
Abstract
Most aspect-level sentiment classification networks include the long short-term memory (LSTM) network, coupled with attention mechanism and memory module, is becoming widely applied in aspect-level sentiment classification. Although it has achieved good results, it cannot extract the global and local information of the context at the same time, and it is only based on the semantic relatedness between an aspect and its corresponding context words to model, while neglecting their syntactic dependencies. This paper proposes the aspect-level sentiment classification by combining convolutional neural network (CNN) and proximity-weighted convolution network (PWCN), as well as a new method to calculate the proximity weight. To obtain contextualized word vectors, corpora has been trained by the model of bidirectional encoder representations from transformers (BERT), which can be taken as text features. The CNN is able to extract sequence features from the text and to take the sequence information from the text into account. In addition, the PWCN can consider the syntactic dependencies inside the sentences. The BERT model also has the ability to model complex features of words, such as their syntactic and semantic changes in a linguistic context. Experiments conducted on the SemEval 2014 benchmark demonstrate compared to the well-established ones, the proposed approach had bigger effectiveness.
Introduction
The aspect-level sentiment classification (also known as the aspect-based sentiment classification). It is a fine-grained sentiment classification task, which aims to identify the polarity of a certain aspect in a particular context, that is, a comment or a review. 1 For instance, for the sentence “the price is reasonable enough the service is poor,” the words “price” and “service” are the aspect ones, and the attitudes to “price” and “service” are positive and negative, separately.
Additionally, there may be totally opposite emotional polarities for different specific aspects in one sentence, the case in point is a positive word “happily,” it may express negative emotions in some specific contexts: Don’t bother me. I’m living happily ever after. So analyzing the specific emotional polarity toward individual aspects can be more effective to help people understand the emotional expression of users, leading to more and more attention in the field. Early works in aspect-level sentiment classification were mainly based on extracting defined features manually from a statistics perspective and adopting machine learning, such as support vector machine, conditional random field, etc.2,3 The feature quality carries a big weight in the performance of these models, and feature engineering is labor intensive.
Currently, with the maturity of attention mechanism and memory network. More and more such methods have been successfully used in aspect-based sentiment classification. 4 Despite the effectiveness of these approaches, the syntactic relationship between the aspect and its context is neglected, this may lead to an undesirable result that the aspect attends on contextual words that are descriptive of other aspects. To overcome this Zhang et al. 5 proposed a convolution network weighing on proximity to provide an aspect-specific representation of contexts that was syntax-aware. Although PWCN is effective in extracting syntactic information and the global emotion information, they cannot capture important local emotion information in sentences. In particular, the linear function cannot accurately describe the position proximity. Also, in a complex sentence, it is possible that each aspect is only related to its adjacent context. It is necessary to estimate the influence scope of each aspect before identifying its sentiment polarity. Therefore, a better language representation model is needed to generate more accurate semantic expressions. Word2Vec 6 and GloVe 7 have been widely used to converts words into real numerical vectors. However, there is a problem with these two. Actually, words may differ in meanings in different contexts, and while the targeted sentences are in different languages, the vector representations in the context are the same. An enhancement for them is ELMo, 8 but it is imperfect since it applies LSTM 9 in its language model. There are two main problems in LSTM. 10 The first issue is that it is unidirectional, meaning it works by reasoning in order. Even the BiLSTM 11 bidirectional model is just a simple addition at the loss, resulting in it being unable to consider the data in the other direction. The other problem is that it is a sequence model. In other words, during its processing, one step cannot proceed until the previous one has completed, leading to poor capability of parallel calculation. The theory behind BERT 12 is similar to ELMo, but the former uses transformer for encoding. When predicting words, a two-way synthesis takes the context characteristics into account, exhibiting remarkable parallel properties. Therefore, we used BERT model to train word vectors in this paper. Inspired by the limitations noted, we propose an aspect-level sentiment classification model by combining convolutional neural network (CNN) and proximity-weighted convolution network (PWCN). The experiments on SemEval 2014 Datasets clearly showed that our model achieved a state-of-art performance.
The major contributions of this paper are summarized as the following:
The PWCN model cannot highlight local features, which plays a significant role in sentiment classification. Thence, an aspect-specific syntax-aware context representation is proposed, which is primarily abstracted by convolutional neural network and bidirectional LSTM, and further strengthened by a proximity-weighted convolution. Results showed that syntactic dependency is effective to improve the outcomes of aspect-level sentiment classification.
The Gaussian function is introduced to substitute the position proximity, so as to better evaluate the proximity weight. The contextual words’ proximity to the aspect is better described, and the model’s performance is further improved.
We use pretrained BERT embeddings to represent the context, which is able to capture obvious word differences such as polysemy. Furthermore, these context-sensitive word embeddings also retrieve other forms of information, which may assist in producing more accurate feature representations and improving model performance.
The rest of this paper is arranged as follows: In Section 2, we review related work. In Section 3 we describe our BERT-CNN-PWCN model in detail. Section 4 is the description of the framework of our model. The experimental results are given and analyzed, which of them prove that our algorithm is effective in Section 5. And finally, we will give a summary to this work.
Related work
In this section, we review related work as follows: First, we discuss the particularities of aspect-based sentiment classification and existing related methods. Secondly, we present recent neural networks for aspect-based sentiment classification. Thirdly, we present some Syntactic Dependency Method for Aspect-Level Sentiment Classification.
Aspect-level sentiment classification
Sentiment analysis (SA) is an hot topic in the area of text mining, which is the calculation of views, sentiments and subjectivity in a text. 13 There are three levels of granularity in opinion mining, namely document-level, sentence-level, and aspect-level. 14 When a document or a sentence involves multiple emotional expressions, emotional analysis on the former two levels will not be able to accurately extract the deep feelings within the text.
Different from other granularity levels in SA, the emotional polarity, which is on different aspects in the sentence, need to be determined in the aspect-level sentiment classification, and it is dependent not only on the context information, but also the emotional information of different aspects. At present, there are three mainstream methods: lexicon-based, traditional machine learning, and deep learning methods. 15 In the first, Deng et al. 16 proposed a novel hierarchical supervision topic model to construct a topic-adaptive sentiment lexicon (TaSL) for higher-level classification tasks. Federici and Dragoni 17 constructed an aspect-based opinion mining system based on the use of semantic resources for the extraction of the aspects from a text and for the computation of their polarities. Kang et al. 18 proposed a Bayesian inference method to explore the latent semantic dimensions as contextual information in natural language. These methods are easy to understand and use, but their accuracy is not high, and there are problems of dimension explosion and gradient disappearance, which limit their wide application in practice. Secondly, such as those proposed by Jiang et al., 2 Marcheggiani et al., 3 which use the support vector machine, conditional random field, etc. The feature quality carries a big weight in the performance of these models, and feature engineering is labor intensive. The third category, deep learning, is receiving increasing attention.
Deep learning for aspect-level sentiment classification
In the late years, more and more techniques, which adopt the deep learning have been integrated into natural language processing (NLP) tasks. 19 Compared with traditional machine learning, they achieves better results in aspect-level emotion classification. Zhou and Long 20 proposed a method, which combined CNN with BiLSTM models to analysis the Chinese product reviews. Xue and Li 21 reported a more accurate and productive model, which was combined convolutional neural networks with gating mechanisms. Dong et al. 22 used adaptive recursive neural network to classify the target-dependent sentiment on Twitter. Vo and Zhang 23 applied sentiment lexicons, together with distributed word representations and neural pooling to improve the capability of sentiment analysis. Ma et al. 24 built a neural architecture for targeted aspect-based sentiment analysis, while being able to incorporate important commonsense. The performance of these conventional neural models have been more outstanding than traditional machine learning in aspect-level sentiment classification. However, they could only capture context information in an implicit way, leading to imperfections in explicitly, which excludes some important context clues in an aspect.
Attention mechanism and memory network for aspect-level sentiment classification
Currently, with the maturity of attention mechanism and memory network. More and more such methods have been used in NLP and had a good effect, such as machine translation, 25 with an improved performance compared to previous approaches. In this field, the generation of representations can be mutually influence by the target and context. For instance, Wang et al. 26 applied an attention-based LSTM network to aspect-level sentiment classification. Long et al. 27 proposed a BiLSTM based multi-headed attention mechanism, which is integrated into a crossing model of text sentiment analysis. Lin et al. 28 built a brand-new framework for aspect-level sentiment classification, which was a deep mask memory network based on semantic dependency and context moment. Zhang et al. 29 designed a convolutional multi-head self-attention memory network for the same task. Ma et al. 30 developed an interactive attention network (IAN) model derived from LSTM networks and attention mechanism. However, syntactic relations among the aspect with its context words are generally neglected in these studies, which may stunte the validity of aspect-based context representation. Besides, the aspect of sentiment polarity is normally hinged on a key phrase. 31 Zhang et al. 5 proposed a convolution network weighing on proximity to provide an aspect-specific representation of contexts that was syntax-aware. However, the long-distance dependencies in the text sequence is only taken into account by this network, therefore the effect of capturing local features is not ideal.
Even though the proposed model is inspired by PWCN, it differs in three main respects. First, it applies convolution neural network to PWCN to extract local emotion information in a text, whereas PWCN uses BiLSTM to obtain the global sentence information, but cannot effectively extract the local aspect information. CNN is forced to capture local information through the use of local receiving domain, shared weight, etc. Therefore, CNN has a strong ability to capture local information. The model adds with convolution neural network can obtain a more comprehensive aspect level text information representation. Secondly, the proposed model use a Gaussian function to calculate the proximity weight for PWCN. As it is experimentally demonstrated that Gaussian function is more consistent with proximity weight than linear function. Thirdly, it applies pretrained BERT embeddings to word embedding to represent the context, whereas PWCN uses Glove. The BERT embeddings is able to capture obvious word differences such as polysemy, but Glove cannot.
The proposed model
In this section, we will introduce BERT-CNN-PWCN, which is to improve the performance of aspect-level sentiment classification. Figure 1 shows a high-level description of our proposed model. First, datasets are pre-processed by BERT as word embeddings. After that, the BERT output is fed into a CNN layer to extract local features. Then BiLSTM is applied to obtain contextual information. The hidden-state representation is used to predict sentiment polarity, which can make further efforts to be enhanced by proximity-weighted convolution.
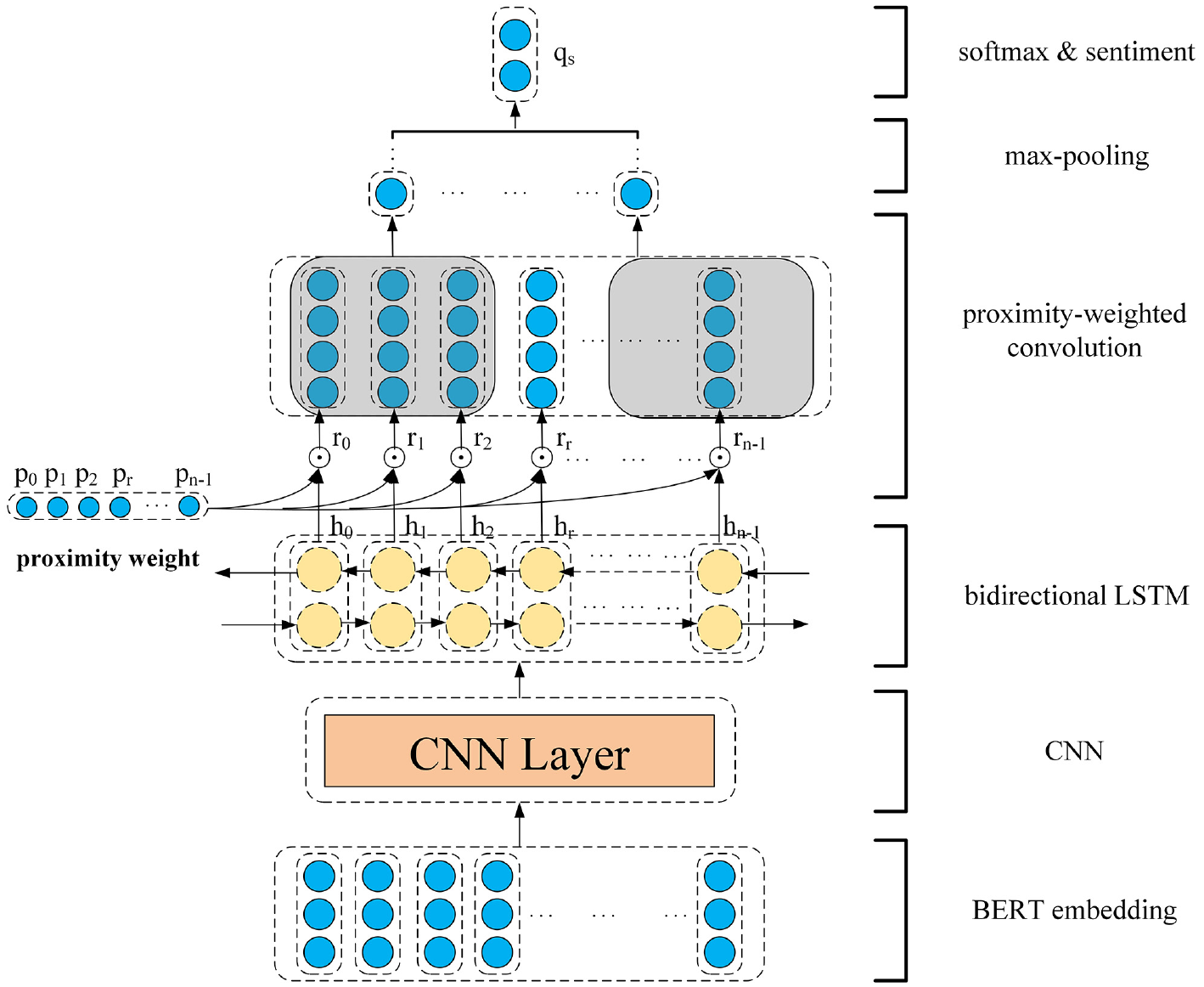
The architecture of the proposed model.
The model structure
Word embedding
The first stage to deal with the natural language tasks for computers is to convert the text into data, so that they can understand it. Text representation is the basis in NLP, which plays an essential part in the performance of the NLP system as a whole, and text vectorization is an important way to achieve it. Through text vectorization, each word is transformed to a real numerical vector. Generally speaking, there are two ways to represent: discrete and distributed representations. The distributed representation is one-hot encoding, which is high in the number of dimensions and low in density, being unable show the direct correlation between words. In addition, such a high-dimensional vector will seriously downregulate the calculation speed. This paper adopts the word embedding, which is a distributed representation, to avoid those defects. Word embedding can integrate the one hot high-dimensional representation of the original word into a continuous vector space of lower dimensions, and the two word embedding algorithms adopted in our model will be introduced afterward.
GloVe
In order to combine the merits of global matrix factorization and local context windows, Pennington et al. introduced the GloVe,
7
which can efficiently leverages statistical information by training only on the non-zero elements in a word-to-word co-occurrence matrix rather than on the entire sparse one or on individual context windows in a large corpus. In the following equations,


We can easily find out by examples that the ratio

Where


Where the empirical motivation value of
Bert
BERT word embedding is based on the model of deep bidirectional transformers.
12
Compared with the conventional GloVe-based embedding layer, BERT can not only consider the context features in a comprehensive manner, but also eliminate polysemy. Consider the input data is denoted by

The BERT-pretrained word embedding will act as the input for subsequent tasks. Apart from the effective semantic feature extraction in the text, it could also improve the performance of the subsequent steps.
Convolutional neural network
Convolutional neural network (CNN, or ConvNet) is among the most important innovations in the computer vision community. Its function is to extract relevant features from sequences. 32 In recent years, CNN has been proved capable to solve many problems in NLP, and has produced unexpected results. In our model, the word vector matrix is adopted as the inputs for the CNN, which are further applied used as the inputs for the BiLSTM. Because the very important information about word position will be lost in the pooling layer in NLP, we applied convolutional neural network without pooling layer.
Convolutional Layer is where a word vector is convolution operated with a specific feature detector containing

Where ⊗ represent the convolution, and the symbol of the weight matrix is denoted by
Bidirectional LSTM
The advantage of bidirectional LSTM over its standard counterpart is its capability to pick up the information from not only the past but also the future. It is comprised of both the forward and backward neural networks, which are responsible for memorizing the past and future information, respectively, promoting text analysis. And both neural networks are concatenated to form the final output

Proximity-weighted convolution network
The proximity-weighted convolution network (PWCN) apply the proximity weight, which is the syntactic proximity of context word to the aspect, to calculate its importance in the sentence, followed by inputting it into a convolutional neural network to obtain n-gram information.
Proximity weight
According to the context representation between the semantic and their corresponding aspect in the component words, their proximity weights are the main way to obtain contextual representations. However, this approach neglects syntactic information, which may reduce the models’ effectiveness. The proximity methods focusing on position and dependency proximity formalize syntactical dependency information as the proximity weight, describing the contextual words’ proximity to the aspect. 5 Moreover, we propose to use Gaussian function to calculate the proximity weight.
Position proximity
The words around the word of one aspect are generally used to describe their core word. Therefore, their position information is regarded as an approximate measure of syntactic proximity. The final representations are given as the following:

Where
Dependency proximity
Syntax dependency parsing tree is used to calculate the distance between words in our approach. The dependency proximity weights are calculated by:

Where
Gaussian proximity
The former two methods are linear. However, the contextual words’ proximity to the aspect is actually nonlinear, which may lead to false weight results and loss of information. On the other hand, the curve for Gaussian distribution is bell-shaped, and as a value move closer to the center, it becomes larger, and vice versa. This excellent pattern can effectively prevent interfering noises in the information, conforming nonlinear characteristics of position information. Therefore, Gaussian function is a desirable mode for weight distribution. The Gaussian proximity weights of the sentence are defined as:
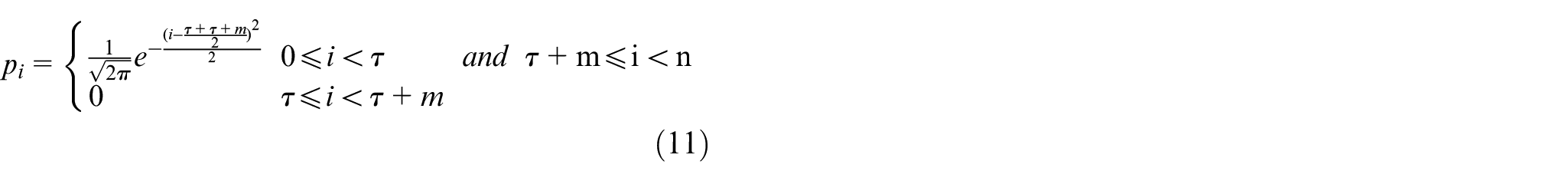
Proximity-weighted convolution
Proximity-Weighted Con-volution is actually a 1-dimensional convolution with a kernel of length l and its proximity weight assigned in advance. The weight

The convolution is performed as:


Where

Where
The filtered representation for the most obvious feature

Where
The standard gradient descent algorithm is adopted to train our model, where the cross-entropy loss with

Where
Experiment
The datasets and experimental environment
In this paper, for the sake of illustrating the performance of our model, which was tested on two real-world datasets from SemEval 2014, 33 including about the Laptop and Restaurant. Moreover, Accuracy and Macro-Averaged F1 Metrics were adopted to verify improvement over the models of comparison.
Precision (P):

Recall (R):

F1-Score (F1):

Accuracy (Acc):

Macro-Precision (Macro-P):

Macro-Recall (Macro-R):

Macro-Recall (Macro-R):
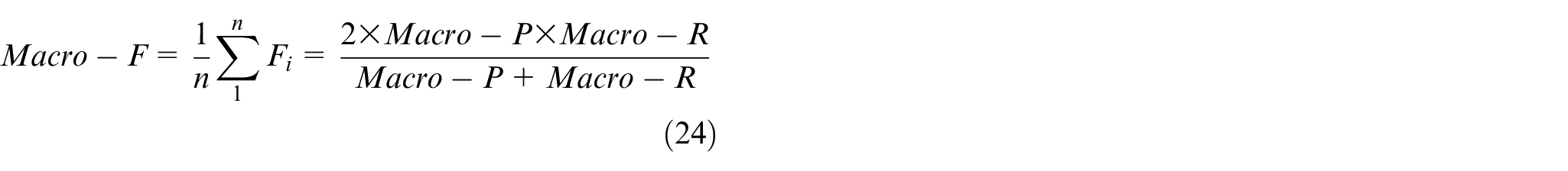
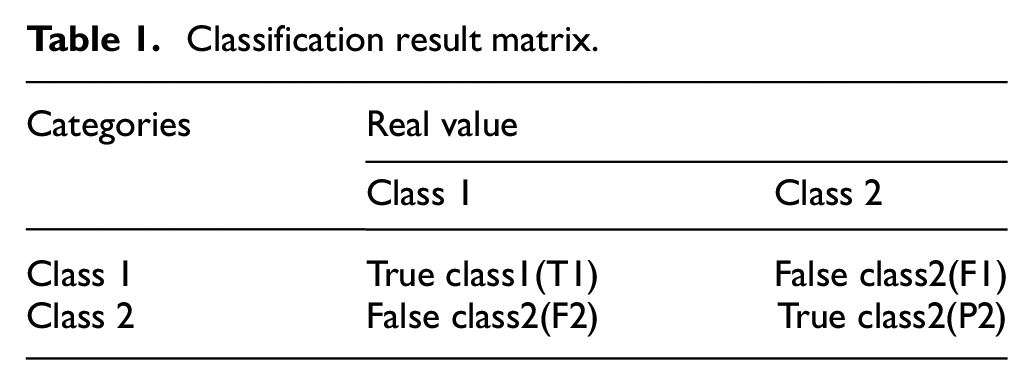
In our experiments, we used the GloVe 7 word vector and the pre-trained language model word representation BERT 12 as the word embedding methods, the dimensionalities of which were 300 and 768, respectively. The Adam 34 algorithm was adopted as the optimizer for the cross entropy loss function with a learning rate of 0.01. The value of L2-regularization weight was 0.0001 and batch size was 8. The convolutional neural network using 512 filters, and the filter window size was 3 (Table 1).
Classification result matrix.
Model comparison
We evaluate the performance of this model by comparing with six baseline models, which were:
Experimental results
Model comparison results on the datasets are shown in Table 2, which is obtained by randomly initializing the average performance of three runs since the performance fluctuates with random initialization. We observe that the BERT-CNN-PWCN-Gauss model get the best performance, especially in laptop reviews. The model in this paper is the most similar to PWCN-Pos and PWCN-Dep, with CNN and Gaussian Proximity added and the utilization of BERT on the pre-training word vector. Compared with PWCN-Dep or PWCN-Pos, our approach improve the accuracy in laptop dataset and Macro-F1 dataset by 0.1125, 0.149, and 0.1537, respectively. The three PWCN approaches, namely BERT-CNN-PWCN-Pos, BERT-CNN-PWCN-Dep, and BERT-CNN-PWCN-Gauss, outperform BERT-PWCN-Pos, BERT-PWCN-Dep, and BERT-PWCN-Gauss by about 0.0006, 0.0081, and 0.0076 on accuracy, respectively. The same three approaches reveal better accuracy for 0.0215, 0.0516, and around 0 on Macro-F1 dataset, suggesting that CNN-based PWCN model is better than PWCN model alone.
Experimental results.
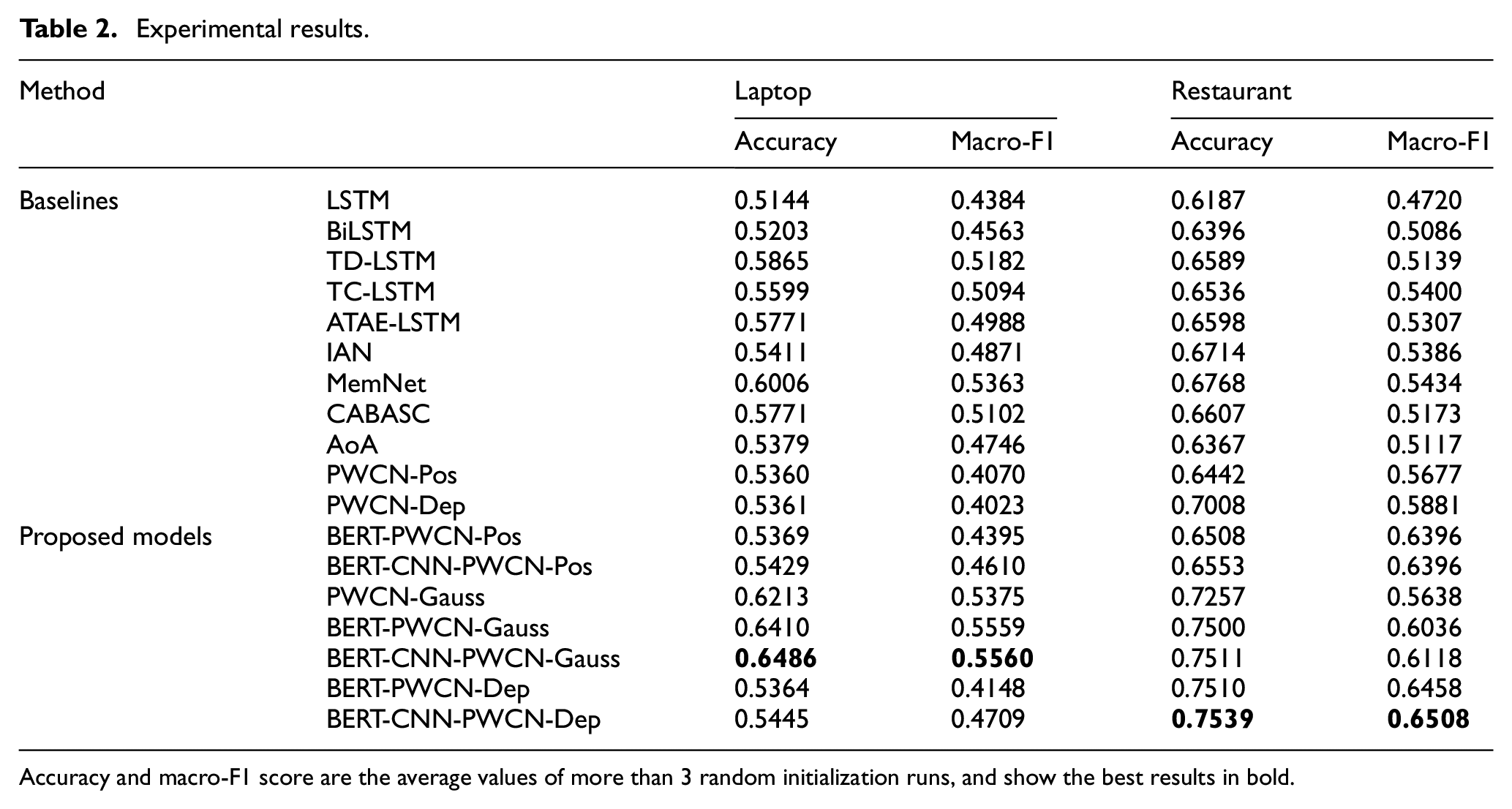
Accuracy and macro-F1 score are the average values of more than 3 random initialization runs, and show the best results in bold.
In order to highlight the advantages of Gaussian proximity. We put the model experimental results before and after using Gaussian proximity into Table 3. It can be seen that the model which used Gaussian Proximity outperforms the model used linear function in most cases, mainly because the Gaussian Proximity is more consistent with the contextual words’ proximity to the aspect.
Experimental results using Gaussian Proximity.
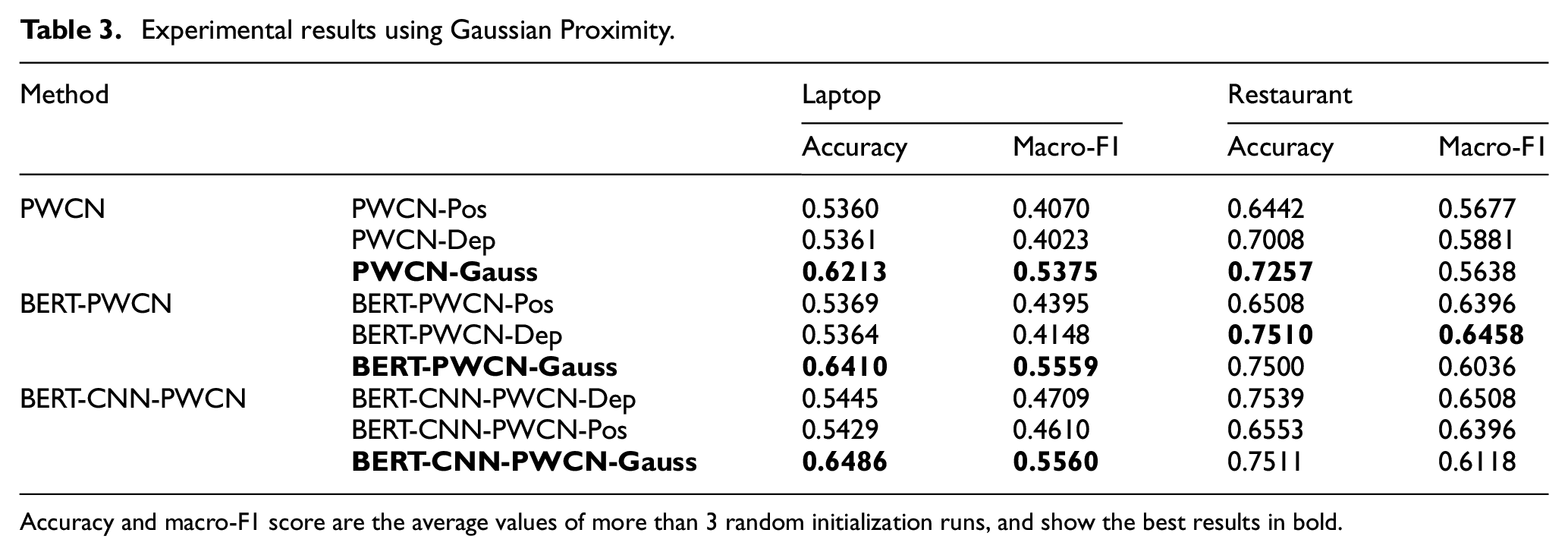
Accuracy and macro-F1 score are the average values of more than 3 random initialization runs, and show the best results in bold.
Discussion and conclusion
In this paper, we developed a new CNN-based PWCN model, which not only combines CNN and PWCN together, but also proposed Gaussian proximity as a new method of calculating proximity weight. The experimental results demonstrated that our model is better than single PWCN model, such as PWCN-Pos and PWCN-Dep, in terms of aspect-level sentiment analysis based on syntactic dependency. Meanwhile, we used pretrained BERT embeddings to produce more accurate feature representations, and successfully improved model performance that Glove can not.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Key Research and Development Project (2018YFB1402900)