
Abstract
The SCD (speech control detection) have received a lot of attention in recent years. A framework established by employing DNN-LSTM (deep neural network-long-short term memory) model for speech and text recognition is implemented in the current article. The performance of the build framework is analyzed with many different merits which consider many features, such as (with and without) noise, track number of speeches (ST (single track) and DT (double track)), and dropout ratio of data training. On the other hand, the speech discriminator model is developed and implemented with the DNN-LSTM framework, and the data sets are collected by four different persons. The adopted model performance is evaluated using the four different datasets, and each with 400–5000 training times. There are three parameters considered as the dominators for the performance evaluation of the completed speech platform. The results from the experiment with DT channel case clearly show that it outperforms the case with ST channel. It can see that the accuracy of the DNN-LSTM model increases from 0.3339 to 0.9696 and the loss rate decreases from 1.09984 to 0.19298 after adjusting the dropout ratio during the training step. This shows that the dropout ratio also dominates the accuracy and loss rate. Eventually, the results indicate that the used model compared to other similar methods, Bi-LSTM (bi-directional LSTM), achieves a more efficient preserving a high accuracy level.
Introduction
The ways in communication to the other persons or smart animals are always via speech, voice, and sound, since they are all have the characteristics of high efficiency and convenience. Once these mentioned media become the carrier of language, speech signal is one of the most important mean for people to transmit information in the information society. In recent, the low-level acoustic features are usually by using of the NN (neural network) based methods to predict the probability of speech. In general, the estimate to the speech activity can include but not limited to, ASR (automatic speech recognition), SFD (speech feature detection), SAD (speech activity detection), SSD (speech sentiment detection), SPD (speech person detection), and SCD (speech control detection) and much more.1–3 Although there has been a long history of research on this subject, in the last few years enthusiasm study and research interest have renewed specifically for challenging conditions covering a variety of acoustic environments. The language processing with the means of machine learning in audio, speech, voice, and sound is the most recently developed technologies for communicating to a passive machine, such as in-car computers, electronic vending machines, automated telephone call-centers, smartphones, smart platform, and wearable computing devices. 4 Traditionally, the audio signal is playing as the tool for communicating between different persons, between person and animal, and even between person and activity object. The former behavior can be approached by the natural lingual that expresses the sentiment of the personality. 5 However, the behavior of communication happens at the mentioned later one, person to a passive object has completed through some special of trained tools. The research on automatic speech recognition has been very active and has achieved great success in the past half century years. At the beginning of the research, speech recognition can only recognize individual words in a well clean environment, for example, indoor, quiet spaces. In the current research focus on developing SCD which can provide with remotely control a moving system (a smart platform), for example, a robot, or a sound box, etc. However, the implement environment is limited on short distance between speech source and the controlled system, low-dimension data sets, restricted learning parameters. On the other hand, there has just few conditions is assumed, heavy noise-free, (ST (single track) and DT (double track)), and low layer numbers of NN models. Thus, in the current stage the optimized DNN-LSTM network is selected to play the training platform in which to deploy with many simple hyper parameters is necessary. Furthermore, to be aimed at the speech recognition the accuracy model for deep learning based on LSTM is higher than the classic machine learning, such as CNN, SVM. 6 That is, LSTM has good effect on time series data processing, consequently, the DNN-LSTM model is dominated to play the role of machine learning which developed to complete the activity of speech recognition in this article.
Therefore, the authors deny to apply other famous but complex neuro network models. In general, Bi-LSTMs (bidirectional LSTM) network exploit the input sequence in both directions by means of two LSTMs. As a result, two hidden states are produced at each timestep, but it wastes more time when remember the assigned training corpus database. 7 Besides, RNNs (recurrent neural networks) face the limitation of vanishing gradient. During the backpropagation, the gradients are shrinking at an alarming rate, and it could stop important parameters by lowering their gradients. 8 A new evolution version of RNN is GRU (gated recurrent units) model. Theoretically, GRU removes cell states and uses the hidden state to transfer information. It only has two gates and requires less computational power and time due to fewer parameters. The advantages and limitations of the current study are providing on the rubric of experimental aspects, application, dataset(s) used, and performance metrics. In fact, there have lots of networks are implemented apply to the scenario deployed in the current study. This can include CNN, DNN, GRU, LSTM, or RNN layers. However, these larger and deeper architectures require much longer to compute. Specifically, the adaption of specific neural network framework mainly depends on the dataset dimensions eventually.9,10
In summer, however, there still none of the applying the LSTM framework based DNN to control a robot with speech commands. According to the authors’ knowledge known that the implementation in employing to embed a DNN-LSTM based model into a platform is a brain new demonstration. Thereafter, the following important contributions of algorithmic enhancement for the implementation are provided:
There are four persons invited to recode the speech data which is collected under the assignment of ST and DT micro-phone.
The deployment of DNN-LSTM network employed as the framework for data training after the spectrum of the data has been analyzed. In this work the data spectrum obtained from the gathered data sets is proved in effective.
There are different iterative times to train all the suitable data and the validation with testing illustrated in the DNN-LSTM network. Furthermore, for giving one proof that the experiment is true, the comparison with other methods is held too.
Finally, the trained and verified data sets will be downloaded into a smart platform plays as the command sets to certificate the validation.
The rest of the paper is organized with four sections described as follows, after the Introduction section in section 2 the Related Works are presented. The motivation to solve the problems and apply the DNN-LSTM network is expressed in section 3. In section 4 the implementation of speech recognition with command sets is applied based on the DNN-LSTM architecture. Next, the discussion to the results from evaluation of performance for the applied DNN-LSTM framework is presented in section 5. Eventually, there is a short conclusion draw in section 6.
Related works
Conventionally, the GMM-HMM (Gaussian mixture model-hidden Markov model) was adopted as a model for jointing and entering higher educational training during the 1970s. The GMM-HMM enables speech recognition to be capable of continuous speech recognition of large vocabulary vehicles. This is due to the architecture of GMM-HMM technique also used for training and acoustic decoding, thus, GMM-HMM has been the mainstream acoustic model of automatic speech recognition systems in the past several years. 11 The research on acoustic models mainly focuses on improving GMM-HMM with better model structure and training algorithm. It is wonder that none of different acoustic model methods is better than GMM-HMM when the period which is explored and dominating the speech world. Based on finding in neuroscience that human possesses the template-searching attention mechanism, in Chen et al. 12 the authors propose by using convolution operation to simulate attentions and give a mathematical explanation of our neural attention model. Recently, the deep learning utilized in neural networks fields and their variants have finally replaced pure HMM model. On the other hand, nowadays the hybrid GMM with DNN-HMM (deep neural network-hidden Markov model) has become the acoustic model of most ASR systems. 13 So far, there were new breakthroughs that the development of ASR technology has gradually stagnated until the next about 20 years later in the century. Besides, it has seen the great achievements of deep learning architecture and technology in the fields of computer vision, language, and language learning in the past at most 5 years. 2
The reasons for the raise of utilization in DNN-HMM can be attributed to the following factors: (1) it has architecture and algorithms of deep learning scheme, (2) it equipped with a processor owns the general-purpose computing imprisonment, (3) it is designed with thousands of hours of transcribed speech training data and more unlabeled data, (4) it is easily operating with mobile Internet and cloud computing, (5) there is much more demand for voice recognition, and (6) the weighted finite state machine is used as a language decoder used in ASR. Although, there are many advantages to deploy the mature technology with automatic techniques already, there are still many problems that need to be solved in practice. For instance, different type of smart phone to record the speech, the distance away from the microphone of the phone, and the quality of the recording which all easily affect the accurate rate of speech recognition. Furthermore, if the language used by the speaker is different from the recognizer, or if the speaker’s conversation spans multiple languages, the same results will be generated and obtained by using the factors that aforementioned. In recent, the issue addressing in VAD, the DNN-based models are frequently employed to develop the speech recognition. These methods can be adopted effectively and lead to increase the results of performance for comparing with the most effective traditional ways.14,15 For example, in Tachioka 16 an essential method for automatic speech recognition referred as VAD (voice activity detection) is proposed.
The performance of speech recognition has been improved after the DNN auxiliary features are adopted as target environment. Besides, by extending the VAD and based on a soft decision in the frequency to provide an efficient procedure to detect the double-talk situation is presented in Park et al. 17 It suggested a method of the GNSPP (global near-end speech presence probability) and yields better results compared with the conventional scheme. Apart from, since SAD is a crucial task in any speech processing system, an optimization process for RNN based SAD is proposed in Gauvain and Gelly. 18 All system parameters included in the process is to optimize used for feature extraction, the NN weights, and the back-end parameters. In Zheng et al. 19 the authors apply the MR (manifold regularization) in AE (autoencoder) to promote cross-layer manifold invariance. Specifically, the designed AE is optimized by entropy-stochastic gradient descent, then the reconstruction errors are adopted to determine whether the received signals are authorized.
Furthermore, regarding model with two-stage training method, in Zheng et al. 20 try to regularize the feature boundaries of deep CNN in a two-stage training process from the point of view of data punishment in order to improve the generalization ability of the network. Based on the generalization error boundary for decreasing the model size parameters of 2D deep CNNs, in Zheng et al. 21 a trained deep CNN proposed to prune Drop-path with different lengths. Eventually, the convolutional kernels themselves become sparse, which presents the method to accelerate the network inference. Besides, one related critical on-line recognition technology is ASR which has extensively applied the adaption of LSTM networks. An optimized, low-latency streaming decoder built with bidirectional LSTM acoustic models, together with general interpolated language models published recently in Jorge et al. 22
So far, as the authors’ knowledge that lots of researches employed the popular LSTM model based on DNN to support the applications of speech recognition. A target tracking approach using a monocular camera and mmWave (millimeter-wave) radar sensor fusion is proposed in Sengupta et al. 23 In Chunwijitra et al. 24 there a denoising scheme based VAD (voice activity detection) to cope with the unseen noises is presented. The aim to investigate the use of the newly developed sequence-to-sequence deep learning models with LSTM node applied to grapheme-to-phoneme conversion is signified in Stan. 25 In recent year, the LSTM structure is included to capture spectral correlation information with nonlinear unmixing algorithms has been explored in Zhao et al. 26
The statements of motivation
In this article the DNN-based neural network is adopted as the frame model for training the collected Chinese data set. The formulation of problems which will be solved and the motivation of applying DNN-LSTM network will described in the subsection. Herein, it is important to enhance again the motivation of adopting DNN-LSTM. It is recognized that LSTM is a kind of RNN, generally, in which the inherent memory structures (cell states) is used to store the “time” information and the control structure (gates) is employed to regulate the amount of stored information, respectively.
Problems to be solved
The main study of the article is focusing on the implementation to remotely control a smart platform with the speech command sets over restricted environments. Currently, the smart platform designed as a machine learning model owns lots of advantages, and it has been completely developed equipped with four main subsystems. Totally, include power driving subsystem (battery), moving control (motor controller) subsystem, sensor control subsystem, and data analysis subsystem (speech commands). So far, the movement control of the smart platform successfully adopts as image recognition (face recognition or different objects’ image recognition) with the trained models, that is, the moving control subsystem of the smart platform can be driven when the image is correctly recognized eventually. Normally, the training procedure for the image data set follows up the methods of deep learning techniques. Moreover, the wireless remotely controlled with self-developed application to the smart platform is also a feasible work. On the other hand, the current implementation is trying to establish the previously mentioned model trained with the limited collected speech command sets. Alternatively, the completed trained in DNN-LSTM model will be uploaded into the “Sensor control” subsystem embedded in the smart platform, which is the advanced motivation of the investigation. Accordingly, there are some basic execution steps which are going to follow up the concepts of the flow chart shown in Figure 1.
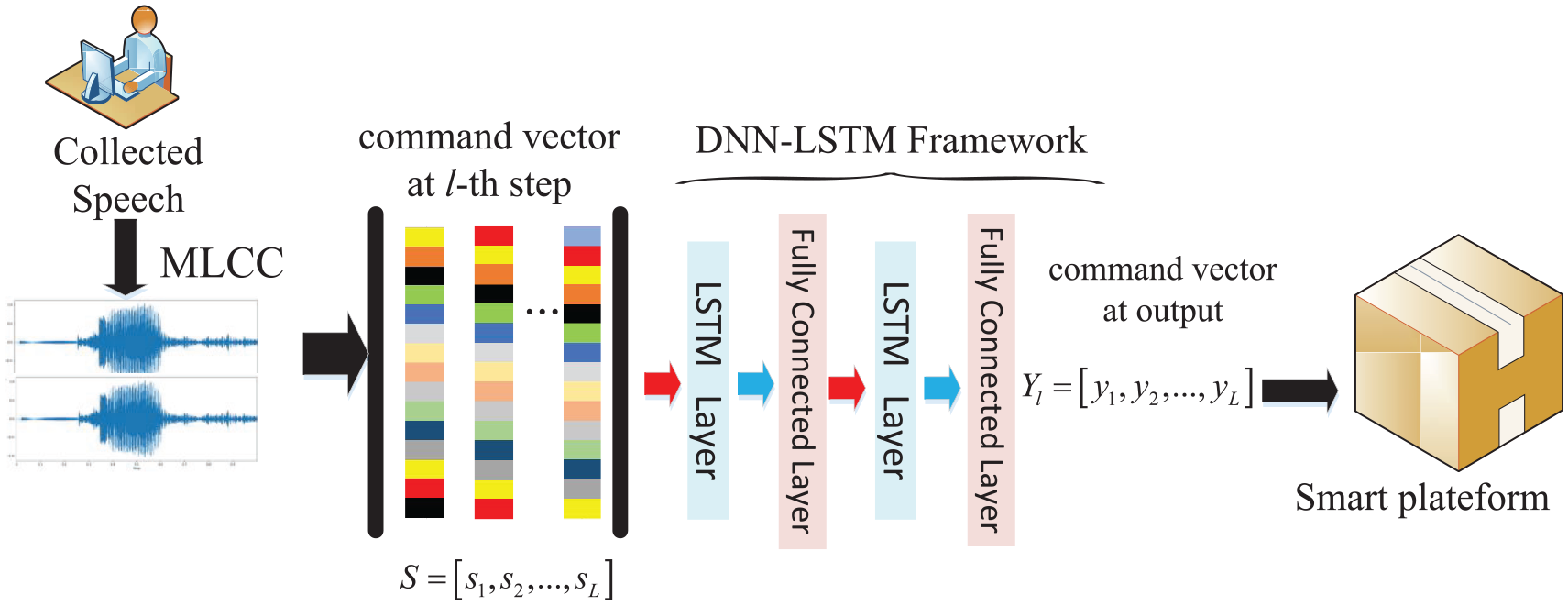
The block diagram of basic execution steps for the applied implementation.
An introduction to the simulation tools
As that mentioned previously a wheeled smart platform designed to adopt the wheeled tractor is going to play the role of carrier. The developed model of speech commands is uploaded into the smart platform to verify the performance of the results of the implementation. The smart platform is going to be introduced briefly in the currently subsection. On the carrier the movement unit has the responsibility for controlling the direction of movement to various positions. Accordingly, the movement unit received the instructions which is processed after the smart platform completes the speech recognition via a micro-phone.
Specifically, the processing to the movement means of the proposed wheeled smart platform is generally using a PID (proportional integral derivative) controller or three-term controllers, which variants to the conditions depend on loading weight. That is, the heavy loading of the wheeled smart platform will cost much higher power and vice versa. Therefore, the platform can move smoothly depends on the normal ratio value detecting from the PID device. Apart from, there are three motors constructed in the wheeled smart platform, which has the function for rotating the arms. The different functions for each of the motor have designed as significantly distinctly and claimed as follows. The first motor is playing as a hand for catching the objects. The second one plays as a rotating handle, which is designed able to rotate fully around 360° so that the object does not fall down the ground. The later third one is established to lift the position of the arm up so that the object is lifted off the ground, even allowing the object or obstacle to be removed away. For the purpose of giving the function of lifting object to the wheeled smart platform, which has been designed to lift the front belt up and down 360° consequently. The usage of lifting the belt is due to lead it allows the platform to avoid obstacles whenever. Hence, by using of deploying a gear motor with the characteristic of 12 V, and 110 RPM connected to a gear with 68 teeth with chain. The control to the activity of the belt is processed and detected via the camera in advance.
A smart platform is expected to be developed to operate by using voice (speech) commands via the phonic sensor installed on the platform. Accordingly, the moving distance of the motor build in the platform is calculated from the degree of a circle, for example an encoder. The platform’s motion system adopts an encoder motor for double sensing to avoid any error when the platform is moving. Both the left and right sides are all installed encoder. The development of the smart platform is planning to be structured in the near future.
The development of speech training framework
In the subsection the development of speech recognition command sets is described step by step. The speeches collection, spectrum analysis of the data, algorithm of recognition, piece of the operation codes, and works of uploading to smart platform and so on, are included in the description.
Recording and analysis spectrum of speech data
At the first time the project collects four persons’ speeches, and the control speech commands are designed over restricted environments where constrained that is without considering any noise and interference. That means the recording space is noise free for the persons who collect the speech commands orderly. On the other hand, the indoor space separated by glass for gathering the speeches is kept well quiet and it is located at the place of authors’ laboratory room. Alternatively, the speech commands are recoded over noisy circumstance which is gathering the corresponding speech commands combining with music sound.
The recoded speech data including four Chinese commands, includes ST and DT, which are “forward” with four ST speech (Chinese “
Each of the collected command data can be analyzed by the MFCC (Mel Frequency Cepstral Coefficients) access, which is the preprocess of the command speech data. Certainly, the recorded speech commands are previously analyzed by the procedure which adopted to process the original voice for speech recognition. Specifically, in Figure 2(a) and (b) show the speech waveform for an example which is one of the speech commands “forward” (Chinese “
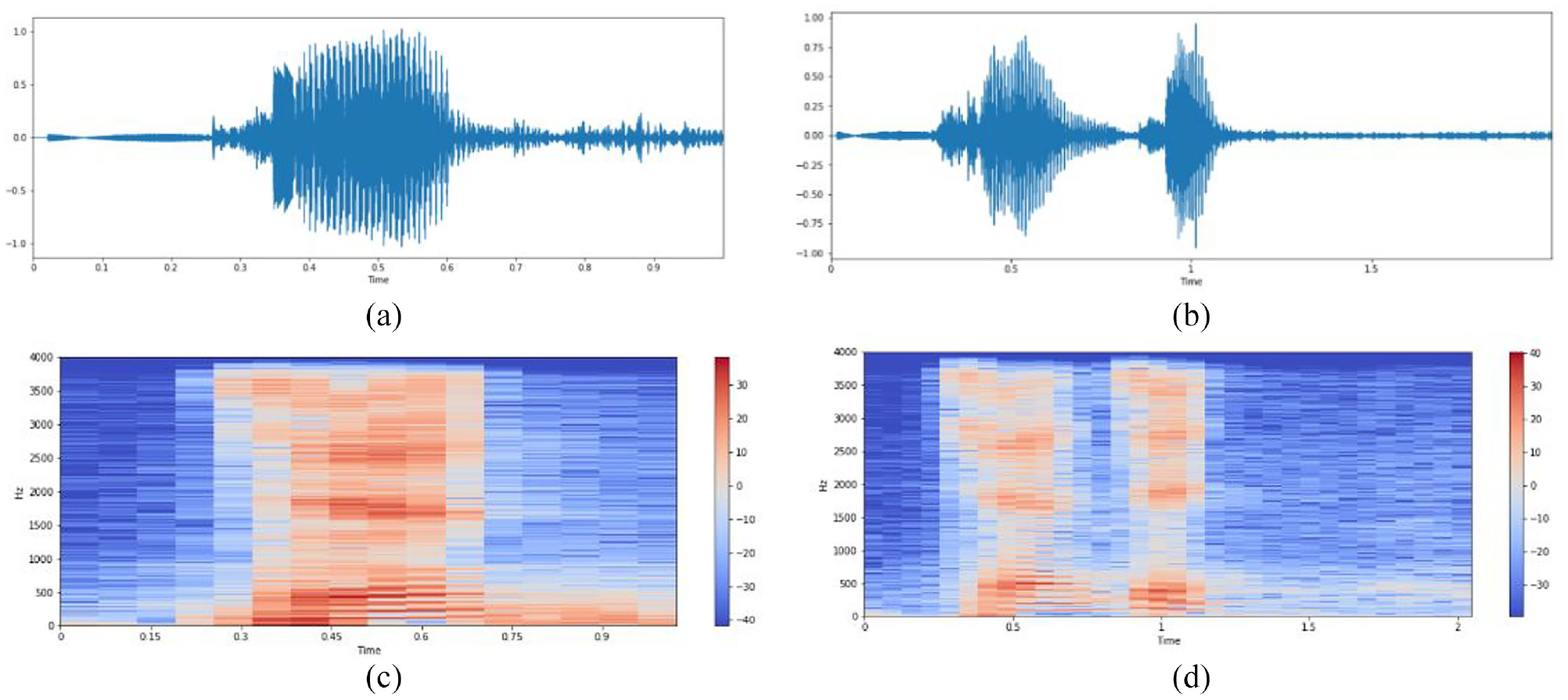
Speech waveform of “forward,” (a) speech waveform of (Chinese “
Speech MFCC spectrum of “forward,” (a) (Chinese “
The DNN-LSTM framework algorithms for the speech recognition
Gathering speech command sets and establishing the algorithms of DNN-LSTM framework are two main stages server to develop the platform in the article. The former step is deploying the speech recognition in order to establish the pre-processing of the speech commands. Then, the later one is the step for training a model which can be used precisely to control the action of the platform. Thus, both stages are going to be described briefly in the subsection.
Steps of training speech data sets
Sometimes by using of traditional methods to build and solve the complex training framework or manually create large number of regular data sets is unnecessary. However, it can be achieved by collecting a large amount of training data from the research field of machine learning. For instance, in building modules with NLP (natural language processing), some details of its standard method have their own special characteristics, which enable it to be different from computer vision and other applications. To a certain extent NLP objects have different phonetic lengths. For example, in English a word may contain multiple characters or even a sentence is composed of word sequences with different lengths. This variability is not limited to NLP. It can also appear in many different application areas, such as signal processing, or video processing, etc., can all be processed in a neural network-like manner. Therefore, the traditional RNN is a standard method of constructing NLP modules because it has a fixed input and output network. However, RNN usually requires more time for training, and may produce some strange behaviors. For example, it could cause loss of shock during training, and sudden amnesia, but RNN still has its practicality for application. If one who wants to deal with variable-length input, RNN can still be announced to be the standard network for building modules. The voice-controlled wheeled robot proposed in this article has particularly established a machine learning method based on a fixed voice length for training. Not same as the applicable field of RNN, and finally based on that previously mentioned requirement, the article adopted DNN-LSTM as a learning model framework.
On the other hand, since the speech control commands used in the article are all short syntax and fixed-length. It focuses on the training process of repetitive actions when training the framework for command sets. For example, “forward,”“backward,”“turn left,”‘turn right”, and “stop,” such short sentences, therefore, following up such conditions the DNN-LSTM framework is adopted as an instruction training method in this article. Besides, because DNN itself has deep training and learning behaviors, plus the LSTM itself has the characteristics of a kind of artificial RNN. Seriously speaking, there is a cell embedded into the LSTM as the memory unit, which can store long-term memory.14,15 By the way, LSTM allows memory of the previous step to persist in the current state and thereby influence the output of current step, it’s behaviors as an RNN architecture. A normal architecture of LSTM is composed of three “regulators” usually referred as gate, namely, an input gate, a forget gate, and an output gate. Thus, the combination of DNN and LSTM is used to train the sentences of control commands in the implementation.
Accordingly, the block diagram of LSTM framework unit is shown in Figure 4, and assumes that there a sequence command is with length L. Onward, the LSTM network is mathematically analyzed and trials to improve the system performance during applications.
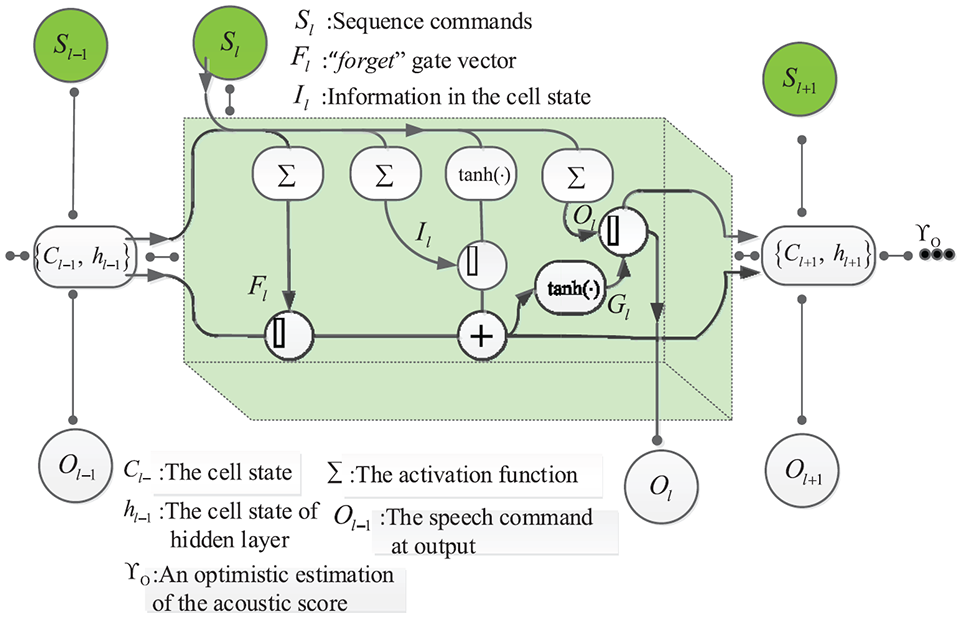
The block diagram of layers for LSTM network.
During the training phase, the actual target speech commands are fed into the network at every time step. That is, the feature of speech at step
Specifically, the first step activity is to remember the important memory and forget the circumstantial memory which is given as
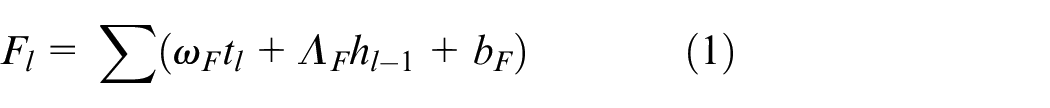
where
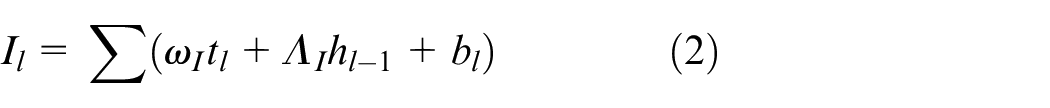
, and the output after activation function is evaluated as
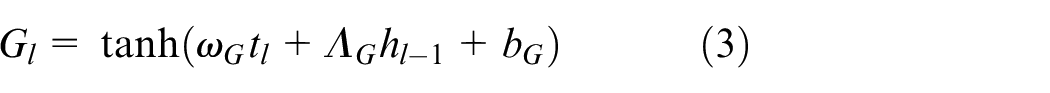
where

where ⊙ demonstrates as the element-wise product. After that, the speech command presented at the output will be chosen and illustrated as
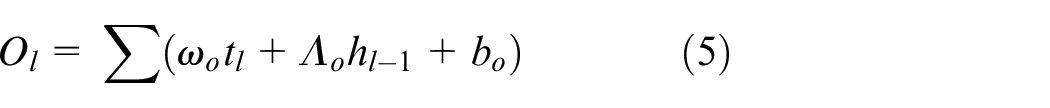
where
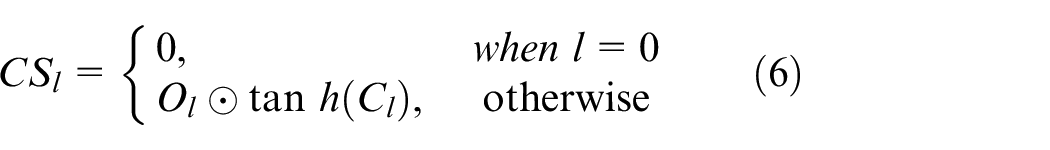
The vector of speech command generated at the output of LSTM is obtained as,

And an optimistic estimation of the acoustic score,
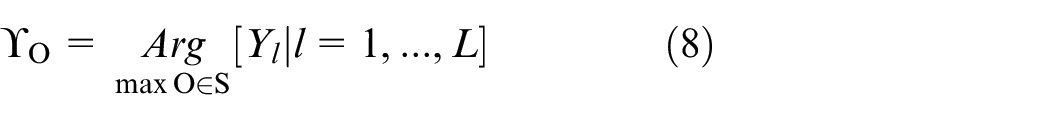
where
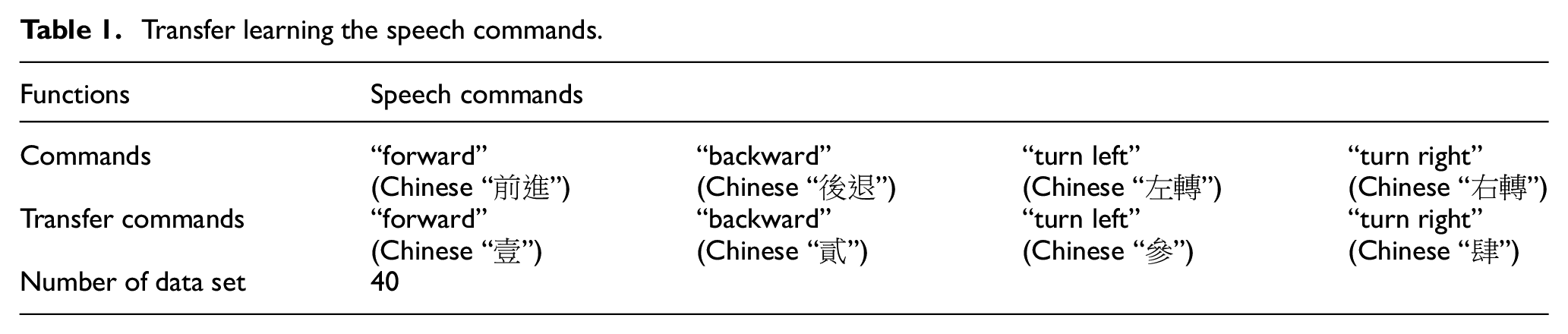
Recently, the technique of transfer learning has been frequently used to the investigation of NLP (natural language processing) field, it is always called as domain adaption. Specifically, there are lots of applications point out that many of data mining and machine learning algorithms are usually considerable the training and future data that existed in the same feature space, even the same distribution is required. 27 However, the requirements mentioned previously can be solved by some solutions according to the techniques, such as knowledge transfer, domain adaption, sample selection bias, multitask learning, as well as covariate movement. In Daume 28 the voice classifiers training adopted standard discriminative learning means. The authors present a function referred as kernel-mapping function for solving the problem occurs in NLP study. The most contribution in there is transferring the collected data to a high-dimensional feature spaces from target and original field. Hereafter, in Argyriou et al. 29 the multitask learning in which the inductive transfer learning setting are employed to learn a low-dimensional format. Accordingly, by using of the knowledge transfer learning, thus, the speech commands are simply handled with the rules shown in Table 1.
Transfer learning the speech commands.
The DNN-LSTM training model and experimental setup
The multiple fully connected hidden layers between the input and output layers are introduced to construct a typical feed-forward DNN-LSTM, where each layer consists of several neurons. The cost function has a minimized objective during the training process involves feeding the DNN-LSTM with labeled inputs. On the other hand, it is in this case to obtain least MSE (mean square error) of the predicted output which respects to the desired output. Certainly, it can be achieved by vanilla/variation of gradient descent using back-propagation algorithms.
23
In Figure 4 show the structures of the traditionally DNN-LSTM framework layer and the applied DNN-based model, respectively. Let
The implementation to the training of those command sets, which demonstrated in Table 1, is the next important stage. Based on the DNN-LSTM, parts of program code developed for training job and establishes the command sets model according to the gathered transfer learning speech commands are presented in Figure 5. Hereafter, for easily understand the development of the framework is directly shown with the Python@ code. The work from first line to seventh line in Figure 5 is for importing suitable applied modules. The training data sets and the preset parameters are shown in line 8–line 14. Besides, the operation of DNNs’ neurons fully connected hidden layers is described from 16th line to 26th line. From lines 27 and 28 which are codes for executing to the activation function of “tanh” and function of “loss,” respectively. Eventually, epoch parameter and the framework of the command sets saved files are programed at the end of the code. The file structure of all the assignment to the command training and implementation to the moving of smart platform is described in Figure 6. There is a tree shaped directory, named as “Speaker,” consists of five sub-directories, data_set, test_data, model, main_code, and Acc_Loss_data. Herein, the description of the programing code is completed.
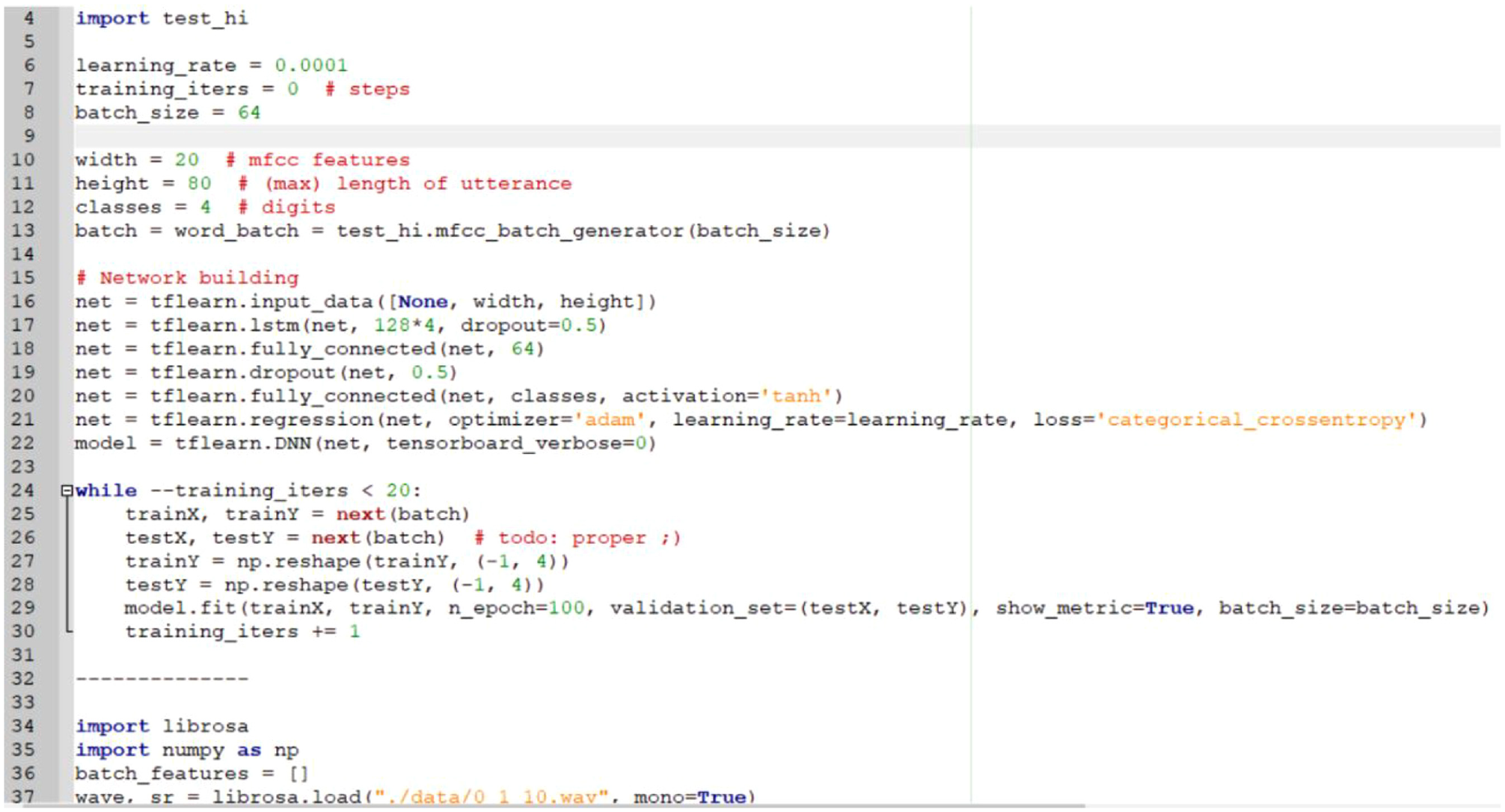
Piece of code developing the command sets training with DNN-LSTM model.
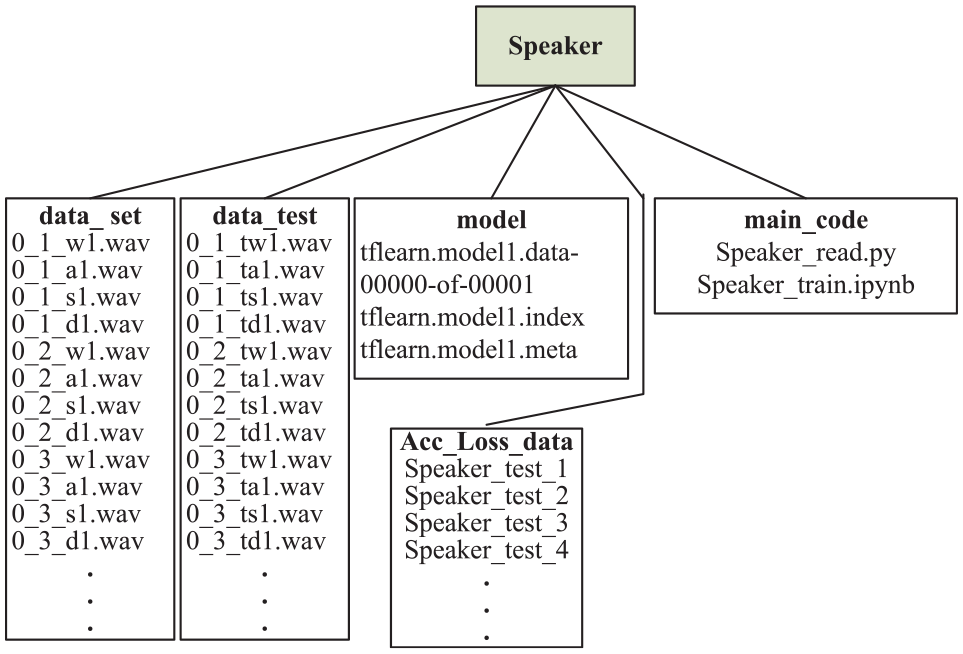
The file structure for training speech commands.
The operation of combining command sets with smart platform
The combination of frame established by training work with smart platform is an important and complicate event. The procedure of installing DNN-LSTM based trained model into the control modular is described in Figure 7(a) where the Tensorflow@ package command, “tflearn” is used. The Raspiberry pi_3@ is the device selected as the controller in the implementation employed in the article, and the OS (operating system) is Linux, which is similar as a microcomputer device and has the basic configuration of a general computer. There many control devices are setup in the smart platform corresponding to the previously discussed subsystems which is shown in Figure 7(b) including some main labeled blocks. The SD card stores OS and programs, video output is HDMI interface, four USB slots and Ethernet port. The product models of USB are divided into Type A and Type B. The data source is the latest information provided by the official website. 31 Hereafter, the introduction to the constitution of the developed smart platform is illustrated briefly. It mainly consisted of three main parts, including “moving control subsystem,”“sensor control subsystem,” and “power driving subsystem.” Certainly, the introduction to the mechanical structure is ignored due to the reason of the limitation in editorial size. The moving subsystem is going to give the signal for controlling the motors’ movement way (“forward,”“backward,”“turn left,” and “turn right”) after accept the appropriate one speech commands from a person. There is a micro-phone to receive the speech command embedded in the “sensor control sub-system.”
The commands to transplant the speech commands.
Results and discussions
In the section the requirement of training parameters is introduced first, and followed by the discussion to the results from the experimental implementation. Hereafter, the analytic of the training and validation results of the speech commands and the precisely control to the smart platform are interpreted detail.
Specified equipment for training
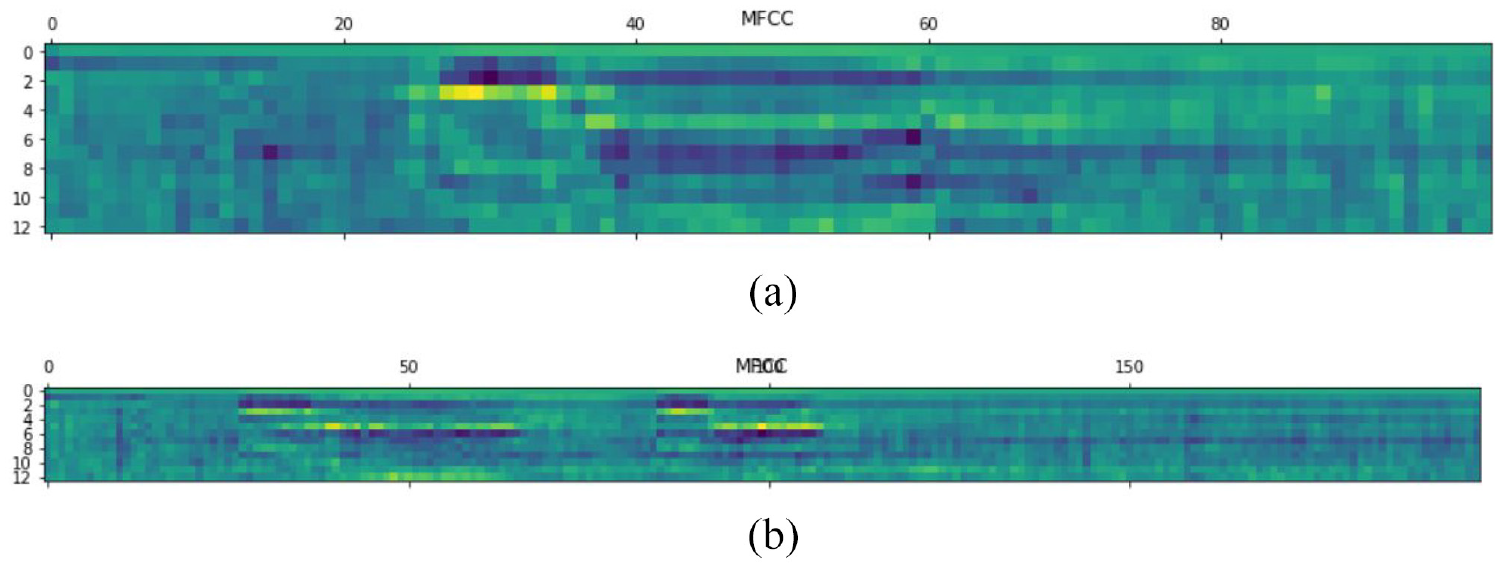
The implementation of collecting the speech commands is deeply described in this sub-section. Initially, the DNN modeled from “tflearn” package of the pre-trained weights from the NN is loaded for performing transfer learning and fine-tuning using the LSTM framework. The augmented input dataset is trained using the specified equipment mentioned in sub-section 4.3. Iteration size is chosen as one of the four different numbers which depend on the repeat times multiply training times, the learning rate is 10e−4, batch size of 64, weight decay of 0.0005, and different dropout numbers which affect the learning performance of the network are deployed and discussed in the next section. An Intel® Core™ i7-8750H CPU@2.20GHz processor, 24 GB memory size, and GDDR5X memory type is utilized to train the DNN-LSTM Net. Similarly, the four kinds of speech commands (“forward,”“backward,”“turn left,”“turn right”) have been processed by the normal pre-processing, and their sampling waveform and MFCC spectrums are demonstrated in Figure 8(a) to (d) respectively.
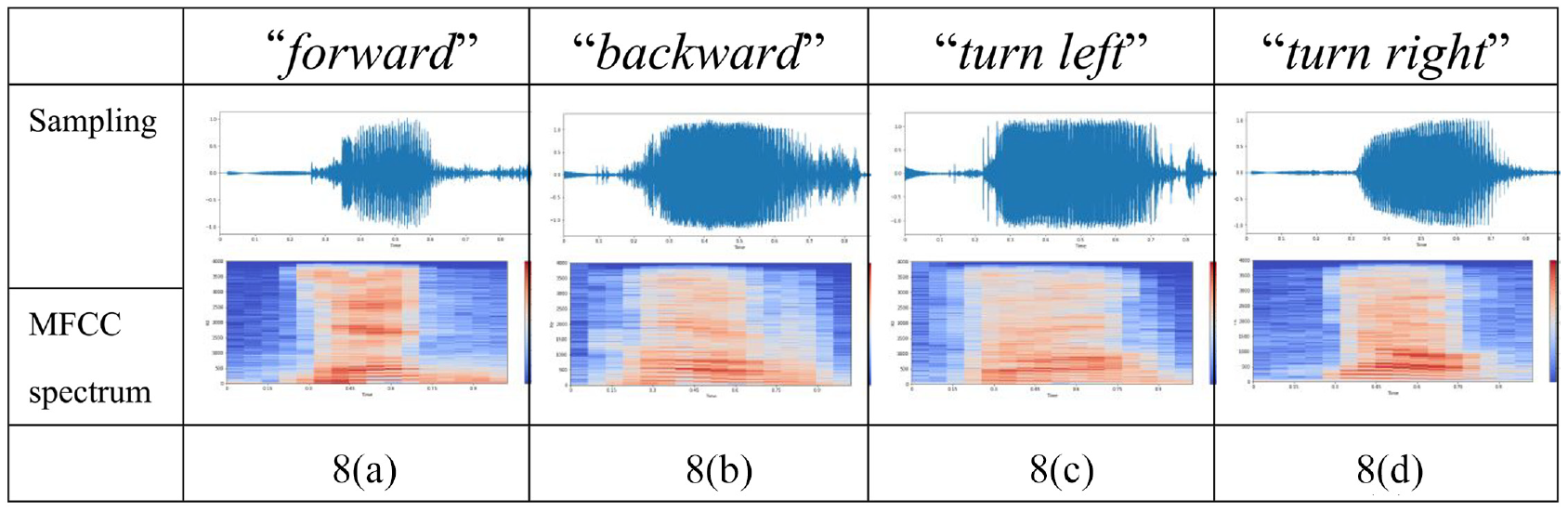
Sampling waveform and MFCC spectrums for speech commands.
It is worth noting that the execution time taken to produce the model of DNN-LSTM framework is wasting in place of fully connected layers utilized due to reduce the cross-entropy loss. However, the crucial point isn’t going to be discussed in the article, because it doesn’t the mainly addressed issue.
Validation and testing network using the input real-world datasets
Real-world speech commands collected from the different persons are also tested using the trained DNN-LSTN network to analyze the performance. Those speech commands utilized for training held in the last sub-section are deployed to validate real operation of the smart platform. The data sets tested to validate the performance of the applied network in training stage are all same in order to the impartial reason. On the other hand, in fact the applied DNN-LSTM framework is focused on employing to control the smart platform, however, the theoretical analysis is minor issue. There are just 40–240 data sets with four kinds of speech commands used to train the applied DNN-LSTM net. For comparison purpose the merit of evaluation to the performance of validation accurate is also calculated in the experiments as follows.
Performance measurement of the applied framework
The performance of the used DNN-LSTM framework with quantitative and subjective evaluation is analyzed in this subsection significantly. In the training stage the collected data sets are separated as
The performance measurement for ST with 2500 training times.
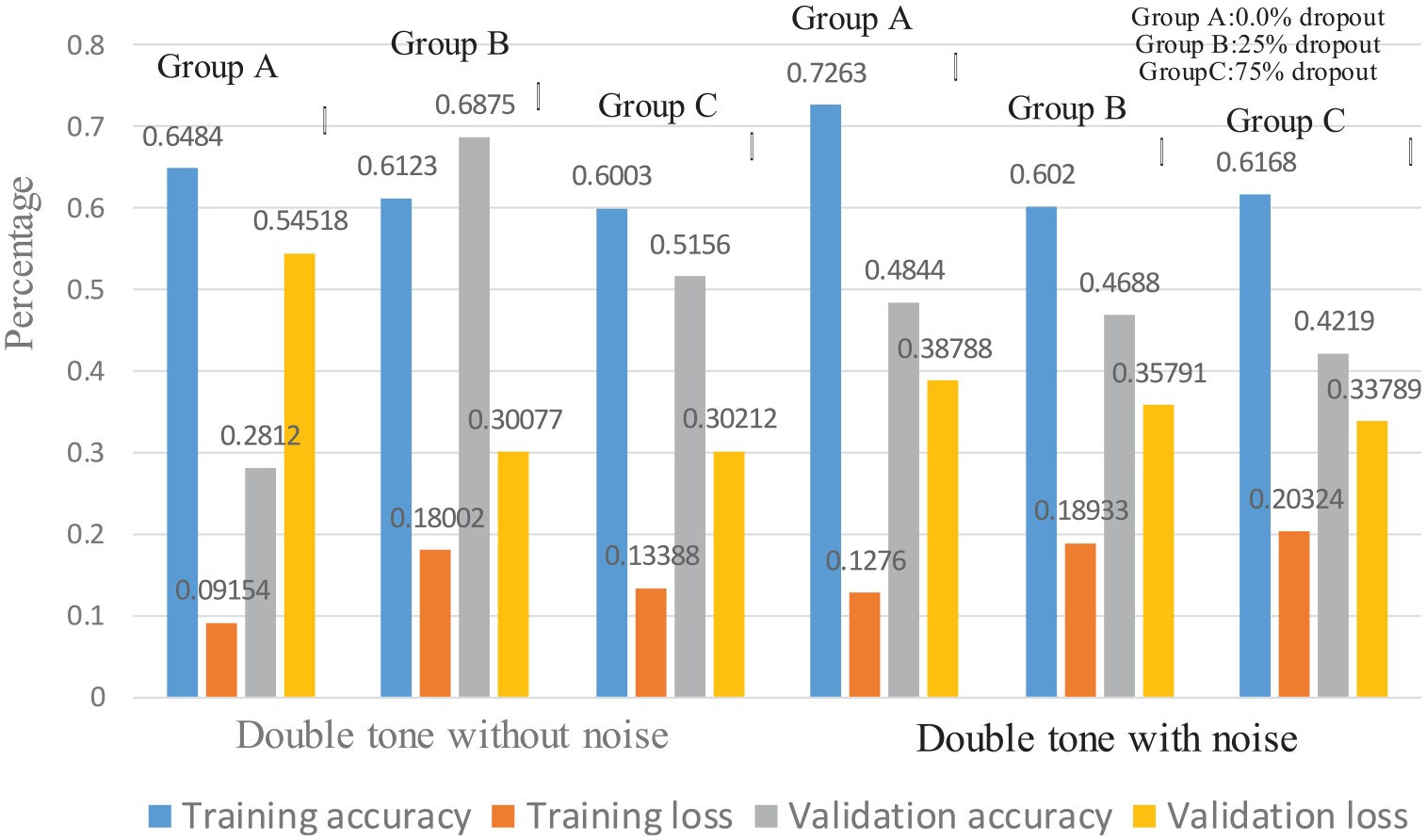
The performance measurement for DT with 5000 training times.
The tone number factor (ST or DT)
The training results from the applied model presented with bar chart in the aforementioned factors rate after

The subroutine of Python code for executing the comparison.
The noise factor (ST or DT)
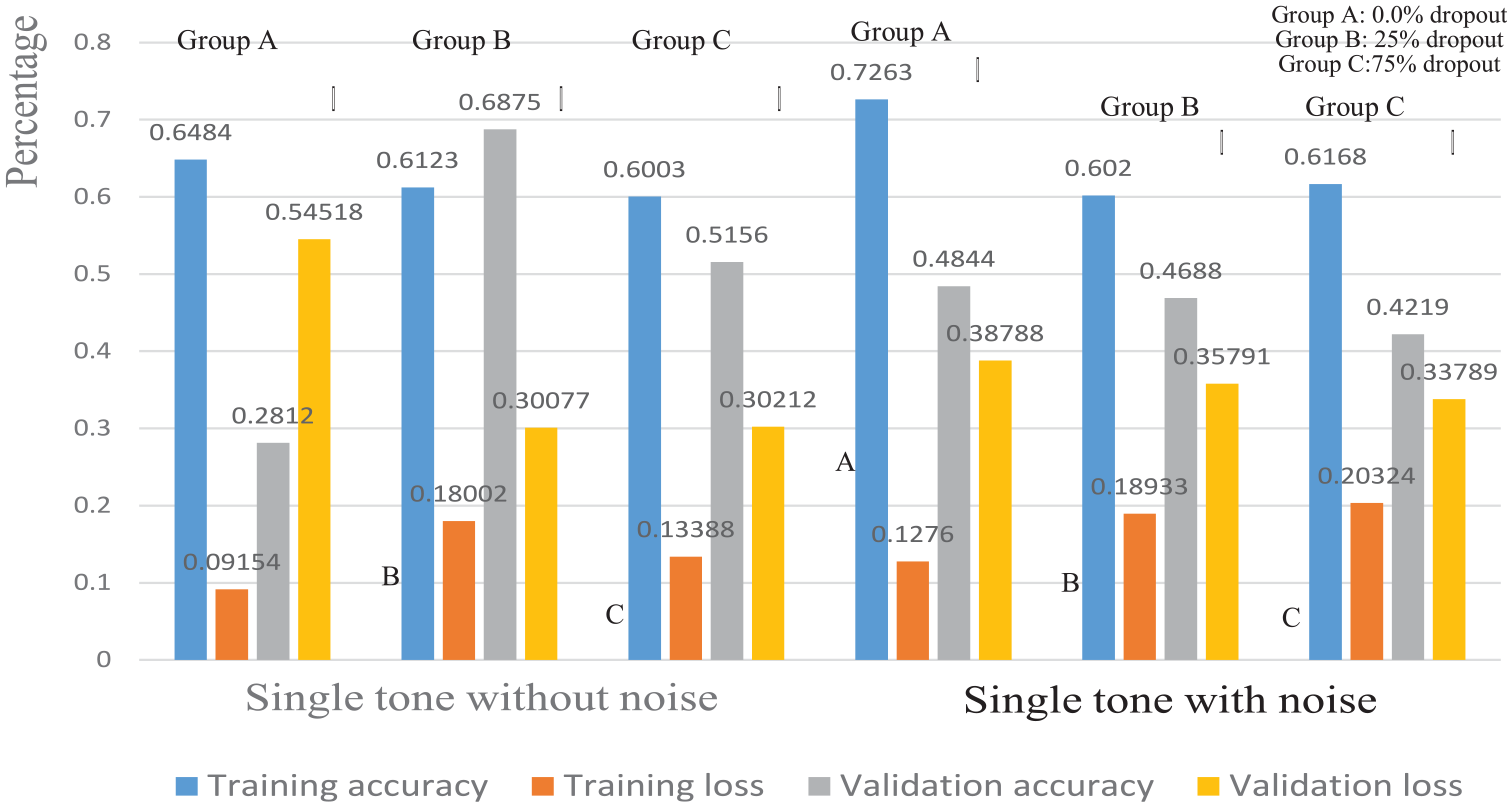
Furthermore, it can be found that the training loss rate generated by the training data without noise is relatively lower than that of being with noise. For example, the sets of {0.091, 0.180, 0.133} and {0.127, 0.189, 0.203} for training loss are corresponding to show in ST without noise and ST with noise in Figure 9. In addition, discussing to the accurate rate of the validation data for those without noise which has obviously occurred higher percentage than those with noise. Such as the cases of {0.281, 0.687, 0.515} and {0.484, 0.468, 0.421} for training accuracy shown in Figure 9. This is easily known that the speech validation activities will be seriously affected by the condition of surrounding noise.
The different dropout ratio factor
Onward, there still a critical point worth noting is the dropout percentage adopted in the training process for DNN-LSTM model. Normally, the performance of a DNN will be improved by the factor of dropout percentage during the data set training stage. 32 It is significantly seen in the case of dropout percentage shown in Figure 9, the group A with 0.0% dropout is always signifying the outperform than the other two groups, 25% and 75% dropout ratio. However, the dropout factor seem doesn’t cause the same results mentioned above. It is believed that the situation of few speech command sets is a reasonable explanation of the appearance for this event. In contrast, the dropout factor hasn’t appeared the same phenomena shown in Figure 10.
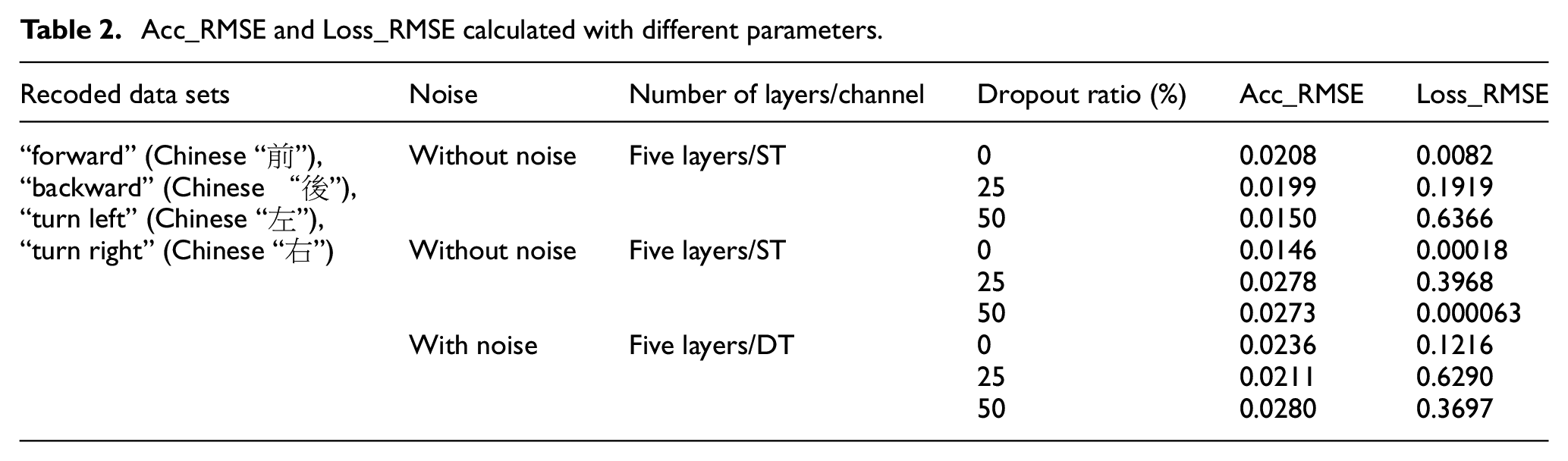
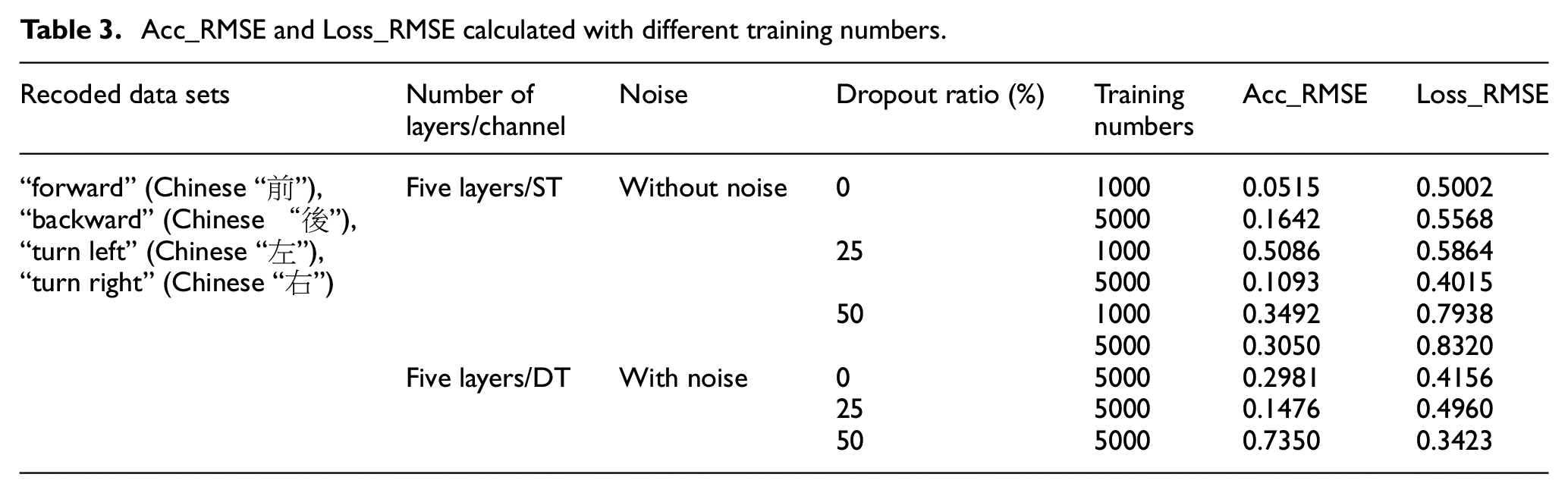
Eventually, the merit of RMSE (Root Mean Square Error) mainly used to measure the differences between the predicted data and tested values of the model is illustrated completely. Hence, the four recoded speech data sets, “forward” (Chinese “
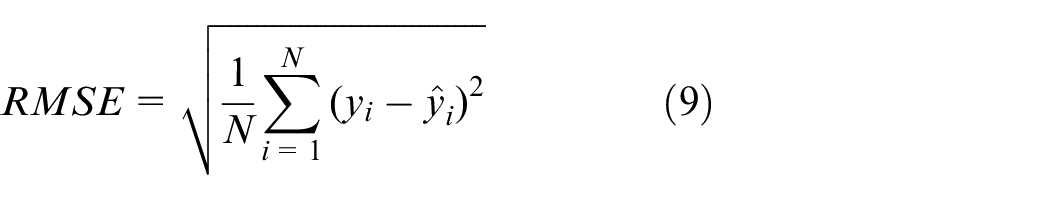
where
Acc_RMSE and Loss_RMSE calculated with different parameters.
Acc_RMSE and Loss_RMSE calculated with different training numbers.
Briefly compared with Bi-LSTM network
The applied model DNN-LSTM is compared with the similar one, Bi-LSTM network, based on the most basic parameters. On the other hand, for the purpose of comparison only the basic hyperparameters are deployed and expressed in Table 4. Iteration size is fixed in 40 training times, the learning rate is 10e−4, batch size of 64, weight decay of 0.0005, and dropout ratio equals 7:3. In Figure 11 shows the definition of LSTM and Bi-LSTM python code which is the demonstration for executing the comparison. The marked with red circle are corresponding to the results of the accurate and loss rate for DNN-LSTN, which are captured in Figure 12. The loss rate and the accurate rate are
The deployed parameters for comparison with the two networks.

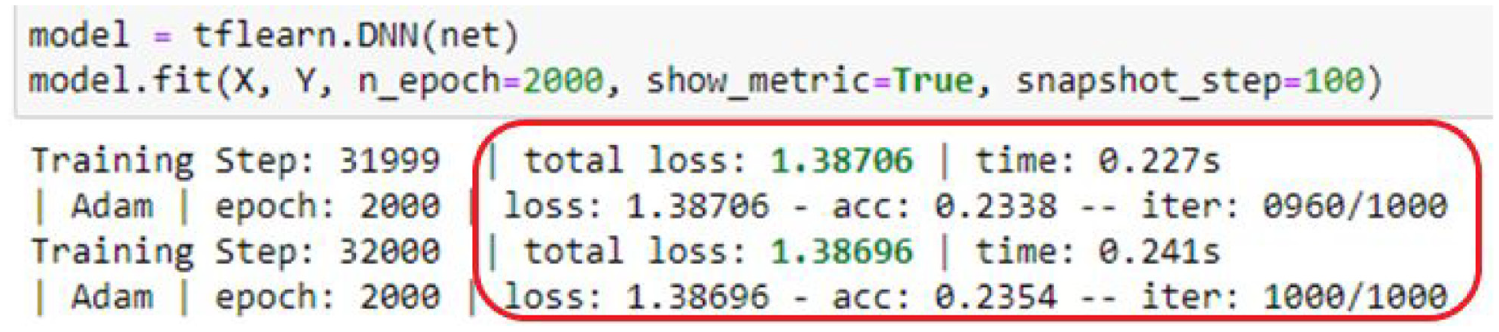
The applied model is compared with Bi-LSTM network based on similar parameters.

(a) The layers scenario of model and (b) part of results from the experiment.
Conclusion and future work
In the current article applies an optimized DNN-LSTM model to speech recognition, and which performance is evaluated under the assumption of many restricted factors. Based on the advantages of DNN-LSTM framework, which can keep more much longer sound for speech discriminator model and low-dimensional format of data sets respectively. Consequently, the optimized DNN-LSTM model has developed and implemented in the self-collected command sets. Few collected command sets include four Chinese speech commands, “
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.