
Abstract
One of the challenging and important subjects in Data Envelopment Analysis (DEA) is the ranking of Decision Making Units (DMUs). In this paper, a new method for ranking the efficient DMUs is firstly proposed by utilizing the DEA technique and also developing a capable metaheuristic, imperialist competitive algorithm, derived from social, political, and cultural phenomena. Efficient DMUs are known as colonizers, and the virtual units, which are within their regions of exclusive domination, are considered as colonies. Efficient units are ranked by utilizing the factor of competition among imperialists to attract each other’s colonies. One advantage of proposed method is that, without solving any mathematical, and complex solution approaches, all extreme and non-extreme units are ranked only by comparing the pairs.
Introduction
Data Envelopment Analysis (DEA) is considered as a non-parametric technique based on mathematical programming, firstly introduced by Charnes et al. 1 DEA assess and measurer the relative efficiency of some homogeneous Decision Making Units (DMUs) which may have multiple inputs and outputs. In the classical models of DEA such as BCC and CCR,1,2 the level of efficiency of inefficient units is less than one and that of efficient units equals one. This issue creates a problem that is usually the case with most of the above-mentioned models; that is, efficient units cannot be segregated. To solve this problem and to increase the power of segregation among the DMUs, many efforts have been made. For example, one can refer to the two main ranking methods such as AP (Andersen and Petersen) 3 and the Cross-Efficiency Method of Sexton et al. 4
Later, an super-efficient model ranking only efficient units was proposed by Anderson and Peterson. 3 They also removed the evaluated decision-making unit is removed from the set of observed DMUs in their approach. Then, the DEA model is utilized for the rest of the DMUs. The main weaknesses of the approach can be stated as to have Instability and infeasibility in some cases, as well as the failure of ranking non-extreme efficient units, and assessments based on different weights.
Recently, to the best of our knowledge, a variety of methods in this area have been developed by researchers to address these infeasibility problems of the super-efficiency models. A MAJ model was proposed by Mehrabian et al. 5 and received some attentions in the literature later. The proposed model addresses the infeasibility in the basic Andersen and Petersen model. Besides, Jahanshahloo et al. 6 used Monte Carlo method in order to develop a method abling to rank all kind of efficient DMUs.
For further information about more ranking methods, refer to Dehnokhalaji et al., 7 Emrouznejad et al., 8 Jahanshahloo et al., 9 Liang et al. 10 In line with this, there are algorithms of optimization and meta-heuristic which are inspired by nature as well as socio-political issues and have achieved considerable success as “smart or intelligent” optimization methods alongside classical ones (for instance see Ahmadi and Bazzazi, 11 Hajiaghaei-Keshteli and Aminnayeri 12 ). In connection with this algorithm, one can refer to the Imperialist Competitive Algorithm presented by Atashpaz-Gargari and Lucas 13 which stems from social, political, and cultural phenomena. This algorithm has shown its superiority to other optimization algorithms, and has addressed many issues in numerous areas. Apart from these basic contributions, one can mention a variety of recent contributions to the further development of Metaheuristic Algorithms. For instance, see the contributions14,15 and review paper. 16
In this paper, the efficient units that are aimed to be ranked are considered as imperialists or colonialists. An efficient unit is a unit which is not conquered by any other observed unit; that is, there is no observed unit with less input and more output. To determine the colonies of each imperialist or colonialist, the region of exclusive domination is defined for units, and each virtual unit is considered as a colony for units in this domination area. These points are obtained randomly by utilizing a uniform graph. Competition is run among colonialists with the use of Imperialist Competitive Algorithm, and the colonialist that finally has supremacy and dominance over the colony of all units’ ranks first. The non-convex variable returns to scale model known as FDH Model 17 utilized to compute the power of colonies and imperialists or colonialists. Based on the structure of the FDH model, it can without solving any model leads to the possibility of comparing the power of each imperialist’s colony with that of the colonizer itself.
The main contributions of our paper are as follows: first, In the proposed algorithm, by combing the DEA technique and the Imperialist Competitive Algorithm, 13 a new type of algorithm is rendered to create a new relation among humanities, mathematics, and social sciences. Second, our proposed approach is fast, memory-efficient, and lacks computational complexity since it does not require solving an optimization model. Third, this proposed method is capable of ranking both extreme and non-extreme units. To illustrate the procedure, we have developed two examples. The first example is a numerical one whose details are rendered in the first stage. In the second example, which included real data, the results were analyzed with those of other existing methods.
The rest of the paper is organized as follows. Section 2 presents a review of the Imperialist Competitive Algorithm and introduces our notation and DEA technology and models. Our proposed algorithm for ranking efficient units is rendered in Section 3. In Section 4, our proposed algorithm is applied to a numerical and a practical example, and Section 5 is the conclusion.
A review of the imperialist competitive algorithm and FDH model in DEA
In this section, first we present the imperialist competitive algorithm proposed by Atashpaz-Gargari and Lucas 13 which stems from social, political, and cultural phenomena. This algorithm has shown its superiority to other optimization algorithms, and has addressed many issues in numerous areas. Then we review some DEA notations and introduce the technology and FDH model.
Imperialist competitive algorithm
In short, the imperialist competitive algorithm begins in its first step with several countries. Actually, countries, which are considered as the possible solution to the problem, are divided into two colonizers or imperialists and colonies. Enforcing the policy of absorption in line with various areas of optimization, colonizers attract colonies to themselves. Colonial competition, alongside the policy of homogeneity forms the key aspects of this algorithm. It also leads to the countries to move toward an absolute minimum. In terms of optimization, colonialism led to the exit of some countries from being at the bottom of civilization and moved them to another minimum point, which in some cases, proved to be better than the previous condition of the colony. However, this movement required the colony’s advancement towards a more powerful imperialist in various economic and cultural areas; this means the destruction of some of the cultural and social structures. Figure 1 clearly demonstrates this condition. In this figure, due to the homogeneity policy, the colony exits from a minimum point, and enters another minimum point which enjoys a better condition. However, the cost paid for this change is closeness to the imperialist as far as economic, political, and social features are concerned. The continuation of this movement could lead to the entire colonialization or occupation of the colony by the colonizer or imperialist.
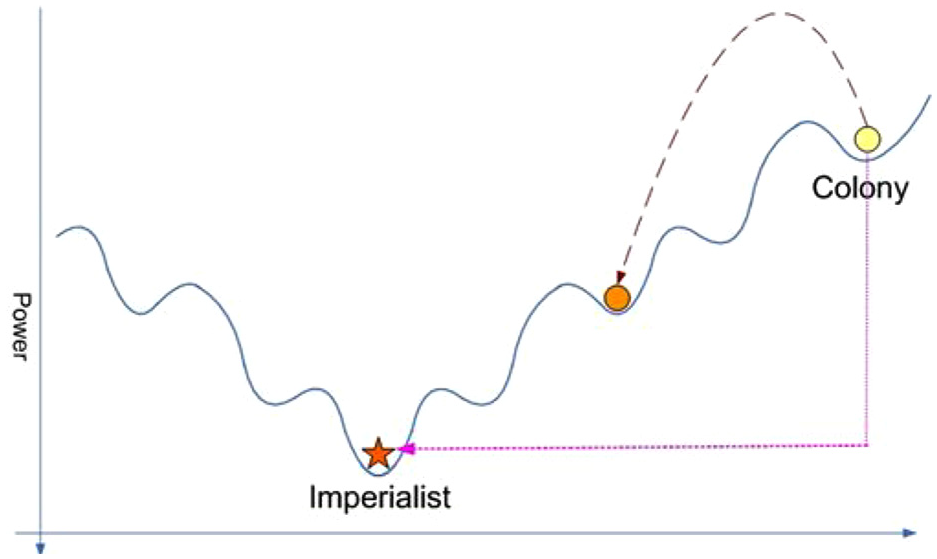
Enforcement of the absorption policy by imperialist on colony.
Here, through the classification of behaviors, finding out their inner order, and finally mathematical modeling of mutual reactions between colonizers and colonies, this complex social phenomenon is organized in the form of a mathematical optimization algorithm. The total power in each empire rests in both emperor and its colonies. In mathematics, this dependence is modeled based on the definition of the imperial power as it equates the power of the emperor adding with a percentage of the average power of its colonies. With the formation of the initial empires, imperialistic rivalry begins among them. Each empire failing to succeed in this competition, will be eliminated from the stage of the colonial competition. Hence, the survival of an empire is subject to its power to attract the colonies of the opponent empires. Consequently, in the course of colonial rivalries, the power of bigger empires shall increase while the weaker ones will be eliminated. To augment their own power, the empires will have to advance their own colonies. With the passage of time, the power of colonies will come close to that of empires, and a kind of convergence shall be observed. The final colonial rivalry ends once there is only one single empire in the world with its colonies.5,13
Molding of initial empires in imperialist competitive algorithm
Generally, in optimization problem, the objective is to find an optimal response according to the variables defined for the problem. So, an array of variables for the problem must be created and optimized. Here, any solution is known as a “country.” A country is an array of 1 ×
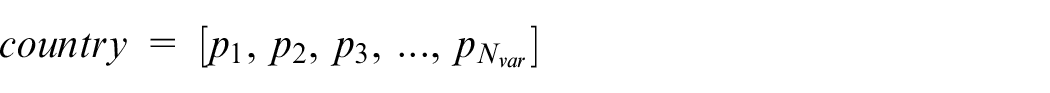
For example, let us assume that we wish to design a PID controller for a control system that has the lowest total sum of the MaxOvershoot and integral of absolute magnitude of the error. In a typical case, possible answers are those that lead to a stable output. For this problem, we create initially a series of possible answers. In this case, Country i will be defined as follows:

To begin with the algorithm, some of these countries (according to the number of the initial countries of the algorithm) should be created. Therefore, the matrix of the entire countries is formed at random.
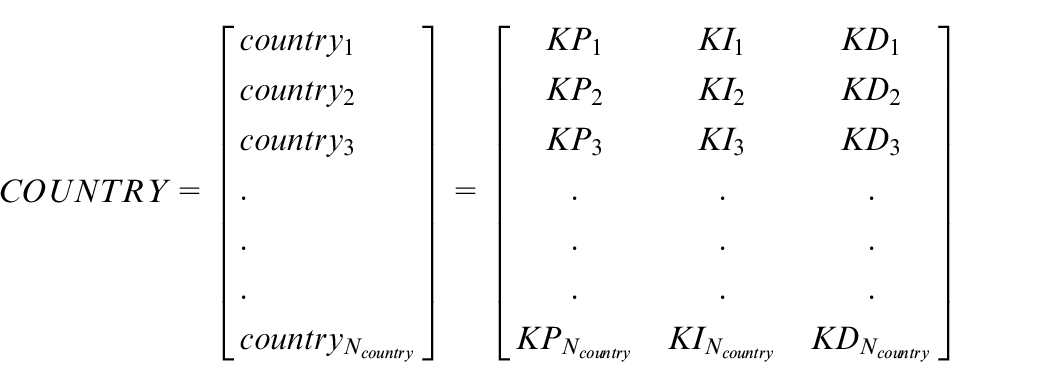
The costs of a country are found in variables
As to the mentioned objective in designing the controller, this function will be as follows:
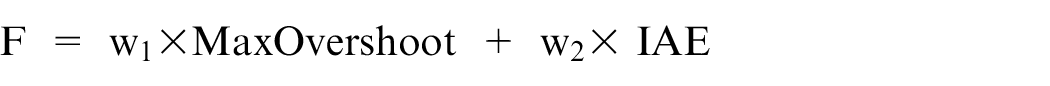
In which, the MaxOvershoot is the maximum total sum, and the IAE is the integral of absolute magnitude of the error.
To begin with the algorithm, we shall create a number of initial

In which,
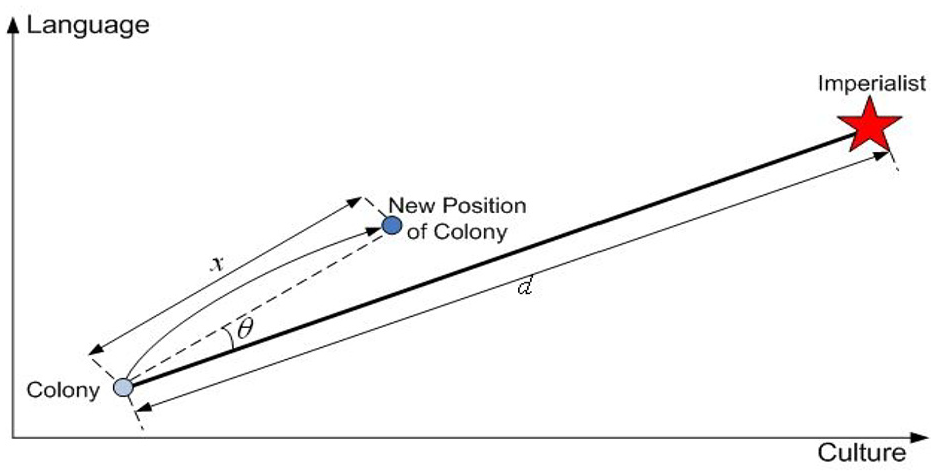
Actual movement of colonies towards colonizers.
The existence of the coefficient
In this regard,
If in the course of the move, a colony reaches a better position in relation to colonizer; their positions will be switched with each other. In addition, the total power will be defined for an empire according to the total power of the imperialist and a percentage of the colonies’ average power. Therefore, the total cost of an empire is as follows:
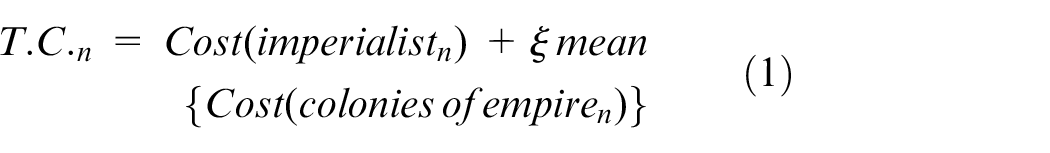
In which
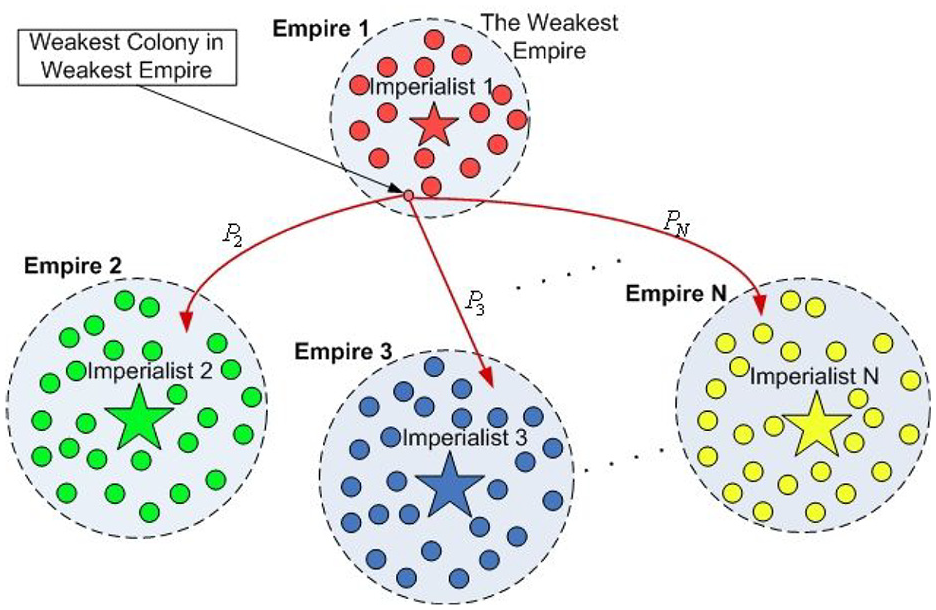
A general view of imperialist competition: Larger empires with a higher degree of probability seize the colonies of other empires.
In this figure, Empire No. (1) is considered as the weakest empire, while empires (2) to (N) compete with each other to seize it. For modeling rivalry among empires to confiscate this colony, at first, the possibility of each empire’s seizure of colony (according to its power) is calculated as follows, taking into account the total cost of the empire. Firstly, the total normalized cost of an empire is calculated from its total cost:
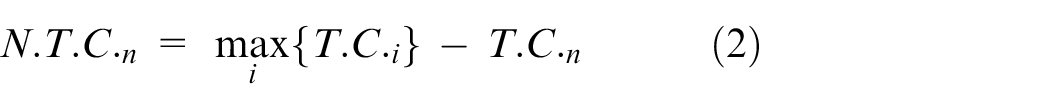

As to any empire’s possibility of seizure, a mechanism is needed to give in the disputed colony to one of the empires based on their possible power. Here, a new mechanism is introduced to implement this process. This mechanism has an extremely lower calculated cost in comparison with other mechanisms such as the roulette wheel in the genetic algorithm since the relatively numerous calculation operations eliminate the collective distribution of possibility function, and requires only the possibility density function. The proposed mechanism proposed by Atashpaz-Gargari and Lucas 13 will be described in the following to give in the disputed colony to the rival empires based on probability.
To divide the colonies among empires randomly according to each empire’s probability of seizure, we form
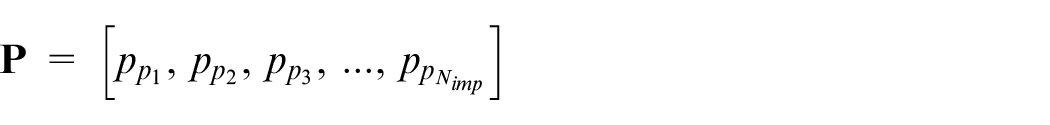
The vector is of a 1 × Nimp size and is formed from the amount of empire’s probable seizure. Then, the random vector
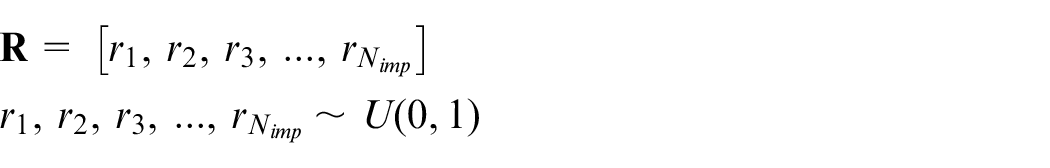
Then, vector
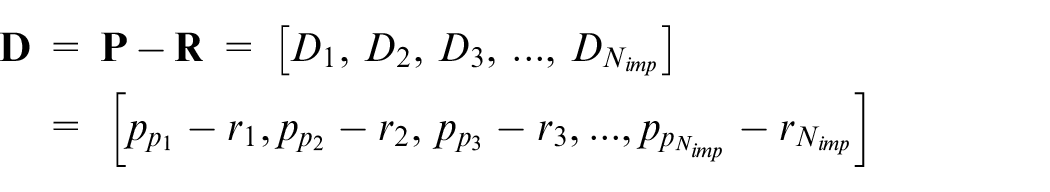
Having vector
Non-convex FDH model in DEA
Let we have
All through this contribution, technology T holds in the following standard axioms:
The observed activities
Strong Disposability, i.e., if
Thechnology T is a convex set.
Further interpretation of these widely adopted axioms are available in, for instance. 9 These assumptions are almost universal. While axiom (iii) is also widespread, we do not always maintain it in this contribution. In the proposed approach, we assume that the production technology is a non-convex and variable returns to scale technology. Therefore, we only consider axioms (i) and (ii).
Let we have K observations
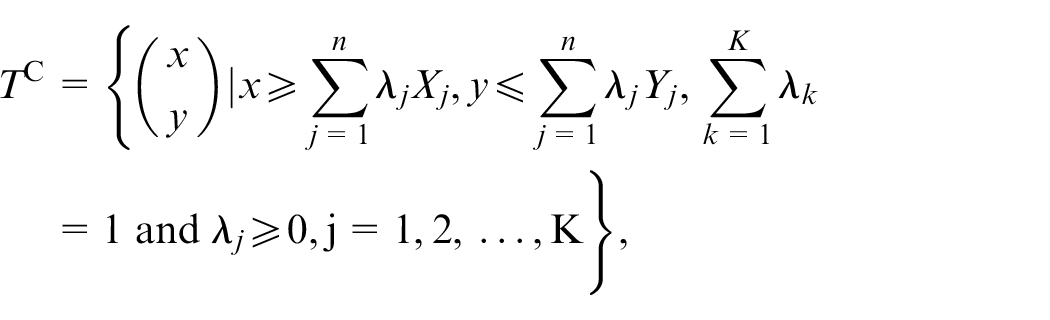
and
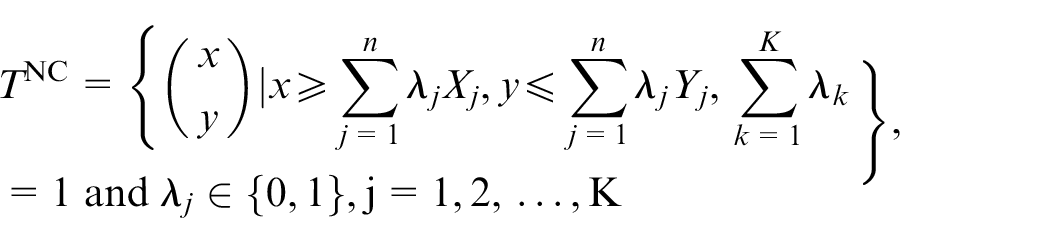
The activity vector
The input-oriented radial technical efficiency model with variable return to scale under non-convex asumption requires the optimization of the following program (see Deprins et al. 17 for more details):
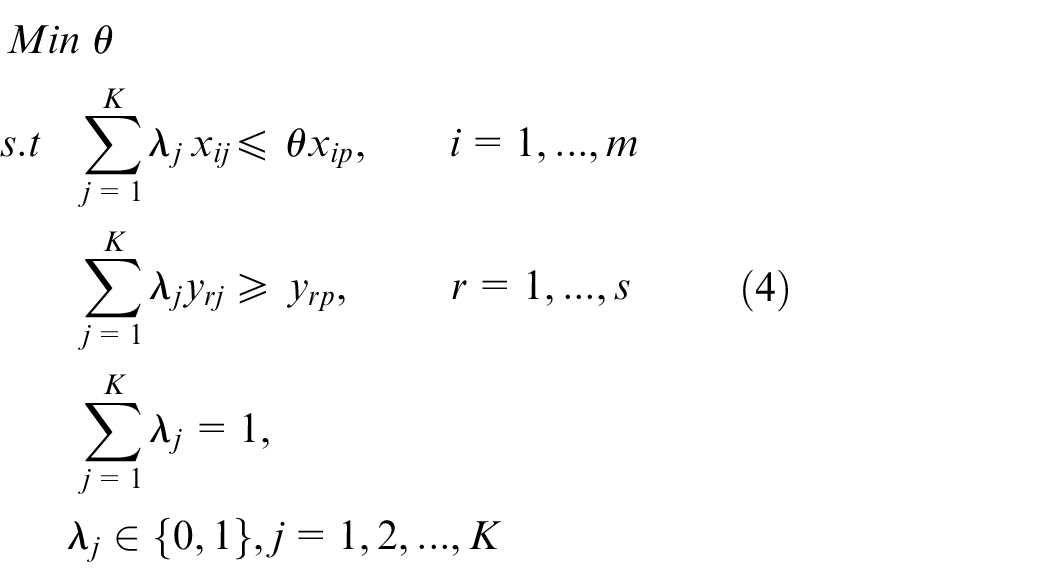
The input-oriented efficiency measure which obtains by solving model (4) is a positive number and smaller or equal to unity
In order to calculate the power of imperialists and colonies in our proposed method, we apply the input-oriented FDH model (4). Note that the FDH model (4) is a binary linear model but we can consider the following equivalent steps to obtain the optimum value of objective function of model (4) without solving any models. First, we consider the following model.
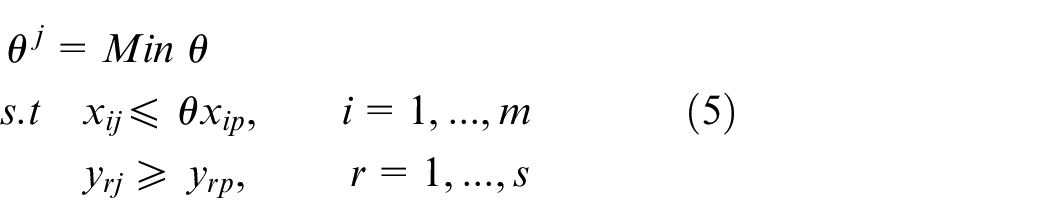
note that model (5) is infeasible for some units.
If
Now, let us assume that

Therefore,
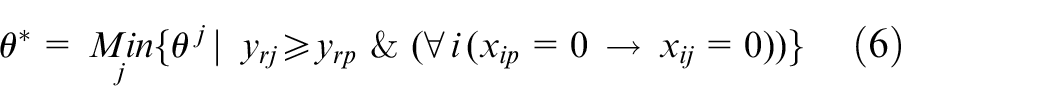
The efficiency value which obtained from equation (6) is always between 0 and 1. If this value is 1, then the evaluated unit is efficient, otherwise the evaluated unit is inefficient. The value obtained from the relation (6) can be considered as the strength of that unit in the imperialist competitive algorithm. The main advantages of this approach is that the model need not to be solved, and the efficient and inefficient points are specified by a simple mathematical calculation. Hence, instead of solving mixed integer model (4), the equation (6) can be solved separately for each unit, and then the efficiency measure of units are obtained.
Ranking DMUs based on the imperialist competitive algorithm
In order to determine the initial empires, since efficient units have higher efficiency score compared with inefficient units, they are chosen as initial empires in the proposed algorithm. We consider the virtual DMUs which are within each unit’s region of domination as the colonies of each efficient unit.
Since the number of virtual units in the domination region of efficient units is unlimited, it is difficult and impossible to obtain all of them. Therefore, we select randomly a finite number of units with an uniformly distribution as the units’ colonies.
Let us assume that
An ideal unit

Also, the counter-ideal unit
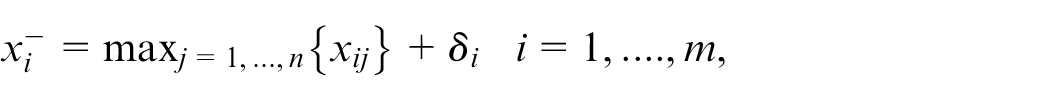
where
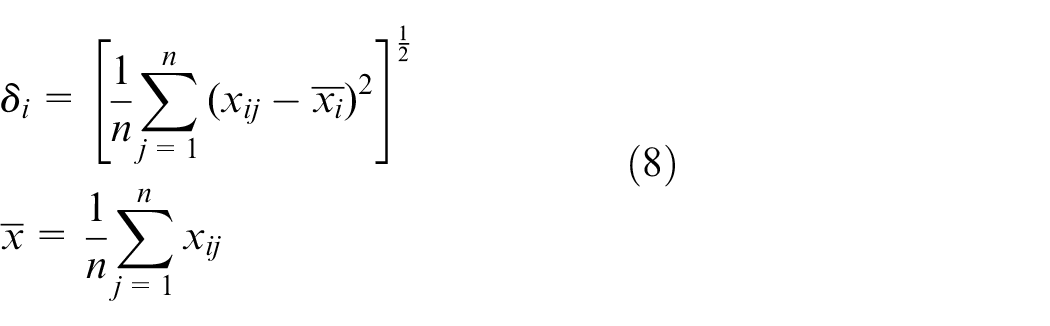
Regarding how to obtain the points
Let us assume that N is a set of vectors that is produced randomly with an uniformly distribution, and

where
In addition, the probability of each empire’s power of seizure to take over the colony of the weakest empire is measured as follows:

Let us assume that
It is important to note that the proposed approach is fast, memory-efficient, and lacks computational complexity since it does not require solving an optimization model. The proposed algorithm was applied using C++on a regular laptop, C++codes available upon request.
First, using a simple numerical example and then a practical or empirical example, we shall demonstrate the results of the algorithm.
Illustrate examples
In this section, a numerical and empirical examples are presented to show our results of the proposed algorithm.
Numerical example
To illustrate our method, consider the example shown in Figure 4. We have 6 DMUs
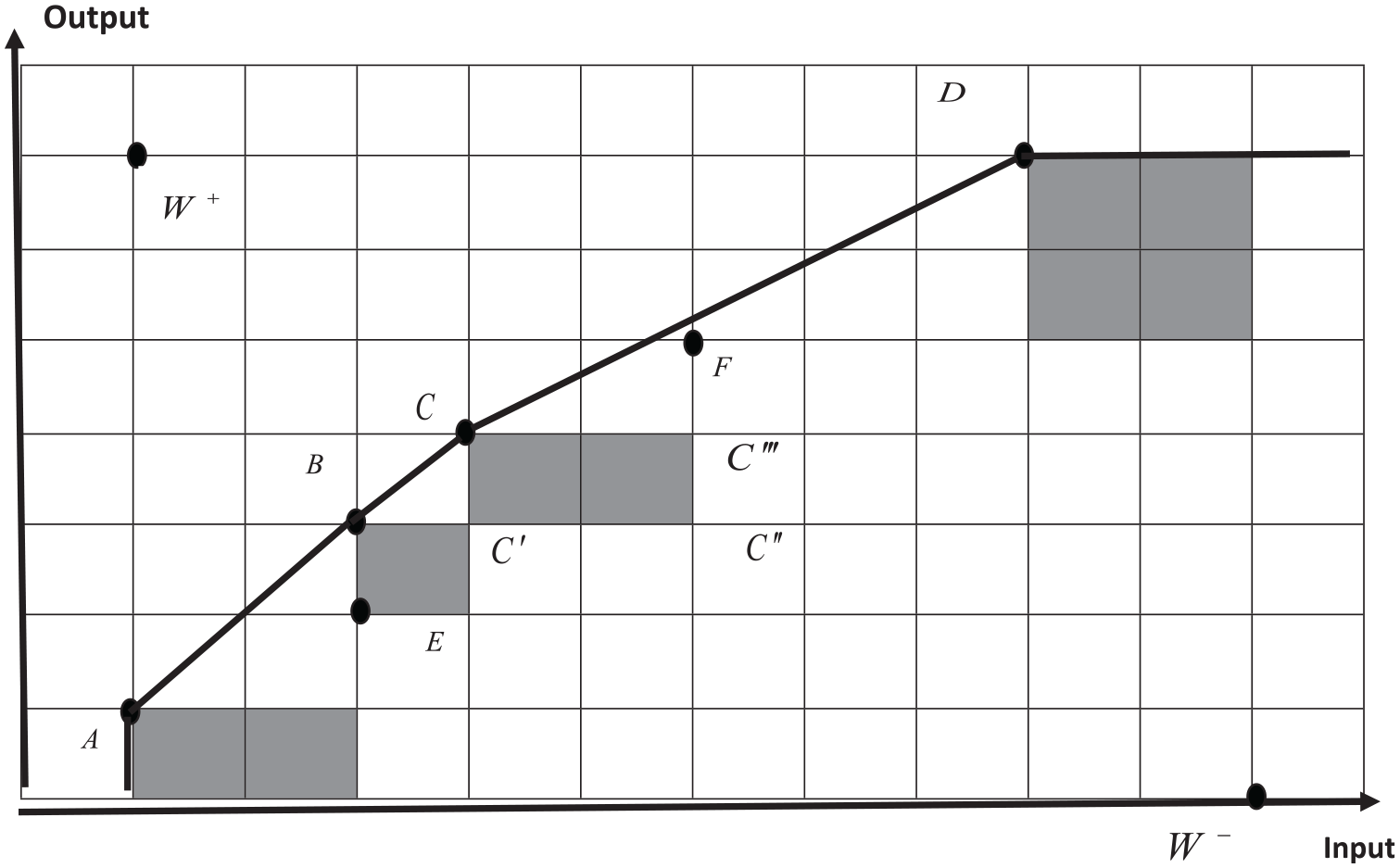
An illustrative example.
In this example, a brief explanation of the results obtained in the first phase of the algorithm is provided.
Step 1: The formation of empires and their colonies
As can be seen in Figure 4, units
The ideal positive and negative points are obtained respectively as such:
To determine the colonies of each empire, a number of
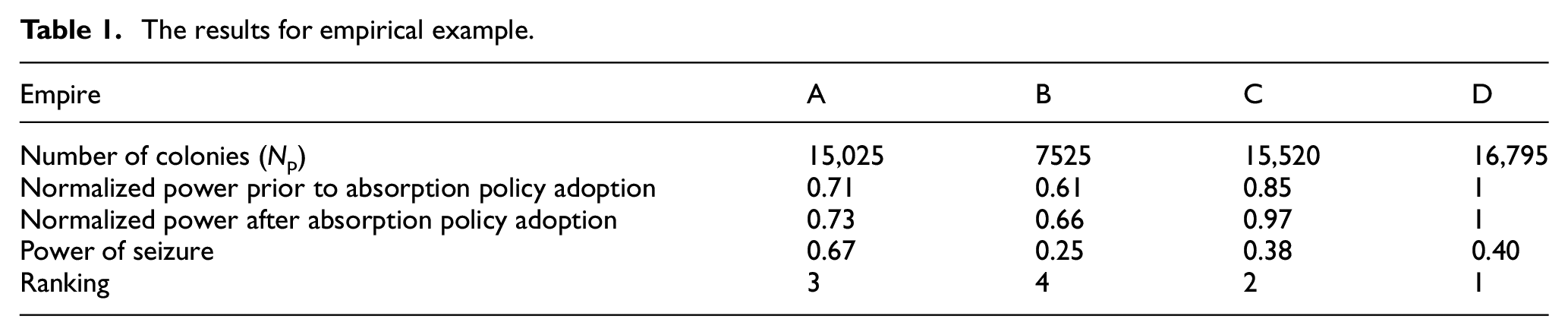
The results for empirical example.
Step 2: Adoption of absorption policy
The power of each empire will undergo changes following the adoption of the absorption policy. The fourth row of Table 1 gives an example of the obtained results from this policy. As it is shown, the normalized power of all units, except for unit
Step 3: Determining an empire with the maximum seizure power
In this phase, the confiscation power of each empire is specified. The fifth row of Table 1 shows each empire’s power to absorb the weak colony. As it is shown, empire A has the maximum power of absorbing the weakest colony of empire B. Hence, this weak colony leaves the domination area of unit B, and is added to unit A.
To save time and space, the details of other phases are ignored. After the complete implementation of algorithm, our results of ranking are illustrated in the last row of Table 1. Unit D has the highest ranking compared with other units. It should be mentioned that it is not necessary that any unit with more colonies rank the highest. Although it is the case in this example, but, generally speaking, it is not true since given the competition among imperialists, it could be possible that the unit with more colonies is defeated and attains a lower ranking. In addition, the inefficient units of
Empirical example
In order to test the proposed algorithm practically, we use the data set of 19 DMUs including two inputs and two outputs, are taken from the paper of Jahanshahloo et al. 6 The information of inputs and outputs are reported in Table 2.
The information of input and output date for empirical example.
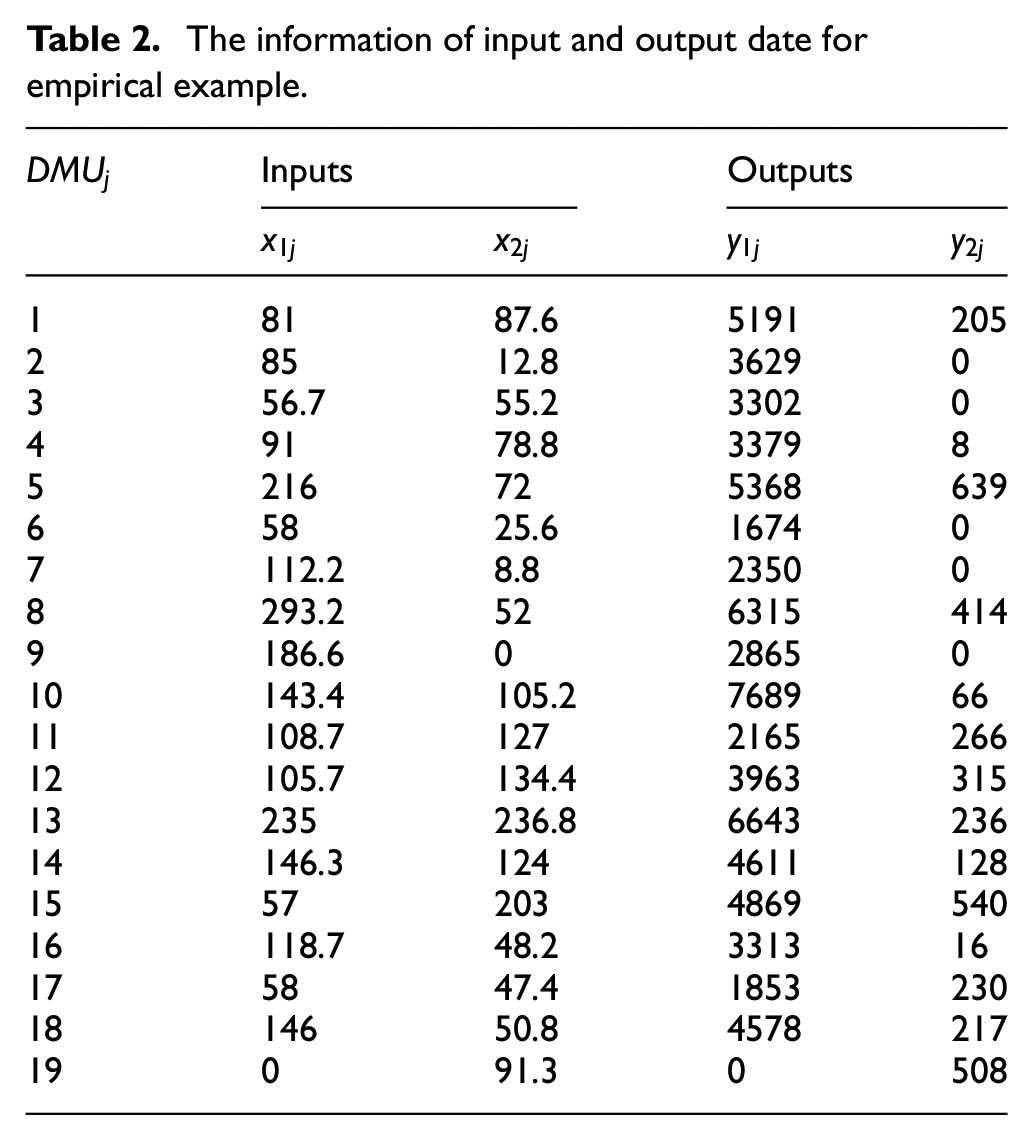
After the implementation of the mentioned algorithm, the results are presented in the Table 3.
The results for empirical example.
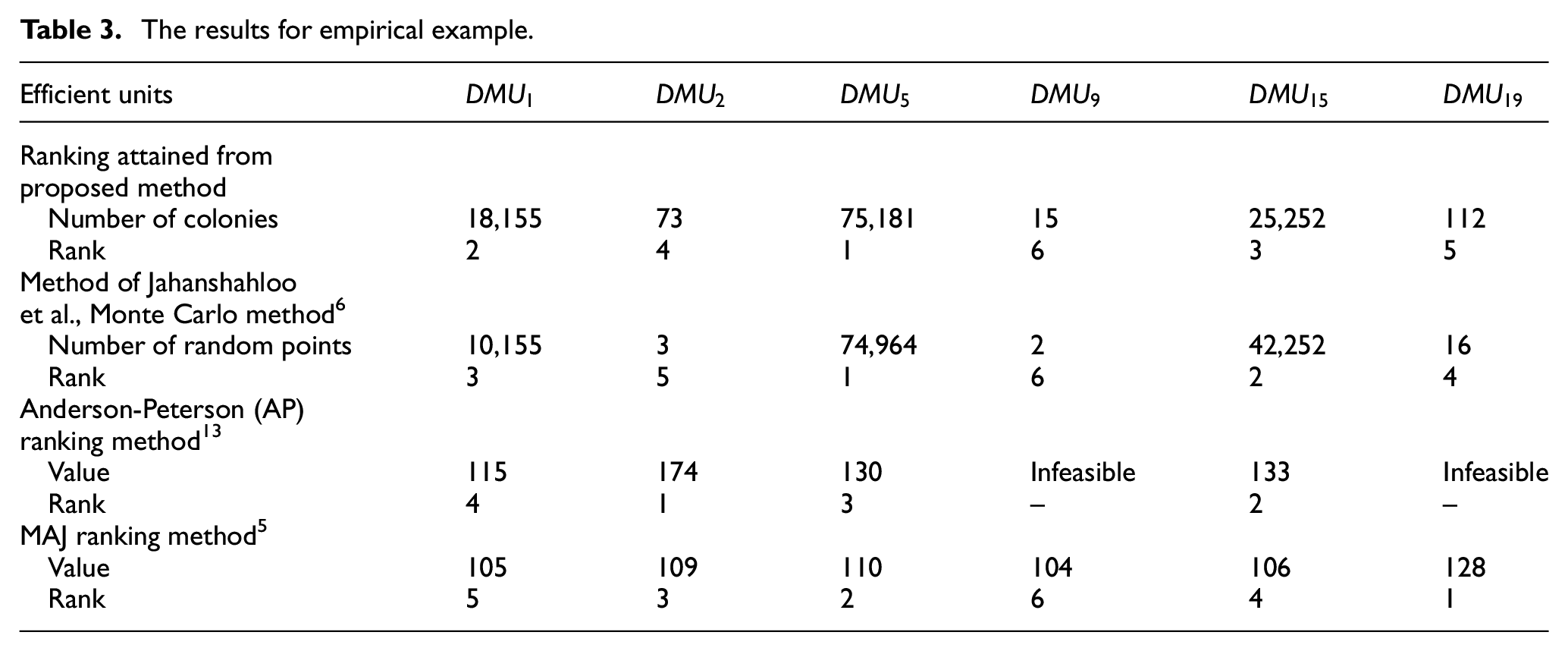
The above Table 3 presents the obtained our results and those from methods such as Monte Carlo, 6 Anderson-Peterson, 3 Mehrabian et al. 5 which is recognized as MAJ Method.
As it is seen in this table about the proposed method, the 15th unit has more colonies compared with the first unit, but they are ranked vice versa; that is, the first unit stands at a higher ranking than the 15th unit. This result shows that in the rivalry of absorbing colonies, the first unit has acted stronger than the 15th unit. In this method, if the units were ranked according to the number of each unit’s colonies, the obtained results from Monte Carlo Method 6 would be the same because ranking is performed deponds on the number of points that randomly lie within each unit’s intended area. However, in the proposed method by utilizing the ICA Method, competition is created among units; this rivalry leads to the confiscation of some units’ colonies by another unit. For this reason, the ranking results obtained from this method are different from those attained from Monte Carlo Method. 6 Compared with Anderson-Peterson 3 and MAJ ranking Methods, 5 the results achieved from the proposed method and those of Monte Carlo Method 6 are closer to each other. This is due to the fact that the main idea of ranking presented in this paper differs. In MAJ and AP Methods, by eliminating the evaluation aspect, ranking of DMUs is performed based on the observations and determining the efficiency scores for these units. But in the other two methods, as mentioned, this is not the case.
Conclusion
As aforementioned, in this paper we developed an algorithm with a novel method in terms of optimization in the research area in order to create a new relation among humanities, mathematics, and social sciences. The connection among these three aspects is in such a way that mathematics, as an accurate and powerful tool, is usually at the service of humanities, and helps to understand, and analyze its results better. On the contrary, the developed algorithm makes the strong point of humanities and social sciences, that is, their generality and wide-ranging outlook, at the service of mathematics, and utilizes it as an instrument for better understanding mathematics and solving mathematical problems. Therefore, even without taking into account the mathematical and practical capabilities of the developed method, the created link among these three apparent and separate branches has great value as an interdisciplinary research.
In this paper, to rank the DMUs a new approach is proposed. In the mentioned algorithm, by combing the DEA technique and the Imperialist Competitive Algorithm, 13 a new type of algorithm is rendered; this algorithm ranks all DMUs without solving the mathematical models only by comparing the data. In addition, this proposed method is capable of ranking both extreme and non-extreme units. to illustrate the procedure, we have developed two examples. The first example is a numerical one whose details are rendered in the first stage. In the second example, which included real data, the results were analyzed with those of other existing methods. Considering the characteristics of the algorithm, its results were acceptable, and created a new horizon for improving ranking methods.
Concerning this, there are some proposition for further investigations: In this article, the FDH model the case of variable return to scale with meta-heuristic imperialist competitive algorithm has been used. However, it is also possible to consider other models in DEA with constant and variable return to scale efficiency, like CCR, and BCC models, with the same meta-heuristic imperialist competitive algorithm and compare them. Other meta-heuristic like Keshtel meta-heuristic algorithm 12 which is a newfangled algorithm with different models in DEA, could as well be used to measure decision making units.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.