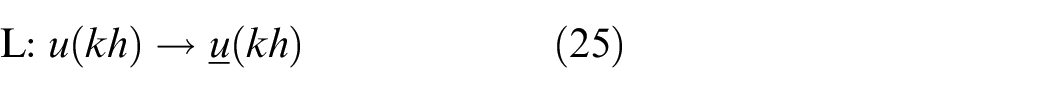
where:
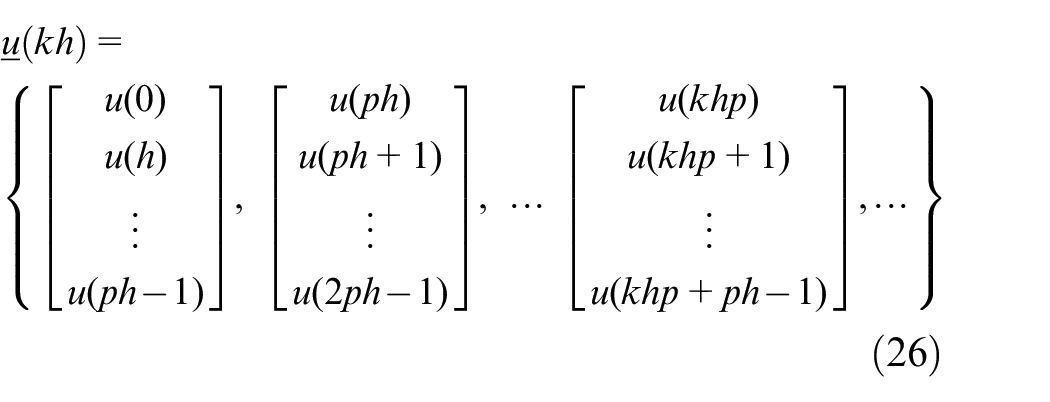
We now can formulate theorem for lifted systems.
1)
2)
Then,
A. Lifted system for system (6) is:
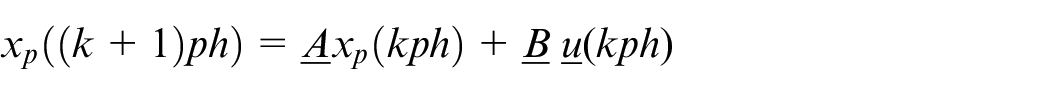
where:
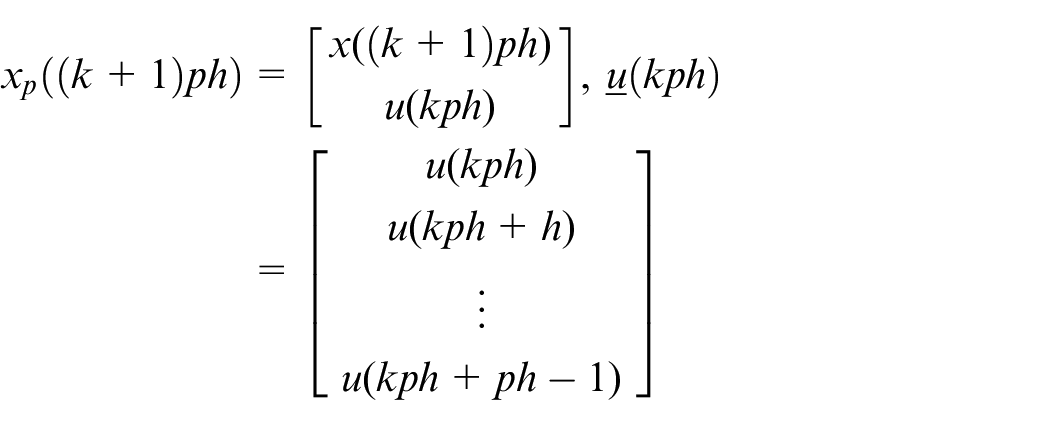
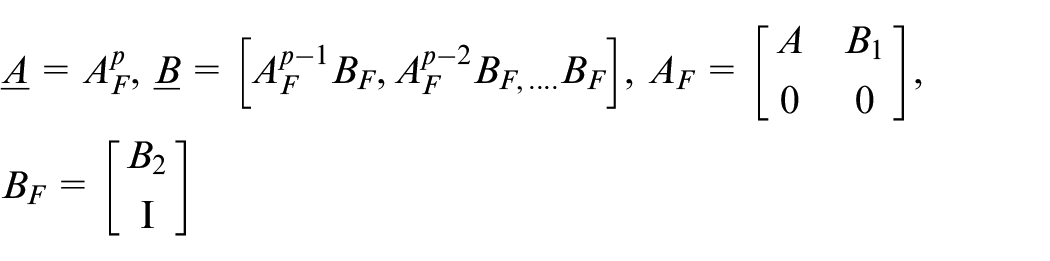
B. The lifted regulator has a gain:
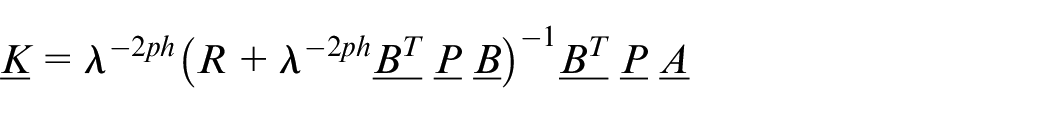
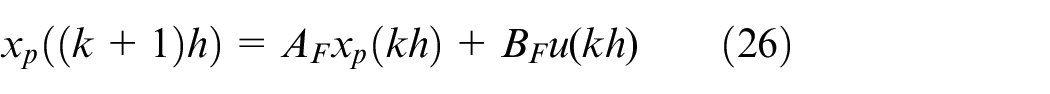
Let us replace k with
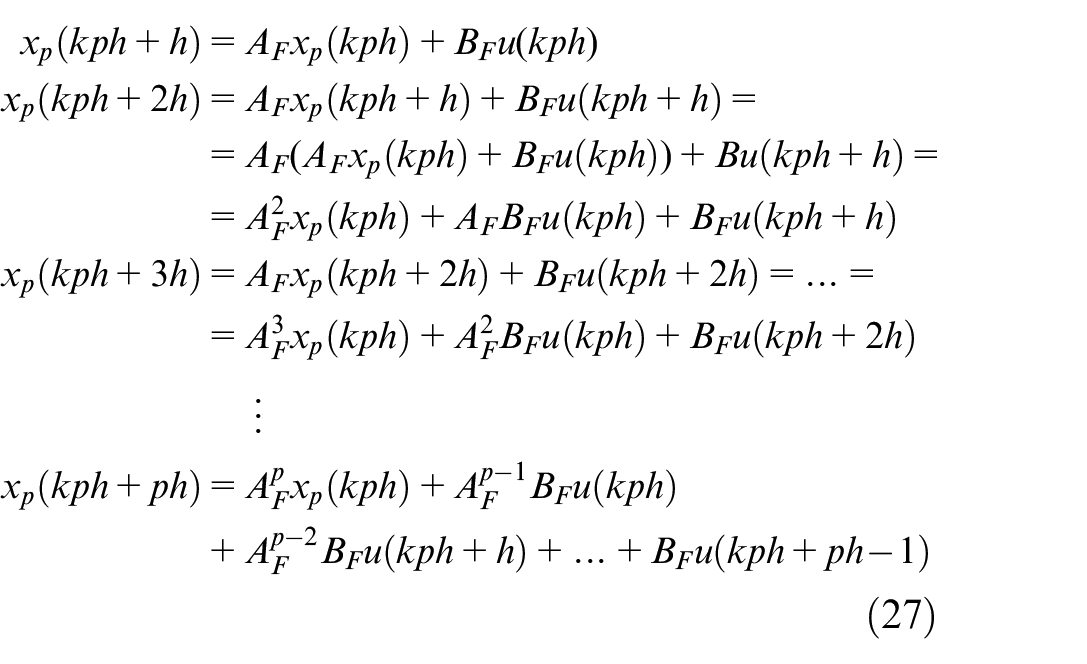
This equation we can rewrite in the next form:
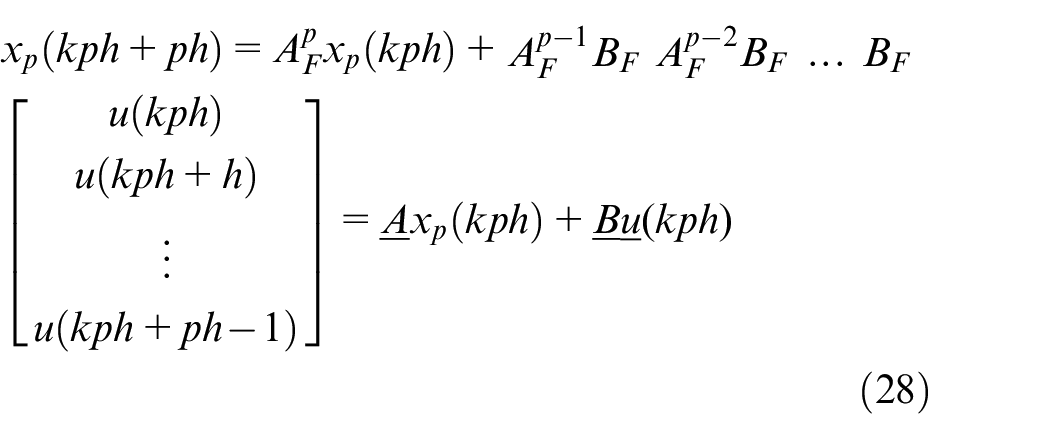
The statement A) is proven. The results of statement B) follows from the solution of Riccati equation when we replace matrices A and B with matrices
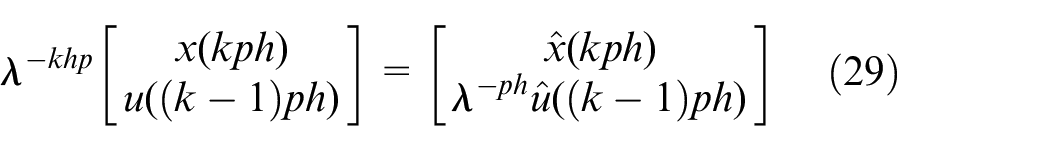

Theorem is proved. According to Reference, 38 we have the next lifted systems:
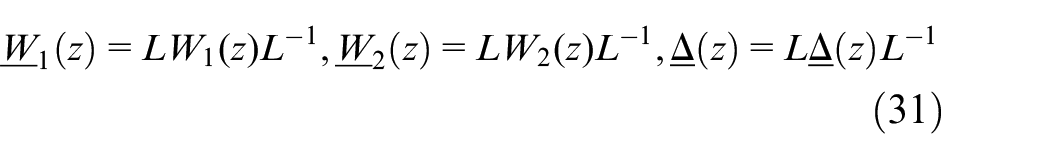
Lastly, we shall determine the lifted transfer function
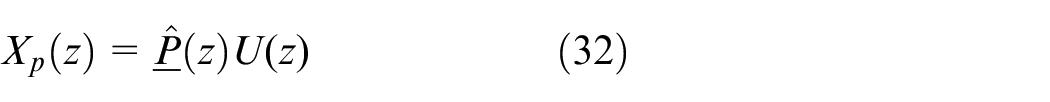
From relations (28) and (32), it follows:

Now we present the model for switch S in Figure 7. According to Reference, 15 we have the situation as shown in the next figure:
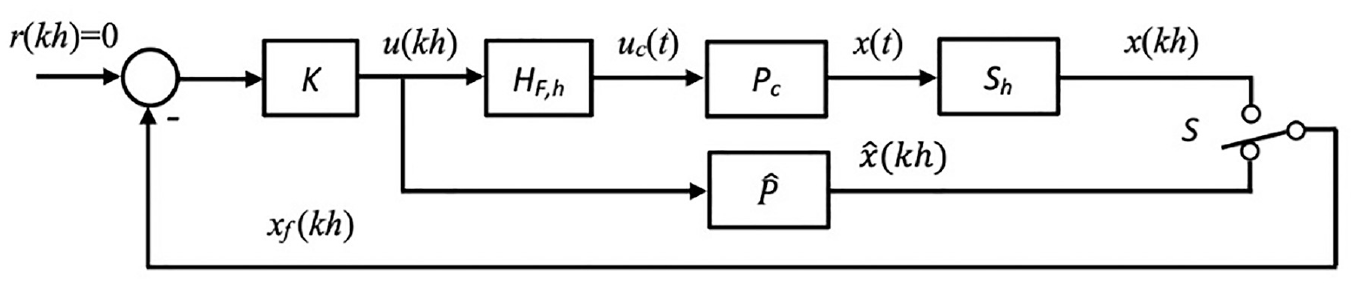
The sampled-data inferential system, HF,h is FOH DA converter,
The R 1 and R 2 are static systems with the following matrix form:
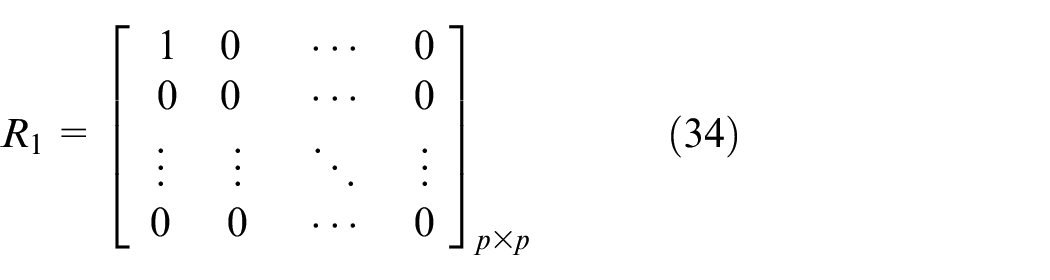
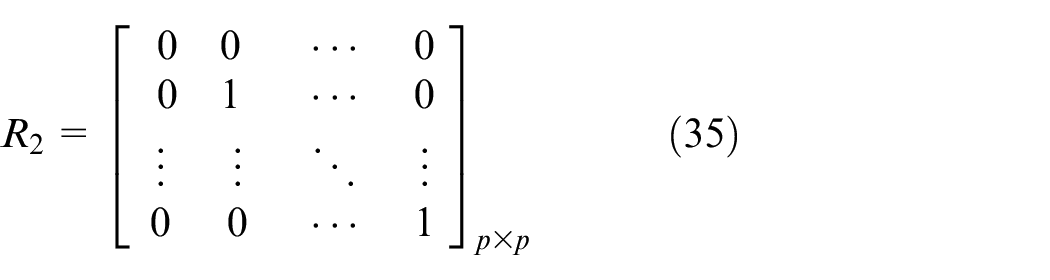
The feedback signal

Let us notice that:
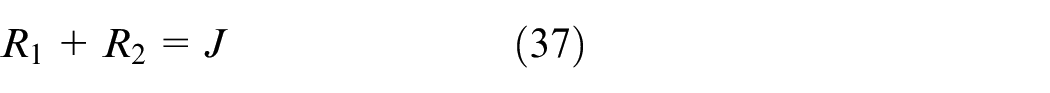
According to Assumption 1, along with relations (24), (34)–(37) and Figures 1 and 8, the following figure can be derived:
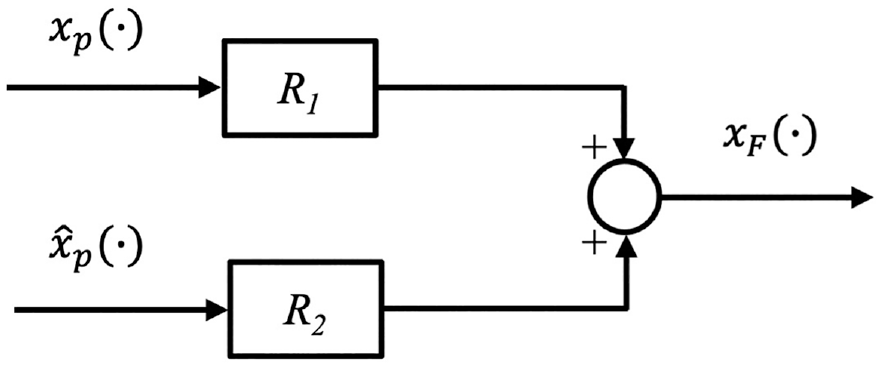
The model of the switch in the sampled data inferential system.
Our main goal is to study the robust stability of dual-rate system in Figure 9. To apply the small gain theorem,
39
we will convert system from Figure 9 to
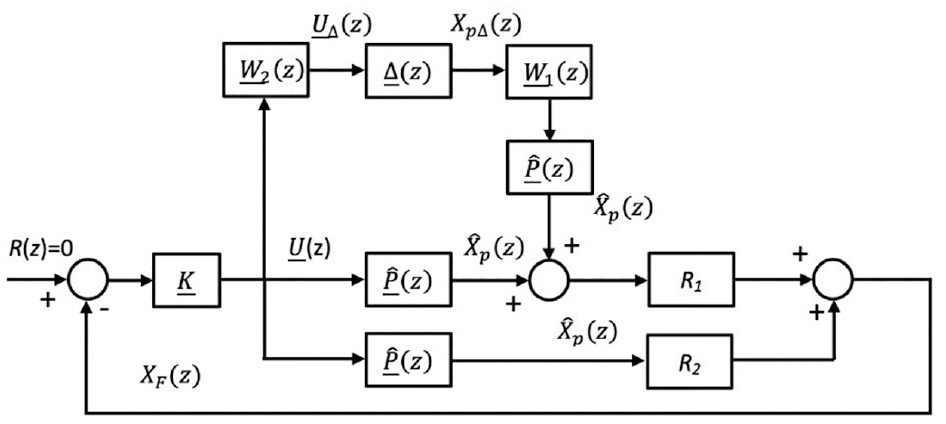
The lifted inferential control system with multiplicative uncertainty.
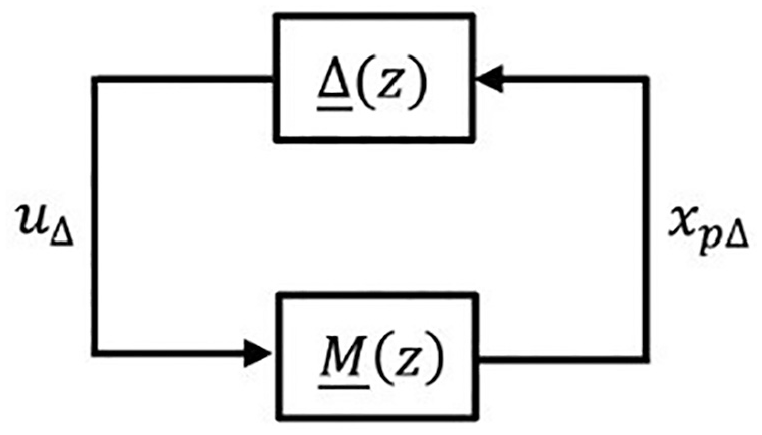
The
Now let’s determine the matrix
1) The perturbation
2)
Then, the matrix
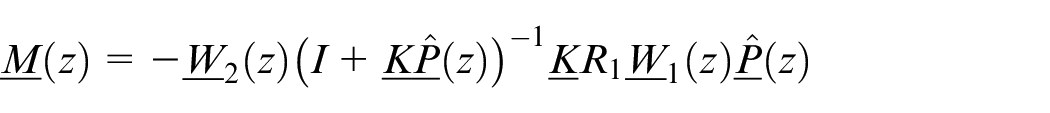

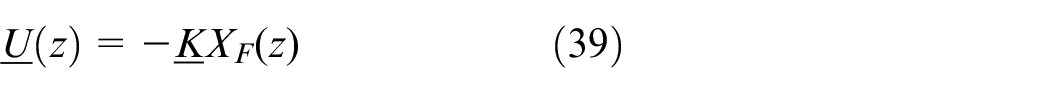
It is also noted that:


Using relation (37), we obtain for the feedback signal
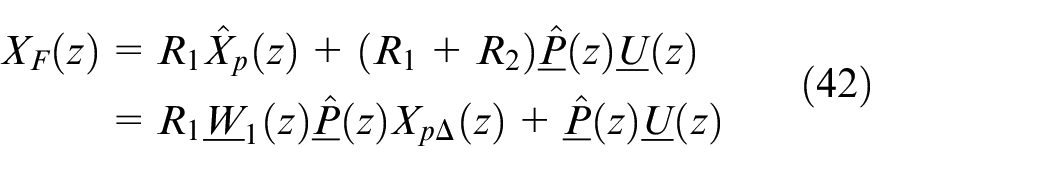
Based on relation (39), it follows that:
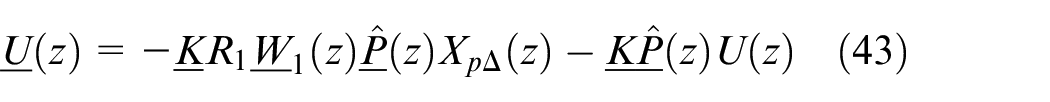
Then we have:
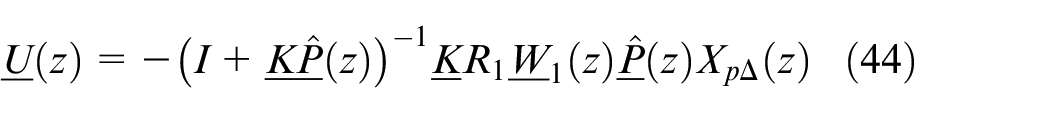
By using relation (39) and (43), it follows that:
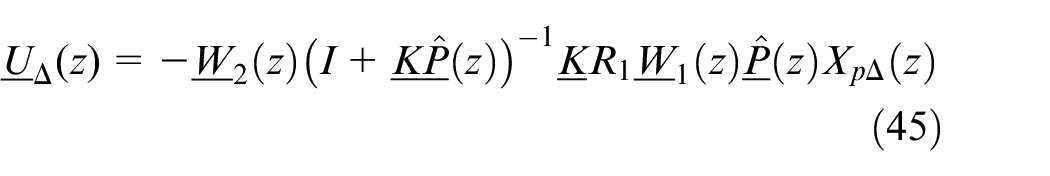
The theorem is thus proved. Finally, we formulate a theorem for robust stability for the dual-rate system.
1) System is nominally stable (K stabilizes
Then,
A. For the dual-rate system to be stable for all admissible perturbation
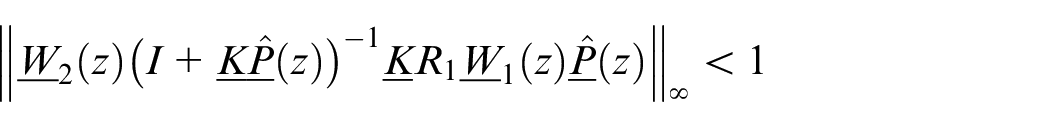
B. The fast single-rate control is no more robust than the dual-rate inferential system.
Model-based policy iteration algorithm for LQ regulator design
In this section, we discuss an online approach for designing regulators, using Hewer’s algorithm to solve the discrete-time Riccati equation. 25 This method is rooted in reinforcement learning. We show that Hewer’s algorithm converges under stability and detectability assumptions.
Reinforcement learning suggests generalized policy iteration, 19 where the algorithm involves iterating l steps to solve the matrix equation in each iteration j. When l = 1, it corresponds to value iteration, and for l = ∞, it represents policy iteration. The algorithm, based on equations (19) and (22), is summarized in the table below.
Select matrices
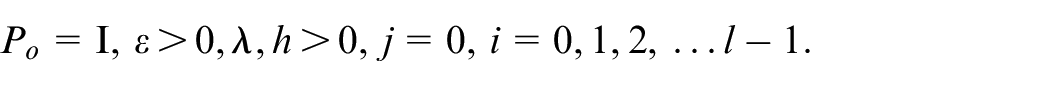
2.

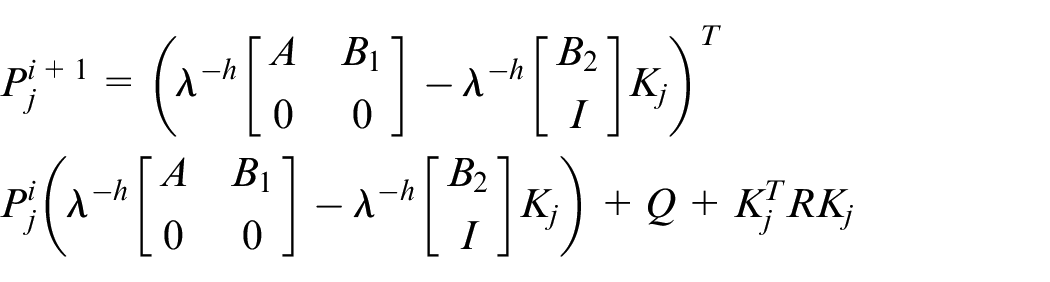
3.
4. Stop if
Otherwise set j = j+1 and return to step 2.
In practical applications, choosing a smaller R speeds up the closed-loop response, while a larger R slows it down. More formal methods for choosing these matrices are detailed in Reference [17, Ch. 6].
The sampling rate must be high relative to the rate of changes in the signal being considered. A common rule of thumb is to ensure the sampling rate is 5–10 times the bandwidth of the system. It’s also common practice to use an analog filter before the sampling process. The sampling rate is equal to the sampling period of fast-rate systems.
The parameter λ∈ (0,1] is crucial; a smaller λ leads to a higher speed of convergence of states.
The first key finding, without unmodeled dynamics, shows that a dual-rate inferential system is equivalent to a single-rate (fast-rate) system. A corresponding LQ regulator with prescribed degree of stability ensures that all closed-loop poles lie within the λ-circle in the complex plane where
The second key result addresses robust stability in the presence of unmodeled dynamics for LQ controllers. This involves transforming the dual-rate system into a single-rate system (lifted model) and establishing the
Illustrative example
The selected illustrative example is a dynamic system involving the translational movement of two elastically coupled masses shown in Figure 11. The system consists of two rigid bodies with masses m1 and m2, which are connected by a spring with an elasticity coefficient k. The bodies move without friction along a fixed horizontal surface. A force, or control signal u, acts on the left body. This subsystem is very common in various mechatronic systems.
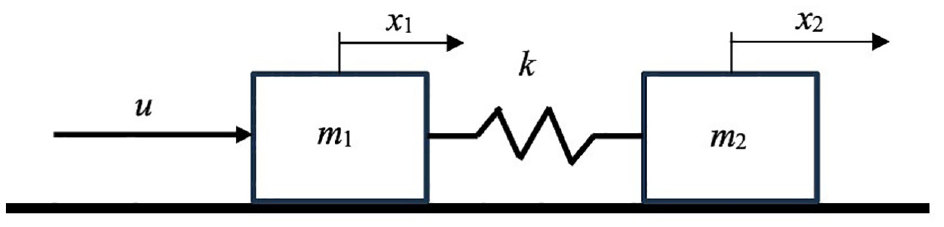
A mechatronic subsystem as an illustrative example of a controlled plant P c .
Let x1 and v1 be the position and velocity of the left rigid body, and x2 and v2 be the position and velocity of the right body. The state vector of the dynamic system is
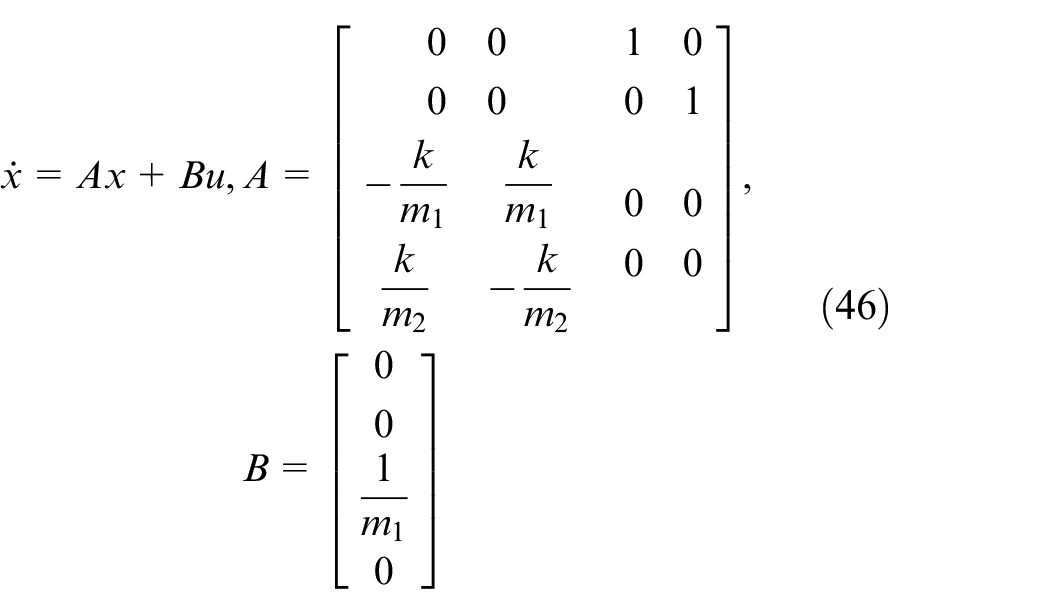
In this illustrative example, we will adopt the following parameter values
Sampling (46) with a sampling time h and using a FOH gives the discrete-time model:
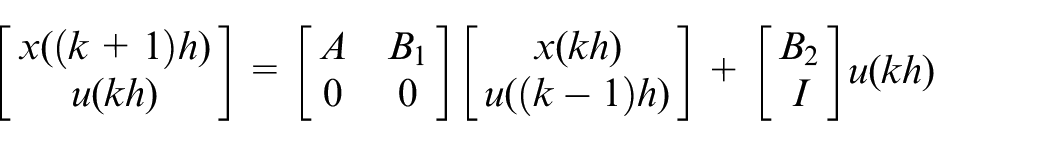
where:

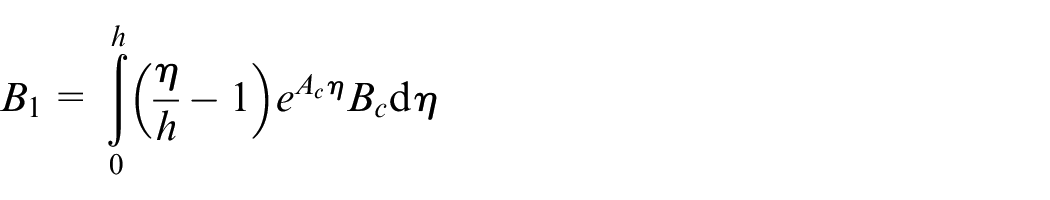
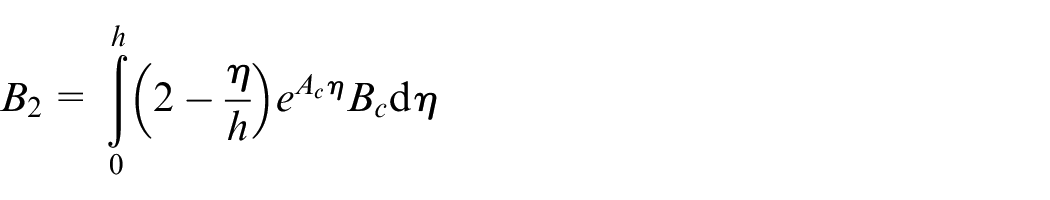
For λ = 0.30, h = 1,
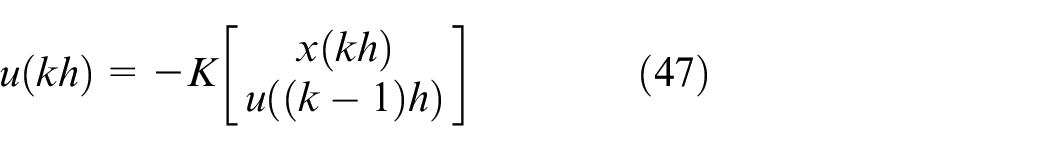
That is,
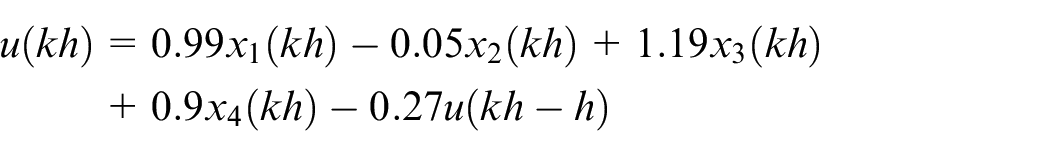
The convergence efficiency of Algorithm 2 is illustrated in Figures 12 and 13.
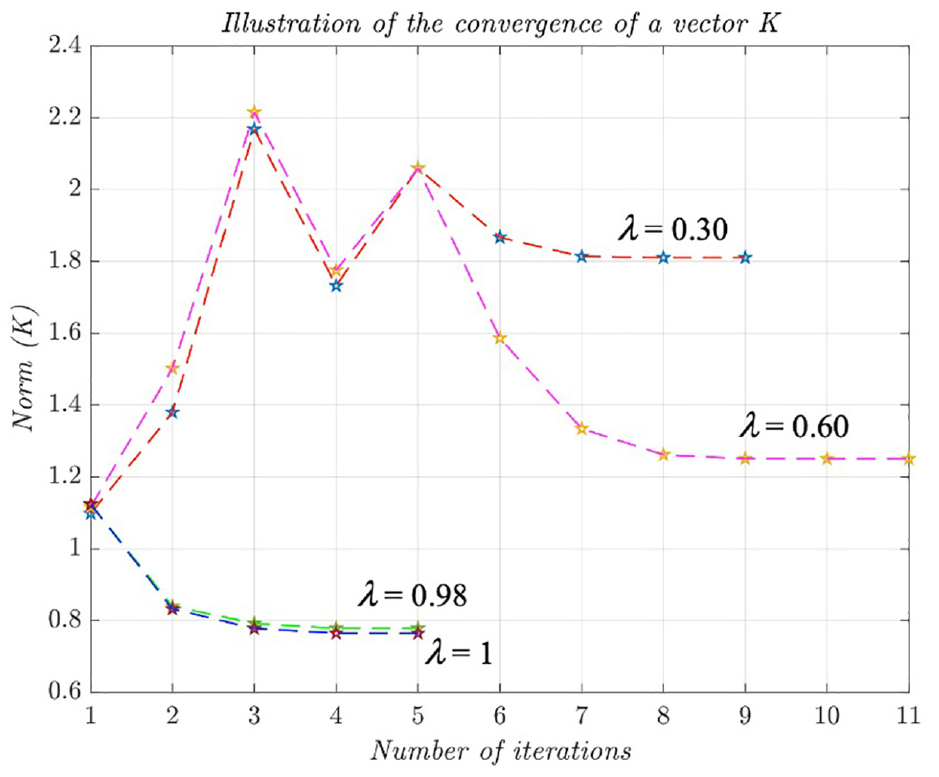
Convergence of a vector K for different λ values.
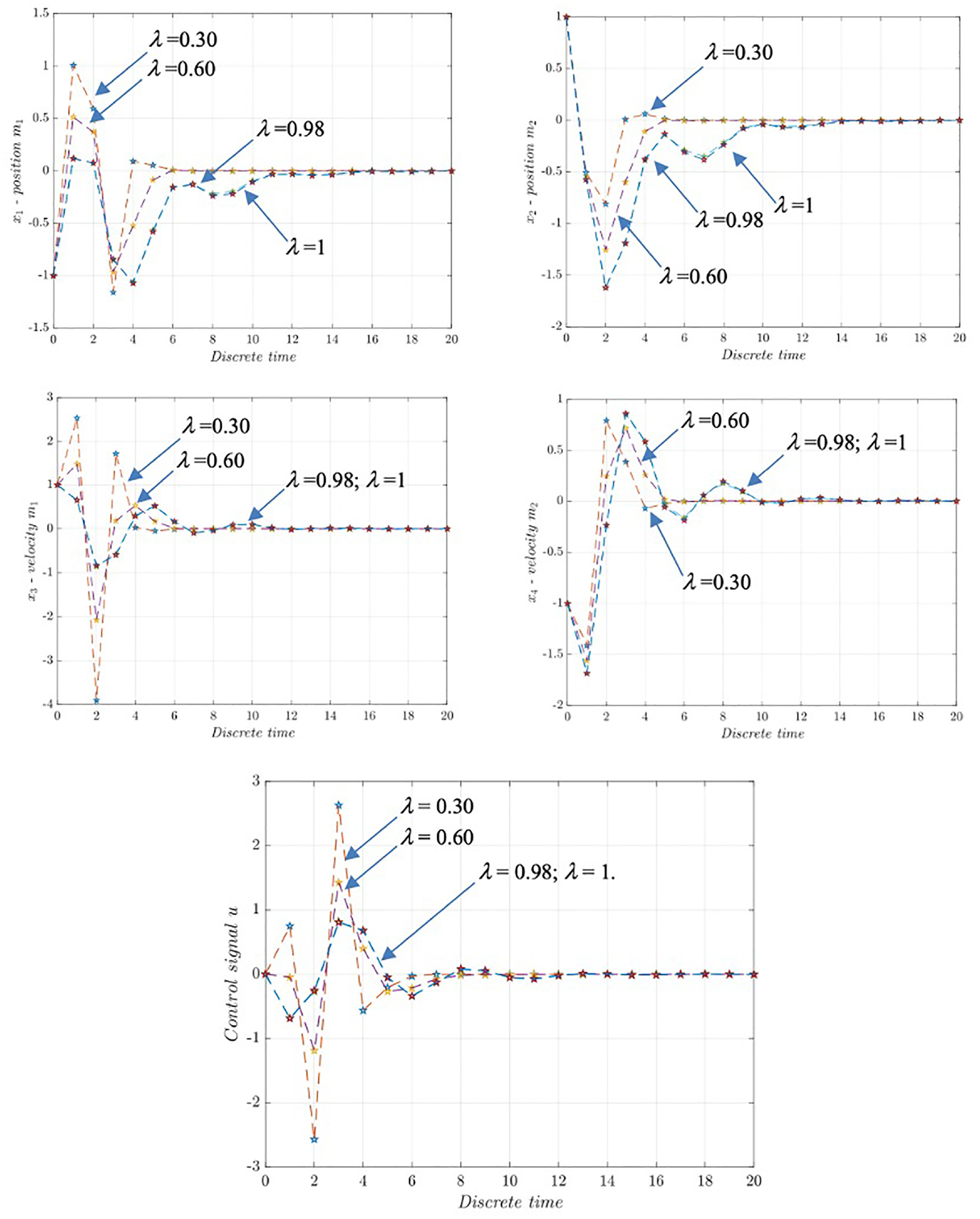
Motion of the autonomous dynamic system (47 and 48), for initial conditions (x1, x2, x3, x4) = (−1, 1, 1, −1) and u = 0: Less λ (0.30) provides a faster transient process, whereby the control signal has larger amplitude changes.
From the above figures it is possible to see that for smaller degree of stability the convergence of state of dynamic system is faster.
Conclusions
This paper discusses the design of a reinforcement learning LQ regulator with a focus on two key aspects:
Many real-world systems inherently operate at multiple rates, offering benefits such as improved stability margins, simultaneous stabilization, 42 and decentralized control 43
The regulator aims to minimize quadratic losses while ensuring that closed-loop poles reside within the specified region of the z-plane (0, 1]. This approach exhibits lower sensitivity to uncertainties in plant parameters compared to conventional methods, although the gain margin may vary.
The study employs a sampled-data model using FOH and introduces an LQ reinforcement learning regulator. It also addresses robustness using lifting techniques. Future research could focus on developing regulator designs that do not require knowledge of the system model, and explore aspects related to the frequency domain. 44 Also, interesting directions are the design RL LQ regulators for multivariable and continuous systems.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study