
Abstract
Recent research on utilizing artificial neural network (ANN) for fault identification of bearings ignores the features of vibration signals as time series, resulting in low interpretability and cannot classify signals of bearing vibration on different dimensions. Time series shapelets is the most identifiable subsequences of time series. Time series can be effectively classified through computing similarities between shapelets and each time series. This paper identifies faulty bearings with a machine learning-based shapelets algorithm, and through modeling, calculation and verification based on CWRU fault bearing data set, some szimportant conclusions are obtained. The results show that this meaningful new method is more accurate and can reduce time consumption compared with traditional time-laboring shapelets, enhancing interpretability of diagnosis in the meantime. Compared with other classification methods, shapelets transforms the classification problem of vibration signal time series into a similarity measurement problem between time series and subsequence shapelets, fully reflecting the essence of bearing vibration signals as a time series. Meanwhile, by using MINDIST distance instead of Euclidean distance in shapelets can effectively reduce the calculation time while ensuring accuracy, which could be a significant method of distance measurement in clustering tasks.
Introduction
Data-driven bearing fault identification methods mainly include support vector machine (SVM) and artificial neural network (ANN), etc. With the fast development of sensor technology, the fault identification method based on condition monitoring gradually replaces the method based on the running time. The problem of the surge in the amount of data caused by this is the focus that academics need to pay attention to in recent years. Cheng et al. 1 performed local mean decomposition (LMD) on bearing vibration signals, and then extracted time-domain statistics and energy features from the components as input to the neural network to classify faults. Jia 2 improved the convolutional neural network with regularized weights and weighted loss functions for the imbalanced sample data set, successfully identifying bearing faults under unbalanced samples, and further researched the physical meanings of the convolution kernel. Hu et al. 3 combined the convolutional neural network with SVM classifier, introducing batch normalization and Dropout processing, and realized high-precision identification of faults of different types and different damage levels.
Methods above are all effective processing methods for massive high-dimensional fault signals, but there are still two shortcomings. First, numerous parameters in math model complicate the optimizing process and the stretched computing time requires more computing power. Second, the model is weakened by low interpretability, ignoring the essence of bearing signal as time series. In order to solve these problems, an algorithm based on subsequences classification called shapelets is introduced to process vibration signals in this paper. The method of shapelets is a classification method based on local features of time series proposed by Ye and Keogh. 4 By calculating the similarities between subsequences and the original sequences, K best shapelets subsequences are extracted. The high-dimensional time series would be reduced to K dimensions, and then classified by a 1 -NN classifier or other traditional methods. Jason Lines et al. 5 separated the discovery of shapelets from the construction of classifiers, effectively improved the classification accuracy, and retained the original interpretation capabilities of shapelets. Yuan et al. 6 proposed a classification method based on logical shapelets transformation, using an intelligent caching based and reusable skill to reduce the time complexity of computing.
In order to overcome the shortcomings such as mode collapse and gradient vanishing, Li et al. 7 proposed a supervised model called modified auxiliary classifier GAN (MACGAN) designed with new framework. Compared with the existing GANs, the proposed method can more efficiently generate multi-mode fault samples with higher qualities, which can be used to assist the training of deep learning-based fault diagnosis models with high accuracy and good stability. Xiao et al. 8 proposed a novel joint transfer network for unsupervised bearing fault diagnosis from the simulation domain to the experimental domain, and two experimental datasets collected from laboratory test rigs are used as the target domains to validate the effectiveness of the proposed method. The results show that the proposed method is superior to other popular unsupervised cross-domain fault diagnosis methods. The literature 9 incorporated the skip-bigram model for the construction of symbiotic word pairs and proposed a novel and fast variable-length word generation method, and used some controlled experiments to verify the effectiveness of the proposed method. Ircio et al. 10 used an adaptation of existing nonparametric mutual information estimators based on the k-nearest neighbor for the purpose of bringing these methods to the time series scenario, and the results show that the method is able to strongly reduce the number of time series while keeping or increasing the classification accuracy. Compared with two shapelet decision tree models, 1 NN models based on different distance functions, and C4.5 models based on different top-k shapelets transformation algorithms, Wang et al. 11 put forward a lazy classification model, and experimental results show that the proposed model has higher accuracy and stronger interpretability.
In our previous study, 12 we’ve already discussed the disadvantages of the two current fault diagnosis methods for rolling bearings, which includes over-reliance on signal processing, complicated model and weak interpretability, and so on. Meanwhile, compared with the shortcomings of traditional fault diagnosis technology, the time series classification method based on shapelets learning algorithm can guarantee the accuracy of fault diagnosis while retaining the strong interpretability of shapelets as the most representative time series subsequences. The improvement of the proposed method based on Dropout improved the generalization performance of the model, and achieved 100% diagnostic accuracy on the training and test sets of bearing fault data, which proves the validity of this proposed methods for fault diagnosis of axlebox bearing of EMU.
This paper applied the method of shapelets to classification of faulty bearings, greatly reducing the discovery time of shapelets, which successfully realizes the classification of fault of rolling bearings. This method of shapelets really simplify the optimizing process and the computing power, and have better interpretabilities compared with previous mentioned methods.
Overview of machine learning-based time series shapelets
Introduction of shapelets
D is defined as time series dataset, including n time series:
Table of symbols.
For time series
Assuming there are N time series and C categories in the dataset, there are

Similarity between time series is measured by distance between each other. For two time series q and c of the same length, Euclidean distance is used to represent the similarity.
For two time series different in length, we slide the shorter time series on the longer time series, and then compute Euclidean distances between the shorter time series and every corresponding segment on the longer time series, of which the minimum value is the subdist of sub-series, that is,
Tuple (s,t) is defined as the split point which includes a sub-series s and a distance threshold t. This point splits dataset D into two disjoint subsets, namely
The information gain from splitting D into two disjoint subsets is defined as:
The split interval of a split point is defined as:
Shapelet is a tuple (s,t) which consists of subsequences s of T and threshold t. For a classification task, shapelets work to minimize the distance between subsequences of the same class and maximize the distance between subsequences of different classes.
For all the candidate shapelets, we need to sort them to prioritize the shapelet with larger information gain. If the information gains are equal, we prioritize the shapelet with larger split interval. If the split intervals are equal, we prioritize the shorter shapelet. If the lengths are the same, we prioritize the first generated shapelet. Generally speaking, we select shapelets from the perspective of information gain, split interval, length and extracting order.
A data transformation algorithm based on regularized Euclidean distances between sub-series and shapelets has been proposed. It also summarized algorithms for shapelets discovery, which is shown in Table 2.
Shapelets discovery algorithm.

Improvements of shapelets
Instead of discovering shapelets, Josif Grabocka et al. 13 proposed a method of learning shapelets from time series. There are mainly two steps in this theory. Firstly, roughly estimated shapelets would be randomly got from subsequences, and then, a loss function is built so that the formal candidate shapelets would be optimized iteratively while minimizing the loss function, which is a method used in machine learning.
For a binary classification task, results could be defined as

Equation (5) defines a loss function to measure the gap between the actual result and the predicted result.
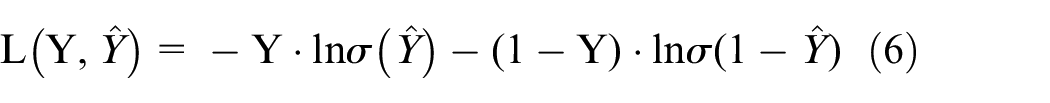
The
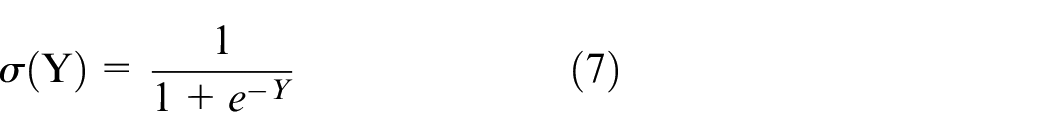
Therefore, the task has been transformed into another task of minimizing the loss function, and the back-propagation algorithm is used to continuously update the bias terms
The network structure is shown in Figure 1.
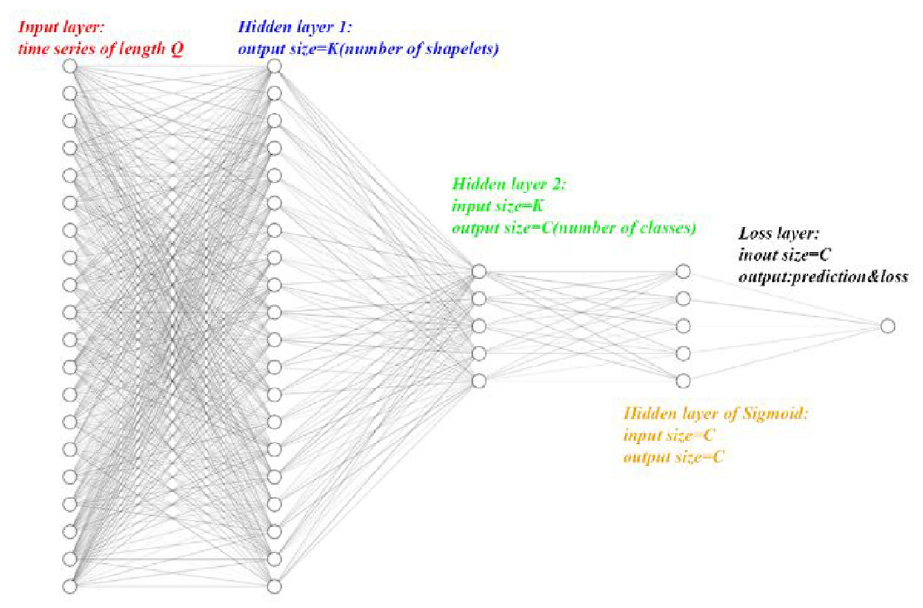
The structure of network is consisted of five layers: one input layer, two hidden layers, one loss layer and one output layer. High-dimensional time series will reduce their dimensions after passing through the network.
Furthermore, in order to speed up convergence and improve the prediction accuracy of the model, pre-processing of data need to be done. In this paper, a method of z-score (zero- mean normalization) is applied to the original data to make the converted time series mean 0 and standard deviation 1, where (8) is used for a time series

Another method to reduce time consumption is to change the measurement of similarity between subsequences and time series. In this paper, a distance representation is applied instead of traditional Euclidean distance.
Symbolic representation of time series (SAX) is a quick distance representation proposed by Jessica Lin et al. 14 In this theory, any normalized time series meets the Gaussian distribution. By piecewise aggregation approximation (PAA), the normalized time series C of length n can be dimensionally exchanged to length of w, which can be represented as:

The i-th element of
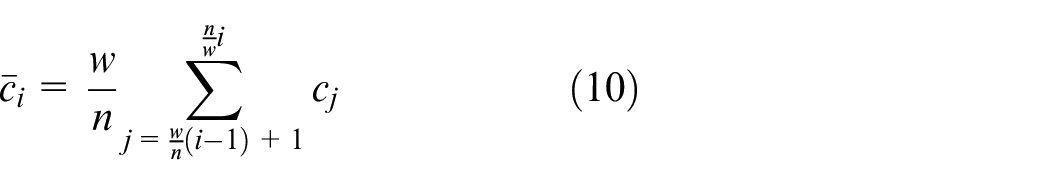
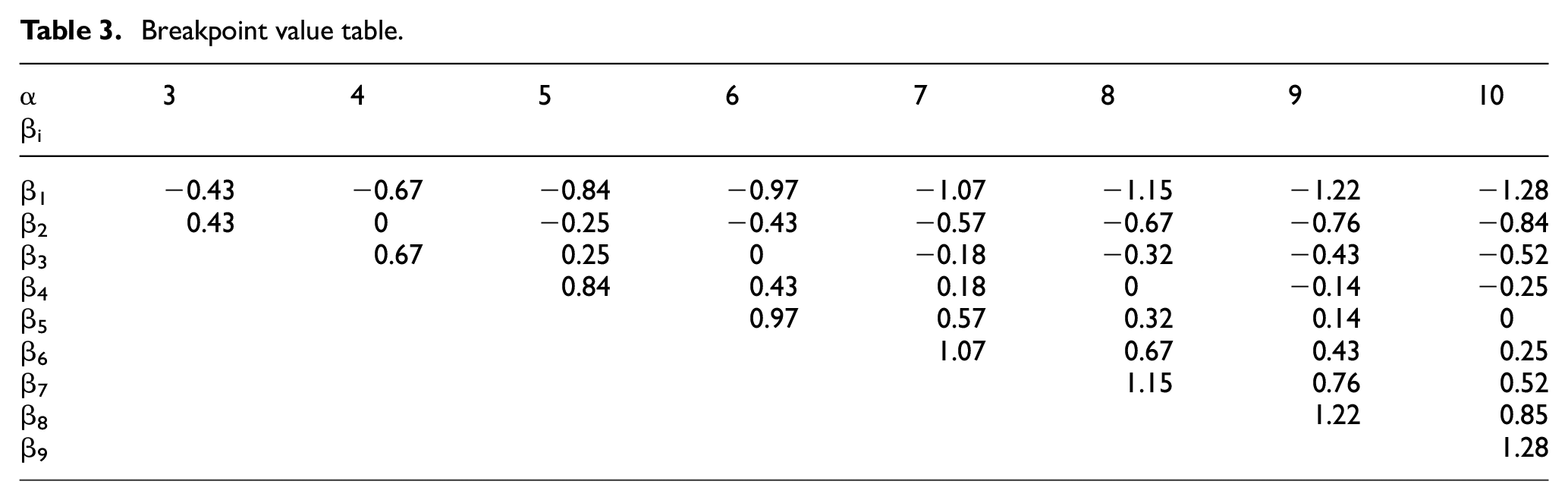
Breakpoints are defined as B = β 1 , β 2 ,…, βα-1, so that in a Gaussian distribution curve, the area under the curve in the interval (β i , β i+1 ) is 1/α, among which β 0 and β α are defined as negative infinity and positive infinity. The changes in the value of β i with the value of α are shown in Table 3.
Breakpoint value table.
SAX is the symbolic representation of time series based on PAA, which defines an alphabet with α symbols: A={A1, A2, A3,…Aα}={a, b, c, …Aα}. For data after PAA processing, when the data point is within the interval of (β i , β i+1 ), this data point is represented as the letter A i . For example, when α = 9, the data of −0.82 is in the interval of (−0.84,−0.52), which can be represented as c. We take a time series from faulty bearings as example, so that IT can be represented as a sentence of ggegdfcgefgeeedegffeddeheefdeehefecfffdg.
SAX processing of this time series is shown as Figure 2.
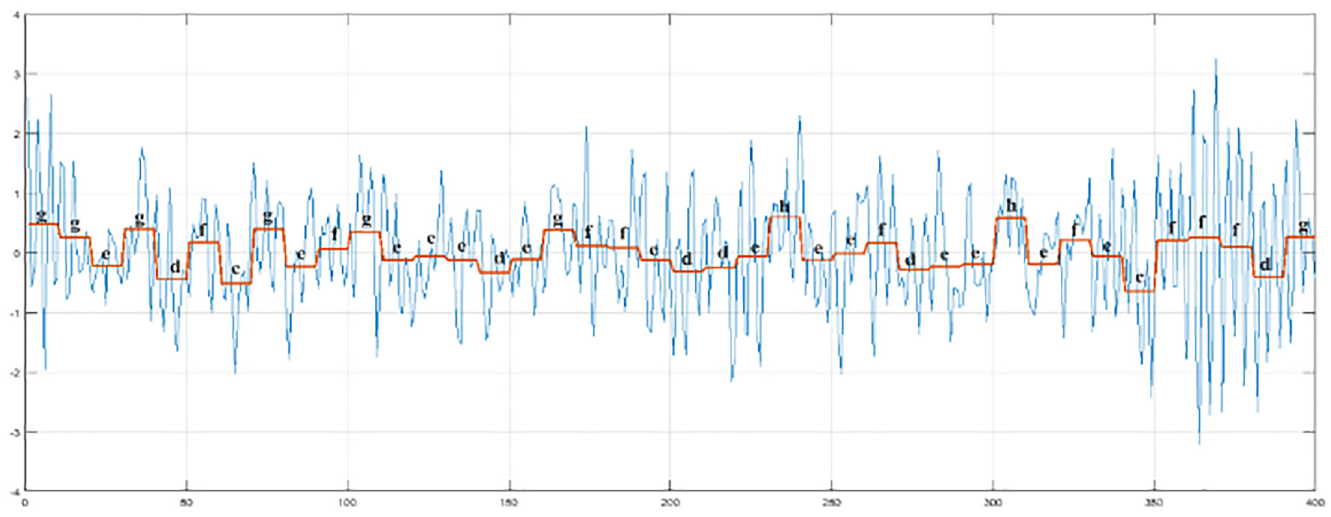
The SAX processing of time series is another method to reduce the dimension and retains local characteristics of time series.
The traditional clustering algorithm mainly calculates the Euclidean distance between sequences and obtains the similarity to achieve clustering.
The SAX method provides a method called MINDIST to achieve this purpose.
For two time series Q and C of length n, the Euclidean distance of the two series can be represented as:
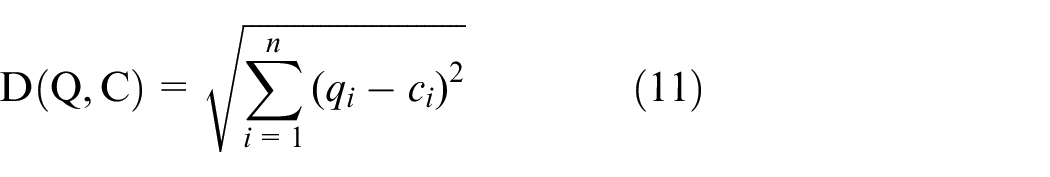
After PAA processing, the distance between
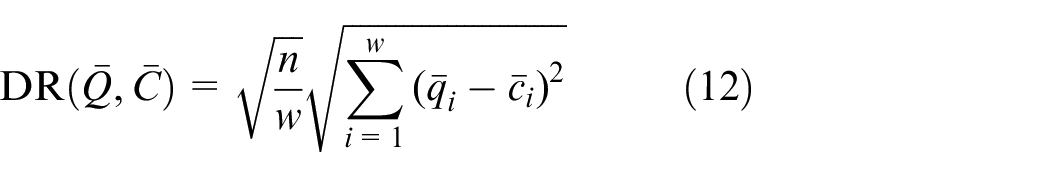
After SAX processing, the distance between two “words” or “sentences” can be represented as:
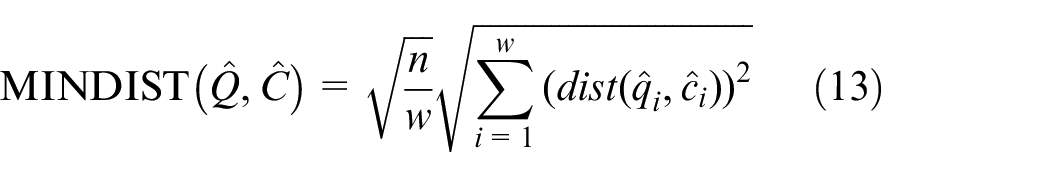
The function of dist() is used to calculate the distance between two letters. The function of local() is defined to represent the location of the letter in the alphabet. For example, if the alphabet is {a, b, c, d, e, f, g}, local(a) = 1,
local(g) = 7. The value of dist() can be obtained from (14).
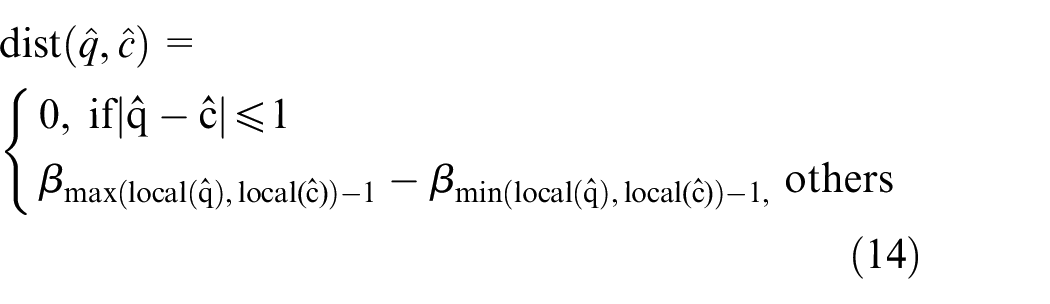
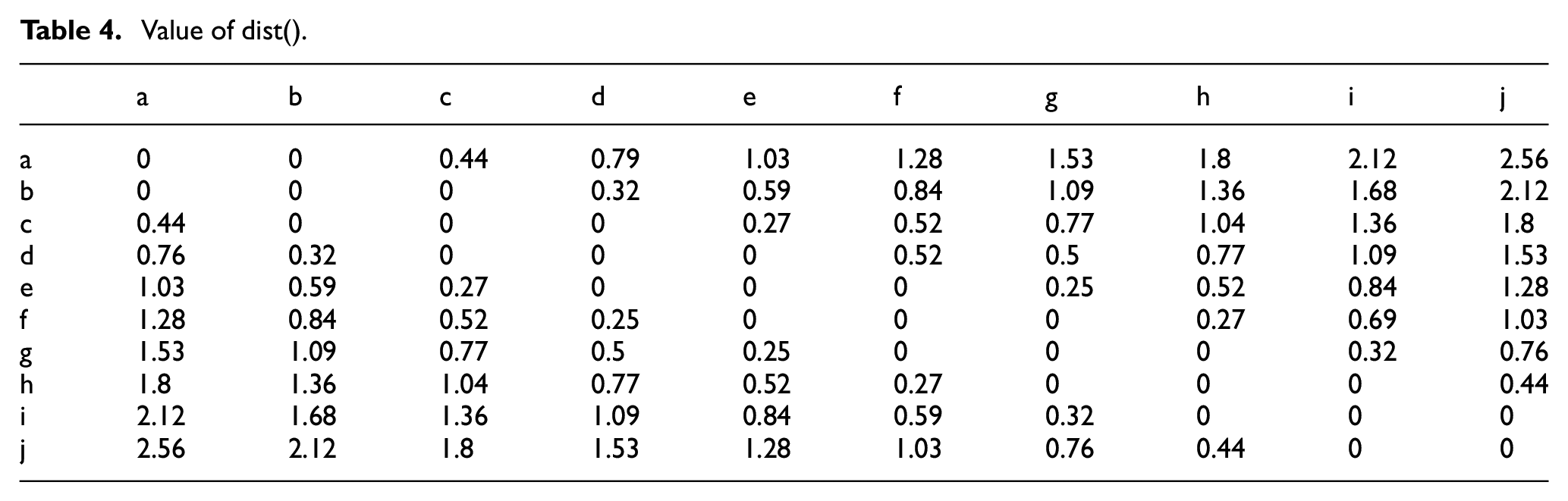
In this paper, the value of α is fixed as 9. The value of dist() is shown as Table 4.
Value of dist().
Keogh et al. 15 has proved that the distance of MINDSIT is a lower-bounding distance measurement than Euclidean distance, which deduces false positive and negative errors during clustering. Simultaneously, when processing high-dimensional time series data, the time consumption of MINDIST is much less.
Modeling and validation based on CWRU dataset
The modeling data is from CWRU open source dataset of faulty bearings. Data is acquired from an experiment, the test of which is composed of a motor, a torque transducer a dynamometer and control electronics. Faults of the bearings are artificially applied to the inner race, outer race and the ball by electro-discharge machining with diameters of 7mils, 14 mils and 21 mils. among which, the outer faults are placed a the position of 3 o’clock, 6 o’clock and 12 o’clock. Motor speed used in the experiment includes 1797 rpm, 1772 rpm, 1750 rpm and 1730 rpm. Data has been collected at a sampling frequency of 12,000 Hz and 48,000 Hz. According to the position and the diameters, faults of bearings can be classified into 10 categories: minor inner fault, moderate inner fault, severe inner fault, minor outer fault, moderate outer fault, severe outer fault, minor ball fault, moderate ball fault, severe ball fault and normal bearings.
In this paper, data of the motor speed of 1797 rpm collated at the sampling frequency of 12,000 Hz is adopted to establish the model and the outer faults of bearing are fixed in the position of 6 o’clock. Faults at 1730 rpm motor speed are used later as the validation dataset to verify the generalization ability of the model. To reduce the complexity of the algorithm and to ensure that each time series contains all local features in at least one rotation period the bearings, original signal is intercepted at every 400 data points. The time-domain waveforms of 10 classes of fault are shown in Figure 3.
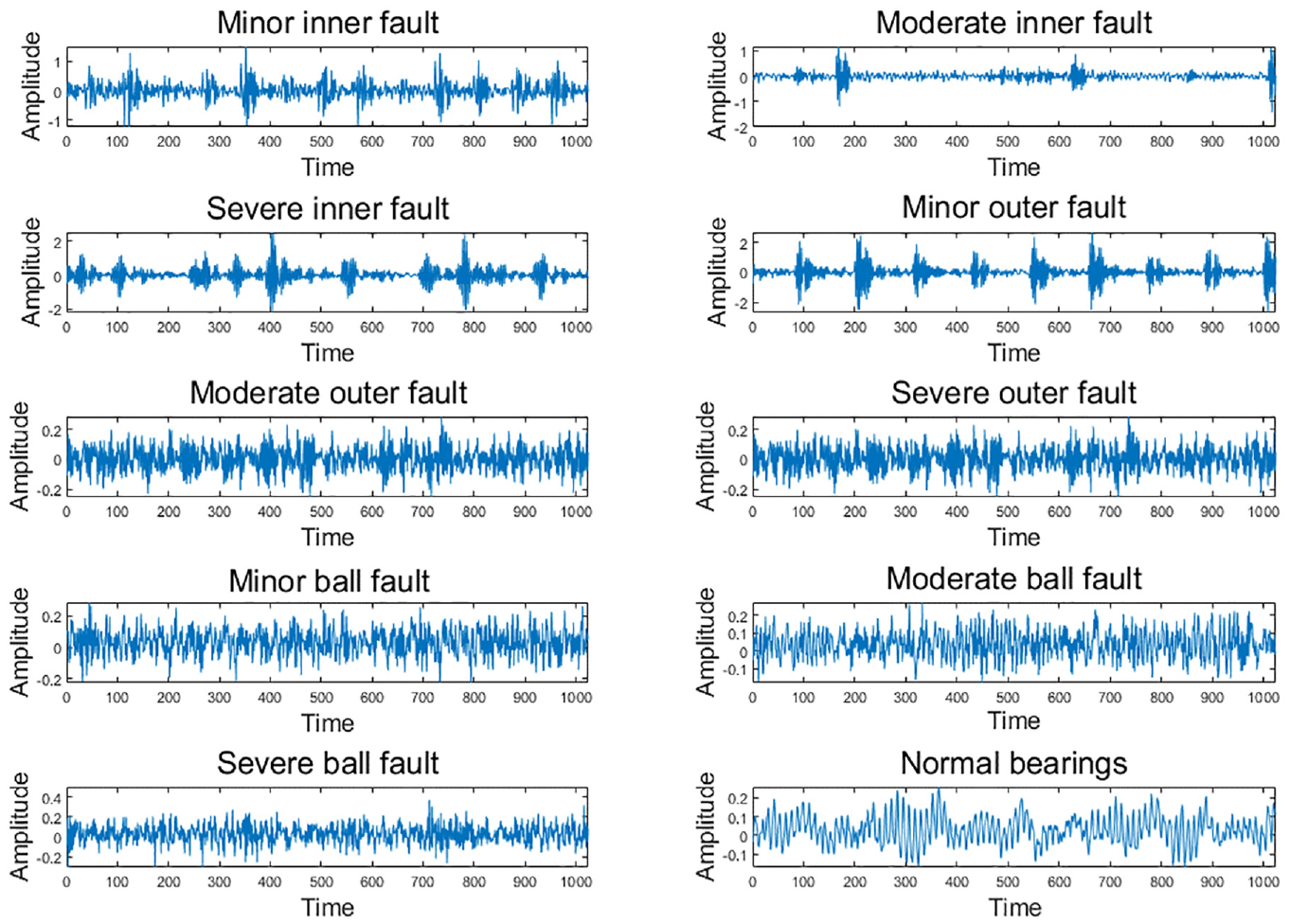
The time domain signal waveform diagram of 10 bearing failure types.
Statistical evaluation of classification model performance
For any binary problem, there are for possible combinations of the classified real situation and predicted results: True Positive (TP), False Positive (FP), True Negative (TN) and False Negative (FN). The confusion matrix of possible faults is as shown in Table 5.
Confusion matrix of possible faults.

Accuracy refers to the proportion of the number of correctly classified samples in the total test set samples in all test set data:
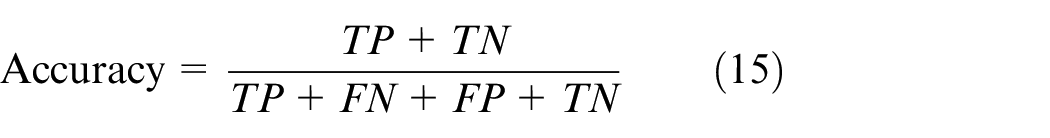
Precision refers to the proportion of the number of true positive samples in the positive samples:

Recall refers to the proportion of the number of correctly classified true positive samples in the actual positive sample:
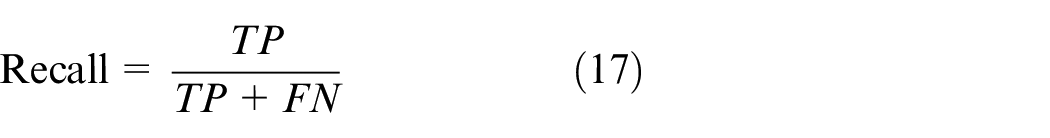
F-Measure is the comprehensive consideration of Recall and Precision, which is defined as the weighted harmonic mean of Recall and Precision:
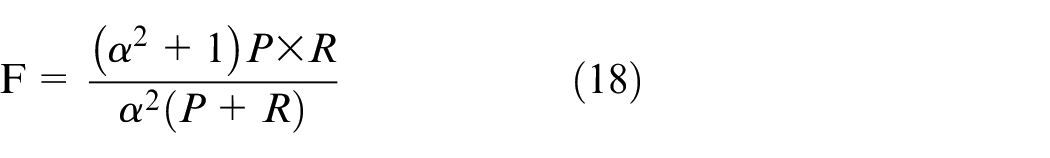
When
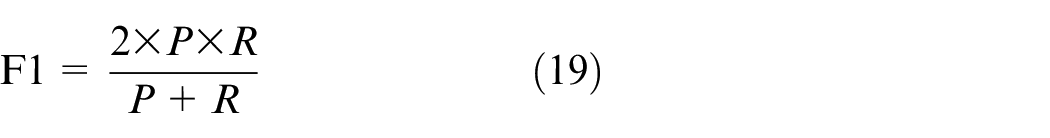
When dealing with multi-classification problems, any two types of failures can be combined to obtain several sets of two-class confusion matrices, and the averages of recall and precision can be obtained. The higher the F1 value, the better the performance of the model would be.
Fault identification experiment
In this section, the method of shapelets is used to identify the location of fault. In order to find early failures in time, data of normal bearings, minor ball faulty bearings, minor inner faulty bearings and minor outer faulty bearings are needed. Model is established by the algorithm of Table 2–2, which is composed of 50 time series for each fault in both training set and test set. Lost function is defined as (5) and SAX distance replaces Euclidean distance to reduce calculation time consumption of time series similarity.
The variation of classification accuracy and loss function with the number of iterations is shown in Figure 4.
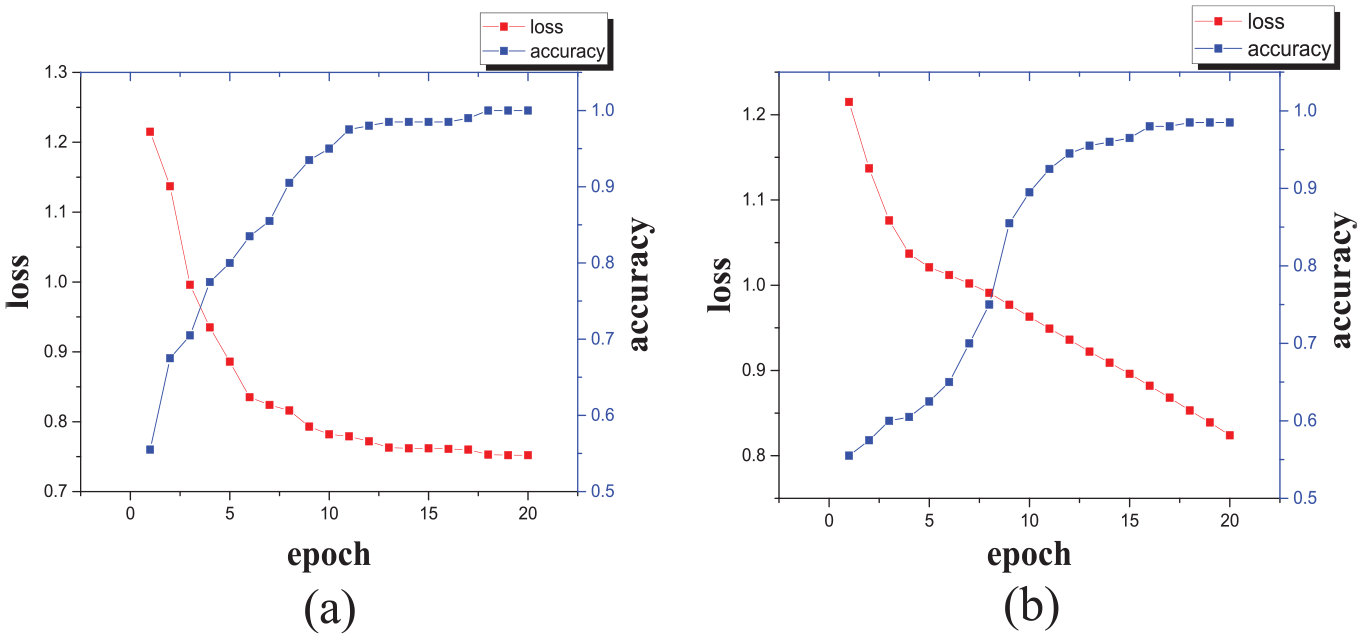
Variation of accuracy and loss function with iterations is as shown: (a) is the result of the use of Euclidean distance and (b) is the result of SAX distance.
The fault diagnosis accuracy of each task has been verified repeatedly for about 200 times, and the value of Precision, Recall and F1-measure are shown in Table 6, and the time consumption comparison is shown in Table 7.
Evaluation index of four classes of faults.
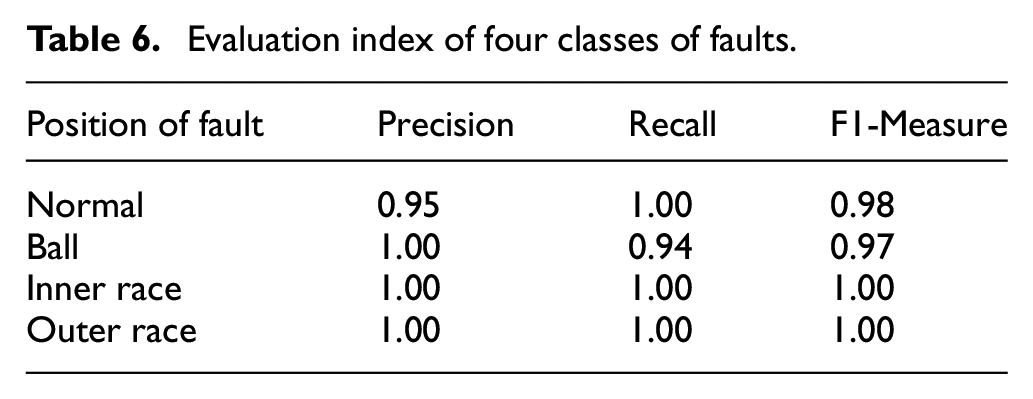
Time consumption comparison.
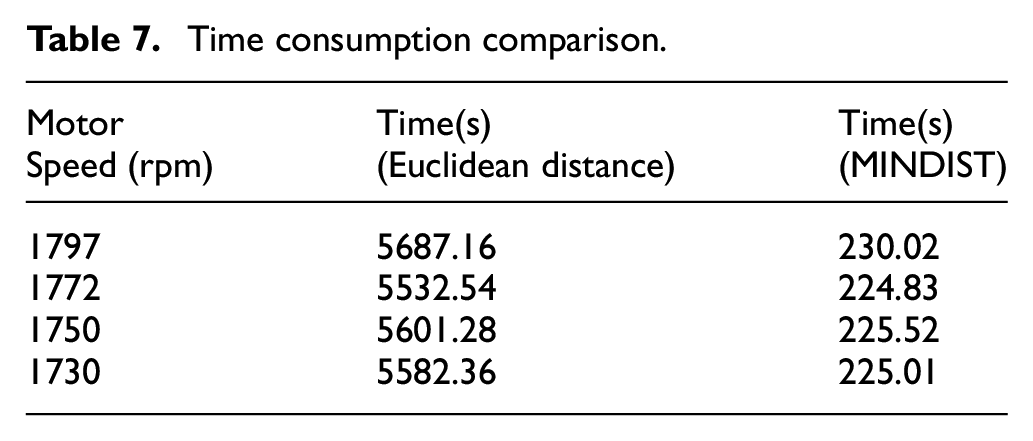
The 24 best shapelets are shown in Figure 5.
The 24 best shapelets are extracted by the above method.
The purpose of using MINDIST distance instead of Euclidean distance is to reduce time consumption. Therefore, we compared the classification time according to the fault location at different motor speeds. The comparison results are shown in the following table.
For the problem of if there is a failure or not (two classes) and the level of faults (three class),we also use the same method to test. Furthermore, if different levels of faults in different locations are considered as an independent fault, it would be a classification task of 10 classes, which has also been finished in this section. Results are shown in Figure 6.
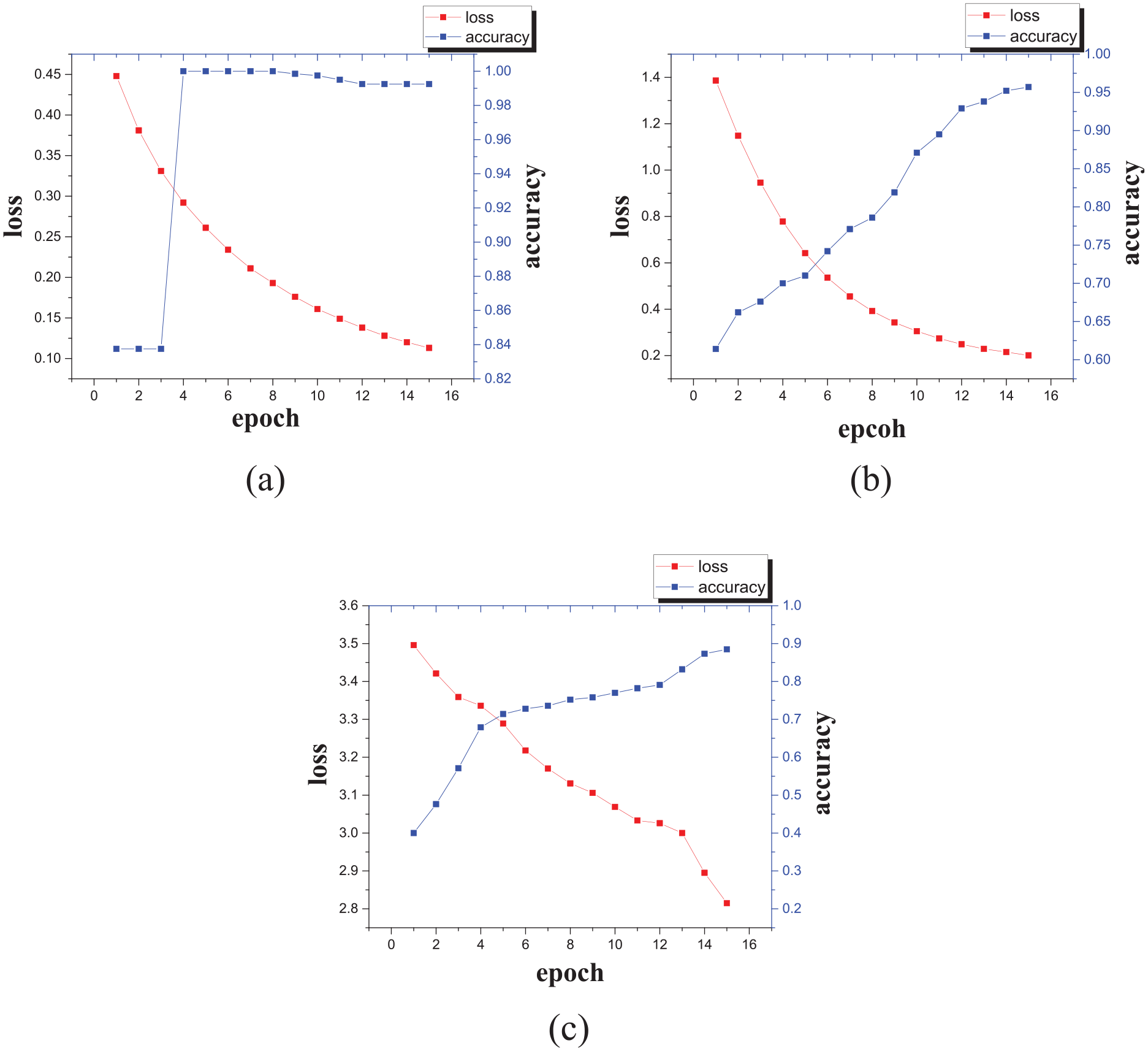
Variation of accuracy and loss function with iterations is shown, which includes two-class task, three-class task and 10-class task: (a) two-class task, (b) three-class task, and (c) 10-class task.
Validation of generalization ability
The generalization ability refers to the ability of the model to adapt to fresh samples, that is, the ability to deal with new datasets with similar laws through the learning of the original dataset. In this section, the bearing vibration signal dataset at the drive end motor speed of 1730 rpm is selected as the validation set to verify the generalization performance of the two-class and multi-class models of the 1797 rpm motor speed vibration signal data set. There are 10 types of faults in the 10-class classification task, including normal bearings, and each type of fault contains 100 time series. The change trend of loss function and classification accuracy with the number of iterations is shown in Figure 7, and the 12 best shapelets are shown in Figure 8.
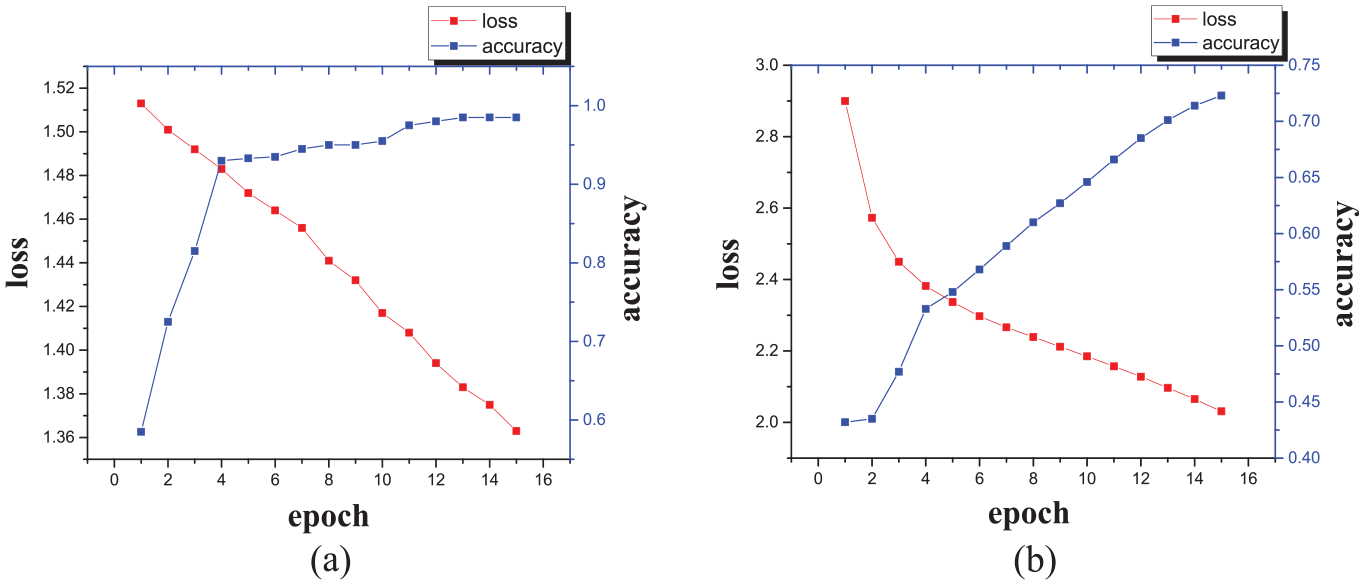
Validation result of multi-class task is as shown. When dealing with task of multi-class task, especially when the number of categories is big, the identification result is not good but is still around the percentage of 75%: (a) validation of two-class task and (b) validation of 10-class task.
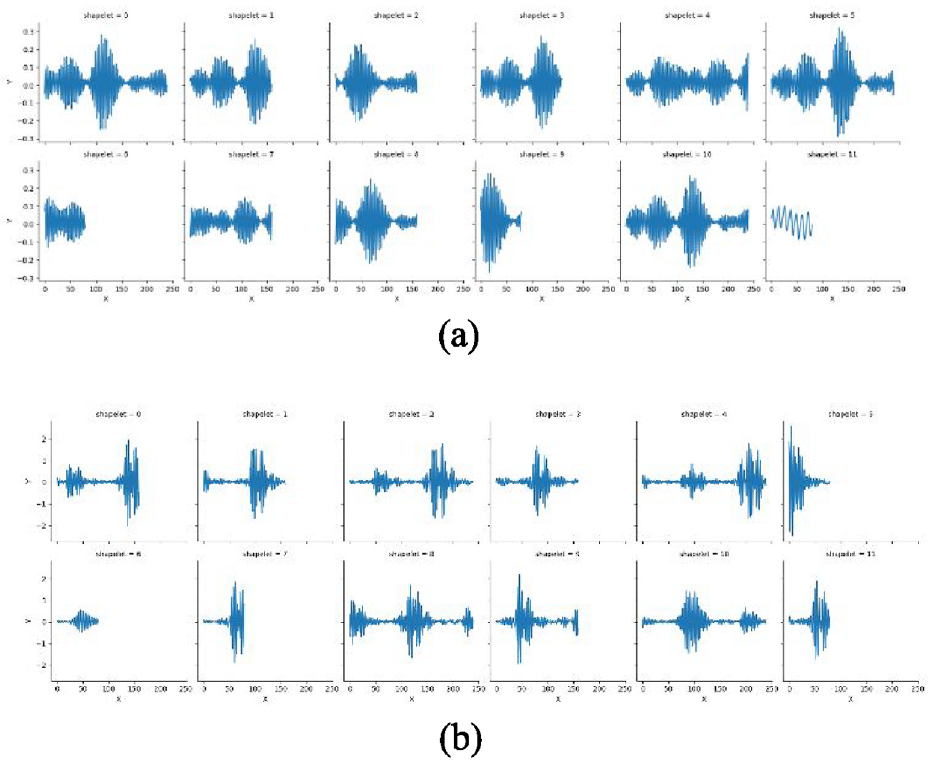
12 best shapelets in validation of multi-class task are shown: (a) 12 best shapelets of two-class classification in validation task and (b) 12 best shapelets of 10-class classification in validation task.
Discussion
For a two-class identification of fault, the evaluation indicators clearly show the high accuracy of this method. The use of SAX distance can greatly save time but the convergence of the model is slower to some extent, which is not a big problem compared to time consumption.
For a multi-class identification, as the number of faults increases, the accuracy of fault identification and the convergence rate of the model decrease. This is a normal phenomenon mainly occurred for two reasons. Firstly, it is an inevitable result of the increase in the amount of data, and secondly, due to the inaccurate measurement in the original data, aliasing phenomenon in time domain representation of different types and degrees of faults is hard to eliminate.
For a practical task of fault identification of bearings, the heart of the problem lies in the discovery of early failures. Any bearing with early failure is not allowed to continue working, which means the decrease of the accuracy of fault identification and the convergence rate when dealing with multi-class identification problem is not a big deal in engineering practice. Actually, the focus is on the position of faults and the above content of this paper has explained the reliability for fault diagnosis of shapelets method when the number of categories is small.
Conclusion
This paper first applied shapelets-based time series classification method to the field of bearing fault identification. Through modeling, calculation and verification based on CWRU fault bearing data set, the conclusion is as follows:
(1) Shapelets-based time series classification method is a feasible method for bearing fault identification with high classification accuracy, strong comprehensive performance of the model, and strong generalization ability when dealing with classification problems with a small number of categories. It can achieve high-precision diagnosis of faulty bearings under different working conditions.
(2) This method has been proved to be of high interpretability. Compared with other classification methods, shapelets transforms the classification problem of vibration signal time series into a similarity measurement problem between time series and subsequence shapelets, fully reflecting the essence of bearing vibration signals as a time series.
(3) Using MINDIST distance instead of Euclidean distance in shapelets can effectively reduce the calculation time while ensuring accuracy, which could be a significant method of distance measurement in clustering tasks.
(4) The reduction of the model’s convergence speed caused by the use of MINDIST distance and the reduction of the accuracy of multi-classification tasks are the main problems that this method needs to solve in the future.
(5) More effort needs to be done to improve the generalization performance of the model as the current model can be used to achieve a specific length of time series classification. Furthermore, when shapelets have been extracted, it is possible to realize the Real-time diagnosis and classification of fault signals, which also needs the assistance of hardware including sensors to collect acceleration signals. It is also a meaningful topic that the whole system can be designed with FUSA function.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.