
Abstract
As the core component of rotating machinery, the fault diagnosis of rolling bearing has important engineering practical significance. Most of the current intelligent fault diagnosis methods are based on the premise that the training data and test data have similar probability distributions. However, in practical scenarios, there will inevitably be discrepancies in the distribution of vibration signals due to internal and external factors such as changes in working conditions, which will significantly affect the diagnostic performance of the intelligent diagnostic model. Aiming at problems that the vibration signal characteristic distribution of rolling bearings is inconsistent under different working conditions and the labels of the samples to be diagnosed are difficult to obtain, a new domain-adaptive fault diagnosis method is proposed in this paper. Firstly, the multi-scale feature extraction module is used to extract the features of the input signals, and the residual network structure is used to avoid the degradation of the model performance. Then, the APReLU activation function is used to make the vibration signals perform different nonlinear transformations according to their own characteristics through adaptive learning. Finally, the Joint Maximum Mean Discrepancy (JMMD) is used to reduce the displacement of both conditional and edge distributions between different domains. Therefore, this method can extract domain-invariant feature information and align the source and target domains, which can be used for cross-domain intelligent fault diagnosis. Six transfer fault diagnosis tasks based on the rolling bearing experimental platform are designed to evaluate the performance and effectiveness of the proposed method. At the same time, four popular methods are selected for comprehensive analysis and comparison. The results show that the method has good robustness and superiority under various diagnostic tasks.
Introduction
Rolling bearing is the most frequently used key component in rotating machinery, which is widely used in modern industrial production. The health status of rolling bearings has an important impact on whether the entire mechanical equipment can run smoothly. Therefore, fault diagnosis can effectively ensure the production safety and life safety in industrial production, which has great practical significance in engineering.
Aeroengines often work in high speed, high temperature, overload, and other extreme conditions, which make them more vulnerable to failure. If the aeroengine fails, the flight performance of the aircraft will be degraded, and in severe cases, it may even lead to a flight accident. In addition, the cost of aeroengines is high, and the cost of maintenance and replacement is huge. Therefore, it is very important to adopt relevant methods for fault diagnosis of aeroengines. Quickly and accurately detecting and locating faults can greatly save maintenance costs of aircraft, avoid flight accidents, and ensure flight safety. In summary, in order to effectively reduce the maintenance cost of aeroengines and improve the safety performance of aeroengines, more and more attention has been paid to the fault diagnosis research of aeroengines.
Bearing vibration signal is a mixed signal composed of vibration source signal and noise signal, which contains a large amount of bearing operating status information. Therefore, by processing and analyzing the vibration signal of the bearing, the running status of the bearing can be diagnosed. In traditional fault diagnosis research, relevant scholars process vibration signals and extract useful fault feature information from them. At present, many classical signal processing methods have emerged, such as fast Fourier transform (FFT), short-time Fourier transform (STFT), wavelet transform (WAT), etc. On this basis, many optimization methods were developed. For example, Zhang et al. 1 proposed a parameter adaptive variational mode decomposition (VMD) method to analyze vibration signals of rotating machinery, and used GOA algorithm to optimize VMD parameters, and finally applied it to bearing fault feature extraction. Li et al. 2 proposed a bandwidth empirical mode decomposition and adaptive multiscale morphological analysis (BEMD-AMMA) method, which weakens the mode aliasing phenomenon of traditional EMD algorithm, and realized early fault diagnosis of rolling bearings by constructing the principal component of the original signal and demodulating it.
However, all the above fault diagnosis methods require considerable professional knowledge of rotating machinery signal processing and a solid mathematical foundation as support. Moreover, in the actual operation process, mechanical equipment usually operates under more complex working conditions, and vibration signals may change with the change of rotating speed, load, and other working conditions, so the effect of fault diagnosis method based on signal processing will become worse. Therefore, some related scholars used machine learning-based fault diagnosis methods to make up for these deficiencies. Shao et al. 3 proposed an intelligent mechanical fault diagnosis method by combining VMD and support vector machine (SVM), and optimized SVM by VHHO algorithm, which can effectively identify different bearing faults. Udmale et al. 4 used spectral kurtosis (SK) to construct the fault feature set of vibration signals, identified the fault feature information by extreme learning machine (ELM), and introduced an improved two-way search method based on local search to determine ELM parameters, which improved the performance of bearing fault diagnosis model.
With the rapid development of artificial intelligence, deep learning has been widely used in the field of fault diagnosis due to its strong learning ability and feature self-extraction ability, and has become a research hotspot today. Deep learning can automatically extract deep fault information, effectively avoiding the limitation of selecting fault features manually. Cao et al. 5 applied the particle swarm optimization (PSO) algorithm to the convolutional neural network (CNN) and proposed an adaptive deep convolutional neural network fault diagnosis model, which improves the diagnostic accuracy and robustness of the traditional deep learning fault diagnosis algorithm. Wen et al. proposed a rolling bearing fault classification method based on CNN with an automatic learning rate scheduler, and improved the stability of diagnosis model by using dual CNN structure. Experiments proved that AutoLR-CNN has advanced fault diagnosis performance. 6 Yan et al. 7 proposed a stack denoising autoencoder (SDA) fault diagnosis algorithm to automatically identify the rolling bearing status, and determined the parameters of the autoencoder model through grasshopper optimization algorithm (GOA), which improves the fault classification accuracy of the autoencoder. Fault diagnosis algorithms based on deep learning such as autoencoders (AE) and CNN do not require traditional artificial signal processing, and can achieve end-to-end fault diagnosis and obtain satisfactory results. In addition, when using deep learning technology, if the network model is deep, the selection and optimization of parameters are very important. For parameter optimization problems, related scholars generally use correlation optimization algorithms to optimize parameters, such as multi-objective optimization technique, 8 Grasshopper optimization Algorithm, 9 Whale Optimization Algorithm, 10 etc.
It is worth mentioning that deep learning is not only widely used in the field of fault diagnosis and classification based on data, but also has important significance in the field of prediction of time series data. Such as Chen et al. 11 proposed a nonlinear combined short-term wind speed prediction method, which combined extreme learning machine (ELM), Elman neural network (ENN), and long short term memory neural network (LSTM), and obtained a better prediction effect; and achieved good prediction results. Zhao et al. 12 proposed a novel short-term traffic flow forecasting model EnLSTM-WPEO based on LSTM neural network, which is of great significance in the field of intelligent transportation. Karasu and Altan 13 used the CHGSO algorithm to select the effective features related to prediction, and used the LSTM neural network model to predict the crude oil time series, which solved the chaotic and nonlinear characteristics of the original data.
However, the above deep learning-based fault diagnosis algorithm needs to be based on the independent and identically distributed (IID) of the training set and the test set. In actual industry, due to the change of temperature, speed, load, and other factors, the distribution of training set and test set usually has a drift phenomenon, which cannot meet the assumption of the same distribution. As a result, the fault diagnosis algorithm trained in the original working condition is difficult to apply to a new working condition, and the generalization performance of the fault diagnosis algorithm is greatly reduced. Therefore, it is of great practical significance to solve the problem that the model applicability is reduced due to the change of data distribution caused by different working conditions, that is, to realize cross-domain fault diagnosis.
For the above cross-domain fault diagnosis problems, the most direct way is to re-collect and label the training data under new working conditions, and re-train the model, but this method requires more manpower, material resources, and time costs. Therefore, relevant scholars apply transfer learning theory in the field of fault diagnosis, and transfer learning can solve related target domain problems through learned source domain knowledge: Learning in the source domain (the training set) and transferring the knowledge learned from the source domain to different but related target domain (the test set), so as to solve new related tasks in the target domain and improve the generalization ability of classification model.14–16
Among them, domain adaptation is a special case of transfer learning. Its core idea is to map the source domain and target domain to a common feature space to eliminate the discrepancies between domains and re-form feature sets with the same distribution. Domain adaptation has strong cross-domain and cross-task learning ability, which is suitable for solving the problem of cross-condition diagnosis of rolling bearings, so that the fault diagnosis model trained under one working condition can adapt to fault diagnosis tasks under different working conditions. The adaptive process is a process of continuously approaching the target. Adaptive is a process that automatically adjusts processing methods, parameters, boundary conditions, or constraint conditions according to data characteristics in the process of processing and analysis, so as to achieve the best processing effect.17,18
CNN has a strong ability to extract features and process complex high-dimensional data due to its characteristics of local linking, weight sharing, and subspace sampling. Therefore, the research on domain adaptation fault diagnosis based on CNN has a great development space. Liu et al. proposed a domain adaptation fault diagnosis algorithm based on deep learning, which consists of stack autoencoder (SAE) and weighted domain discriminator based on Softmax, and conducted confrontational training on the discriminator to minimize the approximate domain discrepancy distance. This significant algorithm improves the accuracy of fault diagnosis in partial domain adaptation (PDA) scenarios. 19 Li et al. integrated the domain adaptation idea into CNN and proposed a deep convolutional transfer learning fault diagnosis algorithm, which uses CNN as a feature extractor to extract fault information and solves the domain shift problem by minimizing the multi-kernel maximum mean discrepancy (MK-MMD) between the two domains. Experiments showed that this method can improve the cross-domain performance of the fault diagnosis model. 20
However, the above papers ignored the influence of vibration coupling on rolling bearings during operation, which brings time multi-scale characteristics to vibration signal in the time domain. Therefore, when bearing damage occurs, the fault features may also show multi-scale characteristics due to vibration coupling. Moreover, the Maximum Mean Discrepancy (MMD) used in the above paper ignores the conditional distribution discrepancy between the source domain and the target domain, so it cannot accurately measure the discrepancy between different domains. In a word, the above papers still have some room for improvement. To solve the above problems, on the basis of the original algorithm, this paper proposes a new regional adaptive fault diagnosis model.
Aiming at the inconsistency in the feature distribution of the fault status signal data collected under different working conditions of the rolling bearing and the unlabeled samples in the target domain, this paper proposes a domain adaptation transfer diagnosis method based on a multi-scale feature fusion residual network. The method is mainly composed of fault feature extraction and domain adaptation. The feature extraction layer is used to extract the common features of the source domain and target domain, this part uses the pre-trained multi-scale feature fusion residual network to extract the general features. The discrepancy between the source domain and the target domain is mainly reflected in the fully connected layer. In the domain adaptation part, the fully connected layer is used to learn the transfer knowledge, and the joint maximum mean discrepancy (JMMD) metric is used to calculate and minimize the joint distribution discrepancy, so as to realize the transfer learning of rolling bearings under different working conditions. The main insights and contributions of this paper are summarized as follows:
In this paper, a domain-adaptive fault diagnosis algorithm for intelligent diagnosis the Residual Joint Adaptive Network based on multi-scale feature fusion is proposed. This algorithm can classify and identify the unknown target domain datasets by using the source domain data with similar fault categories, so as to realize the fault diagnosis of the target domain. And the algorithm does not require any signal processing, which reduces the algorithm’s dependence on signal processing and target domain label data. Experiments show that the algorithm has good adaptability and portability, and has a good application prospect.
In the fault feature extraction part, considering that the vibration signal has multi-scale characteristics, the algorithm uses multi-scale feature extraction and fusion layer in the first layer, which not only accelerates the training speed of the model, but also can extract more comprehensive multi-scale fault features. The residual module is used to deepen the depth of the model and solve the degradation problem of the deep neural network. APReLU activation function is introduced into the residual network to enhance the feature recognition ability of the network. Therefore, the algorithm can obtain more effective fault feature data in the feature extraction part.
In the domain adaptation part, the algorithm introduces JMMD to calculate the distribution discrepancy and minimizes it to achieve domain adaptation. The traditional measure of the MMD metric only considers the marginal distribution discrepancy between source and target domains, whereas JMMD sums the marginal distribution discrepancy and the conditional distribution discrepancy to measure the discrepancy between domains. Therefore, this algorithm can measure the difference between different domains more accurately when performing domain adaptation, and obtain higher accuracy in the transfer learning problem of rolling bearings.
Finally, the bearing vibration signal data sets under different faults and working conditions are obtained on the bearing fault test platform, and six groups of transfer learning bearing fault diagnosis tasks under different working conditions is carried out to explore the effectiveness of the proposed method. At the same time, four common fault diagnosis methods based on deep network and deep transfer learning are selected for comprehensive analysis, and the diagnosis results are explained reasonably. The results further demonstrate the effectiveness and superiority of this method.
The rest of this paper is organized as : the second part introduces the theoretical background of domain adaptation, feature extraction methods, and domain adaptation strategies; The third part explains the construction process of cross-domain fault diagnosis algorithms; The fourth part demonstrates the evaluation and discussion of model performance through related experiments; Finally, the fifth part draws the conclusions and future work directions.
Theoretical background
Problem formulation-domain adaptation
This paper focuses on the problem of domain adaptation in fault diagnosis, which is a branch of transfer learning. The working conditions of aeroengine will change with the external environment and human factors. Even if the fault type of aeroengine rolling bearings is the same, the distribution of vibration signals will change with the change of working conditions. Therefore, the distribution of fault features in the source domain and target domain is usually different under different working conditions. Domain adaptation can map samples of different working conditions (source domain and target domain) to a common space to find their common features, so as to narrow the domain discrepancies and eventually form feature sets with the same distribution.
The data under one condition is considered a domain
In the actual environment, due to the interference of the external environment and the change of working conditions, the problem of domain transfer will occur. Therefore, the data distribution of source domain
By using domain adaptation technology, the cross-condition diagnosis problem is transformed into a general classification problem that satisfies the independent and identical distribution. This technology can improve the generalization ability and robustness of fault diagnosis algorithm, and improve the adaptability of the model to other application scenarios.
Residual network
CNN can fully extract the main features of one-dimensional signals, such as vibration signals, audio signals, etc. It mainly contains convolution layer, pooling layer and fully connection layer.
The function of the convolution layer is to extract local features. Each convolution kernel in the convolution layer convolves local the samples with fixed kernel size and stride, and extracts the corresponding features.
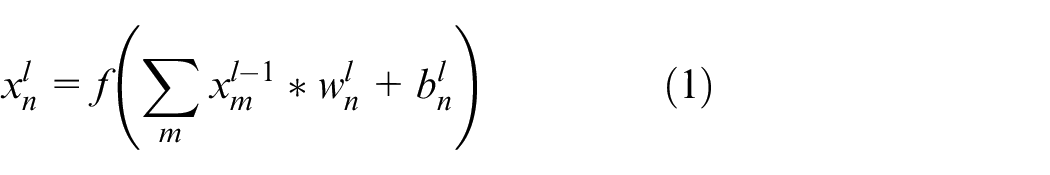
Where
The function of the pooling layer is to reduce the dimension of the feature space, simplify the computational complexity of the network, and reduce model parameters while retaining the main information.

Where
The function of the fully connected layer is to connect all features. It is a transition structure between the convolutional layer and the classifier, which converts the feature map into a one-dimensional array and sends it to the classifier.

Where
The parameters of the CNN model are obtained through chain derivation, which may cause gradient disappearance or gradient explosion, which increases the difficulty of training. In response to the above problems, He et al. 21 proposed the concept of residual network. Residual network directly inputs the output of the neural network of the previous layer into the network of the latter layer through cross-layer links, which effectively solves the problem of gradient dispersion. It consists of a series of residual blocks, each residual block includes convolutional layer, non-linear activation function layer, and cross-layer link. The residual block is shown in Figure 1.

Structure diagram of residual network.
In Figure 1,

For the
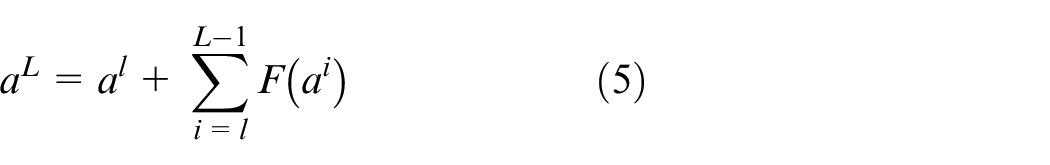
It can be seen that the residual module directly adds the input data of the module to the output data by cross-layer link. Because of the existence of the addition term, when calculating the gradient, the gradient component can be directly transferred to the next layer, which improves the training speed of the model and avoids the degradation of model performance caused by gradient disappearance or gradient explosion.
Adaptively parametric rectifier linear units
In a multi-layer neural network, the output of the upper neuron node and the input of the lower neuron node are connected together by activation function. The activation function can introduce nonlinear characteristics into the neural network, so that the neural network model can learn complex nonlinear functions better. The ReLU function is a commonly used activation function. Compared with other activation functions such as Sigmoid and tanh, it is closer to the biological neural activation mechanism, and has the advantages of simple calculation and fast convergence. ReLU function can be expressed as
For the vibration signals of rolling bearings, the vibration signals under the same fault status may have different characteristics due to changes in temperature, load, speed, and other operating conditions, and the vibration signals under different fault statuses may also have similar characteristics at a certain moment due to changes in working conditions. In traditional deep learning, the activation function adopts the same nonlinear mapping transformation for all vibration signals, so the traditional ReLU activation unit may not be able to map all the input features into the correct regions.
In response to the above problems, in order to enhance feature recognition ability, Zhao et al. 22 combined the attention mechanism with the PReLU activation function and proposed an adaptively parametric rectifier linear unit (APReLU), which can perform different nonlinear transformations on vibration signals through adaptive learning. Zhao et al. applied it in ResNet and proved through experiments that the ResNet-APReLU structure has strong advantages in the field of rolling bearing fault diagnosis. This structure can effectively optimize the parameters in the network and improve the accuracy of fault diagnosis. Therefore, in order to obtain higher diagnostic accuracy under non-stationary operating conditions, this paper introduces the above structure into the transfer learning method.
PReLU activation function is a ReLU activation function with parameters proposed by He et al.,
23
which has stronger fitting ability than traditional ReLU, and its formula is
The structure of APReLU is shown in Figure 2. In APReLU, firstly, the input feature map will be input into two channels respectively, the first channel is used to calculate the global information of positive features, in this channel feature map is subjected to the global average pooling (GAP) operation after

Structure diagram of APReLU.
In the above process, the function retains the information of negative features, the GAP reduces the influence of the vibration signal displacement change, the BN layer improves the model training speed, and finally, in order to prevent the multiplication weight parameter
In this paper, all ReLU activation functions in the residual module are replaced by APReLU activation functions, and the final residual module is shown in Figure 3.

Structure diagram of ResNet-APReLU.
Multi-scale feature extraction and fusion module
The rolling bearing will be affected by vibration coupling during operation, which will bring the time multi-scale characteristics to the vibration time domain signal. When the bearing is damaged, the fault characteristics will also show multi-scale characteristics. In view of the above problems, in order to effectively mine fault information in data and extract multi-scale fault features, in this section, a multi-scale feature extraction and fusion module is added to the residual network, and a residual network model based on multi-scale convolution feature fusion is proposed. Compared with the traditional convolution layer, the multi-scale feature extraction module has stronger feature extraction ability and can obtain more effective fault information. The whole multi-scale convolution feature extraction and fusion module is equivalent to a convolution block.
This section builds a multi-scale feature extraction and fusion module through parallel learning, adopts a parallel three-channel structure for multi-scale feature extraction, and uses convolution kernels of different sizes to extract multi-scale fault features from the signal. The convolution kernel sizes of each branch structure are 64 × 1, 128 × 1, and 256 × 1, respectively. By using convolution of different sizes to extract features of different scales, the model not only retains the details of the shallow layer but also integrates the deep information. Meanwhile, in order to further optimize the model and improve the network diagnosis effect, batch normalization and activation functions are added after each convolutional layer. Finally, feature information of different scales is stacked and spliced together by Concat layer to generate new output features. The residual network model framework based on multi-scale convolution feature fusion is shown in the figure 4.
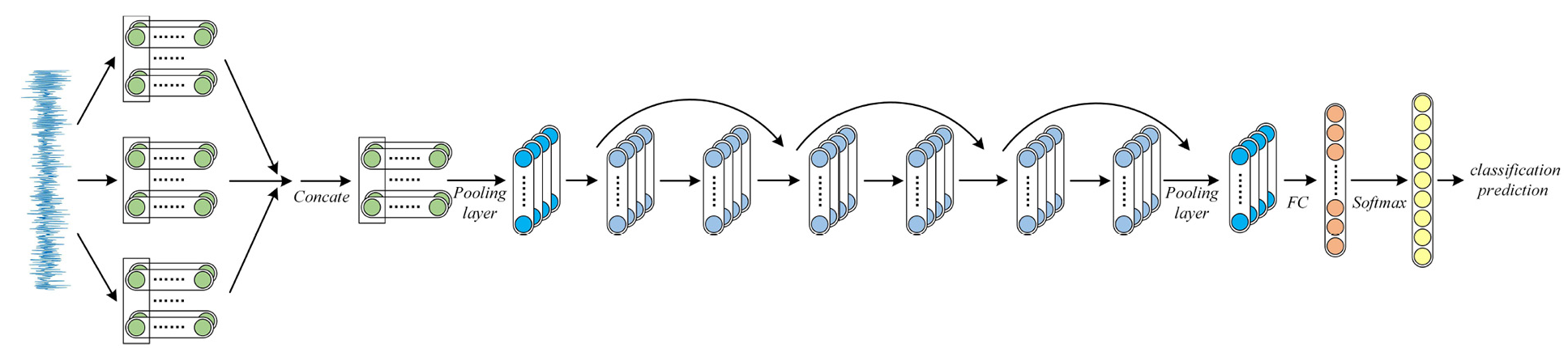
Structure diagram of residual network model based on multi-scale convolution feature fusion.
Table 1 shows the details of the parameters of the convolutional neural network used in this paper. In this network model, the input is vibration signal sample with a length of 2048 data points, and then multiple hidden layers are used to extract more abstract features layer by layer. In order to enhance the fault diagnosis ability of the model, obtain a deeper network and larger receptive field, after the second layer, the convolution kernel dimension of all convolution layers is 3 × 1, and the number of convolution kernels in each layer is twice that of the previous layer.
Parameters of the neural network model.
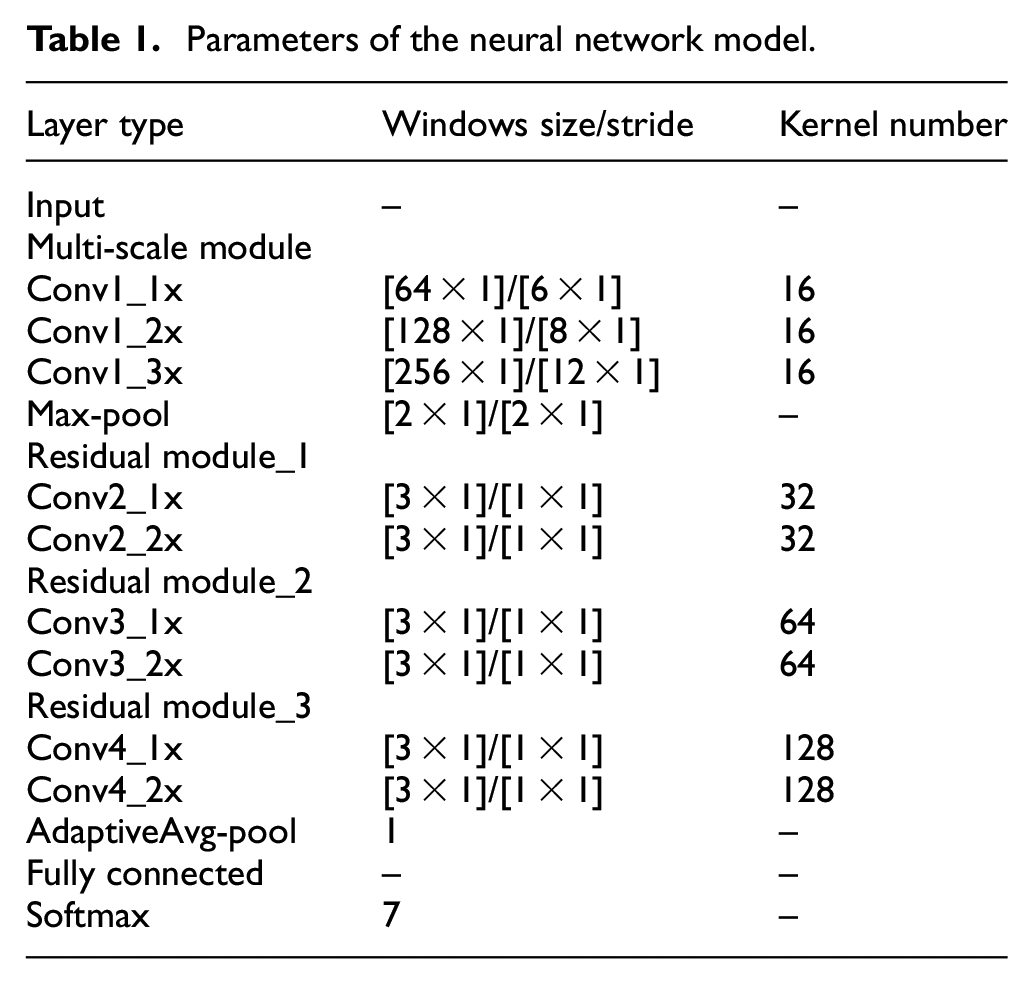
Remark 1. For the convolution kernel size of the multi-scale fusion layer and the number of residual modules, this paper obtained an optimal choice by considering the training speed and model accuracy through experimental comparison.
Joint maximum mean discrepancy
The source domain data is defined as
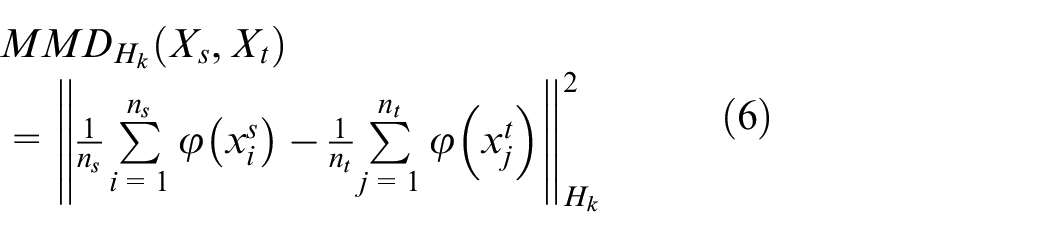
Where
The traditional MMD distribution only considers the marginal distribution, but in practical industrial scenarios, the marginal distribution and conditional distributions of the target domain and the source domain are often different, and they all have different effects on domain adaptation. Therefore this section introduces the joint maximum mean discrepancy (JMMD). 24 JMMD fuses marginal distribution discrepancy and conditional distribution discrepancy. Experiments prove that the model constructed by JMMD can more convincingly represent the actual distribution discrepancies between the source domain and target domain, and has superior robustness. 25
Calculation of the marginal distribution MMD: It can be represented by formula (6):
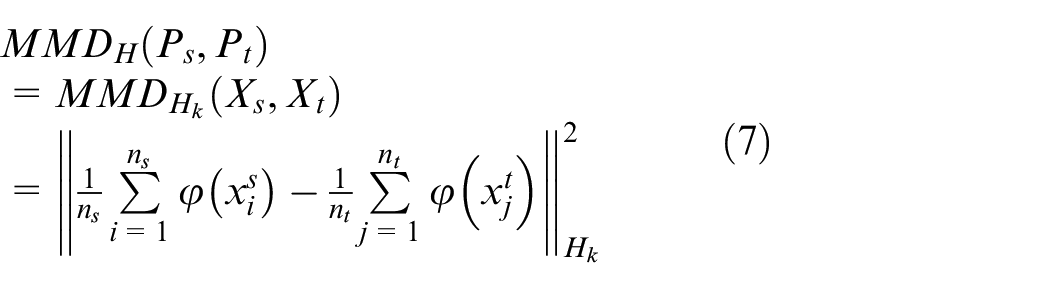
Calculation of conditional MMD: Assuming that there are
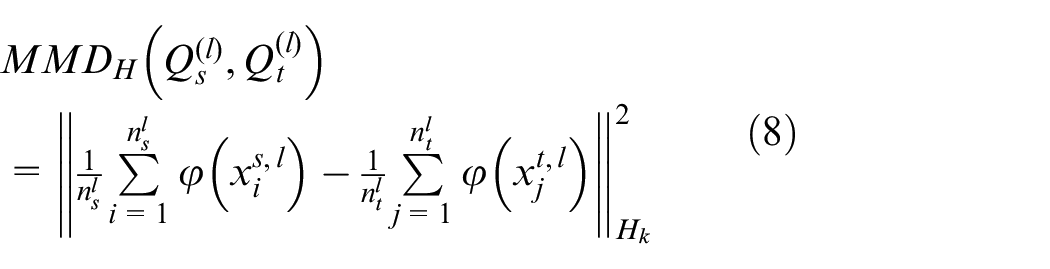
Where
In summary, the formula for calculating the joint maximum mean discrepancy is
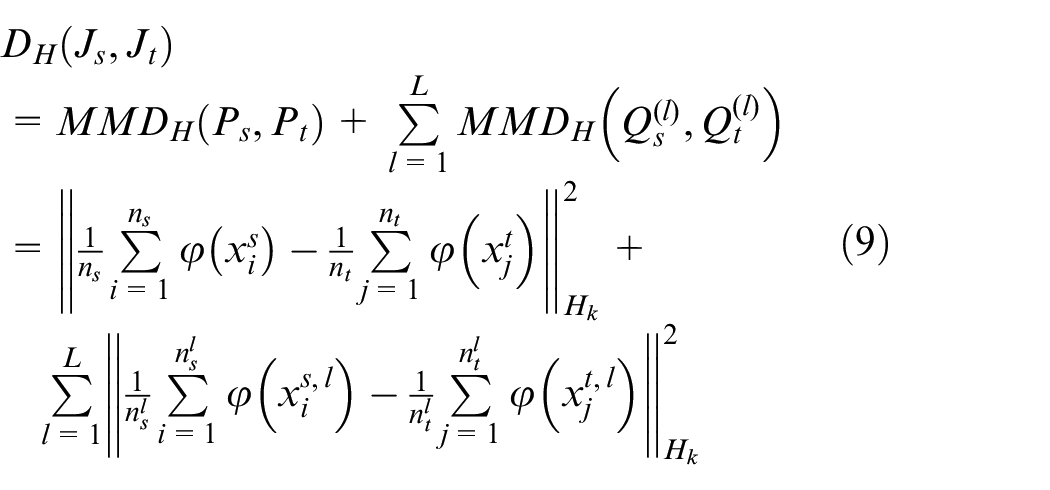
Where
Proposed deep learning method
Build model
Aiming at the problems of inconsistent distribution of data characteristics collected under different working conditions of rolling bearings and no labels of target domain samples, a domain adaptation transfer diagnosis method based on a multi-scale feature fusion residual network is proposed in this paper. The method consists of two parts: fault feature extraction and domain adaptation. The feature extraction part uses the pre-trained multi-scale feature fusion residual network to extract the common features of the source domain and the target domain. The difference between the source domain and the target domain is mainly reflected in the FC layer. The domain adaptation part uses the FC layer to learn the transfer knowledge, and uses the JMMD metric to calculate and minimize the distribution difference, so as to realize the transfer learning of rolling bearings under different working conditions. The method consists of two parts: fault feature extraction and domain adaptation. The feature extraction part uses the pre-trained multi-scale feature fusion residual network to extract the common features of the source domain and the target domain; The domain adaptation part uses the fully connected layer to learn the transfer knowledge, and uses the JMMD metric to calculate and minimize the distribution discrepancy, so as to realize the transfer learning of rolling bearings under different working conditions.
Based on this idea, the model diagram of the method proposed in this paper is shown in Figure 5. First, the bearing vibration signals under different working conditions and different health statuses are preprocessed and divided into the training set and test set; secondly, in order to reduce the training time and accelerate the model convergence, the pre-trained multi-scale feature fusion residual network model is used for general feature extraction, and the JMMD metric is used for domain adaptation; Finally, a Softmax classifier is used for bearing fault diagnosis on the unlabeled target domain.
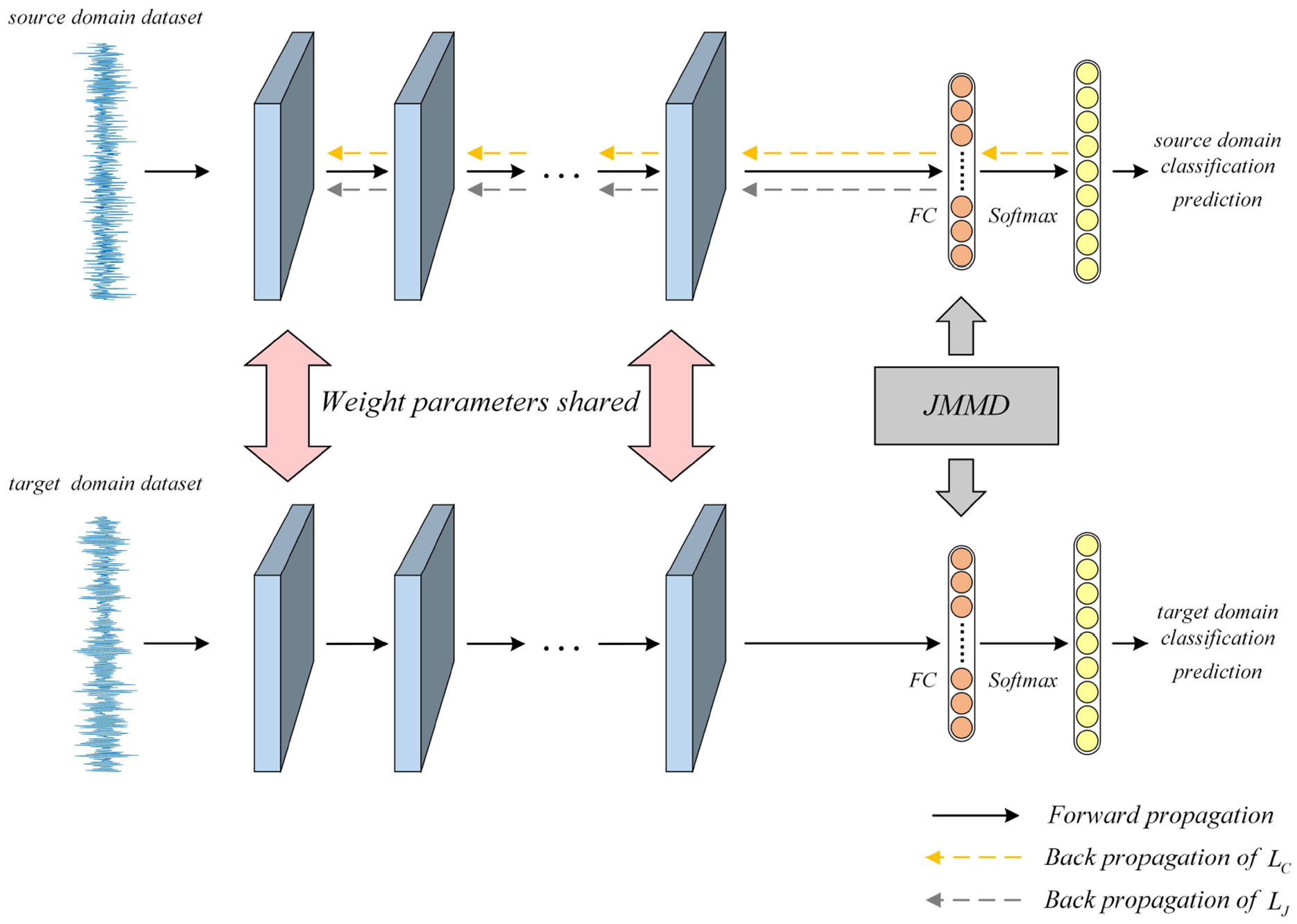
Structure diagram of domain adaptation transfer diagnosis method based on multi-scale feature fusion residual network.
Training method
In this paper, the objective optimization function is minimized to train the domain adaptation model. For the rolling bearing domain adaptation fault diagnosis method proposed in this paper, the objective optimization function includes the following two items: The multi-class loss function
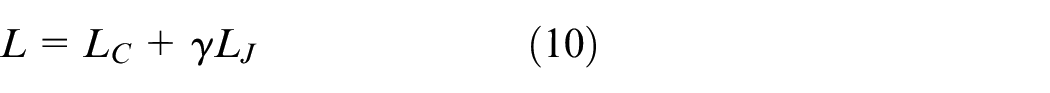
Where
The multi-class loss
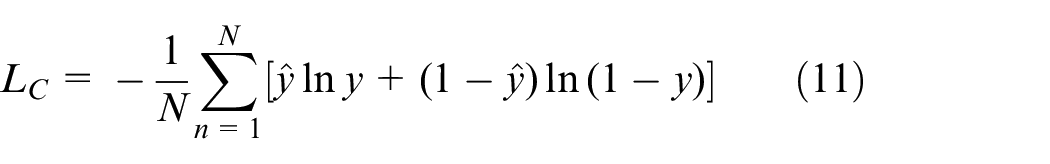
Where
After determining the optimization objective of the model, let
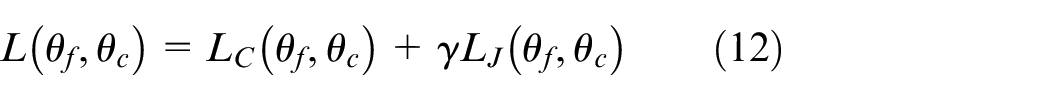
In order to reduce the number of iterations required for convergence, improve the training speed, and reduce the resource utilization, this paper selects the Mini-Batch Gradient Descent (MBGD) optimization algorithm to optimize the mode. The algorithm introduces a batch size, assuming that the size of a single batch is
Based on the above formula and the MSGD algorithm, the parameters
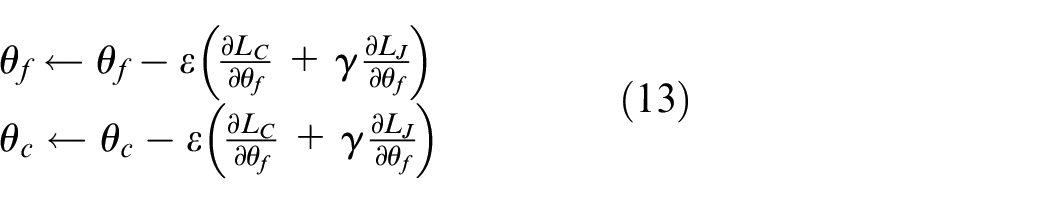
Where
Experimental verification
Datasets preparation
In order to further verify the scientificity and effectiveness of the proposed method, this paper adopts the dynamic balance bearing fault experiment platform of the research team to obtain the required real bearing fault data set. The platform is mainly composed of a variable speed drive motor, JP-680T electrical measurement system, coupling, healthy bearing, test bearing, acceleration sensor, displacement sensor, rotational speed sensor, and OROS vibration signal acquisition and analysis system. In addition, the bearings used are SKF bearings, and the sampling frequency is 25.6 kHz.
Four bearing health statuses are considered in the experiment: normal (NO), inner race fault (IF), outer race fault (OF), and rolling ball fault (BF). The size of bearing fault includes 0.5 and 0.8 mm. In addition, fault simulation experiments with rotating speeds of (
Bearing fault parameter design.
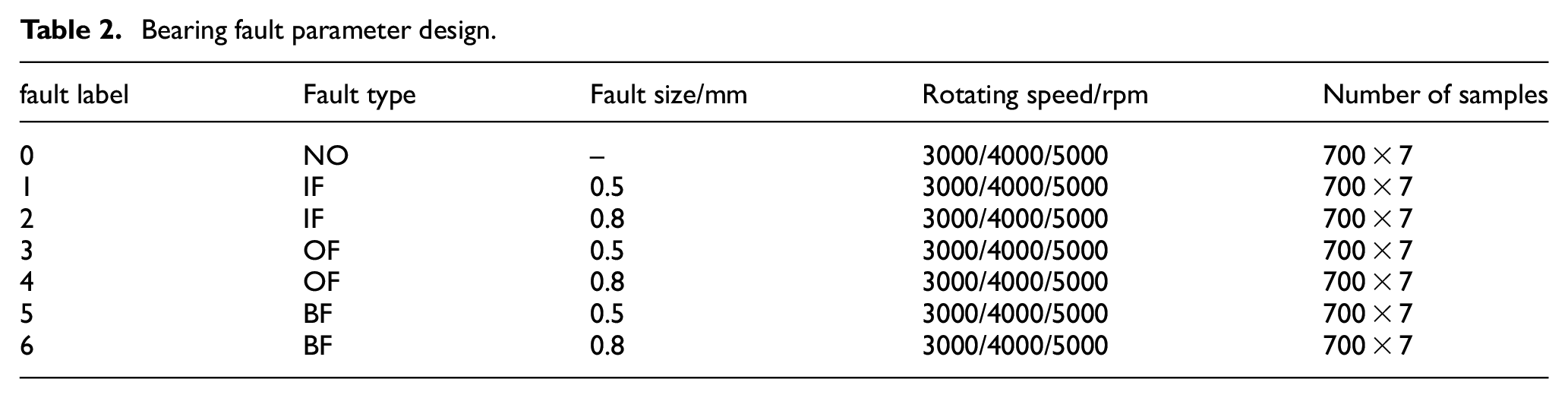
When dividing the sample data, in order to make full use of the data and extract more effective features, the data enhancement method with equally spaced sliding windows is used to overlap the original data. The calculation formula for realizing overlapping sampling is
In order to verify the effectiveness of the proposed fault diagnosis method, a total of 6(
Experimental results and analysis
Diagnosis result analysis
In order to comprehensively evaluate the algorithm and verify the superiority and portability of the proposed method, this section compares this method with other commonly used fault diagnosis methods, which are described in detail below.
In the comparison experiment of fault diagnosis models, this paper uses the same dataset and data division method for all methods, and then uses the optimal parameters of the respective models for comparison. Besides, their feature extraction section is similar to the proposed method in this paper. All our experiments were performed on the PyTorch platform, and in order to reduce the randomness of the experiments, each category of experiments was repeated 10 times and averaged. The main hyperparameters of the model and their setting values include: batch size is set to 128, Epoch is set to 100 times, the optimization algorithm is set to MSGD algorithm, and the initial value of the learning rate is set to 1e−4.
CNN: Use a CNN without domain adaptation. The CNN is trained on the source domain dataset and tested on the target domain data, which is used to demonstrate the inherent generalization ability of the model.
Deep domain confusion (DDC): DDC uses adaptation layer to connect the two CNNs together and calculates the MMD distance in the last layer of the model to reduce the discrepancy between the source and target domains. 26
Deep adaptation network (DAN): DAN combines CNN with multi-kernel MMD, and calculates the MK-MMD distance at the first, second, and third layers from the bottom, which is a classic method of deep transfer learning. 27
Joint adaptation networks (JAN): JAN uses the JMMD distance, combining joint distribution adaptation and adversarial learning. 28 The model does not take into account the multi-scale fusion module and residual structure, which is used to verify the impact of these techniques on the overall performance of the model.
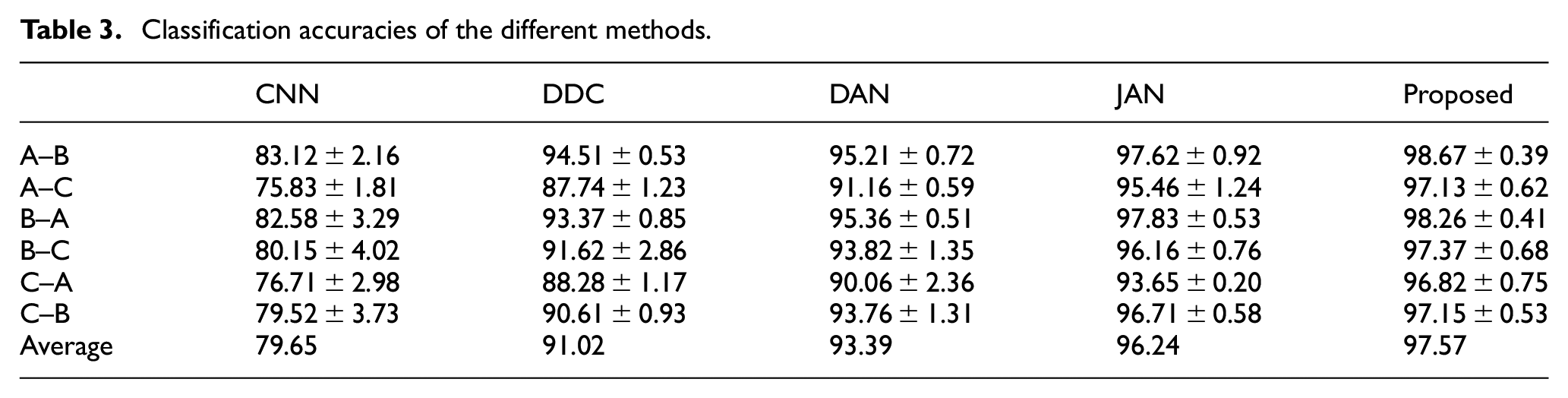
The experimental results of six groups of transfer tasks for five fault diagnosis methods are shown in Table 3 and Figure 6. The histogram uses the height of the column to reflect the difference in the data, which can get a good identification effect. In this experiment, the histogram is used to analyze the effect of different fault diagnosis methods. As can be seen in Figure 6(a), compared with other fault diagnosis methods, the proposed algorithm in this paper has higher accuracy in six transfer learning task scenarios. The radar chart can judge the strength of multiple indicators of the same object or show the comparison of the same indicators of different objects. In this experiment, the radar chart is used to analyze the effect of the same fault diagnosis method on different transfer learning tasks. As can be seen in Figure 6(b), compared with other transfer learning tasks, various fault diagnosis methods have lower accuracy for tasks A–C and C–A. This phenomenon should be due to the large difference between working condition A and working condition C, but the improved algorithm proposed in this paper can still maintain about 96% accuracy in tasks
Classification accuracies of the different methods.
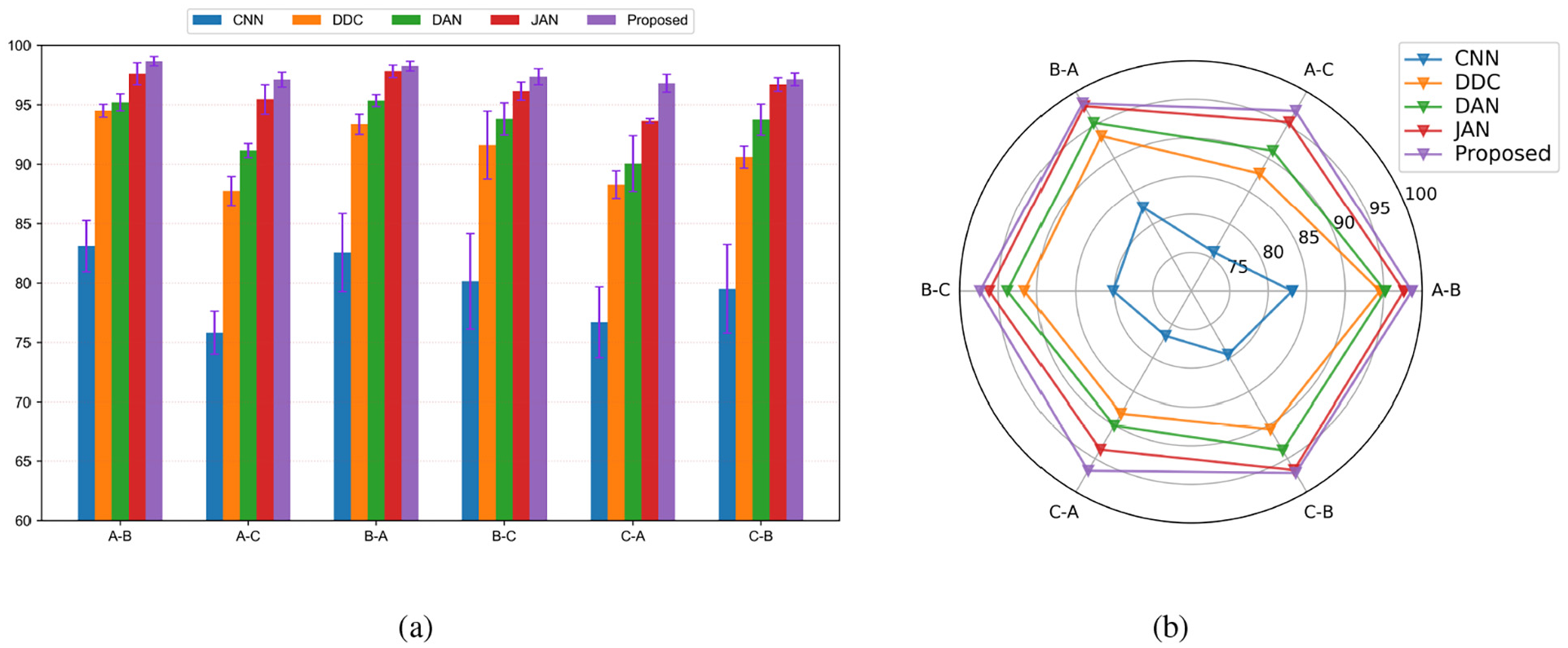
Accuracies of different tasks under different fault diagnosis models: (a) histogram and (b) radar chart.
Although other domain adaptation methods achieve an average accuracy of more than 90% in multiple tasks, these methods have certain discrepancies and fluctuations in different tasks. Among them, the accuracy of
In addition, the confusion matrix can analyze the classification accuracy of each fault diagnosis method in more detail. Randomly select tasks
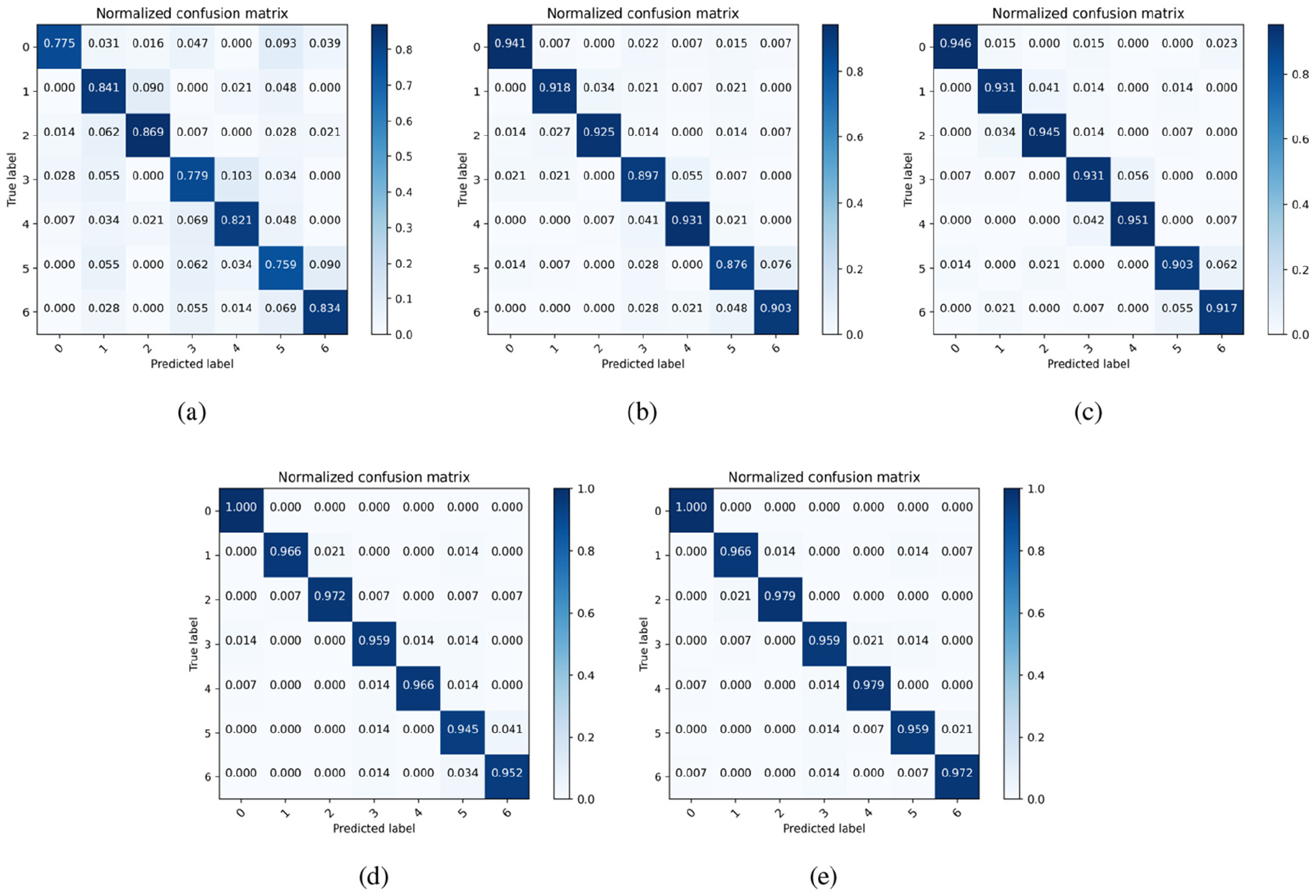
Confusion matrix of different fault diagnosis models: (a) CNN, (b) DDC, (c) DAN, (d) JAN, and (e) proposed.
Feature visualization analysis
Due to the poor interpretability of deep learning, in order to more intuitively analyze the feature extraction ability of the proposed domain adaptation model, this section uses t-SNE (t-distributed stochastic neighbor embedding)
29
to visualize the learned features in a two-dimensional space. The transfer learning task
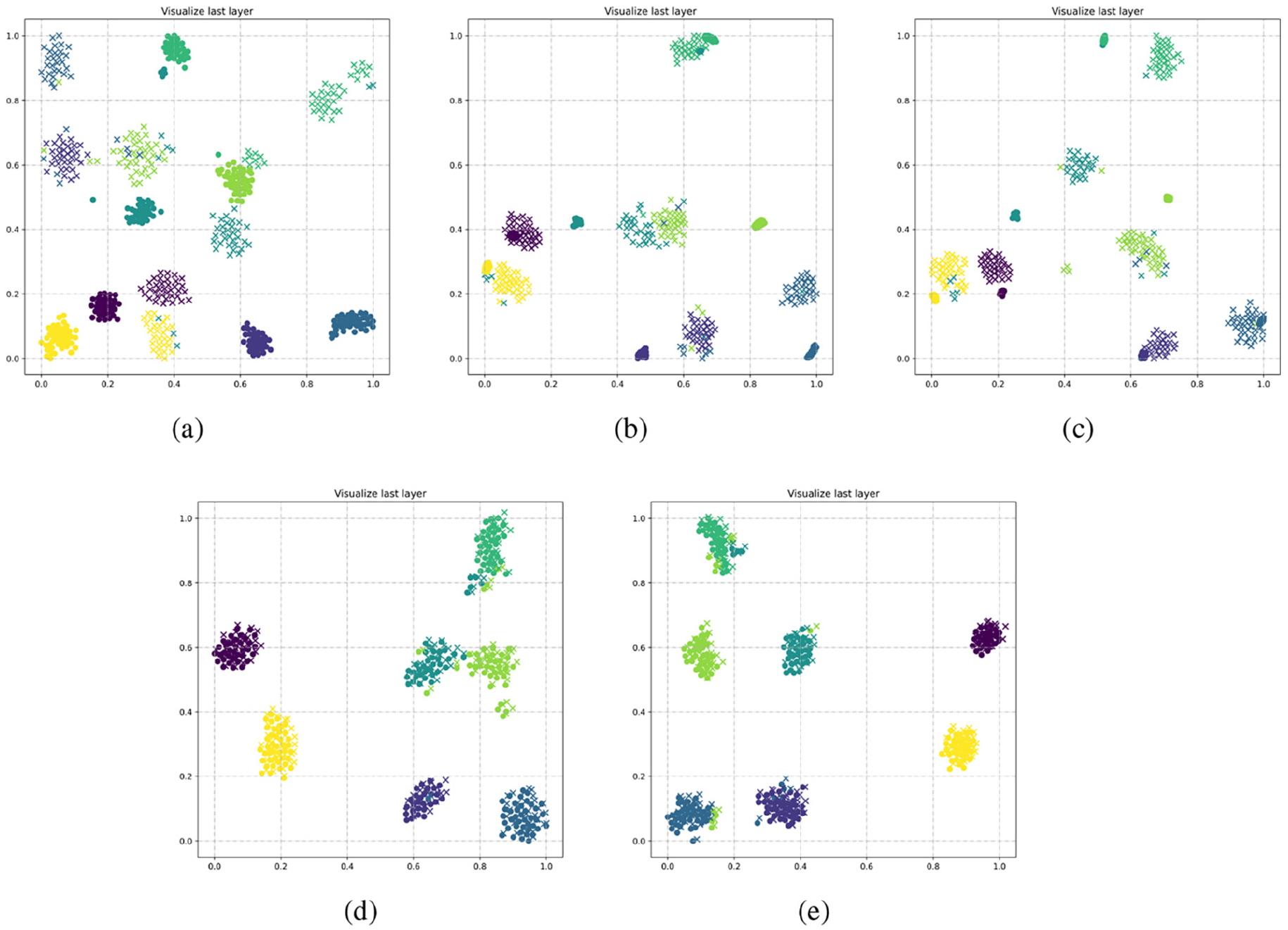
Feature visualization by t-SNE of different fault diagnosis models: (a) CNN, (b) DDC, (c) DAN, (d) JAN, and (e) proposed.
As can be seen in Figure 8(a), the feature visualization results of the CNN method are very confusing, overlapping, and with poor distinguishability, indicating that the knowledge learned from the source domain is not well generalized to the target domain.
In contrast, Figure 8(b) and (c) shows that the feature clustering results of these two methods have been improved, but there are still some discrepancies between the source and target domains, and there are still some misclassifications. In Figure 8(d) and (e), samples of the same fault category from the source and target domains are clustered more closely together, but the method proposed in this paper has better feature separation for different conditions. To sum up, the proposed method has better classification performance and domain adaptation ability.
Therefore, the proposed method in this paper has better clustering ability and distinguishing ability, and the shared features can be extracted more effectively. This method is not only able to learn fault discriminative features for accurate condition recognition, but also has strong transferability to reduce domain differences.
Conclusion
In this paper, an intelligent fault diagnosis algorithm based on domain adaptation is proposed for rotating machinery systems. Considering that the characteristic distribution of rolling bearing vibration signals collected under different working conditions is inconsistent and the samples to be diagnosed have no labels, the algorithm consists of a feature extraction part and a domain adaptation part, which improves the generalization performance and classification accuracy of the model in the target domain. In the feature extraction part, the multi-scale feature extraction module is used to extract features from the input signal to maximize the effective features of the fault data, and the APReLU activation function is introduced into the residual network to further enhance the feature recognition ability of the network. In domain adaptation, a more comprehensive domain adaptation framework is used, which introduces Joint Maximum Mean Difference to optimize the domain adaptation model. Finally, by analyzing different experimental results and comparing with other fault diagnosis methods, it is found that the proposed model has excellent fault identification ability and domain adaptive performance, which can obtain more accurate classification results, and has good results and excellent stability in various migration scenarios.
Although the proposed method in this paper has achieved good experimental results, there are still some limitations: First of all, the distribution of the current dataset among different fault statuses is relatively balanced, but in practical applications, it is usually easier to obtain bearing data for the health state, while data for different fault states are lacking. Therefore, we should further investigate whether the model can effectively extract domain invariant features between the source domain and target domain under unbalanced training datasets. In addition, through time-consuming analysis, it can be found that the time-consuming performance of the proposed model is not so good, which is not suitable for online scenarios with high real-time requirements. The above limitations will be further investigated in future work.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by Key Laboratories for National Defense Science and Technology (6142605200402), National Key Laboratory of Science and Technology on Helicopter Transmission (Grant No. HTL-O-21G11), the Aeronautical Science Foundation of China (20200007018001), the Aero Engine Corporation of China Industry-University-Research Cooperation Project (HFZL2020CXY011), and the Research Fund of State Key Laboratory of Mechanics and Control of Mechanical Structures (Nanjing University of Aeronautics and Astronautics, MCMS-I-0121G03).