
Abstract
The ongoing COVID-19 pandemic remains a significant threat, emphasizing the critical importance of mask-wearing to reduce infection risks. However, existing methods for mask detection encounter challenges such as identifying small targets and achieving high accuracy. In this paper, we present an enhanced YOLOv7 model tailored for mask-wearing detection. we employing a Generative Adversarial Network (GAN) to augment the original dataset, introducing the Convolutional Block Attention Module (CBAM) mechanism into the YOLOv7 model to enhance its small target detection capabilities, and replacing the model’s activation function with Parametric Rectified Linear Unit (FReLU) to improve overall performance. Experimental validation on a dataset showcases an average precision of 97.8% and a real-time inference speed of 64 frames per second (fps), meeting the real-time mask-wearing detection requirements effectively.
Introduction
The COVID-19 pandemic has highlighted the critical role of mask detection in ensuring public health and safety, 1 rendering it a vital element of contemporary computer vision systems. Leveraging the advancements in deep learning technology, substantial headway has been achieved in the realm of object detection, 2 with a particular focus on mask detection. Convolutional neural networks (CNNs) have brought about a transformation in target detection and now serve as the cornerstone of deep learning-based object detection models. In object detection, two primary approaches exist: the two-stage detection algorithm and the one-stage detection algorithm.
With the recent advancements in deep learning technology, it has found widespread utility in the domain of target detection. Traditional target detection systems were constructed by integrating a series of manually designed feature extractors. These models were characterized by their sluggish processing speed and suboptimal accuracy, posing significant limitations in practical engineering applications. However, with the emergence of convolutional neural networks, target detection has witnessed a transformative leap, finding applications across various domains.3–6 In the current landscape, target detection algorithms can be broadly categorized into two mainstream directions: the first is the two-stage detection algorithm, exemplified by approaches such as R-CNN (Region Convolutional Neural Network), 7 Fast R-CNN (Fast Regions with CNN), 8 Faster R-CNN (Fast R-CNN with RPN), 9 and other members of the R-CNN series, including the Libra R-CNN algorithm 10 and Grid R-CNN algorithm. 11 This class of algorithms primarily generates candidate regions from the input image in the initial stage and subsequently refines these candidates to produce the final target bounding box. The second direction is represented by one-stage detection algorithms, with YOLO (You Only Look Once) 12 and SSD (Single Shot Multibox Detector) 13 as notable examples. The fundamental principle underlying these algorithms involves feeding images into the model and directly obtaining information about target bounding box anchors, their locations, and associated class labels.
The one-stage detection algorithm, YOLOv7 (You Only Look Once version 7), is widely used due to its simplicity and speed. However, there is still room for improvement in its accuracy in mask detection. In this paper, we propose an improved version of YOLOv7 for mask detection. Our approach is evaluated on a benchmark dataset, and we compare it with other state-of-the-art methods, demonstrating that our method outperforms existing models.
Related work
With the development of deep learning, researchers have been working on combining deep learning with practical scenarios, such as Zheng et al. introduced DL-PR, a deep learning-based adaptive modulation classification method that significantly enhances AMC accuracy through regularization based on the SNR distribution of samples, 14 Bassiouni et al. employ deep learning to predict transportation risks during the COVID-19 pandemic, achieving approximately 100% accuracy, facilitating proactive decision-making for resilient supply chains. 15 In the identification and detection of masks, Chavda et al. use two-stage CNN architecture to detect whether pedestrians are wearing masks, 16 Susanto et al. use YOLOv4 to detect whether pedestrians are wearing masks., 17 Xue et al. improved upon the basic face detection algorithm for mask detection 18 and introduced the attention mechanism to classify masks. Zhang et al. proposed the Context-Attention R-CNN model, a highly accurate and effective mask detector. 19 El Gannour et al. introduce an automated deep learning model for highly accurate medical face mask detection, achieving an impressive accuracy of 99.74% and a sensitivity of 99%, playing a crucial role in the battle against the COVID-19 pandemic. 20 Habib et al. employ deep learning for mask detection, achieving high accuracy. The goal is to determine correct mask wearing, especially around the chin and nose, with potential applications in traffic management and crime investigation. 21 However, it has limitations in detecting improper mask usage. Although these deep learning methods are slightly better in accuracy and speed than general detection methods, they still face challenges in detecting small and dense targets. In crowded places, face targets become smaller and less clear, and masks can occlude feature information, making real-time detection more difficult. Thus, further improvements in mask detection algorithms are needed.
In this paper, we propose an improvement to the YOLOv7 target detection algorithm to better detect small and dense targets. While YOLOv7 has strong real-time performance and improved accuracy and speed compared to previous detection methods, it still has limitations in small and dense target detection. Our contributions are the following points. Firstly, we address the issue of uneven data distribution and single scene in existing mask datasets by completing data enhancement using Generative Adversarial Network (GAN) algorithm. Secondly, we introduce an attention mechanism module into the feature extraction network to enable the network to pay attention over a larger area and enhance feature detection. Lastly, we replaced the activation function of the original YOLOv7 model with the FReLU function to improve the performance of the network.
Method
Source of data
The data preprocessing begins with two essential steps: grayscale conversion and normalization. Grayscale conversion involves transforming the original data, which is in color, into a grayscale format. This process aggregates the RGB values of each pixel into a single value, effectively reducing the image from three channels to a single channel. This not only simplifies the data but also accelerates and streamlines data processing. Following grayscale conversion, the next step is normalization. This crucial process maps the data values to a standardized range, typically between 0 and 1. The purpose of normalization is to ensure that all features share a consistent metric scale. This standardization contributes to improved training speed and helps prevent issues like gradient explosion and overfitting. The combined effect of grayscale conversion and normalization is demonstrated in Figure 1, illustrating the transformation of an image before and after grayscale processing.

Grayscale processing of images.
When using deep learning for detection, a large number of datasets are required to train the model. However, there are currently only a few datasets available for mask wearing detection in natural scenes, and they mainly consist of homogeneous detection environments, which lack images of incorrectly worn masks. To address this issue, we selected compliant images from public datasets such as MAFA and RMFD, resulting in an original dataset of 5480 images divided into three categories: correctly wearing masks, not wearing masks, and incorrectly wearing masks, captured in public natural scenes such as stations, subway stations, and supermarkets. In this study, the wrong wearing is set as no wearing. Figure 2 shows some of the data.

Sample data display of the data set.
However, due to the relatively small total number of images in the original dataset and the small number of samples wearing masks, this study employs GAN for data augmentation to enhance the diversity of the dataset and increase the generalization ability of the algorithm. GAN is a deep learning algorithm proposed by Goodfellow et al. 22 It consists of a generator (G) and a discriminator (D), both of which are fully connected networks. The core idea of GAN is the mutual confrontation between the generator and discriminator in the training process, through which both generator G and discriminator D can reach the optimal state, and the generator can generate false images. 23 In this paper, we improve the structure of the GAN network using the mask data and build a generative adversarial network structure for mask data. Generating adversarial network structure is show in Figure 3.
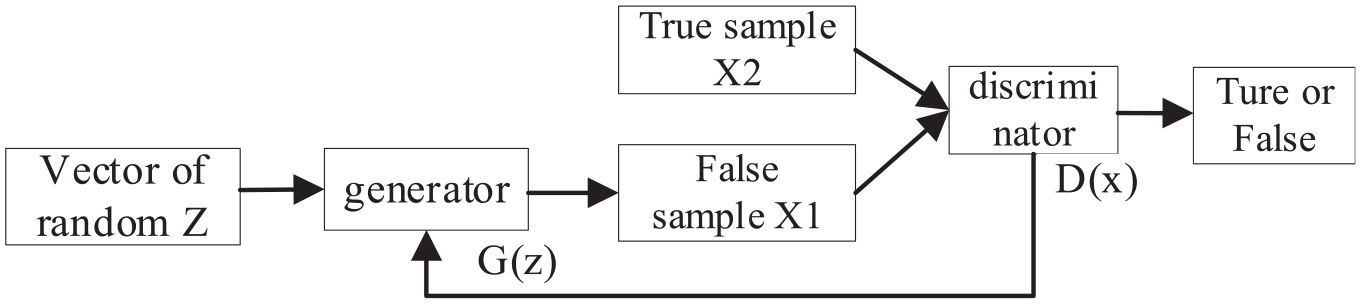
Generating adversarial network structure.
After applying GAN for data augmentation, the total number of images in our dataset increased to 8572. The dataset now includes multiple scenes, allowing for a more comprehensive representation of real-world detection scenarios. By using this method, we can reduce the risk of overfitting during model training and improve the robustness. Figure 4 shows some of the generated data.

Sample of partially generated dataset.
Original YOLOv7 network model
The YOLOv7 detection algorithm is the latest open source model algorithm from the YOLOv4 team. 24 The researchers redesigned the model by redesigning the auxiliary head and lead head for the label assignment piece. Experimental results show that the YOLOv7 model is 551% faster and 2% more accurate than the Transformer-based model SWINL Cascade-Mask R-CNN, and 551% faster and 2% more accurate than the convolution-based model ConvNeXt-XL Cascade-Mask R-CNN. YOLOv7 outperforms the previous models such as YOLOv4 and YOLOv5 in terms of detection speed and accuracy.
The YOLOv7 model contains the latest ideas from recent years, such as efficient aggregation networks, reparameterized convolution, auxiliary head detection, and model scaling. It inherits some elements from the authors’ previous YOLOR proposals, such as the setting of hyperparameters and implicit knowledge learning. The YOLOv7 model proposes the Extended Efficient Long-Range Attention Network (E-ELAN) to achieve continuous enhancement of the network’s learning capability and improved parameter usage and computational efficiency without destroying the original gradient paths. E-ELAN improves the structure of computational blocks by guiding different groups of computational blocks for learning different features. 25 The composite model scaling method is proposed to maintain the properties that the model has at the time of initial design and to maintain the optimal structure. In terms of network optimization strategies, model reparameterization and dynamic label assignment are introduced and improved. YOLOv7 utilizes CSPDarknet53 as its backbone network, an enhanced version of Darknet53 known for improved feature extraction. The CSP (Cross-Stage Partial) structure connects feature maps across different stages, facilitating the flow and reuse of information. YOLOv7 introduces an FPN (Feature Pyramid Network) for multi-scale object detection. This feature pyramid network comprises multiple feature maps with varying resolutions to detect objects of different sizes. The model employs YOLO’s distinctive detection head, responsible for generating bounding boxes and class probabilities. It can predict multiple bounding boxes of different sizes and aspect ratios, enhancing multi-scale object detection performance. YOLOv7 uses a combined loss function, including Mean Square Error (MSE) for localization loss and Cross-Entropy for classification loss. Additionally, it implements training strategies such as Mosaic data augmentation, multi-scale training, and staged training to enhance both model robustness and performance. The structure of YOLOv7 is shown in Figure 5.
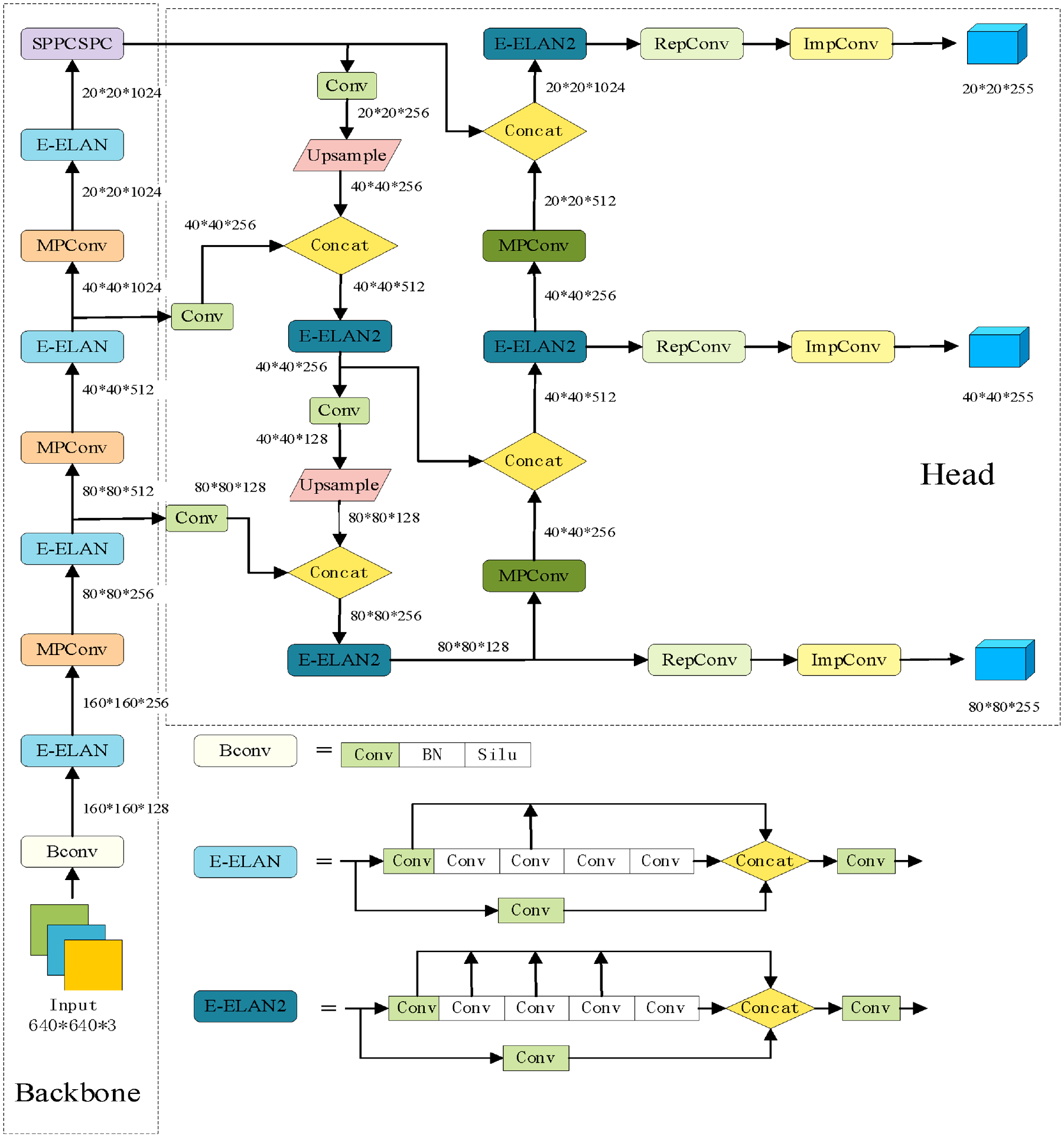
Network structure diagram of YOLOv7.
It is worth noting that the YOLOv7 model also places emphasis on optimizing the training process by incorporating various optimization modules and methods to increase the accuracy of target detection without increasing the inference cost. Table 1 shows a comparison of YOLOv7 with other models, highlighting its superior performance in terms of speed and accuracy.
Comparison between different models.

When compared to YOLOv4, YOLOv7 has 75% fewer parameters, 36% less computation, and achieves a 1.5% higher AP. Similarly, compared to the state of the art YOLOR-CSP, YOLOv7 has 43% fewer parameters, 15% less computation, and achieves a 0.4% higher AP. Therefore, YOLOv7 exhibits superior performance and is easier to deploy, aligning with the design philosophy of this paper.
Improved the YOLOv7 model
Feature extraction network introduces improved attention mechanism module
The attention mechanism is a machine learning data processing method 26 inspired by the way the human brain processes visual information. It is widely used in various machine learning tasks, such as natural language processing, image recognition, and speech recognition, due to its effectiveness. In simpler terms, the attention mechanism enables the network to learn what to focus on in a sequence of images or text automatically. For instance, when a person looks at a painting, their attention is not distributed evenly across all pixels in the painting. Rather, more attention is given to areas that draw their attention. In convolutional neural networks, adding more layers to increase the network’s representation capacity can make the structure of the network too large. In contrast, the attention mechanism focuses on global and local features in the visual perception process, enhancing the image feature information while reducing network parameters.
As a notable example of attention mechanisms, SENet 27 proposed a channel attention mechanism that captures contextual information globally, explicitly constructs interdependencies between feature channels, and outputs the results in reverse to complete the recalibration of the original features in the channel dimension. Building on this work, the Efficient Channel Attention Network (ECA-Net) 28 was developed to further improve the approach. The Convolutional Block Attention Module (CBAM) 29 is another attention module that infers attention along two dimensions, channel and space, by fusing the attention map with the input feature map for adaptive feature optimization. The channel attention module and spatial attention module of CBAM can effectively increase the weight of small targets in the feature map, promoting the network’s ability to learn information related to smaller targets. Additionally, there are other attention mechanisms, such as the multispectral channel compressed attention method-Frequency Domain Attention Network (FcaNet), 30 dual attention mechanism-DANet, 31 and others.
Compared to other attention mechanism modules, the CBAM module is advantageous due to its good applicability and low computational cost. In this paper, the CBAM attention module is integrated into the YOLOv7 network to improve its feature extraction capability and focus on the detection target, addressing the issue of degraded detection accuracy caused by complex environments. In object recognition, complex background information can often interfere with the detection of small targets, such as the mask target. The feature information of small targets can easily be lost during the sampling process in the original YOLOv7 algorithm model, leading to missed and false detections. To address this issue, an attention mechanism is introduced in the backbone network of YOLOv7 to increase the weight of small targets in the overall features, allowing for better capture and learning of their feature information.
The CBAM module contains both a channel attention mechanism and a spatial attention module, which independently focus on the channel and spatial dimensions of the input feature map, respectively. The CBAM module infers the attention map along both the channel and spatial dimensions and then performs adaptive feature optimization by multiplying the attention map with the input feature map. By introducing the CBAM module, the model can more effectively extract important features and achieve higher accuracy in discriminating objects. The structure of the CBAM attention mechanism is shown in Figure 6.
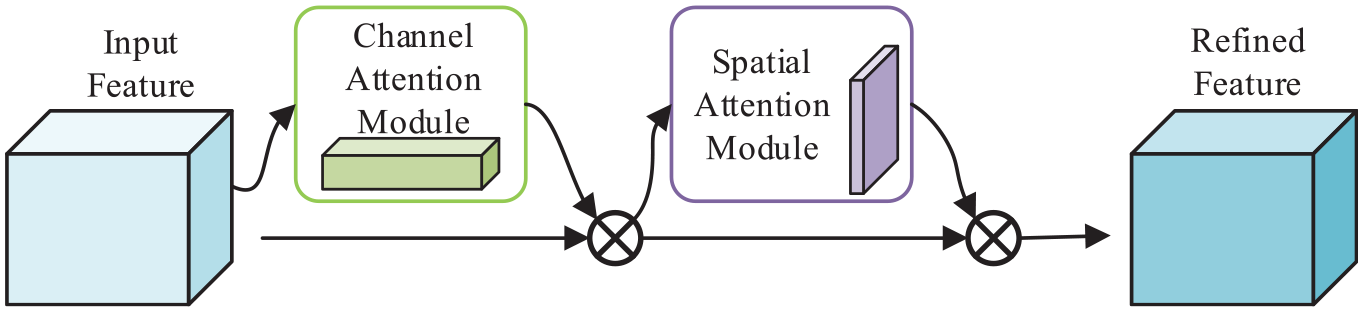
Convolutional block attention module.
The channel attention module calculates the weight of each channel, and the module calculates the formula as in equation (1).
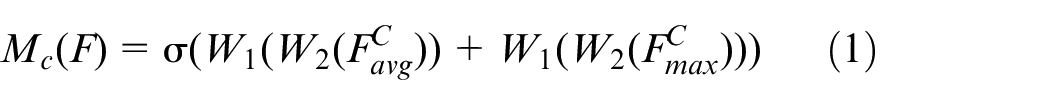
Equation (2) represents the average pooling, which computes the weight of each channel based on the feature map after the maximum pooling. The calculated weights are then multiplied with the original feature map, and the resulting output is passed on to the spatial attention module. The module can be visualized in Figure 7.
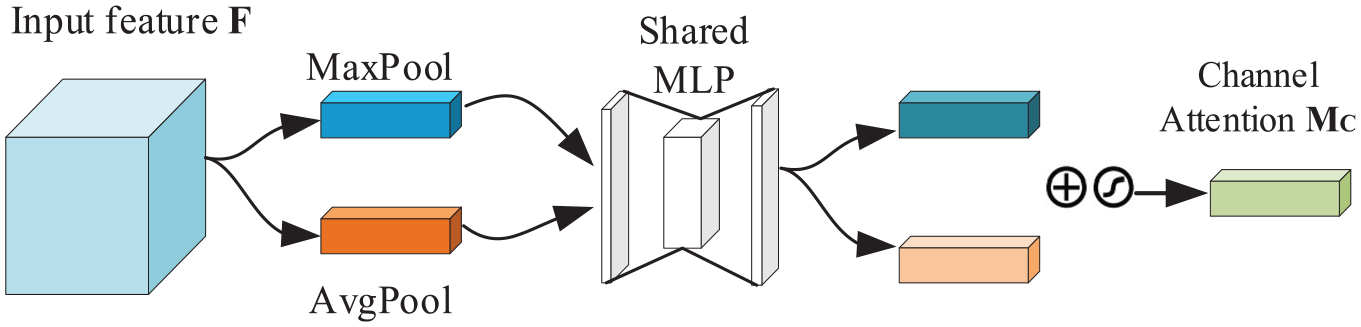
Channel attention mechanism.
After the maximum pooling and average pooling operations in the spatial attention module, the spatial attention weight map is obtained by reducing the dimension to 1 channel through the convolution operation, and the expression is calculated as:
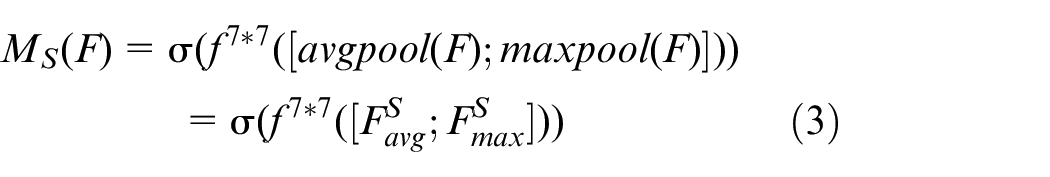
The spatial attention module is shown in Figure 8.
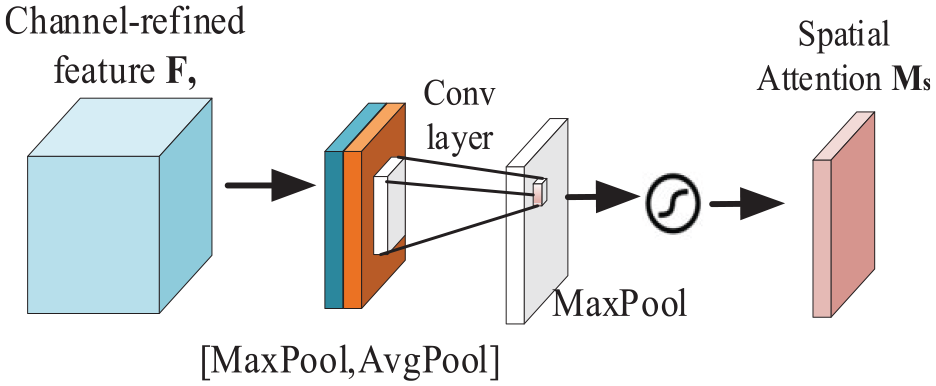
Spatial attention mechanism.
Activation function improvement
The goal of the activation function is to introduce nonlinearity into the neural network, enabling it to learn complex patterns and relationships in the data. Activation functions are generally continuous and differentiable, allowing for efficient optimization using gradient-based methods. There are several commonly used activation functions as shown in Figure 9.
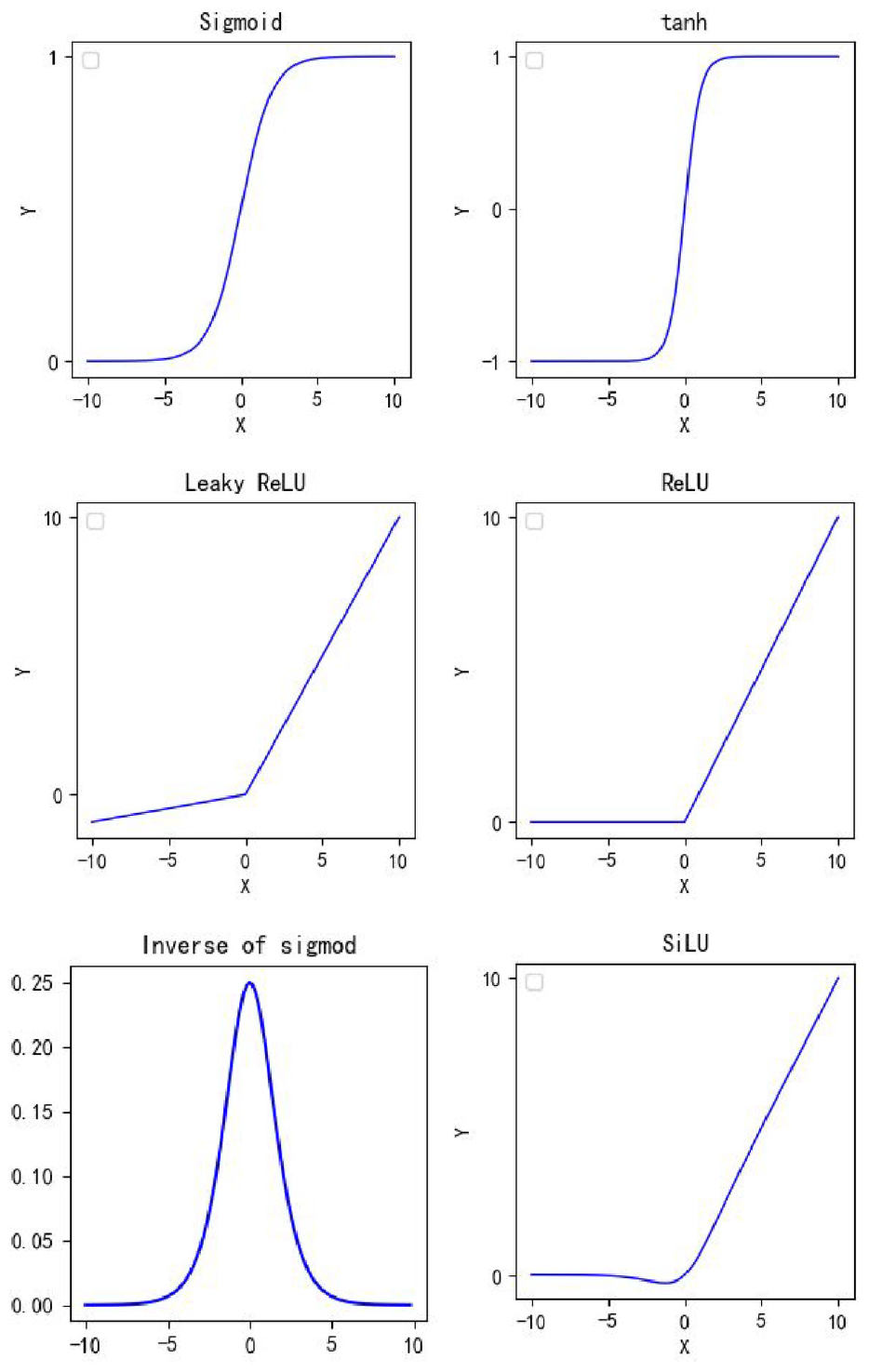
Several commonly used loss functions.
The activation function used in the YOLOv7 model is the SiLU function, which is a weighted linear combination of the Sigmoid function. The expression for the ordinary Sigmoid function is:

where x is the input to the function. The SiLU function is defined as:
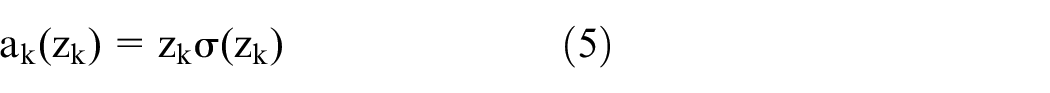
The SiLU function is a smooth and non-monotonic activation function that is self-stabilizing, making it effective in suppressing the learning of a large number of weights. However, it can be computationally intensive, leading to slow convergence and difficulties in training. To overcome these issues, this paper proposes a modification of the Conv layer by replacing the SiLU activation function with the FReLU activation function.
The FReLU activation function is defined as:
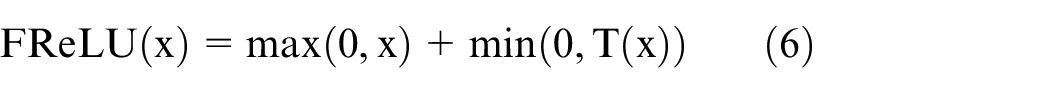
where x is the input tensor, max(0, x) is the ReLU activation function, and T(x) is the spatial contextual feature extractor. This function introduces a funnel-like shape to the ReLU function, allowing for the activation of spatially insensitive information in the network. The spatial contextual feature extractor T(x) is defined as T(x) = max_pool(conv(x)), where conv(x) is a 2D convolutional operation on x, and max_pool() is a max pooling operation. This operation is designed to extract spatial contextual features, which can improve the detection accuracy of the network. The ReLU activation function is shown in Figure 10.
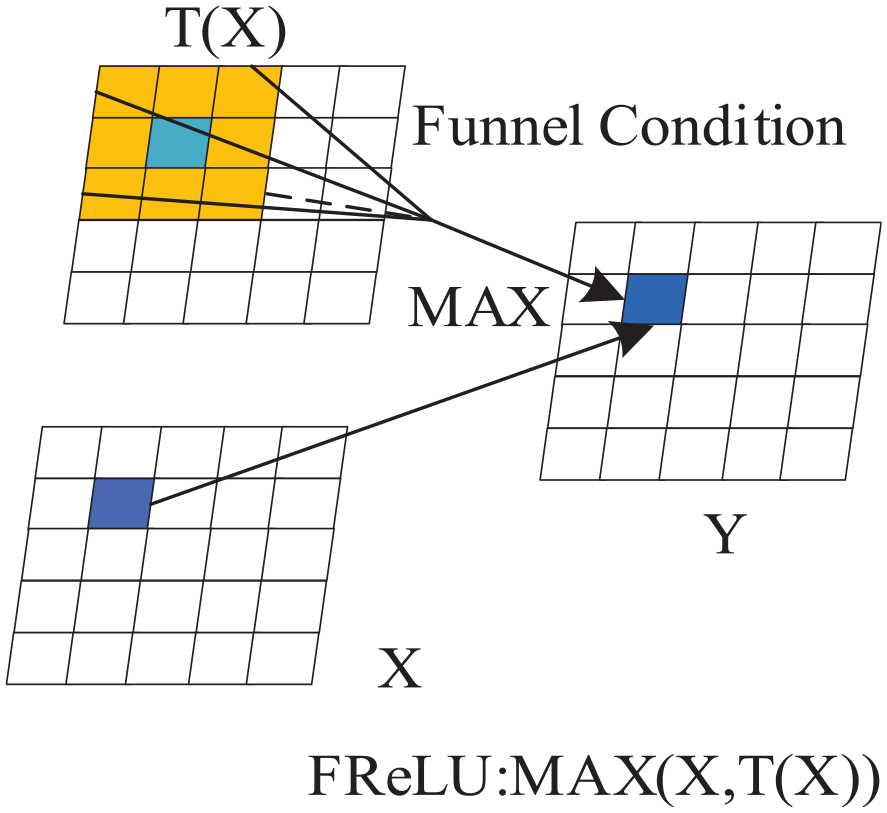
Schematic diagram of ReLU activation function.
In summary, the ReLU activation function combines the benefits of the ReLU function and the spatial contextual feature extractor, improving the accuracy of vision tasks while maintaining low computation and overfitting risks. It improves computational efficiency by activating only spatially-relevant information, reducing unnecessary computations. It also enhances the accuracy of detection tasks by reducing information loss and suppressing overfitting.
Results and analysis
Evaluation criteria
In the field of object detection, performance evaluation metrics such as precision, recall, average precision (mAP), and frames per second (FPS) are commonly used. Before discussing these metrics, it is necessary to introduce the following concepts: True Positives (TP) refers to the number of positive samples that are correctly predicted. True Negatives (TN) refers to the number of negative samples that are correctly predicted. False Positives (FP) refers to the number of positive samples that are incorrectly predicted. False Negatives (FN) refers to the number of negative samples that are incorrectly predicted. mAP (mean Average Precision) is a metric that computes the average precision at different IoU thresholds and then calculates the mean. mAP (0.5, 0.95) is the mean AP for IoU thresholds between 0.5 and 0.95 in steps of 0.05.
The formula for calculating mAP is shown below.



mAP is often used to indicate network performance, and m is the total number of samples in the assay.
Experimental equipment
For this study, we conducted experiments in an environment consisting of the Windows 10 operating system, an i5-12400F CPU, and a GeForce RTX 3080ti graphics card. We utilized the PyTorch deep learning framework to build and train our model. The dataset, as mentioned earlier, was preprocessed and used. During training, we set the number of iterations to 200, with a batch size of 16. Additionally, we applied a weight decay coefficient of 0.0005 and utilized a learning rate momentum of 0.05 to mitigate the risk of overfitting.
The process of experiment
To evaluate the efficiency of the network operation at different training stages, numerical estimates of the loss function of the neural network operation were compared. The loss function provides a numerical estimate that determines the performance of the model. It includes the coordinate loss, confidence loss, and classification loss, as shown in equation.

The performance of the model is evaluated based on the loss function, with smaller loss function values indicating better performance. To achieve optimal model performance, the model needs to be continuously trained in iterations to improve its results. Figure 10 shows that the loss function significantly improves as the number of iterations increases. After 50 iterations, the function metric reaches an acceptable value for practical use. The function changes are shown in Figure 11.
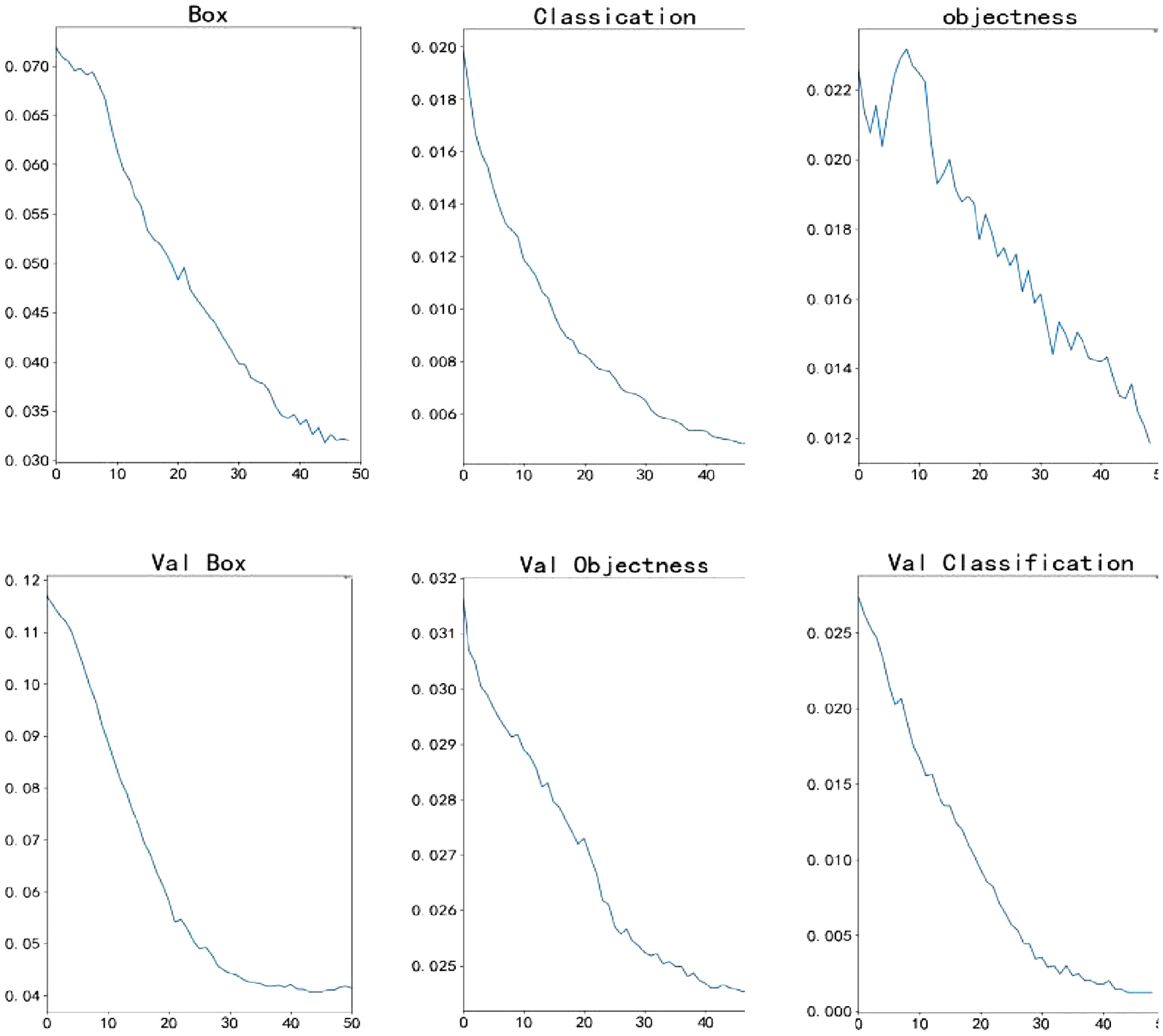
Loss function index plot for 50 iterations of the loss function.
It was observed that the detection indexes increased rapidly from 0 to 100 iterations, followed by a slower increase until the values stabilized, indicating that the model reached its optimal state. Figure 12 shows the change in detection index over the course of training.
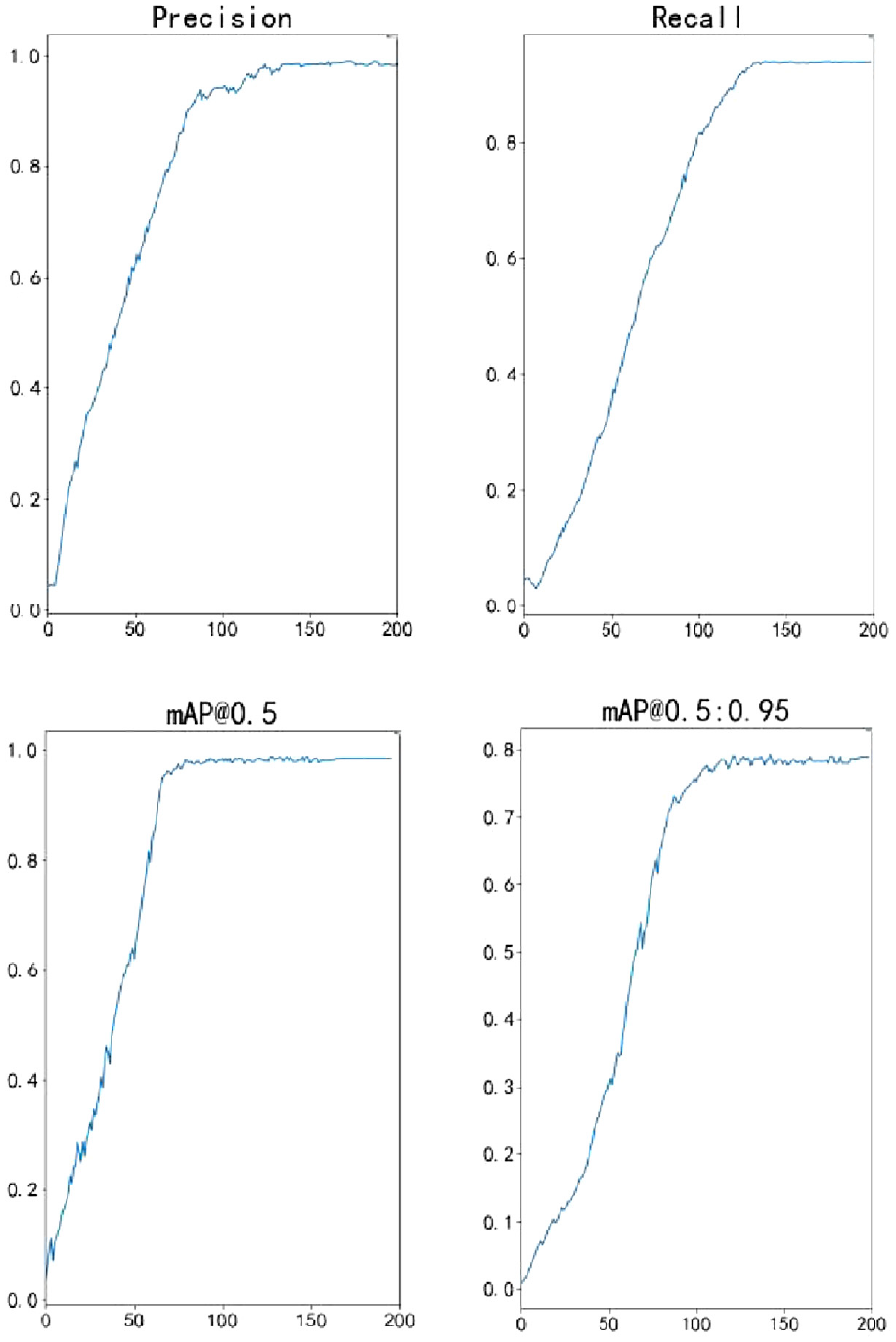
Graph of detection metrics for 200 iterations of YOLOv7 network.
Comparison of recognition results
To demonstrate the advantages of the improved model, a comparison was made with Faster-RCNN, SSD, and other YOLO series models for detection results. All models were trained and validated in the same experimental environment using the same dataset. The comparison results are presented in Table 2.
Comparison of experimental results of different methods.
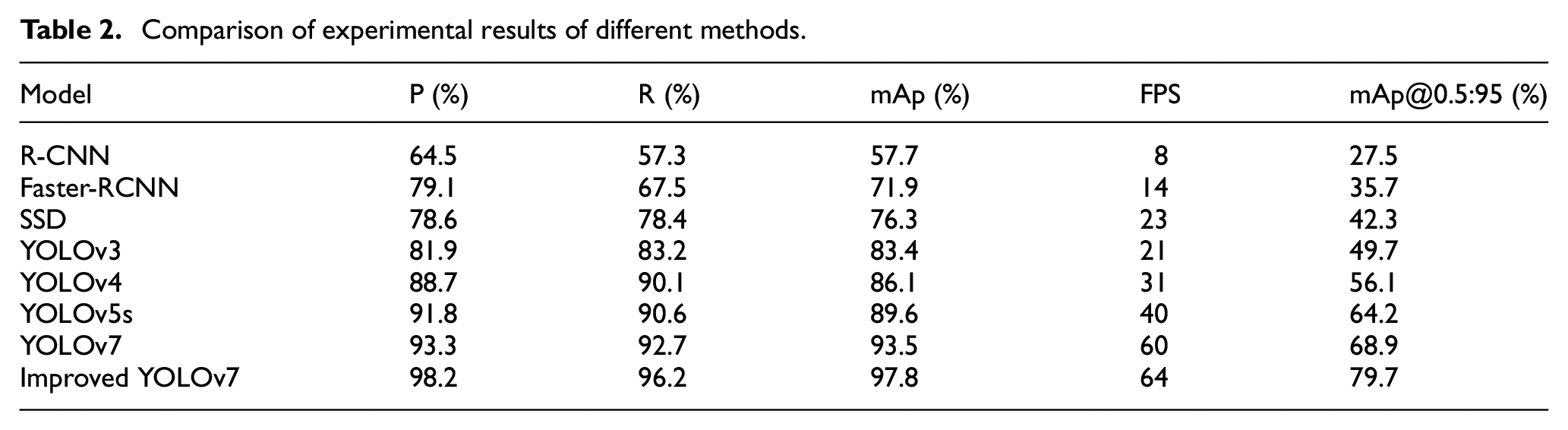
Based on the comparison in the table, the improved algorithm proposed in this paper has demonstrated significant improvements in the accuracy of detection. The average detection accuracy for people wearing masks is 97.8%, which is notably higher compared to other models. Additionally, the recall rate of the improved algorithm also outperforms other models. Moreover, the detection inference speed of 64 FPS meets the requirement for real-time detection.
To get a more in-depth analysis and explain the reasons for these improvements, we consider the following points. The improved algorithm incorporates specific optimizations and enhancements designed for the detection task. These optimizations involve modifying the model architecture, refining the loss functions, and employing advanced training techniques. These enhancements lead to significantly improved accuracy in detecting masked faces. Furthermore, the algorithm utilizes more effective methods to extract and represent features from the input data. By capturing more discriminative information, it becomes better equipped to identify masked faces accurately, resulting in higher detection accuracy. To further enhance performance, the algorithm employs data augmentation techniques and specialized training procedures. Data augmentation diversifies and increases the quantity of training samples, enabling the algorithm to learn from a broader range of scenarios. The improved algorithm also introduces architectural advancements or modifications to enhance its ability to detect masked faces accurately. These advancements may involve innovative network architectures, attention mechanisms, or feature fusion strategies. By incorporating these enhancements, the algorithm achieves superior detection accuracy compared to other models. Overall, these optimizations, advanced feature representation methods, data augmentation, specialized training procedures, and architectural advancements collectively contribute to the improved algorithm’s remarkable performance in detecting masked faces.
In order to verify the optimization effect of each improvement module, the optimization comparison experiment is conducted in this paper, and the experimental results are shown in Table 3.
Comparison of ablation experiments.

The YOLOv7 model was modified by adding a CBAM and subsequently applying a ReLU function to enhance its object detection performance. The experimental results demonstrate that these modifications led to significant improvements in precision, mAP, and recall, while still maintaining a reasonable trade-off between accuracy and speed. The addition of CBAM improved precision, mAP, and recall by 4.4%, 3.4%, and 6.1% respectively. While there was a slight decrease in speed, it is important to note that this reduction in FPS was minimal considering the noticeable performance enhancements achieved. Furthermore, applying the ReLU function to the CBAM modified model resulted in an additional improvement of 0.5%, 0.9%, and 0.6% respectively in precision, mAP, and recall. More importantly, this modification led to a 4% increase in speed, demonstrating how the model could strike a better balance between accuracy and speed. These results indicate that both CBAM and ReLU function are effective in improving the performance of the YOLOv7 model. CBAM helps the model better identify and classify objects, while ReLU introduces non-linearity to enable the model to learn more complex relationships between inputs and outputs. By combining these techniques, the model achieves higher accuracy and robustness in object detection tasks without sacrificing much speed. Overall, the experimental findings suggest that the enhancements made to the YOLOv7 model, through the addition of CBAM and ReLU function, effectively improve its performance in detecting face masks. Moreover, they also indicate that a reasonable trade-off between accuracy and speed can be achieved, ensuring that the model strikes the right balance in real-world scenarios.
To demonstrate the detection effect more intuitively, real scene pictures were used to show the results. Figure 13 displays the detection results.

Improve YOLOv7 model to detect mask.
Conclusion
This paper tackles the challenges related to low accuracy and insufficient discrimination of obscured targets in current mask-wearing detection algorithms. To enhance the YOLOv7 network model’s performance, we introduced a CBAM attention mechanism, effectively improving target discrimination. The experimental results provide compelling evidence that this enhanced model significantly boosts target detection accuracy while maintaining real-time detection capabilities with high precision.
In our future research endeavors, we will place a strong emphasis on reducing the network model’s parameters and computational demands. This optimization will further enhance the algorithm’s efficiency, making it more practical and applicable across a wide range of real-world scenarios. Our aim is to develop an algorithm that not only excels in accuracy but is also resource-efficient, ensuring its usability and impact in diverse practical settings.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by the Guangdong Provincial Department of Education Features Innovative Projects (2022ktscx236 and 2020KTSCX363) and the Science and Technology Project of Qingyuan Polytechnic (ZK21001).