
Abstract
This paper studies the distributed convex optimization of bipartite containment control problem for a class of higher order nonlinear multi-agent systems with uncertain states. For the optimization problem, the penalty function is constructed by summing the local objective function of each agent and combining the penalty term formed by the adjacency matrix. For the unknown nonlinear function and unpredictable states in the system, this paper construct radial basis function Neural-networks and state observer for approaching, respectively. In order to avoid “explosion of complexity,” under the framework of Lyapunov function theory, we propose the dynamic surface control (DSC) technology and design the distributed adaptive backstepping neural network controller to ensure all the signals remain semi-global uniformly ultimately bounded in the closed-loop system and all agents can converge to the convex hull containing each boundary trajectory as well as its opposite trajectory different in sign. Simulation results confirm the feasibility of the proposed control method.
Keywords
Introduction
Over the recent decades, multi-agent systems (MASs) have been widely concerned by scholars in the field of control because of their importance in practical applications.1–5 Many control problems for multi-agent systems are presented. Such as neural network and disturbance observer are used to deal with the influence of the input dead zone and the external disturbance on multi-agent formation respectively. 6 Olfati-Saber present a theoretical framework for design and analysis of distributed flocking algorithms to deal with the multi-agent flocking problem. 7 Guo et al. propose a novel technique to control the relative motion of multiple mobile agents as they stabilize to a desired configuration. 8 Chen et al. propose four resilient state feedback based leader–follower tracking protocols. 9
Generally speaking, the control methods of multi-agent systems can be divided into two categories. One is decentralized control, the other is distributed control. With the decentralized control method, the follower can get the state of the leader.10,11 However, for distributed control, the follower cannot get the state of the leader and needs to exchange information through the communication topology.12,13 Generally, distributed control is more widely used and currently it is the main multi-agent control method. Ren et al. 12 study the finite-time positiveness and distributed control problem for a class of Lipschitz nonlinear multi-agent systems. Wang 14 propose a distributed consensus algorithm to deal with the leaderless consensus control problem for higher-order nonlinear MASs with completely unknown non-identical control directions. The leader-follower issue of MASs considering network transmission delay is solved by an observer-based distributed control triggered by adaptive event-triggered. 13 The switched stochastic nonlinear MASs control method is proposed. 15 Zou et al. 16 focus on the mean square practical leader-following consensus of nonlinear MASs with noises and unmodeled dynamics.
The bipartite containment problem of MASs will make agents converge to a convex hull, it’s not necessarily the optimal convergence route. Therefore, an optimal problem is introduced to create a distributed optimal controller, so that all agents converge to the optimal solution. In the existing bipartite containment control papers, the main focus is that the model and does not take into account output optimization. Through the study of Zhang et al., 17 the distributed bipartite containment control problem for high-order nonlinear MASs with time-varying powers is solved. A bipartite containment fuzzy controller for nonlinear MASs with unknown external interference and quantized inputs is designed by Li et al. 18 Wu et al. 19 proposed a fixed-time adaptive fuzzy quantization controller in order to ensure that the nonlinear MASs with unknown external disturbances and unknown Bouc–Wen hysteresis is controlled by bipartite containment. Similarly, controllers designed for distributed optimization problems in MASs do not take into account the bipartite containment problem. Kang et al. 20 proposed a backstepping controller for distributed optimization of high order nonlinear MASs with strict feedback. Guo et al. 21 solve the distributed optimization problem of MASs subjected to exogenous disturbances. Guo and Kang 22 by constructing a two-layer control framework, the optimal trajectory is obtained by adaptive control technology, and then MASs are tracked to the optimal trajectory by state integral feedback control (SIFC). Yu Zhiyong proposes some distributed methods to solve the MASs optimization problem with equality constraints. 23 Through the study of Wang et al., 24 the distributed convex optimization problem of multi-agent systems with nonlinear terms interfered by random noise is solved. The bipartite containment of fractional order system is analyzed and a controller with good control performance is proposed by Chen and Yuan. 25 The control analysis of consistency optimization problem is carried out by Yang et al. 26
In the actual model, there are many nonlinear uncertain functions, which will seriously affect the operation of the agent, so scholars use neural network(NN) and fuzzy logic systems to approximate unknown nonlinear functions.27–29 Guo et al. 30 use the command-filtered backstepping control method, approximates the unknown nonlinear function by NNs, so as to solve MASs bipartite containment control problem. An adaptive NNs output feedback controller is designed for MASs with time delays and unmodeled dynamics by Li et al. 31
Based on the aforementioned research, this paper proposes an adaptive backstepping neural network dynamic surface controller to solve the distributed optimization problem for MASs with unknown nonlinear functions and bipartite containment problem. Every agent in the MASs need to solve their local objective function optimally. Compared with the previous research work, the main contributions of the method in this paper are as follows.
In this paper, a controller is proposed for the optimization of MASs with bipartite containment control. A penalty function is designed to make each agent gradually approach the optimal solution of the global objective function while being contained in the convex hull. Unlike the study of Guo and Zhang, 32 where the controller was designed only for consensus control problem, but the bipartite containment problem in the control process is analyzed in this paper. Compared with the study of Zhang et al., 17 the optimization problem of minimizing the sum of squares of distance difference between the agent and the upper and lower bounds is considered when designing the controller.
Compared with the study of Liu et al., 33 this paper uses backstepping control method to extend the optimal bipartite containment control method to higher-order MASs, and solve the explosion of complexity problem caused by high order system by using filter.
Compared with the study of Liu et al., 34 this paper solves the problem of unmeasurable state of high order system by introducing observer, and approximates the nonlinear term of high order system by RBF neural network.
The rest of this paper is as follows. Section 2 introduces the theoretical knowledge of distributed optimization and the model of MASs. In section 3, an observer model is established to estimate the state variables of the system, and then the controller and the adaptive weight update law are designed according to the backstepping method. Section 4 proved the effectiveness of the controller by simulation. In section 5, the work of the full text is summarized.
Prerequisites
Graph theory
There is information interaction between multiple agents, and an undirected graph
Convex analysis
If a function
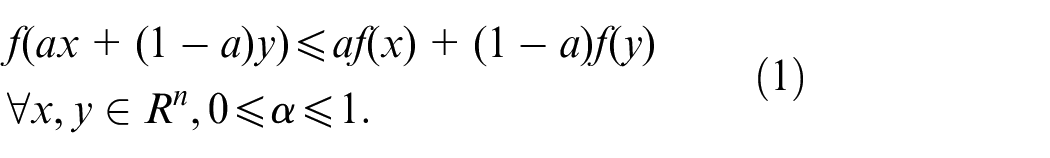
If a differentiable function
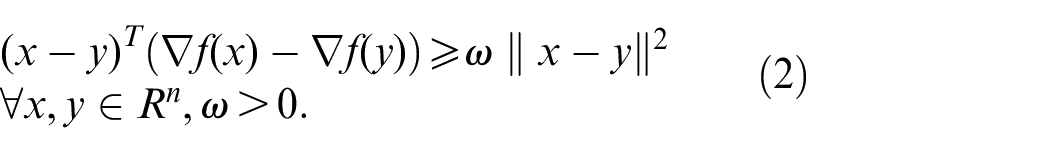
if a function
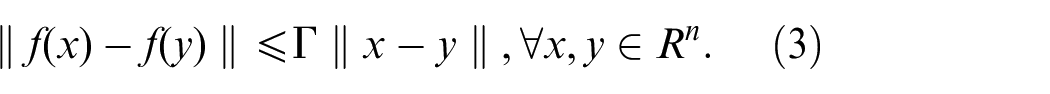
Problem formulation
In this paper, we study the following high-order nonlinear multi-agent systems for agent
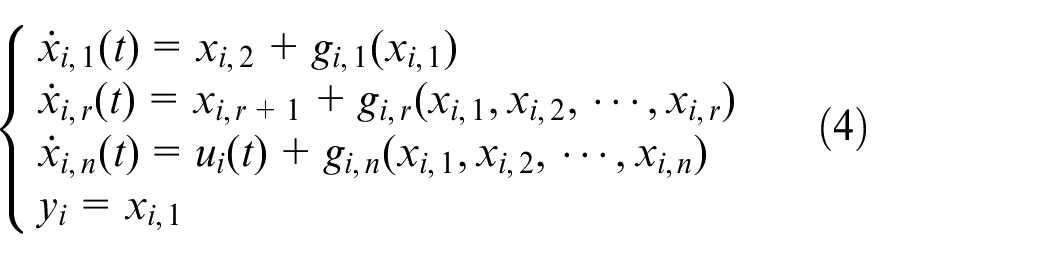
where
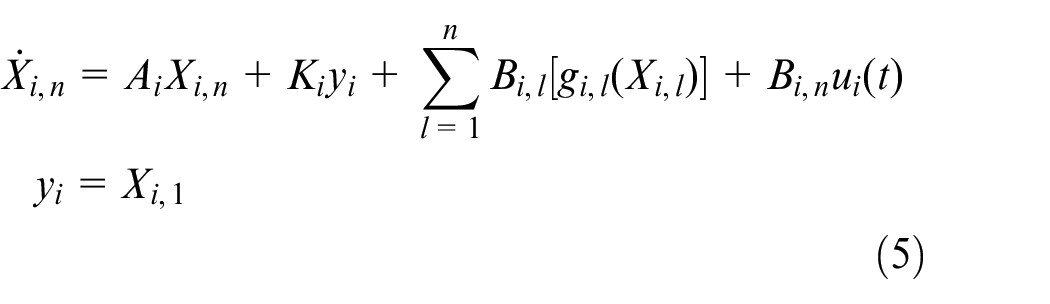
where

The distributed optimization problem
In this paper, we must not only solve the optimization problem of the global objective function, but also solve the optimization problem of the local objective function of agents
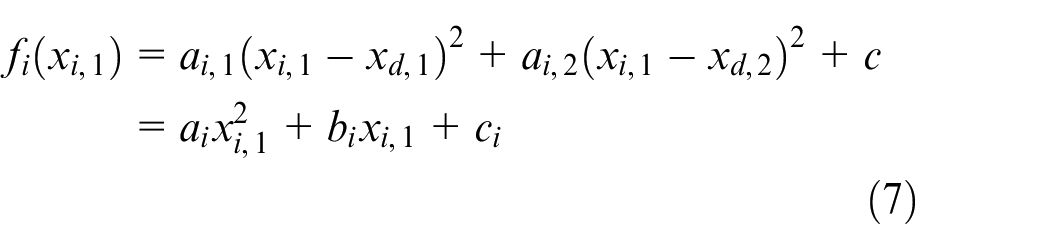
where

Because the local objective function is an absolute convex function, the global objective function is also a strictly convex function. Define
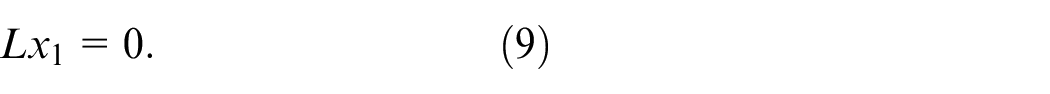
Therefore, we can design penalty term as follows
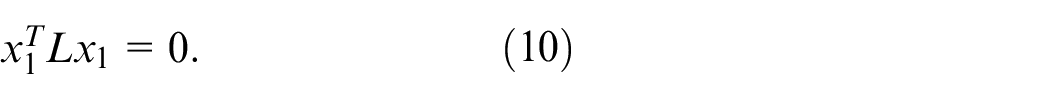
Penalty function is defined as follows 36
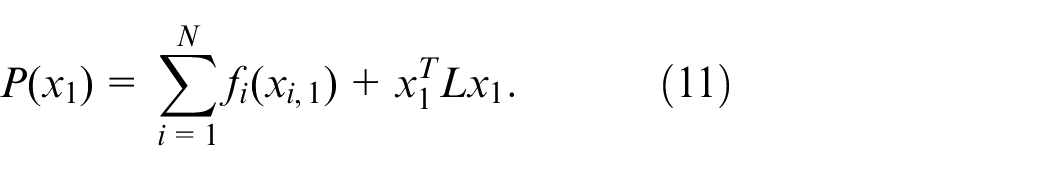
Because the global objective function is an absolute convex function, the penalty function is also a strictly convex function.
Let each multi-agent have its own local objective function, and finally make its objective function optimized. Thus obtaining the optimal trajectory
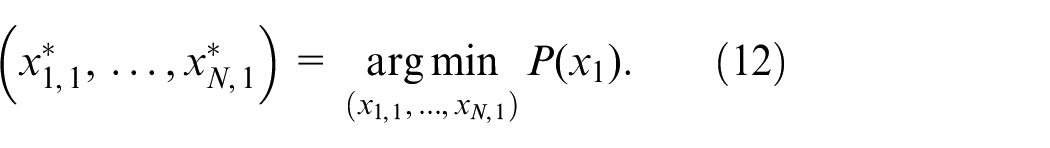
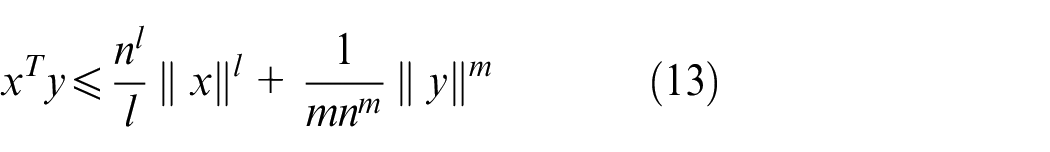
where

Control objectives: This paper aims to design an neural network controller
Main results
Observer design
The state variables of the system (4) in this article are agnostic, so we design an observer to estimate the system variables of Agent
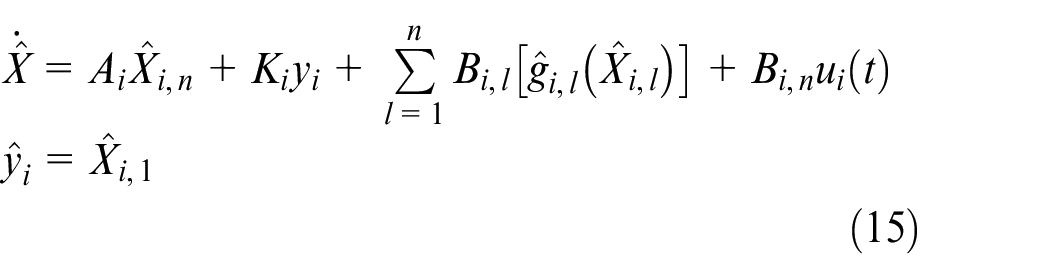
where
Since
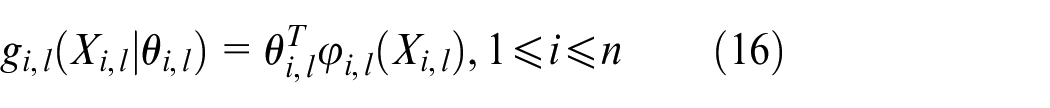
where
By Assumption 1, we can obtain
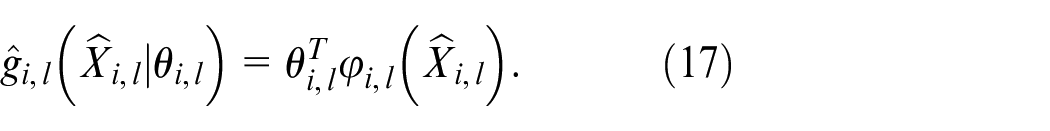
The observer model (15) can be converted into the following model
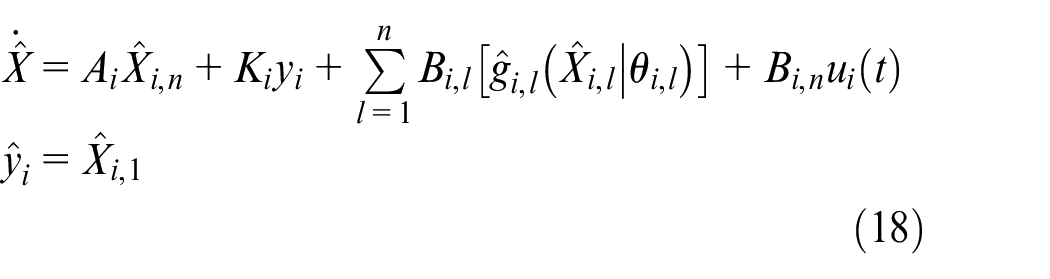
Let
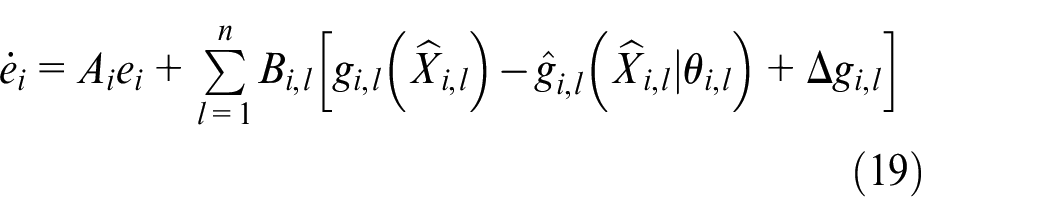
where
The vectors of optimal parameters are defined as
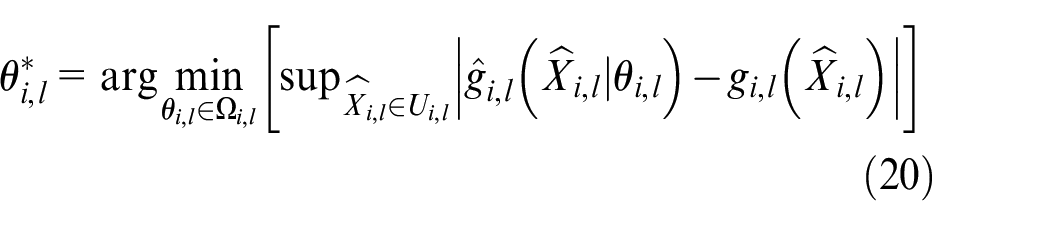
where
Define errors of the optimal approximation
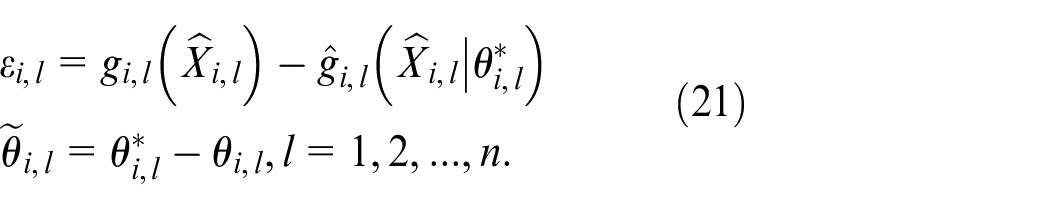
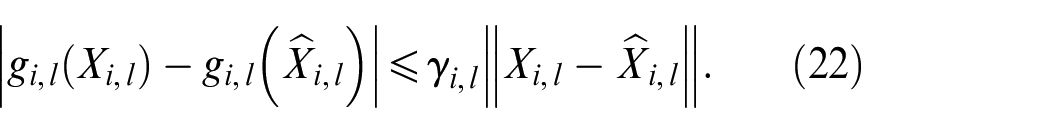
By equations (19) and (21), we have
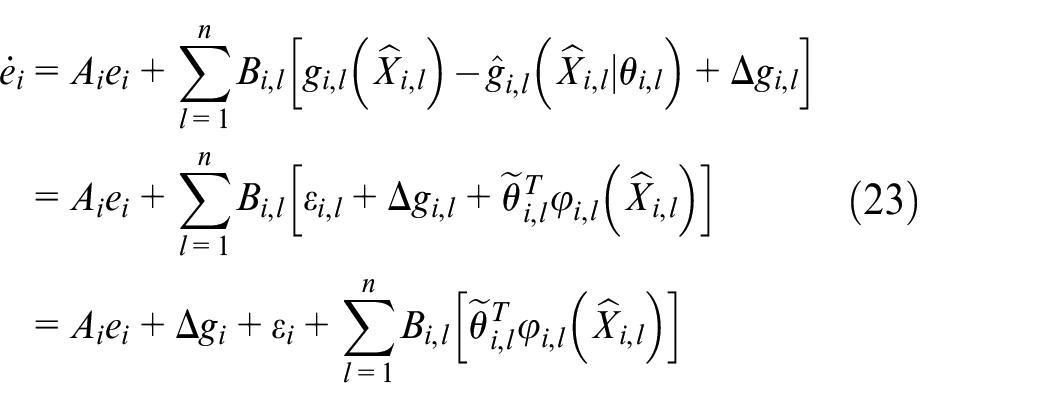
Where
Constructing the Lyapunov function as:

Then, we can obtain
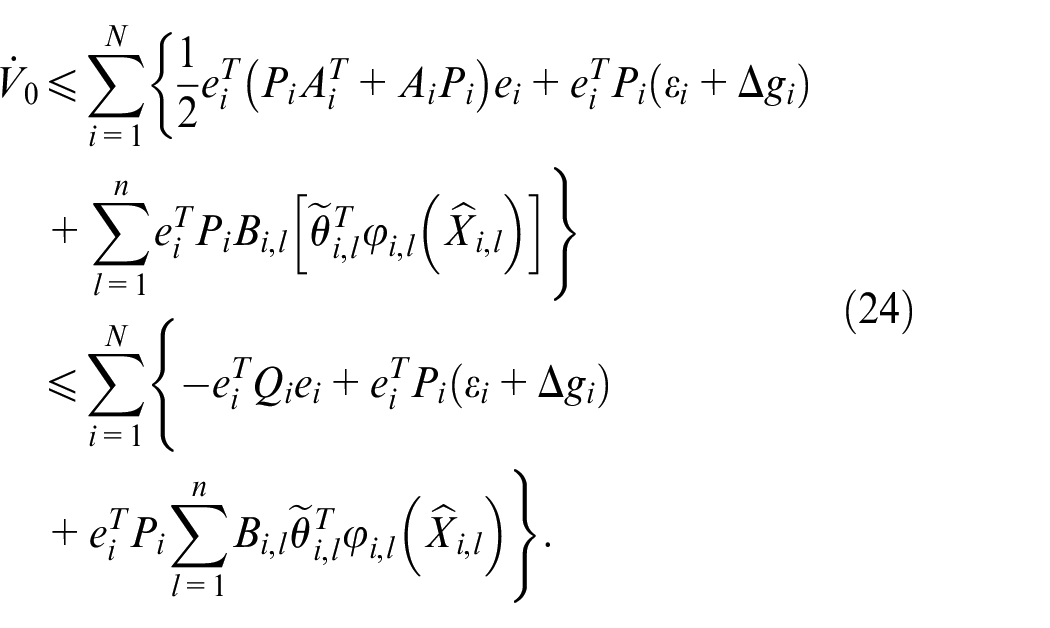
By Lemma 2 and Assumption 3, we obtain
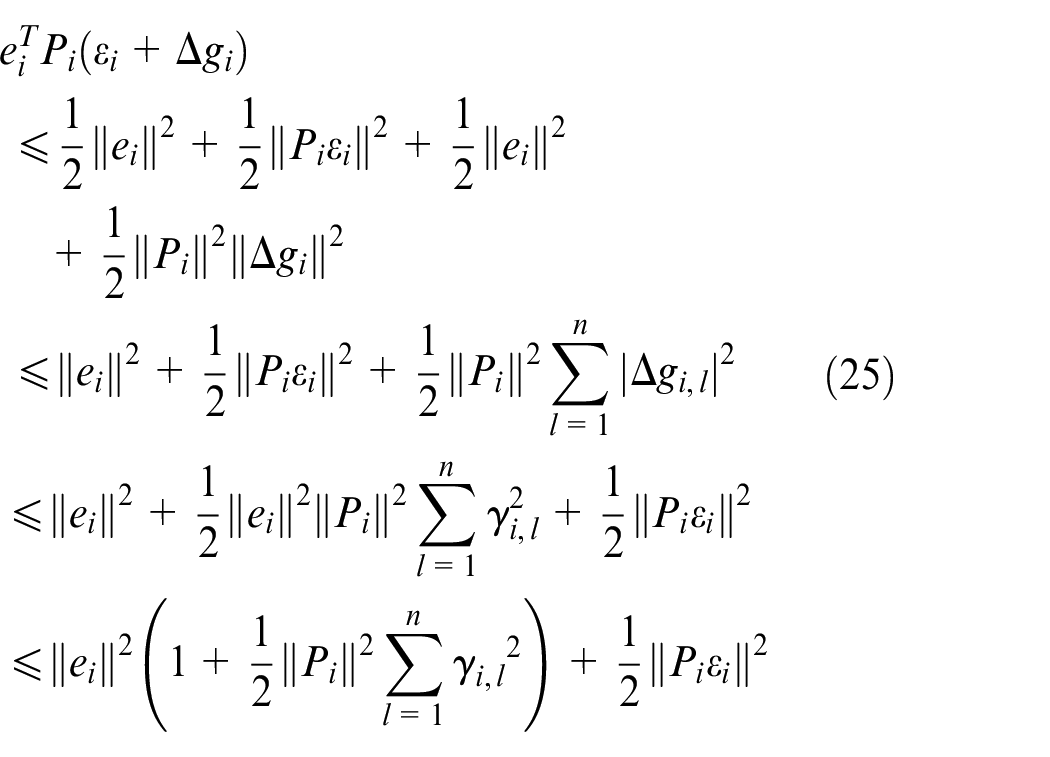
In a similar way, we have
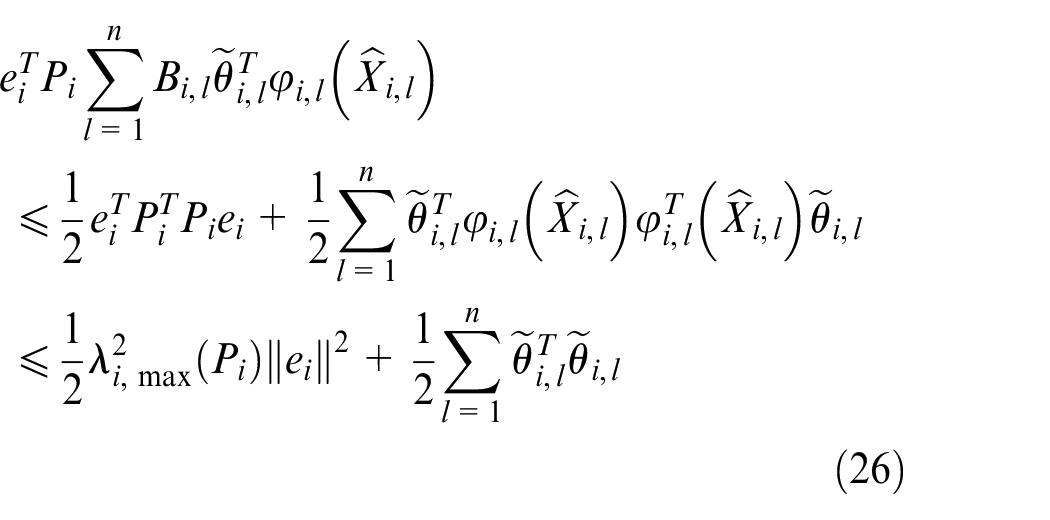
Where
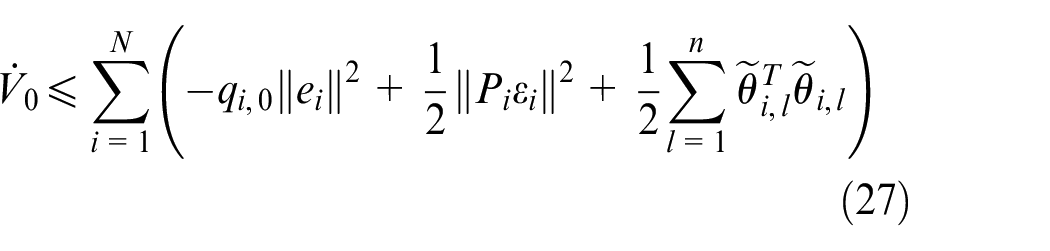
Where
Then, we can obtain
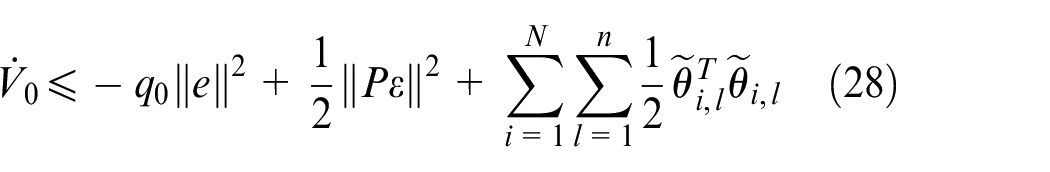
Where
Controller design
For the MASs (4), design state observer (15), by designing a Neural network optimal backstepping controller (80), virtual control laws (48), (58), and (69), filter (29), together with the presented designs can ensure that all the signals remain semi-global uniformly ultimately bounded in the closed-loop system and enables all agents converge to the convex hull of the target trajectory.
This paper uses virtual controller
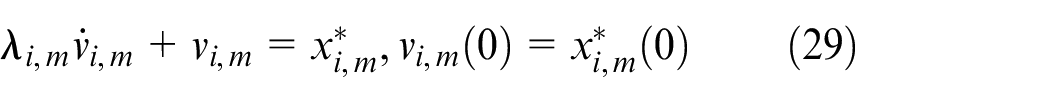
Where,
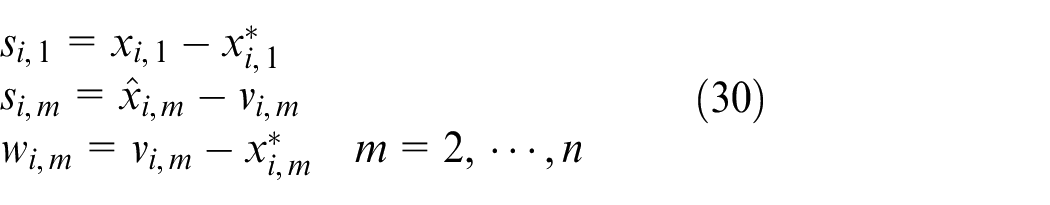
Where,
By the equations (29) and (30), we have
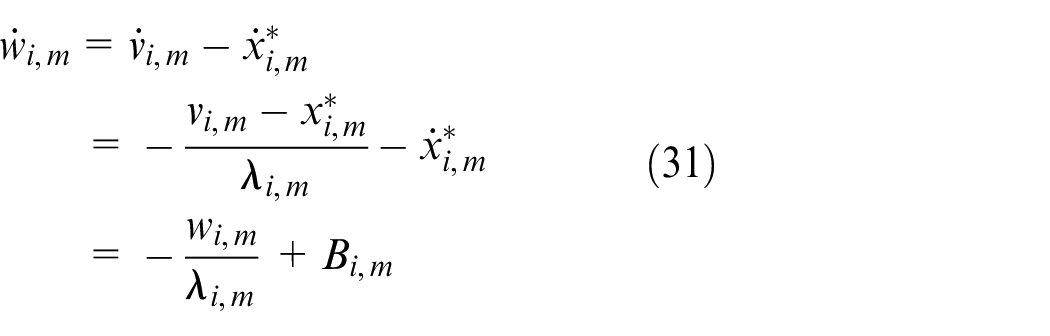
Where
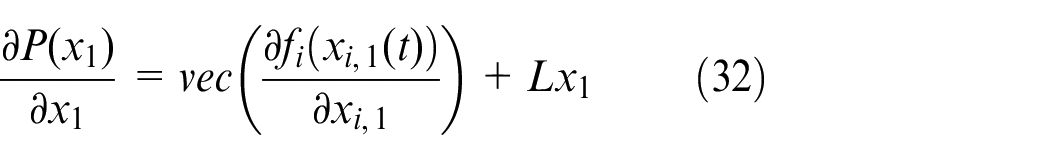
Where

By equations (11) and (32), we have
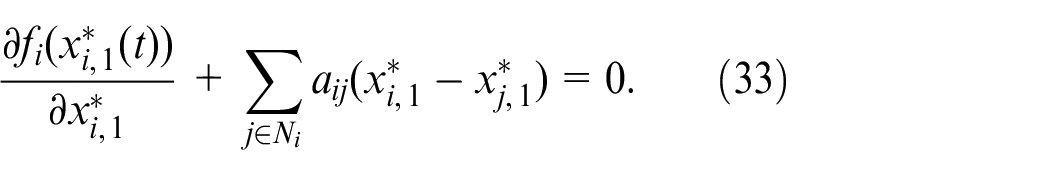
Substitute the equation (7) into (33) to get
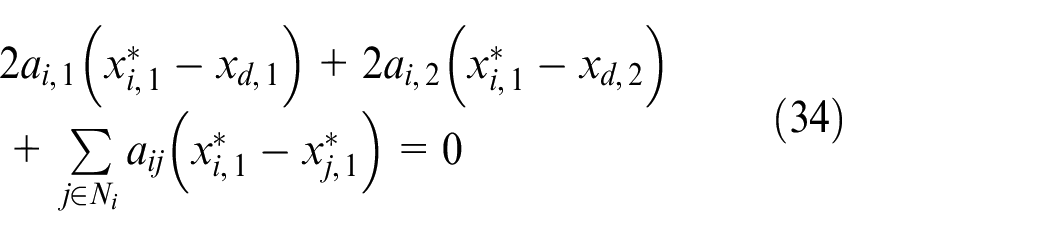
Then according to (32) and (34), we have
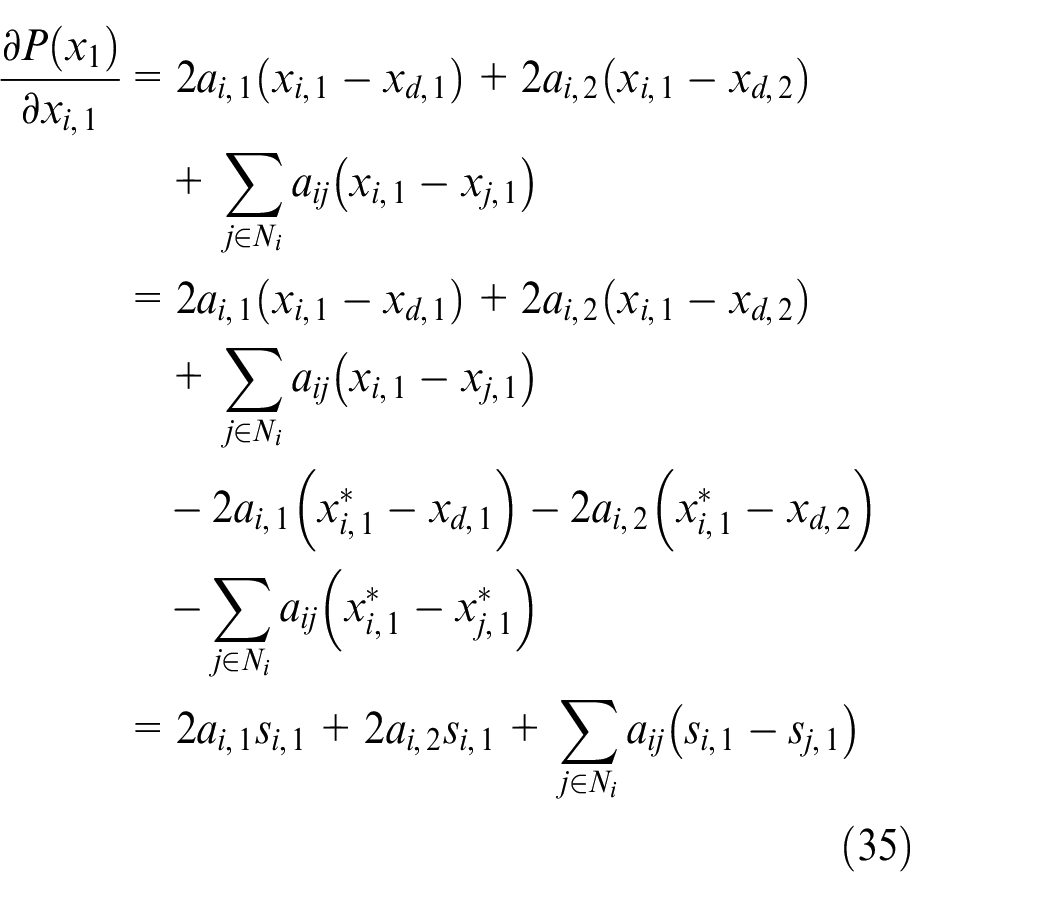
Let

Where
Then, we construct the Lyapunov function
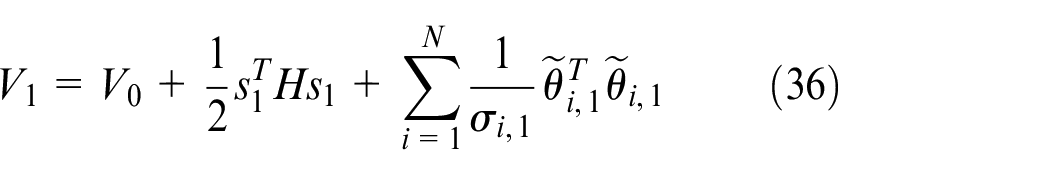
Where
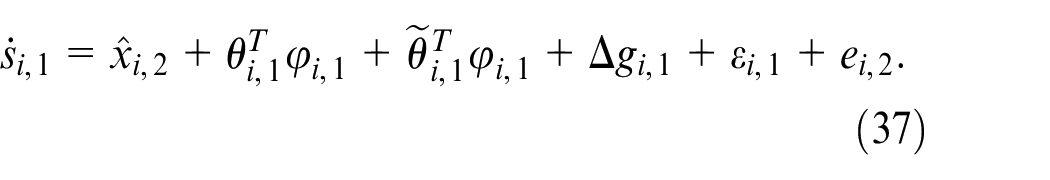
Take the derivative of
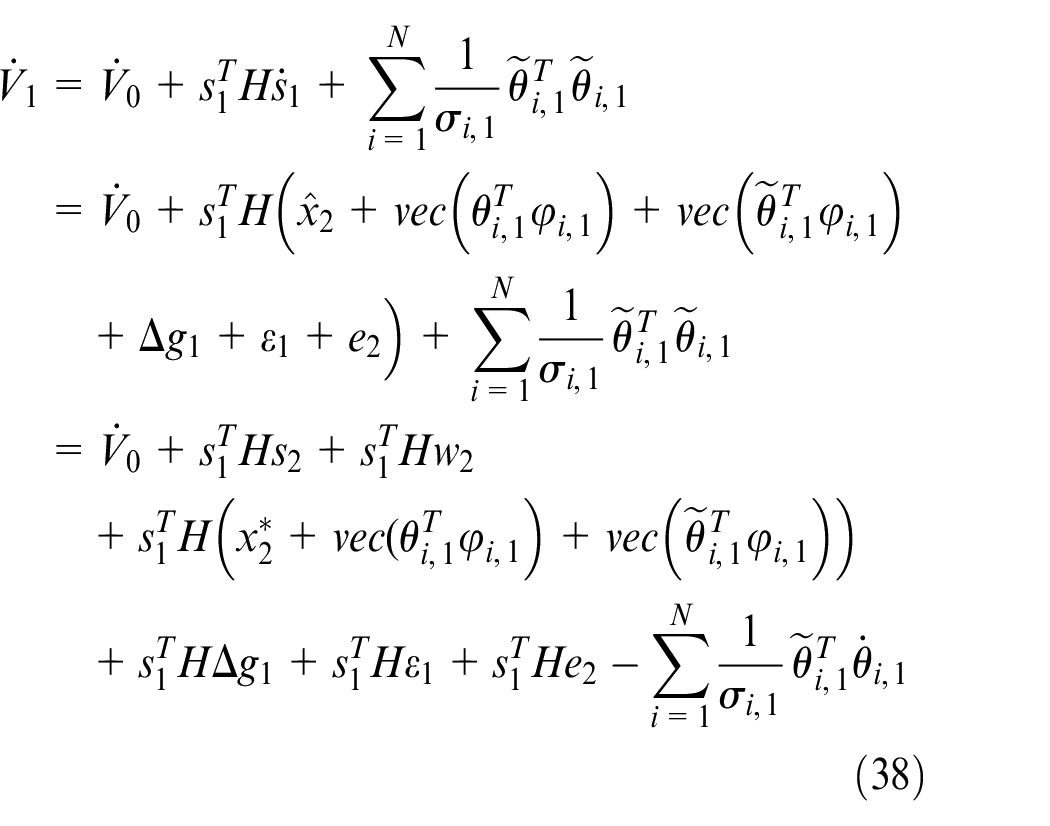
where
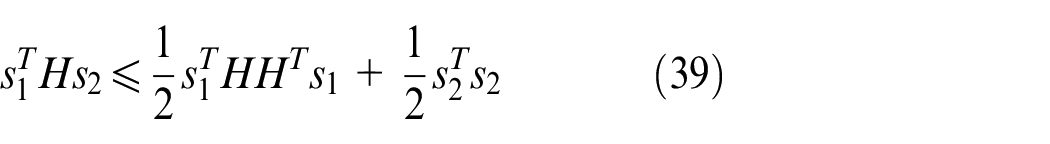
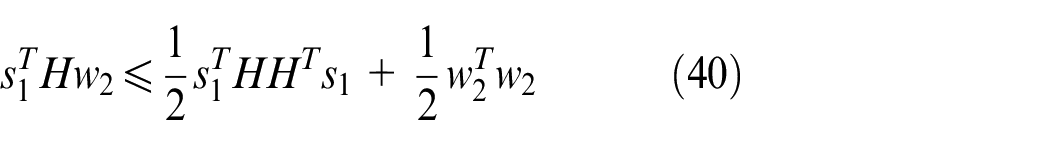
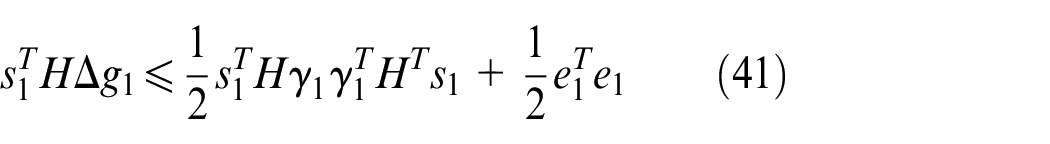
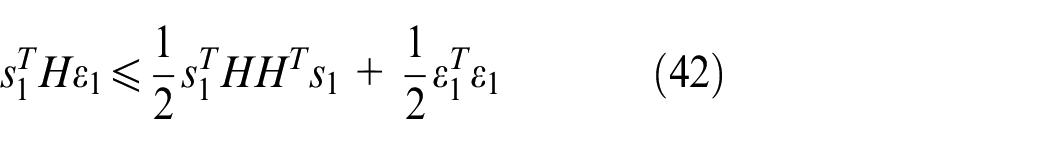
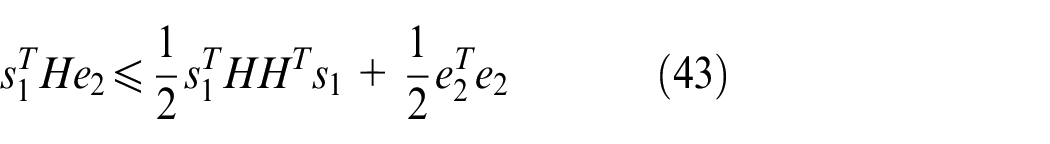
where
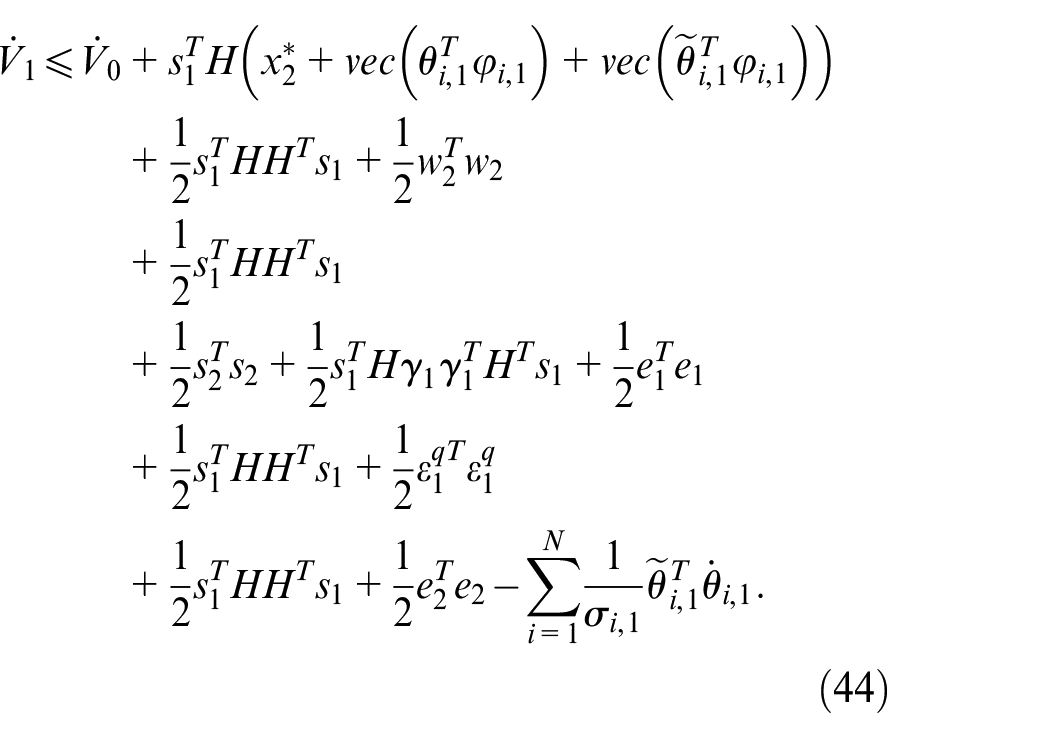
According to Lemma 1, we have
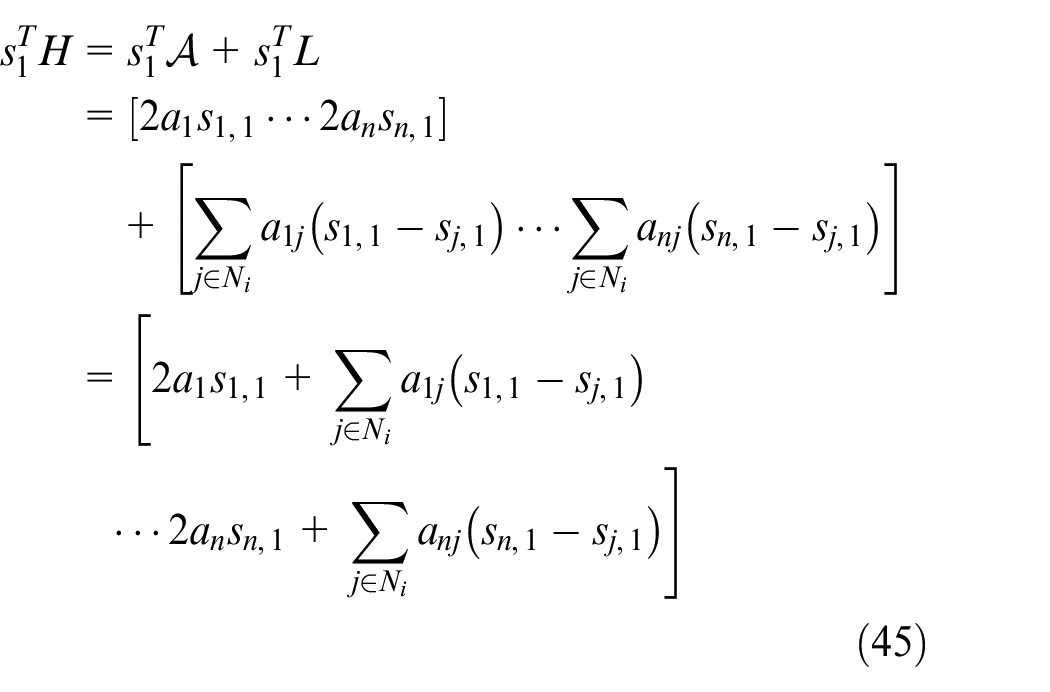
Then, we can obtain
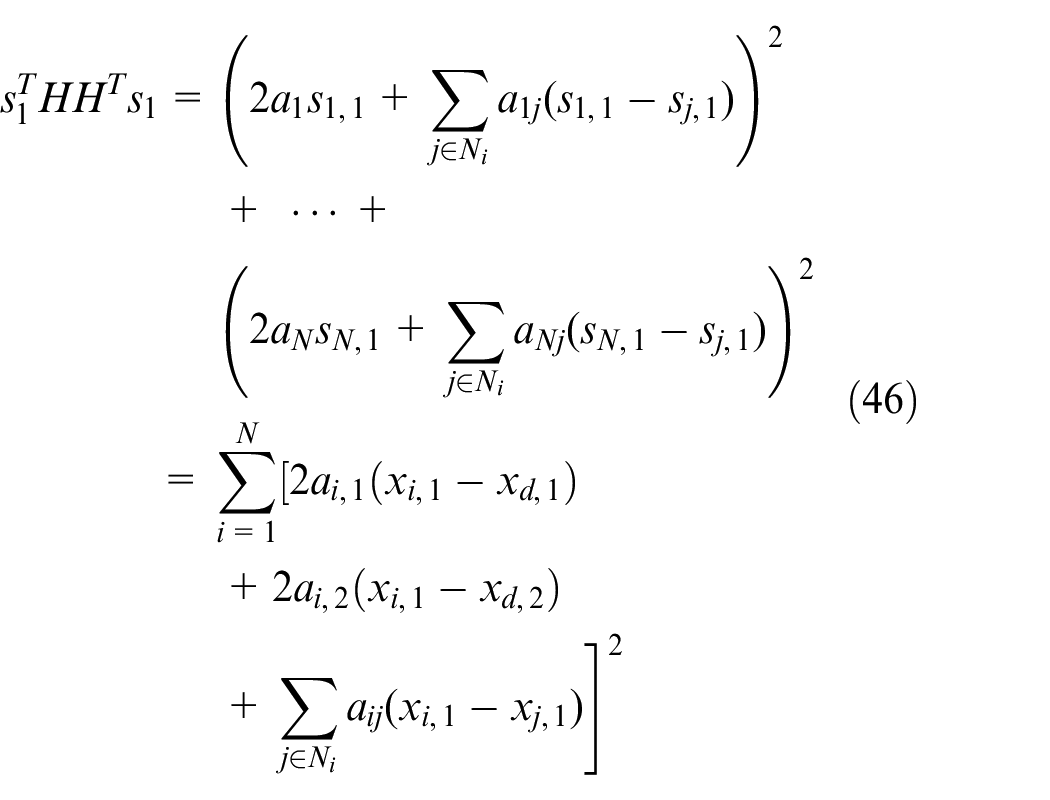
and
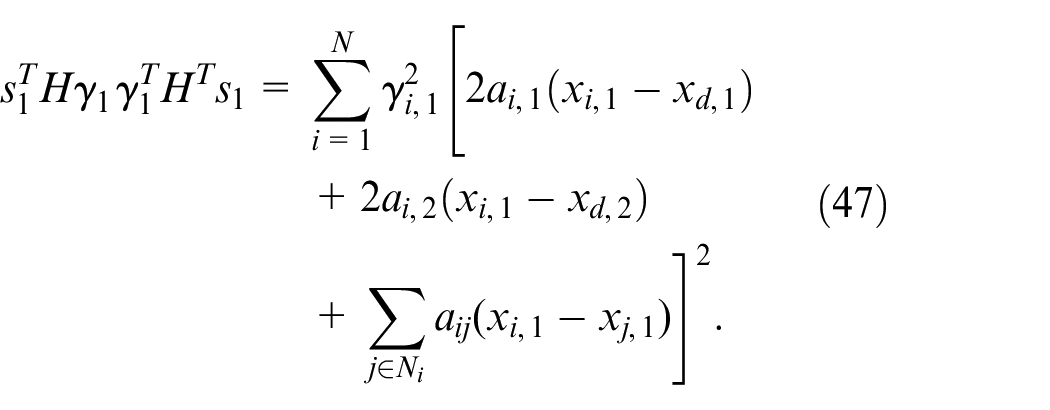
By equations (44), (46), and (47), the virtual controller
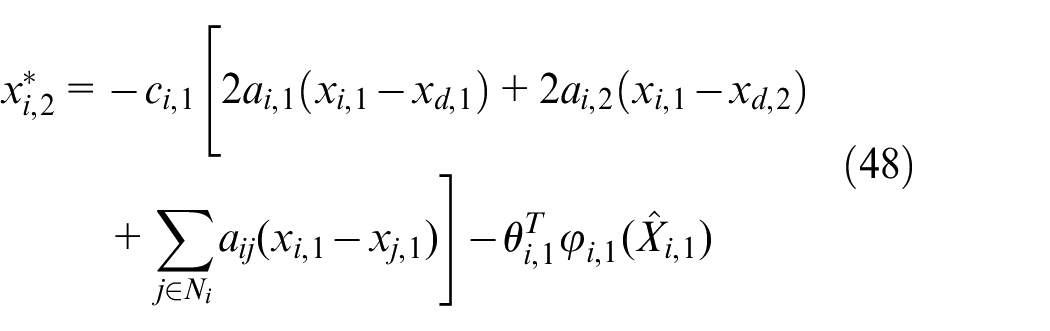
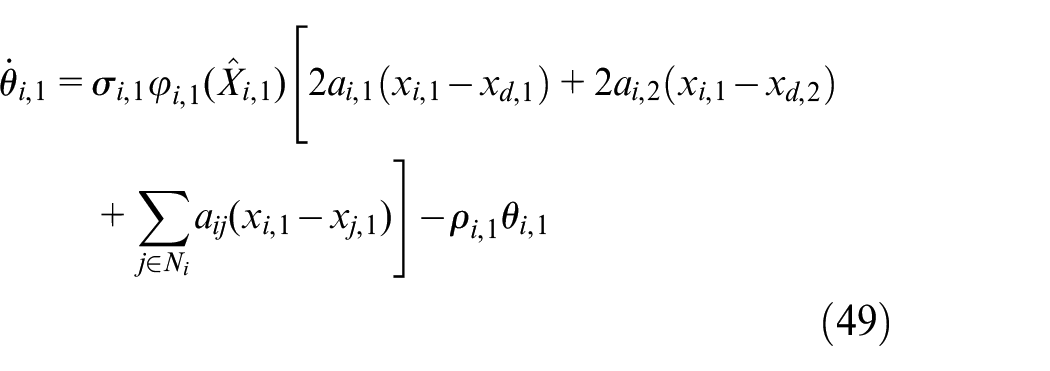
Where
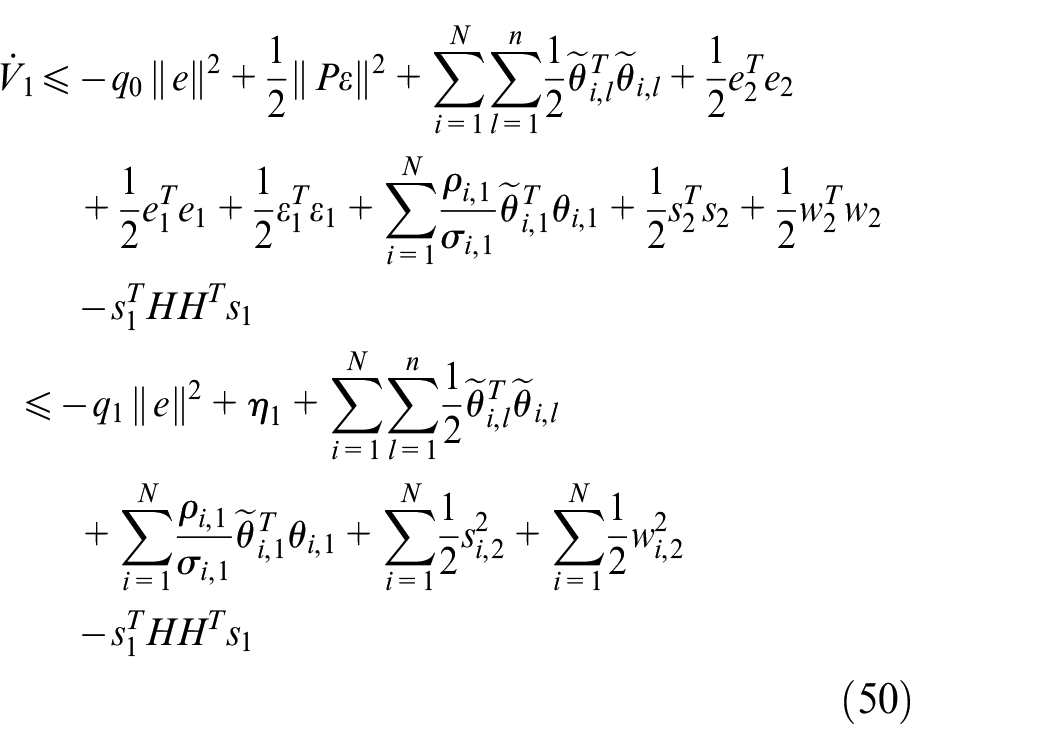
Where
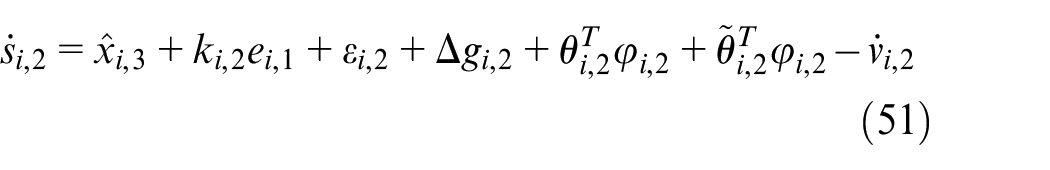
Construct the Lyapunov function
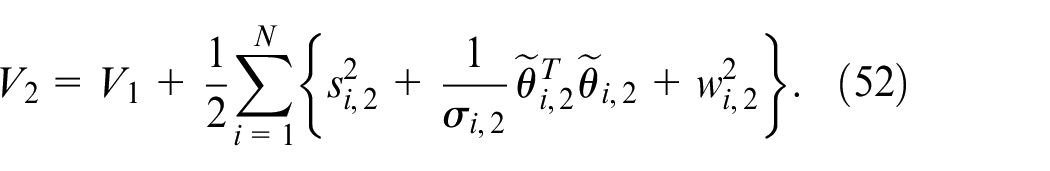
where
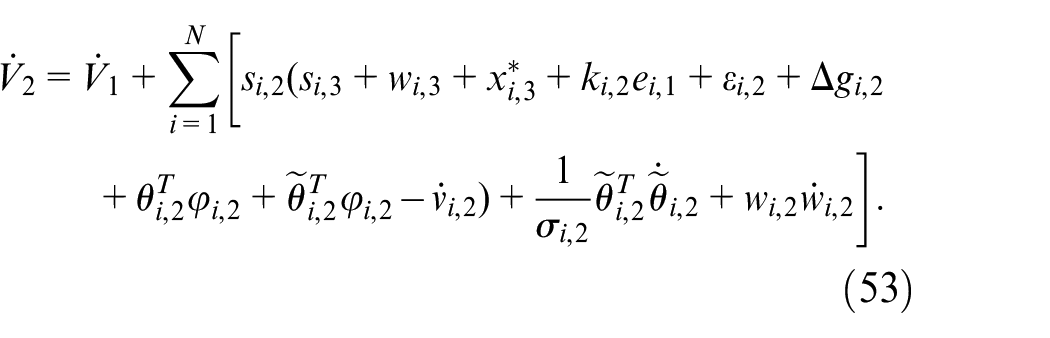
According to Lemma 2, we obtain
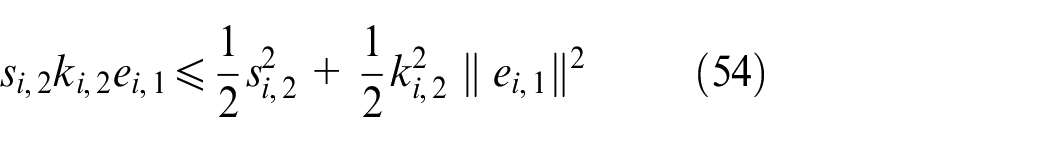
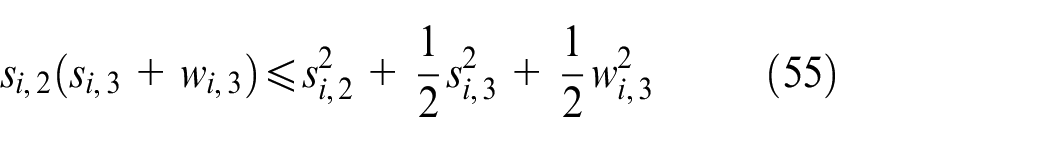
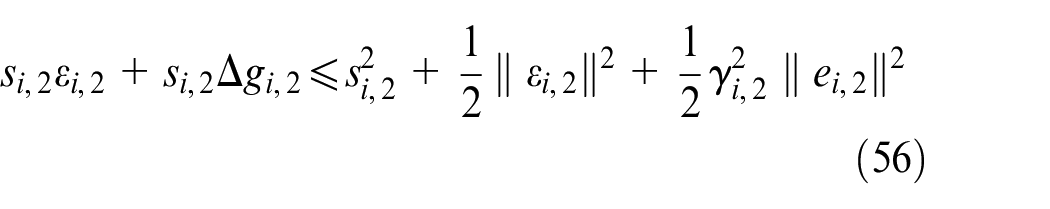
Substituting (54)–(56) into (53) can be written as
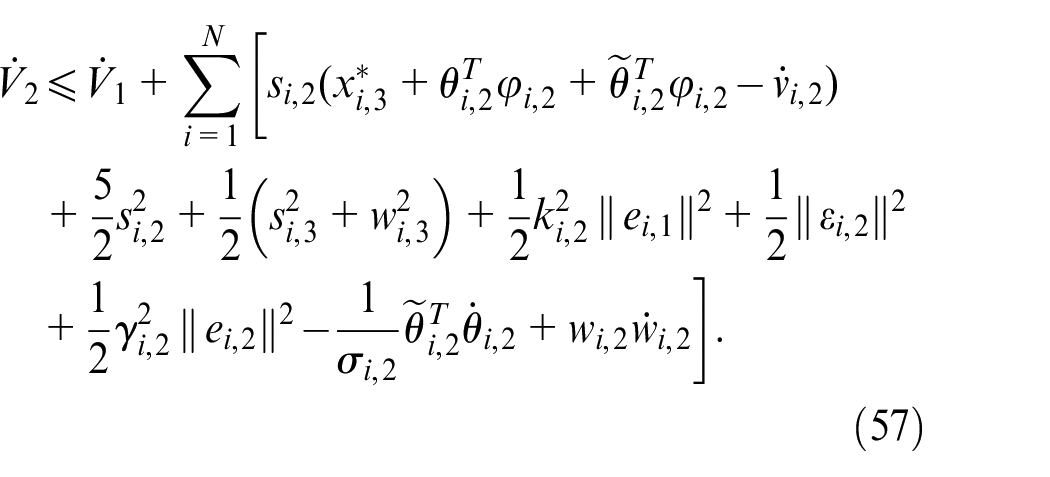
According to Theorem 1, the virtual controller
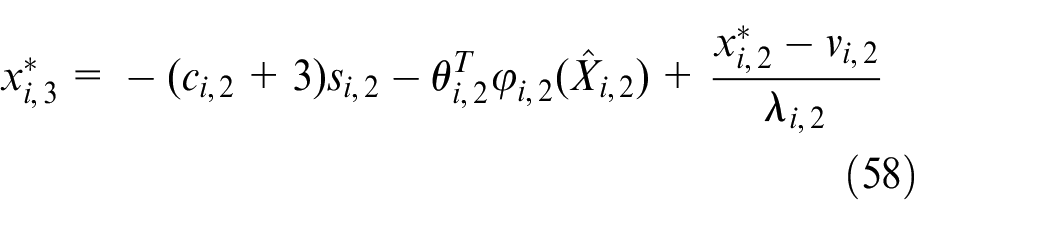
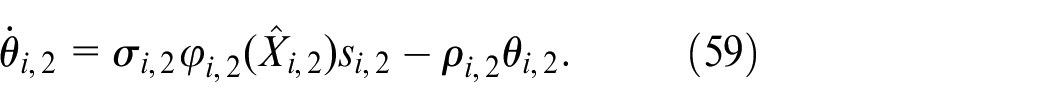
where
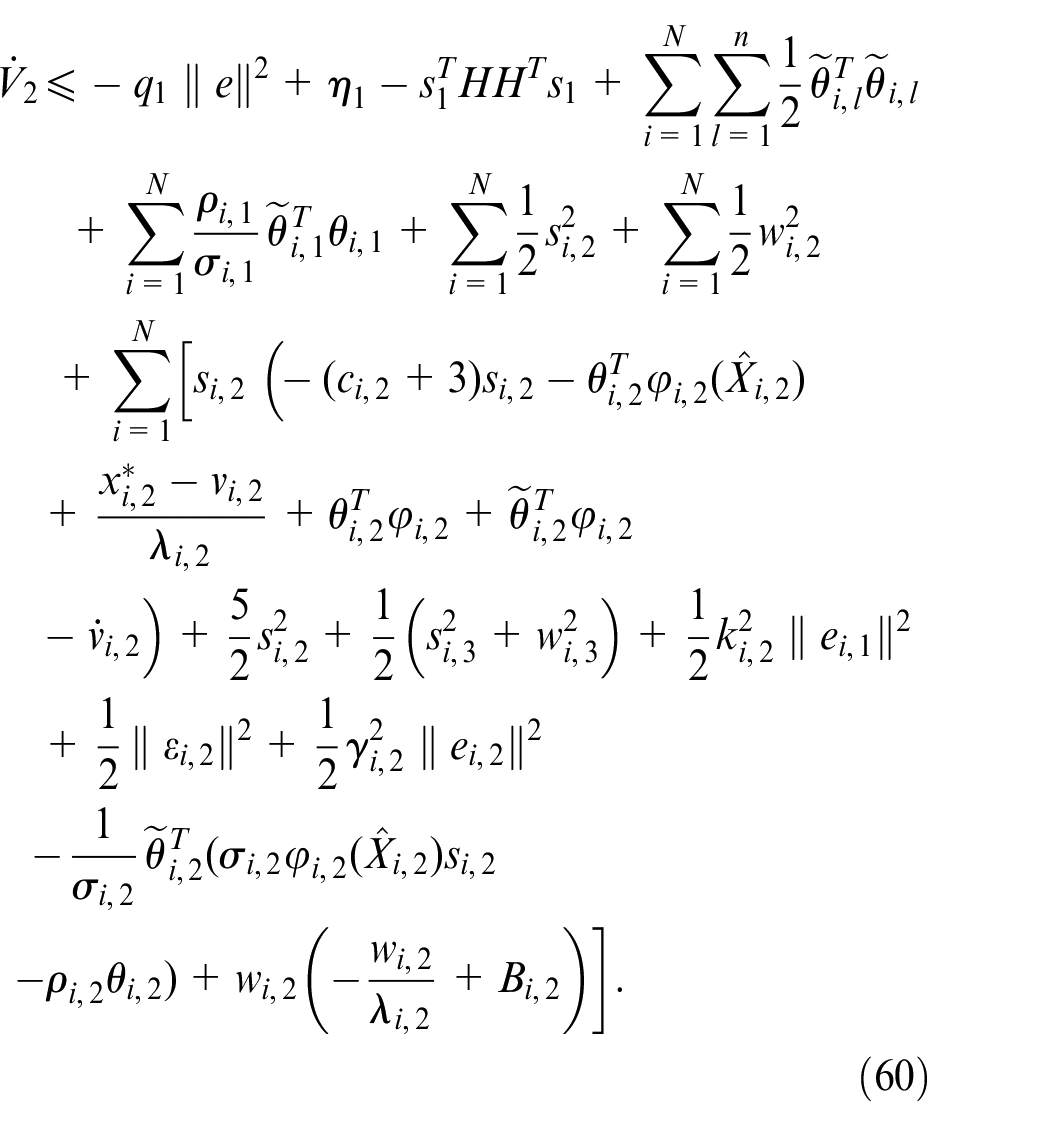
According to Lemma 2, we have
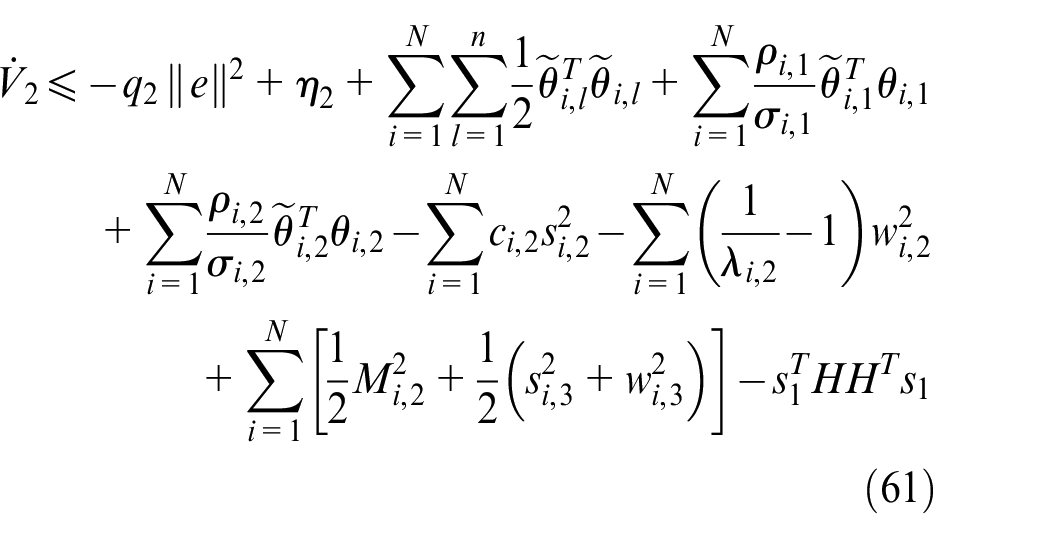
where
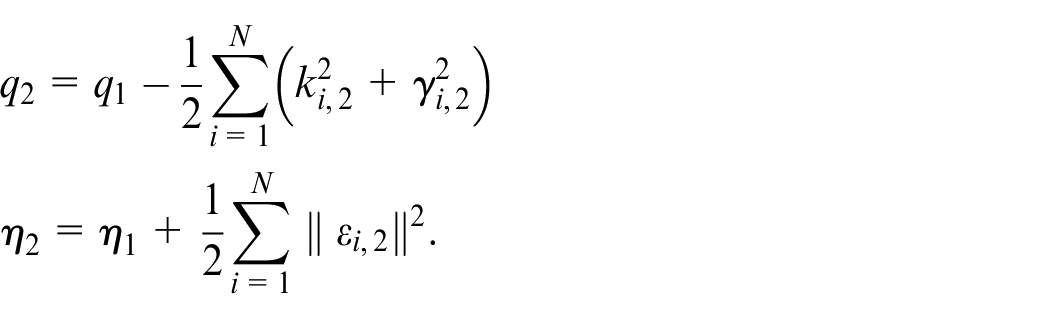
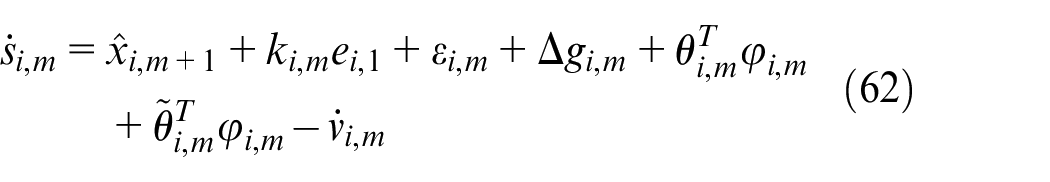
Construct the Lyapunov function
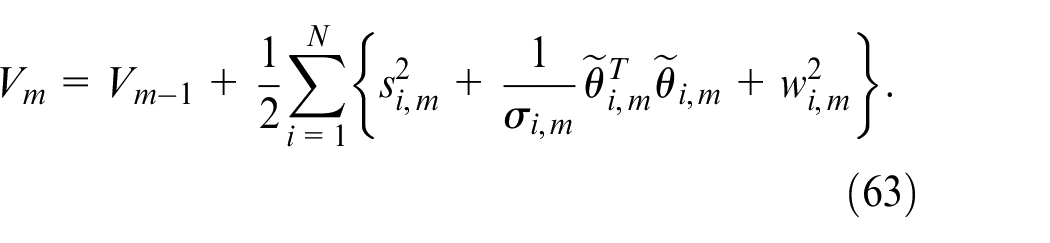
where
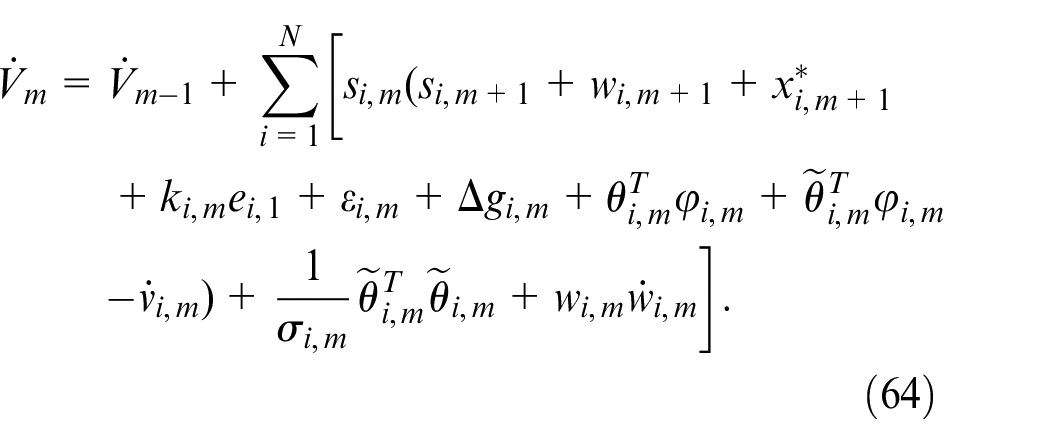
According to Lemma 2, we obtain
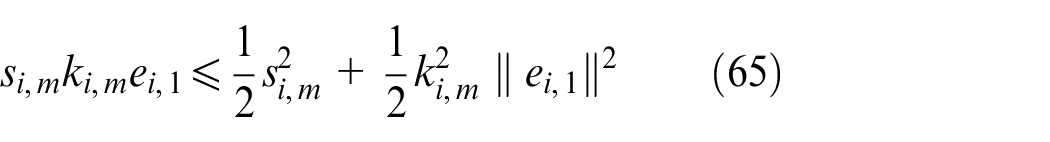
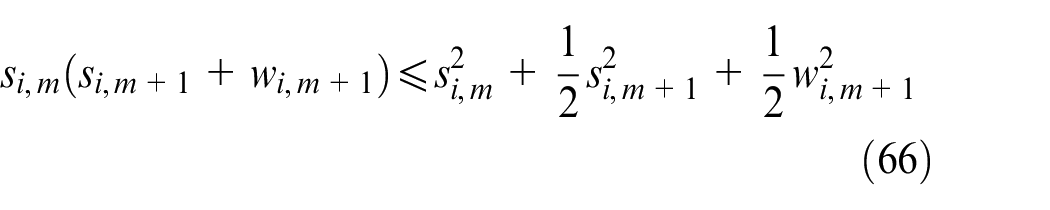
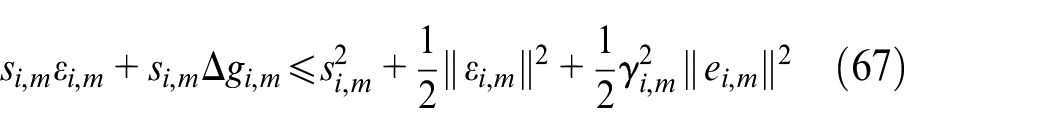
Substituting (65)−(67) into (64) can be written as
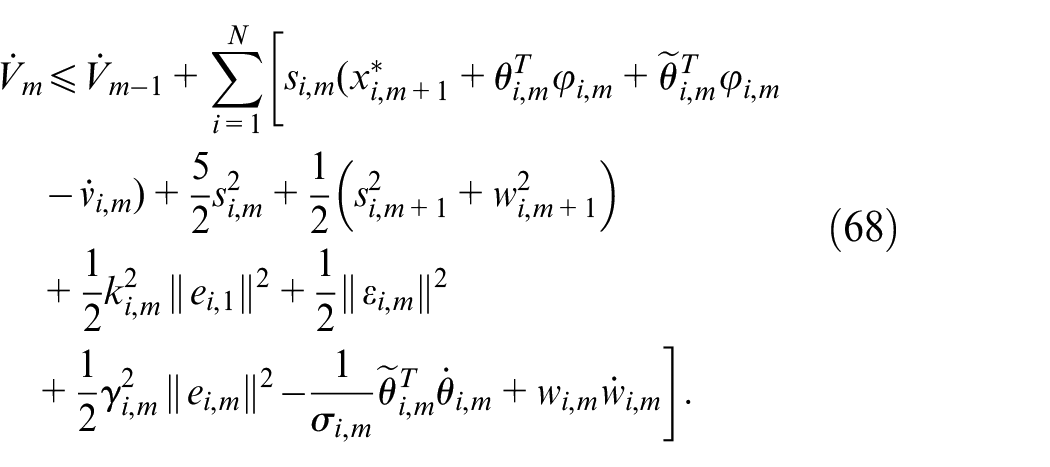
According to Theorem 1, the m-order virtual controller
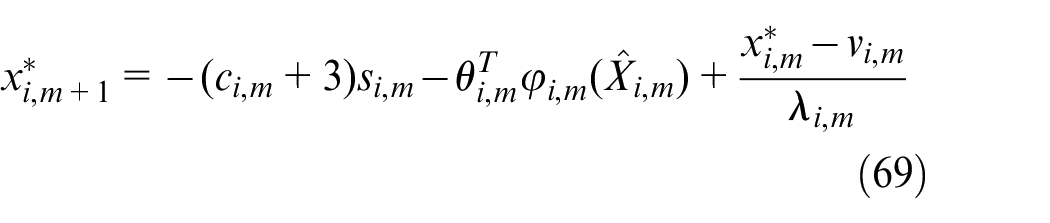
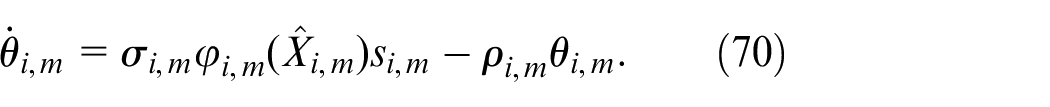
where
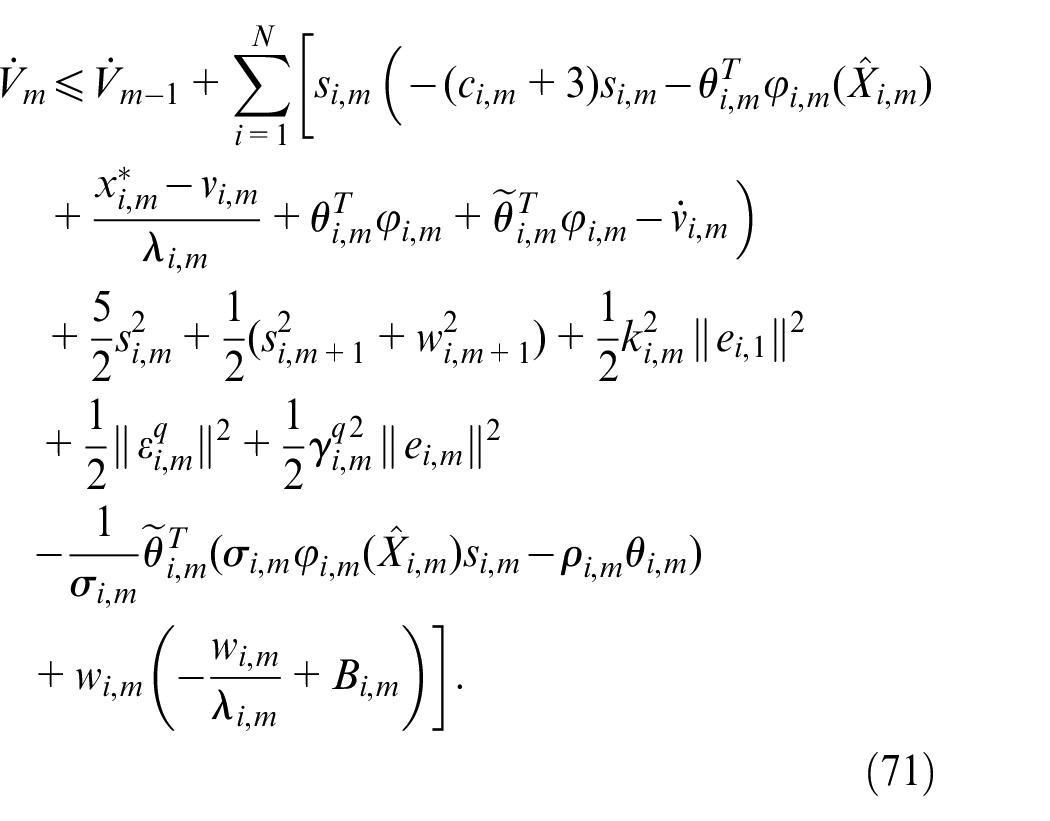
According to Lemma 2, we have
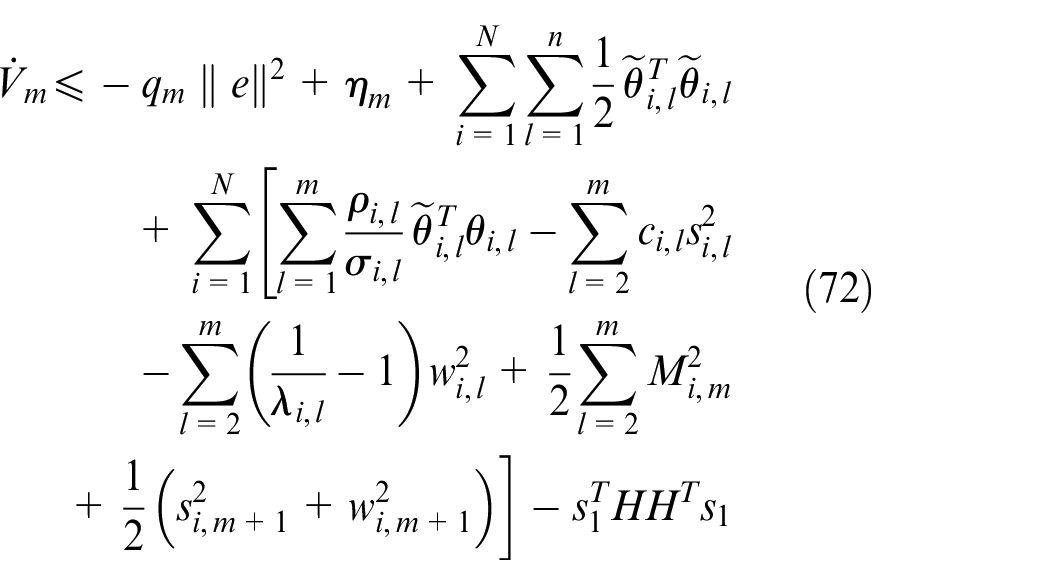
where
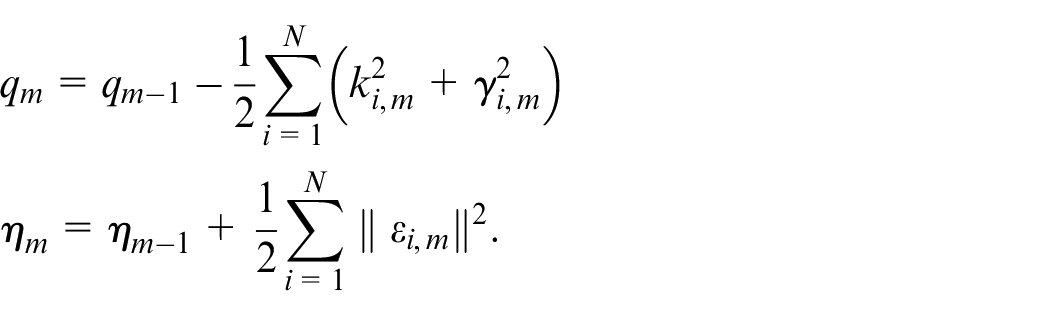
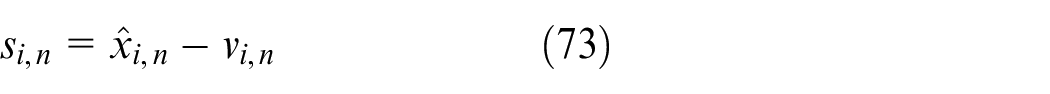

Then, we have
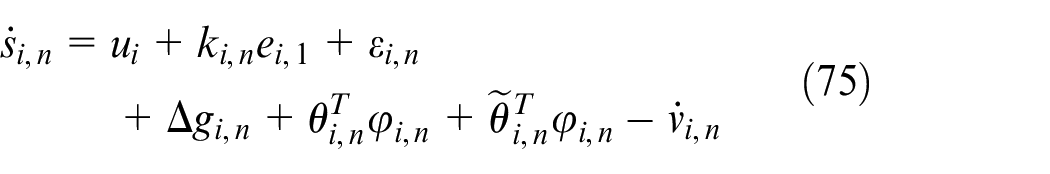
The Lyapunov function is constructed as
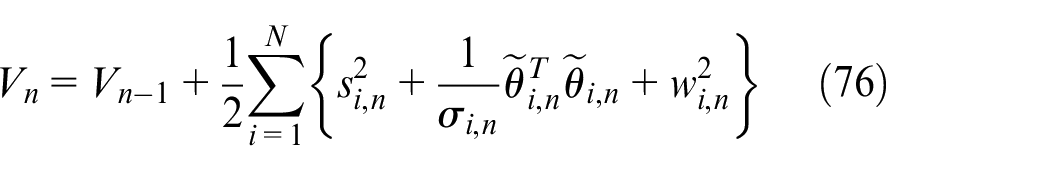
where
Combining (73) and (76), we can obtain
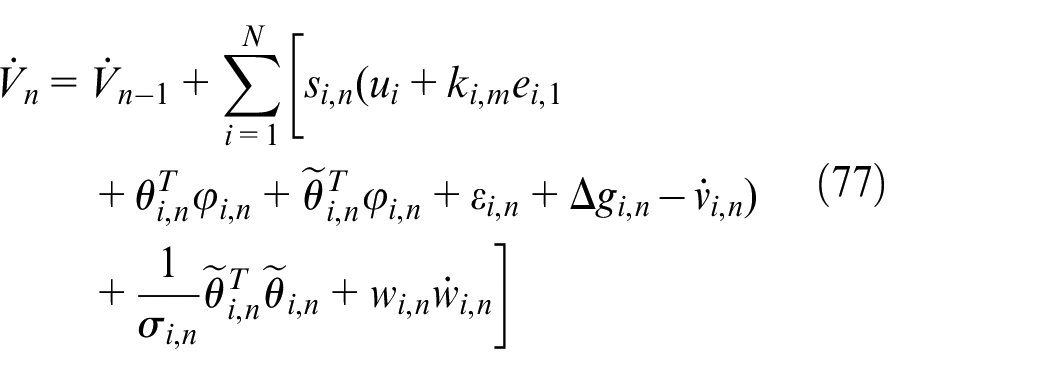
According to Lemma 2, the following inequalities hold
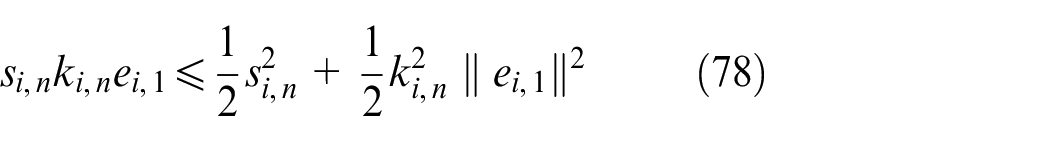
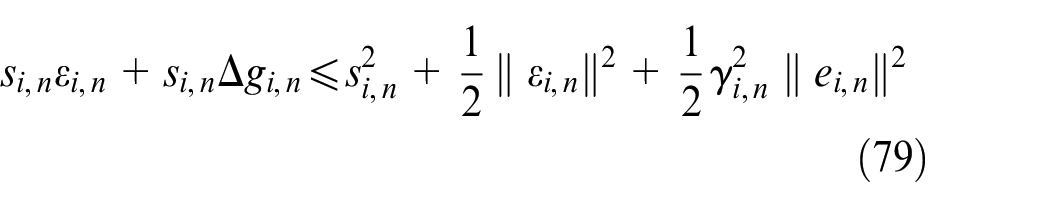
Design the multi-agent system control law
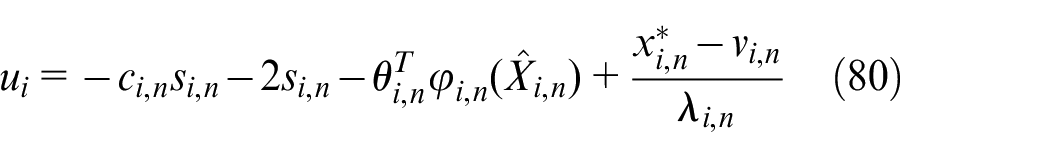
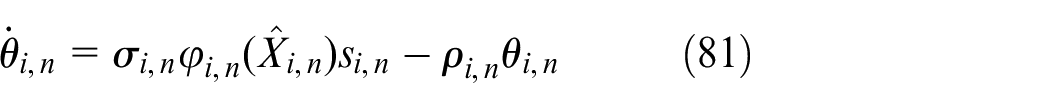
where
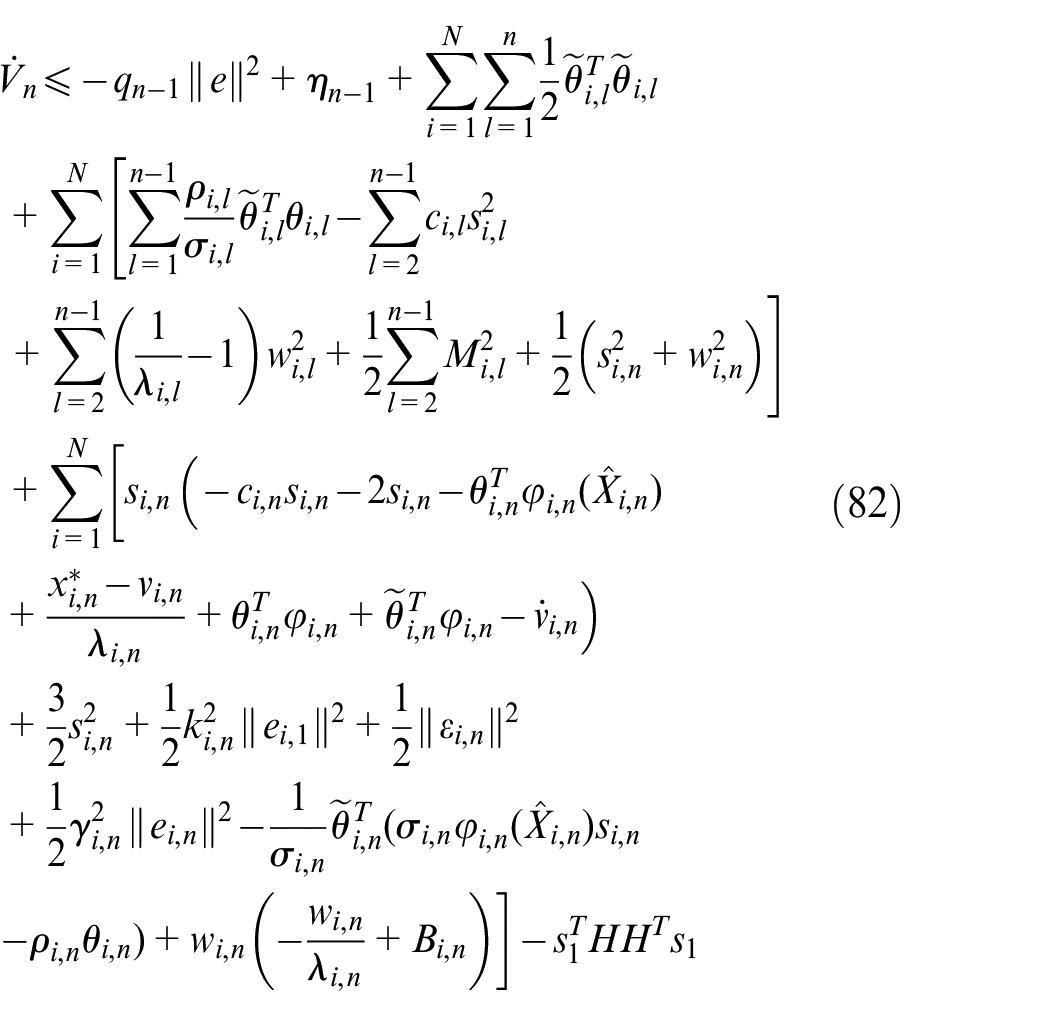
According to Lemma 2, we have
where
According to Lemma 2, we obtain
Then, we can obtain
Define
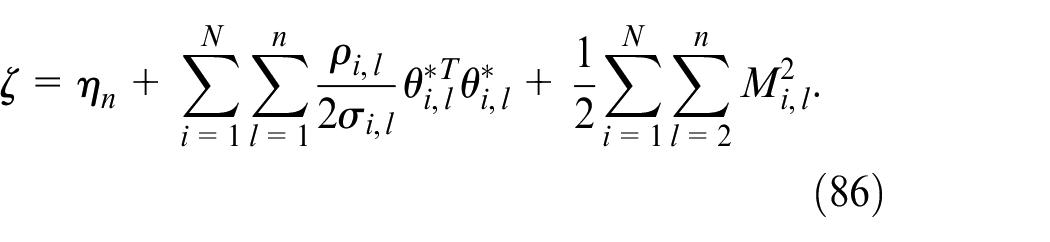
Then, equation (85) can be written as
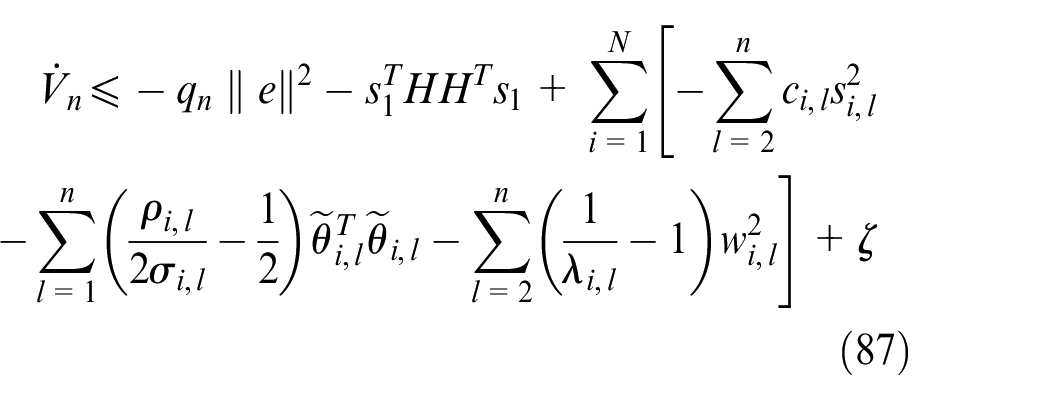
where
Define
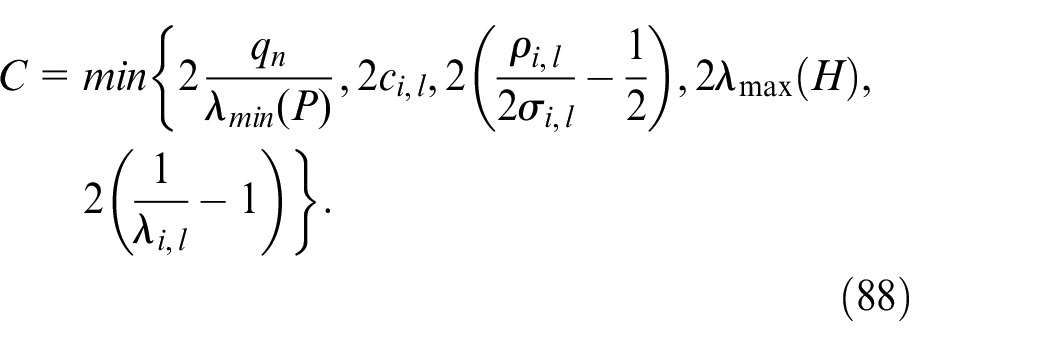
Then, equation (87) becomes

According to Lemma 3, we know that the output variables of each multi-agent remain SGUUB in the entire multi-agent nonlinear closed-loop system. And ensure that the sum of the local objective functions of each multi-agent is minimal, other words, each multi-agent converges to the optimal containing position. The margin of error is shown below.
By solving the inequality (89), we have
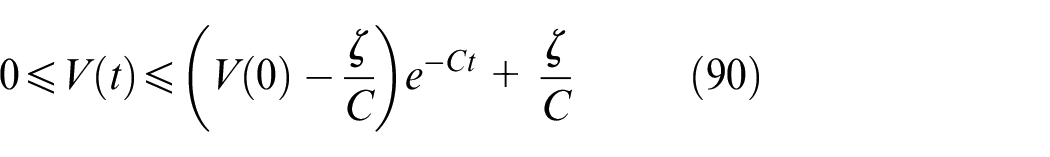
Substituting (36) into (90) yields, we have
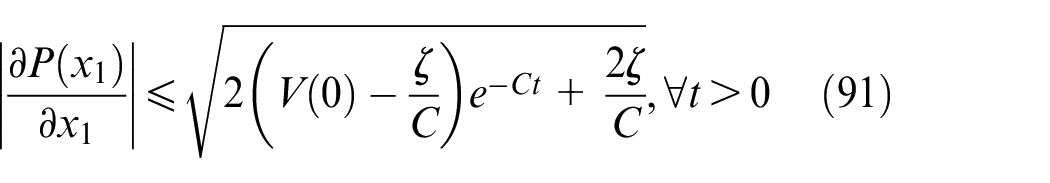
As can be seen from (91), when time approaches infinity, the error satisfies
Simulations
In this section, we will use simulation to verify the control effect of the control method. The system model used in this section is as follows, 41
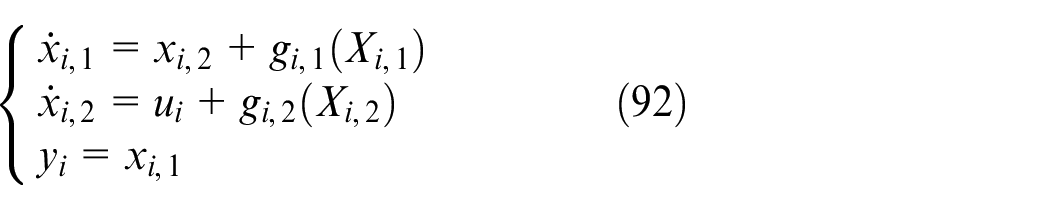
where
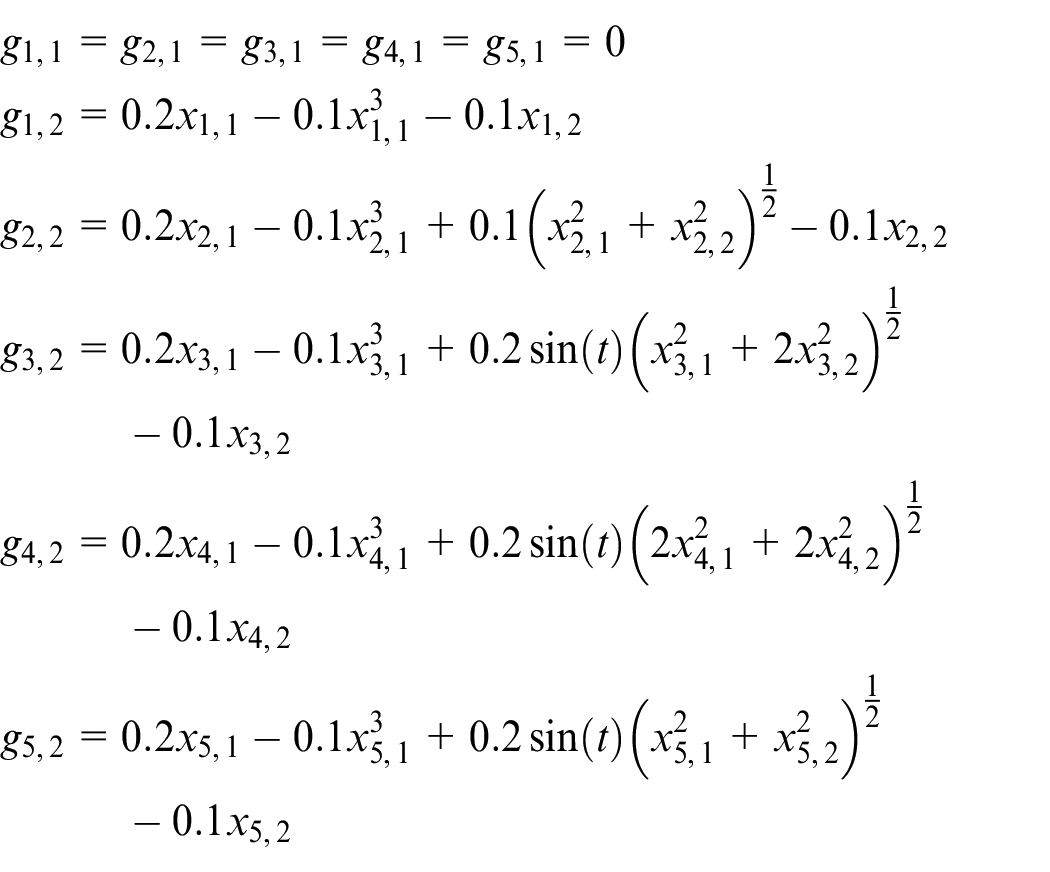
We assumption multi-agent system to exchange information in the manner shown in Figure 1. The local objective function of multi-agent system is as follows
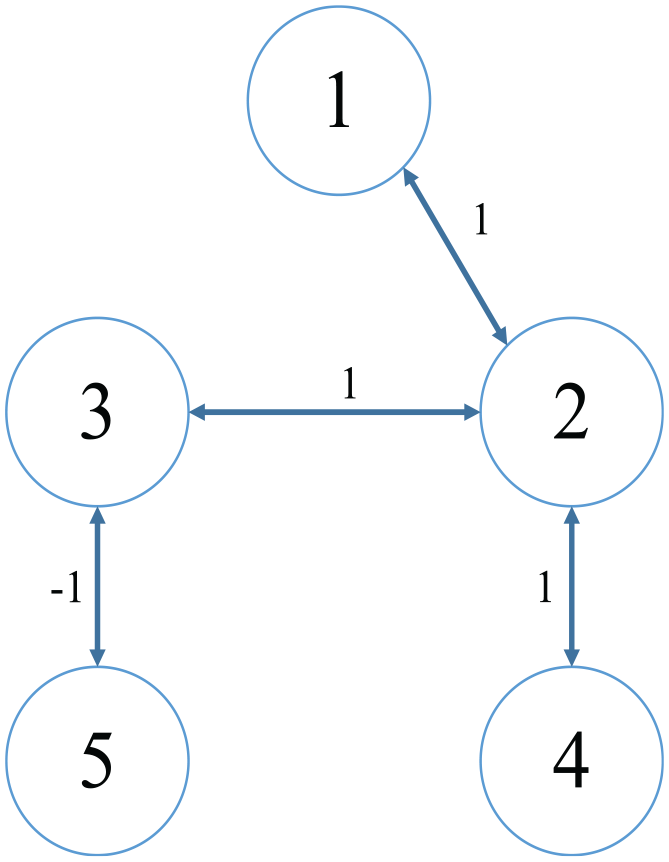
Undirected topology among MASs.
The penalty function is shown below
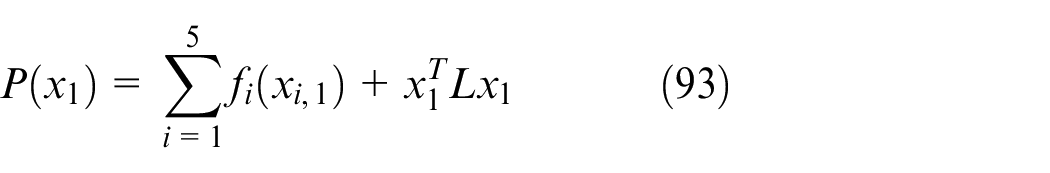
The condition of its optimal solution is

where
According to Theorem 1 and equations (48), (49), (80), and (81), the design of the virtual control law, the adaptive weight update law and the control input are as follow
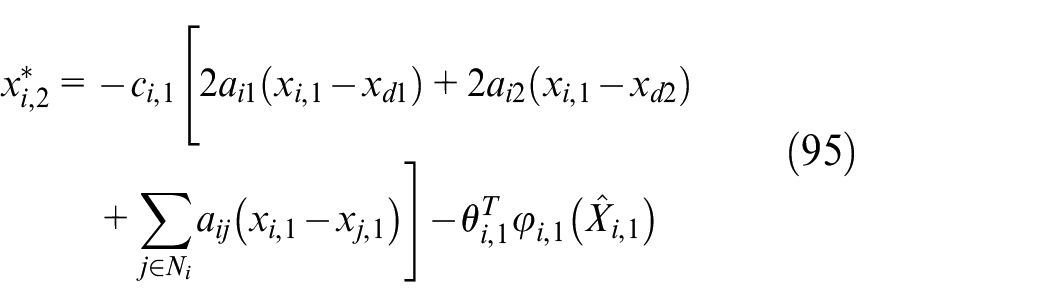
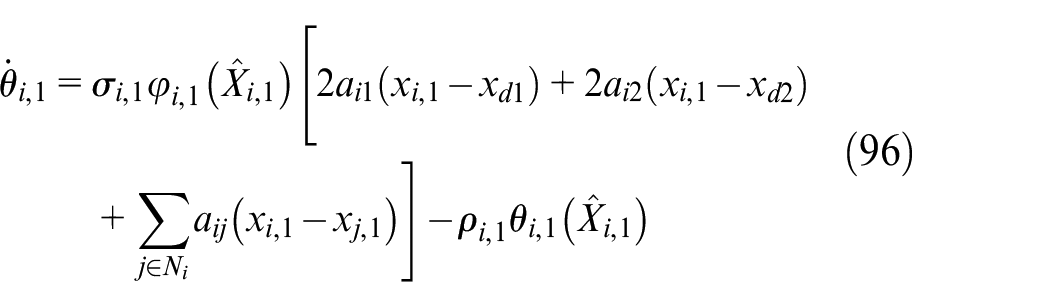
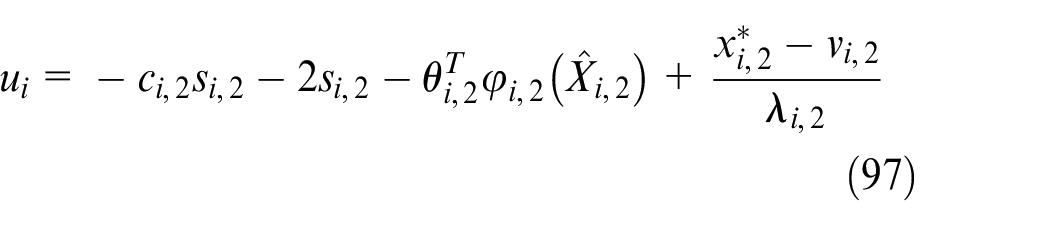
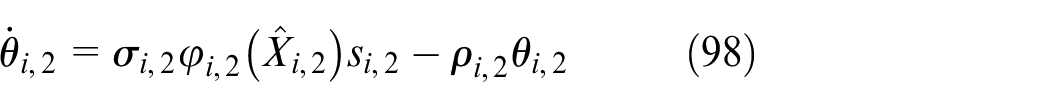
The necessary parameters in equations (95), (96), (97), and (98) are selected as
In the simulation, Figures 2–8 are the results of simulation. Figure 2 shows the trajectories of
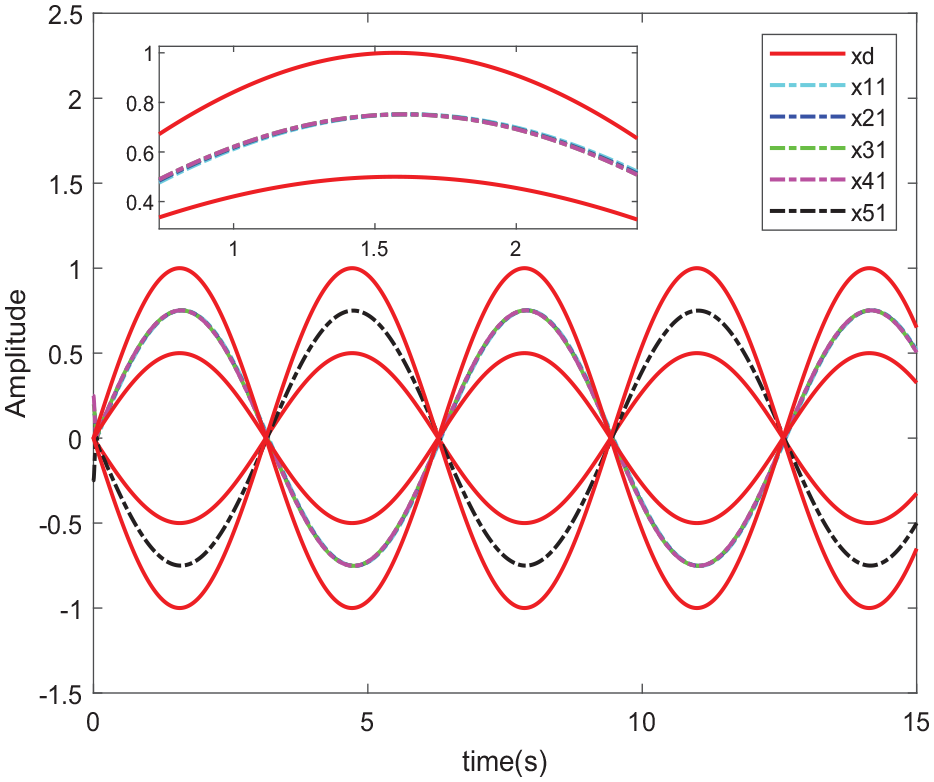
The trajectories of
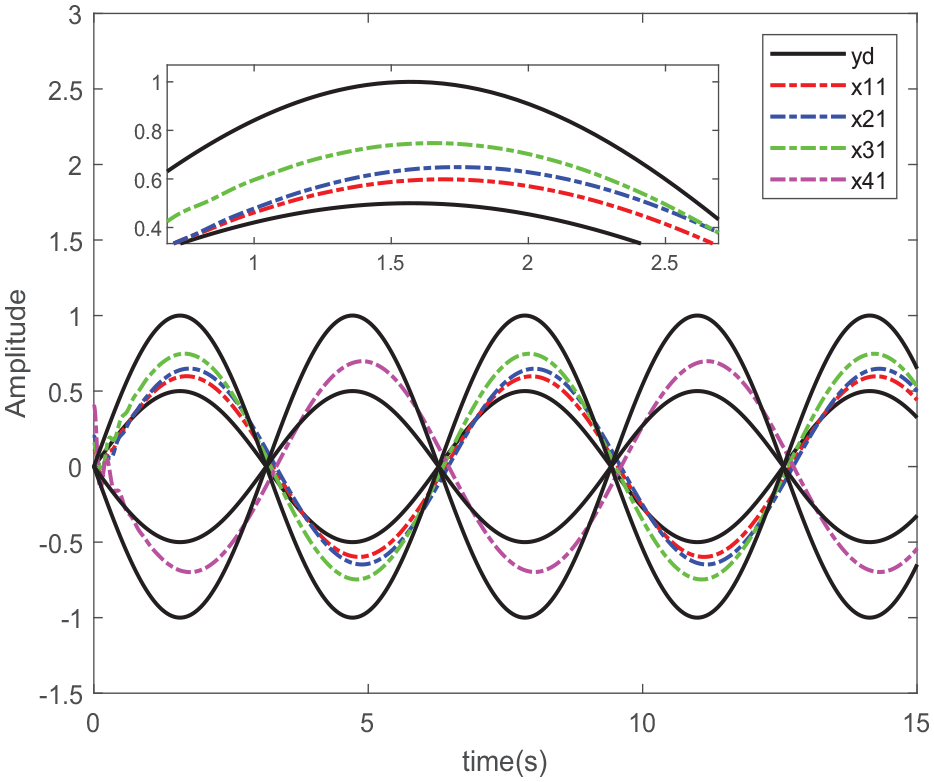
Bipartite containment control without considering distributed optimization.
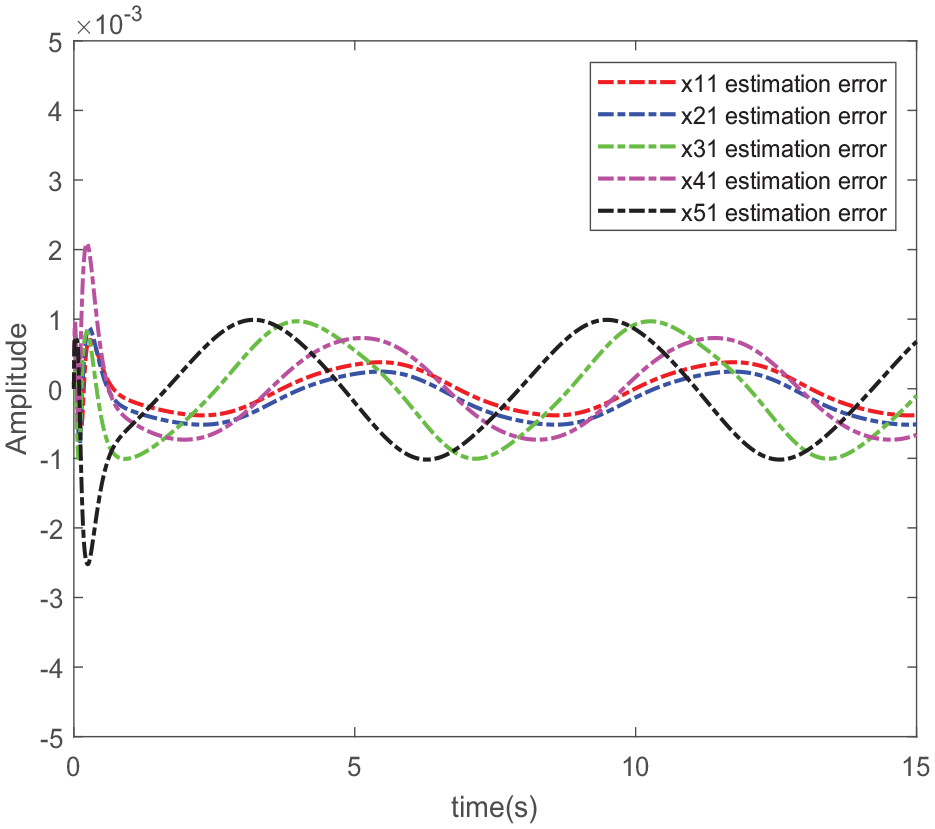
The values of
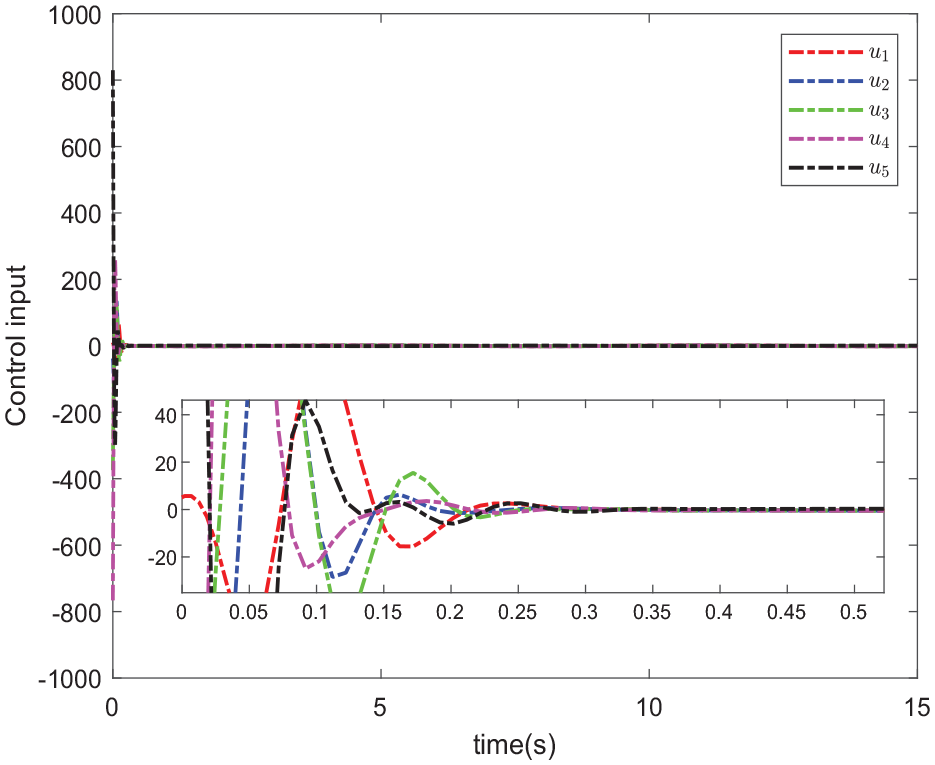
The values of
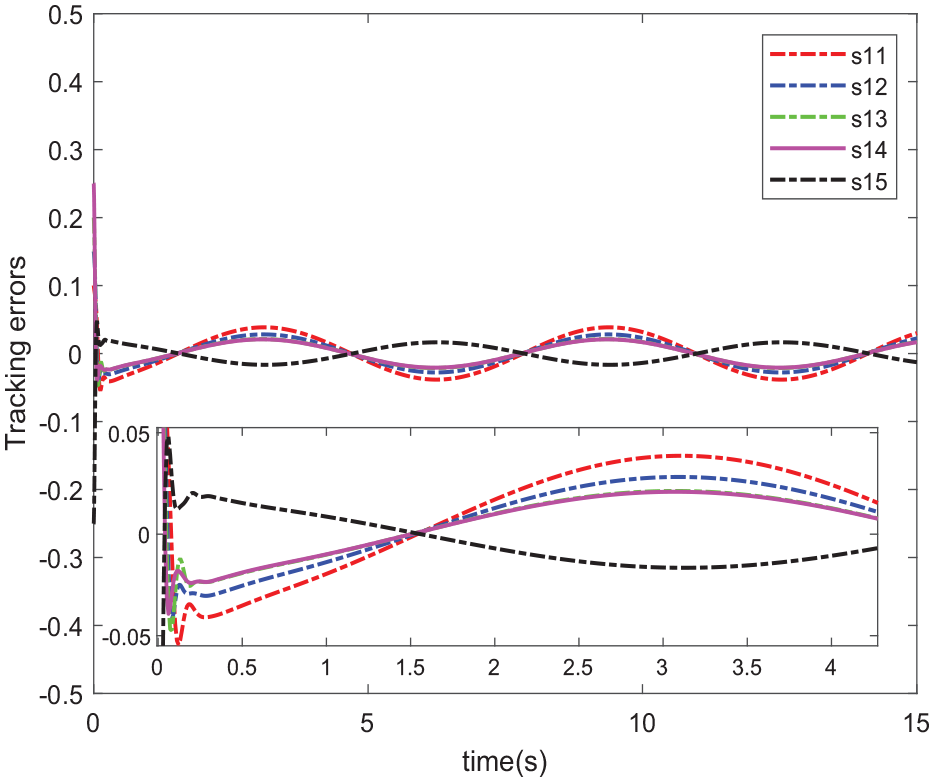
The value of the error between the system output and the optimal trajectory
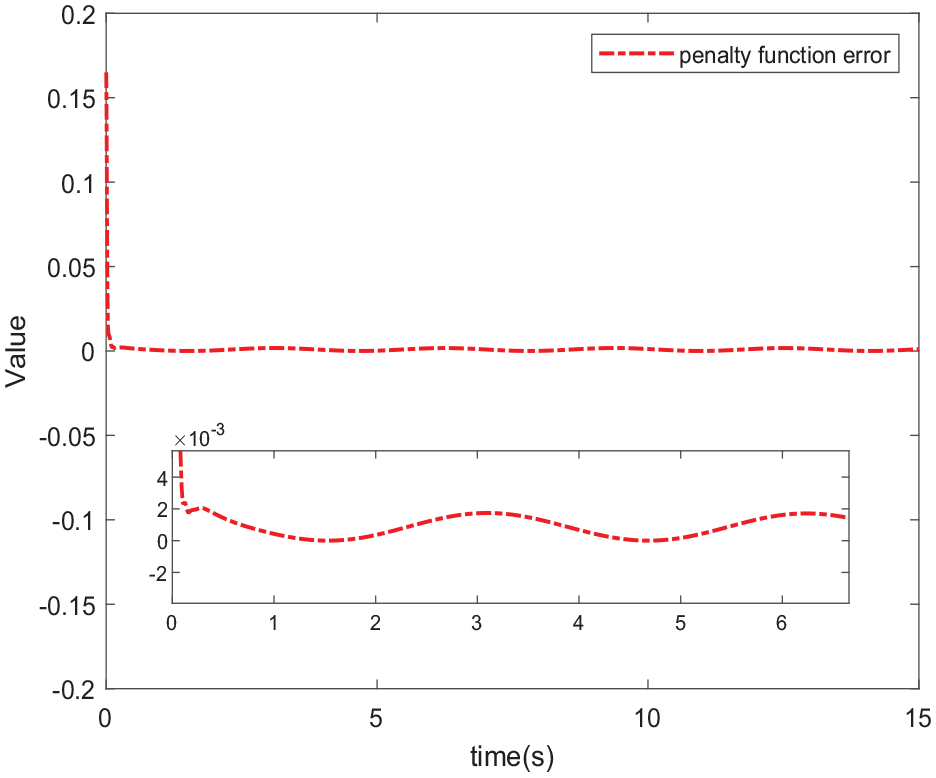
The error of penalty function.
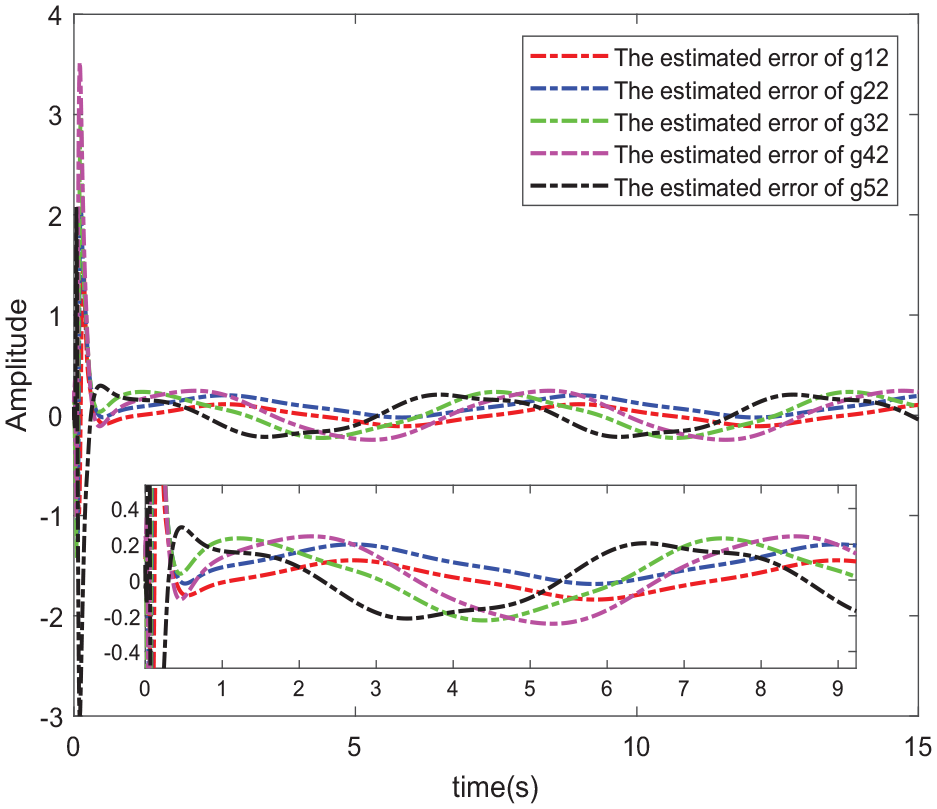
Approximation error of nonlinear function
Conclusions
In this paper, the optimal bipartite containment problem for multi-agent systems with unknown nonlinear functions is studied. the penalty function is constructed by combining the bipartite containment definition. Moreover, We define a local objective function for each agent to ensure agents can track the target accurately. We use DSC technology to construct an adaptive inversion controller to avoid “explosion of complexity.” We construct Lyapunov functions to guarantee the stability of systems. The result of simulation show that the control method can control agents to converge to the optimal solution quickly under the condition of obtaining the optimal solution of the optimization problem, so that agents can satisfy the optimal solution and achieve the bipartite containment objective. On the basis of this paper, distributed optimization problems will continue to be studied in the future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.