
Abstract
This paper presents a self-learning control algorithm for model uncertain suspension systems using single network adaptive critic (SNAC) approach. First, a differential neural network (DNN) observer in conjunction with the weight updating law is established to observe the uncertain dynamic. Then, the nominal optimal value function is approximated by a critic NN whose weight is updated by a novel design learning law driven by the filtered parameter error. The online self-learning control policy is thus derived by approximately solving the Hamilton–Jacobi–Bellman (HJB) equation based on SNAC technique. The Lyapunov approach is synthesized to ensure the convergent characteristics of the entire closed-loop system composed of the DNN observer and the self-learning control policy. Computer simulation of a quarter car suspension system is established to verify the effectiveness of the proposed approach. Simulation results illustrated that the designed method can ensure the good performance in terms with the road hold and ride quality. In addition, independent of model and online self-learning characteristics make it possible to design a high-performance vehicle active suspension controller.
Introduction
A high-performance suspension system is the key to the pursuit of a smoother and safer car. 1 Correspondingly, the suspension system is expected to have more intelligence to adapt to different road inputs. It needs to be pointed out that the suspension system is affected by unknown road input, resulting in unavoidable vibrations related to vehicle ride comfort. Therefore, when designing the controller of the active suspension system, state variable information related to the vertical dynamics of the vehicle should be provided. 2 However, the implementation of suspension control system based on traditional observation theory brings great challenges because unknown road input is difficult to measure or observation when the vehicle is driving. Moreover, the uncertainty of parameters, such as sprung mass, also brings difficulties to the design of suspension observer and controller. Enhancing active vibration control performances as shown in refs. 3 and 4 is the main target of suspension control.
To deal with model uncertainty, robust approach, 5 LMI based approach, 6 sliding mode approach, 7,8,43 and globally bounded Jacobian approach 9 have been used to develop the observer. In ref. 10, a robust decoupling observer considering disturbance is achieved, but the rank condition in terms with the output and input distribution matrix is difficult to meet. To avoid the requirement of rank constraints related to the system matrix, Sedighi et al. 11 present a new development for the unknown input observers design, which guarantees the stability of the error closed-loop system and provides designers with a greater degree of freedom in design space. In ref. 12, a controller and fault identification method based on the separation principle is proposed to realize the simultaneous decoupling identification and control. In ref. 13, an adaptive extended state observer with lumped uncertainties and unmeasured states is proposed to estimate the unknown coefficient. However, most of the above observer designs rely on knowing the model information a priori, which poses a strict restriction to real application.
Neural network with good nonlinear approximation capability is very suitable to design the observer of model uncertain systems. The structure of a neutral observer mainly includes two parts, that is, a neural network to identify the unknown nonlinearity and a traditional Luenberger-like observer to estimate the state. In refs. 14 and 15, in the case of imposing strong strict positive real (SPR) conditions on the output error equation, a structure using two independent single layer neural networks is proposed to estimate the state of affine and non-affine SISO nonlinear systems. Furthermore, a nonlinear observer for the MIMO system using a single layer neural network was developed in refs. 16 and 17, where the SPR restrict condition has been weakened to a certain extent. Furthermore, a neural network observer with the modified backpropagation algorithm was proposed in ref. 18, where the SPR condition and any other strong restrictions are canceled. In particular, the differential neural network (DNN), 19 incorporating the feedback design, provides a more efficient way to solve the state estimation problem of model uncertainty systems. In ref. 20, a DNN observer with sliding mode updating rule was reported and the relevant observational conditions have been removed. New passivity analysis of DNN proposed by Xiao et al. 21 illustrates that the boundedness of external input can ensure the boundedness of the input–output signals for each block of closed-loop error dynamics, which therein avoids the requirement of persistency excitation (PE) condition.
Recent studies have shown that the design of a self-learning controller based on approximate dynamic programming (ADP) can avoid the requirement of model accuracy and achieve optimal control at the same time. 22,23 As we all know, the curse of dimensionality of dynamic programming and offline learning characteristics make the existing optimal control strategies based on dynamic programming inefficient. ADP is inspired by biological systems, which can greatly improve the computing power for solving optimal control problems, but it will not bring obvious approximation errors. Since Werbos 24 introduced a commonly used actor-critic (AC) scheme for self-learning control design, various modifications to ADP have been developed, such as action dependent heuristic dynamic programming (ADHDP), 25 heuristic dynamic programming (HDP), 26 dual heuristic programming (DHP), 27 and Q-learning. 28 The natural recursive characteristics of ADP are very suitable for solving discrete systems, and its related results cannot be directly used for reference in the continuous field. Ref. 29 proposes a self-learning control method for continuous nonlinear systems, where an identifier is used to identify unknown nonlinear dynamics, and then the online self-learning rate is obtained by approximately solving HJB through an evaluation network. However, it is limited to nonlinear affine system. As claimed in refs. 30 and 31, self-learning control method with the single network adaptive critic (SNAC) scheme has been proved to be an effective method to solve the HJB online and obtain the optimal control action.
It should be pointed that most of the above-mentioned self-learning control research are based on the premise that the state is fully known, which is a strong constraint condition, because in most cases the system state is not completely obtainable, such as the suspension system to be studied in this paper. The main contributions of this paper can be summarized as: (1) It is the first time that the self-learning control of model uncertain suspension system using only the input and output of the system is investigated. Unlike the commonly used LQR controller design depending on the system model, this paper introduces the observer-based self-learning controller design without prior knowledge of the system dynamics, which makes the proposed method become more suitable for practical application. (2) The investigated algorithm is implemented based on the observer–critic framework. First, a DNN observer with a reasonably designed weight online update law is used to identify unknown system dynamics based on the known system input/output information. Then, the self-learning control policy is derived with the help of SNAC method. With introducing two novel tuning laws for the DNN observer and the SNAC, the improved performance in terms of adaptability and robustness is realized compared with the general ADP-based self-learning method. (3) In addition, the entire learning process of the proposed method was updated online, and the stability of the entire closed-loop system was guaranteed by properly designed composite Lyapunov method. The model free and self-learning characteristics of the designed self-learning control method make it possible to develop a good performance active suspension controller that can avoid the influence of uncertainty. The simulation results on a quarter car suspension model encountered unknown road input are presented to demonstrate the effectiveness of the designed self-learning control method.
The overall structure of this article is organized as follows. Section 2 presents the formulation of the question. Section 3 illustrates the DNN observer design process. Observer-based self-learning control method for a quarter car active suspension system is developed in the Section 4. Simulation results carried on a quarter car suspension system with time varying road input are given in Section 5. Finally, the conclusions are concluded in Section 6.
Problem formulation
As we all know, the quarter car suspension model as shown in Figure 1 is commonly used in the design of active suspension control systems.
32
The state space equation considering the time varying parameters of a quarter car active suspension system can be expressed as Diagram of a quarter car suspension model.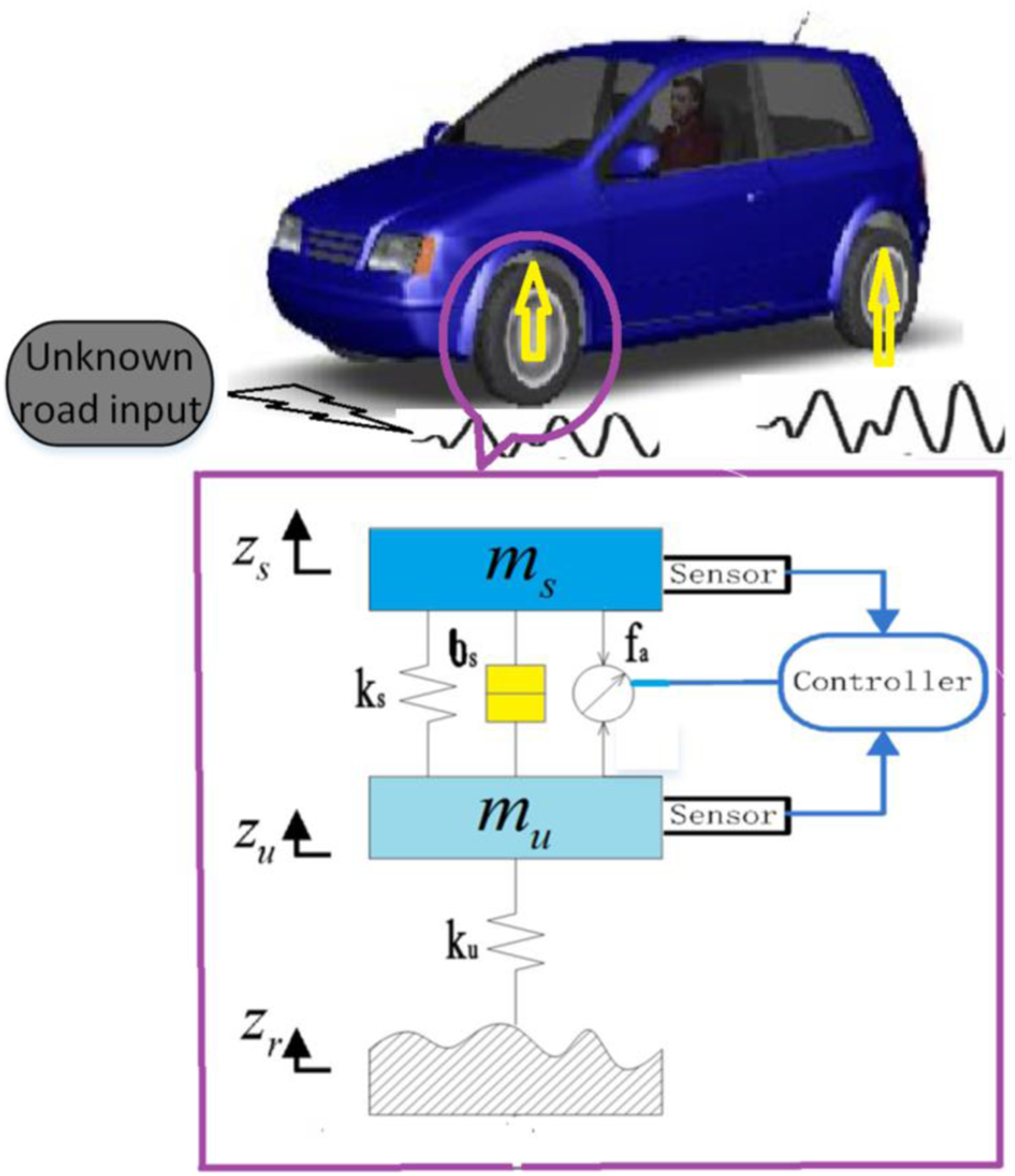
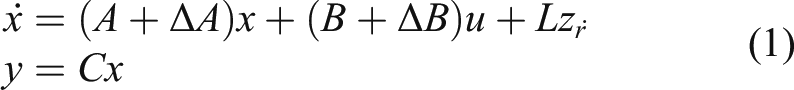
The requirements of active suspension system controller design should meet the following three aspects 1) The first main aspect is to ensure high-performance riding quality. This task aims to weaken the vibration force transmitted from unsprung mass to sprung mass through an advanced control approach, which is achieved by minimizing the sprung mass acceleration in the face of parameter uncertainties caused by sprung mass and time varying road input. 2) In addition, the wheel should maintain firm and uninterrupted contact with the road surface, and the normal tire load change related to the vertical deflection of the tire should be small to ensure good road holding performance. 3) Finally, the suspension space constraint should be less than the maximum suspension deflection
The goal of active suspension design is to find a control policy that can not only keep the system state stable, but also minimize the required performance indicator, such that
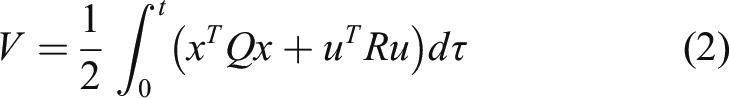
As claimed by Liews,
33
if With the help of knowledge in the field of optimal control, the Hamiltonian of (1) can be defined as The nominal optimal valued function Meanwhile, equation (4) should satisfy the following HJB equation Then, the HJB equation (5) can be further expressed with respect to equation (6) as follows It can be seen that the nominal value function 1) Based on the input/output information from the suspension system, an adaptive DNN observer with the weight updating law was established to observe the unknown state. 2) Based on the observations, a self-learning controller with the observer critic structure is developed via the single network adaptive critic approach.
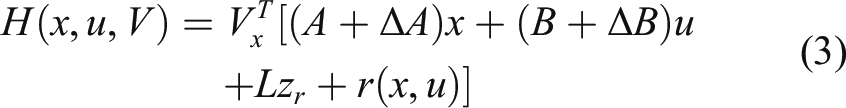
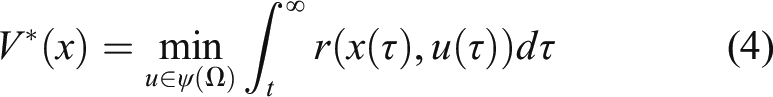
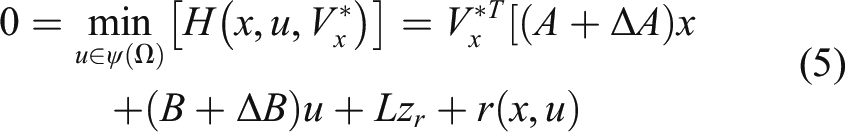
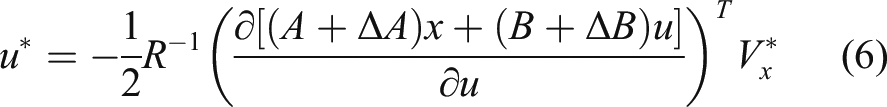
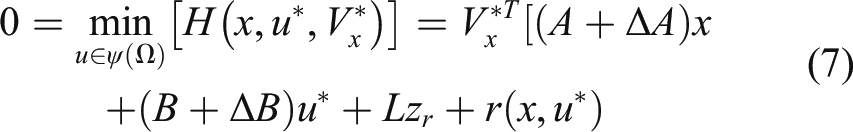
The common LQR controller designs
34–36
are often based on formula (2) where all parameters are available in advance. In addition, the corresponding feedback control law is obtained by solving the Riccati equation offline. The disadvantage of this method is that the control gain cannot be updated online according to the system uncertainties caused by m
s
and unknown road displacement z
r
. This will inevitably lead to unsatisfactory control performance. Therefore, the design of active suspension systems is expected to introduce a self-learning intelligent control method that can adapt to various driving conditions.
The differential neural network observer
Consider the following DNN to identify nonlinear system (1), such that
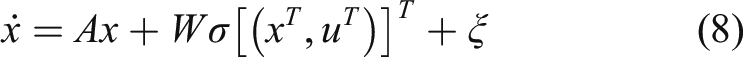
Fact 1. Garces
37
As we all know, the nonlinear activation function Considering the following the neuro-observer
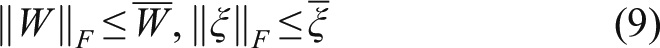
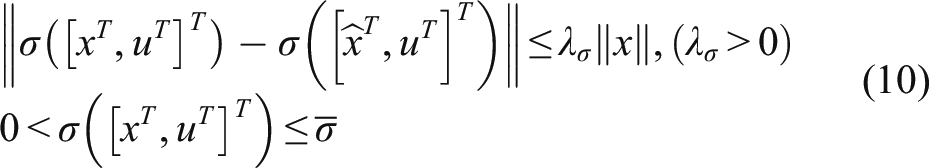
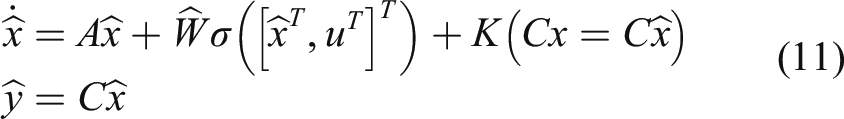
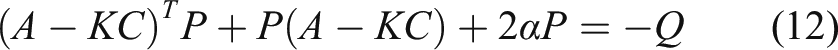
The state observation error is expressed as

From (8) and (11), the equation in terms with the observation error is derived as
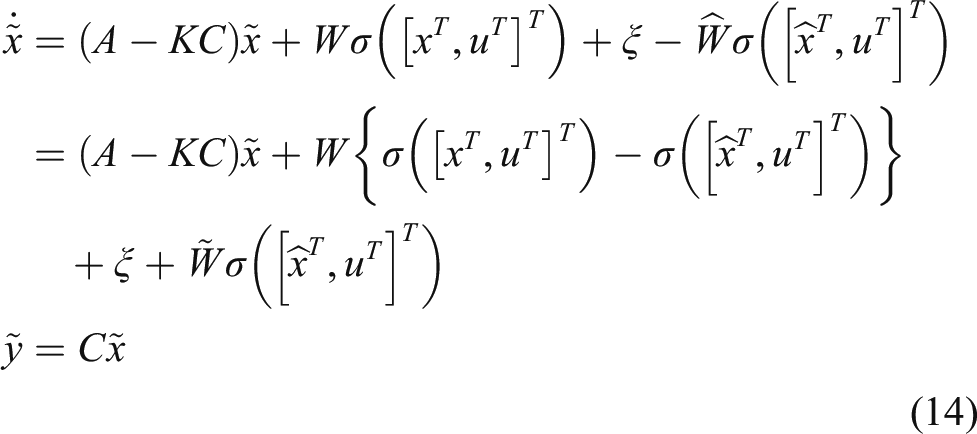
Once the architecture of the DNN observer is determined, the next step is to design appropriate update rules to implement online learning. There are generally the following two design ideas
1) Based on commonly used learning rules, such as back propagation algorithm, the online learning rate of DNN observer is designed, and then suitable candidate of Lyapunov function is designed to prove the convergence characteristics of the system. 11,15
2) In order to ensure the stability of the closed-loop system, the online learning rate is designed by defining the quadratic function which is related to the weight error and the observation error, and the time derivative of Lyapunov function is proved to be negative. 38,39
The main drawback of the previous work in the first way is the approximate treatment of the dynamic backpropagation problem by using the gradient approximation, which inevitably leads to parameter overflow problems. Therefore, we choose the second way to develop the updating law for the propose DNN observer in this paper.
The uncertain suspension model (1) is identified by the DNN observer model (11) with the following updating law
The time derivative of Since the DNN weight is updated by (15) and satisfies the inequality Define
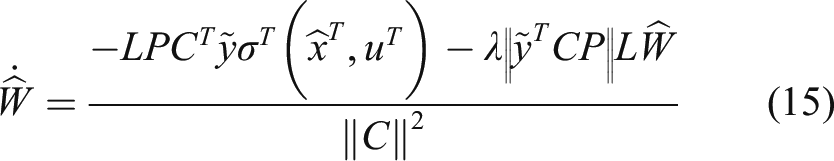
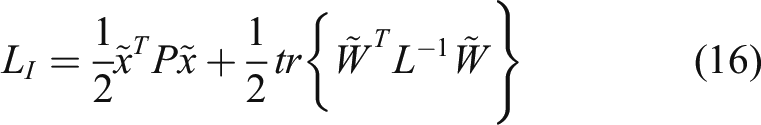
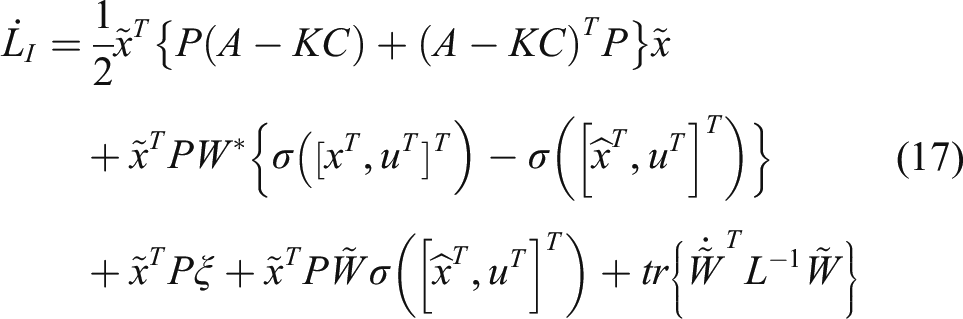
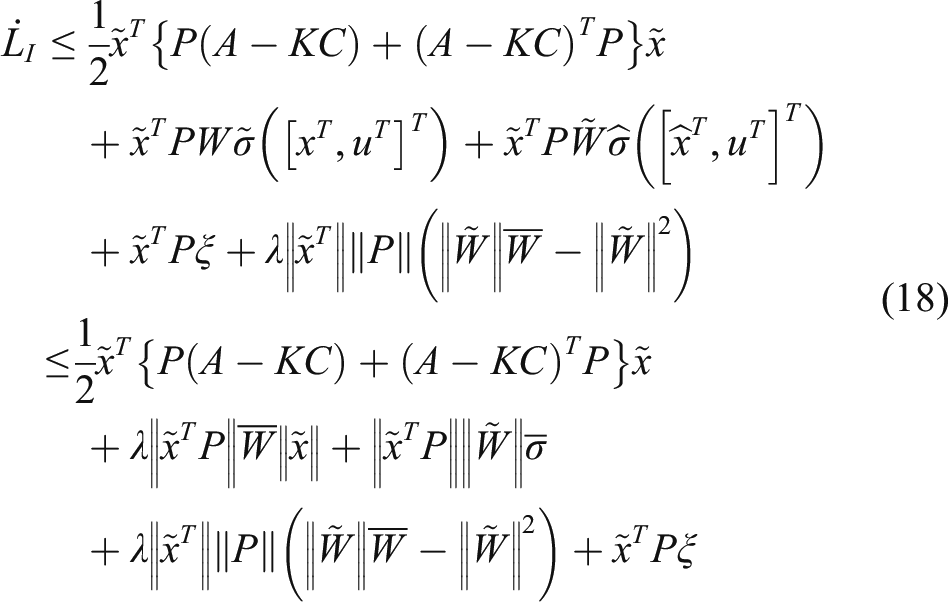
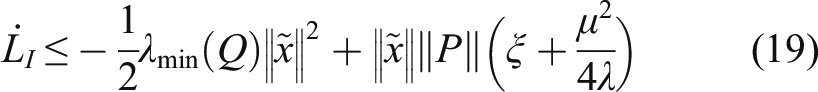
The negative definiteness of
can been guaranteed if
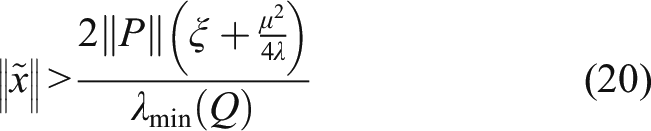
Thus
Since we can select
Observer-based self-learning controller design
This section is mainly devoted to the design of a self-learning control policy with the aid of the above-mentioned DNN observer using the single network adaptive critic approach.
The following single critic neural network is used to approximate the optimal value function, such that
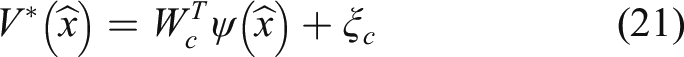
The derivative of the optimal value function (21) in terms of
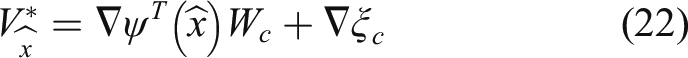
By substituting (22) into (7), the self-learning control policy is derived as
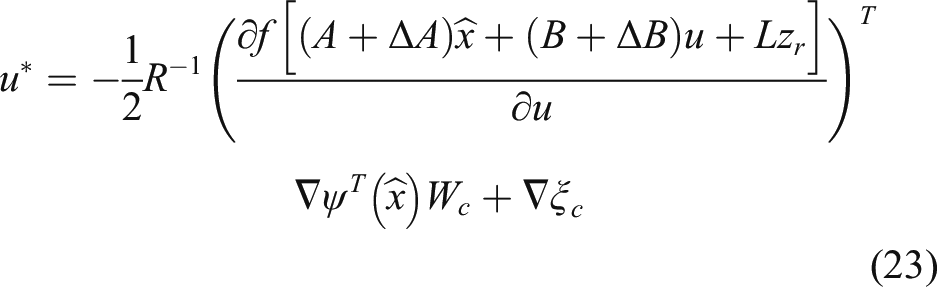
Then, the approximate self-learning control is represented as
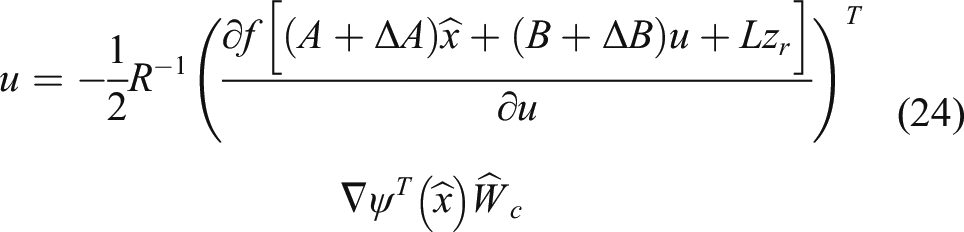
Next, after substituting equation (22) into equation (6), the HJB equation can be further obtained as follows
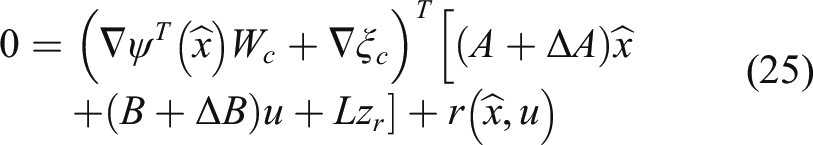
The expression
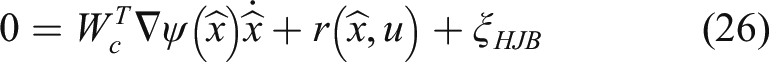
Our previous study
40
show that, compared with the traditional observer design driven by observation error, the adaptive learning law including parameter error information can make the closed-loop system converge as soon as possible. Inspired by this result, the following analysis will be devoted to develop a novel learning law for critic neural networks driven by parameter errors, rather than the existed least square
33
or gradient methods.
41
The auxiliary variables
and
are defined,
as
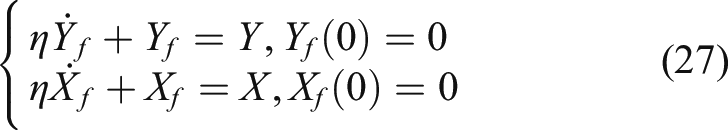
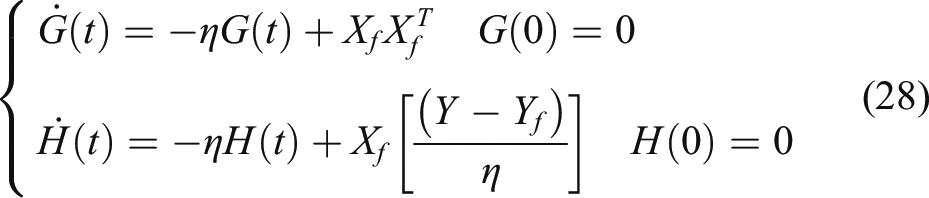
By solving the differential equation shown in (28), the following expression can be obtained
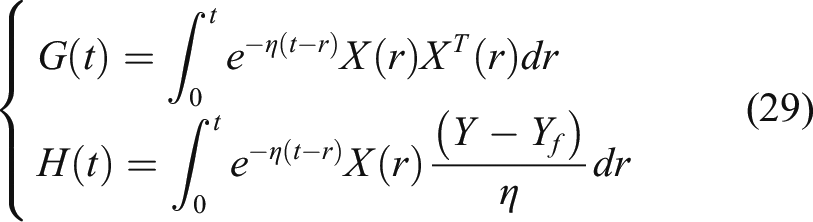
In the end, the learning rule of

A control mechanism composed of a DNN observer (11) with an update law (15) and a self-learning control (23) with a learning law (30) is used to control the system (1), then all the signals
From (29), we have As claimed by Na,
42
if the X satisfies the persistently excited (PE) condition, then the matrix Based on the well-known Cauchy’s inequality, that is, Then the derivative of With the assumption that the following conditions hold Then, Based on the above analysis, the mechanism of the DNN observer-based self-learning control approach for model uncertain suspension systems is shown in Figure 2.

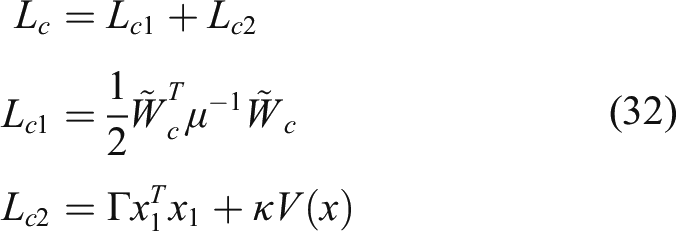
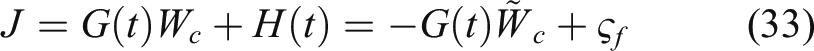
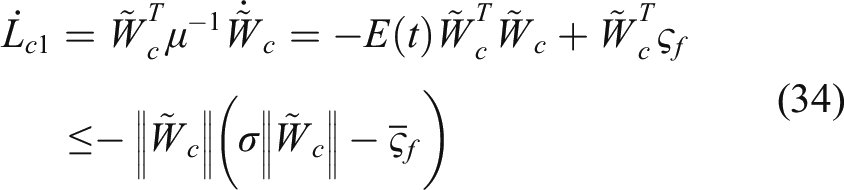
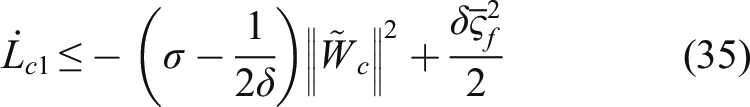
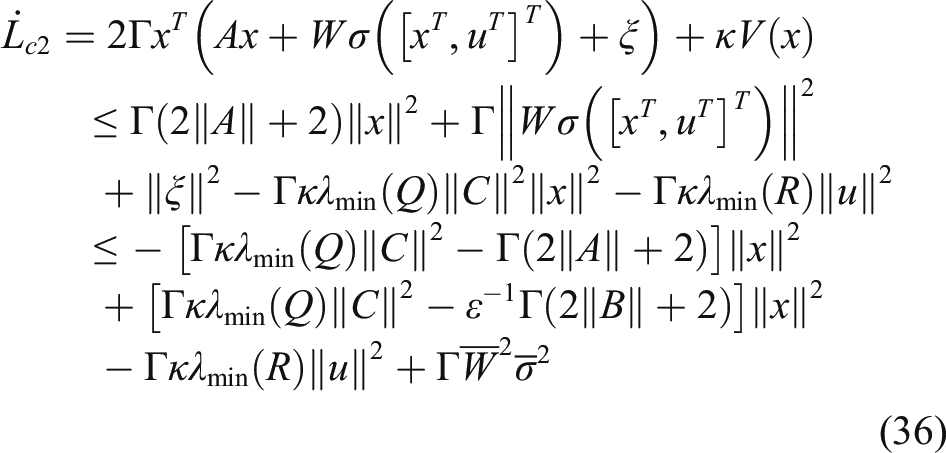
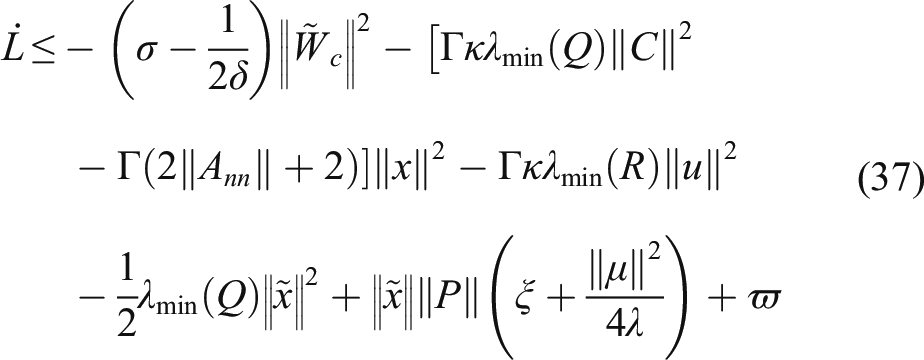
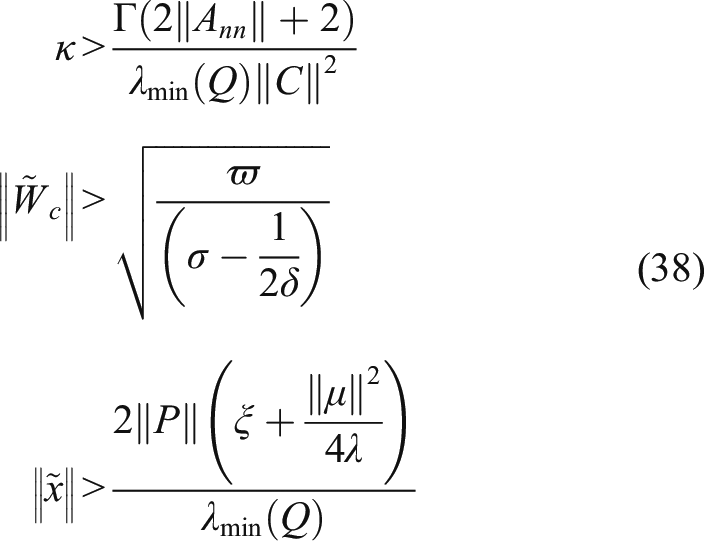
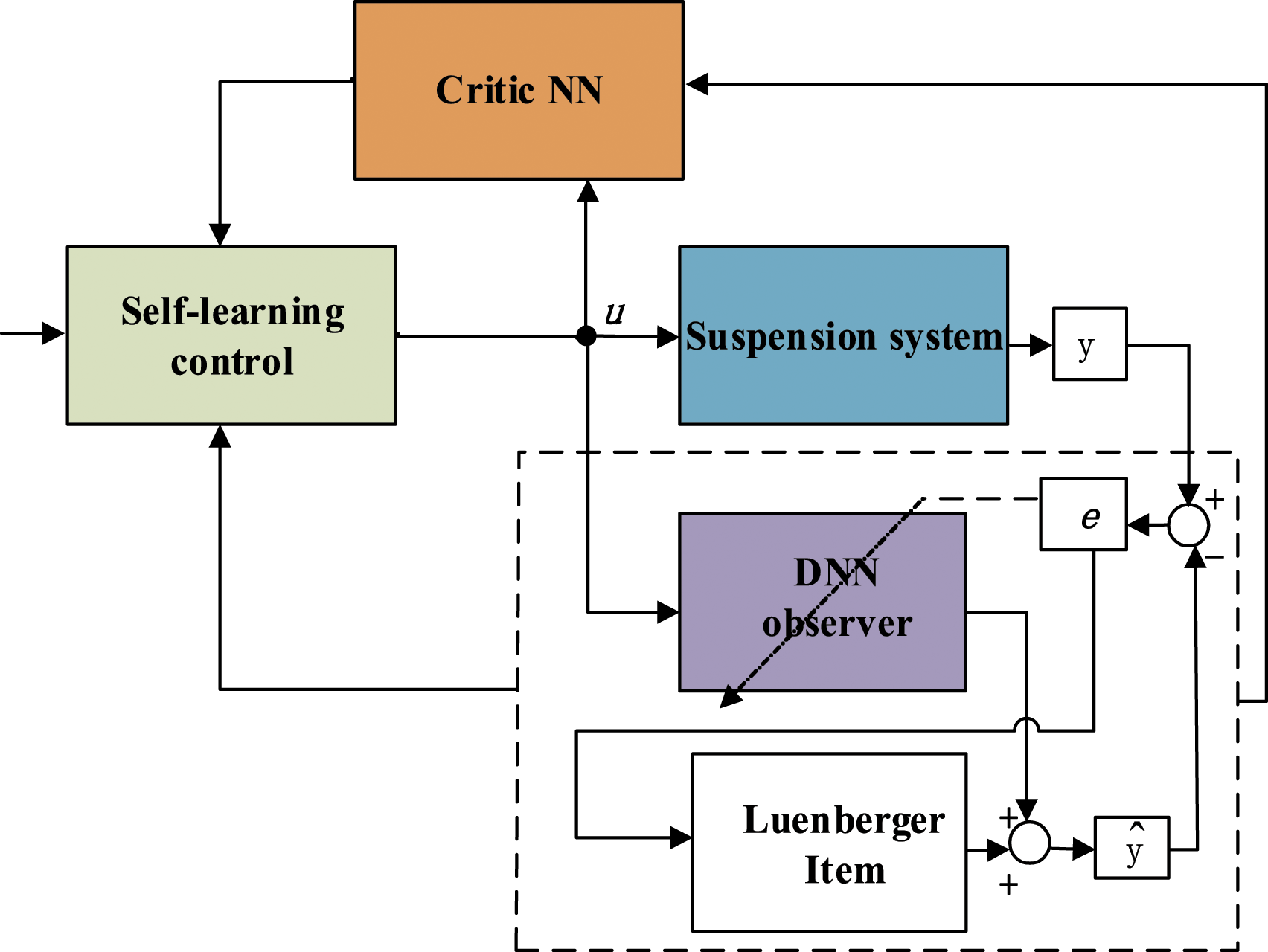
Mechanism of the self-learning controller.
A self-learning control method is proposed for uncertain suspension system. The significant advantage of the proposed method is that it gets rid of the limitations of the model, which is achieved by employing an DNN observer to identify the unknown dynamic and system state, where the weight updating law obtained by properly designed Lyapunov function instead of the commonly used backpropagation algorithm.
43
Moreover, all the signals implied in the entire learning process are UUB. Based on the above analysis, the flowchart of the proposed control algorithm is depicted in Figure 3 and can be summarized as follows. Step 1. Select the proper initial values of active functions Step 2. Then, the inputs/outputs data of the suspension system is used to train the neural network including the DNN observer in equation (11) and critic NN in equation (21). Step 3. Finally, self-learning control law expressed in equation (24) is obtained based on the first two steps.
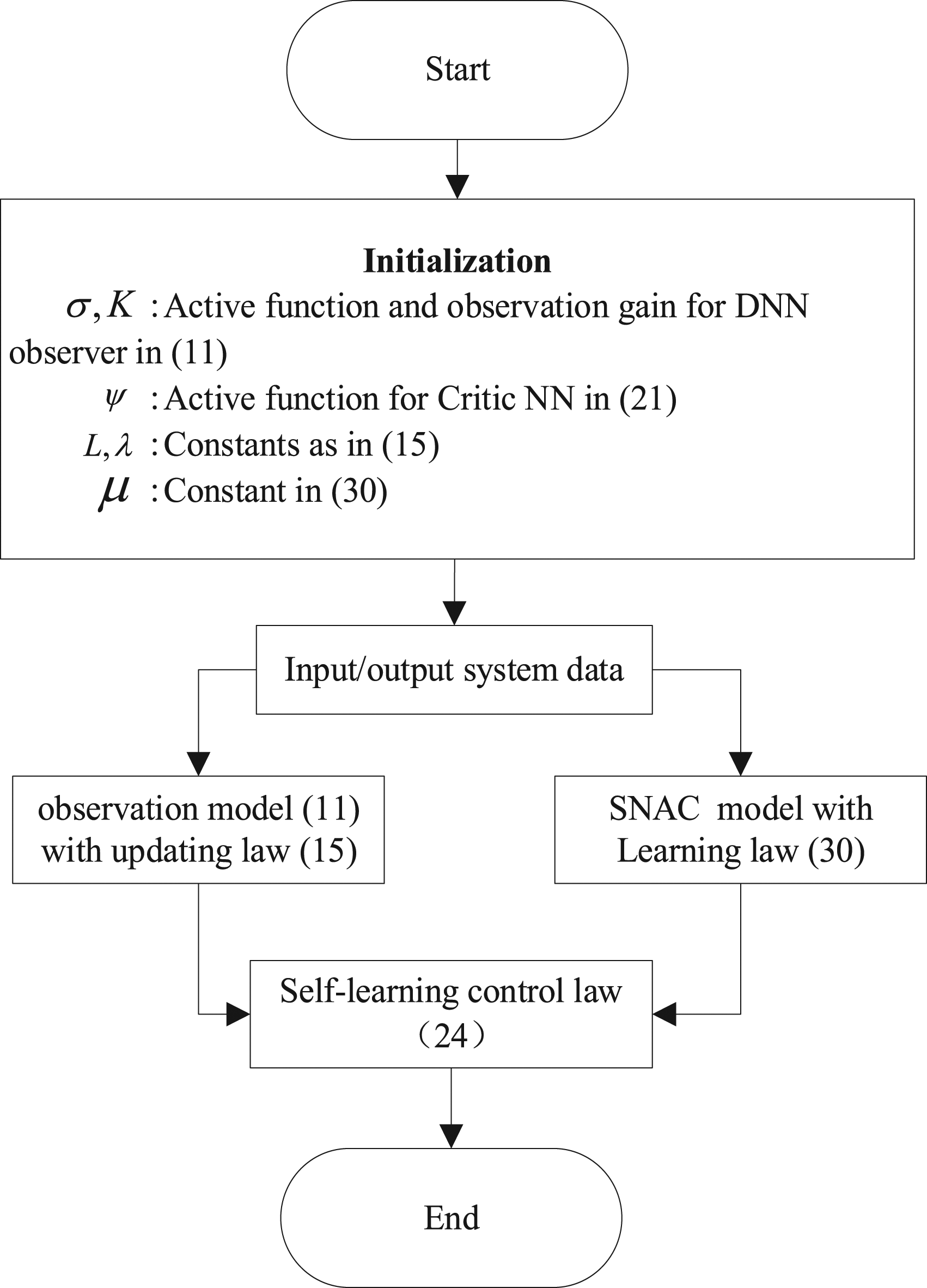
Flowchart of the proposed control algorithm.
Simulation and analysis

In order to verify the robustness of the proposed method, we adopt the following random road input model as following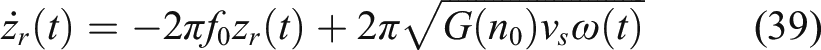
Here, related parameters in (39) are chosen by
The following smooth function is used to approximate the optimal value function of the self-learning controller, such that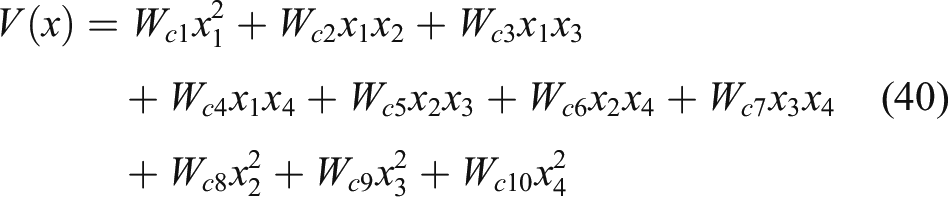
Random uncertain road input considering pavement roughness as showed in (39) is performed in this paper to compare the effectiveness of the proposed control method with the LQR control method. 44 Moreover, time varying parameter of the longitudinal velocity is also considered in the simulations, such that
Case A. Simulations results with the road input (39) and velocity 20 km/h are illustrated in Figures 4 to 7. The simulation results indicated that the proposed self-learning control approach is more effective than the LQR control suspension, the ride quality has been improved observably with respect to the suspension deflection, sprung mass acceleration, tire deflection and unsprung mass velocity, which means the suspension system can be brought back to the stable state as fast as possible when encountering unknown road input. The suspension performances in terms with the road hold quality is thus greatly improved. The suspension deflection response. The sprung mass acceleration response. The tire deflection response. The unsprung mass velocity response.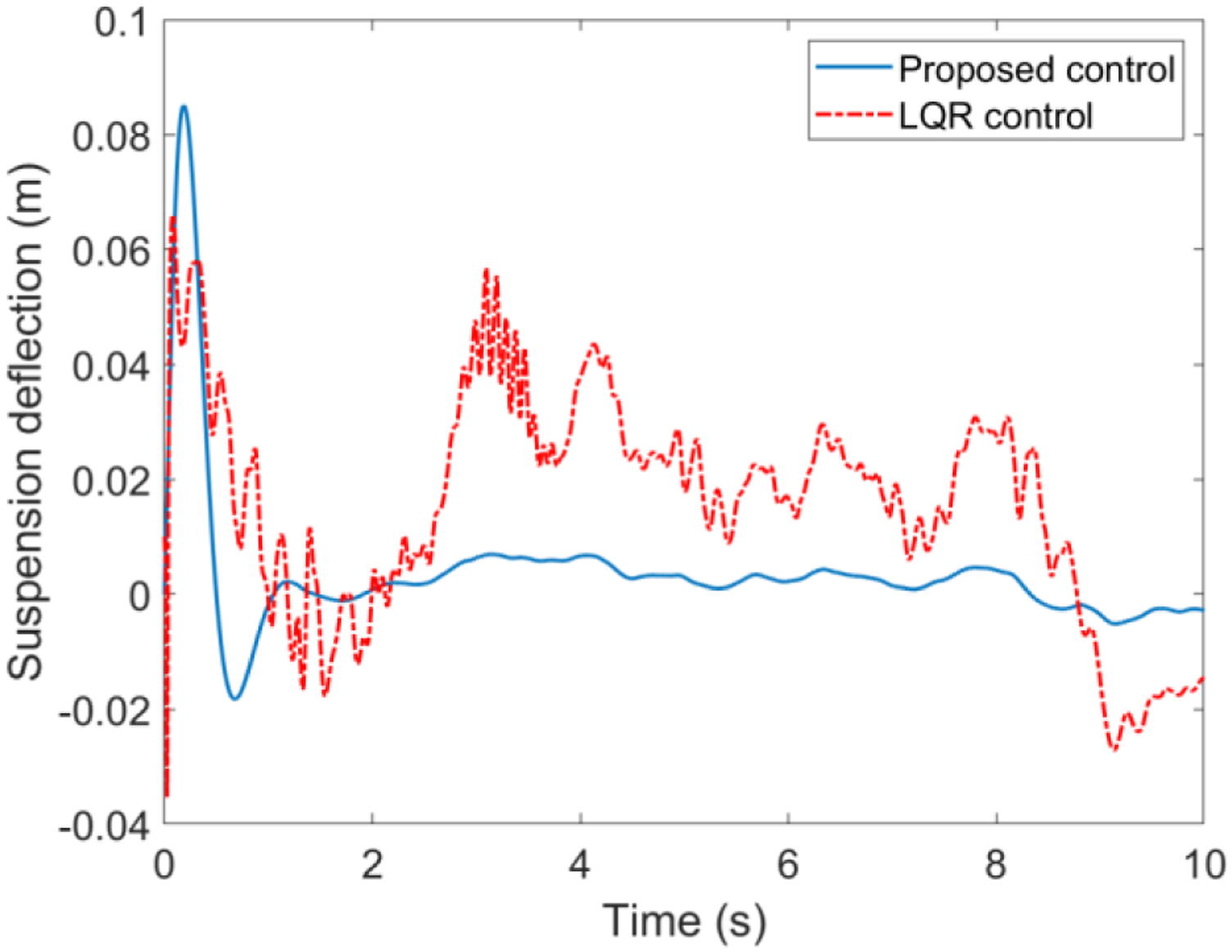
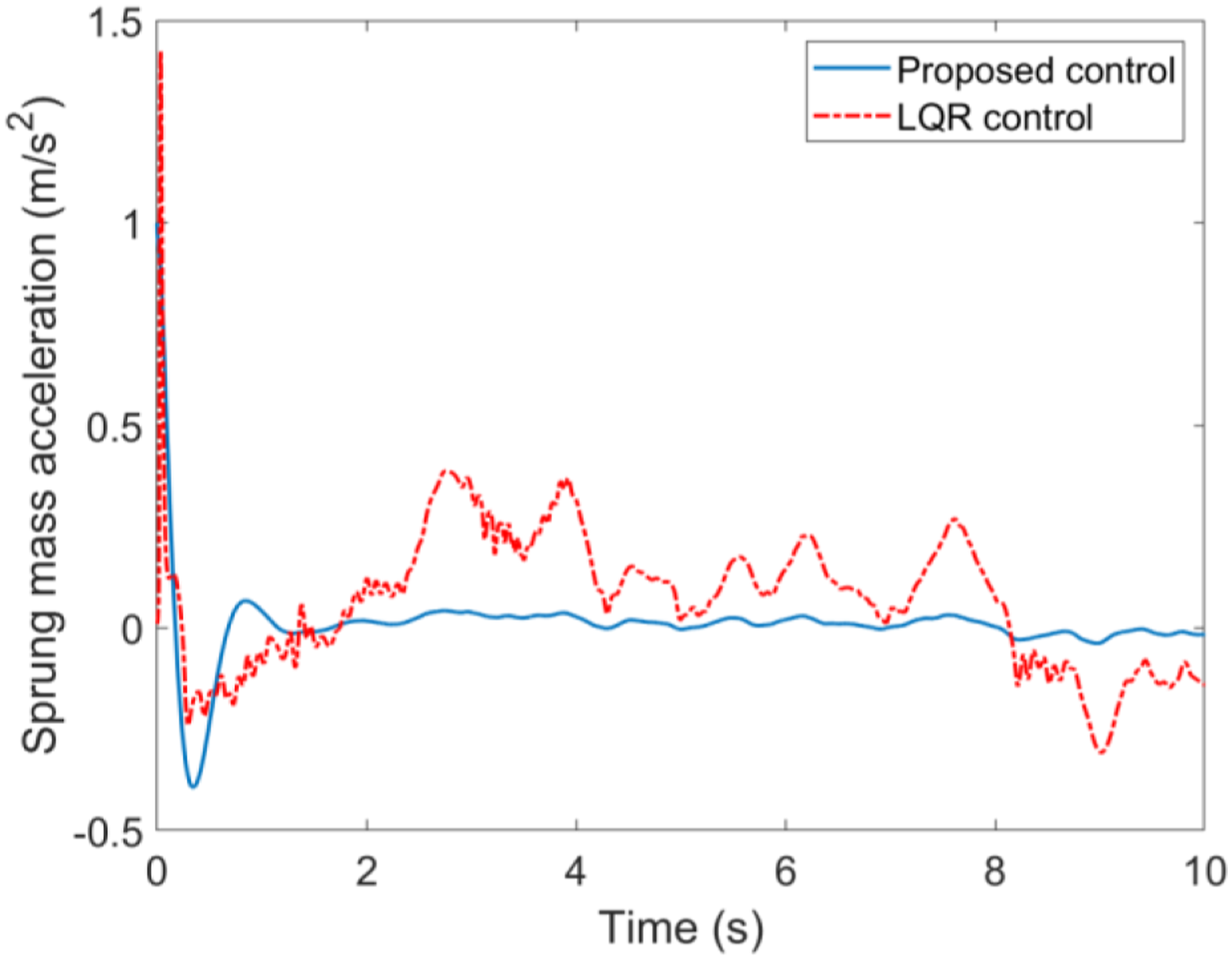
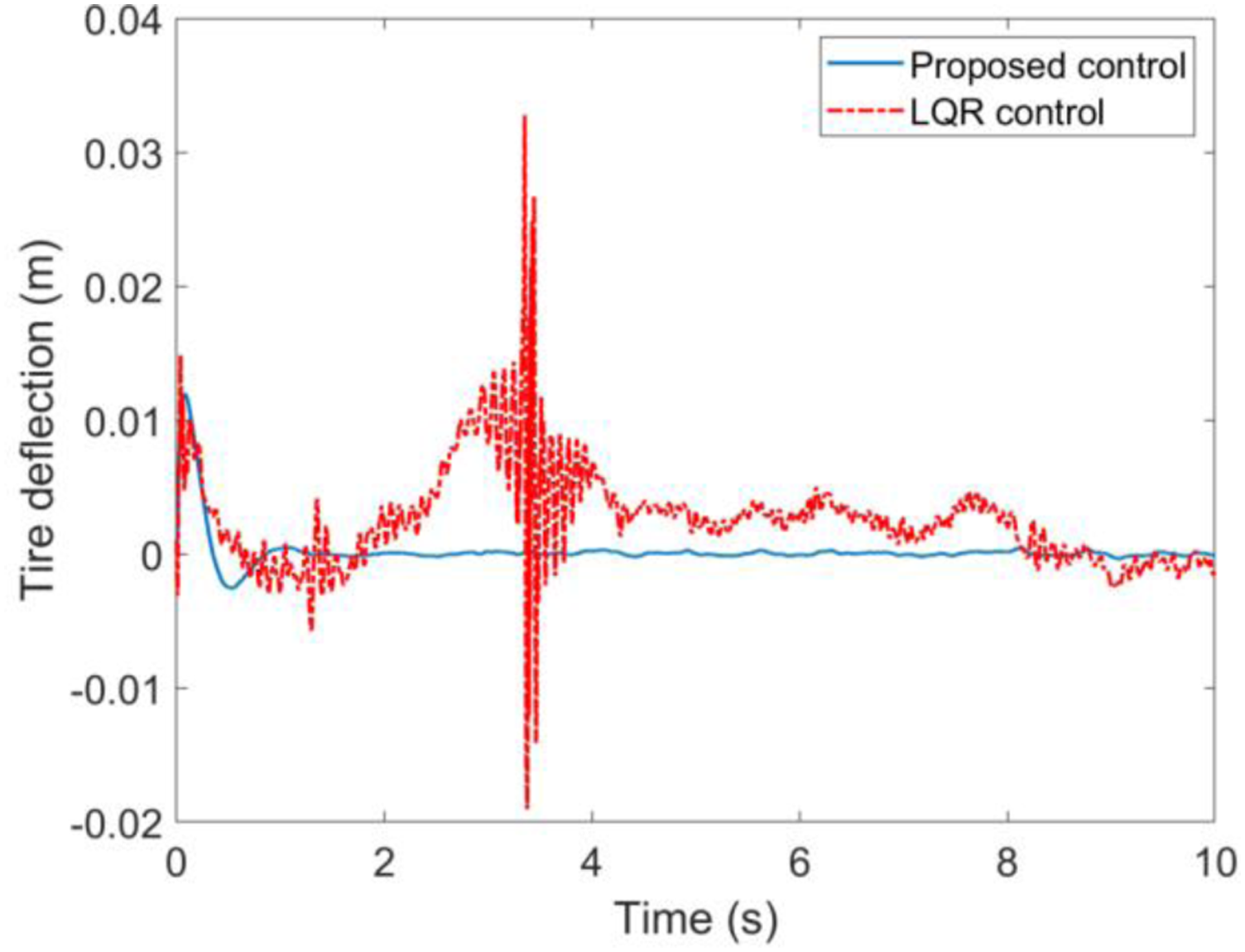
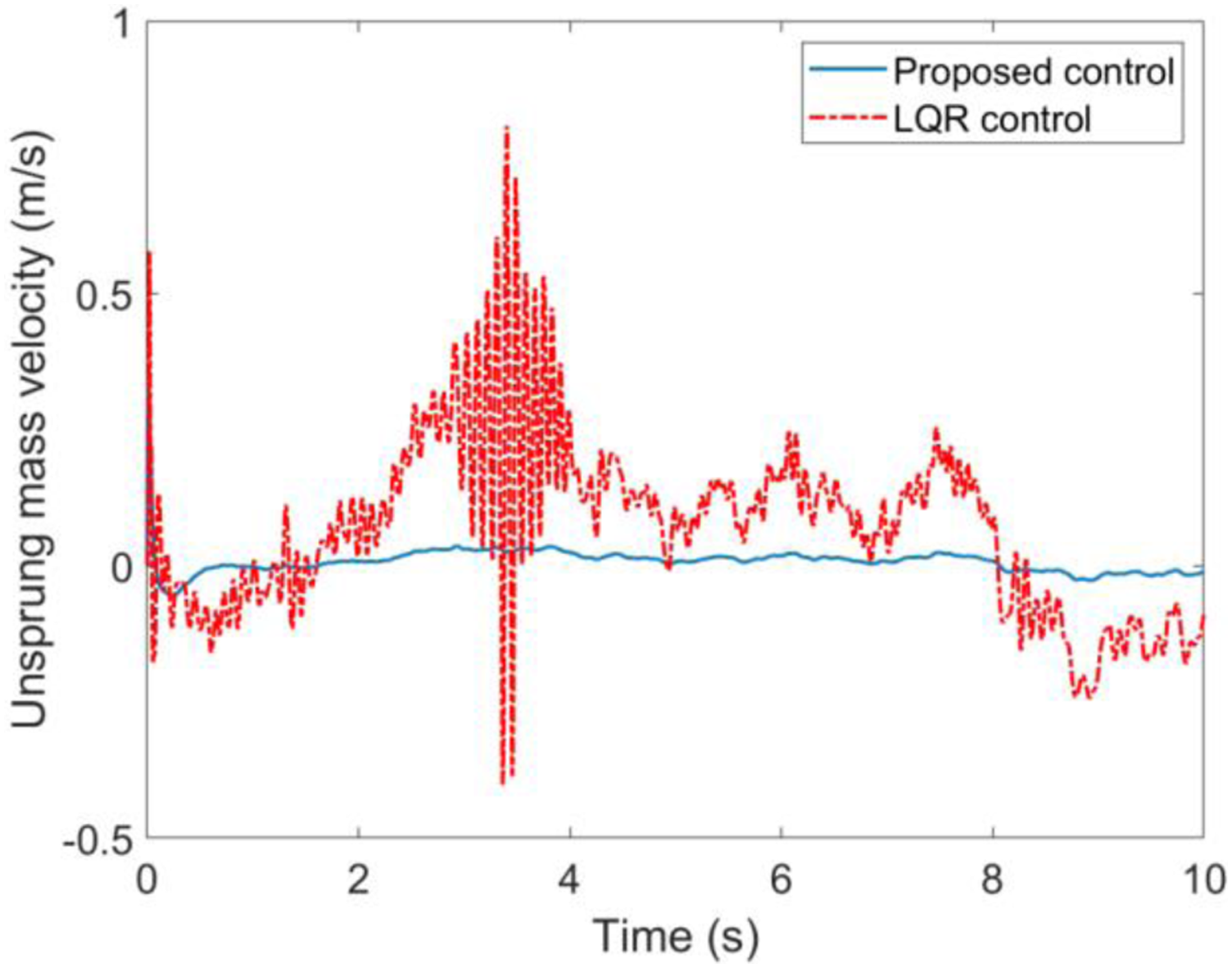
Case B: Simulations results with the road input (39) and velocity v = 60 km/h are presented in Figures 8–11. One can easily find that the proposed control method still has better performance with smaller fluctuations when encountering different longitudinal speeds compared with the commonly used LQR control method. These facts further verify the strong robustness and self-adaptive properties of the proposed control method. It should be mentioned that there are two main reasons for the performance improvements with the proposed control method in the simulation results above. First, the control law of the LQR method is based on the accurate suspension model, the control accuracy cannot be guaranteed when subjecting to time varying parameters. However, the proposed control method is not limited to a mathematical model, but based on the inputs/outputs data of suspension system. Second, the feedback control law of the proposed method can be updated online with the time varying parameters like longitudinal speed and random road input, whereas for the LQR method and other model-based methods, the feedback control law is fixed in advance. Therefore, it could be concluded that self-adaptive property of the proposed method provides a more effective solution for the suspension controller design and can greatly enhance the vehicle riding performance. The suspension deflection response. The sprung mass acceleration response. The tire deflection response. The unsprung mass velocity response.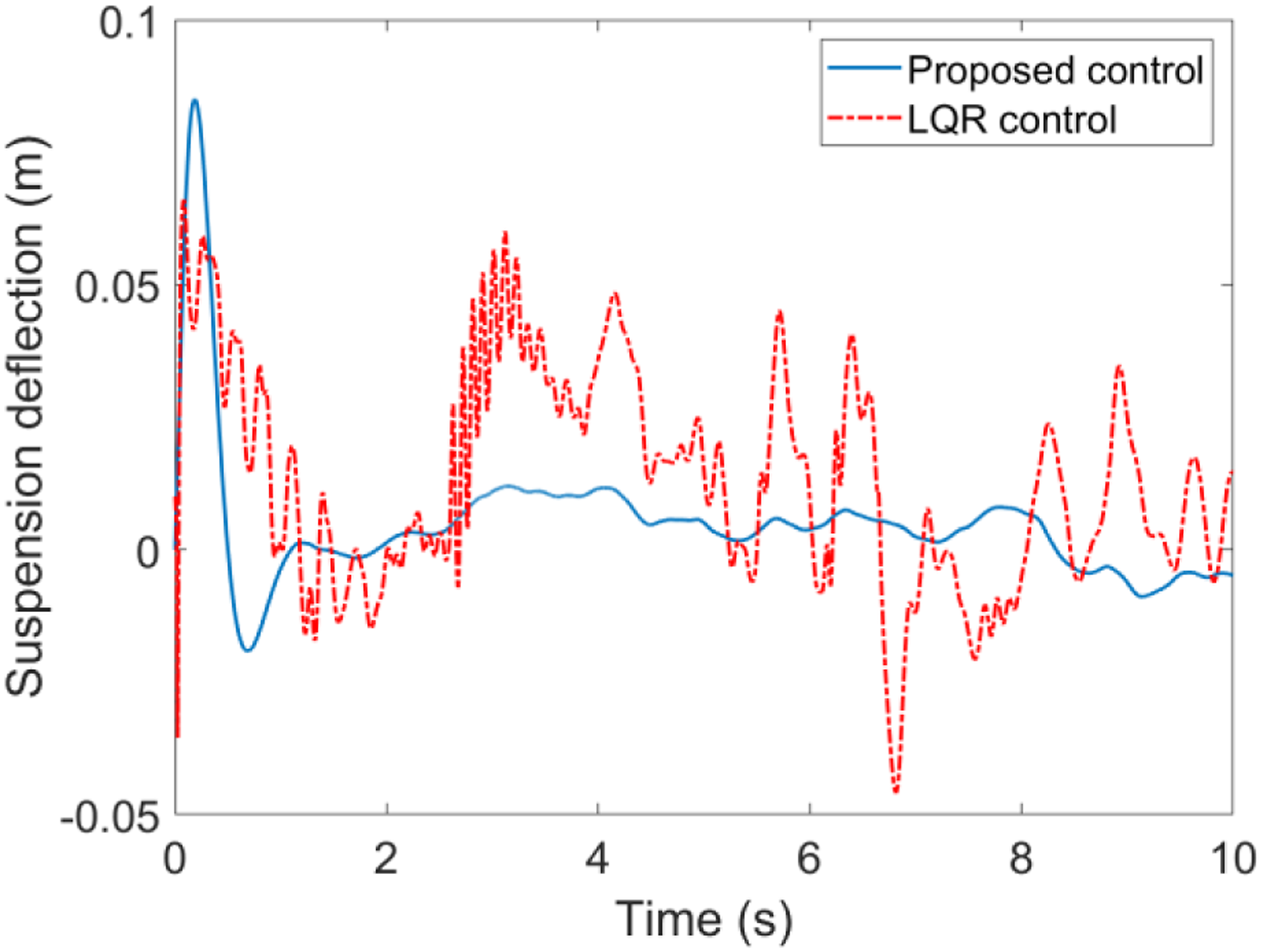
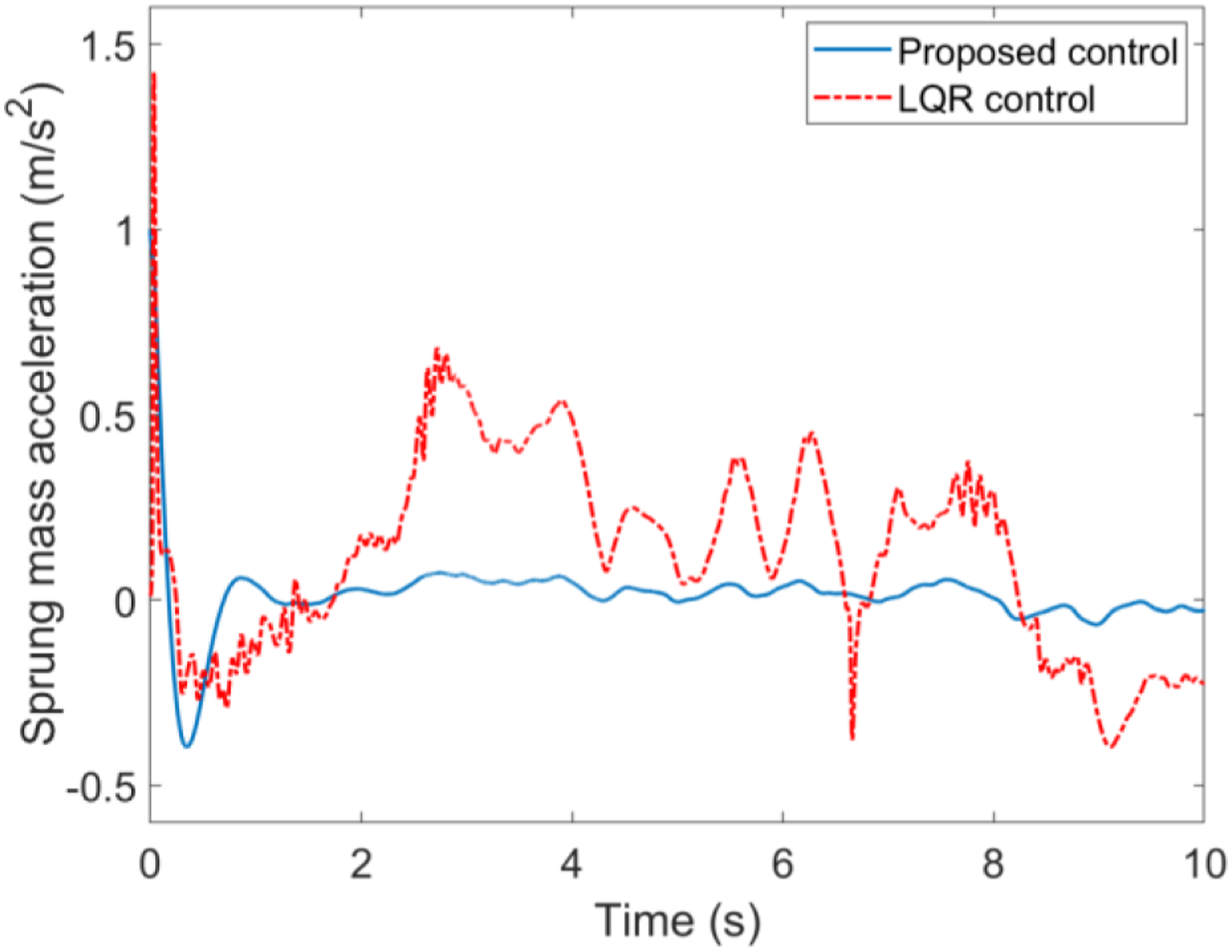
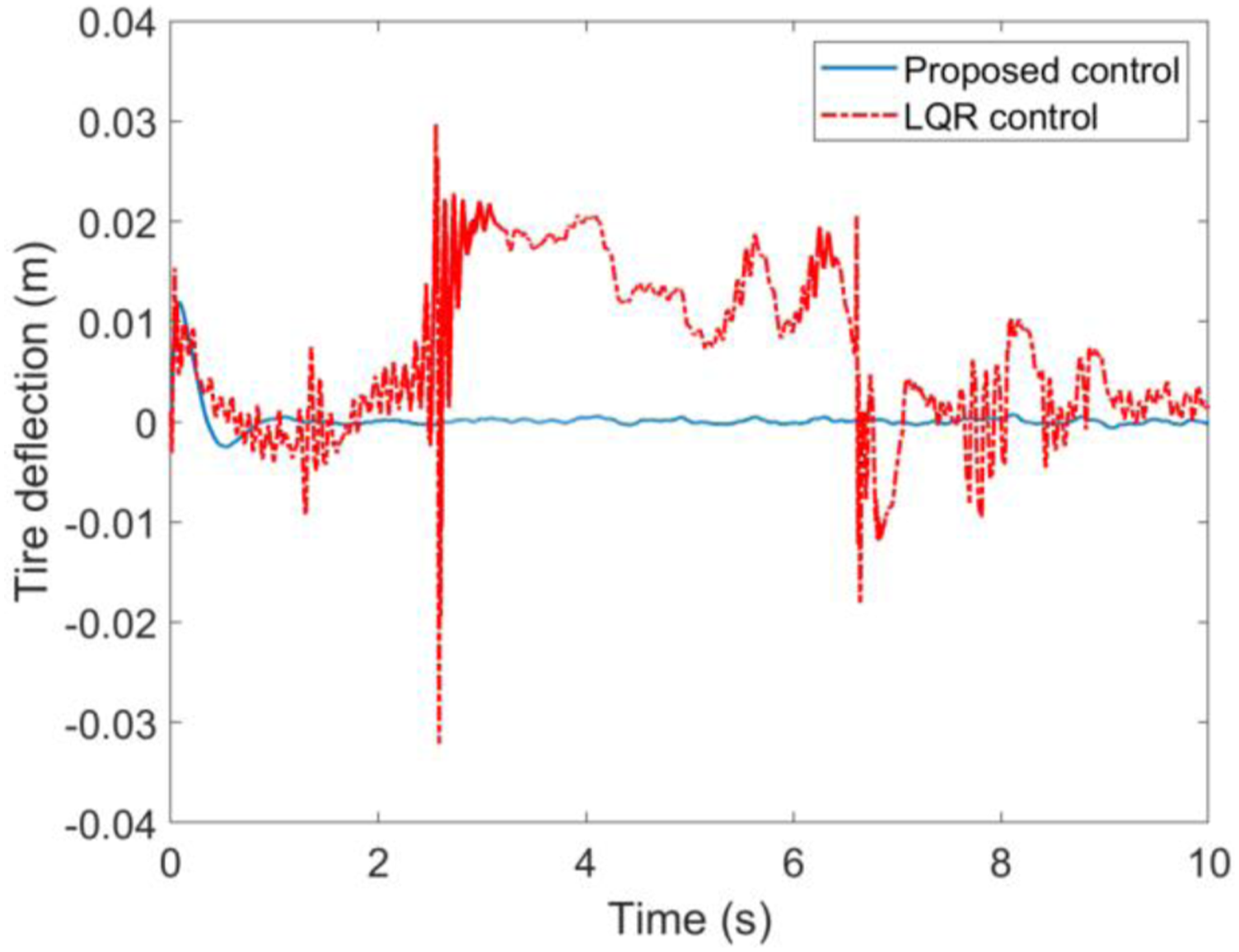
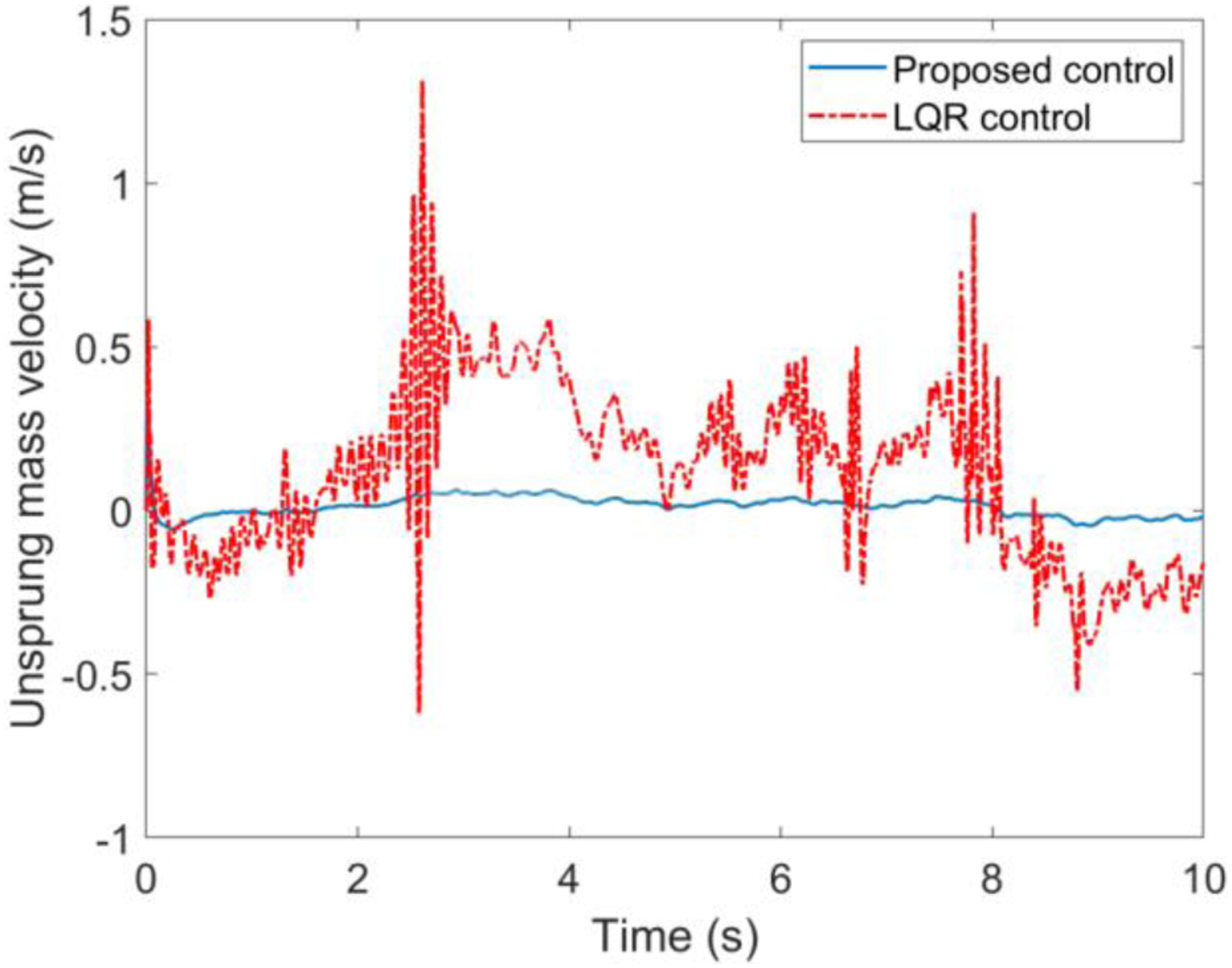
To show the control performance of the proposed method, the performance index—Root Mean Square (RMS) for the states error has been adopted for the purpose of comparison.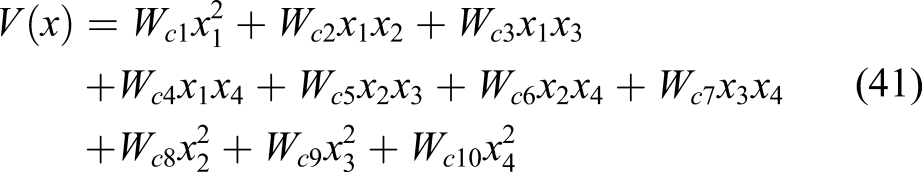
where n is number of the simulation steps,
The Root Mean Square Values.
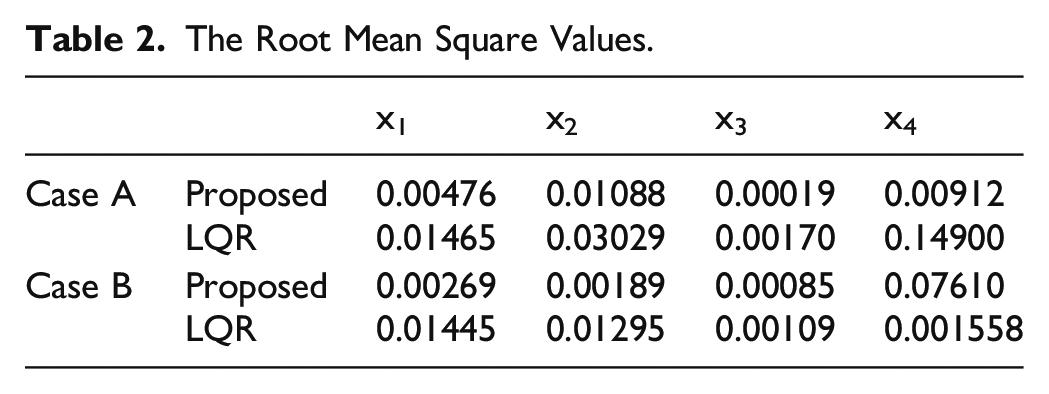
The above simulation results using the proposed DNN observer and self-learning controller indicated that all the evaluation indexes of suspension systems have been improved compared with the commonly used LQR control method. The proposed observer-based self-learning mechanism can realize online self-renewal according to the unknown road displacement without the complete suspension model. It therefore concluded that self-learning and model independent characteristics of the developed self-learning control approach opens a new idea for the design of model uncertain suspension control system and can apparently improve the car road hold and ride quality. Therefore, the aim of pursuing a high-performance suspension system is achieved.
Conclusions
This paper presents a new way to realize simultaneous online state observation and control for model uncertain suspension systems. This article has achieved the following main innovations. First, the proposed self-learning control method does not require the complete information of suspension system, this feature makes it become easier to be applied in practical system. Second, the self-learning control policy can be updated online with the unknown road input, which can greatly enhance the suspension performances in terms with the road hold and ride quality. Finally, simulation results performed on a quarter car suspension system considering unknown road input are presented. The suspension responses with respect to suspension deflection, spring mass acceleration, tire deflection and velocity of unsprung mass are presented to validate the effect of the proposed approach. The future work will focus on developing a more practical intelligent controller for automotive suspension systems considering actual state constraints and actuator saturation limits.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (Grant No.62073298), Key Scientific and Technological Project of Henan Province (Grant No. 212102310454 and No. 212102210237) and ZZULI Doctoral Fund for Scientific Research (Grant No. JDG20190099).