
Abstract
As a generalized input-output model, the state-dependent exogenous variable autoregressive (SD-ARX) model has been intensively utilized to model complex nonlinear systems. Considering that more freedom can be provided by the state feedback control with variable feedback gain for constructing robust controllers, we propose a robust model predictive control (RMPC) algorithm with variable feedback gain on the basis of the SD-ARX model. First, the polytopic state space models (SSMs) of the system are constructed and the prediction accuracy of the SSMs is further improved by using the parameter variation rate information of the SD-ARX model. Then, an RMPC algorithm with variable feedback gain is synthesized for increasing the design freedom and enhancing the control performance. Two simulation examples, that is, the modeling and control of a continuous stirred tank reactor (CSTR) and a water tank system, are provided to demonstrate the feasibility and effectiveness of the proposed RMPC algorithm.
Keywords
Introduction
Nonlinear systems with physical constraints can be controlled by a model-based control technique called model predictive control (MPC), which has been attracting widespread attention from both the academic sphere and the industrial domain, respectively. 1 For the MPC, accurate system model is very important, because usually this kind of algorithm needs to solve an optimal control problem based on model prediction at each sampling interval. However, in actual industrial systems, it is difficult to obtain accurate explicit models due to various uncertainties. 2 So far, dealing with systemic uncertainties such as modeling errors and external disturbances is one of the main topics in MPC research. 3
Since the dynamics of nonlinear and/or uncertain systems can be conveniently wrapped by the models in the polytopic form, the polytopic model has attracted much attention. 4 Moreover, based on this type of model, robust model predictive control (RMPC) algorithms for the system with disturbances and/or uncertainties can also be conveniently constructed to achieve a reasonable performance. For a system with uncertain parameters, Kothare et al. 5 proposed a linear matrix inequality (LMI)-based RMPC algorithm for state feedback control optimization of the controller. For input-constrained linear parameter varying (LPV) systems, Lee et al. 6 proposed an RMPC algorithm based on novel sufficient conditions for the cost monotonicity. Lu and Arkun 7 proposed two quasi-min-max MPCs for polytopic linear parameter varying (PLPV) systems. For the input-constrained LPV system with unknown but bounded disturbances, He et al. 8 proposed an input-to-state stable RMPC algorithm. For the constrained PLPV systems with bounded disturbances, Casavola et al. 9 used a novel RMPC for addressing feedback regulation problems. Li et al. 10 proposed a new RMPC algorithm with constrained feedback for uncertain systems. Polytopic form model-based RMPCs have produced effective results,5–9 but the majority of the research has aimed to deal with the problems of system’s state or output tracking by assuming the given or accurately measurable steady states of a system. 11 Nevertheless, the steady states of most systems remain unknown or beyond quantification in practicality, owing to extraneous disturbances or inescapable approximative disparities. 12
To solve these problems, attention has been focused on system state estimator-based RMPC synthesis schemes. 13 For polytopic systems, Ding et al. 13 proposed a novel feedback RMPC with a state estimator-based synthesis scheme. For LPV systems, Park et al. 12 proposed a quasi-min–max RMPC algorithm. Song et al. 14 proposed a distributed RMPC with output feedback. For uncertain systems, Hu and Ding 15 proposed a dynamic output feedback RMPC. However, employing observers for the purpose of estimating the states may introduce additional complexity, and when the constraints of the variables such as the state, input, and output are activated, the closed-loop performance may be greatly degraded in terms of input disturbance rejection.11,16
It is important to directly construct an output feedback RMPC with an input-output type model, since modeling an actual system with an input-output equation is generally easier. 16 As a generalized input-output model, the state-dependent exogenous variable autoregressive (SD-ARX) model is intensively applied in complex nonlinear system modeling,17,18 and it belongs to a quasi-LPV model and its state-dependent coefficients and flexible model structure can be convenient for the design of subsequent robust controller.19,20 By approximating the functional coefficients in an SD-ARX model with radial basis function (RBF) neural networks, the RBF-ARX model can be obtained.21–23 The SD-ARX model-based RMPC for systems without disturbance was first studied in the work of Peng et al. 24 Based on this type of model, an RMPC with unknown steady-state information was proposed in Zhou et al. 25 To decrease the conservativeness of the LPV models in studies such as Peng et al, 24 Zhou et al. 25 Zhou et al. 26 proposed an RMPC synthesis method using the model’s parameter boundary information, and based on this model, they 27 further proposed a one-stage scheduling RMPC. So far, many meaningful researches of SD-ARX model-based RMPC have been reported,24–27 whereas the research has mainly focused on studying single-constant feedback RMPC algorithms. According to the research results in Lu et al., 2 Li et al., 10 the improvement of the performance and the enlargement of the feasible region with more freedom of the RMPC can be achieved if variable feedback gains are used, compared with the case of using constant single feedback gains.
Considering that more freedom can be provided by the state feedback control with variable feedback gain for constructing robust controllers, in this paper, we propose a SD-ARX model-based RMPC with variable feedback gain for nonlinear systems. The information of parameter variation rate in the process of constructing the system’s state space models is further explored to both decrease the conservatism and increase the predication accuracy. In this paper, the RMPC algorithm has been designed without using the steady-state information of the system, which differs from those with given by5–9 or calculated with steady-state information.12–14 The rest of the work is constructed as follows: the construction process of an identified SD-ARX model-based polytopic state space model (SSM) is presented in Section II, the design of the RMPC with variable feedback gain is introduced in Section III, the numerical example is illustrated in Section IV. Finally, the conclusions are described in Section V.
Design of polytopic state space models
Considering that the nonlinearity of many practical problems depends on one or more system variables,17,18 the SD-ARX model 19 can be used to present the dynamics of the system. By approximating the functional coefficients with RBF networks, the following RBF-ARX model can be obtained 28 :
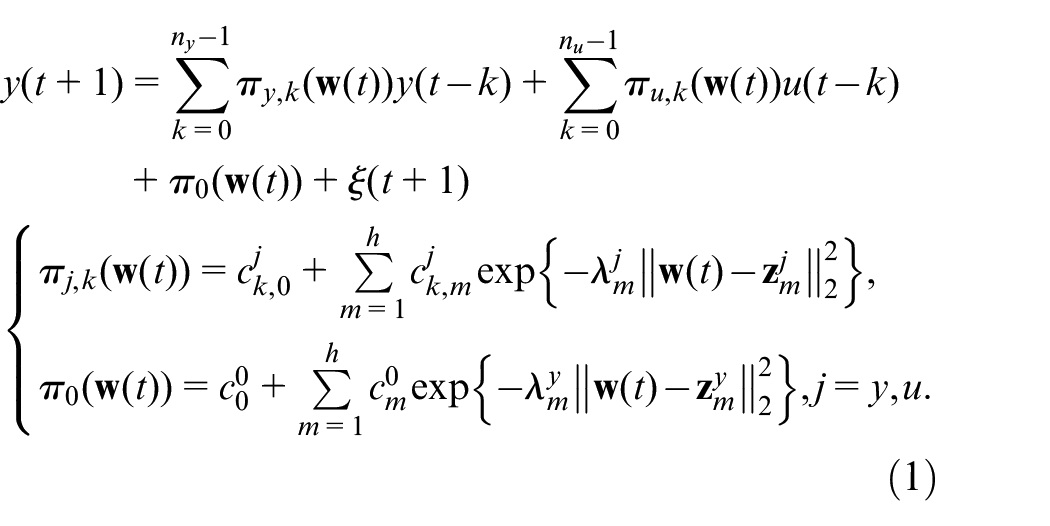
where
If the bounded external disturbance of the system is considered, then the following more general system model can be obtained:
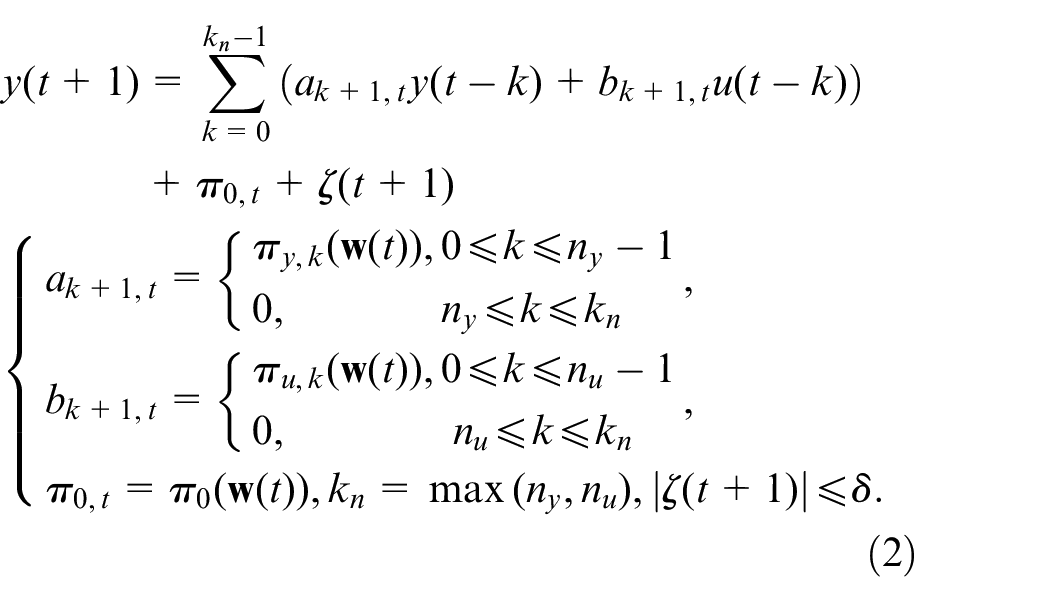
where
To obtain the polytopic model of the system, we first define the input and output increments as follows:
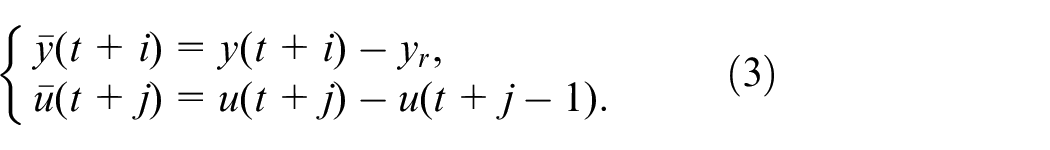
where
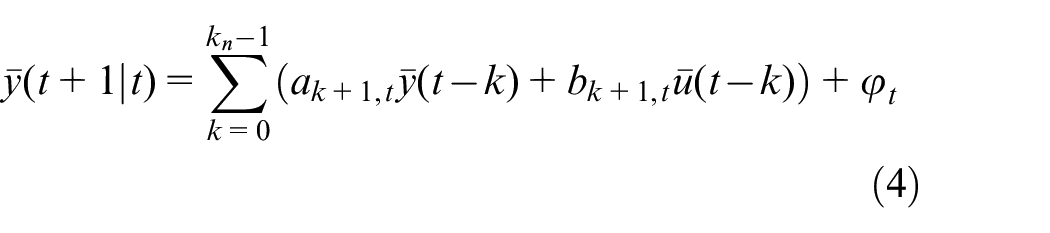
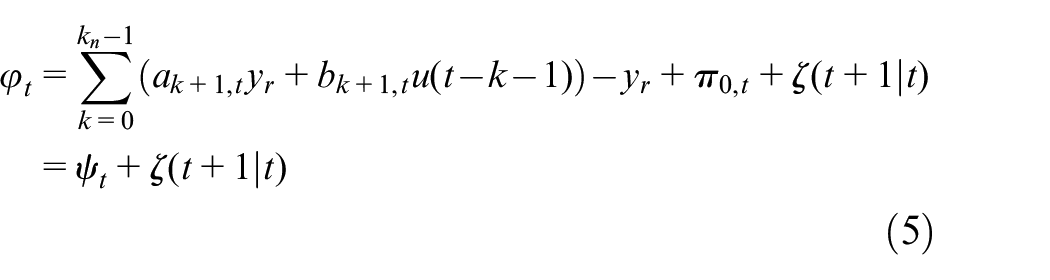
where
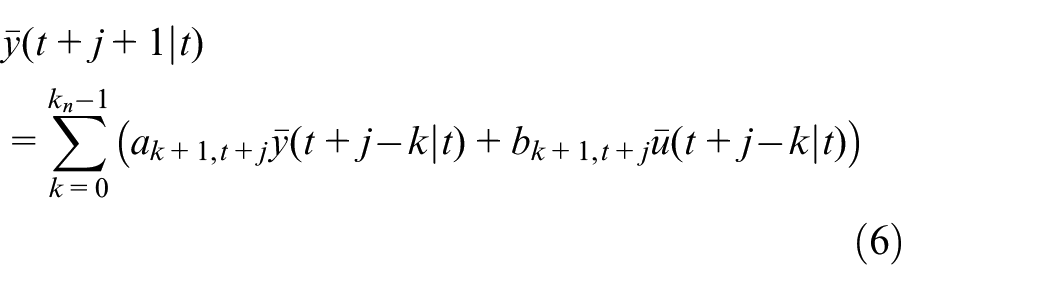
where
To establish the state space model of the system, first, the state vector of the system is defined as follows:
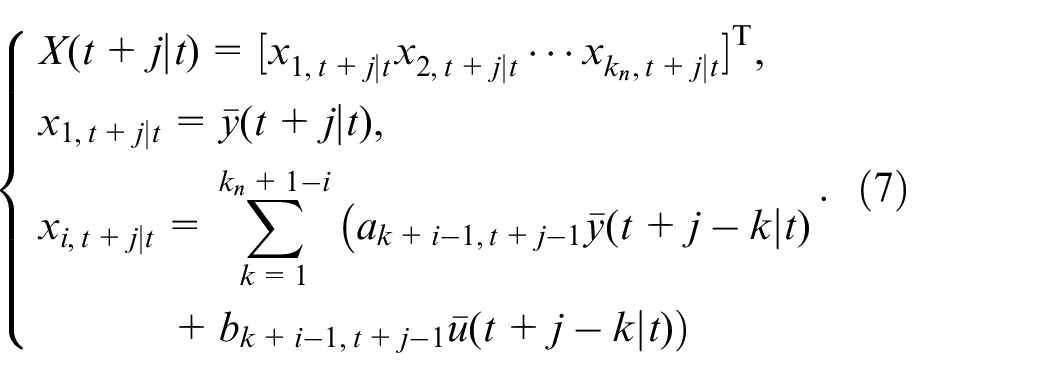
where
Thus, the state space models corresponding to the polynomial models (4) and (6) can be obtained as follows:
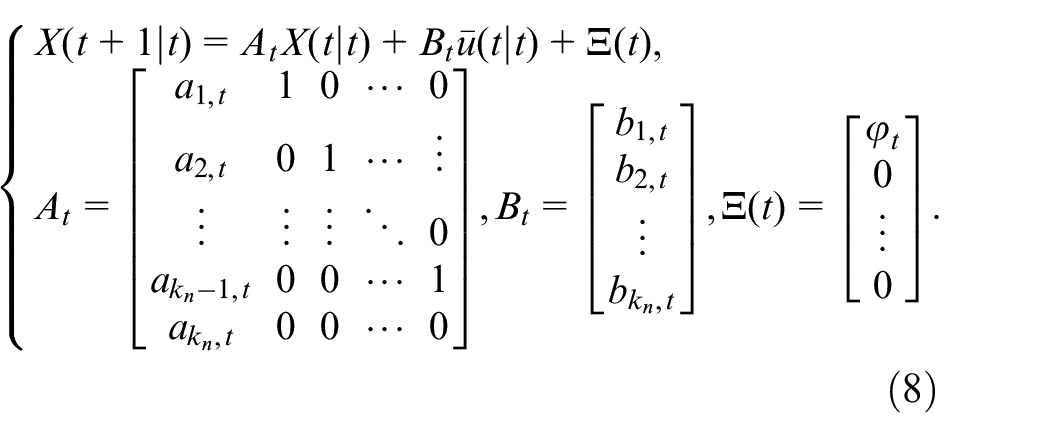
and
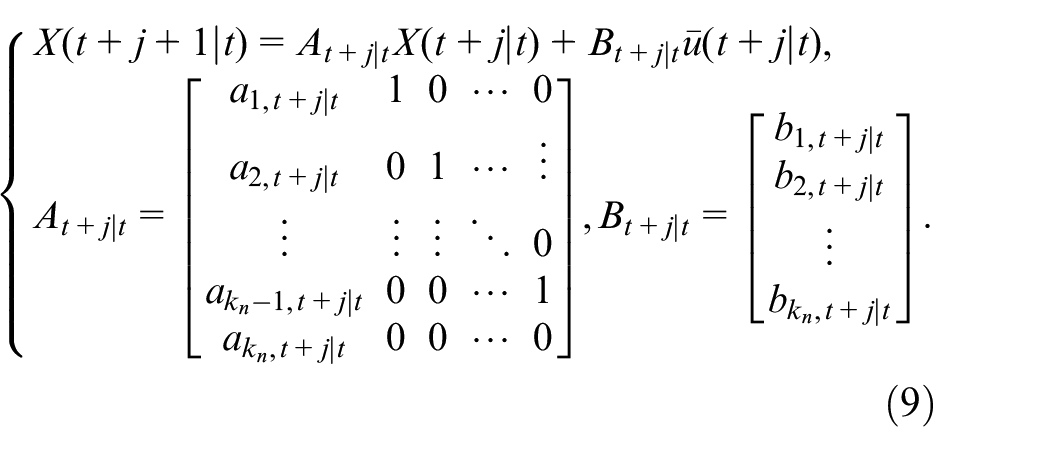
Based on model (1) and state vector
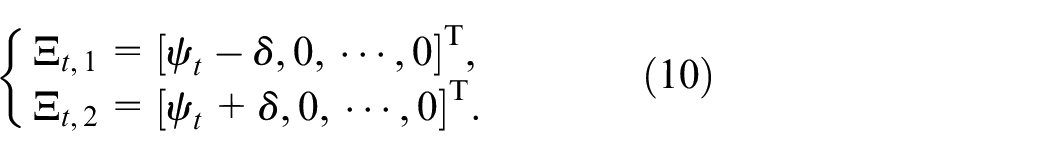
Remark 1:
First, based on the current state matrix set
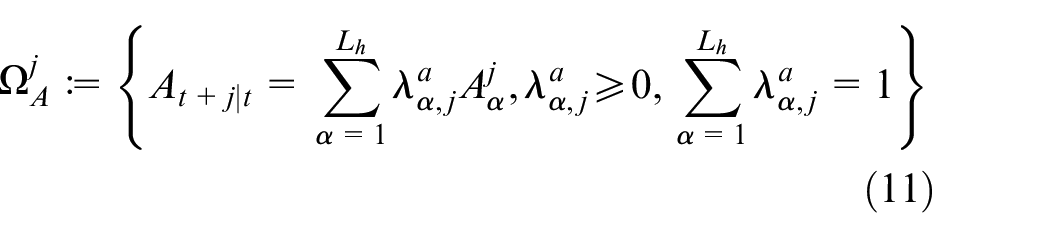
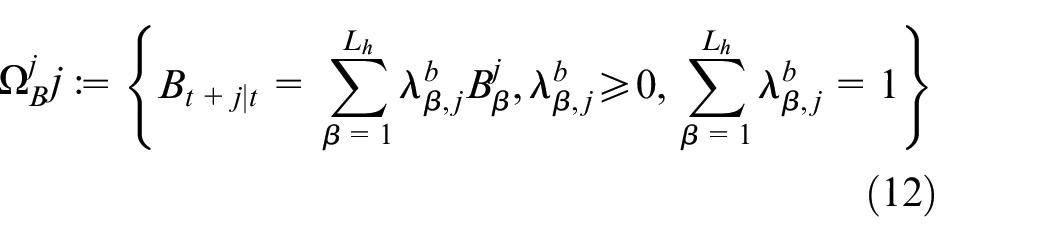
where
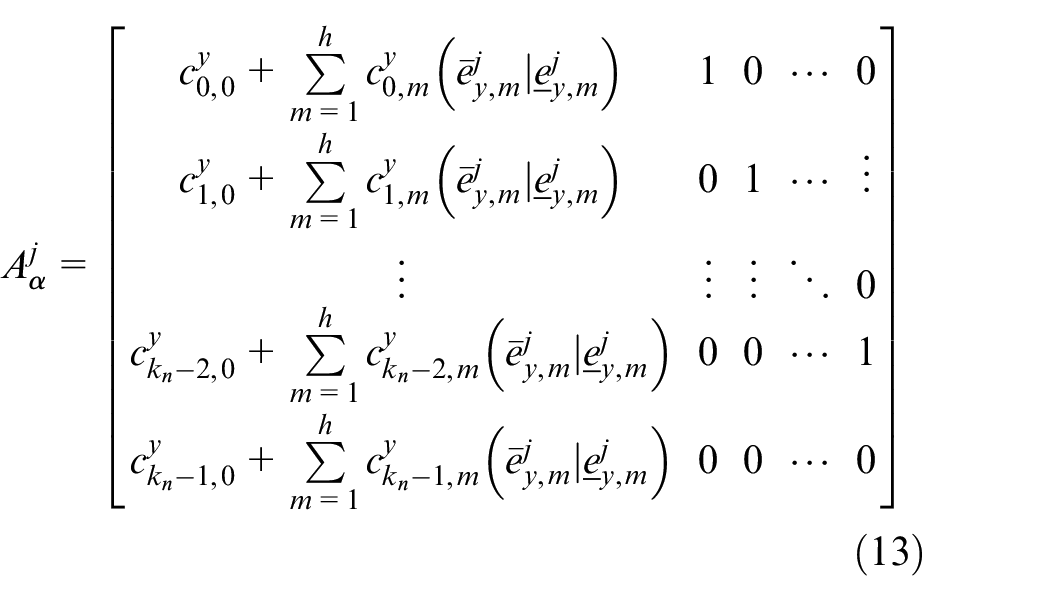
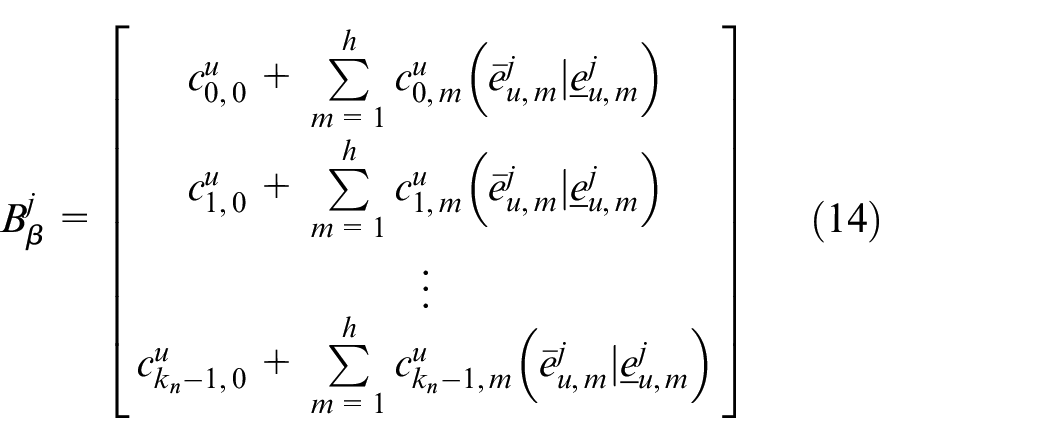
where
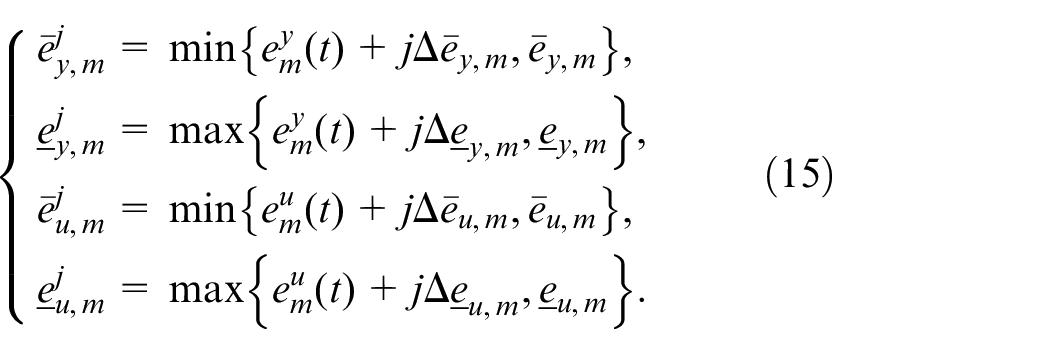
where
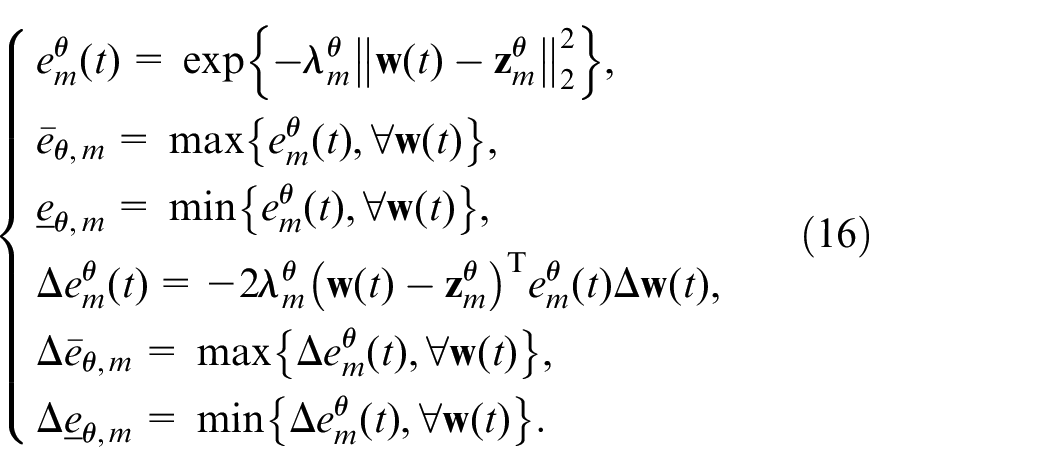
where
Remark 2: Using the information of the parameter variation rates and the boundaries of model (1), the variation ranges
Next, to facilitate the robust controller design, the convex polytopic set, which wraps the range of set
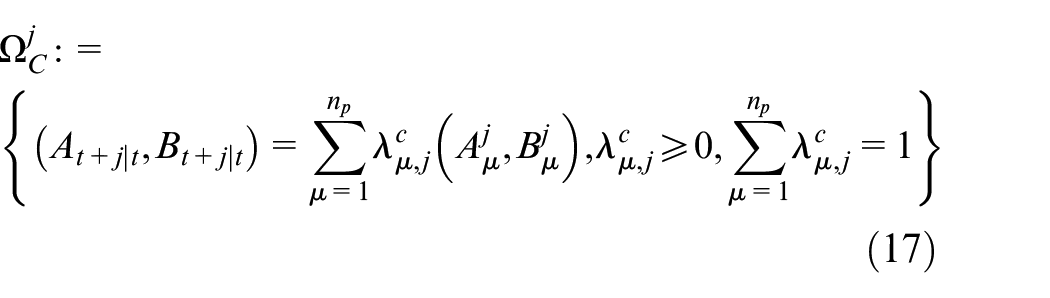
where
Remark 3: The limitation of our method is that it consumes relatively large online computation resources, especially with high model order
Overall, one can get the convex polytopic set
Synthesis method of the robust MPC with variable feedback gain
In this section, an output tracking RMPC with variable feedback gain are designed based on the SSMs of the system which is established in the previous section. First, the following cost function is utilized in the RMPC synthesis:
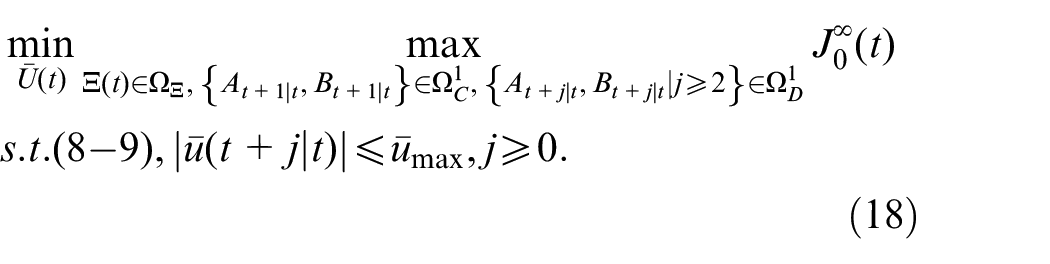
where
Then, by dividing function (18) into two parts, one can obtain:

where
In this paper, the control strategy for the RMPC algorithm with variable feedback gain is designed as follows:
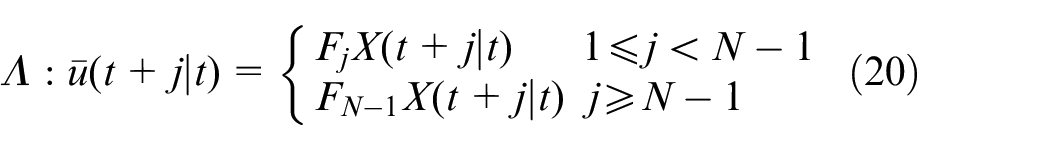
where
Next, the Lyapunov function of the robust controller is designed as follows:

where
From the selected Lyapunov function
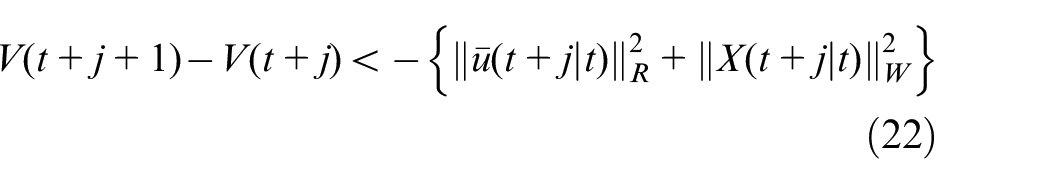
Add inequality (22) from
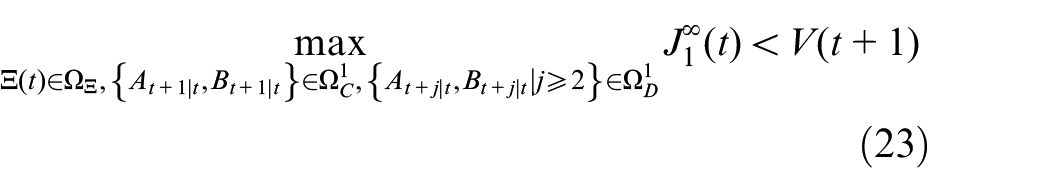
Therefore, the optimization problem (18) can be rewritten as follows:
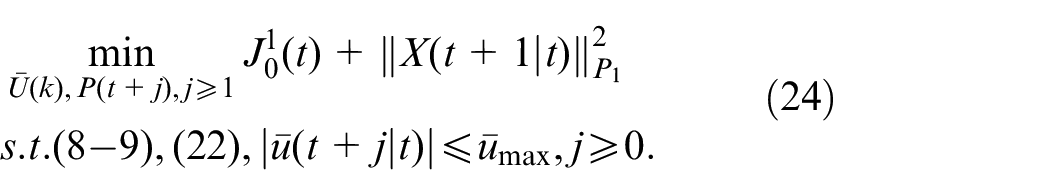
Thus, as shown in Theorem 1, the optimization problem (18) can be converted into a linear programing problem (LPP) for solution.
Theorem 1: The optimizing problem (18) with the control strategy as in (20) is identical with the following LMI constrained convex optimization problem:
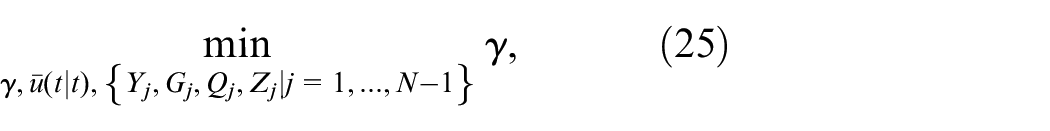
subject to
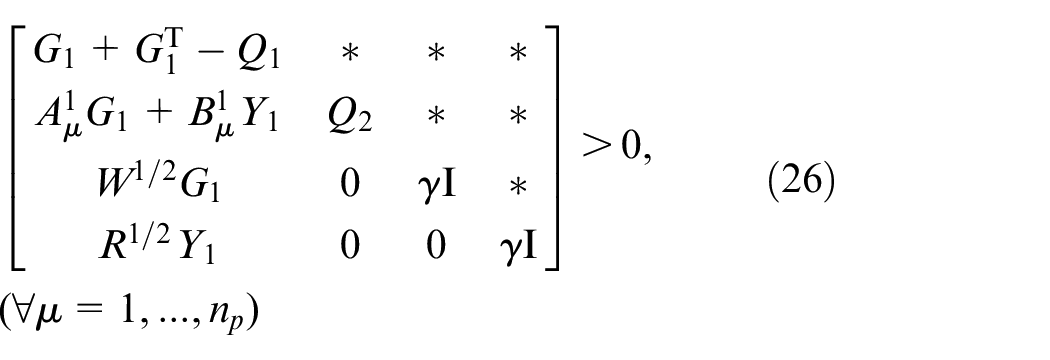
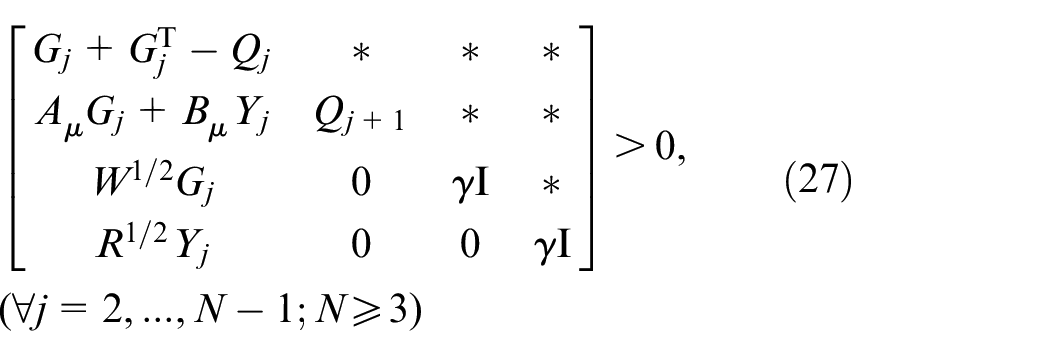
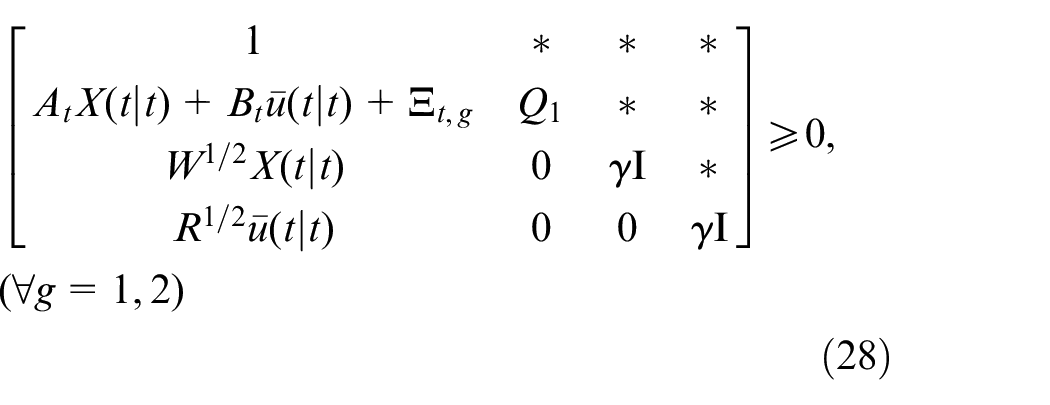

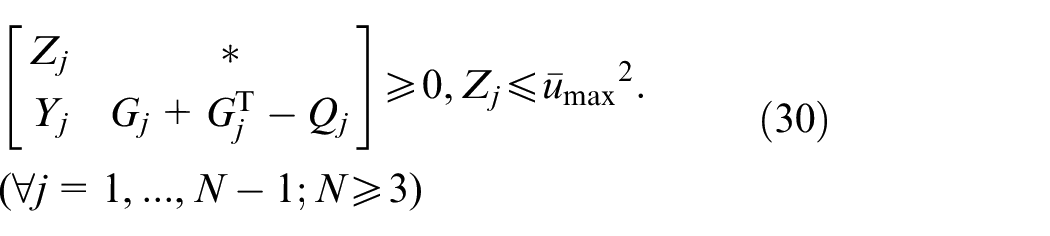
where
Proof of Theorem 1: Substitute (20–21) and model (9) into (22), and one can obtain:
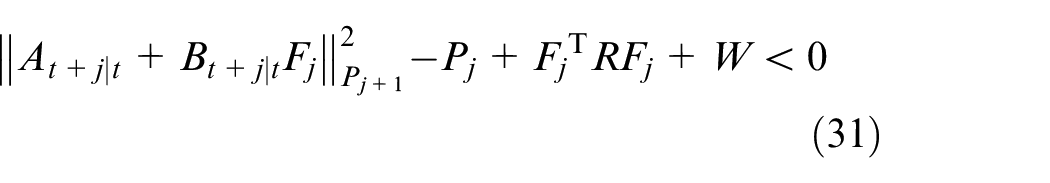
Considering that
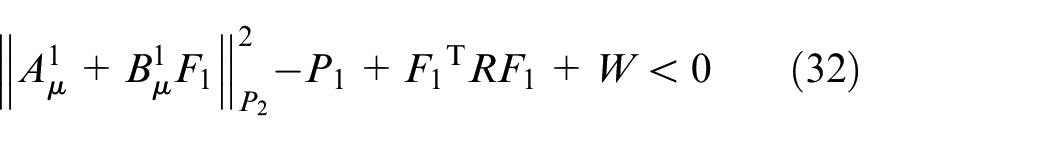
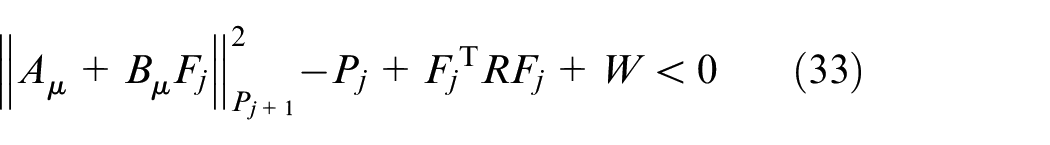
In (32–33),
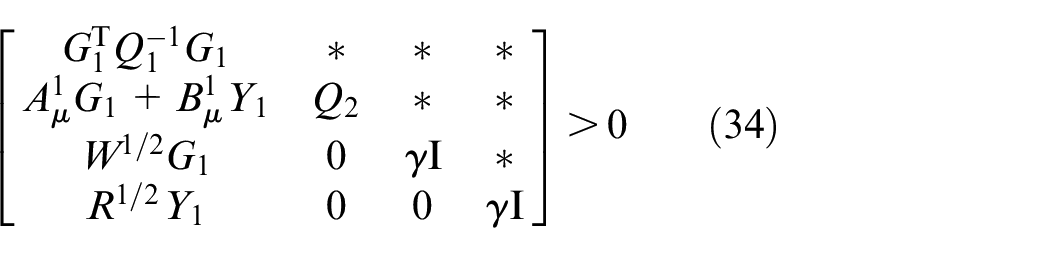
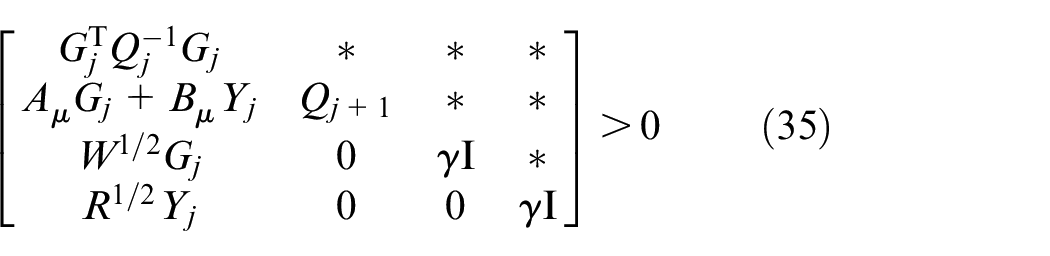
Following Zhou et al.,
25
one can obtain
Thus, we can convert the form of the minimization problem (24) into the following form:
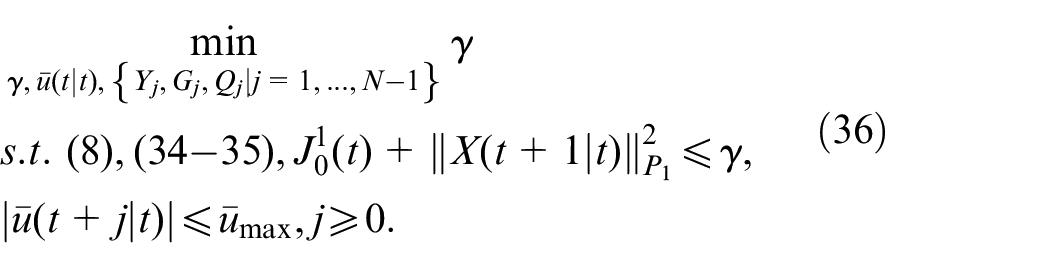
Considering that the vector
Moreover, referring to Zhou et al., 25 one can convert the input and input increment constraints imposed in (36) into the LMIs (29–30).
In the end, the min-max optimization problem shown in (18) is transformed into the minimization problem
The computation process of the proposed RMPC algorithm is summarized as follows.
Step 1: SD-ARX model (1) is used to model the nonlinear system, and the regularized-SNPOM is used to optimize the parameters of the model (1).
Step 2: Initialize controller parameters
Step 3: At sampling time
Step 4: Based on the identified model (1) and the historical state vectors obtained from the global identification data, calculate vertices
Step 5: Solve the optimization problem (25) to get the input increment
Step 6: Calculate control law
Theorem 2: When the robust MPC synthesis method is implemented with a rolling-horizon strategy, the stability can be guaranteed by the feasibility of the LPP (25).
Proof of Theorem 2: For Models (8–9), because LPP (25) is feasible at time
Remark 4: Based on the uncertain SSMs (8–9) and Theorems 1 and 2, when there is a feasible solution for the LPP (25) at time t, one can achieve the output-tracking RMPC without steady-state offset to nonlinear system (2) because there is a
A numerical example
Case I – CSTR process
Considering that continuous stirred tank reactor (CSTR)
29
is very important in the core equipment for chemical production, a CSTR process is selected and utilized to verify the performance of the RMPC strategy. The selected CSTR process is an irreversible first-order exothermic reaction (
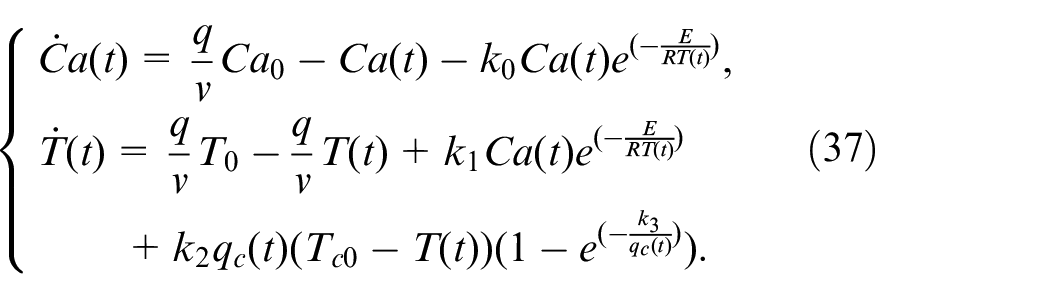
where
CSTR parameters in (37).

Polytopic SSM construction process
First, the basic model structure of the process can be selected as:
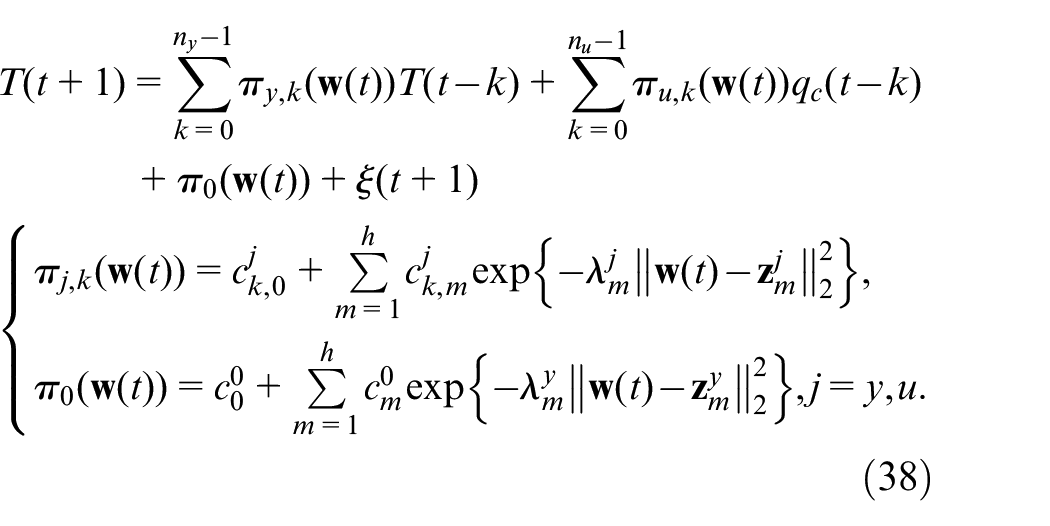
where the system input and the corresponding output are the coolant flow rate
In this paper, to get a set of globally varying input/output data, a set of sine signals and step signals are set to be the required outputs under the PID controller for the CSTR, which make the input and output of the system adequately vary within a large range, and a set of Gaussian white noise signal with small power is also added to the inputs in order to excite the systems’ various dynamic modes. The global identification data of the CSTR process with a sampling period of 0.05 min are shown in Figure 1. We use the first and the last 2500 data points for training and testing of the model, respectively. In the modeling process, the step response performance of the identified model is evaluated as the criterion for determining the model orders in (38) and the final selected model orders in (38) are
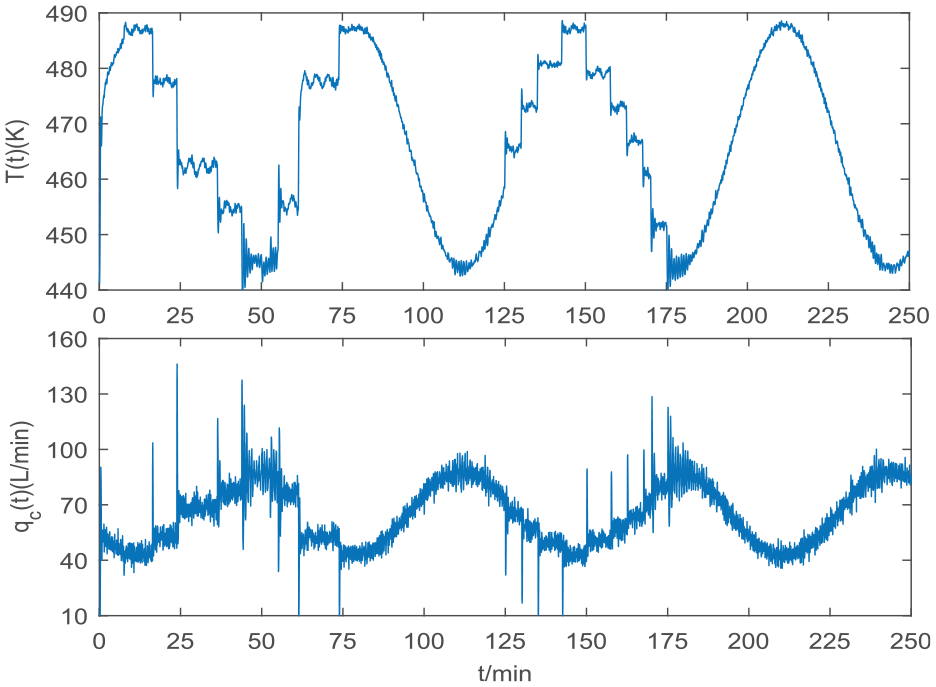
Global identification data of the process.
Based on the state vector defined in (7) and the global identification data of the process, the SSMs of the system can be achieved at each sampling instant. Their poles, varying with the variable
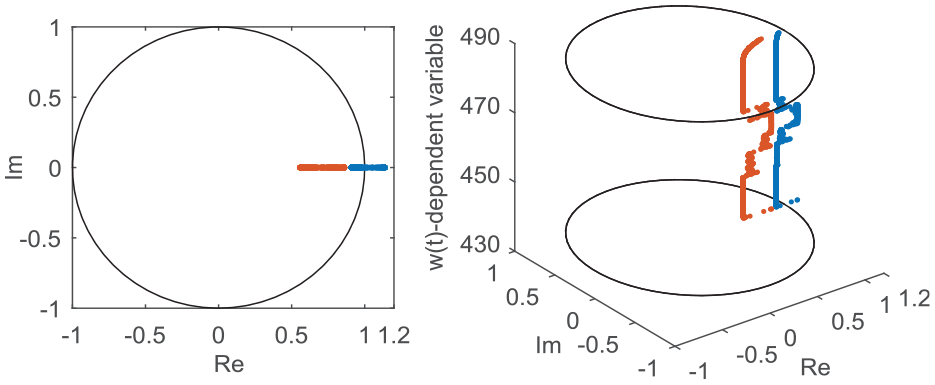
Poles of SSMs varying with
Control results and analysis of the RMPC algorithms
The numerical experiments are conducted under the MATLAB R2017b running on a computer equipped with an Intel Core i7-3770 CPU and 16 GB RAM. In this CSTR process, the constraints of the control variable
Figure 3 shows the control results of our RMPC for several predictive feedback horizons
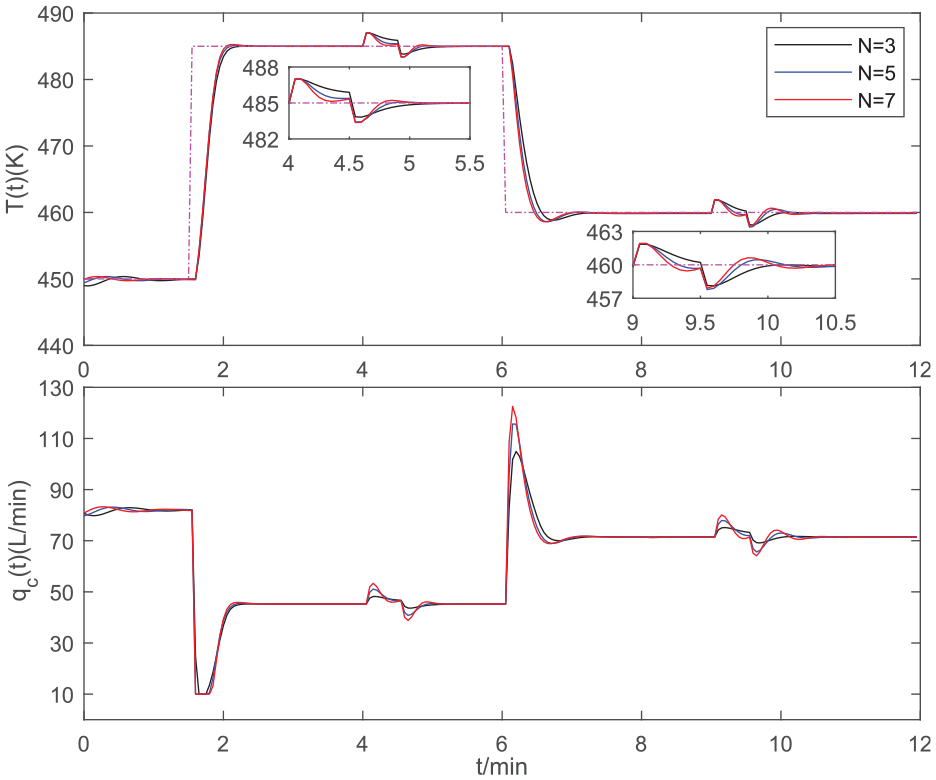
Control results of our RMPC for selected predictive horizons.
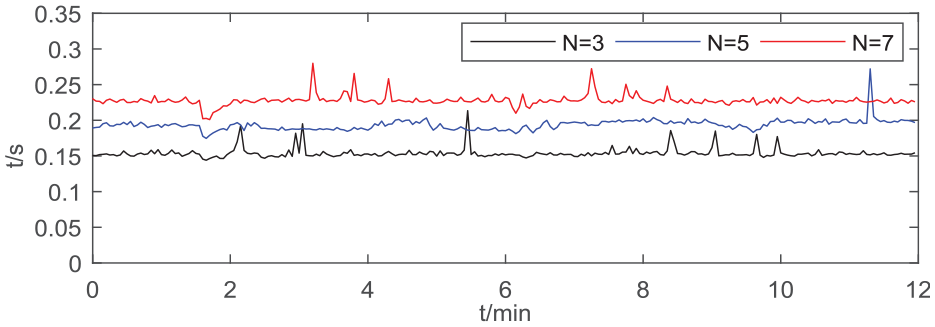
Online computational burden corresponding to the results in Figure 3.
From Figure 3, it can be seen that the control results of our RMPC are improved with the increase of the predictive feedback horizon
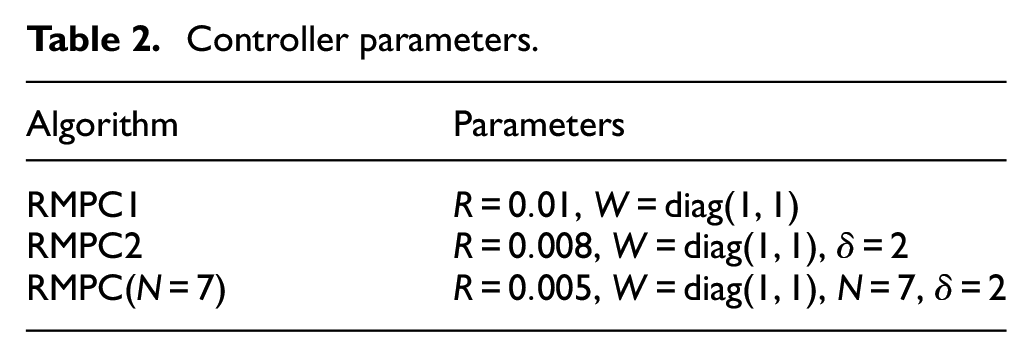
In this subsection, two RBF-ARX model-based RMPC algorithms suggested in Peng et al., 24 Zhou et al. 26 (named RMPC1 and RMPC2, respectively) are also performed for comparative research. To be fair, the same RBF-ARX model obtained previously is used in both RMPC algorithms. After a series of trials and errors, the well-adjusted parameters of the three RMPCs are presented in Table 2.
Controller parameters.
The control results of the 3 RMPCs are shown in Figure 5, and the corresponding online computational burden is shown in Figure 6.
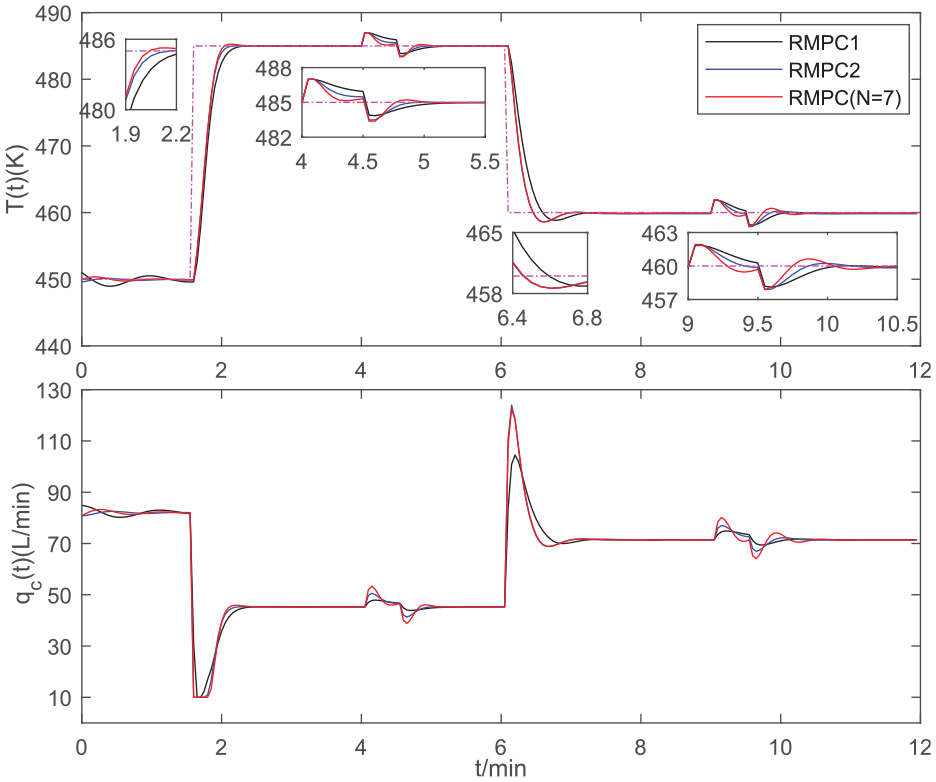
Control results of the three RMPCs for CSTR.
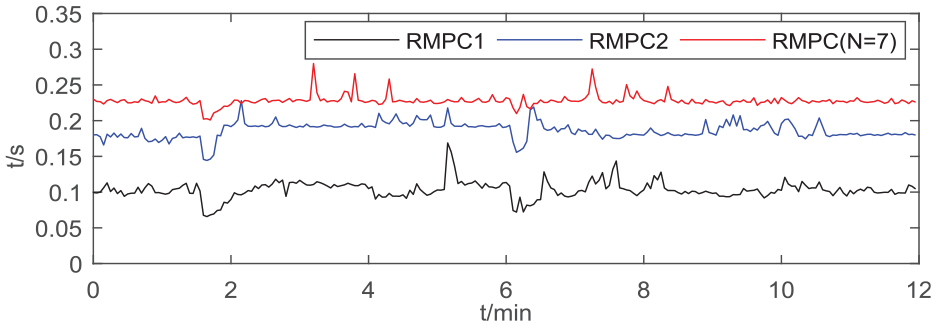
Online computational burden corresponding to the results in Figure 5.
From Figure 5, one can see that the control results of the RMPC1 are worse than those of the others. The control results of the RMPC2 and RMPC(N = 7) are not significantly different when the system has no external interference. However, when the system is interfered with by the square wave disturbance, the RMPC(N = 7) has a better anti-interference performance than the RMPC2. From Figure 6, it is also clearly that the RMPC(N = 7) shows a heavier online computing burden compared with the other two algorithms. However, its maximal value is still far smaller than that of the control system with a 0.05 min sampling period.
Case II – water tank system
Level control of the water tank system is often used in literatures30,31 for comparison study. The mass and energy balance equations for the water tank system are given in Zhou et al.
30
In this case study, the control problem is to control the level
The numerical experiments are conducted under the same software and hardware environment as in the previous subsection. The sampling period of the control system is 1.5 s. In this water tank system, the constraints of the control variable
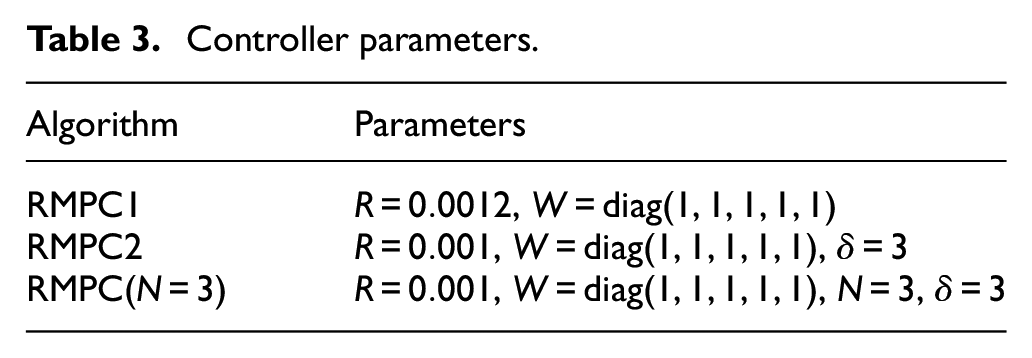
Controller parameters.
The control results of the three RMPCs for the water tank system are shown in Figure 7, and the corresponding online computational burden is shown in Figure 8.
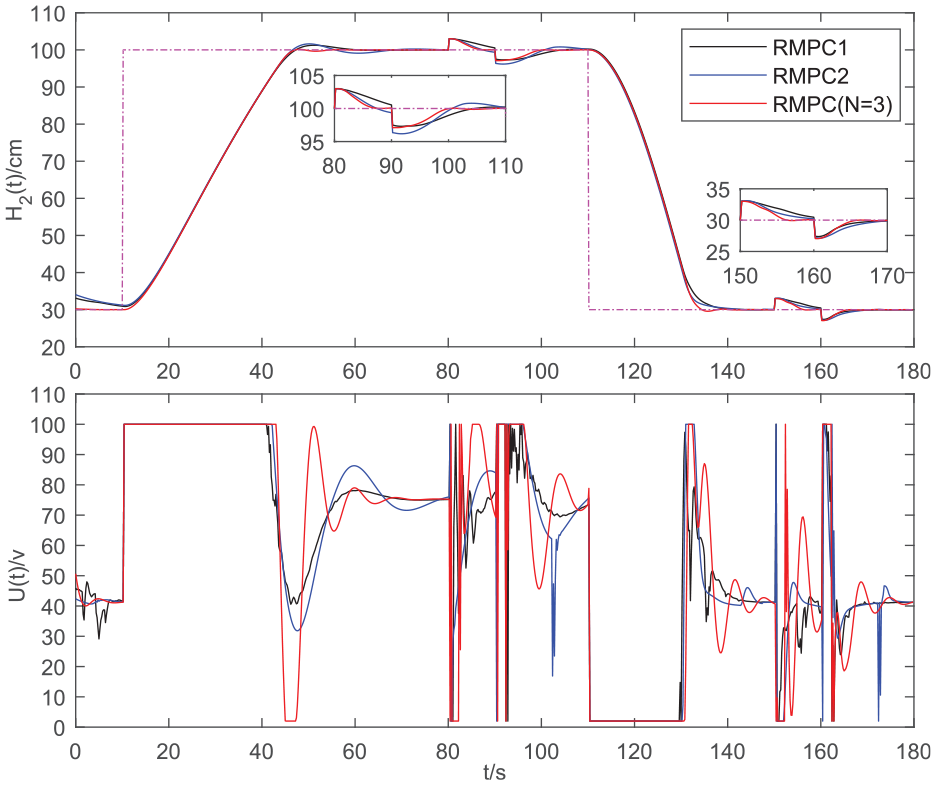
Control results of the three RMPCs for water tank system.
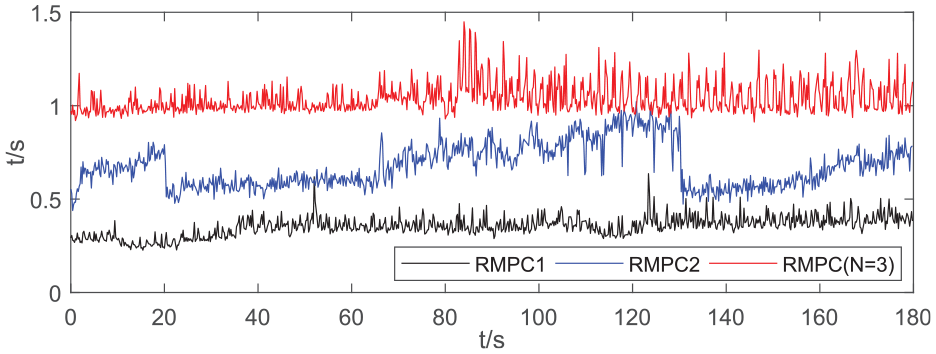
Online computational burden corresponding to the results in Figure 7.
From Figure 7, one can see that the control results of the RMPC(N = 3) are better than those of the others, especially in terms of the step response performance. From Figure 8, it is also clearly that the RMPC(N = 3) shows a heavier online computing burden compared with the others. However, its maximal value is still a little smaller than that of the system sampling period 1.5 s. It is worth noting that when
Conclusions
In this paper, a SD-ARX model-based RMPC algorithm with variable feedback gain for nonlinear systems were proposed. First, the construction process of the polytopic SSMs of the system was introduced. Then, the synthesis method of the proposed RMPC was designed. In general, the proposed approach has two advantages: by using the information of the variation rate of the SD-ARX model parameters, our scheme has the ability to shrink the variation regions of the state matrices in the system’s polytopic SSMs, and by using the control policy with variable feedback gain, it also presents the ability to enlarge the robust controller design freedom. The feasibility and effectiveness of the algorithm were verified by two numerical examples. However, the limitation of the RMPC is its relatively large computation burden, especially as the predictive feedback horizon
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (52377168, 61903049), the Education Department of Hunan Province, China (21B0776) and the Natural Science Foundation of Hunan Provincial, China (2020JJ5622).
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.