
Abstract
With the continuous development of robotics and computer vision technology, mobile robots have been widely applied in various fields. In this process, semantic maps for robots have attracted considerable attention because they provide a comprehensive and anthropomorphic representation of the environment. On the one hand, semantic maps are a tool for robots to depict the environment, which can enhance the robot’s cognitive expression of space and build the communication bond between robots and humans. On the other hand, semantic maps contain spatial location and semantic properties of entities, which helps robots realize intelligent decision-making in human-centered indoor environments. In this paper, we review the primary approaches of semantic mapping proposed over the last few decades, and group them according to the type of information used to extract semantics. First, we give a formal definition of semantic map and describe the techniques of semantic extraction. Then, the characteristics of different solutions are comprehensively analyzed from different perspectives. Finally, the open issues and future trends regarding semantic maps are discussed in detail. We wish this review provides a comprehensive reference for researchers to drive future research in related field.
Keywords
Introduction
Recently, indoor mobile robots are becoming more and more common in our daily lives, assisting humans in various tasks,1–4 such as: domestic service, warehousing and logistics, medical care. Especially in the global outbreak of COVID-19, the medical service robot can replace humans to complete ward disinfection and drug delivery, reducing the workload of medical staff and the risk of cross-infection. To adapt to increasingly complex application scenarios, it is important for mobile robots to improve their environmental perception capabilities.5,6 During this process, maps are the medium for the robot to perceive its surroundings and perform navigation tasks.7–9
Currently, the maps used by indoor mobile robots to achieve localization and navigation are mainly metric maps. This kind of map only extracts the geometric features of the environment, and lacks the high-level information for the robot to fully understand the indoor scenes.10–12 In this case, robots cannot perform interactive tasks in a human- understandable mode, which hinder the practical application of robot intelligent services. 13 In the future, indoor mobile robots are expected to work in human-robot interaction environments. Thereby, it is essential for robots to close cooperation with humans. For example, for indoor service robots used in supermarkets and restaurants, the scenario is densely populated and the environment is high complex. In this case, the robot needs to interact with dense mobile crowds frequently and constantly perform dynamic obstacle avoidance or emergency stop. To efficiently complete these real-time and dynamic tasks, the robot must not only “see” but also “understand” the surroundings. Traditional grid maps and topological maps obviously cannot fulfill requirements. To solve this problem, it is more and more critical for robots to construct a semantic map that contains semantic properties of indoor environments.14,15 Generally, semantic maps contain semantic properties and spatial location of each entity (such as scenes and objects) in indoor environments. Based on semantic maps, robots can not only imitate the way humans understand the surroundings, but also complete intelligent decision-making by means of semantic information. Therefore, semantic maps are the prerequisite for robots to perform high-level intelligent operations.
Extensive research has been conducted on semantic mapping techniques. 16 In 2008, Nüchter and Hertzberg 17 first proposed the concept of semantic map. By building a 3D point cloud model of the environment. This work can help mobile robots identify some simple planar structures and objects (ceilings, walls, doors, etc.) in indoor scenes through constructing a 3D model of environments based on point cloud data. Early semantic map construction approaches mostly use offline methods, such as Markov method for geometric map semantic annotation.18,19 This method needs to process the map offline, cannot be used on robots. Later, with the rise of machine learning methods, some researchers tried to adopt conditional random fields (CRF), Random Forest and other algorithms to obtain semantic labels in scenes,20,21 but such algorithms have low efficiency and poor accuracy of semantic fusion, and cannot be applied to actual environments. In order to help robots better understand entities in the environment, some scholars proposed to fuse maps and pre-constructed object models and then to segment entities from maps.22,23 However, this method relies on prior knowledge and limits the application scenarios of semantic maps. With the emergence of deep learning technology, extensive work adopts CNN to extract the semantics of the environment for semantic mapping, such as object detection and semantic segmentation. At the same time, many dense semantic map systems emerged: Mesh-based semantic map,24,25 Octree-based semantic map,7,26 large-scale semantic map, 27 etc.
In this paper, we discuss and review the existing related researches regarding semantic mapping recently. In these literature reviews, we mainly focus on the techniques of semantic extraction, the process of semantic mapping, and the challenges for semantic mapping. The rest of this paper is organized as follows. First, we introduce the background of semantic mapping, including the definition of semantic maps and the extraction of semantics. Then, we enumerate semantic mapping methods from different perspectives. After that, the open issues and potential directions of semantic mapping methods are presented in detail. Finally, we conclude this paper.
Background
Semantic mapping problem definition
Before we give the formal definition of semantic mapping, we first explain the concept of semantics. Semantics are the basic elements of semantic maps. As the robot traverses the environment, it collects information of entities such as scenes and objects through various sensors. Generally, the environmental information perceived by robots can be abstracted into features layer by layer. Most of the low layer features are semantics such as points and lines, the features of the middle layer can be extracted into some local parts of entities, the features of the upper layer rise to the level of entities. From this perspective, the so-called semantics is to further summarize and organize environmental features to a level that humans can understand. In order to clarify the research objects and carry out related discussions, this paper combines the existing research literature to give a general descriptive definition of “semantic map.” The semantic map is a representation that provides the following three types of environmental information for robots: geometric features that provide the robot with spatial location of environments to perform navigation, semantic description of entities for human-robot interaction, association information between entities and properties which empower a robot the ability of logical reasoning.
Then, we give a detailed description of semantic maps. The world W is composed of various entities
Generally, the process of semantic mapping consists of features extraction, entity reignition, data association and pose estimation, as depicted in Figure 1.
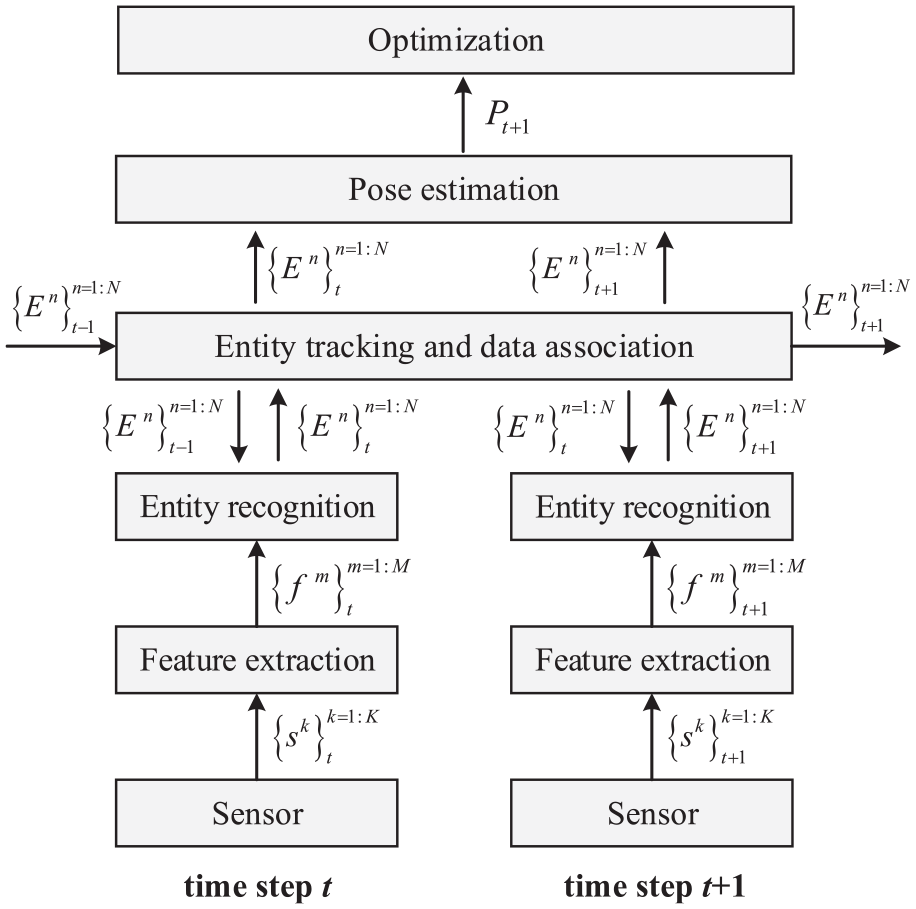
Typical process of semantic mapping.
Techniques of semantic extraction
The key to building semantic maps is the semantic extraction of various entities in the environment. Generally, the existing techniques of semantic extraction could be grouped to the following two classes: object-oriented methods, scene-oriented methods. Object-oriented semantic extraction methods mainly use specific techniques to recognize objects from the environment, such as object recognition 28 and instance segmentation, 29 etc. Overall, object detection is suitable for coarse-grained semantic reasoning, while instance segmentation is more general as it is suitable for fine-grained semantic processing. To enable the obtained semantics to support robots in performing various tasks, Object-oriented semantic extraction methods also need to locate the object in the environment, calculate its accurate pose and map it into the semantic map, after obtaining the object semantics. Liao et al. 30 and Brucker et al. 31 proposed a semantic labeling method that proposed a semantic labeling system that perform room recognition and object segmentation based on an RGB-D camera. Besides, to realize the information association of object detections and room types, they adopted a conditional random field for jointly reasoning. In order to facilitate human-robot interaction in robot operation tasks, Martins et al. 32 presented a learning-based framework which can build an augmented semantic map representation of environments. They achieved object segmentation and spatial localization based on a Kinect camera. Moreover, to improve the accuracy of target mapping, EKF is adopted to track and update the pose of the identified objects in scenes. For object-oriented semantic extraction, a considerable challenge is the object semantic mapping. 33 Robots may detect a same object in different places at different times during the mapping process. To solve this problem, most of the research utilizes the confidence level for object association. However, due to the interference of angle or illumination, the instance may be mapped repeatedly on the semantic map. In this case, it is difficult to guarantee the pose accuracy of the semantic object during the mapping process.
Compared with object-oriented semantic extraction methods, scene-oriented semantic extraction methods are more widely applied to semantic maps due to its easy availability and high accuracy of semantics. 34 Scene-oriented semantic extraction methods mainly focus on recognizing local scenes in the environment through specific techniques, such as scene recognition 35 and semantic segmentation,25,36 etc. Both scene recognition and semantic segmentation can assign scene semantic labels to each pixel of the image, but semantic segmentation is relatively more suitable for fine-grained scene semantic processing. McCormac et al. 37 proposed a semantic mapping framework based on dense point cloud. The approach adopted the ElasticFusion algorithm to update spatial poses of the camera and performs dense pixel-level semantic segmentation through deep learning technology. To improve accuracy and robustness, pixel predictions are optimized from different angles based on Bayesian estimation and conditional random fields to build dense 3D semantic maps. Although providing real-time and closed-loop solutions for indoor semantic mapping systems, this system is mainly suitable for small-scale and structured indoor scenes. Rozumnyi et al. 38 proposed a deep fusion framework based on machine learning, which fuses semantic 3D reconstruction and scene recognition based on multi-sensor data. The method automatically extracts sensor attributes and scene parameters from training data and represents them in the form of confidence values to construct high-precision semantic depth maps, which requires the use of only a small amount of training data to obtain a good generalization ability.
Map representation
After extracting the semantic information of environments, it is necessary to organize them and represent them on the map according to certain rules. Generally, there are mainly two types of methods to implement this process: semantic labeling and logical reasoning. Semantic labeling is the most common means of semantic mapping. It directly annotates semantics (such as scenes and objects) on the corresponding metric map. Each location on the metric map is marked with a different color, representing different semantic categories. In this way, an exact correspondence is established between semantics and geometric information. Besides simple labeling, there are some sophisticated structures that require establishing a knowledge model of the environment for semantic mapping, which endows the capacity of logical reasoning. Logical reasoning based methods usually construct a hierarchy structure of conceptual knowledge based on ontology model. The lower levels of hierarchy structure contain geometric information of environments. The upper levels of hierarchy structure contain conceptual knowledge of different entities and semantic reasoning rules. Therefore, logical reasoning based methods require constructing the reasoning system in advance to manage the ontology model. Meanwhile, reasoning system construction methods vary in different scenarios.
Semantic mapping methods for robots in indoor environments
To realize vision-based mapping and navigation tasks, it is essential to evaluate different semantic mapping methods. Generally, from the perspective of semantic extraction, the semantic mapping methods could be grouped as: scene-oriented semantic mapping methods and object-oriented semantic mapping methods. Scene-oriented semantic mapping methods39,40 use technologies such as semantic segmentation and scene recognition to extract scene semantics in images and perform pixel-level annotation for semantic mapping. This type of method focuses on the robot’s scene perception in indoor environments. Although scene-oriented semantic maps can assist the robot to better learn the overall layout structure of environments and construct more expressive environmental maps, this approach is not conducive for robots to understand objects and local details in the environment. The inability to interact with objects in environments affects the application scenarios of robots. Therefore, some works have proposed object-oriented semantic mapping approaches. In contrast, object-oriented semantic maps41,42 contain semantic information of object instances, and the semantic information is independent of the map in a clustered manner. Therefore, robots can be allowed to operate and maintain the semantics of each entity in the map. For robots, this map form that stores entity information in the environment in a clustered manner is more conducive for robots to perceive the environment and interact with entities.
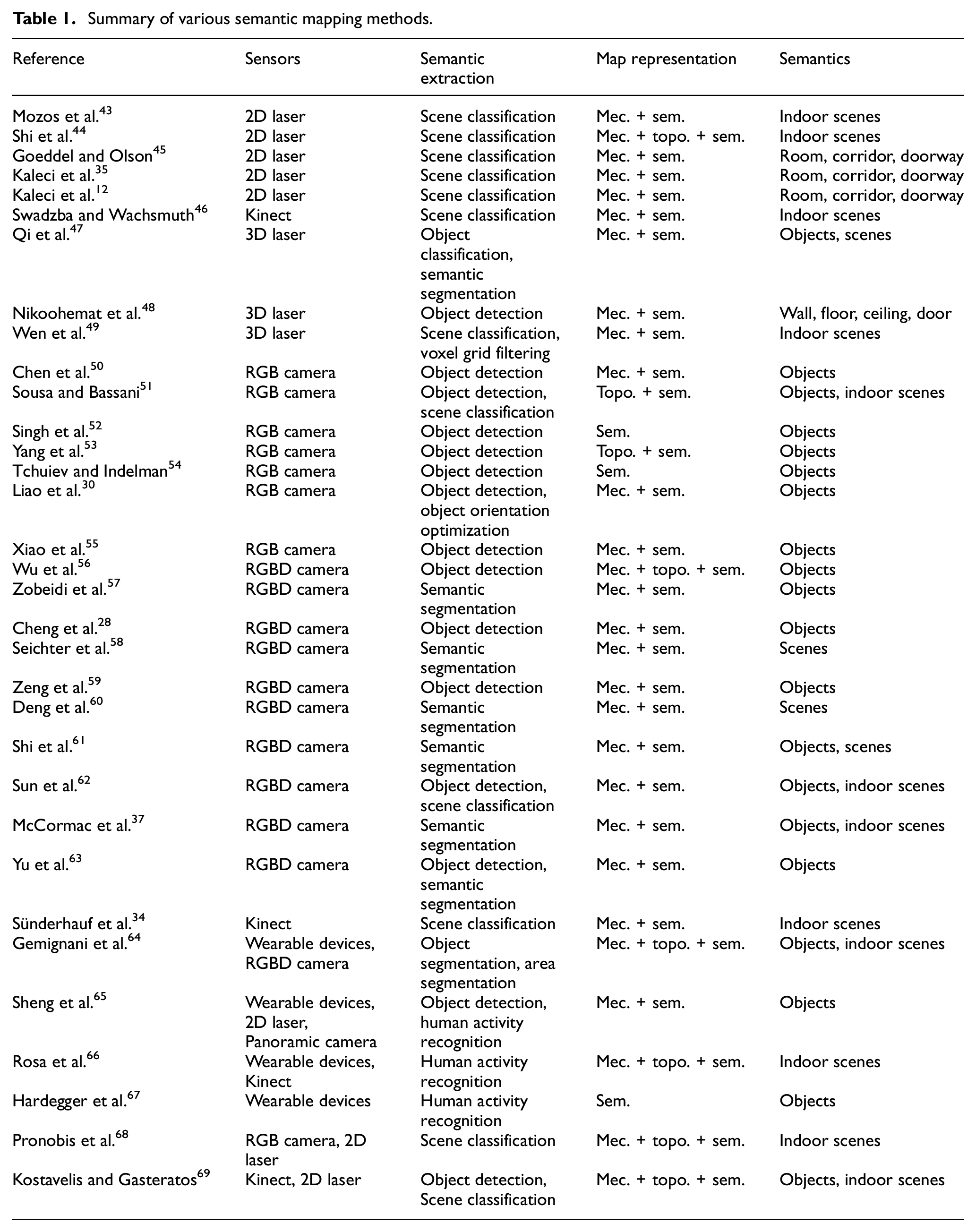
From the perspective of the type of information used to extract semantics, the semantic mapping methods can be distinguished into the following four classes: methods based on geometric information, methods based on visual features, methods based on human guidance information, and methods based on combined approaches. Note that methods based on combined approaches could be a fusion of two or more types of semantic information. In this paper, to make the paper more understandable, we review and discuss the existing related researches regarding semantic mapping according to this classification way. Figure 2 depicts a graphical description of this classification. In recent years, extensive works have proposed various semantic mapping methods, as listed in Table 1. For each method, the table presents the used sensors, semantic extraction techniques, map representation and the constructed semantics in semantic map. Note that the abbreviations mec., topo., and sem. in the table represent metric map, topological map, and semantic map respectively.
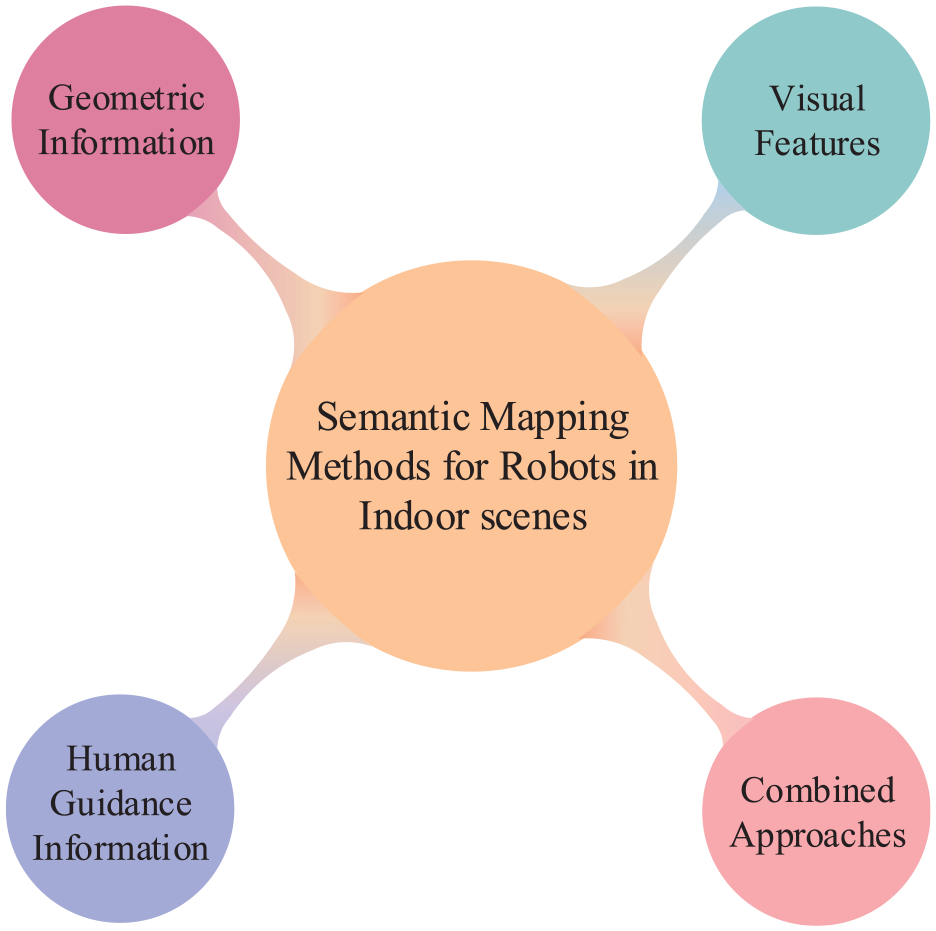
Taxonomy for classifying semantic mapping methods according to the type of information acquired.
Summary of various semantic mapping methods.
Methods based on geometric information
Generally, the geometric information refers to points, lines, and surfaces in the environment. The distance sensor can easily obtain the geometric information of environment, such as laser and sonar. Since it is not prone to affected by the changes of lighting and perspective, and its data is stable and reliable, the geometric information is suitable for constructing high-precision maps. However, it is a tricky issue to extract the semantics of environments by relying only on geometric features. This is because the information from distance sensors is too poor, so that only the features closely related to geometric structure of the environment can be extracted for classification, which is incompetent for complex scenes. Nonetheless, the geometric information from laser is very accurate, providing the basis for the subsequent complex perception tasks of indoor mobile robots. From the perspective of the dimension of information, this kind of semantic mapping methods can be distinguished as: 2D geometric information based semantic mapping and 3D geometric information based semantic mapping.
2D geometric information based semantic mapping
Semantic mapping methods based on 2D geometric information are mainly focus on extracting scene semantics by means of scene classification, since it cannot obtain high-level details of surrounding environments. The scene semantics provide robot with valuable cues for anthropomorphic navigation and human-robot interaction. Generally, these methods extract the 2D features of the environment and construct scene semantic maps through 2D laser. Theoretically, rang scans acquired in different positions of indoor environments possess distinctive geometric shapes. For example, the scan of a warehouse is usually disorganized than a conference room, the outline of a corridor is generally long and narrow.
For a long time, 2D laser based semantic mapping has been the focus of many researches. Mozos et al. 43 presented a supervised learning approach for classifying different places in indoor environments, in which the accuracy of scene classification ranged from 82% to 92% on different datasets. In this approach, an AdaBoost algorithm is adopt to boost single geometric information obtained by a 2D laser scan for scene classification. Based on the constructed semantic map, the robot can distinguish the concept of different indoor scenes, such as “corridor,”“doorway” and “room.” Inspired by the above method, Sousa et al. 70 used the Support Vector Machine (SVM) classifier to identify “room” and “corridor”. Mozos and Burgard 71 proposed a topological semantic mapping approach by means of the above AdaBoost algorithm. In this semantic map, each node represents a specific semantic region in indoor environments and each edge represents the connection between nodes, as shown in Figure 3.
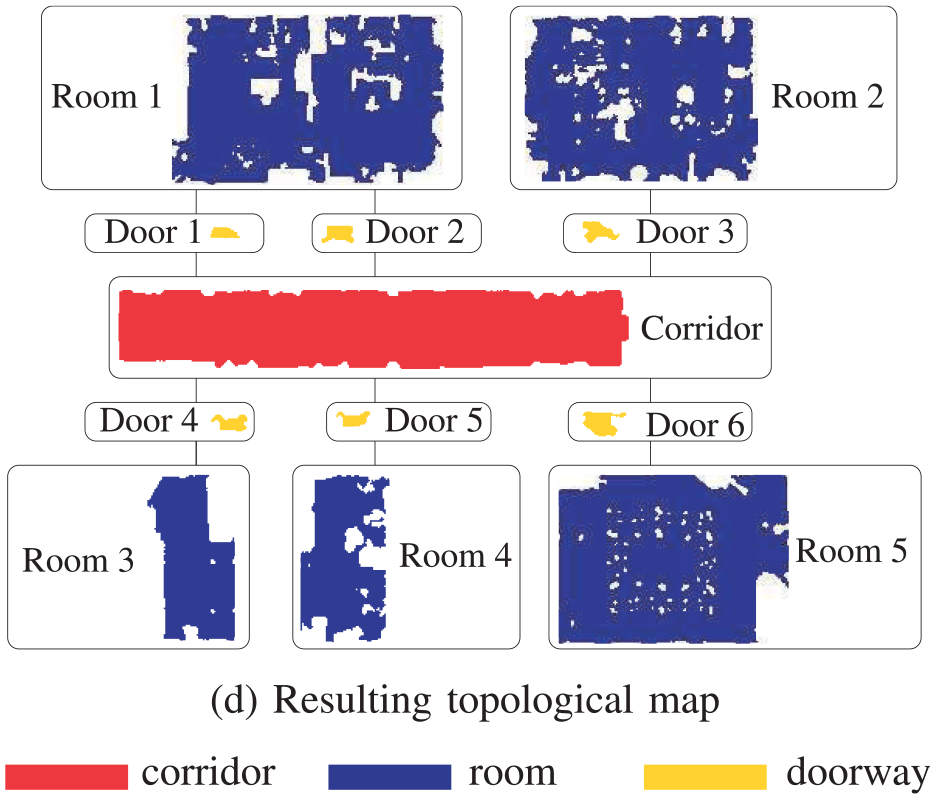
An example of constructed semantic map based on 2D laser in Mozos and Burgard. 71
In order to facilitate human-computer interaction, Shi et al. 72 adopted a L2-regularized logistic regression as a multi-class classifier to label indoor environments into different scenes through a laser range finder. Although the accuracy of the above method on specific datasets can reach more than 96% for multiclass scene classification, classification ambiguities may occur in some semantic scenarios. To address the above challenges, Shi et al. 44 presented a semi-supervised learning method to perform semantic scene classification for the nodes of Generalized Voronoi Graph (GVG). In this process, a probabilistic graphical model named Voronoi Random Fields (VRF) is employed to construct the topological structure of surroundings. Kaleci et al. 73 proposed a probabilistic approach fusing K-means and Learning Vector Quantization (LVQ). This method constructs feature vectors from raw laser data to realize the semantic classification for three scenes in indoor environments: room, corridor, and door.
Generally, 2D geometric information based semantic mapping methods are prone to failure in dynamic environments due to frequent corrupted observations. Additionally, due to the high similarity of layout and structure in the indoor environment, different scenes may have homologous geometric semantic representations, resulting in global ambiguities. To address this challenge, Park and Park 74 proposed a place classification method by means of two-dimensional principal component analysis (2DPCA). To represent geometric features at different locations, the 2DPCA is utilized to train a set of classifiers based on the 2D histogram of scan data in this method. Experimental results indicate that the performance of this method is robust even when the 2D laser data is frequently interrupted in a dynamic environment. This is mainly because the 2D histogram of scan data exploits the global geometric features of environments rather than local geometric features. Due to the robustness of the laser to illumination changes, Premebida et al. 75 proposed a supervised semantic place classification approach based on 2D laser, named Dynamic Bayesian Mixture Models (DBMM). DBMM integrates a general probability model with a conditional probability model containing time prior information, to relieve potential abrupt changes and improve the accuracy in classification performance. Extensive experiments were conducted on different publicly available datasets and the results demonstrate the competitive performance of DBMM. Goeddel and Olson 45 proposed a CNN-based location recognition method, proving that CNN can be successfully applied to semantic scene mapping based on 2D scanning data. Especially for “room” and “corridor,” the accuracy can reach more than 92%. Moreover, the presented CNN model can avoid the problem of confusion between classes.
Currently, 2D geometric information based scene mapping methods can successfully distinguish “corridor” and “room.” However, the classification accuracy of “doorway” is still very low due to the influence of the heading angle change of robots during mapping. For this reason, Kaleci et al. 35 presented a rule-based semantic mapping approach by means of scene recognition, which adopted a learning vector quantization algorithm to model the training data, and then realize the detection of “doorway”. Experiment results indicated that this method could not only enhance the recognition accuracy of “doorway”, but also be robust to heading error of the robots compared with other methods. Liao et al. 76 presented an end-to-end learning-based approach to solve the place classification problem in semantic mapping, as depicted in Figure 4. In this method, graph regularization is performed to ensure local consistency between adjacent samples based on multi-scale laser data. Experiment results indicated that the above operation can significantly enhance the performance of scene classification.
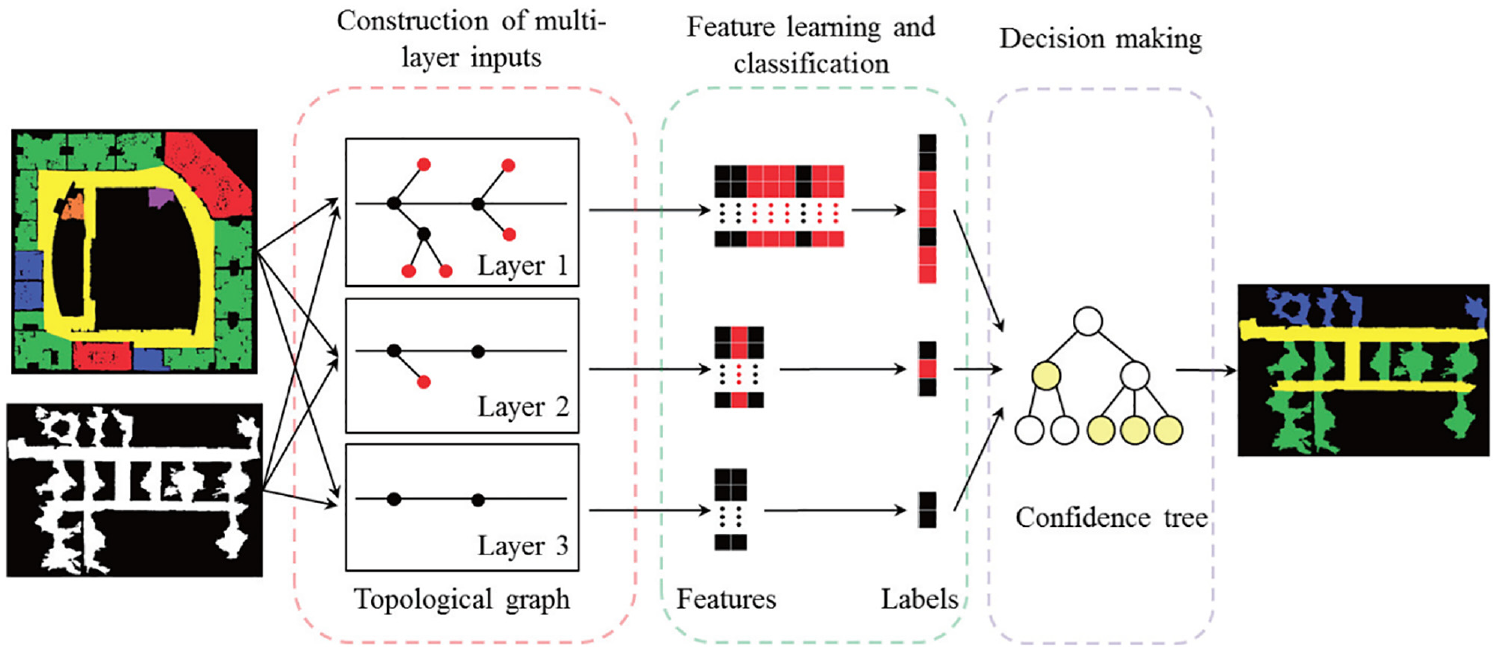
Pipeline of the semantic mapping system in Liao et al. 76
Overall, since 2D geometric features contain relatively little environment information, the above methods are only suitable for extracting scene semantics closely related to geometric structure, and not competent for the perception task of complex places such as the indoor environments with repetitive geometric structure and layouts. In addition, when the structural complexity of the indoor scene increases, it becomes more difficult to determine an appropriate feature form for 2D geometric information based classification methods. Nevertheless, due to the high reliability and precision of 2D geometric features, 2D geometric information based classification methods are suitable for providing a perceptual basis for semantic mapping in complex environments.
3D geometric information based semantic mapping
As the operation scenarios of mobile robot become increasingly complex, 2D geometric information based semantic maps may not meet the task requirements. Taking the service robot in a restaurant as an example, the restaurant scene is densely populated with high feature complexity. When the robot works, it not only needs to interact with humans frequently, but also needs to deals with the dense mobile population and avoid obstacles dynamically. In this case, in order to safety and efficiently complete these real-time tasks based on target requirements, robots need to construct a 3D semantic map of environments, which contains a 3D model of the surroundings and 3D pose of objects of interest. This type of semantic map provides robots with the ability to make intelligent behavior decisions and human-robot interaction.
Swadzba and Wachsmuth46,77 pointed out that geometric features of the scene are conducive to build instantaneous concept of indoor environments for robots while object detection plays a minor role. Hence, in order to comprehensively study indoor scene classification based on 3D geometric features, they constructed a public indoor dataset composed of 3D geometric information, and presented an approach to extract 3D geometric features from planar surface for scene classification. This method expands the types of places that can be processed by using geometric information and provides a new research approach for the study of scene perception. However, there are still some open problems. For example, the physical separation structure in the indoor environment (such as wall) is involved in the process of scene classification. Therefore, the feasibility and reliability of this method need to be further discussed for complex open spaces. The work proposed by Qi et al. 47 is pioneering research on 3D point cloud classification. Different from other methods of converting point clouds into 3D voxel grids, this paper proposed a CNN model named PointNet to directly process point clouds, considering the permutation invariance of the input point cloud sequence. The PointNet in this work adopts a unified framework for multi-tasking, such as 3D shape classification and scene semantic comprehension. A result of semantic segmentation in proposed method is depicted in Figure 5. Nikoohemat et al. 48 presented a 3D LiDAR based semantic mapping system, which exploited Indoor Mobile Laser Scanners (IMLS) to collect data along a trajectory instead of at discrete scanner positions. In this process, indoor topology and plane primitives are used to label the range scanner point clouds with different semantics, such as wall, floor, and ceiling. However, this semantic mapping method could not perform in real-time, and the generated semantics is too simple to perform localization in indoor dynamic environments for robots.

An example of the semantic segmentation in Qi et al. 47
Noting that the above semantic perception approaches based on geometric features are generally difficult to obtain meaningful place connotation interpretation of environments for human beings through semantic reasoning.
Methods based on visual features
Most of the environmental information we receive comes from our eyes. Vision is an important mean of perceiving the world. With the rapid development of machine vision, it is possible for robots to realize humanoid environment perception through visual sensors. Compared with geometric information, visual information can provide richer detailed features of environments, such as color, shape, and texture. Methods based on vision can construct more abundant semantic information of environments for robots. Moreover, because of the low price and easy operation, vision-based semantic mapping methods has always been the focus of relevant research. From the perspective of the dimension of information, this kind of semantic mapping methods can be divided into: methods based on 2D visual information and methods based on 3D visual information.
2D visual features based semantic mapping
In the early years, the 2D visual features based semantic mapping methods mainly represented scene locations in the environments through stored hand-crafted visual features. For example, Pronobis and Caputo 78 proposed a visual place recognition method, estimating the confidence of the output of SVM classifier based on SIFT features 79 ; similarly, Valgren and Lilienthal 80 exploited panoramic images to incrementally construct appearance-based topological semantic map for robot localization based on SUFT features. 81
The key of semantic mapping based on 2D vision information is to find a suitable description of visual features and corresponding processing framework for specific semantics. In order to make the robot depict surroundings in a human compatible manner, Vasudevan and Siegwart 82 proposed a semantic mapping method, in which Naive Bayes Classifier was adopted for space conceptualization and place classification. In this process, the concept models contain objects of interest in indoor environments and their spatial relationships of reasoning. Further, the reasoning relationships of different objects could enhance the performance of place classification. Viswanathan et al. 83 proposed a spatial-semantic mapping method with better robustness and automation. This method can autonomously learn the semantics of typical objects and scenes in environments and the logical relations of object-place based on online annotated image database. Yang et al. 53 presented a monocular semantic mapping system for indoor robot navigation. First, they constructed a topological map of indoor environments based on frame sequences captured from a monocular camera, in which each keyframe was stored in the topological node in the form of visual feature vector. Then, an improved deformable part model is exploited to perform object detection. The results of object detection can provide semantic properties to the corresponding topological nodes. To address the issue of data association and coupling of semantics and geometric features in visual semantic mapping, Tchuiev and Indelman 54 proposed a distributed consistent semantic mapping system for multi-robot. Since the appearance of objects and scenarios usually changes with different viewpoint, they estimated the distributed hybrid belief over continuous variables by means of viewpoint-dependent classifier model, while taking the coupling of multimodal information into account. Since the accuracy of semantic mapping system is usually reduced due to the problems of partial observation and angle occlusion, to ensure the robustness of semantic mapping in indoor dynamic environments, Liao et al. 30 proposed a monocular semantic object SLAM system based on the two approach of single frame initialization and orientation fine optimization. Recently, more and more works integrate CNN with monocular vision. They use CNN to obtain convolution features of environments from a monocular camera and construct semantic information that is easy to be understood by human beings, such as regional scene semantics and individual object semantics. Environmental understanding is a basic skill for mobile robot to perform various tasks in indoor environments. To this end, Sun et al. 62 presented a unified CNN-based framework that could realize scene classification and object detection simultaneously. This architecture with multi-task objectives can obtain a competitive performance on both object detection and scene classification by means of feature fusion. Also, the proposed system is integrated in real robot platform for semantic mapping and autonomous grasping task with a low time delay. To enhance the precision of vision-based scene classification while reducing computational burden, Ran et al. 84 presented a shallow CNN for indoor robot navigation. Ni et al. 85 presented a monocular semantic SLAM framework combining visual SLAM with semantic scene classification based on ResNet50. In visual SLAM, to enhance the anti-interference capability, they adopted a variant of ORB algorithm to perform feature matching. Bavle et al. 86 pointed out that the extracted semantics can not only assist robots perceive the surroundings more comprehensively, but also enhance the certainty of robot pose estimation. They proposed a lightweight and real-time semantic mapping system. This system improves the mapping robustness by integrating the low-level visual-inertial odometry with object semantics. Another challenge in semantic mapping is dynamic environments. During mapping process, dynamic objects are difficult to detect and filter. To this end, Xiao et al. 55 presented a monocular semantic SLAM system for dynamic objects. They achieved objects detection and dynamic filtering based on prior information. Additionally, on the foundation of SSD model, they presented a compensation approach for false detection to enhance object detection recall.
Generally, the semantic properties of each entity in current research are predefined and only suitable for specific scenarios. In this case, the visual information captured during semantic mapping will be lost. The constructed semantic map only contains the identified semantic attributes of each entity. As a result, this would make the semantic mapping system unsuitable for undefined scenarios and new operational tasks. To this end, Sousa and Bassani 51 proposed a topological semantic mapping system fusing regional visual information, as shown in Figure 6. The method utilized GoogLeNet to extract deep visual features from multiple views of RGB images, and constructed a unified representation of the regional visual features in each topological node through persistence and habits of vision. These consolidated representations enable the robot to identify the semantic properties of each entity more flexibly and can also be applied to undefined scenarios and new operational tasks.
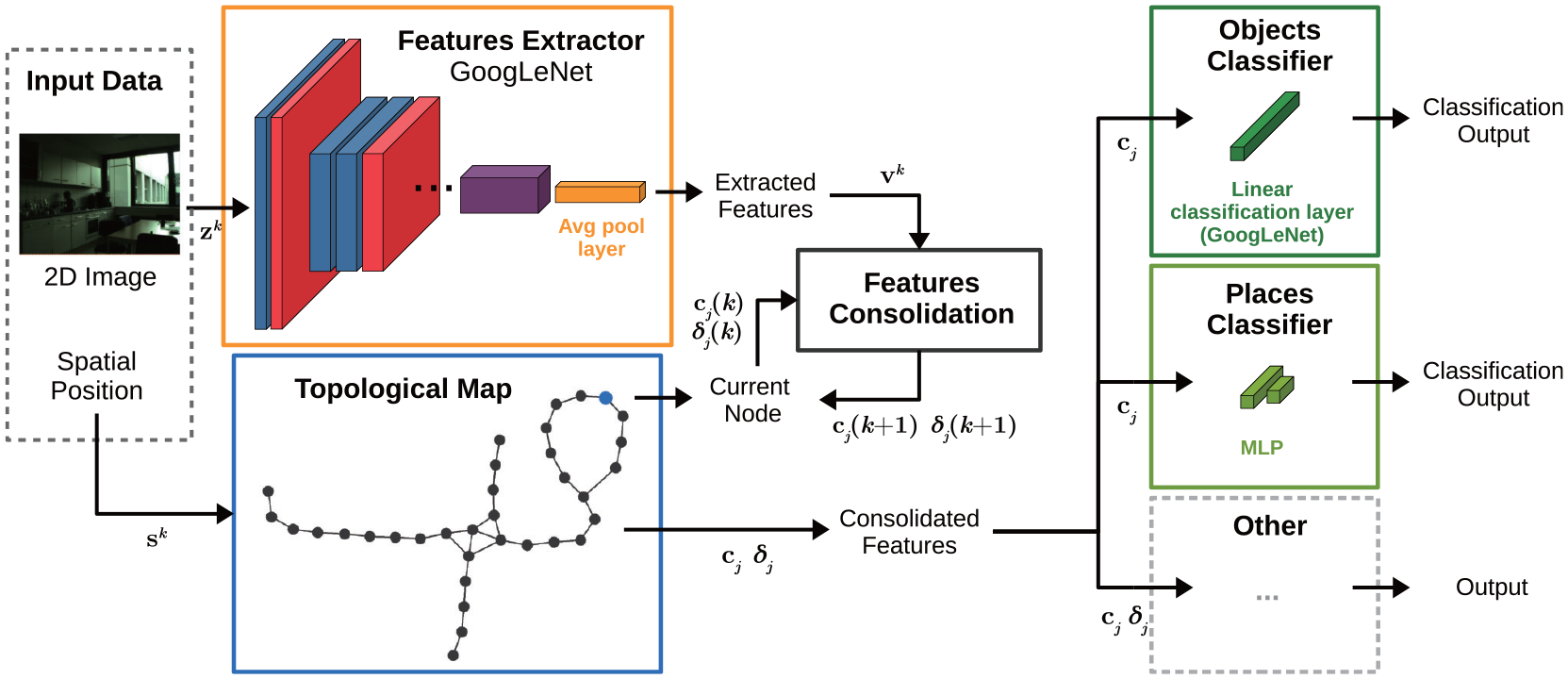
Pipeline of the semantic mapping system in Sousa and Bassani. 51
Generally, the above methods adopt the planar image information of indoor environments to construct semantics in the process of semantic mapping, but lack the 3D spatial information, which makes it difficult to calculate the pose of semantic description. Although some methods estimate the relative pose of semantics by feature matching between adjacent frames or odometry, the accuracy and robustness of semantic map are difficult to guarantee. Especially in the open space, the problem of semantic localization becomes more importance. Inaccurate localization may cause the temporal-spatial confusion of semantic association.
3D visual features based semantic mapping
3D visual sensor is widely applied for constructing semantic maps, such as Kinect and RGB-D camera. On the one hand, the introduction of 3D visual information can bring more pose optimization conditions for visual odometer and loop closure detection, and boost the performance of accuracy and robustness in complex scenarios. On the other hand, 3D visual information upgrades the semantic association from pixel-level to object-level, promoting the comprehensive environmental understanding and human-robot interaction for robots.
The depth information from 3D visual sensor is conducive for robots to estimate the spatial pose of semantics and achieve semantic localization. Romero-González et al. 87 pointed out that 3D visual sensors are more robustness and can adopt to more challenging indoor environments. Additionally, they presented a 3D spatial pyramid model to directly extract feature descriptors for semantic classification. Gan et al. 88 presented a unified framework for 3D semantic occupancy mapping. In this framework, they extended the Bayesian reasoning model for gird map to semantic map, and built a scalable dense semantic map of environments from noisy point clouds. In this process, the Bayesian reasoning model broadens the independent assumption, which is conductive to improving the smoothness of map construction. Thus, the local correlation between semantics in indoor environments could be employed to boost the mapping precision, as shown in Figure 7. Zhao et al. 89 proposed a dense semantic mapping approach. In this system, a Pixel-Voxel network which comprehensively considers the advantages of different modes is exploited to semantically label point clouds in 3D maps. PixelNet is responsible for learning global semantic information while VoxelNet is responsible for extracting geometrical features. Additionally, Pixel-Voxel network adaptively adjusts the weights of PixelNet and VoxelNet through a weighted fusion mechanism. Although the semantic mapping system has achieved competitive performance on the public dataset, the real-time performance is still difficult to meet. Data association is an increasingly significant challenge for semantic mapping. Semantic parameterization in some studies relies on strict assumptions, which may affect the robustness and accuracy of semantic associations in complicated conditions. To address the above issue, Wu et al. 56 presented a unified object-oriented semantic mapping system to handle advanced tasks such as Intelligent grasping and scene understanding. In this work, they performed data association by means of fusing the parametric and nonparametric statistic tests. Further, in order to parametrically model detected objects in complex environments, a novel iForest based method was adopted to obtain the precise pose of semantic objects. Experimental results on various public datasets show that this method performs better in terms of accuracy and robustness. However, this method is more suitable for small-scale scenarios such as object grabbing due to its computational complexity. An example of object-oriented semantic map is depicted in Figure 8.

An example of the semantic segmentation in Gan et al. 88

An example of object-oriented semantic map in Wu et al. 56
For occluded or dynamic objects in indoor environments, Zeng et al. 59 proposed an object-oriented semantic mapping system named CT-map. They adopted CRF to calculate the spatial pose of semantic objects in a probabilistic form based on RGB-D observations, which can correlate the context of semantic objects and guarantee temporal consistency of poses. How to enhance the semantic understanding capability of robots in dynamic environments is the key to semantic mapping method. To this end, Yu et al. 63 presented a semantic SLAM system called DS-SLAM. DS-SLAM consists of dynamic object tracking and semantic segmentation. For processing the dynamic objects in indoor environments, DS-SLAM first adopts a semantic segmentation network to determine the local region on RGB images, and then uses a moving consistency check mechanism to detection the dynamic objects. This method can effectively improve the accuracy of semantic mapping in indoor dynamic environments. For human-robot interaction, Romero-González et al. 87 presented a dense 3D semantic mapping system named ElasticFusion. First, they adopted ElasticFusion system to build the metric maps of environments. Then, dense pixel-level semantic segmentation was performed by CNN. Finally, to construct 3D semantic map, pixel prediction was optimized from different perspective based on Bayesian estimation and CRF. Although it provides real-time and closed-loop solutions for indoor semantic interaction, this work focusses on small-scale structured scenarios.
Overall, the method based on 3D vision has better performance than the method based on 2D vision on accuracy and robustness of semantic mapping due to the introduction of depth information. In complex scenarios, it may be necessary to simultaneously extract multidimensional semantics from 3D point clouds, which affects the real-time performance. The 3D visual semantic map construction technology provides the possibility for the further development of intelligent operations such as robot intelligent obstacle avoidance and human-robot interaction. On the one hand, based on regional scene semantics and personalized object semantics, the robot can stereoscopically recognize dynamic objects and dangerous scenes. This enables robots to realize human-like intelligent obstacle avoidance and ensure the safety of the robot and pedestrians. On the other hand, 3D visual semantic maps assist robots to perform fine operation on human-robot interaction through semantic recognition and semantic segmentation of scene information and independent entities in indoor environments. Taking the sweeping robot as an example, its intelligence is still relatively low, and it lacks in personalized human-computer interaction. 3D visual semantic map provides the possibility for the refined human-computer interaction operation of the robot, such as semantic object tracking, local region cleaning and so on.
Methods based on human guidance information
In the semantic mapping method based on human guidance information, users generally locate them and record their activity data by means of QR code, acoustic sensor, or wearable devices. In this way, semantics of environments obtained by activity data and rules of the real world can be directly imparted to the robot.
To improve the autonomy and intelligence of indoor robot navigation, Wu et al. 90 presented a topological semantic mapping approach by means of QR code. During construction of the hybrid map, the QR code is responsible for imparting knowledge of semantic descriptions and attributive relations of objects and scenes in indoor environments to robots. On this basis, spectrum clustering algorithm is adopted to divide the indoor environment into separate function areas represented as topological nodes by means of SIFT feature matching. This global topological representation of environments can assist robots for operational services and human-like navigation. Gemignani et al. 64 proposed an incremental semantic mapping method, allowing nonprofessionals to impart symbolic knowledge of entities to robots by means of speech-based human-robot collaboration.
Traditional vision-based semantic mapping methods may be heavily influenced in the application scenarios where the illumination changes strongly or multiple humans appear in the field of vision. To address this limitation, Sheng et al. 65 and Li et al. 91 proposed an object-oriented probabilistic semantic mapping system integrating semantics into metric maps by means of human-robot interaction in the shared environment. They used smart wearables to recognition human activity and then estimate the probability distribution of object semantics such as chair, bed, and desk in indoor environments based on pre-trained models. Additionally, to obtain the temporal consistency, Bayesian estimation is adopted to fuse human activities and the positions to update the semantics on the metric map. Rosa et al. 66 presented a semantic mapping method for social interaction of robots in a human-robot coexistence environment. To enhance the scenario awareness of robots in intelligent workplaces, they combined mobile robots with wearable devices. In this system, a metric map is first constructed by means of a distance sensor equipped on the robot platform. Then, the wearable devices worn by humans can record the probability distribution of user activities. Based on the user activity data, a variational bidirectional LSTM is adopted to recognize the scene semantics for robots. Finally, the geometrical information obtained from metric map and the scene semantics generated from user activity data constitute a hierarchical semantic map. In this process, the information sharing mechanism between robots and humans facilitates the robot’s understanding of surroundings. Chen et al. 92 proposed a semantic mapping system integrating SLAM and semantic segmentation network based on RGB-D cameras and wearable auxiliary devices for visually impaired people and robots.
A problem in wearable devices based methods is that human activities in dynamic environments sometimes affect surroundings. Consequently, misidentification for the observations may occur. To tackle this challenge, Hardegger et al. 67 presented a unified framework called S-SMARRT, which could simultaneously realize semantic mapping, localization, and interaction recognition. In the component of semantic mapping, a dynamic semantic map containing objects with semantic attributes and state probability distribution is constructed in a self-contained manner by means of wearable devices. Additionally, to enhance the precision of activity tracking and the scalability of semantic mapping by combining the context information of scenarios, S-SMARRT adopt Bayesian theory to estimate the joint probability distribution of position tracking and activity identification. To represent the objects in indoor environments accurately and richly, Suriani et al. 93 proposed a semantic mapping method named S-AvE from a different perspective based on the assumption that semantic mapping is an integration of motion and perception. In the process of semantic mapping, they used prior information about the typical dimensions of common objects to estimate the candidate poses of detected objects. Experiments shown that this strategy can significantly enhance the precision and completeness of semantic mapping.
Combined with human activity, instructions or annotation information, the robot can directly learn the semantic concepts of the environment. In this process, humans are responsible for providing semantic labels of the environment and correcting the robot’s perception information online. In essence, it is still necessary to seek some reasonable feature description and processing mechanism, so that the robot can form the environmental representation consistent with human as far as possible, and then ensure that the extracted semantic label is compatible with human. Overall, although the methods based on human guidance information can make the robot understand the surroundings more comprehensively and accurately, it requires too much human involvement and the semantic mapping process is relatively cumbersome. Moreover, this kind of method is not scalable. When robots are placed in a new indoor environment, human guidance information for semantic mapping needs to be reconstructed.
Methods based on combined approaches
To maximize the advantages of different types of methods and make up for their shortcomings, some researchers have proposed semantic mapping solutions based on multi-source information fusion. In addition, mobile robots often carry multiple sensors to cooperate with each other in practical application. The detection distance, accuracy, and function of different types of sensors are different. Therefore, in order to ensure the reliable and real-time of system decision-making, it is necessary to effectively integrate multi-source information from different sensors.
To this end, Pronobis et al. 68 proposed a multi-modal semantic place labeling method fusing multiple cues of global visual features, local visual features, and geometric features. This method can achieve robust place semantic labeling in a dynamic environment with condition variations over a long time, such as the change of illumination and scene layout. This mainly due to the integration of the versatility of visual features and the stability of geometrical information. Inspired by this work, Martinez Mozos et al. 94 conducted extensive experiments on a self-built indoor image dataset to evaluate the performance of different modalities. The experiment results show that the fusion of depth information and gray features can greatly reduce uncertainty and improve the accuracy of semantic classification while using multiple cues. Meanwhile, depth information performs better than gray features because of its inherent illumination-invariance.
For multiple modalities based approach, Kostavelis and Gasteratos 69 developed a metric-topological-semantic map with geometric and semantic attributes, representing the logical relationship of objects and scenes in environments. When constructing the multi-layer map, the method employed an appearance-based consistency histograms to perform scene recognition, and a hierarchical temporal memory network based on saliency attentional mechanism to detect the objects in environments. Extensive comparative experiments have been carried out in real-life scenarios, indicating that the proposed hybrid mapping approach can provide a unified solution for human-robot interaction environment. In terms of geometric-topological-semantic hybrid maps, in addition to the above work, Luo and Chiou 95 also developed a semantic mapping approach by means of a camera and a laser. Unlike other methods for scene recognition based on a single image, they extracted and aggregated the geometric and topological information by room segmentation method, classified the scene semantics based on Bayesian estimation, and then extracted the object semantics from each topological node by a lightweight CNN to build the hybrid map. Experiment results showed that the semantic classification accuracy of the proposed method could reach more than 80%. Rozumnyi et al. 38 developed a novel depth information fusion approach for semantic reconstructions. This approach used a sensor confidence network to extract sensor properties and scene parameters automatically from training data. The extracted features can be adopted in form of confidence values to balance the contribution of each sensor according to their noise statistics. In addition, the developed sensor confidence network can also obtain better generalization on the training dataset of small sample. An example of the constructed semantic map in this method is shown in Figure 9.
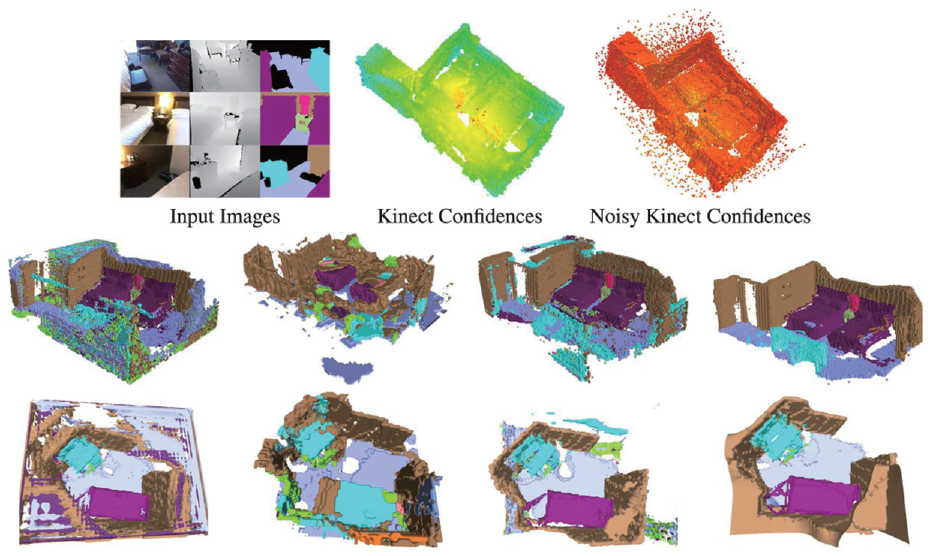
An example of the constructed semantic map in Rozumnyi et al. 38
Wang et al. 96 presented a unified system to simultaneously realize camera posture estimation and scene understanding in the semantic mapping process. This method fused the sensor information of camera video and IMU, and used RNN containing time scale to construct the three-dimensional semantic label of environments. Also, the study built a standard data set of 3D point cloud and image to verify its performance. Experiment results demonstrated that the proposed method could effectively enhance the robustness and efficiency of the semantic mapping system. Cheng et al. 97 proposed a semantic mapping framework for mobile robots in dynamic environments. This method constructed a 3D dense semantic map by integrating geometric features, visual semantics, and human activity. To better address the uncertainty of semantic maps in the dynamic environment, they adopted a Bayesian model to update the dynamic state of environments based on the prior information generated by the observations from geometric and semantic perspectives. Additionally, the human activity during the mapping process of mobile robots was recorded for map reuse afterward.
Currently, for semantic mapping methods based on multiple clues, it is not difficult to achieve multi-sensor fusion at the hardware level. The focus is on how to achieve fusion between algorithms and sensors. In addition, the fusion problem in dynamic and unknown environments will also be another difficult problem faced by multi-sensor fusion. In the future, with the continuous progress of technology, algorithm fusion problems will be well solved, and multi-sensor fusion technology may soon be widely applied in real life.
Discussion
In this section, we summarize and discuss the above four types of semantic mapping methods. Overall, the semantic mapping method based on visual features is the most widely used in practical scenarios due to its rich feature representation of environments, as well as its low price and easy operation. Semantic representations constructed from visual features can help robots recognize and understand surroundings from a human perspective. However, vision sensors are insufficient in perceptual accuracy due to the influence of illumination and perspective. In some cases, in order to improve the accuracy of semantic extraction, visual features and geometric information are usually fused for semantic mapping. Since the geometric information from distance sensors is stable and reliable, it is suitable for constructing high-precision maps. Although there are many researches on semantic mapping based on geometric information, it is only suitable for structured scenes with simple layout. Human guidance information is a most intuitive way for robots to build a semantic map. It has considerable advantages in human-robot interaction. However, due to the complexity of the implementation, methods based on human guidance information are only applied in specific scenarios. Methods based on combined approaches can maximize the advantages of different types of methods and make up for their shortcomings. Therefore, robots often carry multiple sensors to cooperate with each other in practical application. The key to this type of method is how to achieve fusion between different algorithms and sensors.
Open issues and future trends
Establishment of benchmark evaluation database and evaluation system
In traditional mapping methods based on geometric information, the merits of a mapping system are generally evaluated using either absolute trajectory error (ATE) or relative pose error (RPE). Yet, both of these evaluation criteria are centered around the pose estimation of a mapping system. At present, there are no recognized and reliable evaluation criteria for benchmark databases and semantic mapping methods.
For semantic mapping systems, the existing semantic mapping methods are oriented to different forms of perceptual objects, sensors, and robot platforms. These circumstances make it difficult to construct a unified benchmark database to evaluate the methods. In order to comprehensively and objectively evaluate the performance of different semantic mapping methods, it is important to establish a standard semantic map database that contains multiple environmental information. In the future, the following factors need to be considered to establish a unified benchmark evaluation database for semantic mapping methods:
The benchmark evaluation database needs to cover multiple types, multiple manifestations, and multiple layouts of environments.
Any sensor configuration can be expanded on the baseline robot platform. For example: carrying and expanding different types of sensors of different types, and the number and installation locations of sensors can be adjusted according to the needs of the sensing method.
The benchmark evaluation database needs to ensure the information completeness of the collected data. When constructing the benchmark evaluation database, in addition to saving the sensor data frames, information such as the frame’s corresponding timestamp, robot position, and sensor parameters should also be saved.
In addition to the benchmark evaluation database, it is also necessary to establish a set of standard evaluation system. How to establish a unified quantitative standard is the key for  semantic extraction and semantic mapping techniques. Generally, a feasible solution is to use CAD and other 3D modeling methods to construct a virtual 3D environment, and use manual annotation methods to mark the semantic information as the ground-truth of the environment model. However, such methods consume a lot of resources and are difficult to prove the validity of the constructed ground-truth. Therefore, it is necessary to determine a series of user-oriented evaluation indicators in the future, such as: perceptual result acceptability rate, perceptual behavior anthropomorphism score, number of intuitive semantic types, etc.
Semantic mapping in complex scenes
In general, the environment conditions of robot mapping in existing research work are relatively ideal, and there is still a certain distance from the practical application in daily life. It is manifested in the following ways: the form of semantic map is relatively simple, the layout of environment is relatively regular, and the environment remains static during the process of semantic map construction, etc.
Robustness is an important evaluation metric for semantic mapping systems, which is a guarantee for robots to carry out navigation and operations based on semantic maps. In complex environments such as missing texture features, large illumination changes and high-speed dynamic scenes, semantic mapping systems are prone to semantic features loss and semantics mis-matching. In the future, how to enhance the universality and robustness of semantic mapping systems in various scenarios is a challenging research topic.
Abstract concept transfer and unknown entity perception
Although current research can deal with the variability between the test set and the training set, this variability is still far from the actual situation. Some methods can only handle a limited homogeneous-places. The generalization performance of the relevant algorithms is far from the requirement of “limited training, sensing everywhere.” This phenomenon indicates that the training process of existing methods in fact still cannot capture the essence of semantic concepts, and only stays in the stage of superficial data pattern classification or shallow concept learning, which makes it difficult to migrate the learned concepts to new unknown environments.
On the other hand, generalization ability of concept level is also the key of semantic map. The complexity and diversity of indoor environment result in the possibility of semantic types that do not exist in prior knowledge. At present, most of the semantic mapping methods can only divide unknown objects in the environment into known semantic classes by means of semantic classification. Therefore, it is necessary to do further research on the effective discovery and concept establishment of unknown classes in unknown environment. Abstract concept transfer ability and unknown category perception ability are the two key problems of robot semantic mapping technology from laboratory to practical application. The former is the full understanding and generalization of known semantic concepts, and the latter is the discovery and active perception of unknown semantic concepts.
How to fully apply the established semantic map
Obviously, semantic maps were originally proposed to promote human-computer interaction and help robots perform various tasks in an anthropomorphic manner, such as domestic service robots, industrial operating robots, and driverless vehicles, etc. However, although there is currently many researches on semantic maps, there is no stable and mature solution that can be applied to real environments. Moreover, after constructing semantic map, the above work does not deeply discuss how to parse and apply the data of semantic map in robot navigation process. This results in that although the semantic map contains rich environmental features and semantic attributes, there is no suitable method to fully utilize the semantic information or directly support the execution of navigation tasks. Therefore, in order to enhance the capability to understand and interact surroundings for robots, it is essential to establish a system from environment semantic recognition to semantic map construction to semantic information-driven navigation and operation.
Conclusion
Compared with traditional grid maps, semantic maps can extract the semantic representation of each entity in the environment, helping robots achieve human-like environment understanding behavior and human-robot interaction. In recent years, many semantic mapping methods have provided solutions from different perspectives. Based on the elaboration and analysis of some basic concepts in semantic mapping, we mainly reviews four class methods according to the type of information used to extract semantics, including: methods based on geometric information, methods based on visual features, methods based on human guidance information and methods based on combined approaches. The solutions and working principles of each method to the semantic mapping problem are explained, and their characteristics and limitations are discussed in detail. Finally, we analyze the open issues and future trends regarding semantic maps.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Knowledge Innovation Program of Wuhan-Shuguang Project (Grant No. 2023010201020443), and the School-level Scientific Research Project Funding Program of Jianghan University (Grant No. 2022XKZX33).
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.