
Abstract
In order to make full use of the absolute position information of fault signal, this paper designs a new multi-head attention (MHA) mechanism focusing on data positional information, proposes a novel MHA-based fault diagnosis method and extends it to the fault diagnosis scenario with missing information. Based on the absolute positional information and the trainable parameter matrix of the fault data, a novel attention weight matrix is generated, and the fault features are extracted by a fully connected network with the attention mechanism. By integrating the positional information into the weight matrix, the new MHA mechanism has the ability to extract more effective data features, compared with the traditional MHA method. Furthermore, the proposed method is also developed for the fault diagnosis scenarios with missing information. A special attention weight modified method is designed to reduce the impact of missing data on fault diagnosis results. In the experiment simulations, the data sampled from ZHS-2 multi-function motor flexible rotor test bed and the Tennessee- Eastman process data are utilized to test the performance of the algorithm. The results show that the proposed method can effectively extract fault features and reduce the impact of missing data.
Introduction
In recent years, due to intelligent data acquisition systems and advanced computer control systems, the integration and automation of industrial production processes have been greatly improved. Meanwhile, highly interrelated subsystems and control units have increased the complexity of industrial processes. Most industrial processes have more urgent needs for reliability and safety. Once an accident occurs, it may cause serious property damage and personal injury. Therefore, the operation monitoring and fault diagnosis of modern industrial production systems are very necessary and important. As is well known, compared with model-based and knowledge-based fault diagnosis methods, data-driven methods do not need to establish accurate models or depend on expert systems. Because computer control systems collect a large amount of process data, data-driven fault diagnosis algorithms are paid increasingly attentions. 1
In recent decades, a variety of data-driven fault diagnosis methods have been extensively studied, including the K-nearest neighbor classifier, 2 support vector machine, 3 fisher discriminant analysis, 4 and random forest. 5 Most of the methods mentioned above are applied to fault diagnosis scenarios with a small amount of data. However, in the scenarios with multiple working conditions and massive amounts of data, these methods will encounter the problems such as one-sided analysis results, poor accuracy or low efficiency. Last few years, deep learning is developing rapidly,6,7 and presenting a breakthrough advantage over traditional fault diagnosis methods. Deep learning has replaced the feature extraction approach of traditional algorithms, and automatically mines the deep features of input data, which reduces the reliance on expert knowledge. Representative deep learning models include deep belief networks, 8 sparse auto-encoders, 9 convolutional neural networks (CNNs), 10 and recurrent neural networks (RNNs). 11 At present, deep learning has been widely used in the field of fault diagnosis.12–16
On the other hand, the attention mechanism method has been rapidly developed in the field of deep learning in recent years. The attention mechanism was first applied in the field of computer vision, where its function is to direct greater attention to the areas that need to be studied in image. 17 Subsequently, the attention mechanism was widely applied in natural language processing tasks and considerably developed. Bahdanau et al. 18 used the attention mechanism to connect an RNN-based encoder and decoder and applied an attention mechanism to machine translation tasks. Ashish Vaswani et al. 19 proposed a fully connected architecture with multi-head attention. The attention mechanism succeeds in these tasks, because the pivotal features of data are emphasized, while the redundant features are weakened.20,21 In this way, the feature extraction process of deep learning is expected to enhance the reliability and effectiveness of data-driven methods. The attention mechanism is an end-to-end recognition method. It eliminates feature extraction steps and has been employed in mechanical fault diagnosis. In the field of fault diagnosis, Huang et al. 22 proposed a shallow multiscale convolutional neural network with attention to improve the accuracy of bearing fault diagnosis. Yang et al. 23 proposed a method using gated recurrent units with attention to improve the accuracy of bearing fault diagnosis. Canizo et al. 24 proposed a multi-head CNN–RNN, a supervised multi-time series anomaly detection method based on deep learning, which is used to deal with anomaly detection in multi-sensor systems. Yao et al. 25 proposed a deep convolutional neural network with attention that has good real-time and generalization performance for gear fault diagnosis. Currently, most attention mechanisms used in the fault domain are based on the improvement of CNNs and RNNs. A CNN is a parallel model, but its feature extraction ability is limited by the size of its convolution kernel. An RNN has a strong ability to extract long-range information, but it has to compute units one by one, which hinders the full exploitation of GPU parallelism.
It is worth noting that the multi-head attention mechanism has good performance in global data characteristic extraction and parallel computation. In this paper proposes a multi-head attention fault diagnosis method based on the data positional information. Different from the existing self-attention mechanism, which generates the attention weight matrix from the data values, The new multi-head attention fault diagnosis method utilizes the absolute positional information of data to generate the attention weight matrix. This method can extract the features of fault information more effectively, alleviate the low-rank bottleneck problem in multi-head attention and enhance the sensitivity of the multi-head attention model to the positional features of data. In addition, this paper also designs a special missing data weight modified method for the scenario with missing data, to reduce the influence of missing data on the fault diagnosis results.
The main contributions of this paper are summarized as follows. (1) In the multi-head attention mechanism focusing on data positional information designed in this paper, positional encoding is used to replace the input data to generate weight matrix. More positional information is integrated into the neural network. This extra information increases the sensitivity of the model to the data directionality. (2) The fault diagnosis methods are presented on the basis of the new multi-head attention mechanism, for the scenarios with and without missing data. For the fault diagnosis scenarios with missing data, by using the interpretability of attention weight matrix, a special attention weight modified method for missing data is designed to reduce the influence of missing data on fault diagnosis results.
Preliminaries
In this section, we will review the basic knowledge of multi-head attention fault diagnosis method.
Scale dot product attention
In fault diagnosis, the input data matrix is assumed to be
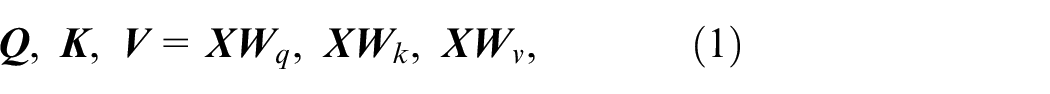
where

where
Multi-head attention
To extract more interaction information, the multi-head attention mechanism was developed, which can be formulated as
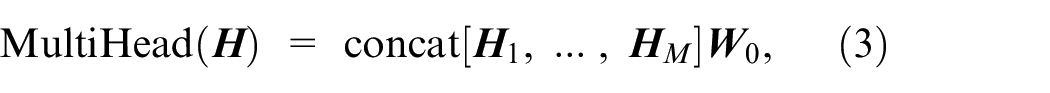
The above formula indicates that multiple attention matrices are concatenated into one matrix and then multiplied by the parameter
Positional encoding
In the multi-head attention network, the input data do not contain positional information. In other words, there is no difference between the input data from different positions in the multi-head attention model. Therefore, positional encoding is introduced to reflect the positional relationship between different positions of the input data. An existing positional encoding method is given as follows:
Define the positional encoding
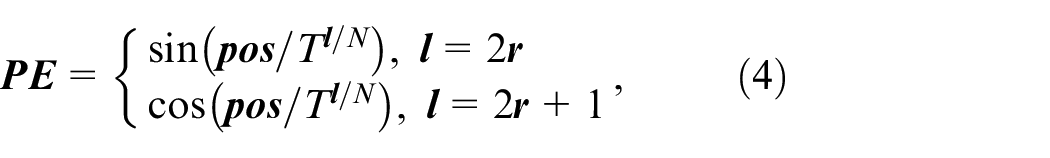
where
For a single sample
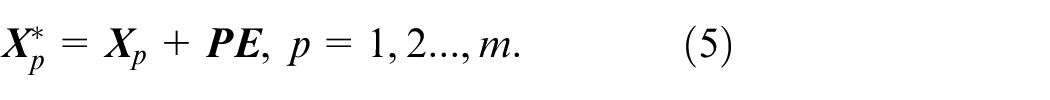
By introducing positional encoding into the input data, the neural network can extract data features efficiently.
Main work
The attention focusing on data positional information
In the multi-head attention neural network, the input data do not contain positional information. In other words, there is no difference between the input data from different positions in the multi-head attention model. Therefore, positional encoding is introduced to reflect the positional relationship between different positions of the input data. The positional encoding in equation (4) can reflect the absolute position of information. However, multi-head attention still has some shortcomings in extracting positional information. For instance, Bi-LSTM can discriminatively collect the information of a sample from its left and right sides. But it is not easy for the multi-head attention neural network to distinguish which side the data information comes from. 22
According to the analysis above, a positional encoding is introduced into the attention weight matrix to make it easier for the neural network to distinguish the directionality of information, in this sub-section.
It is defined as follows:
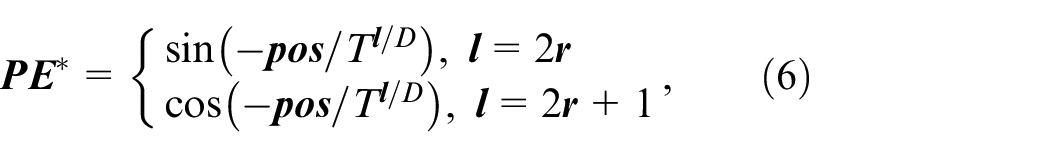
Because

For the input data to be processed by the neural network, the forward and backward positional encoding are the same for the cos terms but opposite for the sin terms. Therefore, the neural network will be more conducive to distinguish the different directions of the information by using equations (4) and (6) at the same time. The new positional encoding is integrated into the attention weight network in a certain form, which is helpful for the neural network to distinguish the directionality of data and improve the final classification accuracy.
Based on the above discussion, a new multi-head attention mechanisms is designed as shown in Figure 1.
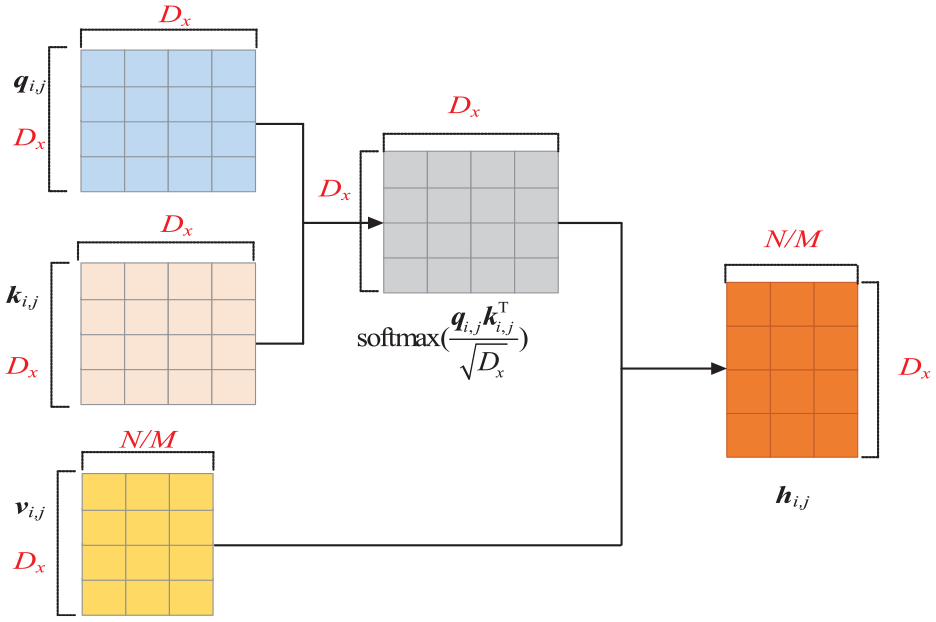
the attention Focusing on Data Positional Information.
In Figure 1, the attention output is expressed as:
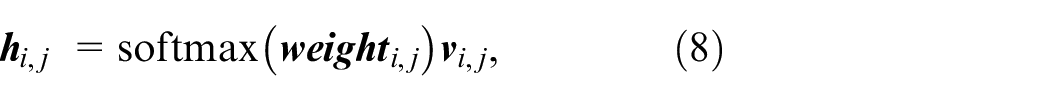
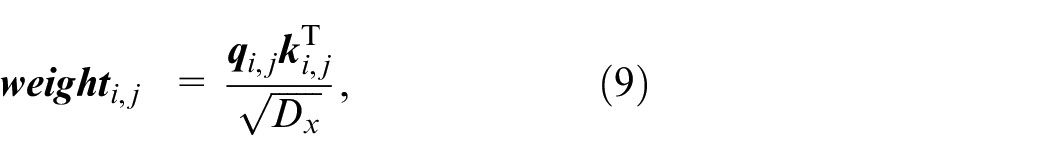
where
In order to improve the discrimination ability of neural network to data location information,

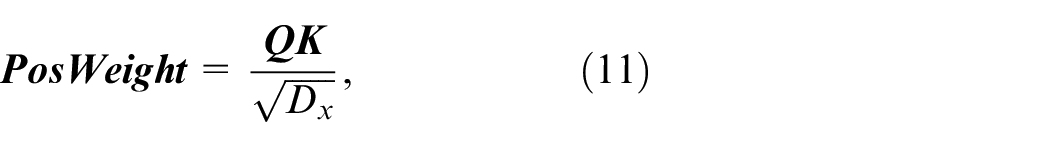
where
Attention weight modified method for missing data
As shown in Figure 2(a),
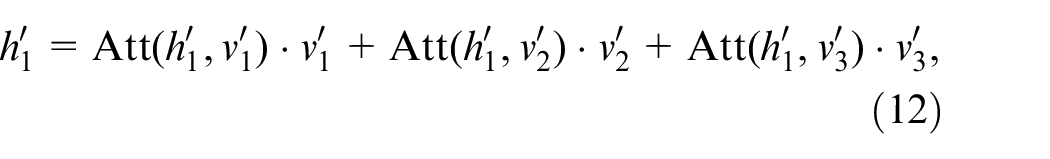
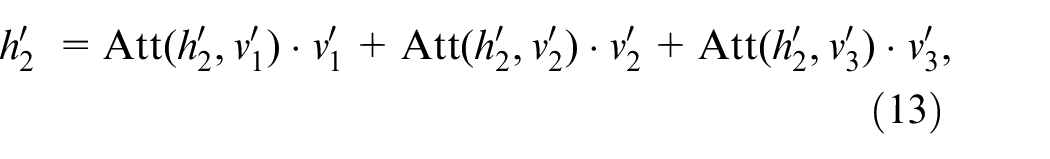
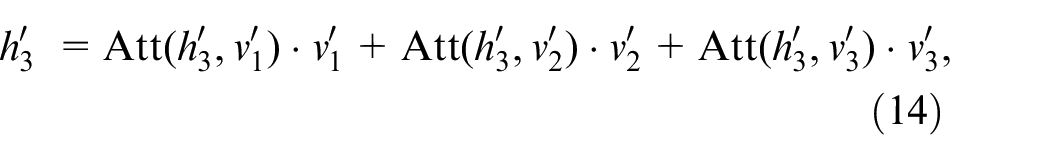
where Att(
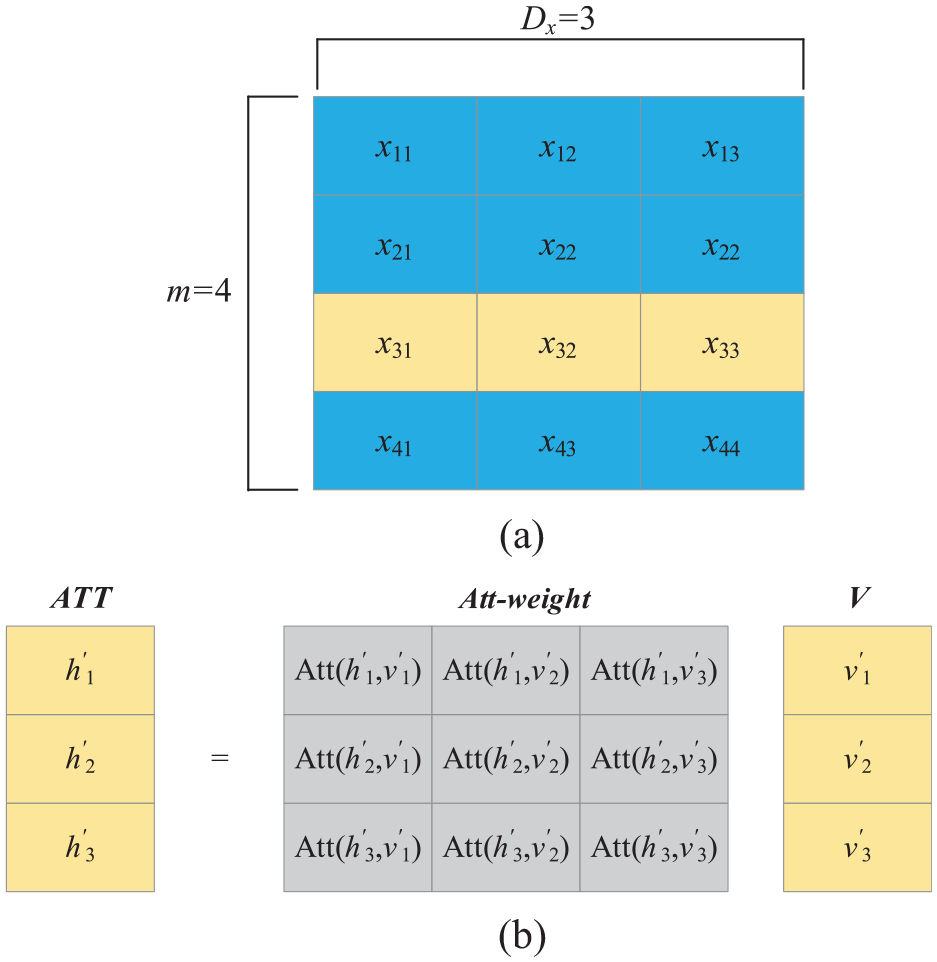
(a) The historical measurement data and (b) the calculation of attention.
Some signal may be missing in sample sequences, due to such sensor performance as sensor fault, inconsistent sensor measurement rate, etc. Compared with convolution neural network, multi-head attention neural network has better interpretability. For these unreliable or missing values, their corresponding weights in the attention weight matrix can be masked or modified, which is very useful for fault diagnosis.
Since the attention weight has the advantage of interpretability, we can further improve the accuracy of fault diagnosis under the scenarios with missing data, by modifying the weight value corresponding to missing data in the attention weight matrix. The position of the missing data is recorded by constructing a mark matrix
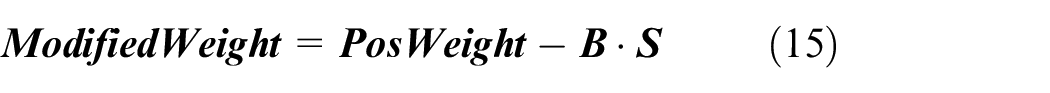
where
For a single sample:
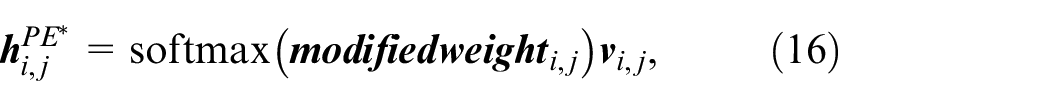
where i = [1,2, …, m], j = [1,2, …, M], m is the number of samples, M is the number of heads of attention.
In Figure 2(a), Assume that

Modified attention weight process.
Algorithm: modified-MHA.

Fault diagnosis model of multi-head attention based on positional information
In this section, the fault diagnosis method based on the above multi-head attention mechanism is proposed for the sample data sequence without missing data. The whole method is divided into two stages: offline modeling training and online diagnosis.
The process of offline model training:
(a) The historical measurement data
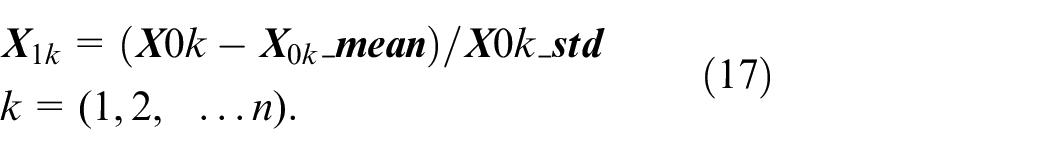
where,
(b)
(c) The new data
Sublayer 1: Using equation (16),
The above formula describes multiple
where
Sublayer 2: The second sublayer is a fully connected neural network. This sublayer includes two layers of a feedforward neural network. The number of neurons in these two layers is a superparameter. Here, we take the first layer with 2N neurons and the second layer with N neurons. The second layer uses the ReLU activation function. 31 The sublayer residual connectors with the layer norm are expressed as
where
(d) The result of (c) is sent to a fully connected neural network, activated by the ReLU function, and then flattened. Finally, we utilize the softmax classifier to recognize fault conditions. The following cross-entropy loss function is used in this work,
where m indicates the sample size, yk and tk denote the actual tag value and the predicted value of the kth sample, respectively. Moreover, this work adopts the Adam optimizer 32 to minimize the loss function and update the network parameters.
(e) Steps (b) to (d) are repeated until the accuracy of fault classification is met or the number of set iterations is reached. The complete algorithm flow chart is shown in Figure 4.
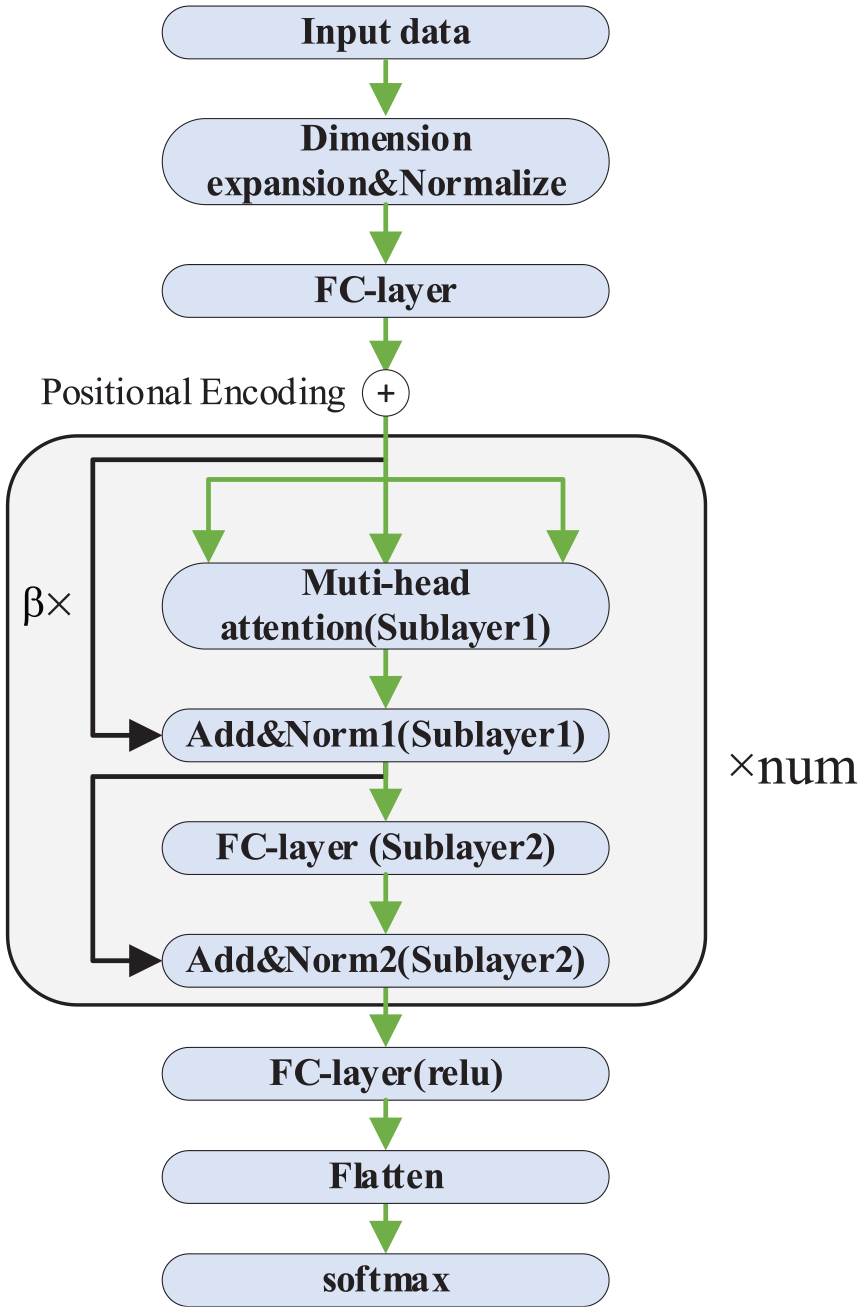
Structure of the multi-head attention fault diagnosis model.
(f) Several samples to be diagnosed are collected from the actual production process, and the data are standardized and used as the input data.
(g) The data obtained by (f) are sent to the multi-head attention fault diagnosis model to obtain the fault classification results and complete the online fault diagnosis.
Fault diagnosis model of multi-head attention under the scenarios with partial missing data
In sample data sequences, some signal may be missing, due to such sensor performance as sensor fault, inconsistent sensor measurement rate, etc. It is common to fill the gaps with the upper and lower averages of the data column. However, these filled values are often inaccurate. Furthermore, the inaccurate filled values will deteriorate the performance of the multi-head attention fault diagnosis proposed in the previous section. How to reduce the impact of these inaccurate values on the overall data is a key issue of fault diagnosis under the scenarios with partial missing data.
In this section, a multi-head attention fault diagnosis approach is presented for the sample data sequence with missing data, by using the attention weight modified method. The whole method is divided into two stages: online diagnosis and offline model training.
(a) The historical measurement data
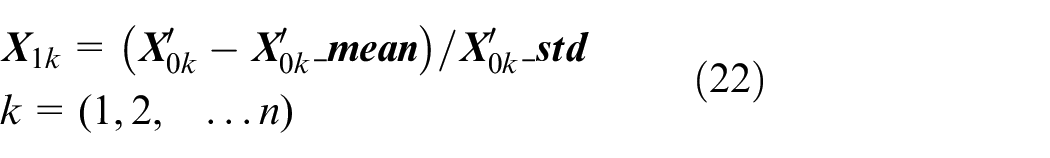
The formula indicates that each column in
(b) The matrices
where
(c)
(d) The new data
(e) For the output
Experimental simulation
Experiment with ZHS-2 multi-function motor flexible rotor test bed
The experimental data are collected from ZHS-2 multi-functional motor flexible rotor test-bed. Eight vibration acceleration sensors are installed in the horizontal direction of the rotor support. The sensors are adsorbed on the base of the test bed and arranged evenly. The collected signal is the vibration signal of the rotating machine rotor, which is transmitted to the upper computer through HG8902 data collection box. The rotor speed of the motor is 1500 r/m. The test-bed can simulate a variety of operation modes of rotating machinery, including rotor unbalance fault mode, fan blade broken fault mode, pedestal looseness fault mode, etc. The structure of the test bench is shown in the following Figure 5.
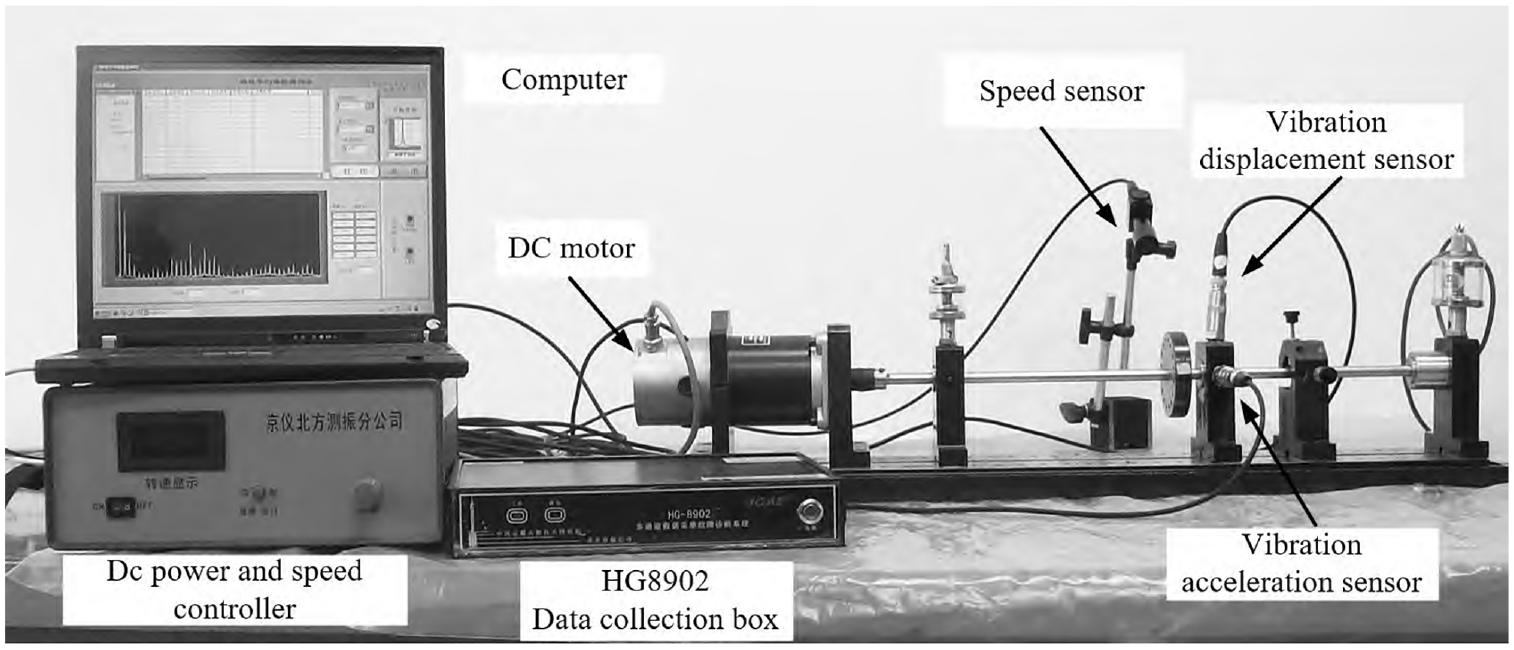
Test bench structure.
Seven operation modes are used to test the performance of the proposed fault diagnosis in this experimental simulation: rotor imbalance with one screw (bph1), rotor imbalance with three screws (bph3), rotor imbalance with five screws (bph5), rotor imbalance with seven screw(bph7), pedestal looseness (jzsd), fan blade breakage (fjdy), and normal mode (zc). In each mode, each sensor continuously collects 3,072,000 data in 240 s. As can be seen in Figure 6, the signal waveforms of various fault states are very similar, so it is difficult to accurately diagnose faults. In order to improve the accuracy of fault diagnosis and training efficiency, we need to expand a single sample. We take 8 times of the original sample for each line of data, that is Dx = 64, N = 64, M = 8, num = 2. The training set size is
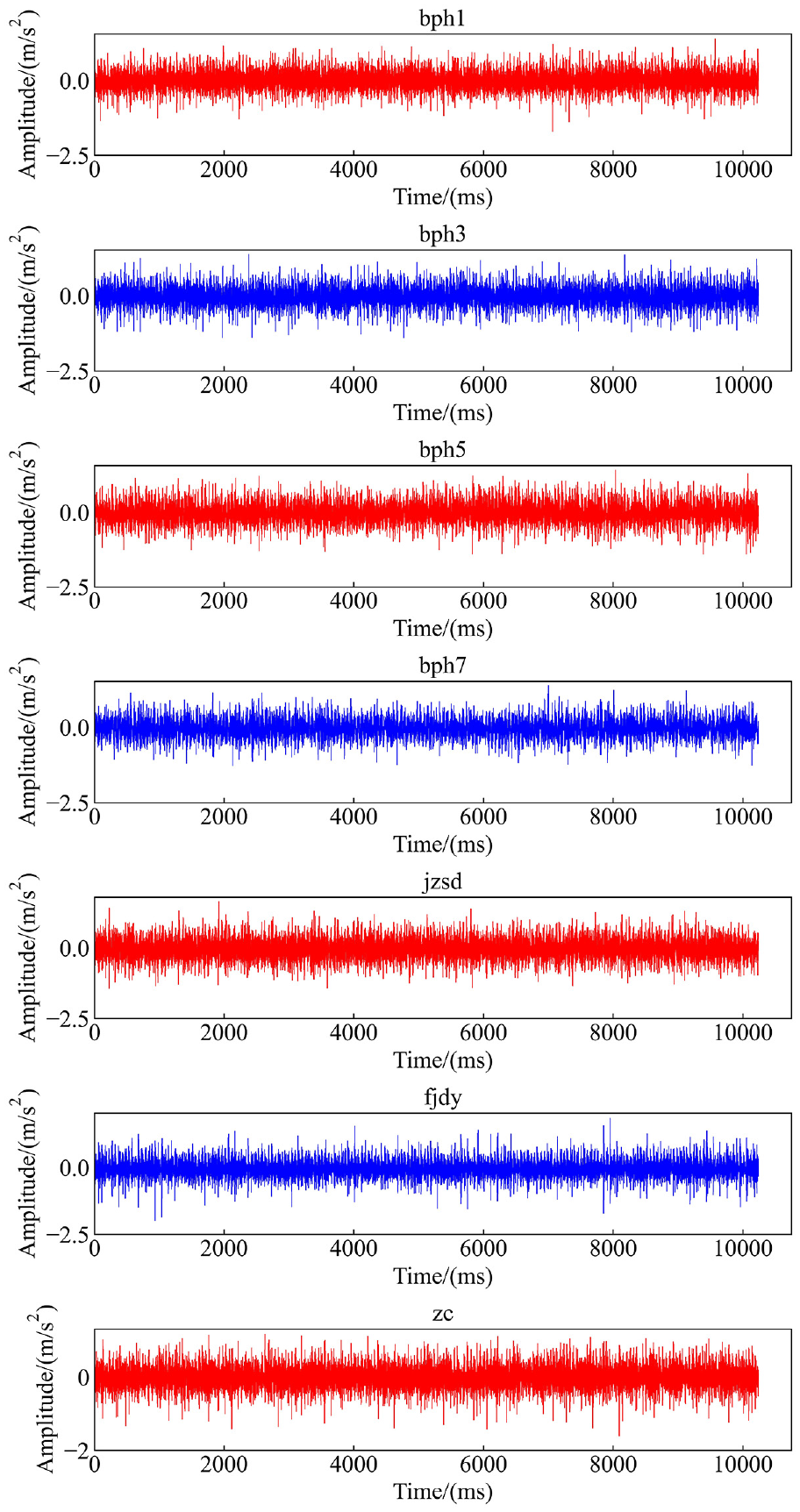
Vibration signals of 7 modes.
The F1 score is used as the comprehensive evaluation index:
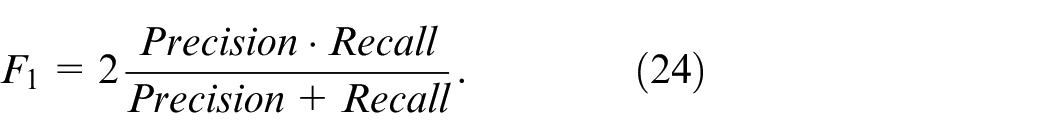
Several deep learning models are selected as the control group, which are the residual structure of the one-dimensional convolutional neural network (1D-CNN), the normal multi-head attention (MHA) neural network, and the Pos-MHA proposed in this paper. The structure and parameters of these comparison models are introduced as follows.
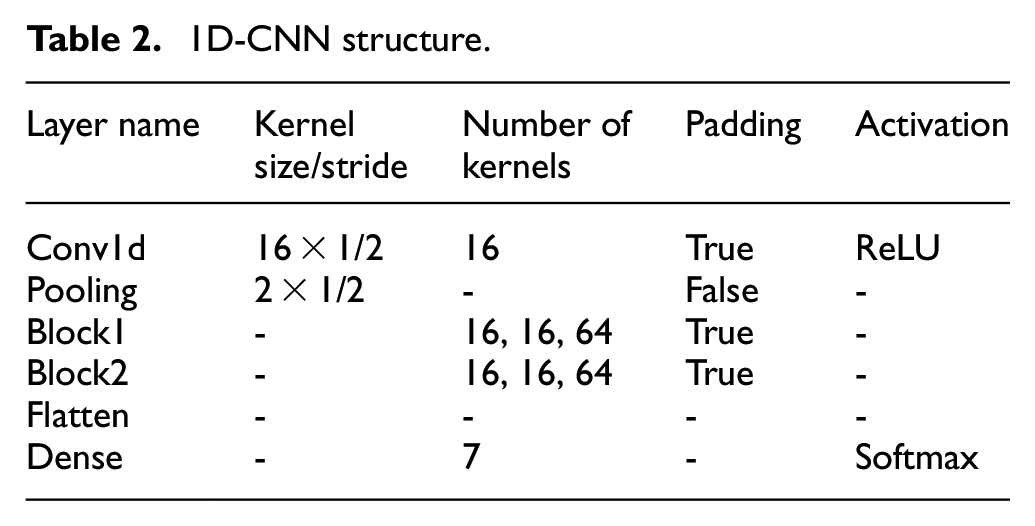
One-dimensional convolutional neural network with residual structure (1D-CNN). The network structure is shown in Table 2. The structures of block1 and block2 are shown in Figure 7.
The normal multi-head attention (MHA) neural network uses the attention mechanism given in Vaswani et al. 19
Pos-MHA, its attention mechanism is shown in equation (12).
1D-CNN structure.
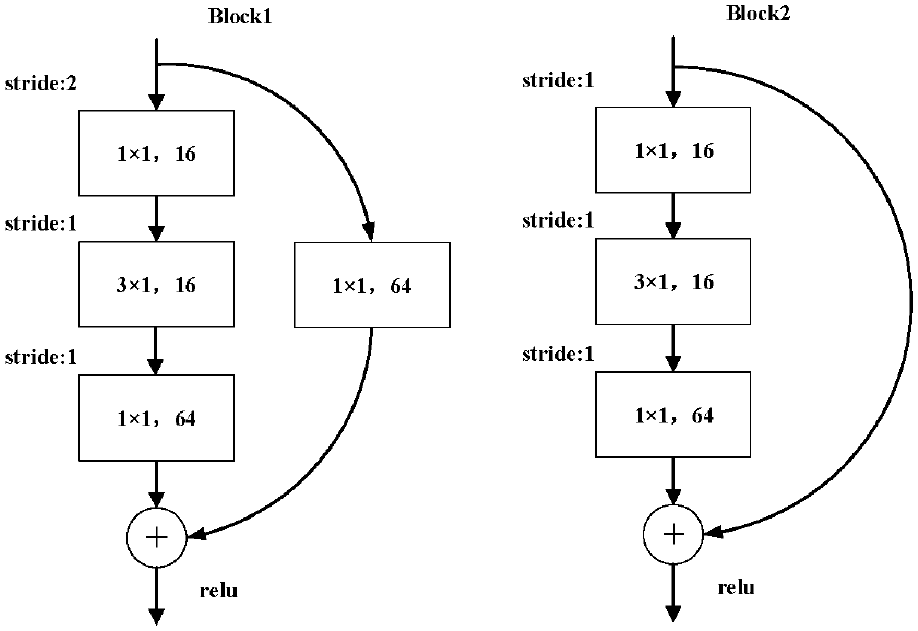
Residual structure Block1 and Block2.
Figure 8 shows the learning curves of the three depth models in the test set without missing fault values. Because the correlation information extracted by 1D-CNN is limited by the size of the convolutional kernel, the classification accuracy fluctuates greatly. Pos-MHA integrates more positional information into the weight matrix, uses equations (8) and (9) to alleviate the MHA low-rank bottleneck problem, and integrates more positional information to achieve higher classification accuracy than MHA.
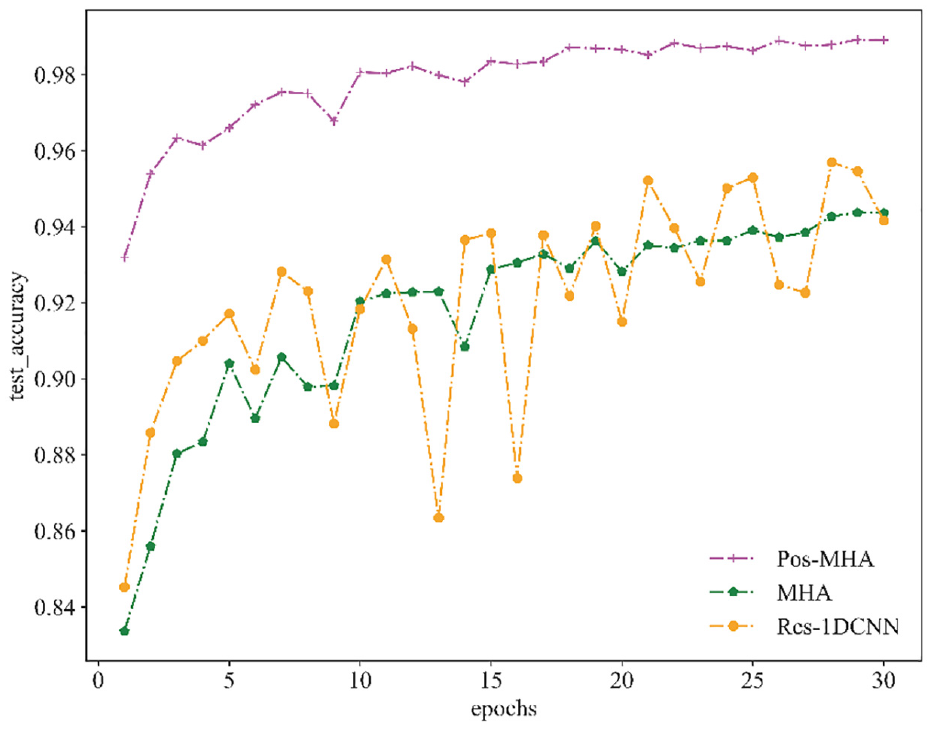
Learning curves of the three models in the test set with normal data.
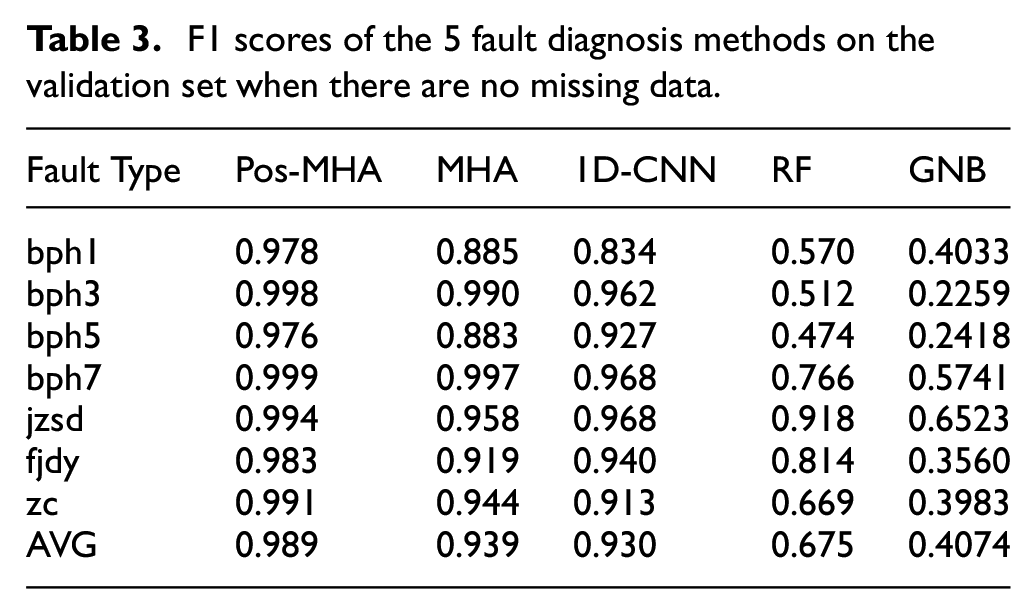
We also compare Pos-MHA with several traditional data-driven fault diagnosis methods on the verification set in Table 3. Among them, RF is a random forest with 50 decision trees classifier, GNB is a Gauss Naive Bayes classifier. It can be seen from Table 3 that the Pos-MHA network proposed in this paper alleviates the low-rank bottleneck of multi-head attention, integrates more location information, and improves the classification accuracy significantly. The average F1 score reaches 98.9%, which is nearly 10% higher than that of other data-driven fault diagnosis algorithms. Especially in the fault diagnosis of bph1, bph5 and jzsd, compared with other algorithms, the F1 score of Pos-MHA is improved by more than 10%−200%. Pos-MHA has the highest F1 score for all 7 types of fault diagnosis and has obvious advantages compared with the other fault diagnosis methods.
F1 scores of the 5 fault diagnosis methods on the validation set when there are no missing data.
In order to further explore the performance of the data-driven fault diagnosis algorithm under complex conditions, we also compare the performance of the Modified-Pos-MHA network proposed in this paper with other algorithms in the case with missing data. Modified-Pos-MHA is a kind of fault diagnosis algorithm for missing data. It is different from Pos-MHA that it uses equation (15) to modify the attention weight matrix of the missing data (Figures 9 and 10).
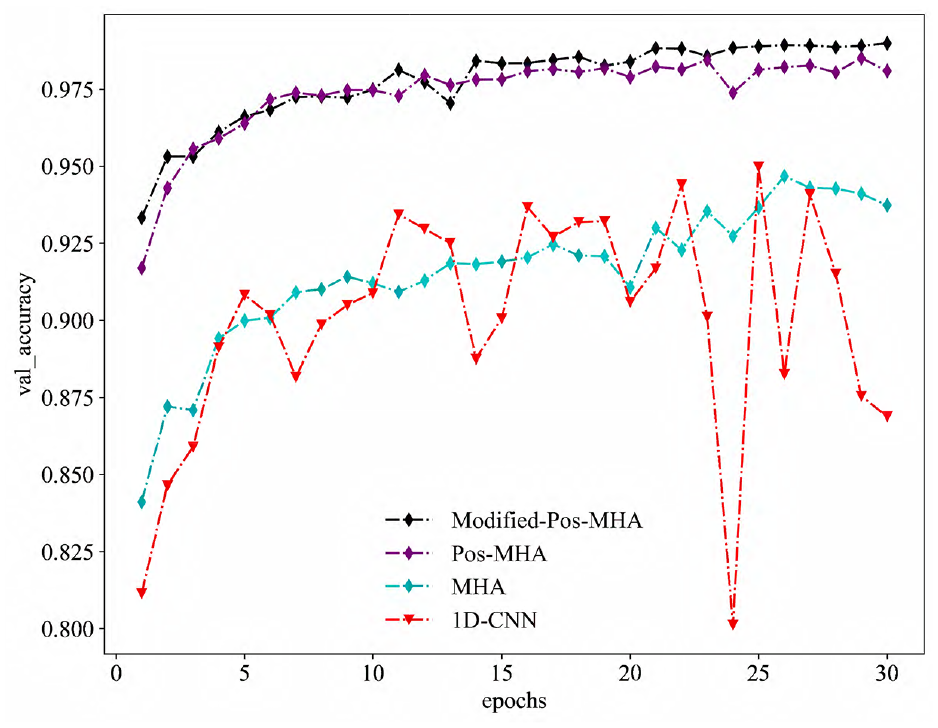
Learning curves of the three models of the test set with missing data.
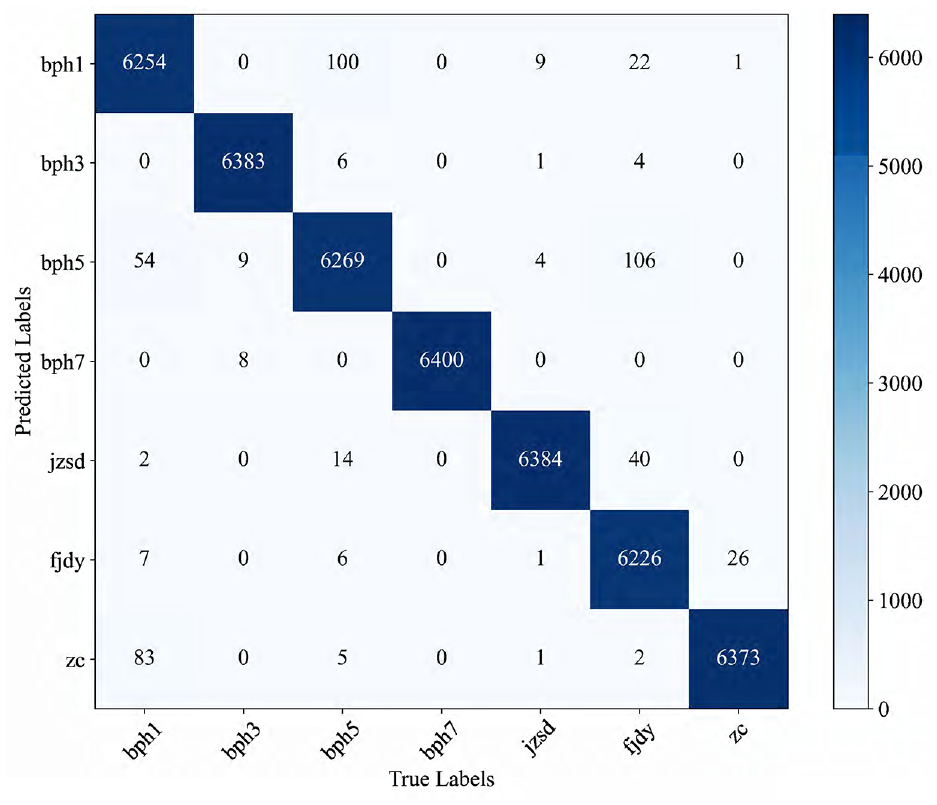
The confusion matrix of Pos-MHA of the validation set without missing data.
The figure above shows the learning curves of the four depth models with 1/8 of the whole sample is randomly set as missing data and filled with the average of adjacent values in the test set. Among them, the Modified-Pos-MHA neural network uses equation (15) to modify the attention weight matrix. MHA is a common multi-head attention fault diagnosis method, and 1D-CNN is a one-dimensional convolutional neural network with the residual structure described in Table 2. It can be seen that the Modified-Pos-MHA modifies the weight of the filled values and achieves higher accuracy.
In Table 4, it can be seen from the above table that when the average value of adjacent values is used to fill in the null values, the fault classification accuracy of each model decreases to a certain extent. Modified-Pos-MHA modifies the attention weight corresponding to the filled values and further improves the accuracy of Pos-MHA. The average F1 score of Modified-Pos-MHA reaches 98.4%, which is the highest among all methods. Among the seven kinds of fault diagnosis, Modified-Pos-MHA has the highest F1 score in all kinds of fault diagnosis, which is better than that of the other algorithms.
The F1 scores of the 6 fault diagnosis methods on the validation set when the fault data includes missing data.
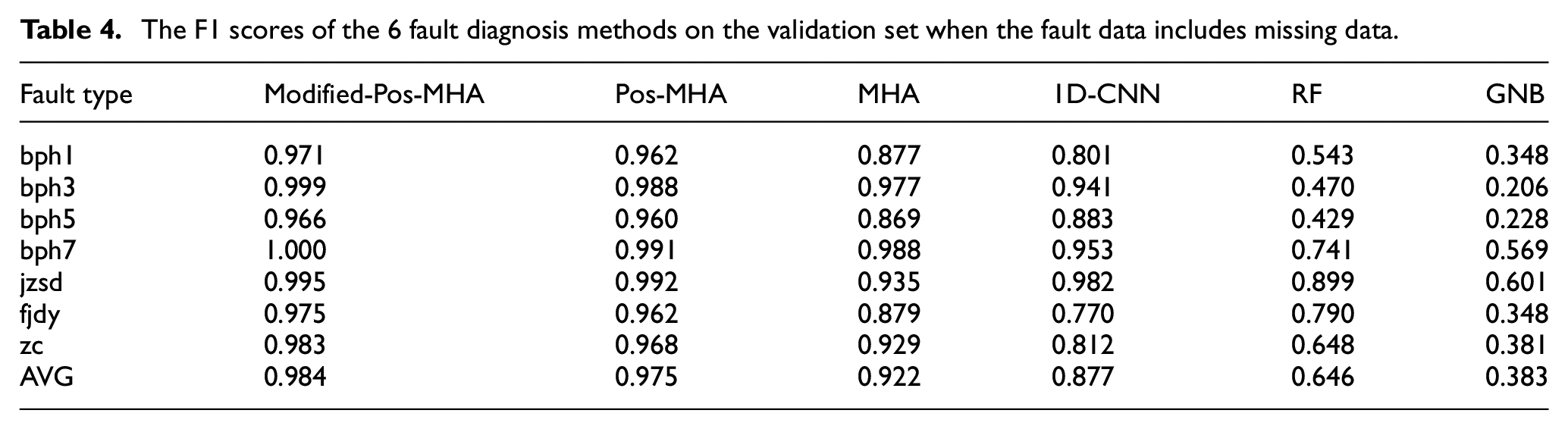
The above figure shows the confusion matrix of Pos-MHA for the validation set when using normal data. There are 7 fault states in the validation set and 6400 samples for each fault type. When there are no missing data, Pos-MHA can predict faults very well, with an average F1 score of 99.8% and 99.9% in the classification tasks of bph3 and bph7.
Figures 11 and 12 are the confusion matrices of Pos-MHA and Modified-Pos-MHA. When the fault data have missing data and the adjacent mean values of the missing data are used to fill in. The results show that the performance of Pos-MHA decreases when the data have missing data. Compared with Pos-MHA, Modified-Pos-MHA with the modified attention weight achieves a higher average fault diagnosis accuracy.
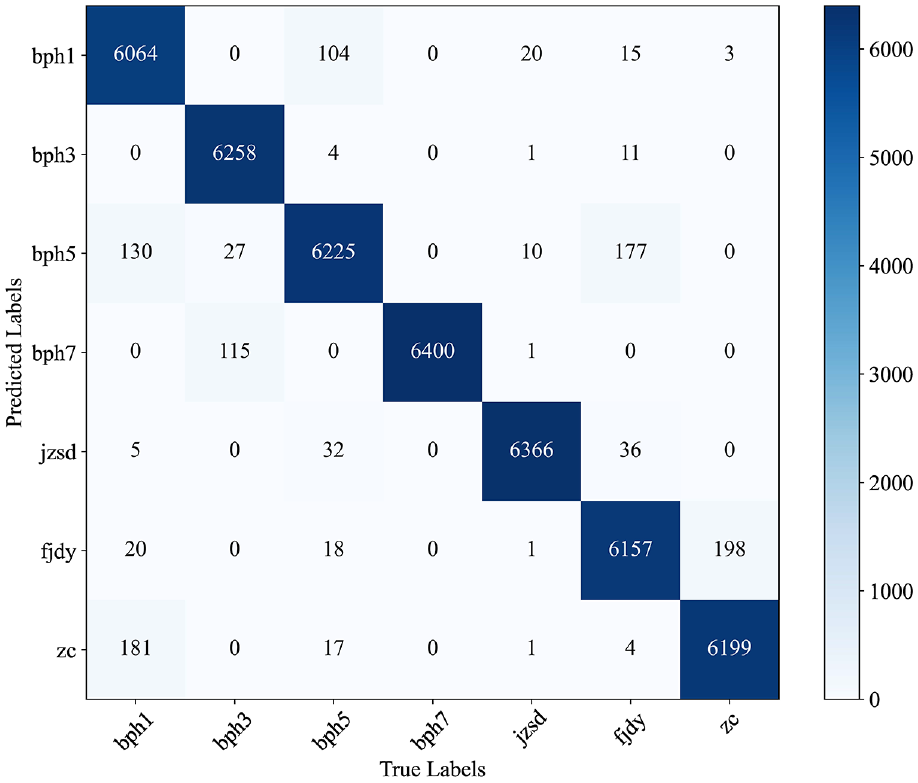
The confusion matrix of Pos-MHA of the validation set with missing data.
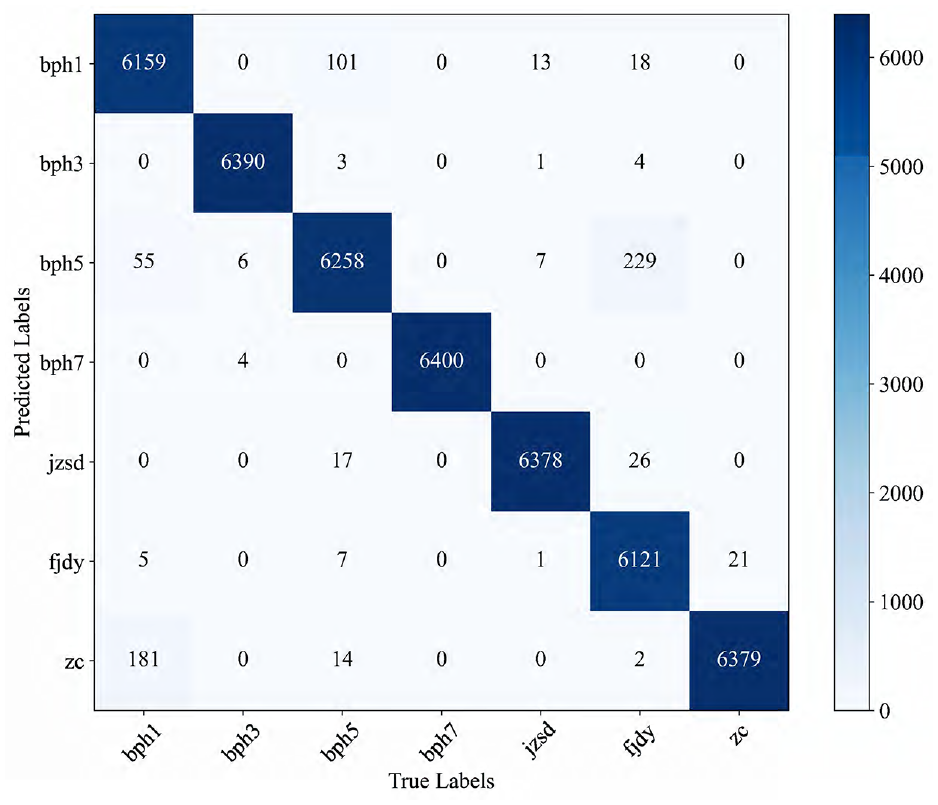
The confusion matrix of Modified-Pos-MHA of the validation set with missing data.
Simulation with Tennessee-Eastman process data
In order to verify the effectiveness of the proposed method in actual industrial production, this method is used in Tennessee-Eastman Process (TEP) data sets for experiments. 33 The TE process is widely used to test the monitoring performance of a process monitoring scheme. The process consists of five typical units: reactor, condenser, tripper, separator, and compressor. In this study, the benchmark data available at http://web.mit.edu/braatzgroup/links.html are employed. The TEP dataset contains 22 process variables, 19 component variables, and 12 operating variables. In TEP, 21 types of faults are presented. In this experiment, we use all 21 kinds of fault states for the experiment. In order to verify the performance of the model, 800 samples are collected for each fault, so a total of 16,800 samples are collected for model training and method testing. First, we divide 10% of the data into validation sets, which do not participate in model training, and we only use the trained model for prediction. For the remaining data, the whole data set is randomly scrambled and then divided into a training set and a test set according to the ratio of 4:1.
SVC is a support vector machine classifier using the RBF kernel function, and LR is logistic regression. As shown in Table 5, the Pos-MHA network proposed in this paper integrates more location information, and improves the classification accuracy significantly. The average F1 score reaches 88%, which is more than 10% higher than that of other data-driven fault diagnosis algorithms. Especially in the fault diagnosis of fault 10, fault 16 and fault 19, compared with other algorithms, the F1 score of Pos-MHA is improved by more than 40%−200%. Pos-MHA has the highest F1 score for all 21 types of fault diagnosis and has obvious advantages over other fault diagnosis methods.
The F1 scores of the 5 fault diagnosis methods on TEP validation set when there are no missing data.
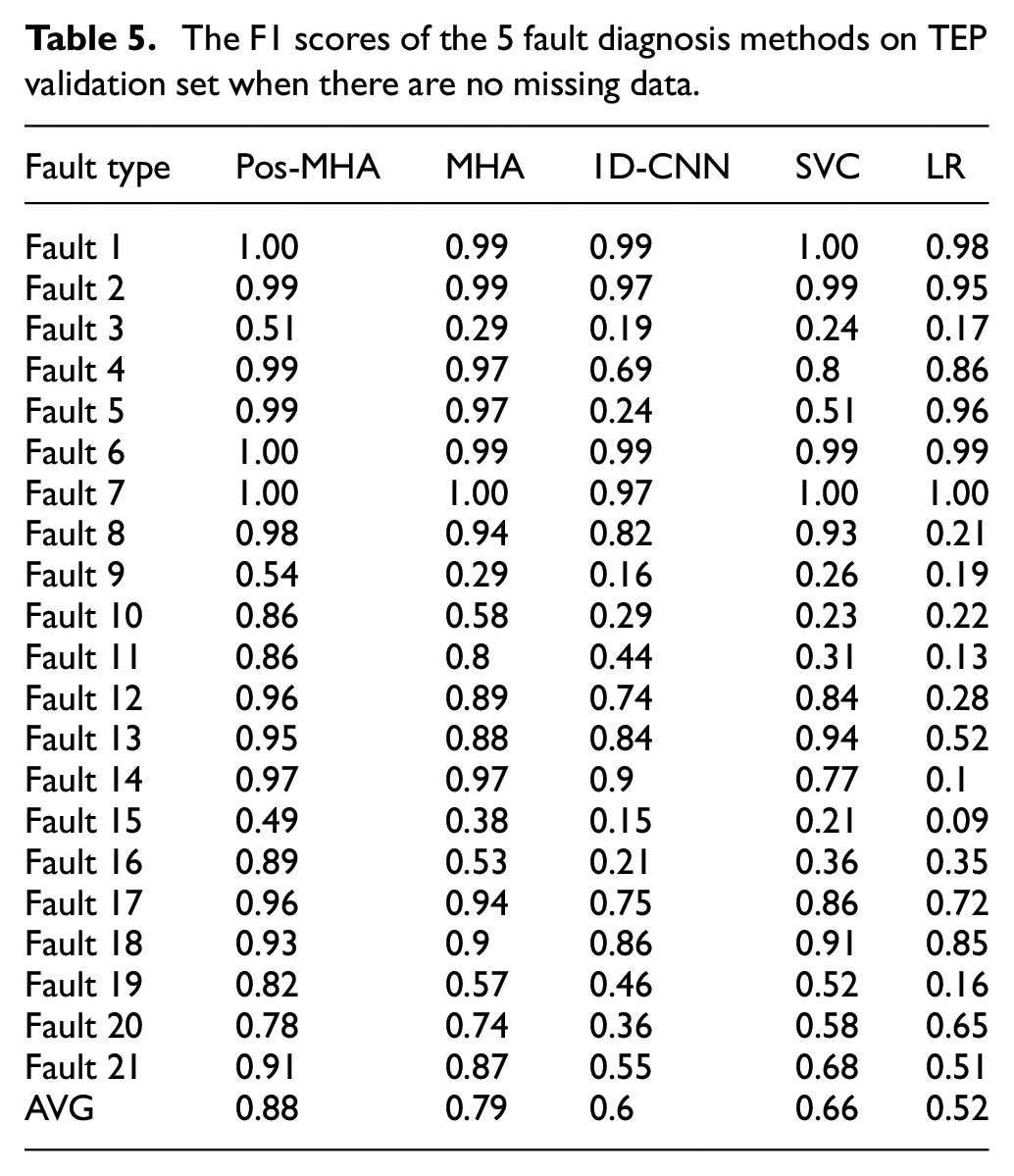
Figure 13 shows the learning curves of the three depth models in the test set without missing fault values.
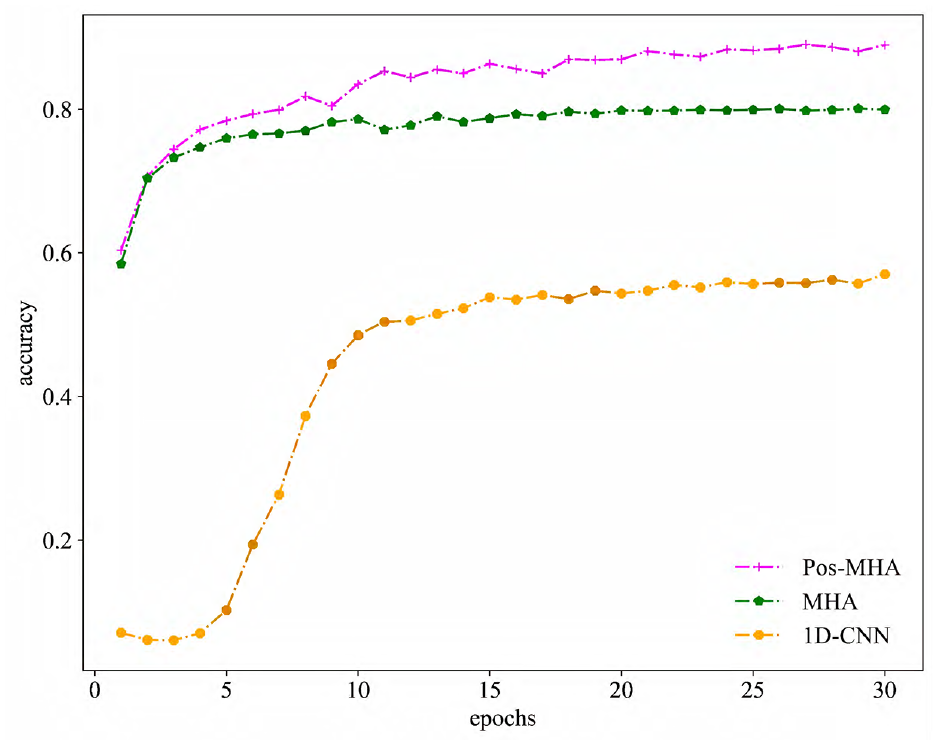
Learning curves of the three models in TEP test set when using normal data.
In Table 6, Randomly change 1/8 of the original data to a null value and fill it with the upper and lower average values. It can be seen from the above table that when the average value of adjacent values is used to fill in the null values, the fault classification accuracy of each model decreases to a certain extent. Modified-Pos-MHA further improves the accuracy of Pos-MHA. The average F1 score reaches 74%, which is the highest among all methods. Among the 21 kinds of fault diagnosis, Modified-Pos-MHA has the highest F1 score in 13 kinds of fault diagnosis, which is better than that of the other algorithms.
The F1 score of the 6 fault diagnosis methods on the validation set when the fault data have missing data.
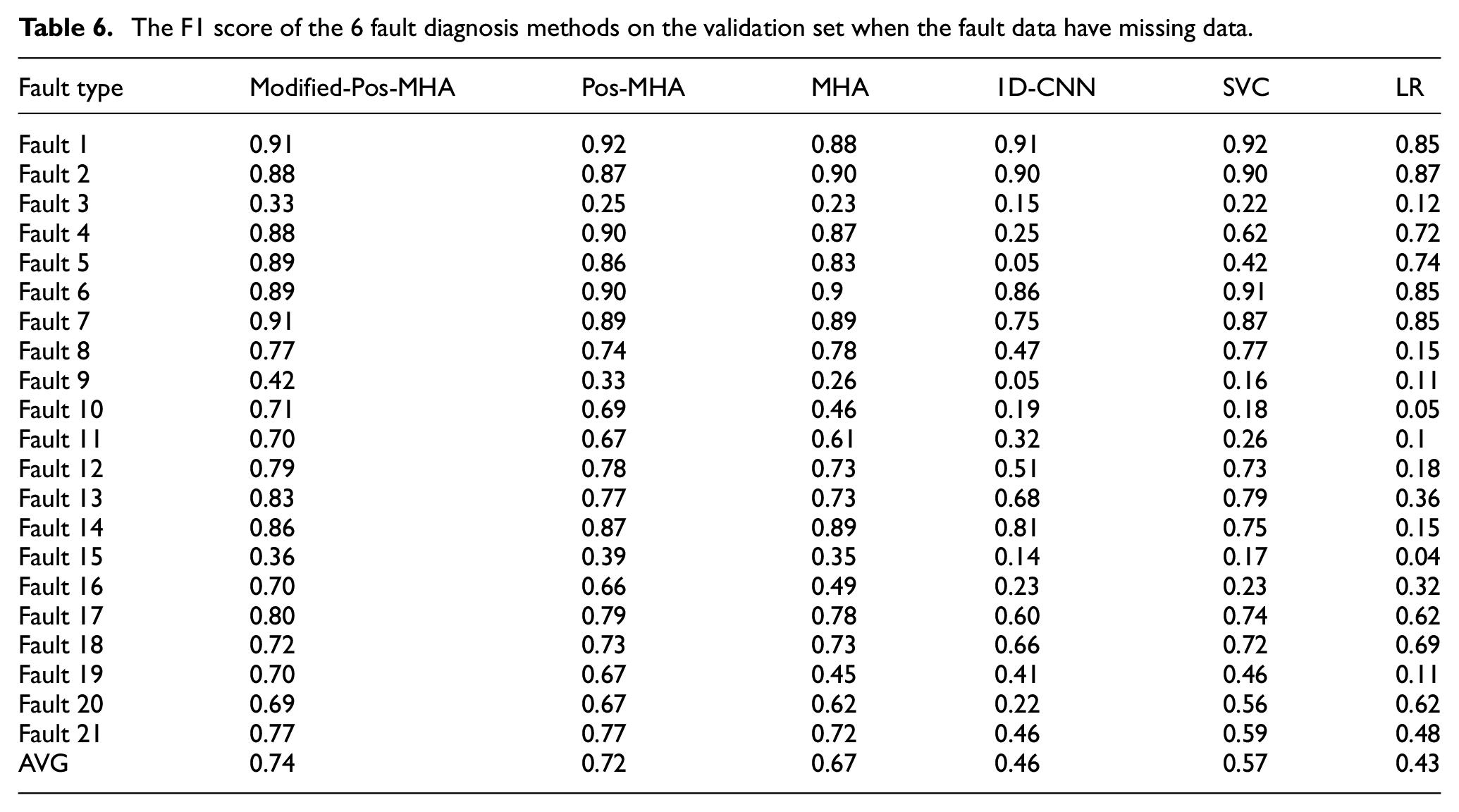
Figure 14 shows the learning curves of the four depth models with 1/8 of the whole sample is randomly set as missing values and filled with the average of adjacent values in the test set.
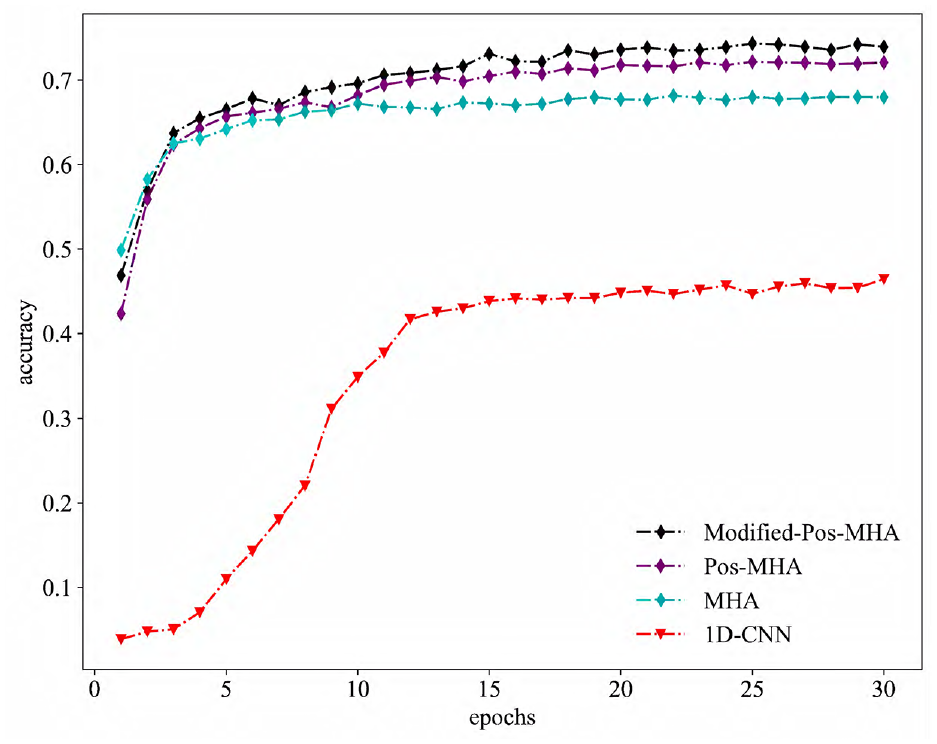
Learning curves of the three models in TEP test set when data are missing.
In TEP experiments, the effectiveness of the proposed method in real industrial data is also verified.
Conclusion
This paper studies a kind of multi-head attention fault diagnosis method, in which, the weight matrix is generated by using positional encoding instead of its own data. The new method alleviates the low-rank bottleneck of multi-head attention, and increases the sensitivity of the model to positional data. This paper also designs a special attention method for missing data. Using the interpretability of attention weight matrix, additional learnable parameters are given to the generated data, so that they have different markers from the real data in the neural network. This method can effectively reduce the influence of missing data on the fault diagnosis results. The experimental results show that the proposed Pos-MHA method improves the classification accuracy, compared with the traditional MHA-based and other data-driven fault diagnosis methods. For the sample data with missing data, the Modified-Pos-MHA network proposed in this paper reduces the influence of the missing data on the neural network and further improves the fault classification accuracy, compared with Pos-MHA.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant U1804163, Grant 620732136 and Grant 61973209, by Hubei Superior and Distinctive Discipline Group of “New Energy Vehicle and Smart Transportation”, and by the central government guides local science and technology development projects of HuBei province (2018ZYYD049).