
Abstract
The operational cycle identification of the load-haul-dump (LHD) can help support the production process optimization in the underground mining industry and thus reduce mining costs. However, most of the existing research works use only the hydraulic bucket signal of LHD as the data source, and the stability and robustness of the identification method are poor. A few advanced research works use the variational Bayesian Gaussian mixture model to introduce other signals, but the accuracy of this recognition method is not perfect at present. In addition, the current identification methods are unable to simultaneously recognize the four working conditions of the LHD which include loading, hauling, dumping, and transiting. To solve these problems, a random forest feature selection (RFFS) and bidirectional long short-term memory (Bi-LSTM) based operation cycle recognition algorithm is proposed. Firstly, RFFS is used to remove redundant features based on the multi-sensor signals of the LHD. Then, Bi-LSTM is applied to fully exploit the temporal correlation between different operation regimes and accurately recognize the operation cycles. The effectiveness and superiority of the algorithm are verified by the experiment on the actual data of the LHD. The proposed algorithm can recognize four working conditions simultaneously, among which the recognition accuracy of loading conditions is the highest, up to 95.42%, and the weighted accuracy of this algorithm can reach 91.75% using the occupied time of each working condition as the weighting factor.
Keywords
Introduction
The load-haul dump (LHD) is the leading equipment for ore transportation in the underground mining industry. The operating cost of the LHD, including depreciation, maintenance, fault repair, operator salary, etc., accounts for a substantial portion of the mining cost. 1 Production process optimization is a powerful means to reduce the operation cost of the LHD, which includes analyzing the utilization of machines, evaluating production efficiency, and formulating a production optimization strategy for the LHD. In 2011, Mkhwanazi 2 recommended that Denmark Colliery improves machine utilization and reduces the traveling time of the LHD. After several years, Mbhalati 3 proposed a similar production process optimization strategy through a detailed investigation of the Conzal mine and an in-depth analysis of the causes of production inefficiencies. In 2016, Fukui et al. 4 considered that the LHD has both excavation and transportation functions, so they installed these functions on separate machines to reveal the factors affecting productivity. According to the above research work, to achieve production process optimization, it is necessary to collect information from different sources characterizing different evaluation indicators.
The operation cycle was formally introduced as a performance indicator in 2015. 5 According to the investigation of mines, the LHD always works in cycles, first loading the blasted ore from the mining face with a bucket, next hauling it to the dumping point, then dumping it, and finally returning to the mining face. Thus, an operation cycle means a set of the abovementioned operations of the LHD. By detecting the operating cycle of the LHD, its continuous working time can be calculated to support production optimization.
However, there are still fewer papers on the recognition of the operation cycle of the LHD. In 2014, Wyłomańska and Zimroz 6 proposed an automatic segmentation method of diagnostic signals that can be used to detect and recognize certain regimes in the operation cycle. In 2015, Stefaniak et al. 5 proposed a threshold segmentation method based on kernel density estimation to distinguish the work conditions of the LHD. In 2016, Polak et al. 7 found that the bucket jitter is more noticeable when the LHD is loading, so, based on these characteristics, they subdivided the heavy load working condition into loading and hauling with the help of statistical analytical tools. In 2020, Koperska et al.8,9 proposed a convolution of the smoothed signal with an inverted step function to reduce signal interference and then applied this method to recognize loading, hauling, and dumping. In addition, Wodecki et al. 10 published a short review of smoothing methods for the hydraulic signal from the LHD. In the abovementioned works, the detection of the operation cycle only used the bucket hydraulic signal of the LHD, but in a real system, there is a risk of losing the hydraulic signal. In 2018, Saari and Odelius 11 employed the front axle vibration signal and the Cardan axis speed signal to recognize the operation regimes of the LHD by the variational Bayesian Gaussian mixture (VBGM) model. VBGM is an unsupervised clustering algorithm, which does not need a large number of monitoring data with known labels, so it is applied in numerous industry scenarios.12–14 The application of VBGM to recognize the operation cycle of the LHD is undoubtedly a breakthrough, but at present, the accuracy of this algorithm is not perfect when it is used to recognize the operation cycle.
Considering the small number of relative papers on the recognition of the operation cycle of the LHD, research work on the recognition of the operation cycle of other mining equipment is also reviewed. In 2019, Kozlowski et al. 15 pointed out that for mining trucks, the number of operation cycles during a single work shift can also be used as indicators of a machine and operator performance evaluation and proposed a signal segmentation method based on engine speed and brake system pressure. This work is very important, but the engine speed, brake system pressure, and other hydraulic signals have a risk of losing. To solve this problem, in 2020, Krot et al. 16 used brake pressure, gear selection, vehicle speed, and engine speed signals to recognize the unloading conditions of the truck. These works are excellent, but the signals they used are greatly affected by driving habits, so the stability and robustness of this algorithm are poor. In 2020, Gawelski et al. 17 argued that the application of multidimensional sensor data for the recognition of truck cycle conditions could avoid the effects caused by the loss of hydraulic signals and proposed a corresponding method for the recognition of operating cycles. In the same year, Wodecki et al. 18 also proposed a multidimensional data technique based on current and pressure signals for recognizing the operation cycles of heavy drilling rigs. These works show that operation cycle recognition based on multidimensional sensor data is a direction for research with great potential.
In conclusion, the above-mentioned related research work shows two problems with the current operation cycle recognition of the LHD. One is the lack of stability and robustness of the operation cycle recognition algorithm relying only on hydraulic signals, and the other is the inability to recognize loading, hauling, unloading, and transiting simultaneously. And the research on other mining equipment, such as dump trucks, shows the great potential of using multidimensional sensor data for operation cycle recognition. At the same time, as vehicle automation evolves, onboard monitoring systems for the LHD are becoming more common.19–21 These systems can provide the multidimensional sensor data needed for operation cycle recognition. Therefore, taking the above factors into account, it is necessary to develop an operation cycles recognition algorithm based on multidimensional sensor data for the LHD, which can be regarded as a solution for the classification problem of time series.
Considering that in solving this type of problem, long short-term memory networks (LSTM) are widely utilized seeing that LSTM has a strong ability to mine the temporal dependency in sequence data.22–25 Further, a backward layer can be superimposed to build a Bi-LSTM based on the classical LSTM. Bi-LSTM can use not only past information but also future information, which may achieve better experimental results.26,27 In addition, we consider that making full use of the monitoring system’s multidimensional sensor data can improve the recognition algorithm’s stability and robustness. Still, those sensor data certainly have irrelevant or redundant features. Hence, feature selection must be performed to select the relevant characteristics. Currently, Random forest feature selection (RFFS) is an advanced feature selection method that uses out-of-bag (OOB) data to measure the importance of features and select features with high importance. 28
Aiming at the above problems and based on the above methods, we proposed an operation cycle recognition algorithm based on RFFS and Bi-LSTM, which can realize the recognition of loading, hauling, unloading, and transiting for the LHD. To develop this algorithm, we have completed the following work. Firstly, we extracted the multidimensional sensor data from the onboard system, and then they were cleaned and normalized. Secondly, three common feature selection methods were compared, and the selected feature signal was input into Bi-LSTM to train the operation cycle recognition model. Finally, the superiority of Bi-LSTM was verified compared with the classification algorithms commonly used in industrial data. The main contributions of our work are as follows. Firstly, we integrated RFFS and Bi-LSTM to select correlated features and excavate the temporal dependency of the selected feature sequentially. This approach can fully use the monitoring data and achieve a more stable and robust operation cycle recognition algorithm. Secondly, the proposed method can distinguish loading, hauling, dumping, and transiting. Whereas existing methods only recognize loading, hauling, and no-load. Dumping and transiting are included in un-load conditions and are not differentiated. Thirdly, the proposed method can be extended to other mining equipment with operation cycle characteristics, such as dump trucks and heavy drilling rigs. The paper is structured as follows: In Section 2, we introduce the basic algorithm theory involved in this paper. The methodology that recognizes the LHD operation cycle is described in Section 3. Section 4 presents the results obtained from the experiments on the actual data of the LHD. The last section contains the conclusions and future research directions.
Basic algorithm theory
Random forest feature selection
A random forest model is a strong classifier integrated by multiple weak classifiers which usually called decision trees, the structure is given in Figure 1.
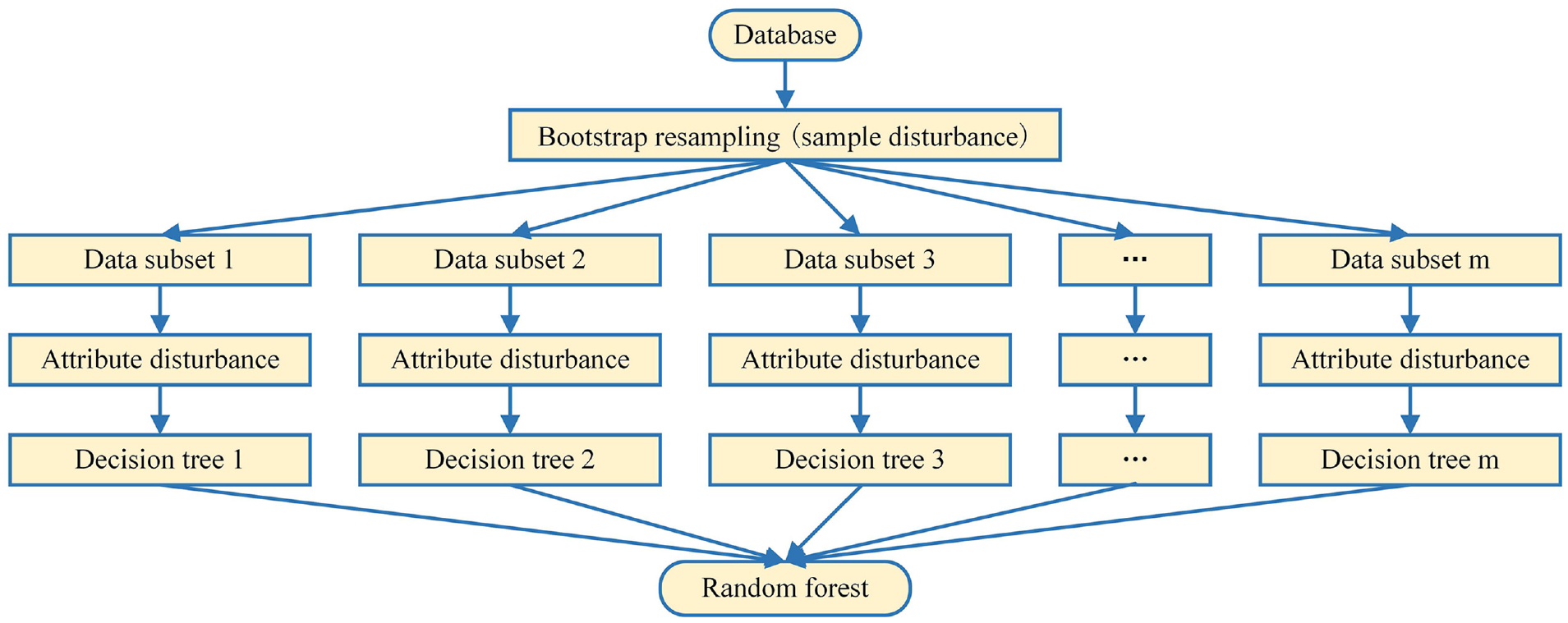
The structure of a random forest.
Considering that RFFS is to use OOB data to measure the importance of features and select features with higher importance, when calculating the importance of a feature
Step 1: For each decision tree, the corresponding OOB data is selected to calculate the accuracy, which is recorded as
Step 2: Random noise interference is added to the feature
Step 3: it is supposed that there are trees in the forest, then the importance of the feature is equal to
The reason why
Bidirectional long short-term memory network
LSTM is a sequence learning method 29 and is widely utilized in time series classification. The architecture of LSTM is presented in Figure 2. The calculation of the LSTM cell is shown in equation (1).
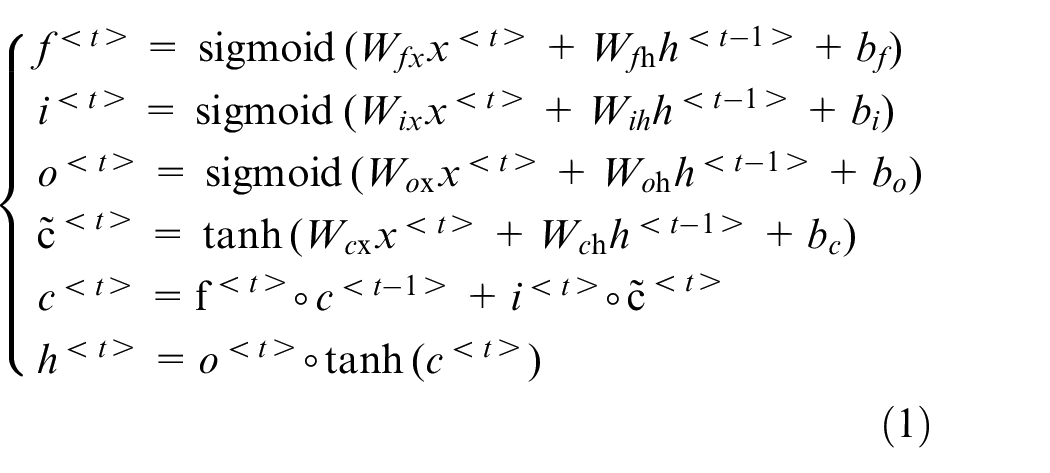
where
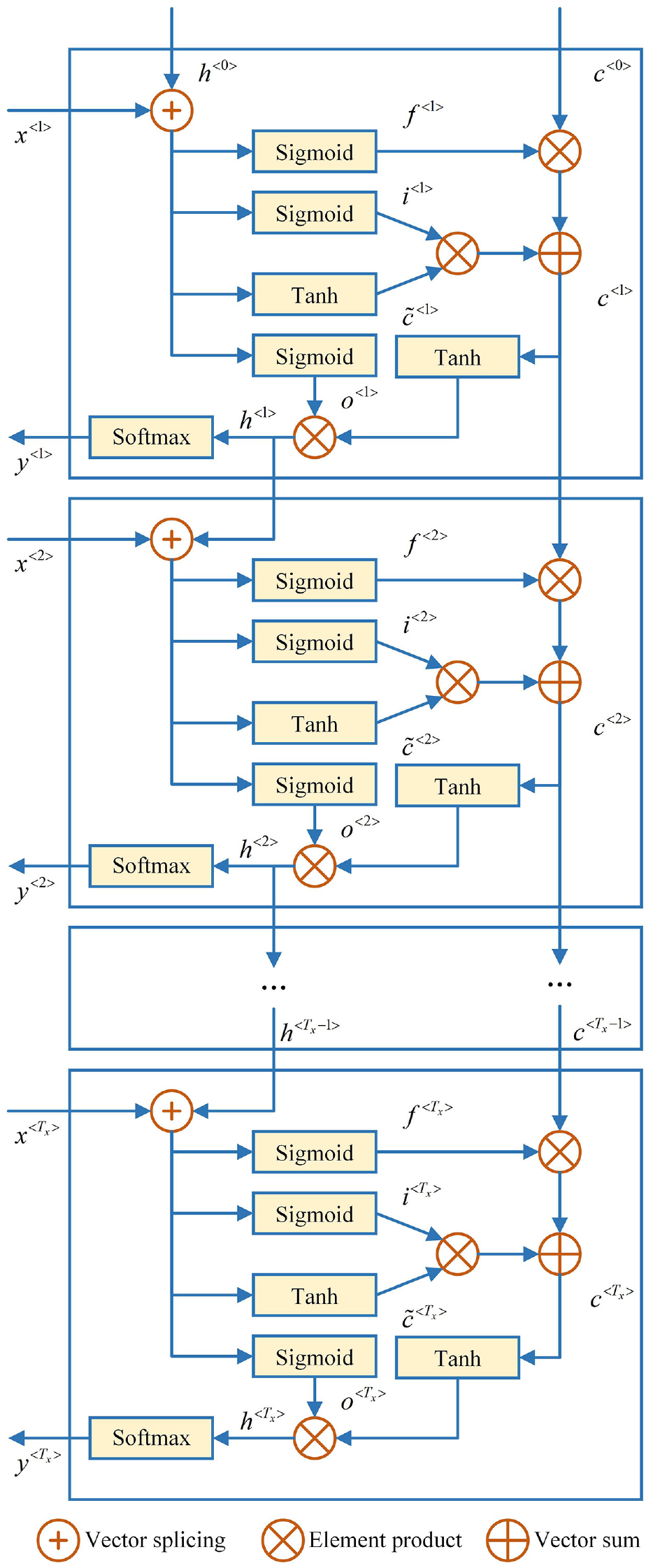
Long short-term memory network.
The general LSTM structure only uses the past signals and does not use the future signals. Therefore, referring to the existing work,26,27 a bidirectional LSTM structure is proposed, as shown in Figure 3. Bi-LSTM takes into account both sequential and reverse training network parameters, and the bidirectional parameters are finally merged to predict the results.
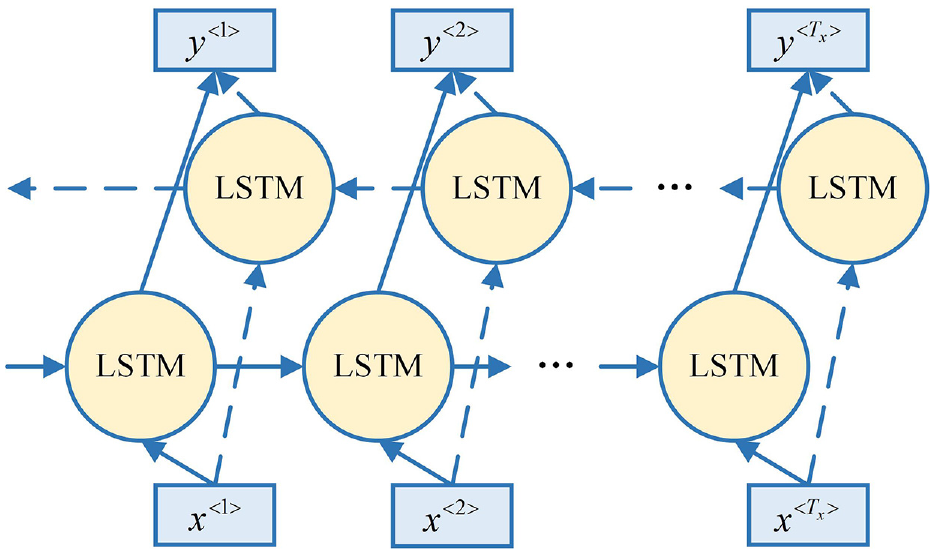
Bidirectional long short-term memory network.
Methodology
Operation cycles of the LHD
This research aims to develop a procedure that can reliably and quickly recognize the operation cycles of the LHD. The operation regimes can be divided into four different phases, as shown in Figure 4.
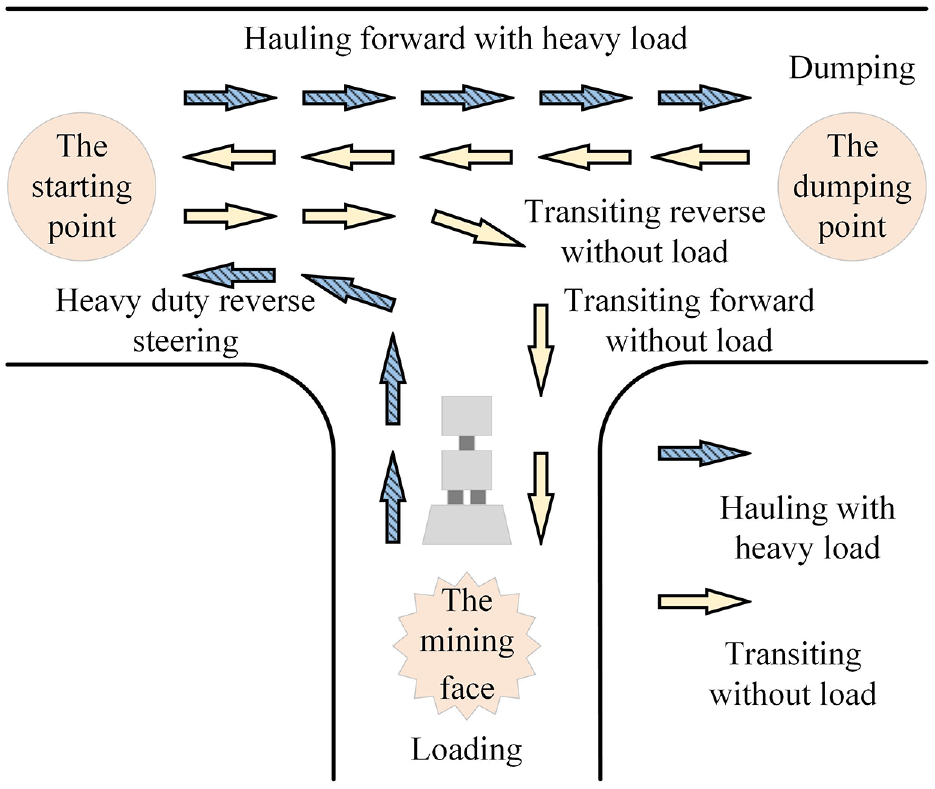
Operation cycles of the LHD.
Loading
Loading is the event when the ore is picked up after it has been drilled and blasted from the working face. During this phase, the LHD is normally operated at a lower speed. As the shoveling process progresses, engine intake manifold pressure and engine oil pressure gradually rise. Additionally, the pressure between the boom and the bucket is higher than that under no-load conditions because the bucket works.
Hauling
During the hauling phase, the ore is transported to the dumping point. The difference between the hauling regime and the transiting regime is that the average speed during the hauling regime is less than that during the transiting regime.
Dumping
Dumping is very quick. Due to the rapid dumping of ore in the bucket, the pressure of the boom and bucket will drop sharply. Meanwhile, the gear will change from forwarding gear to reverse gear, and the transmission oil pressure will fluctuate.
Transiting
As the LHD moves without load, boom and bucket pump pressure is very small, the speed is relatively fast and the engine fuel rate is low. If the roadway surface is flat, there is almost no need to brake, so the brake circuit charging pressure is small during the whole process. At the same time, the brake pressure of the front axle and rear axle will also be maintained in a low-level range.
Pre-processing of source data
The data set utilized in this research come from the onboard monitoring system of Sandvik LH514 underground LHD, as shown in Figure 5. These data are primarily stored in the data collection unit of the vehicle, then transmitted to the message-oriented middleware, and finally transmitted to the ground SQL server for storage.

Sandvik LH514 underground LHD.
The parameters available for the analysis of the underground LHD are listed in Table 1. The sampling period of the first 20 parameters in Table 1 is 5 s and the remaining five parameters are collected in real-time. The first 20 parameters are sensor monitoring data. Actual gear is a real-time gear record, negative four to positive four indicate that the LHD is from reverse gear 4 to forward gear 4, respectively. Idle, Operation, Utilization, and Parking Brake On are records of operation modes, and the correspondence between the operation mode and the values of these parameters is shown in Table 2.
List of parameters monitored in the underground LHD.
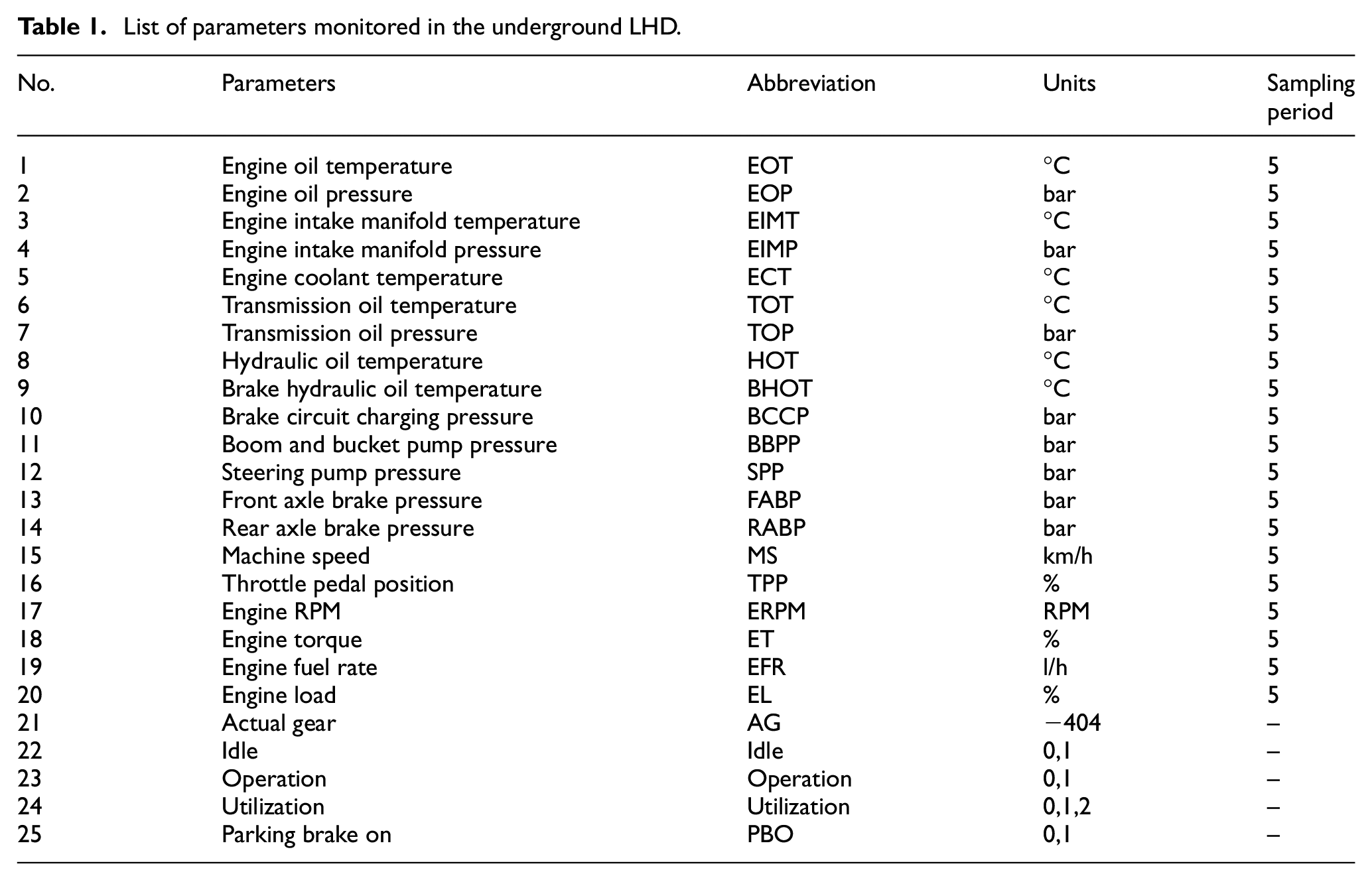
Representation rules of the underground LHD operation mode.
The data is first manually retrieved and exported into *.csv files using Python to obtain the data for analysis. Then, the filling method with the existing value is used to solve the time asynchrony problem of the LHD monitoring data caused by inconsistent sensor acquisition frequency.
Due to the instability of the data transmission process of the LHD, there are large segment vacancy values at some continuous sampling times of the source data. This part of missing data accounts for a very small proportion of the total data. Deleting the missing data will not affect the result of cycle recognition. Therefore, it is deleted directly in the data preprocessing stage. In addition, there will be occasional data loss of some parameters, such as transmission oil temperature. Considering that the temperature and pressure are changing slowly, the interpolation method is employed for data filling.
Moreover, the data can be deleted according to Table 2 when Parking Brake On is equal to 1 since this research is to recognize the cycles. And then the remaining data is the cycle data. Finally, the procedure of normalizing is implemented to eliminate the influence of different units between different parameters. And then, the data are represented with the same scale on the graphs.
Signal selection
The purpose of this study is to recognize the operation regimes of the LHD based on the monitoring data. Hence, it is necessary to select the characteristics related to the cycles of the LHD from 21-dimensional available data. Idle, Operation, Utilization, and Parking Brake On are records of operation modes and are utilized to determine whether the machines work or not. On the one hand, feature selection can reduce the number of features, improve the accuracy of the model, and speed up the running speed. On the other hand, eliminating irrelevant variables which increase the degree of freedom of the model can minimize the risk of overfitting. In this study, RFFS is applied to implement signal selection. The process is exhibited in Figure 6.
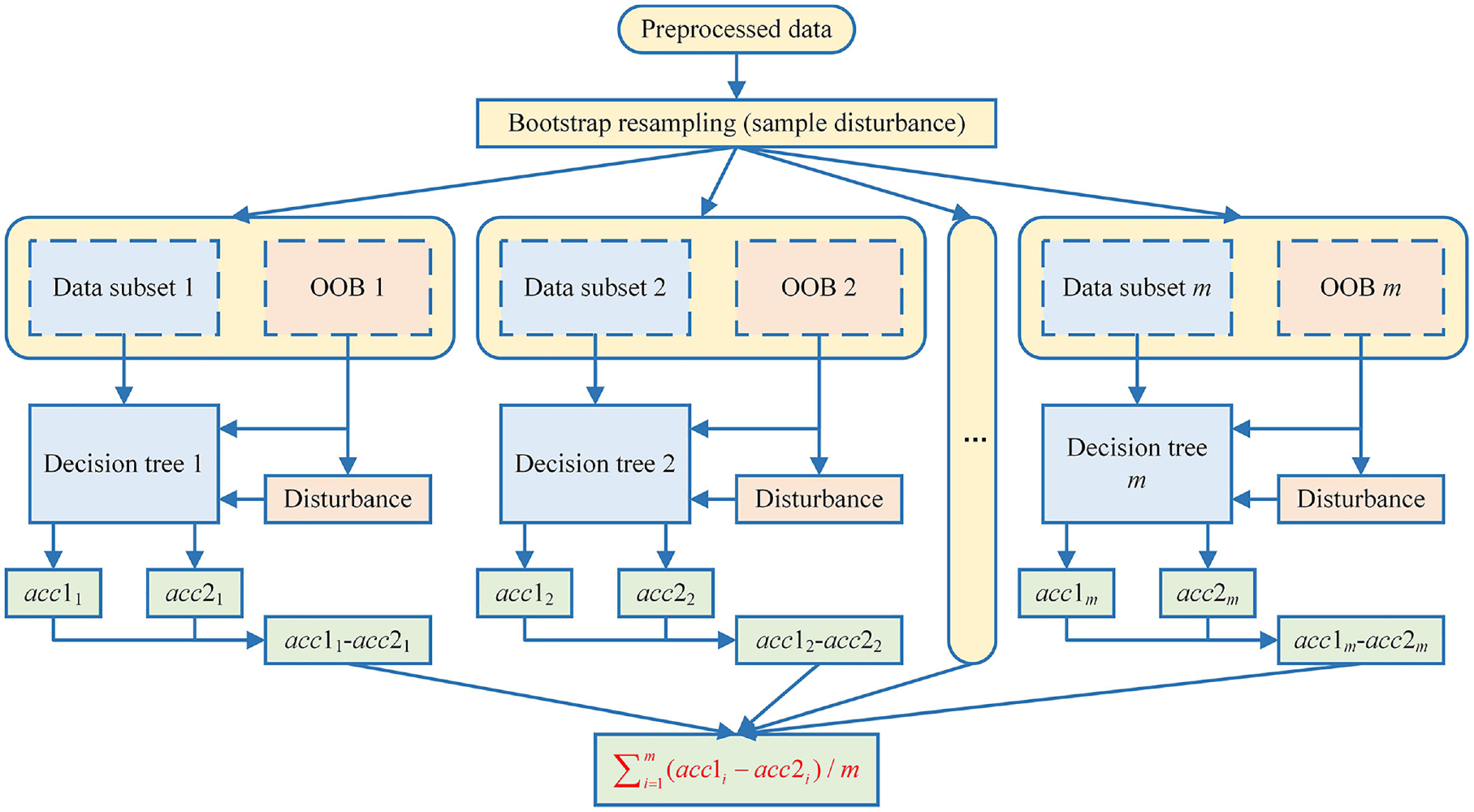
The flow chart of random forest feature selection.
It can be observed that there are 21-dimensional data. Then all samples from 21 sensors are bootstrap resampled to gain data subsets and OOBs. Data subsets are used to train different decision trees. OOBs are classified by corresponding decision trees and gain the accuracy recorded as
Operation cycle recognition model construction
The monitoring signals of the LHD belong to time series data. The purpose of this research is to use the monitoring signals to recognize the cycles. According to the above analysis of the cycles, the LHD always repeat four sub-processes: loading, hauling, dumping, and transiting. The essence of recognizing operation regimes based on monitoring signals can be regarded as the time series classification problem. The four sub-processes of the cycles have a fixed-order relationship and a strong time-dependent relationship. Consequently, Bi-LSTM is applied to recognize the cycles. The proposed cycle recognition model based on multi-sensor feature selection and Bi-LSTM is presented in Figure 7.
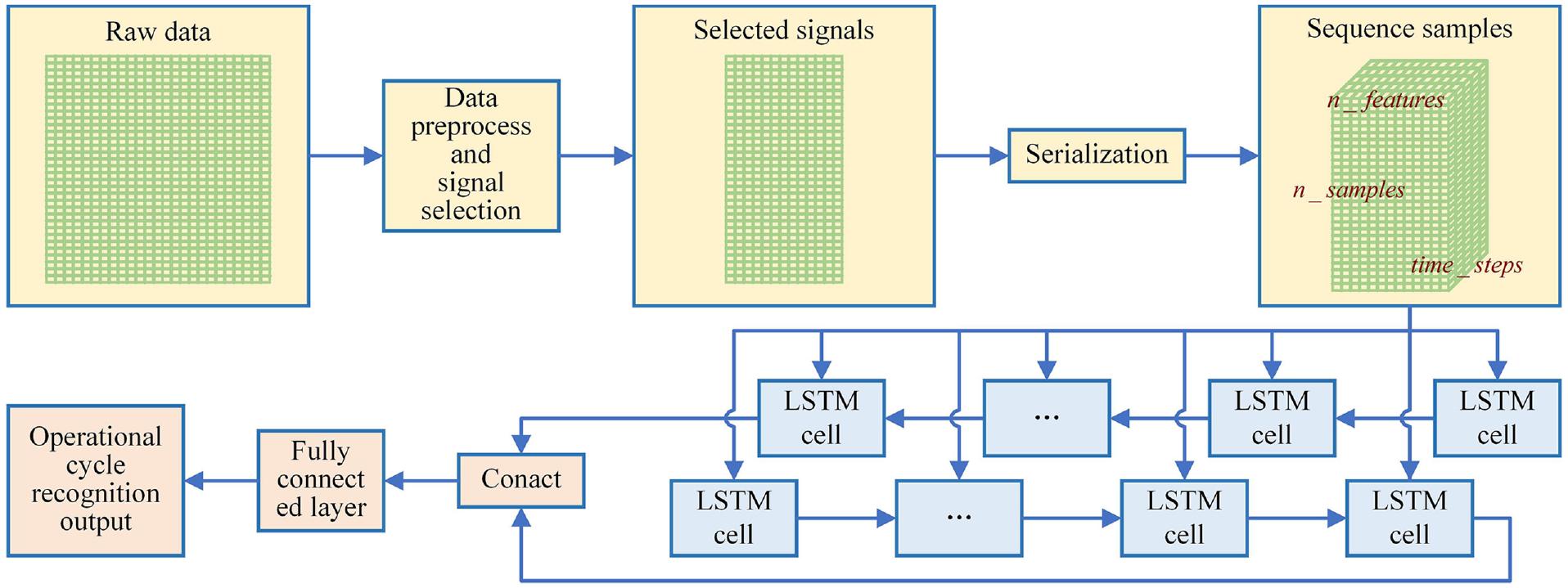
The flow chart of the cycle recognition model construction.
It can be seen that raw data are preprocessed and feature selection is conducted. And then, the selected signals are serialization. Assume
Step 1: To solve the time asynchrony problem and process dirty data, raw data from multi-sensors are preprocessed, including time synchronization, data cleaning, and normalization.
Step 2: To obtain the closely related characteristics to the cycles, feature selection is conducted on the preprocessed data.
Step 3: Two layers of Bi-LSTM networks are designed. The input is sequence samples which are the serialization of the acquired data by the above two steps.
Step 4: A fully connected neural network is designed to yield the operation regimes recognition results.
The abovementioned algorithm needs to be trained by using the labeled dataset to obtain the weight matrices and bias matrices. The loss function can be defined as:
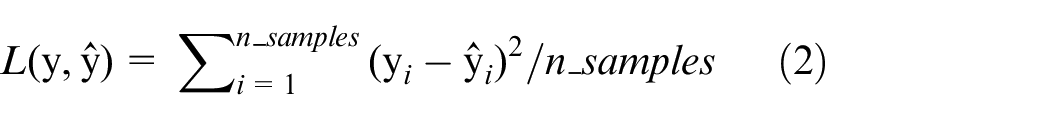
where
The adaptive moment estimation (Adam) is utilized to obtain the weight matrices and bias matrices of the proposed networks, and the learning rate is set to 0.001.
Algorithm verification on real data
Experimental platforms and evaluation index
The experiment platform is composed of central processing unit i7-4702MQ 2.20GHz, 16 GB memory, 64-bit Windows10 operating system, and the algorithm is written based on Keras (2.1.3) and TensorFlow (2.1.0) framework under python (3.7.9).
In this study, the score, which is the harmonic average of the accuracy rate and recall rate, is applied to assess the performance of the model. The expressions are given as follows.
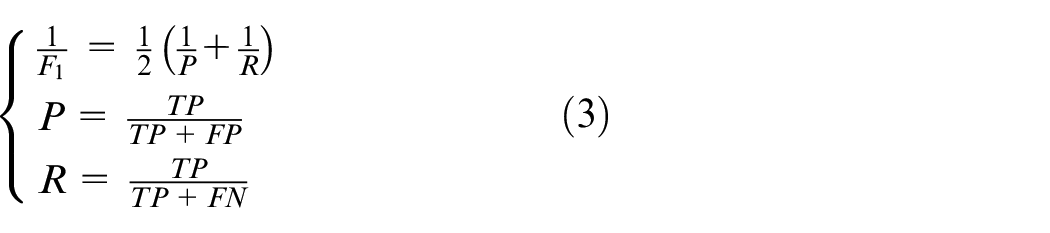
According to the four operation regimes of the LHD, define
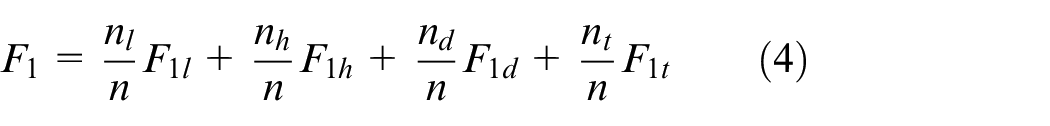
where
Experiment results discussion and algorithm comparison
The preprocessed multidimensional sensor data extracted from the onboard monitoring system of the Sandvik LH514 LHD are shown in Figure 8.
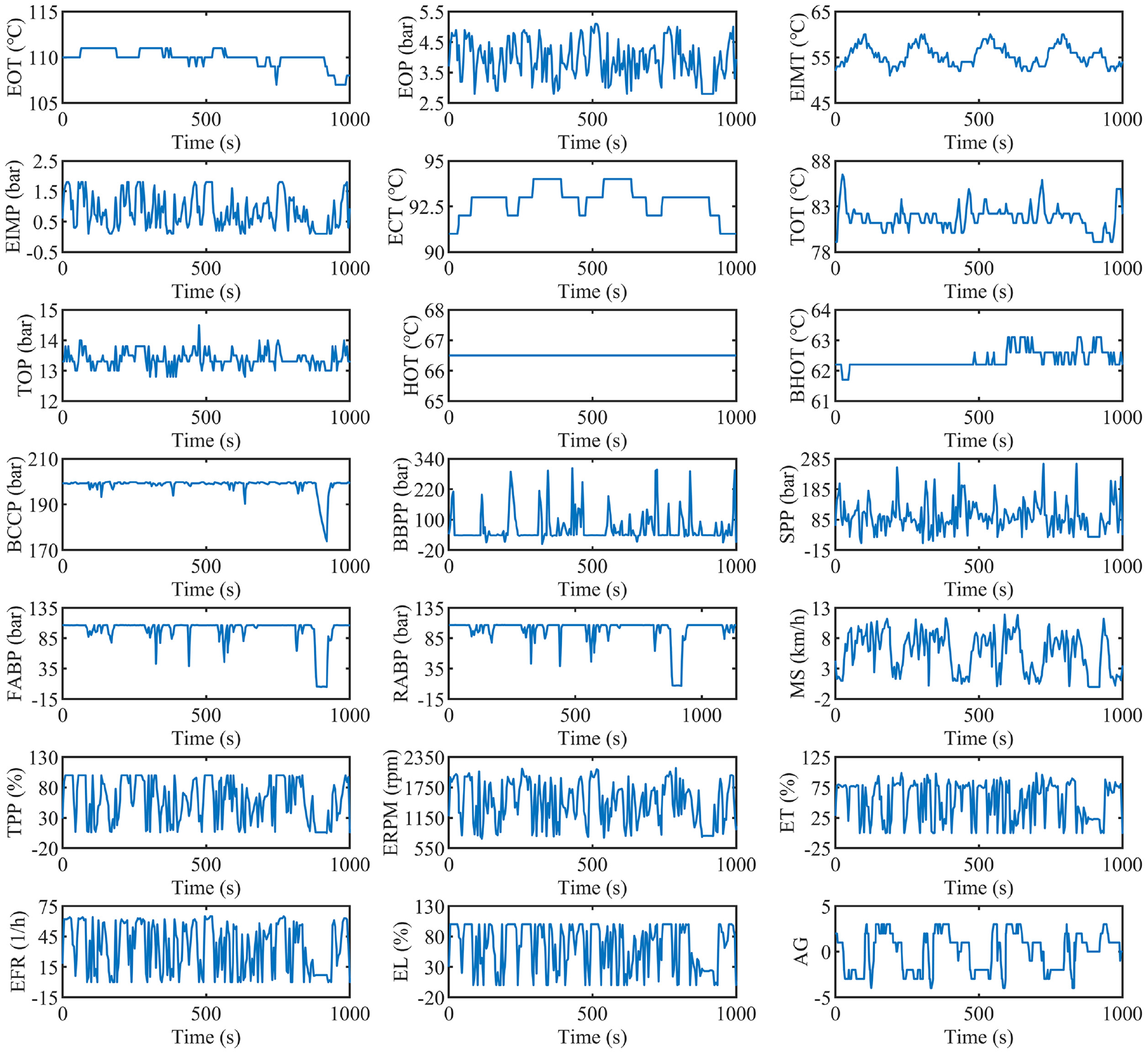
Raw data of the Sandvik underground LHD.
The first case of the experiment is the comparison of different feature selection algorithms. RFFS is applied to select the related features to the cycles based on the preprocessed data. Experiments show the effectiveness of feature selection compared with no feature selection. Moreover, other commonly used methods, including mechanism analysis and ReliefF algorithm, 30 were selected to compare the recognition accuracy to verify the superiority of RFFS. The sensitive features determined by the above methods are given in Figure 9.
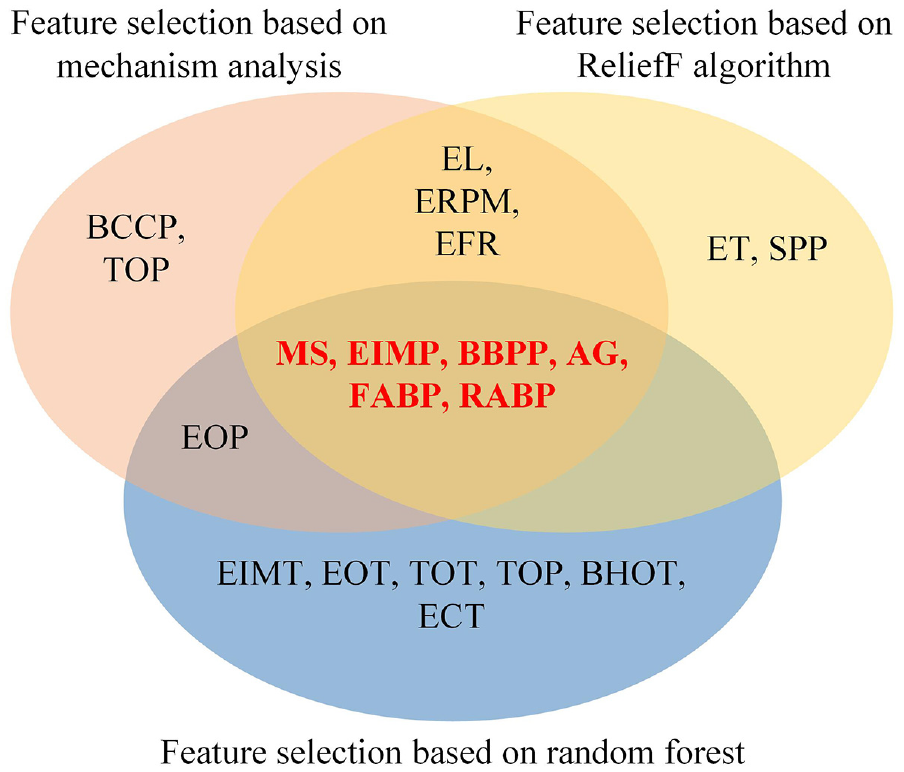
The sensitive features determined by different methods.
The comparison of cycle recognition results of different feature selection methods is presented in Table 3 and Figure 10. It can be observed that the method without feature selection performs worst, which illustrates the necessity of feature selection. Besides, the performance of recognizing loading, hauling, dumping, and transiting events based on RFFS is the highest score compared with the other methods. In short, feature selection can promote recognition accuracy and RFFS outperforms all the other compared methods.
Comparison of different feature selection algorithms.

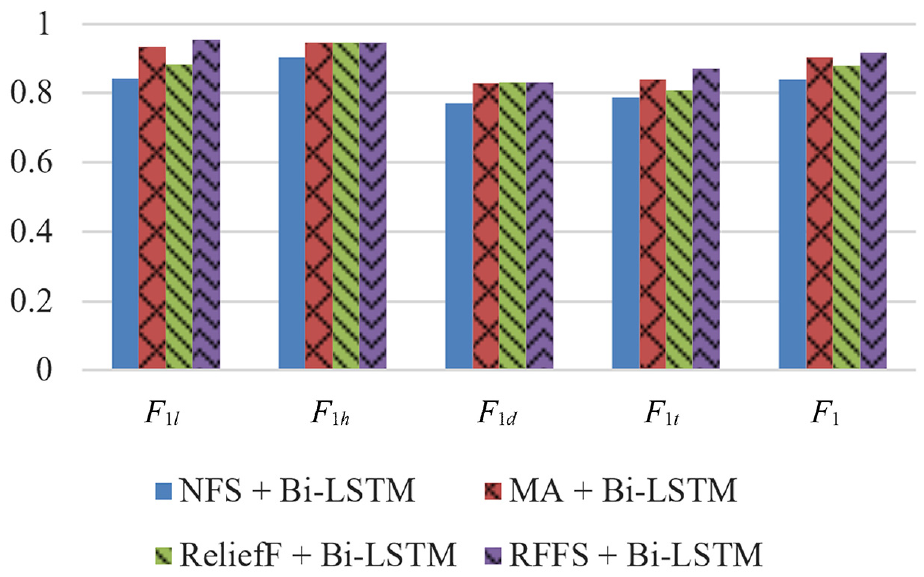
The recognition performance scores with different feature selection methods.
Hence, the reasons for explaining why selected RFFS in this study are summarized as follows. On the one hand, feature selection based on mechanism analysis mainly depends on experience. There are differences between different devices, which need to be analyzed separately. On the other hand, the ReliefF algorithm and RFFS can determine sensitive features automatically since there is no need to have too much equipment-related professional knowledge. Besides, RFFS obtains higher accuracy than the ReliefF algorithm.
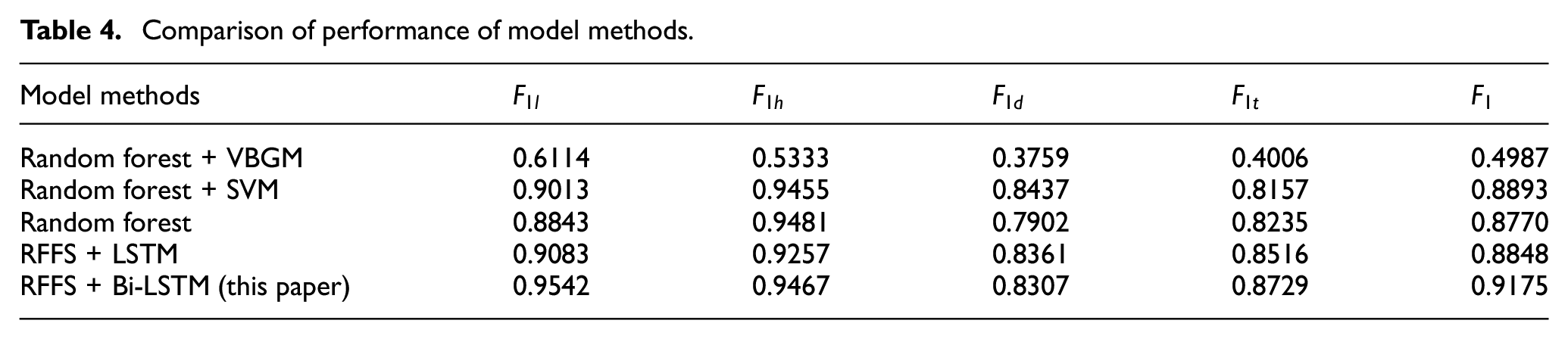
The second case of the experiment is the comparison of different classification models. The feature signals selected by RFFS are input into the Bi-LSTM network to construct an operation regime recognition model. Compared with the VBGM model in Saari and Odelius,
11
the proposed method performs significantly better. Additionally, to confirm the effectiveness of the RFFS + Bi-LSTM algorithm, other typical classification algorithms used in the industry are selected to compare the recognition accuracy. The comparison of the performance of different models is presented in Table 4 and Figure 11. It can be seen that
Comparison of performance of model methods.
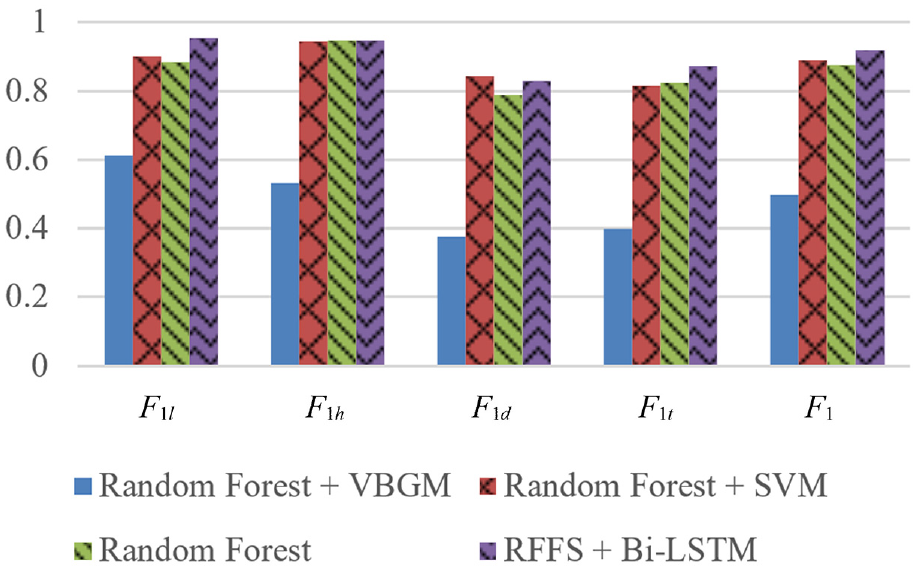
The recognition performance scores of different classification algorithms.
Figure 12 below shows the visualized result of the RFFS + Bi-LSTM model used in the test set. The solid line in the figure represents the true label, and the dotted line represents the model prediction results. And labels 1, 2, 3, and 4 correspond to loading, hauling, dumping, and transiting. It can be seen that the recognition rate of loading and hauling is very high, and error recognition occurs usually when the operation regimes are switched. The reason for the relatively low recognition rate of dumping and transiting may be that in a complete cycle, the duration of dumping and transiting accounts for less, the data in the corresponding period is less, and the corresponding training samples will be less.
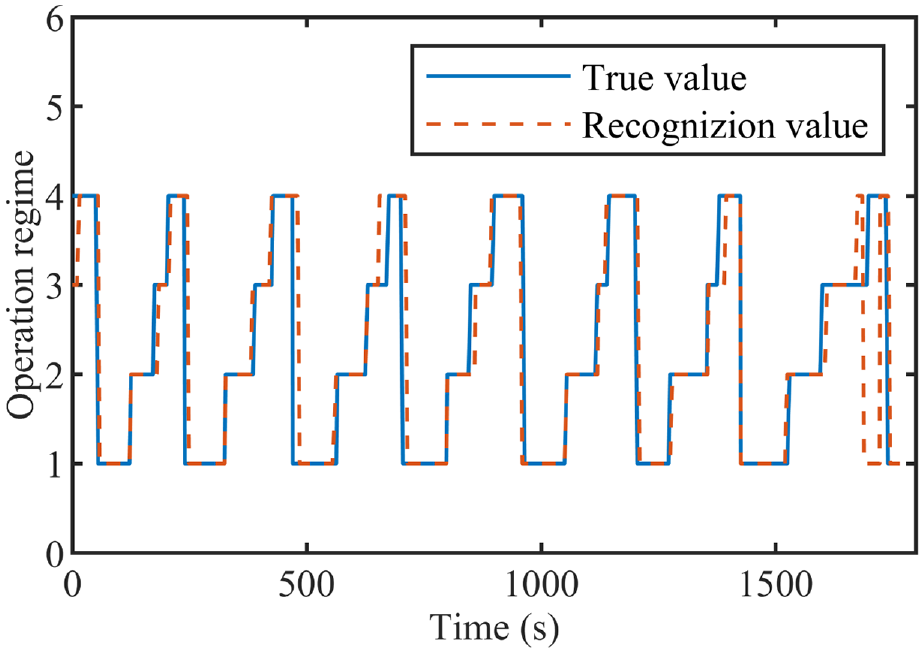
Visualized result of cycle recognition based on RFFS + Bi-LSTM.
Conclusions
In this paper, a novel method based on random forest feature selection and bidirectional long short-term memory is proposed for the recognition of cycles for the LHD, which can recognize loading, hauling, dumping, and transiting simultaneously. Random forest is used to select the characteristic signals which are strongly correlated with cycles in the monitoring signals of the LHD. And then, these selected signals are input into Bi-LSTM for training. Using the advantages of recurrent neural networks in sequence data, the RFFS + Bi-LSTM model can extract the characteristics of time series and achieve better recognition performance. The main conclusions can be listed as follows.
Firstly, utilizing the random forest to select sensitive signals with the cycles is effective, which can remove redundant information to avoid unnecessary interference to model training and acquire better achievements.
Secondly, there is a close time-dependent relationship between different operation regimes in the operation cycles. Bi-LSTM can fully learn this relationship and achieve extraordinary outcomes. Compared with the existing or other typical classification methods, the proposed method is more accurate and effective.
In addition, three future research directions are considered. The first is to use the proposed algorithm for the operation cycle recognition of other mining equipment, such as trucks, drilling rigs, etc. The second is to explore a better recognition algorithm compatible with more complex application scenarios through experiments on different neural networks, such as the explainable deep belief network.31,32 The last is to discuss the influence of data filtering, feature selection, and other methods on recognition algorithms from the perspective of data processing.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Key Research and Development Program of China (2019YFC0605300, 2018YFE0192900), the National Natural Science Foundation of China (52202505), the China Postdoctoral Science Foundation (2022M710354), the Science and Technology Plan Project of China Nonferrous Metals Group (2018KJJH01) and the Fundamental Research Funds for the Central Universities (FRF-MP-20-07).