
Abstract
In order to predict the remaining useful life (RUL) of rolling bearings in complex environmental conditions, a bearing RUL prediction method based on fractal dimension and one-dimensional convolutional neural network (1D-CNN) is proposed. This method uses fractal dimension to characterize the degeneration process of the rolling bearing and combines the features of time domain, frequency domain, wavelet packet domain, and entropy domain. Fractal dimension provides an analytical method for characterizing the complexity of vibration signals. The features extracted from different feature domains can complement each other’s advantages, reveal the degradation state of the bearing more comprehensively and achieve better performance. Then, the percentage of the remaining life of the bearing is used as the degradation tracking index of the rolling bearing. Based on the idea of stratified sampling, the training samples and test samples are constructed, and then a 6-layer CNN is constructed to train the model. Finally, three commonly used data sets of full-life bearings are used to verify the model, namely, IEEE prognostics and health management 2012 Data Challenge, IMS dataset, and XJTU-SY dataset. The experimental results show that, on the three experimental datasets, compared to the long short-term memory network (LSTM) and the extreme learning machine (ELM) methods, the prediction effect of the RUL of the bearing based on the fractal dimension and 1D-CNN proposed in our paper is better. Its mean absolute error and root mean square error (RMSE) and mean absolute percentage error (MAPE) have been reduced, and the correlation index (R2), adjusted_R2, and relative accuracy (RA) have been improved, which can predict the RUL of the bearing more accurately.
Keywords
Introduction
With the continuous advancement of science and technology, machinery and equipment are increasingly developing in the direction of large-scale, precise, intelligent, automated, and systematic. In order to meet the needs of production, machinery and equipment are becoming more and more intelligent and complex. However, the working environment is often harsh and changeable. The equipment will gradually age after long-term operation, and the remaining useful life (RUL) will gradually decrease, thereby greatly increasing the potential for failure. 1 Driven by big data and artificial intelligence, research on fault prediction and prognostics and health management (PHM) technology has become more in-depth. This technology is not only traditional problem diagnosis, but also predictive performance analysis and intelligent maintenance of future states. Therefore, accurately predicting the RUL of the equipment is of great significance to the preventive maintenance decision-making of mechanical equipment.
Bearings are a key part of rotating electromechanical equipment, and their reliable operation can improve the safety and efficiency of modern production equipment. Generally speaking, bearings usually work in different environments, and different types of failures often occur during operation. If effective protective measures are not taken in time, it may cause the entire machine to malfunction and cause a lot of economic losses. Therefore, RUL prediction of bearings will be a very important task. It can provide early warning reports for equipment maintenance personnel and replace parts in advance, thereby reducing expensive unplanned maintenance and improving the safety of equipment operation. 2
At present, the mainstream prediction methods of RUL mainly fall into three categories: prediction methods based on physical models, data-driven, and hybrid models.3−4 Essentially, these three methods can find applications in practical problems. However, the use of physical mechanisms and hybrid-based methods may be limited in practice, due to the lack of underlying physical knowledge in many practical components and systems. Remaining useful life prediction methods based on physical mechanisms generally have problems such as greater difficulty in modeling systems with higher complexity and lower universality of the established models on other systems. Because it is difficult to clearly and comprehensively describe the complex process of bearing degradation, data-driven can automatically infer hidden data. The causal relationship in the system directly extracts the degradation characteristics of the complex system, which can better process the massive monitoring data and provide accurate RUL prediction results.5−6 Generally speaking, the data-driven RUL prediction process includes three steps. First, different types of monitoring data, such as vibration or sound wave emission signals, are obtained through various sensors. Second, representative features are extracted from them using signal processing techniques, and then the selected features are input into Gaussian process regression, 7 support vector machine (SVM), 8 recurrent neural network (RNN), 9 and other learning models to train the degradation behavior of the machine. Finally, these models are used to predict and estimate RUL.
With the continuous improvement of computer hardware level, deep learning10,11 technology has received more and more attention in data-driven RUL prediction. Scholars have also conducted some research on machine RUL prediction based on deep learning. Kang et al. 12 used an improved sparse autoencoder to extract features, combined with a bi-directional LSTM (Bi-LSTM) to construct a prediction model, and estimate rolling elements Bearing RUL. Tian et al. 13 developed a method based on artificial neural network (ANN) to achieve more accurate RUL prediction for state monitoring equipment, but the prediction results for small samples are not ideal. Sun et al. 14 developed a RUL prediction model based on SVM and applied the model to bearing life prediction. The model is applied to the life prediction of bearings, and the results show that the model has high accuracy, but this method cannot extract the features needed to fully reflect the bearing degradation by using traditional feature extraction methods. Ren et al. 15 proposed a deep learning method for predicting the RUL of multiple bearings by combining time domain and frequency-domain features. Cao et al. 16 proposed a new deep prediction network-parallel multiple CNN with compression excitation mechanism and Bi-LSTM to integrate the entire network, using RUL prediction for rolling bearings. Han et al. 17 tried to use the horizontal vibration acceleration signal and the vertical acceleration signal of the bearing to construct a one-dimensional CNN to realize automatic feature extraction. By setting the starting degradation point of the bearing sample, the RUL of the training sample is more accurate. Ding et al. 18 proposed a stratified sampling which is different from the traditional time series data division method and applied to data division, in order to fully understand the data characteristics, use the fast Fourier transform to obtain the frequency characteristics from the original data, and use the mean square The root is used as the tracking metric; finally, a deep convolutional neural network model with no pooling layer composed of three convolutional layers and two fully connected layers is constructed. J. Yoo et al. 19 developed a time-frequency image to construct a health index (HI) and used CNN to predict RUL. In order to improve the RUL prediction value, RNN, 20 AE, and bi-directional combined gated recurrent unit (Bi-GRU) 21 have also been applied to the prediction of RUL bearings. CNN has also obtained excellent RUL prediction results due to its wide application and powerful feature extraction capabilities.
When rolling bearings are in different fault states, due to the difference in stiffness non-linearity, clearance, friction, and external load, different non-linear and non-stationary influencing factors are caused. These influences are reflected by vibration signals. How to extract effective fault features from the fault vibration signal is the key to fault diagnosis. The complexity of the geometric shape of the vibration signal of rolling bearings is related to the degree of non-linearity of the system. Fractal dimension provides an analysis method to characterize the complexity of the vibration signal. It can extract the state information of the equipment as a whole. It has been successfully applied in many fields.22−25 Fractal dimension is to characterize the irregularity and complexity of the fractal set at different scales. The fractal dimension obtained according to the fractal theory can describe the structural characteristics of the signal. Therefore, this paper takes fractal features into account in the extraction of the degradation characteristics of rolling bearings and combines the time-domain, frequency-domain, and time-frequency-domain features proposed in the previous literature 26 to better reflect the degradation state of the bearing.
The main tasks of this article are as follows: 1. Three commonly used data sets in the field of bearing failure health management, PHM 2012 challenge data set, IMS data set, and XJTU-SY data set were selected. Systematically analyze the bearing degradation information in these three data sets and deeply understand the degradation status of bearings under different environmental conditions. 2. Introduce the fractal dimension into the measurement to characterize the degradation of rolling bearings. Combine multiple feature domains such as time domain, frequency domain, wavelet packet domain, and entropy domain to extract the multi-dimensional fusion features of the original bearing. The percentage of remaining life is used as the tracking metric label of the training model. 3. The method of data stratified sampling is used to divide the training set and the test set, in which the length of the intercepted data is consistent with the dimension of the extracted features. The method of data stratified sampling can make the training model robust. 4. Construct a 6-layer CNN to fit the hidden mapping relationship between the degradation index and the multi-dimensional fusion features. CNN can automatically extract deep features. Due to its generalization and robustness, the prediction effect on other bearings is also better without changing the super parameters of the model.
The organization work of this article is as follows: The Preliminaries section introduces the basic knowledge of CNN structure and fractal dimension; the Experimental framework section explains the construction of the model and the evaluation indicators used in this article; the Experiment section presents the specific experimental results and analysis; The last section is the conclusion of this article and discusses future work.
Preliminaries
CNN structure
Convolutional neural network is a very popular deep learning framework model with powerful feature extraction capabilities and has been well applied in image recognition, natural language processing, and other fields. The weight-sharing network structure of CNN makes it more similar to a biological neural network, which reduces the complexity of the network model and reduces the number of weights. This advantage is more obvious when the input of the network is a multi-dimensional image, so that the image can be directly used as the input of the network, avoiding the complicated process of feature extraction and data reconstruction in traditional recognition algorithms.
Convolutional neural network mainly consists of three main components: convolutional layer, pooling layer, and fully connected layer. Generally, the convolutional layer and the pooling layer will appear in pairs. The neurons in the convolutional layer in CNN are only connected to certain neurons instead of connecting to all neurons. Local connection, weight sharing, and sub-sampling in space or time make the three structural characteristics of CNN. The more common CNN structure is shown in Figure 1. General convolutional neural network structure.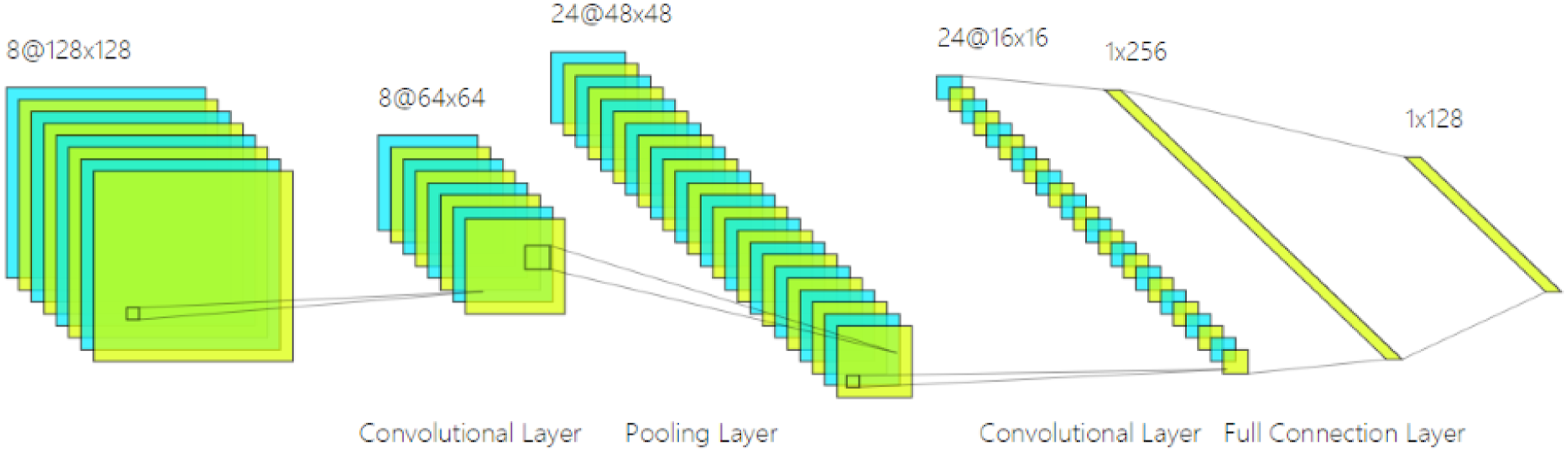
The function of the convolutional layer is to perform feature extraction by performing convolution operations on the local area of the input data and the convolution kernel, and to make the local receptive field traverse the entire input data by sliding the convolution kernel window. Each element that composes the convolution kernel corresponds to a weight coefficient and a bias, which is similar to the neuron of a feedforward neural network. Each neuron in the convolutional layer is close to the area of the previous layer. Each neuron is connected, and the size of the region depends on the size of the convolution kernel, which is called ”receptive field” in the literature.
The convolution formula is defined as follows
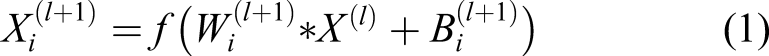
The convolution process of CNN enables the convolution kernel to act on the feature area through a specified step size, thereby extracting new features. The weight of the same convolution kernel is the same, and different convolution kernels will get different outputs, and all outputs The features constitute the feature input of the next layer of pooling.
After feature extraction in the convolutional layer, the input features will be passed to the pooling layer for feature selection and information filtering. The pooling layer contains a preset pooling function, and its function is to replace the result of a single point of the feature map with the feature statistics of the adjacent area. The pooling layer selects the pooling area in the same steps as the scanning feature of the convolution kernel, which is controlled by the pooling size, step size, and filling. The role of the pooling layer is spatial merging or down sampling, which can reduce the dimension of the feature map while maintaining the most important signals. Generally, there are average pooling and maximum pooling; the expression for maximum pooling is as follows Max pooling.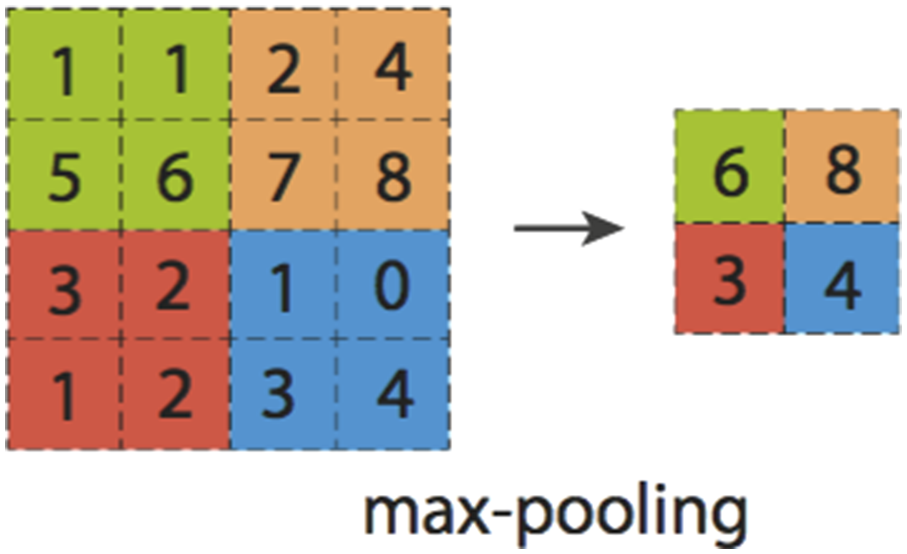
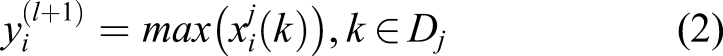
In the CNN structure, after multiple convolutional layers and pooling layers, one or more fully connected layers are finally connected. Each neuron in the fully connected layer is fully connected with all neurons in the previous layer. The fully connected layer can integrate the local information of the convolutional layer or the pooling layer.
Fractal dimension
Because the fractal dimension uses numerical methods to describe the fault characteristics, compared with the frequency spectrum method, the fault description is cleaner and more intuitive, and the amount of calculation is smaller.
Fractal dimension is a parameter used to quantitatively describe the complexity and irregularity of an object. It can describe the object as a whole without relying on mathematical models.
23
Therefore, the fractal dimension is an important feature of describing an object. At present, the more common fractal dimensions are box dimension, similar dimension, information dimension, correlation dimension, and generalized dimension. The box dimension is currently the most commonly used method for calculating the fractal dimension. Its calculation method is simple. The specific method is to cover the entire graph with small squares, and calculates the dimension by counting the number of all small squares covering the graph.The box dimension is specifically calculated by the following formula
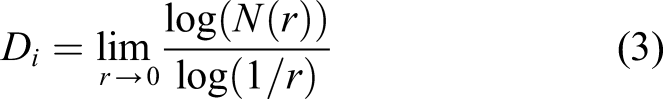
The size of the fractal dimension indicates the complexity and irregularity of the fractal object, and the larger the fractal dimension, the more complex the object and the more detailed components. Multifractal is a further extension of fractal theory. It uses a spectral function to describe the deeper and more detailed characteristics of the signal. With more in-depth research on fractal theory, scholars have found that only a single fractal cannot be described well. The more detailed characteristics of complex signals, and the generation of multifractals solves this problem.
Multifractal is not like a single fractal, which is a dimensional value. It is a collection of singularity measures of multiple scale indexes. Multifractal spectrum is usually used to express the relationship between the part and the whole.
The vibration signal of a rolling bearing is a non-linear and non-stationary signal. The fractal method is used to study it. Single fractal and multifractal are used to extract the characteristics of the rolling bearing vibration signal. Multifractal spectrum can more finely reflect the detail information contained in bearing signal and the degree of degradation information. The remaining life prediction is carried out by selecting the fractal box dimension and the multifractal spectrum corresponding to the original vibration signal as part of the degradation characteristics of the rolling bearing. The feature quantities extracted from the time domain, frequency domain, time-frequency domain, entropy domain, and fractal domain can complement each other’s advantages. Combining the features of multiple feature domains can reveal the degradation state of the bearing more comprehensively and achieve a more accurate remaining life prediction.
Experimental framework
In this section, all steps of the proposed RUL prediction method will be explained in detail.Our paper provide the whole sketch map of the proposed method as shown in Figure 3. First, extract 19-dimensional features from the fractal domain, time domain, frequency domain, wavelet packet domain, and entropy domain from the original vibration signal of the rolling bearing. Each feature can reflect the degradation process of the bearing throughout its life. Normalization processing can effectively avoid the impact of differences in the data itself. Then, the extracted 19-dimensional features are expanded into a one-dimensional vector in chronological order, where the first set of features represent the features extracted at the first sampling time, and the last set of features are the comprehensive features extracted at the last sampling time. CNN secondary feature extraction is performed on the unfolded one-dimensional vector, and the remaining percentage of the bearing is used as the tracking metric. The size of the convolution kernel of the first convolution layer is 19*1, and the step size is also 19, which means that each step The operation calculates 19 comprehensive features at the same time. The activation function uses the ReLU activation function, which can effectively avoid the insufficient gradient of the Sigmoid activation function or the insufficient gradient explosion. The maximum pooling layer is used to reduce the dimensionality of features, while not losing useful features as much as possible, and can greatly speed up training. Finally, two fully connected layers are connected to integrate the features after convolution and predict the final output result. Flowchart of the proposed method.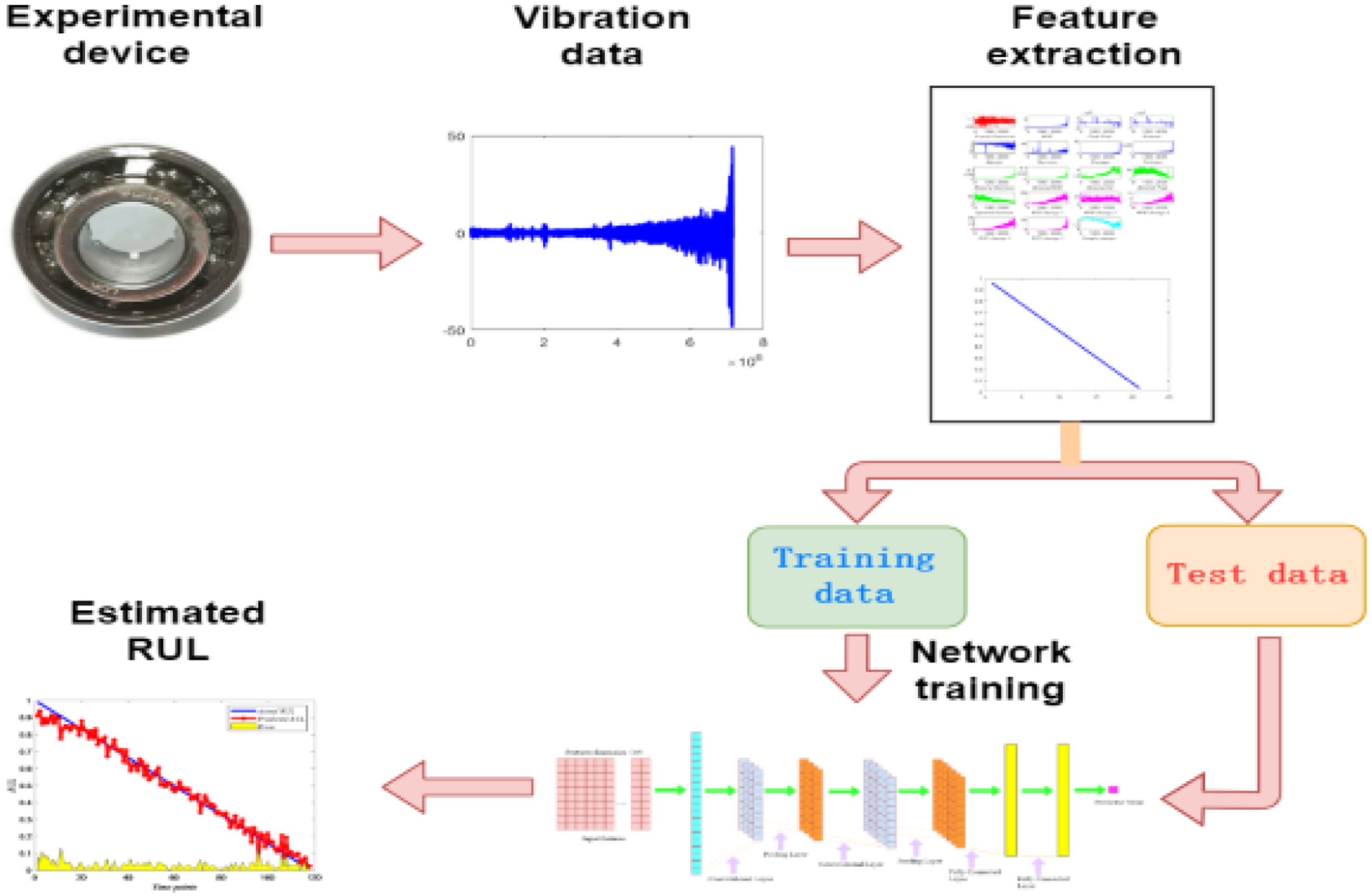
Bearing feature extraction
Time domain features and frequency-domain features can roughly reflect the decay process and fault information of rolling bearings. However, due to the non-linear characteristics of the bearing signal, the time-domain or frequency-domain features are very insensitive to non-linear components. When there are subtle changes, they cannot truly reflect their characteristics.
Wavelet packet decomposition is based on wavelet transform (WT), which can locally characterize the bearing signal characteristics. According to the research in Ref. 26, morlet is selected as the mother wavelet to extract part of the impact characteristics in the bearing, the number of decomposition layers is 4, and the first five normalized energies are used as time-frequency domain characteristic parameters. 26
In the entropy domain, the physical meaning of sample entropy and approximate entropy is roughly similar. They both measure the complexity of the time series by measuring the probability of generating new patterns in the signal. The greater the probability of a new pattern, the greater the complexity of the sequence. Compared with approximate entropy, sample entropy has two advantages: the calculation of sample entropy does not depend on the length of the data and sample entropy has better consistency, that is, changes in parameters m and r have the same effect on sample entropy. The lower the value of sample entropy, the higher the self-similarity of the sequence; the larger the value of sample entropy, the more complex the sample sequence. At present, sample entropy has applications in evaluating the complexity of physiological time series (EEG, sEMG, etc.) and diagnosing pathological conditions.
In the fractal domain, single fractal and multifractal are used to extract the characteristics of rolling bearing vibration signals. The multifractal spectrum can more finely reflect the detailed information contained in the bearing signal and the degree of degradation information. The remaining life prediction is carried out by selecting the fractal box dimension and the multifractal spectrum corresponding to the original vibration signal as part of the degradation characteristics of the rolling bearing.
Characteristic index.

It can be seen from the above Figure 4 that the feature quantities extracted from the time domain, frequency domain, time-frequency domain, entropy domain, and fractal domain can complement each other. Starting from the characteristics of multiple feature domains, it can reveal the degradation state of the bearing more comprehensively, to achieve a more accurate remaining life prediction. Feature extraction map.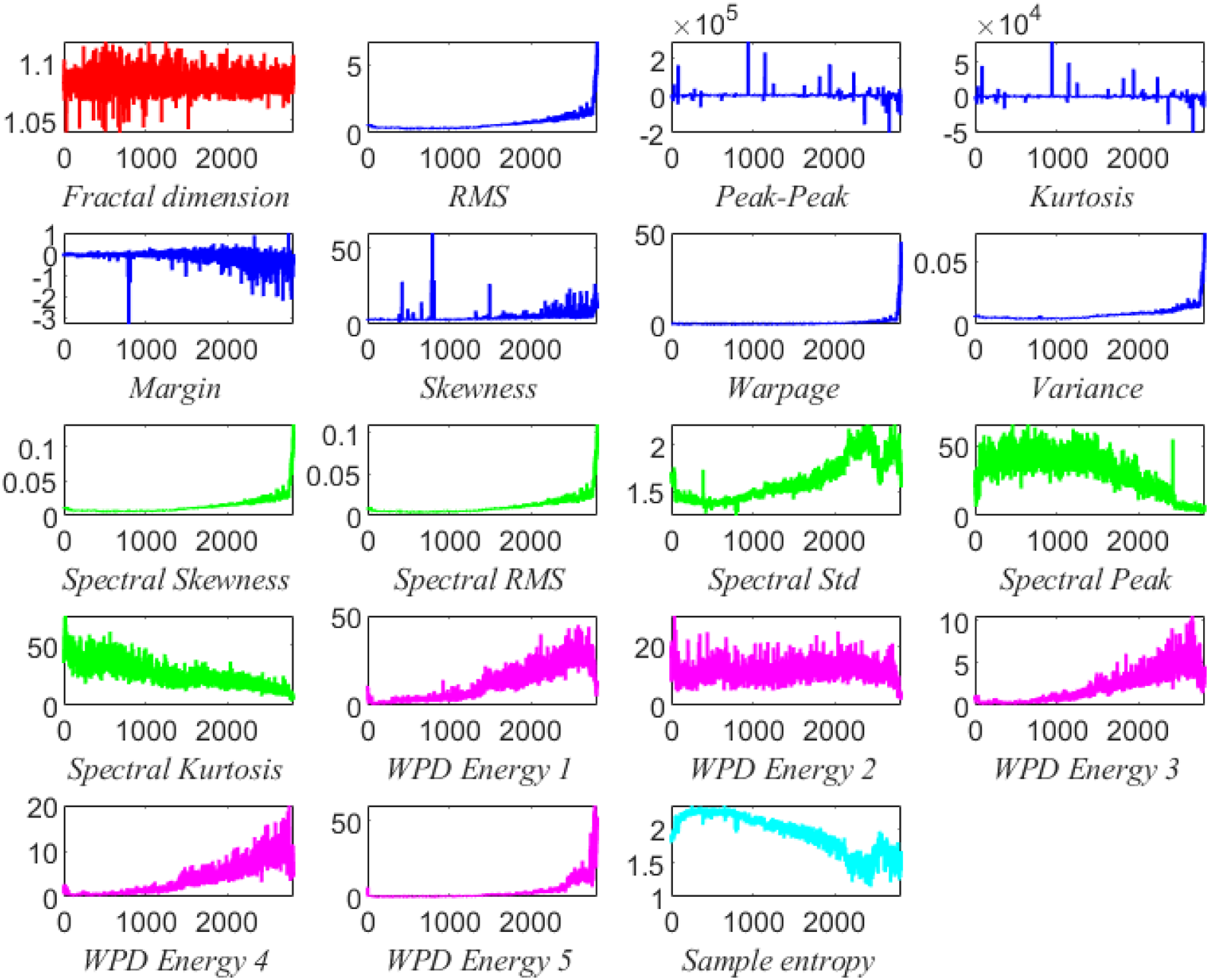
Percentage of Remaining Useful Life
Under normal operating conditions, the life of rolling bearings can reach thousands or tens of thousands of hours. However, running such a long time in a laboratory environment obviously does not conform to the actual conditions of the experiment. For the feasibility of the experiment, artificial methods are used to change the acceleration degradation process of the bearing. The main methods are to increase the speed of the rolling bearing, apply the extra load pressure of the rolling bearing, and reduce the use of lubricating oil. Therefore, the acquisition of bearing vibration signals is generally equal interval sampling.
For an experimental dataset, assuming that a total of n samples are taken during the experiment, the sampling frequency of the sensor is f, and the duration of each collection is s, then k (k = f*s) data are collected each time, If the sampling interval is m, the life of the bearing is n*m. Set the number of rows as the number of acquisitions, and the number of columns as the length of the data collected once.
For example, for the IMS data set, each bearing in the second set of experiments was collected 984 times, 20,480 data were collected each time, its life was 984*10 = 9840 min, a total of 164 h, the number of rows was set to be the number of times of collection, and the number of columns was the length of the data collected once.
Set the life label of the i-th row of data, which represents the ratio of the time from the time corresponding to the i-th row to the time when the bearing fails, and the ratio of the time from the start time of the bearing to the time when the bearing fails. Calculated as follows
In formula (4), n is the number of rows currently in, and i is the total number of rows. The normalization of the life label can reduce the difference between different working conditions and different life values of the bearing, which is beneficial to improve the prediction accuracy of the RUL. Obviously, when the signal is first collected, the percentage of remaining life of the bearing is 1, and when the signal is finally collected, the percentage of remaining life of the bearing is 0.
Dataset division
Refer to the idea in the Ref. 18, using a stratified sampling method to divide the training set and the test set in order to better understand the entire degradation state of the data. The specific division steps are shown in the Figure 5. First, the extracted multi-domain features are expanded in a time series, and then extracted at a ratio of 19:1. The first 19 points of each group of data are taken as the training set, and the last point of each group of data is taken as test set. The advantage of dividing the training set and the test set in this way is to understand the degraded state of the bearing during the entire operation process and improve the accuracy of model training. Figure data stratified sampling method.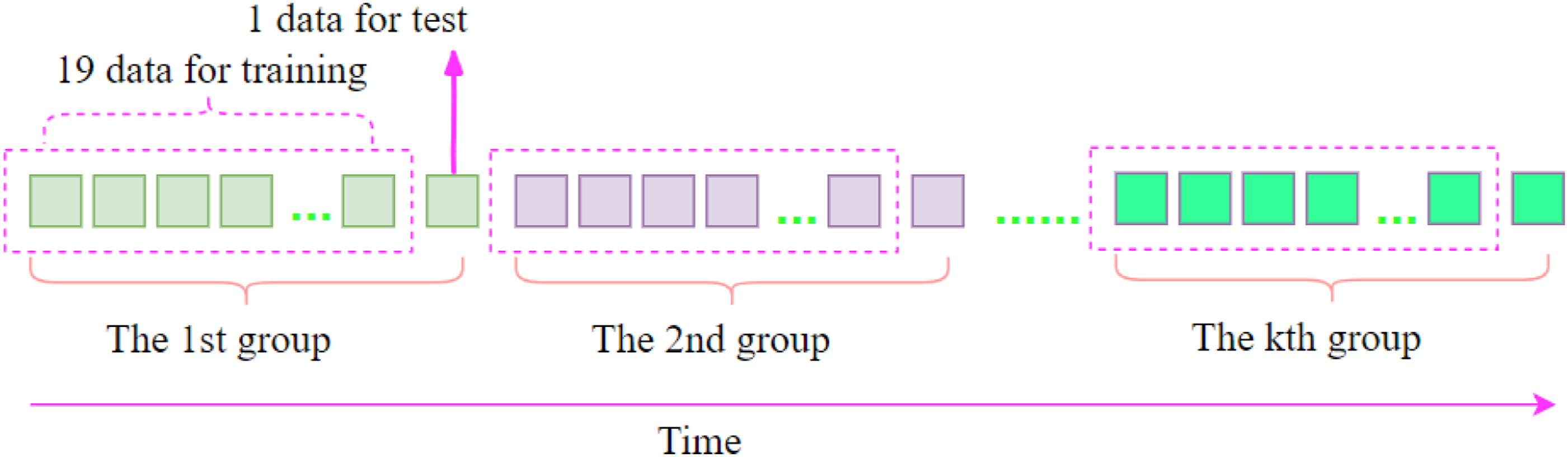
Evaluation index
The following six indicators are used to measure the prediction effect of the proposed prediction model: mean absolute error (MAE), root mean squared error (RMSE), mean absolute percentage error (Mean), absolute percentage error (MAPE), and related indexes (R2),Adjusted_R2. The calculation methods are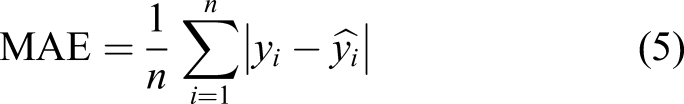
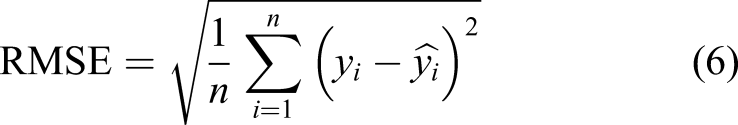
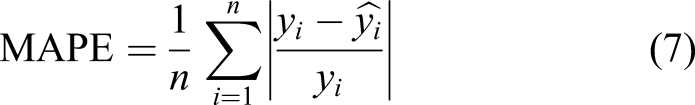
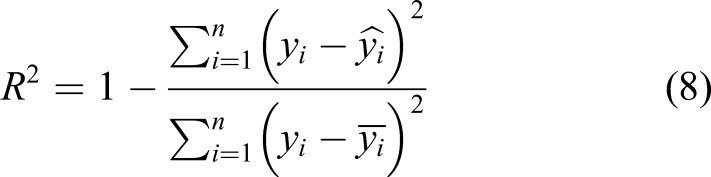
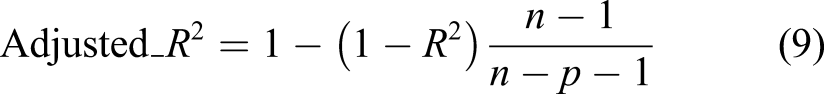
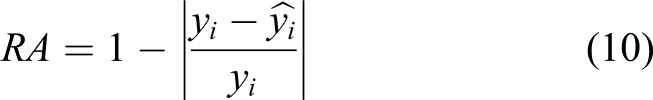
In formulas (5)–(10),
In order to avoid the excessive influence caused by the error caused by the excessive number of data samples, the adjusted R2 is used to estimate the correlation index, where n represents the number of sample data, and p represents the dimension of the data feature. The relative accuracy (RA) definition is used to measure the difference between the predicted value and the true value. The result is between 0 and 1. The closer to one, the better the result.
Experiment
Experimental dataset
Under normal operating conditions, the life of rolling under normal operating conditions, the life of rolling bearings can reach thousands or tens of thousands of hours. However, running such a long time in a laboratory environment obviously does not conform to the actual conditions of the experiment. For the feasibility of the experiment, the accelerated degradation process of the bearing is changed by manual methods. The main method is to increase the speed of the rolling bearing, apply the additional load pressure of the rolling bearing and reduce the use of lubricants. The effectiveness of the method proposed in this paper is verified by using three experimental data sets. 1. FEMTO-ST bearing dataset(IEEE PHM 2012)
PHM bearing test condition information.

The experiment set up three different working conditions, of which the first and second working conditions have seven bearings, and the third working condition has three bearings. A total of the lateral vibration signals and longitudinal vibration signals of these 17 bearings during the entire service life are collected. Here, the horizontal vibration signals are selected for the experiment. The sampling frequency of the data is 25.6k Hz, and the data is recorded every 10 s, the length of each recording is 0.1 s, and the length of data collected each time is 2560.
For example, bearing1_2 has collected 871 times, 2560 data each time, its life span is 871*10 = 8710 s, set the number of rows as the number of collections, and the number of columns as the length of the data collected once.
The original vibration signals of rolling bearings under three different working conditions and the corresponding root mean square values are shown in the Figure 6. It can be seen that under the three working conditions, the degradation degree and degradation process of each bearing are different. 2. IMS dataset Prognostics and health management bearing data information. (a) Raw vibration signal of the prognostics and health management bearing 1_1, 2_1, 3_1. (b) RMS of the prognostics and health management bearing 1_1, 2_1, 3_1.
IMS bearing test bed condition information.

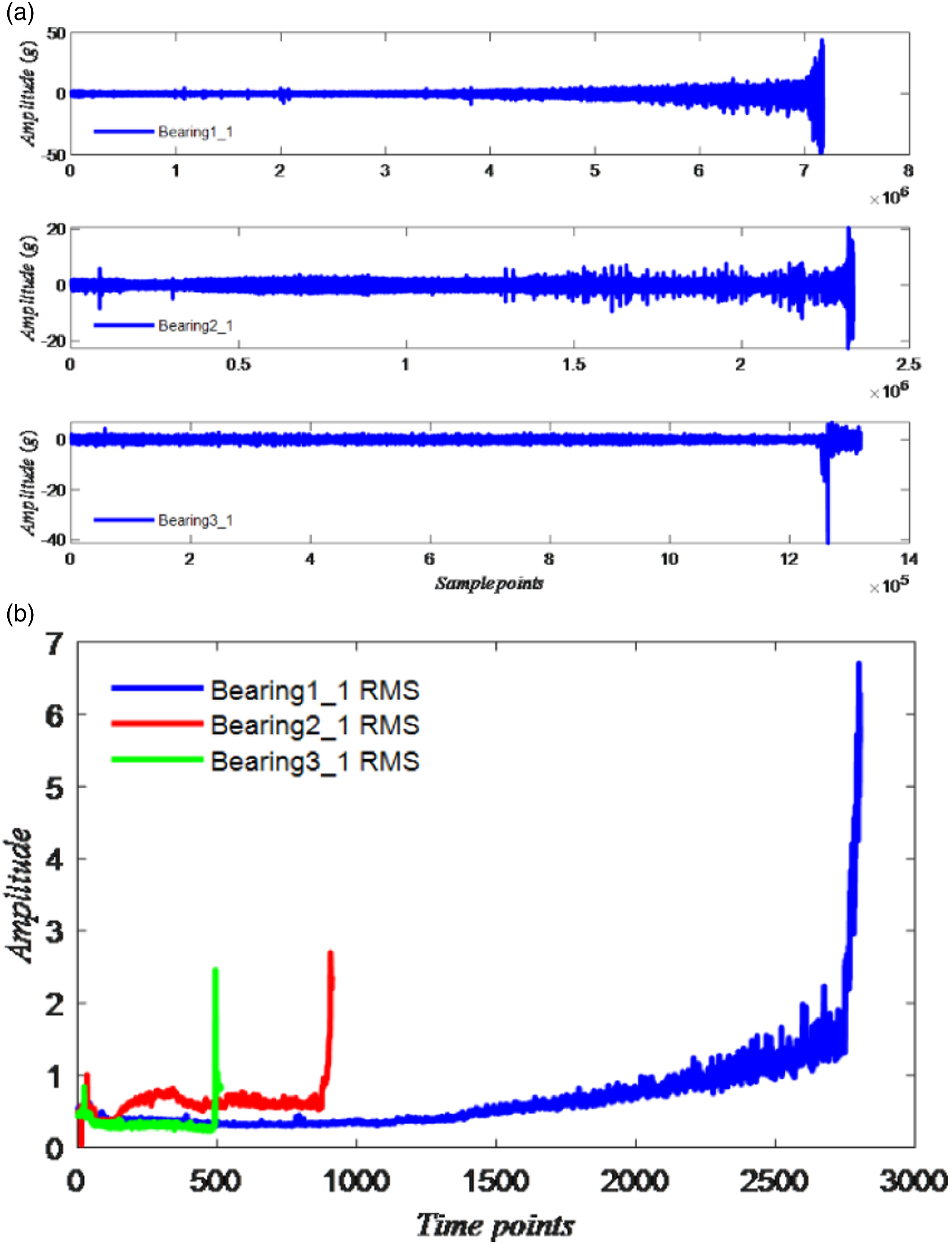
This paper selects the vibration acceleration signals of the four rolling bearings in the second set of experiments in the database as the signal data of the full life of the bearing. Each bearing in the second set of experiments is sampled 984 times, and the data is sampled every 10 min, and the sampling time is 1s each time., The sampling frequency is 20 kHz, so the number of acquisition points each time is 20 480, and the outer ring fault frequency is 236.4 Hz. The original vibration signals of rolling bearings under three different working conditions and the corresponding root mean square values are shown in the Figure 7. 3. XJTU-SY dataset Intelligent Maintenance System bearing data information. (a) Raw vibration signal of the Intelligent Maintenance System bearing 1,2,3,4. (b) RMS of the Intelligent Maintenance System bearing 1,2,3,4.
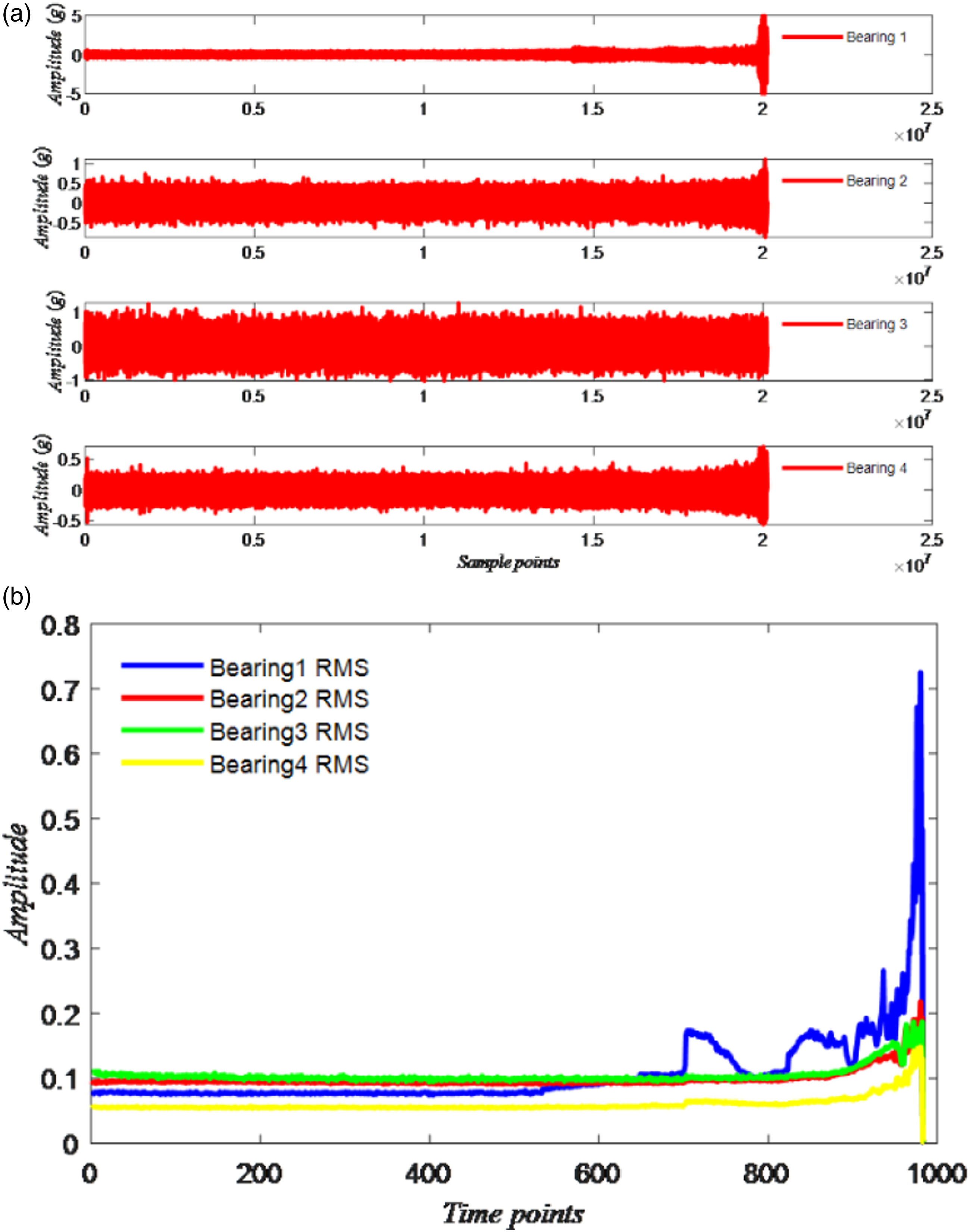
XJTU-SY bearing test bed condition information.

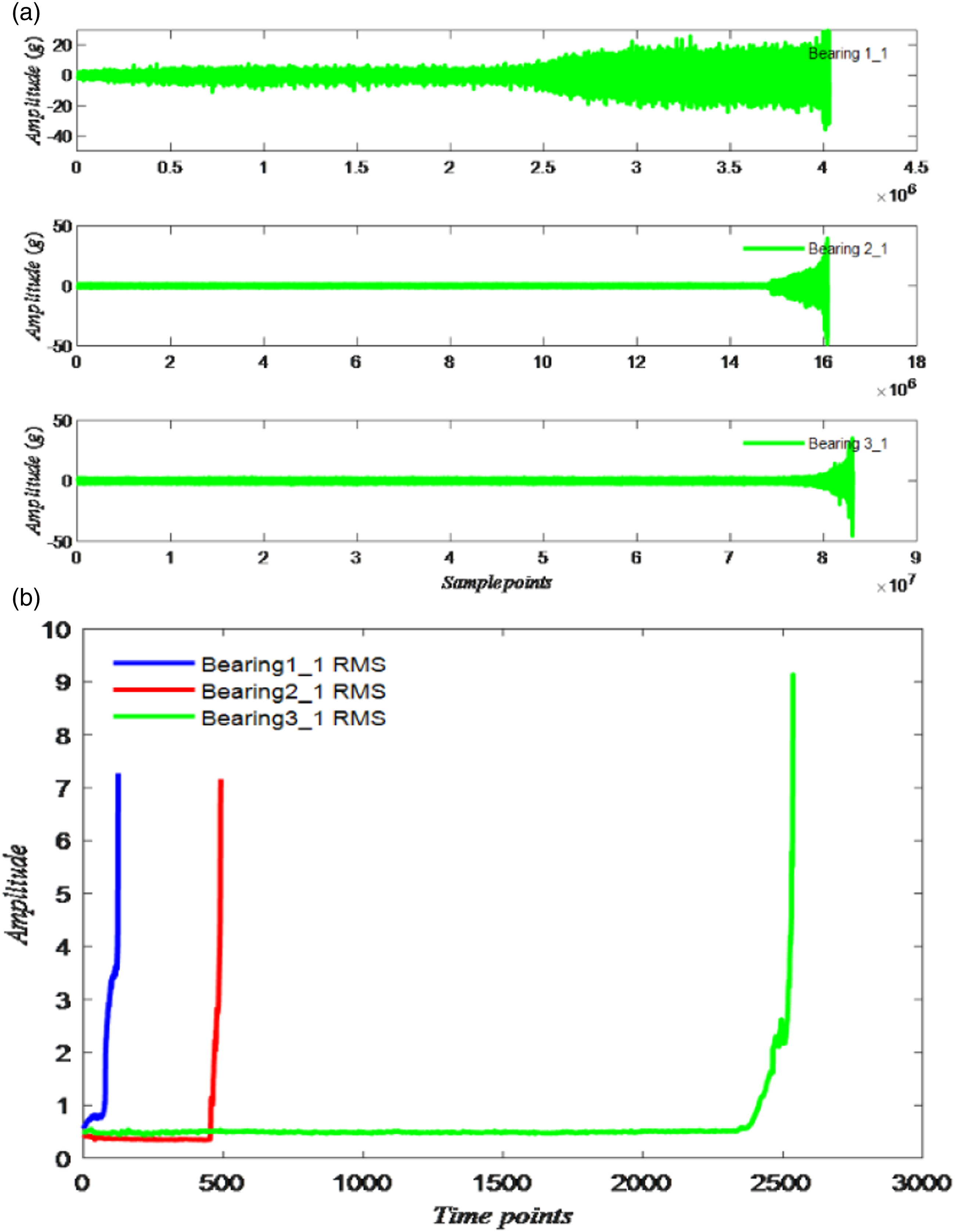
XJTU-SY bearing data information. (a) Raw vibration signal of the XJTU-SY bearing 1_1.2_1.3_1. (b) RMS of the XJTU-SY bearing 1_1.2_1.3_1.
The abscissa of the bearing in the three working conditions of the PHM data set represents the time point of the bearing operation; the interval between each time point is 10 s; the ordinate is the value corresponding to the RMS at different time points. The analysis shows that the degradation trend of each bearing varies with the running time, which indicates that the degradation trend of the four bearings is different. The sampling interval of the IMS data set is 10 min. The sampling interval of the XJTU-SY data set is 1 min. The sensor sampling frequency and sampling time interval of the three experimental data sets are not the same, so that the complex situation in the actual working conditions can be better reflected.
Experiment procedure
A CNN model is constructed to estimate the RUL. The hidden hyperparameters of CNN are robust. This CNN structure has six layers, including two convolutional layers, two maximum pooling layers, and two fully connected layers. The specific structure of the network is shown in Figure 9. The experiment was carried out using Windows 10 system, and the central processing unit (CPU) used the 1.80 GHz i5 processor internal storage to be 8.0 GB, and the real test software was used. The version of MATLAB R2019a was used for the experiment. Structure of convolutional neural network.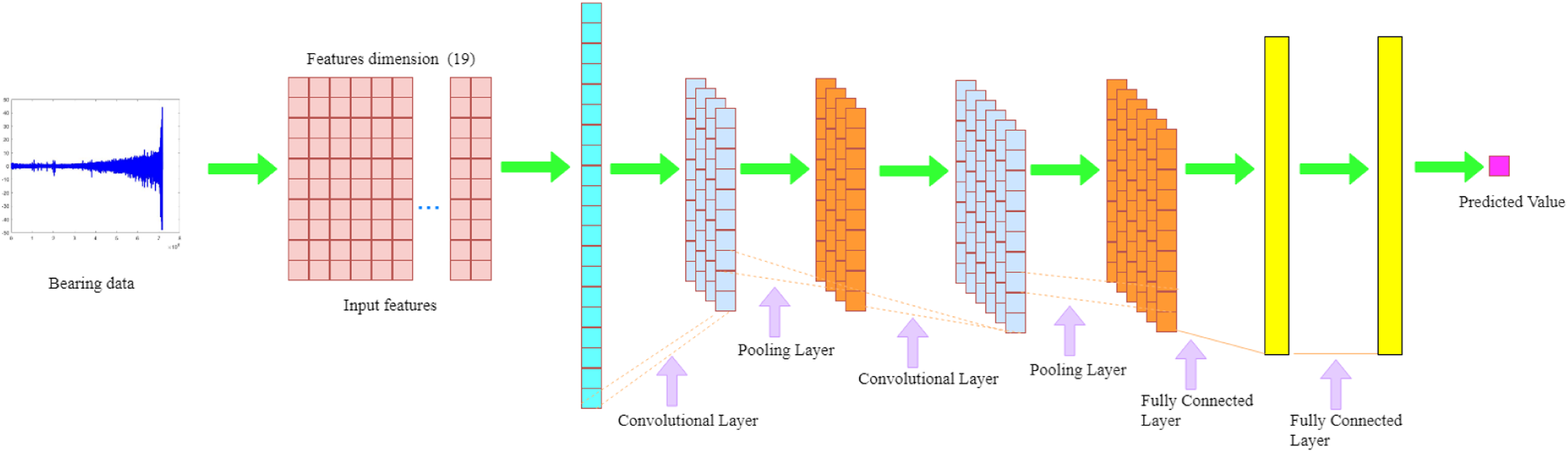
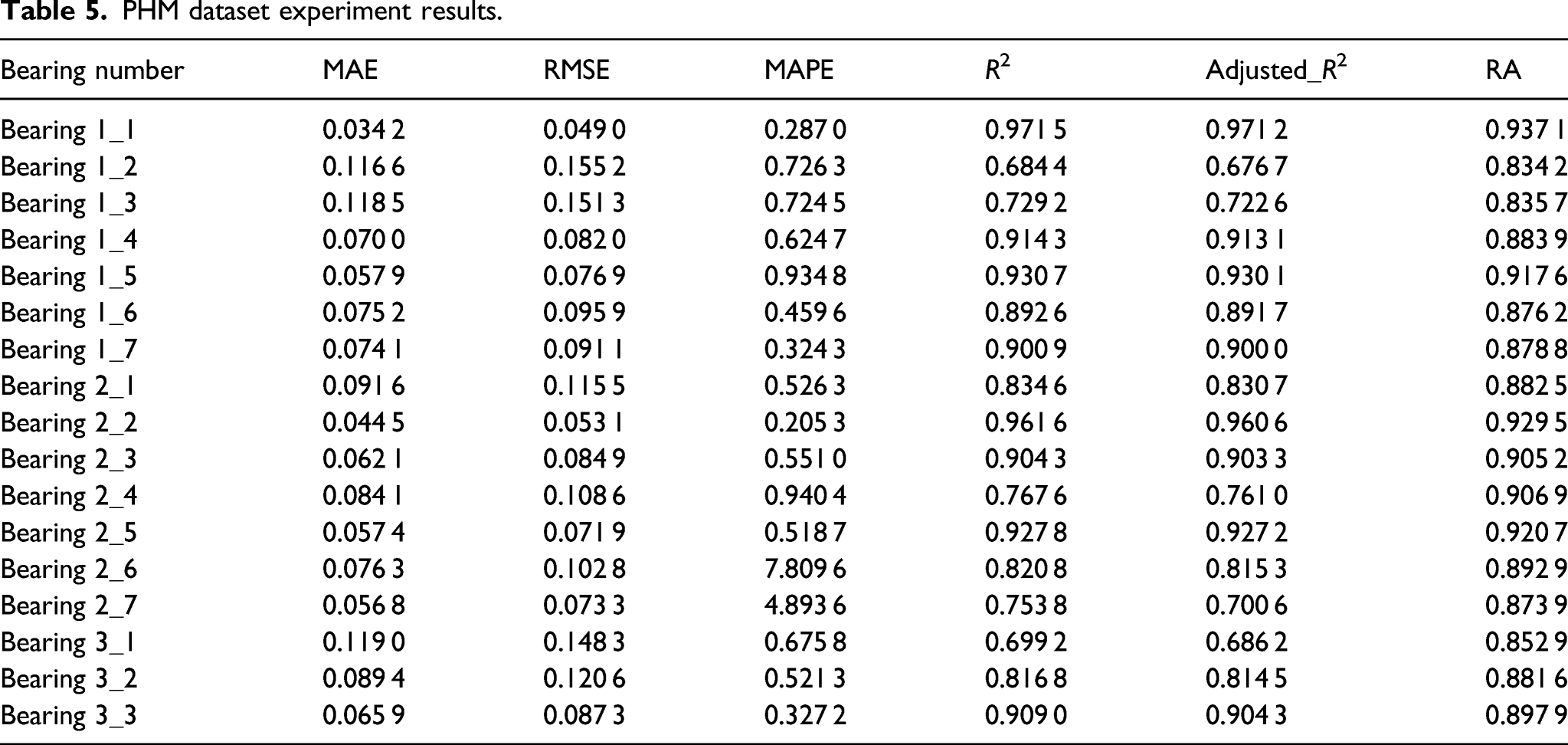
PHM dataset experiment results.
IMS dataset experiment results.

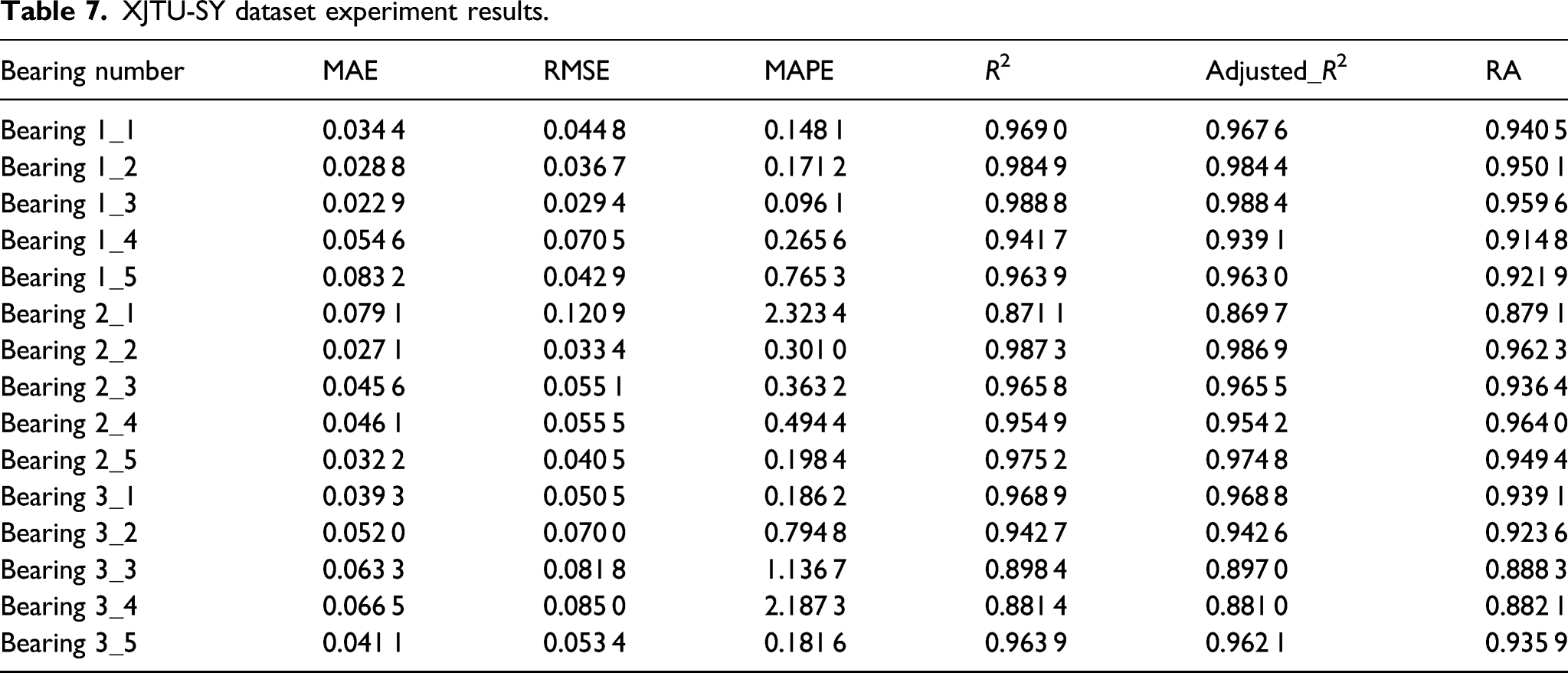
XJTU-SY dataset experiment results.
1. PHM dataset experiment results
For the PHM 2012 data set test, it can be seen that the prediction effect under the three working conditions is still relatively good, and the trend of the remaining life of the bearing can be predicted relatively well. The load of the first working condition is 4 kN, which is relatively low in the comparative experimental load, so the running time of the bearing is relatively long. The corresponding acquisition time is relatively long, and the collected training data is relatively long, so the training effect of the model is better. The load of the second working condition is 4.2 kN. As the load increases, the rotation speed decreases accordingly. The running time of the bearing decreases correspondingly, and the collected data also decreases, but the CNN model after training can still predict it well. The load of the third working condition is 5 kN. In the same period experiment, the load of the third working condition is the largest, the running time of the corresponding bearing is shorter, and the collected data is less. The number of CNN model training samples is greatly reduced, and the error of the corresponding model is also relatively large. However, due to the use of stratified sampling training ideas, the prediction effect of the model is still relatively good, and the RUL of the bearing can still be predicted relatively well (Figure 10 and 11). Prediction results of three types of bearings. (a) prognostics and health management bearing 1_1 predicted result, (b) prognostics and health management bearing 1_3 predicted result (c) Intelligent Maintenance System bearing one predicted result, (d) Intelligent Maintenance System bearing four predicted result, (e) XJTU-SY bearing 1_1 predicted result, (f) XJTU-SY bearing 3_1 predicted result. Comparative evaluation indicators of three types of bearings. (a) prognostics and health management bearing 1_1 comparative evaluation indicators, (b) prognostics and health management bearing 1_3 comparative evaluation indicators, (c) Intelligent Maintenance System bearing 1 comparative evaluation indicators, (d) Intelligent Maintenance System bearing 4 comparative evaluation indicators, (e) XJTU-SY bearing 1_1 comparative evaluation indicators, (f) XJTU-SY bearing 3_1 comparative evaluation indicators. 2. IMS dataset experiment results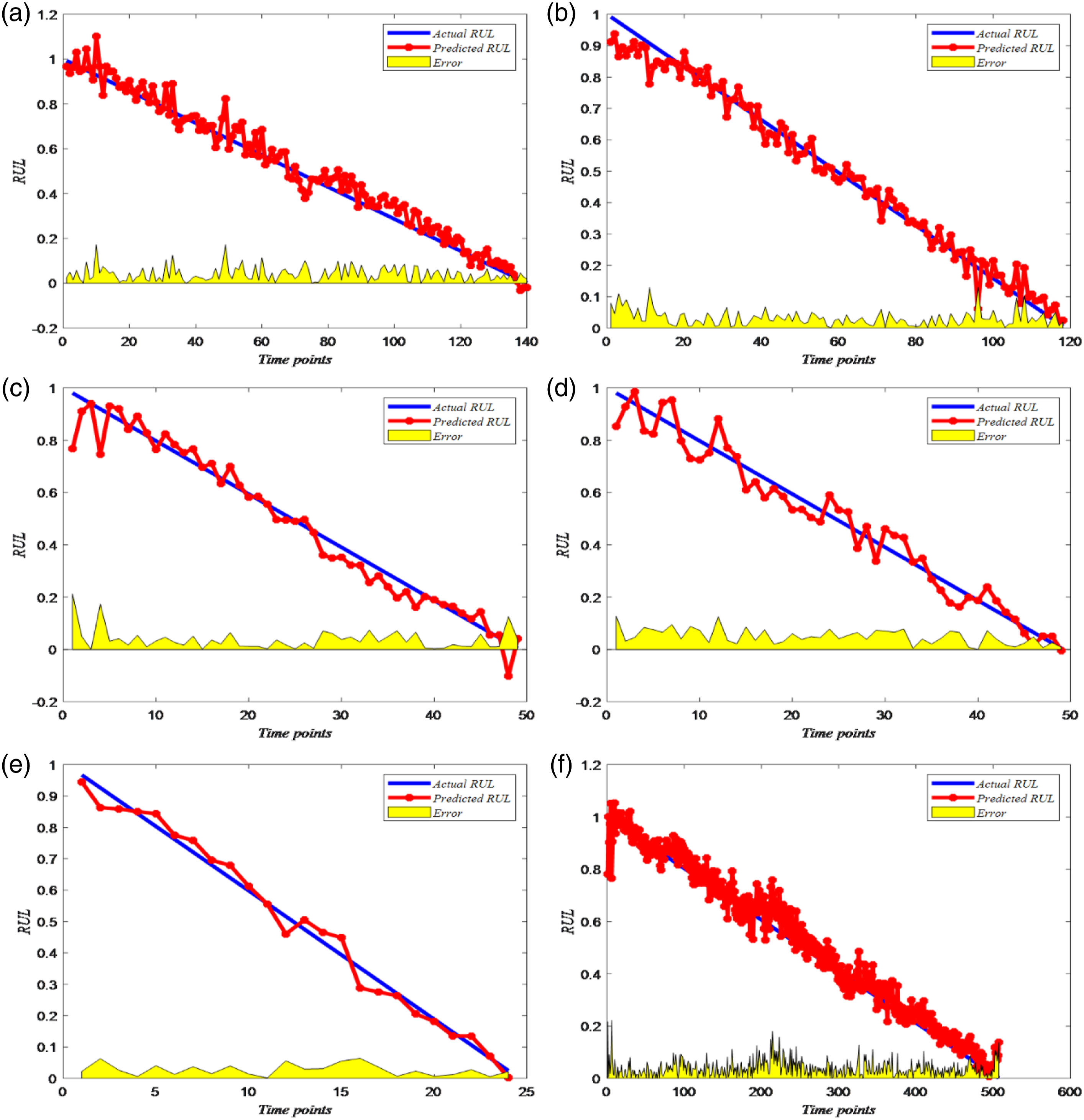
For the IMS dataset, the vibration acceleration signals of the four rolling bearings in the second set of experiments of the database selected in this paper are used as the signal data of the full life of the bearing. The fault type is manifested as an outer ring fault with a total duration of 164 h. It has a radial load of 26.69 kN and is installed on the same shaft. It maintains a constant speed of 2000 r/min. It can be seen that the test results of the IMS data set show that the effects of bearing 1, bearing 2 and bearing 4 are better. The result of bearing 3 is slightly worse, but the remaining life of the bearing can still be predicted comparatively. 3. XJTU-SY dataset experiment results
For the XJTU-SY dataset, the radial load of the five bearings in working condition one is 12 kN, which is the largest in the same period of experiment, and the corresponding speed is the lowest. Therefore, the running time of the bearing is also relatively short. The data is relatively small, but the prediction effect of our proposed method is still relatively good. The radial load of working condition 2 is 11 kN, and the speed increases as the radial load decreases. Therefore, the amount of collected data is also relatively large, and the prediction results of the model are also relatively good. The radial load of working condition 3 is 10 kN, the maximum speed is 2400 r/min, and the collected data is also the most. Therefore, the trained CNN model is better, and the final prediction result is also better.
Evaluation indicators
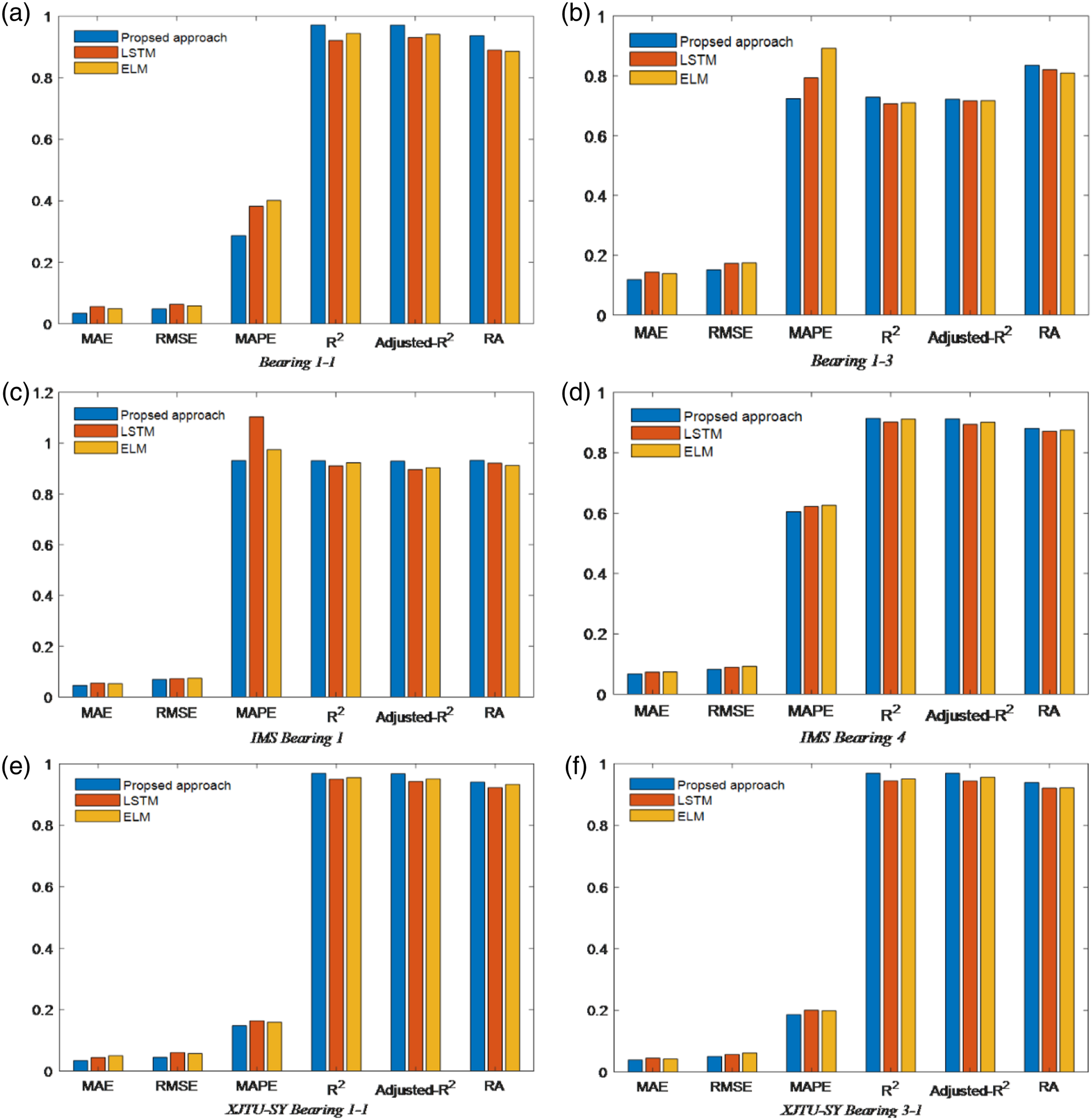
As a comparison, LSTM and ELM are selected for comparative experiments. Among them, the number of nerve cells in each hidden layer of LSTM is 200, and the number of hidden layers is 5. The weights of the ELM input layer and the offset of the hidden layer are randomly selected numbers. The results show that the experimental results in this article are due to the above two methods. Two bearings are selected for each data set for comparison experiment.
In the two datasets selected for PHM, the MAE of Bearing 1_1 is 0.034 2, RMSE is 0.049 0, MAPE is 0.287 0, R2 is 0.971 5, Adjusted_R2 is 0.971 2, and RA is 0.937 1. Among them, MAE, RMSE, and MAPE are all smaller than the prediction effects obtained by ELM and LSTM, and R2, Adjusted_R2, and RA are all higher than the prediction accuracy of the above two models, indicating that the model proposed in this paper is superior to the above two models.
In the two datasets selected for IMS, the MAE of Bearing 1 is 0.046 2, RMSE is 0.069 1, MAPE is 0.931 1, R2 is 0.930 5, Adjusted_R2 is 0.929 0, and RA is 0.931 6. Among them, MAE, RMSE, and MAPE are all smaller than the prediction effects obtained by ELM and LSTM, and R2, Adjusted_R2, and RA are all higher than the prediction accuracy of the above two models.
However, the MAPE of the IMS dataset is generally a little larger, mainly because the sampling frequency of the IMS is relatively high, and the number of sampling data points is relatively large. MAPE is a cumulative sum index, so compared to other datasets, the MAPE result of the IMS dataset is a bit larger.
In the two datasets selected for XJTU-SY, the MAE of Bearing 1_1 is 0.034 4, RMSE is 0.044 8, MAPE is 0.148 1, R2 is 0.969 0, Adjusted_R2 is 0.967 6, and RA is 0.940 5. Among them, MAE, RMSE, and MAPE are all smaller than the prediction effects obtained by ELM and LSTM, and R2, Adjusted_R2, and RA are all higher than the prediction accuracy of the above two models, indicating that the model proposed in our paper is superior to the above two models.
Among the three RUL prediction methods, it is obvious that proposed method has the smallest error and best fitting effect compared with other methods.
Conclusion
In this paper, a new RUL prediction method based on fractal dimension and convolution neural network is proposed. First, this method introduces fractal dimension into the characterization of rolling bearing fault characteristics, and combines time domain, frequency domain, wavelet packet domain and entropy domain to construct multi-dimensional fusion features, which can reveal the degradation state of rolling bearings more comprehensively. Secondly, the percentage of remaining life of the bearing is used as a tracking metric label, and training samples and test samples are divided based on the idea of hierarchical data sampling. Finally, a 6-layer one-dimensional convolutional neural network is constructed to fit the hidden non-linear mapping relationship between the multi-dimensional fusion features and the percentage of remaining life, so as to perform RUL prediction. Experimental verification is carried out on three common full-life rolling bearing data sets. The results show that compared with LSTM and ELM, the prediction effect of rolling bearing remaining life based on fractal dimension and CNN is improved.
In the future, we will consider the remaining life prediction of different types of bearings, and combine the currently popular methods of constructing health indexes(HI) to predict RUL. Moreover, some methods of adaptively extracting and extracting features should also be applicable. Other potential degradation indicators will be attempted to be combined with the CNN model for even higher health prognosis accuracy.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant 61671338 and Grant 51877161.