
Abstract
This paper presents an efficient OCR system for the recognition of offline Pashto isolated characters. The lack of an appropriate dataset makes it challenging to match against a reference and perform recognition. This research work addresses this problem by developing a medium-size database that comprises 4488 samples of handwritten Pashto character; that can be further used for experimental purposes. In the proposed OCR system the recognition task is performed using convolution neural network. The performance analysis of the proposed OCR system is validated by comparing its results with artificial neural network and support vector machine based on zoning feature extraction technique. The results of the proposed experiments shows an accuracy of 56% for the support vector machine, 78% for artificial neural network, and 80.7% for the proposed OCR system. The high recognition rate shows that the OCR system based on convolution neural network performs best among the used techniques.
Keywords
Introduction
Handwriting refers to the writing accomplished by using pen or pencil. It differs radically from one person to another, and can may even be varies for a given individual depending on the mood and condition in which he/she is writing. Drastic differences in the handwriting of boys and girls can be observed at the stages as early as seven years. Unlike printed characters, handwritten characters are varying based on their curves or edges which make it vague by nature. Furthermore, different people have different styles of writing and a different size of characters as well. In the case of Pashto handwriting, the task of recognition becomes more complex as compared to the languages; including Arabic and English. Pashto is an important language in the Asian region as it is the official way of communication in Afghanistan as well as the major language spoken in Pakistan (northern areas i-e. Khyber Pakhtunkhwa). 1 Approximately, 40 to 60 million people are the native speaker of the Pashto language. 1 However, compared to the English and Arabic, the ratio of contribution regarding automatic recognition of the Pashto text is much low. However, significant contributions are added and efforts are made by experts from around the world. 2
For the Arabic language, researchers exploited the Optical Character Recognition (OCR) systems based on character’s features such as its statistical measures, structure and morphological attributes. In the case of the Urdu language, OCR is exploited by including the water reservoir, topological and contour features. 3 Furthermore, Kopparapu et al. 4 suggested the application of machine learning techniques for recognition of handwritten Devnagari letters by using a neural classifier that uses chain line histogram, intersection, shadow, and straight-line fitting features. The fuzzy approach is adopted for the recognition of Arabic handwritten letters by using preprocessing techniques such as extracting contour, thinning and connected components detection. Pseudo-Zernike moments are used for the extraction of the features in their case. Classification in their approach is achieved using the Fuzzy ARTMAP neural network which is proved to be efficient as well as have support for incremental learning. Several machine learning approaches are adopted in the domain based on deep and shallow architectures. Ahmad et al. 5 and Khan et al. 1 proposed K-Nearest Neighbor (KNN) for the recognition of printed cursive scripts. Scale, rotation, and location invariant method are proposed by Ahmad et al. 6 for the recognition of printed Pashto script. Experts show a greater interest in enhancing the efficiency of existing recognition algorithms to provide more intelligent solutions to perform the recognition task.
From the literature cited, it is concluded that there is no significant work reported for the automatic recognition of the Pashto language. The curvy nature of the Pashto language and the inherent variations pose significant challenges for designing and developing an automated recognition system. Furthermore, previous work reported for the Pashto language is limited to the automated recognition of the printed characters only and not for the hand-written text and automatic recognition of handwritten text effectively remains unaddressed. This paper presents a decent size dataset (first of its kind) and an efficient, cost-effective and intelligent recognition framework. The contributions of this work are summarized below:
A database of handwritten characters of Pashto language. The dataset will be made available for research purposes, free of cost.
A benchmark on automatic recognition of handwritten characters of Pashto language. The reported results will provide a good baseline for future research work on Pashto text processing.
The performance of three models namely: SVM, ANN, and CNN are reported for the recognition of handwritten Pashto characters. In this way, we present an insight into the performances of traditional machine learning approaches and deep learning approaches for the targeted language.
The rest of the paper is organized as follows; Section 2 discusses the related work. Section 3 presents the primary information regarding the algorithms used for the classification in the proposed research work. Methodology for the proposed research work is discussed in Section 4. Section 5 shows the experimental setup made for conducting the research and presents the results obtained. Finally, the concluding remarks are given in Section 6.
Related work
Several diverse approaches are available for text recognition systems. For the recognition of Persian/Arabic handwritten digits, Salimi and Geviki 7 used singular value decomposition for feature extraction purposes and for the classification they have used KNN classification tool. Another approach exploited the support vector machine classification algorithm for the recognition of handwritten Arabic letters in combination to Orthogonal Fourier-Millen movements, T Chebyshey and Gegenbauer methods. Multiple preprocessing techniques include; centering algorithm, edge detection, thresholding, and median filter are reported in their work. 8 Applications of morphological operations and genetic algorithm for the extraction and recognition of Persian letter by Keyvanpour et al. 9 while feature extraction and recognition of Persian/Arabic zip code can be seen in the work of. 10 For identifying the most suitable methods for the recognition among multiple alternatives, a survey is conducted by Impedovo and Pirlo, 11 which analyzed several state of the art approaches such as the fuzzy approach, neural networks. Comparatively, techniques based on neural networks are considered to be efficient and reliable in the domain of the off-line recognition system. Significant recognition results are calculated for these techniques. In that regard, Ayyaz et al. 12 used hybrid features extraction method for features extraction and multi-class Support Vector Machine (SVM).
Ali et al. 13 developed an OCR system and a dataset for the Urdu language. Their OCR model uses convolution neural network and deep auto-encoder for the recognition purposes. Maalej and Khairallah improved the DBLSTM model for the online recognition of Arabic text. Memon et al. 14 performed a systematic study of the OCR models developed for the recognition of the handwritten characters. Carbune et al. 15 developed a multi-language OCR system for the recognition of online handwritten text recognition. Habib et al. 16 proposed an OCR system for the recognition of degraded Urdu and Devanagari text. There model capable of performing preprocessing steps on the degraded images of the text to extract the significant features and perform the identification process. Many researchers also exploited the Zoning features extraction techniques for acquiring significant numerical values from the character images. In this regard, recognition of Thai letters is achieved using an Anti-minor algorithm that uses 4 × 3 zoning grid to extract end-point and closed loop features for a handwritten image. 17 A variant of the Zoning grid of 4 × 4 is utilized by Negi et al. 18 to derive pixel density in each zone. Cha et al. 19 exploited the application of zoning grid for extracting the information from an image based on gradient, structure and concavity features. Similarly, adopting the same approach, Kimura and Shridhar 20 extract information from the contour profile of an image. In this approach, to count the number of segments, four orientation steps are used such as; 00, +45°, −45°, 90°. Liu et al. 21 used a zoning grid of 4 × 4 size for the recognition of the Chinese letter with a technique known as directional decomposition.
Sharma and Gupta proposed variant zoning grids including 4 × 4, 6 × 6 and 8 × 8 22 for the recognition of text. These variants are used over a pattern image to measure the density of pixels, while, 5 × 5 grid is utilized for feature extraction. 23 For feature extraction, the average distance is calculated between the pixel and the letter centroid in a row or column. Adapting the same configuration of the grid, local density is measured in a letter image while for profile projection features extraction, zoning grid of 1 × 10 and 10 × 1 is used for extracting these features in the vertical and horizontal directions. 24 Studies including25,26 based on an approach that uses circular ring partitioning criteria as well as convex hull ring. Their presented approach, is shaped based where convex hull circles are made using a letter 'convex hull shape. In their approach concentric circles refer to a set of circular rings and the center of these concentric rings is the pattern’s minimum enclosing center. According to arithmetic progression, selection for the radii of circles belonging to the set is made. For making the rotation invariant for the set of the system, features are based angular information of the letter pixels 'internal and external contour.
Based on studying the literature, many interesting approaches work for the text recognition in major languages such as; Urdu, Arabic, and Persian languages. However, for the recognition of handwritten letters in the Pashto language, no significant work is reported. Keeping in view the efforts made for the recognition of handwritten Pashto letters, we presented a novel framework for the recognition of handwritten characters in the Pashto language named as PHCR system.
Background
The section gives a background detail of characters modeling for Pashto language and a discussion on the classification techniques namely; support vector machine, artificial neural network and convolution neural network.
Pashto script
Several pronunciations are suggested for the Pashto such as Pukhto, Pushto, or Pakhto. It is also known as Afghani in the context of Indo-European language as well as treated as a sister language of Indo-Iranian language family too. Dialect of Pashto language are mainly categorized as “soft” and “hard” which are known as southern and northern respectively. Major differences between these dialects are on the phonological level, such as northern pronunciation references “Pashto” word as “Pakhto” or “Pukhto” and the southern refer the same word as “Pashto”. In the context of this paper “Pashto” word is used in both of the dialects that will reference the same word “Pashto”. There is one other dialect that is considered as standard and used as a spelling system or manuscript for Pashto words known as Pata Khazana. 1
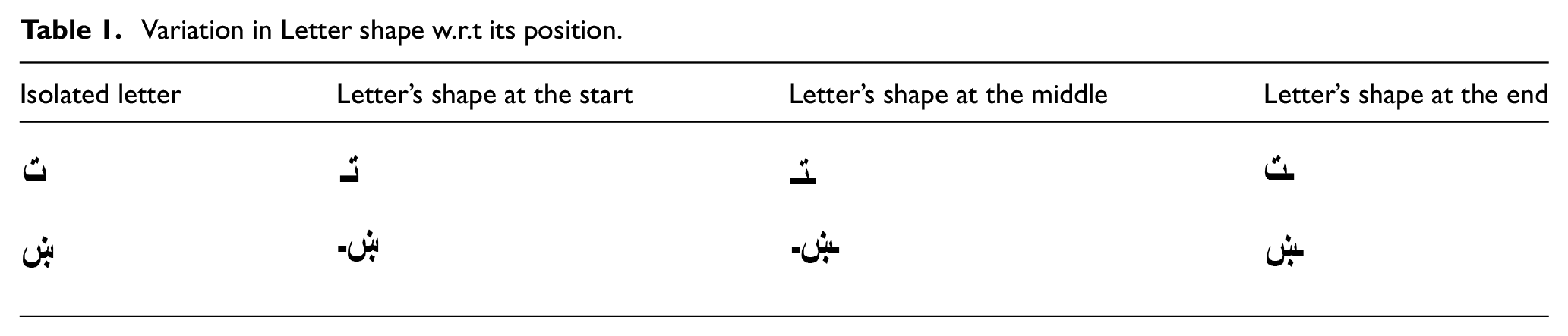
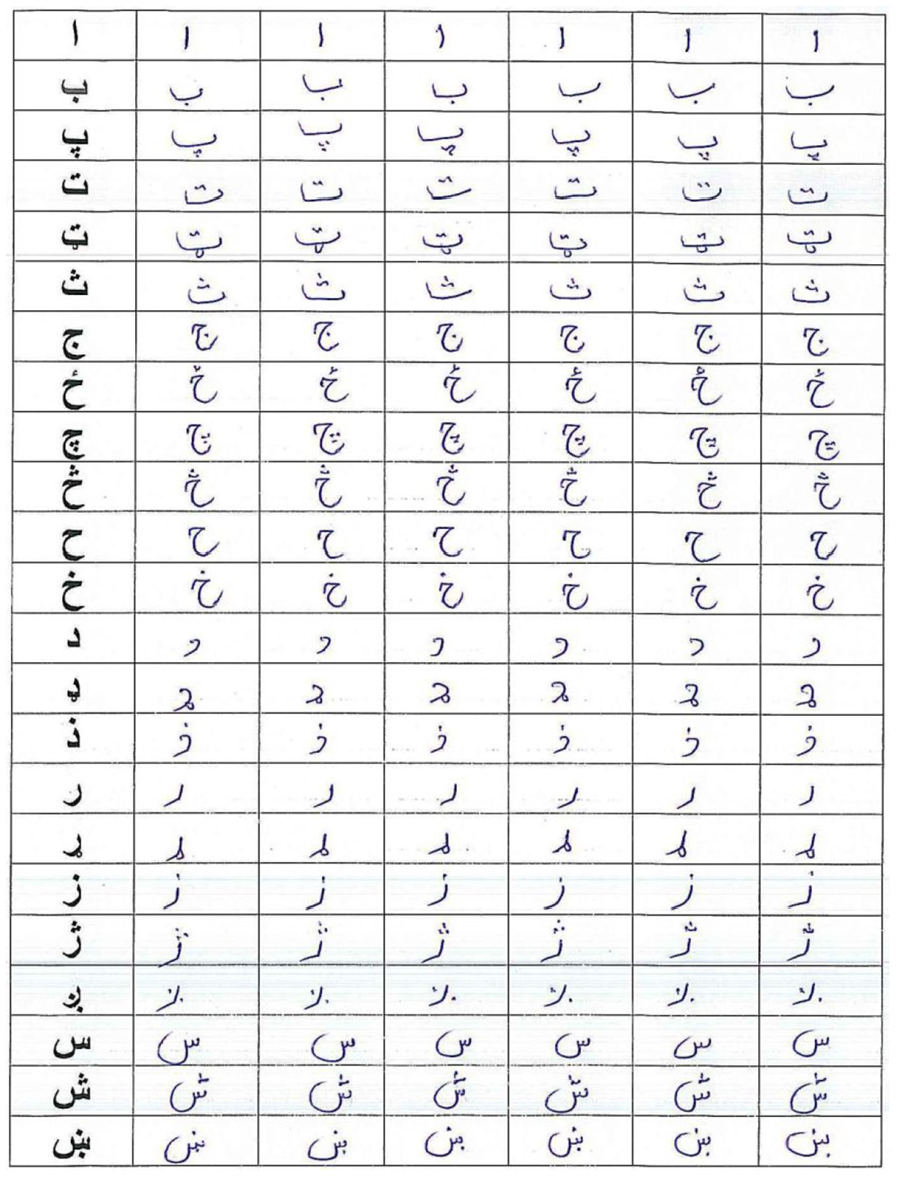
Pashto is derived from Perso-Arabic characters as a modified pattern of it. Pashto writing can be done in a version of Persian script that is a derivation from the Arabic script as well. There are a total of 44 characters in the Pashto language as shown in Figure 1. For written Pashto script, several characters can be merged to make a word as well as a combined character. Furthermore, according to the position of a word, the shape of the character change as well. Due to some variations in character’s shape during the formation of the word make it more challenging as the shape of the character varies to its appearance in the word. For example shape of a character appearing at the start of a word is different if the same character appears in the middle or at the end of the word as shown in Table 1.
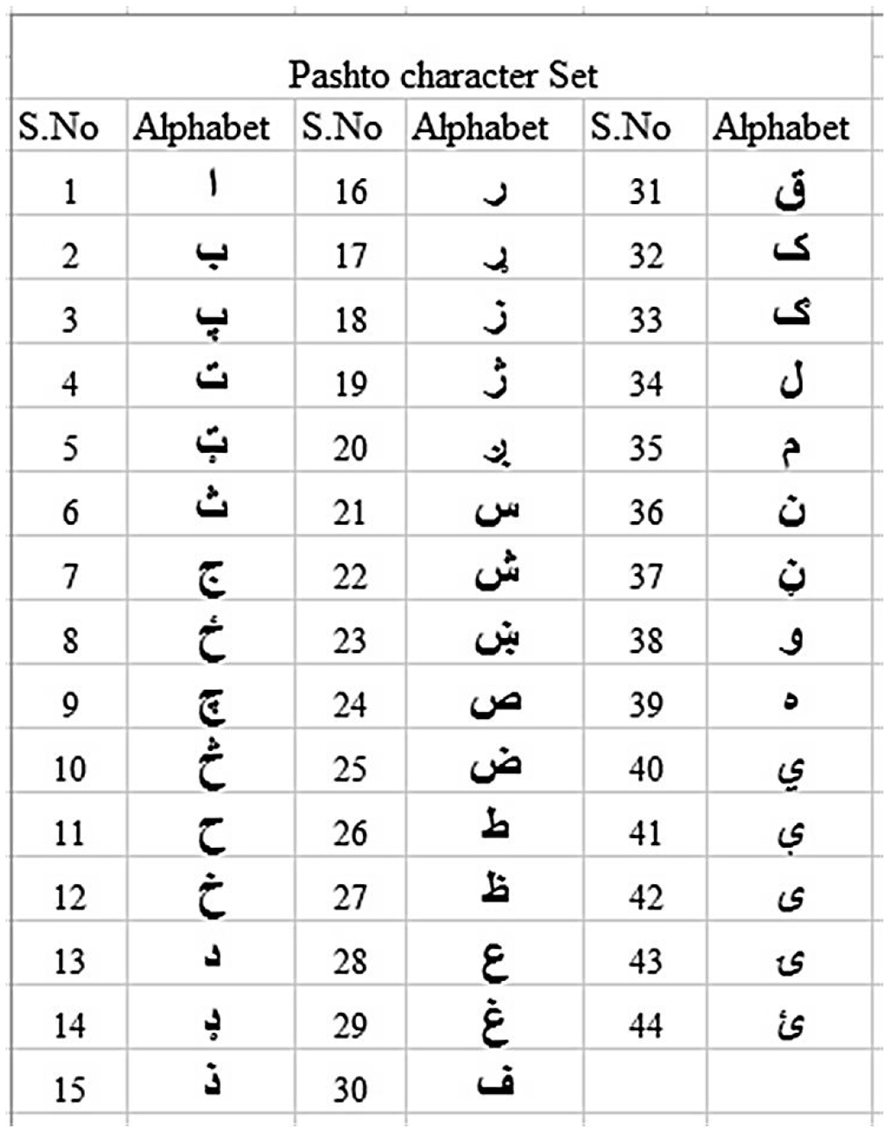
Standard Pashto character set.
Variation in Letter shape w.r.t its position.

These variations and shape shifting of characters are associated with various contexts make the recognition process more complex. However, in this paper, we have confined our study to the recognition of isolated characters. As discussed earlier that alphabets of the Pashto language are derived from the Persian alphabets. For defining phenomena that should be more specific to Pashto, several characters are summed and modified. One of the most widely used script for writing Urdu and Persian is the Nasta’liq script. In case of Pashto language, both kind of script are used for its writing such as Nasakh and Nasta’liq. However, among these two scripts, Nasakh has used a standard to write Pashto script. 27 The Pashto language includes the character belong to the Persian language in its characters dataset. The Pashto language includes 32 characters from the Persian language, among which it covers the 28 Arabic characters with addition to four character that is specific to the Persian language. On the other hand, the Urdu language that is a modified version of the Persian language consisting of six specific characters to the Urdu language while 32 Persian script characters. As a result, the Urdu language has a total of 38 characters. Interestingly Pashto language does include five Urdu specific characters with minor changes in their shape as shown in Table 2.
Urdu character’s Pashto equivalent.


Seven characters that are specific to the Pashto language are shown in Table 3.
Pashto specific characters.


After accumulating all these characters, the Pashto language has a total of 44 characters in its dataset that is shown in Figure 1.
Support vector machine
Support Vector Machine (SVM) is followed as a successful machine learning techniques for the recognition and/classification tasks. SVM is proposed by Cortes and Vapnik in the ends of 1990’s. 28 Generally, SVM is used for the classification of linear and non-linear problems. Optimum results for the classification process can be obtained by resolving the quadratic task that depends on the regularization parameter. For their transformation, kernel functions are used such as radial basis, polynomial kernel, sigmoid, and linear.
Linear Kernel –
Sigmoid Kernel –
RBF (Radial Basis Function) Kernel –
Polynomial Kernel –
With d,

Where
SVM is binary classifier while in our case there are 44 classes i-e. 44 Pashto characters (multi-class problem). In order to address this issue two different possibilities can be made to the SVM that are:
One versus all approach (1:M)
One versus each (iterative approach)
This research work uses one versus all approach (1: M) as shown in Figure 2.
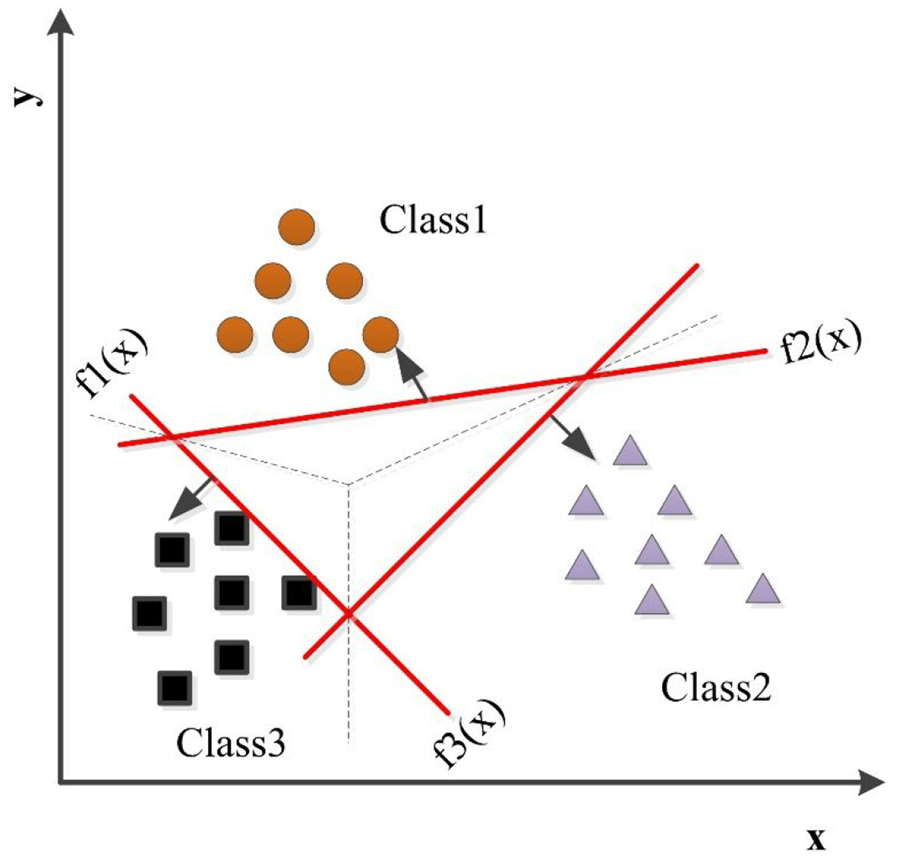
One versus all (1: M) approach for SVM.
One of the reasons for using this approach is that it is simpler in implementation as well as computationally efficient. Transformation is made by using a non-linear operator such as
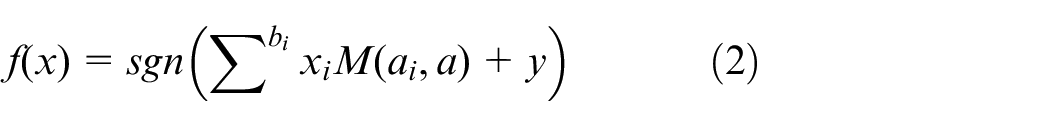
Where
Overall SVM is a better classifier but in our case, it has poor accuracy. Furthermore, results of SVM are not good comparatively Artificial Neural network and the convolution neural network. If the results of these algorithms are compared, then we find the SVM accuracy much lesser against the 78% and 80.7% for ANN and CNN respectively. After much training and testing, it becomes evident that SVM performs for binary classification. However, in multi-class class problems (Pashto has 44 classes in our case), the SVM is not prominent as this is good in binary classification. The classification results of SVM are shown in Figure 14.
Artificial neural network
Artificial Neural Network works by predicting the results from the set of input variables. Inspired from the human brain where many neurons pass information to each other to perform certain pattern matching and recognition task efficiently and accurately the idea of ANN is developed. Due to the high classification and recognition abilities, ANN is exploited in the field of handwritten characters recognition. 29 In their study, the features based on diagonals are extracted which are then used by ANN for recognition of handwritten alphabets. ANN is also used for solving quantum many-body problems. 30 Feed forward Neural Network is presented by Zhao et al. 31 for the recognition of characters via surface mount technology (SMT) products. The efficiency of SMT is further enhanced by introducing the additional back propagation algorithm in the approach. The approach exploits momentum item for that results in avoiding oscillations, divergences and convergence is also improved. In the proposed research work a back propagation neural network is used consists of an input layer, two hidden layers, and an output layer as shown in Figure 3.
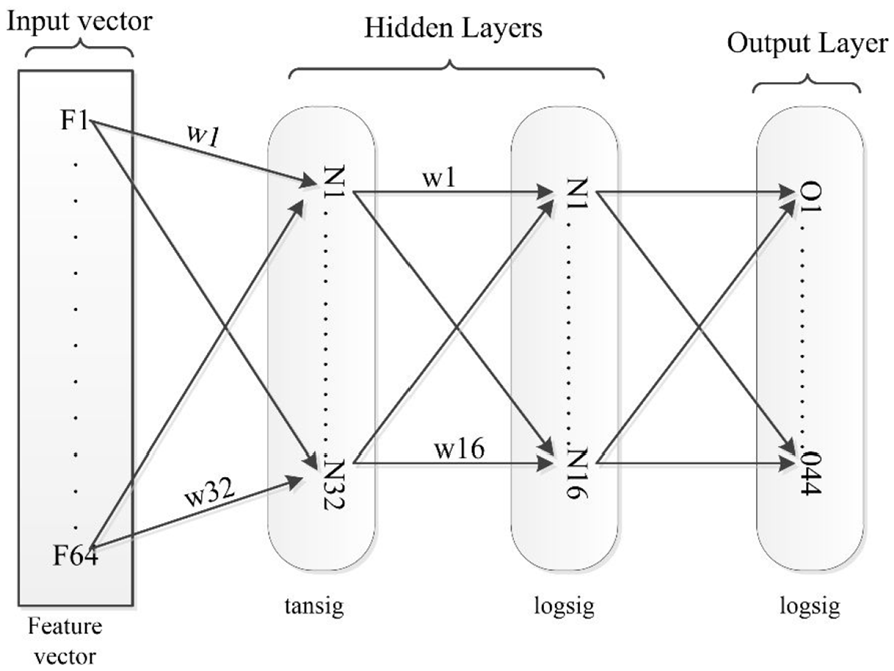
Generalize two hidden layer neural network.
Convolution neural network
As a result of having multi-layered and hierarchical neural network training via back-propagation procedure using architecture of deep supervised learning, Convolution Neural Network (CNN) has an automatic feature extraction capability as well as work as classifier. Main aim of the CNN is to work in the situation where we have more complex and data with many dimensional. CNN differs from other learning algorithms due to investigation of convolution layers and sub-sampling is performed. Due to the variations that occur in shapes, CNN are used for classification and recognition of objects, handwritten digits, 32 as well as to recognize Urdu Nasta’liq.33,34 CNN is usually used for the problems associated to pattern recognition to get the efficient performance. CNN is based on three main steps which is performed in hierarchy such as weight sharing, spatial, and subsampling to insure the invariance to distortion, shift, and scale respectively. Model of the CNN for recognition of Pashto handwritten recognition is shown in Figure 4. In the first step, filters (F hidden layers) are applied on the input data which convolved the data for the object to get feature map values. For the reduction of dimensionality such as S hidden layer of features map’s spatial resolution, convolution layers that are obtained from the previous step and then engaged with the help of sub-sampling layer. Furthermore, convolution layer trigger the feature-extractor to get or retrieve features by altering the sub-sample layers. Further these layers get engaged by layers such as output and two fully connected layers (FCL). Subsequently, the output from the previous layer is accepted as an input by each subsequent layer.
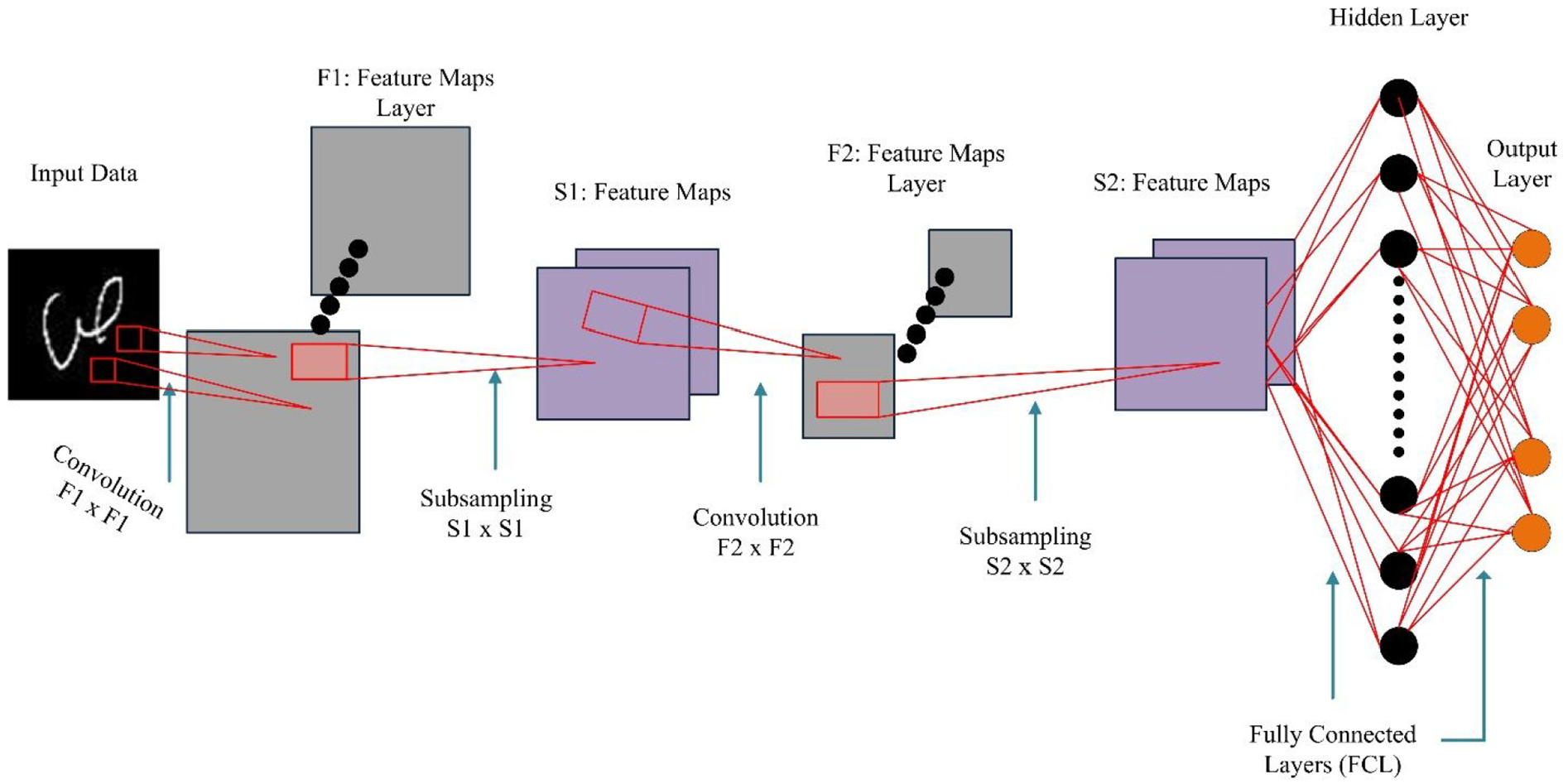
Conventional CNN model.
The number of parameters used in the proposed research work for the CNN model are;
Proposed methodology
Framework designed for the recognition of Pashto character is achieved through implementing in using three major steps or phases that is shown in Figure 5.
Characters database development
Features extraction
Model training and recognition (SVM, ANN, CNN based classification)
This is discussed in the following sections.
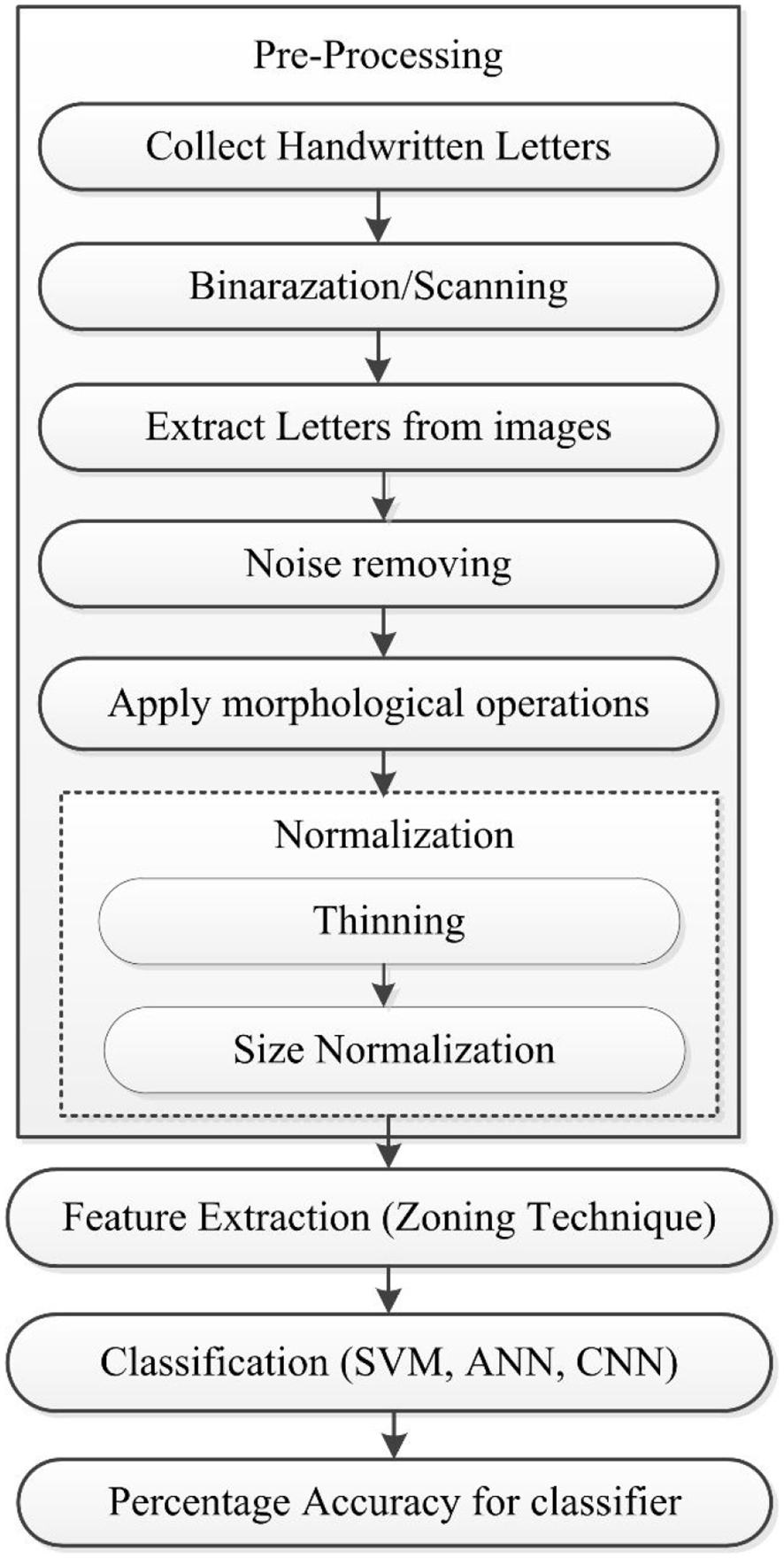
Proposed PHCR system.
Character database development
To the best of our knowledge, there is no standard dataset available for handwritten Pashto letters. In order to address this, we present a medium sized database for the handwritten Pashto letters. The main steps involved are discussed below:
Repository of handwritten letters
For the proposed handwritten Pashto characters database development phase several universities around Khyber Pakhtunkhwa, Pakistan are visited for handwritten samples collection. Repository or database of handwritten letter is made by collecting samples of handwritten letter wrote by people on a page of having A4 size. Each given page was sectioned in six number of column in order to get number of possible variations of Pashto letters or alphabets that occur among the writing style of people. The handwriting samples were collecting from volunteers (mainly students) who willingly participated in the samples collection for use in this research study. The distribution of volunteers is summarized in Table 4. During the database development phase (characters accumulation process) 98% of the writers are right handed and the rest of the 2% are left handed, while the minimum age level of the volunteers at the university level was 17 years.
Gender-wise collection of text samples of Pashto.

Binarization
The accumulated handwritten Pashto letter from different people are scanned in order to store it in the computer for further processing and applying machine learning algorithms. Figure 6 depicts the scanned samples for Pashto handwritten alphabets that were stored in the computer.
First 23 scanned characters of Pashto language.
Letters extraction
After the accumulation of handwritten characters the next step is to extract each letter from the scanned samples to develop a handwritten Pashto characters database for the simulation and research purposes. The upcoming section gives information about the handwritten characters extraction and database development process. Figure 7 shows some examples of the extracted letter from scanned samples.

Extracted characters.
During the accumulation of the handwritten Pashto characters, a fixed size window is selected for each character, however, using the same algorithm to extract characters from the non-titled and title document causes many problems to perform extraction from the scanned samples. To avoid such a problem in character extraction, all the images are brought to have the same fixed size
Thresholding
These spots are easily visible after zooming the extracted letter image as shown in Figure 8.

Zoomed character.
Removing black spots (noise) from the characters images, several methods like thresholding and average filtering are handy in such cases. In our case thresholding gives optimum results. On the other hand, averaging filter has the remove black spots along with the meaningful dots that are actually a part of the word. So removing these dots incur more problems instead of giving solutions. Therefore, in our approach, we have used thresholding for noise removal by defining the threshold to an optimum level so that the noise has to be removed but also keeping the potential dots in the images. Using different threshold values and experiments we have to find out 20 to be an optimum value in the context of the current setup. Equation (3) shows the mathematical depiction of the thresholding procedure we have applied:

Resultant images produced after thresholding is represented in Figure 9. The images shown in Figures 8 and 9 show that, the thresholded image is the better representation of the handwritten character.

Thresholded image.
Morphological operations and centralizing Letters
Noise can be produced due to the imperfect segmentation. So in this step, the noise in the shape of cutting edges and holes is removed from the images. Furthermore, each character or alphabet is positioned centralized to make each image equally a fair candidate for classifier as well as to eliminate image classification affected by the variations of the position in the images which is shown in Figure 10.

Centralized character image.
For the position of the letter to be centered, we have applied centralization techniques that calculate or measure the center of the images and subtract pixels such that the letter is centered now. The result of centralization is shown in Figure 12. With these steps, we finally get a dataset for the 44 letters of Pashto, where each letter appears with 102 variations. In the end, each character is stored in the dataset as an
With this dataset developed, we use this to train the model for automatic recognition of Pashto handwritten letters. To the best of our knowledge, this is the first available dataset for Pashto handwritten characters.
Feature extraction
For extracting features from handwritten characters, a zoning technique is selected. In this technique, a zoning grid is overlapped on the considered images and the significant feature values are accumulated based on the density of pixels, color or values of pixels in corresponding grids. This technique works on u × v grid that divides an image into uniform sub-samples and the resultant sub-samples having identical shapes. These identical shapes know called zones. In Figure 11(a) we have represented an example of zoning methods of having uniform shaped on a grid with 2 × 2 dimensions. Furthermore, (Figure 11(b)) shows the variations of the technique on 3 × 2 dimension grid, effect for 3 × 3 grid is shown in (Figure 11(c)), (Figure 11(d)) represents 4 × 4, and 5 × 4 is depicted in (Figure 11(e)).
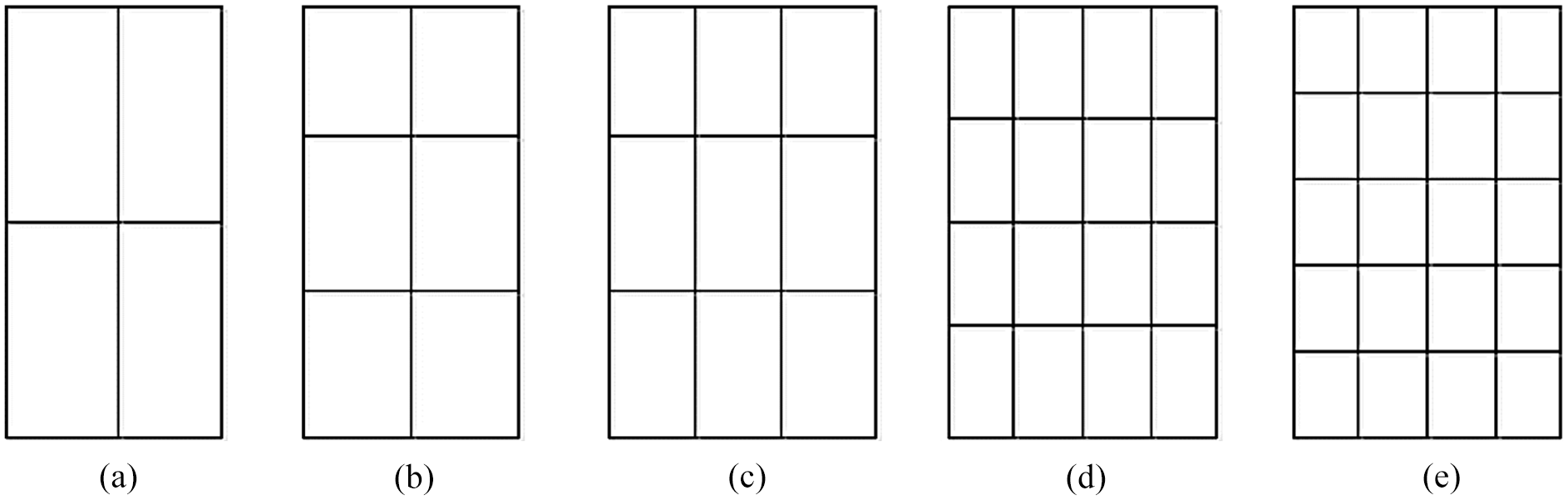
Uniform zoning grids of 2 × 2, 3 × 2, 3 × 3, 4 × 4, and 5 × 4 sizes respectively.
Numbers of approaches are proposed with variant size of grids in association to the evolving of distinctive part for handwritten characters. Such example includes grid of 2 × 2, 1 × 2, 2 × 1, and 3 × 2. 35 For recognition of digits based on calculation counter is presented by Morita et al. 36 and Blumenstain et al. 37 where they have used grid of 3 × 2 size. Variant of approaches such as 3 × 2 grid is used to examine handwritten characters. 38 Zoning grids with 3 × 2 dimension is exploited for extracting counter-based features [50] which is then further been adopted by Verma et al., 39 for the recognition of handwritten character along with back-propagation neural network algorithm. Another approach uses zoning grid has 3 × 3 dimensions to extract distribution of geometrical features for each individual zone. 40 Using the same zoning grid, features are extracted for handwritten characters and digits by Hewitt. 41 Recently, advance filtering techniques are used by number of preprocessing approaches which can be seen from the studies of Imani. 42
In the proposed PHCR system, a zoning grid of 8 × 8 dimension is selected for feature extraction purposes as shown in Figure 12. Computationally, the grid size such as 16 × 16 is more expensive to be used due to the high consumption of resources. Furthermore, from experiments, it is found that for extracting a limited number of features, a grid with a size 8 × 8 is much faster in results. In the next step, we have also counted the density in each zone for a white pixel. Furthermore, the results of the zoning are normalized to make the values in the range [1, –1]. The skeleton of the image is worthy to make the efficient use algorithm.

A 8 × 8 zoning grid.
Classification setup and results
Classification in the heart of any OCR system. Based on the zoning feature map, the results of the artificial neural network and support vector machine are generated and compared with the results calculated from the convolution neural network. The overall summary regarding results for each classifier is discussed below.
Support vector machine
The recognition results of the SVM technique are generated based on the feature map calculated in the previous step. The feature map is divided into training set and testing set based on 2:1. In 102 handwritten samples for each individual character in Pashto language, training set includes 68 samples while test set is made of 34 samples. The results of overall accuracy for SVM classifier using the selected training and test set is 56%. The accuracy results of the SVM classifier is depicted in Figure 13.
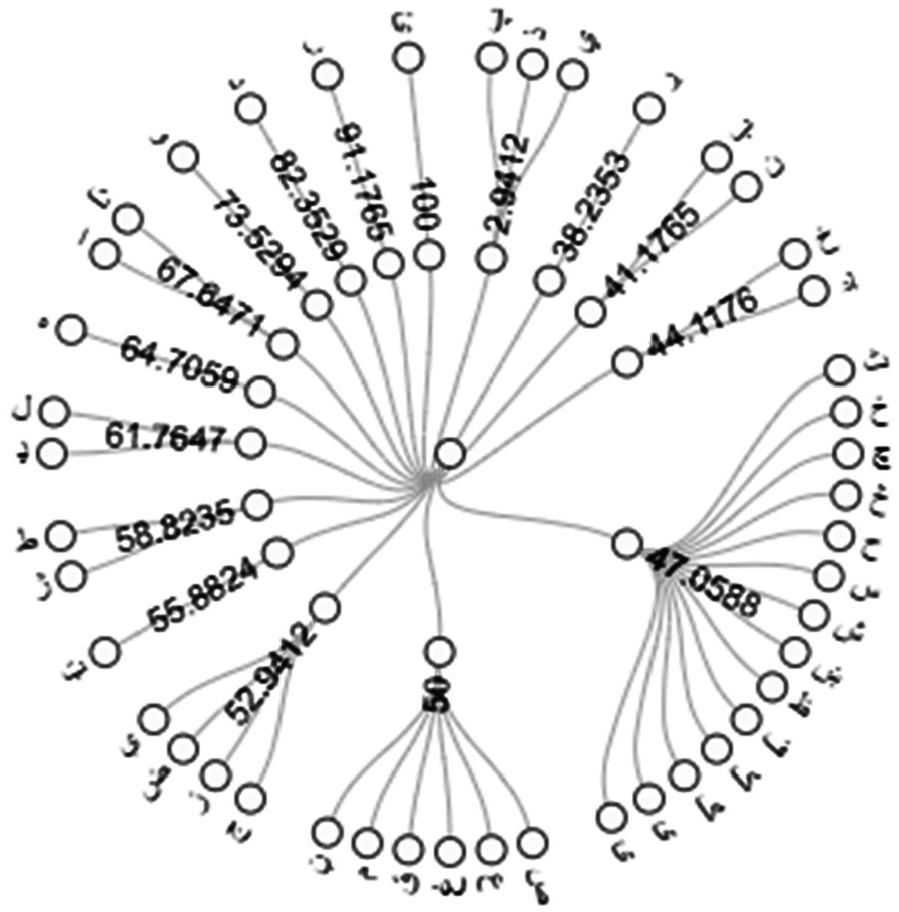
SVM results for proposed PHCR system.
In Figure 14 the end-nodes represents the Pashto characters and the nodes at the middle represents the accuracies for the corresponding letters. It is concluded from the Figure 14 that slight change in character’s shape confuses the classifier in recognizing the characters accurately. While multi-class problem is another big barrier to the SVM model, as the Pashto language consists of 44 characters (44 different classes).
ANN recognition results for the proposed PHCR system.
Artificial neural network
In the proposed research work, the back propagation neural network is trained based on multi-layer feed forward network. To assign the input provided to the ANN model in a batch file format as the proposed problem consists of a huge featured matrix (64 × 4488). Every individual handwritten Pashto character sample consists of 64 features that are composed in a feature matrix. The results obtained for Pashto handwritten character by Artificial Neural Network (ANN) is shown in Figure 14.
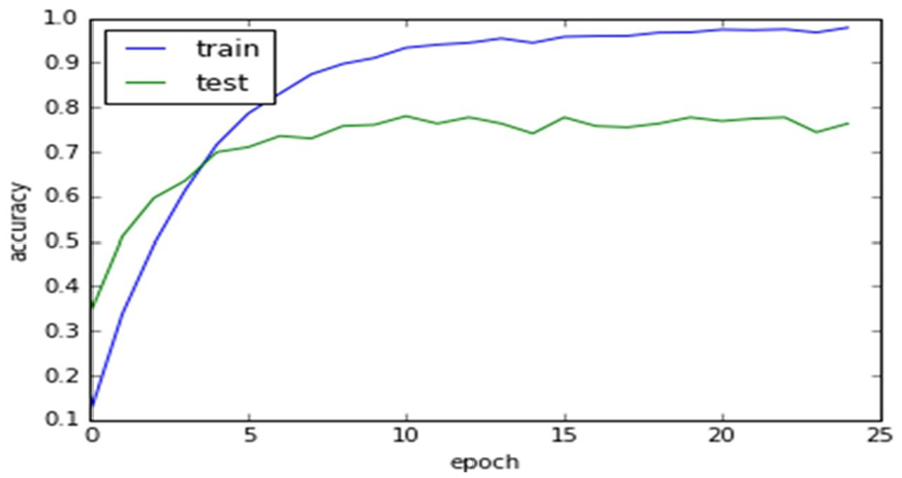
Figure 14 includes the problem of over-fitting which is necessary to be minimized as possible for increasing the accuracy of the proposed PHCR system. The PHCR system is validated for varying training and test sets to identify the time consumed and the recognition rate achieved for each variation. From the experiments, it is concluded that training size has positively influenced the classifier accuracy and derive better generalization as shown in Figure 15.
ANN recognition results for varying training and test sets.
The ANN classifier efficiency in terms of recognition abilities is calculated based on varying training and test set. Also, the proposed PHCR system is tested for varying training and test sizes based on epoch size. The time consumed and accuracy generated based on epoch size and training and test sets are depicted in Figure 16. From the results, it can be seen that size of the training set has a direct relationship with time consumption and classifier’s accuracy. The same relationship is followed for the variation in the number of epochs.
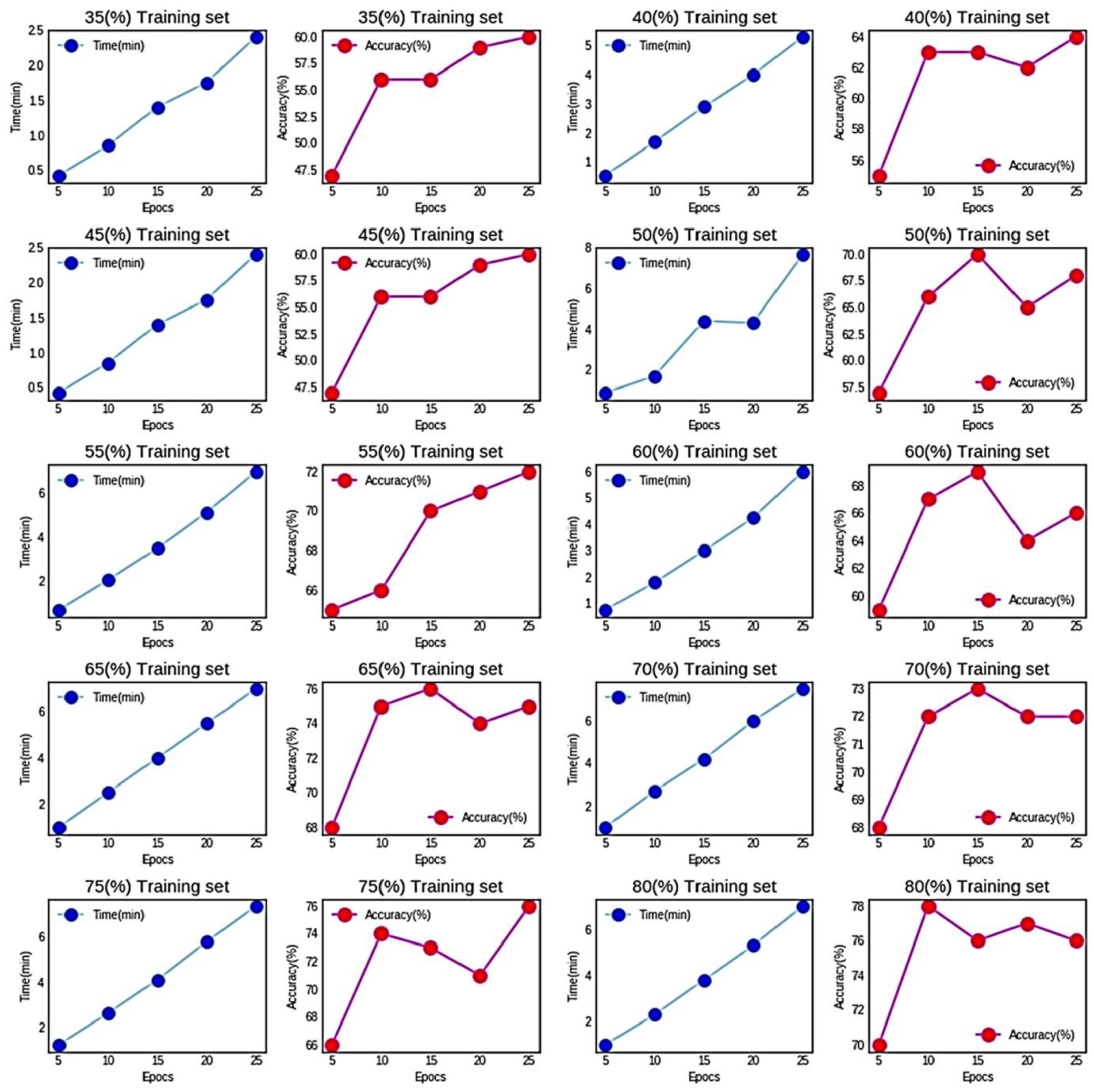
Time consumption and accuracy results of ANN for varying training and test sets based on number of epochs.
Convolution neural network
In the proposed research work a five layered CNN model is selected consist of three hidden layers and an input and output layer. Handwritten characters images are provided as an input to the first layer. While the second and fourth layers of the model act as a convolution layer with subsampling layer as an alternator, that accepts the pooled feature map as an input. CNN is an automatic feature extractor these layers automatically extract features from the raw/input images that are more and more invariant to local transformation. A fully connected layer (FCL) is the last layer of the CNN model, in our case, this is the fifth layer. This layer decides the output based on neurons selected. The overall result of the convolution neural network is shown in Figure 17 during its performance checking.
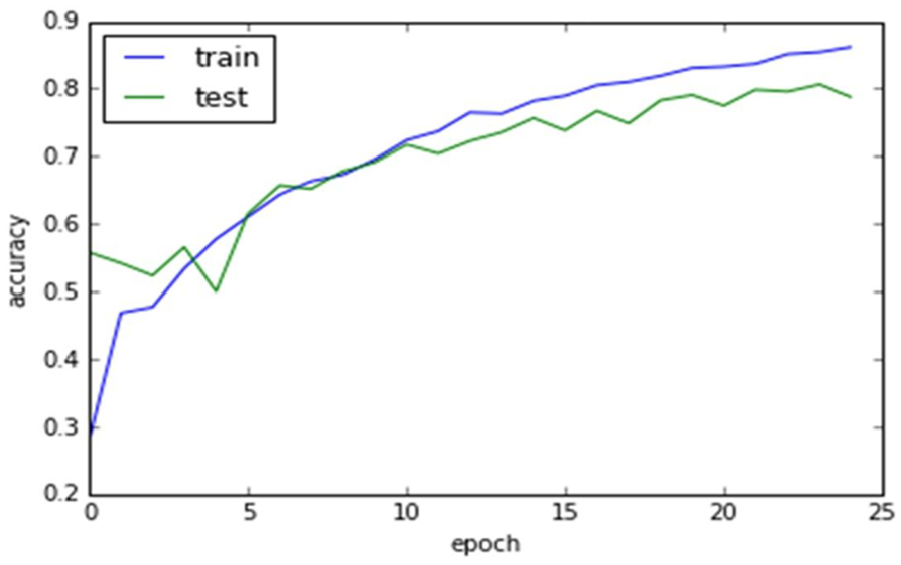
CNN performance results for PHCR system.
The graphs represented in Figure 17 also have overfitting however, this over fitting is smaller as compare to the ANN results shown in Figure 15.
CNN is also tested for varying training and test sets sizes and the results are generated accordingly that is shown in Figure 18. It is evident from the Figure 18 as the training set size increases, the recognition accuracy of the CNN model also increases.
CNN results for varying training and test sets.
The recognition ability and time consumption of the CNN classifier is tested based on epochs size for varying training and test sets. The results are shown in Figure 19. It is evident from Figure 19 that as the training set size increases, the time (taken during a simulation process) and accuracy of the classifier increase. Same scenario is repeated for the epoch size (when epoch size increase accuracy and time increases).
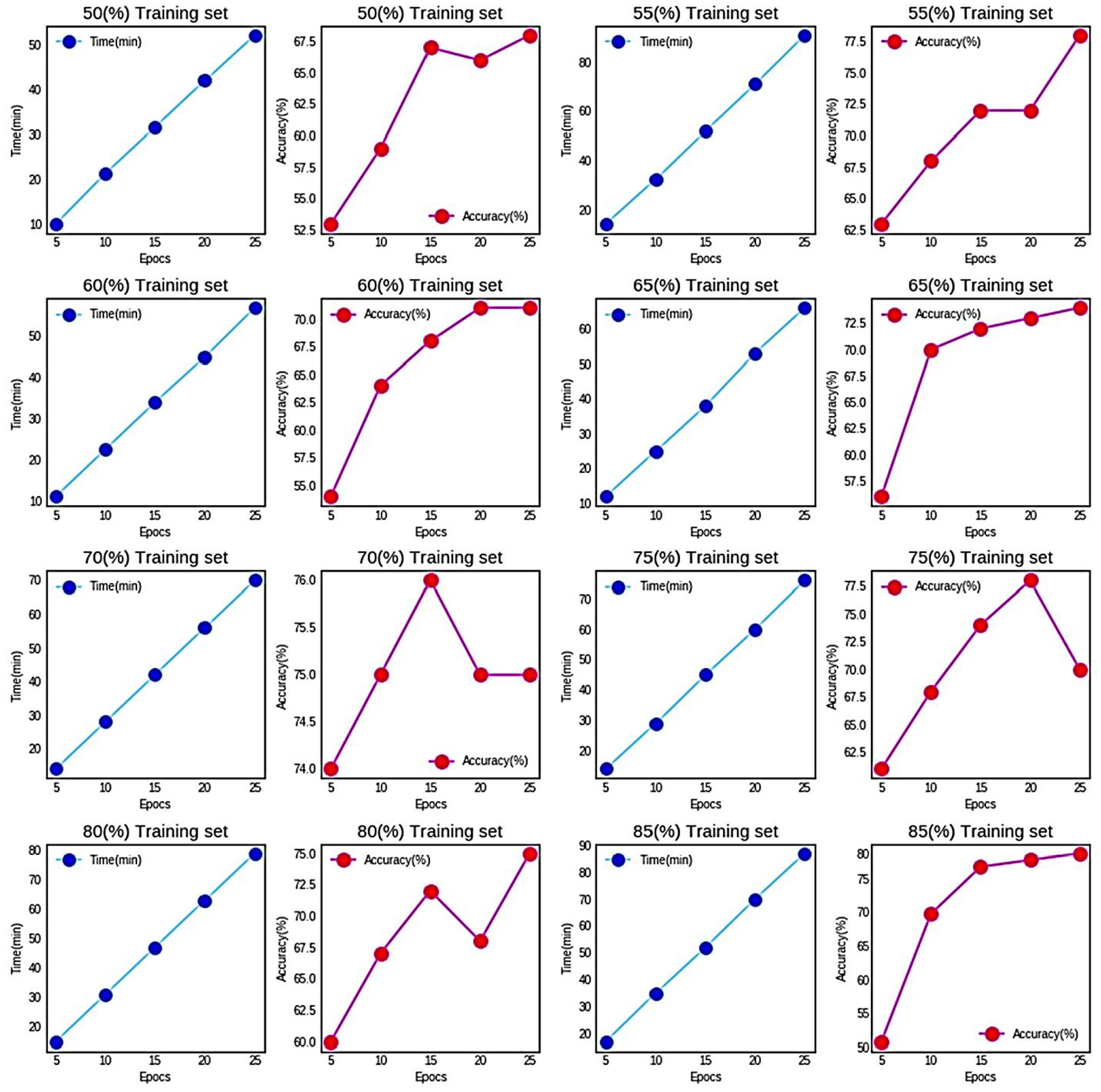
The time consumed and accuracy measured graph for varying training and test sets based on epoch size.
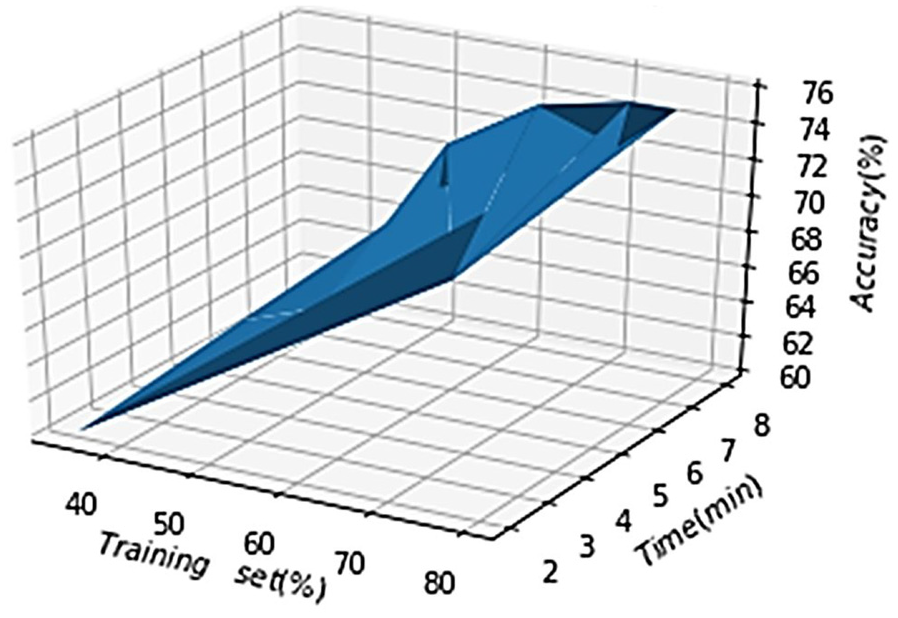
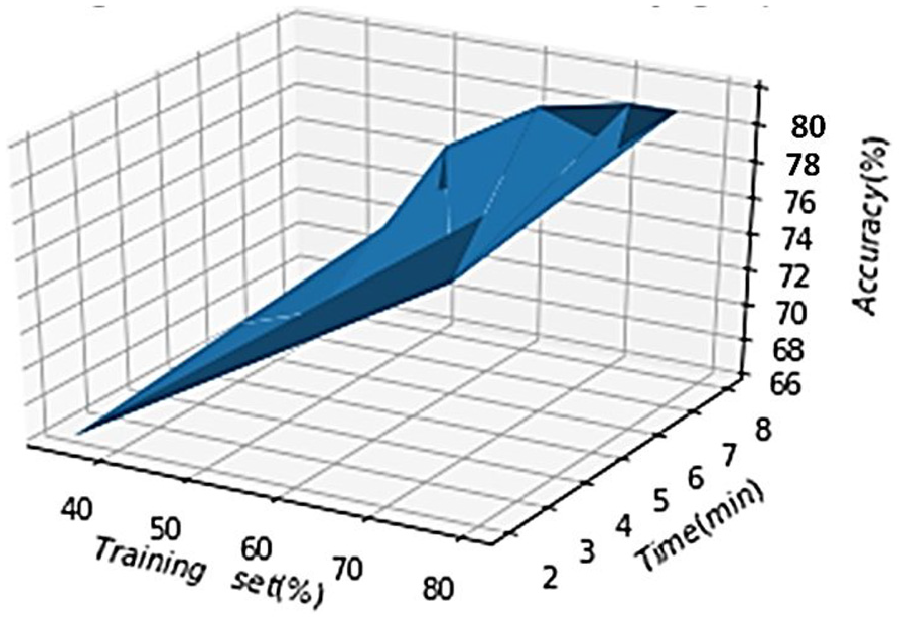
After examining the results of each model (SVM, ANN, and CNN), the convolution neural network achieves prominent recognition results. The proposed CNN model is also tested for varying training sets and test sets and generated different time and accuracy charts based on these training and test sets. The results are depicted in Figure 20.
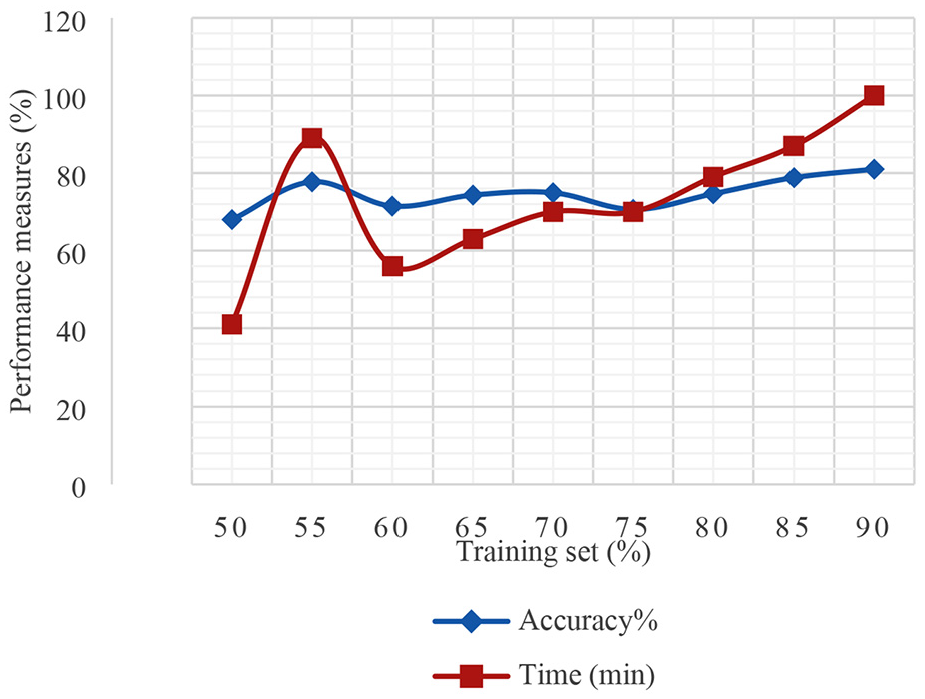
CNN model accuracy and time with training set size.
The model loss for the proposed PHCR system based on the CNN model is depicted in Figure 21.
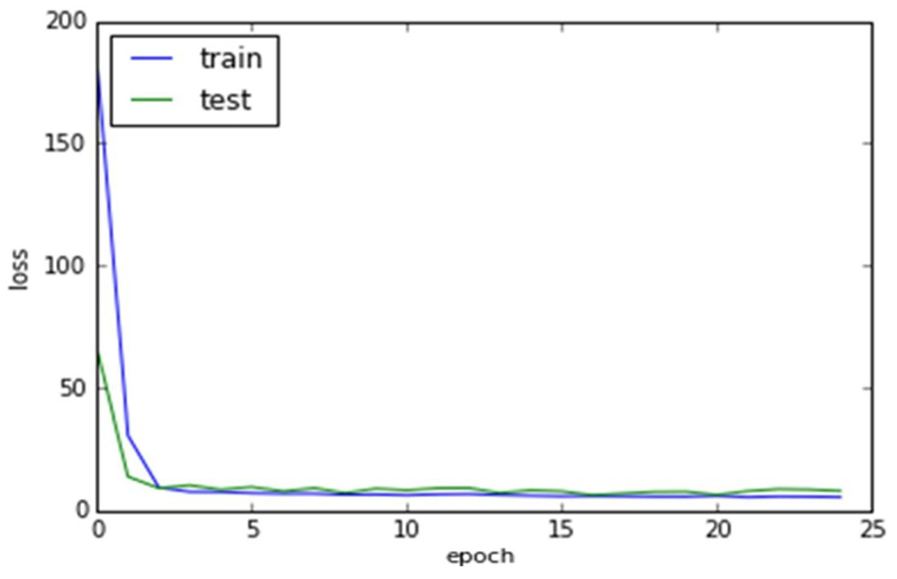
CNN model loss for PHCR system.
After testing each classifier for the proposed problem it is concluded that CNN provides better results than SVM and ANN classifiers as shown in Figure 22. CNN gives 80.7% accuracy for the proposed PHCR system while SVM and ANN gives 56% and 78% recognition accuracies, respectively.

PHCR recognition abilities based on different techniques.
Conclusion
This paper presents an optimal OCR system for the recognition of handwritten Pashto characters. For the proposed research work a medium-sized dataset for handwritten Pashto characters is developed for simulation purposes. SVM, ANN and CNN models are applied to perform the automatic recognition of the Pashto characters. Experimental results have shown the accuracy of 56% for SVM, 78% for ANN and 80.7% for CNN based framework. Mainly the contributions of the proposed research work are the following: Firstly, the dataset will act as a resource for future research work on Pashto handwritten letters. This can further help in preserving the old literature of Pashto history and culture. Secondly, the results obtained will provide a baseline accuracy for future research work on Pashto text processing. Third, since Pashto has encapsulated characters from Persian, Arabic, and Urdu languages so the OCR system developed for the Pashto language will ultimately work in recognizing the characters in these languages.
In the future, we want to test our algorithm for a larger database of handwritten Pashto letters. In addition to that, online recognition of connected words in Pashto will be our main focus. Also, we will extend the proposed research work to handwritten Pashto words recognition. The use of advanced machine learning techniques, such as deep neural networks with a higher number of hidden layers can result in robust recognition of connected words and even a higher accuracy rate.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work is supported by Department of Computer Science, University of Swabi, Swabi Pakistan.