
Abstract
For modern sport training, critical posture recognition of athletes can be helpful for athlete training. This paper proposes convolutional neural networks using a two-stage evaluation mechanism to recognize four critical postures of a weightlifter, that is, force releasing, knee flexion, knee extension and highest point. Using the proposed convolutional neural networks classify images and extract image features. Meanwhile, a two-stage evaluation mechanism is adopted to calculate the scores of image features, based on the calculated scores, the four critical postures can be accurately recognized. Experimental results show that the accuracy of our method is 92.85% in the recognition of the four critical postures, which defeats the competitive methods in critical posture recognition. Moreover, the training time of the proposed method linearly augments along with the increasing of data volume, that is, non-exponential growth, consequently, our method can be applied to large-scale image datasets. We demonstrate that the two-stage mechanism can calculate the scores of image features independently of specific scenarios, which assist neural networks improve classification capabilities. Moreover, using the two-stage mechanism can simplify the designed complexity of neural network architectures, thus reducing the training parameter of neural networks in the process of critical posture recognition.
Introduction
Generally, for weightlifting training and competitions, coaches need to propose corresponding training plans based on the individual situations of different athletes to improve their skills. 1 The traditional training methods employ training plans through utilizing the training theory and experience proposed by coaches, then combining with the technical level of weightlifters. This training manner is subjective, moreover, coaches consume much time to analyze athletes’ postures, which difficultly and objectively evaluate training effectiveness of athletes. 2 However, the core of modern sports training is precision and efficiency, and coaches can accurately evaluate athlete’s postures to improve training effectiveness. As such, it is great significance for improving scientific nature of coaches’ training plans and improving training effectiveness of athletes through accurately identifying training postures of weightlifters. 3
Weightlifting gesture recognition belongs to a kind of human gesture recognition. Currently, there are two main methods of human gesture recognition. One is inertial sensor recognition, and the basic idea is that an athlete’s body is equipped with a simple and lightweight data acquisition sensor, which sends the collected data in real-time to the processing terminal, and then recognizes athlete’s postures based on various posture data. The disadvantage is the large number of devices, which is not conducive to promotion and application. The other one image recognition, according to the number of image acquisition devices, posture recognition based on image acquisition can be divided into monocular video recognition and multi eye video recognition. The general idea of image acquisition gesture recognition is to capture athlete’s images or video through using a camera, then to extract the motion features hidden in the image and video, finally to design a classifier to recognize athlete’s gestures.
Some efforts regarding action recognition have been widely obtained by using computer vision and multimedia community technics. Currently, existing most methods mainly focus on human posture estimation, foreground segmentation, and local foreground motion modeling to explore the characteristics of action performers. For example, Simonyan and Zisserman 4 proposed a two-stream Convolution-Net network to combine spatial and temporal information for action recognition. Li et al. 5 utilized a temporal attention model to create global guidance for fusing visual and motion features. Additionally, aiming at posture estimation and action recognition, these method in references 6–11 are proposed. To achieve action recognition, Li et al. 12 sufficiently take account into hand motion features, gaze features, and object features. To identify different actions, Cai et al. 13 considered the relationship between grip types and object attributes. While, in detecting object instance action, Baradel et al. 14 proposed an object relationship network to infer semantically meaningful spatiotemporal interactions.
For action recognition, some method uses full action sequences for pattern learning, 15 such as, these methods implemented in references16–18, but they often overlooked semantics. In fact, there is a mutually reinforcing relationship between action recognition and motion prediction. With the development of deep learning techniques, some recurrent neural networks (RNNs) models have captured temporal correlations along consecutive frames, 19 and convolutional neural networks also gain remarkable achievements,20,21 such as the RNNs in references22–25. These methods rarely study joint relationships and lack key dynamics. In order to capture richer features, Yan et al. 15 proposed a skeleton graph with nodes. The references26,27 established a relationship between thicker body parts. These methods are essentially based on the aggregation of body structure information, while ignoring some implicit relationships related to movements. In addition, graph-based methods also attract attention.28–32 Graphs can effectively represent data related to non-grid structures,33,34 for instance, Simonyan and Zisserman 4 leveraged graph convolution for action recognition. Besides these methods, the methods proposed by the references35–37 provide the insightful suggestions for the image recognition.
Motivations
Our research goal is to recognize the four critical postures of a weightlifter, that is, force releasing, knee flexion, knee extension and highest point, thus providing some insights to weightlifter training. Therefore, to achieve the motivation, we designed convolutional neural networks with four convolutional layers, namely F-CNNs. Furthermore, we proposed a two-stage evaluation mechanism to assist the model for the recognition of the four critical postures. From the perspective of model structures, convolutional neural networks are capability of image classification and feature extraction. This ability can assist us to classify image and capture image features. From the view of a method, the two-stage evaluation mechanism can evaluate the four critical postures through calculating the scores of image features. In summary, the four critical postures can be well recognized by combining convolutional neural networks with a two-stage evaluated mechanism.
Contributions
We summarized main contributions of this work.
(1) We proposed a two-stage evaluated mechanism to recognize the four critical postures. The two-stage evaluated mechanism calculates the scores of image features independently of specific scenarios. The calculation scores yielded by the mechanism can assist neural networks to improve classification accuracy.
(2) We propose that the training time of our method does not increase exponentially, that is, linearly with the increase of data volume, since we simplified the design of neural network, meanwhile, the two-stage evaluated mechanism does not yield too consumption during training. Therefore, our method can be applied to large-scale image datasets.
(3) Our convolutional neural networks do not take into account complex network structures, although complex network structures can improve the learning ability of a model itself. Here, we use a two-stage mechanism instead of the design of complex network architectures. By so doing, the time consumption during training can be reduced.
This paper is arranged as follows. Section 2 interprets the method and the model. Experiments are designed in Section 3, and Section 4 analyzes and Section 5 discusses the experimental results. Section 6 summarizes the conclusion and directs the future work.
Methodology
This section introduces posture evaluation and model implementations. To accurately recognize the four postures, we designed a two-stage evaluated mechanism, which construct an evaluation indicator of calculating feature regions to evaluate the scores of different postures. For model implementation, we chose the network architectures based on convolutional neural networks. Using convolutional neural networks can well learn these features in images and classify images.
The thought of the proposed method is that convolutional neural networks classify the input image sets into four categories, meanwhile, label feature regions of images, that is, feature labeling. Then, the scores of the features obtained in images are calculated, based on the calculated scores, it can be determined which type of image corresponds to which posture.
Posture evaluation
We analyzed the four postures of a weightlifter, such as force releasing (Posture 1), knee flexion (Posture 2), knee extension (Posture 3) and highest point (Posture 4), as shown in Figure 1. To recognize the four postures, we construct the evaluated indicator regarding the four postures.

Four postures of a weightlifter.
We took account into athlete’s body regions as a marker, that is, feature regions, and then these four postures are identified by calculating the posture score. Feature regions are marked with blue rectangles, in addition, the horizontal position of a barbell is labeled with a yellow line, illustrated in Figure 2. Here, we calculate the vertical distance d between the yellow line labeling the barbell and the center of the blue rectangle labeling the body region. Meanwhile, taking the athlete’s sole as a horizontal reference baseline, we calculate the vertical distance D between the barbell and the athlete’s sole, that is, the D is equal to the vertical distance from the yellow line to the bottom of blue rectangle. The height H of the marked feature region is equal to the vertical distance between the athlete’s head and her feet, that is, the H is height of the blue rectangle. The details of evaluation indicator are as follows
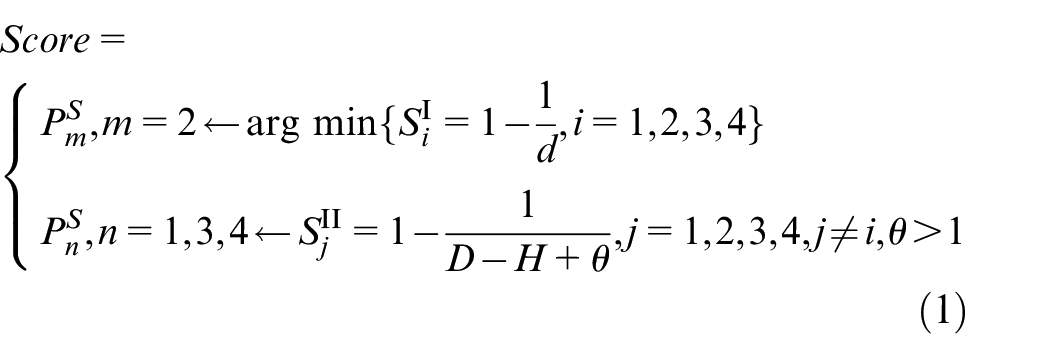
Where

Posture evaluation. Using blue rectangles to mark feature regions, and yellow lines are used to mark the horizontal position of barbells.
Two-stage evaluated mechanism
The principle is to calculate the scores of the features obtained in images, and then to identify these postures based on the calculated scores. Two stages adopt a different evaluated indicator to calculate the scores. In first-stage evaluated mechanism, we utilize
Thereafter, in second-stage evaluated mechanism, the second stage scores of these features screened from first-stage are obtained by using
Model implementations
Convolutional neural networks have outstanding ascendency to image classification and feature extraction, therefore, we designed convolution neural networks with four convolutional layers, namely F-CNNs. Figure 3 displays the structure of F-CNNs, which uses four convolutional layers with
(1)
(2)

F-CNNs structure. The structure consists of four convolutional layers, four pooling layers and a fully connection layer.
Four pooling layers use the max pooling, and a fully connection layer is used. Having that
(3)
(4) a fully connection layer is considered.
Hyper parameters of F-CNNs need to be determined, for example, batch size, base learning rate, etc., here, we carefully studied following hyper parameters.
(i) Learning rate and training epoch. During the training, the loss begins to decline rapidly and then fluctuates significantly in subsequent training, which may be caused by high learning rate. In this scenario, we suggest to tune learning rate. If there is a slight upward curve in the loss, we proposed to reduce the training epoch, since there may exist over-fitting risk. Figure 4
38
unveils the relations between learning rate, loss and epoch. In this work, we used a certain range of tuning the learning rate and training epoch, where learning rate
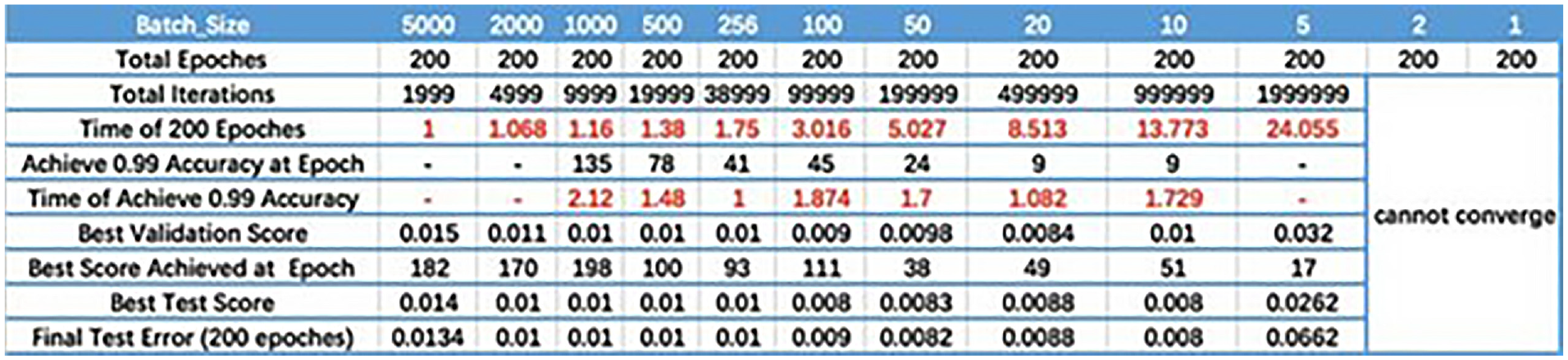
(ii) Batch size. When the configuration of batch size is not appropriate, local optimum may occur. For instance, a small batch size introduces greater randomness, which leads to difficult converge. Within a certain range, the larger batch size is, the more accurate descent direction, and the smaller the training shock obtain. However, when batch size reaches a certain extent, the descent direction basically does not change. Hoffer et al. 39 et al. pointed out that the performance degradation in large batches is due to insufficient training time. Smith et al. 40 and Smith and Le 41 demonstrated that for a fixed learning rate, there is an optimal batch size that can maximize the accuracy of the testing. Additionally, batch size is positively correlated with learning rate and the size of a training set. Considering batch size, epoch, and precision, Figure 539–41 unveils the relationship among batch size, training epoch, and accuracy. It can be seen that the speed to treat the same amount of data augments along with the increasing of batch size. Taking Figure 5 as a reference, we dynamically tune batch size during the training process based on the relations between epoch and accuracy.
(iii) Convergence. Currently, it is difficult to accurately determine whether neural networks are fully trained and obtain an optimal value by using existing methods. However, there are still some ways to evaluate whether the networks have converged, thereby assisting us stop training at the appropriate location (i.e. obtaining better results without over-fitting). One method is to monitor loss curves, for instance, when training loss and testing loss remain relatively stable, the gap of both is almost constant, the networks are regarded as basic convergence.
(iv) Activation function. ReLU function is used as the activation function of convolutional layer.
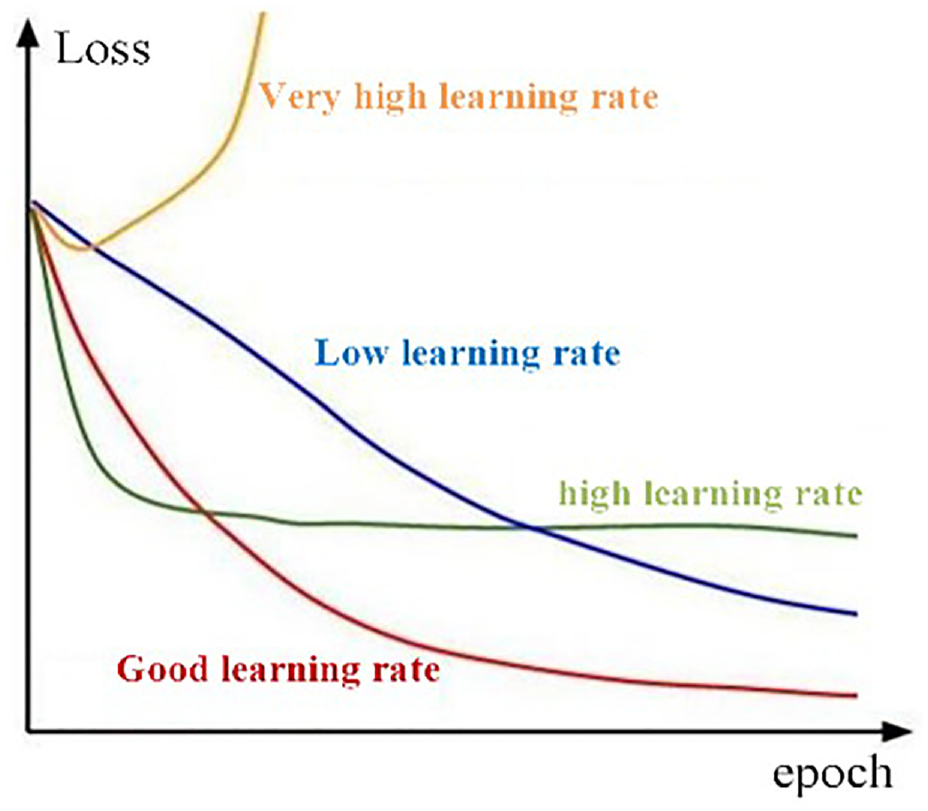
Relation of learning rate, loss and epoch. 38
Experiments
Datasets and competitive methods
We processed the video into frames and then extracted the images. Among them, there are a total of 583 training images (namely training set), 182 validation images (i.e. validation set), and 184 test images (i.e. testing set).
To evaluate the detection ability of F-CNNs, apart from our method, four mainstream approaches were selected from a view of neural network structures, including Graph convolution neural networks (G-CNNs), 34 Feature-steered graph convolutions (F-SGC), 33 Graph convolutional lstm network (GC-lstm), 26 recurrent neural networks model (RNN-M). 23 We implemented the algorithms corresponding to the five methods (our method and four competitive methods) by Python language in Tensorflow Framework in Linux Operation System. Unless otherwise stated, all experiments run on the same GPU, and using the same environment.
Experimental designs
Here, we carried out multiple experiments to verify the proposed method from different perspectives. As follows
Experiment (1). Visualization analysis. To observe the recognized process of the four postures, F-CNNs is trained using the training set, and we visualized the process that the four convolutional layers learn the four postures. Then, visualized results were observed.
Experiment (2). Posture recognition. To verify the ability to recognize the four postures, our method was run on the testing set and validation set. Then, the results were analyzed.
Experiment (3). Performance comparisons. To evaluate method’s performance, the five methods (our method and four competitive methods) were run on the testing set and validation set. Then, comparison results were evaluated.
Experiment (4). Execution efficiency. To analyze algorithm’s efficiency, we compared the training time and testing time of the five algorithms corresponding to the five methods.
Results analysis and discussions
Visualization analysis
We visualized the results learning the four postures on the four convolutional layers, illustrated in Figure 6. Convolutional layer visualization is very useful since those well trained network weights typically appear smooth filters, instead, if it appears noise patterns, this may indicate that networks are not sufficiently trained or that over-fitting of networks has occurred. From Figure 6, it can be seen that the first convolutional layer conv1 in F-CNNs is smooth, indicating good convergence performance. Additionally, we also observe that a portion of the network weights is responsible for color feature extraction, and the other part is responsible for gray feature extraction.
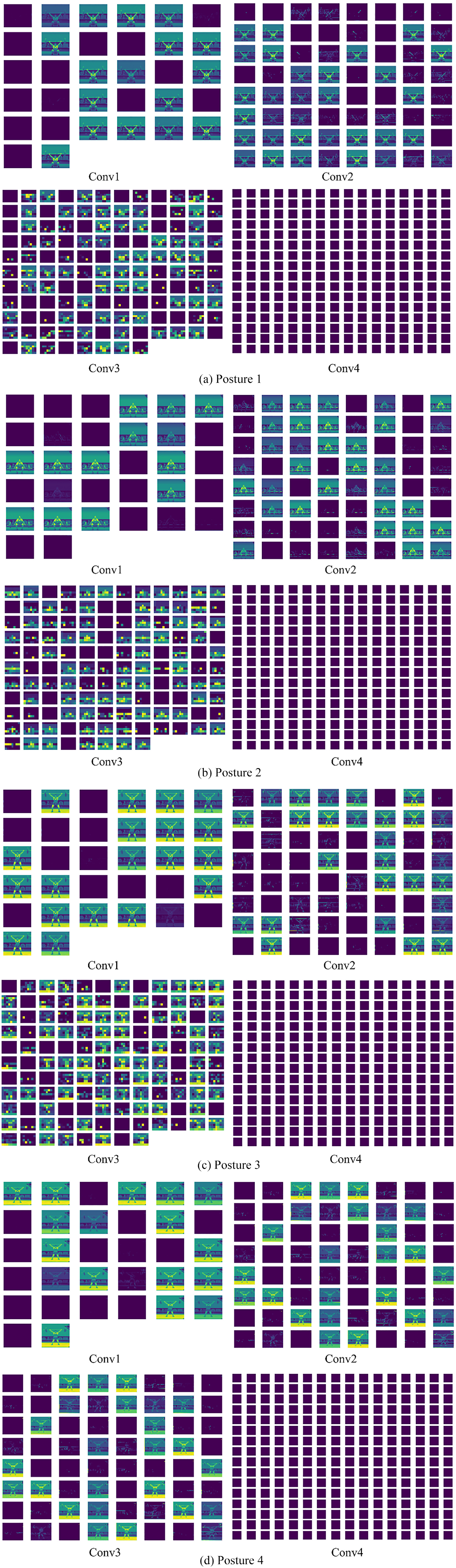
Visualizations of four convolutional layers in F-CNNs.
Posture recognition
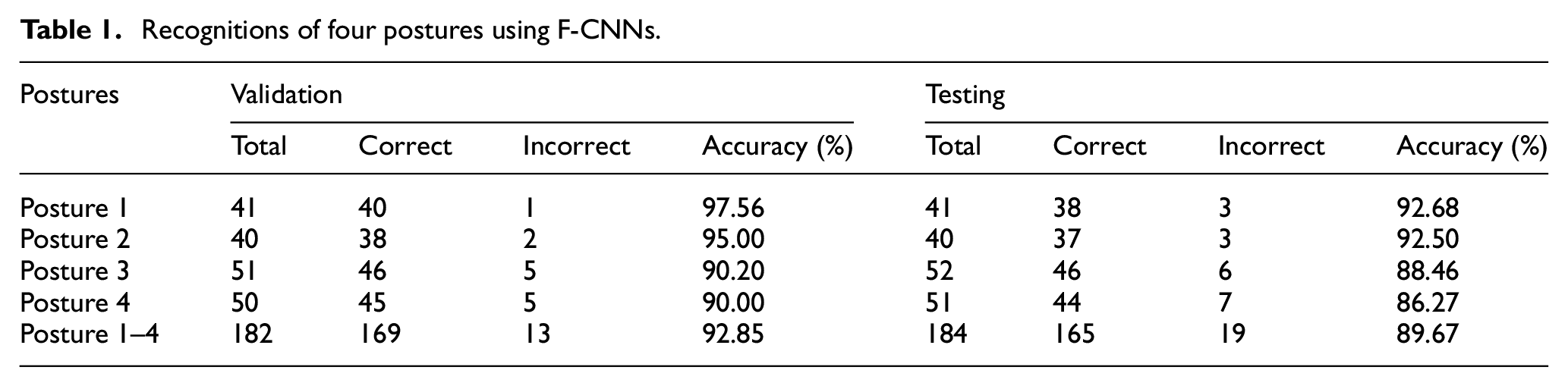
This experiment used 182 images (validation set) to verify F-CNNs, and then used 184 images (testing set) to test the performance of F-CNNs. In the testing set, 41 images are Posture 1, and 40 images are Posture 2, and 52 images are Posture 3, and 51 images are Posture 4. The validation and testing results are given Table 1, showing that validation accuracy and testing accuracy are 92.85%, 89.67%, respectively. Through comparing with Posture 1 and Posture 2, it can be seen that the validation and testing accuracy of Posture 3 and Posture 4 are relatively low due to they have great similarity. (Please see Figure 2).
Recognitions of four postures using F-CNNs.
Performance comparisons
Table 2 unveils the accuracy recognizing the four postures using F-CNNs and competitive methods, indicating that F-CNNs defeats the four competitors in recognizing the four postures. Indeed, compared with convolutional neural networks, recurrent neural networks are not good at classify images, therefore, RNN-M obtains a relative low accuracy.
Performance of different methods.

Execution efficiency
We compared the training time and testing time of the five algorithms, illustrated in Table 3. We find that F-CNNs does not show significant ascendency in training time, nevertheless, the training efficiency of F-CNNs is superior to that of both F-SGC and GC-lstm. The training time of neural networks is related to network structures and the number of hyper parameters. The network architectures implemented by F-SGC and GC-lstm are more complex than that of F-CNNs, so that they spend more cost on training network parameters than F-CNNs. Additionally, F-CNNs carried out an operation of calculating two stage posture score during training, which is also main consumption of training time. Therefore, the efficiency of G-CNNs and RNN-M defeat that of F-CNNs. While for testing time, there is not much difference between these five algorithms. Consequently, we find that the difference in efficiency between models is mainly reflected in the training time. Although the testing time has an effect, but it is not a critical factor affecting the efficiency.
Efficiency of algorithms. The five algorithms were trained on the training set until they converge, and then they were tested on the testing set.

The computational complexity of these methos based on neural network architectures depends on the number of hidden layers for training and the scale of image sets. Generally, to learn more meaningful features, more hidden layers might be considered, so the computational complexity increases along with the scale of hidden layers. In terms of our method, the time complexity relies on the number of hidden layers and the scale of image sets.
Some observations can be obtained from Figure 6 and Tables 1 to 3.
(1) The two-stage evaluated mechanism effectively recognizes the four critical postures. The calculation scores created by the two-stage evaluated mechanism can assist the model to improve classification accuracy.
(2) The training time of the model does not increase exponentially, that is, linearly with the increase of data volume, since the two-stage evaluated mechanism does not spend too consumption. Consequently, the model can be suitable for large-scale image datasets.
(3) Although complex network structures can improve the learning ability of a model itself, we used the two-stage mechanism instead of the design of complex network architectures, so that the time consumption during training can be reduced.
Discussions
Advantages
Our method defeats the four competitors because of adopting the two-stage evaluated mechanism. The details are as follows.
The proposed two-stage evaluation mechanism is used to recognize the four critical postures, that is, force releasing, knee flexion, knee extension and highest point. And the scores of the features for the four critical postures are calculated by the two-stage evaluation mechanism. Using the scores to evaluate postures is more accuracy than directly using features to classify postures. Indeed, from the perspective of network structure, our method or the four competitive methods adopted the structure of convolutional neural networks, moreover, the network structures used by the four competitors have more complex than our network structures. However, we introduced the two-stage evaluation mechanism instead of the design of complex network architectures. Consequently, this is also unique advantages of our method.
Limitations
Although our method wins over these competitive methods, however, our method has relative low accuracy in the identified ability for Posture 3 and Posture 4, since the scores are relatively close in the second stage evaluation when there is great similarity between Posture 3 and Posture 4. Not only is our method like this, but the competitive methods also encounter this embarrassment. In additional, the two-stage evaluation mechanism increases the training time of our model, so the training time might increase linearly on large-scale datasets.
Insights
The principle of image recognition relies on the extracted features from images. The recognition accuracy not only depends on the method itself, but also on an image quality. For example, noise interference, image distortion, etc., these negative effects can reduce the recognition accuracy of the methods. Convolutional neural network methods, as a mainstream image recognition method, aims to extract features from images, and then classify or recognize images based on the extracted features. Hence, feature extraction is the most important sector, since this means how to extract features that can distinguish images to the greatest extent possible. Due to the local perception characteristics of convolution operations, Convolutional neural networks are relatively sensitive to changes in position and scale in images. This may require additional processing and special design of the model for objects at different positions and scales to improve the robustness and generalization ability of the model.
Conclusion
This paper proposed convolutional neural networks fusing with a two-stage evaluation mechanism to recognize four critical postures of a weightlifter. The principle is that we designed convolutional neural networks with four convolutional layers to classify images, and to extract the feature regions of images. Then, the two-stage evaluation mechanism is used to calculate the scores of feature regions, based on the calculated scores, the different postures can be accurately recognized. Experimental results show our method defeats the competitors in critical posture recognition. The training time of our method does not increase exponentially, that is, the training time linearly augments along with the increasing of data volume. Consequently, we indicated that our method can be effectively applied to large-scale image datasets. In addition, the two-stage evaluated mechanism is independently of specific scenarios. In future work, we will explore the posture recognition under noise interference. Noise hidden in images may mislead convolutional neural networks, so as to weaken the classification ability of convolutional neural networks.
Footnotes
Contributions
Quantao He and Wenquan Tang proposed the methodology. Quantao He wrote the manuscript. Wenjuan Li and Baoguan Xu implemented the source code, designed the experiments and analyzed experimental results.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by The second batch of industry-university cooperative education project of the Higher Education Department of the Ministry of Education in 2021, “Virtual Simulation Teaching Reform and Exploration of Physical Education Based on VR/AR/MR Technology ”(202102509004), and the Research on AI+ Online Open Course Learning Support Service Innovation, General topic of Online Open Course in Universities of Guangdong Province (2022ZXKC401), and 2022 Shenzhen Stability Support Program Project “Development and Research of AI Intelligent Sports Training System” (20220811094439002), and “Research on the Exercise Control of Physical Education Teaching by Modern Technology,” the Mentoring Project of Shenzhen University.
Ethical approval
This manuscript does not contain any studies with human participants or animals performed by any of the authors.
Data availability
Data will be made available on request.