
Abstract
The extensive application of artificial intelligence in wireless communication, 3D reconstruction, and target location has successfully solved the modeling problem. Grasping specific objects in a stacked scene is a difficult task to achieve robot grasping. In this paper, a semi-supervised anchor-less single-gun grasping detection framework is proposed to help robots grasp objects easily. The framework first designs the AFMaskDetDep (AFMDD) network and then predicts the contours of objects by looking at sensing modules. Finally, the boundary value of the minimum boundary rectangle is obtained by judging the optimal target and the optimal grasping point of the inference module, and the final result is obtained by rotating back to the coordinate output on the original image area. Our proposed approach yields state-of-the-art performance with improved accuracy and computational speed on the VMRD and Cornell datasets, respectively. Experiments show that the algorithm can help the robot grasp a single specific object and has a high success rate in overlapping scenes. The success rate of each grip exceeds 93.5%.
Introduction
Robots have been considered significant in various human life applications, such as healthcare, home services, space debris removal, and edutainment.1–5 Grasping objects is an important step in completing tasks. 6 Typically, an object grasping, it would first perceive the overall environment through the eyes, then locate the object to determine the appropriate grasping site, and finally perform the grasping. For robots, a complete grasping operation involves multiple aspects. As the first step, object detection and grasping-pose generation are prerequisites for successful grasping, which helps the subsequent grasping path planning and the realization of the whole grasping action.
In literature, 7 visual perception and tactile perception are interrelated, both of which are very important for robot grasping results. A hybrid depth architecture network combining visual sensing and tactile sensing is designed. The advantages of intermediate step and fast end-to-end training can be observed for robot classification grasp detection. A multistage spatial transformer networks detection method is proposed in literature. 8 Aiming at the problem that grasp detection and object detection are not exactly the same in robot grasp detection, literature 9 designed a grasp detection model that is more fair to evaluate grasp point candidates. However, objects often exist cluttered and stacked in practical applications. Many studies were conducted to enable robots to grasp the target object among many other objects, like humans. To solve the grasping problem of irregular objects in sheet and column shape, a bionic soft robot was developed in literature. 10 In order to improve the degree of freedom of robot hands, a human-like grasping synthesis algorithm was proposed in literature. 11 Recent robotic grasping methods 12 have achieved promising results in detecting grasping sites and grasping postures in cluttered scenes with multiple objects. However, without considering the grasping order, it may cause varying degrees of damage to objects and robots in the stacked object scene.
Related works
Previously, the main focus was on detecting grip points, while neglecting the thinking of grip methods. Inspired by the progress of deep learning, in Lenz et al., 13 a neural network predicts whether there is a suitable grasping position for the input image. However, such a screening process required a complex network structure, which limited the real-time processing.
With various improvements on Lenz, 14 excellent performance was achieved on several public datasets such as Cornell and CMU grasping datasets. 15 However, such methods and datasets were oriented toward detecting grasps in single-object scenarios. Faced with real-life scenarios where multiple objects are often present, the practicability of those methods was limited. In order to overcome this problem, several works were conducted to deal with multi-object grasp detection in cluttered scenes. In Chu et al., 16 a novel depth architecture was proposed to predict grasp candidate frames for multiple objects simultaneously. In Zeng et al., 17 an affordance-based object agnostic perceptual framework was proposed, which allows fast and robust picking of multiple objects. In Wada et al. 18 proposed an instance occlusion segmentation approach to find and capture target objects by removing interfering objects in a pile of objects in proper order. However, these methods did not analyze the interrelationships between objects well, limiting performance on overlapped objects.
In Guo et al. 19 proposes a network structure that combines object detection and grab detection. In the method, the most exposed target was detected as the topmost object and grasped. However, this method has two fatal drawbacks: it only detects one object at a time and does not clearly define the most exposed object. The training dataset is very small and limited to fruit objects. Therefore, the training process may be prone to overfitting. In Zhang et al., 20 a visual manipulated relational network (VMRN) combined the relationship between multiple objects with grasping detection. Also, the VMRD grasping dataset was constructed, including multiple object relationship inference. 21 Subsequent works have improved the network to varying degrees. However, those improvements were only focused on the detection part.
Proposed method
The proposed robot grasping system architecture can accomplish the robot grasping task in cluttered multi-object occlusion scenarios. Modern robotic grasping systems usually use detection followed by a grasping model. It consists of a detection model for target localization and a grasping model for judging the pose of the robot. The separate operation of these two models requires an inefficient computation of two steps running. Existing real-time robot grasping systems were focused on grasping models, which were essentially robot pose determination methods rather than real-time robot grasping systems. This paper proposes a robotic grasping system that allows a shared model to learn target detection and robot pose-judgment.
Specifically, we integrate the depth prediction and contour generation into a single-stage anchor-free detector so that the model can output both depth map and contour. Then, in the post-processing, the depth map and object contour are combined to compute the best target, grasping point, and grasping vector. For this purpose, we implement a complete process of observation perception, judgment inference, and completion capture, where the first two processes are our main tasks implemented through AFMDNet.
Overall network structure
Our proposed AFMaskDetDep architecture is shown in Figure 1. The proposed AFMaskDetDep architecture is described in the following. First, the anchor-free method is adopted. The anchor-free method is a popular approach used in object detection and is designed to benefit from a larger and more flexible solution space. The anchor-free method eliminates the need for hand-designed anchor boxes and instead directly predicts the bounding boxes, objectness scores, and class probabilities of objects. To achieve high performance and computational efficiency, the proposed grasping model adopts an anchor-free object detection method. This method eliminates the need for pre-defined anchor boxes, and instead directly predicts the object bounding boxes, objectness scores, and class probabilities. This approach allows for a more flexible solution space and reduces computational complexity. One of the main challenges with anchor-based methods is the issue of super-references, where multiple anchor boxes may be assigned to the same object, leading to confusion and imprecise predictions. There are several methods used for avoid super references problem in anchor-based detection systems. These include: Non-Maximum Suppression (NMS), Intersection over Union (IoU) Penalty, Focal Loss, Refining Anchor Boxes. These techniques can be used in combination to effectively avoid super-references and improve the accuracy of object detection systems based on anchor boxes. In this way, the anchor-based method can avoid the problems of many super-references (scale, aspect ratio, IOU threshold), more redundant frames, and serious imbalance between positive and negative samples.
(1) The efficient network, MobileNet v2, is used as the backbone network, which consists of depth-separable convolution, depthwise separable convolution, depthwise, and pointwise. The MobileNet v2 is used to extract features with a lower number of parameters and lower operational cost than conventional convolutional operations, which decompose an m × m × n standard convolutional layer into n m × m depthwise layers and a 1 × 1 pointwise layer. Since each filter in the depth-separable convolutional layer convolves with only one input channel, and each filter in the standard convolutional layer convolves with all input channels, the complexity of the depth-separable convolutional layer is much lower than that of the standard convolutional layer. The extracted features are then fed into the FPN, where they are gradually subsampled, refined, and merged to form the final high-resolution output depth map.
(2) FPNs use a top-down architecture that combines high-resolution features from the lower levels of a deep neural network with low-resolution features from the higher layers of a network. This architecture enables the network to generate multi-dimensional feature representations of the same scale image under a single image view in a hierarchical manner. The information from each layer is used to obtain the final combination of expressed features. The features generated from top to bottom processing are also correlated with each other, that is, the higher-level features affect the lower-level features. Finally, all the features are used as the input of each branch in the next step.
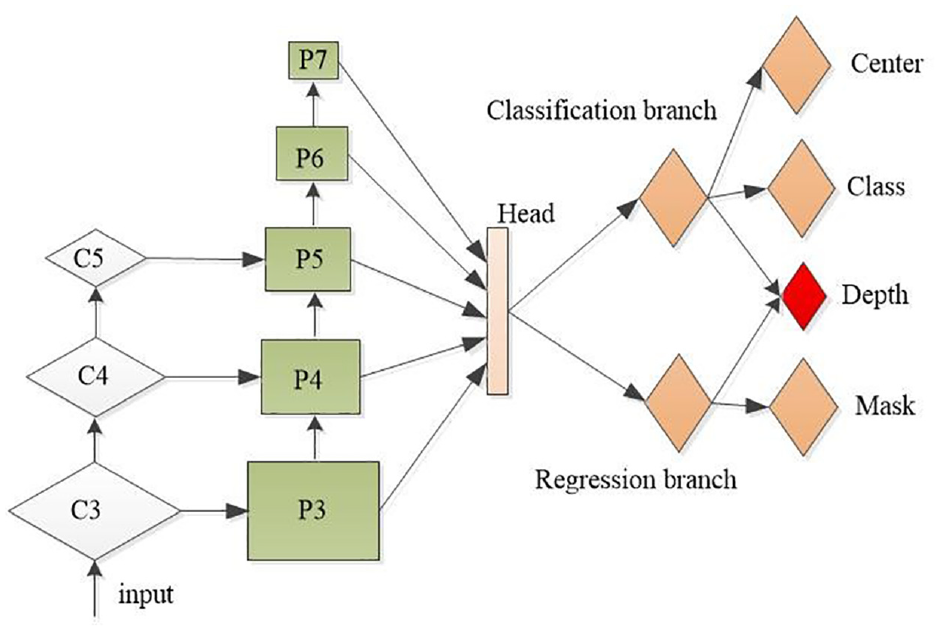
Architecture diagram of AFMaskDetDep.
The proposed network structure is fully convolutional with deep separable convolution in both the backbone network and feature pyramid network (FPN), significantly reducing the computational and memory complexity.
(3) Our network has multiple task heads, where each head is independent of the other and has its own loss function.
Observation perception module
Contour prediction
For any target, its contour can be modeled using polar centers and countless rays. The Contour polar coordinates is shown in Figure 2. In this way, the contour generation is modeled as a dense distance regression in target center classification and polar coordinates. When the center point

Where,
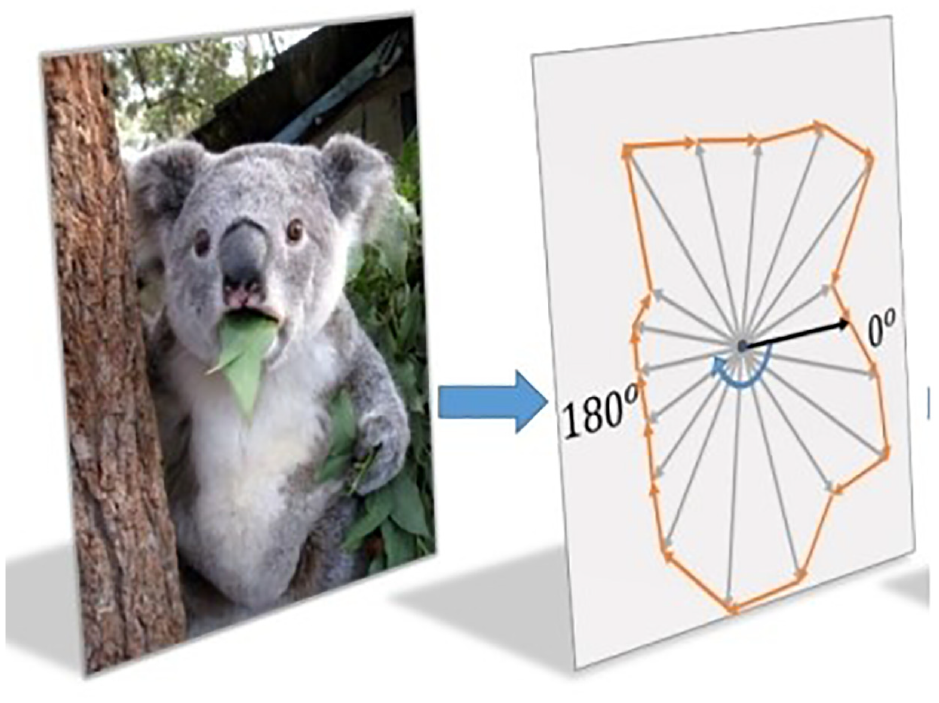
Contour polar coordinates.
Polar IoU loss
A simple but effective polar IoU is used for computing contours. The polar IoU loss can be represented by formula (2).
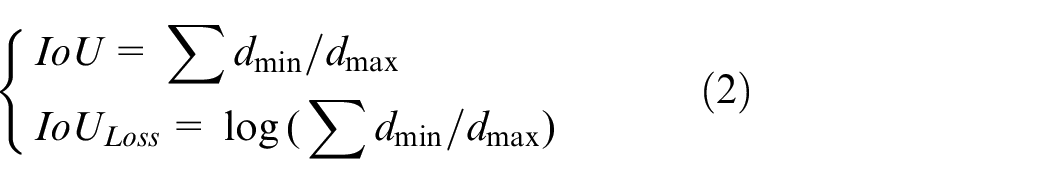
Where,
Depth loss
The depth branch adopts a different loss function and target data from the contour branch. For depth prediction,
Judgmental inference module
Optimal to be grasped target inference
This module fuses the predicted contour
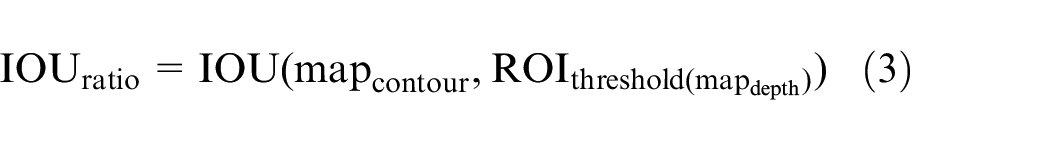

Optimal grasping point judgment
The optimal grasping point is obtained by analyzing and calculating the most pending grasping target obtained in the previous step. Connected components play an important role in computer vision and image processing by providing a method for analyzing and extracting regions of interest from binary images. Automatic image analysis applications that can be extracted from connected components from a binary image include: object detection, object counting, region of interest detection, object tracking, image segmentation, character recognition, biomedical image analysis. The core of automatic image analysis is to extract connected components from binary images. The following iterative process accomplishes this.
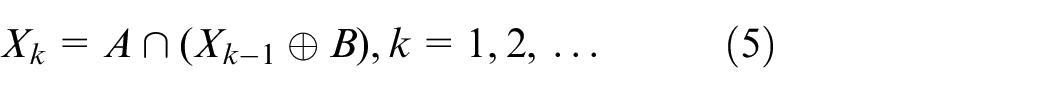
Where, A is a point for each connecting component, B is an appropriate structural element, and the iterative process ends when
Obtain the minimum outer rectangle
The confirmation of the maximum and minimum boundary values is based on the maximum values in the x-axis and y-axis directions and the coordinates of the convex hull boundary vertices, respectively. The first step in boundary rotation is to obtain the horizontal angles
The convex hull is rotated around the center of the coordinate system by selecting the horizontal angle of each line segment as the rotation angle in order. The rotated coordinates
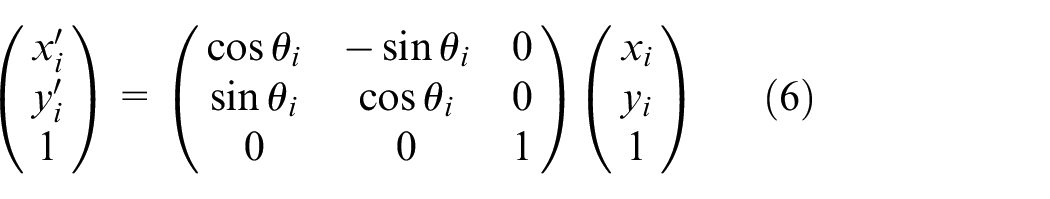
The maximum and minimum values of the rotated convex hull boundary in the x-axis and y-axis directions are determined as the minimum external rectangle after rotation. The area of the current external rectangle and the angle of rotation, as well as the maximum and minimum coordinates of the boundary, are calculated and recorded.
Finally, the coordinates of the external rectangle are counter-rotated around the origin of the image coordinate system by the same rotation angle to the original image area. Assuming that the vertex coordinates are
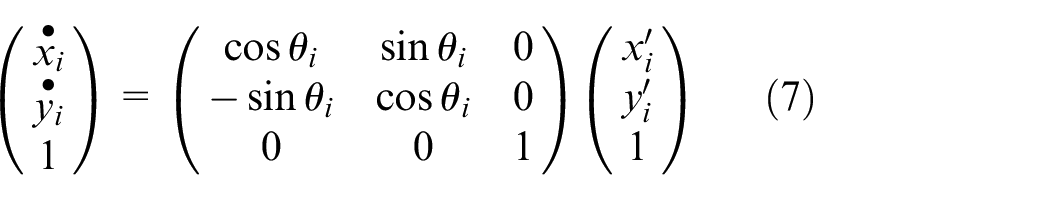
Due to the large number and complexity of convex edges of the graphic contour, the existence of the same horizontal angle induces an increased number of boundary rotations. Therefore, it is necessary to unify these angles into the first quadrant, which can reduce the number of rotations and accordingly heighten the efficiency. The horizontal angle after unification
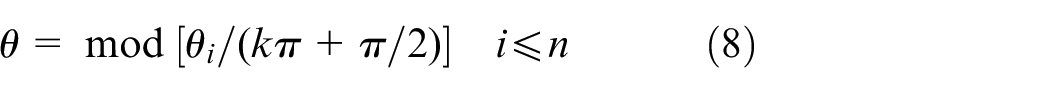
Then, the same angle in
Experiments
Experimental setup
MobileNet v2 is used as our backbone network with the same hyperparameters as fully convolutional one-stage object detection (FCOS). The network is iteratively trained using stochastic gradient descent (SGD). The initial learning rate is 0.01, and the batch size is 16. The initial value of weight attenuation is 0.0001, and the initial value of momentum is 0.9.
Data preprocessing
We trained the network using Cornell and VMRD datasets. The Cornell capture dataset contains 5110 RGB D images of real objects labeled as positive samples and 2909 RGB D images of real objects labeled as negative samples. Grasp dataset best fits our pixel grasping representation. The VMRD dataset consists of 4683 images, of which 4233 and 450 are in the training and test sets, respectively. This dataset considers object-object affiliation relationships, where 2–5 objects are superimposed with overlap and occlusion in each image.
The proposed network consists of multiple sub-branch networks that require depth and mask datasets to be trained. However, the Cornell and VMRD datasets do not include the depth and mask labels. Thus, mask and depth labels were generated with the Mask RCNN and Monodepth, respectively. Figure 3 shows the comparison of estimated depths between the proposed model and the GT model on the NYU depth v2 dataset.

Comparison of depth estimation results of different models in NYU Depthv2 data: (a) input image, (b) GT, and (c) proposed model.
Experiments on robot grasping
The robot grasping experiment was evaluated in two different tasks: random selection and target selection. Random picking strategies are commonly used in robotics and automation systems for selecting targets, such as objects or parts, for further processing or inspection. There are two types of random picking strategies, including: uniform random picking, stratified random picking. For the Cornell dataset, which includes images of fruits and vegetables, uniform random picking can be an effective strategy since there is no specific clustering or organization in the dataset. For the VMRD dataset, which includes veterinary medical images, stratified random picking based on the medical condition or organ of interest is a useful strategy. The VMRD dataset and the Cornell grasp dataset are both labeled datasets for object detection, but they differ in their domain and characteristics. The VMRD dataset focuses on veterinary medical instruments, while the Cornell grasp dataset contains labeled images of fruits and vegetables. The Cornell grasp dataset provides depth and grasp labels, while the VMRD dataset does not include depth labels.
In random selection tasks, the goal of a robot is to move objects from one place to another without priority. In the target picking task, the robot aims to pick specified objects and remove obstacles. Random picking strategies can be used even in target picking.
There are two typical failure scenarios for random picking, the next target object is obstructed and the picking is not possible due to collision. The first type of fault can lead to picking failure, waste of time, and damage to items, while the latter causes dropped items and wrong picking counts. In order to overcome the above problems, the most optimal target is judged as the next target by our robotic grasping system. The developed suction grasper is used to randomly create cluttered scenes in the bins with the center point as the suction point. Experiments were conducted on robotic random picking based on occluded area segmentation. In 67 experiments of selecting an object, the robot successfully selected 63 times, with a success rate of 94.0%. Failed to grasp two times (3%) due to incorrect view segmentation, failed to pick one time (1.5%) due to collision with other objects, and mistakenly picked two objects simultaneously one time (1.5%) due to incorrect segmentation of the occluded region. The results indicate that the model has a high success rate in capturing non occluded objects.
We studied AFDMMNet on the Cornell dataset, including dataset size and training data type, to demonstrate the effectiveness of the proposed model. Furthermore, we will verify the model’s ability to capture multiple cluttered objects.
While predicting the best grasp for a new real target, our model can predict the topmost target and grasp it one at a time. The success rate of each grasp is 93.5%. Figure 4 illustrates the grasping ability of the robot under multiple targets. This indicates that our network can be extended to the robustness of capturing multiple other targets.

The robot’s ability to grasp under multiple targets.
Figure 5 shows the removal of the top obstacle and target object grasping of the our method. The robot grasping results show that the algorithm can effectively pick up the target with severe occlusion.

Effectively perform target pickup tasks under occlusion.
The object being caught is a more complex three-dimensional structure, such as not a cylinder or a rectangle. The image determination based on depth information is still effective. Figure 6 shows that the captured object is a more complex three-dimensional structure such as a towel, and the image determination based on depth information in this article is still valid.

Effectively performing target picking tasks in more complex 3D structures.
Conclusion
This paper proposes a single shot semi supervised multi task robot grasping system based on an anchor free method to address the success rate of object grasping in specific individual objects and stacked scenes. The relevant work was reviewed in the second section. Our proposed algorithm is described in detail in the third section. The fourth section presents the experimental results, including validation using VMRD and Cornell datasets and robot experiments. Depth information is added to the traditional anchor-free instance segmentation, which combines depth features with object contours. The robot grasping results show that our method outperforms traditional grasp detection methods in terms of speed and accuracy, proving the effectiveness of the model in various target pickup tasks.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the School-Level Research Projects of West Anhui University under grant (WXZR202211), West Anhui University High-Level Personnel Research Funding Project (WGKQ2022013, WGKQ2022015), West Anhui University School-Level Quality Engineering Project (wxxy2022085), Anhui Provincial Quality Engineering Project (2021sysxzx031, 2022sx171), the Open Fund of Anhui Undergrowth Crop Intelligent Equipment Engineering Research Center (AUCIEERC-2022-05), Key Project of Natural Science Research of Anhui Provincial Department of Education (KJ2021A0945, KJ2021A0946), Anhui Colleges and Universities Scientific Research Project (2022AH010091, 2022AH040241, 2022AH051675).
Availability of data and material
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.